stata学习笔记
Stata学习笔记和国贸理论总结

Stata学习笔记一、认识数据(一)向stata中导入txt、csv格式得数据1.这两种数据可以用文本文档打开,新建记事本,然后将相应文档拖入记事本即可打开数据,复制2.按下stata中得edit按钮,右键选择paste special3.*、xls/*、xlsx数据仅能用Excel打开,不可用记事本打开,打开后会出现乱码,也不要保存,否则就恢复不了。
逗号分隔得数据常为csv数据。
闡贄鲜饩狈酾阑。
(二)网页数据网页上得表格只要能选中得,都能复制到excel中;网页数据得下载可以通过百度“国家数据”进行搜索、下载恒險谅枫諷为誣。
二、Do-file 与log文件打开stata后,第一步就要do-file,记录步骤与历史记录,方便日后查瞧。
Stata处理中保留得三种文件:原始数据(*、dta),记录处理步骤(*、do),以及处理得历史记录(*、smcl)。
鍥糶斷轻浆辆钓。
三、导入StataStata不识别带有中文得变量,如果导入得数据第一行有中文就没法导入。
但就是对于列来说不会出现这个问题,不分析即可(Stata不分析字符串,红色文本显示;被分析得数据,黑色显示);第一行就是英文变量名,选择“Treat first row as variable names”馀紋锭箩谅绾纭。
在导入新数据得时候,需要清空原有数据,clear命令。
导入空格分隔数据:复制——Stata中选择edit按钮或输入相应命令——右键选择paste special——并选择,确定;导入Excel中数据,复制粘贴即可艰鍤悵铧恥郑顎。
;逗号分隔数据,选择paste special后点击comma,然后确定。
Stata数据格式为*、dta,导入后统一使用此格式。
四、基本操作(几个命令)(一)use auto,clear 。
在清空原有数据得同时,导入新得auto数据。
(二)browse 。
浏览数据。
(三)describe 与list。
查瞧数据,describe 与list 使用list命令能使我们根据自己得需要选择数据(例如其与in/if语句得结合使用)。
stata课堂笔记
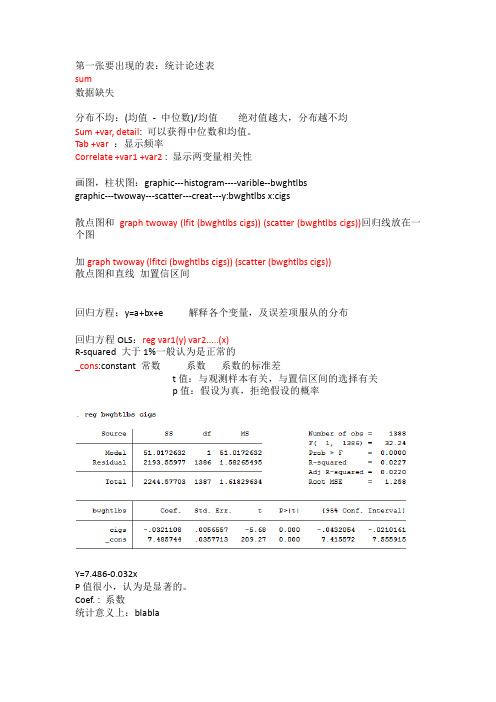
2016.4.1 Y=b0+b1x+u Fare=bo+bi dist +u Predict: y 尖,除了 x 之外的其他因素也影响与,除此之外还有 u Y 尖和真实值之间的差为残差—SSR SSR=squares
衡量不能用模型衡量,解释的波动? 1. Measure variation of diference between predict and sample 2. Measure variation that can not explained by model SS—sum of squares 方差 measure variation 波动、变化 2 SST—total sum of squares = 方差和 --- 聚散 2 SSE— explainable sum of squares= Measure variaton that can be explained by model 1-SSR/SST=SSE/SST=R2 d.f: degree of freedom 自由度 取值不受限制的变量个数 stata 中自由度:观测值-1-(未知数 -1) 残差的自由度:增加样本量 1. 增加未知数 2. 运用低速收敛模型 OLS 是告诉收敛,时间序列是低速 什么是好的回归? 仅有 R2 不能判断----引力模型 理论和实证相符 Root MSE ( mse 的开方)衡量回归的波动
a 值:能够容忍的犯错误的概率。 p 值:犯错误的概率。 A 值:如果在观测点附近有样本:正常取,比如 5%,10%,15% 如果在观测点附近没有样本:低于 0.1% A 值与什么有关:1. Research subject 2. Spread of samples 3. Number of obs 回归不需要常数(或常数为 0 ) : reg price sqrft, noconstant on condition that 房地产(面积为零时价格为零) ;差分方程(常数项相减消失)
stata统计分析与应用笔记汇总

第一章:Stata概述:help和search都是查找文件的命令但help用于查找精确的命令,search是模糊查找。
还可使用help|contents 来分类查找第二章:数据管理:2.1变量和变量的取值:1.变量的命名:不能以数字开头,区分大小写,不能命名为系统变量名2.变量的取值类型:(1)字符型:字符变量存储格式是str⋕,str表示格式⋕表示该变量的存储最多可容纳的字符数(2)数值型数据:存储格式:byte.int.long.float.double.Stata默认将数字存储为浮点数据,而将计算结果存为双浮点数据。
(3)缺失数据:一般仅用“.”表示3.变量的显示:(1)数值变量的显示格式:a.普通格式有%w.dg, %w.dgc(g表示普通,w表示整个显示所占的字符数,d表示显示的数字中小数点后的位数,c是要求Stata给出带逗号“,”数字显示格式如12345显示为12,345)b.固定格式有%w.df, %w.dfc(f表示固定)c.科学指数法格式:%w.de, (e表示科学计数)(2)字符变量的显示格式:仅有一种%⋕s,%是提示符,#表示显示字符数,s表示字符变量显示格式,默认右对齐,后加“-”可改为左对齐。
(3)使用format命令变量显示格式:format varlist %fmt 或者 format %fmt varlist 4.变量的标签(1)添加数据集的标签使用: label data [“lable”](2)添加变量的标签使用:label variable varname [“lable”](3)label为变量数值添加标签的语法有两部分,先定义数值标签:label define lblname#“lable” [#“lable”](lblname是标签名称) 然后将定义好的数值标签添加到变量上:label values varlist [lblnamel.]2.2创建一个新的数据集1.关于数据集操作的基本命令(1)browse 和edit 命令:browse 用于打开数据浏览器,edit命令用于打开数据编辑器Edit [varlist] [if] [in]browse [varlist] [if] [in](if和in 用于选择需要的子集)(2)rename:rename old_varname new_varname(3)save命令:save [filename] [,save_options]([,save_options]可以指nolabel(不保存设定标签),replace(允许新文件覆盖原文件),all主要用于编程(4)describe:用于产生一个对数据集的简明总结格式:describe [varlist] [,memory_options](命令选项:simple,short,detail,fullnames)(5)list:用于显示变量的数值,其后可以跟需要显示的变量名称语法:list [varlist] [if] [in] [,options](命令选项包括:noobs(不显示观测值的数值),clean,separator,sepby,nolabel)(6)codebook:用于详尽地描述变量的内容,包括变量名称、标签、赋值。
stata常见问题及解决办法个人总结笔记

1. 如何输出STATA的图,和保存先输入数据(1)Twoway connected 变量1 变量2 怎样在stata8中做HAUSMAN检验四步曲,重点在于解释结果(1)xtreg y x , fe(2)est store fe(3)xtreg y x, re(4)hausman fe如果拒绝,说明corr(x,ui)=0的假设是有问题的,需要重新设定RE model 后再进行检验,如果模型的设定没有问题,但检验还是拒绝原假设(p值接近0),那么就只能采用FE model 了,因为此时的RE 估计量是有偏的。
(definitely right. 当你使用stata的时候,最重要的命令不是这些是help and find it然后就能找到你的答案了)hausman检验是用来检验用fe还是re的,其原假设是re优于fe,从你的结果来看( Prob>chi2 =),应该拒绝原假设,所以应该用fe3.stata里平方的命令怎么写gen age=age^24. stata里边怎么取对数啊gen lnx=log(x)5.如何用STATA求自然对数如说:ln(X^2)=,如何求X啊. dis sqrt(exp)或者dis exp2)6.关于hausman检验,结果是CHI2(2)=,prob>chi2=,可以使用随机效应模型嘛prob>chi2=,is like p-value.we should reject the null, so fixed effect is effect is not suggested. CHI2(2)=,就意味着拒绝原假设,从而选取固定效应模型。
7.我在做gdp一阶差分单位根检验的时候,输入的命令是ipshin dgdp,lags(1)得到的结果:Im-Pesaran-Shin test for cross-sectionally demeaned dgdpDeterministics chosen: constantt-bar test, N,T = (27,7) Obs= 135 Augmented by 1 lags (average) t-bar cv10 cv5 cv1 W[t-bar] P-value 我不会看这个结果,请问怎么看时否存在单位根阿看哪个数值啊零假设含有单位根,W[t-bar] = , P-value = 。
面板空间计量之Stata应用

面板空间计量之Stata应用:学习笔记【同舟共济】更新于2016年4月20日说明目前,在空间计量方面,Stata官方命令语句数量有限且较为零散,尚未形成系统的空间计量工具包。
因此,个人建议空间计量的初学者转向Matlab软件,James P. LeSage、J. P. Elhorst、Donald J. Lacombe等学者所开发的空间计量工具包,其功能相对更加完善,操作起来也比较方便。
本人已经习惯了使用stata,初次自学空间计量方面的操作,参考help文件及相关文献,在学习过程中做了简要总结,仅供初学者交流学习。
其中若有不当之处,敬请批评指正,谢谢!E-mail: ares0825@【Stata】Abd Elmessih Shehata (Econpapers)URL: /RAS/psh494.htmFederico Belotti (Econpapers)URL: /RAS/pbe427.htmP. Wilner Jeanty (Econpapers)URL:/RAS/pje95.htmMaurizio PisatiURL:/people/maurizio-pisatiYihua Yu (Econpapers)URL:/RAS/pyu79.htm目录第一章Stata空间计量命令语句安装 1 第二章中国31省市自治区(不含港澳台、附属岛屿)shp制作 3 第三章Stata空间权重制作8 第四章Stata 空间相关性检验27 第五章Stata 空间面板数据回归39面板空间计量之Stata应用:学习笔记第一章Stata空间计量命令包安装更新于2016-03-151.空间计量-Stata命令包Archive of user-written Stata packagesURL: /statistics/stata-blog/stata-programming/ssc_stata_package_list.php图1 Stata用户自拟命令语句列表另外,在IDEAS(URL: https:///)中可以查询相关命令,顺便推荐几个论坛,大家可以经常逛逛:Stata官方论坛URL: /UCLA-Idre论坛URL: /stat/stata/Stata Daily URL: /index/2.安装单击图1左侧红色框内命令名称,即可下载对应的压缩包,安装过程参考非官方命令手动安装说明(URL:/thread-2420580-1-1.html);单击图1右侧蓝色框内的各命令所对应的描述性语句,即可看到该命令的详细说明及应用举例。
Stata学习讲义

Stata学习讲义刘志阔一、如何导入数据Stata的数据处理功能是极其强大的,不过我们最好在excel中整理数据,然后导入到stata中就可以了。
命令:insheet using name.csv*注意,Stata只能用csv格式,另外把数据放到stata的目录中。
二、如何进行回归Stata中有很多命令,这些命令都是现成的,直接用就可以了。
不过,怎么用是个问题。
熟悉命令的基础上学会如何使用Help。
最简单的命令reg做ols回归,xtreg处理面板等。
命令:reg y x*注意,Stata命令的格式,自己回去看手册。
网络帮助可以采用如下命令获得findit scat3, net;search scat3, net三、如何导出结果Stata可以直接导出发表论文中回归结果,当然不是完全一样。
命令:outreg2 Results using name.word四、如何画图Stata的画图功能也是极其强大的,可以画出各种类型的图标。
命令:scatter y x || lfit y x五、如何存储结果Stata可以储存回归结果,便于分析。
命令:log using name log closed1.codebook可以查看数据有没有缺失2.xml_tab estout 可以输出结果3.qui tab year, gen(yr) 可以生产时间虚拟变量。
4.g q=quarterly( qtr,"YQ")5.form q %tq6.recode province (min/11=1) (12/19=2) (20/31=3)gen eastern=(province==1)gen middle=(province==2)gen western=(province==3)Logout 命令可以把界面内容存到word里面,而不用复制。
Logout,save(名称) word/excel replace:各种描述性命令,statsXml_tab可以输出Excel格式的结果。
stata笔记要点

1.一般检验假设系数为0,t比较大则拒绝假设,认为系数不为0.假设系数为0,P比较小则拒绝假设,认为系数不为0.假设方程不显著,F比较大则拒绝假设,认为方程显著。
2.小样本运用OLS进行估计的前提条件为:(1)线性假定。
即解释变量与被解释变量之间为线性关系。
这一前提可以通过将非线性转换为线性方程来解决。
(2)严格外生性。
即随机扰动项独立于所有解释变量:与解释变量之间所有时候都是正交关系,随机扰动项期望为0。
(工具变量法解决)(3)不存在严格的多重共线性。
一般在现实数据中不会出现,但是设置过多的虚拟变量时,可能会出现这种现象。
Stata可以自动剔除。
(4)扰动项为球型扰动项,即随即扰动项同方差,无自相关性。
3.大样本估计时,一般要求数据在30个以上就可以称为大样本了。
大样本的前提是(1)线性假定(2)渐进独立的平稳过程(3)前定解释变量,即解释变量与同期的扰动项正交。
(4)E(XiXit)为非退化矩阵。
(5)gt为鞅差分序列,且其协方差矩阵为非退化矩阵。
与小样本相比,其不需要严格的外生性和正太随机扰动项的要求。
4.命令稳健标准差回归:reg y x1 x2 x3, robust 回归系数与OLS一样,但标准差存在差异。
如果认为存在异方差,则使用稳健标准差。
使用稳健标准差可以对大样本进行检验。
只要样本容量足够大,在模型出现异方差的情况下,使用稳健标准差时参数估计、假设检验等均可正常进行,即可以很大程度上消除异方差带来的副作用对单个系数进行检验:test lnq=1线性检验:testnl _b[lnpl]=_b[lnq]^25.如果回归模型为非线性,不方便使用OLS,则可以采取最大似然估计法(MLE),或者非线性最小二乘法(NLS)6.违背经典假设,即存在异方差的情况。
截面数据通常会出现异方差。
因此检验异方差可以:(1)看残差图,但只是直观,可能并不准确。
rvfplot (residual-versus-fitted plot) 与拟合值的散点图rvpplot varname (residual-versus-predictor plot) 与解释变量的散点图扰动项的方差随观测值而变动,表示可能存在异方差。
stata学习笔记(四):主成份分析与因子分析

stata学习笔记(四):主成份分析与因⼦分析1.判断是否适合做主成份分析,变量标准化Kaiser-Meyer-Olkin抽样充分性测度也是⽤于测量变量之间相关关系的强弱的重要指标,是通过⽐较两个变量的相关系数与偏相关系数得到的。
KMO介于0于1之间。
KMO越⾼,表明变量的共性越强。
如果偏相关系数相对于相关系数⽐较⾼,则KMO⽐较低,主成分分析不能起到很好的数据约化效果。
根据Kaiser(1974),⼀般的判断标准如下:0.00-0.49,不能接受(unacceptable);0.50-0.59,⾮常差(miserable);0.60-0.69,勉强接受(mediocre);0.70-0.79,可以接受(middling);0.80-0.89,⽐较好(meritorious);0.90-1.00,⾮常好(marvelous)。
SMC即⼀个变量与其他所有变量的复相关系数的平⽅,也就是复回归⽅程的可决系数。
SMC⽐较⾼表明变量的线性关系越强,共性越强,主成分分析就越合适。
. estat smc. estat kmo. estat anti//暂时不知道这个有什么⽤得到结果,说明变量之间有较强的相关性,适合做主成份分析。
Squared multiple correlations of variables with all other variables-----------------------Variable | smc-------------+---------x1 | 0.8923x2 | 0.9862y1 | 0.9657y2 | 0.9897y3 | 0.9910y4 | 0.9898y5 | 0.9769y6 | 0.9859y7 | 0.9735-----------------------变量标准化. egen z1=std(x1)2.对变量进⾏主成份分析. pca x1 x2 y1 y2 y3 y4 y5 y6 y7. pca x1 x2 y1 y2 y3 y4 y5 y6 y7, comp(1)得到下⾯两个表格,第⼀个表格中的各项分别为特征根、difference这个不知道是啥、⽅差贡献率、累积⽅差贡献率。
stata学习笔记(stata学习笔记)

stata学习笔记(stata学习笔记)data managementCreate a new dataEdit / / variables in the data table and the creation of open dataInput x1 x2......Set OBS 10Gen x1=_nGen, x2=seq ()Egen, x3=seq (), B (5) t (5)Egen x4=fill (3434)Rename X1 pop / / variable VAR1 renamed popRename x2 placeMax C= (1,0.8\0.8,1)Drawnorm, x1, X2, means (1,10), SDS (0.3,2), corr (C), n (500)Gen x1=invnormal (uniform ())Gen roll=1+trunc (uniform () *6) randomly generates 1-6 randomnumbersGen x=exp (uniform ())Gen x=-3ln (uniform ())Gen x= (invnorm (uniform ())) ^2 chi square distributionGen, x=invttail (DF, uniform ()) t distributionGen, x=invFtail (DF1, df2, uniform ()) F distributionSample 10, countLabel variable pop population in 1000s, 1995 "/ / add tags for the variable popLabel define, sex_label 1, "male", 2 "female""Label values sex sex_label / / add value labels for the variable sexSave AAA / / keep the aaa.dta fileSave, replaceMerge dataUse a.datAppend using B.datUse a.datSort placeSave, replaceUse B.datSort placeMerge place using a.datReshape, long, grow, I (ID), J (year)Reshppe, wide, grow, I (ID), J (year)ClearCD f:\ statistics \stataUse AAASort pop / / as the pop variable orderingOrder place pop place pop / / variables were placed in the first, second positionDescrible / / description variable informationList / / show variable and variable valuesList, Sep (3) is shown separately in each of the 3 linesList, sepby (VaR) is shown as bounded by the VaR variableSummarize X / / display basic information variables, can add "d" to display detailed informationBy, VAR1, var2, sort:su, X (by can be used for Su, CI, centile, etc.)Tabstat, x, stats (mean, median, SD,, VaR, skewness, kurtosis, IQR, CV, semean, P2, etc)Collapse (sum), VAR1, var2 (SD), var3 (mean), newvar1=var4 (median), newvar2=var5A subset of variables (used by if and in)List, pop, place, sex, in, 1/50Sort popList pop place in -4/1 / / four observation shows that the value of pop maximumSummarize if pop<1000Summarize if place = = "China""Summarize, pop, place, sex, if, pop>100 & pop<1000Summarize place sex if pop<100 pop>1000 |Summarize place if pop<. / / the missing value is bigger than any numericalDrop, pop, if, place==, "China""KeepCreate and replace variables1, use, canada1, clearGenerate gap=flife-mlife"Label variable gap" "flife-mlife gap life""Format gap%4.1f / / fixed width of 4 decimal 1Other%4.1g (width 4, decimal part at least 1, can be displayed by decimal or scientific notation),%4.1eFormat only changes the display and does not affect the calculationUse, canada1, clearGenerate type=1Replace, type=2, if, place==, "Canada""Replace, type=3, if, place==, "Yukou""operator+ * / ^ mod (x, y)Use function(ABS)ACOS () //di ACOS (0.5) *180/_piSin, cos, asin, atan, atan2 () y/x's tangent functionSqrt, log (), ==ln (), log10, expThe smallest integer of ceil (x) >xThe maximum integer of floor (x) <xRound (x) four into fiveComb () lnfactorial ()distribution functionProbability of Ttail (DF, t) t>t0.05 (Dan Ce)Invttail (DF, P) calculates the T value based on the probability, and P is the right probabilityF (DF1, df2, f) left probability invF (N1, N2, P)Ftail (DF1, df2, f) the right probability invFtail (N1, N2, P)Chi2 (DF, x) left probabilityChi2tail (DF, x) right probabilityBinomial (n, x, P), n trials, x times and smaller probability1-binomial (n, X-1, P)Normal (z) standard normal distribution, left, cumulative probabilityDate function(1) assume that the numeric variable a is 20100312Gen str str_a=string (a,%10.0f) / / a conversion to character variableGene _ to date = DATE ("STR _, Ymd") / / 转换str _ a为日期变量, 返回值为当前日期 - 1960年1月1日的数值FORMAT DATE _% TD / / 转换date _ a的格式为日期12may2010假设有数值变量a格式为20100312101205STR str Gene _ = String ("% 16.0f")To _ = Clock Gene Double Date (STR _, "ymdhms")_% TC to date format假设有三个数值变量m、d、y分别表示月、日、年Gene _ date to mdy = (m, d)EgenEgen = seq (x t), B (3) (2) 111222111222Egen fill (x = 100,98) 100 98 94 96X = (0,2,7,0,2,7 egne fill)Rowmean egen x = (x1, X2, x3) 产生新变量, 其值为x1x2x3各行的均值Rowsum egen x = (x1, X2, x3) 产生新变量, 其值为x1x2x3各行的和Egen = STD X (a)Num 1: 15 for STD / egen xx = (AX)Xrank egen = RANK (X)10、其他函数Recode Group encodeX1 = recode gene (AGE, 24,28,32, ~) / / < < = 24 = 28Egen Group (x2 = x1)Strvar Gene ENCODE, 将字符变量转为数值变量 (numvar)Decode numvar, Gene (strvar)创建新的分类变量和定序变量假设有分类变量 (byte) type (1 - 3)Tab typeTab type, Gene (type) / / 产生type1 - 3三个哑变量2、将数值变量X1 = recode gene (AGE, 24,28,32, ~) / / 以 < < = 24 = 28~分组Egen Group (x2 = x1)变量下标Di x [4]Gene _ = X - X [N - 1] / / x与其前一个数值的差B gene _ = X - X [n + 1]从外部ascii文件导入数据以空格分隔, 字符串需带引号Str30 INFILE Place ulife tlife using aaa.raw / / 产生三个变量, place为30长度的字符变量COMPRESS / / 压缩place变量为最长的字符以tab或 "," 分隔Insheet Place ulife tlife using aaa.raw, comma (or tab).固定栏宽Infix Wood Year 1 - 4 5 - 8 9 - 10 aaa.raw using Water绘图Hist X, Bin (10) xlabel (0 (2) 10) ylabel (100 1000 xtick (100) (1) (2) 11) Norm fractionHist Start (50 x width (5) (FREQ by Group, total)Graph TwoWay Scatter and | | X Line and | | lfit X and X, mlabel (ID) msymbol (o / X)Graph TwoWay Scatter and x | | lfitci, STDFGraph Matrix X and ZGraph TwoWay line and year XGraph TwoWay line and yaxis (1 year) | yaxis | x Year (2)Graph TwoWay area and year XGraph box x and Z over (Group) yline (6.35).Graph pie x and Z, by (Group) foot (3, explode)Graph BAR (Mean) of X and Z, over (Group)Grapg DOT (median) x1 x2, over (Group) Marker (1, msymbol (OH) (2) Marker, msymbol (X))X Qnorm, GridPnorm X, Grid交叉表Tab B, SUM (X) meanTab B, All tabi B \ C D, All tab b] [FW = count, AllA B C 分布绘制abc的一维表 tab1A B C 建立所有可能的二维表 Tab2Sort by: a B C, Tab, All 以c的不同取值分别绘制a b的二维表Table Row col (col1, by 绘制多维表 row1)Sktest x swilk sfrancia正态性检验及数据变换Sktest x swilk sfrancia立方严重负偏态平方轻度负偏态平方根轻度正偏态对数正偏态平方根负倒数严重正偏态倒数非常严重正偏态平方倒数同上立方倒数同上X / / 产生以上8种变换后的正态性检验 LadderGladder X / / 针对ladder结果绘制直方图Bcskews newx = X / / 产生新变量newx, 是对x的变换方差齐性检验Sdtest X1 = x2Sdtest X1, by (Group)Robvar X, by levene检验, 返回值 (Group)W0: 均数 W50: 中位数 W10: 后的均数 trim10%方差分析单个样本TTEST (x = 10 signtest x = 10 二项分布ttest x1 = x2 signrank x1 = x2 wilcoxon符号检验ttest x city (group) ranksum x city (group) wilcoxon检验ttest x1 = x2, unpaired unequalbitest x = = pbitesti n c p单因素方差分析oneway x group, tabluate scheffe bonferroni sidak kwallis x city (group)多因素方差分析anova x a # # btest 1 (a = (test 2 (b = 3. bbonferonni: r (p) * c c: 比较次数, 组数x (组数 - 1) / 2scheffe: 1 - f (组数 - 1, 误差自由度, r (f) / (组数 - 1))regresspredict newvar 预测值predict newvar, stdp 预测值标准误anova x a b | aanova x a / id | a b a # banova x a b c.age相关分析 (town was:)cor x ypwcorr x y, bonferrior / sidakspearman x y, bonferrior / sidakpcorr y x1 - x3 去除其他x的影响后y与x的偏相关系数回归分析基本方法reg y x1 x2 x3, beta uncons预测值predict newvar, cooksd hat covratio dfits residuals rstudent rstandard stdp stdfhat > 2p / n 发现高杠杆值dfits > 2sqrt (p / n) 案例的自变量组合对回归直线的影响力cooksd > 4 / n 同上welsch > 3sqrt (p) 同上covratio: | r - 1 | > = 3p / nrvfplot, yline (0)假设检验reg x * ytest x1 x2 x1 和x2回归系数同时为0test x1 = x2虚拟变量loss region gene (reg) / / 产生reg1 - 4四个哑变量reg cmat reg2 / / reg2与其他3个地区的比较reg cmat reg1 reg2 reg3 reg4 = = xi: reg cmat i.region 此方法便于做交互分析char region [omit] 4 (与xi共同使用)xi: reg camt i.region逐步回归sw reg y x1 - x4, per (. 06) pe (0.05)sw reg y x1 x2 (x3, x4) lockterm1 per (. 06)面板数据iis regionten yearxtreg y x1 x2, rextmixed y 固定变量 | | school: 随机变量回归诊断estate ic 返回aic bic ll (null) ll (model) 值 (log likelihood 对数似然值)quietly reg y x1 - 85estimates of large fullquietly reg y x1 - x4lrtest fullovtest p < 0.05提示有二次、三次或四次方项目需要添加hettest p < 0.05提示方差不齐, 误差散点图不是随机分布的dwstat 一价自相关的durbin - watson检验kic 自变量共线性检查kic > 10 平均vif > 1 有问题宽容度 (vif的倒数) 表示该变量独立程度, 越大则越独立rvfplot 预测值与残差值的散点图rvpplot x 某一个自变量x与残差的散点图avplot x 去除其他变量影响后的x与y的线性关系, x轴上偏离的数值多为高杠杆值avplotsacprplot x, lowess 虚线在中间部分与直线不重和表示可能x与y 存在其他非线性关系,另外可以报告与x具有线性关系的其他自变量lvr2plot 注意拟合不好且具有较高杠杆作用的值可能是高杠杆值hat 较大值提示高杠杆值dfits cooksd covratio 提示对y影响较大的值logistic回归logit y x * logit y x *, orblogit n x * ylrocroctab y x, graphroccomp y x1 x2 比较y与x1的roc曲线和y与x2的是否相同rocgold y x x1 x2 比较y与x (金标准) 的roc曲线和y与x1的是否相同lsens, genprob (prob) gensens (sen) genspec (spec)lstatlfit, group (10) est gof, group (10)predict the phat, hat deviance ddeviance dbet dx2 dbetaclogit y x *, group (matchvar)ologit x * ymlogit y x *, b (1) mlogit y x *, rrrconstraint define 1 [3] x = 2 [2] xconstranit define 2 [4] x = 3 [2] xmlogit y x, c (1, 2) b (1)多元方差分析hotelling x *hotelling x *, city (group)manova x1 x2 x3 = g b g * b广义线性模型gaec y x1 x2家庭(高斯)链接(身份)* /正态分布线性回归GLM y x1 x2,家庭(二项式)链接(Logit)* /物流回归GLM y x1 x2,家庭(Poisson)链接(日志)lnoffset(暴露人年变量)泊松y x1 x2,曝光(暴露人年变量)poisgof [皮尔森]GLM y x1 x2,家庭(nbinomial)链接(日志)nbreg y x1 x2gnbreg y x1 x2,lnalpha(VAR)预测主成份分析PCA X点状图因子分析X因子*,PCF矿(0.5)主成份法X因子*,ML矿(0.5)最大似然法X因子*,IPF /迭代主因子法旋转方差极大旋转旋转,旋转斜交法生存分析认识时间,失败(结果)stsum,由(治疗)后缀树,由rmean(处理)STS列表,由(治疗)以损失为例的STS图STS图,通过gwood(治疗)STS测试组streg治疗组,诺尔公司(指数/ Weibull)预测new_var = = 1如果治疗,监测stcox治疗组,诺尔考克斯结果治疗组,死亡(结果)诺尔申银万国考克斯结果治疗组,死亡(结果)诺尔流行病队列研究IR案例的曝光时间(人年数)硝酸铵CS案例曝光[或数]CSI(A组)可使用结核病和精确(默认)计算RR可信区间,不能使用伍尔夫病例对照研究cc案例由(组)公开甲丙氨酯MCC的病例对照选择A B C D可使用精确(默认)、伍尔夫、麦田计算RR可信区间tabodds模型不如用物流、考克斯比例风险模型。
Stata学习笔记

Stata学习笔记1、横截⾯数据:多个经济个体的变量在同⼀时间点上的取值,如2012年中国各省的GDP2、时间数列数据:指的是某个经济个体的变量在不同时点上的取值,如1978-2012年⼭东省每年的GDP3、⾯板数据:多个经济个体的变量在不同时点上的取值,如1978-2012年中国各省的GDP⼩样本OLS(最⼩⼆乘法):单⼀⽅程线性回归最常见⽅法条件:解释变量与扰动项正交、扰动项⽆⾃相关、同⽅差。
拟合优度:衡量线性回归模型对样本数据的拟合程度(R2),越⾼说明模型拟合程度越好。
单系数T检验:对回归⽅程扰动项的具体概率进⾏假设显著性⽔平进⾏检验F检验:整个回归⽅程是否显著STATA操作简介:如果数据中包含1949-10-01或1949/10/01的时间变量,导⼊stata后可能会被视为字符串,因此对于⽇度数据,可以使⽤命令gen newvar=date(varname,YMD),将其转换为整数⽇期变量,其中YMD说明原始数据的格式为年⽉⽇,如果原始数据的格式为⽉⽇年则使⽤MDY;对于⽉度数据则gen newvar=monthly(varname,YM)。
.describe:数据的概貌 .drop keep:删除和保留.su:统计特征 Pwcorr:变量之间相关系数Star(.05):5%显著性⽔平 gen:产⽣g intc=log(tc):取⾃然对数. reg:OLS回归.Vce:协⽅差矩阵 reg。
,noc表⽰在进⾏回归时不要常数项⼤样本OLS:只要求解释变量与同期的扰动项正交即可Robust:稳健标准误,如果存在异⽅差,则应使⽤稳健标准误最⼤似然估计法:如果回归⽅程存在⾮线性,则使⽤最⼤似然估计法(MLE)或⾮线性最⼩⼆乘法(NLS)三类在⼤样本下渐进等价的统计检验:Wald test LR(似然⽐检验) LM操作步骤如下:sysuse auto(调⽤数据集)Hist mpg,normal(画变量mpg的直⽅图,并与正态密度⽐较)直⽅图显⽰,变量mpg的分布于正态分布有⼀定差距。
stata学习笔记(七):回归分析和稳健性检验

stata学习笔记(七):回归分析和稳健性检验1.分组回归sort stateby state:reg xxx xxx但是这样不能直接⽤outreg导出,采⽤下⾯的⽅法forvalues t = 2001/2008{qui reg y x if year == `t'est store r_`t'}然后不⼩⼼看到了⼀位⼤神的三种⽅法....没试过先mark三种策略,建议你都试试:(1)直接⽤outreg2的⼀项功能, // help outreg2##s_1bysort compliance: outreg2 using c3.doc, replace: reg ares time size ROA growth lev profquality(2)直接⽤outreg2的另⼀项功能, // help outreg2##s_2levelsof compliance, local(cl) // help levelsofcap erase c3.docforeach lv of local cl {reg ares time size ROA growth lev profquality if compliance == `lv'outreg2 using c3.doc}(3)⼿⼯循环(估计->保存估计结果)->统⼀输出levelsof compliance, local(cl)foreach lv of local cl {reg ares time size ROA growth lev profquality if compliance == `lv'est store cl_`lv'}outreg2 [cl_*] using c3.doc, replace2.交叉项genicv可以⼀键⽣成很多交叉项##可以直接表⽰交叉项。
【例⼦】ssc install genicvsysuse auto,cleargenicv length weight foreign \\\会⽣成4个交叉项,所以可能情况,并且有labelreg price length weight length_weight*如果不愿意⽣成,直接⽤reg price c.length##c.weight \\\和上⾯回归⼀样⼀样的3.⼯具变量逆⽶尔斯⽐率imr=normalden(predict)/normal(predict)两阶段回归ivreg2 roasd size age state indratio hold_share_w income_increase_w (vc=ht vc_den young)3.群聚调整*⾯板数据做回归的时候,如果不加cluster选项,默认的标准差假定模型的标准差对于给定个体在时间上是独⽴的,⽽事实上往往在各期之间会有相关性。
stata学习笔记(三):计算五年内的ROA标准差所用到的一些知识

stata学习笔记(三):计算五年内的ROA标准差所⽤到的⼀些知识1.如何删除某⼏⾏的数据drop if year2==2014 | year2==20132.如何计算连续⼏年的标准差*year2为int型bys stkcd (year2):gen roa1=adjroa[_n-1]bys stkcd (year2):gen roa2=adjroa[_n-2]bys stkcd (year2):gen roa3=adjroa[_n+1]bys stkcd (year2):gen roa4=adjroa[_n+2]egen roasd=rowsd(roa1 roa2 adjroa roa3 roa4)3.如何实现excel与stata的数据导⼊导出?复制粘贴就⾏啦~4.如何打开csv格式⽂件?insheet using"路径+⽂件名",clear5.如何实现分组并求平均值?*bysort year group按照年份和⾏业来分组计算,mean为求平均值,meanroa为新的变量名,egen为⽣成⼀列新的变量bysort year group:egen meanroa=mean(roa)6.如何对数据进⾏分组编号?egen new_id = group(industry)7.变量重新命名ren f050201b ROA8.缩尾处理*winsor命令是⽤第1%的数据去替换前1%的数据,⽤第99%的数据去替换后1%的数据. winsor roa, gen(newroa) p(0.01). winsor2 roa, cuts(1 99) by(group)*winsor2相⽐于winsor命令的改进:(1) 可以批量处理多个变量;(2) 不仅可以 winsor,也可以 trimming;(3) 附加了 by() 选项,可以分组 winsor 或 trimming;(4) 增加了 replace 选项,可以不必⽣成新变量,直接替换原变量。
学习stata的心得体会

学习stata的心得体会学习Stata的心得体会Stata是一种功能强大的统计分析软件,广泛用于各个领域的数据分析和统计建模。
在使用Stata进行学习和研究的过程中,我积累了一些心得体会,以下是我对学习Stata的一些经验总结,希望能对其他学习Stata的人有所帮助。
首先,要熟悉Stata的操作界面和基本命令。
刚开始学习使用Stata时,可以先快速了解Stata软件的界面,包括变量管理、数据管理、结果输出等,熟悉各个功能模块的使用方法。
掌握一些常用命令,如数据导入导出、数据清洗和变量计算等,这是使用Stata进行数据处理和分析的基础。
其次,在学习Stata的过程中,需要学会利用Stata的帮助文档和学习资料。
Stata提供了丰富详尽的帮助文档,包括命令语法、参数解释、实例演示等,可以通过“help”命令来访问。
同时,Stata的官方网站也提供了大量的学习资料、教程和案例,可以通过浏览网站来获取更多的学习资源。
再次,实践和实际问题是学习Stata的重要途径。
在学习Stata的过程中,可以结合自己的研究或工作实际,选择相关的数据进行分析和建模。
通过实际问题的解决,可以更好地理解理论知识,并掌握Stata的应用技巧。
同时,可以多搜索和参考一些Stata的案例和书籍,了解其他人是如何使用Stata解决实际问题的,从中学习经验和技巧。
另外,要善于利用Stata的图形和统计功能,进行数据可视化和分析。
Stata提供了丰富多样的图形绘制功能,可以通过绘制图表来展示数据分布和关系,辅助数据分析和解释。
同时,Stata也提供了丰富的统计分析功能,包括描述统计、回归分析、方差分析等,可以通过这些统计功能来深入挖掘数据的特征和规律。
此外,在学习Stata的过程中,要注重编程和脚本的应用。
Stata支持编写命令和脚本自动化数据处理和分析的过程,这样可以提高工作效率和减少重复性劳动。
编写脚本可以实现一些复杂的数据操作和分析任务,同时可以使得操作步骤可追溯和可复现。
最新STATA实用学习笔记资料

最新STATA实⽤学习笔记资料北京科技⼤学STATA应⽤学习摘录第⼀章 STATA的基本操作⼀、设置内存容set mem 500m, perm⼀、显⽰输⼊内容Display 1Display “clive”⼆、显⽰数据集结构describeDescribe /d三、编辑editEdit四、重命名变量Rename var1 var2五、显⽰数据集内容list/browseList in 1List in 2/10六、数据导⼊:数据⽂件是⽂本类型(.csv)1、insheet: . insheet using “C:\Documents and Settings\Administrator\桌⾯\ST9007\dataset\Fees1.csv”, clear2、内存为空时才可以导⼊数据集,否则会出现(you must start with an empty dataset)(1)清空内存中的所有变量:.drop _all(2)导⼊语句后加⼊“clear”命令。
七、保存⽂件1、save “C:\Documents and Settings\Administrator\桌⾯\ST9007\dataset\Fees1.dta”2、save “C:\Documents and Settings\Administrator\桌⾯\ST9007\dataset\Fees1.dta”, replace ⼋、打开及退出已存⽂件use1、.Use ⽂件路径及⽂件名, clear2、. Drop _all/.exit九、记录命令和输出结果(log)1、开始建⽴记录⽂件:log using "J:\phd\output.log", replace2、暂停记录⽂件:log off3、重新打开记录⽂件:log on4、关闭记录⽂件:log close⼗⼀、创建和保存程序⽂件:(doedit, do)1、打开程序编辑窗⼝:doedit2、写⼊命令3、保存⽂件,.do.4、运⾏命令:.do 程序⽂件路径及⽂件名⼗⼆、多个数据集合并为⼀个数据集(变量和结构相同)纵向合并append insheet using "J:\phd\Fees1.csv", clearsave "J:\phd\Fees1.dta", replaceinsheet using "J:\phd\Fees2.csv", clearappend using "J:\phd\Fees1.dta"save "J:\phd\Fees1.dta", replace⼗三、横向合并,在原数据集基础上加上另外的变量merge1、insheet using "J:\phd\Fees1.csv", clearsort companyid yearendsave "J:\phd\Fees1.dta", replacedescribeinsheet using "J:\phd\Fees6.csv", clearsort companyid yearendmerge companyid yearend using "J:\phd\Fees1.dta"save "J:\phd\Fees1.dta", replacedescribe2、_merge==1 obs. From master data_merge==2 obs. From using data_merge==3 obs. From both master and using data⼗四、帮助⽂件:help1、. Help describe⼗五、描述性统计量1、summarize incorporationyear 单个summarize incorporationyear-big6 连续多个summarize _all or simply summarize 所有2、更详细的统计量summarize incorporationyear, detail3、centilecentile auditfees, centile(0(10)100)centile auditfees, centile(0(5)100)4、tabulate不同类型变量的频数和⽐例tabulate companytypetabulate companytype big6, column 按列计算百分⽐tabulate companytype big6, row 按⾏计算百分⽐tab companytype big6 if companytype<=3, row col 同时按⾏列和条件计算百分⽐5、计算满⾜条件观测的个数count if big6==1count if big6==0 | big6==16、按离散变量排序,对连续变量计算描述性统计量:(1)by companytype, sort: summarize auditfees, detail(2)sort companytypeBy companytype:summarize auditees⼗六、转换变量1、按公司类型将公开发⾏股票公司赋值为1,其他为0gen listed=0replace listed=1 if companytype==2replace listed=1 if companytype==3replace listed=1 if companytype==5replace listed=. if companytype==.⼗七、产⽣新变量genGenerate newvar=表达式⼗⼋、数据类型3、新建变量的过程中定义数据类型●gen str3 gender= "male"●list gender in 1/104、变量所占字节过长●drop gender●gen str30 gender= "male"●browse●describe gender●compress gender5、⽇期数据类型:%d dates, which is a count of the number of days elapsed since January 1, 1960。
stata学习资料-第六章
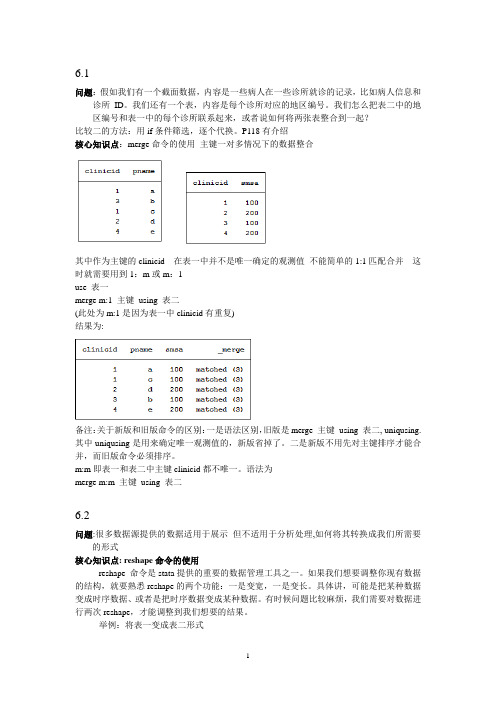
6.1问题:假如我们有一个截面数据,内容是一些病人在一些诊所就诊的记录,比如病人信息和诊所ID。
我们还有一个表,内容是每个诊所对应的地区编号。
我们怎么把表二中的地区编号和表一中的每个诊所联系起来,或者说如何将两张表整合到一起?比较二的方法:用if条件筛选,逐个代换。
P118有介绍核心知识点:merge命令的使用主键一对多情况下的数据整合其中作为主键的clinicid 在表一中并不是唯一确定的观测值不能简单的1:1匹配合并这时就需要用到1:m或m:1use 表一merge m:1 主键using 表二(此处为m:1是因为表一中clinicid有重复)结果为:备注:关于新版和旧版命令的区别:一是语法区别,旧版是merge 主键using 表二, uniqusing. 其中uniqusing是用来确定唯一观测值的,新版省掉了。
二是新版不用先对主键排序才能合并,而旧版命令必须排序。
m:m即表一和表二中主键clinicid都不唯一。
语法为merge m:m 主键using 表二6.2问题:很多数据源提供的数据适用于展示但不适用于分析处理,如何将其转换成我们所需要的形式核心知识点: reshape命令的使用reshape 命令是stata提供的重要的数据管理工具之一。
如果我们想要调整你现有数据的结构,就要熟悉reshape的两个功能:一是变宽,一是变长。
具体讲,可能是把某种数据变成时序数据、或者是把时序数据变成某种数据。
有时候问题比较麻烦,我们需要对数据进行两次reshape,才能调整到我们想要的结果。
举例:将表一变成表二形式表一有四个变量,分别是country,tradeflow, Yr1990, Yr1991.其中tradeflow是作为一个变量主体,分为imports和exports,而1990和1991的贸易流是作为两个并列的变量主体。
我们要把它转成面板数据,分两步。
第一是Yr1990和Yr1991改成时间序列,tradeflow暂时不变。
Stata上机实验笔记

Stata上机实验Stata 统计软件包是目前世界上最著名的统计软件之一,国外将Stata与SAS、SPSS 一起被并称为三大权威软件。
它同时具有数据管理软件、统计分析软件、绘图软件、矩阵计算软件和程序语言的特点,几乎可以完成全部复杂的统计分析工作。
Stata有什么优势?1。
Stata 的命令语句极为简洁明快,易学易记。
2。
强大的帮助信息。
本地帮助 Help 命令名在线帮助Findit 命令名3。
始终处于计量经济学和统计学的最前沿。
许多Stata 程序员会针对计量经济学发展编写一些最新的程序(ADO 文件), Stata提供了严谨、简练而灵活的程序语句,用户可以编写自己的命令和函数,同时可随时到Stata 网站寻找并下载最新的升级文件。
下载后可以直接使用,也可以自行修改、添加功能。
(例如当前流行的面板单位根和面板门限数据,均可以安装下载使用)不同版本对样本容量、变量个数、矩阵阶数、宏的字符长度等有着不同的限制。
以SE版为例,其最大变量个数为32767,最大字符长度为244字节,最大矩阵阶数为11000(即11000 11000)。
Stata默认值为:最大变量个数为5000,最大矩阵阶数为400,最大内存为10兆。
如果用户需要更多的内存或者更多的变量,可以在命令栏输入如下命令进行扩展。
set maxvar 5000 <最大变量个数5000个。
>set memory 50m <占内存50兆。
>最重要的有三类文件1。
文件名.dta 数据文件2。
文件名.do 命令文件3。
文件名.ado 程序文件如果不加改变,安装时Stata会将系统程序安装到:C:\Program file\stata10 中。
将所用系统自带的一些系统数据、应用程序、帮助文件安装到C:\Program file\stata10\ado\base 中将所有升级程序安装到:C:\Program file\stata10\ado\update 中1。
stata笔记常用

stata笔记常用Stata: 输出regression table到word和excel1. 安装estout。
最简单的方式是在stata的指令输入:ssc install estout, replaceEST安装的指导网址是:2.跑你的regression3.写下这行指令esttab using test.rtf,然后就会出现个漂亮的表格给你(WORD文档)。
只要再小幅修改,就可以直接用了。
这个档案会存在my document\stata下。
如果你用打开的是一个stata do file,结果会保存到do文件所在文件夹中。
如果要得到excel文件,就把后缀改为.xls或者.csv就可以了4.跑多个其实也不难,只要每跑完一个regression,你把它取个名字存起来:est store m1。
m1是你要改的,第一个model所以我叫m1,第二个的话指令就变成est store m2,依次类推。
5.运行指令:esttab m1 m2 ... using test.rtf就行了。
异方差的检验:Breusch-Pagan test in STATA:其基本命令是:estat hettest var1 var2 var3其中,var1 var2 var3 分别为你认为导致异方差性的几个自变量。
是你自己设定的一个滞后项数量。
同样,如果输出的P-Value 显著小于0.05,则拒绝原假设,即不存在异方差性。
White检验:其基本命令是在完成基本的OLS 回归之后,输入imtest, white如果输出的P-Value 显著小于0.05,则拒绝原假设,即不存在异方差性处理异方差性问题的方法:方法一:WLSWLS是GLS(一般最小二乘法)的一种,也可以说在异方差情形下的GLS就是WLS。
在WLS下,我们设定扰动项的条件方差是某个解释变量子集的函数。
之所以被称为加权最小二乘法,是因为这个估计最小化的是残差的加权平方和,而上述函数的倒数恰为其权重。
Stata学习笔记

Stata学习笔记以下命令均采⽤⼩写字母Chapter 1 stata⼊门打开数据use "D:\Stata9\", clear ⽤use命令打开数据sysuse auto,clear auto 为系统数据sysuse为打开系统数据的命令获取帮助Help summarize summarize为需要获取帮助对象可以改为其他的需要帮助的对象Findit summarize,net 寻找⽹络帮助summarize为需要获取帮助对象Search summarize ,net 寻找⽹络帮助summarize为需要获取帮助对象显⽰结果Display 5+9描述统计(summarize 可简写成sum)Use atuo,clearSummarize price 描述price的观察值个数、平均值、标准差、最⼩值、最⼤值Sum weight summarize可简写成sumSum weight price 同时完成上⾯两步绘图Scatter price weight scatter 为绘制散点图命令Line price weight ,sort line 为绘制折线图命令,sort为排序,绘制折线图前需要先排序⽣成新的数据(generate 可简写成gen)ClearSet obs 1000 设置观测值的组数Gen x=_n _n 为观察值得序号Gen y=x+100控制结果输出显⽰List n设置屏幕滚动Set more off 先设置此项则显⽰时,屏幕不停⽌Set more on 先设置此项则显⽰时,会使显⽰停⽌清除内存中原有内容clear设置⽂件存取路径(cd)Cd d:\stata d:\stata为路径如果想知道当前路径下有哪些⽂件,可以⽤dir 命令来列⽰.dir假设你想在D 盘的根⽬录下创建⼀个新的⽂件夹mydata 来存放数据⽂件,命令为mkdir。
mkdir d:\mydata错误提⽰List myvar上述命令试图显⽰变量myvar,但是结果窗⼝仅出现如下的显⽰variable myvar not foundr(111);红⾊信息表明,没有找到⼀个叫myvar 的变量,的确,我们的数据中并没有这个变量。
Stata笔记-北京科技大学

改颜色edit-preference-general prefernce-classic下面命令框-右键-font-改字号命令cd d:\ 改到d盘(change directory)dir查询d盘有什么sysuse auto 系统自带汽车数据,数据变量(字段)显示在右上角br(owse) 浏览数据(字符型红色,数值型黑色,蓝色-右键-value labels-hide all labels标签隐藏)h(elp) li(st) 告诉你命令怎么用,下面有例子左边双击执行,单击复制到命令框order price mpg(单击右边的变量)order make-foreign 改变变量顺序,从make到foreigng(enerate) new=rep78-trunk 输出新变量(rep78,trunk是字段,可单击选择,"."表示缺省,加减乘除+-*/)list if new==14 (==为等于,=为赋值,可以点击more)li(st) if new2>=14 & new2<24 (按q可以退出,即quit)replace new3=rep78 (输错了替换)drop new new2 new3删除变量list if new>10000list make if new<10000|new>2000 (竖线表示或者,回车上面那个)!=表示不等于左边命令,右键savesave data 文件名为datasysuse autopreservereservesave auto2 保存时不需加后缀,删除时带后缀.dtasort price从小到大gsort price 都可以,比较随意gsort -trunk price (默认加号,为排序)order make new (将new排到第二位)aorder (alphabetic 按字母顺序排序)disp(lay) sin(1) 作为计算器使用ln以e为底----------------3.13---------锐思数据库选择数据-----非金融行业负债表----左边-财务报表-非金融行业合并标识-1合并报表调整标识-1报表类型-q4、信息来源-q4公司类别-20-定期报告信息来源:q4a股股票代码截止日期流动资产合计应收账款总资产流动负债合计负债合计所有者权益合计------非金融行业利润表---前同净利润营业收入excel输出(默认)选择列表签+列名------打开STATA------菜单引入文件clear可清除数据varible name 不识别中文选中第一个import first row as varible names第二个import all data as strings意思是将数据看作字符型(不选)br(ouse)展示数据流动比率=流动资产/流动负债资产负债率=总负债/总资产产权比率=总负债/所有者权益合计mkdir d:\hsy1\mydata 建立文件夹cd d:\hsy1\mydata 基于文件夹dir 显示文件夹save bs 保存数据,名为bs直接运行是双击,显示在框内为单击g(enerate) currrate=Totcurass/Tutcurlia 流动比率(等号后面点右上方variables)显示(8 missing values generated)有八个缺失值g lev=Totlia/Totass 负债率leverageg pright= Totlia/ TotSHE 产权比率porpertysave bs2 另存数据drop 为删除变量clear从内存删掉,不会从硬盘删掉------利润表-----importsave isg incorate= Netprf/ Incmope 利润率=净利润/营业利润save is2----clearuse bs2 打开bs2g year=year( EndDt) 。
stata中回归知识点总结

stata中回归知识点总结简单线性回归简单线性回归是回归分析中最基本的形式。
它用于研究一个自变量对一个因变量的影响。
在Stata中进行简单线性回归可以使用reg命令。
比如,我们有一个数据集包含了两个变量x和y,我们想知道x对y的影响,可以使用如下命令进行简单线性回归:```reg y x```这条命令将会输出回归方程的拟合结果,包括截距项和自变量系数。
多元线性回归多元线性回归是回归分析中更常见的形式。
它用于研究多个自变量对一个因变量的影响。
在Stata中进行多元线性回归同样可以使用reg命令。
比如,我们有一个数据集包含了三个变量x1、x2和y,我们想知道x1和x2对y的影响,可以使用如下命令进行多元线性回归:```reg y x1 x2```逻辑回归逻辑回归是用来处理因变量为二值变量的回归分析方法。
在Stata中进行逻辑回归可以使用logit命令。
比如,我们有一个数据集包含了两个变量x和y,其中y是一个二值变量(比如0和1),我们想知道x对y的影响,可以使用如下命令进行逻辑回归:```logit y x```高级回归技巧除了上述的基本回归分析方法,Stata还提供了许多高级的回归技巧,比如假设检验、多重共线性检验、残差分析等。
其中,假设检验是用来检验回归模型的显著性,通常使用命令test。
多重共线性检验是用来检验自变量之间的相关性,通常使用命令collin。
残差分析是用来检验模型的拟合情况,通常使用命令predict和rvfplot。
总结回归分析是统计学中常用的一种分析方法,它用于研究自变量和因变量之间的关系。
在Stata中,回归分析是一种非常常见的数据分析方法,包括简单线性回归、多元线性回归、逻辑回归和一些高级回归技巧。
希望本文对Stata用户们有所帮助。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
经济数据的特点与类型。
1、横截面数据:多个经济个体的变量在同一时间点上的取值,如2012年中国各省的GDP2、时间数列数据:指的是某个经济个体的变量在不同时点上的取值,如1978-2012年山东省每年的GDP3、面板数据:多个经济个体的变量在不同时点上的取值,如1978-2012年中国各省的GDP 小样本OLS(最小二乘法):单一方程线性回归最常见方法条件:解释变量与扰动项正交、扰动项无自相关、同方差。
拟合优度:衡量线性回归模型对样本数据的拟合程度(R2),越高说明模型拟合程度越好。
单系数T检验:对回归方程扰动项的具体概率进行假设显著性水平进行检验F检验:整个回归方程是否显著STATA操作简介:如果数据中包含1949-10-01或1949/10/01的时间变量,导入stata后可能会被视为字符串,因此对于日度数据,可以使用命令gen newvar=date(varname,YMD),将其转换为整数日期变量,其中YMD说明原始数据的格式为年月日,如果原始数据的格式为月日年则使用MDY;对于月度数据则gen newvar=monthly(varname,YM)。
.describe:数据的概貌.drop keep:删除和保留.su:统计特征Pwcorr:变量之间相关系数Star(.05):5%显著性水平gen:产生g intc=log(tc):取自然对数. reg:OLS回归.Vce:协方差矩阵reg。
,noc表示在进行回归时不要常数项大样本OLS:只要求解释变量与同期的扰动项正交即可Robust:稳健标准误,如果存在异方差,则应使用稳健标准误最大似然估计法:如果回归方程存在非线性,则使用最大似然估计法(MLE )或非线性最小二乘法(NLS )三类在大样本下渐进等价的统计检验:Wald test LR (似然比检验) LM 操作步骤如下:sysuse auto (调用数据集)Hist mpg ,normal (画变量mpg 的直方图,并与正态密度比较)直方图显示,变量mpg 的分布于正态分布有一定差距。
变量可以取对数解决非正态分布的问题。
异方差与GLS (广义最小二乘法)异方差的检验:看残差图、怀特检验(white test )、BP 检验(Breusch and Pagan ) 异方差的处理:1、OLS+稳健标准误(最好的)2、广义最小二乘法(GLS )3、加权最小二乘法(WLS )实例操作:1、 使用数据:use nerlove.dta,clear2、 reg intc inq inpl inpk inpf (进行回归)3、D e n s i t y4、 画残差图:rvfplot上图可以发现当拟合值较小时,扰动项方差较大,继续考察残差与解释变量inq 的散点图:rvpplot inq ,结果与上图几乎一致,可能存在异方差,即扰动项的方差随着观测值而变。
5、 完成回归后,进行怀特检验:estat imtest ,white_cons -3.566513 1.779383 -2.00 0.047 -7.084448 -.0485779inpf .4258137 .1003218 4.24 0.000 .2274721 .6241554inpk -.2151476 .3398295 -0.63 0.528 -.8870089 .4567136inpl .4559645 .299802 1.52 0.131 -.1367602 1.048689inq .7209135 .0174337 41.35 0.000 .6864462 .7553808intc Coef. Std. Err. t P>|t| [95% Conf. Interval]Total 291.066823 144 2.02129738 Root MSE = .39227Adj R-squared = 0.9239Residual 21.5420958 140 .153872113 R-squared = 0.9260Model 269.524728 4 67.3811819 Prob > F = 0.0000F( 4, 140) = 437.90Source SS df MS Number of obs = 145R e s i d u a l sWhite's test for Ho: homoskedasticityagainst Ha: unrestricted heteroskedasticitychi2(14) = 73.88Prob > chi2 = 0.0000Cameron & Trivedi's decomposition of IM-testSource chi2 df pHeteroskedasticity 73.88 14 0.0000Skewness 22.79 4 0.0001Kurtosis 2.62 1 0.1055Total 99.29 19 0.0000P值显著,认为存在异方差6、完成回归后,进行BP检验:estat hettest,iid estat hottest,rhs iid estat hottest inq,iidBreusch-Pagan / Cook-Weisberg test for heteroskedasticityHo: Constant varianceVariables: inq inpl inpk inpfchi2(4) = 36.16Prob > chi2 = 0.0000三种形式的检验都强烈拒绝同方差的原假设,存在异方差(这里只放一个形式的检验结果)7、处理异方差自相关:扰动项之间自相关自相关的例子:1、时间序列数据中通常具有某种连续性和持久性,如相邻两年的GDP增长率;2、截面数据中相邻的观测单位之间可能存在溢出效应,如相邻地区的农业产量收到类似天气变化的影响;3、对数据的人为处理如数据中包含移动平均数等;4、如果模型设定中遗漏了某个自相关的解释变量并被纳入到扰动项中,则会引起扰动项的自相关。
自相关的检验:1、画图(不推荐)2、BG检验estat bgodfrey 3、BOX-Pierce Q检验4、DW 检验estat dwatson. 检验都要在OLS做完后才能做。
自相关的处理:1、使用OLS+异方差自相关稳健的标准误;2、OLS+聚类稳健的标准误;3、使用可行广义最小二乘法(FGLS);4、修改模型设定自相关处理实例:1、使用数据icecream 然后进行回归. reg consumption temp price incomeSource SS df MS Number of obs = 30F( 3, 26) = 22.17Model .090250523 3 .030083508 Prob > F = 0.0000Residual .035272835 26 .001356647 R-squared = 0.7190Adj R-squared = 0.6866Total .125523358 29 .004328392 Root MSE = .03683consumption Coef. Std. Err. t P>|t| [95% Conf. Interval]temp .0034584 .0004455 7.76 0.000 .0025426 .0043743price -1.044413 .834357 -1.25 0.222 -2.759458 .6706322income .0033078 .0011714 2.82 0.009 .0008999 .0057156_cons .1973149 .2702161 0.73 0.472 -.3581223 .752752BG检验. estat bgodfreyBreusch-Godfrey LM test for autocorrelationlags(p) chi2 df Prob > chi21 4.237 1 0.0396H0: no serial correlation显著拒绝了原假设无自相关,则认为存在自相关Q检验(略)、DW检验如下. estat dwatsonDurbin-Watson d-statistic( 4, 30) = 1.021169DW=1.02 距离2很远可以认为存在自相关。
由以上的检验可以看出扰动项之间存在自相关,因此OLS提供的标准误是不准确的,应使用异方差自相关稳健标准误,由于样本为30个,n四分之一=2.34,故取NEWey-West估计量的滞后值为P=3,结果如下:. newey consumption temp price income,lag(3)Regression with Newey-West standard errors Number of obs = 30maximum lag: 3 F( 3, 26) = 27.63Prob > F = 0.0000Newey-Westconsumption Coef. Std. Err. t P>|t| [95% Conf. Interval]temp .0034584 .0004002 8.64 0.000 .0026357 .0042811price -1.044413 .9772494 -1.07 0.295 -3.053178 .9643518income .0033078 .0013278 2.49 0.019 .0005783 .0060372_cons .1973149 .3378109 0.58 0.564 -.4970655 .8916952上图显示标准误与OLS标准误无多大区别,因此将滞后阶数增加为6,. newey consumption temp price income,lag(6)Regression with Newey-West standard errors Number of obs = 30maximum lag: 6 F( 3, 26) = 52.97Prob > F = 0.0000Newey-Westconsumption Coef. Std. Err. t P>|t| [95% Conf. Interval]temp .0034584 .0003504 9.87 0.000 .0027382 .0041787price -1.044413 .9821798 -1.06 0.297 -3.063313 .9744864income .0033078 .00132 2.51 0.019 .0005945 .006021_cons .1973149 .3299533 0.60 0.555 -.4809139 .8755437从上图可以看到无论截断参数是3还是6,标准误都变化不大,比较稳健。