Linux设备驱动程序学习(10)-时间、延迟及延缓操作
linux延时函数

linux延时函数
Linux内核中包含了一些延时函数,他们被应用在很多情况下,用于
控制系统内部多个线程与进程执行的先后顺序,通常被用来保证数据的正
确性和及时的处理步骤。
Linux下常用的延时函数有:
1、usleep:usleep函数会让调用进程暂停指定的时间,其参数是指
定的暂停时间,以微秒为单位,当暂停时间到达后,就会激活当前的进程。
2、nanosleep:nanosleep函数的参数也是指定的暂停时间,但是精
度比usleep函数更精确,它是以纳秒为单位设定暂停时间,暂停时间到
达后,也会激活当前的进程。
3、sleep:sleep函数被用来暂停调用进程,它的参数以秒为单位,
指定了暂停时间,当暂停时间到达后,就会唤醒当前进程。
4、schedule_timeout():schedule_timeout()函数会指定一个超时
时间,当计时器到达设定时间时,就会激活当前的进程,继续执行后续的
操作。
以上就是Linux常用的延时函数,它们可以精确控制进程执行,保证
数据的正确性和及时处理,它们为Linux内核的设计和提供了一定的便利。
你需要了解Linux设备驱动之定时与延时的区别

你需要了解Linux设备驱动之定时与延时的区别Linux通过系统硬件定时器以规律的间隔(由HZ度量)产生定时器中断,每次中断使得一个内核计数器的值jiffies累加,因此这个jiffies就记录了系统启动开始的时间流逝,然后内核据此实现软件定时器和延时。
Demo for jiffies and HZ#include unsigned long j, stamp_1, stamp_half, stamp_n; j = jiffies; /* read the current value */ stamp_1 = j + HZ; /* 1 second in the future */ stamp_half = j + HZ/2; /* half a second */ stamp_n = j + n * HZ / 1000; /* n milliseconds */内核定时器硬件时钟中断处理程序会唤起TIMER_SOFTIRQ 软中断,运行当前处理器上到期的所有内核定时器。
定时器定义/初始化在Linux内核中,TImer_list结构体的一个实例对应一个定时器:/* 当expires指定的定时器到期时间期满后,将执行funcTIon(data) */ struct TImer_list { unsigned long expires; /*定时器到期时间*/ void (*function)(unsigned long); /* 定时器处理函数*/ unsigned long data; /* function的参数*/ ... }; /* 定义*/ struct timer_list my_timer; /* 初始化函数*/ void init_timer(struct timer_list * timer); /* 初始化宏*/ TIMER_INITIALIZER(_function, _expires, _data) /* 定义并初始化宏*/ DEFINE_TIMER(_name, _function, _expires, _data)定时器添加/移除/* 注册内核定时器,将定时器加入到内核动态定时器链表中*/ void add_timer(struct timer_list * timer); /* del_timer_sync()是del_timer()的同步版,在删除一个定时器时需等待其被处理完,因此该函数的调用不能发生在中断上下文*/ void del_timer(struct timer_list * timer); void del_timer_sync(struct timer_list * timer);定时时间修改int mod_timer(struct timer_list *timer, unsigned long expires);。
嵌入式汇编延时指令

嵌入式汇编延时指令
在嵌入式汇编中,延时通常用于控制程序的执行速度或等待某些事件发生。
以下是一些常见的延时指令:NOP (No Operation):这是一个空操作,它不会对任何数据进行操作。
它在一些情况下可以用于产生微小的延时。
assembly复制代码
NOP
DELAY:这是一个自定义的延时指令,具体的延时时间取决于你的硬件和编译器。
它通常会执行一系列的NOP或其他无操作指令来产生延时。
assembly复制代码
DELAY
HLT (Halt):这会导致处理器暂停执行,直到收到一个中断。
它可以用于产生更长的延时,但会消耗CPU时间。
assembly复制代码
HLT
WAIT:这个指令会使程序暂停执行,直到某个条件满足。
它通常与中断或某个特定的状态寄存器一起使用。
assembly复制代码
WAIT
循环:通过循环执行某些指令可以产生延时。
例如,你可以循环执行NOP或其他无操作指令来产生延时。
assembly复制代码
LOOP: NOP
...
...
JMP LOOP
请注意,这些只是常见的延时指令,具体的实现可能会根据你使用的硬件和编译器有所不同。
在实际应用中,你可能需要根据你的特定需求和硬件平台来调整这些指令。
linux驱动开发知识点总结

linux驱动开发知识点总结Linux驱动开发是指在Linux操作系统下开发和编写设备驱动程序的过程。
Linux作为一种开源操作系统,具有广泛的应用领域,因此对于驱动开发的需求也非常重要。
本文将从驱动程序的概念、驱动开发的基本步骤、常用的驱动类型以及驱动开发的注意事项等方面进行总结。
一、驱动程序的概念驱动程序是指控制计算机硬件和软件之间通信和交互的程序。
在Linux系统中,驱动程序负责与硬件设备进行交互,实现对硬件的控制和管理。
二、驱动开发的基本步骤1. 确定驱动的类型:驱动程序可以分为字符设备驱动、块设备驱动和网络设备驱动等。
根据具体的硬件设备类型和需求,选择合适的驱动类型。
2. 编写设备注册函数:设备注册函数用于向系统注册设备,使系统能够识别和管理该设备。
3. 实现设备的打开、关闭和读写操作:根据设备的具体功能和使用方式,编写设备的打开、关闭和读写操作函数。
4. 实现设备的中断处理:如果设备需要进行中断处理,可以编写中断处理函数来处理设备的中断请求。
5. 编写设备的控制函数:根据设备的需求,编写相应的控制函数来实现对设备的控制和配置。
6. 编译和安装驱动程序:将编写好的驱动程序进行编译,并将生成的驱动模块安装到系统中。
三、常用的驱动类型1. 字符设备驱动:用于控制字符设备,如串口、打印机等。
字符设备驱动以字符流的方式进行数据传输。
2. 块设备驱动:用于控制块设备,如硬盘、U盘等。
块设备驱动以块为单位进行数据传输。
3. 网络设备驱动:用于控制网络设备,如网卡。
网络设备驱动实现了数据包的收发和网络协议的处理。
4. 触摸屏驱动:用于控制触摸屏设备,实现触摸操作的识别和处理。
5. 显示驱动:用于控制显示设备,实现图像的显示和刷新。
四、驱动开发的注意事项1. 熟悉硬件设备的规格和寄存器的使用方法,了解硬件设备的工作原理。
2. 确保驱动程序的稳定性和可靠性,避免出现系统崩溃或死机等问题。
3. 对于需要频繁访问的设备,要考虑性能问题,尽量减少对硬件的访问次数。
Linux驱动技术关键之一:内核定时器与延迟工作

Linux驱动技术关键之一:内核定时器与延迟工作内核定时器软件上的定时器最终要依靠硬件时钟来实现,简单的说,内核会在时钟中断发生后检测各个注册到内核的定时器是否到期,如果到期,就回调相应的注册函数,将其作为中断底半部来执行。
实际上,时钟中断处理程序会触发TIMER_SOFTIRQ软中断,运行当前处理器上到期的所有定时器。
设备驱动程序如要获得时间信息以及需要定时服务,都可以使用内核定时器。
jiffies要说内核定时器,首先就得说说内核中关于时间的一个重要的概念:jiffies变量,作为内核时钟的基础,jiffies每隔一个固定的时间就会增加1,称为增加一个节拍,这个固定间隔由定时器中断来实现,每秒中产生多少个定时器中断,由在中定义的HZ宏来确定,如此,可以通过jiffies获取一段时间,比如jiffies/HZ表示自系统启动的秒数。
下两秒就是(jiffies/HZ+2),内核中用jiffies来计时,秒转换成的jiffies:seconds*HZ,所以以jiffiy为单位,以当前时刻为基准计时2秒:(jiffies/HZ+2)*HZ=jiffies+2*HZ如果要获取当前时间,可以使用do_getTImeofday(),该函数填充一个struct TImeval结构,有着接近微妙的分辨率。
//kernel/TIme/timekeeping.c 473 /** 474 * do_gettimeofday - Returns the time of day in a timeval 475 * @tv: pointer to the timeval to be set 476 * 477 * NOTE: Users should be converted to using getnstimeofday() 478 */ 479 void do_gettimeofday(struct timeval *tv)驱动程序为了让硬件有足够的时间完成一些任务,常常需要将特定的代码延后一段时间来执行,根据延时的长短,内核开发中使用长延时和短延时两个概念。
linuxsleep命令参数及用法详解(linux休眠延迟执行命令)

linuxsleep命令参数及⽤法详解(linux休眠延迟执⾏命令)使⽤权限 : 所有使⽤者使⽤⽅式 : sleep [--help] [--version] number[smhd]说明 : sleep 可以⽤来将⽬前动作延迟⼀段时间参数说明 :--help : 显⽰辅助讯息--version : 显⽰版本编号number : 时间长度,后⾯可接 s、m、h 或 d其中 s 为秒,m 为分钟,h 为⼩时,d 为⽇数例⼦ :显⽰⽬前时间后延迟 1 分钟,之后再次显⽰时间 :date;sleep 1m;date这个命令更多应⽤于shell脚本编程⾥和程序⾥如下⾯的⼀段程序:应⽤程序:复制代码代码如下:#include <syswait.h>usleep(n) //n微秒Sleep(n)//n毫秒sleep(n)//n秒驱动程序:#include <linux/delay.h>mdelay(n) //milliseconds 其实现#ifdef notdef#define mdelay(n) (\{unsigned long msec=(n); while (msec--) udelay(1000);})#else#define mdelay(n) (\(__builtin_constant_p(n) && (n)<=MAX_UDELAY_MS) ? udelay((n)*1000) : \({unsigned long msec=(n); while (msec--) udelay(1000);}))#endif调⽤asm/delay.h的udelay,udelay应该是纳秒级的延时Dos:sleep(1); //停留1秒delay(100); //停留100毫秒Windows:Sleep(100); //停留100毫秒Linux:sleep(1); //停留1秒usleep(1000); //停留1毫秒每⼀个平台不太⼀样,最好⾃⼰定义⼀套跨平台的宏进⾏控制秒还是微秒?关于延时函数sleep()因为要写⼀段代码,需要⽤到sleep()函数,在我印象中,sleep(10)好像是休眠10微秒,结果却是休眠了10秒(在Linux 下)。
linux系统delay函数 -回复

linux系统delay函数-回复Linux系统中的delay函数旨在实现程序在一定时间内停止执行。
它广泛应用于各种领域,如实时系统、嵌入式系统和网络通信等。
本文将从原理、使用方式以及一些常见问题等方面进行解答,以帮助读者更好地理解和使用delay函数。
一、delay函数的原理delay函数在Linux系统中是由内核提供的一个软件延迟函数。
具体原理是利用循环进行空操作,即不做任何有意义的工作,从而使程序暂停一段时间。
延迟的时间是通过计算循环次数来实现的。
二、使用delay函数1. 头文件引入:使用delay函数前,需要引入头文件<unistd.h>。
2. 函数原型:delay函数的原型为:void delay(unsigned int milliseconds)。
3. 延迟时间设置:参数milliseconds表示需要延迟的毫秒数。
可以根据实际需求进行设置。
4. 调用delay函数:在需要延迟的地方调用delay函数即可。
三、delay函数使用示例下面通过一个简单的示例来演示delay函数的使用方式。
c#include <unistd.h>int main() {延迟500毫秒delay(500);其他操作...return 0;}在上述示例中,程序将会在delay函数的调用处暂停500毫秒,然后继续执行其他操作。
四、delay函数的注意事项1. 精度问题:由于delay函数是通过循环次数来实现延迟的,所以实际延迟的时间可能会和参数设置有一定的误差。
因此,在对延迟时间要求较高的场景中,建议使用更精确的方法。
2. CPU占用:delay函数是通过循环来实现延迟的,因此在延迟期间会占用CPU资源。
如果需要长时间延迟或者需要同时进行其他计算密集型任务,可能会导致系统性能下降。
3. 不适用于实时场景:由于Linux系统的多任务调度机制,delay函数无法保证实时性。
如果需要在实时场景中进行精确的延迟控制,建议使用专门的实时延迟函数。
LINUX设备驱动开发详解

LINUX设备驱动开发详解概述LINUX设备驱动开发是一项非常重要的任务,它使得硬件设备能够与操作系统进行有效地交互。
本文将详细介绍LINUX设备驱动开发的基本概念、流程和常用工具,帮助读者了解设备驱动开发的要点和技巧。
设备驱动的基本概念设备驱动是连接硬件设备和操作系统的桥梁,它负责处理硬件设备的输入和输出,并提供相应的接口供操作系统调用。
设备驱动一般由设备驱动程序和设备配置信息组成。
设备驱动程序是编写解决设备驱动的代码,它负责完成设备初始化、IO操作、中断处理、设备状态管理等任务。
设备驱动程序一般由C语言编写,使用Linux内核提供的API函数进行开发。
设备配置信息是定义硬件设备的相关参数和寄存器配置的文件,它告诉操作系统如何与硬件设备进行交互。
设备配置信息一般以设备树或者直接编码在设备驱动程序中。
设备驱动的开发流程设备驱动的开发流程包括设备初始化、设备注册、设备操作函数编写和设备驱动注册等几个主要步骤。
下面将详细介绍这些步骤。
设备初始化设备初始化是设备驱动开发的第一步,它包括硬件初始化和内存分配两个主要任务。
硬件初始化是对硬件设备进行基本的初始化工作,包括寄存器配置、中断初始化等。
通过操作设备的寄存器,将设备设置为所需的状态。
内存分配是为设备驱动程序分配内存空间以便于执行。
在设备初始化阶段,通常需要为设备驱动程序分配一块连续的物理内存空间。
设备注册设备注册是将设备驱动程序与设备对象进行关联的过程,它使得操作系统能够正确地管理设备。
设备注册包括设备号分配、设备文件创建等操作。
设备号是设备在系统中的唯一标识符,通过设备号可以找到设备对象对应的设备驱动程序。
设备号分配通常由操作系统负责,设备驱动程序通过注册函数来获取设备号。
设备文件是用户通过应用程序访问设备的接口,它是操作系统中的一个特殊文件。
设备文件的创建需要通过设备号和驱动程序的注册函数来完成。
设备操作函数编写设备操作函数是设备驱动程序的核心部分,它包括设备打开、设备关闭、读和写等操作。
延时程序原理

延时程序原理延时程序是一种常见的编程技术,用于暂停程序的执行一段指定的时间。
它的原理基于计算机的时钟频率和指令执行的速度。
在大多数计算机系统中,时钟频率是一个固定的值,它定义了CPU每秒钟可以执行多少条指令。
例如,如果某台计算机的时钟频率为2GHz(即每秒执行2亿条指令),那么每秒钟的时间单位被分为了2亿个小的时间片。
延时程序利用了这个特性,通过在指令执行过程中插入一个空操作(NOP)或者空循环,来消耗一定数量的时间片。
具体的延时时间取决于循环次数或者空操作的数量。
简单的延时程序可以使用循环来实现。
例如,下面是一个使用C语言编写的延时程序示例:```c#include <stdio.h>#include <time.h>void delay(unsigned int milliseconds) {clock_t start_time = clock(); // 记录开始时间while (clock() < start_time + milliseconds); // 循环直到达到指定的延时时间}int main() {printf("开始延时\n");delay(1000); // 延时1秒printf("延时结束\n");return 0;}```在这个示例中,延时函数 `delay` 使用了一个循环来暂停程序的执行。
它先记录开始时间,然后通过检查当前时间是否超过开始时间加上指定的延时时间来判断是否继续循环。
当循环结束后,延时时间就达到了指定的值。
需要注意的是,延时程序的精确性取决于计算机的性能,特别是处理器的时钟频率。
不同的计算机系统可能由于硬件性能的差异而导致延时时间存在一定的误差。
总结起来,延时程序利用计算机的时钟频率和指令执行速度,通过循环或者空操作来暂停程序的执行一段指定的时间。
它在很多场景中都有广泛的应用,例如需要精确控制程序行为、模拟实时系统等。
Linux下的定时任务和延时任务的详解
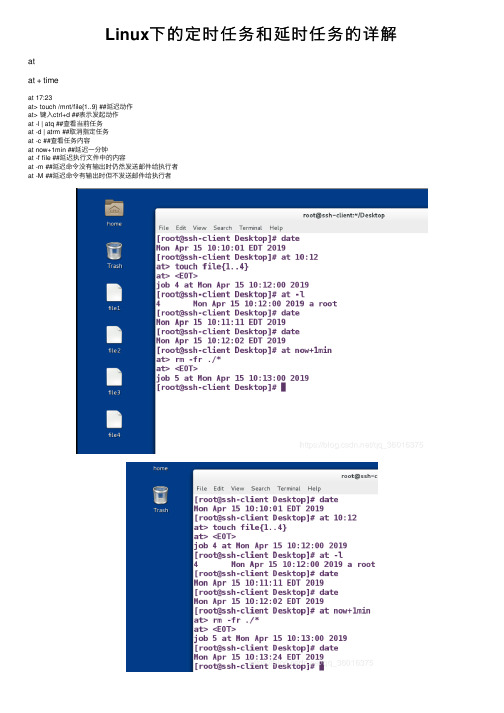
Linux下的定时任务和延时任务的详解atat + timeat 17:23at> touch /mnt/file{1..9} ##延迟动作at> 键⼊ctrl+d ##表⽰发起动作at -l | atq ##查看当前任务at -d | atrm ##取消指定任务at -c ##查看任务内容at now+1min ##延迟⼀分钟at -f file ##延迟执⾏⽂件中的内容at -m ##延迟命令没有输出时仍然发送邮件给执⾏者at -M ##延迟命令有输出时但不发送邮件给执⾏者at 命令的执⾏权⼒设定/etc/at.deny ##⽤户⿊名单,在此名单中出现的⽤户不能执⾏at命令/etc/at.allow ##⽤户⽩名单,名单默认不存在,但名单⼀旦出现,⿊名单失效系统所有⽤户默认不能执⾏at,只有在名单中出现的⽤户可以使⽤at命令crontab发起⽅式⼀crontab -u username -e ##编辑crontab⼯作内容crontab -u username -r ##移除所有crontab⼯作内容crontab -u username -l ##查询crontab⼯作内容发起⽅式⼆vim /etc/cron.d/filename ##编辑此⽂件内容分钟⼩时天⽉周⽤户动作* * * * * root rm -fr /mnt/* #超级⽤户每分钟清理⼀次/mntcrontab 命令的执⾏权⼒设定/etc/cron.deny ##⽤户⿊名单,在此名单中出现的⽤户不能执⾏crontab命令/etc/cron.allow ##⽤户⽩名单,名单默认不存在,但名单⼀旦出现,⿊名单失效。
系统所有⽤户默认不能执⾏crontab,只有在名单中出现的⽤户可以使⽤临时⽂件系统中服务在正常运⾏时会产⽣临时⽂件vim /usr/lib/tmpfiles.d/*.conf ##系统中临时⽂件的配置⽂件类型⽂件名称⽂件权限⽂件所有⼈⽂件所有组⽂件存在时间d /mnt/westos 777 root root 10ssystemd-tmpfiles –create /usr/lib/tmpfiles.d/* ##执⾏临时⽂件配置vim /usr/lib/tmpfiles.d/test.confsystemd-tmpfiles –clean /usr/lib/tmpfiles.d/* ##清理临时⽂件以上所述是⼩编给⼤家介绍的Linux下的定时任务和延时任务详解整合,希望对⼤家有所帮助,如果⼤家有任何疑问请给我留⾔,⼩编会及时回复⼤家的。
linux init_delayed_work原理

在Linux中,`INIT_DELAYED_WORK()`是一个被广泛应用的宏,主要用于处理需要延迟执行的操作。
其基本工作原理如下:
首先,我们需要定义一个延迟的工作队列和任务对象。
例如,我们可以定义一个名为ms_workqueue的工作队列和一个名为ms_queue_work的任务对象。
然后,我们会定义一个周期性执行的函数,比如`work_func()`。
这个函数会在指定的时间间隔内反复执行某些操作,如读取某些外设数据等。
接着,我们利用`INIT_DELAYED_WORK()`宏将任务对象添加到工作队列中。
这样,当特定的条件满足时(如系统启动后),工作队列就会开始执行对应的任务。
此外,我们还可以使用`queue_delayed_work()`或`schedule_delayed_work()`函数来进一步控制任务的执行时机。
其中,`queue_delayed_work()`需要自行指定工作队列,而`schedule_delayed_work()`则在系统默认的工作队列上执行一个work。
总的来说,通过使用这些机制,Linux内核能够有效地管理系统资源,避免了在中断中处理过多操作的风险,保证了对中断的及时响应。
linux系统delay函数

linux系统delay函数“[Linux系统delay函数]”,我将为你一步一步回答,向你解释这个主题,帮助你理解Linux系统下的delay函数。
第一步:引言和概述(150-200字)在Linux系统中,delay函数是一种用于实现延迟操作的函数。
在编程中,我们经常需要在程序的某些位置实现延迟,以便正确处理数据、控制流和用户输入。
delay函数提供了一种简单而有效的方法来实现这一目标。
本文将详细讨论Linux系统下的delay函数,包括其工作原理、用法和一些常见的使用案例。
我们还将提供代码示例和进一步的资源,以帮助读者更好地理解和应用delay函数。
第二步:delay函数的工作原理(200-300字)delay函数的工作原理是利用系统定时器来实现延迟。
在Linux系统中,系统定时器是一个硬件或软件组件,用于测量和跟踪时间。
delay函数使用系统定时器来生成一段延迟,并使程序在这段时间内等待。
具体来说,当我们调用delay函数时,它会读取系统定时器的当前值,并将其与期望的延迟时间相比较。
如果当前值小于延迟时间,delay函数将等待一段时间,然后再次读取系统定时器的值,以检查是否已达到所需的延迟时间。
这个过程会一直重复,直到达到所需的延迟时间为止。
延迟时间通常以毫秒为单位,但具体取决于系统定时器的精度和计时单位。
因此,在使用delay函数时,我们应该明确指定延迟的时间单位,并确保所选的单位与系统定时器一致。
第三步:delay函数的用法(200-300字)要在Linux程序中使用delay函数,我们需要包含相关头文件,如<time.h>。
该头文件提供了与时间相关的函数和结构体的定义。
使用delay函数的一般语法如下:cpp#include <time.h>void delay(unsigned int milliseconds) {获取开始时间unsigned int start_time = clock();将毫秒转换为时钟滴答数unsigned int delay_ticks = milliseconds * CLOCKS_PER_SEC / 1000;等待到达指定的延迟滴答数while (clock() < start_time + delay_ticks) {空循环,直到达到延迟时间}}上述代码展示了一个简单的delay函数实现,它使用clock函数获取系统时钟,并通过计算将毫秒转换为时钟滴答数。
linux上时间不对的调整方案

linux上时间不对的调整方案在Linux上调整时间的方法有多种,具体取决于你的系统版本和所使用的工具。
以下是一些常见的调整时间的方法:1. 使用date命令手动调整时间:可以使用date命令来手动设置系统时间。
例如,要将时间设置为2022年1月1日12点00分,可以使用以下命令:sudo date -s "2022-01-01 12:00:00"请注意,这需要root权限。
2. 使用timedatectl命令:许多Linux发行版都提供了timedatectl命令,可以用来管理系统时间和时区。
你可以使用该命令来设置系统时间、时区、同步网络时间等。
例如,要将系统时间设置为UTC时间,可以使用以下命令:sudo timedatectl set-timezone UTC.要同步网络时间,可以使用以下命令:sudo timedatectl set-ntp true.3. 使用NTP服务:NTP(Network Time Protocol)是一种用于同步计算机系统时间的协议。
你可以配置系统以从NTP服务器同步时间。
大多数Linux发行版都提供了NTP客户端软件包,例如ntp或chrony。
你可以安装并配置这些软件包,以便系统可以自动从NTP服务器同步时间。
4. 检查硬件时钟:有时,系统时间不正确可能是由于硬件时钟的问题。
你可以使用hwclock命令来检查和调整硬件时钟。
例如,要将硬件时钟设置为和系统时间一致,可以使用以下命令:sudo hwclock --systohc.总的来说,调整Linux系统时间的方法有很多种,你可以根据具体情况选择合适的方法来进行调整。
如果你遇到时间不对的问题,建议先检查系统时间和时区设置,然后再考虑是否需要同步网络时间或调整硬件时钟。
Linux系统网络延迟测试脚本通过Python实现的用于测试Linux系统网络延迟的工具

Linux系统网络延迟测试脚本通过Python实现的用于测试Linux系统网络延迟的工具近年来,随着互联网的迅猛发展和人们对网络传输速度的不断追求,网络延迟成为了一个重要的指标。
特别是对于Linux系统用户来说,如何测试网络延迟成为了一项必备技能。
本文将介绍一种通过Python实现的Linux系统网络延迟测试脚本,它能够准确地测试出网络延迟,并通过图表形式展示结果,方便用户进行分析和优化。
一、脚本原理及实现方式Linux系统网络延迟测试脚本利用Python编程语言的socket模块,基于TCP/IP协议实现了网络延迟的测量。
其主要步骤如下:1. 导入必要的Python模块,包括socket、time和matplotlib等。
2. 创建一个socket对象,并与服务器建立连接。
3. 发送一段数据到服务器,并记录发送时间。
4. 接收服务器返回的数据,并记录接收时间。
5. 计算网络延迟,即接收时间减去发送时间。
6. 将测试结果保存到一个文件中,方便后续分析。
7. 利用matplotlib库绘制图表,显示测试结果的变化情况。
二、脚本使用方法使用该脚本进行网络延迟测试非常简便。
用户只需按照以下步骤进行操作:1. 在Linux系统上安装Python的最新版本。
2. 下载并解压网络延迟测试脚本。
3. 打开终端,进入脚本所在的目录。
4. 运行命令"python network_latency_test.py"。
5. 根据脚本的提示,输入要测试的服务器IP地址或域名。
6. 脚本将开始测试网络延迟,并将结果保存到指定文件中。
7. 测试完成后,可以通过绘制图表来分析网络延迟的变化趋势。
三、脚本的优势和适用范围与其他网络延迟测试工具相比,Linux系统网络延迟测试脚本具有以下优势:1. 简单方便:用户只需几个步骤就能进行网络延迟测试,无需繁琐的配置和设置。
2. 准确可靠:脚本利用Python的socket模块进行测量,能够准确地获取网络延迟。
linux延时函数

linux延时函数
Linux是一个多功能的操作系统,其中一个重要的功能就是提供了一系列的延时函数。
延时函数在编写多线程程序时必不可少,是让程序可以按照用户预定的程序顺序执行的基础。
本文将介绍Linux系统提供的延时函数,以及它们的具体实现和用法。
Linux系统提供了几种延时函数,其中最常用的三种延时函数是sleep,usleep,以及usleep_range。
sleep函数可以使进程按指定的时间进行延时,单位为秒,但它不能精确到毫秒。
它通常会延时比用户指定的时间长,所以它并不适合精确延时的应用。
usleep函数用于精确延时,单位为微妙(μs),它与sleep函数的区别是,usleep函数不会延时比用户指定的时间长。
usleep_range函数是一个新的函数,可以精确延时,但它允许用户指定一个范围,而不是一个确切的时间值。
关于延时函数的使用,最重要的就是确认用户需要延时的时间,以及选择正确的函数。
一般来说,如果需要按秒进行延时,就可以使用sleep函数;如果需要按微妙(μs)进行延时,就可以使用usleep 函数;如果需要按微妙(μs)范围进行延时,就可以使用usleep_range 函数。
此外,也要注意,尽管延时函数可以让进程按照指定的时间执行,但它也有一定的限制,例如,在进行延时操作的过程中,Linux的线程还是会继续执行,即使在延时期间新的线程也可能会被调度。
最后,Linux提供的延时函数具有一定的灵活性,可以根据用户实际需求和程序逻辑进行不同的延时操作,但要注意延时函数的限制以及它们的使用,以便使程序能够按照我们预期的顺序运行。
Linux底层驱动开发从入门到精通的学习路线推荐

Linux底层驱动开发从入门到精通的学习路线推荐Linux底层驱动开发是一项涉及操作系统核心的技术,对于想要深入了解Linux系统内部工作原理的开发人员来说,是一门重要的技能。
本文将为你推荐一条学习路线,帮助你从入门到精通掌握Linux底层驱动开发。
一、基础知识学习阶段在开始学习Linux底层驱动开发之前,你需要掌握一些基础知识。
以下是你可以参考的学习路线:1.1 Linux操作系统基础学习Linux操作系统的基础知识是理解和使用Linux底层驱动的前提。
可以选择阅读《鸟哥的Linux私房菜》等入门书籍,了解Linux的基本概念、命令行操作等。
1.2 C语言编程C语言是Linux底层驱动开发的主要语言。
建议学习《C Primer Plus》等经典教材,掌握C语言的基本语法和编程技巧。
1.3 Linux系统编程学习Linux系统编程是理解Linux内核和驱动开发的关键。
推荐学习《Linux系统编程手册》等教材,学习Linux系统调用、进程管理等知识。
1.4 数据结构与算法良好的数据结构和算法基础对于优化和设计高效的驱动程序至关重要。
可以学习《算法导论》等经典教材,掌握数据结构和常用算法的原理和实现。
二、Linux内核了解与分析阶段在掌握了基础知识后,你需要进一步了解Linux内核和驱动的工作原理。
以下是你可以参考的学习路线:2.1 Linux内核源码阅读通过阅读Linux内核源码,你可以深入了解Linux的内核机制和实现细节。
可以选择《深入理解Linux内核》等相关书籍,逐步学习Linux内核代码的组织结构和关键部分。
2.2 设备驱动模型了解Linux内核的设备驱动模型对于编写高效且可维护的驱动程序至关重要。
可以学习Linux设备驱动模型的相关文档和教程,例如Linux Device Drivers (LDD)等。
2.3 内核调试与分析工具掌握一些常用的内核调试和分析工具是进行底层驱动开发的必要技能。
linux 延时函数

linux 延时函数Linux时函数,也称软件、空循环或无限循环延时,是指通过软件循环来指定程序停留某一段时间的一种延时形式。
在一些复杂的程序、设备或系统中,延时通常是指指定在某些特定的时间内,某个操作要求程序保持不变,不予响应的情况。
Linux时函数的最大优势在于它的软件实现,软件实现的 Linux时函数可以适应不同的硬件平台,不必担心不同的硬件平台产生的问题,因为硬件变化不影响 Linux时函数的功能。
Linux时函数可以简单分为两类:“阻塞型”和“非阻塞型”。
前者指的是,程序在规定的时间范围内,不断运行,而不允许其他程序抢占 CPU间;后者则是程序在规定的时间范围内,一直运行,但CPU以中断程序来处理其他任务。
Linux 下常用的延时函数有:sleep()和usleep()。
前者的参数是以秒为单位的,它可以让进程暂停执行多少秒,后者的参数是以毫秒来计算的,比 sleep()数精度更高。
另外一个常用的延时函数为 nanosleep(),它可以控制延时的精度到纳秒级,相对而言更加精确。
此外,Linux 也提供了循环延时函数,例如,下面的 C言程序示例:void delay(int milliseconds){int i;int max = (int) (milliseconds * 16000);for (i = 0; i < max; i++);}delay数实现了一个休眠函数,用于指定程序停留多长时间,它的原理是利用一个空的“for”循环,但它缺点是运行效率低,因为它必须一次执行一个代码,同时,它也会消耗CPU源,使系统性能受影响。
Linux gettimeofday()数是比较常用的 Linux时函数之一,它可以获取以197011零时起的 UTC时间来计算,这种方式实现的延时函数精度要比循环延时函数要高得多,而且它的效率也很高,也不会消耗 CPU源。
此外,Linux 中还有一些封装好的定时函数,如timer_create()数。
linux调时间后误差

linux调时间后误差
标题,Linux系统时间调整引发的误差。
在日常使用Linux操作系统时,我们经常需要对系统时间进行
调整,以确保系统时间与实际时间保持一致。
然而,有时候在调整
系统时间后,可能会引发一些误差,导致系统时间与实际时间不一致,这给我们的日常使用带来了一些困扰。
Linux系统中,我们可以使用命令行工具来调整系统时间,比
如使用date命令来手动设置系统时间,或者使用NTP服务来自动同
步系统时间。
然而,无论是手动设置还是自动同步,都存在一定的
误差。
误差可能来源于多个方面,比如硬件时钟的不准确、网络延迟、NTP服务器的负载等等。
当系统时间与实际时间存在误差时,可能
会导致一些问题,比如文件的时间戳不准确,定时任务执行时间不
准确等。
为了减少误差,我们可以采取一些措施。
首先,我们可以使用
更精确的时间同步服务,比如选择可靠的NTP服务器进行时间同步。
其次,我们可以定期手动校准系统时间,以确保系统时间与实际时
间保持一致。
此外,如果是在虚拟化环境中使用Linux系统,还可
以考虑使用宿主机的时间作为参考,以减少误差。
总的来说,Linux系统时间调整后可能会引发一些误差,我们
需要注意这些误差可能带来的影响,并采取相应的措施来减少误差,以确保系统时间与实际时间保持一致。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Linux设备驱动程序学习(10)-时间、延迟及延缓操作Linux设备驱动程序学习(10)-时间、延迟及延缓操作度量时间差时钟中断由系统定时硬件以周期性的间隔产生,这个间隔由内核根据HZ 值来设定,HZ 是一个体系依赖的值,在<linux/param.h>中定义或该文件包含的某个子平台相关文件中。
作为通用的规则,即便如果知道HZ 的值,在编程时应当不依赖这个特定值,而始终使用HZ。
对于当前版本,我们应完全信任内核开发者,他们已经选择了最适合的HZ值,最好保持HZ 的默认值。
对用户空间,内核HZ几乎完全隐藏,用户HZ 始终扩展为100。
当用户空间程序包含param.h,且每个报告给用户空间的计数器都做了相应转换。
对用户来说确切的HZ 值只能通过/proc/interrupts 获得:/proc/interrup ts 的计数值除以/proc/uptime 中报告的系统运行时间。
对于ARM体系结构:在<linux/param.h>文件中的定义如下:也就是说:HZ 由__KERNEL__和CONFIG_HZ决定。
若未定义__KERNEL__,H Z为100;否则为CONFIG_H Z。
而CONFIG_HZ是在内核的根目录的.config文件中定义,并没有在make menuconfig的配置选项中出现。
Linux的\arch\arm\configs\s3c2410_defconfig文件中的定义为:所以正常情况下s3c24x0的HZ为200。
这一数值在后面的实验中可以证实。
每次发生一个时钟中断,内核内部计数器的值就加一。
这个计数器在系统启动时初始化为0,因此它代表本次系统启动以来的时钟嘀哒数。
这个计数器是一个64-位变量( 即便在32-位的体系上)并且称为“jiffies_64”。
但是驱动通常访问jiffies 变量(unsigned long)(根据体系结构的不同:可能是jiffies_64 ,可能是jiffies_64 的低32位)。
使用jiffies 是首选,因为它访问更快,且无需在所有的体系上实现原子地访问64-位的jiffies_64 值。
使用jiffies 计数器这个计数器和用来读取它的工具函数包含在<linux/jiffies.h>,通常只需包含<linux/sched.h>,它会自动放入jiffi es.h 。
jiffies 和jiffies_64 必须被当作只读变量。
当需要记录当前jiffies 值(被声明为volatile 避免编译器优化内存读)时,可以简单地访问这个unsigned long 变量,如:以下是一些简单的工具宏及其定义:用户空间的时间表述法(struct timeval 和struct timespec )与内核表述法的转换函数:访问jiffies_64 对于32-位处理器不是原子的,这意味着如果这个变量在你正在读取它们时被更新你可能读到错误的值。
若需要访问jiffies_64,内核有一个特别的辅助函数,为你完成适当的锁定:处理器特定的寄存器若需测量非常短时间间隔或需非常高的精度,可以借助平台依赖的资源。
许多现代处理器包含一个随时钟周期不断递增的计数寄存器,他是进行高精度的时间管理任务唯一可靠的方法。
最有名的计数器寄存器是TSC ( timestamp counter), 在x86 的Pentium 处理器开始引入并在之后所有的CPU 中出现(包括x86_64 平台)。
它是一个64-位寄存器,计数 CPU 的时钟周期,可从内核和用户空间读取。
在包含了<asm/msr.h> (一个 x86-特定的头文件, 它的名子代表"machine-specific registers")的代码中可使用这些宏:一些其他的平台提供相似的功能, 并且内核头文件提供一个体系无关的功能用来代替rdtsc,称get_cycles(定义在<asm/timex.h>( 由<linux/timex.h> 包含)),原型如下:获取当前时间驱动一般无需知道时钟时间(用年月日、小时、分钟、秒来表达的时间),只对用户程序才需要,如cron 和syslogd。
内核提供了一个将时钟时间转变为秒数值的函数:为了处理绝对时间, <linux/time.h> 导出了d o_gettimeofday 函数,它填充一个指向struct timeval 的指针变量。
绝对时间也可来自xtime 变量,一个struct timespec 值,为了原子地访问它,内核提供了函数current_kernel_time。
它们的精确度由硬件决定,原型是:以上两个函数在ARM平台都是通过xtime 变量得到数据的。
全局变量xtime:它是一个timeval结构类型的变量,用来表示当前时间距UNIX时间基准1970-01-01 00:00:00的相对秒数值。
结构timeval是Linux内核表示时间的一种格式(L inux内核对时间的表示有多种格式,每种格式都有不同的时间精度),其时间精度是微秒。
该结构是内核表示时间时最常用的一种格式,它定义在头文件include/linux/time.h中,如下所示:struct timeval {time_t tv_sec; /* seconds */suseconds_t tv_usec; /* micr oseconds */};其中,成员tv_sec表示当前时间距UNIX时间基准的秒数值,而成员tv_usec则表示一秒之内的微秒值,且1000000>tv_usec>=0。
Linux内核通过timeval结构类型的全局变量xtime来维持当前时间,该变量定义在kernel/timer.c文件中,如下所示:/* The current time */volatile struct timeval xtime __attribute__ ((aligned (16)));但是,全局变量xtime所维持的当前时间通常是供用户来检索和设置的,而其他内核模块通常很少使用它(其他内核模块用得最多的是j iffies),因此对xtime的更新并不是一项紧迫的任务,所以这一工作通常被延迟到时钟中断的底半部(bottom half)中来进行。
由于bottom half的执行时间带有不确定性,因此为了记住内核上一次更新xtime是什么时候,Linux内核定义了一个类似于jiffies的全局变量wall_jiffies,来保存内核上一次更新xtime 时的jiffies值。
时钟中断的底半部分每一次更新xtime的时侯都会将wall_jiffies更新为当时的jiffies值。
全局变量wall_jiffies定义在kernel/timer.c文件中:/* jiffies at the most recent update of wall time */unsigned long wall_jiffies;原文网址:/freedom1013/archive/2007/03/13/1528310.aspx延迟执行设备驱动常常需要延后一段时间执行一个特定片段的代码, 常常允许硬件完成某个任务.长延迟有时,驱动需要延后执行相对长时间,长于一个时钟嘀哒。
忙等待(尽量别用)若想延迟执行若干个时钟嘀哒,精度要求不高。
最容易的( 尽管不推荐) 实现是一个监视jiffy 计数器的循环。
这种忙等待实现的代码如下:对cpu_relex 的调用将以体系相关的方式执行,在许多系统中它根本不做任何事,这个方法应当明确地避免。
对于ARM体系来说:也就是说在ARM上运行忙等待相当于:这种忙等待严重地降低了系统性能。
如果未配置内核为抢占式, 这个循环在延时期间完全锁住了处理器,计算机直到时间j1 到时会完全死掉。
如果运行一个可抢占的内核时会改善一点,但是忙等待在可抢占系统中仍然是浪费资源的。
更糟的是, 当进入循环时如果中断碰巧被禁止, jiffies 将不会被更新, 并且while 条件永远保持真,运行一个抢占的内核也不会有帮助, 唯一的解决方法是重启。
让出处理器忙等待加重了系统负载,必须找出一个更好的技术:不需要CPU时释放CPU 。
这可通过调用schedule函数实现(在 <linux/sched.h> 中声明):在计算机空闲时运行空闲任务(进程号0, 由于历史原因也称为swapper)可减轻处理器工作负载、降低温度、增加寿命。
超时实现延迟的最好方法应该是让内核为我们完成相应的工作。
(1)若驱动使用一个等待队列来等待某些其他事件,并想确保它在一个特定时间段内运行,可使用:(2)为了实现进程在超时到期时被唤醒而又不等待特定事件(避免声明和使用一个多余的等待队列头),内核提供了schedule_timeout 函数:短延迟当一个设备驱动需要处理硬件的延迟(latency潜伏期), 涉及到的延时通常最多几个毫秒,在这个情况下, 不应依靠时钟嘀哒,而是内核函数ndelay, udelay 和mdelay ,他们分别延后执行指定的纳秒数, 微秒数或者毫秒数,定义在<asm/delay.h>,原型如下:重要的是记住这 3 个延时函数是忙等待; 其他任务在时间流失时不能运行。
每个体系都实现udelay, 但是其他的函数可能未定义; 如果它们没有定义,<linux/delay.h> 提供一个缺省的基于udelay 的版本。
在所有的情况中, 获得的延时至少是要求的值, 但可能更多。
udelay 的实现使用一个软件循环, 它基于在启动时计算的处理器速度和使用整数变量loos_per_jiffy确定循环次数。
为避免在循环计算中整数溢出, 传递给udelay 和ndelay的值有一个上限,如果你的模块无法加载和显示一个未解决的符号:__bad_udelay, 这意味着你调用udleay时使用太大的参数。
作为一个通用的规则:若试图延时几千纳秒, 应使用udelay 而不是ndelay; 类似地, 毫秒规模的延时应当使用md elay 完成而不是一个更细粒度的函数。
有另一个方法获得毫秒(和更长)延时而不用涉及到忙等待的方法是使用以下函数(在<linux/delay.h> 中声明):若能够容忍比请求的更长的延时,应使用schedule_timeout, msleep 或ssleep。
内核定时器当需要调度一个以后发生的动作, 而在到达该时间点时不阻塞当前进程, 则可使用内核定时器。
内核定时器用来调度一个函数在将来一个特定的时间(基于时钟嘀哒)执行,从而可完成各类任务。