第11章 多重线性回归分析思考与练习参考答案
多元线性回归模型习题与答案

第三章多元线性回归模型习题与答案1、极大似然估计法的基本思想2、多元线性回归模型的基本假设是什么?试说明在证明最小二乘估计量的无偏性和有效性的过程中,哪些基本假设起了作用?3、以企业研发支出(R&D)占销售额的比重为被解释变量(Y),以企业销售额(X1)与利润占销售额的比重(X2)为解释变量,一个有32容量的样本企业的估计结果如下:099 .0)046.0()22.0()37.1(05.0)log(32.0472.022 1=++ =RX XY其中括号中为系数估计值的标准差。
(1)解释log(X1)的系数。
如果X1增加10%,估计Y会变化多少个百分点?这在经济上是一个很大的影响吗?(2)针对R&D强度随销售额的增加而提高这一备择假设,检验它不虽X1而变化的假设。
分别在5%和10%的显著性水平上进行这个检验。
(3)利润占销售额的比重X2对R&D强度Y是否在统计上有显著的影响?4、1960-1982年美国对子鸡的需求。
为了研究美国每人的子鸡消费量,我们提供如下的数据:表1 1960-1982年子鸡的消费情况年份Y X2 X3 X4 X5 X61960 27.8 397.5 42.2 50.7 78.3 65.8 1961 29.9 413.3 38.1 52.0 79.2 66.9 1962 29.8 439.2 40.3 54.0 79.2 67.8 1963 30.8 459.7 39.5 55.3 79.2 69.6 1964 31.2 92.9 37.3 54.7 77.4 68.7 1965 33.3 528.6 38.1 63.7 80.2 73.6 1966 35.6 560.3 39.3 69.8 80.4 76.3 1967 36.4 624.6 37.8 65.9 83.9 77.2 1968 36.7 666.4 38.4 64.5 85.5 78.1 1969 38.4 717.8 40.1 70.0 93.7 84.7 1970 40.4 768.2 38.6 73.2 106.1 93.3 1971 40.3 843.3 39.8 67.8 104.8 89.7 1972 41.8 911.6 39.7 79.1 114.0 100.7 1973 40.4 931.1 52.1 85.4 124.1 113.5 1974 40.7 1021.5 48.9 94.2 127.6 115.3 1975 40.1 1165.9 58.3 123.5 142.9 136.7 1976 42.7 1349.6 57.9 129.9 143.6 139.2 1977 44.1 1449.4 56.5 117.6 139.2 132.0 1978 46.7 1575.5 63.7 130.9 165.5 132.1 1979 50.6 1759.1 61.6 129.8 203.3 154.4 1980 350.1 1994.2 58.9 128.0 219.6 174.91981 51.7 2258.1 66.4 141.0 221.6 180.8 198252.92478.770.4168.2232.6189.4资料来源:Y 数据来自城市数据库;X 数据来自美国农业部。
(完整版)多元线性回归模型习题及答案

多元线性回归模型一、单项选择题1.在由30n =的一组样本估计的、包含3个解释变量的线性回归模型中,计算得多重决定系数为0.8500,则调整后的多重决定系数为( D )A. 0.8603B. 0.8389C. 0.8655D.0.8327 2.下列样本模型中,哪一个模型通常是无效的(B ) A.iC (消费)=500+0.8iI (收入)B. di Q (商品需求)=10+0.8i I (收入)+0.9i P (价格) C. si Q (商品供给)=20+0.75i P (价格)D. iY (产出量)=0.650.6i L (劳动)0.4i K (资本)3.用一组有30个观测值的样本估计模型01122t t t ty b b x b x u =+++后,在0.05的显著性水平上对1b 的显著性作t 检验,则1b 显著地不等于零的条件是其统计量t 大于等于( C )A.)30(05.0t B.)28(025.0t C.)27(025.0t D.)28,1(025.0F4.模型tt t u x b b y ++=ln ln ln 10中,1b 的实际含义是( B )A.x 关于y 的弹性B. y 关于x 的弹性C. x 关于y 的边际倾向D. y 关于x 的边际倾向5、在多元线性回归模型中,若某个解释变量对其余解释变量的判定系数接近于1,则表明模型中存在( C )A.异方差性B.序列相关C.多重共线性D.高拟合优度6.线性回归模型01122......t t t k kt t y b b x b x b x u =+++++ 中,检验0:0(0,1,2,...)t H b i k ==时,所用的统计量服从( C )A.t(n-k+1)B.t(n-k-2)C.t(n-k-1)D.t(n-k+2)7. 调整的判定系数 与多重判定系数之间有如下关系( D )A.2211n R R n k -=-- B. 22111n R R n k -=---C. 2211(1)1n R R n k -=-+-- D. 2211(1)1n R R n k -=----8.关于经济计量模型进行预测出现误差的原因,正确的说法是( C )。
回归思考与练习参考答案

第18章Logistic回归思考与练习参考答案一、最佳选择题1. Logistic回归与多重线性回归比较,( A )。
A.logistic回归的因变量为二分类变量B.多重线性回归的因变量为二分类变量C.logistic回归和多重线性回归的因变量都可为二分类变量D.logistic回归的自变量必须是二分类变量E.多重线性回归的自变量必须是二分类变量2. Logistic回归适用于因变量为( E )。
A.二分类变量B.多分类有序变量C.多分类无序变量D.连续型定量变量E.A、B、C均可3. Logistic回归系数与优势比OR的关系为( E )。
A.0等价于OR>1 B.0等价于OR<1 C.=0等价于OR=1 D.<0等价于OR<1 E.A、C、D均正确4. Logistic回归可用于( E )。
A.影响因素分析B.校正混杂因素C.预测D.仅有A和C E.A、B、C均可5. Logistic回归中自变量如为多分类变量,宜将其按哑变量处理,与其他变量进行变量筛选时可用( D )。
A.软件自动筛选的前进法B.软件自动筛选的后退法C.软件自动筛选的逐步法D.应将几个哑变量作为一个因素,整体进出回归方程E.A、B、C均可二、思考题1. 为研究低龄青少年吸烟的外在因素,研究者采用整群抽样,在某中心城区和远城区的初中学校,各选择初一年级一个班的全部学生进行调查,并用logistic回归方程筛选影响因素。
试问上述问题采用logistic回归是否妥当?答:上述问题采用logistic回归不妥当,因为logistic回归中参数的极大似然估计要求样本结局事件相互独立,而研究的问题中低龄青少年吸烟行为不独立。
2. 分类变量赋值不同对logistic回归有何影响? 分析结果一致吗?答:(1)若因变量交换赋值,两个logistic回归方程的参数估计绝对值相等,符号相反;优势比互为倒数,含义有所区别,实质意义一样;模型拟合检验与回归系数的假设检验结果相同。
回归分析练习题及参考答案
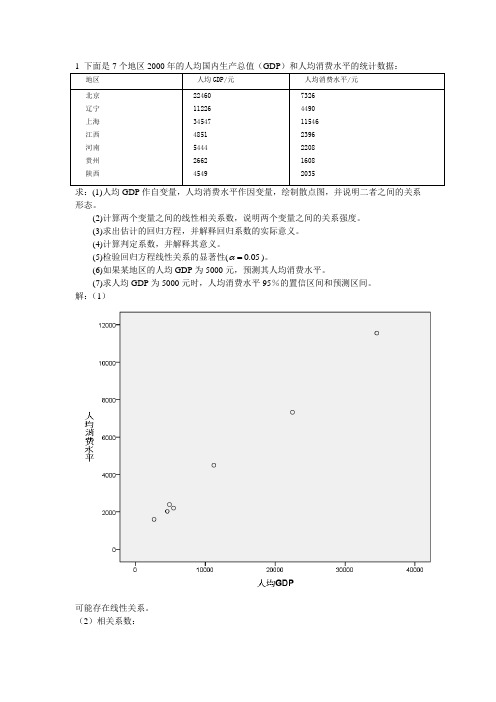
求:(1)人均GDP 作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(0.05α=)。
(6)如果某地区的人均GDP 为5000元,预测其人均消费水平。
(7)求人均GDP 为5000元时,人均消费水平95%的置信区间和预测区间。
解:(1)可能存在线性关系。
(2)相关系数:(3)回归方程:734.6930.309y x=+回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型非标准化系数标准化系数t 显著性B 标准误Beta1 (常量)734.693 139.540 5.265 0.003人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%人均GDP对人均消费的影响达到99.6%。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
模型摘要模型R R 方调整的R 方估计的标准差1 .998(a) 0.996 0.996 247.303a. 预测变量:(常量), 人均GDP(元)。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(5)F 检验:回归系数的检验:t 检验注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型 非标准化系数标准化系数t 显著性B 标准误 Beta1(常量) 734.693 139.540 5.2650.003 人均GDP (元)0.3090.0080.99836.4920.000a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(6)某地区的人均GDP 为5000元,预测其人均消费水平为 734.6930.30950002278.693y =+⨯=(元)。
《应用回归分析》课后题答案解析

《应用回归分析》部分课后习题答案第一章回归分析概述1.1 变量间统计关系和函数关系的区别是什么?答:变量间的统计关系是指变量间具有密切关联而又不能由某一个或某一些变量唯一确定另外一个变量的关系,而变量间的函数关系是指由一个变量唯一确定另外一个变量的确定关系。
1.2 回归分析与相关分析的联系与区别是什么?答:联系有回归分析和相关分析都是研究变量间关系的统计学课题。
区别有 a.在回归分析中,变量y称为因变量,处在被解释的特殊地位。
在相关分析中,变量x和变量y处于平等的地位,即研究变量y与变量x的密切程度与研究变量x与变量y的密切程度是一回事。
b.相关分析中所涉及的变量y与变量x全是随机变量。
而在回归分析中,因变量y是随机变量,自变量x可以是随机变量也可以是非随机的确定变量。
C.相关分析的研究主要是为了刻画两类变量间线性相关的密切程度。
而回归分析不仅可以揭示变量x对变量y的影响大小,还可以由回归方程进行预测和控制。
1.3 回归模型中随机误差项ε的意义是什么?答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y与x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
1.4 线性回归模型的基本假设是什么?答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值xi1.xi2…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.1.5 回归变量的设置理论根据是什么?在回归变量设置时应注意哪些问题?答:理论判断某个变量应该作为解释变量,即便是不显著的,如果理论上无法判断那么可以采用统计方法来判断,解释变量和被解释变量存在统计关系。
管理统计学习题参考答案第十一章

十一章1. 解:回归分析是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。
回归分析按照涉及的变量的多少,分为一元回归和多元回归分析;在线性回归中,按照因变量的多少,可分为简单回归分析和多重回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。
如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。
如果回归分析中包括两个或两个以上的自变量,且自变量之间存在线性相关,则称为多元线性回归分析。
相关分析,相关分析是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度,是研究随机变量之间的相关关系的一种统计方法。
相关分析和回归分析是研究客观现象之间数量联系的重要统计方法。
既可以从描述统计的角度,也可以从推断统计的角度来说明。
所谓相关分析,就是用一个指标来表明现象间相互依存关系的密切程度。
所谓回归分析,就是根据相关关系的具体形态,选择一个合适的数学模型,来近似地表达变量间的平均变化关系。
它们具有共同的研究对象,在具体应用时,相关分析需要依靠回归分析来表明现象数量相关的具体形式,而回归分析则需要依靠相关分析来表明现象数量变化的相关程度。
只有当变量之间存在着高度相关时,进行回归分析寻求其相关的具体形式才有意义。
由于相关分析不能指出变量间相互关系的具体形式,所以回归分析要对具有相关关系的变量之间的数量联系进行测定,从而为估算和预测提供了一个重要的方法。
在有关管理问题的定量分析中,推断统计加具有更加广泛的应用价值。
需要指出的是,相关分析和回归分析只是定量分析的手段。
通过相关与回归分析,虽然可以从数量上反映现象之间的联系形式及其密切程度,但是现象内在联系的判断和因果关系的确定,必须以有关学科的理论为指导,结合专业知识和实际经验进行分析研究,才能正确解决。
因此,在应用时要把定性分析和定量分析结合起来,在定性分析的基础上开展定量分析。
应用回归分析课后习题参考答案_全部版__何晓群_刘文卿

第一章回归分析概述1.2 回归分析与相关分析的联系与区别是什么?答:联系有回归分析和相关分析都是研究变量间关系的统计学课题。
区别有 a.在回归分析中,变量y称为因变量,处在被解释的特殊地位。
在相关分析中,变量x和变量y处于平等的地位,即研究变量y与变量x的密切程度与研究变量x与变量y的密切程度是一回事。
b.相关分析中所涉及的变量y与变量x全是随机变量。
而在回归分析中,因变量y是随机变量,自变量x可以是随机变量也可以是非随机的确定变量。
C.相关分析的研究主要是为了刻画两类变量间线性相关的密切程度。
而回归分析不仅可以揭示变量x对变量y的影响大小,还可以由回归方程进行预测和控制。
1.3回归模型中随机误差项ε的意义是什么?答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y与x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
1.4 线性回归模型的基本假设是什么?答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值xi1.xi2…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.第二章一元线性回归分析思考与练习参考答案2.1一元线性回归有哪些基本假定?答:假设1、解释变量X是确定性变量,Y是随机变量;假设2、随机误差项ε具有零均值、同方差和不序列相关性:E(εi)=0 i=1,2, …,nVar (εi)=σ2i=1,2, …,nCov(εi,εj)=0 i≠j i,j= 1,2, …,n假设3、随机误差项ε与解释变量X之间不相关:Cov(X i, εi)=0 i=1,2, …,n假设4、ε服从零均值、同方差、零协方差的正态分布εi~N(0, σ2) i=1,2, …,n2.3 证明(2.27式),∑e i =0 ,∑e i X i =0 。
《计量经济学》多媒体课件-多元线性回归模型习题参考解答

《计量经济学》多媒体课件-多元线性回归模型习题参考解答自己整理的《计量经济学》多媒体课件-多元线性回归模型习题参考解答相关文档,希望能对大家有所帮助,谢谢阅读!为了研究我国各地区入境旅游情况,建立了旅游外汇收入(Y,百万美元)、旅行社从业人数(X1,人)、国际游客人数(X2,万人)模型。
利用某年31个省市的横断面数据对结果进行了估计,具体如下:t=(-3.066806)(6.652983)(3.378064)R2=0.934331华氏度=191.1894牛顿=31 (1)从经济意义上考察估计模型的合理性。
(2)在5%显著性水平上,分别检验参数的显著性。
(3)在5%显著性水平下,模型的总体显著性得到检验。
3.2试根据以下数据估算偏回归系数、标准误差、可确定系数和修正可确定系数:经研究发现,家庭书刊的消费受几位户主受教育年限的影响。
该表显示了从某一地区一些家庭的抽样调查中获得的样本数据:家庭书刊年消费支出(元)y家庭月平均收入(元)x户主受教育年限(年)t家庭书刊年消费支出(元)y家庭月平均收入(元)x户主受教育年限(年)t450 1027.2 8 793.2 1998.6 14 507.7 1045.2 9 660.8 2196 10 613。
12 792.7 2105.4 12 563.4 1312.2 9 580.8 2147.4 8 501.5 1316.4 7 612.7 2154 10 781.5 1442.4 15 890.8 2231.4 14 541.8 1641 9 1121 2611.8 18 611.1 1768.8 10 1099(2)利用样本数据估计模型参数;(3)检查户主受教育年限对家庭书刊消费是否有显著影响;(4)分析估算模型的经济意义和作用。
3.4考虑以下“预期-扩大菲利普斯曲线”模型:其中:=实际通货膨胀率(%);=失业率(%);=预期通货膨胀率(%)下表是某国的相关数据。
多重共线性习题及答案

多重共线性一、单项选择题1、当模型存在严重的多重共线性时,OLS估计量将不具备()A、线性B、无偏性C、有效性D、一致性2、经验认为某个解释与其他解释变量间多重共线性严重的情况是这个解释变量的VIF()A、大于B、小于C、大于5D、小于53、模型中引入实际上与解释变量有关的变量,会导致参数的OLS估计量方差()A、增大B、减小C、有偏D、非有效4、对于模型y t=b0+b1x1t+b2x2t+u t,与r12=0相比,r12=0.5时,估计量的方差将是原来的()A、1倍B、1.33倍C、1.8倍D、2倍5、如果方差膨胀因子VIF=10,则什么问题是严重的()A、异方差问题B、序列相关问题C、多重共线性问题D、解释变量与随机项的相关性6、在多元线性回归模型中,若某个解释变量对其余解释变量的判定系数接近于1,则表明模型中存在( )A 异方差B 序列相关C 多重共线性D 高拟合优度7、存在严重的多重共线性时,参数估计的标准差()A、变大B、变小C、无法估计D、无穷大8、完全多重共线性时,下列判断不正确的是()A、参数无法估计B、只能估计参数的线性组合C、模型的拟合程度不能判断D、可以计算模型的拟合程度二、多项选择题1、下列哪些回归分析中很可能出现多重共线性问题()A、资本投入与劳动投入两个变量同时作为生产函数的解释变量B、消费作被解释变量,收入作解释变量的消费函数C、本期收入和前期收入同时作为消费的解释变量的消费函数D、商品价格、地区、消费风俗同时作为解释变量的需求函数E、每亩施肥量、每亩施肥量的平方同时作为小麦亩产的解释变量的模型2、当模型中解释变量间存在高度的多重共线性时()A、各个解释变量对被解释变量的影响将难以精确鉴别B、部分解释变量与随机误差项之间将高度相关C、估计量的精度将大幅度下降D、估计对于样本容量的变动将十分敏感E、模型的随机误差项也将序列相关3、下述统计量可以用来检验多重共线性的严重性()A、相关系数B、DW值C、方差膨胀因子D、特征值E、自相关系数4、多重共线性产生的原因主要有()A、经济变量之间往往存在同方向的变化趋势B、经济变量之间往往存在着密切的关联C、在模型中采用滞后变量也容易产生多重共线性D、在建模过程中由于解释变量选择不当,引起了变量之间的多重共线性E、以上都正确5、多重共线性的解决方法主要有()A、保留重要的解释变量,去掉次要的或替代的解释变量B、利用先验信息改变参数的约束形式C、变换模型的形式D、综合使用时序数据与截面数据E、逐步回归法以及增加样本容量6、关于多重共线性,判断错误的有()A、解释变量两两不相关,则不存在多重共线性B、所有的t检验都不显著,则说明模型总体是不显著的C、有多重共线性的计量经济模型没有应用的意义D、存在严重的多重共线性的模型不能用于结构分析7、模型存在完全多重共线性时,下列判断正确的是()A、参数无法估计B、只能估计参数的线性组合C、模型的判定系数为0D、模型的判定系数为1三、简述1、什么是多重共线性?产生多重共线性的原因是什么?2、什么是完全多重共线性?什么是不完全多重共线性?3、完全多重共线性对OLS估计量的影响有哪些?4、不完全多重共线性对OLS估计量的影响有哪些?5、从哪些症状中可以判断可能存在多重共线性?6、什么是方差膨胀因子检验法?四、判断(1)如果简单相关系数检测法证明多元回归模型的解释变量两两不相关,则可以判断解释变量间不存在多重共线性。
第11章 多重线性回归分析思考与练习参考答案

第11章 多重线性回归分析 思考与练习参考答案一、 最佳选择题1. 逐步回归分析中,若增加自变量的个数,则( D )。
A. 回归平方和与残差平方和均增大B. 回归平方和与残差平方和均减小C. 总平方和与回归平方和均增大D. 回归平方和增大,残差平方和减小E. 总平方和与回归平方和均减小2. 下面关于自变量筛选的统计学标准中错误的是( E )。
A. 残差平方和(残差SS )缩小B. 确定系数(2R )增大C. 残差的均方(残差MS )缩小D. 调整确定系数(2ad R )增大E. p C 统计量增大3. 多重线性回归分析中,能直接反映自变量解释因变量变异百分比的指标为 ( C )。
A. 复相关系数B. 简单相关系数C.确定系数D. 偏回归系数E. 偏相关系数 4. 多重线性回归分析中的共线性是指( E )。
A.Y 关于各个自变量的回归系数相同B.Y 关于各个自变量的回归系数与截距都相同C.Y 变量与各个自变量的相关系数相同D.Y 与自变量间有较高的复相关E. 自变量间有较高的相关性5. 多重线性回归分析中,若对某一自变量的值加上一个不为零的常数K ,则有( D )。
A. 截距和该偏回归系数值均不变B. 该偏回归系数值为原有偏回归系数值的K 倍C. 该偏回归系数值会改变,但无规律D. 截距改变,但所有偏回归系数值均不改变E. 所有偏回归系数值均不会改变二、思考题1. 多重线性回归分析的用途有哪些?答:多重线性回归在生物医学研究中有广泛的应用,归纳起来,可以包括以下几个方面:定量地建立一个反应变量与多个解释变量之间的线性关系,筛选危险因素,通过较易测量的变量估计不易测量的变量,通过解释变量预测反应变量,通过反应变量控制解释变量。
2. 多重线性回归模型中偏回归系数的含义是什么?答:偏回归系数的含义是:在控制其他自变量的水平不变的情况下,该自变量每改变一个单位,反应变量平均改变的单位数。
3. 请解释用于多重线性回归参数估计的最小二乘法的含义。
《计量经济学》思考与练习参考答案 孙敬水主编

一元线性回归模型
7.D
8.D
9.B 22.C
10.C 23.B
11.B 24.B
12.D 25.B
13.B 26.C
14.D 27.A
16.A
20.D
21.A
28.B 29.C 30.D
二、多项选择题
1.ACD 2.ABCDE 3.ABC 4.BE 5.AC 6.CDE 7.ABCDE 8.BCDE 9.ABCDE 10.ABDE
素后,消费函数为:
Ct = a0 + b0Yt + ∑ bi Dit + ut
i =1
6
或者: Ct = a0 + b0Yt +
∑ bi Dit + ∑ ai DitYt + ut
i =1 i =1
6
6
14.设某饮料需求 Y 依赖于收入 X 的变化外,还受: (1) “地区” (农村、城市)因素影 响其截距水平; (2) “季节” (春、夏、秋、冬)因素影响其截距和斜率。试分析确定该种饮 料需求的线性回归模型。
三、简答题、分析与计算题
1.什么是虚拟变量?它在模型中有什么作用? 参考答案:(1)反映定性(或属性)因素变化,取值为 0 和 1 的人工变量称为虚拟变量。 (2)在模型中引入虚拟变量,主要是为了将定性因素或属性因素对因变量的影响数量化。 ①可以描述和测量定性因素的影响;②能够正确反映经济变量之间的相互关系,提高模型的 精度;③便于处理异常数据。 2.引入虚拟解释变量的两种基本方式是什么?它们各适用于什么情况? 参考答案:引入虚拟变量基本方式:加法方式与乘法方式。前者主要适用于定性因素对 截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。此外还可以用 二者组合的方式引入,这时,可以测定定性因素对截距项和斜率项同时产生影响的情况。
管理统计学习题参考答案第十一章

一章1. 解:回归分析是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。
回归分析按照涉及的变量的多少,分为一元回归和多元回归分析;在线性回归中,按照因变量的多少,可分为简单回归分析和多重回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。
如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。
如果回归分析中包括两个或两个以上的自变量,且自变量之间存在线性相关,则称为多元线性回归分析。
相关分析,相关分析是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度,是研究随机变量之间的相关关系的一种统计方法。
相关分析和回归分析是研究客观现象之间数量联系的重要统计方法。
既可以从描述统计的角度,也可以从推断统计的角度来说明。
所谓相关分析,就是用一个指标来表明现象间相互依存关系的密切程度。
所谓回归分析,就是根据相关关系的具体形态,选择一个合适的数学模型,来近似地表达变量间的平均变化关系。
它们具有共同的研究对象,在具体应用时,相关分析需要依靠回归分析来表明现象数量相关的具体形式,而回归分析则需要依靠相关分析来表明现象数量变化的相关程度。
只有当变量之间存在着高度相关时,进行回归分析寻求其相关的具体形式才有意义。
由于相关分析不能指出变量间相互关系的具体形式,所以回归分析要对具有相关关系的变量之间的数量联系进行测定,从而为估算和预测提供了一个重要的方法。
在有关管理问题的定量分析中,推断统计加具有更加广泛的应用价值。
需要指出的是,相关分析和回归分析只是定量分析的手段。
通过相关与回归分析,虽然可以从数量上反映现象之间的联系形式及其密切程度,但是现象内在联系的判断和因果关系的确定,必须以有关学科的理论为指导,结合专业知识和实际经验进行分析研究,才能正确解决。
因此,在应用时要把定性分析和定量分析结合起来,在定性分析的基础上开展定量分析。
《应用回归分析》课后题答案[整理版]
![《应用回归分析》课后题答案[整理版]](https://img.taocdn.com/s3/m/603529c1f242336c1eb95eca.png)
《应用回归分析》课后题答案[整理版] 《应用回归分析》部分课后习题答案第一章回归分析概述 1.1 变量间统计关系和函数关系的区别是什么, 答:变量间的统计关系是指变量间具有密切关联而又不能由某一个或某一些变量唯一确定另外一个变量的关系,而变量间的函数关系是指由一个变量唯一确定另外一个变量的确定关系。
1.2 回归分析与相关分析的联系与区别是什么, 答:联系有回归分析和相关分析都是研究变量间关系的统计学课题。
区别有a.在回归分析中,变量y称为因变量,处在被解释的特殊地位。
在相关分析中,变量x和变量y处于平等的地位,即研究变量y与变量x的密切程度与研究变量x与变量y的密切程度是一回事。
b.相关分析中所涉及的变量y与变量x全是随机变量。
而在回归分析中,因变量y是随机变量,自变量x可以是随机变量也可以是非随机的确定变量。
C.相关分析的研究主要是为了刻画两类变量间线性相关的密切程度。
而回归分析不仅可以揭示变量x 对变量y的影响大小,还可以由回归方程进行预测和控制。
1.3 回归模型中随机误差项ε的意义是什么, 答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为一个随机方程,使得我们可以借助随机数学方法研究y与x1,x2…..xp的关系,由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
1.4 线性回归模型的基本假设是什么,答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值xi1.xi2…..xip是常数。
2.等方差及不相关的假定条件为{E(εi)=0 i=1,2….Cov(εi,εj)=,σ^23.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,即n>p.1.5 回归变量的设置理论根据是什么,在回归变量设置时应注意哪些问题,答:理论判断某个变量应该作为解释变量,即便是不显著的,如果理论上无法判断那么可以采用统计方法来判断,解释变量和被解释变量存在统计关系。
多元线性回归模型(习题与解答)

Yi = β 0 + β1 X i3 + ε i
Yi = β 0 + β 1 log X i + ε i log Yi = β 0 + β1 log X i + ε i Yi = β 0 + β 1 ( β 2 X i ) + ε i
Yi =
5)
β0 + εi β1 X i
6) 7)
Yi = 1 + β 0 (1 − X iβ1 ) + ε i Yi = β 0 + β 1 X 1i + β 2 X 2i 10 + ε i
X 1 (年)
家庭月可支配收 入 X 2 (元/月) 171.2 174.2 204.3 218.7 219.4 240.4 273.5 294.8 330.2 333.1 366.0 350.9 357.9 359.0 371.9 435.3 523.9 604.1
4 4 5 4 4 7 4 5 10 7 5 6 4 5 7 9 8 10
R 2 = 0.98
Cov(b K , b L ) = 0.055
其中括号内数值为参数标准差。请检验以下零假设: (1)产出量的资本弹性和劳动弹性是等同的; (2)存在不变规模收益,即 α + β = 1 。 3-14.对模型 y i =
β 0 + β1 x1i + β 2 x 2i + L + β k x ki + u i 应用 OLS 法,得到回归方程如下:
ˆ +β ˆ X +β ˆ X ˆ=β 的回归方程: Y 0 1 1 2 2
(2)对 β 1 , β 2 的显著性进行 t 检验;计算 R 和 R ;
第10章-简单线性回归分析思考与练习参考答案

第10章 简单线性回归分析思考与练习参考答案一、最佳选择题1.如果两样本的相关系数21r r =,样本量21n n =,那么( D )。
A. 回归系数21b b = B .回归系数12b b < C. 回归系数21b b > D .t 统计量11r b t t = E. 以上均错2.如果相关系数r =1,则一定有( C )。
A .总SS =残差SSB .残差SS =回归SSC .总SS =回归SSD .总SS >回归SS E.回归MS =残差MS3.记ρ为总体相关系数,r 为样本相关系数,b 为样本回归系数,下列( D )正确。
A .ρ=0时,r =0B .|r |>0时,b >0C .r >0时,b <0D .r <0时,b <0 E. |r |=1时,b =14.如果相关系数r =0,则一定有( D )。
A .简单线性回归的截距等于0B .简单线性回归的截距等于Y 或XC .简单线性回归的残差SS 等于0D .简单线性回归的残差SS 等于SS 总E .简单线性回归的总SS 等于05.用最小二乘法确定直线回归方程的含义是( B )。
A .各观测点距直线的纵向距离相等B .各观测点距直线的纵向距离平方和最小C .各观测点距直线的垂直距离相等D .各观测点距直线的垂直距离平方和最小E .各观测点距直线的纵向距离等于零二、思考题1.简述简单线性回归分析的基本步骤。
答:① 绘制散点图,考察是否有线性趋势及可疑的异常点;② 估计回归系数;③ 对总体回归系数或回归方程进行假设检验;④ 列出回归方程,绘制回归直线;⑤ 统计应用。
2.简述线性回归分析与线性相关的区别与联系。
答:区别:(1)资料要求上,进行直线回归分析的两变量,若X 为可精确测量和严格控制的变量,则对应于每个X 的Y 值要求服从正态分布;若X 、Y 都是随机变量,则要求X 、Y 服从双变量正态分布。
直线相关分析只适用于双变量正态分布资料。
统计学第十一章课后习题答案

11。
1(1)绘制产量与生产费用的散点图,判断二者之间的关系形态。
散点图如下:从上图,可以看出产量与生产费用的关系为正的线性相关关系。
(2)计算产量与生产费用之间的线性相关系数.r=0.920232(3)对相关系数的显著性进行检验(a=0。
05),并说明二者之间的关系系数。
假设:H o :ρ=0,H 1:ρ≠0 计算检验的统计量:t=|r|√n−21−r²=|0。
92—232|√12−21−0.920232²=7.435当a=0。
05时,t 0.052⁄(12-2)=2.228。
由于检验统计量t=7。
435>t a 2⁄=2.228,拒绝原假设。
表明产量与生产费用之间的线性关系显著.11.2(1)散点图如下:(2)r=0.8621,正相关11。
3(1)0ˆβ=10表示当X=0时Y 的期望值为10 (2)1ˆβ=—0.5表示X 每增加1个单位,Y 平均下降0.5个单位。
(3)X=6时,E (Y )=10—0。
5x6=711.4.(1)%90436362=+=+==SSE SSR SSR SST SSR R ,%902=R 表示,在因变量y 取值的变差中,有90%可以由x 与y 之间的线性关系来解释. (2)5.021842n =--=SSE S e 。
5.0=e S 表示,当用x 来预测y 时,平均的预测误差为0.5。
11.5(1)散点图如下:(2)r=0。
9489,因为r>0.8,所以运送时间与运送距离有较强的正线性关系。
(3)利用最小二乘法求出估计的回归方程,并解释回归系数的实际意义。
得到的回归方程为x 003585.0118129.0y ˆ+=,回归系数003585.0ˆ=β表示运送距离每增加1公里,运送时间平均增加0.003585天.11.6(1)散点图如下:从上图可知,人均gdp 和人均消费水平为正相关关系(2)r=0.998128,具有非常强的正线性关系。
第11章多重线性回归分析案例辨析及参考答案
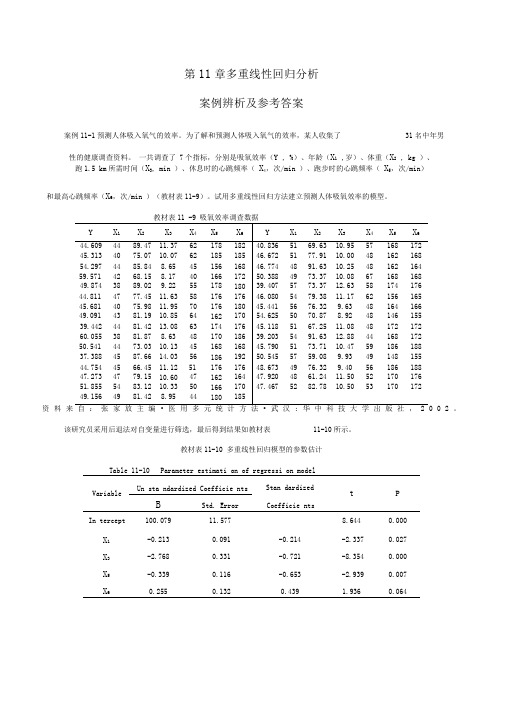
第11章多重线性回归分析案例辨析及参考答案案例11-1预测人体吸入氧气的效率。
为了解和预测人体吸入氧气的效率,某人收集了31名中年男性的健康调查资料。
一共调查了 7个指标,分别是吸氧效率(Y , %)、年龄(X1,岁)、体重(X2, kg )、跑1.5 km所需时间(X3, min )、休息时的心跳频率(X4,次/min )、跑步时的心跳频率(X5,次/min)和最高心跳频率(X6,次/min )(教材表11-9)。
试用多重线性回归方法建立预测人体吸氧效率的模型。
教材表11 -9 吸氧效率调查数据Y X1 X2X3 X4 X5 X6 Y X1 X2X3 X4 X5 X644.609 44 89.47 11.37 62 178 182 40.836 51 69.63 10.95 57 168 17245.313 40 75.07 10.07 62 185 185 46.672 51 77.91 10.00 48 162 16854.297 44 85.84 8.65 45 156 168 46.774 48 91.63 10.25 48 162 16459.571 42 68.15 8.17 40 166 172 50.388 49 73.37 10.08 67 168 16849.874 38 89.02 9.22 55 178 180 39.407 57 73.37 12.63 58 174 17644.811 47 77.45 11.63 58 176 176 46.080 54 79.38 11.17 62 156 16545.681 40 75.98 11.95 70 176 180 45.441 56 76.32 9.63 48 164 16649.091 43 81.19 10.85 64 162 170 54.625 50 70.87 8.92 48 146 15539.442 44 81.42 13.08 63 174 176 45.118 51 67.25 11.08 48 172 17260.055 38 81.87 8.63 48 170 186 39.203 54 91.63 12.88 44 168 17250.541 44 73.03 10.13 45 168 168 45.790 51 73.71 10.47 59 186 18837.388 45 87.66 14.03 56 186 192 50.545 57 59.08 9.93 49 148 15544.754 45 66.45 11.12 51 176 176 48.673 49 76.32 9.40 56 186 18847.273 47 79.15 10.60 47 162 164 47.920 48 61.24 11.50 52 170 17651.855 54 83.12 10.33 50 166 170 47.467 52 82.78 10.50 53 170 17249.156 49 81.42 8.95 44 180 185资料来自:张家放主编•医用多元统计方法•武汉:华中科技大学出版社,2002。
多元统计思考题及答案

多元统计分析思考题第一章 回归分析1、回归分析是怎样的一种统计方法,用来解决什么问题答:回归分析作为统计学的一个重要分支,基于观测数据建立变量之间的某种依赖关系,用来分析数据的内在规律,解决预报、控制方面的问题;2、线性回归模型中线性关系指的是什么变量之间的关系自变量与因变量之间一定是线性关系形式才能做线性回归吗为什么答:线性关系是用来描述自变量x 与因变量y 的关系;但是反过来如果自变量与因变量不一定要满足线性关系才能做回归,原因是回归方程只是一种拟合方法,如果自变量和因变量存在近似线性关系也可以做线性回归分析;3、实际应用中,如何设定回归方程的形式答:通常分为一元线性回归和多元线性回归,随机变量y 受到p 个非随机因素x1、x2、x3……xp 和随机因素的影响,形式为:01p βββ⋅⋅⋅是p+1个未知参数,ε是随机误差,这就是回归方程的设定形式;4、多元线性回归理论模型中,每个系数偏回归系数的含义是什么答:偏回归系数01p βββ⋅⋅⋅是p+1个未知参数,反映的是各个自变量对随机变量的影响程度;5、经验回归模型中,参数是如何确定的有哪些评判参数估计的统计标准最小二乘估计法有哪些统计性质要想获得理想的参数估计值,需要注意一些什么问题答:经验回归方程中参数是由最小二乘法来来估计的;评判标准有:普通最小二乘法、岭回归、主成分分析、偏最小二乘法等;最小二乘法估计的统计性质:其选择参数满足正规方程组,1选择参数01ˆˆββ分别是模型参数01ββ的无偏估计,期望等于模型参数; 2选择参数是随机变量y 的线性函数要想获得理想的参数估计,必须注意由于方差的大小表示随机变量取值的波动性大小,因此自变量的波动性能够影响回归系数的波动性,要想使参数估计稳定性好,必须尽量分散地取自变量并使样本个数尽可能大;6、理论回归模型中的随机误差项的实际意义是什么为什么要在回归模型中加入随机误差项建立回归模型时,对随机误差项作了哪些假定这些假定的实际意义是什么答:随机误差项的引入使得变量之间的关系描述为一个随机方程,由于因变量y 很难用有限个因素进行准确描述说明,故其代表了人们的认识局限而没有考虑到的偶然因素;7、建立自变量与因变量的回归模型,是否意味着他们之间存在因果关系为什么答:不是,因果关系是由变量之间的内在联系决定的,回归模型的建立只是一种定量分析手段,无法判断变量之间的内在联系,更不能判断变量之间的因果关系;8、回归分析中,为什么要作假设检验检验依据的统计原理是什么检验的过程是怎样的答:因为即使我们已经建立起了模型,但是尚且不知这个回归方程是否能够比较好地反映所描述的变量之间的影响关系,必须进行统计学上的假设检验;假设性检验原理可以用小概率原理解释,通常认为小概率事件在一次试验中几乎不可能发生的,即对总体的某个假设是真实的,那么不支持这一个假设事件在一次试验中是几乎不可能发生的,要是这个事件发生了,我们就有理由怀疑这一假设的真实性,拒绝原假设;检验过程:1提出统计假设H0和H1;2构造一个与H相关的统计量,称其为检验统计量;3根据其显着性水平 的值,确定一个拒绝域;4作出统计决断;9、回归诊断可以大致确定哪些问题回归分析有哪些基本假定如果实际应用中不满足这些假定,将可能引起怎样的后果如何检验实际应用问题是否满足这些假定对于各种不满足假定的情形,分别采用哪些改进方法答:回归诊断解决:1回归方程的线性假定;2是否存在多重共线性;3误差项的正态性假定;4误差项的独立性假设;5误差项同方差假定;6是否存在数据异常;原基本假定H:1假设回归方程不显着;2假设回归系数不显着;引起后果:与模型误差相比,自变量对因变量的影响是不重要的模型误差太大、自变量对y的影响确实太小;如何检验:用F统计量或者P值法来检验方程的显着性;改进方法:1对于模型的误差太大,我们要想办法缩小误差,检查是否漏掉了重要的自变量,或检查自变量与y的非线性关系;2对于自变量对y影响较小,此时应该放弃回归分析方法;10、回归分析中的R2有何意义它能用来衡量模型优劣吗答:R2是回归平方和与总离差平方和之比,作为评判一个模型拟合度的标准,称为样本决定系数,其值越接近1,意味着模型的拟合优度越高;但是其不是衡量模型优劣唯一标准,增加自变量会使得自由度减少,因此需要引入自由度修正的复相关系数;这些都需要视具体的情况而定;11、如何确定回归分析中变量之间的交互作用存在交互作用时,偏回归系数的意义与不存在交互作用的情形下是否相同为什么答:交互作用是指因素之间联合搭配对试验指标的影响作用,存在交互作用是,偏回归系数肯定与不存在是的系数不同,毕竟变量之间有相互影响的关系;12、有哪些确定最优回归模型的准则如何选择回归变量答:1修正的复相关系数2aR达到最大;2预测平方和达到最小;3定义Cp 统计量值小,选择pC p小的回归方程;4赤池信息量达到最小;按照以上准则进行回归变量的选择;13、在怎样的情况下需要建立标准化的回归模型标准化回归模型与非标准化模型有何关系形式有否不同答:在多元线性回归分析中,由于涉及到的变量量纲不同,差别很大,需要对变量进行中心化和标准化,数据中心化处理相当于将坐标原点移至样本中心坐标系的平移不改变直线的斜率;标准化处理后建立的回归方程模型比非标准化的回归方程少一个常数项,系数存在关系;14、利用回归方法解决实际问题的大致步骤是怎样的答:1根据预测目标,确定自变量和因变量;2建立回归预测模型;3进行相关分析;4检验回归预测模型,计算预测误差;5计算并确定预测值;15、你能够利用哪些软件实现进行回归分析能否解释全部的软件输出结果答:目前会用的软件是SPSS和matlab,关于地球物理的软件如grapher也可以进行回归分析;对于SPSS的一些输出结果,还是不太理解;第二章判别分析1、判别分析的目的是什么答:在自然科学和社会科学研究中,研究对象用某种方法已经划分为若干类别,当得到一个新的样本数据时,要确定该样本属于已知的哪一类;2、有哪些常用的判别分析方法这些方法的基本原理或步骤是怎样的它们各有什么特点或优劣之处答:1距离判别法:根据已知分类数据,分别计算各类的重心,即是分类的均值;判别方法是—对于任意一个样品,若它与第i类的重心距离最近,就认为它来自第i类;特点是对各类数据分布并无特定的要求2Fisher判别法:其基本思想是投影,将k组m元数据投影到某一个方向,使得投影后组与组之间尽可能分开,其中利用了一元方差分析的思想导出判别函数;其特点是对总体的分布没有特殊要求,是处理概率分布未知的一种方法;3逐步判别法:逐步引入一个“最重要”的变量进入判别式,同时对先引入判别式的一些变量进行检验,如果判别能力随着引入新变量而变得不显着,则将它从判别式中剔除,直到没有新的变量能够进入,依然没有旧变量需要剔除为止;3、判别分析与回归分析有何异同之处答:1相同点:这两种方法都有关于数据预测的功能;不同点:这个估计太多了,一般来讲判别分析功能是将样品归类,回归分析是探究样品对因变量的变动影响;4、判别分析对变量与样本规模有何要求答:判别分析对总体分布没有要求,但是判别分析的假设之一是要求每一个变量不能是其他判别变量的线性组合,即不能存在多重共线性;5、如何度量判别效果有哪些影响判别效果的因素答:通过评价判别准则来度量判别效果,常用方法:1误判率回代法;2误判率交叉确认估计;影响因素是个总体之间的差异程度,各个总体之间差异越大,就越有可能建立有效的判别准则,如果差异太小,则判别分析的意义不大;当各个总体服从多元正态分布,我们可以根据各总体的均值向量是否相等进行统计检验;当然也可以检验各总体的协方差矩阵是否相等来采用判别函数;6、逐步判别是如何选择判别变量的基本思想或步骤是什么答:在判别分析中,并不是观测变量越多越好,而是选择主要变量进行判别分析,将各个变量在分析中起的不同作用,将影响力比较低的变量保留在判别式中,会增加干扰,影响效果;因此选择显着判别力的变量来建立判别式就是逐步判别法;基本思想:其与逐步回归法类似,都是采用“有进有出”的算法,即逐步引入一个“最重要”的变量进入判别式,同时对先引入的判别式进行检验,如果其判别能力随着新引入的变量显着性降低,则该因素应该被剔除,直到变量全部进入为止;7、判别分析有哪些现实应用举例说明;答:判别分析在实际中的应用无处不在;例如我们根据各种经济指标把各个国家分为发达国家和发展中国家,通过这些指标成功的判定了一个国家的经济发展水平;第三章聚类分析1、聚类分析的目的是什么与判别分析有何异同这种方法有哪些局限或欠缺答:把某些方面相似的东西进行归类,以便从中发现规律性,达到认识客观事物规律的目的;其与判别分析相同的地方是都是研究分组的问题;不同的是各自对于预先分组对象不一样,聚类分析是未知类别,判别分析是已知类别;2、有哪些常用的聚类统计量答:1Q型统计量:对样本进行聚类,用“距离”来描述样本之间的接近程度;R型统计量:对变量进行聚类,用“相似系数”来度量变量之间的近视程度;3、系统谱系聚类法的基本思想是怎样的它包含哪些具体方法答:先将待聚类的n个样品或变量各自看成一类,共有n类,然后按照事先选定的聚类方法计算每两类之间的聚类统计量,即某种距离或者相似系数,将关系最密切的两类并为一类,其余不变,即的n-1类,再按照前面的计算方法计算新类与其他类之间的距离或者相似系数,再将关系最密切的两类归为一类,其余不变,即得n-2类,继续下去,每次重复都减少一类,直到所有样品或者变量都归于一类;4、聚类分析对变量与样本规模有何要求有哪些因素影响分类效果要想减少不利因素的影响,可以采取哪些改进方法答:聚类分析要求其样本规模较大,需要变量之间相关性较弱,变量个数小于样本数;5、实际应用问题,如何确定分类数目答:按理来说聚类分析的分类数目是事先不知道的,但是在实际应用中,应该根据相关专业知识确定分类数目,结合聚类统计量参考确定,并使用误判定理具体分析;6、快速聚类法K—均值法的基本思想或步骤是怎样的答:如果待分类样品比较多,应先给出一个大概的分类,然后不断对其进行修正,一直到分类结果比较合理为止;7、有序样品的最优分别法的基本思想或步骤是怎样的答:将n个样品看成一类,然后根据分类的误差函数逐渐增加分类,寻求最优分割,用分段的方法找出使组内离差平方和最小的分割点;8、应用聚类分析解决实际问题的基本步骤是怎样的应该注意哪些方面的问题答:1n个变量样品各自成一类,一共有n类,计算两两之间的距离,构成一个对称矩阵;2选择这个对称矩阵中主对角元素以外的上或者下三角部分中的最小元素,合成的新类,并计算其与其他类之间的距离;3划去与新类有关的行和列,将新类与其余类别的距离组成新的n-1阶对称矩阵;4再重复以上步骤,直到n个样品聚为一个大类;5记录下合并类别的编号以及所对应的距离,绘制聚类图;6决定类的个数和聚类结果;第四章主成分分析与典型相关分析1、主成分分析的基本思想是什么在低维情况下,如何利用几何图形解释主成分的意义答:构造原始变量的适当线性组合,使其产生一系列互不相关的新变量,从中选出少量的几个新变量并使它们含有足够多的原始变量的信息,从而使这几个新变量代替原始变量分析问题和解决问题提供了可能;几何解释,可以借用平面上旋转坐标系方法来达到降维的目的;2、什么是主成分的贡献率与累计贡献率实际应用时,如何确定主成分的个数答:主成分中,描述第k个主成分提取的信息占据原来变量总信息的比重,称为第k个主成分的贡献率;若将前m个主成分提取的总信息的比重相加,称为主成分的累计贡献率;实际应用中,通常选取前m个主成分的累积贡献率达到一定的比列来确定主成分的个数;3、主成分有哪些基本性质答:1每一个主成分都是原始变量的线性组合;2主成分的数目大大小于原始变量的数目;3主成分保留了原始变量所包含的绝大部分信息;4各个主成分之间互不相关;4、对于任何情形的多个变量,都可以采取主成分方法降维吗为什么答:肯定不是,必须要满足适合主成分分析的要求才可以降维;举个简单的例子,其适用范围是各个变量之间应该具有比较强的相关性,如果多个变量均为各项同性,则主成分分析效果不明显;5、怎样的情况下需要计算标准化的主成分答:因为实际问题的变量有很多量纲,不同的量纲会引起各个变量的取值的分散程度差异较大,总体方差将主要受到方差较大的变量的控制;如果用协方差矩阵 求主成分,则优先照顾方差大的变量,可能会得到不合理的结果,因此为了消除量纲的影响,需要计算标准化的主成分;6、主成分有哪些应用答:它的主要作用是降维,因此应用范围比较广泛,举个例子,衡量一个城市的综合发展指数涉及到的变量参数相当多,但是如果运用主成分的思想,只需要考虑较少的变量样品就好,一般选择GDP指数、环境指数、人口、面积等;7、如何解释主成分的实际含义答:主成分的实际意义需要结合到实际应用中,其往往不是最终目的,重要的是利用降维的思想来综合分析原始信息,利用有限的主成分来解释规律,从而进行相关研究;8、典型相关分析的基本思想是什么有何实际用途答:是研究两组变量间的相互依赖关系,把两组变量之间的关系变为研究两个新变量的相关,而又不抛弃原来变量的信息;因为这两组变量所代表的内容不同,可以直接考虑其相关关系来反映两组变量之间的整体相关性;例如工厂考察使用原料质量对生产产品质量的影响,需要对产品各种各样质量指标与所使用的原料指标之间的相关关系进行评判;9、典型相关分析与回归分析、判别分析、主成分分析、因子分析有何关联试比较这些方法的异同之处;答:这是一个涉及面很大的问题,总的来讲这些方法的存在能够帮助我们对于客观数据现象的相关关系有一个更加深刻的了解,有的是对另外一种方向的优化与推广,有的本质思想与另外一种分析方法很接近,异同点可以根据教科书进行两两比对;10、典型相关分析有哪些基本假定答:线性假定影响典型相关分析的两个方面,首先任意两个变量间的相关系数是基于线性关系的;如果这个关系不是线性的,一个或者两个变量需要变换;其次,典型相关是变量间的相关,如果关系不是线性的,典型相关分析将不能测量到这种关系;11、如何解释典型相关函数的实际意义答:1典型权重标准化系数;2典型荷载结构系数;3典型交叉载荷;用以上三种参数来使多个变量与多个变量的相关性转化为两个变量的相关性;12、典型相关方法中冗余度分析的意义是什么答:冗余度主要说明典型变量对各组观测变量总方差的代表比例和解释比例;第五章因子分析与对应分析1、因子分析是怎样的一种统计方法它的基本目的和用途是什么答:其根据相关性大小将变量分组,使得同组内的变量之间相关性较高,不同组的相关性较低,每组变量代表一个基本结构,用一个不可观测的综合变量表示,这个基本结构成为公共因子,对所研究的问题就可以用最少的个数的不可观测的所谓公共因子的线性函数与特殊因子之和来描述原来观测的每一个分量;目的:利用降维的思想,从研究原始变量相关矩阵内部结构出发,把一些具有错综复杂关系的变量归结为少数几个综合因子;用途:对变量进行分类,根据因子得分值在其轴所构成的空间中吧变量点画出来,从而分类;2、因子分子中的KMO统计量与巴特莱特球形性检验的目的是什么答:KMO统计量:通过比较各个变量之间简单相关系数和偏相关系数的大小判断变量间的相关性,相关性强时,偏相关系数远小于简单相关系数,KMO值接近1.一般KMO>非常适合做因子分析;而大于都可以,但是一下不适合;巴特莱特球形检验:用于检验相关矩阵是否是单位矩阵,及各个变量是否是独立的;它以变量的相关系数矩阵为出发地点,如果统计量数值较大,且相伴随的概率值小于用户给定的显着性水平,则应该拒绝原假设;反之,则认为相关系数矩阵可能是一个单位阵,不适合做因子分析;3、因子分析有哪些类型它们有何区别Q型因子分析与聚类分析有何异同答:Q型和R型两种;Q型:对样本进行因子分析,R型:对变量进行因子分析;Q型因子分析可以认为是考虑指标的重要性,保留哪些去掉哪些;Q型聚类分析考虑的是指标的相关性,哪几类指标可能组成一类,使得组内距离尽可能小,组间距离尽可能大; 4、因子分析中的变量类型是怎样的因子分析对变量数目有没有要求对样本规模有没有要求答:被描述的变量一般来讲都是可观测的随机变量;变量必须是标准化的;样品的数目大于变量的数目;5、因子分析有怎样的基本假定对样本特点或性质有何要求答:各个共同因子之间不相关,特殊因子之间也不相关,共同因子与特殊因子之间也不相关;样本之间相关性越强越好;6、因子分析模型中,因子载荷、变量共同度、方差贡献等统计量的统计意义是什么答:1因子载荷:指综合因子与公共因子的相关关系,表示其依赖公共因子的程度,反映了第i个变量对第j个公共因子的相对重要性,也是其间的密切程度,也是其公共因子的权;2变量共同度:指因子载荷矩阵中各行元素的平方和,表示x的第i个分量对于公共因子的每一个分量的共同依赖程度;3方差贡献:指因子载荷矩阵第j列各个元素的平方和,是衡量公共因子相对重要性的指标;7、因子分析与主成分分析有何区别与联系它们分别适用于怎样的情况答:联系:均是降维的处理变量样品的方法;区别:因子分析是把变量表示成各个因子的线性组合,而主成分分析是把主成分表示成变量的线性组合;因子分析重点是解释各个变量之间的协方差,主成分分析是解释变量的总方差;因子分析需要一些假定,共同因子之间不相关,特殊因子之间不相关,以上两者也不相关,而主成分分析不需要假设;因子分析中因子不是独特的,可以旋转得到不同的因子,主成分分析中对于给定的协方差和相关矩阵特殊值,成分是独特的;因子个数需要分析者指定,而主成分中成分的数量是一定的;8、如何确定公共因子数目如何解释公共因子的实际意义答:用方差累计贡献率,一般只要前几个达到80%即可,或者碎石图也可以确定;公共因子的含义,与实际问题相关,表示变量之间内部错综复杂的关联性;9、怎样的情况下,需要作因子旋转答:如果求出主因子解,但是主因子代表的变量不是很突出,容易使因子的含义模糊不清,需要做旋转;10、有哪些估计因子得分的方法因子得分的估计是普通意义下的参数估计吗为什么答:回归估计法、巴特莱特估计法、汤姆逊估计法;不是普通意义下的参数估计,需要用公共因子F用变量的线性组合来表示;11、对应分析的基本思想或原理是什么试举例说明它的应用;答:为了克服因子分析的不足之处,寻求R型和Q型变量的内在联系,将两者统一起来,将样品和变量反映到相同的坐标轴上进行解释;比如对某一行业的经济效益进行综合性评价,要研究企业与企业的信息,指标与指标的内部结构、企业与指标的内在联系,这三个方面是一个密不可分的整体;12、对应分析中总惯量的意义是什么答:代表总体两个变量相互联系的总信息量,可以反映某种变量特征属性的接近程度,及时对数据组分进行约束;。
第九章【思考与练习】题与答案

【思考与练习】一、判断题:1、正相关指的是两个变量之间的变动方向都是上升的。
()2、相关系数是测定变量之间相关密切程度的唯一方法。
()3、负相关指的就是两个变量变化趋势相反,一个上升而另一个下降。
()4、甲产品产量与单位成本的相关系数是-0.89。
乙产品单位成本与利润率的相关系数是-0.93。
因此,甲比乙的相关程度高。
()5、回归分析和相关分析一样,所分析的两个变量都一定是随机变量。
()6、相关系数r是在曲线相关条件下,说明两个现象之间相关关系密切程度的统计分析指标。
()7、回归分析中,对于没有明显因果关系的两个变量可以求得两个回归方程。
()8、估计标准误差指的就是实际值y与估计值y的平均误差程度。
()c9、一个回归方程只能作一种推算,即给出自变量的数值估计因变量的可能值。
()10、产量增加,则单位产品成本降低。
这种相关关系属于正相关。
()答案:1.×、2.×、3.√、4.×、5.×、6.×、7.√、8.×、9.√、10.×二、单项选择题:1、当自变量的数值确定后,因变量的数值也随之完全确定,这种关系属于()。
A.相关关系B.函数关系C.回归关系D.随机关系2、测定变量之间相关密切程度的代表性指标是()。
A.估计标准误差B.两个变量的协方差C.相关系数D.两个变量的标准差3、现象之间的相互关系可以归纳为两种类型,即()。
A.相关关系和函数关系 B.相关关系和因果关系C.相关关系和随机关系 D.函数关系和因果关系4、相关系数的取值范围是()。
A.0≤r≤1 B.-1<r<1 C.-1≤r≤1 D.-1≤r≤05、在价格不变的条件下,商品销售额和销售量之间存在着()。
A.不完全的依存关系 B.不完全的随机关系C.完全的随机关系D.完全的依存关系6、下列( )两个变量之间的相关程度高。
A.商品销售额和商品销售量的相关系数是0.9B.商品销售额和商业利润率的相关系数是0.84C.平均流通费用率与商业利润率的相关系数是-0.94D.商品销售价格与销售量的相关系数是-0.917、回归分析中的两个变量()。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第11章多重线性回归分析
思考与练习参考答案
一、最佳选择题
1.逐步回归分析中,若增加自变量的个数,则(D)。
A.回归平方和与残差平方和均增大
B.回归平方和与残差平方和均减小
C.总平方和与回归平方和均增大
D.回归平方和增大,残差平方和减小
E.总平方和与回归平方和均减小
2.下面关于自变量筛选的统计学标准中错误的是(E)。
A.残差平方和(SS
残差)缩小B.确定系数(R)增大
2
C.残差的均方(MS
残差)缩小D.调整确定系数(R
ad)增大
2
E.C
p统计量增大
3.多重线性回归分析中,能直接反映自变量解释因变量变异百分比的指标为(C)。
A.复相关系数
B.简单相关系数
C.确定系数
D.偏回归系数
E.偏相关系数
4.多重线性回归分析中的共线性是指(E)。
A.Y关于各个自变量的回归系数相同
B.Y关于各个自变量的回归系数与截距都相同
C.Y变量与各个自变量的相关系数相同
D.Y与自变量间有较高的复相关
E.自变量间有较高的相关性
5.多重线性回归分析中,若对某一自变量的值加上一个不为零的常数K,则有(D)。
A.截距和该偏回归系数值均不变
B.该偏回归系数值为原有偏回归系数值的K 倍
C.该偏回归系数值会改变,但无规律
D.截距改变,但所有偏回归系数值均不改变
E.所有偏回归系数值均不会改变
二、思考题
1.多重线性回归分析的用途有哪些?
答:多重线性回归在生物医学研究中有广泛的应用,归纳起来,可以包括以下几个方面:定量地建立一个反应变量与多个解释变量之间的线性关系,筛选危险因素,通过较易测量的变量估计不易测量的变量,通过解释变量预测反应变量,通过反应变量控制解释变量。
2.多重线性回归模型中偏回归系数的含义是什么?
答:偏回归系数的含义是:在控制其他自变量的水平不变的情况下,该自变量每改变一个单位,反应变量平均改变的单位数。
3.请解释用于多重线性回归参数估计的最小二乘法的含义。
答:最小二乘法的含义是:残差的平方和达到最小。
4.如何判断和处理多重共线性?
答:如果自变量之间存在较强的相关,则存在多重共线性。
可以通过分析自变量之间的相关系数、计算方差膨胀因子和容忍度等指标判断是否存在多重共线性。
如果自变量间存在多重共线性,最简单的处理办法是删除变量,即在
相关性较强的变量中删除测量误差大的、缺失数据多的、从专业上看意义不是很重要的或者在其他方面不太满意的变量。
其次,也可采用主成分回归方法。
5.如何判断、分析自变量间的交互作用?
答:基于专业背景知识,构造可能的交互作用项,并检验交互作用项是否有统计学意义。
6.多重线性回归模型的基本假定有哪些?如何判断资料是否满足这些假定?如果资料不满足假定条件,常用的处理方法有哪些?
答:多重线性回归的前提条件是线性、独立性、正态性和等方差性,可以借助残差分析等方法判断资料是否满足条件。
如果资料不满足前提条件,可以采用变量变换和非线性回归等方法处理。
三、计算题
为确定老年妇女进行体育锻炼还是增加营养会减缓骨骼损伤,一名研究者用光子吸收法测量了骨骼中无机物含量,对三根骨头主侧和非主侧记录了测量值,结果见教材表11-20。
分别用两种桡骨测量结果作为反应变量对其他骨骼测量结果作多重线性回归分析,提出并拟合适当的回归模型,分析残差。
解:答案提示,需要对自变量进行筛选,而且要考虑是否存在多重共线性,如果存在,应进行适当的处理。
教材表11-20骨骼中无机物的含量
受试者编号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25主侧桡骨1.103
0.842
0.857 0.795 0.787 0.933 0.799 0.945 0.921 0.792 0.815 0.755 0.880 0.900 0.764 0.733 0.932 0.856 0.890 0.688 0.940 0.493
0.915桡骨
1.052
0.859
0.873
0.744
0.809
0.779
0.880
0.851
0.876
0.906
0.825
0.751
0.724
0.866
0.838
0.757
0.748
0.898
0.786
0.532
0.850
0.616
0.752
0.936主侧肱骨2.139
1.873
1.887
1.739
1.734
1.509
1.695
1.740
1.811
1.954
1.624
2.204
1.508
1.786
1.902
1.863
2.028
1.390
2.187
1.650
2.334
1.037
1.509
1.971肱骨
2.238
1.741
1.809
1.547
1.715
1.474
1.656
1.777
1.759
2.009
1.657
1.458
1.811
1.606
1.794
1.869
2.032
1.324
2.087
1.378
2.225
1.268
1.422
1.869主侧尺骨0.873
0.590
0.767
0.706
0.549
0.782
0.737
0.853
0.823
0.686
0.678
0.662
0.810
0.723
0.586
0.672
0.836
0.578
0.758
0.533
0.757
0.546
0.618
0.869尺骨0.872
0.744
0.713
0.674 0.654 0.571 0.803 0.682 0.777 0.765 0.668 0.546 0.595 0.819 0.677 0.541 0.752 0.805 0.610 0.718 0.482 0.731 0.615 0.664
0.868资料来源:《实用多元统计分析》(第4版),Richard A. Johnson & Dean W. Wichern,陆璇译,清华大学出版社。
(郝元涛张岩波)。