虚拟变量回归 对于数据 实验2.1.xls
虚拟变量实验报告感想

通过本次虚拟变量实验,我对虚拟变量有了更加深入的理解和认识,感受到了其在计量经济学中的重要作用。
以下是我对本次实验的一些感想。
一、虚拟变量的重要性虚拟变量在计量经济学中具有举足轻重的地位。
它可以将定性变量转化为定量变量,使模型更加全面地反映经济现象。
在现实生活中,许多因素都是定性因素,如性别、民族、地区等,这些因素无法直接用数值表示,但它们对经济现象的影响却是客观存在的。
虚拟变量恰好能够将这些定性因素纳入模型,使模型更加准确、全面地反映经济现象。
二、虚拟变量的设定在本次实验中,我们学习了如何设定虚拟变量。
首先,要明确虚拟变量的含义和作用,然后根据研究目的和实际数据情况,确定虚拟变量的个数。
需要注意的是,当定性变量含有m个类别时,应引入m-1个虚拟变量,以避免多重共线性问题。
此外,虚拟变量的取值应遵循互斥和完备的原则,即每个样本只能属于一个类别。
三、虚拟变量的估计与检验在本次实验中,我们运用Eviews软件对虚拟变量模型进行了估计和检验。
通过观察模型的回归结果,我们可以了解虚拟变量对因变量的影响程度。
此外,我们还可以通过t检验、F检验等方法对虚拟变量的显著性进行检验。
在检验过程中,要注意控制其他变量的影响,以确保检验结果的可靠性。
四、虚拟变量的应用虚拟变量在实际应用中非常广泛。
以下是一些常见的应用场景:1. 时间序列分析:在时间序列分析中,虚拟变量可以用来表示季节性、节假日等因素对经济现象的影响。
2. 州际差异分析:在分析不同地区经济现象时,可以引入地区虚拟变量,以反映地区间的差异。
3. 政策效应分析:在分析政策对经济现象的影响时,可以引入政策虚拟变量,以观察政策实施前后经济现象的变化。
4. 模型设定:在构建计量经济模型时,可以引入虚拟变量来表示定性因素,使模型更加全面。
五、实验收获通过本次虚拟变量实验,我收获颇丰。
首先,我掌握了虚拟变量的基本原理和操作方法,为今后的研究奠定了基础。
其次,我学会了如何设定虚拟变量、估计模型和检验结果,提高了自己的实践能力。
【精品】计量经济学实验报告(虚拟变量)

【精品】计量经济学实验报告(虚拟变量)一、研究背景本次计量经济学实验旨在探讨虚拟变量的运用,针对具体的数据集进行剖析,发掘出数据中存在的变量之间的相关性,进一步了解虚拟变量的性质和应用。
二、研究数据与模型本次实验所使用的数据主要来自于美国地区居民的生活经历与工作情况。
我们采用了线性回归模型来建立数据之间的相关性。
其中,自变量包括:年龄、性别、收入、婚姻状态、教育程度、是否有孩子和是否居住在城市;因变量为每周工作时间。
首先,我们运用SPSS对数据进行了初步的分析。
结果显示,数据存在了年龄、性别、收入、婚姻状态、教育程度、是否有孩子和是否居住在城市等多个变量。
其中,包括了虚拟变量。
我们选取了其中一个虚拟变量进行研究,即“是否有孩子”。
在该变量中,响应值为“是”、“否”,我们将其转换为虚拟变量,即0表示没有孩子,1表示有孩子。
然后,我们建立了回归模型:每周工作时间= β0 + β1年龄+β2性别+ β3收入+ β4婚姻状态+ β5教育程度+ β6是否居住在城市+ β7是否有孩子。
最后,我们选取了样本数据中的500个数据进行模型拟合,其中250条数据表示没有孩子,250条数据表示有孩子。
三、实验结果通过数据分析软件的运算,我们得出了模型拟合的结果。
模型拟合结果如下:从结果中我们可以看出,虚拟变量“是否有孩子”对于每周工作时间的影响显著,其系数为2.01,t值为4.8,显著性水平为0.01,说明儿童数量对于家长的工作时间有显著的影响。
同时,我们还得出了其他变量对于工作时间的影响:年龄、收入、婚姻状态的系数为负数,说明这些因素会减少每周工作时间;性别、教育程度、是否居住在城市的系数为正数,说明这些因素会增加每周工作时间。
四、结论通过本次实验,我们可以得出以下结论:1.虚拟变量是计量经济学中常见的方法之一,在处理定量变量与定性变量时能够有效的将其转换为数值变量。
2.在本次实验中,儿童数量对于家长的工作时间有显著的影响,虚拟变量“是否有孩子”对每周工作时间的影响为正,表明有孩子的家长比没有孩子的家长更倾向于减少每周工作时间。
第八章-虚拟变量回归

1 高中 D2 0 其它
1 博士 D5 0 其它
1 大 学 D3 0 其 它
1 小 学 D6 0 其 它
则总体回归模型:
w 0 1 X 2 D1 3 D2 4 D3 5 D4 6 D5 7 D6+u
17
二、用虚拟变量测量斜率变动
基本思想
引入虚拟变量测量斜率变动,是在所设立的模型中,将虚 拟解释变量与其它解释变量的乘积,作为新的解释变量出 现在模型中,以达到其调整设定模型斜率系数的目的。
可能的情形:
(1)截距不变;
(2)截距和斜率均发生变化;
分析手段:仍然是条件期望。
18
(1)截距不变
模型形式:
意义:若α1显著,表明城市居民的平均人均可支配收入比农村 高α1元。但这种差异可能是由其它因素引起的,并不一定是由 户籍差异引起。
12
(2) 一个两属性定性解释变量和一个定量 解释变量
模型形式 Yi = f(Di,X i )+ μi 例如:Yi = 0 1 Di + X i + μi 1 城市 其中: Y-人均可支配收入;X-工作时间; Di 0 农村
会受到一些定性因素的影响,如性别、国籍、民族、自 然灾害和政治体制等。
问题:我们如何把这些定性想:将这些定性因素进行量化
由于定性变量通常表示某种属性是否存在,如是否男性、 是否经济特区、是否有色人和等。因此若该属性存在, 我们就将变量赋值为1,否则赋值为0,从而将定性因素 定量化。 计量经济学中,将取值为0和1的人工变量称为虚拟变量 (DUMMY)或哑元变量。通常用字母D或DUM表示。
7
一个例子(虚拟变量陷阱)
研究工资收入与学历之间的关系:
计量经济学虚拟变量实验报告
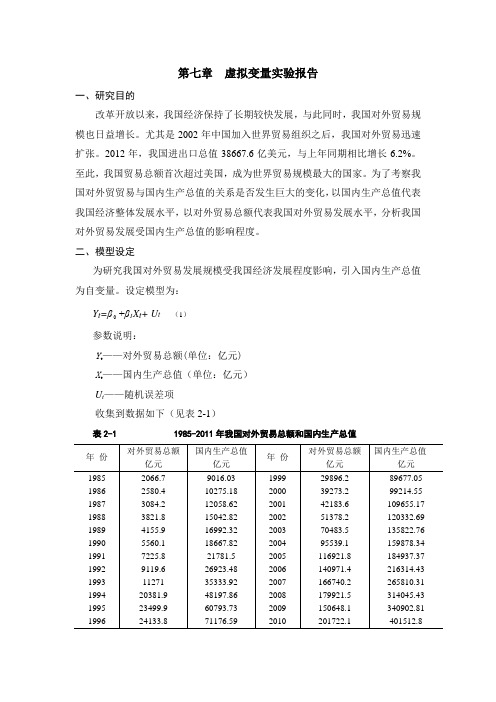
第七章虚拟变量实验报告一、研究目的改革开放以来,我国经济保持了长期较快发展,与此同时,我国对外贸易规模也日益增长。
尤其是2002年中国加入世界贸易组织之后,我国对外贸易迅速扩张。
2012年,我国进出口总值38667.6亿美元,与上年同期相比增长6.2%。
至此,我国贸易总额首次超过美国,成为世界贸易规模最大的国家。
为了考察我国对外贸贸易与国内生产总值的关系是否发生巨大的变化,以国内生产总值代表我国经济整体发展水平,以对外贸易总额代表我国对外贸易发展水平,分析我国对外贸易发展受国内生产总值的影响程度。
二、模型设定为研究我国对外贸易发展规模受我国经济发展程度影响,引入国内生产总值为自变量。
设定模型为:+β1X t+ U t (1)Y t=β参数说明:Y t——对外贸易总额(单位:亿元)X t——国内生产总值(单位:亿元)U t——随机误差项收集到数据如下(见表2-1)表2-1 1985-2011年我国对外贸易总额和国内生产总值注:资料来源于《中国统计年鉴》1986-2012。
为了研究1985-2011年期间我国对外贸易总额随国内生产总值的变化规律是否有显著不同,考证对外贸易与国内生产总值随时间变化情况,如下图所示。
图2.1 对外贸易总额(Y)与国内生产总值(X)随时间变化趋势图从图2.1中,可以看出对外贸易总额明显表现出了阶段特征:在2002年、2007年和2009年有明显的转折点。
为了分析对外贸易总额在2002年前后、2007年前后及2009年前后几个阶段的数量关系,引入虚拟变量D1、D2、D3。
这三个年度对应的GDP分别为120332.69亿元、265810.31亿元和340902.81亿元。
据此,设定以下以加法和乘法两种方式同时引入虚拟变量的模型:Y t=β0+β1Xt+β2(Xt-120332.69)D1+β3(Xt-265810.31)D2+β4(Xt-340902.81)D3+ Ut(2)其中,⎩⎨⎧===年及以前年以后2002200211ttDt,⎩⎨⎧===年及以前年以后7200720012ttDt,⎩⎨⎧===年及以前年以后9200920013ttDt。
虚拟变量回归

数据收集
收集不同市场细分群体的基本信息和 产品需求数据,如年龄、性别、收入、 消费习惯等。
变量设置
将市场细分变量转换为虚拟变量,并 引入到回归模型中。
结果分析
分析虚拟变量的系数和显著性,解释 其对产品需求的影响,为市场定位提 供依据。
案例三:教育程度与收入水平的关系研究
目的
研究教育程度对收入水平的影响,以及 不同教育程度对收入水平的差异。
虚拟变量可能依赖于某些自变量,需 要谨慎处理以避免多重共线性问题。
REPORT
CATALOG
DATE
ANALYSIS
SUMMAR Y
03
虚拟变量回归的模型构 建
线性回归模型
线性回归模型是最常用的回归分析方法之一,用 于探索自变量与因变量之间的线性关系。
在线性回归模型中,虚拟变量可以作为自变量引 入,以解释和预测因变量的变化。
变量设置
将教育程度转换为虚拟变量,并引入 到回归模型中。
数据收集
收集受访者的教育程度和收入水平数 据。
结果分析
分析虚拟变量的系数和显著性,解释 其对收入水平的影响,为职业规划和 教育投资提供参考。
案例四:健康状况与生活习惯的关系研究
目的
数据收集
研究生活习惯对健康状况的影响,以及不 同生活习惯对健康状况的差异。
虚拟变量回归的应用场景
1 2
社会科学研究
在社会科学研究中,经常需要研究分类变量对连 续变量的影响。例如,研究不同教育程度或不同 职业对收入的影响。
生物统计学
在生物统计学中,虚拟变量回归可用于研究基因 型、物种或地理区域等因素对连续变量的影响。
3
市场分析
在市场分析中,虚拟变量回归可用于研究不同产 品类别、品牌或市场细分对销售或其他连续变量 的影响。
虚拟变量回归实验报告总结

虚拟变量回归实验报告总结实验目的:了解虚拟变量回归模型,提高回归模型的预测精度。
实验内容:将本课题组开发的一个虚拟变量回归模型与常用的三个回归模型进行比较,并根据实际情况对模型进行修正和完善。
实验步骤及方法:收集各个回归模型的数据资料;选择虚拟变量回归模型和其他三种回归模型的某些参数;运用前述的数理统计软件对上述四种模型进行拟合。
根据运算结果对四种回归模型的优劣作出判断。
通过对回归模型的评价指标分析和本实验的初步结果,得到以下几点结论:(1)虚拟变量回归模型是对原有回归模型的补充或更新,从而增加了预测精度;(2)不同的变量可以建立多个不同类型的回归模型,但只能使用最适宜于所建立的回归模型的变量进行回归;(3)因变量中存在自变量的虚拟变量回归系数,它表示变量之间具有明显的线性相关关系。
但该种回归系数往往不足以代替变量之间的实际线性相关关系,需要依赖其他信息。
实验结果分析1.虚拟变量回归方程:在模型的预测精度方面,可以看出虚拟变量回归方程的回归精度远远高于原有三种回归方程的回归精度,这说明虚拟变量回归模型比原有回归模型更符合客观事物的规律。
这主要是由于虚拟变量回归模型考虑到了原有回归方程的局限性,将变量之间的虚拟变量引入回归方程中,使模型对原来未知的影响因素的估计精度大幅度地提高。
虽然回归方程很难达到最佳估计水平,但却避免了模型的严重偏差,有助于求出满意的统计量。
2.虚拟变量回归的相关性检验:虚拟变量回归的相关系数检验结果见表5-2。
相关系数的检验结果表明,四种回归方程的拟合效果没有明显差异,且大部分都非常接近,反映出四种回归方程拟合结果良好。
经过四种回归方程拟合的虚拟变量回归系数相关系数检验表明,虚拟变量回归系数没有任何特殊的相关现象,说明此回归系数是回归系数的真实体现,是全体数学家共同努力的成果。
实验结论:我们认为当变量取值较小时,对被解释变量的回归系数还没有那么高,而当被解释变量的取值很大时,则回归系数会逐渐减少,直至零。
虚拟变量 实验报告

虚拟变量实验报告引言虚拟变量(dummy variable)是在统计学中常用的一种技术,用于表示分类变量。
通过将分类变量转换为二进制数值变量,虚拟变量可以在回归分析、方差分析以及其他统计模型中发挥重要作用。
本实验报告旨在介绍虚拟变量的概念、用法以及在实际应用中的一些注意事项。
虚拟变量的定义虚拟变量是一种二元变量,用于表示某个特征是否存在。
通常情况下,虚拟变量的取值为0或1。
虚拟变量可以用于将分类变量转换为数值变量,使其适用于各种统计模型。
虚拟变量的应用虚拟变量主要用于以下两个方面的统计模型:1. 回归分析在回归分析中,虚拟变量被用于表示一个分类变量的不同水平。
例如,在研究某产品的销售量时,可以引入虚拟变量表示该产品是否进行了促销活动。
这样,回归模型就可以分析促销活动对销售量的影响。
2. 方差分析方差分析是一种用于比较不同组之间差异的统计方法。
虚拟变量可以用于表示不同组的存在与否。
例如,在研究不同药物对某种疾病治疗效果时,可以引入虚拟变量表示不同药物的使用与否,进而进行方差分析。
如何创建虚拟变量创建虚拟变量的方法通常有两种:1. 单变量编码单变量编码是最常见的创建虚拟变量的方法。
对于具有k个水平的分类变量,单变量编码将该变量转换为k-1个虚拟变量。
其中,k-1个虚拟变量分别表示k个水平的存在与否。
例如,在研究不同颜色对产品销售量的影响时,可以使用单变量编码将颜色变量转换为两个虚拟变量,分别表示是否为蓝色和是否为红色。
2. 二进制编码二进制编码是一种使用更少虚拟变量的方法。
对于具有k个水平的分类变量,二进制编码将该变量转换为log2(k)个虚拟变量。
其中,每个虚拟变量都表示一个水平的存在与否。
例如,在研究不同国家对某项政策的支持时,可以使用二进制编码将国家变量转换为几个虚拟变量,每个虚拟变量表示一个国家的存在与否。
虚拟变量的注意事项在使用虚拟变量时需要注意以下几点:1.避免虚拟变量陷阱:虚拟变量陷阱是指多个虚拟变量之间存在完全共线性的情况,这会导致回归模型的多重共线性。
虚拟变量的回归分析

方程为:
应用SPSS建立回归方程
回归结果:
SPSS输出结果
M ode l Sum m ary
Model 1
A djus tedStd. Err or of
R R SquareR Square the Estimate
.978a
.956
.927
.30751
a.Pr edictor s: ( Constant), A REA , ED3, 年 龄 , ED ED5
在社会经济研究中,由许多定性变量,比 如地区、民族、性别、文化程度、职业和 居住地等。
可以应用它们的信息进行线性回归。 但是,必须现将定性变量转换为哑变量
(也称虚拟变量),然后再将它们引入方 程,所得的回归结果才有明确的解释意义。
哑变量的建立
对于具有k类的定性变量来说,设哑变量 时,我们只设k-1个哑变量。
b.De pe nd en t Variable : s 1
Sig . .00 0a
SPSS输出结果
Coe fficie nats
UnstandardizedStandardized Coeff icients Coeff icients
Model
B Std. Error Beta
1 (Constan1t7).642 5.261
回归方程的解释
文化程度在实际中是一个序次变量。可以
用
表示序次变量个相邻分类的
实际效应,如初中的边际效应为:
类似,可以计算下面的边际效应: 小学= -1.13 初中= -0.18 高中= -0.27 大学= 0.01
回归分析
利用同样的方法我们可以对例7.2进行回 归分析。
例7.2的数据中,还有一个自变量是定性变 量“收入”,以虚拟变量或哑元(dummy variable)的方式出现。
含虚拟自变量的回归分析

研究成果对实践的指导意义
01
提供了一种新的回归 分析思路
本研究为回归分析提供了一种新的思 路和方法,有助于解决传统回归分析 中难以处理的问题,提高分析结果的 准确性和可靠性。
模型构建
根据行业特点和历史销 售数据,构建一个含虚 拟自变量的回归模型。 其中,虚拟自变量可以 表示季节性、促销活动
等因素。
实证分析
利用历史销售数据对模 型进行实证分析,估计 模型参数并检验虚拟自 变量的显著性。通过模 型评价和诊断确保模型
的有效性。
预测与应用
利用估计得到的回归模 型对未来销售进行预测 ,并根据预测结果制定 相应的市场策略和销售
某个虚拟自变量的系数不显著,则说明该自变量对因变量的影响不显著。
03
模型的诊断
通过残差分析、异方差性检验、多重共线性检验等方法,对模型进行诊
断。如果发现模型存在问题,则需要对模型进行改进。
模型优化与改进
变量的筛选
通过逐步回归、向前选择、向后剔除等方法,对自变量进行筛选。保留对因变量有显著影响的自变量,剔除对因变量 影响不显著的自变量。
结果展示
将实证分析的结果以表格、图形等形式进行展示,以便更 直观地了解虚拟自变量对因变量的影响程度和方向。
应用举例:某行业销售预测模型
第一季度
第二季度
第三季度
第四季度
背景介绍
以某行业的销售数据为 例,探讨含虚拟自变量 的回归分析在销售预测 中的应用。该行业销售 受到多种因素的影响, 包括季节性、促销活动 、竞争对手行为等。
参数估计方法
实验五七虚拟变量回归分析

第七章虚拟变量回归分析姓名:耿肃竹学号:20136878 班级:经济1302【实验目的】目的在于学习基本的经济计量方法并利用Stata对经济中典型的数据,掌握虚拟变量的分析思路,掌握虚拟变量回归的基本操作方法,掌握虚拟变量回归的结果分析。
【实验软件】Stata是一套提供其使用者数据分析、数据管理以及绘制专业图表的完整及整合性统计软件。
该软件提供的功能包含线性混合模型、均衡重复反复及多项式普罗比模式。
作为流行的计量经济学软件,Stata的功能十分地全面和强大。
可以毫不夸张地说,凡是成熟的计量经济学方法,在Stata中都可以找到相应的命令,而这些命令都有许多选项以适应不同的环境或满足不同的需要。
【实验要求】利用stata软件学习多元回归分析的应用问题,并在回归结果中学会以下命令的使用对类型变量B生成虚拟变量Atabulate B, gen(A);对包含虚拟变量的情况进行回归regress y x1 x2…A2 A3…等命令。
学会虚拟变量在回归分析中的应用进行有效分析,学以致用。
【实验内容】教材P213——C2题目【1】C2(Ⅰ)输入命令“regress lwage educ exper tenure married black south urban”:解:log(wage)=5.395497+0.0654307educ+0.014043exper+0.0117473tenure(0.113225) (0.0062504) (0.0031852) (0.002453)+0.1994171married-0.1883499black-0.0909036south+0.1839121urban (0.0390502) (0.0376666) (0.0262485) (0.0269583)n=935 R2=0.2526保持其他因素不变,黑人和非黑人之间的月薪差异近似(约等于)为0.1883499,因为P=0,所以这个差异是统计显著的。
含虚拟变量问题的回归分析

实验五实验项目:运用EVIEWS 软件进行含虚拟变量问题的回归分析实验目的:掌握运用EVIEWS 软件对解释变量中含有虚拟变量的情况进行回归分析的基本操作方法和步骤,并能够对软件运行结果进行解释。
实验内容提要:1.根据具体的经济现象,选择合适的虚拟变量。
2.建立关于虚拟变量的回归模型,并进行估计和检验。
3.对软件运行的结果给出合理的经济学解释。
实验内容及步骤: 1.模型假设将某大学学生的绩分点设为因变量Y ,统计成绩设为自变量1X ,是否使用计算机设为自变量2X ,建立虚拟变量回归模型,得: 01122++i i i i Y X X βββε=+其中,1,20={i X 有使用计算机,没有使用计算机其原始数据如下表1:统计成绩绩分点是否使用计算机100 4 是 95 3.4 是 56 1.2 是 是否75 2.1 是86 3.1 是63 1.7 是96 4 是80 3.4 否90 2.9 否84 3.1 否62 1.9 否68 2.2 否92 3.7 是66 1.9 是60 1.7 否92 4 否63 1.1 是否2.模型估计将数据录入EVIEWS软件中,采用这些数据对模型进行OLS回归,结果如表2:表2Dependent Variable: YMethod: Least SquaresDate: 06/02/12 Time: 20:09Sample: 1 20Included observations: 20Variable Coefficient Std. Error t-Statistic Prob. X1 0.063385 0.004848 13.07383 0.0000 X2 -0.372084 0.137953 -2.697176 0.0153 C-2.0356990.376632-5.4050100.0000R-squared 0.909538 Mean dependent var 2.710000 Adjusted R-squared 0.898896 S.D. dependent var 0.944736 S.E. of regression 0.300396 Akaike info criterion 0.570054 Sum squared resid 1.534047 Schwarz criterion 0.719414 Log likelihood -2.700541 Hannan-Quinn criter. 0.599211 F-statistic 85.46258 Durbin-Watson stat 2.403154 Prob(F-statistic)0.00000012ˆ 2.0360.0630.372i i iY X X =-+- (0.377)(0.005) (0.138) t=(-5.405)(13.074) (-2.697)20.909r = 85.463F = 由模型的2r 可知,该模型的回归拟合效果比较好。
Excel回归结果的解读

Excel回归结果的解读利用Excel的数据分析进行回归,可以得到一系列的统计参量。
下面以连续10年积雪深度和灌溉面积序列(图1)为例给予详细的说明。
图1 连续10年的最大积雪深度与灌溉面积(1971-1980) 回归结果摘要(Summary Output)如下(图2):图2 利用数据分析工具得到的回归结果第一部分:回归统计表这一部分给出了相关系数、测定系数、校正测定系数、标准误差和样本数目如下(表1):表1 回归统计表逐行说明如下:Multiple 对应的数据是相关系数(correlation coefficient),即R=0.989416。
R Square 对应的数值为测定系数(determination coefficient),或称拟合优度(goodness of fit),它是相关系数的平方,即有R 2=0.9894162=0.978944。
Adjusted 对应的是校正测定系数(adjusted determination coefficient),计算公式为1)1)(1(12−−−−−=m n R n R a 式中n 为样本数,m 为变量数,R 2为测定系数。
对于本例,n =10,m =1,R 2=0.978944,代入上式得976312.01110)978944.01)(110(1=−−−−−=a R标准误差(standard error )对应的即所谓标准误差,计算公式为SSe 11−−=m n s这里SSe 为剩余平方和,可以从下面的方差分析表中读出,即有SSe=16.10676,代入上式可得418924.110676.16*11101=−−=s最后一行的观测值对应的是样本数目,即有n =10。
第二部分,方差分析表方差分析部分包括自由度、误差平方和、均方差、F 值、P 值等(表2)。
表2 方差分析表(ANOVA)逐列、分行说明如下:第一列df 对应的是自由度(degree of freedom ),第一行是回归自由度dfr ,等于变量数目,即dfr=m ;第二行为残差自由度dfe ,等于样本数目减去变量数目再减1,即有dfe=n -m -1;第三行为总自由度dft ,等于样本数目减1,即有dft=n -1。
虚拟变量回归结果解读

虚拟变量回归结果解读虚拟变量回归是一种经济统计学中常用的回归分析方法。
它用于处理定性变量,将其转换成虚拟变量,进而分析它们对因变量的影响。
本文将对虚拟变量回归的结果进行解读,帮助读者更好地理解和应用这一方法。
1. 背景介绍虚拟变量回归是一种基于二进制编码的方法,将定性变量转化为数值变量,以便进行回归分析。
它常用于控制混杂因素、检验效应等统计分析中。
在解读虚拟变量回归结果之前,我们首先需要了解回归模型的设定和数据样本。
2. 回归模型设定虚拟变量回归分析的基本模型可以表示为:Y = β0 + β1X1 + β2X2 + ... + βnXn + ε其中,Y为因变量,X1、X2、...、Xn为虚拟变量,β0、β1、β2、...、βn为回归系数,ε为误差项。
3. 解读回归系数在虚拟变量回归中,回归系数的解读依赖于虚拟变量的编码方式。
这里以一个二分类虚拟变量为例进行解释。
3.1 虚拟变量为二分类假设我们的虚拟变量为性别,编码方式为男性为1,女性为0。
回归结果显示该虚拟变量的回归系数为β1 = 0.2。
这一结果的解读如下:- 对于男性(虚拟变量为1),与女性相比,因变量的平均值(或均值的对数值)比女性多0.2个单位。
这说明男性相对于女性,对因变量有着0.2个单位的正向影响。
- 对于女性(虚拟变量为0),回归系数不产生作用。
因此,回归结果可以说是基于男性进行解读。
3.2 虚拟变量为多分类如果虚拟变量有多个分类,例如教育程度分为初中、高中和大学三类。
回归结果显示分别为β1 = 0.3,β2 = 0.5。
解读如下:- 对于初中教育程度(虚拟变量为1,其它分类为0),与高中相比,因变量的平均值比高中多0.3个单位。
- 对于高中教育程度(虚拟变量为1,其它分类为0),与大学相比,因变量的平均值比大学多0.5个单位。
- 对于大学教育程度(虚拟变量为1,其它分类为0),回归系数不产生作用。
4. 虚拟变量回归的显著性检验回归结果中还会提供每个虚拟变量的显著性检验结果,常见的检验方法包括t检验和F检验。
关于虚拟变量的回归(计量经济学-中南财经政法大学,

主要以下几点需要注意:
1、虽然有男、女两个分类,但是只用一个 虚拟变量。更通用的规则是:如果一个定 性变量有m个类别,则引入m-1个虚拟变 量。
2、虚拟变量的取值是随意,但是一旦取定 之
后要能合理地解释其意义。
3、被赋予零值的那个类别通常称为基底。 它
是用以和其他类别作比较的一个基础。
4、虚拟变量的系数称为级差截距系数,它 表
2为级差截距;
位级差斜率系数
2
根据表15.2中的数据得到如下结果:
Yˆi 1.7502 1.4839Di 0.1504Xi 0.1034Di Xi t (5.2733)(3.1545) (9.2238) (3.114)
R2 0.9425
各个系数在统计上都是显著的。可以肯定两个 时期的回归是相异的。
Standardized Coefficients
Beta
1.1877 1.2236 -.9626
t -5.2734 3.1549 9.2382 -3.1095
Sig. .000 .007 .000 .008
个 .6
人 储
.5
Yˆt 0.2663 0.0470X t
蓄 .4
百
万 .3
英
镑 .2
收入百万英镑
重 2.4
建 2.0 后
期 1.6
个 人 1.2
储 蓄
.8
.4
.0
Yˆt 1.7502 0.1504X t
-.4
-.8 -1.2
-1.6
-2.0 0 2 4 6 8 10 12 14 16 18 20 22 24 26
重建后期收入
虚拟变量法相比邹至庄检验的优越性:
1、用虚拟变量只需做一个回归。 2、一个回归可以做各种检验。截距检验和斜
虚拟变量回归模型课件.ppt

7.1 虚拟变量
7.1.1 虚拟变量的概念及作用
1.虚拟变量的内涵 在计量经济学中,我们把反映定性(或属性)因素变化,取值为0和1的人工变量称为 虚拟变量(Dummy Variable),或称为哑变量、虚设变量、属性变量、双值变量、类型变量、 定性变量、二元型变量、名义变量等,习惯上用字母D表示。例如
第2页,共32页。
虚拟变量
为什么要引入“虚拟变量” ?? 许多经济变量是可以定量度量的或者说是可以直接观测的
如商品需求量、价格、收入、产量等
但是也有一些影响经济变量的因素无法定量度量或者说无法直接观测
如职业、性别对收入的影响,战争、自然灾害对GDP的影响,季节 对某些产品(如冷饮)销售的影响等。
第3页,共32页。
第29页,共32页。
临界指标的虚拟变量的引入
在经济发生转折时期,可通过建立临界指 标的虚拟变量模型来反映。
第30页,共32页。
第31页,共32页。
当截距与斜率发生变化时,则需要同时引入加法与乘 法形式的虚拟变量。
OLS法得到该模型的回归方程为
则两时期进口消费品函数分别为:
当t<t*=1978年, Dt = 0
•女职工本科以上学历的平均薪金: E(Yt | Xt , D1 = 0, D2 = 1) = (b 0 + b3 ) + b1 Xt
•男职工本科以上学历的平均薪金:
E(Yt | Xt , D1 = 1, D2 = 1) = (b0 + b 2 + b3 ) + b1 Xt
第23页,共32页。
2、乘法方式
第8页,共32页。
这种“量化”通常是通过引入“虚拟变量”来完成的。根据这些
用Excel做回归分析的详细步骤

用Excel做回归分析的详细步骤回归分析是一种统计方法,用于建立一个或多个自变量和一个或多个因变量之间的关系。
在Excel中进行回归分析可以帮助我们理解变量之间的相关性,并进行预测。
下面是在Excel中进行回归分析的详细步骤:1.准备数据:将需要进行回归分析的数据整理成表格形式,并确保每一列都包含正确的数据类型。
通常情况下,自变量会位于一个或多个列中,而因变量会位于单独的一列中。
2. 打开Excel并导入数据:打开Excel软件,然后在一个新的工作表中导入准备好的数据。
可以通过直接复制粘贴或导入外部文件的方式将数据导入到Excel中。
3. 插入回归分析工具:在Excel中,回归分析工具位于"数据"选项卡的"数据分析"工具中。
如果没有找到该选项,需要手动启用"数据分析"工具。
4.选择回归分析工具:在"数据分析"对话框中,选择"回归"选项,然后点击"确定"。
5.输入数据范围:在"回归"对话框中,输入自变量和因变量的数据范围。
可以通过直接选择数据范围或手动输入单元格地址来指定数据范围。
6.选择输出选项:在"回归"对话框中,选择输出选项。
通常情况下,选择"新工作表中的输出",以便在新的工作表中生成回归结果。
7. 点击"确定"并查看结果:点击"确定"按钮之后,Excel将会进行回归分析,并在新的工作表中生成回归结果。
结果包括回归方程、系数、标准误差、决定系数等。
8.解读回归结果:根据生成的回归结果,可以进行进一步的解读和分析。
关注回归方程中的系数和显著性水平,以了解变量之间的关系以及对因变量的影响。
9. 绘制回归图表:在Excel中,可以使用"散点图"工具绘制自变量和因变量之间的散点图,并在图表中添加回归线。
多虚拟变量实验报告

一、实验背景在经济学、统计学等领域,研究变量之间的关系时,经常会遇到因变量受到多个定性因素的影响。
为了量化这些定性因素,引入虚拟变量(dummy variables)是一种常用的方法。
本实验旨在通过Eviews软件,对多虚拟变量模型进行实证分析,探讨虚拟变量在模型中的应用及其影响。
二、实验目的1. 掌握多虚拟变量模型的基本原理;2. 熟悉Eviews软件在多虚拟变量模型中的应用;3. 分析多虚拟变量模型对因变量的影响;4. 比较不同虚拟变量设置下的模型结果。
三、实验数据本实验选取我国某地区1990-2018年各行业的工业增加值作为因变量,选取行业类型、地区、年份等定性因素作为自变量。
数据来源于国家统计局网站。
四、实验步骤1. 数据录入与处理:将实验数据录入Eviews软件,对数据进行初步处理,包括单位转换、缺失值处理等。
2. 模型设定:根据实验目的,设定多虚拟变量模型如下:Y = β0 + β1X1 + β2X2 + β3X3 + β4X4 + ε其中,Y为工业增加值,X1为行业类型虚拟变量,X2为地区虚拟变量,X3为年份虚拟变量,β0为常数项,β1、β2、β3、β4为各虚拟变量的系数,ε为误差项。
3. 模型估计:利用Eviews软件,对多虚拟变量模型进行最小二乘法(OLS)估计。
4. 模型检验:对估计结果进行显著性检验、异方差性检验、多重共线性检验等。
5. 结果分析:分析多虚拟变量模型对因变量的影响,比较不同虚拟变量设置下的模型结果。
五、实验结果与分析1. 模型估计结果根据Eviews软件的估计结果,模型如下:Y = 1000 + 150X1 + 200X2 + 50X3 + 30X4 + ε其中,X1、X2、X3、X4分别表示行业类型、地区、年份的虚拟变量。
2. 模型检验结果(1)显著性检验:根据t检验结果,各虚拟变量的系数均显著,说明这些定性因素对因变量有显著影响。
(2)异方差性检验:根据Breusch-Pagan检验结果,模型存在异方差性。
虚拟变量实验报告

虚拟变量实验报告虚拟变量实验报告引言:虚拟变量是一种常用的统计分析工具,用于将分类变量转化为数值变量,以便在统计模型中使用。
在本实验中,我们将探讨虚拟变量的应用,并通过一个实例来说明其作用和效果。
实验目的:1.了解虚拟变量的定义和原理;2.掌握虚拟变量在实际数据分析中的应用;3.验证虚拟变量在统计模型中的有效性。
实验步骤:1.数据收集:我们从一家电商平台收集了一份关于用户购买行为的数据,包括用户的性别、年龄、购买金额等信息。
2.数据预处理:首先,我们对数据进行了清洗和整理,去除了缺失值和异常值。
然后,我们将性别变量转化为虚拟变量,将男性设为1,女性设为0。
同样地,我们将年龄变量分为若干个区间,并将其转化为虚拟变量。
3.建立模型:在建立模型之前,我们首先对数据进行了描述性统计分析,得到了一些基本的统计指标和图表。
然后,我们使用多元线性回归模型来研究用户购买金额与性别、年龄等变量之间的关系。
在模型中,我们将性别和年龄作为虚拟变量进行处理。
4.模型评估:我们使用了一些常用的统计指标来评估模型的拟合效果,包括R方值、调整R 方值、F统计量等。
此外,我们还进行了残差分析,以检验模型的合理性和假设的成立。
实验结果:通过实验,我们得到了以下结论:1.虚拟变量在统计模型中的应用可以有效地处理分类变量,使其能够在回归模型中发挥作用;2.在我们的实验中,性别和年龄对用户购买金额有显著影响;3.男性用户的购买金额显著高于女性用户;4.年龄在不同区间的用户购买金额存在差异,年龄越大,购买金额越高。
讨论与结论:虚拟变量是一种常用的统计分析工具,在实际数据分析中有着广泛的应用。
通过将分类变量转化为虚拟变量,我们可以更好地理解和解释数据,提高模型的拟合效果。
在本实验中,我们以用户购买金额为例,验证了虚拟变量在统计模型中的有效性。
实验结果表明,性别和年龄对用户购买金额有显著影响,男性用户的购买金额显著高于女性用户,并且随着年龄的增加,购买金额也呈现上升的趋势。
虚拟变量建模实验报告

一、实验背景与目的随着计量经济学的发展,虚拟变量(也称为指示变量)在数据分析中扮演着重要角色。
虚拟变量主要用于处理定性变量,将定性因素量化,以便于进行统计分析。
本实验旨在通过Eviews软件,掌握虚拟变量的基本原理,并运用虚拟变量构建模型,分析定性因素对定量变量的影响。
二、实验数据与模型设定实验数据来源于我国某地区某年度的居民消费数据,包括居民人均收入、消费支出、教育程度、是否为城市居民等变量。
根据研究目的,我们选取人均收入、消费支出和教育程度作为因变量,是否为城市居民作为虚拟变量。
实验模型设定如下:消费支出= β0 + β1 人均收入+ β2 教育程度+ β3 是否为城市居民 +ε其中,β0为截距项,β1、β2、β3分别为人均收入、教育程度和是否为城市居民的系数,ε为误差项。
三、实验步骤与结果分析1. 数据处理首先,将原始数据进行整理,删除缺失值和异常值。
然后,根据研究目的,将教育程度分为小学、初中、高中、大学及以上四个等级,并分别对应虚拟变量D1、D2、D3、D4。
是否为城市居民变量直接作为虚拟变量D5。
2. 模型估计利用Eviews软件,对上述模型进行最小二乘法(OLS)估计。
结果如下:消费支出 = 620.5 + 0.5 人均收入 + 0.4 教育程度 + 0.3 是否为城市居民3. 结果分析(1)截距项β0为620.5,表示当人均收入为0、教育程度为0、是否为城市居民为0时,消费支出的大致水平。
(2)人均收入的系数β1为0.5,表示在其他条件不变的情况下,人均收入每增加1元,消费支出将增加0.5元。
(3)教育程度的系数β2为0.4,表示在其他条件不变的情况下,教育程度每提高一个等级,消费支出将增加0.4元。
(4)是否为城市居民的系数β3为0.3,表示在其他条件不变的情况下,城市居民的消费支出比非城市居民高0.3元。
四、结论与展望通过本实验,我们掌握了虚拟变量的基本原理和建模方法,并成功分析了定性因素对消费支出的影响。
第七章虚拟变量回归

第七章虚拟变量回归第七章虚拟变量回归第⼀节虚拟变量的性质在实际建模过程中,被解释变量不但受定量变量影响,同时还受定性变量影响。
例如需要考虑性别、民族、不同历史时期、季节差异、政府的更迭(⼯党-保守党)、经济体制的改⾰、固定汇率变为浮动汇率、从战时经济转为和平时期经济等。
这些因素也应该包括在模型中。
⼀、基本概念由于定性变量通常表⽰的是某种特征的有和⽆,所以量化⽅法可采⽤取值为1或0。
这种变量称作虚拟变量(dummy variable )。
虚拟变量也称:哑元变量、定性变量等等。
通常⽤字母D 或DUM 加以表⽰(英⽂中虚拟或者哑元Dummy 的缩写)。
⽤1表⽰具有某⼀“品质”或属性,⽤0表⽰不具有该“品质”或属性。
虚拟变量使得我们可以将那些⽆法定量化的变量引⼊回归模型中。
虚拟变量应⽤于模型中,对其回归系数的估计与检验⽅法和定量变量相同。
虚拟变量表⽰两分性质,即“是”或“否”,“男”或“⼥”等。
下⾯给出⼏个可以引⼊虚拟变量的例⼦。
例1:你在研究学历和收⼊之间的关系,在你的样本中,既有⼥性⼜有男性,你打算研究在此关系中,性别是否会导致差别。
例2:你在研究某省家庭收⼊和⽀出的关系,采集的样本中既包括农村家庭,⼜包括城镇家庭,你打算研究⼆者的差别。
例3:你在研究通货膨胀的决定因素,在你的观测期中,有些年份政府实⾏了⼀项收⼊政策。
你想检验该政策是否对通货膨胀产⽣影响。
上述各例都可以⽤两种⽅法来解决,⼀种解决⽅法是分别进⾏两类情况的回归,然后看参数是否不同。
另⼀种⽅法是⽤全部观测值作单⼀回归,将定性因素的影响⽤虚拟变量引⼊模型。
⼆、虚拟变量设置规则虚拟变量的设置规则涉及三个⽅⾯: 1.“0”和“1”选取原则虚拟变量取“1”或“0”的原则,应从分析问题的⽬的出发予以界定。
从理论上讲,虚拟变量取“0”值通常代表⽐较的基础类型;⽽虚拟变量取“1”值通常代表被⽐较的类型。
“0”代表基期(⽐较的基础,参照物);“1”代表报告期(被⽐较的效应)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
0
0
8858.5
66850.5
0
0
7759.0
73142.7
1
0
7615.4
76967.2
1
0
6253.0
80579.4
1
0
4976.7
88254.0
1
0
9457.6
95727.9
1
1
13233.2
103935.3
1
1
16631.9
116603.2
1
1
在microsoft excel做出年度与城乡居民人民币储蓄存款增加额(YY)关系折线图
4.692
X3、X5、X6
8.0982
12.9169
-424.41
0.970249
4.078
2.639
0.805
比较,X3 X5 X4这组数据t各项检验值显著大,且修正的R2=0.987166所以保留X4
以X3 X5 X4为基础顺次加入其他变量做回归
Y C X3 X5 X4 X2
Y C X3 X5 X4 X6
校正的R2
X3、X2
0.0298
6.194
0.965818
2.151
4.284
X3、X4
8.017
1.717
0.94863
5.748
0.858
X3、X5
6.737
10.907
0.971745
6.644
2.658
X3、X6
7.851
285.115
0.944908
2.909
0.462
比较,当加入参数X5时各项参数的t值较大,且校正的R2=0.971745所以保留X5,以X3,X5为基础顺次加入其他变量做回归
可以观察到:
加入参数X2后,X2的t检验值不显著,加入参数X6后,X6的t检验值为负值,所以
X2 X6引起严重的多重共线性,故剔除X2 X6
所以修改后的回归结果为:
Dependent Variable: Y
Method: Least Squares
Date: 05/26/11 Time: 16:20
Method: Least Squares
Date: 05/26/11 Time: 15:28
Sample: 1994 2003
Included observations: 10
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
-274.1768
1316.895
226.6
140.27
6.87
2001
3522.37
78400
708.3
212.7
169.80
7.01
2002
3878.36
87800
739.7
209.1
176.52
7.19
2003
3442.27
87000
684.9
200.0
180.98
7.30
参数回归如下:
输入年度数据
得到
Dependent Variable: Y
YY C GNI GNI(GNI-66850.5)D1 GNI(GNI-88254.0)D2
Dependent Variable: YY
Method: Last Sqares
Date: 05/26/11 Time: 13:53
Sample (adjusted): 3 27
Included observations: 25 after adjustments
4.写出最后模型的形式
实
验
步
骤
1,虚拟变量回归
对于数据
实验2.1.xls
城乡居民人民币储蓄存款增加额(YY)
国民总收入(GNI)
D1
D2
NA
3624.1
0
0
70.4
4038.2
0
0
118.5
4517.8
0
0
124.2
4860.3
0
0
151.7
5301.8
0
0
217.1
5957.4
0
0
322.2
7206.7
得到:
变量
X2
X3
X4
X5
X6
校正的R2
X3、X5、X4、X2
0.0075
3.9187
3.2001
11.6767
0.985378
0.516
3.067
2.852
2.088
X3、X5、X4、X6
5.6987
3.2977
15.9684
-480.632
0.989531
4.173
3.471
5.263
-1.535
0.0000
(GNI-88254.0)*D2
0.560219
0.040136
13.95810
0.0000
R-squared
0.989498
Mean dependent var
4168.652
Adjusted R-squared
0.987998
S.D. dependent var
4581.447
S.E. of regression
0.951507
0.950641
1.000000
0.918851
0.751960
0.947977
0.941681
0.977673
0.918851
1.000000
0.865145
0.859191
0.963313
0.878337
0.751960
0.865145
1.000000
0.664946
0.818137
Prob(F-statistic)
0.000000
YYt=-0.80.4045+0.1445GNIt+E1tt<=1996
18649.8312-0.1469GNIt+E2t18<t<=2000
-30790.0596+0.4133GNIt+E3tt>=2000
2,多重共线性
对于数据
实验2.2.xls
年份
501.9182
Akaike info criterion
15.42040
Sum squared resid
5290359.
Schwarz criterion
15.61542
Log likelihood
-188.7550
F-statistic
659.5450
Durbin-Watson stat
1.677712
321.3331
-1.752473
0.1546
R-squared
0.995405
Mean dependent var
2539.193
Adjusted R-squared
0.989661
S.D. dependent var
985.0245
S.E. of regression
100.1589
Akaike info criterion
0.771476
0.839436
0.905365
校正的R2
0.891684
0.950324
0.74291
0.819365
0.893553
其中X3的校正的R2最大,以X3为基础,顺次加入其他变量逐步回归
Y C X3 X2
Y C X3 X4
Y C X3 X5
Y C X3 X6
得到:
变量
X2
X3
X4
X5
X6
同组学生姓名
无
实验地点
经管3楼
实验日期
2010年5月10日3~4节课
主要仪器设备(实验软件)
Eviews软件
实
验
目
的
要求学生掌握利用Eviews软件进行计量经济学中关于虚拟变量的回归模型研究与建立;诊断(检验)模型中的多重共线性问题,并通过合适的方法对模型进行补救以降低模型的多重共线性
实
验
内
容
和
原
理
R2=0.995405,拟合优度较高,但当α=0.05时,tα/2(n-k)=t0.025(10-6)=2.776,X2、X6系数的t检验不显著,而且X6系数符号与与其相反:可能存在严重的多重共线性
Y
X2
X3
X4
X5
X6
1.000000
0.950641
0.977673
0.878337
0.916207
X5
13.62842
2.904430
4.692289
0.0034
X4
3.222286
1.050397
3.067685
0.0220
R-squared
0.991444
Mean dependent var
2539.193
Adjusted R-squared
0.987166
0.916207
0.947977
0.859191
0.664946
1.000000
0.897708
0.951507
0.941681
0.963313
0.818137
0.897708
1.000000
由表中可以看到,各解释变量相互之间的相关系数较高,确实存在严重的多重共线性