华南理工大学数据库研究生复习题
华南理工07至09复试上机题目

09华工计算机复试题目(数据库)一、数据库设计(30分)给3张表1 要求定义创建3张表的SQL语句, 并建立参照约束关系(也即外键约束)15分2有三张表对应的Excel格式数据,请导入到三张表中 5分3 创建索引 5分4 创建视图 5分二、数据库编程(60分)1.要求程序与数据库能进行有效连接,并具有完善的人机交互界面,要求有参数输入界面和执行按钮,在界面上有结果输出展现区;(10分)2.查询(15分),统计(15分),增,删,改(10分)。
3具有数据完整性校验功能,当出现数据异常和操作异常时,程序应给出清楚完整的异常提示信息。
(10分)三.数据库的备份和恢复(10分)07华工计算机复试题目(数据库)数据库要求建立一个人事管理系统,先用sqlserver2000建立两张表,每张表所包含的列是给定的,一张职员表包括职工号、姓名、工资、所属部门;另一张部门表包括部门号,部门名称,负责人。
另外要求每个职工只属于一个部门,每个部门只有一位负责人,还有就是职工的工资不可改动(这个俺不会实现,惭愧)。
建好表后用高级语言连接数据库,还要弄个界面出来。
在界面上要实现的功能有查看各个表的信息,添加、删除、修改表项内容,另外还有一个查询功能,要求输入职员姓名即可显示该职员所在部门的负责人信息。
数据库还要求写一份文档,说明建库建表语句,以及连数据库的大概步骤08 华工计算机复试题目(数据库)一.建库,建表(30分)建立一个学生管理系统的数据库.用查询分析器建立三张表(学院表,班级表,学生表),并设置主外键、约束之类的东西.最后录入数据.二.界面(65分)1.实现对学生表的维护功能(也就是添加、删除、修改之类的功能)2.以学生姓名(模糊检索)、班级名、学院名为关键字,实现组合条件查询(包括单条件、多条件).结果用列表显示,且查询结果按一定的要求排序.3.统计各个学院的学生人数,以及按(入学年份)统计学生人数.4.保证你的程序有一定的健壮性.当用户做了错误操作时,你的程序不会崩溃,数据不会不一致.还需把错误信息反馈给用户.5. 具有数据完整性校验功能,当出现数据异常和操作异常,给出异常操作信息三、文档(5分)1.readme.txt(说明开发环境)2.将三张表导出为Excel的表3.源代码4.主文档(包括:1.建表和录入数据的脚本2.连接数据库的步骤,必要时说明运行参数3.若程序无法运行,则需将关键代码拷贝至此文档中)。
华南理工大学《数据挖掘》复习资料

华南理工大学《数据挖掘》复习资料【英文缩写】BI(商务智能): Business IntelligenceOLAP(联机分析处理): Online Analytical ProcessingOLTP(联机事务处理): Online Transaction ProcessingETL(提取/变换/装入): Extraction/Transformation/Loading KDD(数据中的知识发现):Knowledge Discovery in DatabasesLecture 1.【知识发现的主要过程】(1)数据清理〔消除噪声和不一致的数据〕(2)数据集成〔多种数据源可以组合在一起〕(3)数据选择〔从数据库中提取与分析任务相关的数据〕(4)数据变换〔数据变换或同意成适合挖掘的形式,如通过汇总或聚集操作〕(5)数据挖掘〔基本步骤,使用只能方法提取数据模式〕(6)模式评估〔根据某种兴趣度度量,识别表示只是的真正有趣的模式〕(7)知识表示〔使用可视化和只是表示技术,向用户提供挖掘的知识〕【挖掘的知识类型】(1)概念描述:特征划与区分(概化、摘要、以及比照数据特征)(2)关联〔相关性或者因果关系〕(3)分类与预测:对类或概念构造模型或函数以便对未来数据进行预测(4)聚类分析:类标识符是未知的,把数据分成不同的新类,使得同一个类中的元素具有极大的相似性,不同类元素的相似性极小。
(5)趋势与偏差分析:序列模式挖掘(6)孤立点分析:孤立点,不符合该类数据的通用行为的数据,不是噪声或异常。
【数据挖掘在互联网、移动互联网的应用】(1)Web用法挖掘〔Web日志挖掘〕:在分布式信息环境下捕获用户访问模式(2)权威Web页面分析:根据Web页面的重要性、影响和主题,帮助对Web页面定秩(3)自动Web页面聚类和分类:给予页面的内容,以多维的方式对Web页面分组和安排(4)Web社区分析:识别隐藏的Web社会网络和社团,并观察它们的演变Lecture 2.【为什么需要数据预处理】现实世界中的数据很“脏”,具有以下特性:(1)不完整的: 缺少属性值, 感兴趣的属性缺少属性值, 或仅包含聚集数据(2)含噪声的: 包含错误或存在孤立点(3)不一致的: 在名称或代码之间存在着差异数据预处理技术可以改良数据的质量,从而有助于提高其后的挖掘过程的精度和性能。
华工2020秋数据库随堂练习(111到 120题)
参考答案:√
问题解析:
120.(判断题) “为哪些表,在哪些字段上,建立什么样的索引”这一设计内容应该属于数据库逻辑设计阶段。
答题:对.错.(已提交)
参考答案:×
问题解析:
答题:A. B. C. D.(已提交)
参考答案:C
问题解析:
118.(单选题)下图所示的E-R图转换成关系模型,可以转换为()关系模式。
A.1个B.2个C.3个D.4个
答题:A. B. C. D.(已提交)
参考答案:C
问题解析:
119.(判断题)数据库设计的几个步骤是需求分析、概念设计、逻辑设计、物理设计、系统实施和系统运行和维护。
参考答案:B
问题解析:
116.(单选题)概念模型独立于()。
A.E-R模型B.硬件设备和DBMS C.操作系统和DBMS D.DBMS
答题:A. B. C. D.(已提交)
参考答案:B
问题解析:
117.(单选题)数据流程图(DFD)是用于描述结构化方法中()阶段的工具。
A.可行性分析B.详细设计C.需求分析D.程序编码
111.(单选题)在关系数据库设计中,设计关系模式是()的任务。
A.需求分析阶段B.概念设计阶段C.逻辑设计阶段D.物理设计阶段
答题:A. B. C. D.(已提交)
参考答案:C
问题解析:
112.(单选题)数据库物理设计完成后,进入数据库实施阶段,下列各项中不属于实施阶段的工作是()。
A.建立库结构B.扩充功能C.加载数据D.系统调试
A.M端实体的关键字B.N端实体的关键字
C.M端实体关键字与N端实体关键字组合D.重新选取其他属性
答题:A.Байду номын сангаасB. C. D.(已提交)
华南理工数据库随堂练习上

31.(单选题) 设有关系R,按条件f对关系R进行选择,正确的是。
答题: A. B. C. D. (已提交)参考答案:C问题解析:32.(单选题) SQL语言是的语言,易学习。
A.过程化B.非过程化C.格式化D.导航式答题: A. B. C. D. (已提交)参考答案:B问题解析:33.(单选题) SQL语言是语言。
A.层次数据库B.网络数据库C.关系数据库D.非数据库答题: A. B. C. D. (已提交)参考答案:C问题解析:34.(单选题) SQL语言具有的功能。
A.关系规范化、数据操纵、数据控制B.数据定义、数据操纵、数据控制C.数据定义、关系规范化、数据控制D.数据定义、关系规范化、数据操纵答题: A. B. C. D. (已提交)参考答案:B问题解析:35.(单选题) SQL语言具有两种使用方式,分别称为交互式SQL和。
A.提示式SQL B.多用户SQL C.嵌入式SQL D.解释式SQL答题: A. B. C. D. (已提交)参考答案:C问题解析:36.(单选题) 假定学生关系是S(S#,SNAME,SEX,AGE),课程关系是C(C#,CNAME,TEACHER),学生选课关系是SC(S#,C#,GRADE)。
要查找选修“COMPUTER”课程的“女”学生姓名,将涉及到关系。
A.S B.SC,C C.S,SC D.S,C,SC答题: A. B. C. D. (已提交)参考答案:D问题解析:37.(单选题) 如下面的数据库的表中,若职工表的主关键字是职工号,部门表的主关键字是部门号,SQL操作不能执行。
A.从职工表中删除行(‘025’,‘王芳’,‘03’,720)B.将行(‘005,’,‘乔兴’,‘04’,750)插入到职工表中C.将职工号为,‘001’的工资改为700D.将职工号为,’038’的部门号改为‘03’答题: A. B. C. D. (已提交)参考答案:B问题解析:38.(单选题) 若用如下的SQL语句创建一个student表:CREATE TABLE student(NO C(4) NOT NULL,NAME C(8) NOT NULL,SEX C(2),AGE N(2))参考答案:B问题解析:77.(单选题) 数据流程图(DFD)是用于描述结构化方法中阶段的工具。
华南理工大学网络教育学院 数据库答案

答案:第一章1.A2.A3.D4.A5.C6.A7.数据库管理系统(DBMS)、数据库管理员(DBA)8. 概念模式或逻辑模式9.人工管理、数据库10.概念模式第二章1.B2.C3.C4.C5.A6.A7.B8.109. 课程名,课程号10. 答:外键的充要条件:1) FK和K的取值域是一样的;2) 对于R中任何一个元组t,要么t[FK]上的值为null,要么存在R'中的元组 t',使得t[FK]=t'[K]。
作用:形成关系(表)与关系(表)之间的联系11. 答:每个关系应有一个主键,每个元组的主键的应是唯一的。
这就是实体完整性约束。
如关系:student(学号,姓名,性别)中,有一个主键“学号”,每条学生记录的学号都不同,这是就关系student中的实体完整性约束。
12.R4为:A Ba1 b1a2 b113.ПENO(EPM σmanager=’001’(DEPT))= ПENO(σmanager=’001’(EPM╳DEPT))SELECT ENO FROM EMP, DEPT WHERE DEPT.MANAGER=‘001’ AND EMP.DNO=DEPT.DNO14.答:1.2.客户(身份证号,客户姓名,联系电话,地址,邮政编码) 主键:身份证号业务员(业务员代号,业务员姓名,电话号码)主键:业务员代号房间(房间号,居室数,使用面积,建筑面积,单位,金额,合同号) 主键:房间号 外键:合同号合同(合同号,日期,付款方式,总金额,身份证号,业务员代号) 主键:合同号 外键:身份证号,业务员代号15.司机(驾照号,姓名,地址,邮编,电话)PK=驾照号机动车(牌照号,型号,制造厂,生产日期)PK=牌照号警察(警察编号,姓名)PK=警察编号处罚通知(编号,日期,时间,地点,驾照号,牌照号,警告,罚款,暂扣,警察编号)PK=编号FK=驾照号,牌照号,警察编号第三章1.B2.A3.B4.A5.B6.B7.D8.grant revoke9.(1)select sname from student,course,sc where credit>3 and grade<70 and student.sno=sc.sno and o=o(2) ПSNAME(σs.sno=sc.sno and o=o and credit>3 and grade<70 (STUDENT×COURSE×SC))(3) select sname,o,credit from student, course ,sc where grade is null and student.sno=sc.sno and o=o(4) Select cno,count(sno),max(grade),min(grade), avg(grade) from sc where group by cno order by cno(5) 二步:第一步:CREATE TABLE FGRADE(SNAME VARCHAR(8) NOT NULL,CNO CHAR(6) NOT NULL,GRADE DEC(4,1) DEFAULT NULL);第二步:INSERT INTO FGRADE SELECT SNAME,CNO,GRADE FROM STUDENT,SC WHERE STUDENT.SNO=SC.SNO AND SEX=‘女’;10.(1) select ename,dname from emp,dept where salary>=600 and emp.dno=dept.dno(2)select dname from emp,dept where eno=’001’and emp.dno=dept.dnoПdname(σeno=’001’and emp.dno=dept.dno (emp×dept)) 或者Пdname dept)(3) update emp set salary=salary*1.1 where salary<600 and dno in (select dno from dept where dname=’销售部’)(4) 查询编号为“001” 的部门经理的职工号。
华南理工大学《数据库》(研究生)复习提纲2

华南理工大学《数据库》(研究生)复习提纲2故障类型分为一下三种:1.事务失败:包括逻辑错误(一个事务由于其内部错误,导致不能正常结束如是不内部的死循环)和系统错误(系统进入一个不良如死锁等状态,导致事务无法执行,但该事务在以后的某个时间是可以重新执行的);2.系统崩溃:如电源问题、其他软硬件引起的系统停机,导致缓存、内存等易失存储设备数据丢失,但是非易失存储设备数据一般不会丢失;3.硬盘故障:人为或是自然灾害等因素造成的硬盘损害导致数据的丢失。
故障恢复策略:事务故障和系统故障的恢复方法是:撤销故障发生时未完成事务对DB的所有影响,确保事务的原子性,重做已经成功提交的事务,实现事务的持久性,以上操作一般是由系统在重启时自动完成,不需要用户干预。
灾难性或磁盘失败恢复策略:使用归档存储设备(通常是磁带)上的数据库备份进行恢复,并从备份日志重新应用或者重做已经提交的事务的操作来重构故障钱数据库的最新状态。
缓存目录:跟踪哪些数据项在缓冲区中。
脏位(dirty bit ):每个缓冲区都和一个脏位相关联,它用来指示该缓冲区是否有所修改。
钉住拔去位(pin-unpin bit):即如果缓冲中的页目前还不能写回到磁盘,则称该页被钉住(该位的值为1)。
X所在的缓冲块Bx上的操作output(Bx)不需要在write(X)执行后立即执行,因为块Bx可能包含其他仍在被访问的数据项原位更新(in-place update):将缓冲区写回磁盘原来的位置,因而会覆盖被修改的数据项在磁盘上的旧值(必须使用日志帮助);镜像更新(Shadow update):将缓冲区写到磁盘不同的位置,可以保存数据项的多个版本;非潜入(no-steal):缓存中被事务更新的某个页在事务提交前不能写回磁盘;潜入(steal):允许事务在提交前将已经更新的缓冲区写回磁盘;强制(force):事务所有的已经更新的页在事务提交时被立即写回磁盘;非强制制(no-force):无事所有做的更新的页在事务提交时不立即写回磁盘。
2022年华南理工大学信息管理与信息系统专业《数据库概论》科目期末试卷B(有答案)

2022年华南理工大学信息管理与信息系统专业《数据库概论》科目期末试卷B(有答案)一、填空题1、____________和____________一起组成了安全性子系统。
2、安全性控制的一般方法有____________、____________、____________、和____________视图的保护五级安全措施。
3、完整性约束条件作用的对象有属性、______和______三种。
4、在关系数据库的规范化理论中,在执行“分解”时,必须遵守规范化原则:保持原有的依赖关系和______。
5、“为哪些表,在哪些字段上,建立什么样的索引”这一设计内容应该属于数据库设计中的______阶段。
6、数据库系统在运行过程中,可能会发生各种故障,其故障对数据库的影响总结起来有两类:______和______。
7、数据库恢复是将数据库从______状态恢复到______的功能。
8、如果多个事务依次执行,则称事务是执行______;如果利用分时的方法,同时处理多个事务,则称事务是执行______。
9、数据仓库主要是供决策分析用的______,所涉及的数据操作主要是______,一般情况下不进行。
10、关系规范化的目的是______。
二、判断题11、在CREATEINDEX语句中,使CLUSTERED来建立簇索引。
()12、可以用UNION将两个查询结果合并为一个查询结果。
()13、全码的关系模式一定属于BC范式。
()14、可以用UNION将两个查询结果合并为一个查询结果。
()15、并发执行的所有事务均遵守两段锁协议,则对这些事务的任何并发调度策略都是可串行化的。
()16、在关系数据库中,属性的排列顺序是可以颠倒的。
()17、在第一个事务以S锁方式读数据R时,第二个事务可以进行对数据R加S锁并写数据的操作。
()18、等值连接与自然连接是同一个概念。
()19、关系中任何一列的属性取值是不可再分的数据项,可取自不同域中的数据。
华南理工大学《数据库》(研究生)复习提纲
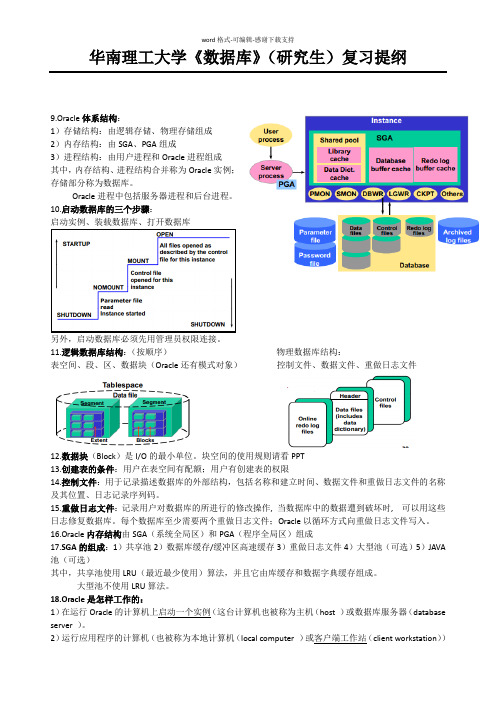
华南理工大学《数据库》(研究生)复习提纲9.Oracle体系结构:1)存储结构:由逻辑存储、物理存储组成2)内存结构:由SGA、PGA组成3)进程结构:由用户进程和Oracle进程组成其中,内存结构、进程结构合并称为Oracle实例;存储部分称为数据库。
Oracle进程中包括服务器进程和后台进程。
10.启动数据库的三个步骤:启动实例、装载数据库、打开数据库另外,启动数据库必须先用管理员权限连接。
11.逻辑数据库结构:(按顺序)物理数据库结构:表空间、段、区、数据块(Oracle还有模式对象)控制文件、数据文件、重做日志文件12.数据块(Block)是I/O的最小单位。
块空间的使用规则请看PPT13.创建表的条件:用户在表空间有配额;用户有创建表的权限14.控制文件:用于记录描述数据库的外部结构,包括名称和建立时间、数据文件和重做日志文件的名称及其位置、日志记录序列码。
15.重做日志文件:记录用户对数据库的所进行的修改操作, 当数据库中的数据遭到破坏时, 可以用这些日志修复数据库。
每个数据库至少需要两个重做日志文件;Oracle以循环方式向重做日志文件写入。
16.Oracle内存结构由SGA(系统全局区)和PGA(程序全局区)组成17.SGA的组成:1)共享池2)数据库缓存/缓冲区高速缓存3)重做日志文件4)大型池(可选)5)JAVA 池(可选)其中,共享池使用LRU(最近最少使用)算法,并且它由库缓存和数据字典缓存组成。
大型池不使用LRU算法。
18.Oracle是怎样工作的:1)在运行Oracle的计算机上启动一个实例(这台计算机也被称为主机(host )或数据库服务器(database server )。
2)运行应用程序的计算机(也被称为本地计算机(local computer )或客户端工作站(client workstation))中启动了用户进程(user process )。
客户端应用程序使用与所在网络环境相匹配的Oracle网络服务驱动与服务器建立连接。
华工数据库复习提纲

华工数据库复习提纲复习主要内容题型:选择题30个共30分,判断题10个共10分、简答题2个共10分,关系代数和SQL设计30分,数据库规范化20分章节主要复习内容:一、概述1)理解E-R图图示的表示方法实体型——矩形属性——椭圆形联系——菱形2)实体之间的联系形式主要有哪几种?两个实体型之间:一对一(班级和班长),一对多(班级和学生),多对多(学生和课程)3)理解概念模型、逻辑模型、物理模型概念模型:对用户观点进行信息建模逻辑模型:主要用于数据库系统的实现,包括层次模型,关系模型,面向对象数据模型物理模型:对数据最底层抽象模型4)什么叫物理独立性?什么叫逻辑独立性?物理独立性:应用程序与数据库中数据物理存储相互独立逻辑独立性:应用程序与数据库逻辑结构相互独立5)数据库管理系统的主要管理功能?数据定义功能(DDL、DML、数据库的事务和运行管理、数据库的建立和维护功能)二、关系代数6)熟练掌握选择、投影、并、交、差运算选择:在关系R中选择满足给定条件的诸元祖投影:从关系R中选择出若干属性组成新的关系7)投影和选择运算要重点掌握,投影后,元组数量不发生变化,选择后,属性数量不发生变化8)理解候选键、主键、外键的概念及关系;关系表有多个候选键,但只能选定其中一个做为主键候选码:若某一属性组的值能唯一地标识一个元组,而其子集不能,则称该属性组为候选码主码:从多个候选码中选取一个作为主码外码:设F是基本关系R的一个或一组属性,但不是关系R的码,K是基本关系S的主码。
如果F和K相对应,则称F是R的外码9)理解自然连接、外连接(左、右、全外连接)自然连接:一种特殊的等值连接。
要求两个关系中进行比较的分量必须是同名的属性全外连接:将悬浮元组保存在结果关系中,其他属性填空值。
左外连接:只保留左边关系中的悬浮元组右外连接:只保留右边关系中的悬浮元组10)熟悉几种完整性约束,参照完整性违约处理包括拒绝执行(受限)、级联操作和设置为空值三种实体完整性:主属性不能为空值参照完整性:外码的取值必须是被参照关系主码域中,或者为空值11)关系代数表达式R-(R-S)表示的是R∩S三、SQLSQL这章所占分数最多12)要掌握单表查询、多表连接查询、嵌套查询、分组运算、排序、选择、投影等操作单表查询:仅涉及一个表的查询(选择表中的若干列:指定列,全部列,经计算的值;选择表中的若干元组:消除取值重复的行(distinct),查询满足条件的元组(where子句:比较大小(<>=),确定范围(between),确定集合(in),字符匹配(like,%,_);order by语句:asc升序(默认),desc降序;聚集函数:count (*)统计元组个数,count ()统计一列中的值的个数,sum()计算一列值的总和,avg()计算一列值的平均值,max()计算一列值中的最大值,min()求一列中的最小值;Group by语句:分组后聚集函数将作用于每一个组,即每一个组都有一个函数值,用having短语指定筛选条件)多表连接查询:等值和非等值连接。
华工 数据库期末重点

复习提纲一、题型1)由选择题、填空题、简答题、sql语言应用、综合题构成。
2)选择题30-40分之间(A、B卷题数不一样)。
填空题大约10分,简答题10分两题,sql语言25-35之间。
综合题15分3)Sql语言要掌握创建对象(表、索引、视图、存储过程)、查询操作、增删改操作、连接、分组、分组过滤、授权(grant)与收回revoke。
Grant 与revoke没有讲,实验有,大家要重视。
4)综合题主要是给定一个关系,能写出键码和函数依赖、候选码,判断最高属于第几范式,能规范化到第三范式或BC范式。
二、复习主要内容1.数据库系统是由数据库、数据库管理系统(DBMS)、数据库管理员(DBA)用户和应用程序构成。
它的核心是数据库管理系统。
2.反映现实世界中实体及实体间联系的信息模型是什么?E-R图用来建立数据库的概念模型。
能根据场景理解和绘制E-R图。
理解联系的几种形式。
3.数据库三级模式结构是什么,描述数据库中全体数据的全局逻辑结构和特征的是什么?要保证数据库的数据独立性,需要修改什么?数据库的物理独立性是指什么?4.理解关系表中行、列、属性、元组等概念5.关系数据库中基于数学上两类运算是关系代数运算和关系演算。
6.在关系代数运算中,五种基本运算是什么?7.能表示sql语句的关系代数形式。
8.理解自然连接。
9.理解全外连接、左外连接、右外连接、自然连接。
10.在SQL中,与关系代数中的选择、投影运算对应的关键字是什么11.熟练掌握数据库对象的授权Grant和收回授权Revoke的操作。
非常重要。
12.数据库三类约束是什么?各类约束要详细理解在sql中的定义。
13.函数依赖最小集中的每一个函数依赖的右部()A.至少一个属性 B.至多一个属性 C.必须是多个属性 D.以上皆不是14.熟练掌握数据库的三范式及BCNF范式,能进行应用的二三级范式规范化,二元关系模式的最高范式是BCNF。
15.能判断一个关系模式属于第几范式。
华南理工大学《数据挖掘》复习资料全

华南理工大学《数据挖掘》复习资料【英文缩写】BI(商务智能): Business IntelligenceOLAP(联机分析处理): Online Analytical Processing OLTP(联机事务处理): Online Transaction Processing ETL(提取/变换/装入): Extraction/Transformation/LoadingKDD(数据中的知识发现):Knowledge Discovery in DatabasesLecture 1.【知识发现的主要过程】(1)数据清理(消除噪声和不一致的数据)(2)数据集成(多种数据源可以组合在一起)(3)数据选择(从数据库中提取与分析任务相关的数据)(4)数据变换(数据变换或同意成适合挖掘的形式,如通过汇总或聚集操作)(5)数据挖掘(基本步骤,使用只能方法提取数据模式)(6)模式评估(根据某种兴趣度度量,识别表示只是的真正有趣的模式)(7)知识表示(使用可视化和只是表示技术,向用户提供挖掘的知识)【挖掘的知识类型】(1)概念描述:特征划与区分(概化、摘要、以及对比数据特征)(2)关联(相关性或者因果关系)(3)分类与预测:对类或概念构造模型或函数以便对未来数据进行预测(4)聚类分析:类标识符是未知的,把数据分成不同的新类,使得同一个类中的元素具有极大的相似性,不同类元素的相似性极小。
(5)趋势与偏差分析:序列模式挖掘(6)孤立点分析:孤立点,不符合该类数据的通用行为的数据,不是噪声或异常。
【数据挖掘在互联网、移动互联网的应用】(1)Web用法挖掘(Web日志挖掘):在分布式信息环境下捕获用户访问模式(2)权威Web页面分析:根据Web页面的重要性、影响和主题,帮助对Web页面定秩(3)自动Web页面聚类和分类:给予页面的内容,以多维的方式对Web页面分组和安排(4)Web社区分析:识别隐藏的Web社会网络和社团,并观察它们的演变Lecture 2.【为什么需要数据预处理】现实世界中的数据很“脏”,具有以下特性:(1)不完整的: 缺少属性值, 感兴趣的属性缺少属性值, 或仅包含聚集数据(2)含噪声的: 包含错误或存在孤立点(3)不一致的: 在名称或代码之间存在着差异数据预处理技术可以改进数据的质量,从而有助于提高其后的挖掘过程的精度和性能。
数据库试卷(含答案)

华南理工大学期末考试 《 数 据 库 》试卷1. 考前请将密封线内各项信息填写清楚;所有答案请直接答在试卷上(或答题纸上);.考试形式:闭卷;选择题、 数据库(DB ),数据库系统(DBS )和数据库管理系统(DBMS )之间的关系是()。
A. DBS 包括DB 和DBMSB. DBMS 包括DB 和DBSC. DB 包括DBS 和DBMSD. DBS 就是DB ,也就是DBMS、 用户或应用程序看到的那部分局部逻辑结构和特征的描述是( )。
A. 模式B. 物理模式C. 子模式D. 内模式、 区分不同实体的依据是( )。
A. 名称B. 属性C. 对象D. 概念4、假设有关系R和S,关系代数表达式R-(R-S)表示的是()。
A.R∩SB.R∪SC.R-SD.R×S5、在视图上不能完成的操作是()。
A.更新视图B.查询C.在视图上定义新的表D.在视图上定义新的视图6、设关系数据库中一个表S的结构为S(SN,CN,grade),其中SN为学生名,CN为课程名,二者均为字符型;grade为成绩,数值型,取值范围0-100。
若要把“张二的化学成绩80分”插入S中,则可用()。
A. ADD INTO S VALUES(’张三’,’化学’,’80’)B.INSERT INTO S VALUES(’张三’,’化学’,’80’)C. ADD INTO S VALUES(’张三’,’化学’,80)D. INSERT INTO S VALUES(’张三’,’化学’,80)7、消除了部分函数依赖的1NF的关系模式,必定是()。
A.1NFB.2NFC.3NFD.BCNF8、X→Y,当下列哪一条成立时,称为平凡的函数依赖()。
A.X ∈YB.Y∈XC.X∩Y=ΦD.X∩Y≠Φ9、以下()不属于实现数据库系统安全性的主要技术和方法。
A.存取控制技术B.视图技术C.审计技术D.出入机房登记和加防盗门10、下述SQL命令中,允许用户定义新关系时,引用其他关系的主码作为外码的是()。
2022年华南理工大学计算机科学与技术专业《数据库原理》科目期末试卷A(有答案)

2022年华南理工大学计算机科学与技术专业《数据库原理》科目期末试卷A(有答案)一、填空题1、数据管理技术经历了______________、______________和______________3个阶段。
2、使某个事务永远处于等待状态,得不到执行的现象称为______。
有两个或两个以上的事务处于等待状态,每个事务都在等待其中另一个事务解除封锁,它才能继续下去,结果任何一个事务都无法执行,这种现象称为______。
3、数据的安全性是指____________。
4、数据库系统是利用存储在外存上其他地方的______来重建被破坏的数据库。
方法主要有两种:______和______。
5、如果多个事务依次执行,则称事务是执行______;如果利用分时的方法,同时处理多个事务,则称事务是执行______。
6、视图是一个虚表,它是从______导出的表。
在数据库中,只存放视图的______,不存放视图对应的______。
7、从外部视图到子模式的数据结构的转换是由______________实现;模式与子模式之间的映象是由______________实现;存储模式与数据物理组织之间的映象是由______________实现。
8、SQL Server中数据完整性包括______、______和______。
9、设某数据库中有商品表(商品号,商品名,商品类别,价格)。
现要创建一个视图,该视图包含全部商品类别及每类商品的平均价格。
请补全如下语句: CREATE VIEW V1(商品类别,平均价格)AS SELECT商品类别,_____FROM商品表GROUP BY商品类别;10、在SQL Server 2000中,数据页的大小是8KB。
某数据库表有1000行数据,每行需要5000字节空间,则此数据库表需要占用的数据页数为_____页。
二、判断题11、关系中任何一列的属性取值是不可再分的数据项,可取自不同域中的数据。
华南理工大学《数据库》(研究生)复习资料

《数据库复习》黄炜杰201230590051Ch 1.【数据库发展的3 个阶段】(1)第一代数据库系统:层次和网状数据库系统(2)第二代数据库系统:关系数据库系统(3)新一代数据库系统【层次、网状数据库共同特点】(1)支持三级模式的体系结构(2)用存取路径来表示数据之间的联系(3)独立的数据定义语言(4)导航的数据操纵语言, 需要用户了解做什么,还要指出怎么做。
【关系数据库】关系数据库是以关系模型为基础的。
关系模型组成成分:1)数据结构2)关系操作3)数据完整性【关系数据库的局限】(1)模型过于简单,不便于表达复杂的嵌套需求。
(2)支持基本数据类型有限,不能支持程序设计中的许多数据结构。
(3)编程语言与操作语言分离,存在阻抗失配问题。
【新一代数据库特征】(1)应支持数据管理、对象管理和知识管理, 以支持面向对象数据模型为主要特征(2)必须保持或继承第二代数据库系统的技术(3)必须对其他系统开放: 支持数据库语言标准, 网络上支持标准网络协议, 具有良好的可移植性、可连接性、可扩展性和可操作性【数据库的发展】主要表现在三个方面:1)数据模型的发展2)数据库技术与其他技术相结合3)面向领域的数据库新技术【数据模型的发展】(1)对传统的关系模型(1NF) 进行扩充,引入了少数构造器,称为复杂数据模型(2)一种是偏重于结构的扩充,如表达“表中表”(3)一种是侧重于语义的扩充,如支持关系之间的继承,关系上定义函数和运算符(4)增加全新的数据构造器和数据处理原语,以表达复杂的结构和丰富的语义(5)面向对象的数据模型(6)XML数据模型【数据库技术与其他相关技术相结合】分布式数据库系统、并行数据库系统、知识库系统和主动数据库系统、多媒体数据库系统、模糊数据库系统等、移动数据库系统等、Web数据库等【面向领域的数据库新技术】1)工程数据库2)空间数据库【NoSQL】non-relational或Not Only SQL。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
华南理工大学《数据库》(研究生)复习题1.基于锁的协议有几种?什么是基于时间标签的协议?什么是基于验证的协议?基于锁的协议即两段锁协议,是指指所有事务必须分两个阶段对数据项加锁和解锁。
具体又分为:基本2PL、保守2PL 、严格2PL和精确2PL基于时间标签的协议:事务被施加了一个基于时间戳的顺序要求并发控制器检查事务对每个DB对象的读写请求看是否能遵循基于时间戳的串行顺序。
以上这个原则性要求,可具体表达为:对任两事务Ti和Tj,若Ti先于Tj,即TS(Ti)<TS(Tj),则必须确保在执行期间,当事务Ti的动作ai与Tj的动作aj冲突时,总有ai先于aj。
如果有某个动作违反了这个串行顺序原则,则相关事务就必须被中止撤销。
每个事务开始启动时,要附上一个时间标记(timestamp)。
后启动事务的标记值大于先启动事务的标记值。
对每个数据库数据项Q,要设置两个时间标记:读时间标记tr,表示成功读过该数据的所有事务的时间标记的最大值。
写时间标记tw:表示成功写过该数据的所有事务的时间标记的最大值。
基于验证的协议:基于验证是一种基于优化的并发控制,允许事务不经过封锁直接访问数据,并在“适当的时候”检查事务是否以可串行化的方式运转(这个“适当时候”主要指事务开始写DB对象之前的、一个称被为“有效确认”的、很短的瞬间阶段)。
事务T的执行过程分为三个阶段:读阶段:事务正常执行所有操作,此时数据修改放在局部临时变量中而不更新数据库。
检验阶段:进行有效性检查,T和已经比它先提交的事务进行比较,发现是否有冲突。
写阶段:如果检验阶段发现无冲突,则事务提交,否则卷回T。
每个事务T的三个阶段对应三个时间标签:start(T):开始执行时间validation(T):开始进入验证的时间finish(T):完成写阶段的时间注意:(1)不同的事务的三个阶段可以交叉执行,但三个阶段的顺序不能改变。
(2)事务最终执行的调度顺序是按照事务的进入验证的时间标签来排。
2.处理死锁的方法有哪些?处理死锁的两种基本方法:预防法和检测法。
预防法:TB已对某数据对象加锁,而TA对该数据对象申请加锁时,选择某事务卷回重执,避免死锁出现。
卷回策略分为等待-死亡策略(若老则等年轻,若年轻则卷回)和击伤等待策略(若年轻则等老,若老则年轻卷回)检测法:基于等待图。
每个活跃事务对应图中的一个节点,如果事务Ti正等待事务Tj 所持有的某个锁,则有一条从Ti对应节点指向Tj对应节点的边。
它可清晰表达事务等待其它事务持有锁的情况。
封锁管理器通过维护等待图来检测死锁循环。
3.什么是多版本并发控制技术?定义:这种技术维护同一数据项的多个版本,把正确的版本分配给事务的读操作。
与其他技术不同的是,这种技术从不拒绝读操作。
目标:事务只读DB元素时无需等待方法:维护最近被修改对象的多个版本(每个版本都带有一个写时间戳),当读事务T 到来时,让它读TS(T)之前的最近的版本。
4.什么是数据锁转换?什么是锁升级?数据锁转换(lock conversion):是指在特定的条件下,允许已经对数据项X持有锁的事务把锁从一种锁定状态变换到另一种状态。
Oracle会尽可能在最低级别锁定(即限制最少的锁),如果必要,会把这个锁转换为一个更受限的级别。
锁升级(lock escalation):是指处于同一粒度级别上的锁被数据库升级为更高粒度级别上的锁。
举例来说,数据库系统可以把一个表的100个行级锁变成一个表级锁,但可能会锁住以前没有锁定的大量数据。
如果数据库认为锁是一种稀有资源,而且想避免锁的开销,这些数据库就会频繁使用锁升级。
Oracle数据库中不存在锁升级。
锁升级将会显著地增加死锁的可能性5.什么是延迟更新与即时更新?延迟更新是指所有事务的更新都记录在局部事务的工作区(或缓存区),只有在事务到达提交点后才真正更新磁盘上的数据库。
如果事务在提交前失败,则它不会修改数据库。
即时更新是指更新一旦发生就被施加到数据库,而无需等待到提交时刻。
若事务的某些操作达到提交点前被写入数据库,恢复时需要UNDO/REDO;如果事务在达到提交点前所有的更新已被写入数据库,需要算法UNDO/NO-REDO6.什么是原位更新和镜像更新?将修改过的缓冲区刷新到磁盘,有两种策略原位更新(in-place update):将缓冲区写回磁盘原来的位置,因而会覆盖被修改数据项在磁盘上的旧值,基于原位更新的恢复必须使用日志。
镜像更新(Shadow update):将缓冲区写到磁盘不同的位置,可保存数据项的多个版本。
7.理解用日志进行恢复的过程。
一种日志是把写操作记录下来:1.当事务Ti开始时,Ti先在日志文件中写入如下的记录:<Ti start>2.当Ti对记录X执行写操作write(X)时,首先写入日志记录<Ti, X, V1, V2>, 其中V1是旧值,V2是新值3.当Ti结束最后一条语句时,写入<Ti commit>的日志记录4.这里可以先假设日志记录是不经过缓存直接写到稳定的存储介质上的。
另外一种日志形式中,把上述X取为一个物理块,则一个日志记录包含了如下三部分:1. 前像(Before Image):当一个事务更新数据时,所涉及的物理块在更新前的映像称为该事务的前像,可以据此使数据库恢复到更新前的状态(撤消更新undo)。
2 .后像(After Image)当一个事务更新数据时,所涉及的物理块在更新后的映像称为该事务的后像,可以据此使数据库恢复到更新后的状态(重做redo)。
3 .事务状态成功(committed)/失败(rollback,abort);辅助的结构有活动事务表和提交事务表WAL规则(The Write-Ahead Logging Protocol)1. 先写日志:更新时先写日志再把数据写到磁盘(保证原子性)2.在事务提交前写事务相关的所有日志记录到稳定存储介质(保证持久性)日志恢复例子恢复例子:撤消阶段(Undo Phase)恢复例子:重做阶段(Redo Phrase)8.什么是潜入/非潜入和强制/非强制?潜入/非潜入和强制/非强制确定了何时把数据页从高速缓存写回磁盘潜入(Steal):缓存中的数据可在事务提交前写回磁盘非潜入(No-Steal): 缓存中的数据不能在事务提交前写回磁盘强制(Force): 缓存中的数据在事务提交后直接写回磁盘(强制地)非强制(No-Force): 即使修改过的内存块没被写回磁盘,事务也可以提交(因为重做的信息已记录在日志中)。
9.理解ARIES恢复管理算法(PDF db04 page30)ARIES简介:它试图以概念上相对简单且系统化的方式,提供一套能确保事务原子性和持性的、具有良好性能的恢复管理算法。
它能与绝大多数并发控制机制很好协调工作的。
这里使用并发封锁控制默认时都假定使用基于strict-2PL协议的封锁调度器,并假设主要基于页级封锁。
少数场合,如逻辑日志中,也可能涉及元组级封锁。
算法流程:采用基于“steal/no-force”工作模式。
当系统崩溃后重启时,恢复管理器将被激活,并按以下三个阶段进行处理:分析(Analysis):鉴别崩溃发生时,缓冲区中的脏页和当时仍活跃的事务。
重做(Redo):重做从日志的适当起点(比如,被修改的最早脏页对应日志记录)开始的所有动作,恢复系统到崩溃时的DB状态。
撤消(Undo):撤消上次崩溃时所有未提交事务的动作效果,使DB只反映已提交事务的影响。
(建议看下PDF db04 p33-38的例子加深理解)10.性能调整的系统的方法有哪些?优化器做些什么?调优通常涉及哪些问题?性能调整的系统的方法有:(1)正确地设计应用程序(2)调整应用程序的SQL代码(3)调整内存(4)调整I/O(5)调整争用和其他问题优化器做的事情是:1. SQL 转换2. 选择访问路径3. 选择连接方法4. 选择连接顺序调优涉及的问题:•如何避免对锁的争用,从而增加事务之间的并发性•如何最小化日志开销,以及不必要的数据转储•如何优化缓存区的大小,以及进程的进度•如何对磁盘、RAM和进程之类的资源进行分配使其利用效率最高•这些问题大都可以通过设置合适的物理DBMS参数、改变设备的配置、修改操作系统的参数参数、改变设备的配置、修改操作系统的参数和其他类似的动作得以解决。
11.什么情况下进行索引的调优?怎么进行索引的调优?基于以下几个原因需要对索引进行调优:(1)由于缺乏索引,某些查询的执行时间过长(2)某些索引自始自终没有被使用(3)某些索引建立在被频繁改变的属性上导致系统的¾某些索引建立在被频繁改变的属性上,导致系统的开销过大怎样进行索引调优:•借助于相关工具,DBA 可从系统获得关于查询执行过程的信息,通过分析执行计划,可以得到产生上述问题的原因基于调优分析可得到产生上述问题的原因,基于调优分析,可能会删除某些索引,也可能要增加新的索引。
•通过重建索引也可以改进系统的性能12.如何考虑数据库设计的调优?• 如果由于需要频繁使用两个或多个表中的某些属性,可能需要逆规范化现有的表• 必要的时候对表进行垂直划分.(垂直划分,即按照功能划分,把数据分别放到不同的数据库和服务器)• 必要的时候对表进行水平划分.(水平划分,,即把一个表的数据划分到不同的数据库,两个数据库的表结构一样。
怎么划分,应该根据一定的规则,可以根据数据的产生者来做引导,上面的数据是由人产生的,可以根据人的id来划分数据库。
然后再根据一定的规则,先获知数据在哪个数据库)13.了解查询的调优的原则和方法?需要进行查询调优的典型情况(1)查询导致过多的磁盘存取(比如一个精确的匹配查询要对整个表进行扫描) 整个表进行扫描)(2)查询计划表明相关的索引并没有被使用查询的调优的原则和方法(1)有些DISTINCT 是多余的,在不改变查询结果的前提下可以省略(2)把多个查询合并为一个查询,可避免使用不必要的临时结果表(3)FROM子句中表的出现顺序可能会影响连接操作(4)某些查询优化器在嵌套查询上的性能要比等价的非嵌套查询差(5)如果选择条件通过OR连接,可能优化器不会使用任何索引(6把NOT条件转化为肯定表达式(7)可用连接替换使用IN、=ALL、=ANY、=SOME的嵌入式SELECT块(8)可以使用多个列上的索引重写WHERE条件(PDF db05 25-29页很多原则,百度出来的结果也有三十多条,这里我主要列了其中一些比较简单字数少的规则)14.结合oracle体系结构,理解oracle调优的方法.(通知该题不用整理)15.什么是数据库集群?为什么要研究数据库集群?数据库集群分类有哪些?数据库集群技术的实现机理?提高处理速度的办法?提高可用性的方法?主流产品有哪些?数据库集群技术现状及前景。