计量经济学 李子奈版例题eviews数据
计量作业计量经济学第三版李子奈

计量作业计量经济学第
三版李子奈
文档编制序号:[KKIDT-LLE0828-LLETD298-POI08]
计量经济学第三版李子柰
12 下表是中国内地2007年各地区税收Y和国内生产总值GDP的统计资料。
单位:(亿元)
Y GDP
3357065
594
625
434
9200
88
629
要求,以手工和运用Eviews软件(或其它软件):
(1)做出散点图,建立税收随国内生产总值GDP变化的一元线性回归方程,并解释斜率的经济意义;
(2)对所建立的回归方程进行检验;
(3)若2008年某地区国内生产总值为8500亿元,求该地区税收入的预测值机预测区间。
解:下图是运用Eviews软件分析出的结果。
Dependent Variable: Y
Method: Least Squares
Date: 09/17/11 Time: 15:13
Sample: 2 32
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
GDP
Adjusted R-squared . dependent var
. of regression Akaike info criterion
Sum squared resid 2760310. Schwarz criterion
Log likelihood F-statistic
Durbin-Watson stat Prob(F-statistic)。
计量经济学案例Eviews实现

2.8:散点图:graph01。
建立一元线性回归模型。
参数估计:eq02。
可得出模型:t t x y 69.031.135+=预测:graph02。
得到1990年、2000年某城镇居民年人均消费性支出预测值为:1354.89、1424.05.3.7进行回归分析,建立回归模型。
1用最小二乘法做参数估计:eq02/stats 。
得到回归方程:i i i x x y 219117.00494.05398.158-+=。
回归标准差为:20.217572经济意义检验:可得出所有的回归系数的符号和大小都与经济理论及人们的经验期望值相一致。
3统计检验:(1) 拟合优度检验:得出样本回归方程较好的拟合了样本观测值。
(2) F 检验:F=72.9065>4.46,所以回归方程是显著的.(3) t 检验:t1=10.5479>2.306即1β显著不等于0;9213.02-=t <2.306不能否定02=β即x2不能作为解释变量进入模型.4预测eq02/resids在2000年我国城镇居民家庭人均可支配收入为5800,耐用消费价格指数为135,进行预测可得2000Y 的置信度为0.95的预测区间为(267.2001,376.7605)4.31对CES 函数进行线性化处理,再用最小二乘法做参数估计:eq02/stats.得出回归方程:2)]([0602.00293.11693.17145.8)(LK Ln LnL LnK LnGDP -++-=分别得到A m ,,ρδ的估计值A=0.00016、δ=0.5318、ρ=0.2199、m=2.1986.2 预测:eq02/resids最后得出CES 的生产函数为2199.01986.22199.02199.0]4682.05318.0[00016.0---+=L KGDP当2199.0=ρ时得出K 与L 的替代弹性8197.0=σ5.51建立计量经济模型i i i u X Y ++=10ββ用普通最小二乘法估计:eq03。
李子奈《计量经济学》考试试卷(48)

某财经学院李子奈《计量经济学》课程试卷(含答案)__________学年第___学期考试类型:(闭卷)考试考试时间:90 分钟年级专业_____________学号_____________ 姓名_____________1、判断题(3分,每题1分)1. 消除序列相关的一阶差分变换假定自相关系数ρ必须等于1。
()正确错误答案:正确解析:消除序列相关的一阶差分变换假定自相关系数ρ=1,即假设随机干扰项之间是完全正序列相关的,这样广义差分方程就转化为一阶差分方程。
2. 随机干扰项μi和残差项ei是一回事。
()正确错误答案:错误解析:随机干扰项是针对总体回归模型而言的,它是模型中其他没有包含的因素的综合体;而残差项是针对样本回归模型而言的,它是实际观测值与样本回归线上值的离差。
两者的含义不同,后者只能说成是对前者的一个估计。
3. 在C-D生产函数Y=AKαLβ中,α和β分别是劳动与资本的产出弹性。
()正确错误答案:错误解析:在C-D生产函数Y=AKαLβ中,α和β分别是资本与劳动的产出弹性。
2、名词题(5分,每题5分)1. 总体回归函数答案:总体回归函数是指在给定量下Y,分布的总体均值与X所形成的函数关系(或者说将总体被解释变量的条件期望表示为解释变量的某种函数)。
由于变量间关系的随机性,回归分析关心的是根据解释变量的已知或给定值,考察被解释变量的总体均值,即当解释变量取某个确定值时,与之统计相关的被解释变量所有可能出现的对应值的平均值。
解析:空3、简答题(25分,每题5分)1. 表3-1列出了某地区家庭人均鸡肉年消费量Y,与家庭月平均收入X,鸡肉价格P1,猪肉价格P2与牛肉价格P3的相关数据。
表3-1(1)求出该地区关于家庭鸡肉消费需求的如下模型:lnY=β0+β1lnX+β2lnP1+β2lnP2+β3lnP3+μ(2)请分析,鸡肉的家庭消费需求是否受猪肉及牛肉价格的影响?答案:(1)Eviews软件的回归结果如图3-1所示。
李子奈《计量经济学》课后习题详解(非经典截面数据计量经济学模型)【圣才出品】

李子奈《计量经济学》课后习题详解(非经典截面数据计量经济学模型)【圣才出品】第6章非经典截面数据计量经济学模型1.在经典截面数据计量经济学模型中,通常选择哪些类型的数据作为样本数据?对被解释变量样本数据有哪些假定?答:(1)在经典的截面数据计量经济学模型中,通常选择横截面数据作为样本数据。
(2)对被解释变量的样本数据,通常有以下假定:①假定被解释变量都是连续型的随机抽取的变量;②假定被解释变量和随机干扰项所服从的分布类型是一致的;③假定得到的被解释变量的样本观测值可以完全反映被解释变量的实际状态。
2.某一截面数据计量经济学模型Y i=β′X i+μi,被解释变量服从正态分布,其样本观测值为Y1,Y2,…,Y n,其中Y1,Y2,Y3取相同的值α,其他观测值均大于α。
分别将该组样本看作未受限制的随机抽取样本、以α为截断点的选择性样本、以α为归并点的选择性样本,分别采用最大似然法估计模型。
(1)写出3种情况下的对数似然函数表达式。
(2)比较3种情况下对数似然函数值的大小,并加以简单证明。
解:(1)①在假设该组样本为未受限制的随机抽样样本时,其似然函数为:()()()()()()()223222141221/212/21,,,,212ii ni i i i i Y X n n na X Y X n nL P Y Y Y eeβσββσβσπσπσ==--??--+-∑∑∑===对该似然函数方程的左右两边分别取对数,可得其对数似然函数表达式为:()()()32222141ln ln 222ni i i i i n L a X Y X πσββσ==??=---+-??∑∑②当假设所取的样本为以α为截断点的选择性样本时,其似然函数为:()()224431ln ln 2ln 122nni iii i a X n L YX βπσβσσ==?-?-??=-----Φ?? ????∑∑③当假设所取的样本为以α为归并点的选择性样本时,Y i 的概率密度似然函数分为两部分为两部分,一部分是Y i =α的前三个点,其概率密度函数为:()()i i i i a X P Y P a X βαμβσ-??==≤-=Φ另一部分是后n -3个点,他们服从正态分布N (X i β,σ2),其概率密度函数为:()()2221i i Y X i f Y eβσ--=于是,当假设所取的样本为以α为归并点的选择性样本时,有如下似然函数:()()2322141,i i Y X ni i i a X L e βσββσσ-==??-??=∏Φ?∏相应的对数似然函数为:()()32224131ln ln 2ln 22ni iii i a X n L Y X βπσβσσ==--??=---+Φ ∑∑(2)①比较截断模型与归并模型的对数最大似然函数值。
计量经济李子奈第三版154第九题作业:序列相关实验
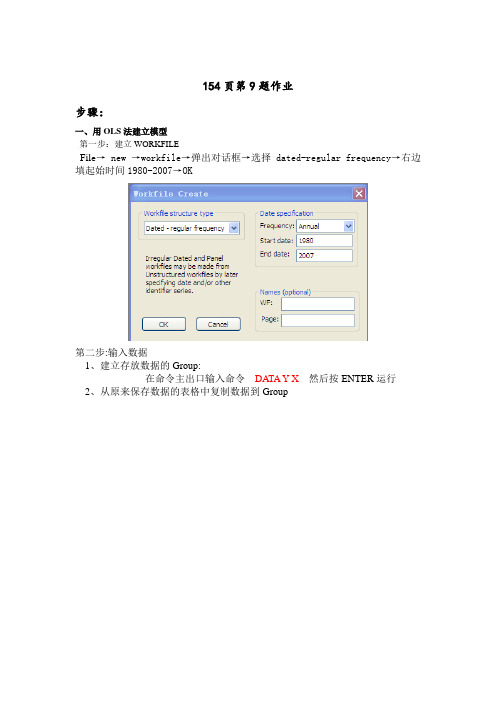
154页第9题作业步骤:一、用OLS法建立模型第一步:建立WORKFILEFil e→ new →workfile→弹出对话框→选择dated-regular frequency→右边填起始时间1980-2007→OK第二步:输入数据1、建立存放数据的Group:在命令主出口输入命令DATA Y X然后按ENTER运行2、从原来保存数据的表格中复制数据到Group第三步:软件操作OLS法主命令窗口输入:LS log(Y) C log(X) 按ENTER运行注意:一定要看清楚模型的设定,到底哪个是自变量,哪个是因变量,变量的形式是如何的,比如是否取对数回归。
结果如图所示:普通最小二乘法的估计结果如下:.1=5885ln+.08544XY ln11.8459 60.0906(0.0000)(0.0000)R2=0.9929 D.W.=0.3793 F=3601.8785 RSS=0.3282 估计结果显示,lnY变化的99.29%可由lnX的变化来解释,模型拟合程度很好。
在1%的显著性水平下,lnX的参数显著,参数为0.8544,其经济意义表示全社会固定投资的对数增加1%,工业增加值的对数增加0.755%。
2、检验模型是否存在序列相关第一种方法:图示法第一步:求原来模型的参差项(e~的值)i只要对原来的模型进行普通最小二乘估计就可以求的残差项,残差项在系统中默认为resid.Resid的位置在workfile窗口,如下图所示。
第二步:生成随机干扰项序列E命令窗口输入:genr e=resid 然后按enter运行或者手动操作:workfile界面点genr →对话框输入:e=resid → ok第三步:画图1、画残差e与时间的图Quick→Graph→弹出对话框→输入year(横轴) →resid^2(纵轴) →OK→下拉菜单选 scatter diagram→ok (结果如下图)2、e和e(-1)的相关图操作:主界面点Quick → Graph →对话框输入:e(-1) e →ok →下拉菜单选Scatter Diagram → ok结果如下图所示:从上图可以看出残差的点大多数落在第一象限和第三象限,表明随机误差项存在正序列相关。
李子奈版计量经济学作业

中国1980-2000年投资总额X 与工业总产值Y 的统计资料如表所示,试问: (1) 当设定模型为01ln ln t t t Y X ββμ=++时,是否存在序列关?(2) 若按一阶自相关假设1t t t μρμε-=+,试用杜宾两步法与广义最小二乘法估计原模型。
(3) 采用差分形式**1t t t 1Y Y Y t t t X X X --=-=-与作为新数据,估计模型**01t t t Y X ααυ=++,该模型是否存在序列相关?(1)先用最小二乘法回归,得到以下回归结果。
Dependent Variable: LOG(Y) Method: Least Squares Date: 04/13/09 Time: 20:55 Sample: 1980 2000 Included observations: 21Variable Coefficient Std. Error t-Statistic Prob.C 1.452109 0.190925 7.605641 0.0000 LOG(X)0.8704190.02172740.061860.0000R-squared0.988300 Mean dependent var 9.031179 Adjusted R-squared 0.987684 S.D. dependent var 1.062296 S.E. of regression 0.117889 Akaike info criterion -1.347752 Sum squared resid 0.264059 Schwarz criterion -1.248273 Log likelihood 16.15139 F-statistic 1604.952 Durbin-Watson stat0.451709 Prob(F-statistic)0.000000得到如下方程:Ln(Y) = 1.45210911 + 0.8704188768*Ln(X)进行序列相关性检验 1) 残差图分析:点击EViews 方程输出窗口的按钮Resids 可得到残差图在残差图中,残差的变动有系统模式,连续为正和连续为负,表明残差项存在正自相关,模型中t 统计量和F 统计量的结论不可信,需采取补救措施。
李子奈计量经济学课件 Eviews使用介绍 第二章 回归分析基本方法

2、回归分析的基本概念
回归分析(regression analysis)是研究一个变量关于另一个 回归分析 是研究一个变量关于另一个 变量的具体依赖关系的计算方法和理论。 (些)变量的具体依赖关系的计算方法和理论 其用意:在于通过后者的已知或设定值,去估计和(或)预 其用意:在于通过后者的已知或设定值,去估计和( 测前者的(总体)均值。 测前者的(总体)均值 这里:前一个变量被称为被解释变量(Explained Variable) 被解释变量( 被解释变量 ) 或应变量(Dependent Variable), 应变量( ),后一个(些)变量被称为解 应变量 ), 解 Variable) 自变量 自变量( 释变量( 释变量(Explanatory Variable)或自变量(Independent Variable)。 ) 回归分析构成计量经济学的方法论基础,其主要内容包括: 回归分析构成计量经济学的方法论基础,其主要内容包括: (1)根据样本观察值对经济计量模型参数进行估计,求得回 回 归方程; 归方程; (2)对回归方程、参数估计值进行显著性检验; ) (3)利用回归方程进行分析、评价及预测。
总体回归模型n个随机方程的矩阵表达式为 总体回归模型 个随机方程的矩阵表达式为 个随机方程的矩阵表达式
Y = X β+ μ
其中
1 1 X = M 1 X 11 X 12 M X 1n X 21 X 22 M X 2n L L L X k1 X k2 M X kn n × ( k +1 )
二、一元总体回归函数
回归分析关心的是根据解释变量的已知或 回归分析关心的是根据解释变量的已知或 给定值,考察被解释变量的总体均值,即当解 给定值,考察被解释变量的总体均值 释变量取某个确定值时,与之统计相关的被解 释变量所有可能出现的对应值的平均值。
(李子奈计量经济学配套课件)2.5 实例:时间序列(Eviews简介)

采用Eviews软件 软件进行回归分析的结果见下表 软件
的回归( 表 2.5.2 中国居民人均消费支出对人均 GDP 的回归(1978~2000) ) LS // Dependent Variable is CONSP Sample: 1978 2000 Included observations: 23 Variable C GDPP1 Coefficient 201.1071 0.386187 Std. Error 14.88514 0.007222 t-Statistic 13.51060 53.47182 Prob. 0.0000 0.0000 905.3331 380.6428 7.092079 7.190818 2859.235 0.000000
R-squared 0.992709 Adjusted R-squared 0.992362 S.E. of regression 33.26711 Sum squared resid 23240.71 Log likelihood -112.1945 Durbin-Watson stat 0.550288
表 2.5.1 中国居民人均消费支出与人均 GDP(元 /人) ( 人 年份 人均居民消费 CONSP 395.8 437.0 464.1 501.9 533.5 572.8 635.6 716.0 746.5 788.3 836.4 779.7 人均GDP GDPP 675.1 716.9 763.7 792.4 851.1 931.4 1059.2 1185.2 1269.6 1393.6 1527.0 1565.9 年份 人均居民消费 CONSP 797.1 861.4 966.6 1048.6 1108.7 1213.1 1322.8 1380.9 1460.6 1564.4 1690.8 人均GDP GDPP 1602.3 1727.2 1949.8 2187.9 2436.1 2663.7 2889.1 3111.9 3323.1 3529.3 3789.7
计量经济学实验二--李子奈

实验二 可化为线性的非线性回归模型估计、受约束回归检验及参数稳定性检验一 实验目的:(1)掌握可化为线性的非线性回归模型的估计方法; (2)模型参数的线性约束检验方法; (3)掌握Chow 检验的基本原理和主要用途;(4)掌握Chow 分割点检验和Chow 预测检验的操作过程,判断分割点。
二 实验要求:应用教材P83例子3.5.1做可化为线性的非线性回归模型估计,利剑受约束回归检验,掌握Chow 稳定性检验。
三 实验原理:普通最小二乘法、模型参数线性受约束检验法、Chow 检验法。
四 预备知识:最小二乘估计原理、t 检验、F 检验、Chow 检验。
五 实验内容:下表列出了中国某年按行业分的全部制造业国有企业及规模以上制造业非国有企业的工业总产值Y ,资产合计K 及职工人数L 。
Y Ak l eαβμ=(1)利用上述资料,进行回归分析。
(2)回答:中国概念的制造总体呈现规模报酬不变状态吗?六 实验步骤:建立工作文件并导入全部数据,如图 1所示 (1)设定并估计可化为线性的非线性回归模型:0lnY alnK lnL ββμ=+++在Eviews 软件下,点击主界面菜单Qucik/Estimate Equation ,在弹出的对话框中输入log(Y) C log(K) log(L),点击确定即可得到回归结果,如图2所示。
根据图2中的数据,得到模型的估计结果为:ln 1.15399 0.60924ln K 0.360807lnLY ∧=++(1.586) (3.454) (1.790)R 2=0.809925 2R =0.796348 D.W.=0.793209∑e i 2=5.070303 F=59.65501 df=(2,28)随机干扰项的方差估计值为:2ˆσ=()2i e /n 3∑-=5.070303/28=0.18108225 回归结果表明,这一年lnY 变化的81%可由lnK 和lnL 的变化来解释。
《计量经济学》李子奈第三版课后习题Eviews实验报告
《计量经济学》实验报告实验一:EViews5.0软件安装及基本操作1.Eviews5.0的安装过程解压安装包,双击“Setup.exe”,选择安装路径进行安装;安装完毕后,复制“eviews5.0破解文件夹”下的“eviews5.reg文件”和“eviews5.exe文件”到安装目录下;双击“Eviews5.reg”进行注册,安装完毕。
2.基本操作(数据来源于李子奈版课后习题P61.12)运行Eviews,依次单击file→new→work file→unstructed→observation 31。
命令栏中输入“data y gdp”,打开“y gdp”表,接下来将数据输入其中。
做出“y gdp”的散点图,依次单击quick→graph→scatter→gdp y。
结果如下:开始进行LS回归:回归方程为:Y = -10.39340931 + 0.0710********GDP对回归方程做检验:斜率项t值9.59大于t在5%显著水平下的检验值2.045,拒绝零假设;截距项t 值0.121小于2.045,接受零假设。
可决系数0.76,拟合较好,方程F检验值91.99通过F检验。
下面进行预测:拓展工作空间:打开work file窗口,单击 Proc→Structure,将End date 的数据31→32;确定预测值的起止日期:打开work file窗口,点击Quick→Sample,填入“1 32”。
打开GDP数据表,在GDP的最下方填,按回车键。
在出现的Equation界面,点击Forecast出现相应界面如下:实验二:回归模型的建立与检验(数据来源于李子奈版课后习题P105.11)运行Eviews,依次单击file→new→work file→unstructed→observation 10。
命令栏中输入“data y x1 x2”,打开“y x1 x2”表,接下来将数据输入其中。
开始进行LS回归:估计方程:依次单击view→representations,得到回归方程为:Y = 626.5092847 - 9.790570097*X1 + 0.028*********X2,参数估计完毕。
计量经济学 李子奈 课程设计
表明可建立如下中国居民消费函数:Y^=2091.29+0.4375X 可决系数R2 =0.9880,截距项与斜率的 t 检验值均大于 5%显著性水平下自由度为 n-2=27 的临界值t 0.025 (27)=2.05,且斜率项符合经济理论中边际消费倾向在 0 与 1 之间的绝对收入假说,斜率项 0.438 表明,在 1978—2006 年间,以 1990 年 价计的中国居民可支配总收入每增加 1 亿元,居民总量消费支出平均增加 0.438 亿元。 预测:2007 年,以当年计价的中国 GDP 为 263242.5 亿元,税收入总额 45621.9 亿元,居民消费价格指数为 409.1,由此可得到以 1990 年价计的可支配总收入 X 约 95407.4 亿元,由上述回归方程可得 2007 年居民总量消费预测的点估计值: Y2007=2091.3± 0.4375*95407.4=43834.6(亿元) 下面给出 2007 年中国居民总量消费的预测区间,由于 E(X)=29174.1 Var(X) =463039370 在 95%置信度下,E(Y2007)的预测区间为 43834.6 ± 2.051*
Y 4.17 0.381 ln x1 1.222 ln x 2 0.081 ln x3 0.048 ln x 4 0.102 ln x5
(-2.16) (7.59) (9.03) (-5.30) (-1.06) D.W.=1.79 (-1.76)
R =0.9816
2
R2 =0.9768
讨论:第一步,在初始模型中引入 X2,模型拟合优度提高,且参数符号合理, 变量也通过了 t 检验,D.W.检验也表明不存在 1 阶序列相关性; 第二步,引入 X3,拟合优度再次提高,且参数符号合理,变量也通过了 t 检验;只是 D.W.值落入了无法判断的区域,但由 LM 检验知仍不存在 1 阶自相关 性; 第三步,引入 X4,修正的拟合优度反而略有下降,同时 X4 的参数未能通过 t 检验; 第四步, 去掉 X4, 引入 X5, 拟合优度虽有提高, 但 X5 参数未能通过 t 检验, 且参数符号与经济意义不符。 第三步与第四步表明,X4 与 X5 是多余的,同样还可以继续验证,如果用与 X1 高度相关的 X4 替代 X1,则 X4 与 X2,X3,X5 间的任意线性组合,均达不高 以 X1, X2, X3 为解释变量的回归效果。 因此, 最终的粮食生产函数应以 Y=f (X1, X2,X3)为最优,拟合结果如下 lnY=-5.996+0.323lnX1+1.290lnX2-0.087lnX3
计量的eviews软件的使用例题

1.建立深圳地方预算内财政收入对GDP的回归模型,建立EViews文件。
可作散点图:可看出财政收入和GDP的关系近似直线关系,可建立回归模型:=i Y i i 21μββ++GDP利用EViews 估计其参数结果为即 =i γ-3.611151+0.134582GDP i(4.16179) (0.003867)t=(-0.867692) (34.80013)R=0.99181 F=1211.049经检验说明,GDP 对地方财政收入确有显著影响。
R=0.99181,说明GDP 解释了地方财政收入变动的99%,模型拟合程度较好。
模型说明当GDP 每增长1亿元,平均说来地方财政收入将增长0.134582亿元。
当2005年GDP 为3600亿元时,地方财政收入的点预测值为=2005Y -3.611151+0.134582*3600=480.884(亿元)区间预测: 平均值为:∑x x i σ=(n-1)=587.2686*587.2686*(12-1)=3793728.494 (3600-917.5874)*(3600-917.5874)=7195337.357取∂=0.05,Y 平均值置信度95%预测区间为2005GDP =3600时 480.884±2.228*7.5325*494.3293728357.7195337121+=44±25.2735(亿元) Y 个别值置信度95%的预测区间为:即 480.884±2.228*7.5325*494.3293728357.71953371211++=480.884±30.3381(亿元)2. 呈现负相关关系,计算线性相关系数为-0.882607.作散点图:建立描述投诉率(Y )依赖航班按时到达正点率(X )的回归方程:i t 21t μββ++=X Y利用EViews 估计其参数结果为即t Y=6.017832-0.070414t X(1.017832)(-0.014176)t=(5.718961)(-4.967254)R=0.778996 F=24.67361这说明当航班正点到达比率每提高1个百分点,平均说来每10万名乘客投诉次数将下降0.07次。
计量经济学实验七--李子奈
实验七分布滞后模型与自回归模型及格兰杰因果关系检验一实验目的:掌握分布滞后模型与自回归模型的估计与应用,将我格兰杰因果关系检验方法,熟悉Eviews的基本操作。
二实验要求:应用教材P187习题6案例,做有限分布滞后模型的估计、格兰杰因果关系检验。
三实验原理:普通最小二乘法、阿尔蒙法、格兰杰因果关系检验、LM检验。
四预备知识:普通最小二乘法估计的原理、t检验、拟合优度检验、阿尔蒙法、多项式近似。
五实验内容:1970~1991年美国制造业固定厂房设备投资Y和销售量X的相关数据如下表所示。
单位:10 亿美元(1)假定销售量对厂房设备支出有一个分布滞后效应,使用4期滞后和2次多项式去估计此分布滞后模型;(2)检验销售量与厂房设备支出的格兰杰因果关系,使用直至6期为止的滞后并评述你的结果。
六实验步骤:6.1 建立工作文件并录入数据,如图1所示图 16.2 使用4期滞后2次多项式估计模型在工作文件中,点击Quick\Estimate Equation …,然后在弹出的对话框中输入:Y C PDL(X,4,2),点击OK ,得到如图2所示的回归分析结果。
其中,“PDL 指令”表示进行多项式分布滞后(Ploynamial Distributed Lags)模型的估计,X 为滞后序列名,4表示滞后长度,2表示多项式次数。
由图2中的数据,我们得到估计结果如下:01230825540.0117400.2362370.092921( 3.457)(0.087)( 3.476)(1.370)t t t tY W W W ∧=---+---20.981227R = 20.977204R = .. 1.358472D W = 243.9194F = 642.8093RSS =最后得到的分布滞后模型估计式为:123430.825540.832420.317420.011740.155060.11253( 3.457)(4.382)(3.242)(0.087)( 1.679)(0.573)t t t t t t Y X X X X X ∧----=-++-------图 2图2所示输出结果的上半部分格式与一般的回归方程相同,给出了模型参数估计值、t 检验统计量值及对应的概率值,以及模型的其他统计量。
计量经济学实验五--李子奈
实验五 自相关性一 实验目地:掌握自相关性模型的检验方法与处理方法二 实验要求:应用教材P155习题9案例做自相关性模型的图形法检验和DW检验,使用广义最小二乘法和广义差分法进行修正。
三 实验原理:图形法检验、DW 检验、广义最小二乘法和广义差分法。
四 预备知识:最小二乘法、DW 检验、广义最小二乘法和广义差分法。
五 实验内容:中国1980~2007年全社会固定资产投资总额X 与工业总产值Y 的统计资料如下表所示。
试问:(1)当设定模型为01ln ln t t t Y X ββμ=++时,是否存在序列相关性? (2)若按一阶自相关假设1t t t μρμε-=+,试用广义最小二乘法估计原模型。
(3)采用差分形式*1t t t X X X -=-与*1tt t Y Y Y -=-作为新数据,估计模型**01t t t Y X ααυ=++,该模型是否存在序列相关?六 实验步骤:在经济系统中,经济变量前后期之间很可能有关联,使得随机误差项不能满足无自相关性的假设。
本案例将探讨随机误差项不满足无自相关性的古典假定的参数估计问题。
着重讨论自相关性模型的图形法检验、DW 检验与广义最小二乘估计和广义差分法。
6.1 建立Workfile 和对象,录入1980—2007年全社会固定资产投资X 以及工业增加值Y ,如图1所示。
图 1 图 26.2 参数估计、检验模型的自相关性 6.2.1 参数估计设定模型为01ln ln t t t Y X ββμ=++点击主界面菜单Quick\Estimate Equation ,在弹出的对话框中输入log(Y) C log(X),点击确定即可得到回归结果,如图2所示。
根据图2中数据,得到模型的估计结果为:ln 1.58850.8544ln (11.83)(60.09)t tY X ∧=+20.992851R = 20.992576R = ..0.379323D W =3610.878F = 0.328192RSS =该回归方程的可决系数较高,回归系数显著。
计量经济学-李子奈-课程设计

P53例2.6.1为考察中国城镇居民2006年人均可支配收入与消费支出的关系,题中给出中国31个省区以当年价测算的城镇居民家庭年人均收入(X)与年人均支出(Y)两组数据,该题目为截面数据。
首先建立模型,一元回归模型为Y=β0+β1X+μ可以写出分析结果Yî=281.50+0.7146Xi;R Square为决定系数,为0.9714,F为985.66, D.W.=1.46从R2看出,居民人均消费支出变化的97.14%可由人均可支配收入的变化来解释。
从斜率项的t检验值看,大于5%显著性水平下自由度为n-2=29的临界值t0.025(29)=2.05,且该斜率值满足0<0.7146<1,符合经济理论中边际消费倾向在0与1之间的绝对收入假说,表明2006年,中国城镇居民家庭人均可支配收入每增加1元,人均消费支出增加0.7146元预测:假设要关注2006年人均可支配收入在20000元这一档的中国城镇家庭的人均消费支出问题,由上述回归方程可得该类家庭人均消费支出的预测值为Y0̂=281.50+0.7146*20000=14572.6(元)下面给出该家庭人均消费支出95%置信预测区间E(X)=11363.69 Var(X)=10853528则E(Y0)置信区间为14572.6±2.045*√489138831−2∗[131+(20000−11363.69)2(31−1)∗10853528]=14572.6±429.3或(14143.3,15001.9)同样的,在95%置信度下,该家庭人均消费支出的预测区间为14572.6±2.045*√489138831−2∗[1+131+(20000−11363.69)2(31−1)∗10853528]=14572.6±943.2或(13629.3,15515.8)P56例2.6.2表中给出了中国名义支出法国内生产总值GDP、名义居民总消费CONS以及表示宏观税赋的税收总额TAX、表示价格变化的居民消费价格指数CPI (1990=100),并由这些数据整理出实际支出法国内生产总值GDPC=GDP/CPI、居民实际消费总支出Y=CONS/CPI,以及实际可支配收入X=(GDP-TAX)/CPI。
中级计量经济学-第四章-习题以及解答思路(EViews)

中级计量经济学-第四章-习题以及解答思路(EViews)第4章习题一表1给出了1965~1970年美国制造业利润和销售额的季度数据。
假定利润不仅与销售额有关,而且和季度因素有关。
要求对下列二种情况分别估计利润模型:(1)如果认为季度影响使利润平均值发生变异,应如何引入虚拟变量?(2)如果认为季度影响使利润对销售额的变化率发生变异,如何引入虚拟变量?表1Quarterly 65-70Quick- Equation EstimationY c x @seas(1) @seas(2) @seas(3)Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 18:38Sample: 1965Q1 1970Q4Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C6868.0151892.766 3.6285590.0018 X0.0382650.011483 3.3322520.0035 @SEAS(1)-182.1690654.3568-0.2783940.7837 @SEAS(2)1140.294630.6806 1.8080380.0865 @SEAS(3)-400.3371636.1128-0.6293490.5366R-squared0.525596Mean dependentvar12838.54Adjusted R-squared0.425721S.D. dependentvar1433.284S.E. of regression1086.160Akaike infocriterion17.00174Sum squared resid22415107Schwarz criterion17.24716 Log likelihood-199.0208F-statistic 5.262563Durbin-Watson stat0.388380Prob(F-statistic)0.005024T和P在5%情况下都不通过,第二季度相对还好一点假设第二季度显著,结果的经济含义是什么?Y c x @seas(2) @seas(3) @seas(4)Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 18:47Sample: 1965Q1 1970Q4Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C6685.8461711.618 3.9061550.0009 X0.0382650.0114833.3322520.0035 @SEAS(2)1322.463638.4258 2.0714440.0522 @SEAS(3)-218.1681632.1991-0.3450940.7338@SEAS(4)182.1690654.35680.2783940.7837R-squared0.525596Mean dependentvar12838.54Adjusted R-squared0.425721S.D. dependentvar1433.284S.E. of regression1086.160Akaike infocriterion17.00174Sum squared resid22415107Schwarz criterion17.24716 Log likelihood-199.0208F-statistic 5.262563Durbin-Watson stat0.388380Prob(F-statistic)0.005024第二季度依旧显著影响四种都试一下(去掉一个季节),选一个最显著的124Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 18:51Sample: 1965Q1 1970Q4Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C6467.6781789.178 3.6148880.0018 X0.0382650.011483 3.3322520.0035 @SEAS(1)218.1681632.19910.3450940.7338 @SEAS(2)1540.632628.3419 2.4519000.0241 @SEAS(4)400.3371636.11280.6293490.5366R-squared0.525596Mean dependentvar12838.54Adjusted R-squared0.425721S.D. dependentvar1433.284S.E. of regression1086.160Akaike infocriterion17.00174Sum squared resid22415107Schwarz criterion17.24716 Log likelihood-199.0208F-statistic 5.262563Durbin-Watson stat0.388380Prob(F-statistic)0.005024134Dependent Variable: Y Method: Least SquaresDate: 11/26/14 Time: 18:52 Sample: 1965Q1 1970Q4 Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C8008.3091827.543 4.3820090.0003 X0.0382650.011483 3.3322520.0035 @SEAS(1)-1322.463638.4258-2.0714440.0522 @SEAS(3)-1540.632628.3419-2.4519000.0241 @SEAS(4)-1140.294630.6806-1.8080380.0865R-squared0.525596Mean dependentvar12838.54Adjusted R-squared0.425721S.D. dependentvar1433.284S.E. of regression1086.160Akaike infocriterion17.00174Sum squared resid22415107Schwarz criterion17.24716 Log likelihood-199.0208F-statistic 5.262563Durbin-Watson stat0.388380Prob(F-statistic)0.005024(2)Y=c+βx+α1D1X+α2D2X+α3D3XD1=1(第一季度)0(其他)Y c x @seas(1)*x @seas(2)*x @seas(3)*xDependent Variable: Y Method: Least SquaresDate: 11/26/14 Time: 19:00 Sample: 1965Q1 1970Q4 Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C6965.8521753.642 3.9722200.0008 X0.0373630.011139 3.3542150.0033 @SEAS(1)*X-0.0008930.004259-0.2095880.8362 @SEAS(2)*X0.0077120.003962 1.9465020.0665 @SEAS(3)*X-0.0022910.004041-0.5669850.5774R-squared0.528942Mean dependentvar12838.54Adjusted R-squared0.429771S.D. dependentvar1433.284S.E. of regression1082.323Akaike infocriterion16.99466Sum squared resid22257030Schwarz criterion17.24009 Log likelihood-198.9359F-statistic 5.333675Durbin-Watson stat0.418713Prob(F-statistic)0.004722Dependent Variable: Y Method: Least SquaresDate: 11/26/14 Time: 19:10 Sample: 1965Q1 1970Q4 Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C8008.3091827.543 4.3820090.0003 X0.0382650.011483 3.3322520.0035 @SEAS(1)-1322.463638.4258-2.0714440.0522 @SEAS(3)-1540.632628.3419-2.4519000.0241 @SEAS(4)-1140.294630.6806-1.8080380.0865R-squared0.525596Mean dependentvar12838.54Adjusted R-squared0.425721S.D. dependent 1433.284varS.E. of regression1086.160Akaike infocriterion17.00174Sum squared resid22415107Schwarz criterion17.24716 Log likelihood-199.0208F-statistic 5.262563Durbin-Watson stat0.388380Prob(F-statistic)0.005024Dependent Variable: Y Method: Least SquaresDate: 11/26/14 Time: 19:11 Sample: 1965Q1 1970Q4 Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C6965.8521753.642 3.9722200.0008 X0.0350720.011790 2.9746750.0078 @SEAS(1)*X0.0013980.0042410.3297360.7452 @SEAS(2)*X0.0100030.004068 2.4588230.0237 @SEAS(4)*X0.0022910.0040410.5669850.5774R-squared0.528942Mean dependentvar12838.54Adjusted R-squared0.429771S.D. dependentvar1433.284S.E. of regression1082.323Akaike infocriterion16.99466Sum squared resid22257030Schwarz criterion17.24009 Log likelihood-198.9359F-statistic 5.333675Durbin-Watson stat0.418713Prob(F-statistic)0.004722Dependent Variable: Y Method: Least SquaresDate: 11/26/14 Time: 19:11 Sample: 1965Q1 1970Q4 Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C6965.8521753.642 3.9722200.0008 X0.0364710.012353 2.9524150.0082 @SEAS(2)*X0.0086040.004237 2.0305390.0565 @SEAS(3)*X-0.0013980.004241-0.3297360.7452@SEAS(4)*X0.0008930.0042590.2095880.8362R-squared0.528942Mean dependentvar12838.54Adjusted R-squared0.429771S.D. dependent 1433.284varS.E. of regression1082.323Akaike infocriterion16.99466Sum squared resid22257030Schwarz criterion17.24009 Log likelihood-198.9359F-statistic 5.333675Durbin-Watson stat0.418713Prob(F-statistic)0.004722。
计量经济学 案例分析 Eviews
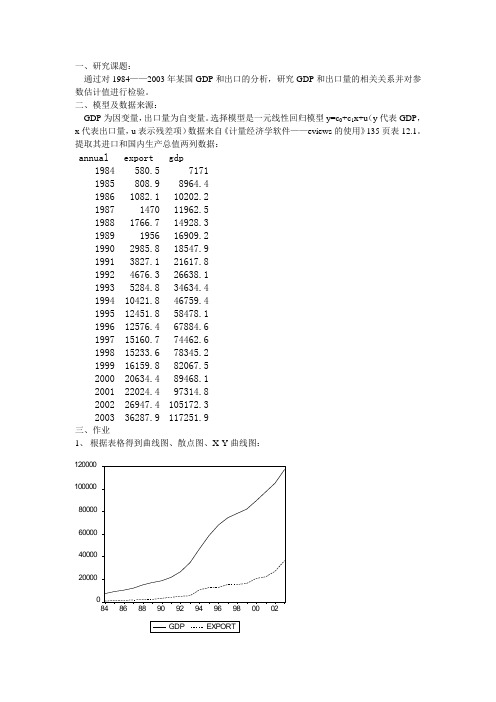
一、研究课题:通过对1984——2003年某国GDP和出口的分析,研究GDP和出口量的相关关系并对参数估计值进行检验。
二、模型及数据来源:GDP为因变量,出口量为自变量。
选择模型是一元线性回归模型y=c0+c1x+u(y代表GDP,x代表出口量,u表示残差项)数据来自《计量经济学软件——eviews的使用》135页表12.1。
提取其进口和国内生产总值两列数据:annual export gdp1984 580.5 71711985 808.9 8964.41986 1082.1 10202.21987 1470 11962.51988 1766.7 14928.31989 1956 16909.21990 2985.8 18547.91991 3827.1 21617.81992 4676.3 26638.11993 5284.8 34634.41994 10421.8 46759.41995 12451.8 58478.11996 12576.4 67884.61997 15160.7 74462.61998 15233.6 78345.21999 16159.8 82067.52000 20634.4 89468.12001 22024.4 97314.82002 26947.4 105172.32003 36287.9 117251.9三、作业1、根据表格得到曲线图、散点图、X-Y曲线图:1200001000008000060000400002000084868890929496980002曲线图05000010000015000010000200003000040000EXPORTG D P散点图20000400006000080000100000120000100002000030000EXPORTG D PX-Y 曲线图2、数据描述统计分析024681001234563、简单的回归估计Dependent Variable: GDP Method: Least Squares Date: 06/14/09 Time: 16:38 Sample: 1984 2003 Variable Coefficient Std. Error t-Statistic Prob. C 11772.77 2862.419 4.112873 0.0007 R-squared0.946953 Mean dependent var 49439.02 Adjusted R-squared 0.944006 S.D. dependent var 36735.19 S.E. of regression 8692.656 Akaike info criterion 21.07298 Sum squared resid1.36E+09 Schwarz criterion21.17256Log likelihood -208.7298 F-statistic 321.3229Durbin-Watson stat 0.604971 Prob(F-statistic) 0.000000y t=-11772.77+3.547790x t R2=0.946953 df=18检验回归系数显著性的原假设和备择假设是(给定α = 0.05)H0:c1= 0;H1:c1≠ 0。
计量经济学时间序列课后习题eviews解答

2.1980年-2013年中国全社会固定资产投资总额X与工业总额增加Y的统计资料如下:
试问:
(1)当设定模型为lnY=B0+B1lnX+u时是否存在序列相关?
(2)采用普通最小二乘法和稳定标准误差方法分别估计模型,比较参数估计的差异和它们标准差的误差,并说明稳定标准误差法克服序列相关后果的原理。
(3)若原模型存在序列相关性,试用广义最小二乘法估计模型。
(1)1.图示法
从图中可以残差项的变化图形判断随机干扰项的序列相关性为正相关。
2.原模型OLS估计
由于DW值为0.28,dL(k=2,T=34)=1.39
DW值小于dL,应此可以判断模型存在序列相关。
3.LM检验
、
根据nR^2统计量对应的值得出LM=34*0.699=23.76,在5%显著性水平下存在一阶序列相关性。
再继续LM检验的2阶序列相关性检验,发现在5%显著性水平下,原模型存在2阶序列相关性,但在t-test中,RESID(-2)的参数为0的假设。
故不存在2阶序列相关性。
(2)序列相关稳健标准误差法
与原模型OLS估计对比
发现变量X的对应参数修正后的标准差OLS结果有所增大,表明原模型OLS估计结果低估了X的标准差。
(3)广义最小二乘法估计
由于LM检验只要一阶序列相关性,故:
估计的原回归模型可以写为:。