Spark开发环境配置及流程(Intellij IDEA)
大数据spark开发手册

大数据开发手册[电子邮件地址]目录大数据开发手册 (2)1、开发 (2)2、打包 (7)3、运行 (10)大数据开发手册1、开发1.1打开IntelliJ IDEA,单击Create New Project1.2单击Java,选择jdk1.7,然后选择Scala-sdk插件,单击Next1.3在弹出的窗口中填写项目名称,例如Demo,单击Finish1.4单击File->Project Structrue1.5在弹出的窗口中单击Libraries,单击+1.6单击+后在弹出的窗口中引入spark开发包。
例如:spark-1.6.0-bin-hadoop2.6.0->lib ->spark-assembly-1.6.0-hadoop2.6.0.jar至此开发环境基本配置完毕,可能用到的jar包都已引入。
1.7新建Scala文件,右击src ->New->Scala.Class1.8填写Scala文件的名称及Kind,单击OK在相应的Scala文件中编写代码,如下所示1.9引入Oracle的驱动包ojdbc14.jar,如下图所示2、打包2.1单击File->Project Structure->Artifacts->+ 在弹出的窗口中选择Main Class。
如下图所示2.2单击OK之后选择Build on make->Apply->OK2.3单击Build->Build Artifacts…->Build,如下图所示打包完成之后会在,如下图所示的目录下产生一个对应的jar包2.4右击jar包->Show in Explorer3、运行3.1将Demo.jar提交到指定的目录下,例如/data/Demo.jar3.2将ojdbc14.jar复制到spark->lib下,并修改spark/conf/目录下的spark-env.sh,增加如下内容:export SPARK_CLASSPATH=data/spark/spark-1.6.0/lib/ojdbc.jar重新启动spark3.3打开Linux命令终端输入如下内容:spark-submit --class testSpark --master spark://172.20.184.23:7077 /data/Demo.jar注:spark://172.20.184.23:7077是http://172.20.184.23:8080/所展示的Spark Master Url,如下所示。
idea下spark开发环境搭建及常见问题

idea下spark开发环境搭建及常见问题1.准备⼯作1.1 安装jdk1.81.2 安装scala2.11.81.3 安装idea版本按⾃⼰需要选择即可,以上过程不在本⽂中详细讲解,有需要在其他⽂章中分享。
1.4 注意事项1. jdk和scala都需要配置JAVA_HOME和SCALA_HOME的环境变量。
2. 在idea下需要下载scala插件3. 创建项⽬时通过maven创建,需要下载scala sdk4. 下载maven包,解压缩后配置maven的settings.xml⽬录,同时本地仓库位置5. maven项⽬创建完成后,在项⽬名称上右键点击Add Framework Support,然后添加scala⽀持2.spark环境配置2.1 在pom.xml添加spark包主要是spark-core,spark-sql,spark-mllib,spark-hive等,根据项⽬需要添加依赖即可。
使⽤maven下的加载按钮加载⼀下导⼊的依赖,会有⾃动下载jar包的过程。
<dependencies><!-- https:///artifact/org.apache.spark/spark-core --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.3.0</version></dependency><!-- https:///artifact/org.apache.spark/spark-sql --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>2.4.8</version><scope>provided</scope></dependency><!-- https:///artifact/org.apache.spark/spark-mllib --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib_2.11</artifactId><version>2.4.8</version><!--<scope>provided</scope>--></dependency><!-- https:///artifact/org.apache.spark/spark-hive --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.11</artifactId><version>2.4.8</version><!--<scope>provided</scope>--></dependency></dependencies>2.2 创建scala object,添加配置启动spark环境import org.apache.spark.{SparkConf, SparkContext}import org.apache.spark.sql.SparkSessionobject readcsv_demo {def main(args: Array[String]): Unit = {System.setProperty("hadoop.home.dir", "D:\\Regent Wan\\install\\hadoop-common-2.2.0-bin-master")lazy val cfg: SparkConf =new SparkConf().setAppName("local_demo").setMaster("local[*]")lazy val spark: SparkSession =SparkSession.builder().config(cfg).enableHiveSupport().getOrCreate()lazy val sc: SparkContext =spark.sparkContext}}2.3 常见问题2.3.1 Exception in thread "main" ng.NoClassDefFoundError: org/apache/spark/sql/SparkSession$ Exception in thread "main" ng.NoClassDefFoundError: org/apache/spark/sql/SparkSession$Caused by: ng.ClassNotFoundException: org.apache.spark.sql.SparkSession$原因:在导⼊spark模块时在maven复制了如下code,⽽其中默认添加了<scope>provided</scope><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>2.4.8</version><scope>provided</scope></dependency>解决办法:注释<scope>provided</scope>,再重新加载即可。
大数据处理平台Spark的安装和配置方法

大数据处理平台Spark的安装和配置方法大数据处理平台Spark是一种快速且可扩展的数据处理框架,具有分布式计算、高速数据处理和灵活性等优势。
为了使用Spark进行大规模数据处理和分析,我们首先需要正确安装和配置Spark。
本文将介绍Spark的安装和配置方法。
一、环境准备在开始安装Spark之前,需要确保我们的系统符合以下要求:1. Java环境:Spark是基于Java开发的,因此需要先安装Java环境。
建议使用Java 8版本。
2. 内存要求:Spark需要一定的内存资源来运行,具体要求取决于你的数据规模和运行需求。
一般情况下,建议至少有8GB的内存。
二、下载Spark1. 打开Spark官方网站(不提供链接,请自行搜索)并选择合适的Spark版本下载。
通常情况下,你应该选择最新的稳定版。
2. 下载完成后,将Spark解压到指定的目录。
三、配置Spark1. 打开Spark的安装目录,找到conf文件夹,在该文件夹中有一份名为spark-defaults.conf.template的示例配置文件。
我们需要将其复制并重命名为spark-defaults.conf,然后修改该文件以配置Spark。
2. 打开spark-defaults.conf文件,你会看到一些示例配置项。
按照需求修改或添加以下配置项:- spark.master:指定Spark的主节点地址,如local表示使用本地模式,提交到集群时需修改为集群地址。
- spark.executor.memory:指定每个Spark执行器的内存大小,默认为1g。
- spark.driver.memory:指定Spark驱动程序的内存大小,默认为1g。
3. 如果需要配置其他参数,可以参考Spark官方文档中的配置指南(不提供链接,请自行搜索)。
4. 保存并退出spark-defaults.conf文件。
四、启动Spark1. 打开命令行终端,进入Spark的安装目录。
spark学习10(win下利用IntellijIDEA搭建spark开发环境)

spark学习10(win下利⽤IntellijIDEA搭建spark开发环境)第⼀步:启动IntelliJ IDEA,选择Create New Project,然后选择Scala,点击下⼀步,输⼊项⽬名称wujiadong.spark继续下⼀步File——Project Structure——Libraries——点+号——点java——选择下载好的spark-assembly-1.5.1-hadoop2.6.0.jar包——点ok第三步:创建WordCount类编写代码第四步:导出jar包依次选择“File”–> “Project Structure” –> “Artifact”,选择“+”–> “Jar” –> “From Modules with dependencies”,选择main函数,并在弹出框中选择输出jar位置,并选择“OK”。
最后依次选择“Build”–> “Build Artifact”编译⽣成jar包。
具体如下图所⽰。
第五步:spark-submit提交运⾏hadoop@master:~/wujiadong$ spark-submit --class wujiadong.spark.WordCount --executor-memory 500m --total-executor-cores 2 /home/hadoop/wujiadong/wujiadong.spark.jar hdfs://master:9000/wordcount.txt 17/02/02 20:27:34 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable17/02/02 20:27:37 INFO Slf4jLogger: Slf4jLogger started17/02/02 20:27:37 INFO Remoting: Starting remoting17/02/02 20:27:37 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@192.168.1.131:52310]17/02/02 20:27:41 WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.17/02/02 20:27:44 INFO FileInputFormat: Total input paths to process : 117/02/02 20:27:51 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id17/02/02 20:27:51 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id17/02/02 20:27:51 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap17/02/02 20:27:51 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition17/02/02 20:27:51 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id(spark,1)(wujiadong,1)(hadoop,1)(python,1)(hello,4)17/02/02 20:27:52 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.17/02/02 20:27:52 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.17/02/02 20:27:52 INFO RemoteActorRefProvider$RemotingTerminator: Remoting shut down.。
spark开发环境配置及流程(intellijidea)
Spark开发环境配置及流程之前已经将集群配置完成(详见Hadoop2.6.0搭建过程.doc和Spark1.2搭建过程.doc文档),开发环境中的JDK,Scala部分就不介绍了,下面直接介绍我们用的开发工具Interlij IDEA。
为什么选择Intellij IDEA?因为它更好的支持Scala 项目,目前Spark开发团队使用它作为开发环境。
1.下载直接到官方网站下载页面下载(/idea/download/)。
有收费的完整版,也有免费的基本版本,收费的网上也有破解方案。
2.解压解压到/usr/local,这是因为之前的Scala和Spark都放这里,也可以根据自己喜好。
[hadoop@lenovo0 Downloads]$ sudo tar -vxzf ideaIC-14.1.tar.gz -C /usr/local/ 改个名字,然后授权给hadoop用户。
[hadoop@lenovo0 local]$ cd /usr/local/[hadoop@lenovo0 local]$ sudo mv ideaIC-14.1 ideaIC14[hadoop@lenovo0 local]$ sudo chown -R hadoop:hadoop ideaIC14/3.启动在解压的文件夹下有个文件介绍怎么打开应用,还有一些设置信息,大家可以看一看:通过cat命令可以查看,我只截了一些关键的:根据提示,我们直接进入到文件夹bin目录下执行./idea.sh即可启动:之后便可以根据UI提示界面创建快捷方式,方便下次启动。
4.在IDEA中安装Scala插件在IDEA的设置里面,直接搜索“plugins”,在右边的展开中搜索“scala”,点击相应的按钮添加插件即可:5.配置Spark应用开发环境这里以SparkPi程序为例子。
5.1创建Scala Project,设置名称,JDK和Scala路径:5.2选择菜单中的“File”→“project structure”→“Libraries”,然后点击“+”导入spark-assembly-1.2.0-hadoop2.4.0.jar。
第9课:使用ieda开发spark实战

/** * 第 2 步:创建 SparkContext 对象 * SparkContext 是 Spark 程序所有功能的唯一入口,无论是采用 Scala、Java、Python、
R 等都必须有一个 SparkContext * SparkContext 核心作用:初始化 Spark 应用程序运行所需要的核心组件,包括
常差(例如
* 只有 1G 的内存)的初学者
*
*/
val conf = new SparkConf() //创建 SparkConf 对象
conf.setAppName("Wow,My First Spark in IDEA!") //设置应用程序的名称,在
程序运行的监控界面可以看到名称
conf.setMaster("local") //此时,程序在本地运行,不需要安装 Spark 集群
/** * 第 4 步:对初始的 RDD 进行 Transformation 级别的处理,例如 map、filter 等高阶
函数等的编程,来进行具体的数据计算 * 第 4.1 步:讲每一行的字符串拆分成单个的单词 */
val words = lines.flatMap { line => line.split(" ")} //对每一行的字符串进行单词拆分并把 所有行的拆分结果通过 flat 合并成为一个大的单词集合
/**
* 第 3 步:根据具体的数据来源(HDFS、HBase、Local FS、DB、S3 等)
通过 SparkContext 来创建 RDD
* RDD 的创建基本有三种方式:根据外部的数据来源(例如 HDFS)、根据
Scala 集合、由其它的 RDD 操作
spark本地开发环境搭建

spark本地开发环境搭建前提1.CDH集群为6.0.1(hadoop对应版本为3.0.0)安装scala1.配置环境变量SCALA_HOME和path安装maven安装比较简单,过程略。
安装winutils(windows才需要安装)参考idea安装scala插件打开settings安装scala插件安装完成后重启ideaidea配置打开Project Structure添加scala Libraries选择scala目录idea 创建项目创建maven项目点击“Next”输入项目信息点击“Next”完成点击“Finish”即可项目创建好以后,暂时删除test目录,把java文件夹修改为scala(这一步不是必须,看个人爱好)1.创建test.txt文件,写入几行数据,上传到hdfs中2.把hadoop集群的配置文件core-site.xml和hdfs-site.xml复制到项目的resources目录下经过测试,linux下运行idea,没有这两个文件也能连上hadoop集群3.创建scala代码package hdfs import org.apache.spark.sql.SparkSession object HdfsTest { def mai n(args: Array[String]): Unit = { // 如果在windows本地跑,需要从widnows访问HDFS,需要指定一个合法的身份 // System.setProperty("HADOOP_USER_NAM E", "hdfs") val spark = SparkSession.builder( .appName("hdfs-test") .master ("local") // 设置参数 .config("e.datanode.hostname", "false") .g etOrCreate(; // spark.sparkContext.setLogLevel("DEBUG") //支持通配符路径,支持压缩文件读取 val path = "hdfs://10.121.138.145:8020/test.txt" val rd d = spark.read.textFile(path) //统计数量 println("count = "+rdd.count() //停止spark spark.stop( } }重点说明:1.如果在windows下运行,请添加System.setProperty("HADOOP_USER_NAME", "hdfs")代码,否则会提示Permission Denied2.CDH默认e.datanode.hostname为true,意思为使用hostname连接hdfs,如果我们不修改本机的host文件,本地是无法连接datanode机器。
windows本地环境Spark开发环境配置

Spark开发环境准备1. 准备环境准备环境包括:(1)JDK安装包(exe、zip):/technetwork/java/javase/downloads/index-jsp-138363.html (2)Scala安装包(msi、zip):/download/(3)IDEA安装包:https:///idea/(6)Spark安装包:https:///downloads.html安装JDK配置环境变量(1.7以上版本)JA V A_HOME = C:\Program Files\Java\jdk1.7.0_71CLASSPATH =.;%JA V A_HOME%\lib;PATH +=;%JA V A_HOME%\bin;%JA V A_HOME%\jre\bin;进入cmd界面测试jdk是否安装成功。
安装Scala安装完毕配置环境变量,增加PA TH变量:SCALA_HOME = C:\Program Files\scala-2.11.8PATH += %SCALA_HOME%\bin;进入cmd界面测试scala是否安装成功。
spark安装1.解压压缩文件至指定目录spark-1.6.2-bin-hadoop2.6.tgz2.配置环境变量HADOOP_HOME = D:\spark-1.6.2-bin-hadoop2.6在path变量中增加;%HADOOP_HOME%\bin3.添加winutils.exe(注意32位和64位不兼容)将winutils.exe添加至目录bin中4.验证CMD输入:spark-shell退出输入":quit"2 构建IntelliJ IDEA开发环境官方提供了Ultimate版和Community 版可供选择,主要区别:1)Ultimate版功能齐全的IDE,支持Web和Enterprise,免费试用30天,由官方提供一个专有的开发工具集和架构支持。
Intellij IDEA 搭建Spark开发环境
1,环境window7jdk1.8.0_91scala-2.11.8.msispark-assembly-1.6.1-hadoop2.6.0.jarInterllij IDEA 2016.1.3(可以在scala官网上链接下载 /download/)2,安装 jdk 及 scala,并配置环境变量。
下载JDK:到Java官网(/technetwork/java/javase/downloads/index.html)建议安装JDK6以上版本。
l 配置JAVA_HOME环境变量为JDK的安装目录,如下图所示:l 配置CLASSPATH环境变量为“.;%JAVA_HOME%/lib;%JAVA_HOME%/lib/tools.jar”,如下图所示:l 在Path环境变量最后追加配置“%JAVA_HOME%/bin”,如下图所示:验证JDK是否安装成功:打开控制台,输入“java -version”命令,如果出现Java版本及版权相关信息,说明JDK安装成功。
如下图所示:scala安装,验证scala安装是否成功在控制台输入“scala -version",如果出现scala版本及版权信息,说明scala安装成功。
3,Intellij IDEA 2016.1.3安装及配置点击Scala的Install安装点击“Create New Project”进入主页面,在菜单栏File->New->Project...,选择Scala点击next进入如下界面,输入工程名,并选择相应的SDK,选择jdk及scala安装的所在目录即可。
工程建好,选择菜单File/Project Structure/Libraries/ 导入相应的Spark及Scala的jar包。
4,在Interllij IDEA下开发Spark应用程序。
在创建的工程src选项的文件夹下再创建两个文件夹,文件夹名为main和scala。
IntelliJIDEAWindows下Spark开发环境部署

IntelliJIDEAWindows下Spark开发环境部署0x01 环境说明1.1 本地OS: windows 10JDK: jdk1.8.0_121Scala: scala-2.11.11IDE: IntelliJ IDEA ULTIMATE 2017.2.11.2 服务器OS: CentOS_6.5_x64JDK: jdk1.8.111Hadoop: hadoop-2.6.5Spark: spark-1.6.3-bin-hadoop2.6Scala: scala-2.11.110x02 windows端配置2.1 安装JDK配置环境变量JAVA_HOMECLASSPATHPath2.2 配置hosts⽂件位置C:\Windows\System32\drivers\etc新增如下内容(和集群的hosts⽂件内容⼀样,根据⾃⼰集群的实际情况修改)192.168.1.10 master192.168.1.11 slave1192.168.1.12 slave22.3 安装IntelliJ IDEA注意插件安装Maven2.4 IDEA中安装scala插件0x03 服务器端配置3.1 安装JDK0x04 测试4.1 新建maven项⽬4.2 添加依赖包File -> Project Structure -> Libraries添加spark-assembly-1.6.3-hadoop2.6.0.jar(位置在服务器端spark/lib/下) 4.3 新建ConnectionUtil类在src\main\java⽬录下新建java类ConnectionUtilimport org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaSparkContext;public class ConnectionUtil {public static final String master = "spark://master:7077";public static void main(String[] args) {SparkConf sparkConf = new SparkConf().setAppName("demo").setMaster(master);JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);System.out.println(javaSparkContext);javaSparkContext.stop();}}4.4 编译运⾏如果出现上图结果则证明,运⾏正确。
Spark开发环境搭建和作业提交

Spark开发环境搭建和作业提交Spark⾼可⽤集群搭建在所有节点上下载或上传spark⽂件,解压缩安装,建⽴软连接配置所有节点spark安装⽬录下的spark-evn.sh⽂件配置slaves配置spark-default.conf配置所有节点的环境变量spark-evn.sh[root@node01 conf]# mv spark-env.sh.template spark-env.sh[root@node01 conf]# vi spark-env.sh加⼊export JAVA_HOME=/usr/local/jdk#export SCALA_HOME=/software/scala-2.11.8export HADOOP_HOME=/usr/local/hadoopexport HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop#Spark历史服务分配的内存尺⼨#export SPARK_DAEMON_MEMORY=512m#下⾯的这⼀项就是Spark的⾼可⽤配置,如果是配置master的⾼可⽤,master就必须有;如果是slave的⾼可⽤,slave就必须有;但是建议都配置。
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark" #当启⽤了Spark的⾼可⽤之后,下⾯的这⼀项应该被注释掉(即不能再被启⽤,后⾯通过提交应⽤时使⽤--master参数指定⾼可⽤集群节点)#export SPARK_MASTER_IP=master01#export SPARK_WORKER_MEMORY=1500m#export SPARK_EXECUTOR_MEMORY=100m-Dspark.deploy.recoveryMode=ZOOKEEPER #说明整个集群状态是通过zookeeper来维护的,整个集群状态的恢复也是通过zookeeper来维护的。
spark本地开发环境搭建及打包配置
spark本地开发环境搭建及打包配置在idea中新建⼯程删除新项⽬的src,创建moudle在⽗pom中添加spark和scala依赖,我们项⽬中⽤scala开发模型,建议scala,开发体验会更好(java、python也可以)<?xml version="1.0" encoding="UTF-8"?><project xmlns="/POM/4.0.0"xmlns:xsi="/2001/XMLSchema-instance"xsi:schemaLocation="/POM/4.0.0 /xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.shaozhiqi.bigdata</groupId><artifactId>spark-demo01</artifactId><packaging>pom</packaging><version>1.0-SNAPSHOT</version><modules><module>spark-core</module></modules><properties><piler.source>1.8</piler.source><piler.target>1.8</piler.target><scala.version>2.11.7</scala.version><spark.version>2.4.3</spark.version><encoding>UTF-8</encoding></properties><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>${spark.version}</version></dependency></dependencies></project>在我们Moudle中配置打包插件<?xml version="1.0" encoding="UTF-8"?><project xmlns="/POM/4.0.0"xmlns:xsi="/2001/XMLSchema-instance"xsi:schemaLocation="/POM/4.0.0 /xsd/maven-4.0.0.xsd"><parent><artifactId>spark-demo01</artifactId><groupId>com.shaozhiqi.bigdata</groupId><version>1.0-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><artifactId>spark-core</artifactId><build><pluginManagement><plugins><!-- 编译scala的插件 --><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.2</version></plugin></plugins></pluginManagement><plugins><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><executions><execution><id>scala-compile-first</id><phase>process-resources</phase><goals><goal>add-source</goal><goal>compile</goal></goals></execution><execution><id>scala-test-compile</id><phase>process-test-resources</phase><goals><goal>testCompile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><executions><execution><phase>compile</phase><goals><goal>compile</goal></goals></execution></executions></plugin><!-- 打包插件 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.1</version><configuration><transformers><!-- add Main-Class to manifest file --><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><!--you can add you want to need the main class--><!----><mainClass>com.shaozhiqi.bigdata.spark.WordCount</mainClass></transformer></transformers><createDependencyReducedPom>false</createDependencyReducedPom></configuration><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><filters><filter><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters></configuration></execution></executions></plugin></plugins></build></project>安装scala开发插件到idea安装后重启设置scalasdk,选我们新建的moudleimage.png新建scala对象编写代码:def main(args: Array[String]): Unit = {//1.创建配置信息val conf =new SparkConf().setAppName("wordcount").setMaster("local[*]")//2.创建sparkcontextval sc= new SparkContext(conf)//3.处理业务数据,我们统计每个单词的个数// 我们要在集群上尝试所以就将textFile的参数参数化,如果在本地执⾏则写本地的绝对路径 val lines=sc.textFile("G:\\temp\\input.txt")val words=lines.flatMap(_.split(" "))val keyMap=words.map((_, 1))val result =keyMap.reduceByKey(_+_)result.foreach(println)//4.关闭连接sc.stop()}本地调测试(1233,1)(llll,1)(hhh,1)(ddd,2)(55,2)(,1)(kkkk,1)(jjj,1)。
简单描述搭建spark环境的流程

简单描述搭建spark环境的流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor. I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!搭建 Spark 环境的流程如下:1. 安装 Java下载 Java 安装包,可以从 Oracle 官网下载。
Spark入门之环境搭建

Spark⼊门之环境搭建本教程是虚拟机搭建Spark环境和⽤idea编写脚本⼀、前提准备需要已经有搭建好的虚拟机环境,具体见教程需要已经安装了idea或着eclipse(教程以idea为例)⼆、环境搭建1、下载Spark安装包(我下载的 spark-3.0.1-bin-hadoop2.7.tgz)下载地址2、上传到虚拟机并解压(没备注就是主节点运⾏)tar -zxvf spark-3.0.1-bin-hadoop2.7.tgz3、修改权限chown -R hadoop /export/server/spark-3.0.1-bin-hadoop2.7chgrp -R hadoop /export/server/spark-3.0.1-bin-hadoop2.74、创建软连接ln -s /export/server/spark-3.0.1-bin-hadoop2.7 /export/server/spark5、启动spark交互式窗⼝/export/server/spark/bin/spark-shell还是很炫酷的哈哈哈,出现这个说明spark环境就搭建好了吗?漏6、配置Spark集群cd /export/server/spark/confmv slaves.template slavesvim slaves添加node02node03node047.配置mastercd /export/server/spark/confmv spark-env.sh.template spark-env.shvim spark-env.sh增加如下内容:## 设置JAVA安装⽬录JAVA_HOME=/linmob/install/jdk1.8.0_141## HADOOP软件配置⽂件⽬录,读取HDFS上⽂件和运⾏Spark在YARN集群时需要,先提前配上HADOOP_CONF_DIR=/linmob/install/hadoop-3.1.4/etc/hadoopYARN_CONF_DIR=/linmob/install/hadoop-3.1.4/etc/hadoop## 指定spark⽼⼤Master的IP和提交任务的通信端⼝#SPARK_MASTER_HOST=node01SPARK_MASTER_PORT=7077SPARK_MASTER_WEBUI_PORT=8080SPARK_WORKER_CORES=1SPARK_WORKER_MEMORY=1gSPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2## 配置spark历史⽇志存储地址SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node01:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"8、将配置好的将 Spark 安装包分发给集群中其它机器,命令如下:cd /export/server/scp -r spark-3.0.1-bin-hadoop2.7 hadoop@node02:$PWDscp -r spark-3.0.1-bin-hadoop2.7 hadoop@node03:$PWDscp -r spark-3.0.1-bin-hadoop2.7 hadoop@node04:$PWD9、创建软连接(每个节点都运⾏⼀遍)ln -s /export/server/spark-3.0.1-bin-hadoop2.7 /export/server/spark10、配置Yarn历史服务器并关闭资源检查vim /export/server/hadoop/etc/hadoop/yarn-site.xml少的部分补上<configuration><!-- 配置yarn主节点的位置 --><property><name>yarn.resourcemanager.hostname</name><value>node01</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 设置yarn集群的内存分配⽅案 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>20480</value></property><property><name>yarn.scheduler.minimum-allocation-mb</name><value>2048</value></property><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value></property><!-- 开启⽇志聚合功能 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置聚合⽇志在hdfs上的保存时间 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property><!-- 设置yarn历史服务器地址 --><property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value></property><!-- 关闭yarn内存检查 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property></configuration>注意:如果之前没有配置,现在配置了需要分发并重启yarn(重启需要每个节点都运⾏)cd /export/server/hadoop/etc/hadoopscp -r yarn-site.xml hadoop@node02:$PWDscp -r yarn-site.xml hadoop@node03:$PWDscp -r yarn-site.xml hadoop@node04:$PWD/export/server/hadoop/sbin/stop-yarn.sh/export/server/hadoop/sbin/start-yarn.sh11、配置Spark的历史服务器和Yarn的整合cd /export/server/spark/confmv spark-defaults.conf.template spark-defaults.confvim spark-defaults.conf添加spark.eventLog.enabled truespark.eventLog.dir hdfs://node01:8020/sparklog/press truespark.yarn.historyServer.address node01:18080⼿动创建hadoop fs -mkdir -p /sparklog12、修改⽇志级别cd /export/server/spark/confmv log4j.properties.template log4j.propertiesvim log4j.properties修改分发-可选,如果只在node1上提交spark任务到yarn,那么不需要分发cd /export/server/spark/confscp -r spark-env.sh hadoop@node02:$PWDscp -r spark-env.sh hadoop@node03:$PWDscp -r spark-env.sh hadoop@node04:$PWDscp -r spark-defaults.conf hadoop@node02:$PWDscp -r spark-defaults.conf hadoop@node03:$PWDscp -r spark-defaults.conf hadoop@node04:$PWDscp -r log4j.properties hadoop@node02:$PWDscp -r log4j.properties hadoop@node03:$PWDscp -r log4j.properties hadoop@node04:$PWD13、配置依赖的Spark的jar包hadoop fs -mkdir -p /spark/jars/hadoop fs -put /export/server/spark/jars/* /spark/jars/vim /export/server/spark/conf/spark-defaults.conf添加内容spark.yarn.jars hdfs://node1:8020/spark/jars/*分发同步-可选cd /export/server/spark/confscp -r spark-defaults.conf hadoop@node02:$PWD scp -r spark-defaults.conf hadoop@node03:$PWDscp -r spark-defaults.conf hadoop@node04:$PWD 14、启动服务- 启动HDFS和YARN服务,在主节点上启动spark集群/export/server/spark/sbin/start-all.sh-启动MRHistoryServer服务,在node01执⾏命令mr-jobhistory-daemon.sh start historyserver- 启动Spark HistoryServer服务,,在node01执⾏命令/export/server/spark/sbin/start-history-server.sh15、测试看下个博客三、总结:在主节点上启动spark集群/export/server/spark/sbin/start-all.sh在主节点上停⽌spark集群/export/server/spark/sbin/stop-all.shspark: 4040 任务运⾏web-ui界⾯端⼝spark: 8080 spark集群web-ui界⾯端⼝spark: 7077 spark提交任务时的通信端⼝hadoop: 50070集群web-ui界⾯端⼝hadoop:8020/9000(⽼版本) ⽂件上传下载通信端⼝。
使用IntelliJ IDEA配置Spark应用开发环境及源码阅读环境 含提交

使用IntelliJ IDEA配置Spark应用开发环境及源码阅读环境含提交使用intellijidea配置spark应用开发环境及源码阅读环境含提交使用intellijidea配置spark应用开发环境及源码阅读环境(基础)时间2021-03-0413:13:09极客头条原在本地搭建好spark1.6.0后,除了使用官方文档中的sbt命令打包,spark-submit提交程序外,我们可以使用intellijidea这个ide在本地进行开发调试,之后再将作业提交到集群生产环境中运行,使用ide可以提升我们的开发效率。
0.加装intellijidea我的系统环境(ubuntu14.04.4lts)下载最新版本的intellijidea,官网地址:1.以本地local模式运转spark程序1)创建“newproject”,选择“scala”。
“projectsdk”选择jdk目录,“scalasdk”选择scala目录。
2)挑选菜单中的“file”->“projectstructure”->“libraries”->+“java”,引入spark加装目录/home/tom/spark-1.6.0/lib下的“spark-assembly-1.6.0-hadoop2.6.0.jar”。
3)运行scala示例程序sparkpi:spark安装目录的examples目录下,可以找到scala编写的示例程序sparkpi.scala,该程序计算pi值并输出。
在project的main目录下新建sparkpitest.scala,复制spark示例程序代码。
挑选菜单中的“run”->“editconfigurations”,修正“mainclass”和“vmoptions”。
运行结果:特别注意:在我最初运转spark的测试程序sparkpi时,页面运转,发生了如下错误:exceptioninthread\urlmustbesetinyourconfiguration从提示信息中可以窥见打听没程序运行的master,此时需要配置环境变量。
IntelliJ IDEA下的Spark程序开发

1、打开IDEA的官网地址,地址如下:/idea/2、点击DOWNLOAD,按照自己的需求下载安装,我们用免费版即可。
3、双击ideaIU-15.0.2.exe安装包,点击Next。
4、选择安装路径,点击Next。
5、可以选择是否创建桌面快捷方式,然后点击Next。
6、点击Install。
7、安装过程8、点击Finish,安装成功9、双击IntelliJ IDEA 15.0.2的图标,打开IntelliJ IDEA。
10、可以导入自己的设置,没有就选择下面的即可,然后点击OK。
11、选择自己喜欢的风格(1) 风格1(2) 风格212、选择完风格后,点击Next Default plugins13、点击Next Featured plugins14、点击Scala Custom Languages 下面的Install15、安装过程16、显示Installed就代表安装成功了,然后点击Start using IntelliJ IDEA。
17、点击Create New Project,创建新工程。
18、选择Scala,点击Next。
19、填写Project name和Project location。
20、设置Project SDK,点击New。
21、点击New打开的小窗口里点击JDK。
22、选择安装JDK的路径,点击OK23、Project SDK会变成如下面图所示,是你安装的JDK版本24、设置Scala SDK,点击Create。
25、选择这台机器安装的2.10.x版本,然后点击OK。
26、然后就变成如图所示,然后点击Finish。
27、出现这个提示,直接点击OK。
28、出现这个窗口,把Show Tips on Startup勾掉,点击Close即可。
29、项目创建成功以后的目录如下:30、下载spark-1.6.0-bin-hadoop2.6.tgz,解压spark-1.6.0-bin-hadoop2.6.tgz,解压以后目录如下:31、添加Spark的jar依赖,File-> Project Structure -> Libraries,点击号,选择Java。
Windows上IDEA搭建最新Spark2.4.3源码阅读及调试的开发环境
Windows上IDEA搭建最新Spark2.4.3源码阅读及调试的开发环境相信很多同学都想通过阅读⼀些框架的源码,来提⾼⾃⼰的代码能⼒,但往往在第⼀步,搭建环境的时候就碰了壁。
本篇就来介绍下如何在Windows下,将最新版的Spark2.4.3编译,并导⼊到IDEA编译器中。
最后通过在IDEA运⾏Spark⾃带的⼀共Example代码结尾。
1.搭建Spark源码环境所需准备搭建Spark源码环境所需要准备的⼀些东西需要先准备好。
这⾥也有我踩过的⼀些坑,我也会⼀并介绍。
⾸先需要先下载maven,并将maven的源地址修改为阿⾥源,相信很多同学都已经配置好maven了,这⾥简单提下,maven源地址在国外,不改成阿⾥源,那在下载依赖的时候,那速度会让你怀疑⼈⽣的。
然后下载下scala2.11.8/scala2.11.12,因为⽬前spark似乎还不⽀持2.12+,所以需要scala2.11+,⾄于2.11.8还是2.11.12,应该没什么影响,不过我⾃⼰机器上是2.11.8就是。
下载spark源码,不过不能直接github到spark的仓库⾥⾯直接下载,⽬前仓库⾥⾯的是3.+的测试版,应该要到releases⾥⾯去找。
不过我已经帮你们把那个链接找到了,复制到浏览器地址就有下载页。
下载完后解压,准备⼯作就算做完了。
2.编译Spark源码直接导⼊项⽬是不⾏的,因为有些⽂件需要先编译才会产⽣,不过要编译环境也不难,之前不是已经配置过的maven嘛。
将下载好的spark2.4.3解压,进⼊到其⽬录,打开cmd,运⾏如下命令就⾏mvn -T 4 -DskipTests clean package这⾥要注意⼀下,spark2.4.3⽬录下的pom.xml⽂件,有两个地⽅需要修改。
第⼀个是pom.xml⾥⾯的属性,⾥⾯默认是3.5.4,需要改成⾃⼰maven的版本,⽐如我电脑是3.5.2。
电脑上的maven版本可以通mvn --version这个命令查看。
田毅-Spark开发及本地环境搭建指南

DEBUG时需要注意
• 断点不要设置过多, 调试Scala程序的断点开 销远远大于Java, 超过2个断点就会使你的 程序慢的要死 • 如果需要增加Debug日志, 可以将一个hive-‐ log4j.properaes文件拷贝到classpath对应的 目录下面
搭建本地DEBUG环境的好处
• 快速了解程序运行的流程 • 对于解决Spark的BUG非常有用 • 本身Intellij IDEA提供了很多快捷功能, 减少 敲代码编译等等工作
Github上贡献自己的代码
创建github帐号
• 略
fork社区项目
fork成功啦
使用maven编译Ma源自en编译成功编译准备• 目前Spark的代码中存在一些BUG会导致 IDEA无法直接编译Spark代码 • Yarn模块 (本地调试可不勾选此Profile) • FlumeSink模块(用不到的人可以在pom.xml 中删除Flume相关的module定义)
如果解决的是一个BUG
• 尽量详细地描述bug的
○ 重现步骤 ○ 症状(异常、stacktrace) ○ 可能的原因 ○ 可能的解决方案 ○ 可能相关的其他issue、PR
• 学习 hfps:///jira/browse/ SPARK-‐2129
Spark开发及本地环境搭建指南
目录
• 构建本机开发环境 • 向社区提交PR
构建本机上的Spark开发环境
使用IDEA进行Spark开发与调试
• 环境准备
– 推荐使用CentOS, Redhat, Fedora等Linux操作系统 – 推荐使用MacOS – 如果使用PySpark (python on Spark) 需要使用JDK1.6.x – 安装IntelliJ IDEA (后续使用IDEA13举例) – 安装Scala 2.10.4 – 安装Maven – 安装git客户端
IntellijIdea搭建Spark开发环境

IntellijIdea搭建Spark开发环境在中介绍了Spark的安装与配置。
在那⾥还介绍了使⽤spark-submit提交应⽤。
只是不能使⽤vim来开发Spark应⽤。
放着IDE的⽅便不⽤。
这⾥介绍使⽤Intellij Idea搭建Spark的开发环境。
1、Intellij Idea的安装因为Spark安装在Ubuntu环境中。
这⾥的Idea也安装在Ubuntu中。
⾸先是下载,到官⽹下载就可以。
下载完后解压到待安装的⽂件夹:sudo tar -zxvf ideaIU-2016.1.tar.gz -C /usr/local/我解压在了/usr/local⽂件夹下,然后更改⽂件夹名:mv ideaIU-2016.1 idea然后改动⽂件的⽤户和⽤户组:sudo chown -R hadoop:hadoop idea这⾥的hadoop是我的username和组名。
这样idea就成功安装了。
为了启动idea,进⼊idea/bin⽂件夹。
运⾏⾥⾯的idea.sh:bin/idea.sh这样就能够启动idea。
只是这样不⽅便。
能够在桌⾯新建⽂件idea.desktop,输⼊例如以下内容:[Desktop Entry]Name=IdeaIUComment=Rayn-IDEA-IUExec=/usr/local/idea/bin/idea.shIcon=/usr/local/idea/bin/idea.pngTerminal=falseType=ApplicationCategories=Developer;这样就创建了⼀个桌⾯快捷⽅式。
2、maven的安装与配置Maven 是⼀个项⽬管理和构建⾃⼰主动化⼯具。
作为⼀个程序猿,都有过为了使⽤某个功能⽽在项⽬中加⼊jar包的经历,使⽤的框架多了。
须要加⼊的jar包也多,⽽maven可以⾃⼰主动为我们加⼊须要的jar包。
⾸先在maven官⽹上下载maven:下载之后在Downloads⽂件夹下有例如以下⽂件:liu@Binja:~/Downloads$ lsapache-maven-3.3.9-bin.tar.gz解压到待安装的⽂件夹:liu@Binja:~/Downloads$ sudo tar -zxvf apache-maven-3.3.9-bin.tar.gz -C /usr/local/相同,改动⽬录名和username:liu@Binja:/usr/local$ sudo mv apache-maven-3.3.9/ mavenliu@Binja:/usr/local$ sudo chown -R liu:liu mavenliu@Binja:/usr/local$ ll maventotal 52drwxr-xr-x 6 liu liu 4096 3⽉ 28 20:24 ./drwxr-xr-x 12 root root 4096 3⽉ 28 20:26 ../drwxr-xr-x 2 liu liu 4096 3⽉ 28 20:24 bin/drwxr-xr-x 2 liu liu 4096 3⽉ 28 20:24 boot/drwxr-xr-x 3 liu liu 4096 11⽉ 11 00:38 conf/drwxr-xr-x 3 liu liu 4096 3⽉ 28 20:24 lib/-rw-r--r-- 1 liu liu 19335 11⽉ 11 00:44 LICENSE-rw-r--r-- 1 liu liu 182 11⽉ 11 00:44 NOTICE-rw-r--r-- 1 liu liu 2541 11⽉ 11 00:38 README.txtliu@Binja:/usr/local$然后将maven加⼊到环境变量中:sudo vim ~/.bashrc在最后加⼊以下的内容:export PATH=$PATH:/usr/local/maven/bin使更改⽣效:liu@Binja:/usr/local$ source ~/.bashrc这样maven就安装好了。
SparkIdeaMaven开发环境搭建
SparkIdeaMaven开发环境搭建⼀、安装jdkjdk版本最好是1.7以上,设置好环境变量,安装过程,略。
⼆、安装Maven我选择的Maven版本是3.3.3,安装过程,略。
编辑Maven安装⽬录conf/settings.xml⽂件,<!-- 修改Maven 库存放⽬录--><localRepository>D:\maven-repository\repository</localRepository>三、安装Idea安装过程,略。
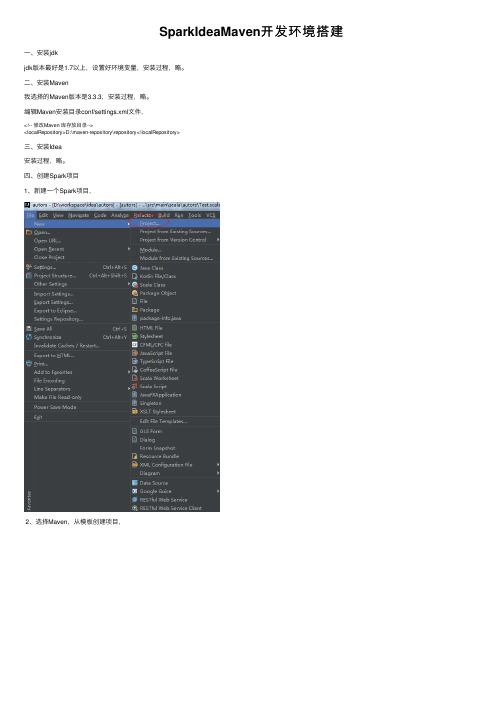
四、创建Spark项⽬1、新建⼀个Spark项⽬,2、选择Maven,从模板创建项⽬,3、填写项⽬GroupId等,4、选择本地安装的Maven和Maven配置⽂件。
5、next6、创建完毕,查看新项⽬结构:7、⾃动更新Maven pom⽂件8、编译项⽬如果出现这种错误,这个错误是由于Junit版本造成的,可以删掉Test,和pom.xml⽂件中Junit的相关依赖,即删掉这两个Scala类:和pom.xml⽂件中的Junit依赖:<dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency> 9、刷新Maven依赖10、引⼊Jdk和Scala开发库11、在pom.xml加⼊相关的依赖包,包括Hadoop、Spark等<dependency><groupId>commons-logging</groupId><artifactId>commons-logging</artifactId><version>1.1.1</version><type>jar</type></dependency><dependency><groupId>mons</groupId><artifactId>commons-lang3</artifactId><version>3.1</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.9</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.1</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.1</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.7.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.10</artifactId><version>1.5.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.10</artifactId><version>1.5.1</version></dependency> 然后刷新maven的依赖,12、新建⼀个Scala Object。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Spark开发环境配置及流程
之前已经将集群配置完成(详见Hadoop2.6.0搭建过程.doc和Spark1.2搭建过程.doc文档),开发环境中的JDK,Scala部分就不介绍了,下面直接介绍我们用的开发工具Interlij IDEA。
为什么选择Intellij IDEA?因为它更好的支持Scala 项目,目前Spark开发团队使用它作为开发环境。
1.下载
直接到官方网站下载页面下载(/idea/download/)。
有收费的完整版,也有免费的基本版本,收费的网上也有破解方案。
2.解压
解压到/usr/local,这是因为之前的Scala和Spark都放这里,也可以根据自己喜好。
[hadoop@lenovo0 Downloads]$ sudo tar -vxzf ideaIC-14.1.tar.gz -C /usr/local/ 改个名字,然后授权给hadoop用户。
[hadoop@lenovo0 local]$ cd /usr/local/
[hadoop@lenovo0 local]$ sudo mv ideaIC-14.1 ideaIC14
[hadoop@lenovo0 local]$ sudo chown -R hadoop:hadoop ideaIC14/
3.启动
在解压的文件夹下有个文件介绍怎么打开应用,还有一些设置信息,大家可以看一看:
通过cat命令可以查看,我只截了一些关键的:
根据提示,我们直接进入到文件夹bin目录下执行./idea.sh即可启动:
之后便可以根据UI提示界面创建快捷方式,方便下次启动。
4.在IDEA中安装Scala插件
在IDEA的设置里面,直接搜索“plugins”,在右边的展开中搜索“scala”,点击相应的按钮添加插件即可:
5.配置Spark应用开发环境
这里以SparkPi程序为例子。
5.1创建Scala Project,设置名称,JDK和Scala路径:
5.2选择菜单中的“File”→“project structure”→“Libraries”,然后点击“+”导入spark-assembly-1.2.0-hadoop2.4.0.jar。
这个jar包包含Spark的所有依赖包和Spark源码。
一开始我们下载的Spark版本是预编译版本的(见《Spark on yarn搭建过程》),所以这个包可以在解压的Spark目录下lib目录里找到,假如说下载的没有编译的,需要通过sbt/sbt assembly命令打包。
同样的,假如IDEA不能识别Scala库,也是用这种方法,路径是Scala的安装路
径。
5.3现在可以开发Scala程序。
右键新建一个scala类,就可以写程序了。
我们直接复制
SparkPi的代码,这个代码在Spark文件example目录下可以找到源码:
口,第二句调用addJar方法将我们压缩好的jar包提交到Spark集群(压缩方法在后面介绍)。
6.运行Spark程序
像上面我们编写完代码,有两种方法运行我们的程序,一个是IDEA中的run方法,
另一个是将我们的程序打包成jar包,在Spark集群上用命令行执行。
在集群上运行Spark应用Jar包:
选择“File”→“Project Structure”→“Artifact”,单机“+”,选择“JAR”→“From Modules with dependencies”,然后选择main函数和Jar包的输出路径:
在主菜单中选择“Build”→“Build Artifact”编译生成Jar包。
最后到jar包的目录下执行java -jar SparkTest.jar即可。
Run方法:
在IDEA菜单中选择“Run”→“Edit Configurations”出现如下界面:
点左上角的“+”,选择“Application”,在右边的拓展中改一下name,选择Main 函数:
然后点击右上角的绿色运行箭头即可:
以上介绍了整个Spark应用开发流程以及如何编译调试程序。