华南理工大学数据库期末考试卷考点整理_共6页
数据库期末考试试题及答案

数据库期末考试试题及答案一、名词解释(每小题2分,共10分)1. 数据库(Database)2. 数据模型(Data Model)3. 表(Table)4. 字段(Field)5. 记录(Record)6. 主键(Primary Key)7. 外键(Foreign Key)8. 索引(Index)9. 视图(View)10. 存储过程(Stored Procedure)二、选择题(每小题2分,共20分)1. 下列哪个是关系型数据库管理系统?A. OracleB. MyBatisC. MongoDBD. Redis2. 在数据库中,哪个字段用于唯一标识一条记录?A. 字段名B. 数据类型C. 主键D. 索引3. 以下哪个不属于数据库的基本操作?A. 插入B. 删除C. 修改D. 格式化4. 下列哪个SQL语句用于创建表?A. SELECTB. INSERTC. CREATE TABLED. UPDATE5. 在SQL中,哪个关键字用于删除表?A. DROP TABLEB. DELETEC. ALTER TABLED. TRUNCATE TABLE6. 下列哪个SQL语句用于查询所有字段?A. SELECT FROM table_nameB. SELECT table_name FROMC. SELECT FROM table_nameD. SELECT table_name7. 以下哪个函数用于计算两个日期之间的差值?A. DATEDIFFB. TIMESTAMPDIFFC. DATE_ADDD. DATE_SUB8. 下列哪个SQL语句用于修改表的结构?A. MODIFY TABLEB. ALTER TABLEC. CHANGE TABLED. RENAME TABLE9. 下列哪个关键字用于创建外键约束?A. FOREIGN KEYB. CONSTRAINTC. PRIMARY KEYD. INDEX10. 以下哪个存储过程用于备份数据库?A. BACKUP DATABASEB. RESTORE DATABASEC. CREATE DATABASED. DROP DATABASE三、填空题(每小题2分,共20分)1. 在SQL中,用于插入数据的语句是______。
华南理工大学《数据库》(研究生)复习题解析

华南理工大学《数据库》(研究生)复习题1.基于锁的协议有几种?什么是基于时间标签的协议?什么是基于验证的协议?基于锁的协议即两段锁协议,是指指所有事务必须分两个阶段对数据项加锁和解锁。
具体又分为:基本2PL、保守2PL 、严格2PL和精确2PL基于时间标签的协议:事务被施加了一个基于时间戳的顺序要求并发控制器检查事务对每个DB对象的读写请求看是否能遵循基于时间戳的串行顺序。
以上这个原则性要求,可具体表达为:对任两事务Ti和Tj,若Ti先于Tj,即TS(Ti)<TS(Tj),则必须确保在执行期间,当事务Ti的动作ai与Tj的动作aj冲突时,总有ai先于aj。
如果有某个动作违反了这个串行顺序原则,则相关事务就必须被中止撤销。
每个事务开始启动时,要附上一个时间标记(timestamp)。
后启动事务的标记值大于先启动事务的标记值。
对每个数据库数据项Q,要设置两个时间标记:读时间标记tr,表示成功读过该数据的所有事务的时间标记的最大值。
写时间标记tw:表示成功写过该数据的所有事务的时间标记的最大值。
基于验证的协议:基于验证是一种基于优化的并发控制,允许事务不经过封锁直接访问数据,并在“适当的时候”检查事务是否以可串行化的方式运转(这个“适当时候”主要指事务开始写DB对象之前的、一个称被为“有效确认”的、很短的瞬间阶段)。
事务T的执行过程分为三个阶段:读阶段:事务正常执行所有操作,此时数据修改放在局部临时变量中而不更新数据库。
检验阶段:进行有效性检查,T和已经比它先提交的事务进行比较,发现是否有冲突。
写阶段:如果检验阶段发现无冲突,则事务提交,否则卷回T。
每个事务T的三个阶段对应三个时间标签:start(T):开始执行时间validation(T):开始进入验证的时间finish(T):完成写阶段的时间注意:(1)不同的事务的三个阶段可以交叉执行,但三个阶段的顺序不能改变。
(2)事务最终执行的调度顺序是按照事务的进入验证的时间标签来排。
数据库试卷(B卷)

,考试作弊将带来严重后果!华南理工大学期末考试《数据库》试卷B1. 考前请将密封线内各项信息填写清楚; 所有答案请直接答在试卷上; .考试形式:闭卷;20小题,每小题1分,共20分, 请将答案填在下表内)下面列出的数据库管理技术发展的三个阶段中,没有专门的软件对数据进行管理的是( )。
.人工管理阶段 .文件系统阶段 .数据库阶段 和 II 只有 II 和 III 只有 I数据库设计中,用E -R 图来描述信息结构但不涉及信息在计算机中的表示,这是数据库 )。
需求分析阶段 逻辑设计阶段 概念设计阶段 物理设计阶段3. 对由SELECT--FROM—WHERE—GROUP--ORDER组成的SQL语句,其在被DBMS处理时,各子句的执行次序为()。
A. SELECT—FROM—GROUP—WHERE—ORDERB. FROM——SELECT--WHERE——GROUP——ORDERC. FROM——WHERE——GROUP——SELECT——ORDERD. SELECT——FROM——WHERE——GROUP——ORDER4. 下列四项中,不属于数据模型要素的是()。
A. 数据结构B. 数据冗余C. 数据操作D. 完整性约束5. 现有如下关系:学生(学号,姓名,性别,出生日期,专业,系编号)系(系编号,系名称,系主任,电话,地点)其中,学生关系中的外码是()。
A. 系编号B. 学号C. 系编号和系名称D. 系编号和学号6.关系模型中实现实体间 N:M 联系是通过增加一个()。
A. 关系或一个属性实现B. 属性实现C. 关系实现D. 关系和一个属性实现7. 五种基本关系代数运算是()。
A. U,n,x,π和σB. U,-,∞,π和σC. U,n,∞,π和σD. U,-,×,π和σ8. SQL语言中,删除一个索引的命令是()。
A. DELETEB. DROPC. CLEARD. REMOVE9. 若要在基本表S中增加一列CN(课程名),可用()。
数据库期末考试复习题库(非常全面)

数据库期末考试复习题库(非常全面)第一部分第一章:一选择题:1.在数据管理技术的发展过程中,经历了人工管理阶段、文件系统阶段和数据库系统阶段。
在这几个阶段中,数据独立性最高的是阶段。
A.数据库系统 B.文件系统 C.人工管理 D.数据项管理答案:A 2.数据库的概念模型独立于。
A.具体的机器和DBMS B.E-R图 C.信息世界 D.现实世界答案:A 3.数据库的基本特点是。
A.(1)数据可以共享(或数据结构化) (2)数据独立性 (3)数据冗余大,易移植 (4)统一管理和控制B.(1)数据可以共享(或数据结构化) (2)数据独立性 (3)数据冗余小,易扩充 (4)统一管理和控制C.(1)数据可以共享(或数据结构化) (2)数据互换性 (3)数据冗余小,易扩充 (4)统一管理和控制D.(1)数据非结构化 (2)数据独立性 (3)数据冗余小,易扩充 (4)统一管理和控制答案:B4. 是存储在计算机内有结构的数据的集合。
A.数据库系统 B.数据库 C.数据库管理系统 D.数据结构答案:B5.数据库中存储的是。
A.数据 B.数据模型 C.数据以及数据之间的联系 D.信息答案:C 6. 数据库中,数据的物理独立性是指。
A.数据库与数据库管理系统的相互独立 B.用户程序与DBMS的相互独立C.用户的应用程序与存储在磁盘上数据库中的数据是相互独立的 D.应用程序与数据库中数据的逻辑结构相互独立答案:C7. .数据库的特点之一是数据的共享,严格地讲,这里的数据共享是指。
A.同一个应用中的多个程序共享一个数据集合 B.多个用户、同一种语言共享数据C.多个用户共享一个数据文件 D.多种应用、多种语言、多个用户相互覆盖地使用数据集合答案:D8.据库系统的核心是。
A.数据库B.数据库管理系统C.数据模型D.软件工具答案:B9. 下述关于数据库系统的正确叙述是。
A.数据库系统减少了数据冗余 B.数据库系统避免了一切冗余 C.数据库系统中数据的一致性是指数据类型一致D.数据库系统比文件系统能管理更多的数据答案:A10. 数将数据库的结构划分成多个层次,是为了提高数据库的①和②。
华南理工大学期末考试试卷及参考答案_B2008a

,考试作弊将带来严重后果!华南理工大学期末考试《信号与系统》试卷B1. 考前请将密封线内填写清楚;所有答案请直接答在试卷上(或答题纸上); .考试形式:闭 卷;2分/题,共20分)1) 信号x(n), n=0,1,2,3,…是能量有限的意思是a) x(n)有限;b) |x(n)|有界;c)()2n x n ∞=<∞∑; d)()01Nn x n N=<∞∑。
c2) 一个实信号x(t)的偶部是a) x(t)+x(-t); b) 0.5(x(t)+x(-t)); c) |x(t)|-|x(-t)|; d) x(t)-x(-t)。
b 3) LTI 连续时间系统输入为(),0ate u t a ->,冲击响应为h(t)=u(t), 则输出为a)()11at e a --; b) ()()11at e t a δ--; c) ()()11ate u t a --; d) ()()11at e t aδ---。
c 4) 设两个LTI 系统的冲击响应为h(t)和h 1(t),则这两个系统互为逆系统的条件是 a) ()()()1h t h t t δ*=; b) ()()()1h t h t u t *=; a c) ()()()1h t h t u t *=-; d) ()()10h t h t *=。
5) 一个LTI 系统稳定指的是a) 对于周期信号输入,输出也是周期信号;b)对于有界的输入信号,输出信号趋向于零;c)对于有界输入信号,输出信号为常数信号;d)对于有界输入信号,输出信号也有界 d6) 离散信号的频谱一定是a) 有界的;b) 连续时间的;c) 非负的;d) 连续时间且周期的。
d 7) 对于系统()()()dy t y t x t dtτ+=,其阶跃响应为 a) ()/1t e u t τ-⎡⎤-⎣⎦; b) ()/1t e t τδ-⎡⎤-⎣⎦; c) ()/1t e u t τ-⎡⎤+⎣⎦; d) ()/1t e t τδ-⎡⎤+⎣⎦. a8) 离散时间LTI 因果系统的系统函数的ROC 一定是a) 在一个圆的外部且包括无穷远点; b)一个圆环区域;c) 一个包含原点的圆盘;d) 一个去掉原点的圆盘。
2022年华南理工大学信息管理与信息系统专业《数据库概论》科目期末试卷B(有答案)

2022年华南理工大学信息管理与信息系统专业《数据库概论》科目期末试卷B(有答案)一、填空题1、____________和____________一起组成了安全性子系统。
2、安全性控制的一般方法有____________、____________、____________、和____________视图的保护五级安全措施。
3、完整性约束条件作用的对象有属性、______和______三种。
4、在关系数据库的规范化理论中,在执行“分解”时,必须遵守规范化原则:保持原有的依赖关系和______。
5、“为哪些表,在哪些字段上,建立什么样的索引”这一设计内容应该属于数据库设计中的______阶段。
6、数据库系统在运行过程中,可能会发生各种故障,其故障对数据库的影响总结起来有两类:______和______。
7、数据库恢复是将数据库从______状态恢复到______的功能。
8、如果多个事务依次执行,则称事务是执行______;如果利用分时的方法,同时处理多个事务,则称事务是执行______。
9、数据仓库主要是供决策分析用的______,所涉及的数据操作主要是______,一般情况下不进行。
10、关系规范化的目的是______。
二、判断题11、在CREATEINDEX语句中,使CLUSTERED来建立簇索引。
()12、可以用UNION将两个查询结果合并为一个查询结果。
()13、全码的关系模式一定属于BC范式。
()14、可以用UNION将两个查询结果合并为一个查询结果。
()15、并发执行的所有事务均遵守两段锁协议,则对这些事务的任何并发调度策略都是可串行化的。
()16、在关系数据库中,属性的排列顺序是可以颠倒的。
()17、在第一个事务以S锁方式读数据R时,第二个事务可以进行对数据R加S锁并写数据的操作。
()18、等值连接与自然连接是同一个概念。
()19、关系中任何一列的属性取值是不可再分的数据项,可取自不同域中的数据。
华南理工大学《数据库》(研究生)复习提纲
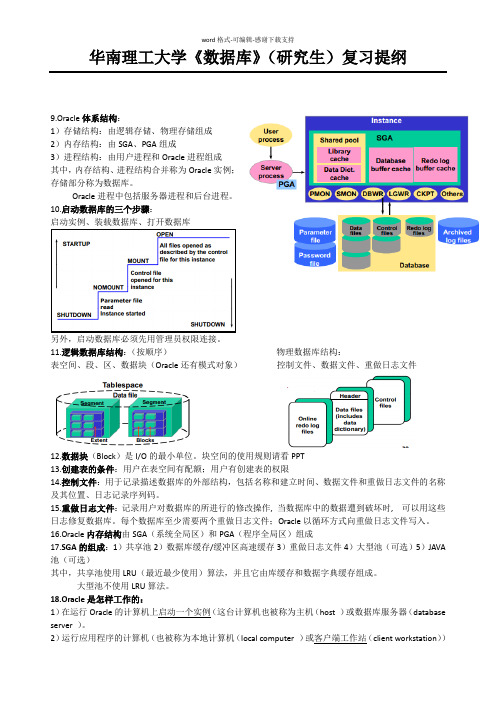
华南理工大学《数据库》(研究生)复习提纲9.Oracle体系结构:1)存储结构:由逻辑存储、物理存储组成2)内存结构:由SGA、PGA组成3)进程结构:由用户进程和Oracle进程组成其中,内存结构、进程结构合并称为Oracle实例;存储部分称为数据库。
Oracle进程中包括服务器进程和后台进程。
10.启动数据库的三个步骤:启动实例、装载数据库、打开数据库另外,启动数据库必须先用管理员权限连接。
11.逻辑数据库结构:(按顺序)物理数据库结构:表空间、段、区、数据块(Oracle还有模式对象)控制文件、数据文件、重做日志文件12.数据块(Block)是I/O的最小单位。
块空间的使用规则请看PPT13.创建表的条件:用户在表空间有配额;用户有创建表的权限14.控制文件:用于记录描述数据库的外部结构,包括名称和建立时间、数据文件和重做日志文件的名称及其位置、日志记录序列码。
15.重做日志文件:记录用户对数据库的所进行的修改操作, 当数据库中的数据遭到破坏时, 可以用这些日志修复数据库。
每个数据库至少需要两个重做日志文件;Oracle以循环方式向重做日志文件写入。
16.Oracle内存结构由SGA(系统全局区)和PGA(程序全局区)组成17.SGA的组成:1)共享池2)数据库缓存/缓冲区高速缓存3)重做日志文件4)大型池(可选)5)JAVA 池(可选)其中,共享池使用LRU(最近最少使用)算法,并且它由库缓存和数据字典缓存组成。
大型池不使用LRU算法。
18.Oracle是怎样工作的:1)在运行Oracle的计算机上启动一个实例(这台计算机也被称为主机(host )或数据库服务器(database server )。
2)运行应用程序的计算机(也被称为本地计算机(local computer )或客户端工作站(client workstation))中启动了用户进程(user process )。
客户端应用程序使用与所在网络环境相匹配的Oracle网络服务驱动与服务器建立连接。
数据库原理-期末考试试题及答案

数据库原理-期末考试试题及答案------------------------------------------作者------------------------------------------日期数据库原理-期末考试试题及答案(本大题共 小题,每小题 分,共 分✆在每小题列出的四个备选项中只有一个是符合题目要 求的,错选、多选或未选均无分。
要保证数据库的数据独立性,需要修改的是( )✌.三层模式之间的两种映射 .模式与内模式.模式与外模式 .三层模式 下列四项中说法不正确的是( )✌.数据库减少了数据冗余 .数据库中的数据可以共享.数据库避免了一切数据的重复 .数据库具有较高的数据独立性 公司中有多个部门和多名职员,每个职员只能属于一个部门,一个部门可以有多名职员,从职员到部门的联系类型是( )✌.多对多 .一对一.多对一 .一对多. 将☜模型转换成关系模型,属于数据库的( )✌.需求分析 .概念设计.逻辑设计 .物理设计. 五种基本关系代数运算是( )✌.∪, ,×,π和σ .∪, ,,π和σ.∪,∩,×,π和σ .∪,∩,,π和σArray. 下列聚合函数中不忽略空值 ☎☠✞☹☹✆ 的是( )。
✌. ✞ ☎列名✆ . ✌✠ ☎列名✆ . ✞☠❆ ☎ ✉ ✆ .✌✞☝ ☎列名✆ ✈☹中,下列涉及空值的操作,不正确的是( )。
✌ ✌☝☜ ✋ ☠✞☹☹ ✌☝☜ ✋ ☠❆ ☠✞☹☹ ✌☝☜ ☠✞☹☹ ☠❆ ☎✌☝☜ ✋ ☠✞☹☹✆ 已知成绩关系如表 所示。
执行 ✈☹语句:☜☹☜❆ ✞☠❆( ✋❆✋☠❆学号)☞成绩☟☜☜分数> 查询结果中包含的元组数目是( )表 成绩关系 . 在视图上不能完成的操作是( )✌ 更新视图 查询 在视图上定义新的基本表 在视图上定义新视图 关系数据模型的三个组成部分中,不包括( )✌ 完整性约束 数据结构 恢复 数据操作 假定学生关系是 ( #, ☠✌☜, ☜✠,✌☝☜),课程关系是 ( #, ☠✌☜,❆☜✌☟☜),学生选课关系是 ( #, #,☝✌☜)。
(完整版),数据库期末考试复习试题与答案,推荐文档

CREATE UNIQUE INDEX
Stusname ON student(Sname)
4. SELECT语句查询条件中的谓词 “ !=ALL ”与运算符 NOT IN
等价
5. 关系模式 R(A , B, C , D) 中,存在函数依赖关系 {A → B, A→ C, A→ D,( B, C )→ A} ,则侯选码是 , R∈ AB NF 。
CREATE TABLE Student(Sno CHAR(4) PRIMARY KEY,
Sname CHAR(8) NOT NULL,
Sex CHAR(2),
Age INT)
可以插入到表中的元组是(
D)
A. '5021' , '刘祥 ',男, 21 C. '5021' , NULL,男, 21
B. NULL,'刘祥 ', NULL, 21 D. '5021' , '刘祥 ', NULL ,NULL
Unlock C
..
..
B. Slock A … Slock B … Xlock C ………… Unlock C … Unlock B … Unlock A
C. Slock A … Slock B … Xlock C ………… Unlock B … Unlock C … Unlock A
D. Slock A … Unlock A …… Slock B … Xlock C ……… ...Unlock B … Unlock C
17. 数据库恢复的基础是利用转储的冗余数据。这些转储的冗余数据是指(
C
)
A. 数据字典、应用程序、审计档案、数据库后备副本
2004-2005学年度第一学期期末考试试卷

华南理工大学计算机科学与工程学院2004—2005学年度第一学期期末考试《数据挖掘与数据仓库技术》试卷专业:双语班年级:2001 姓名:学号:注意事项:1. 本试卷共四大题,满分100分,考试时间120分钟;2. 所有答案请直接答在试卷上;一.Fill in the following blanks. (1 point per blank, the total: 20 points)1. A data warehouse is a __________, __________, __________and __________collection of data in support of management’s decision making process.2.The most popular data model for a data warehouse is a multidimensional model. Sucha model can exist in the form of a _____schema, a __________schema, or a__________ schema.3.OLTP is the abbreviation for ____________________, and OLAP is the abbreviationfor ____________________.4.Measures can be organized into the following three categories, based on the kind ofaggregate functions used, __________, __________, and ________.5.Methods for data preprocessing can be organized into the following categories:__________, __________, __________ and __________.6.List four knowledge types to be mined: __________, __________, __________ and__________.二.True or False: if you think the following statement is true then mark it with √, otherwisemark it with ⨯. (1 point per decision, the total: 10 points)1.Decision tree induction is an unsupervised learning method. ( )2.Clustering is a supervised learning method. ( )3.The OLTP system is operational processing-oriented, while the OLAP system isinformational processing-oriented. ( )4.The access operation to the OLTP system is mostly read/write, while the accessoperation to the OLAP system is mostly read. ( )5.Outlier and noisy data are useless for data mining task and should be removed. ()6.For an itemset S, the constraint S ⊆ V is anti-monotone. ( )7.For an itemset S, the constraint min(S)≥ v is monotone. ( )8.The aggregate functions min()and max()are distributive, where min()is used tocompute the minimum value of a data set and max() is used to compute the maximum value of a data set. ( )9.The aggregate function avg() is holistic, where avg() is used to compute the averagevalue of a data set. ( )10.The difference between K-means and K-medoids clustering method is that the formeruses the centroid to represent a cluster, while the latter uses the real object to represent a cluster. ( )三.Miscellaneous questions. (8 points per question, the total: 24 points)1.Suppose that a data warehouse consists of the three dimensions time, doctor, andpatient, and the two measures count and charge, where charge is the fee that a doctor charges a patient for a visit. Draw the star schema diagram for the above data warehouse.2.Given the following table (Table 1):rule. For example, ∀X, Guangzhou(X) ⇔ TV(X) [t: x%, d: y%] ∨⋯.(2).M ap the class Computer (target class) into a (bi-directional) quantitative descriptiverule.3.Given frequent itemset m and subset s of m, prove that the confidence of the rule“s'⇒(m-s')” can not be more than the confidence of “s⇒(m-s)”, where s' is a subset of s.四.Problems. (The total: 46 points)1.In information retrieval, keywords-based retrieval method is the dominant method.Document is represented by a set of words, called keywords, and when you want to retrieve some documents, you just need to present some keywords. Given the following keywords-document table (Table 2), the first row means that the document D1 is represented by keywords K1, k2 and K4.(1).F ind all frequent patterns of keywords using Apriori algorithm, and generate strongassociation rules from L2 (i.e. the frequent 2-pattern). Assume the support count is 2 and the confidence is 80%. (12 points)(2).D raw the frequent pattern tree. (6 points)2.Table 3 presents a training set of data tuples about whether to play tennis. Given atuple (Outlook=sunny, temperature=cool, Humidity=high, Wind=strong), decide that the target class Playtennis is yes or no using Bayesian naïve classifier. (18 points)3.Table 4 presents distances between any two objects, e.g. the distance between objects1and 2is 2.5. Assume the distance between two clusters d(C1, C2)is defined as follows: d(C1, C2) = Min{d ij| i ∈ C1, j ∈ C2}, where C1, C2 are two clusters, and d ij is the distance between objects i and j, Min is used to compute the minimum value of a set. Clustering the objects using the agglomerative hierarchical clustering method and draw the dendrogram (i.e. shows how the clusters are merged hierarchically). (10 points)。
2022年华南理工大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)

2022年华南理工大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)一、选择题1、n个结点的完全有向图含有边的数目()。
A.n*nB.n(n+1)C.n/2D.n*(n-1)2、用数组r存储静态链表,结点的next域指向后继,工作指针j指向链中结点,使j沿链移动的操作为()。
A.j=r[j].nextB.j=j+lC.j=j->nextD.j=r[j]->next3、若线性表最常用的操作是存取第i个元素及其前驱和后继元素的值,为节省时间应采用的存储方式()。
A.单链表B.双向链表C.单循环链表D.顺序表4、有六个元素6,5,4,3,2,1顺序入栈,下列不是合法的出栈序列的是()。
A.543612B.453126C.346521D.2341565、动态存储管理系统中,通常可有()种不同的分配策略。
A.1B.2C.3D.46、已知关键字序列5,8,12,19,28,20,15,22是小根堆(最小堆),插入关键字3,调整后的小根堆是()。
A.3,5,12,8,28,20,15,22,19B.3,5,12,19,20,15,22,8,28C.3,8,12,5,20,15,22,28,19D.3,12,5,8,28,20,15,22,197、下列关于无向连通图特性的叙述中,正确的是()。
Ⅰ.所有的顶点的度之和为偶数Ⅱ.边数大于顶点个数减1 Ⅲ.至少有一个顶点的度为1A.只有Ⅰ B.只有Ⅱ C.Ⅰ和Ⅱ D.Ⅰ和Ⅲ8、已知一棵二叉树的前序遍历结果为ABCDEF,中序遍历结果为CBAEDF,则后序遍历结果为()。
A.CBEFDAB.FEDCBAC.CBEDFAD.不定9、一个具有1025个结点的二叉树的高h为()。
A.11B.10C.11至1025之间D.10至1024之间10、一组记录的关键码为(46,79,56,38,40,84),则利用快速排序的方法,以第一个记录为基准得到的一次划分结果为()。
华南理工大学数据结构

or greater than the right child.(6) The most effective way to reduce the time required by a disk-based program is to:( B )(A) Improve the basic operations. (B) Minimize the number of disk accesses.(C) Eliminate the recursive calls. (D) Reduce main memory use.(7) The max-heap constructed by a sequence of key (46, 79, 56, 38, 40, 84) is( )?(A) 79, 46, 56, 38, 40, 84 (B) 84, 79, 56, 46, 40, 38(C) 84, 79, 46, 38, 40, 56 (D) 84, 56, 79, 40, 46, 38(8) If there is 0.5MB working memory, 4KB blocks, yield 128 blocks for working memory. By the multi-way merge in external sorting, the average run size and the sorted size in one pass of multi-way merge on average are separately ( A )?(A) 1MB, 128MB (B) 1MB, 64MB(C) 2MB, 64 MB (D) 0.5 MB, 128MB(9) Tree indexing methods are meant to overcome what deficiency in hashing?( D )(A) Inability to handle range queries. (B) Inability to maximum queries(C) Inability to handle queries in key order (D) All of above.(10) Assume that we have eight records, with key values A to H, and that they are initially placed in alphabetical order. Now, consider the result of applying the following access pattern: E D F G B G F A F E G B, if the list is organized by the move-to-front heuristic, then the final list will be ( B ).(A)B G E F D A C H (B) B G E F A D C H(C) A B F D G E C H (D) F D G E A B C H2. Fill the blank with correct C++ codes: (13 scores)(1)Given an array storing integers ordered by value, modify the binary searchroutines to return the position of the first integer with the greatest value less than K when K itself does not appear in the array. Return ERROR if the least value in the array is greater than K: (10 scores)// Return position of greatest element <= Kint newbinary(int array[], int n, int K) {int l = -1;int r = n; // l and r beyond array boundswhile (l+1 != r) { // Stop when l and r meet___ int i=(l+r)/2_____; // Look at middle of subarrayif (K < array[i]) __ r=i ___; // In left halfif (K == array[i]) __ return i ___; // Found itif (K > array[i]) ___ l=i ___ // In right half}// Search value not in array___ return l __; // l at first value less than K// l=-1, no value less than K}(2) A full 5-ary tree with 100 internal vertices has ___501___vertices. ( 3 scores)3. A certain binary tree has the preorder enumeration as ABECDFGHIJ and the inorder enumeration as EBCDAFHIGJ. Try to draw the binary tree and give the postorder enumeration. (The process of your solution is required!!!) (8 scores)Postorder enumeration : EDCBIHJGFA4. Determine Θ for the following code fragments in the average case. Assume that all variables are of type int.(9 scores)(1) sum=0;for (i=0; i<3; i++)for (j=0; j<n; j++)sum++; solution : Θ___(n)_______(2) sum = 0;for(i=1;i<=n;i++)for(j=1;j<=i;j++)sum++; solution : Θ__(n 2)________(3) sum=0;if (EVEN(n))for (i=0; i<n; i++)sum++;elsesum=sum+n; solution : Θ___(n)_____5. Trace by hand the execution of radix sort algorithm on the array:int a[] = {265 301 751 129 937 863 742 694 76 438} (9 scores)initial: 265 301 751 129 937 863 742 694 76 438pass 1: [] [301 751] [742] [863] [694] [265] [76] [937] [438] [129]pass 2: [301] [] [129] [937 438] [742] [751] [863 265] [76] [] [694]pass 3: [76] [129] [265] [301] [438] [] [694] [742 751] [863] [937]final sorted array:76 129 265 301 438 694 742 751 863 9376. Build the Huffman coding tree and determine the codes for the following set of letters and weights:A B C D E F G H5 25 36 10 11 36 4Draw the Huffman coding tree and give the Huffman code for each letters. What is the expected length in bits of a message containing n characters for this frequency distribution? (The process of your solution is required!!!) (8 scores)Total length: 4 * 5 + 2 * 25 + 4 * 3 + 4 * 6 + 3 * 10 + 3 * 11 + 2 * 36 + 4 * 4 = 257Expected length: 257/100=2.577. Assume a disk drive is configured as follows. The total storage is approximately 675M divided among 15 surfaces. Each surface has 612 tracks; there are 144 sectors/track, 512 byte/sector, and 16 sectors/cluster. The interleaving factor isfive. The disk turns at 7200rmp (8.33 ms/r). The track-to-track seek time is 20 ms, and the average seek time is 80 ms. Now how long does it take to read all of the data in a 320 KB file on the disk? Assume that the file ’s clusters are spread randomly across the disk. A seek must be performed each time the I/O reader moves to a new track. Show your calculations. (The process of your solution is required!!!) (8 scores)Answer :The first question is how many clusters the file requires?A cluster holds 16*0.5K = 8K . Thus, the file requires 320/8=40 clusters.The time to read a cluster is seek time to thecluster+ latency time + (interleaf factor ×rotation time).Average seek time is defined to be 80 ms. Latency time is 0.5 *8.33 ms(60/7200≈8.33ms),and cluster rotation time is 5 * (16/144)*8.33.Seek time for the total file read time is40* (80 + 0.5 *8.33+ 5 * (16/144)*8.33 ) ≈3551.85 ms Or 3551.51 when (60/7200≈8.3ms)which is pretty slow by to day’s standards.8. Using closed hashing, with double hashing to resolve collisions, insert the following keys into a hash table of eleven slots (the slots are numbered 0 through 10). The hash functions to be used are H1 and H2, defined below. You should show the hash table after all eight keys have been inserted. Be sure to indicate how you are using H1 and H2 to do the hashing. ( The process of your solution is required!!!)H1(k) = 3k mod 11 H2(k) = 7k mod 10+1Keys: 22, 41, 53, 46, 30, 13, 1, 67. (8 scores)Answer:H1(22)=0, H1(41)=2, H1(53)=5, H1(46)=6, no conflictWhen H1(30)=2, H2(30)=1 (2+1*1)%11=3,so 30 enters the 3rd slot;H1(13)=6, H2(13)=2 (6+1*2)%11=8, so 13 enters the 8th slot;H1(1)=3, H2(1)=8 (3+5*8)%11= 10 so 1 enters 10 (pass by 0, 8, 5, 2 );H1(67)=3, H2(67)=10 (3+2*10)%11= 1 so 67 enters 1(pass by 2)9. You are given a series of records whose keys are integers. The records arrive in the following order: C, S, D, T, A, M, P, I, B, W, N, G, U, R. Show the 2-3 tree that results from inserting these records. (the process of your solution is required!!!)(7 scores)MSBD P UA C GI N R T W10.1) Use Dijkstra’s Algorithm to find the shortest paths from C to all other vertices.(4 scores)2) Use Kruskal’s algorithm to find the minimum-cost spanning tree. (3 scores)3) Show the DFS tree for the following graph, starting at Vertex A. (3 scores)C to A: 4 (C,A); CF: 5(C,F); CD: 6(C,A,D); CB: 12(C,A,D,B); CG:11 (C,F,G); CE: 13(C,A,D,B,E)1)2)3)A---->B---->D--->F---->CGE。
华工 数据库期末重点

复习提纲一、题型1)由选择题、填空题、简答题、sql语言应用、综合题构成。
2)选择题30-40分之间(A、B卷题数不一样)。
填空题大约10分,简答题10分两题,sql语言25-35之间。
综合题15分3)Sql语言要掌握创建对象(表、索引、视图、存储过程)、查询操作、增删改操作、连接、分组、分组过滤、授权(grant)与收回revoke。
Grant 与revoke没有讲,实验有,大家要重视。
4)综合题主要是给定一个关系,能写出键码和函数依赖、候选码,判断最高属于第几范式,能规范化到第三范式或BC范式。
二、复习主要内容1.数据库系统是由数据库、数据库管理系统(DBMS)、数据库管理员(DBA)用户和应用程序构成。
它的核心是数据库管理系统。
2.反映现实世界中实体及实体间联系的信息模型是什么?E-R图用来建立数据库的概念模型。
能根据场景理解和绘制E-R图。
理解联系的几种形式。
3.数据库三级模式结构是什么,描述数据库中全体数据的全局逻辑结构和特征的是什么?要保证数据库的数据独立性,需要修改什么?数据库的物理独立性是指什么?4.理解关系表中行、列、属性、元组等概念5.关系数据库中基于数学上两类运算是关系代数运算和关系演算。
6.在关系代数运算中,五种基本运算是什么?7.能表示sql语句的关系代数形式。
8.理解自然连接。
9.理解全外连接、左外连接、右外连接、自然连接。
10.在SQL中,与关系代数中的选择、投影运算对应的关键字是什么11.熟练掌握数据库对象的授权Grant和收回授权Revoke的操作。
非常重要。
12.数据库三类约束是什么?各类约束要详细理解在sql中的定义。
13.函数依赖最小集中的每一个函数依赖的右部()A.至少一个属性 B.至多一个属性 C.必须是多个属性 D.以上皆不是14.熟练掌握数据库的三范式及BCNF范式,能进行应用的二三级范式规范化,二元关系模式的最高范式是BCNF。
15.能判断一个关系模式属于第几范式。
(完整版)华南理工大学数字电子技术试卷(含答案)

诚信应考,考试作弊将带来严重后果!华南理工大学期末考试《数字电子技术》试卷A注意事项:1. 考前请将密封线内填写清楚;2. 所有答案请直接答在试卷上(或答题纸上);3.考试形式: 闭卷;4. 本试卷共四大题,满分100分,考试时间120分钟。
题号一二三四总分得分评卷人一. 单项选择题:(在每小题的备选答案中选出一个正确的答案,并将正确答案的字母填入下表中对应的格子里。
每小题2分,共20分。
)题号10123456789答案1.十进制数128的8421BCD码是()。
A.10000000B. 000100101000C.100000000D.1001010002.已知函数F的卡诺图如图1-1, 试求其最简与或表达式3. 已知函数的反演式为,其原函数为()。
A. B .C. D.4.对于TTL数字集成电路来说,下列说法那个是错误的:(A)电源电压极性不得接反,其额定值为5V;(B)不使用的输入端接1;(C)输入端可串接电阻,但电阻值不应太大;(D)OC门输出端可以并接。
5.欲将正弦信号转换成与之频率相同的脉冲信号,应用A.T,触发器B.施密特触发器C.A/D转换器D.移位寄存器6.下列A/D转换器中转换速度最快的是()。
A.并联比较型B.双积分型C.计数型D.逐次渐近型7. 一个含有32768个存储单元的ROM,有8个数据输出端,其地址输入端有()个。
A. 10B. 11C. 12D. 88.如图1-2,在TTL门组成的电路中,与非门的输入电流为I iL≤–1mA‚I iH≤20μA。
G1输出低电平时输出电流的最大值为I OL(max)=10mA,输出高电平时最大输出电流为I OH(max)=–0.4mA 。
门G1的扇出系数是()。
A. 1B. 4C. 5D. 109.十数制数2006.375转换为二进制数是:A. 11111010110.011B. 1101011111.11C. 11111010110.11D. 1101011111.01110. TTL或非门多余输入端的处理是:A. 悬空B. 接高电平C. 接低电平D.接”1”二.填空题(每小题2分,共20分)1.CMOS传输门的静态功耗非常小,当输入信号的频率增加时,其功耗将______________。
华南理工大学操作系统期末考试卷考点整理

华南理工大学操作系统期末考试卷考点整理第一章1.操作系统扩展的机器资源管理操作系统是由程序模块组成的系统软件,它能够以尽量有效、合理的方式管理计算机底层硬件资源、规划计算机工作流程、控制程序的执行、提供各种服务功能,为用户提供计算机抽象接口,使得用户能够方便、灵活的使用计算机,计算机系统得以高效运行。
2.操作系统的特征并发共享虚拟异步性3.操作系统的功能处理机管理存储管理设备管理信息管理用户接口4. 操作系统的设计原则可维护性:改错性维护、适应性维护、完善性维护。
可靠性:正确性、稳健性。
可理解性:易于理解,以方便测试、维护和交流。
性能:有效地使用系统资源,尽可能快地响应用户请求。
5.操作系统结构1)单体系统:主过程,服务过程,实用过程•特点:模块由众多服务过程(模块接口)组成,可以随意调用其他模块中的服务过程。
•优点:具有一定灵活性,在运行中的高效率。
•缺点:功能划分和模块接口难保正确和合理,模块之间的依赖关系(功能调用关系)复杂,降低了模块之间的相对独立性,不利于修改。
2)层次式系统:(5)操作员(4)用户程序(3)I/O管理(2)操作员-IPC(1)存储器和磁鼓管理(0)处理器的分配和多道程序设计·优点:功能明确,调用关系清晰(高层对低层单向依赖,调用有序性),有利于保证设计和实现的正确性;低层和高层可分别实现(便于扩充);高层错误不会影响到低层;避免递归调用。
·缺点:降低了运行效率。
3)客户/服务器模型:把操作系统分成若干分别完成一组特定功能的服务进程,等待客户提出请求;而系统内核只实现操作系统的基本功能(如:虚拟存储、消息传递)。
优点:•良好的扩充性:只需添加支持新功能的服务进程即可。
•可靠性好:调用关系明确,执行转移不易混乱。
•便于网络服务,实现分布式处理:以同样的调用形式,在下层可通过核心中的网络传送到远方服务器上。
缺点:•消息传递比直接调用效率要低一些 (但可以通过提高硬件性能来补偿 )。
数据库试卷(含答案)

华南理工大学期末考试 《 数 据 库 》试卷1. 考前请将密封线内各项信息填写清楚;所有答案请直接答在试卷上(或答题纸上);.考试形式:闭卷;选择题、 数据库(DB ),数据库系统(DBS )和数据库管理系统(DBMS )之间的关系是()。
A. DBS 包括DB 和DBMSB. DBMS 包括DB 和DBSC. DB 包括DBS 和DBMSD. DBS 就是DB ,也就是DBMS、 用户或应用程序看到的那部分局部逻辑结构和特征的描述是( )。
A. 模式B. 物理模式C. 子模式D. 内模式、 区分不同实体的依据是( )。
A. 名称B. 属性C. 对象D. 概念4、假设有关系R和S,关系代数表达式R-(R-S)表示的是()。
A.R∩SB.R∪SC.R-SD.R×S5、在视图上不能完成的操作是()。
A.更新视图B.查询C.在视图上定义新的表D.在视图上定义新的视图6、设关系数据库中一个表S的结构为S(SN,CN,grade),其中SN为学生名,CN为课程名,二者均为字符型;grade为成绩,数值型,取值范围0-100。
若要把“张二的化学成绩80分”插入S中,则可用()。
A. ADD INTO S VALUES(’张三’,’化学’,’80’)B.INSERT INTO S VALUES(’张三’,’化学’,’80’)C. ADD INTO S VALUES(’张三’,’化学’,80)D. INSERT INTO S VALUES(’张三’,’化学’,80)7、消除了部分函数依赖的1NF的关系模式,必定是()。
A.1NFB.2NFC.3NFD.BCNF8、X→Y,当下列哪一条成立时,称为平凡的函数依赖()。
A.X ∈YB.Y∈XC.X∩Y=ΦD.X∩Y≠Φ9、以下()不属于实现数据库系统安全性的主要技术和方法。
A.存取控制技术B.视图技术C.审计技术D.出入机房登记和加防盗门10、下述SQL命令中,允许用户定义新关系时,引用其他关系的主码作为外码的是()。
2022年华南理工大学计算机科学与技术专业《数据库原理》科目期末试卷A(有答案)

2022年华南理工大学计算机科学与技术专业《数据库原理》科目期末试卷A(有答案)一、填空题1、数据管理技术经历了______________、______________和______________3个阶段。
2、使某个事务永远处于等待状态,得不到执行的现象称为______。
有两个或两个以上的事务处于等待状态,每个事务都在等待其中另一个事务解除封锁,它才能继续下去,结果任何一个事务都无法执行,这种现象称为______。
3、数据的安全性是指____________。
4、数据库系统是利用存储在外存上其他地方的______来重建被破坏的数据库。
方法主要有两种:______和______。
5、如果多个事务依次执行,则称事务是执行______;如果利用分时的方法,同时处理多个事务,则称事务是执行______。
6、视图是一个虚表,它是从______导出的表。
在数据库中,只存放视图的______,不存放视图对应的______。
7、从外部视图到子模式的数据结构的转换是由______________实现;模式与子模式之间的映象是由______________实现;存储模式与数据物理组织之间的映象是由______________实现。
8、SQL Server中数据完整性包括______、______和______。
9、设某数据库中有商品表(商品号,商品名,商品类别,价格)。
现要创建一个视图,该视图包含全部商品类别及每类商品的平均价格。
请补全如下语句: CREATE VIEW V1(商品类别,平均价格)AS SELECT商品类别,_____FROM商品表GROUP BY商品类别;10、在SQL Server 2000中,数据页的大小是8KB。
某数据库表有1000行数据,每行需要5000字节空间,则此数据库表需要占用的数据页数为_____页。
二、判断题11、关系中任何一列的属性取值是不可再分的数据项,可取自不同域中的数据。
华南理工大学《数据库》(研究生)复习资料

《数据库复习》黄炜杰201230590051Ch 1.【数据库发展的3 个阶段】(1)第一代数据库系统:层次和网状数据库系统(2)第二代数据库系统:关系数据库系统(3)新一代数据库系统【层次、网状数据库共同特点】(1)支持三级模式的体系结构(2)用存取路径来表示数据之间的联系(3)独立的数据定义语言(4)导航的数据操纵语言, 需要用户了解做什么,还要指出怎么做。
【关系数据库】关系数据库是以关系模型为基础的。
关系模型组成成分:1)数据结构2)关系操作3)数据完整性【关系数据库的局限】(1)模型过于简单,不便于表达复杂的嵌套需求。
(2)支持基本数据类型有限,不能支持程序设计中的许多数据结构。
(3)编程语言与操作语言分离,存在阻抗失配问题。
【新一代数据库特征】(1)应支持数据管理、对象管理和知识管理, 以支持面向对象数据模型为主要特征(2)必须保持或继承第二代数据库系统的技术(3)必须对其他系统开放: 支持数据库语言标准, 网络上支持标准网络协议, 具有良好的可移植性、可连接性、可扩展性和可操作性【数据库的发展】主要表现在三个方面:1)数据模型的发展2)数据库技术与其他技术相结合3)面向领域的数据库新技术【数据模型的发展】(1)对传统的关系模型(1NF) 进行扩充,引入了少数构造器,称为复杂数据模型(2)一种是偏重于结构的扩充,如表达“表中表”(3)一种是侧重于语义的扩充,如支持关系之间的继承,关系上定义函数和运算符(4)增加全新的数据构造器和数据处理原语,以表达复杂的结构和丰富的语义(5)面向对象的数据模型(6)XML数据模型【数据库技术与其他相关技术相结合】分布式数据库系统、并行数据库系统、知识库系统和主动数据库系统、多媒体数据库系统、模糊数据库系统等、移动数据库系统等、Web数据库等【面向领域的数据库新技术】1)工程数据库2)空间数据库【NoSQL】non-relational或Not Only SQL。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
华南理工大学数据库期末考试卷考点整理第一章1.DBMS功能(1)数据定义功能(2)数据组织、存储和管理(3)数据操纵功能(4)数据库的事务管理和运行管理(5)数据库的建立和维护功能(6)其它功能2.数据库系统的特点(1)数据结构化(与文件系统的本质区别)(2)数据的共享性高,冗余度低,易扩充(3)数据独立性高(4)数据由DBMS统一管理和控制3.试述数据库系统的组成。
数据库系统一般由数据库,数据库管理系统(及其开发工具),应用系统,数据库管理员和用户构成。
3.两类数据模型(1)概念模型(2)逻辑模型(关系模型)和物理模型4.数据模型的组成要素(1)数据结构(静态特性)(2)数据操作(动态特性)(3)完整性约束5.E-R图(1)实体:矩形(2)属性:椭圆(3)联系:菱形6.关系模型——关系的每一个分量必须是一个不可分的数据项,即不允许表中还有表关系(表)元组(行)属性(列)7.数据库系统结构(1)三级模式——外模式(用户)、模式(逻辑)、内模式(存储)(2)二级映像——外模式/模式映像(逻辑独立性)、模式/内模式映像(物理独立性)第三章1.SQL特点(1)综合统一(2)高度非过程化(3)面向集合的操作方式(非关系数据模型面向记录)(4)以同一种语法结构提供多种使用方式(5)语言简洁,易学易用定义功能:定义表、视图、索引。
分为:数据定义,数据查询,数据更新和数据控制4大部分。
2.定义模式CREATE SCHEMA <模式名> AUTHORIZATION <用户名>[<表定义子句>|<视图定义子句>|<授权定义子句>]3.删除模式DROP SCHEMA <模式名> <CASCADE|RESTRICT>CASCADE(级联)4. 定义基本表CREATE TABLE <表名>(<列名> <数据类型>[ <列级完整性约束条件> ][,<列名> <数据类型>[ <列级完整性约束条件>] ] …[,<表级完整性约束条件> ] );CREATE TABLE Student(Sno CHAR(9) PRIMARY KEY,/* 列级完整性约束条件*/Sname CHAR(20) UNIQUE,/* Sname取唯一值*/Ssex CHAR(2),Sage SMALLINT,Sdept CHAR(20));CREATE TABLE Course( Cno CHAR(4) PRIMARY KEY,Cname CHAR(40),Cpno CHAR(4) ,Ccredit SMALLINT,FOREIGN KEY (Cpno) REFERENCES Course(Cno)); Cpno是外码、被参照表是Course、被参照列是CnoCREATE TABLE SC(Sno CHAR(9),Cno CHAR(4),Grade SMALLINT,PRIMARY KEY (Sno,Cno),/* 主码由两个属性构成,必须作为表级完整性进行定义*/ FOREIGN KEY (Sno) REFERENCES Student(Sno),/* 表级完整性约束条件,Sno是外码,被参照表是Student */ FOREIGN KEY (Cno) REFERENCES Course(Cno)/* 表级完整性约束条件,Cno是外码,被参照表是Course*/ );5.修改基本表ALTER TABLE <表名>[ ADD <新列名> <数据类型> [ 完整性约束] ][ DROP <完整性约束名> ][ ALTER COLUMN<列名> <数据类型> ];ALTER TABLE Student ALTER COLUMN Sage INT;6.删除基本表(RESTRICT不能删除有视图)DROP TABLE <表名>[RESTRICT| CASCADE];DROP TABLE Student CASCADE ;7.建立索引CREATE [UNIQUE] [CLUSTER] INDEX <索引名>ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…);CREATE CLUSTER INDEX Stusname ON Student(Sname);CREATE UNIQUE INDEX Stusno ON Student(Sno);CREATE UNIQUE INDEX Coucno ON Course(Cno);CREATE UNIQUE INDEX SCno ON SC(Sno ASC,Cno DESC);Student表按学号升序建唯一索引Course表按课程号升序建唯一索引SC表按学号升序和课程号降序建唯一索引8.删除索引DROP INDEX <索引名>;9.数据查询SELECT [ALL|DISTINCT(去重)] <目标列表达式> [,<目标列表达式>] …FROM <表名或视图名>[,<表名或视图名> ] …[ WHERE <条件表达式> ][ GROUP BY <列名1> [ HAVING <条件表达式> ] ][ ORDER BY <列名2> [ ASC|DESC ] ];10.数据更新INSERTINTO <表名> [(<属性列1>[,<属性列2 >…)]VALUES (<常量1> [,<常量2>] …)11.修改数据UPDATE <表名>SET <列名>=<表达式>[,<列名>=<表达式>]…[WHERE <条件>];12.删除数据DELETEFROM <表名>[WHERE <条件>];13.建立视图CREATE VIEW<视图名> [(<列名> [,<列名>]…)]AS <子查询>[WITH CHECK OPTION];14.删除视图DROP VIEW <视图名> (CASCADE级联);第四章自主存取控制:1.2.1.授权GRANT语句的一般格式:GRANT <权限>[,<权限>]...[ON <对象类型> <对象名>]TO <用户>[,<用户>]...[WITH GRANT OPTION];WITH GRANT OPTION子句:▪指定:可以再授予▪没有指定:不能传播不允许循环授权2.回收REVOKE授予的权限可以由DBA或其他授权者用REVOKE语句收回REVOKE语句的一般格式为:REVOKE <权限>[,<权限>]...[ON <对象类型> <对象名>]FROM <用户>[,<用户>]...;3. 数据库角色被命名的一组与数据库操作相关的权限角色是权限的集合可以为一组具有相同权限的用户创建一个角色简化授权的过程一、角色的创建CREATE ROLE <角色名>二、给角色授权GRANT <权限>[,<权限>]…ON <对象类型>对象名TO <角色>[,<角色>]…三、将一个角色授予其他的角色或用户GRANT <角色1>[,<角色2>]…TO <角色3>[,<用户1>]…[WITH ADMIN OPTION]四、角色权限的收回REVOKE <权限>[,<权限>]…ON <对象类型> <对象名>FROM <角色>[,<角色>]…4.审计[例15]对修改SC表结构或修改SC表数据的操作进行审计AUDIT ALTER,UPDATEON SC;[例16]取消对SC表的一切审计NOAUDIT ALTER,UPDATEON SC;5.什么是数据库的审计功能,为什么要提供审计功能?审计功能指DBMS的审计模块在用户对数据库的所有操作自动地记录下来放入审计日志中。
因为任何系统的安全措施都不是完美无缺的,蓄意盗窃,破坏数据的人总是想法设法打破控制。
DBA可以通过审计跟踪的信息,找出非法存取数据的人,时间和内容等。
6. 什么是基本表?什么是视图?两者的区别和联系是什么?答:基本表是实际存储在数据库中的二维表,它是本身独立存在的表,在SQL中一个关系就对应一个表。
视图是关系数据库系统提供给用户以多种角度观察数据库中数据的重要机制。
区别:视图是从一个或几个基本表(或视图)中导出的表,是一个虚表,数据库中只存放视图的定义,而不存放视图对应的数据,这些数据仍存放在原来的基本表中。
7.简述关系数据库系统中视图(VIEW)的定义,引进VIEW的概念有什么优点?1.简化用户操作2.视图使用户能以多个不同的方式看待同一数据3.视图对重构数据库提供了一定程度的逻辑独立性4.视图能够对机密数据提供安全保护5.适当使用视图可以更清晰的表达查询8.所有的视图是否都可以更新?为什么?不是。
视图是不实际存储数据的虚表,因此对视图的更新,最终要转换为对基本表的更新。
因为有些视图的更新不能惟一有意义地转换成对相应基本表的更新,所以,并不是所有的视图都是可更新的.不是所有的视图都可以更新,因为视图不是实际存在的表,而是通过对基本表的查询得出的数据视图,例如视图用集函数AVG对表查询得出平均值,则不能更新视图,因为系统无法通过修改表的各项值使平均值变成更新的值。
9. 试述实现数据库安全性控制的常用方法和技术。
答:实现数据库安全性控制的常用方法和技术有:( l )用户标识和鉴别:该方法由系统提供一定的方式让用户标识自己的名字或身份。
每次用户要求进入系统时,由系统进行核对,通过鉴定后才提供系统的使用权。
( 2 )存取控制:通过用户权限定义和合法权检查确保只有合法权限的用户访问数据库,所有未被授权的人员无法存取数据。
例如CZ 级中的自主存取控制( DAC ) , Bl 级中的强制存取控制(MAC )。
( 3 )视图机制:为不同的用户定义视图,通过视图机制把要保密的数据对无权存取的用户隐藏起来,从而自动地对数据提供一定程度的安全保护。