19决策树讲义与随机森林
决策树与随机森林

决策树与随机森林⼀、决策树决策树(decision tree)是⼀种基本的分类与回归⽅法,本篇主要讨论⽤于分类的决策树。
1.决策树模型分类决策树模型是⼀种描述对实例进⾏分类的树形结构。
决策树由结点(node)和有向边(directed edge)组成。
结点有两种类型:内部结点(internal node)和叶节点(leaf node)。
内部结点表⽰⼀个特征或属性,叶节点表⽰⼀个类。
下图为⼀个决策树的⽰意图,图中圆和⽅框分别表⽰内部结点和叶节点。
2.特征选择如何选择特征?即需要确定选择特征的准则。
如果⼀个特征具有更好的分类能⼒,或者说,按照这⼀特征将训练数据集分割成⼦集,使得各个⼦集在当前条件下有更好的分类,那么就更应该选择这个特征。
2.1 熵在信息论与概率统计中,熵(entropy)是表⽰随机变量不确定性的度量。
设X是⼀个有限的离散随机变量,其概率分布为P(X=x i)=p i,i=1,2,...,n则随机变量X的熵定义为H(X)=−n∑i=1p i log p i上式中,对数以2为底或以e为底。
如有0概率,定义0log0=0。
由定义可知,熵只依赖于X的分布,⽽与X的取值⽆关,所以也可将X的熵记作H(p),即H(p)=−n∑i=1p i log p i熵越⼤,随机变量的不确定性就越⼤。
2.2 条件熵条件熵(conditional entropy)H(Y|X)表⽰在已知随机变量X的条件下随机变量Y的不确定性。
设有随机变量(X,Y),其联合概率分布为P(X=x i,Y=y j)=p ij,i=1,2,...,n;j=1,2,...,m随机变量X给定的条件下随机变量Y的条件熵H(Y|X),定义为X给定条件下Y的条件概率分布的熵对X的数学期望H(Y|X)=n∑i=1p i H(Y|X=x i)当熵和条件熵中的概率由数据估计(特别是极⼤似然估计)得到时,所对应的熵与条件熵分别称为经验熵(empirical entropy)和经验条件熵(empirical conditional entropy)。
《决策树与随机森林》课件

交叉验证
使用交叉验证来评估模型的泛化能力,以避 免过拟合。
随机森林的参数调整
1 2
决策树数量
调整决策树的数量,以找到最优的模型性能。
特征子集大小
调整在每一步分裂中选择的特征子集大小,以找 到最优的模型性能。
3
决策树深度
调整决策树的深度限制,以防止过拟合或欠拟合 。
05
决策树与随机森林的应用场景
分类问题
THANKS
感谢观看
随机森林的优缺点
可解释性强
每棵决策树都可以单独解释,有助于理解模型的工作原理。
鲁棒
对异常值和噪声具有较强的鲁棒性。
随机森林的优缺点
对参数敏感
随机森林中的参数如树的数量、特征选择比例等对模型性能影响较大。
可能产生过拟合
当数据集较小或特征过多时,随机森林可能产生过拟合。
04
随机森林算法
随机森林的生成
决策树的基本原理
特征选择
选择最能划分数据集的特征进行分裂,以减少决 策树的深度和复杂度。
剪枝
通过去除部分分支来降低过拟合的风险,提高模 型的泛化能力。
决策规则
将每个叶子节点映射到一个类别或值,根据该节 点所属类别或值进行预测。
决策树的优缺点
优点
易于理解和解释,分类效果好,对异常值和缺失值容忍度高 。
在构建每棵决策树时,随 机选择一部分特征进行划 分,增加模型的泛化能力 。
多样性
通过生成多棵决策树,增 加模型的多样性,降低过 拟合的风险。
集成学习
将多棵决策树的预测结果 进行汇总,利用投票等方 式决定最终输出,提高分 类任务的准确率。
随机森林的优缺点
高效
能够处理大规模数据集,计算效率高 。
python实现决策树、随机森林的简单原理

python实现决策树、随机森林的简单原理本⽂申明:此⽂为学习记录过程,中间多处引⽤⼤师讲义和内容。
⼀、概念决策树(Decision Tree)是⼀种简单但是⼴泛使⽤的分类器。
通过训练数据构建决策树,可以⾼效的对未知的数据进⾏分类。
决策数有两⼤优点:1)决策树模型可以读性好,具有描述性,有助于⼈⼯分析;2)效率⾼,决策树只需要⼀次构建,反复使⽤,每⼀次预测的最⼤计算次数不超过决策树的深度。
看了⼀遍概念后,我们先从⼀个简单的案例开始,如下图我们样本:对于上⾯的样本数据,根据不同特征值我们最后是选择是否约会,我们先⾃定义的⼀个决策树,决策树如下图所⽰:对于上图中的决策树,有个疑问,就是为什么第⼀个选择是“长相”这个特征,我选择“收⼊”特征作为第⼀分类的标准可以嘛?下⾯我们就对构建决策树选择特征的问题进⾏讨论;在考虑之前我们要先了解⼀下相关的数学知识:信息熵:熵代表信息的不确定性,信息的不确定性越⼤,熵越⼤;⽐如“明天太阳从东⽅升起”这⼀句话代表的信息我们可以认为为0;因为太阳从东⽅升起是个特定的规律,我们可以把这个事件的信息熵约等于0;说⽩了,信息熵和事件发⽣的概率成反⽐:数学上把信息熵定义如下:H(X)=H(P1,P2,…,Pn)=-∑P(xi)logP(xi)互信息:指的是两个随机变量之间的关联程度,即给定⼀个随机变量后,另⼀个随机变量不确定性的削弱程度,因⽽互信息取值最⼩为0,意味着给定⼀个随机变量对确定⼀另⼀个随机变量没有关系,最⼤取值为随机变量的熵,意味着给定⼀个随机变量,能完全消除另⼀个随机变量的不确定性现在我们就把信息熵运⽤到决策树特征选择上,对于选择哪个特征我们按照这个规则进⾏“哪个特征能使信息的确定性最⼤我们就选择哪个特征”;⽐如上图的案例中;第⼀步:假设约会去或不去的的事件为Y,其信息熵为H(Y);第⼆步:假设给定特征的条件下,其条件信息熵分别为H(Y|长相),H(Y|收⼊),H(Y|⾝⾼)第三步:分别计算信息增益(互信息):G(Y,长相) = I(Y,长相) = H(Y)-H(Y|长相) 、G(Y,) = I(Y,长相) = H(Y)-H(Y|长相)等第四部:选择信息增益最⼤的特征作为分类特征;因为增益信息⼤的特征意味着给定这个特征,能很⼤的消除去约会还是不约会的不确定性;第五步:迭代选择特征即可;按以上就解决了决策树的分类特征选择问题,上⾯的这种⽅法就是ID3⽅法,当然还是别的⽅法如 C4.5;等;⼆、决策树的过拟合解决办法若决策树的度过深的话会出现过拟合现象,对于决策树的过拟合有⼆个⽅案:1.剪枝-先剪枝和后剪纸(可以在构建决策树的时候通过指定深度,每个叶⼦的样本数来达到剪枝的作⽤)2.随机森林 --构建⼤量的决策树组成森林来防⽌过拟合;虽然单个树可能存在过拟合,但通过⼴度的增加就会消除过拟合现象三、随机森林随机森林是⼀个最近⽐较⽕的算法,它有很多的优点:在数据集上表现良好在当前的很多数据集上,相对其他算法有着很⼤的优势它能够处理很⾼维度(feature很多)的数据,并且不⽤做特征选择在训练完后,它能够给出哪些feature⽐较重要训练速度快在训练过程中,能够检测到feature间的互相影响容易做成并⾏化⽅法实现⽐较简单随机森林顾名思义,是⽤随机的⽅式建⽴⼀个森林,森林⾥⾯有很多的决策树组成,随机森林的每⼀棵决策树之间是没有关联的。
决策树、支持向量机、logistic、随机森林分类模型的数学公式

决策树、支持向量机、logistic、随机森林分类模型的数学公式决策树(Decision Tree)是一种基于树状结构进行决策的分类和回归方法。
决策树的数学公式可以表示为:对于分类问题:f(x) = mode(Y), 当节点为叶子节点f(x) = f_left, 当 x 属于左子树f(x) = f_right, 当 x 属于右子树其中,mode(Y) 表示选择 Y 中出现最频繁的类别作为预测结果,f_left 和 f_right 分别表示左子树和右子树的预测结果。
对于回归问题:f(x) = Σ(y_i)/n, 当节点为叶子节点f(x) = f_left, 当 x 属于左子树f(x) = f_right, 当 x 属于右子树其中,Σ(y_i) 表示叶子节点中所有样本的输出值之和,n 表示叶子节点中样本的数量,f_left 和 f_right 分别表示左子树和右子树的预测结果。
支持向量机(Support Vector Machine,简称 SVM)是一种非概率的二分类模型,其数学公式可以表示为:对于线性可分问题:f(x) = sign(w^T x + b)其中,w 是超平面的法向量,b 是超平面的截距,sign 表示取符号函数。
对于线性不可分问题,可以使用核函数将输入空间映射到高维特征空间,公式变为:f(x) = sign(Σα_i y_i K(x_i, x) + b)其中,α_i 和 y_i 是支持向量机的参数,K(x_i, x) 表示核函数。
Logistic 回归是一种常用的分类模型,其数学公式可以表示为:P(Y=1|X) = 1 / (1 + exp(-w^T x))其中,P(Y=1|X) 表示给定输入 X 的条件下 Y=1 的概率,w 是模型的参数。
随机森林(Random Forest)是一种集成学习方法,由多个决策树组成。
对于分类问题,随机森林的数学公式可以表示为:f(x) = mode(Y_1, Y_2, ..., Y_n)其中,Y_1, Y_2, ..., Y_n 分别是每个决策树的预测结果,mode 表示选择出现最频繁的类别作为预测结果。
决策树培训讲义(PPT 49页)

Married 100K No
Single 70K
No
Married 120K No
Divorced 95K
Yes
Married 60K
No
Divorced 220K No
Single 85K
Yes
Married 75K
No
Single 90K
Yes
3. samples = { 2,3,5,6,8,9,10 } attribute_list = { MarSt, TaxInc }
选择TaxInc为最优分割属性:
Refund
Yes
No
NO < 80K
Single TaxInc
MarSt
Married Divorced
>= 80K
NO
YES
▪ 问题1:分类从哪个属性开始?
——选择分裂变量的标准
▪ 问题2:为什么工资以80为界限?
——找到被选择的变量的分裂点的标准( 连续变量情况)
分类划分的优劣用不纯性度量来分析。如果对于所有
分支,划分后选择相同分支的所有实例都属于相同的类,
则这个划分是纯的。对于节点m,令 N m 为到达节点m的训练
实例数,
个实例中
N
i m
个属于Ci
类,而
N
i m
Nm 。如果一
个实例到节点m,则它属于 类的概率估i 计为:
pˆ (Ci
|
x, m)
pmi
N
i m
10
Single 125K No
Married 100K No
Single 70K
No
Married 120K No
逻辑回归、决策树、随机森林模型

逻辑回归、决策树、随机森林模型文章标题:深入解析逻辑回归、决策树和随机森林模型一、引言在机器学习领域,逻辑回归、决策树和随机森林模型都是极具影响力和广泛应用的算法。
它们分别代表了线性分类模型、非线性分类模型和集成学习模型,对于解决分类问题具有重要意义。
本文将从简到繁,由浅入深地探讨这三种模型的原理、应用和优缺点,帮助读者更全面地理解和运用这些算法。
二、逻辑回归1. 原理逻辑回归是一种用于解决二分类问题的线性模型。
其原理是利用Sigmoid函数将线性方程的输出映射到0和1之间,从而进行分类预测。
2. 应用逻辑回归广泛应用于医学、金融和市场营销等领域,如疾病诊断、信用评分和客户流失预测。
3. 优缺点逻辑回归简单、易于理解和实现,但对于非线性问题表现不佳,且对特征间相关性敏感。
三、决策树1. 原理决策树是一种基于树结构的非线性分类模型,通过逐步划分特征空间来进行分类。
2. 应用决策树广泛应用于数据挖掘和模式识别领域,如用户行为分析和商品推荐系统。
3. 优缺点决策树能够处理非线性问题,易于解释和可视化,但容易过拟合和对噪声敏感。
四、随机森林模型1. 原理随机森林是一种基于集成学习的分类模型,通过随机选择特征和样本子集构建多个决策树,再进行投票或平均来进行分类。
2. 应用随机森林广泛应用于图像识别、文本分类和生物信息学等领域,如人脸识别和基因序列分类。
3. 优缺点随机森林能够处理高维数据和大规模数据集,具有很高的预测准确度,但模型训练时间较长。
五、总结和回顾逻辑回归、决策树和随机森林模型分别代表了线性分类、非线性分类和集成学习的算法。
它们在解决分类问题时各有优劣,需要根据具体问题选择合适的模型。
随机森林的集成学习思想对于提高模型的鲁棒性和准确度具有重要意义。
六、个人观点和理解在实际应用中,我更倾向于使用随机森林模型来解决分类问题。
因为随机森林能够处理高维数据和大规模数据集,具有较高的准确度和鲁棒性,而且能够有效降低过拟合的风险。
逻辑回归、决策树、随机森林模型

逻辑回归、决策树、随机森林模型摘要:1.逻辑回归模型a.简介b.原理c.应用场景2.决策树模型a.简介b.原理c.应用场景3.随机森林模型a.简介b.原理c.应用场景4.总结与比较a.优缺点比较b.适用场景分析c.我国在相关领域的研究现状与展望正文:一、逻辑回归模型逻辑回归是一种用于分类问题的线性模型,它使用逻辑函数(sigmoid 函数)将线性模型的输出映射到[0,1] 区间,从而实现二分类。
逻辑回归模型的主要目标是最小化负样本的损失函数。
它广泛应用于信用评分、文本分类、垃圾邮件过滤等领域。
二、决策树模型决策树是一种树形结构的分类与回归模型。
它通过递归地选择特征,将数据集分为不同的子集,最终得到一个叶子节点,表示分类结果或预测值。
决策树模型的构建过程包括特征选择、剪枝等步骤。
它适用于数据集具有明显特征划分和具有较高噪声的情况。
三、随机森林模型随机森林是一种集成学习方法,它由多个决策树组成。
在随机森林中,每个决策树在训练数据的一个随机子集上进行训练,从而形成一个森林。
随机森林模型的主要优点是具有较高的预测能力和泛化能力,能有效地处理过拟合问题。
它广泛应用于图像识别、生物信息学、金融风险管理等领域。
四、总结与比较逻辑回归、决策树和随机森林模型都是机器学习领域中常用的模型。
逻辑回归适用于二分类问题,其原理简单;决策树模型可以处理多分类问题,但其可解释性较差;随机森林模型具有较强的预测能力和泛化能力,但计算复杂度较高。
在实际应用中,我们需要根据问题的特点和需求来选择合适的模型。
近年来,我国在机器学习领域的研究取得了显著成果,包括上述模型在内。
但与国际先进水平相比,我国在理论研究、算法优化和实际应用等方面仍有一定差距。
随机森林课件

23/33
2019/3/13
随机森林的生成
一开始提到的随机森林中的“随机”就是指的a和b中的两个随机 性。两个随机性的引入对随机森林的分类性能至关重要。由于它们的 引入,使得随机森林不容易陷入过拟合,并且具有很好得抗噪能力( 比如:对缺省值不敏感)。 为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树 分类结果也是完全一样的,这样的话完全没有集成的必要;
优点:
1.两个随机性的引入,使得随机森林不容易陷入过拟合; 2.两个随机性的引入,使得随机森林具有很好的抗噪声能力; 3.对数据集的适应能力强:既能处理离散型数据,也能处理连续型 数据,数据集无需规范化且能够有效地运行在大数据集上; 4.能够处理具有高维特征的输入样本,而且不需要降维; 5.在生成过程中,能够获取到内部生成误差的一种无偏估计;
9/33
2019/3/13
决策树
Claude Shannon 定义了熵和信息增益。 用熵来表示信息 的复杂度,熵越大,则信息越复杂。公式如下:
信息增益,表示两个信息熵的差值。信息增益在决策树算法中是 用来选择特征的指标,信息增益越大,则这个特征的选择性越好。
10/33
2019/3/13
决策树
首先计算未分类前的熵,总共有8位同学,男生3位,女生5位。
随机森林的简单实例分析
描述:
根据已有的训练集已经生成了对应的随机森林,随机森林如何利用某一 个人的年龄(Age)、性别(Gender)、教育情况(Highest Educational Qualification)、工作领域(Industry)以及住宅地( Residence)共5个字段来预测他的收入层次。
集成学习
随机森林.ppt

两个重要的代码
randomForest
主要参数是ntree,mtry
Predict
第一步,随机森林的安装
随机森林是基于R语言运行,安装过程分两步: 1.ubuntu系统下首先安装R语言包。
用一行代码。 sudo apt-get install R 然后ubuntu系统就自动的帮你安装完R。 2.安装random forest 意想不到的简单。 打开终端 ,输入R,就算进入到了R语言的编码界面。 在大于号后面入
决策树的定义
Hale Waihona Puke 决策树是这样的一颗树:每个内部节点上选用一个属性进行分割 每个分叉对应一个属性值 每个叶子结点代表一个分类
A1
a11 A2
a12 c1
a21
a22
c1
c2
a13
A3
a31
a32
c2
c1
决策树框架
决策树生成算法分成两个步骤
树的生成
开始,数据都在根节点 递归的进行数据分片
0,mtry=3,proximity=TRUE,importance=TRUE) print(iris.rf) iris.pred<-predict( iris.rf,iris[ind==2,] ) table(observed=iris[ind==2,"Species"],predicted=iris.pred )
随机森林的特点
两个随机性的引入,使得随机森林不容易陷入过 拟合
两个随机性的引入,使得随机森林具有很好的抗 噪声能力
对数据集的适应能力强:既能处理离散型数据, 也能处理连续型数据,数据集无需规范化。
《随机森林简介》PPT课件

• 可以得到变量重要性排序(两种:基于OOB误分 率的增加量和基于分裂时的GINI下降量)
主要参考文献
1. J.R. Quinlan. Induction of Decision Trees[J].Machine learning 1986,1:81-106.
基尼指数——Gini index (Classification and Regression Tress,CART,Breiman,1984) • 能够适用于离散和连续值字段
信息增益
• 任意样本分类的期望信息:
– I(s1,s2,……,sm)=-∑Pi log2(pi) (i=1..m)
• 其中,数据集为S,m为S的分类数目, Pi≈|Si/|S|
2. S.L. Salzberg.Book Review:C4.5 Programs for Machine Learning by J.Ross Quinlan[J]. Machine Learning,1994,3:235-240.
3. L.Breiman, J.Friedman,al.et. Classification and Regression Trees[M]. New York: Chapman & Hall,1984.
– 树的生成
• 开始,数据都在根节点 • 递归的进行数据分片
– 树的剪枝
• 防止过拟合
• 决策树使用: 对未知数据进行分割
– 按照决策树上采用的分割属性量
原则:分类效果最好的(或分类最纯的, 或能使树的路径最短)的属性
最新19决策树与随机森林

I(X,Y)= H(X) + H(Y) - H(X,Y) 有些文献将该式作为互信息的定义式
试证明:H(X|Y) ≤H(X) ,H(Y|X) ≤H(Y)
11
强大的Venn图:帮助记忆
12
决策树示意图
决策树的生成过程
26
决策树的生成过程
27
决策树的生成过程
28
决策树的生成过程
29
决策树的生成过程
30
决策树的生成过程
31
决策树的生成过程
32
决策树的生成过程
ID3 C4.5 CART
16
信息增益
概念:当熵和条件熵中的概率由数据估计(特别是 极大似然估计)得到时,所对应的熵和条件熵分别 称为经验熵和经验条件熵。
信息增益表示得知特征A的信息而使得类X的信息 的不确定性减少的程度。
定义:特征A对训练数据集D的信息增益g(D,A), 定义为集合D的经验熵H(D)与特征A给定条件下D 的经验条件熵H(D|A)之差,即:
p(x) p( y)
x
y
p ( x , y ) log
p ( x ) p ( x , y ) log
x,y
p(x, y) p(x) p( y)
p ( x , y ) log p ( x ) p ( x , y ) log p ( x , y )
x,y
x,y
p(x) p( y)
p ( x , y ) log p ( x , y )
19决策树与随机森林
目标任务与主要内容
复习信息熵
熵、联合熵、条件熵、互信息
决策树与随机森林算法

决策树与随机森林算法决策树决策树模型是⼀种树形结构,基于特征对实例进⾏分类或回归的过程。
即根据某个特征把数据分划分到若⼲个⼦区域(⼦树),再对⼦区域递归划分,直到满⾜某个条件则停⽌划分并作为叶⼦节点,不满⾜条件则继续递归划分。
⼀个简单的决策树分类模型:红⾊框出的是特征。
决策树模型学习过程通常包3个步骤:特征选择、决策树的⽣成、决策树的修剪。
1.特征选择选择特征顺序的不同将会产⽣不同决策树,选择好的特征能使得各个⼦集下标签更纯净。
度量特征对产⽣⼦集的好坏有若⼲⽅法,如误差率,信息增益、信息增益⽐和基尼指数等。
1.1误差率训练数据D被特征A分在若⼲⼦结点后,选择⼦节点中出现数⽬最多的类标签作为此结点的返回值,记为yc^。
则误差率定义为1|D|∑i=1|Dc|I{yi≠yc}1.2信息增益熵与条件熵:熵表⽰随机变量不确定性的度量。
设计随机变量X为有限离散随机变量,且pi=P(X=xi)。
熵的定义为H(X)=?∑ni=1pilog(pi)。
熵越⼤,随机变量的不确定性就越⼤,当X取某个离散值时概率为1时,则对应的熵H(X)为0,表⽰随机变量没有不确定性。
条件熵:表⽰已知随机变量X的条件下随机变量Y的不确定性,定义H(Y|X)=∑ni=1piH(Y|X=xi),其中pi=P(X=xi)。
这⾥X表⽰某个特征,即表⽰根据某个特征划分后,数据Y的熵。
如果某个特征有更强的分类能⼒,则条件熵H(Y|X)越⼩,表⽰不确定性越⼩。
信息增益:特征A对训练数据集D的信息增益定义为g(D,A)=H(D)-H(D|A).即有特征值A使得数据D的不确定性下降的程度。
所以信息增益越⼤,表明特征具有更强的分类能⼒。
1.3信息增益⽐信息增益⽐也是度量特征分类能⼒的⽅法。
定义训练数据D关于特征A的值的熵HA(D)=?∑ni=1|Di||D|log2(|Di||D|),|D|表⽰训练数据的总数,|Di|表⽰训练数据D中特征A取第i个值的总数⽬。
第十章 决策树与随机森林

,即变量
| 表示在已知分组 的
=1
中第组的样本量与总样本量的商;
=
=1
2
对应的经验概率为
2
情况下,变量取第种值的条件
基尼指数,其中
表示分组
内变量取第种值的频率。
决策树节点字段的选择
02
基尼指数
2
3
2
−本科 =
的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的
分类。这样的机器学习就被称之为监督学习。
常用算法:ID3, C4.5, CART等。
01 决策树的算法原理
目
02 决策树节点字段的选择
录
03 决策树的剪枝技术
04 随机森林的思想解读
05 模型的评估方法
06 决策树与随机森林的应用实战
_ =
其中, 为事件的信息熵。事件的取值越多, 可能越大,但同时
也会越大,这样以商的形式就实现了 的惩罚。
02
决策树节点字段的选择
信息增益率
各自变量的信息熵:
= −
5
5
4
4
5
5
2
− 2
− 2
的用户有9个,没有购买的用户有5个,所以对于是否购买这个事件来说,它的
经验信息熵为:
= −
9
9
5
5
2
−
2
= 0.940
14
14 14
14
02
决策树节点字段的选择
02
信息增益
条件熵: |A = |
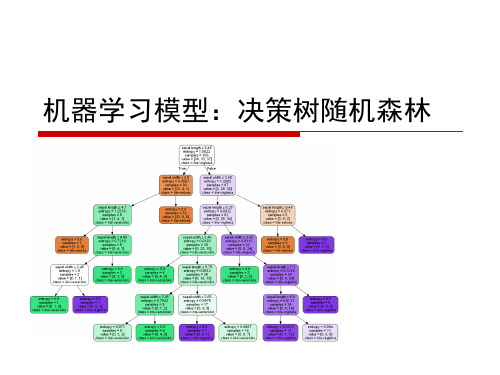
2.2.机器学习模型:决策树随机森林ok
(n) = (n −1)!
给定方差的最大熵分布
建立目标函数
arg max H (X ) = − p(x)ln p(x)
p(x)
x
E(X ) =
s.t.
Var
(
X
)
=
2
使用方差公式化简约束条件
Var(X ) = E(X 2 )− E2(X )
( ) E X 2 = E2(X )+Var(X ) = 2 + 2
p(x,
y)log
p(x,
y
)
=
−
x
y
p(x,
y)
log
p(x)
+
−
y
x
p(x,
y)
log
p( y )
+
x,y
p(x,
y)log
p(x,
y)
= − p(x, y)log p(x)− p(x, y)log p(y)+ p(x, y)log p(x, y)
x,y
x, y
x,y
= p(x, y)(log p(x, y)− log p(x)− log p(y))
x
=
−
x
p(x)ln
p(x)+
1 x
xp (x ) −
+
2 x
x2
p(x)−
2
−
2
L p
=
− ln
p(x)−1+
1x
+
2 x2
==0
ln
p(x)
=
2 x2
+
1x
−1
P(x)的对数是关于随机变量x的二次形式,所以,该 分布p(x)必然是正态分布!
【高等教育】机器学习与算法分析:决策树和随机森林实验

实例:建立决策树模型并评估
# 建立决策树模型 model = DecisionTree.trainClassifier(trainData,
numClasses=3, # 类别的数目 categoricalFeaturesInfo={}, # 提前指定类别变量,如{n:k}表示第n个变量为标称变量,共k个值 impurity='gini', # 信息增益计算方法,可选香浓熵与基尼不纯度,默认基尼不纯度 maxDepth=5, # 树最大深度 maxBins=32, # 特征切割区间箱化个数 minInstancesPerNode=1, # 当节点中包含样本量小于这个值,则该节点不会再被划分 minInfoGain=0.0 # 当节点的信息增益小于这个值,则该节点不会再被划分 )
决策树的主要优点
1.简单直观,生成的决策树很直观。 2.基本不需要预处理,不需要提前归一化,处理缺失值。 3.使用决策树预测的代价是O(log2m)O(log2m)。 m为样本数。 4.既可以处理离散值也可以处理连续值。很多算法只是专注于离散值或者 连续值。 5.可以处理多维度输出的分类问题。 6.相比于神经网络之类的黑盒分类模型,决策树在逻辑上可以得到很好的 解释 7.可以交叉验证的剪枝来选择模型,从而提高泛化能力。 8.对于异常点的容错能力好,健壮性高。
实例: 初始化spark,数据处理划分
# -*-coding:utf-8-*from pyspark import SparkConf, SparkContext from pyspark.mllib.evaluation import MulticlassMetrics from pyspark.mllib.tree import DecisionTree, RandomForest from pyspark.mllib.regression import LabeledPoint # 初始化sparkContext conf = SparkConf().setMaster("local").setAppName("My Demo") sc = SparkContext(conf=conf) # 读取数据 wine_rdd = sc.textFile(u"file:/root/Documents/liangdong/work/laboratory/wine数据集.txt").map(
【学习笔记】分类算法-决策树、随机森林

【学习笔记】分类算法-决策树、随机森林⽬录决策树是⼀种基本的分类⽅法,当然也可以⽤于回归。
我们⼀般只讨论⽤于分类的决策树。
决策树模型呈树形结构。
在分类问题中,表⽰基于特征对实例进⾏分类的过程,它可以认为是if-then规则的集合。
在决策树的结构中,每⼀个实例都被⼀条路径或者⼀条规则所覆盖。
通常决策树学习包括三个步骤:特征选择、决策树的⽣成和决策树的修剪。
特征选择特征选择在于选取对训练数据具有分类能⼒的特征。
这样可以提⾼决策树学习的效率,如果利⽤⼀个特征进⾏分类的结果与随机分类的结果没有很⼤差别,则称这个特征是没有分类能⼒的。
经验上扔掉这样的特征对决策树学习的影响不⼤。
通常特征选择的准则是信息增益,这是个数学概念。
通过⼀个例⼦来了解特征选择的过程。
类别ID年龄有⼯作信贷情况类别有⼯作有⾃⼰的房⼦有⾃⼰的房⼦信贷情况1青年否否⼀般否2青年否否好否3青年是否好是4青年是是⼀般是5青年否否⼀般否6中年否否⼀般否7中年否否好否8中年是是好是9中年否是⾮常好是10中年否是⾮常好是11⽼年否是⾮常好是12⽼年否是好是13⽼年是否好是14⽼年是否⾮常好是15⽼年否否⼀般否我们希望通过所给的训练数据学习⼀个贷款申请的决策树,⽤以对⽂中的贷款申请进⾏分类,即当新的客户提出贷款申请时,根据申请⼈的特征利⽤决策树决定是否批准贷款申请。
特征选择其实是决定⽤那个特征来划分特征空间。
下图中分别是按照年龄,还有是否有⼯作来划分得到不同的⼦节点。
问题是究竟选择哪个特征更好些呢?那么直观上,如果⼀个特征具有更好的分类能⼒,是的各个⾃⼰在当前的条件下有最好的分类,那么就更应该选择这个特征。
信息增益就能很好的表⽰这⼀直观的准则。
这样得到的⼀棵决策树只⽤了两个特征就进⾏了判断:通过信息增益⽣成的决策树结构,更加明显、快速的划分类别。
信息的度量和作⽤我们常说信息有⽤,那么它的作⽤如何客观、定量地体现出来呢?信息⽤途的背后是否有理论基础呢?这个问题⼀直没有很好的回答,直到1948年,⾹农在他的论⽂“通信的数学原理”中提到了“信息熵”的概念,才解决了信息的度量问题,并量化出信息的作⽤。
认真的聊一聊决策树和随机森林

认真的聊一聊决策树和随机森林随机森林是一种简单又实用的机器学习集成算法。
“随机“表示2种随机性,即每棵树的训练样本、训练特征随机选取。
多棵决策树组成了一片“森林”,计算时由每棵树投票或取均值的方式来决定最终结果,体现了三个臭皮匠顶个诸葛亮的中国传统民间智慧。
那我们该如何理解决策树和这种集成思想呢?01 决策树以分类任务为代表的决策树模型,是一种对样本特征构建不同分支的树形结构。
决策树由节点和有向边组成,其中节点包括内部节点(圆)和叶节点(方框)。
内部节点表示一个特征或属性,叶节点表示一个具体类别。
预测时,从最顶端的根节点开始向下搜索,直到某一个叶子节点结束。
下图的红线代表了一条搜索路线,决策树最终输出类别C。
决策树的特征选择假如有为青年张三想创业,但是摸摸口袋空空如也,只好去银行贷款。
银行会综合考量多个因素来决定张三是不是一个骗子,是否给他放贷。
例如,可以考虑的因素有性别、年龄、工作、是否有房、信用情况、婚姻状况等等。
这么多因素,哪些是重要的呢?这就是特征选择的工作。
特征选择可以判别出哪些特征最具有区分力度(例如“信用情况”),哪些特征可以忽略(例如“性别”)。
特征选择是构造决策树的理论依据。
不同的特征选择,生成了不同的决策树。
决策树的特征选择一般有3种量化方法:信息增益、信息增益率、基尼指数。
信息增益在信息论中,熵表示随机变量不确定性的度量。
假设随机变量X有有限个取值,取值对应的概率为,则X的熵定义为:如果某件事一定发生(太阳东升西落)或一定不发生(钓鱼岛是日本的),则概率为1或0,对应的熵均为0。
如果某件事可能发生可能不发生(天要下雨,娘要嫁人),概率介于0到1之间,熵大于0。
由此可见,熵越大,随机性越大,结果越不确定。
我们再来看一看条件熵,表示引入随机变量Y对于消除X不确定性的程度。
假如X、Y相互独立,则X的条件熵和熵有相同的值;否则条件熵一定小于熵。
明确了这两个概念,理解信息增益就比较方便了。
随机森林决策树概念总结(updated)

随机森林决策树概念总结(updated)随机森林和决策树常问概念总结,⽬的是针对⾯试,答案或许不完善甚⾄有错误的地⽅,需要不断updated。
1. 随机森林是什么?随机森林是⼀种集成学习组合分类算法,属于bagging算法。
集成学习的核⼼思想:将若⼲个分类器组合起来,得到⼀个分类性能显著优越的分类器。
随机森林强调两个⽅⾯:随机+森林。
随机是指抽样⽅法随机,森林是指由很多决策树构成。
2. 随机森林⽣成⽅法/构造过程是什么?a. 通过随机⾏采样,有放回的重采样。
(重采样⽅法,有放回的采样。
使⽤局部样本,⽽不是全部的样本。
要是采样使⽤全部的样本,那么就忽略了局部样本的规律,降低了模型的鲁棒性)b. 通过随机列采样,得到k个特征。
(不是全部特征,避免过拟合)c. 重复以上m次,得到m颗树。
m个结果采取投票的机制。
(bagging的策略)3. 随机森林的优点?a.可以处理⾼纬度数据,并且数据可以不做特征选择,数据集可以不做规范化处理。
b.⾏、列随机抽样的⽅法引⼊,降低了过拟合以及增强了抗噪声能⼒。
c.训练速度⽐较快,可以做并⾏化计算。
d.擅长处理特征缺失数据和不平衡数据。
e.在创建随机森林的时候,对泛化误差使⽤⽆偏差模型,泛化能⼒强。
4. 随机森林的缺点?a.可能出现相似的决策树和分类能⼒不强的树。
b.对⼩数据集或者维度低的数据集,不能产⽣很好的分类。
c.模型可解释性不好,要是树深度很⼤的话。
d.解决回归问题没有分类问题好,它不能给出⼀个连续输出,同时也不能预测超过数据集范围的预测。
5.随机森林为什么泛化能⼒⽐较好?随机森林的泛化能⼒与单个决策树的分类强度s成正相关,与决策树之间的相关性p成负相关。
也就是说决策树分类强度越⼤,相关性越⼩的话,模型的泛化能⼒越强,泛化误差越⼩。
⽽随机森林的随机抽样(⾏、列抽样)保证了决策树之间的相关性p较⼩,如果每个决策树分类能⼒都很强的话,那么泛化误差就会到收敛到⼀个很⼩的边界,边界越⼩,泛化误差越⼩,泛化能⼒也越好。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
x,y
p(x)p(y)
9
计算H(X)-I(X,Y)
H (X ) I(X ,Y )
p ( x ) log p ( x ) p ( x , y ) log p ( x , y )
x
x,y
p(x) p( y)
x
y
p ( x , y ) log
p ( x ) p ( x , y ) log
3
复习:熵
将离散随机变量X的概率分布为P(X=xi),则定义熵
为:
HXx Xpxlogp1x
若P为连续随机变量,则概率分布变成概率密度函 数,求和符号变成积分符号。
在不引起混淆的情况下,下面谈到的“概率分布函 数”,其含义是:
1、若X为离散随机变量,则该名称为概率分布函数; 2、若X为连续随机变量,则该名称为概率密度函数。
一般的,D(p||q) ≠D(q||p) D(p||q)≥0、 D(q||p) ≥0 提示:凸函数中的Jensen不等式
8
互信息
两个随机变量X,Y的互信息,定义为X,Y 的联合分布和独立分布乘积的相对熵。
I(X,Y)=D(P(X,Y) || P(X)P(Y))
I(X,Y) p(x,y)logp(x,y)
4
对熵的理解
熵是随机变量不确定性的度量,不确定性越 大,熵值越大;若随机变量退化成定值,熵 为0
均匀分布是“最不确定”的分布
熵其实定义了一个函数(概率分布函数)到一 个值(信息熵)的映射。
P(x)H (函数数值) 泛函
回忆一下关于“变分推导”章节中对于泛函的内容。
5
联合熵和条件熵
两个随机变量X,Y的联合分布,可以形成 联合熵Joint Entropy,用H(X,Y)表示
H(X,Y) – H(Y)
(X,Y)发生所包含的信息熵,减去Y单独发生包 含的信息熵——在Y发生的前提下,X发生“新” 带来的信息熵
该式子定义为Y发生前提下,X的熵:
条件熵H(X|Y) = H(X,Y) – H(Y)
6
推导条件熵的定义式
H ( X ,Y ) H (Y )
p ( x , y ) log p ( x , y ) p ( y ) log p ( y )
信息增益表示得知特征A的信息而使得类X的信息 的不确定性减少的程度。
定义:特征A对训练数据集D的信息增益g(D,A), 定义为集合D的经验熵H(D)与特征A给定条件下D 的经验条件熵H(D|A)之差,即:
x,y
p(y)
p ( x , y ) log p ( x | y )
x,y
7
相对熵
相对熵,又称互熵,交叉熵,鉴别信息,Kullback 熵,Kullback-Leible散度等
设p(x)、q(x)是X中取值的两个概率分布,则p对q的 相对熵是
说明:
相对熵可以度量两个随机变量的“距离” 在“贝叶斯网络”、“变分推导”章节使用过
19决策树与随机森林
精品jin
目标任务与主要内容
复习信息熵
熵、联合熵、条件熵、互信息
决策树学习算法
信息增益 ID3、C4.5、CART
Bagging与随机森林的思想
投票机制
分类算法的评价指标
ROC曲线和AUC值
2
决策树的实例(Weka自带测试数据)
注:Weka的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),是一款免费的,非 商业化(与之对应的是SPSS公司商业数据挖掘产品-Clementine )的,基于JAVA环境下开源的机器学习 (machine learning)以及数据挖掘(data minining)软件。它 和它的源代码可在其官方网站下载。
I(X,Y)= H(X) + H(Y) - H(X,Y) 有些文献将该式作为互信息的定义式
试证明:H(X|Y) ≤H(X) ,H(Y|X) ≤H(Y)
11
强大的Venn图:帮助记忆
12
决策树示意图
13
决策树 (Decision Tree)
决策树是一种树型结构,其中每个内部结点 表示在一个属性上的测试,每个分支代表一 个测试输出,每个叶结点代表一种类别。
x,y
H (X |Y )
10
整理得到的等式
H(X|Y) = H(X,Y) - H(Y) 条件熵定义
H(X|Y) = H(X) - I(X,Y) 根据互信息定义展开得到 有些文献将I(X,Y)=H(Y) – H(Y|X)作为互信息的定义式
对偶式 H(Y|X)= H(X,Y) - H(X) H(Y|X)= H(Y) - I(X,Y)
x,y
p(x, y) p(x) p( y)
p ( x , y ) log p ( x ) p ( x , y ) log p ( x , y )
x,y
x,y
p(x) p( y)
p ( x , y ) log p ( x , y )
x,y
p(y)
p ( x , y ) log p ( x | y )
决策树学习是以实例为基础的归纳学习。 决策树学习采用的是自顶向下的递归方法,
其基本思想是以信息熵为度量构造一棵熵值 下降最快的树,到叶子节点处的熵值为零, 此时每个叶节点中的实例都属于同一类。14Fra bibliotek策树学习算法的特点
决策树学习算法的最大优点是,它可以自学 习。在学习的过程中,不需要使用者了解过 多背景知识,只需要对训练实例进行较好的 标注,就能够进行学习。
显然,属于有监督学习。 从一类无序、无规则的事物(概念)中推理出决策
树表示的分类规则。
15
决策树学习的生成算法
建立决策树的关键,即在当前状态下选择哪 个属性作为分类依据。根据不同的目标函数, 建立决策树主要有一下三种算法。
ID3 C4.5 CART
16
信息增益
概念:当熵和条件熵中的概率由数据估计(特别是 极大似然估计)得到时,所对应的熵和条件熵分别 称为经验熵和经验条件熵。
x,y
y
p ( x , y ) log p ( x , y ) p ( x , y ) log p ( y )
x,y
y x
p ( x , y ) log p ( x , y ) p ( x , y ) log p ( y )
x,y
x,y
p ( x , y ) log p ( x , y )