进化树选择
生物进化中的演化树

生物进化中的演化树生物进化是指生物在漫长的时间内通过遗传变异和适应环境的选择而逐渐发展和改变的过程。
而演化树(也称为系统进化树或谱系树)是一种用来描述不同物种之间进化关系的图形工具。
本文将就生物进化中的演化树进行探讨,分析其构建方法、意义以及应用。
一、演化树的构建方法演化树的构建基于大量的分子生物学和遗传学数据,包括DNA序列、蛋白质序列及其他分子标记。
通过对这些数据进行分析和比较,可以揭示出不同物种之间的遗传关系和进化距离。
常用的演化树构建方法包括距离法、最大似然法和贝叶斯法等。
距离法是通过计算不同物种之间的遗传距离来构建演化树,距离越短表示亲缘关系越近。
最大似然法则是通过估计进化模型参数,找到使观测数据出现概率最大的树形结构。
贝叶斯法则是根据贝叶斯定理,通过计算概率分布来构建演化树。
这些方法都具有各自的优缺点,研究者应根据实际情况选择合适的方法。
二、演化树的意义演化树能够揭示物种之间的进化关系,显示出不同物种的分支和演化路径。
通过演化树,我们可以了解物种的起源、扩散和分化过程,推测不同物种之间的共同祖先以及进化速率的差异。
此外,演化树还可以用来研究生物的起源和进化动力学,揭示生物多样性的形成和演化的规律。
三、演化树的应用演化树在生物学研究中有着广泛的应用。
在系统发育学中,演化树可以用来分类和鉴定物种,帮助我们了解物种间的亲缘关系以及演化的历史。
在人类起源和进化研究中,通过演化树可以追溯人类的进化历程和与其他灵长类动物的亲缘关系。
在遗传学研究中,演化树可以用于分析基因家族的起源和进化,研究基因表达的差异以及基因功能的演化等。
此外,演化树还可以应用于生物多样性保护和物种保护的决策制定。
通过了解物种的进化历史和亲缘关系,可以指导保护工作的开展,制定合理的保护策略和措施,保护濒危物种和生态系统的完整性。
总结:生物进化中的演化树是一种用来描述不同物种之间进化关系的图形工具,通过构建演化树可以揭示物种的起源、进化历程以及亲缘关系。
生物进化树怎么分析?

生物进化树(Phylogenetic tree)用于描述不同物种之间的进化关系和亲缘关系。
分析生物进化树可以帮助我们理解物种的演化历史和形成过程。
以下是分析生物进化树的一般步骤:
1. 收集数据:首先,收集相关物种的形态特征、遗传信息或分子序列数据。
这些数据可以包括形态特征的测量值、DNA 或蛋白质序列等。
2. 构建数据矩阵:将收集到的数据转化为一个数据矩阵,每行代表一个物种,每列代表一个特征或基因。
3. 选择进化模型:选择合适的进化模型来描述物种之间的进化过程。
不同的模型适用于不同类型的数据,例如形态数据、DNA序列或蛋白质序列。
常用的模型包括最大似然法、贝叶斯推断等。
4. 构建进化树:使用进化模型和数据矩阵来构建进化树。
构建进化树的方法包括邻接法、最小演化法、最大似然法、贝叶斯推断等。
这些方法根据不同的原理和假设来计算物种之间的进化关系。
5. 评估进化树:通过计算进化树的可靠性指标来评估树的准
确性。
这可以包括计算节点的支持值(如Bootstrap值)或进行统计模拟。
6. 解读进化树:根据构建的进化树,可以对物种之间的进化关系进行解读。
进化树提供了关于物种的共同祖先、形态特征的演化和物种分类等信息。
值得注意的是,生物进化树的构建是一个复杂的过程,涉及到数据收集、模型选择和数据分析的多个环节。
因此,对于具体的研究目的,可能需要结合专业知识和相应的软件工具来进行生物进化树的分析。
植物基因家族进化树的构建

植物基因家族进化树的构建一、数据收集在构建植物基因家族进化树之前,需要收集相关的基因序列数据。
这些数据可以通过各种数据库,如NCBI、Ensembl等获取。
在收集数据时,需要注意以下几点:1. 选择具有代表性的物种,覆盖尽可能多的系统发育分支;2. 确保所收集的基因序列数据质量可靠,无测序错误和拼接错误;3. 对于每个基因家族,应尽可能收集多个成员的序列,以便进行多序列比对和树的构建。
二、序列比对在获得基因序列数据后,需要进行多序列比对。
比对的目的是为了找到不同物种间基因序列的相似性和差异性,从而确定它们之间的系统发育关系。
常用的多序列比对软件有MUSCLE、CLUSTAL W等。
在进行多序列比对时,需要注意以下几点:1. 选择合适的比对参数,以保证比对结果的准确性和可靠性;2. 在比对过程中,需要注意保持基因序列的原始阅读框,避免引入不必要的拼接错误;3. 对于较长的基因序列,可以分段进行比对,以提高计算效率和准确性。
三、距离矩阵计算在多序列比对的基础上,需要计算不同物种间基因序列之间的距离。
距离矩阵的计算是树构建的重要步骤之一。
常用的距离矩阵计算方法有:1. 欧氏距离法:直接计算不同物种间基因序列的差异数目,得到距离矩阵;2. Kimura距离法:基于Kimura模型计算不同物种间基因序列的差异概率,得到距离矩阵;3. Jukes-Cantor距离法:考虑基因序列的突变率和进化速率,计算不同物种间基因序列的差异概率,得到距离矩阵。
在选择距离矩阵计算方法时,需要根据具体情况选择适合的方法。
如果数据量较大或序列较短时,可以考虑使用欧氏距离法;如果数据量较小或序列较长时,可以考虑使用Kimura或Jukes-Cantor距离法。
四、树构建方法选择在获得距离矩阵后,需要选择合适的树构建方法来构建进化树。
常用的树构建方法有:1. UPGMA(Unweighted Pair Group Method with Arithmetic Mean):将距离矩阵中的行或列进行聚类分析,根据聚类结果构建树;2. Neighbor Joining:基于距离矩阵中的最近邻关系构建树;3. Maximum Parsimony:基于树的构建准则函数(如最小改变数、最小代价等)构建树。
系统进化树的构建方法

系统进化树的构建方法系统进化树(systematic phylogenetic tree)是用于描述不同物种之间进化关系的一种图形化表示方法,可以帮助我们理解物种的起源、演化和分类。
构建系统进化树主要涉及到物种的分类学和进化生物学知识,以及系统发育分析方法。
下面将介绍系统进化树的构建方法。
1.选择研究对象:确定研究的物种范围,通常会选择有代表性的物种,包括已知的和新发现的物种。
2.收集DNA序列数据:从每个研究对象中提取DNA样本,并通过PCR扩增得到所需的基因序列。
常用的基因包括线粒体基因COI、核基因ITS 等,根据具体研究目的和对象进行选择。
3.序列比对:将收集到的DNA序列进行比对,通常采用计算机程序进行全局比对,比对结果会显示序列之间的同源区域和差异。
4. 构建系统进化树:有多种方法可以构建系统进化树,其中最常用的是系统发育建模方法,如最大简约法(maximum parsimony)、最大似然法(maximum likelihood)和贝叶斯推断(Bayesian inference)等。
最大简约法是最简单和最常用的构建系统进化树的方法之一、它基于简约原则,认为进化过程中最少的演化步骤是最可能的。
方法将不同物种的序列进行比对,统计共有的字符以及不同的字符,根据最小化改变的原则,得到进化树。
最大似然法使用概率模型来计算物种之间的进化关系,根据序列数据的概率分布确定最可能的进化树。
这种方法考虑了不同序列字符的不同演化速率以及序列之间的相关性。
贝叶斯推断方法基于贝叶斯统计学原理,通过计算不同进化树的后验概率来确定最有可能的进化树。
该方法能够对不同进化模型和参数进行全面的推断,但计算复杂度较高。
5.进行分支长度调整和进化树根的定位:进化树的分支长度表示物种间的差异,可以根据各个物种间的差异大小进行调整。
进化树的根通常是已知的进化历史或已知的进化事件,如灭绝事件等,可以通过分析群体间的基因流动等信息进行推断。
利用MEGA-X选择模型及构建美化进化树

利⽤MEGA-X选择模型及构建美化进化树今天主要介绍的是在MEGA-X图形界⾯下构建系统发育树并且对发育树进⾏美化。
下载安装好MEGA-X后,⾸先打开软件。
此处我们以⼀株细菌的16S rRNA序列为⽬标序列,⾸先在NCBI中进⾏Blast⽐对,下载将要⼀起⽐对建树的菌株序列。
在NCBI中输⼊序列或者上传⽂件,选择数据库时可以选择「Nucleotide collection(nr/nt)」或者「16S ribosomal RNA sequences」数据库,⼀般来说nr/nt库信息⽐较全⾯。
我们选择了10个不同种的16S rRNA序列进⾏下载。
另外,此处还可以⽐对下载2-3条⼤肠杆菌(Escherichia coli)和沙门⽒杆菌(Salmonella)的16S rRNA序列作为外类群(在Organism选项中进⾏物种限定),后⾯推断进化时间的时候可以⽤到。
将所有下载的序列整理在⼀个⽂件中,为了⽅便后⾯的建树可以将菌株名称后⾯多余的信息在这⾥替换删除掉(只是名称上的信息,不要改动碱基序列),然后将⽂件的扩展名改为.fasta。
在MEGA-X⾸页选择DATA,点击Open a File/Session,选择刚才的⽂件。
打开⽂件时询问「Analyze or Align File?」,此处点击Align。
序列中可能会出现混合碱基符号,混合碱基符号指两种或多种碱基(核苷)混合物的表⽰符号,或未完全确定可能属于某两种或多种碱基(核苷)的符号:R表⽰A+G;Y表⽰C+T;M表⽰A+C;K表⽰G+T;S表⽰C+G;W 表⽰A+T;H表⽰A+C+T;B表⽰C+G+T;V表⽰A+C+G;D表⽰A+G+T;N表⽰A+C+G+T。
接下来选择序列⽐对的⽅法:Muscle或者ClustalW。
ClustalW的基本原理是⾸先做序列的两两⽐对,根据该两两⽐对计算两两距离矩阵,是⼀种经典的⽐对⽅法,使⽤范围也⽐较⼴泛。
Muscle的功能仅限于多序列⽐对,它的最⼤优势是速度,⽐ClustalW的速度快⼏个数量级,⽽且序列数越多速度的差别越⼤。
菌株系统进化树的构建-概述说明以及解释

菌株系统进化树的构建-概述说明以及解释1.引言1.1 概述概述菌株系统进化树的构建是一项重要的研究工作,它能够帮助我们了解不同菌株之间的进化关系和演化历史。
菌株系统进化树可以被看作是一种表示不同菌株间亲缘关系的有向无环图,它能够揭示这些菌株之间的共同祖先和演化路径。
菌株系统进化树是基于菌株间的遗传差异来构建的。
通过对不同菌株的基因组、基因序列和遗传标记进行比较分析,我们可以获得它们之间的遗传距离或相异度。
这些数据可以用来构建菌株系统进化树,从而揭示菌株间的进化关系。
构建菌株系统进化树的过程通常包括以下几个步骤:首先收集不同菌株的样本,提取其基因组或基因序列;然后对这些样本进行测序并得到相应的遗传数据;接着利用生物信息学方法对这些数据进行分析和比较,计算出菌株间的遗传距离;最后利用分子进化模型和统计方法构建进化树,并对其进行进一步的验证和分析。
菌株系统进化树的构建具有重要的应用价值。
首先,它可以帮助我们确定不同菌株之间的亲缘关系,进一步理解它们之间的演化过程和机制。
其次,菌株系统进化树可以为微生物分类学和菌群动态变化研究提供重要的参考和指导。
此外,对于研究菌株的致病性、抗药性和生物学特性等方面,菌株系统进化树也具有重要意义。
综上所述,构建菌株系统进化树是一个重要而复杂的研究课题。
通过比较和分析菌株间的遗传数据,我们可以揭示菌株间的亲缘关系和进化历史,进一步推动微生物学和生物进化学的发展。
在接下来的内容中,我们将详细介绍构建菌株系统进化树的方法和应用,以及对未来研究的展望。
1.2 文章结构文章结构是指文章的组织框架和各个部分的排列顺序。
一个良好的文章结构能够帮助读者更好地理解和掌握文章的内容,并且能够使文章的逻辑关系更加清晰和流畅。
本文的结构分为引言、正文和结论三个部分,具体如下:引言部分(Introduction):在引言部分,首先要对菌株系统进化树的概念进行介绍,解释其所涉及的基本概念和理论背景。
进化树软件MEGA最新6.06说明书

第一步:打开软件下面介绍菜单的使用:Data菜单:Creat a new :创建一个新的数据比对文件,也就是说当我们比对完一组后,想接着比对另一组,那么使用它就可以不用退出直接把数据文件导入;Open :打开先前已经比对并保存好的文件,它包含两个子菜单:retive sequence from file 和saved aligment session ;Close: 关闭当前的比对数据文件;Save session :保存当前比对结果,可以给比对的结果一个文件名;Export alignment :将当前的序列比对结果输出到指定文件,有两种输入格式可供选择:MGTA 和FASTA.DNA sequence :使用它来选择输入的数据DNA 序列,这里需要说明的是如果你输入的数据是氨基酸序列的话,比对窗口只显示一个标签,若是DNA 序列的话则显示两个标签,一个是DNA 序列的,另一个是氨基酸序列的。
Protein sequences :选择输入的氨基酸序列,选择后,所以的位点就被当作氨基酸残基位点来对待。
Translate/untranslate :只有比对的序列是编码蛋白的DNA序列的时候才可用。
它可以根据指定的遗传密码表将DNA 序列翻译成特定的氨基酸序列。
Select genetic code table :使用它将编码蛋白的DNA 翻译成特定的蛋白序列。
R everse complement :将选择的一整行的DNA 序列变为与之互补配对碱基序列。
Exit alignment explorer :退出序列比对的资源管理窗口Edit 菜单:使用这个菜单可以对我们的比对序列进行想要的一些编辑工作具体为Undo:撤销上一步操作;Copy:复制;Cut:剪切;Paste:粘贴;这三个操作都可以只针对一个碱基或氨基酸残基也可以是一段甚至是整个序列;Delete:从比对表格中删除一段序列;Delete gaps:去掉序列中的空缺;Insert blank sequence:重新插入一空行;标签和序列都是空的;Insert sequence from file :从已保存的文件中插入新的序列;Select sites :选择一列序列,与点击比对表上方的灰白空格作用类似;Select sequence:选择一行序列,与点击比对表格左侧的标签名作用类似;Select all:全选;Allow base editing :只读保护,只有选择后才能对序列进行编辑操作,否则所以的序列为只读格式,不能进行任何编辑操作。
基因进化树意义

基因进化树意义基因进化树是基于生物学家对生物基因及其关系的研究,根据相同基因序列和序列间不同之处构建起来的一种树状结构。
这种结构以浅色为根,深色为枝,树干上的节点代表基因的共同祖先,树枝代表了基因的演化历程和进化关系,而叶子则表示基因的存在状态。
基因进化树的意义是研究基因进化关系的重要工具之一,也是生物分类学、演化生物学、种群遗传学、分子进化、生物系统学等领域的基础。
首先,基因进化树可以揭示生物进化的关系。
生物进化受到环境和基因的影响,进而在漫长的进化史中形成了多样化的生物形态。
基因序列是生物进化最为基础的组成部分之一。
基因在不同物种间的变异、突变以及分离等环节,携带的信息也有所不同,经过多次变异和选择后,就能由单个基因发展演化而来。
因此,基因进化树可以反映不同物种之间的进化关系和演化过程,有助于逐一还原和分析生物种类的演化流程。
其次,基因进化树的研究可以帮助构建基因家族。
同一个种类的生物,都有着相似或相同的基因家族类型,这些基因家族的产生和演化的关系都通过基因进化树来反映。
对研究生物家族的形成过程,有助于加深对某些生物的组成和属性的科学认知,使人们对生命的认识更加深化。
第三,基因进化树还能研究群体遗传学与进化过程。
进入二十一世纪,随着生物技术的发展,基因序列比对和分析技术也相应的发展和进步了。
基因进化树可以揭示不同种群间的遗传标记,推断种群遗传结构和演化路线,更好地解决种群遗传学和进化生物学中的问题。
例如,在生命树中,通过基因进化树的系统发育分析,可以推断在哺乳动物之类的动物中,不同物种的共同祖先、进化路线和演化模式,以及不同物种间的生物地理分布等。
第四,基因进化树还可以揭示分类学。
现代分类学起源于卡尔·林奈的工作,随后发展成为若干分类学派别,旨在将不同物种归类为不同的种类,同时研究物种间的相似性和差异性。
基因进化树将不同物种的基因序列联系起来,有助于将不同的有机体归类和分析它们之间的关系,以更好地反映生命的本质和分类学。
进化树分析

V 氨基酸
 例:血红蛋白分子的外区的功能要次于内区的功能,外区的进化速率 是内区进化速率的10倍。
V 核苷酸
 例:DNA密码子的同义替代频率高于非同义替代频率;内含子上的核 苷酸替代频率较高。
分子钟: 进化时间的估计
1. 遗传距离d的计算:
V A. 氨基酸序列:p-距离,d-距离,Γ-距离; V B. DNA序列: Jukes-Cantor距离,Kimura距离;
2. 物种分歧点:使用考古数据确定共有祖先;确 定分化时间T; 3. 计算分子的分化/进化的速率:r=d/2T; 4. 对新的序列,计算分化时间: Tnew=dnew/2r
系统发育分析术语
直系同源(orthologs): 同源的基因是由于共同的 祖先基因进化而产生的. 旁系同源(paralogs): 同源的基因是由于基因复 制产生的.
以上定义源自Fitch, W.M. (1970) Distinguishing homologous from analogous proteins. Syst. Zool. 19, 99–113
系统发育树:三种类型
分支图
Taxon B Taxon C Taxon A Taxon D
1 1
进化树
6
时间度量树
Taxon B Taxon B Taxon C Taxon A Taxon D
Taxon C
Taxon A Taxon D
只用分支 信息,无 支长信息
遗传变化
时间
phastcons使用时物种进化树选择标准

在研究基因组学和生物信息学领域中,物种进化树选择标准是非常重要的。
其中,phastcons作为一种常用的工具,在物种进化树的选择中扮演着关键的角色。
本文将对phastcons的使用时物种进化树选择标准进行全面评估和深入探讨。
1. phastcons的基本概念phastcons是一种用于比较基因组学的工具,可以对多个物种的DNA 序列进行比较,并据此预测基因组的保守元素。
在物种进化树的选择中,phastcons可以帮助确定哪些基因组部分是高度保守的,并可用于筛选重要的进化信息。
2. 物种进化树选择标准的重要性在构建物种进化树时,选择合适的物种是非常重要的。
物种的选择标准需要考虑到它们的进化关系、代表性和可比性等因素。
基于phastcons的分析可以帮助科研人员更好地选择适合的物种,以获得可靠的进化信息。
3. phastcons在物种进化树选择中的应用通过phastcons分析,我们可以识别出哪些物种在特定基因组部分具有高度保守的序列。
这些信息可以用于筛选物种,选择那些对于特定进化问题更有代表性和信息含量的物种。
phastcons也可以帮助确定哪些部分是不适合用于进化分析的,从而避免分析中的误差或偏差。
4. 个人观点和理解在我的理解中,phastcons的使用可以提高物种进化树选择的准确性和可靠性。
通过对基因组的保守元素进行识别,我们可以更好地选择合适的物种进行进化分析,从而获得更为准确和全面的结果。
在未来的研究中,我将继续关注phastcons在物种进化树选择中的应用,并不断改进我的研究方法。
总结回顾phastcons在物种进化树选择中具有重要作用。
它可以帮助我们识别出基因组的保守元素,从而更好地选择适合的物种进行进化分析。
在进行物种选择时,我们应当优先考虑phastcons的分析结果,以获得更为准确和可靠的进化信息。
希望本文的深入探讨能够帮助您更全面、深刻和灵活地理解phastcons在物种进化树选择中的重要性。
系统发育进化树构建

系统发育进化树构建系统发育进化树(Phylogenetic tree)是一种用于描述物种或群体之间进化关系的图形表示。
通过构建系统发育进化树,我们可以了解不同物种之间的亲缘关系,以及它们的共同祖先。
本文将介绍系统发育进化树的构建方法和其在生物学领域中的应用。
一、系统发育进化树的构建方法1. 选择合适的基因或序列:构建系统发育进化树需要选择适当的基因或序列进行分析。
常用的基因包括核糖体RNA(rRNA)和线粒体DNA(mtDNA)等。
2. 收集物种样本:从不同物种中收集样本,并提取相应的基因或序列。
3. 序列比对:将收集到的序列进行比对,找出它们之间的相同和差异。
4. 构建进化模型:根据序列比对的结果,选择适当的进化模型,如最大似然法或贝叶斯推断等。
5. 构建进化树:利用选定的进化模型,根据序列的相似性和差异性,构建系统发育进化树。
二、系统发育进化树的应用1. 物种分类:系统发育进化树可用于物种分类,帮助我们理解不同物种之间的亲缘关系。
通过比较进化树上的分支长度和节点位置,我们可以判断物种之间的相似性和差异性。
2. 进化研究:系统发育进化树可用于研究物种的进化历史和进化速率。
通过比较不同物种之间的进化树,我们可以了解它们的共同祖先以及它们之间的演化路径。
3. 分子演化研究:系统发育进化树在分子演化研究中起着重要的作用。
通过比较不同物种的基因或序列,我们可以推断它们的演化历史和演化速率。
4. 物种保护:系统发育进化树可用于指导物种保护工作。
通过研究物种的进化关系,我们可以了解哪些物种是濒危物种或有特殊保护需求的物种。
5. 药物开发:系统发育进化树可用于药物开发。
通过比较不同物种的基因或序列,我们可以了解它们之间的差异,并找到可能具有药用潜力的物种。
总结:系统发育进化树是一种重要的工具,用于描述物种或群体之间的进化关系。
通过构建系统发育进化树,我们可以了解不同物种之间的亲缘关系,以及它们的共同祖先。
系统发育进化树在物种分类、进化研究、分子演化研究、物种保护和药物开发等领域都有着广泛的应用。
MEGA构建系统进化树的步骤(以MEGA7为例)

MEGA构建系统进化树的步骤(以MEGA7为例)本文是看中国慕课山东大学生物信息学课程总结出来的分子进化的研究对象是核酸和蛋白质序列。
研究某个基因的进化,是用它的DNA序列,还是翻译后的蛋白质序列呢?序列的选取要遵循以下原则:1)如果DNA序列的两两间的一致度≥70%,选用DNA 序列。
因为,如果DNA序列都如此相似,它的蛋白质会相似到看不出区别,这对构建系统发生树是不利的。
所以这种情况下应该选用DNA序列,而不选蛋白质序列。
2)如果DNA序列的两两间的一致度≤70%,DNA序列和蛋白质序列都可以选用。
1. 将要用于构建系统进化树的所有序列合并到同一个fasta格式文件,注意:所有序列的方向都要保持一致( 5’-3’)。
想要做系统发生树先要做多序列比对,然后把多序列比对的结果提交给建树软件进行建树,所以在用MEGA建树时可以输入一个已经比对好的多序列比对,也可以输入一条原始序列,让MEGA先来做多序列比对,再建树(一般我们都是原始序列)。
所以我们以后者为例。
2.打开MEGA软件,选择主窗口的”File”→“Open A File”→找到并打开fasta文件,这时会询问以何种方式打开,我们是原始序列,需要先进行多序列比对,所以选择“Align”。
如果是比对好的多序列比对可以直接选择“Analyze”。
3.在打开的Alignment Explorer窗口中选择”Alignment”-“Align by ClustalW”进行多序列比对(MEGA提供了ClustalW和Muscle两种多序列比对方法,这里选择熟悉的ClustalW),弹出窗口询问“Nothing selected for alignment,Select all?”选择“OK”。
4. 之后,弹出多序列比对参数设置窗口。
这个窗口和EMBL在线多序列比对一样,可以设置替换记分矩阵、不同的空位罚分(罚分填写的是正数,计算时按负数计算)等参数。
祖先采样算法-概述说明以及解释

祖先采样算法-概述说明以及解释1.引言1.1 概述祖先采样算法是一种用于在进化树中选择祖先节点的方法。
在进化生物学中,进化树可以帮助我们理解物种之间的演化关系和进化路径。
祖先采样算法通过模拟随机采样的方式,可以有效地选择进化树中的祖先节点,并用于估计进化树的参数。
本文将介绍祖先采样算法的概念、应用及其优缺点,希望通过对这一算法的深入探讨,能够加深对进化生物学中的祖先节点推断方法的理解,并为未来的研究提供一定的参考。
1.2 文章结构:本文主要分为引言、正文和结论三个部分。
在引言部分,将介绍祖先采样算法的概述、文章结构和目的。
在正文部分,将详细讨论祖先采样算法的概念、应用以及优缺点。
最后,在结论部分,将对全文进行总结,探讨祖先采样算法的未来发展方向,并给出结论。
通过这样的结构安排,读者可以清晰地了解祖先采样算法的相关内容,从而更好地理解和应用该算法。
1.3 目的:祖先采样算法作为一种重要的随机采样方法,在计算机科学和其他领域具有广泛的应用。
本文旨在深入探讨祖先采样算法的概念、应用和优缺点,以便读者更加全面地了解该算法的原理和特点。
同时,通过对祖先采样算法进行分析和比较,帮助读者更好地理解和运用该算法,提高数据处理的效率和准确性。
此外,本文还将探讨祖先采样算法的未来发展方向,为相关领域的研究和应用提供思路和参考。
通过本文的阐述,读者将能够更好地理解祖先采样算法以及其在实际应用中的价值和作用。
2.正文2.1 祖先采样算法的概念祖先采样算法是一种用于从给定的数据集中通过采样方法找到祖先节点的算法。
在树状结构或有向图中,祖先节点是指一个节点向上追溯到根节点的路径中的所有节点。
祖先采样算法通过随机采样的方式,从数据集中选择一定数量的节点,并找出这些节点的祖先节点。
祖先采样算法的核心思想是利用随机采样的方式来快速找到目标节点的祖先节点,从而实现对目标节点的有效分析和处理。
通过对祖先节点的采样,可以更好地了解目标节点在整个结构中的位置和影响。
第七章分子系统发育分析进化树

D C F GA B E†
系统进化树的概念
直系同源(orthol。
旁系同源(paralogs): 同源的基因是由于基因复制产生的。 用于分子进化分析中的序列必须是直系同源的,才能真实
反映进化过程。
旁系同源
直系同源
系统进化树的种类
Eukaryote 4
系统进化树的种类
——物种树、基因树
物种树:代表一个物种或 群体进化历史的系统进化 树,两个物种分歧的时间 为两个物种发生生殖隔离 的时间
基因树:由来自各个物种 的一个基因构建的系统进 化树(不完全等同于物种 树),表示基因分离的时 间。
基因分裂
基因分裂 基因分裂 物种分裂
关于分子钟的讨论和争议
1、对长期进化而言,不存在以恒定速率替换的生物大分子 一级结构;(基因功能的改变、基因数目的增加)
2、不存在通用的分子钟;
3、争议: 分子钟的准确性 中性理论(分子钟成立的基础)
第一节 生物进化的分子机制
分子途经研究生物进化的可行性 分子进化的模式 分子进化的特点 研究分子进化的作用
末端节点:代表最终分类, 可以是物种,群体,或者蛋 白质、DNA、RNA分子等
A
B
C
D 祖先节点/树根
内部节点/分歧点,该
E
分支可能的祖先节点
系统进化树的概念
进化树分支的图像称为进化的拓扑结构 理论上,一个DNA序列在物种形成或基因复制时,
分裂成两个子序列,因此系统进化树一般是二歧 的。
A BC D F G E†
氨基酸
例:血红蛋白分子的外区的功能要次于内区的功能,外区的进化速率 是内区进化速率的10倍。
核苷酸
例:DNA密码子的同义替代频率高于非同义替代频率;内含子上的核 苷酸替代频率较高。
怎样使用MEGA建立进化树

怎样使用MEGA建立进化树在进行生物信息学研究中,建立进化树是一项非常重要的任务。
MEGA (分子进化遗传学分析)是一款常用的软件,专门用于进行进化树和多序列分析。
下面将详细介绍如何使用MEGA建立进化树。
安装完成后,打开MEGA软件。
在MEGA的主界面上,有几个常用的功能选项,包括「File」、「Edit」、「View」、「Tools」、「Align」、「Phylogeny」和「Help」。
我们主要关注「Phylogeny」(进化树)选项。
在新窗口中,我们需要选择构建进化树的方法。
MEGA支持多种构建进化树的方法,包括Neighbor Joining、Maximum Parsimony、Maximum Likelihood和Bayesian等。
在这里,我们以Neighbor Joining方法为例进行演示。
在Neighbor Joining方法中,我们需要先选择计算进化距离的方法。
MEGA支持许多计算进化距离的方法,如P-distance、Kimura 2-parameter、Tamura 3-parameter等。
在这里,我们选择P-distance方法。
在选择了计算进化距离的方法后,我们还需要选择树的标准。
MEGA支持Bootstrap(Bootstrap方法是统计学中一种用于评估统计性信号和树的可靠性的方法)和Nearest-Neighbor Interchange等标准。
在这里,我们选择Bootstrap标准。
在选择了进化距离的方法和树的标准后,我们需要选择输入序列数据的文件格式。
MEGA支持多种格式的序列文件,如FASTA、PHYLIP和MEGA 等。
选择相应的格式后,我们需要导入序列数据。
可以通过从文件中导入或从剪贴板中粘贴来导入序列数据。
MEGA是一款非常强大的进化树分析软件,但对于初学者来说,可能需要一些时间去了解其中的各种选项和功能。
因此,建议在使用MEGA之前,先阅读相关文档和教程,以便更好地使用MEGA进行进化树的构建和分析。
进化树分析
二、系统发育树重建分析步骤
多序列比对(自动比对,手工校正) 确定替换模型 建立进化树 进化树评估
2.1多序列比对
序列多重比对的结果反映了序列之间的相似性, 为系统发育树的构建提供了有价值的信息。为提 高模型估算的精确性,不仅需要选择合适的比对 方法和参数,还需要对后续比对结果进行合理修 正,从中提取有意义的数据集用于系统发育树的 构建。
分子系统发育分析
一、分子进化的基本理论
系统发育(或种系发育、系统发生,phylogeny) 是指生物形成或进化的历史。 系统发育学(phylogenetics)研究物种之间的进化 关系,其基本思想是比较物种的特征,并认为特 征相似的物种在遗传学上接近。
一、分子进化的基本理论
系统发育学是进化生物学的一个重要研究领域, 系统发育分析早在达尔文时代就已经开始。从那 时起,科学家们就开始寻找物种的源头,分析物 种之间的进化关系,给各个物种分门别类。
一、分子进化的基本理论
所有的生物都可以追溯到共同的祖先,生物的产 生和分化就像树一样地生长、分叉,以树的形式 来表示生物之间的进化关系是非常自然的事。可 以用树中的各个分支点代表一类生物起源的相对 时间,两个分支点靠得越近,则对应的两群生物 进化关系越密切。
经典系统发育学
经典系统发育学 主要是物理或表型特征 如生物体的大小、颜色、触角个数 通过表型比较来推断生物体的基因型 (genotype),研究物种之间的进化关系
系统发育树:三种类型
分支图
Taxon B Taxon C Taxon A Taxon D
1 1
进化树
6
时间度量树
Taxon B Taxon B Taxon C Taxon A Taxon D
细菌分类鉴定规程

细菌分类鉴定规程细菌分类鉴定规程杜艳、余翔、罗国升新菌鉴定主要流程:1、潜在新菌的确定拿到拼接好的16Sr RNA gene序列后,进入NCBI blastN (或EzTaxon server (进行比较,同源性低于98%的序列(同源性处于98-97%之间的序列最好少于3株),可初步判断存在新菌的可能。
2、选择标准菌株构建进化树选择参考菌株构建三种进化树(NJ、MP和ML),构建进化树是需要注意以下几点:1)所选择的序列必须都是在IJSEM上正式发表的序列,2)所选择的参考菌株必须包含新菌所在属的所有标准菌株,3)需要选择新菌所在科的一些与新种所在属相近的属的type species作为参考菌株,4)需要选择一个远源的菌株作为参考菌株,如:E. coli。
3、购买标准菌株根据进化树位置和同源性高低选择标准菌株作为参考菌株,联系相关保藏机构购买标准菌株。
具体信息可以在上查找。
标准菌株的选择需遵循以下几点:1) 如果要用到不同的属但不是用这些属的所有的种,则要选择这些属的模式种,并且要选择模式种的模式菌株。
2) 一个属的模式种是最重要的参照微生物,如果一个新种被认为属于这个属,就一定要与该属的模式种进行比较,而其他的种可能分类时出现错误,可能将来会被重新分类。
总之,进行种、属、甚至是科的比较研究时,都要用模式微生物,这就涉及到模式属的模式种,模式种的模式菌。
4、表型特征实验培养特征:菌落特征(如菌落的形状、大小、颜色、隆起、表面状况、质地、光泽、水溶性色素等)。
细胞形态:形态(球形、杆状、弧形、螺旋形、丝状、分枝及特殊形状),大小,排列(单个、成对、成链或其他特殊排列方式)。
特殊的细胞结构:鞭毛(着生位置、数量),芽胞(形状、着生位置、是否膨大),孢子(孢子形状、着生位置、数量、排列),其它(荚膜、细胞附属物为柄、丝状物、鞘、蓝细菌的异形胞、静止细胞和连鞘体等)。
超微结构:细胞壁、细胞内膜系统、放线菌抱子表面特征等。
进化树构建参数

进化树构建参数一、概述进化树构建是生物信息学中的一个重要研究领域,它涉及到许多参数的选择和优化。
进化树构建是基于已知序列的演化关系,通过计算分子进化模型的距离或相似度,从而推断不同物种之间的进化关系。
本文将详细介绍构建进化树时需要考虑的参数。
二、参数种类1. 样本选择:样本选择是构建进化树时必须考虑的第一个因素。
样本数量和种类的选择对于构建出准确可靠的进化树至关重要。
2. 进化模型:不同基因序列在演变过程中所遵循的进化模型是不同的,常见有Jukes-Cantor模型、Kimura 2-parameter模型、HKY85模型等。
3. 距离度量方法:距离度量方法包括无权法(UPGMA)、加权法(WPGMA)、最小演化法(ME)、最大简约法(MP)等。
4. 系统发育假设:系统发育假设包括分子钟假说和非分子钟假说两种,分别应用于有无时间信息两种情况下。
5. 支持率阈值:支持率阈值指代各节点的支持率,通常以Bootstrap值或Bayesian后验概率等指标表示。
支持率阈值越高,节点的可靠性越高,但会导致树的拓扑结构出现偏差。
三、参数选择1. 样本选择:样本应该代表各个物种的演化历史,并且应该包含足够数量的序列以减少噪音和随机误差对结果的影响。
2. 进化模型:进化模型应该选择最适合数据集特征的模型。
可以使用模型比较方法(如AIC、BIC等)来确定最优模型。
3. 距离度量方法:距离度量方法应该根据不同数据集和研究问题进行选择。
UPGMA适用于相对简单的数据集,而ME和MP适用于复杂的数据集。
4. 系统发育假设:系统发育假说应该根据具体情况进行选择。
分子钟假说适用于有时间信息的数据集,而非分子钟假说则适用于无时间信息或时间信息不可靠的数据集。
5. 支持率阈值:支持率阈值应该根据具体情况进行选择。
通常建议设置在70%以上。
四、参数优化1. 交叉验证法:交叉验证法可以用来选择最优的进化模型和距离度量方法。
2. Bootstrap分析:Bootstrap分析可以用来评估节点的支持率阈值,并且可以用来检测树的拓扑结构是否稳定。
进化树步骤
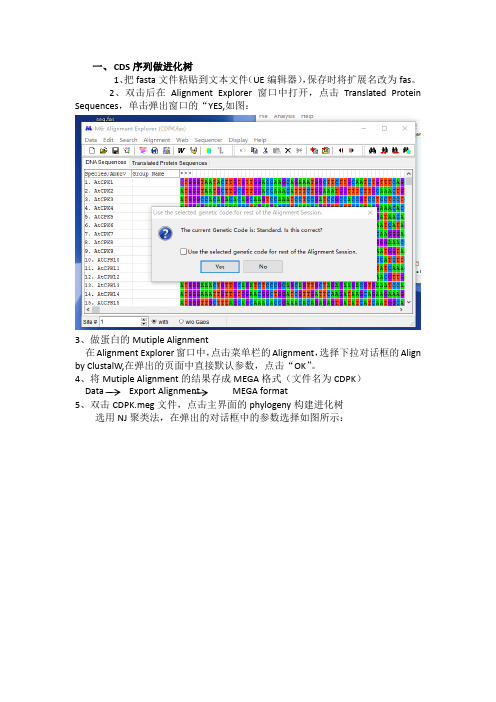
一、CDS序列做进化树
1、把fasta文件粘贴到文本文件(UE编辑器),保存时将扩展名改为fas。
2、双击后在Alignment Explorer窗口中打开,点击Translated Protein Sequences,单击弹出窗口的“YES,如图:
3、做蛋白的Mutiple Alignment
在Alignment Explorer窗口中,点击菜单栏的Alignment,选择下拉对话框的Align by ClustalW,在弹出的页面中直接默认参数,点击“OK”。
4、将Mutiple Alignment的结果存成MEGA格式(文件名为CDPK)
Data Export Alignment MEGA format
5、双击CDPK.meg文件,点击主界面的phylogeny构建进化树
选用NJ聚类法,在弹出的对话框中的参数选择如图所示:
点击compute,进行计算,计算完成后就得到了树状图,保存结果就好了。
二、Consistency序列做进化树
1、把fasta文件粘贴到文本文件(UE编辑器),保存时将扩展名改为fas。
2、双击该文件,在Alignment Explorer窗口中打开,Data E xport Alignment
MEGA format(文件的扩展名是.meg)。
3、双击.meg文件,点击主界面的phylogeny构建进化树
选用NJ聚类法,在弹出的对话框中的参数选择如图所示:
进行计算后就得到了进化树图,进行保存就可以了。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
系统进化树构建及数据分析的简介Posted on 08 六月2009 by 柳城,阅读1,278 简洁版繁體一、引言开始动笔写这篇短文之前,我问自己,为什么要写这样的文章?写这样的文章有实际的意义吗?我希望能够解决什么样的问题?带着这样的疑惑,我随手在丁香园(DXY)上以关键字“进化分析求助”进行了搜索,居然有289篇相关的帖子(2006年9月12日)。
而以关键字“进化分析”和“进化”为关键字搜索,分别找到2,733和7,724篇相关的帖子。
考虑到有些帖子的内容与分子进化无关,这里我保守的估计,大约有3,000~4,000篇帖子的内容,是关于分子进化的。
粗略地归纳一下,我大致将提出的问题分为下述的几类:1.涉及基本概念例如,“分子进化与生物进化是不是一个概念”,“关于微卫星进化模型有没有什么新的进展”以及“关于Kruglyak的模型有没有改进的出现”,等等。
2.关于构建进化树的方法的选择例如,“用boostrap NJ得到XX图,请问该怎样理解?能否应用于文章?用boostrap test中的ME法得到的是XXX树,请问与上个树比,哪个更好”,等等。
3.关于软件的选择例如,“想做一个进化树,不知道什么软件能更好的使用且可以说明问题,并且有没有说明如何做”,“拿到了16sr RNA数据,打算做一个系统进化树分析,可是原来没有做过这方面的工作啊,都要什么软件”,“请问各位高手用ClustalX做出来的进化树与phylip做的有什么区别”,“请问有做过进化树分析的朋友,能不能提供一下,做树的时候参数的设置,以及代表的意思。
还有各个分支等数值的意思,说明的问题等”,等等。
4.蛋白家族的分类问题例如,“搜集所有的关于一个特定domain的序列,共141条,做的进化树不知具体怎么分析”,等等。
5.新基因功能的推断例如,“根据一个新基因A氨基酸序列构建的系统发生树,这个进化树能否说明这个新基因A和B同源,属于同一基因家族”,等等。
6.计算基因分化的年代例如,“想在基因组水平比较两个或三个比较接近物种之间的进化年代的远近,具体推算出他们之间的分歧时间”,“如何估计病毒进化中变异所需时间”,等等。
7.进化树的编辑例如生成的进化树图片,如何进行后续的编辑,比如希望在图片上标注某些特定的内容,等等。
由于相关的帖子太多,作者在这里对无法阅读全部的相关内容而致以歉意。
同时,作者归纳的这七个问题也并不完全代表所有的提问。
对于问题1所涉及到的基本的概念,作者推荐读者可参考由Masatoshi Nei与Sudhir Kumar所撰写的《分子进化与系统发育》(Molecular Evolution and Phylogenetics)一书,以及相关的分子进化方面的最新文献。
对于问题7,作者之一lylover一般使用Powerpoint进行编辑,而Photoshop、Illustrator及Windows自带的画图工具等都可以使用。
这里,作者在这里对问题2-6进行简要地解释和讨论,并希望能够初步地解答初学者的一些疑问。
二、方法的选择首先是方法的选择。
基于距离的方法有UPGMA、ME(Minimum Evolution,最小进化法)和NJ(Neighbor-Joining,邻接法)等。
其他的几种方法包括MP(Maximum parsimony,最大简约法)、ML(Maximum likelihood,最大似然法)以及贝叶斯(Bayesian)推断等方法。
其中UPGMA法已经较少使用。
一般来讲,如果模型合适,ML的效果较好。
对近缘序列,有人喜欢MP,因为用的假设最少。
MP一般不用在远缘序列上,这时一般用NJ或ML。
对相似度很低的序列,NJ往往出现Long-branch attraction(LBA,长枝吸引现象),有时严重干扰进化树的构建。
贝叶斯的方法则太慢。
对于各种方法构建分子进化树的准确性,一篇综述(Hall BG. Mol Biol Evol 2005, 22(3):792-802)认为贝叶斯的方法最好,其次是ML,然后是MP。
其实如果序列的相似性较高,各种方法都会得到不错的结果,模型间的差别也不大。
对于NJ和ML,是需要选择模型的。
对于各种模型之间的理论上的区别,这里不作深入的探讨,可以参看Nei的书。
对于蛋白质序列以及DNA序列,两者模型的选择是不同的。
以作者的经验来说,对于蛋白质的序列,一般选择Poisson Correction(泊松修正)这一模型。
而对于核酸序列,一般选择Kimura 2-parameter(Kimura-2参数)模型。
如果对各种模型的理解并不深入,作者并不推荐初学者使用其他复杂的模型。
Bootstrap几乎是一个必须的选项。
一般Bootstrap的值>70,则认为构建的进化树较为可靠。
如果Bootstrap的值太低,则有可能进化树的拓扑结构有错误,进化树是不可靠的。
对于进化树的构建,如果对理论的了解并不深入,作者推荐使用缺省的参数。
需要选择模型的时候(例如用NJ或者ML建树),对于蛋白序列使用Poisson Correction模型,对于核酸序列使用Kimura-2参数模型。
另外需要做Bootstrap检验,当Bootstrap值过低时,所构建的进化树其拓扑结构可能存在问题。
并且,一般推荐用两种不同的方法构建进化树,如果所得到的进化树类似,则结果较为可靠。
三、软件的选择表1中列出了一些与构建分子进化树相关的软件。
构建NJ树,可以用PHYLIP(写得有点问题,例如比较慢,并且Bootstrap检验不方便)或者MEGA。
MEGA是Nei开发的方法并设计的图形化的软件,使用非常方便。
作者推荐MEGA 软件为初学者的首选。
虽然多雪列比对工具ClustalW/X自带了一个NJ的建树程序,但是该程序只有p- distance模型,而且构建的树不够准确,一般不用来构建进化树。
构建MP树,最好的工具是PAUP,但该程序属于商业软件,并不对学术免费。
因此,作者并不建议使用PAUP。
而MEGA和PHYLIP也可以用来构建进化树。
这里,作者推荐使用MEGA来构建MP树。
理由是,MEGA是图形化的软件,使用方便,而PHYLIP则是命令行格式的软件,使用较为繁琐。
对于近缘序列的进化树构建,MP方法几乎是最好的。
构建ML树可以使用PHYML,速度最快。
或者使用Tree-puzzle,速度也较快,并且该程序做蛋白质序列的进化树效果比较好。
而PAML则并不适合构建进化树。
ML的模型选择是看构出的树的likelihood值,从参数少,简单的模型试起,到likelihood值最大为止。
ML也可以使用PAUP或者PHYLIP来构建。
这里作者推荐的工具是BioEdit。
BioEdit集成了一些PHYLIP的程序,用来构建进化树。
Tree- puzzle是另外一个不错的选择,不过该程序是命令行格式的,需要学习DOS命令。
PHYML的不足之处是没有win32的版本,只有适用于64位的版本,因此不推荐使用。
值得注意的是,构建ML树,不需要事先的多序列比对,而直接使用FASTA格式的序列即可。
贝叶斯的算法以MrBayes为代表,不过速度较慢。
一般的进化树分析中较少应用。
由于该方法需要很多背景的知识,这里不作介绍。
表1 构建分子进化树相关的软件软件网址说明ClustalX http://bips.u-strasbg.fr/fr/Documentation/ClustalX/ 图形化的多序列比对工具ClustalW /biosi/resear ... loads/clustalw.html 命令行格式的多序列比对工具GeneDoc /biomed/genedoc/ 多序列比对结果的美化工具(可以导入fasta格式的文件,出来的图可用于发表,我用过)BioEdit /BioEdit/bioedit.html 序列分析的综合工具MEGA / 图形化、集成的进化分析工具,不包括MLPAUP / 商业软件,集成的进化分析工具PHYLIP /phylip.html 免费的、集成的进化分析工具PHYML http://atgc.lirmm.fr/phyml/ 最快的ML建树工具PAML /software/paml.html ML建树工具Tree-puzzle http://www.tree-puzzle.de/ 较快的ML建树工具MrBayes / 基于贝叶斯方法的建树工具MAC5 /software/mac5/ 基于贝叶斯方法的建树工具TreeView /rod/treeview.html 进化树显示工具(加红色标注的为最通用的分析软件)需要注意的几个问题是,其一,如果对核酸序列进行分析,并且是CDS编码区的核酸序列,一般需要将核酸序列分别先翻译成氨基酸序列,进行比对,然后再对应到核酸序列上。
这一流程可以通过MEGA 3.0以后的版本实现。
MEGA3现在允许两条核苷酸,先翻成蛋白序列比对之后再倒回去,做后续计算。
其二,无论是核酸序列还是蛋白序列,一般应当先做成FASTA格式。
FASTA格式的序列,第一行由符号“>”开头,后面跟着序列的名称,可以自定义,例如user1,protein1等等。
将所有的FASTA格式的序列存放在同一个文件中。
文件的编辑可用Windows自带的记事本工具,或者EditPlus(google搜索可得)来操作。
另外,构建NJ或者MP树需要先将序列做多序列比对的处理。
作者推荐使用ClustalX进行多序列比对的分析。
多序列比对的结果有时需要后续处理并应用于文章中,这里作者推荐使用GeneDoc工具。
而构建ML树则不需要预先的多序列比对。
因此,作者推荐的软件组合为:MEGA + ClustalX + GeneDoc + BioEdit。
四、数据分析及结果推断一般碰到的几类问题是,(1)推断基因/蛋白的功能;(2)基因/蛋白家族分类;(3)计算基因分化的年代。
关于这方面的文献非常多,这里作者仅做简要的介绍。
推断基因/蛋白的功能,一般先用Blast工具搜索同一物种中与不同物种的同源序列,这包括直向同源物(ortholog)和旁系同源物(paralog)。
如何界定这两种同源物,网上有很多详细的介绍,这里不作讨论。
然后得到这些同源物的序列,做成FASTA格式的文件。
一般通过NJ构建进化树,并且进行Bootstrap分析所得到的结果已足够。
如果序列近缘,可以再使用MP构建进化树,进行比较。
如果序列较远源,则可以做ML树比较。
使用两种方法得到的树,如果差别不大,并且Bootstrap总体较高,则得到的进化树较为可靠。
基因/蛋白家族分类。
这方面可以细分为两个问题。
一是对一个大的家族进行分类,另一个就是将特定的一个或多个基因/蛋白定位到已知的大的家族上,看看属于哪个亚家族。