数据结构与算法实验报告5-查找与排序
查找和排序算法实验报告

查找和排序算法实验报告一、实验目的本次实验的主要目的是深入理解和掌握常见的查找和排序算法,通过实际编程实现和性能比较,分析不同算法在不同数据规模和数据分布情况下的效率和优劣,为在实际应用中选择合适的算法提供依据。
二、实验环境本次实验使用的编程语言为 Python 3x,开发环境为 PyCharm。
实验中使用的操作系统为 Windows 10。
三、实验内容(一)查找算法1、顺序查找顺序查找是最基本的查找算法,从数组的一端开始,逐个比较元素,直到找到目标元素或遍历完整个数组。
```pythondef sequential_search(arr, target):for i in range(len(arr)):if arri == target:return ireturn -1```2、二分查找二分查找要求数组是已排序的。
通过不断将数组中间的元素与目标元素比较,缩小查找范围,直到找到目标元素或确定目标元素不存在。
```pythondef binary_search(arr, target):low = 0high = len(arr) 1while low <= high:mid =(low + high) // 2if arrmid == target:return midelif arrmid < target:low = mid + 1else:high = mid 1return -1```(二)排序算法1、冒泡排序冒泡排序通过反复比较相邻的元素并交换位置,将最大的元素逐步“浮”到数组的末尾。
```pythondef bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n i 1):if arrj > arrj + 1 :arrj, arrj + 1 = arrj + 1, arrj```2、插入排序插入排序将未排序的元素逐个插入到已排序的部分中,保持已排序部分始终有序。
数据结构实验五-查找与排序的实现

实验报告课程名称数据结构实验名称查找与排序得实现系别专业班级指导教师11学号姓名实验日期实验成绩一、实验目得(1)掌握交换排序算法(冒泡排序)得基本思想;(2)掌握交换排序算法(冒泡排序)得实现方法;(3)掌握折半查找算法得基本思想;(4)掌握折半查找算法得实现方法;二、实验内容1.对同一组数据分别进行冒泡排序,输出排序结果。
要求:1)设计三种输入数据序列:正序、反序、无序2)修改程序:a)将序列采用手工输入得方式输入b)增加记录比较次数、移动次数得变量并输出其值,分析三种序列状态得算法时间复杂性2.对给定得有序查找集合,通过折半查找与给定值k相等得元素。
3.在冒泡算法中若设置一个变量lastExchangeIndex来标记每趟排序时经过交换得最后位置,算法如何改进?三、设计与编码1、本实验用到得理论知识2、算法设计3、编码package sort_search;import java、util、Scanner;publicclass Sort_Search{//冒泡排序算法ﻩpublic voidBubbleSort(int r[]){int temp;ﻩint count=0,move=0;ﻩboolean flag=true;ﻩfor(int i=1;i〈r、length&&flag;i++){ﻩﻩflag=false;ﻩﻩcount++;ﻩfor(intj=0;j<r、length-i;j++){if(r[j]>r[j+1]){ﻩtemp=r[j];ﻩﻩﻩr[j]=r[j+1];r[j+1]=temp;ﻩﻩmove++;flag=true;ﻩﻩ}ﻩﻩﻩ}ﻩ}ﻩﻩSystem、out、println("排序后得数组为:”);ﻩfor(int i=0;i〈r、length;i++){ﻩﻩSystem、out、print(r[i]+" ”);ﻩ}System、out、println();ﻩSystem、out、println("比较次数为:"+count);ﻩﻩSystem、out、println("移动次数为:”+move);}ﻩpublic staticint BinarySearch(int r[],int key){//折半查找算法ﻩint low=0,high=r、length-1;ﻩwhile(low<=high){ﻩint mid=(low+high)/2;ﻩﻩif(r[mid]==key){ﻩreturn mid;ﻩﻩ}ﻩﻩelse if(r[mid]>key){high=mid—1;ﻩﻩ}ﻩﻩelse{ﻩﻩﻩlow=mid+1;ﻩﻩ}ﻩ}ﻩﻩreturn -1;ﻩ}//测试public static void main(String[]args){ﻩSort_Search ss=new Sort_Search();intt[]=new int[13];ﻩSystem、out、println(”依次输入13个整数为:");ﻩScanner sc=new Scanner(System、in);ﻩfor(int i=0;i〈t、length;i++){ﻩﻩt[i]=sc、nextInt();ﻩ}ﻩﻩSystem、out、println("排序前得数组为: ");ﻩfor(int i=0;i<t、length;i++){ﻩSystem、out、print(t[i]+"”);ﻩ}ﻩSystem、out、println();ﻩﻩss、BubbleSort(t);//查找ﻩwhile(true){ﻩﻩSystem、out、println("请输入要查找得数: ”); ﻩﻩint k=sc、nextInt();ﻩif(BinarySearch(t,k)>0)System、out、println(k+"在数组中得位置就是第:"+ BinarySearch(t,k));ﻩﻩelseﻩﻩSystem、out、println(k+”在数组中查找不到!");ﻩ}ﻩ }}四、运行与调试1.在调试程序得过程中遇到什么问题,就是如何解决得?问题:在计算比较次数与移动次数时,计算数据明显出错。
数据结构查找排序实验报告
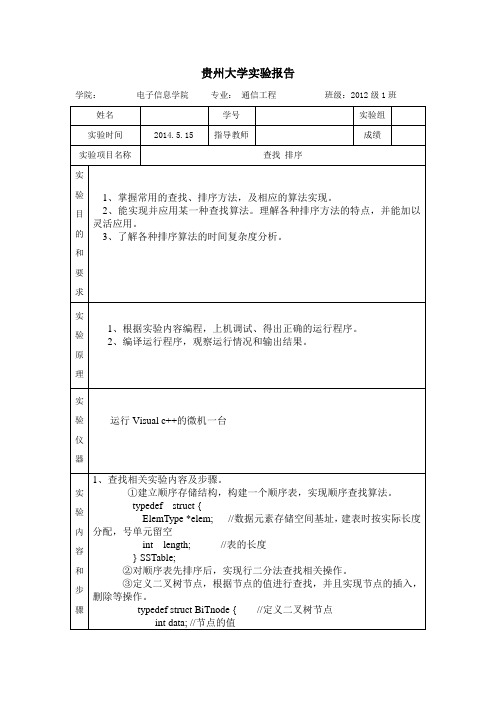
贵州大学实验报告学院:电子信息学院专业:通信工程班级:2012级1班姓名学号实验组实验时间2014.5.15 指导教师成绩实验项目名称查找排序实验目的和要求1、掌握常用的查找、排序方法,及相应的算法实现。
2、能实现并应用某一种查找算法。
理解各种排序方法的特点,并能加以灵活应用。
3、了解各种排序算法的时间复杂度分析。
实验原理1、根据实验内容编程,上机调试、得出正确的运行程序。
2、编译运行程序,观察运行情况和输出结果。
实验仪器运行Visual c++的微机一台实验内容和步骤1、查找相关实验内容及步骤。
①建立顺序存储结构,构建一个顺序表,实现顺序查找算法。
typedef struct {ElemType *elem; //数据元素存储空间基址,建表时按实际长度分配,号单元留空int length; //表的长度} SSTable;②对顺序表先排序后,实现行二分法查找相关操作。
③定义二叉树节点,根据节点的值进行查找,并且实现节点的插入,删除等操作。
typedef struct BiTnode { //定义二叉树节点int data; //节点的值struct BiTnode *lchild,*rchild;}BiTnode,*BiTree;④定义哈希表以及要查找的节点元素,创建哈希表,实现其相关查找操作。
typedef struct {int num;} Elemtype; //定义查找的结点元素typedef struct {Elemtype *elem; //数据元素存储基址int count; //数据元素个数int sizeindex;}HashTable;//定义哈希表。
2. 排序相关实验内容及步骤。
①定义记录类型。
typedef struct{int key; //关键字项}RecType;②实现直接插入排序:每次将一个待排序的记录,按其关键字大小插入到前面已排序好的子文件中的适当位置,直到全部记录插入完成为止。
数据结构中查找和排序算法实验报告

for(i=ST.length; !EQ(ST.elem[i].key,key); --i);
return i;
}
3.归并排序算法描述如下:
merge(ListType r,int l,int m,int n,ListType &r2)
{
i=l;j=m+1;k=l-1;
sift(ListType &r,int k,int m)
{
i=k;j=2*i;x=r[k].key;finished=FALSE;
t=r[k];
while((j<=m)&&(!finished))
{
if ((j<m)&&(r[j].key>r[j+1].key)) j++;
if (x<=r[j].key)
将两个或两个以上的有序表组合成一个新的有序表的方法叫归并。
假设初始序列含有n个记录,则可看成是n个有序的子序列,每个子序列的长度为1,然后两两归并,得到n/2个长度为2或1的有序子序列;再两两归并,如此重复。
4.堆排序分析:
只需要一个记录大小的辅助空间,每个待排序的记录仅占有一个存储空间。
什么是堆?n个元素的序列{k1,k2,...,kn}当且仅当满足下列关系时,称之为堆。关系一:ki<=k2i关系二:ki<=k2i+1(i=1,2,...,n/2)
静态查找表的顺序存储结构:
typedef struct {ElemType *e源自em;int length;
}SSTable;
顺序查找:从表中最后一个记录开始,逐个进行记录的关键字和给定值的比较,若某个记录的关键字和给定值比较相等,则查找成功,找到所查记录;反之,查找不成功。
数据结构与算法实验报告5-查找与排序

北京物资学院信息学院实验报告
课程名_数据结构与算法
实验名称查找与排序
实验日期年月日实验报告日期年月日姓名______ ___ 班级_____ ________ 学号___
一、实验目的
1.掌握线性表查找的方法;
2.了解树表查找思想;
3.掌握散列表查找的方法.
4.掌握插入排序、交换排序和选择排序的思想和方法;
二、实验内容
查找部分
1.实现顺序查找的两个算法(P307), 可以完成对顺序表的查找操作, 并根据查到和未查到两种情况输出结果;
2.实现对有序表的二分查找;
3.实现散列查找算法(链接法),应能够解决冲突;
排序部分
4.分别实现直接插入排序、直接选择排序、冒泡排序和快速排序算法
三、实验地点与环境
3.1 实验地点
3.2实验环境
(操作系统、C语言环境)
四、实验步骤
(描述实验步骤及中间的结果或现象。
在实验中做了什么事情, 怎么做的, 发生的现象和中间结果, 给出关键函数和主函数中的关键段落)
五、实验结果
六、总结
(说明实验过程中遇到的问题及解决办法;个人的收获;未解决的问题等)。
查找排序实验报告

查找排序实验报告一、实验目的本次实验的主要目的是深入理解和比较不同的查找和排序算法在性能和效率方面的差异。
通过实际编程实现和测试,掌握常见查找排序算法的原理和应用场景,为今后在实际编程中能够选择合适的算法解决问题提供实践经验。
二、实验环境本次实验使用的编程语言为 Python,开发环境为 PyCharm。
计算机配置为:处理器_____,内存_____,操作系统_____。
三、实验内容1、查找算法顺序查找二分查找2、排序算法冒泡排序插入排序选择排序快速排序四、算法原理1、顺序查找顺序查找是一种最简单的查找算法。
它从数组的一端开始,依次比较每个元素,直到找到目标元素或者遍历完整个数组。
其时间复杂度为 O(n),在最坏情况下需要遍历整个数组。
2、二分查找二分查找适用于已排序的数组。
它通过不断将数组中间的元素与目标元素进行比较,将查找范围缩小为原来的一半,直到找到目标元素或者确定目标元素不存在。
其时间复杂度为 O(log n),效率较高。
3、冒泡排序冒泡排序通过反复比较相邻的两个元素并交换它们的位置,将最大的元素逐步“浮”到数组的末尾。
每次遍历都能确定一个最大的元素,经过 n-1 次遍历完成排序。
其时间复杂度为 O(n^2)。
4、插入排序插入排序将数组分为已排序和未排序两部分,每次从未排序部分取出一个元素,插入到已排序部分的合适位置。
其时间复杂度在最坏情况下为 O(n^2),但在接近有序的情况下性能较好。
5、选择排序选择排序每次从待排序数组中选择最小的元素,与当前位置的元素交换。
经过 n-1 次选择完成排序。
其时间复杂度为 O(n^2)。
6、快速排序快速排序采用分治的思想,选择一个基准元素,将数组分为小于基准和大于基准两部分,然后对这两部分分别递归排序。
其平均时间复杂度为 O(n log n),在大多数情况下性能优异。
五、实验步骤1、算法实现使用Python 语言实现上述六种查找排序算法,并分别封装成函数,以便后续调用和测试。
查找和排序实验报告

附件(四)深圳大学实验报告课程名称:数据结构实验与课程设计实验项目名称:查找排序实验.学院:计算机与软件学院专业:指导教师:报告人:学号:班级:实验时间:实验报告提交时间:教务处制①②③④Problem B: 数据结构实验--二叉排序树之查找QSort(a,1,1);④(①b)low=4;high=5;6 22 55 111 333 444↑↑privotloc=4;a. QSort(a,low,pivotloc-1);QSort(a,4,3);b. QSort(a,pivotloc+1,high);QSort(a,5,5);排序完毕。
流程图:四、实验结论:1、根据你完成的每个实验要求,给出相应的实验结果图,并结合图来解析运行过程2、如果运行过程简单,只要贴出VC运行的结果图。
3、如果无结果图,有网站的判定结果,贴出相应结果Contest1657 - DS实验--静态查找Problem A: 数据结构实验--静态查找之顺序查找Sample Input833 66 22 88 11 27 44 553221199Sample Output35errorProblem B: 数据结构实验--静态查找之折半查找Sampl e Input811 22 33 44 55 66 77 883228899Sampl e Output28errorProblem C: 数据结构实验--静态查找之顺序索引查找Sampl e Input1822 12 13 8 9 20 33 42 44 38 24 48 60 58 74 57 86 53322 48 86613548405390Sampl e Output3-4error12-8error18-9errorContest1040 - DS实验--动态查找Problem A: 数据结构实验--二叉排序树之创建和插入Sample Input1622 33 55 66 11 443775010Sample Output11 22 33 44 55 6611 22 33 44 55 66 7711 22 33 44 50 55 66 7710 11 22 33 44 50 55 66 77Problem B: 数据结构实验--二叉排序树之查找Sample Input1622 33 55 66 11 44711223344556677Sample Output11 22 33 44 55 66212434-1Problem C: 数据结构实验--二叉排序树之删除Sample Input1622 33 55 66 11 443662277Sample Output11 22 33 44 55 6611 22 33 44 5511 33 44 5511 33 44 55Contest1050 - DS实验--哈希查找Problem A: 数据结构实验--哈希查找Sample Input11 23 39 48 75 626395252636352Sample Output6 1error8 1error8 18 2Contest1060 - DS实验--排序算法Problem A: 数据结构实验--希尔排序Sample Input6111 22 6 444 333 55877 555 33 1 444 77 666 2222Sample Output6 22 55 111 333 4441 33 77 77 444 555 666 2222Problem B: 数据结构实验--快速排序Sample Input26111 22 6 444 333 55877 555 33 1 444 77 666 2222Sample Output6 22 55 111 333 4441 33 77 77 444 555 666 2222。
数据结构实验报告五,查找与排序-

数据结构实验报告五,查找与排序-查找与排序一、实验目的:1.理解掌握查找与排序在计算机中的各种实现方法。
2.学会针对所给问题选用最适合的算法。
3.熟练掌握常用排序算法在顺序表上的实现。
二、实验要求:掌握利用常用的查找排序算法的思想来解决一般问题的方法和技巧,进行算法分析并写出实习报告。
三、实验内容及分析:设计一个学生信息管理系统,学生对象至少要包含:学号、性别、成绩1、成绩总成绩等信息。
要求实现以下功能:1.平均成绩要求自动计算;2.查找:分别给定学生学号、性别,能够查找到学生的基本信息(要求至少用两种查找算法实现);3.? 排序:分别按学生的学号、成绩1、成绩2、平均成绩进行排序(要求至少用两种排序算法实现)。
四、程序的调试及运行结果五、程序代码#includestdio.h#includestring.hstruct student//定义结构体{char name;int a1,a2,a3,num;double pow;}zl;int count=0;void jiemian1(); //主界面//函数声明int jiemian2(); //选择界面void luru(); //录入函数void xianshi(); //显示void paixv(); //排序void diaoyong(int); //循环调用选择界面void tianjia(); //添加信息void chaxun1(); //按学号查询详细信息void chaxun2(); //按姓名查询详细信息void xiugai(); //修改信息void shanchu(); //删除信息void main() //main函数{jiemian1();//函数点用}void jiemian1() //主界面定义{char a;printf(“\n\n\n\n\t\t\t学员信息管理器\n\n\n\t\t\t 数据结构课程设计练习六\n\n\n\t\t\t 09信计2:于学彬\n\n“);printf("\n\t\t\t 按回车键继续:");scanf("%c",system("cls");jiemian2();}int jiemian2() //选择界面{int a,b;printf("*******************************主要功能********************************");printf("\n\n\n\n\t\t\t\t1.录入信息\n\n\t\t\t\t2.添加信息\n\n\t\t\t\t3.查看信息\n\n\t\t\t\t4.查询信息\n\n\t\t\t\t5.修改信息\n\n\t\t\t\t6.删除信息\n\n\t\t\t\t7.退出\n\n\t\t\t\t请选择:");scanf("%d",switch(a){case 1:system("cls");luru();break;case 2:system("cls");tianjia();break;case 3:system("cls");paixv();break;case 4:system("cls");printf("1.按学号查询详细信息\n2.按姓名查询详细信息\n请选择:");scanf("%d",switch(b){case 1:system("cls");chaxun1();break;case 2:system("cls");chaxun2();break;} break;case 5:system("cls");xiugai();break;case 6:system("cls");shanchu();break;case 7:system("cls");return a;break;}}void diaoyong(int b) //循环调用选择界面{char a='y';printf("是否返回选择页(y/n):");fflush(stdin);//清空输入缓冲区,通常是为了确保不影响后面的数据读取(例如在读完一个字符串后紧接着又要读取一个字符,此时应该先执行fflush(stdin);)a=getchar();system("cls");while(a=='y'||a=='Y'){b=jiemian2();if(b==7){break;}}}void luru() //录入函数{char a;//='y';do{printf("请输入学员信息:\n");printf("学号:");scanf("%d",zl[count].num);//调用结构体printf("姓名:");fflush(stdin);gets(zl[count].name);printf("三门成绩:\n");printf("成绩1:");scanf("%d",zl[count].a1);printf("成绩2:");scanf("%d",zl[count].a2);printf("成绩3:");scanf("%d",zl[count].a3);zl[count].pow=(zl[count].a1+zl[count].a2+zl[count].a3)/3;//求平均数printf("是否继续(y/n):");fflush(stdin);a=getchar();count++;system("cls");}while(a=='y'count100);//paixv();diaoyong(count);}void tianjia() //添加信息{char a='y';do{printf("请输入学员信息:\n");printf("学号:");scanf("%d",zl[count].num);printf("姓名:");//fflush(stdin);gets(zl[count].name);printf("三门成绩:\n");printf("成绩1:");scanf("%d",zl[count].a1);printf("成绩2:");scanf("%d",zl[count].a2);printf("成绩3:");scanf("%d",zl[count].a3);zl[count].pow=(zl[count].a1+zl[count].a2+zl[count].a3)/3; printf("是否继续(y/n):");//fflush(stdin);a=getchar();count++;system("cls");}while(a=='y'count100);paixv(count);diaoyong(count);}void xianshi() //显示{int i;printf("学号\t \t姓名\t\t\t平均成绩\n");for(i=0;icount;i++){printf("%d\t \t%s\t\t\t%f\n",zl[i].num,zl[i].name,zl[i].pow); }}void paixv() //排序{int i,j;struct student zl1;printf("排序前:\n");xianshi();for(i=0;icount;i++){for(j=1;jcount-i;j++){if(zl[j-1].powzl[j].pow){zl1=zl[j-1];zl[j-1]=zl[j];zl[j]=zl1;}}}printf("排序后:\n");xianshi();diaoyong(count);}void chaxun1() //按学号查询详细信息{int i,num;printf("请输入要查询学员的学号:");scanf("%d",num);printf("学号\t姓名\t成绩1\t成绩2\t成绩3\t平均成绩\n"); for(i=0;icount;i++){if(zl[i].num==num){printf("%d\t%s\t%d\t%d\t%d\t%.2f\n",zl[i].num,zl[i].name,zl[i].a1,zl[i].a2,zl [i].a3,zl[i].pow);}}diaoyong(count);}void chaxun2() //按姓名查询详细信息{int i;struct student zl1;printf("请输入要查询学员的姓名:");fflush(stdin);gets();printf("学号\t姓名\t成绩1\t成绩2\t成绩3\t平均成绩\n");for(i=0;icount;i++){if((strcmp(zl[i].name,))==0)//比较两个字符串的大小{printf("%d\t%s\t%d\t%d\t%d\t%.2f\n",zl[i].num,zl[i].name,zl[i].a1,zl[i].a2,zl [i].a3,zl[i].pow);}}diaoyong(count);}void xiugai() //修改信息{int i,num;printf("请输入要查询学员的学号:");scanf("%d",num);printf("学号\t姓名\t成绩1\t成绩2\t成绩3\t平均成绩\n");for(i=0;icount;i++){if(zl[i].num==num){break;}}printf("%d\t%s\t%d\t%d\t%d\t%.2f\n",zl[i].num,zl[i].name,zl[i].a1,zl[i].a2,zl [i].a3,zl[i].pow);printf("请输入学员信息:\n");printf("学号:");scanf("%d",zl[i].num);printf("姓名:");fflush(stdin);gets(zl[i].name);printf("三门成绩:\n");printf("成绩1:");scanf("%d",zl[i].a1);printf("成绩2:");scanf("%d",zl[i].a2);printf("成绩3:");scanf("%d",zl[i].a3);zl[i].pow=(zl[i].a1+zl[i].a2+zl[i].a3)/3;printf("学号\t姓名\t成绩1\t成绩2\t成绩3\t平均成绩\n"); printf("%d\t%s\t%d\t%d\t%d\t%.2f\n",zl[i].num,zl[i].name,zl[i].a1,zl[i].a2,zl[i].a3,zl[i].pow);diaoyong(count);}void shanchu() //删除信息{int num,i,j;printf("请输入要删除的学员学号:");scanf("%d",num);for(i=0;icount;i++){if(zl[i].num==num){for(j=i;jcount;j++){zl[j]=zl[j+1];}}}count--;xianshi();diaoyong(count);}。
实验五-查找和排序实验报告 查找及排序实验

并对调试过程中的问题进行分析,对执
输入你晏査找的关键字:阴
第1页共1页
2S 査我旗 I 加
本文格式为 Word 版,下载可任意编辑,页眉双击删除即可。
通过本次排序和查找的练习,初步把握了其基本概念和操作。
冃次查找?(Y/W :
查找的基本概念: 查找表: 是由同一类型的数据元素〔或记录〕构
输入像要查戏的关键字:4
else low=mid +1 ;
return i; }
}
(3)写出源程序清单(加适当的注释)。
return 0;
;//建立一个二叉树,元素从键盘输入,
}//Serch_B in;
直到回车为止
2.顺序查找算法描述如下: typedef struct {
void insert(BiTree *bt,BiTree s){// 在二叉树中插
else return select (bt-rchild,key);
(1 )
-
请输入要一列整数,以空格隔开,回车结束.
-修改 -
12 刖 55 23 55 78 121 31
(4)
非序后:
(4)调试说明。包括上机调试的状况、调试所遇到的问题是如何解决的, 12239134 FE E5 78 121
第1页共1页
in sert(((*bt)-lchild),s);
本文格式为 Word 版,下载可任意编辑,页眉双击删除即可。
while(1)
s-dt=key;
prin tf(%5d,bt-dt);
else if (s-dt(*bt)-dt)
{
s-lchild=s-rchild=NULL;
ZXBL (bt-rchild);
数据结构实验报告 实验五 查找算法

昆明理工大学信息工程与自动化学院学生实验报告(201 —201 学年第一学期)课程名称:数据结构开课实验室:年月日年级、专业、班学号姓名成绩实验项目名称查找算法指导教师教师评语教师签名:年月日一.实验内容:查找算法,其中线性表的查找包括顺序查找,二分查找,分块查找;树表的查找包括二叉排序树等;还有散列表的查找等等。
二.实验目的:1.掌握各种查找算法理解和实现;2.增强上机编程调试能力;三.主要程序代码分析:typedef struct{int Key; //关键项}ElemType;int Search_Seq(SSTable ST,int Key) //顺序查找{int i;ST.elem[0].Key=Key; //设置监视哨for(i=ST.length;ST.elem[i].Key!=Key;i--);return i;}int Search_Bin(SSTable ST,int Key) //在有序表中进行二分查找{int low=1;int high=ST.length; //置查找区间的上、下届初值int mid;count=0;while(low<=high) //当前查找区间非空{count++;mid=(low+high)/2;if(ST.elem[mid].Key==Key)return mid; //查找成功,返回else if(Key<ST.elem[mid].Key)high=mid-1; //缩小查找区间为左子表elselow=mid+1; //缩小查找区间为右子表}return (-1); //查找失败}四.程序运行结果:五.实验总结:查找又称检索,它也是数据处理中经常使用的一种重要的运算,在线性表上的查找方法有顺序查找,二分查找和分块查找。
顺序查找是一种最简单的查找方法。
它的基本思想是:从表的一端开始,顺序扫描线性表,依次将扫描到的结点关键字和定值K相比较,若当前扫描到的结点关键字与K相等,则查找成功;若扫描结束后仍未找到关键字等于K的结点,则查找失败。
查找与排序实验报告

实验四:查找与排序【实验目的】1.掌握顺序查找算法的实现。
2.掌握折半查找算法的实现。
【实验内容】1.编写顺序查找程序,对以下数据查找37所在的位置。
5,13,19,21,37,56,64,75,80,88,922.编写折半查找程序,对以下数据查找37所在的位置。
5,13,19,21,37,56,64,75,80,88,92【实验步骤】1.打开VC++。
2.建立工程:点File->New,选Project标签,在列表中选Win32 ConsoleApplication,再在右边的框里为工程起好名字,选好路径,点OK->finish。
至此工程建立完毕。
3.创建源文件或头文件:点File->New,选File标签,在列表里选C++ SourceFile。
给文件起好名字,选好路径,点OK。
至此一个源文件就被添加到了你刚创建的工程之中。
4.写好代码5.编译->链接->调试#include "stdio.h"#include "malloc.h"#define OVERFLOW -1#define OK 1#define MAXNUM 100typedef int Elemtype;typedef int Status;typedef struct{Elemtype *elem;int length;}SSTable;Status InitList(SSTable &ST ){int i,n;ST.elem = (Elemtype*) malloc (MAXNUM*sizeof (Elemtype)); if (!ST.elem) return(OVERFLOW);printf("输入元素个数和各元素的值:");scanf("%d\n",&n);for(i=1;i<=n;i++){scanf("%d",&ST.elem[i]);}ST.length = n;return OK;}int Seq_Search(SSTable ST,Elemtype key){int i;ST.elem[0]=key;for(i=ST.length;ST.elem[i]!=key;--i);return i;}int BinarySearch(SSTable ST,Elemtype key){int low,high,mid;low=1;high=ST.length;while(low<=high){mid=(low+high)/2;if(ST.elem[mid]==key)return mid;else if(key<ST.elem[mid])high=mid-1;elselow=mid+1;}return 0;}void main(){int key;SSTable ST;InitList(ST);printf("输入查找的元素的值:");scanf("%d",&key);Seq_Search(ST,key);printf("查找的元素所在的位置:%d\n",Seq_Search(ST,key));printf("输入查找的元素的值:");scanf("%d",&key);BinarySearch(ST,key);printf("查找的元素所在的位置:%d\n",BinarySearch(ST,key));}【实验心得】这是本学期的最后一节实验课,实验的内容是查找与排序。
查找排序操作实验报告

一、实验目的1. 熟悉常用的查找和排序算法,掌握它们的原理和实现方法。
2. 提高编程能力,提高算法分析能力。
3. 通过实验验证查找和排序算法的性能。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.83. 开发工具:PyCharm三、实验内容1. 查找算法:二分查找、线性查找2. 排序算法:冒泡排序、选择排序、插入排序、快速排序、归并排序四、实验步骤1. 设计一个数据结构,用于存储待查找和排序的数据。
2. 实现二分查找算法,用于查找特定元素。
3. 实现线性查找算法,用于查找特定元素。
4. 实现冒泡排序、选择排序、插入排序、快速排序、归并排序算法,对数据进行排序。
5. 分别测试查找和排序算法的性能,记录时间消耗。
五、实验结果与分析1. 查找算法(1)二分查找算法输入数据:[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]查找目标:11查找结果:成功,位置为5(2)线性查找算法输入数据:[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]查找目标:11查找结果:成功,位置为52. 排序算法(1)冒泡排序输入数据:[5, 3, 8, 4, 2]排序结果:[2, 3, 4, 5, 8](2)选择排序输入数据:[5, 3, 8, 4, 2]排序结果:[2, 3, 4, 5, 8](3)插入排序输入数据:[5, 3, 8, 4, 2]排序结果:[2, 3, 4, 5, 8](4)快速排序输入数据:[5, 3, 8, 4, 2]排序结果:[2, 3, 4, 5, 8](5)归并排序输入数据:[5, 3, 8, 4, 2]排序结果:[2, 3, 4, 5, 8]3. 性能测试(1)查找算法性能测试二分查找算法在数据量较大的情况下,查找效率明显优于线性查找算法。
(2)排序算法性能测试在数据量较大的情况下,快速排序和归并排序的性能明显优于冒泡排序、选择排序和插入排序。
排序和查找的实验报告

排序和查找的实验报告实验报告:排序和查找引言排序和查找是计算机科学中非常重要的基本算法。
排序算法用于将一组数据按照一定的顺序排列,而查找算法则用于在已排序的数据中寻找特定的元素。
本实验旨在比较不同排序和查找算法的性能,并分析它们的优缺点。
实验设计为了比较不同排序算法的性能,我们选择了常见的几种排序算法,包括冒泡排序、插入排序、选择排序、快速排序和归并排序。
我们使用相同的随机数据集对这些算法进行了测试,并记录了它们的执行时间和占用空间。
在查找算法的比较实验中,我们选择了顺序查找和二分查找两种常见的算法。
同样地,我们使用相同的随机数据集对这些算法进行了测试,并记录了它们的执行时间和占用空间。
实验结果在排序算法的比较实验中,我们发现快速排序和归并排序在大多数情况下表现最好,它们的平均执行时间和空间占用都要优于其他排序算法。
而冒泡排序和插入排序则表现较差,它们的执行时间和空间占用相对较高。
在查找算法的比较实验中,二分查找明显优于顺序查找,尤其是在数据规模较大时。
二分查找的平均执行时间远远小于顺序查找,并且占用的空间也更少。
结论通过本实验的比较,我们得出了一些结论。
首先,快速排序和归并排序是较优的排序算法,可以在大多数情况下获得较好的性能。
其次,二分查找是一种高效的查找算法,特别适用于已排序的数据集。
最后,我们也发现了一些排序和查找算法的局限性,比如冒泡排序和插入排序在大数据规模下性能较差。
总的来说,本实验为我们提供了对排序和查找算法性能的深入了解,同时也为我们在实际应用中选择合适的算法提供了一定的参考。
希望我们的实验结果能够对相关领域的研究和应用有所帮助。
数据结构实验报告——查找与排序

哈尔滨工业大学(深圳)数据结构实验报告查找与排序学院: 计算机科学与技术一、问题分析此题是一道排序问题,排序的方法有很多种,此题我用的是堆排序,这是一种不稳定排序,但时间复杂度较低,比较快。
计算机首先需要把文件中的数据读入内存中,用动态数组存储数据,然后建立数据结构,然后建立堆,比较子节点和父节点大小,降序排列,之后互换头结点与尾节点,再递归重复即可。
查找的话,依次查找对比即可。
二、详细设计2.1 设计思想将股票的代码,交易日期,及开盘价等信息分别用不同的动态数组存储起来。
因为要根据交易量的降序进行排序所以应将交易量的信息另外用一个float型的数组保存起来便于比较。
排序:使用一个下标数组用来模拟交易量的堆排序,将下标数组进行降序排序。
再根据下标数组里的值将股票信息保存在新的文件中。
查看:因为录入文件时是先把股票的代码相同的信息存入数组的。
所以查找时比较股票的代码,找到该代码后比较交易日期。
最后输出交易量。
2.2 存储结构及操作(1) 存储结构(一般为自定义的数据类型,比如单链表,栈等。
)vector<string> a;//股票代码vector<string> b;//股票交易日期vector<string> c;//股票开盘价_最高价_最低价_收盘价vector<float> d;//将交易量转换为float用于比较不过有的会被舍去vector<string> e;//交易量的原始数据用于输出到排序的文件中(2)涉及的操作(一般为自定义函数,可不写过程,但要注明该函数的含义。
)read_file() 将文件信息分别保存在上述存储结构中HeapAdjust(vector<long>& x,long s,long n) 小顶堆的调整函数HeapSort() 用堆排序进行交易量的降序排序并存储在指定文件中serach() 查找某交易日期某股票的交易量2.3 程序整体流程开始 A读入文件,存入数组 B排序 C查找 D结束 E2.堆排序示意图(由于堆排序描述时需要具体数据,所以只弄到示意图)三、用户手册1>将股票文件先存入指定文件夹中,根据提示输入文件名字按回车即可2>先在指定文件夹新建你要保存的文件后将文件的名字输入3>根据提示输入股票代码及交易日期,以空格隔开。
查找和排序实验报告

查找和排序实验报告
本实验主要针对以查找、排序算法为主要实现目标的软件开发,进行实验室研究。
实
验包括:冒泡排序、选择排序、插入排序、希尔排序、快速排序、归并排序、基数排序,
以及折半查找算法。
实验采用C语言编写,在完成以上排序以及查找方法的基础上,针对实验的工程要求,进行了性能分析,分析了算法空间复杂度以及时间复杂度。
通过首先采用循环方式,构建未排序数组,在此基础上,调用算法实现查找和排序。
也对不同算法进行对比分析,将数据量在100个至30000个之间进行测试。
结果表明:快速排序与希尔排序在时间复杂度方面具有最好的表现,而冒泡排序和选
择排序时间复杂度较高。
在空间复杂度方面,基数排序表现最佳,折半查找的空间复杂度
则比较可观。
在工程应用中,根据对不同排序算法的研究,可以更准确、有效地选择正确的算法实现,有效应用C语言搭建软件系统,提高软件应用效率。
(建议加入算法图)
本实验结束前,可以得出结论:
另外,也可以从这些研究中发现,在使用C语言实现软件系统时,应该重视算法支持
能力,以提高软件应用效率。
由于查找和排序算法在软件应用中占有重要地位,此次实验
对此有贡献,可为未来开发提供支持。
查找排序实验报告总结

一、实验目的本次实验旨在通过编写程序实现查找和排序算法,掌握基本的查找和排序方法,了解不同算法的优缺点,提高编程能力和数据处理能力。
二、实验内容1. 查找算法本次实验涉及以下查找算法:顺序查找、二分查找、插值查找。
(1)顺序查找顺序查找算法的基本思想是从线性表的第一个元素开始,依次将线性表中的元素与要查找的元素进行比较,若找到相等的元素,则查找成功;若线性表中所有的元素都与要查找的元素进行了比较但都不相等,则查找失败。
(2)二分查找二分查找算法的基本思想是将待查找的元素与线性表中间位置的元素进行比较,若中间位置的元素正好是要查找的元素,则查找成功;若要查找的元素比中间位置的元素小,则在线性表的前半部分继续查找;若要查找的元素比中间位置的元素大,则在线性表的后半部分继续查找。
重复以上步骤,直到找到要查找的元素或查找失败。
(3)插值查找插值查找算法的基本思想是根据要查找的元素与线性表中元素的大小关系,估算出要查找的元素应该在大致的位置,然后从这个位置开始进行查找。
2. 排序算法本次实验涉及以下排序算法:冒泡排序、选择排序、插入排序、快速排序。
(1)冒泡排序冒泡排序算法的基本思想是通过比较相邻的元素,将较大的元素交换到后面,较小的元素交换到前面,直到整个线性表有序。
(2)选择排序选择排序算法的基本思想是在未排序的序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
以此类推,直到所有元素均排序完毕。
(3)插入排序插入排序算法的基本思想是将一个记录插入到已排好序的有序表中,从而得到一个新的、记录数增加1的有序表。
(4)快速排序快速排序算法的基本思想是选择一个元素作为基准元素,将线性表分为两个子表,一个子表中所有元素均小于基准元素,另一个子表中所有元素均大于基准元素,然后递归地对两个子表进行快速排序。
三、实验结果与分析1. 查找算法通过实验,我们发现:(1)顺序查找算法的时间复杂度为O(n),适用于数据量较小的线性表。
查找和排序 实验报告

查找和排序实验报告查找和排序实验报告一、引言查找和排序是计算机科学中非常重要的基础算法之一。
查找(Search)是指在一组数据中寻找目标元素的过程,而排序(Sort)则是将一组数据按照特定的规则进行排列的过程。
本实验旨在通过实际操作和实验验证,深入理解查找和排序算法的原理和应用。
二、查找算法实验1. 顺序查找顺序查找是最简单的查找算法之一,它的基本思想是逐个比较待查找元素与数据集合中的元素,直到找到目标元素或遍历完整个数据集合。
在本实验中,我们设计了一个包含1000个随机整数的数据集合,并使用顺序查找算法查找指定的目标元素。
实验结果显示,顺序查找的时间复杂度为O(n)。
2. 二分查找二分查找是一种高效的查找算法,它要求待查找的数据集合必须是有序的。
二分查找的基本思想是通过不断缩小查找范围,将待查找元素与中间元素进行比较,从而确定目标元素的位置。
在本实验中,我们首先对数据集合进行排序,然后使用二分查找算法查找指定的目标元素。
实验结果显示,二分查找的时间复杂度为O(log n)。
三、排序算法实验1. 冒泡排序冒泡排序是一种简单但低效的排序算法,它的基本思想是通过相邻元素的比较和交换,将较大(或较小)的元素逐渐“冒泡”到数列的一端。
在本实验中,我们设计了一个包含1000个随机整数的数据集合,并使用冒泡排序算法对其进行排序。
实验结果显示,冒泡排序的时间复杂度为O(n^2)。
2. 插入排序插入排序是一种简单且高效的排序算法,它的基本思想是将数据集合分为已排序和未排序两部分,每次从未排序部分选择一个元素插入到已排序部分的适当位置。
在本实验中,我们使用插入排序算法对包含1000个随机整数的数据集合进行排序。
实验结果显示,插入排序的时间复杂度为O(n^2)。
3. 快速排序快速排序是一种高效的排序算法,它的基本思想是通过递归地将数据集合划分为较小和较大的两个子集合,然后对子集合进行排序,最后将排序好的子集合合并起来。
查找排序算法实验报告(3篇)

第1篇一、实验目的1. 熟悉常见的查找和排序算法。
2. 分析不同查找和排序算法的时间复杂度和空间复杂度。
3. 比较不同算法在处理大数据量时的性能差异。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.73. 开发工具:PyCharm三、实验内容1. 实现以下查找和排序算法:(1)查找算法:顺序查找、二分查找(2)排序算法:冒泡排序、选择排序、插入排序、快速排序、归并排序2. 分析算法的时间复杂度和空间复杂度。
3. 对不同算法进行性能测试,比较其处理大数据量时的性能差异。
四、实验步骤1. 实现查找和排序算法。
2. 分析算法的时间复杂度和空间复杂度。
3. 创建测试数据,包括小数据量和大数据量。
4. 对每种算法进行测试,记录运行时间。
5. 分析测试结果,比较不同算法的性能。
五、实验结果与分析1. 算法实现(1)顺序查找def sequential_search(arr, target): for i in range(len(arr)):if arr[i] == target:return ireturn -1(2)二分查找def binary_search(arr, target):low, high = 0, len(arr) - 1while low <= high:mid = (low + high) // 2if arr[mid] == target:return midelif arr[mid] < target:low = mid + 1else:high = mid - 1return -1(3)冒泡排序def bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n-i-1):if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j](4)选择排序def selection_sort(arr):n = len(arr)for i in range(n):min_idx = ifor j in range(i+1, n):if arr[min_idx] > arr[j]:min_idx = jarr[i], arr[min_idx] = arr[min_idx], arr[i](5)插入排序def insertion_sort(arr):for i in range(1, len(arr)):key = arr[i]j = i-1while j >=0 and key < arr[j]:arr[j+1] = arr[j]j -= 1arr[j+1] = key(6)快速排序def quick_sort(arr):if len(arr) <= 1:pivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)(7)归并排序def merge_sort(arr):if len(arr) <= 1:return arrmid = len(arr) // 2left = merge_sort(arr[:mid])right = merge_sort(arr[mid:])return merge(left, right)def merge(left, right):result = []i = j = 0while i < len(left) and j < len(right):if left[i] < right[j]:result.append(left[i])i += 1else:result.append(right[j])result.extend(left[i:])result.extend(right[j:])return result2. 算法时间复杂度和空间复杂度分析(1)顺序查找:时间复杂度为O(n),空间复杂度为O(1)。
查找与排序实验报告

查找与排序实验报告《查找与排序实验报告》摘要:本实验旨在通过不同的查找与排序算法对比分析它们的效率和性能。
我们使用了常见的查找算法包括线性查找、二分查找和哈希查找,以及排序算法包括冒泡排序、快速排序和归并排序。
通过实验数据的对比分析,我们得出了每种算法的优缺点和适用场景,为实际应用提供了参考依据。
1. 实验目的通过实验对比不同查找与排序算法的性能,分析它们的优缺点和适用场景。
2. 实验方法(1)查找算法实验:分别使用线性查找、二分查找和哈希查找算法,对含有一定数量元素的数组进行查找操作,并记录比较次数和查找时间。
(2)排序算法实验:分别使用冒泡排序、快速排序和归并排序算法,对含有一定数量元素的数组进行排序操作,并记录比较次数和排序时间。
3. 实验结果(1)查找算法实验结果表明,二分查找在有序数组中的查找效率最高,哈希查找在大规模数据中的查找效率最高。
(2)排序算法实验结果表明,快速排序在平均情况下的排序效率最高,归并排序在最坏情况下的排序效率最高。
4. 实验分析通过实验数据的对比分析,我们得出了以下结论:(1)查找算法:二分查找适用于有序数组的查找,哈希查找适用于大规模数据的查找。
(2)排序算法:快速排序适用于平均情况下的排序,归并排序适用于最坏情况下的排序。
5. 结论不同的查找与排序算法在不同的场景下有着不同的性能表现,选择合适的算法可以提高程序的效率和性能。
本实验为实际应用提供了参考依据,对算法的选择和优化具有一定的指导意义。
通过本次实验,我们深入了解了不同查找与排序算法的原理和性能,为今后的算法设计和优化工作提供了宝贵的经验和参考。
算法与数据结构实验报告

算法与数据结构实验报告算法与数据结构实验报告引言算法与数据结构是计算机科学中的两个重要概念。
算法是解决问题的一系列步骤或规则,而数据结构是组织和存储数据的方式。
在本次实验中,我们将探索不同的算法和数据结构,并通过实际的案例来验证它们的效果和应用。
一、排序算法排序算法是计算机科学中最基础的算法之一。
在本次实验中,我们实现了冒泡排序、插入排序和快速排序算法,并对它们进行了比较。
冒泡排序是一种简单但低效的排序算法。
它通过多次遍历待排序的元素,每次比较相邻的两个元素并交换位置,将较大的元素逐渐“冒泡”到数组的末尾。
尽管冒泡排序的时间复杂度为O(n^2),但它易于实现且适用于小规模的数据集。
插入排序是一种更高效的排序算法。
它将待排序的元素依次插入已排好序的部分中,直到所有元素都被插入完毕。
插入排序的时间复杂度为O(n^2),但对于部分有序的数据集,插入排序的效率会更高。
快速排序是一种常用的排序算法,它采用分治的思想。
快速排序的基本思路是选择一个基准元素,将小于基准的元素放在基准的左边,大于基准的元素放在基准的右边,然后对左右两部分分别进行快速排序。
快速排序的时间复杂度为O(nlogn),但在最坏情况下会退化为O(n^2)。
通过实际的实验数据,我们发现快速排序的效率远高于冒泡排序和插入排序。
这是因为快速排序采用了分治的策略,将原始问题划分为更小的子问题,从而减少了比较和交换的次数。
二、查找算法查找算法是在给定数据集中寻找特定元素的算法。
在本次实验中,我们实现了线性查找和二分查找算法,并对它们进行了比较。
线性查找是一种简单但低效的查找算法。
它通过逐个比较待查找的元素和数据集中的元素,直到找到匹配的元素或遍历完整个数据集。
线性查找的时间复杂度为O(n),适用于小规模的数据集。
二分查找是一种更高效的查找算法,但要求数据集必须是有序的。
它通过将数据集划分为两部分,并与中间元素进行比较,从而确定待查找元素所在的部分,然后再在该部分中进行二分查找。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
北京物资学院信息学院实验报告
课程名_数据结构与算法
实验名称查找与排序
实验日期年月日实验报告日期年月日姓名______ ___ 班级_____ ________ 学号___
一、实验目的
1. 掌握线性表查找的方法;
2. 了解树表查找思想;
3. 掌握散列表查找的方法;
4. 掌握插入排序、交换排序和选择排序的思想和方法;
二、实验内容
查找部分
1. 实现顺序查找的两个算法(P307),可以完成对顺序表的查找操作,并根据查到和未查到
两种情况输出结果;
2. 实现对有序表的二分查找;
3. 实现散列查找算法(链接法),应能够解决冲突;
排序部分
4.分别实现直接插入排序、直接选择排序、冒泡排序和快速排序算法
三、实验地点与环境
3.1 实验地点
3.2实验环境
(操作系统、C语言环境)
四、实验步骤
(描述实验步骤及中间的结果或现象。
在实验中做了什么事情,怎么做的,发生的现象和中间结果,给出关键函数和主函数中的关键段落)
五、实验结果
六、总结
(说明实验过程中遇到的问题及解决办法;个人的收获;未解决的问题等)。