spss第二章,数据的编码、录入与整理
实验二SPSS大数据录入与编辑

实验二SPSS大数据录入与编辑实验二 SPSS数据录入与编辑一、实验目的通过本次实验,要求掌握SPSS的基本运行程序,熟悉基本的编码方法、了解如何录入数据和建立数据文件,掌握基本的数据文件编辑与修改方法。
二、实验性质必修,基础层次三、主要仪器及试材计算机及SPSS软件四、实验容1.录入数据2.保存数据文件3.编辑数据文件五、实验学时2学时(可根据实际情况调整学时)六、实验方法与步骤1.开机2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS3.认识SPSS数据编辑窗4.按要求录入数据5.联系基本的数据修改编辑方法6.保存数据文件7.关闭SPSS,关机。
七、实验注意事项1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。
2.遇到各种难以处理的问题,请询问指导教师。
3.为保证计算机的安全,上机过程中非经指导教师和实验室管理人员同意,禁止使用移动存储器。
4.每次上机,个人应按规定要求使用同一计算机,如因故障需更换,应报指导教师或实验室管理人员同意。
5.上机时间,禁止使用计算机从事与课程无关的工作。
八、上机作业一、定义变量1. 试录入以下数据文件,并按要求进行变量定义。
1)对性别(Sex)设值标签“男=0;女=1”。
2)正确设定变量类型。
其中学号设为数值型;日期型统一用“mm/dd/yyyy“型号;生活费用货币型。
3)变量值宽统一为10,身高与体重、生活费的小数位2,其余为0。
2.试录入以下数据文件,保存为“数据1.sav”。
实验三统计图的制作与编辑一、实验目的通过本次实验,了解如何制作与编辑各种图形。
二、实验性质必修,基础层次三、主要仪器及试材计算机及SPSS软件四、实验容1.条形图的绘制与编辑2.直方图的绘制与编辑3.饼图的绘制与编辑五、实验学时2学时六、实验方法与步骤1.开机;2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS;3.按要求完成上机作业;4. 关闭SPSS,关机。
实验二SPSS数据录入与编辑

实验二SPSS数据录入与编辑SPSS数据录入与编辑一、引言SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,广泛应用于社会科学、市场调研、医学研究等领域。
在进行数据分析之前,首先需要将原始数据录入到SPSS软件中,并进行必要的数据编辑。
本文将详细介绍SPSS数据录入和编辑的标准格式。
二、数据录入1. 打开SPSS软件并创建新的数据文件。
在SPSS软件界面上方的菜单栏中,选择"File" -> "New" -> "Data",创建一个新的数据文件。
2. 定义变量名称和属性。
在数据文件中,每一列代表一个变量。
在第一行录入变量的名称,确保名称准确且易于理解。
在第二行录入变量的属性,包括变量的测量类型(如数值型、字符型、日期型等)和宽度(即变量所占的字符数)。
3. 逐行录入数据。
从第三行开始,逐行录入数据。
确保每一列的数据与对应的变量匹配,避免录入错误。
4. 保存数据文件。
在菜单栏中选择"File" -> "Save",保存数据文件。
建议将文件保存为SPSS的标准格式(.sav)。
三、数据编辑1. 缺失值处理。
在数据录入过程中,可能会出现一些数据缺失的情况。
可以使用SPSS软件提供的缺失值标记来表示缺失数据。
在数据文件中,将缺失值用特定的数值或符号表示,方便后续的数据分析。
2. 数据清洗。
数据清洗是指对数据进行筛选、排除异常值、修正错误等操作,以保证数据的质量和准确性。
可以使用SPSS软件提供的数据筛选、变量计算、数据转换等功能进行数据清洗。
3. 数据转换。
在进行数据分析之前,有时需要对数据进行转换,以满足分析的需求。
例如,可以进行数据归一化、对数变换、指标构建等操作。
SPSS软件提供了丰富的数据转换函数和操作,可以根据需求进行相应的数据转换。
SPSS教程第二章2.数据编辑与整理
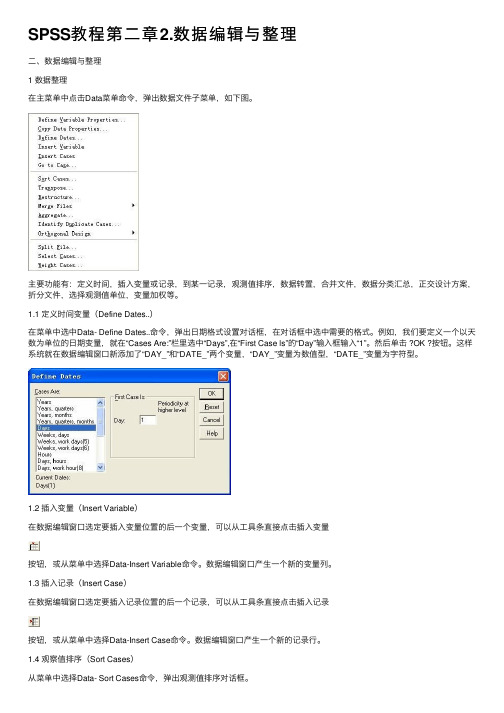
SPSS教程第⼆章2.数据编辑与整理⼆、数据编辑与整理1 数据整理在主菜单中点击Data菜单命令,弹出数据⽂件⼦菜单,如下图。
主要功能有:定义时间,插⼊变量或记录,到某⼀记录,观测值排序,数据转置,合并⽂件,数据分类汇总,正交设计⽅案,折分⽂件,选择观测值单位,变量加权等。
1.1 定义时间变量(Define Dates..)在菜单中选中Data- Define Dates..命令,弹出⽇期格式设置对话框,在对话框中选中需要的格式。
例如,我们要定义⼀个以天数为单位的⽇期变量,就在“Cases Are:”栏⾥选中“Days”,在“First Case ls”的“Day”输⼊框输⼊“1”。
然后单击 ?OK ?按钮。
这样系统就在数据编辑窗⼝新添加了“DAY_”和“DATE_”两个变量,“DAY_”变量为数值型,“DATE_”变量为字符型。
1.2 插⼊变量(Insert Variable)在数据编辑窗⼝选定要插⼊变量位置的后⼀个变量,可以从⼯具条直接点击插⼊变量按钮,或从菜单中选择Data-Insert Variable命令。
数据编辑窗⼝产⽣⼀个新的变量列。
1.3 插⼊记录(Insert Case)在数据编辑窗⼝选定要插⼊记录位置的后⼀个记录,可以从⼯具条直接点击插⼊记录按钮,或从菜单中选择Data-Insert Case命令。
数据编辑窗⼝产⽣⼀个新的记录⾏。
1.4 观察值排序(Sort Cases)从菜单中选择Data- Sort Cases命令,弹出观测值排序对话框。
Sort by:选择排序变量。
对所选变量的观测值排序。
如果选择了两个以上的变量,其排序结果将按变量在本栏的选⼊顺序依次排序。
Sort Order:排序⽅式:⊙ Ascending:升序排列。
数值型变量由⼩到⼤排列,字符型变量按ABCD字母顺序排列。
系统默认项。
○ Descending:数值型变量由⼤到⼩排列,字符型变量按ZYX字母顺序由后向前排列。
第2章 SPSS 17.0 基本操作与数据管理

(2)字符型:
字符型编变量由字符串组成,可以包含数字、字母和一些特殊符号。字符型变 量的默认长度为8,大于8个字符的称为长字符型变量,少于8个字符的称为短字
符型变量,字符型变量最长为32767个字符。他不能参与运算,区分大小写字母。
(3)日期型: 日期型变量用于表示日期和时间,他有29种不同的日期和时间格式,不能参与运算 ,要参与必须通过日期函数进行转换。 如:1-12-2009、29.12.99等
2.1.2 常量、变量、操作符和表达 一 、 常量与变量 式
1.SPSS常量 SPSS中的常量在一定阶段内其取值不随观测而改变的值。有3种类型 (1)数值型: 数据型常量是一个数值。他有两种书写方式: 一是普通书写方式,如:53、74.2等; 二是科学计数书写方式,其使用指数表示数值,通常用于表示贴别大 或特别小的数值。如:1.2E+05 表示1.2×105 (2)字符型: 字符型常量是被单引号或双引号括起来的一串字符。如果本身带有单 引号或半个单引号,则必须使用双引号括起来。 如:beijing 处理时用双引号扩起来,即“beijing” (3)日期型: 按特定格式存储日期数据 ,一般使用较少 格式很多,如:20-AUG-1999
(2)比较表达式
比较表达式是利用关系运算符建立起的两个变量间的比较关系,要求相 互比较的两个量类型一致,他的结果一般逻辑型。
如:x=2,则表达式“x>0”为真,系统返回1(true)。
(3)逻辑表达式
逻辑表达式由逻辑运算符、逻辑型的变量或取值为逻辑型的比较表达式 构成。他的值为逻辑型常量。如:对于表达式“true AND true” 系统 返回“true ” , “true OR false” 系统返回“true ” 。
数据的编码录入与整

量值(Value) 是指问卷中的答案,也称为观测值,在SPSS系统里,单元格中的数
值就是变量值
a
11
六、定义变量
启动SPSS后进入数据编辑窗口,显示为一个空文件,输入数据前首先要 定义变量。
建立数据 文件
定义数据文件结 构
数据加工 整理
1-选;0-不选 1-选;0-不选
选
1
不选 0
1-选;0-不选
选
1
a
7
四、缺失值的处理
1. 概念 缺失值是指在数据采集与整理过程中丢失的内容,往往会给统
计分析带来一些麻烦和误差。
2. 类型 用户缺失值 在问卷调查中把不回答的选项当作缺失值来处理 缺失值可用研究者能识别的数字来表示如“0、9、99”
第5题
A B C(A-1,B-2,C-3)
A
第6题
A B C(A-3,B-2,C-1)
A
样例 1 3
a
5
三、编码类型
2. 非数值型数据的编码
非数值型数据的编码,首先要确定编码规则 ,然后根据规则对变量赋予分值。
双值型变量的编码
多采用“0、1”或“1、2”来赋值;如编码示例中的第1 题
变量名多值型变量的编码 编码
姓名 张三 李四 王五 赵六
性别 男 女 女 男
出生日期 87-1-1 88-6-30 88-8-18
88-12-24
专业编号 01 02 03 02
a
10
五、数据处理中的操作术语
样本(Sample) 是指具有共同属性的所有研究对象,如学生的所有信息 样本包含多个个案,在数据表格中表示为“n行”
变量(Variable) 是指问卷中每一个问题,数据库里字段,数据表格中表示为“一列
第二讲 SPSS简介及数据编码录入

SPSS数据的结构和定义方法
(一)变量名(Variable name)
变量名是变量存取的唯一标志。 起名规则:
不多于8个字符组成 不区分大小写 允许汉字作为变量名 默认变量名为VARn,如:var00001
(二)变量的类型(type)和显示宽度(width)
1、数值型:
标准数值型(Numeric):默认类型 8.2 如: 12345678、12345.67、-1234.56
编码:根据一定的规则将研究资料转换为可 进行统计分析的数码资料的过程。
姓名 周汝今 马帅 丁一 古晨 江峰 孙悦 王小霞 胡萍 张红 曲萍
10名青少年身高体重表
性别 男
年龄 13
身高 156.0
男
13 155.0
男
14 157.9
男
15 166.0
男
14 164.5
女
14 164.7
女
13 158.0
ordinal: 有固有顺序的顺序水准的数值型或字符型数据。 如:职称、年龄段
nominal: 无固有顺序的名义水准的数值型或字符型数据。 如:性别、民族
查看变量的定义情况
菜单选项: Utilities -> Variables
第二节 SPSS数据编码录入
进入SPSS之前的准备工作:
编码 录入
(三)变量名标签(Variable label)
对变量名的一些解释说明,增强分析结果的可视性。 可以省略。
(四)变量值标签(Value label)
对变量所取值的一些解释说明,增强分析结果的可视性。可 以省略。 一般用于品质数据 如:1-男 2-女、1-高 2-中 3-低
(五)缺失值(Missing Values)
spss数据的录入与管理

3、用ODBC接口读取各种数据库文件 demo.mdb 文件 打开数据库 新建查询
2.5 数据的保存
1、保存为SAV格式
2、保存为其他数据格式
第三章 变量级别的数据管理 变量级别的数据管理:转换
文件级别的数据管理:数据
转换
1、计算新变量:最为常用和重要的过程 2、变量转换:从菜单第2项开始的多个计数过程、重编码
过程和离散化过程.实际上可以看成是计算变量过程某1方 面的强化和打包. 3、时间序列模型专用过程:时间和日期向导、创建时间 序列、替换缺失值
4、自动数据准备 5、其他:随机数字生成器第5章、运行挂起的转换
3.1 变量赋值
变量赋值就是指在原有数据的基础上,根据用户的要求, 使用SPSS算术表达式及函数,对所有记录或满足SPSS条件表达 式的某些记录进行四则运算,并将结果存入1个用户指定的变 量中,该指定变量可以是1个新变量,也可以是1个已经存在的 变量.
1、定义验证规则 数据 验证 定义规则 2、进行数据验证 数据 验证 验证数据 3、加载预定义规则 数据 验证 加载预定义规则
Predefined Validation Rules.sav
标识重复个案 标识异常个案
数据的录入与管理
报告人:
第二章 数据录入与数据获取
第三章 变量级别的数据管理 第四章 文件级别的数据管理
第二章 数据录入与数据获取
数据的直接录入 非电子化的原始数据资料,需要直接将调查问卷中的数据录入 进SPSS软件中,建立数据文件.
外部数据的获取 已经被录入为其他数据格式的资料,需要将其内容直接读入 SPSS中.
1、算术表达式:由常量、SPSS变量名、SPSS算术运算 符+、-、、/、圆括号等组成的式子.数据类型和结果均为数 值型.
非常详细的SPSS实用教程

2.3.8 数据次序确定
选择“Transform”菜单中的“Rank Cases”命令,弹出“Rank Cases”对话框,如图2-18所示,在该对话框中可以改变数据排序的次序。
图2-18 “Rank Cases”对话框
图2-19 “Rank Cases:Types”对话框
01
排序类型如下。
2.3.3 数据的排序
图2-10 “Sort Cases”(排序)对话框
在数据文件中,可根据一个或多个排序变量的值重排个案的顺序。
2.3.4 数据的行列互换
图2-11 “Transpose”对话框
2.3.5 选取个案子集
在数据统计中可从所有资料中选择部分数据进行统计分析。
图2-12 “Select Cases”对话框
图2-7 保存为另外的数据格式文件
SPSS Portable(*.por)
用户确定盘符、路径、文件名以及文件格式后单击“Save”按钮,即可保存为指定类型的数据文件。SPSS支持的常见的数据文件存放格式如下。
SPSS/PC+(*.sys)
SPSS(*.sav)
Tab delimited(*.dat)
2
图2-23 “Compute Variable”(计算变量)对话框
图2-24 条件表达式对话框
2.4.4 产生计数变量
在统计过程中,往往需要进行一些计数工作。产生计数变量就是实现计数功能,它对所有个案或满足一定条件的个案,计算若干个变量中有几个变量的值落在指定的区间内,并将计数结果放入一个新变量中。
定 义 变 量
01
启动SPSS后,出现如图2-1所示数据编辑窗口。由于目前还没有输入数据,因此显示的是一个空文件。
spss第二讲数据整理data、transform

38
SPSS统计软件
变量清单
将汇总变量 加入当前数
据 替代当前数
据文件 创建汇 总文件
分组变量
汇总统计 量
汇总统计量清单
39
SPSS统计软件 文件级数据整理 4.文件的拆分
操作提示:Data →Split File…
2)按班号对技能成绩大于60分的成绩进行汇总, 另存为新的数据文件。
3)以姓名定义新变量名,进行行列转置,另存为“转置.sav”。
48
SPSS统计软件
数据管理练习
3、数据:新医学生成绩.sav 要求:1)描述不同班级(号)学生的妇科和儿科平均成绩与标准差,结果保 存为“新成绩.spv”。 2)选出内科成绩大于18的学生,描述其外科成绩平均水平,结果保存为 “外科成绩.spv”。
Recode可以用于字符型变量
23
SPSS统计软件
演示:将数据transform.sav中字符型“city”变量转化为数 值型变量“newcity”。(按照字母排序)
24
SPSS统计软件 变量级数据整理:4.Rank Cases
编秩变量 分组变量
操作提示: Transform →Rank Cases
SPSS统计软件
第二讲 SPSS数据整理
课前复习
1
SPSS统计软件
SPSS的特点
SPSS操作界面----三个窗口 SPSS的保存
(新医学生成绩)
2
SPSS统计软件
SPSS数据格式
1.一条记录占一行(反映某个研究对象具体特征的一组观测值。 ) 2.一个变量占一列(测量指标) 3.SPSS数据分析时特殊数据格式(配对设计、重复测量资料数据) 最终的数据集应当包含原始数据的所有信息
SPSS 第二单元 数据文件的编辑与整理

SPSS应用 应用
Compute过程 2、Compute过程 Compute过程可以根据由若干个旧变量组成的表达 Compute过程可以根据由若干个旧变量组成的表达 式建立新变量,也可以使用SPSS函数建立新变量, SPSS函数建立新变量 式建立新变量,也可以使用SPSS函数建立新变量, 例如,在本例中要建立一个新变量, 例如,在本例中要建立一个新变量,以储存语文与 数学成绩中较好者。 数学成绩中较好者。
SPSS应用 应用
三、记录的插入和删除
插入一个记录: 1、插入一个记录:鼠标单击要插入的一行最左边的 序号单元格后,即可单击Data→Insert Cases菜单 序号单元格后,即可单击Data→Insert Cases菜单 项插入一个记录,也可单击鼠标右键,单击Insert 项插入一个记录,也可单击鼠标右键,单击Insert Cases。 Cases。 2、删除一个记录:鼠标单击要删除的记录的序号单 删除一个记录: 元格,单击Edit→Clear菜单项,或单击鼠标右键, Edit→Clear菜单项 元格,单击Edit→Clear菜单项,或单击鼠标右键, 单击Clear或直接按Delete Clear或直接按Delete键 单击Clear或直接按Delete键。
SPSS应用 应用
从左侧变量框中将一个或若干个要进行分组的变 量名选入Group on框 最多可以选择8 量名选入Group Based on框。最多可以选择8个变 量作为分组的依据。 量作为分组的依据。 如果只选择了一个变量, 如果只选择了一个变量,以后的分析会依据该变 量的每一个值分为一组,分别进行分析。例如, 量的每一个值分为一组,分别进行分析。例如,选 择性别变量,分析时分别按性别=1和性别=2 =1和性别=2把记录 择性别变量,分析时分别按性别=1和性别=2把记录 Case)分为两组进行分析。 (Case)分为两组进行分析。 如果选择了若干个变量, 如果选择了若干个变量,以后的分析将会依据所 选变量各水平的组合分组,对每组分别进行分析。 选变量各水平的组合分组,对每组分别进行分析。
SPSS简介及数据编码录入

或: Data list file=’c:\lianxi\lianxi.dat’/ num 1-4 W01 5 W01a 6-7 W02 8 W03 9 W04 10.
整理课件
19
1-2要求: •变量名不能超过8个字符; •变量名不能以数字开头; •变量名中不能包含+,-,×,/、?、=等运 算和逻辑符号。 •当相邻变量名称上存在顺序且码位相同时,可用 简略方法 : W02 8 W03 9 W04 10.可换为 W02 to W04 8-10. •当变量值是字符时,在码位后加(a);如: W7 12(a); •当变量值包含小数时,在码位后加(n),n表示 小数的位数。如:446.79,在录入时要录成 44679,定义时为:W12 12-16(2);
4-1 格式: Missing Value 变量名 变量名 变量名……(缺失值1, 缺失值2,……) / 变 量 名 变 量 名 变 量 名 ……( 缺 失 值 1 , 缺 失 值 2,……) .
示例: Missing Value W01 W02 W03(9)/W04 (0,9) /W01a W8.1 W8.2 W8.3(99) .
三大社会科学统计软件包之一(SAS、SPSS、
Statis)。我们现在使用的是SPSS for Windows 8.0
版。
整理课件
2
2 进入SPSS之前的准备工作
编码 录入
2-1数据资料的形式及编码 2-1-1数据资料的形式:
矩阵式数据数据要求每一横行为一个个案(Case), 纵列按变量排列,形成矩阵格式。
8‘研究生以上’
/W04 1‘不识字或识字很少’ 2‘初小’ 3‘高小’
4‘初中’
整理课件
26
3-2 要求: •变量名要和已定义过的名称相一致; •标签用中、西文均可,但长度不要超过60个字符, 即30个汉字。
spss第二章,数据的编码、录入与整理
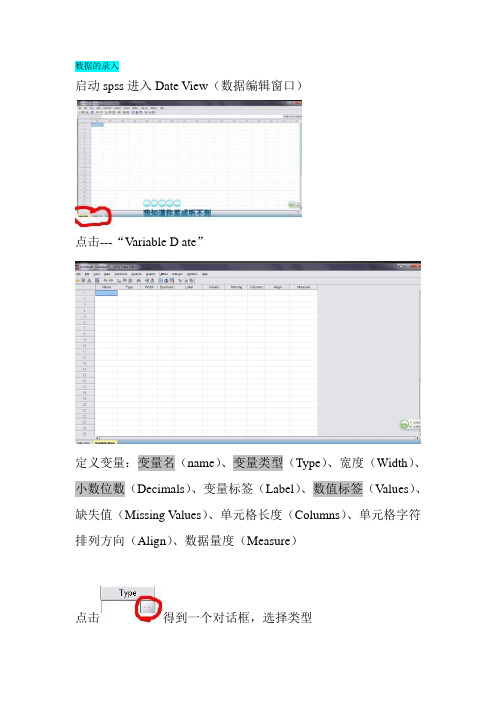
数据的录入启动spss进入Date View(数据编辑窗口)点击---“Variable D ate”定义变量:变量名(name)、变量类型(Type)、宽度(Width)、小数位数(Decimals)、变量标签(Label)、数值标签(Values)、缺失值(Missing V alues)、单元格长度(Columns)、单元格字符排列方向(Align)、数据量度(Measure)点击得到一个对话框,选择类型系统默认宽度为8,小数位2位;一般数字和字符比较常用-------Lable中可以取汉字名字方便查看------Values中可以设定数值标签,既将非数值的记录转换成数值;比如:性别1-女,2-男(一般默认为none)如图填写,点击----“And”----“OK”。
------在Missing中系统默认缺失值“none”用户可自己定义-------其他几项一般都用默认数据的录入-------回到“Date View”中逐个录入数据------“File”--“Save”(或者Ctrl+s)保存到适当的位置内即可数据的导入-----“File”---“Open”---“Date”数据的整理:数据分值转换数据分值的转换时通过对数据的重编码来实现的。
(比如将选项ABCD变成数值进行积分)----数据输入后----“Transform”--“Recode into different Variables”选中其中一个变量将其移到Numeric Variable->Output V ariable在那么中重编码----点击“Change”----“Old And New Values”例如:“Old”中写A----“New”中写1,此时A对应的数值就是1;同理写BCD-------点击“And”----“continue”----回到前一个界面-------将其它需要重编码的都编写一次(不要为了偷懒而一次性写,不会达到相同效果)------编完后-----点击“OK”表2.13前身量表的统分假定一个量表由两个分量表组成,其一为1、2、5、8、9题组成,另一个由3、4、6、7、10题,要求计算出分量表和总量表的分。
spss第二章

开放性问卷的处理方法
• 1、对回答进行分类。 • 2、建立回答类别与对应的数量关系, 进行编码。
• • • • 我最适应的是:_________________________ 我最满意的是:_________________________ 最不适应的是:_______________________ 压力最大的是:_______________________
资料的审查 编码
数据资料的形式: • 封闭性问卷资料与开放性问卷资料。 • 不同的资料形式均要求对资料进行审查,但在编 码时有不同的要求。
资料的审查
• 主要考察二个方面: 1.资料的完整性(关键) 2.资料的合理性
资料的完整性审查
包括资料总体上的完整性和每份资料的完 整性。 整性。 资料总体的完整性主要考虑问卷发放的数 回收率等。 量、回收率等。 每份资料的完整性主要看问卷的填答情况, 每份资料的完整性主要看问卷的填答情况, 是否是有效问卷。 是否是有效问卷。
• 问题5 开学以来我经常从事的休闲活动是 (可以重复选择) 1. □运动 2.□KTV 3.□郊游 4.□跳舞 5. □爬山 6.□玩牌 7.□下棋 8.□逛街 9.□聊天 10.□看书 11.□上网打游戏机 12.□看电视 13.□看电影
多项排序选择题
• 问题 您选择职业考虑的主要因素有(依 问题6 您选择职业考虑的主要因素有( 据重要性大小排列,限选三项) 据重要性大小排列,据
上机练习
1、尝试建立一个有五个变量:学号、性别、英语成绩、数学 、尝试建立一个有五个变量 学号 性别、英语成绩、 学号、 成绩、智商的数据文件,要求输入至少6个个案的数据 个个案的数据。 成绩、智商的数据文件,要求输入至少 个个案的数据。 文件名为:姓名SPSS2a 文件名为:姓名
spss数据的录入与整理

– Select case – 选择20岁以上的case,其他的过滤掉
『/删掉*保存*』
• 数据加权——主要用于计数数据 • 随机选择一定比例的数据样本
练习 1
• 创制年龄包含30个case含有1个变 量age的数据文件。
– 将年龄按10岁为一段重新划分,并存 为新变量cage『10-19,20-29,30-39, 40-49,50-60』
– 假如登录数据为“虚岁”,即多报1 岁 , 请 将 “ age” 转 化 为 “ 实 岁 ” 的 “tage”。
– 数据窗口 – 变量窗口 – 结果窗口——导出为可编辑文本。 – 语法窗口
2数据的录入 2.1编码
• 编码的涵义: 根据一定规则将研究资料转换为可进
行统计分析的数码资料之过程。
问题25:您认为,此次金融危机爆发后重庆人从
地打工地回渝是否会促进本地经济的发展?(单
选)
1□有很大影响
2□有较大影响
变量2
变量2的值
2)制作编码表
• 问题001:您的性别:
• □男
□女
2
• 问题002:您目前的婚姻状况(单选):
• □未婚 □已婚 □离婚后未再婚
• □离婚后再婚 □丧偶后未再婚
• □丧偶后再婚 □未婚同居
3
101011
• 问题011:您家中是否有下列物品: (多选)
• □电话 □传真机 □有线电视 • □卫星电视□计算机□移动电话
5‘高中中专或中技’ 6‘大专’ 7‘大学本科’ 8‘研究生以 上’
0‘不适用’ .
d缺失值定义
一般不需要特意定义
Missing Value 变量名 变量名 变量名……(缺失值1, 缺失值2,……) / 变 量 名 变 量 名 变 量 名 ……( 缺 失 值 1 , 缺 失 值 2,……) .
SPSS软件的操作与应用第2讲 描述性统计 (1)

直方图
1. 用面积表示各组频数的多少,矩形的高度表示每一组的频数或频率 宽度表示各组的组距; 2. 由于分组数据具有连续性,各矩形通常是连续排列; 3. 主要用于展示数值型数据。
二、频数分析
4. SPSS操作及案例 例一:各门成绩统计 结果保存为:3-StudentScore.spo
二、频数分析
5. SPSS操作及案例分析 根据方差齐性检验结果可以看出,语文成绩按照男女分开的样 本显著性水平Sig.值都大于0.05,表明方差的差异不显著,也就是 说方差是齐性的。
四、探索性分析
5. SPSS操作及案例分析 例五:操作步骤(数据文件:4-Explore.sav ) Analyze→Descriptive Statistics→Explore...
平均值(Mean):即算术平均值(=(X1+X2+…+Xn)/n)。 易受极端值影响。 中位数(Median):把变量的值有序排列,位于中间位置的值即中位数。 是位置平均置,不易受极端值的影响。 众数(Mode):样本中出现次数最多的值,代表数据的集中程序。 求和(Sum):所有变量之和,反映变量的总体水平。
三、基本描述统计量
4. 描述分布形态的统计量 考察数据分布形态特征的统计量,例如,数据分布是否对称、偏 斜程度以及陡缓程度,主要有如下两种统计量: 偏度(Skewness):
偏度值>0,为正偏或右偏;偏度值<0,为负偏或左偏。偏度绝对值越大,偏斜越大。
峰度(Kurtosis):
峰度值>0,数据分布比标准正态分布更陡峭,为尖峰分布;峰度值<0,数据分布比 标准正态分布更平缓,为平峰分布。
四、探索性分析
2. 通过茎叶图(Stem-and-Leaf Plots)描述频度分布
spss教程第二章

第二章数据文件的管理(上)(医学统计之星:张文彤)最后一次更新时间:2.1 建立与保存数据文件-File菜单2.1.1 新建数据文件2.1.2.1 直接打开2.1.2.2 使用数据库查询打开2.1.2.3 使用文本导入向导读入文本文件2.1.2 打开其他格式的数据文件2.1.3 保存数据文件2.1.4 File菜单中的其他条目2.2 编辑数据文件2.2.1 定义新变量2.2.1.1 直接定义新变量2.2.1.2 从原有变量计算新变量-Transform菜单2.2.2 数据的录入2.2.2.1 直接录入2.2.2.2 数据录入技巧2.3 进一步整理数据文件-Data菜单不言而喻,一切统计分析都是以数据为基础的,因此统计软件的数据管理能力非常重要。
SPSS以其豪华的界面为依托,为用户提供的便捷的数据管理功能,下面我们就来具体看一下。
§2.1建立与保存数据文件和大多数应用软件相同,SPSS中数据文件的管理功能基本上都集中在了File菜单上,该菜单的组织结构和WORD等也极为相似,因此这里我们只介绍比较有特色的几个菜单项。
SPSS 10.0有三个主要窗口界面:数据管理窗口、程序编辑窗口和结果浏览窗口;另有两个不常用的窗口:结果草稿浏览窗口和VBs脚本语言编辑窗口。
他们共享许多菜单项,如File菜单就大部分相同,这里介绍的许多内容在五个窗口中都是通用的。
2.1.1 新建数据文件如果你正从头开始进行一个新的课题,刚刚把数据收集上来,要做统计分析,自然需要新建一个数据库,然后将所有的数据从纸上请到计算机里。
在SPSS 中,新建一个数据库容易的不得了--已经到了什么都不用做的地步!是这样,当你进入SPSS系统时,系统就已经生成了一个空数据文件,即你看到的空白的数据管理界面。
你只要按自己的需要定义变量,输入数据然后存盘就是了(这些操作马上会讲到)。
2.1.2 打开其他格式的数据文件凡是做过数据输入工作的人都知道:这活又费眼睛又累人,出错太多了还要挨批评,非常影响个人的光辉形象。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据的录入
启动spss进入Date View(数据编辑窗口)
点击---“Variable D ate”
定义变量:变量名(name)、变量类型(Type)、宽度(Width)、小数位数(Decimals)、变量标签(Label)、数值标签(Values)、缺失值(Missing V alues)、单元格长度(Columns)、单元格字符排列方向(Align)、数据量度(Measure)
点击得到一个对话框,选择类型
系统默认宽度为8,小数位2位;
一般数字和字符比较常用
-------Lable中可以取汉字名字方便查看
------Values中可以设定数值标签,既将非数值的记录转换成数值;
比如:性别1-女,2-男(一般默认为none)
如图填写,点击----“And”----“OK”。
------在Missing中系统默认缺失值“none”
用户可自己定义
-------其他几项一般都用默认
数据的录入
-------回到“Date View”中逐个录入数据
------“File”--“Save”(或者Ctrl+s)保存到适当的位置内即可数据的导入
-----“File”---“Open”---“Date”
数据的整理:
数据分值转换
数据分值的转换时通过对数据的重编码来实现的。
(比如将选项ABCD变成数值进行积分)
----数据输入后
----“Transform”--“Recode into different Variables”
选中其中一个变量将其移到Numeric Variable->Output V ariable
在那么中重编码----点击“Change”----“Old And New Values”
例如:“Old”中写A----“New”中写1,此时A对应的数值就是1;同理写BCD-------点击“And”----“continue”----回到前一个界面-------将其它需要重编码的都编写一次(不要为了偷懒而一次性写,不会达到相同效果)------编完后-----点击“OK”
表2.13前身
量表的统分
假定一个量表由两个分量表组成,其一为1、2、5、8、9题组成,另一个由3、4、6、7、10题,要求计算出分量表和总量表的分。
-------点击“Transform”----“Computer”
-----将分量的变量名写入左侧------将公式写入右侧----
点击“OK”即可!另一个分量和总分量同理
见表2.13.
数据的限选
----“Date”---“Sort Case”(或者“Select Case”)
---将左边要选的变量移到“Sort By”中----选取“Desending(递
减)”----“OK”
(1)T ransform(修改)----Recode into Different variable----选定身高------点击“向右箭头”------在“name”下写个名字:eg:T1-------change-------
(此处T1和T2是已经做好的分组)
点击-----old and new values
对其分组---例:Range LOWEST through values :160 new values :1 Rang :160 through :170 2
Range HIGHEST through values :170 3 点击continue-----回到前一个对话框点击------OK
概念
个案(case):一个研究对象就是一个个案,或者案例样品。
(在数据表格中表现为“一行”)
样本(sample)。
样本含多个个案。
变量(variable):问卷中的每个问题,在spss中称之为“变量”,相当于数据库中的“字段(field)”,在数据表格里表现
为一列。
变量名(variable):问卷中答案就是变量值,也成为观测值。
Numeric(数值型)
Comma(加选逗号的数值)
Dot(三位加点数值型)
Scientific(科学计数型)
Date(日期型)
Dollar(货币型)
Custom currency(用户自定义)
String(字符型)
File(文件)
No missing values(没有缺失值)
Discrete missing values(定义1~3个单一数为缺失值)Columns(单元格列长度)
Aling(单元格字符排列方向)
Measure(数据测量)
Sort by(以。
排序)
Sort order(排序顺序)Descending(递减—由大到小)。