音频压缩编码原理及标准共69页文档
语音的压缩编码

长途电话 (8 KHz x 8 bit x 1), 时分多路复用TDM (time-division multiplexing)
应用于全频带数字声音的表示/存储:
CD-DA(CD唱片),DAT (44.1 KHz x 16 bit x 2)
原理: 声音信号具有很强的相关性,可从已知信号来预测未知信号, 即使用前面的样本预测当前的样本,实际样本值与预测值之间的误差往往很小。 利用自适应的思想改变量化阶的大小,即使用小的量化阶(step-size)去编码小的差值,使用大的量化阶去编码大的差值, 效果:量化位数可以显著减少,从而降低了总的码率。
+
预测值
差值
重建信号
DPCM
编码输出
CCITT G.721 ADPCM编码器
A
量化阶适配器
自适应
( 4 位 )
6阶自适应线性预测, 4位的自适应量化器, 输出码率: 8k x 4 = 32 kbps
ADPCM 小结
PCM话音质量 4.5级 ADPCM话音质量 4.34级,码率降低一倍(32 kbps)。 ADPCM应用: 数字语音通信 多媒体应用中的语音(解说词)
ADPCM自适应差分脉冲编码调制 (Adaptive Differential PCM)
增量调制(DM)
差分脉冲编码调制 DPCM
实际样本值
利用样本与样本之间存在的相关性进行编码,即根据前面的样本估算当前样本的大小,然后对预测误差进行量化编码。
差值
线性预测公式: Xn = A1*Xn-1 + A2*Xn-2 + ... + Am*Xn-m
举例
根据输入样本幅度的大小来改变量化阶大小。 可以是瞬时自适应,即量化阶的大小每隔几个样本就改变,也可以是音节自适应,即量化阶的大小在较长时间周期里发生变化。
音频编码和解码原理.doc

每张CD光盘重放双声道立体声信号可达74分钟。
VCD视盘机要同时重放声音和图像,图像信号数据需要压缩,其伴音信号数据也要压缩,否则伴音信号难于存储到VCD光盘中。
一、伴音压缩编码原理伴音信号的结构较图像信号简单一些。
伴音信号的压缩方法与图像信号压缩技术有相似性,也要从伴音信号中剔除冗余信息。
人耳朵对音频信号的听觉灵敏度有其其规律性,对于不同频段或不同声压级的伴音有其特殊的敏感特性。
在伴音数据压缩过程中,主要应用了听觉阈值及掩蔽效应等听觉心理特性。
1、阈值和掩蔽效应(1) 阈值特性人耳朵对不同频率的声音具有不同的听觉灵敏度,对低频段(例如100Hz以下)和超高频段(例如16KHZ 以上)的听觉灵敏度较低,而在1K-5KHZ的中音频段时,听觉灵敏度明显提高。
通常,将这种现象称为人耳的阈值特性。
若将这种听觉特性用曲线表示出来,就称为人耳的阈值特性曲线,阈值特性曲线反映该特性的数值界限。
将曲线界限以下的声音舍弃掉,对人耳的实际听音效果没有影响,这些声音属于冗余信息。
在伴音压缩编码过程中,应当将阈值曲线以上的可听频段的声音信号保留住,它是可听频段的主要成分,而那些听觉不灵敏的频段信号不易被察觉。
应当保留强大的信号,忽略舍弃弱小的信号。
经过这样处理的声音,人耳在听觉上几乎察觉不到其失真。
在实际伴音压缩编码过程中,也要对不同频段的声音数据进行量化处理。
可对人耳不敏感频段采用较粗的量化步长进行量化,可舍弃一些次要信息;而对人耳敏感频段则采用较细小的量化步长,使用较多的码位来传送。
(2)掩蔽效应掩蔽效应是人耳的另一个重要生理特征。
如果在一段较窄的频段上存在两种声音信号,当一个强度大于另一个时,则人耳的听觉阈值将提高,人耳朵可以听到大音量的声音信号,而其附近频率小音量的声音信号却听不到,好像是小音量信号被大音量信号掩蔽掉了。
由于其它声音信号存在而听不到本声音存在的现象,称为掩蔽效应。
根据人耳的掩蔽特性,可将大音量附近的小音量信号舍弃掉,对实际听音效果不会发生影响。
第三讲音频压缩编码.

Effect of temporal and frequency masking
depending on both time and closeness in frequency.
Li & Drew
23
15500
22050
6550
12
1720
2000
280
在时间上相邻的声音之间也有掩蔽现象。时域掩蔽又分为超前掩蔽和滞后掩蔽。超前掩蔽很短,只有大约5~20 ms,而滞后掩蔽可以持续50~200 ms。
4、时域掩蔽
t
后掩蔽
前掩蔽
同期掩蔽强音
时间掩蔽利用
•基于时间掩蔽效应的编码策略是,编码时将时间上相继的一些样值归并成块,并计算每块内最大样值的比例因子;
信噪比(SNR=20lgL/N
信噪比(SNR=6.02n+1.76
N:量化噪声电平,n:量化比特数
重要结论:量化比特数增加1,
量化信噪比提高6dB
。
5、感知编码器原理
•放弃物理上的同一性
•得到感知上的同一性
降低数据率
掩蔽的用途
q去除会被掩蔽的信号分量
v因为即使传输了也不会被听见§同听阈以下的信号部分不能被人耳听到(称不相关部分),不必传送。(去除不相关部分)
–500Hz以下每个临界频带的带宽大约是100Hz,从500Hz起,临界频带带宽线性增加。
–一个临界频带的带宽单位为1巴克(bark。
0Hz
500Hz
20000Hz f
… …
临界频带单位巴克(Bark)
•对于任何掩蔽频率,巴克被定义为一个临界频带的宽度;
音频压缩编码技术

要的作用。由于人们的听觉系统存在着某些不敏感效 应,某些情况下的音频不能被感知,因此从感知效果 来看这些不敏感的音频分量可认为是知觉冗余。如果 将这部分冗余压缩掉,可提高编码效率,这是音频压 缩的另一个理论基础。ຫໍສະໝຸດ 4、对音频数据压缩的两个途径
(1)利用信号本身的统计特性,在完全不丢失 信息的情况下进行高效的熵编码(平均信息量编码) (2)利用人们对音频信号的感知特性,通过省 略人们所不能分辨或不敏感的信息来压缩信息量,这 就是知觉编码。
就找出信噪比的新估计值,重新计算该子带的掩蔽噪声 比。上述过程重复进行,直到再没有多余的比特可分配 了为止,这个过程称为比特分配。 按输入信号的大小来改变量化步长,输入信号小时 用较小的量化步长,输入信号大时用较大的量化步长。 因此,需要将码中的比特分为两组,一组比特用来量化 步长大小,这组比特代表幅度值的“比例因子”,其余 比 特用来均匀量化与这些量化步长对应的信号,这组比特 代表幅度值的“尾数”。通常量化信噪比SNR取决于位 数 的比特数。 MPEG-1音频数据是一帧一帧传送的,Layer1每帧 有32个子带组成,每个子带包括12个样值每帧有384个
PCM输入
32子带滤波 器组
MDCT
非线性量化 比特率控制
Huffman 编码
复
码流 输出
用 1024点FFT 心理声学模型 辅助数据 编码
Layer3音频编码器框图
声音码流
Huffman 编码 解复用 纠错 边信息 编码
比例因子 恢复
IM DCT
32子带综合 样 滤波器组 值
输 出
Layer3音频解码器框图
,如比特率标记。然后是长度为16bit的循环冗余码,接 着是用于描述比特分配长度为4bit的比特分配域,长度 为6bit的比例因子域,以及子带样值域等。
视频压缩编码和音频压缩编码的基本原理

视频压缩编码和⾳频压缩编码的基本原理本⽂介绍⼀下视频压缩编码和⾳频压缩编码的基本原理。
事实上有关视频和⾳频编码的原理的资料很的多。
可是⾃⼰⼀直也没有去归纳和总结⼀下,在这⾥简单总结⼀下,以作备忘。
1.视频编码基本原理(1)视频信号的冗余信息以记录数字视频的YUV分量格式为例,YUV分别代表亮度与两个⾊差信号。
⽐如对于现有的PAL制电视系统。
其亮度信号採样频率为13.5MHz。
⾊度信号的频带通常为亮度信号的⼀半或更少,为6.75MHz或3.375MHz。
以4:2:2的採样频率为例,Y信号採⽤13.5MHz。
⾊度信号U和V採⽤6.75MHz採样,採样信号以8bit量化,则能够计算出数字视频的码率为:13.5*8 + 6.75*8 + 6.75*8= 216Mbit/s如此⼤的数据量假设直接进⾏存储或传输将会遇到⾮常⼤困难,因此必须採⽤压缩技术以降低码率。
数字化后的视频信号能进⾏压缩主要根据两个基本条件:l 数据冗余。
⽐如如空间冗余、时间冗余、结构冗余、信息熵冗余等,即图像的各像素之间存在着⾮常强的相关性。
消除这些冗余并不会导致信息损失,属于⽆损压缩。
l 视觉冗余。
⼈眼的⼀些特性⽐⽅亮度辨别阈值,视觉阈值,对亮度和⾊度的敏感度不同,使得在编码的时候引⼊适量的误差,也不会被察觉出来。
能够利⽤⼈眼的视觉特性。
以⼀定的客观失真换取数据压缩。
这样的压缩属于有损压缩。
数字视频信号的压缩正是基于上述两种条件,使得视频数据量得以极⼤的压缩,有利于传输和存储。
⼀般的数字视频压缩编码⽅法都是混合编码,即将变换编码,运动预计和运动补偿。
以及熵编码三种⽅式相结合来进⾏压缩编码。
通常使⽤变换编码来消去除图像的帧内冗余,⽤运动预计和运动补偿来去除图像的帧间冗余。
⽤熵编码来进⼀步提⾼压缩的效率。
下⽂简介这三种压缩编码⽅法。
(2)压缩编码的⽅法(a)变换编码变换编码的作⽤是将空间域描写叙述的图像信号变换到频率域。
然后对变换后的系数进⾏编码处理。
压缩编码标准

2、数据压缩方法
无损压缩 有损压缩
统计编码
行 程 编 码 哈 夫 曼 编 码 香 农 编 码 算 LZW 术 编 编 码 码
PCM编码 PCM编码
预测编码
变换编码
混合编码
DPCM编码 DPCM编码 ADPCM编码 ADPCM编码 帧间预测 编码
离散余弦 变换 K-L变换 小波变换
JPEG MPEG H.261
二、有损压缩:压缩时会丢失部分数据,且丢失的数 据无法恢复。是不可逆的压缩,即解压缩以后的数据 将模拟量经过采样、量化和编码得到其数字编码。 (脉冲编码调制) 根据算法模型,用已有的样本值对新样本进行预测,得 到一个预测值,将实际值与预测值相减得到预测误差, 再对该误差值进行编码,如果预测越准确,误差值就 对该误差值进行编码, 对该误差值进行编码 越小(那误差的幅度肯定小于原始信号),那编码所需 的位数就可以减少,达到压缩的目的。 将原始信号从一个域(如时间域)变换到另一个域(如 频率域),然后对变换后的信号进行编码。主要用于图 像数据的压缩。
第6章 多媒体数据的压缩
6.1 数据压缩概述
数据压缩的必要性 数据冗余
6.2 数据压缩的基本原理
信息编码基础 数据压缩方法
6.3 数据压缩的编码算法
统计编码( 统计编码(行程编码 预测编码 变换编码
哈夫曼编码
算术编码) 算术编码)
6.4 常用多媒体数据压缩标准
音频压缩编码标准 静态图像压缩标准 动态图像压缩标准视频压缩编码标准
6.1
数据压缩概述
声音、图像、 声音、图像、视频和动画的数据量太大
1、 压缩的必要性
声音 分钟立体声音乐采样频率为44.1KHZ 16位量化精度的数据量为 44.1KHZ, 1分钟立体声音乐采样频率为44.1KHZ,16位量化精度的数据量为 44.1 * 1000 * 16 * 2 *60 / 8 =10.09MB 存储一首4分钟的歌曲约需40MB 存储一首4分钟的歌曲约需40MB 图像
音频压缩编码原理及标准69页PPT

谢谢!
51、 天 下 之 事 常成 于困约 ,而败 于奢靡 。——陆 游 52、 生 命 不 等 于是呼 吸,生 命是活 动。——卢 梭
53、 伟 大 的 事 业,需 要决心 ,能力 ,组织 和责任 感。 ——易 卜 生 54、 唯 书 籍 不 朽。——乔 特
1、不要轻言放弃,否则对不起自己。
2、要冒一次险!整个生命就是一场冒险。走得最远的人,常是愿意 去做,并愿意去冒险的人。“稳妥”之船,从未能从岸边走远。-戴尔.卡耐基。
梦 境
3、人生就像一杯没有加糖的咖啡,喝起来是苦涩的,回味起来却有 久久不会退去的余香。
音频压缩编码原理及标准 4、守业的最好办法就是不断的发展。 5、当爱不能完美,我宁愿选择无悔,不管来生多么美丽,我不愿失 去今生对你的记忆,我不求天长地久的美景,我只要生生世世的轮 回里有你。
55
音频压缩编码原理及标准.共69页

11、获得的成功越大,就越令人高兴 。野心 是使人 勤奋的 原因, 节制使 人枯萎 。 12、不问收获,只问耕耘。如同种树 ,先有 根茎, 再有枝 叶,尔 后花实 ,好好 劳动, 不要想 太多, 那样只 会使人 胆孝懒 惰,因 为不实 践,甚 至不接 触社会 ,难道 你是野 人。(名 言网) 13、不怕,不悔(虽然只有四个字,但 常看常 新。 14、我在心里默默地为每一个人祝福 。我爱 自己, 我用清 洁与节 制来珍 惜我的 身体, 我用智 慧和知 识充实 我的头 脑。 15、这世上的一切都借希望而完成。 农夫不 会播下 一粒玉 米,如 果他不 曾希望 它长成 种籽; 单身汉 不会娶 妻,如 果他不 曾希望 有小孩 ;商人 或手艺 人不会 工作, 如果他 不曾希 望因此 而有收 益。-- 马钉路 德。
25、学习是劳动,是充满思想的劳动。——乌申斯基
谢谢!
21、要知道对好事的称颂过于夸大,也会招来人们的反感轻蔑和嫉妒。——培根 22、业精于勤,荒于嬉;行成于思,毁于随。——韩愈
23、一切节省,归根到底都归——莎士比亚
第6章 音频压缩编码技术及其国际标准-2

6.2.1 MPEG-1音频压缩编码标准
MPEG-1(ISO/IEC11172)标准的第三部分(ISO/ IEC 11172-3),称为MPEG-1 音频。它是世界上第 一个高保真声音数据压缩标准,得到极其广泛的 应用
编码器的输入信号为线性PCM信号 采样率为32, 44.1或48 kHz,16位
12
6.2.1 MPEG-1音频压缩编码标准
动态比特分配
全局掩蔽阈值决定了每个子带所容许的最大量化噪声, 对于那些信掩比小于1的子带,完全不用编码,直接丢 弃就可以了
对于信掩比大于等于1的子带,如果将尾数都量化为相 同的比特数,那么不同子带的掩蔽阈值和量化噪声的比 (掩蔽噪声比)往往是不同的,为了使声音质量最佳, 应当使各个子带的掩蔽噪声比相等。
由于临界频带不是等宽的,所以低频端的子带可能覆盖 了多个临界频带。
MPEG AUDIO 滤波器组频带
频率增加
临界频带
9
6.2.1 MPEG-1音频压缩编码标准
MPEG-1 Audio 的滤波器组输出 第一层每帧包含384个时域样本,每个子带输出 12个频域样本。每32个时域样本每子带输出1个 频域样本。 第二层和第三层每帧为1152个时域样本,每个 子带输出36个频域样本
512点 FFT
心理声学 模型
32 量化编码
比例因子
音频 复 码流 用 器
比特 动态 分配 比特分配
图6.3 Layer I 音频编码器框图
8
6.2.1 MPEG-1音频压缩编码标准
MPEG-1 Audio 的滤波器组
输入的音频信号首先通过一个多通道滤波器组,变换成 等宽的32个子带,这些滤波器组的输出是临界频带系数 样值。
11
数字音频压缩编码

数字音频压缩编码一、 PCM脉冲编码调制PCM 脉冲编码调制是Pulse Code Modulation的缩写。
脉冲编码调制是数字通信的编码方式之一。
主要过程是将话音、图像等模拟信号每隔一定时间进行取样,使其离散化,同时将抽样值按分层单位四舍五入取整量化,同时将抽样值按一组二进制码来表示抽样脉冲的幅值。
编码原理:PCM脉冲编码调制是对连续语音信号进行空间采样、幅度值量化及用适当码字将其编码的总称,即它把连续输入的模拟信号变换为在时域和振幅上都离散的量,然后将其转化为代码形式传输或存储,原理框图如图所示。
在图中,它的输入是模拟声音信号,输出是PCM样本。
图中的“防失真滤波器”是一个低通滤波器,用来滤除声音频带以外的信号;“波形编码器”可暂时理解为“采样器”;“量化器”可理解为“量化阶大小”(Step—Size)生成器或者称为“量化间隔”生成器。
PCM原理框图优点:音源信息保存完整,音质好。
缺点:信息量大,体积大,冗余度过大。
二、DPCM差值编码调制DPCM编码是对模拟信号幅度抽样的差值进行量化编码的调制方式。
这种方式是用已经过去的抽样值来预测当前的抽样值,对它们的差值进行编码。
差值编码可以提高编码频率,这种技术已应用于模拟信号的数字通信之中。
编码原理:DPCM采用预测编码的方式传输信号,所谓预测编码就是根据过去的信号样值来预测下一个信号样值,并仅把预测值与现实样值的差值加以量化,编码后进行数字信号传输。
在接收端经过和发送端相同的预测操作,低通滤波器便可恢复出与原始信号相近的波形。
优点:DPCM的压缩比不高,但它容易硬件实现,成本低,因此应用比较普遍。
缺点:有误码扩散。
即:如果在量化或传输中出现了噪声,那么它不仅仅停留在发生误码的地方,而是继续向以后的象素值扩散。
三、ADPCM自适应差分脉冲编码调制自适应脉冲编码调制是一种根据输入信号幅度大小来改变量化阶大小的一种波形编码技术。
这种自适应可以是瞬时自适应,即量化阶的大小每隔几个样本就改变;也可以是音节自适应,即量化阶的大小在较长时间周期里发生变化。
第3章 数字音频压缩编码技术及标准
层次
算法
压缩比
4:1 6:1~8:1 10:1~12:1
立体声信号所对应的数码率
384 kbit/s 256~192 kbit/s 128~112 kbit/s
54
Ⅰ MUSICAM* Ⅱ MUSICAM Ⅲ ASPEC * *
3.5.2 MPEG-1音频编码的基本原理
MPEG-1使用感知音频编码来达到既压缩音频数 据又尽可能保证音质的目的。 听觉系统有许多特性,感知音频编码的理论依据 是听觉系统的掩蔽效应特性。 其基本思想就是在编码过程中保留有用的信息而 丢掉被掩蔽的信号,其结果是经编解码之后重构 的音频信号与编码之前的原始音频信号不完全相 同,但人的听觉系统很难感觉到它们之间的差别。
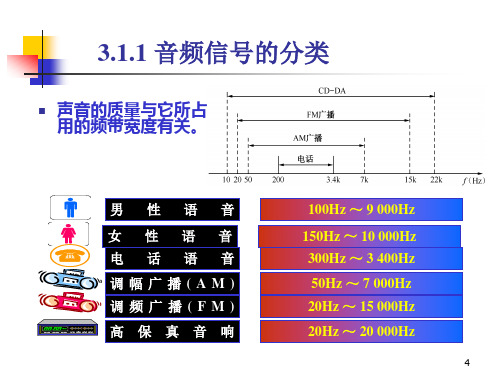
3.1.1 音频信号的分类
声音的质量与它所占 用的频带宽度有关。
男 女 电
性 性 话
语 语 语
音 音 音
100Hz ~ 9 000Hz 150Hz ~ 10 000Hz 300Hz ~ 3 400Hz
调幅广播(AM)
调频广播(FM) 高 保 真 音 响
50Hz ~ 7 000Hz
20Hz ~ 15 000Hz 20Hz ~ 20 000Hz
4
3.2 数字音频压缩编码的必要性和可能性 数字音频压缩的必要性
1秒钟声音文件的数据量(不压缩):
采样频率(Hz) 量化精度(比特数) 声道数 8 1024 1024 (MB)
例:计算1分钟双声道、16bit量化精度、44.1kHz采 样频率声音的不压缩的数据量是多少?
44.1103 16 2 S 60 10.09(MB) 8 1024 1024
56
MPEG-1 Audio Layer II 的码流结构
音频压缩编码原理及标准

三、音频压缩编码原理及标准
编辑p编码的基本原理 2、MPEG-1 音频压缩编码标准 3、杜比AC-3 音频压缩算法 4、 其他MPEG音频压缩编码
编辑ppt
2
音频压缩编码原理及标准
音频压缩编码的基本原理 音频信号压缩编码的必要性 数字音频的质量取决于:采样频率和量化位数这两个参数,为 了保真在时间变化方向上取样点尽量密,取样频率要高;在幅度取 值上尽量细,量化比特率要高 ,直接的结果就是存储容量及传输信 道容量要求的压力 音频信号的传输率 = 取样频率* 样本的量化比特数*通道数
由听觉冗余引出了降低数据率 ,实现更高效率的数字音频传输 的可能
编辑ppt
8
音频压缩编码原理及标准
音频压缩编码的基本原理 音频压缩编码方法的分类及典型代表 编码 信号系统如何把一定的信息内容包含在少量特定信号的排列组
合之中 1、采用一定的格式来记录数字数据 2、采用一定的算法来压缩数字数据以减少存贮空间和提高传
7
音频压缩编码原理及标准
音频压缩编码的基本原理 音频信号压缩编码的可能性 听觉冗余 根据分析人耳对信号频率、时间等方面具有有限分辨能力而设
计的心理声学模型,将通过听觉领悟信息的复杂过程,包括接受信 息,识别判断和理解信号内容等几个层次的心理活动,形成相应的 连觉和意境
由此构成声音信息集合中的所以数据,并非对人耳辨别声音的 强度、音调、方位都产生作用,形成听觉冗余
编辑ppt
4
音频压缩编码原理及标准
音频压缩编码的基本原理 音频信号压缩编码的可能性 数字音频信号中包含的对人们感受信息影响可以忽略的成分称
为冗余,包括时域冗余、频域冗余和听觉冗余 时域冗余 时域冗余的表现形式 1、幅度分布的非均匀性 信号的量化比特分布是针对信号的整个动态范围而设定的,对
音频压缩编码原理及标准

27
统计编码
依据各个信号幅值出现的概率不同进行概率匹配编码 熵编码是依据声音信号幅度的概率分布特点,通过合理
的比特数分配使得信号概率与比特数之间相匹配,以达 到降低平均码长的目的
28
可变字长编码
29
3.2 MPEG-1音频压缩编码标准
比例因子用6个bit来表示 每12采样值并成的块进行一次比特分配,并记录一个比例 因子
35
MPEG-1 层1 3、快速傅里叶变换(FFT)
信号从时域变换到频域的过程 使信号具有高的频率分辨率,为心理声学模型分析提供 信号的频谱特征
4、心理声学模型
MPEG-1 层1把音频信号分到频域子带,然后根据每个子 带内的量化噪声的大小对每个子带进行量化。为了达到 最大的压缩比,应求出每个子带的量化级数使得量化噪 声恰好不被听到
目标:计算子带的信号掩蔽比(SMR)
36
① 数字音频信号用傅里叶FFT变时域为频域 ② 确定每个子带的声压级 ③ 确定安静状态的阈值 ④ 找出声音信号中的纯音和非纯音成分 ⑤ 单独掩蔽域值的计算 ⑥ 总体掩蔽阈值的计算 ⑦ 每个子带最小掩蔽阈值的确定 ⑧ 每个子带的信号-掩蔽比率的计算
37
MPEG-1 层1 5、动态比特分配
变换编码:变换到频域,根据心理声学模型对变换系数 进行量化和编码
22
首先用一组带通滤波器把输入的音频信号分成若干个连 续的子带,然后对每个子带中的音频信号单独编码,在 接收端将各子带单独译码,然后组合、还原成音频信号。
对每个子带的采样值分配不同的比特数。低频分配较多 量化比特,高频分配较少量化比特。利用声音信号的频 谱特点及人耳的感知模型。