统计学(第四版)袁卫庞皓贾俊平杨灿统计学第七章
统计学贾俊平第四版第七章课后答案目前最全

7.1从一个标准差为5的总体中抽出一个容量为40的样本,样本均值为25。
(1) 样本均值的抽样标准差x σ等于多少?(2) 在95%的置信水平下,允许误差是多少?解:已知总体标准差σ=5,样本容量n =40,为大样本,样本均值x =25, (1)样本均值的抽样标准差x σ=n σ=405=0.7906 (2)已知置信水平1-α=95%,得 α/2Z =1.96, 于是,允许误差是E =nα/2σZ =1.96×0.7906=1.5496。
7.2 某快餐店想要估计每位顾客午餐的平均花费金额。
在为期3周的时间里选取49名顾客组成了一个简单随机样本。
(1)假定总体标准差为15元,求样本均值的抽样标准误差。
x nσ=49==2.143 (2)在95%的置信水平下,求边际误差。
x x t σ∆=⋅,由于是大样本抽样,因此样本均值服从正态分布,因此概率度t=2z α 因此,x x t σ∆=⋅2x z ασ=⋅0.025x z σ=⋅=1.96×2.143=4.2 (3)如果样本均值为120元,求总体均值 的95%的置信区间。
置信区间为:(),x x x x -∆+∆=()120 4.2,120 4.2-+=(115.8,124.2) 7.37.4 从总体中抽取一个n=100的简单随机样本,得到x =81,s=12。
要求:大样本,样本均值服从正态分布:2,xN n σμ⎛⎫ ⎪⎝⎭或2,s xN n μ⎛⎫⎪⎝⎭置信区间为:2x z x z n n αα⎛-+ ⎝n 100=1.2 (1)构建μ的90%的置信区间。
2z α=0.05z =1.645,置信区间为:()81 1.645 1.2,81 1.645 1.2-⨯+⨯=(79.03,82.97)(2)构建μ的95%的置信区间。
2z α=0.025z =1.96,置信区间为:()81 1.96 1.2,81 1.96 1.2-⨯+⨯=(78.65,83.35)(3)构建μ的99%的置信区间。
统计学第四版第7章假设检验(简)总结

Z
第三步:选择显著性水平α ,确定临界值
通常显著性水平由实际问题确定,我们这里取 α=0.05,双侧检验,拒绝域在左右两边,查标准 正态分布表得临界值:
Zα/2= Z0.025=1.96 拒绝域是|Z|>1.96。
11
第四步:判断,作出结论
∵ Z = 1.01 < Zα /2=1.96
∴样本统计量的取值落入接受域。 接受原假设,拒绝备选假设,即认为没有 足够的证据证明该天的生产不符合标准要
分布统计量近似,通常用Z检验代替t检验。
19
例
某厂采用自动包装机分装产品,假定每包
产品的重量服从正态分布,每包标准重量
15
解:
1、提出原假设和备择假设;
2、根据抽样分布,计算样本 统计量; 3、选择显著性水平α ,查表 确定临界值;
Z x 1080 1020 2.4 n 100 / 16
∵ Z = 2.4 > Zα = 1.65
∴样本统计量的取值落入拒绝域。
4、判断并得出结论。
拒绝原假设,接受备选假设,
假设检验分为两类:参数检验、非参数检验/自
由分布检验
2
例1
消费者协会接到消费者投诉,指控品牌纸包装饮
料存在容量不足,有欺骗消费者之嫌。包装上标 明的容量为250毫升。消费者协会从市场上随机抽 取50盒该品牌纸包装饮品,测试发现平均含量为 248毫升,小于250毫升。这是生产中正常的波动, 还是厂商的有意行为?消费者协会能否根据该样 本数据,判定饮料厂商欺骗了消费者呢?
双侧检验
左侧检验
右侧检验
用单侧检验还是双侧检验,使用左侧检验还是右侧检验, 决定于备选假设中的不等式形式与方向。
统计学课后题答案(袁卫_庞皓_曾五一_贾俊平_)

版权归wagxjysys所有违者必究第1章绪论1.什么是统计学?怎样理解统计学与统计数据的关系?2.试举出日常生活或工作中统计数据及其规律性的例子。
3..一家大型油漆零售商收到了客户关于油漆罐分量不足的许多抱怨。
因此,他们开始检查供货商的集装箱,有问题的将其退回。
最近的一个集装箱装的是2 440加仑的油漆罐。
这家零售商抽查了50罐油漆,每一罐的质量精确到4位小数。
装满的油漆罐应为4.536 kg。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)描述推断。
答:(1)总体:最近的一个集装箱内的全部油漆;(2)研究变量:装满的油漆罐的质量;(3)样本:最近的一个集装箱内的50罐油漆;(4)推断:50罐油漆的质量应为4.536×50=226.8 kg。
4.“可乐战”是描述市场上“可口可乐”与“百事可乐”激烈竞争的一个流行术语。
这场战役因影视明星、运动员的参与以及消费者对品尝试验优先权的抱怨而颇具特色。
假定作为百事可乐营销战役的一部分,选择了1000名消费者进行匿名性质的品尝试验(即在品尝试验中,两个品牌不做外观标记),请每一名被测试者说出A品牌或B品牌中哪个口味更好。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)一描述推断。
答:(1)总体:市场上的“可口可乐”与“百事可乐”(2)研究变量:更好口味的品牌名称;(3)样本:1000名消费者品尝的两个品牌(4)推断:两个品牌中哪个口味更好。
第2章统计数据的描述——练习题●1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB ACDE A B D D CA DBC C A ED C BC B C ED B C C B C(1) 指出上面的数据属于什么类型;(2)用Excel制作一张频数分布表;(3) 绘制一张条形图,反映评价等级的分布。
统计学课后习题答案(第四版)贾俊平(第4、5、7、10章)

《统计学》第四版 第四章练习题答案众数:M o =1O;中位数:中位数位置=n+1/2=5.5 , M e =10 ;平均数:(2) Q L 位置=n/4=2.5, Q L =4+7/2=5.5 ; Q u 位置=3n/4=7.5 , Q u =12(4) 4.2 和 M O =23。
将原始数据排序后,计算中位数的位置为:中位数位置=n+1/2=13,第13个位置上的数值为23,所以中位数为 M e =23(2)Q L 位置=n/4=6.25, Q L ==19 ; Q u 位置=3n/4=18.75,Q u =26.5茎 叶 频数 5 5 1 6 6 7 8 3 71 3 4 8 85(3)第一种排队方式: 离散程度大于第二种排队方式。
(4 )选方法二,因为第二种排队方式的平均等待时间较短,且离散程度小于第一种排队方 式。
_ Z X i4.4 ( 1)X8223/30=274.14.1 ( 1 ) 二X i X =n96.9,6 102' (X i-X ) _156.4 42n -1, 9由于平均数小于中位数和众数,所以汽车销售量为左偏分布。
(1)从表中数据可以看出,年龄出现频数最多的是 19和23,故有个众数,即 M O =19(3)⑶平均数-A =600/25=24,标准差—(XLX)\ n —1210626.6525-1n(4) 偏态系数SK=1.08,峰态系数K=0.77(5) 分析:从众数、中位数和平均数来看,网民年龄在 23-24岁的人数占多数。
由于标准差较大,说明网民年龄之间有较大差异。
从偏态系数来看,年龄分布为右偏,由于偏态系数 1,所以,偏斜程度很大。
由于峰态系数为正值,所以为尖峰分布。
(1)茎叶图如下: 大于 4.3 —2'(X 一 X ) 4.080.714nn -1■ 8由于两种排队方式的平均数不同,所以用离散系数进行比较。
(2) X 二一^ =63/9=7, S = ■■n中位数位置=n+1/2=15.5 , M e=272+273/2=272.5(2) Q L位置=n/4=7.5, Q L==(258+261)/2=259.5 ; Q u 位置=3n/4=22.5 , Q u=(284+291)/2=287.5' (^-X ^ /3002-7 = 21.17 I n —1 \ 30—12100 +3000 +15004.5 (1)甲企业的平均成本=总成本/总产量=-2100 3000---- + ----- 15 20乙企业的平均成本=总成本/总产量=3255150015006255=18.293255 1500 1500 342____ + _____ + _____152030原因:尽管两个企业的单位成本相同, 但单位成本较低的产品在乙企业的产量中所占比重较 大,因此拉低了总平均成本。
(完整版)统计学贾俊平考研知识点总结

统计学重点笔记第一章导论一、比较描述统计和推断统计:数据分析是通过统计方法研究数据,其所用的方法可分为描述统计和推断统计。
(1)描述性统计:研究一组数据的组织、整理和描述的统计学分支,是社会科学实证研究中最常用的方法,也是统计分析中必不可少的一步。
内容包括取得研究所需要的数据、用图表形式对数据进行加工处理和显示,进而通过综合、概括与分析,得出反映所研究现象的一般性特征。
(2)推断统计学:是研究如何利用样本数据对总体的数量特征进行推断的统计学分支。
研究者所关心的是总体的某些特征,但许多总体太大,无法对每个个体进行测量,有时我们得到的数据往往需要破坏性试验,这就需要抽取部分个体即样本进行测量,然后根据样本数据对所研究的总体特征进行推断,这就是推断统计所要解决的问题。
其内容包括抽样分布理论,参数估计,假设检验,方差分析,回归分析,时间序列分析等等。
(3)两者的关系:描述统计是基础,推断统计是主体二、比较分类数据、顺序数据和数值型数据:根据所采用的计量尺度不同,可以将统计数据分为分类数据、顺序数据和数值型数据。
(1)分类数据是只能归于某一类别的非数字型数据。
它是对事物进行分类的结果,数据表现为类别,是用文字来表达的,它是由分类尺度计量形成的。
(2)顺序数量是只能归于某一有序类别的非数字型数据。
也是对事物进行分类的结果,但这些类别是有顺序的,它是由顺序尺度计量形成的。
(3)数值型数据是按数字尺度测量的观察值。
其结果表现为具体的数值,现实中我们所处理的大多数都是数值型数据。
总之,分类数据和顺序数据说明的是事物的本质特征,通常是用文字来表达的,其结果均表现为类别,因而也统称为定型数据或品质数据;数值型数据说明的是现象的数量特征,通常是用数值来表现的,因此可称为定量数据或数量数据。
三、比较总体、样本、参数、统计量和变量:(1)总体是包含所研究的全部个体的集合。
通常是我们所关心的一些个体组成,如由多个企业所构成的集合,多个居民户所构成的集合。
统计学第四版(贾俊平)课后思考题答案

统计课后思考题答案第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学-思想方法与应用袁卫等第七章方差分析

聚类分析等。
03
R语言
R语言是一款开源的统计分析软件,具有强大的数据处理和分析能力。
它提供了丰富的统计函数和图形展示功能,用户可以自定义函数和算法
进行数据分析。
方差分析软件操作步骤
数据准备
在进行方差分析之前,需要对 数据进行清洗和整理,确保数
据的准确性和完整性。
选择分析方法
根据研究目的和数据特点选择合 适的方差分析方法,如单因素方 差分析、多因素方差分析等。
方差分析的目的在于通过分析不同来 源的变异对总变异的贡献大小,从而 确定可控因素对研究结果影响力的大 小。
总体与样本方差关系
总体方差是描述总体数据波动程度的 统计量,而样本方差则是描述样本数 据波动程度的统计量。
VS
样本方差是总体方差的一个无偏估计 量,当样本量足够大时,样本方差可 以近似地代替总体方差。
依据。
06
方差分析软件实现与结果 解读
常用统计软件介绍
01
SPSS
SPSS是世界上最早的统计分析软件,操作界面极为友好,输出结果美
观。它集数据录入、整理、分析功能于一身,用户可以根据需要选择合
适的方法进行数据分析。
02
SAS
SAS是一款功能强大的统计分析软件,可以进行数据的处理、分析、预
测和建模。它提供了丰富的统计分析方法,包括方差分析、回归分析、
协方差分析能够消除协变量对观测变量的影 响,更准确地评估控制变量对观测变量的效 应,从而提高研究结果的准确性和可靠性。
协方差分析步骤
确定协变量和控制变量
根据研究目的和专业知识,选择合适的协变量和控制变 量。
参数估计
利用样本数据对模型中的参数进行估计,得到参数估计 值。
统计学原理贾俊平PPT-7汇编

什么显著性水平? 1. 是一个概率值 2. 原假设为真时,拒绝原假设的概率
被称为抽样分布的拒绝域
3. 表示为 (alpha)
常用的 值有0.01, 0.05, 0.10
4. 由研究者事先确定
7 - 15
经济、管理类 基础课程
统计学
作出统计决策
1. 计算检验的统计量
2. 根据给定的显著性水平,查表得出相应 的临界值Z或Z/2
总体服从正态分布 若不服从正态分布, 可用正态分布来近似
(n30)
2. 原假设为:H0: =0;备择假设为:H1: 0 3. 使用z-统计量
z x 0 ~ N (0,1) n
7 - 49
经济、管理类 基础课程
统计学
均值的双尾 Z 检验
(实例)
【例】某机床厂加工一种零件,根 据经验知道,该厂加工零件的椭圆 度近似服从正态分布,其总体均值 为 0=0.081mm , 总 体 标 准 差 为 = 0.025 。今换一种新机床进行加工, 抽取n=200个零件进行检验,得到的 椭圆度为0.076mm。试问新机床加 工零件的椭圆度的均值与以前有无 显著差异?(=0.05)
H0: 10 H1: 10
7 - 26
经济、管理类 基础课程
统计学
双侧检验
(确定假设的步骤)
1. 例如问题为: 检验该企业生产的零件平均 长度为4厘米
2. 步骤
从统计角度陈述问题 ( = 4) 从统计角度提出相反的问题 ( 4)
必需互斥和穷尽
提出原假设 ( = 4) 提出备择假设 ( 4)
▪ 除非样本能提供证据表明使用寿命在1000 小时以下,否则就应认为厂商的声称是正确 的
▪ 建立的原假设与备择假设应为
统计学贾俊平_第四版课后习题答案第七章

7.11 (1) 解:已知n=50,1a -=0.9522,ss x z xz nn a aæö-×+×ç÷èø=81.822981.8229101.491.966,101.491.9665050æö-´+´ç÷èø= (100.89,101.91)(2)解:已知n=50,1a -=0.95,2z a =00.0225z =1.96,样本比率p=(50-5)/50=0.9 则食品合格率的95%的置信区间:()()2211,p p p p p zp z nna aæö--ç÷-×+×ç÷èø=()()0.910.90.910.90.9 1.91.966,0.9 1.91.9665050æö---´+´ç÷èø=(0.8168,0.9832)7.22 (1)由题知,该题为大样本,方差已知,则有21m m -的95%的置信区间为:176.12100201001696.1)2325()(2221212/21±=+´±-=+±-n s n s z x x a即(0.824,3.176)(2m m -的95%的置信区间为:()()64.42112212212/21±=÷÷øöççèæ+-+±-n n s n ntxxpa 即(—2.64,6.64) (3)由题知,该题为小样本,方差不同, 则有21m m -的95%的置信区间为:()()64.42112212212/21±=÷÷øöççèæ+-+±-n n s n n tx x p a 即(—2.64,6.64) (4)由题知,该题为小样本,样本量不等,方差相等,则合并估计量为()()713128524211212222112==-+-+-=n n s n s n s p 则有21m m -的95%的置信区间为:()()02.42112212212/21±=÷÷øöççèæ+-+±-n n s n n tx x p a 即(—2.02,6.02) ,2z a =00.0225z =1.96。
统计学(第四版)袁卫 庞皓 贾俊平 杨灿 统计学 第七章练习题参考解答

STATISTICS
单击练此习处题编第部辑七分母章版参标考题解样答式
练习题7.1
1. 设销售收入 为自变量,销售成本 为因变量。现已根据某百货
公司某年12个月的有关资料计算出以下数据:(单位:万元)
(xt x)2 425053.73 x 647.88
(yt y)2 262855.25
F (k 1, n k) F0.05 (1, 26) 2.91
F=17.70503 F0.05 (1, 26) 2.91
所以y和 联合起来对最终消费有显著影响,即回归方 程整体上是显著的。
练习题7.7
下表给出y对x2和x3回归的结果:
离差来源
平方和(SS) 自由度(df)
由F=58.20479,大于临界值 F0.05 (4 1, 22 4) 3.16 ,
说明模型在整体上是显著的。
练习题7.5
为进一步研究前期的消费对本期消费的影响,准备拟合以下
形式的消费函数: ct 1 yt 2ct1 ut
式中:ct 为t 期的消费;ct1 为 t-1期的消费;yt 为国民总收入。
t 2 (n 2) t0.025 (10) 2.2281 t 245.71875 t0.025 (8) 2.2281
H0 : 0 ,检验说明x对y有显著影响.
(4) 假定下年1月销售收入为800万元,利用拟合的回归方 程预测其销售成本,并给出置信度为95%的预测区间
y 549.8
(xt x)(yt y) 334229.09
(1)拟合简单线性回归方程,并对方程中回归系数的经济意义作 出解释。
统计学第四版第七章课后题最全答案

配对号
来自总体A得样本
来自总体B得样本
1
2
3
4
2
5
10
8
0
7
6
5
(1)计算A与B各对观察值之差,再利用得出得差值计算与。
=1、75,=2、62996
(2)设分别为总体A与总体B得均值,构造得95%得置信区间。
解:小样本,配对样本,总体方差未知,用t统计量
均值=1、75,样本标准差s=2、62996
(2)已知:E=0、1,=0、8,=0、05,=1、96
应抽取得样本量为:=≈62
7.20
(1)构建第一种排队方式等待时间标准差得95%得置信区间。
解:估计统计量
经计算得样本标准差=3、318
置信区间:
=0、95,n=10,==19、02,==2、7
==(0、1075,0、7574)
因此,标准差得置信区间为(0、3279,0、8703)
(3)已知=0、01,=2、58
由于n=100为大样本,所以总体均值得99%得置信区间为:
=812、58*813、096,即(77、94,84、096)
7、5(1)已知=3、5,n=60,=25,=0、05,=1、96
由于总体标准差已知,所以总体均值得95%得置信区间为:
=251、96*250、89,即(24、11,25、89)
7、4(1)已知n=100,=81,s=12, =0、1,=1、645
由于n=100为大样本,所以总体均值得90%得置信区间为:
=811、645*811、974,即(79、026,82、974)
(2)已知=0、05,=1、96
由于n=100为大样本,所以总体均值得95%得置信区间为:
《统计学》(第四版)袁卫 课后答案

1.简述评价估计量好坏的标准
答:评价估计量好坏的标准主要有:无偏性、有效性和相合性。设总体参数 的估计量有 和 ,如果 ,称 是无偏估计量;如果 和 是无偏估计量,且 小于 ,那么 比 更有效;如果当样本容量 , ,那么 是相合估计量。
答:总体参数的区间估计是在一定的置信水平下,根据样本统计量的抽样分布计算出用样本统计量加减抽样误差表示的估计区间,使该区间包含总体参数的概率为置信水平。置信水平反映估计的可信度,而区间的长度反映估计的精确度。
答:数据分布特征一般可从集中趋势、离散程度、偏态和峰度几方面来测度。常用的指标有均值、中位数、众数、极差、方差、标准差、离散系数、偏态系数和峰度系数。
4怎样理解均值在统计中的地位?
答:均值是对所有数据平均后计算的一般水平的代表值,数据信息提取得最充分,
具有良好的数学性质,是数据误差相互抵消后的客观事物必然性数量特征的一种反映,在统计推断中显示出优良特性,由此均值在统计中起到非常重要的根底地位。受极端数值的影响是其使用时存在的问题。
条形图〔略〕
2〔1〕采用等距分组:
n=40全距=152-88=64取组距为10
组数为64/10=6.4取6组
频数分布表如下:
40个企业按产品销售收入分组表
按销售收入分组
〔万元〕
企业数
〔个〕
频率
〔%〕
向上累积
向下累积
企业数
频率
企业数
频率
100以下
100~110
110~120
120~130
130~140
原因:尽管两个企业的单位本钱相同,但单位本钱较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均本钱。
11. = 〔万元〕;
统计学课件贾俊平人大课件-2024鲜版

常用的统计软件包括SPSS、SAS、Stata、R等,这些软件提供了丰富的统计功能和数据分析工具,方便研 究者进行数据分析和挖掘。
6
02
描述统计学
2024/3/28
7
数据收集与整理
数据来源
明确数据的来源,包括观察、实 验、调查等。
数据类型
区分数据的类型,如定量数据、 定性数据。 2024/3/28
时间序列图
将时间序列数据绘制成图形,直观展示数据的波动情况。
自相关图
展示时间序列数据与其自身不同时间延迟版本之间的相关性。
2024/3/28
偏自相关图
在给定其他时间延迟的情况下,展示时间序列数据与其自身某个 时间延迟版本之间的相关性。
26
时间序列的预测方法
移动平均法
通过计算历史数据的移动平均值来预测 未来值。
无交互作用的双因素方差分析
当两个因素相互独立时,分别考虑各自对试 验结果的影响
2024/3/28
有交互作用的双因素方差分析
当两个因素存在交互作用时,需同时考虑两 个因素及其交互作用对试验结果的影响
19
05
相关与回归分析
2024/3/28
20
相关分析
2024/3/28
相关关系的概念
介绍相关关系的定义、特点和分类,阐述相关分析与回归分析的关 系。
相关系数的计算与检验
详细讲解皮尔逊相关系数、斯皮尔曼等级相关系数的计算方法和假 设检验,包括检验步骤、检验统计量和决策规则。
相关系数的解释
阐述相关系数的大小、方向和显著性水平对所研究变量的意义,以 及需要注意的问题。
21
一元线性回归分析
一元线性回归模型
介绍一元线性回归模型的形式、 假设和参数估计方法,包括最小 二乘法和最大似然法。
统计学(第三、四版)答案 (作 者: 袁卫庞皓 曾五一 贾俊平主编—)

统计学(第三、四版)作者:袁卫庞皓曾五一贾俊平主编第2章统计数据的描述练习:2.1为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB ACDE A B D D CA DBC C A ED C BC B C ED B C C B C(1) 指出上面的数据属于什么类型;(2)用Excel制作一张频数分布表;(3) 绘制一张条形图,反映评价等级的分布。
2.2某行业管理局所属40个企业2002年的产品销售收入数据如下(单位:万元):1521241291161001039295127104105119114115871031181421351251171081051101071371201361171089788123115119138112146113126(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率;(2)如果按规定:销售收入在125万元以上为先进企业,115万~125万元为良好企业,105万~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
2.3某百货公司连续40天的商品销售额如下(单位:万元):41252947383430384340463645373736454333443528463430374426384442363737493942323635根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
2.4为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果如下:700716728719685709691684705718706715712722691708690692707701708729694681695685706661735665668710693697674658698666696698706692691747699682698700710722694690736689696651673749708727688689683685702741698713676702701671718707683717733712683692693697664681721720677679695691713699725726704729703696717688(1)利用计算机对上面的数据进行排序;(2)以组距为10进行等距分组,整理成频数分布表,并绘制直方图;(3)绘制茎叶图,并与直方图作比较。
2024版统计学课件(贾俊平)人大课件

统计学课件(贾俊平)人大课件contents •统计学概述•统计数据的收集与整理•统计描述分析•统计推断分析•统计决策分析•统计软件应用与实践目录统计学概述统计学的定义与特点定义统计学是一门研究数据收集、整理、分析和解释的方法论科学,旨在探索数据内在的数量规律性。
特点统计学具有广泛的应用性、严密的数学性和明确的目的性。
它通过收集和分析数据来揭示总体特征,为决策提供依据。
03现代统计学时期计算机技术的广泛应用,使得大规模数据处理和复杂模型分析成为可能,推动了统计学的快速发展。
01古典统计学时期主要关注国家管理和人口统计,如古希腊、罗马和中国的古代统计实践。
02近代统计学时期概率论和数理统计学的形成与发展,为现代统计学奠定了基础。
统计学的发展历史统计学的研究对象与分类研究对象统计学的研究对象是数据,包括各种类型、来源和形式的数据。
分类根据研究目的和方法的不同,统计学可分为描述统计学和推断统计学两大类。
描述统计学主要关注数据的整理、描述和可视化;推断统计学则通过样本数据推断总体特征。
社会经济领域生物医药领域工程技术领域环境科学领域统计学的应用领域人口普查、经济分析、市场调研等。
质量控制、可靠性分析、优化设计等。
临床试验、基因测序、流行病学调查等。
环境监测、生态评估、气候变化研究等。
统计数据的收集与整理数据的来源与类型数据来源包括直接来源(如调查、实验)和间接来源(如文献资料、网络数据)。
数据类型包括定性数据和定量数据,其中定量数据又可分为离散型和连续型。
数据收集的方法与步骤方法包括问卷调查、访谈、观察、实验等。
步骤明确调查问题、确定调查对象、选择调查方法、设计调查问卷或实验方案、实施调查或实验、收集并整理数据。
数据整理的原则与方法原则确保数据的准确性、完整性、及时性和一致性。
方法包括数据清洗(如去除重复、异常值处理)、数据转换(如标准化、归一化)、数据分组与编码等。
数据质量的评估与控制评估指标包括准确性、完整性、及时性、一致性、可比性和可解释性等。
贾俊平_统计学(第四版)最完整的答案(用一次就知道是我想要的)
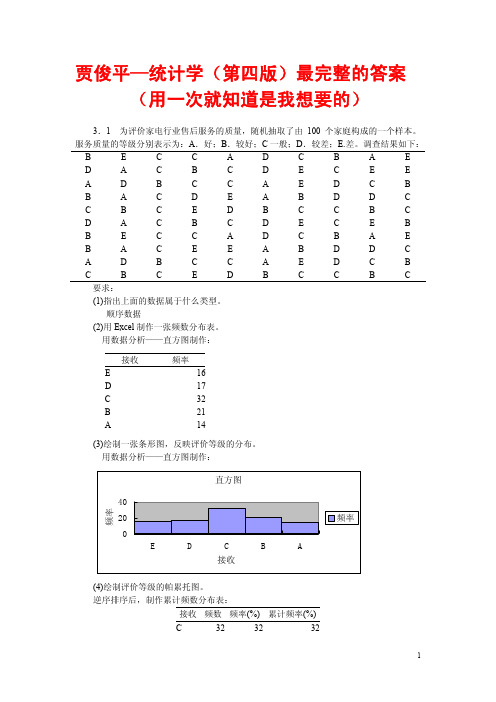
3.6一 种 袋 装 食 品 用 生 产 线 自 动 装 填 ,每 袋 重 量 大 约 为 50g,但 由 于 某 些 原 因 , 每 袋 重 量 不 会 恰 好 是 50g 。 下 面 是 随 机 抽 取 的 100 袋 食 品 , 测 得 的 重 量 数 据 如 下: 单位:g 57 46 49 54 55 58 49 61 51 49 51 60 52 54 51 55 60 56 47 47
直方图:
6
组距3,小于
30
20
Frequency
10
Mean =5.22 Std. Dev. =1.508 N =100 0 0 2 4 6 8 10
组距3,小于
组距 4,上限为小于等于 频数 有效 <= 40.00 41.00 - 44.00 45.00 - 48.00 49.00 - 52.00 53.00 - 56.00 57.00 - 60.00 61.00+ 合计 1 7 28 28 22 13 1 100 百分比 1.0 7.0 28.0 28.0 22.0 13.0 1.0 100.0 累计频数 1 8 36 64 86 99 100 累积百分比 1.0 8.0 36.0 64.0 86.0 99.0 100.0
贾俊平—统计学(第四版)最完整的答案 (用一次就知道是我想要的)
3.1 为评价家电行业售后服务的质量,随机抽取了由 100 个家庭构成的一个样本。 服务质量的等级分别表示为:A.好;B.较好;C 一般;D.较差;E.差。调查结果如下: B D A B C D B B A C E A D A B A E A D B C C B C C C C C B C C B C D E B C E C E A C C E D C A E C D D D A A B D D A A B C E E B C E C B E C B C D D C C B D D C A E C D B E A D C B E E B C C B E C B C
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
统计学一、相关关系的概念
1.变量间的相互关系
◆确定性的函数关系 Y=f (X) ◆不确定性的统计关系—相关关系 Y= f(X)+ε (ε为随机变量) ◆没有关系
变量间关系的图形描述: 坐标图(散点图)
35 30 25 20 15 10 5 0
Y
0
10 X
20
30
统计学
STATISTICS
2、相关关系的类型
统计学
STATISTICS
三、 Spearman等级相关系数
当变量不满足正态分布要求或不是数量型变量时, 简单 线性相关系数不宜使用,可以用Spearman等级相关系数 作相关性分析。 对于样本容量为n的变量x 和y ,如果取值都可以分为n 个等级,而且样本的n个单位分别不重复地属于x和y的 不同等级,没有两个单位取相同等级的情况,并且用 d i 表示样本单位属于x的等级与 y的等级的级差。 Spearman等级相关系数 为:
●
从涉及的变量数量看 简单相关 多重相关(复相关) ● 从变量相关关系的表现形式看 线性相关——散布图接近一条直线(左图) 非线性相关——散布图接近一条曲线(右图)
25 20 15 10 5 0 0 2 4 6 8 10 12
11.2 11 10.8 10.6 10.4 10.2 10 0 2 4 6 8 10
rXY
统计学
STATISTICS
● 样本相关系数
通过x和y 的样本观测值去估计样本相关系数变量 x和y的样本相关系数通常用 rxy 表示
rXY
rxy
( x x )( y y ) (x x) ( y y)
i i __ 2 __ i i
__
__
2
特点:样本相关系数是根据从总体中抽取的随机样本 的观测值计算出来的,是对总体相关系数的估 计,它是个随机变量。
问题: 肥胖症和体重超常与死亡人数真有显著 的数量关系吗? 这些类型的问题可以运用相关分析与回归分析的 方法去解决。
统计学
STATISTICS
第7章 相关与回归分析
7.1 7.2 7.3 7.4
相关分析 一元线性回归分析 线性回归的显著性检验与回归预测 多元线性回归分析
统计学
STATISTICS
35 30 25 20 15 10 5 0 0 5 10 15
统计学
STATISTICS
二、相关系数
●总体相关系数
对于所研究的总体,表示两个相互联系变量相关程度 的总体相关系数为:
Cov( x, y ) Var ( x)Var ( y )
总体相关系数反映总体两个变量X和Y的线性相关程度。 特点:对于特定的总体来说,X和Y的数值是既定的 总体相关系数是客观存在的特定数值。
统计学
STATISTICS
使用相关系数的注意事项:
▲ x和y 都是相互对称的随机变量,所以
xy yx
▲相关系数只反映变量间的线性相关程度,不 能说明非线性相关关系。 ▲相关系数不能确定变量的因果关系,也不能 说明相关关系具体接近于哪条直线。
统计学
STATISTICS
相关系数的检验
为什么要检验? 样本相关系数是随抽样而变动的随机变量, 相关系数的统计显著性还有待检验。 检验的依据: 如果x与都服从正态分布,在总体相关系 数 0 的假设下,与样本相关系数 r 有关的 t 统计量服从自由度为n-2的 t 分布:
统计学
STATISTICS
● 从变量相关关系变化的方向看 正相关——变量同方向变化 A 同增同减 (A) 负相关——变量反方向变化 一增一减 (B) B ● 从变量相关的程度看 完全相关 (B) 不完全相关 (A) C 不相关 (C)
25 20 15 10 5 0 0 2 4 6 8 10 12
25 20 15 10 5 0 0 2 4 6 8 10 12
rs 1
n(n2 1)
6 di2
统计学
STATISTICS
Spearman等级相关系数的特性
统计学
STATISTICS
实例2: 全球吃死的人比饿死的人多?
据世界卫生组织统计,全球肥胖症患者达3 亿人,其中儿童占2200万人,11亿人体重过重。 肥胖症和体重超常早已不是发达国家的“专利”, 已遍及五大洲。目前,全球因”吃”致病乃至死 亡的人数已高于因饥饿死亡的人数。
(引自《光明日报》刘军/文)
学习目标
1、变量间的相关关系与相关系数的计算 2、总体回归函数与样本回归函数 3、线性回归的基本假定 4、一元线性回归参数的估计与检验 5、多元线性回归参数的估计与检验 6、回归预测的方法
统计学
STATISTICS
7.1 相关与回归的基本概念
一、相关关系的概念 二、相关系数 三、相关
STATISTICS
统计学
STATISTICS
第7章
相关与回归分析
统计学 实例1:
STATISTICS
中国妇女生育水平的决定因素是什么?
妇女生育水平除了受计划生育政策影响以外,还可能 与社会、经济、文化等多种因素有关。 1、影响中国妇女生育率变动的因素有哪些? 2、各种因素对生育率的作用方向和作用程度如何? 3、哪些因素是影响妇女生育率主要的决定性因素? 4、如何评价计划生育政策在生育水平变动中的作用? 5、计划生育政策与经济因素比较,什么是影响生育率的 决定因素? 6、如果某些地区的计划生育政策及社会、经济、文化 等因素发生重大变化,预期对这些地区的妇女生育 水平会产生怎样的影响?
统计学
STATISTICS
相关系数的特点:
相关系数的取值在-1与1之间。 当r=0时,表明x与y没有线性相关关系。 当 0 r 1 时,表明x与y存在一定的线性相
关关系: 若 r 0 表明x与y 为正相关; 若 r 0 表明x与y为负相关。 当 r 1 时,表明x与y 完全线性相关: 若r=1,称x与y 完全正相关; 若r=-1,称x与y 完全负相关。
t r n2 1 r 2 ~ t (n 2)
统计学
STATISTICS
相关系数的检验方法
给定显著性水平 , 查自由度为 n-2 的临界值 t
2
若 t t 2 ,表明相关系数 r 在统计上是显著 的,应否定 0 而接受 0 的假设; 反之,若 t t 2 ,应接受 0 的假设。