Oracle全文索引技术-使用说明文档解析
oracle数据库创建索引语句

oracle数据库创建索引语句
创建索引是在Oracle数据库中优化查询性能的重要手段之一。
在Oracle中,创建索引的语句通常如下所示:
CREATE INDEX index_name.
ON table_name (column1, column2, ...);
其中,index_name是要创建的索引的名称,table_name是要在其上创建索引的表的名称,而column1, column2等则是要在其上创建索引的列的名称。
在实际使用中,我们还可以通过指定ASC(升序)或DESC(降序)关键字来定义索引的排序方式。
例如:
CREATE INDEX index_name.
ON table_name (column1 ASC, column2 DESC);
此外,还可以使用其他选项来定义索引的特性,比如唯一性约
束、压缩、并行等。
例如,要创建一个唯一索引,可以使用以下语句:
CREATE UNIQUE INDEX index_name.
ON table_name (column1, column2);
需要注意的是,创建索引会增加数据库写操作的开销,因此在创建索引之前需要仔细评估查询的使用情况,避免过度索引导致性能下降。
另外,索引还会占用额外的存储空间,因此需要权衡空间和性能之间的关系。
总之,创建索引是一个复杂的过程,需要综合考虑数据库的使用情况、性能需求和存储资源等多个方面的因素。
希望以上信息能够对你有所帮助。
使用Oracle全文索引搜索文本

使用Oracle全文索引搜索文本不使用Oracle text功能,也有很多方法可以在Oracle数据库中搜索文本.可以使用标准的INSTR 函数和LIKE操作符实现。
SELECT *FROM mytext WHERE INSTR (thetext, 'Oracle') > 0;SELECT * FROM mytext WHERE thetext LIKE '%Oracle%';有很多时候,使用instr和like是很理想的, 特别是搜索仅跨越很小的表的时候.然而通过这些文本定位的方法将导致全表扫描,对资源来说消耗比较昂贵,而且实现的搜索功能也非常有限,因此对海量的文本数据进行搜索时,建议使用oralce提供的全文检索功能建立全文检索的步骤步骤一检查和设置数据库角色首先检查数据库中是否有CTXSYS用户和CTXAPP脚色。
如果没有这个用户和角色,意味着你的数据库创建时未安装intermedia功能。
你必须修改数据库以安装这项功能。
默认安装情况下,ctxsys用户是被锁定的,因此要先启用ctxsys 的用户。
步骤二赋权在ctxsys用户下把ctx_ddl的执行权限赋于要使用全文索引的用户,例:grant execute on ctx_ddl to pomoho;步骤三设置词法分析器(lexer)Oracle实现全文检索,其机制其实很简单。
即通过Oracle专利的词法分析器(lexer),将文章中所有的表意单元(Oracle 称为term)找出来,记录在一组以dr$开头的表中,同时记下该term 出现的位置、次数、hash 值等信息。
检索时,Oracle 从这组表中查找相应的term,并计算其出现频率,根据某个算法来计算每个文档的得分(score),即所谓的‘匹配率’。
而lexer则是该机制的核心,它决定了全文检索的效率。
Oracle 针对不同的语言提供了不同的lexer, 而我们通常能用到其中的三个:n basic_lexer: 针对英语。
oracle 联合索引原理

oracle 联合索引原理Oracle是一种关系型数据库管理系统,它的联合索引是一种特殊的索引类型,可以提高查询效率和性能。
本文将介绍Oracle联合索引的原理及其优势。
一、联合索引的定义联合索引是由多个列组成的索引,这些列可以是一个表中的任意列。
与普通索引不同的是,联合索引可以通过多个列的组合进行查询,从而提高查询效率。
当查询条件中涉及到联合索引的列时,数据库可以直接利用联合索引进行快速定位,减少了查询的时间和资源消耗。
二、联合索引的原理1. 索引结构Oracle使用B树索引结构来实现联合索引。
B树是一种平衡二叉树,它可以保持索引的有序性,并且在插入、删除和查询操作中都能够保持较高的效率。
对于联合索引来说,B树的每个节点都包含了多个列的值,这样可以根据查询条件中的多个列进行快速定位。
2. 索引的创建在Oracle中,可以通过CREATE INDEX语句来创建联合索引。
语法如下:CREATE INDEX index_name ON table_name (column1,column2, ...);3. 索引的使用当查询条件中涉及到联合索引的列时,Oracle会自动选择使用联合索引进行查询。
数据库会根据联合索引的列顺序以及查询条件中的列顺序进行匹配,以找到满足条件的记录。
如果查询条件中的列顺序与联合索引的列顺序不一致,数据库可能无法使用联合索引,从而导致查询效率下降。
三、联合索引的优势1. 提高查询效率联合索引可以根据多个列的组合进行查询,从而提高查询效率。
当查询条件中涉及到联合索引的列时,数据库可以直接利用联合索引进行快速定位,减少了查询的时间和资源消耗。
2. 减少存储空间相比于多个单列索引,联合索引可以减少存储空间的占用。
联合索引将多个列的值存储在同一个索引结构中,避免了重复存储的问题。
3. 提高数据维护效率使用联合索引可以减少索引的数量,简化了数据库的维护工作。
当表的数据发生变化时,只需维护少量的联合索引,而不需要维护多个单列索引。
oracle 查询索引语句

oracle 查询索引语句一、查询索引定义1. 查询Oracle数据库中所有的索引```SELECT index_name, table_name FROM all_indexes;```2. 查询指定表中的所有索引```SELECT index_name FROM all_indexes WHERE table_name = '表名';```3. 查询指定索引的定义```SELECT index_name, table_name, column_name FROM all_ind_columns WHERE index_name = '索引名';```4. 查询索引的类型```SELECT index_name, table_name, index_type FROM all_indexes;```5. 查询索引的存储方式```SELECT index_name, table_name, index_type, index_subpartition_name, index_partition_name FROM all_indexes;```二、查询索引状态与统计信息1. 查询索引的状态(有效/无效)```SELECT index_name, status FROM all_indexes;```2. 查询索引的使用情况(最后一次访问时间、读取次数等)```SELECT index_name, last_analyzed, num_rows, leaf_blocks, distinct_keys, clustering_factor FROM all_indexes;```3. 查询索引的大小```SELECT index_name, table_name, index_type, ROUND(bytes/1024/1024, 2) AS size_mb FROM dba_segments WHERE segment_type = 'INDEX';```4. 查询索引的碎片化情况```SELECT index_name, table_name, index_type, blevel, leaf_blocks, distinct_keys, clustering_factor FROM all_indexes; ```5. 查询索引的使用情况(是否被频繁访问)```SELECT index_name, table_name, user_reads, user_updates FROM all_indexes;```三、查询索引的相关约束1. 查询索引所属的表的主键约束```SELECT index_name, table_name FROM all_indexes WHERE index_type = 'NORMAL' AND uniqueness = 'UNIQUE';```2. 查询索引所属的表的外键约束```SELECT index_name, table_name FROM all_indexes WHERE index_type = 'NORMAL' AND uniqueness = 'NONUNIQUE';```3. 查询索引所属的表的唯一约束```SELECT index_name, table_name FROM all_indexes WHERE index_type = 'NORMAL' AND uniqueness = 'NONUNIQUE';```4. 查询索引所属的表的检查约束```SELECT index_name, table_name FROM all_indexes WHERE index_type = 'NORMAL' AND uniqueness = 'NONUNIQUE';```5. 查询索引所属的表的默认值约束```SELECT index_name, table_name FROM all_indexes WHERE index_type = 'NORMAL' AND uniqueness = 'NONUNIQUE';```四、查询索引的相关操作1. 查询索引的创建语句```SELECT dbms_metadata.get_ddl('INDEX', '索引名') FROM dual; ```2. 查询索引的重建语句```SELECT 'ALTER INDEX ' || index_name || ' REBUILD;' FROM all_indexes;```3. 查询索引的重命名语句```SELECT 'ALTER INDEX ' || index_name || ' RENAME TO 新索引名;' FROM all_indexes;```4. 查询索引的删除语句```SELECT 'DROP INDEX ' || index_name || ';' FROM all_indexes;```5. 查询索引的禁用语句```SELECT 'ALTER INDEX ' || index_name || ' UNUSABLE;' FROM all_indexes;```五、查询索引的相关性能优化1. 查询索引是否需要重新构建```SELECT index_name, table_name, last_analyzed FROM all_indexes WHERE last_analyzed < SYSDATE - 30;```2. 查询未使用的索引```SELECT index_name, table_name FROM all_indexes WHERE status = 'VALID' AND (user_reads = 0 OR user_updates = 0); ```3. 查询索引碎片化严重的情况```SELECT index_name, table_name, blevel, leaf_blocks, distinct_keys, clustering_factor FROM all_indexes WHERE blevel > 3;```4. 查询索引的大小是否过大```SELECT index_name, table_name, index_type, ROUND(bytes/1024/1024, 2) AS size_mb FROM dba_segments WHERE segment_type = 'INDEX' AND bytes/1024/1024 > 100;```5. 查询索引的选择性是否低```SELECT index_name, table_name, distinct_keys, num_rows, (distinct_keys/num_rows) AS selectivity FROM all_indexes WHERE selectivity < 0.1;```六、查询索引的相关性能统计1. 查询索引的读取次数与更新次数```SELECT index_name, table_name, user_reads, user_updates FROM all_indexes;```2. 查询索引的平均访问时间```SELECT index_name, table_name, blevel, leaf_blocks, distinct_keys, clustering_factor, num_rows, (leaf_blocks/clustering_factor) AS avg_access_time FROM all_indexes;```3. 查询索引的存储效率```SELECT index_name, table_name, blevel, leaf_blocks,distinct_keys, clustering_factor, (leaf_blocks/clustering_factor) AS storage_efficiency FROM all_indexes;```4. 查询索引的选择性```SELECT index_name, table_name, distinct_keys, num_rows, (distinct_keys/num_rows) AS selectivity FROM all_indexes;```5. 查询索引的碎片率```SELECT index_name, table_name, blevel, leaf_blocks, distinct_keys, clustering_factor, (leaf_blocks/clustering_factor) AS fragmentation FROM all_indexes;```以上是关于Oracle查询索引的一些常用语句,通过这些语句可以方便地查询索引的定义、状态、统计信息以及进行相关操作和性能优化。
Oracle索引详解

一.索引介绍1.1 索引的创建语法:CREATE UNIUQE | BITMAP INDEX <schema>.<index_name>ON <schema>.<table_name>(<column_name> | <expression> ASC | DESC,<column_name> | <expression> ASC | DESC,...)TABLESPACE <tablespace_name>STORAGE <storage_settings>LOGGING | NOLOGGINGCOMPUTE STATISTICSNOCOMPRESS | COMPRESS<nn>NOSORT | REVERSEPARTITION | GLOBAL PARTITION<partition_setting>相关说明1) UNIQUE | BITMAP:指定UNIQUE为唯一值索引,BITMAP为位图索引,省略为B-Tree索引。
2)<column_name> | <expression> ASC | DESC:可以对多列进行联合索引,当为expression 时即“基于函数的索引”3)TABLESPACE:指定存放索引的表空间(索引和原表不在一个表空间时效率更高)4)STORAGE:可进一步设置表空间的存储参数5)LOGGING | NOLOGGING:是否对索引产生重做日志(对大表尽量使用NOLOGGING来减少占用空间并提高效率)6)COMPUTE STATISTICS:创建新索引时收集统计信息7)NOCOMPRESS | COMPRESS<nn>:是否使用“键压缩”(使用键压缩可以删除一个键列中出现的重复值)8)NOSORT | REVERSE:NOSORT表示与表中相同的顺序创建索引,REVERSE表示相反顺序存储索引值9)PARTITION | NOPARTITION:可以在分区表和未分区表上对创建的索引进行分区1.2 索引特点:第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
全文索引的原理及定义

全⽂索引的原理及定义全⽂索引时将存储在数据库中的整本书或整篇⽂章中的任意内容信息查找出来的技术。
它可以根据需要获取全⽂中有关章,节,段,句,词等信息,也可以进⾏各种统计和分析。
之前的MySQL数据库中,INNODB存储引擎并不⽀持全⽂索引技术,⼤多数的⽤户转向MyISAM存储引擎,不过这可能进⾏表的拆分,并需要将进⾏全⽂索引的数据存储为MyIsam表。
这样的确能够解决逻辑业务的需求,但是却丧失了INNODB存储引擎的事务性,⽽这在⽣产环境应⽤中同样是⾮常关键的。
从INNODB1.2.x版本开始,INNODB存储引擎开始⽀持全⽂索引,其⽀持myisam的全部功能,并且还⽀持其他的⼀些特性。
倒排索引全⽂索引通常使⽤倒排索引来实现。
倒排索引同B+树索引⼀样,也是⼀种索引结构。
它在辅助表中存储了单词与单词⾃⾝在⼀个或多个⽂档中所在的位置之间的映射。
这通常利⽤关联数组实现,其拥有两种表现形式。
inverted file index, 其表现形式为{单词,单词所在⽂档的ID}full inverted index,其表现形式为{单词,(单词所在⽂档的ID,再具体⽂档中的位置)}【具体来说就是inverted file index只能根据单词找到对应的⽂档,⽽full inverted index不仅能找到对应的⽂档,还能找到单词在⽂档中的具体位置】INNODB全⽂索引INNODB存储从1.2版本开始⽀持全⽂索引的技术,其采⽤full inverted index的技术。
在INNODB存储引擎中将(documentid, position)视为⼀个“ilist”。
因此在全⽂索引的表中,有两个列,⼀个是word字段,另⼀个是ilist字段,并且在word字段上设有索引。
此外,INNODB存储引擎在ilist字段上存放了position信息,故可以进⾏proximity search(邻近查找),⽽myisam不⽀持这个。
oracle的clob类型

Oracle的CLOB类型1. 引言Oracle数据库是一种关系型数据库管理系统,支持高效的数据存储和管理。
其中,CLOB(Character Large Object)类型是Oracle数据库中用于存储大量字符数据的一种数据类型。
本文将深入探讨Oracle的CLOB类型,包括其定义、用途、操作方法和性能优化等方面。
2. CLOB类型的定义与特点2.1 定义CLOB类型是Oracle数据库中用于存储大文本数据的一种数据类型。
它可以存储最大长度为4GB的字符数据,并且支持各种字符集。
CLOB类型通常用于存储文档、报表、XML数据等大量字符数据。
2.2 特点CLOB类型具有以下特点:•存储大容量的字符数据:CLOB类型可以存储最大长度为4GB的字符数据,适合存储大型文档、长报表等数据。
•支持各种字符集:CLOB类型支持多种字符集,可以存储不同语言的字符数据。
•高效存储与检索:Oracle数据库对CLOB类型的存储和检索做了优化,可以提供高效的操作性能。
•支持文本处理函数:CLOB类型可以使用Oracle数据库提供的文本处理函数进行字符串操作、搜索和替换等操作。
3. CLOB类型的用途CLOB类型在很多应用场景中具有广泛的用途:3.1 存储文档和报表CLOB类型可以用于存储各种文档和报表数据,例如Word文档、Excel报表、PDF文件等。
通过CLOB类型,可以将这些文档存储在数据库中,并能够在需要时进行检索和处理。
3.2 存储XML数据CLOB类型可以用于存储XML数据。
XML是一种常用的数据交换格式,通过CLOB类型,可以将XML数据存储在数据库中,并能够使用XML解析器对其进行解析和处理。
3.3 存储大型字符串CLOB类型可以用于存储大型字符串数据,例如长篇文章、博客内容等。
通过CLOB类型,可以将这些大型字符串存储在数据库中,并能够进行全文搜索、关键字提取等操作。
4. CLOB类型的操作方法4.1 创建表时使用CLOB类型使用CLOB类型创建表时,需要在表定义中指定该列的数据类型为CLOB。
Oracle数据库管理员参考手册说明书

7-100SQL ReferenceALTER ROLLBACK SEGMENTPurposeUse the ALTER ROLLBACK SEGMENT statement to bring a rollback segment online or offline, to change its storage characteristics, or to shrink it to an optimal or specified size.PrerequisitesYou must have ALTER ROLLBACK SEGMENT system privilege.Syntaxstorage_clause :See storage_clause on page 11-129.Keywords and Parametersrollback_segmentSpecify the name of an existing rollback segment.ONLINESpecify ONLINE to bring the rollback segment online. When you create a rollback segment, it is initially offline and not available for transactions. This clause brings the rollback segment online, making it available for transactions by your instance.See Also:CREATE ROLLBACK SEGMENT on page 9-149 forinformation on creating a rollback segment ALTER ROLLBACK SEGMENT rollback_segment ONLINEOFFLINEstorage_clauseSHRINK TOinteger KM;SQL Statements: ALTER CLUSTER to ALTER SYSTEM 7-101You can also bring a rollback segment online when you start your instance with the initialization parameter ROLLBACK_SEGMENTS .OFFLINESpecify OFFLINE to take the rollback segment offline.s If the rollback segment does not contain any information needed to roll back anactive transaction, Oracle takes it offline immediately.sIf the rollback segment does contain information for active transactions, Oracle makes the rollback segment unavailable for future transactions and takes it offline after all the active transactions are committed or rolled back.Once the rollback segment is offline, it can be brought online by any instance.To see whether a rollback segment is online or offline, query the data dictionary view DBA_ROLLBACK_SEGS . Online rollback segments have a STATUS value of IN_USE . Offline rollback segments have a STATUS value of AVAILABLE .Restriction: You cannot take the SYSTEM rollback segment offline.storage_clauseUse the storage_clause to change the rollback segment’s storage characteristics.Restriction: You cannot change the values of the INITIAL and MINEXTENTS for an existing rollback segment.SHRINKSpecify SHRINK if you want Oracle to attempt to shrink the rollback segment to an optimal or specified size. The success and amount of shrinkage depend on the available free space in the rollback segment and how active transactions are holding space in the rollback segment.The value of integer is in bytes, unless you specify K or M for kilobytes or megabytes.If you do not specify TO integer , then the size defaults to the OPTIMAL value of the storage_clause of the CREATE ROLLBACK SEGMENT statement that createdSee Also:Oracle8i Administrator’s Guide for more information on making rollback segments available and unavailableSee Also:storage_clause on page 11-129 for syntax and additional informationthe rollback segment. If OPTIMAL was not specified, then the size defaults to theMINEXTENTS value of the storage_clause of the CREATE ROLLBACK SEGMENTstatement.Regardless of whether you specify TO integer:s The value to which Oracle shrinks the rollback segment is valid for theexecution of the statement. Thereafter, the size reverts to the OPTIMAL value ofthe CREATE ROLLBACK SEGMENT statement.s The rollback segment cannot shrink to less than two extents.To determine the actual size of a rollback segment after attempting to shrink it,query the BYTES,BLOCKS, and EXTENTS columns of the DBA_SEGMENTS view.Restriction: For Oracle Parallel Server, you can shrink only rollback segments thatare online to your instance.ExamplesBringing a Rollback Segment Online Example This statement brings the rollbacksegment RSONE online:ALTER ROLLBACK SEGMENT rsone ONLINE;Changing Rollback Segment Storage Example This statement changes theSTORAGE parameters for RSONE:ALTER ROLLBACK SEGMENT rsoneSTORAGE (NEXT 1000 MAXEXTENTS 20);Resizing a Rollback Segment Example This statement attempts to resize arollback segment to 100 megabytes:ALTER ROLLBACK SEGMENT rsoneSHRINK TO 100 M;7-102SQL Reference。
Oracle中文使用手册

1.Oracle的使用1.1. SQLPLUS的命令初始化表的位置:set NLS_LANG=american_7ascii (设置编码才可以使用下面脚本)cd $ORACLE_HOME/rdbms cd demo summit2.sql*********************************我们目前使用的是oralce 9i 9201 版本select * from v$version;恢复练习表命令:sqlplus **/** @summit2.sql //shell要在这个文件的位置。
登陆oracle的命令:sqlplus 用户名/密码show user 显示当前登陆的身份.set pause onset pause off 分页显示.oracle中默认日期和字符是左对齐,数字是右对齐table or view does not exist ; 表或示图不存在edit 命令用于自动打开vi修改刚修执行过的sql的命令。
修改方法二:l 3 先定位到行 c /旧串/新串执行出错时,利用错误号来查错误:!oerr ora 942 (装完系统后会装一个oerr工具,用于通过错误号来查看错误的具体信息)想在sql中执行unix命令时,把所有的命令前加一个!就可以,或者host( 用于从sql从切换至unix环境中去)/*** 初次使用时注意 ****运行角本时的命令:先切换到unix环境下,cd $oracle_home cd sqlplus cd demo 下面有两个角本建表语句。
@demobld.sqlsqlplus nanjing/nanjing @demobid.sql 直接运行角本,后面跟当前目录或者是绝对路径保存刚才的sql语句:save 命令第二次保存时要替换之前的角本 save 文件名 replace把刚才保的sql重新放入 buffer中spool on 开启记录spool off 关闭记录spool 文件名此命令会把所有的操作存在某个文件中去常见缩写:nls national language support 国家语言支持1.2. SQL的结构|DDL 数据库定义|DML 数据库管理SQL――Commit rollback|DCL 数据库控制|grant+revoke 权限管理表分为:系统表(数据字典),用户表注:知道数据字典可以更便于使用数据库。
Oracle Text使用小结

Oracle Text使用小结一、Oracle Text介绍Oracle从7.3开始支持全文检索,即用户可以使用Oracle服务器的上下文(ConText)完成基于文本的查询(具体可采用通配符查找、模糊匹配、相关分类、近似查找、条件加权和词意扩充等方法);在Oracle 8.0.x中称为ConText ;在Oracle 8i 中称为interMedia Text ; Oracle9i中称为Oracle Text。
Oracle Text是9i 标准版和企业版的一部分,Oracle9i将全文检索功能做为内置功能提供给用户,使得用户在创建数据库实例时自动安装全文检索。
Oracle Text使Oracle 9i具备了强大的文本检索能力和智能化的文本管理能力。
使用Oracle Text,可以方便而有效地利用标准的SQL工具来构建基于文本的新的开发工具或对现有应用程序进行扩展。
应用程序开发人员可以在任何使用文本的Oracle数据库应用程序中充分利用Oracle Text搜索,应用范围可以是现有应用程序中可搜索的注释字段,也可是实现涉及多种文档格式(包括doc,excel,txt,pdf等)和复杂搜索标准的大型文档管理系统,还可是来自Internet和文件系统的文本数据搜索XML应用程序。
Oracle Text支持Oracle数据库所支持的大多数语言的基本全文搜索功能。
要使用Oracle Text,必须具有CTXAPP角色或者是CTXSYS用户。
Oracle Text 为系统管理员提供CTXSYS用户,为应用程序开发人员提供CTXAPP角色。
CTXSYS 用户可执行以下任务:启动Oracle Text服务器,执行CTXAPP角色的所有任务。
具有CTXAPP 角色的用户可执行以下任务:创建索引,管理Oracle Text数据字典,包括创建和删除首选项,进行Oracle Text查询,使用Oracle Text PL/SQL程序包。
oracle语法

oracle语法1、说明:创建数据库CREATE DATABASE database-name2、说明:删除数据库drop database dbname3、说明:备份sql server--- 创建备份数据的 deviceUSE masterEEC sp_addumpdevice 'disk', 'testBack','c:\mssql7backup\MyNwind_1.dat'---开始备份BACKUP DATABASE pubs TO testBack4、说明:创建新表create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..)根据已有的表创建新表:A:select into table_new from table_old (使⽤旧表创建新表) B:create table tab_new as select col1,col2… from tab_old definition only<;仅适⽤于Oracle>5、说明:删除新表drop table tabname6、说明:增加⽤个列,删除⽤个列A:alter table tabname add column col typeB:alter table tabname drop column colname注:DB2DB2中列加上后数据类型也不能改变,唯⽤能改变的是增加varchar类型的长度。
7、说明:添加主键: Alter table tabname add primary key(col)说明:删除主键: Alter table tabname drop primary key(col)8、说明:创建索引:create [unique] index idxname ontabname(col….)删除索引:drop index idxname注:索引是不可更改的,想更改必须删除重新建。
oracle 索引触发规则

oracle 索引触发规则
Oracle索引触发规则是指在数据库中使用索引时触发的一系列
规则和行为。
索引在Oracle数据库中起到加快数据检索速度的作用,但同时也会对数据库的性能产生影响。
以下是关于Oracle索引触发
规则的一些重要方面:
1. 查询优化,当查询语句中包含了索引字段时,Oracle数据
库会根据索引触发规则来决定是否使用索引。
通常情况下,数据库
会根据成本估算来决定是否使用索引,以加快查询速度。
2. 索引失效,在某些情况下,索引可能会失效,导致数据库查
询不再使用索引。
这可能是因为索引统计信息过时、数据分布不均
匀或者查询条件不适合使用索引等原因。
3. 索引选择,在执行查询时,Oracle数据库会根据索引触发
规则来选择合适的索引。
这可能涉及到全表扫描和索引扫描之间的
权衡,以及多个索引之间的选择。
4. 索引更新,当对表进行插入、更新或删除操作时,索引也会
相应地进行更新。
这需要遵循一定的索引触发规则,以保证索引的
一致性和有效性。
5. 索引重建,在某些情况下,索引可能需要进行重建以提高性能。
根据索引触发规则,数据库管理员可以选择重新构建索引以解决索引碎片化等问题。
总的来说,Oracle索引触发规则涉及到索引的选择、使用、更新和维护等方面,对于数据库的性能和稳定性都有重要的影响。
在实际应用中,需要根据具体的业务场景和数据库性能进行合理的索引设计和管理,以最大程度地发挥索引的作用。
Oracle-Text-组件-说明

2.1 Oracle 10g中重建2.1.1 Manualinstallation of Text 10gR1 (10.1.0.x)--安装Text 组件
1. Text dictionary, schema name CTXSYS, iscreated by calling following script from SQL*Plus connected as SYSDBA:
CATALOG Oracle Database Catalog Views 11.2.0.3.0
ห้องสมุดไป่ตู้
COMP_ID COMP_NAME VERSION
--------------- ---------------------------------------------
CATPROC Oracle Database Packages and T11.2.0.3.0
APS OLAP Analytic Workspace 11.2.0.3.0
17 rows selected.
MOS上的说明:
Oracle 8i/9i/10g/11g 组件(Components) 说明
/tianlesoftware/article/details/5937382
Oracle Text 组件 说明Oracle Text 组件 说明
一.OracleText 组件说明
在说明之前,我们先用如下SQL 查看一下DB中的组件:
SQL> col comp_id for a15
SQL> col version for a15
SQL> col comp_name for a30
Oracle 全文索引(Oracle Text )

Create index ftidx_n_ban_banlettpiny on n_ban(banlettpiny) indextype is ctxsys.ctxcat
parameters ('lexer cn_lexer index set n_ban_iset') tablespace TBS_INDEX_NAME;
Begin
ctx_ddl.create_index_set('n_ban_iset');
ctx_ddl.add_index('n_ban_iset','recdate');--备案日期加入到索引集,便于排序时使用
End;
--建立索引: n_ban的banlettpiny
-- drop index ftidx_n_ban_banlettpiny force;
--start D:/oracle/product/11.2.0/dbhome_2/ctx/admin/defaults/drdefus.sql
--start D:/oracle/product/11.2.0/dbhome_2/ctx/admin/defaults/drdeffrc.sql
--2、sys 登录赋权
Grant resource, connect, ctxapp to gsywjz;
Grant execute on ctxsys.ctx_cls to gsywjz;
Grant execute on ctxsys.ctx_ddl to gsywjz;
Grant execute on ctxsys.ctx_doc to gsywjz;
ctx_ddl.add_index('n_base_iset','apprauth');
oracle索引及使用原则

oracle索引及使用原则一、索引类型B-tree indexes 平衡二叉树,缺省的索引类型B-tree cluster indexes cluster的索引类型Hash cluster indexes cluster的hash索引类型Global and local indexes 与patitioned table相关的索引Reverse key indexes Oracle Real Application Cluster使用Bitmap indexes 位图索引,索相列的值属于一个很小的范围Function-based indexes 基于函数的索引Domain indexes二、使用索引的原则尽量在插入数据完成后建立索引,因为索引将导致插入数据变慢,特别是唯一索引在正确的表和列上建索引优化索引列顺序提高性能限制每个表的索引个数删除不需要的索引指定索引的block设置估计索引的大小设置存储参数指定索引使用的表空间建索引时使用并行使用nologing建立索引二,各种索引使用场合及建议(1)B*Tree索引。
常规索引,多用于oltp系统,快速定位行,应建立于高cardinality列(即列的唯一值除以行数为一个很大的值,存在很少的相同值)。
Create index indexname on tablename(columnname[columnname...])(2)反向索引。
B*Tree的衍生产物,应用于特殊场合,在ops环境加序列增加的列上建立,不适合做区域扫描。
Create index indexname on tablename(columnname[columnname...]) reverse(3)降序索引。
B*Tree的衍生产物,应用于有降序排列的搜索语句中,索引中储存了降序排列的索引码,提供了快速的降序搜索。
Create index indexname on tablename(columnname DESC[columnname...])(4)位图索引。
oracle全文检索
全文检索(oracle text)Oracle Text使Oracle9i具备了强大的文本检索能力和智能化的文本管理能力,Oracle Text是Oracle9i采用的新名称,在oracle8/8i中被称为oracle intermedia text,oracle8以前是oracle context cartridge。
Oracle Text的索引和查找功能并不局限于存储在数据库中的数据。
它可以对存储于文件系统中的文档进行检索和查找,并可检索超过150种文档类型,包括Microsoft Word、PDF和XML。
Oracle Text查找功能包括模糊查找、词干查找(搜索mice 和查找mouse)、通配符、相近性等查找方式,以及结果分级和关键词突出显示等。
你甚至可以增加一个词典,以查找搭配词,并找出包含该搭配词的文档。
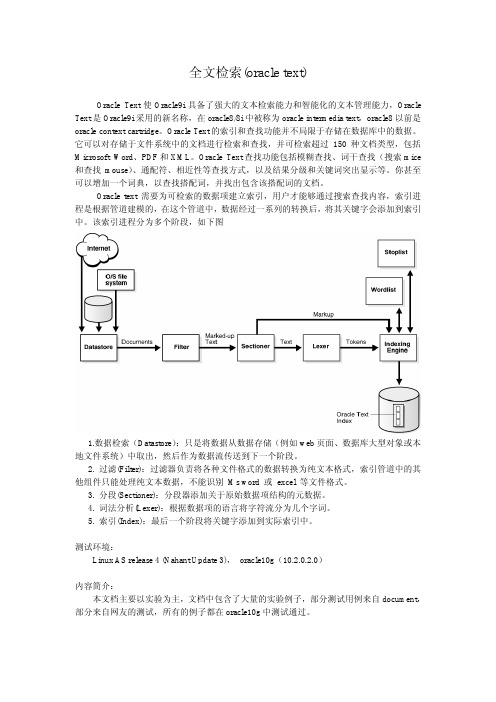
Oracle text 需要为可检索的数据项建立索引,用户才能够通过搜索查找内容,索引进程是根据管道建模的,在这个管道中,数据经过一系列的转换后,将其关键字会添加到索引中。
该索引进程分为多个阶段,如下图1.数据检索(Datastore):只是将数据从数据存储(例如web页面、数据库大型对象或本地文件系统)中取出,然后作为数据流传送到下一个阶段。
2. 过滤(Filter):过滤器负责将各种文件格式的数据转换为纯文本格式,索引管道中的其他组件只能处理纯文本数据,不能识别 Ms word 或 excel 等文件格式。
3. 分段(Sectioner):分段器添加关于原始数据项结构的元数据。
4. 词法分析(Lexer):根据数据项的语言将字符流分为几个字词。
5. 索引(Index):最后一个阶段将关键字添加到实际索引中。
测试环境:Linux AS release 4 (Nahant Update 3), oracle10g(10.2.0.2.0)内容简介:本文档主要以实验为主,文档中包含了大量的实验例子,部分测试用例来自document,部分来自网友的测试,所有的例子都在oracle10g中测试通过。
验收文档--Oracle产品说明、配置、维护

Oracle 技术说明随着计算机技术、通信技术和网络技术的发展,人类社会已经进入了信息化时代。
信息资源已经成为最重要和宝贵的资源之一,确保信息资源的存储,以及其有效性就变得非常重要,而保存信息的核心就是数据库技术。
对于数据库技术,当前应用最为广泛的是关系型数据库,而在关系型数据库中,Oracle公司推出的Oracle数据库是其中佼佼者。
到目前为止,Oracle数据库的最新版本为11g,这也是本系统所基于的数据库。
Oracle数据库11g产品具有丰富的功能以满足当前业务需求。
此外,Oracle还提供了一系列选件来满足某些特殊需求,比如确保关键业务可靠性,数据仓库等复杂需求等。
1.活动数据卫士选件(Actvie Data Guard)Oracle活动数据卫士属于Oracle数据库11g企业版选件,通过将负载压力从一个生产数据库上分担到一个或者多个容灾数据库的方式,加强了数据库对外服务的质量。
Oracle活动数据卫士增强了对物理备用数据库只读访问处理能力,让其可以很好的用来查询,排序,出报表等,同时还可以接受来自主点数据库传输过来的数据变更日志。
Oracle活动数据卫士也支持备用数据库的快速增量备份。
这可以提供更好的可靠性能和容灾保护以应对计划停机和非计划停机。
2.高级压缩选件(Advanced Compression)Oracle数据库11g企业版的高级压缩选件可以管理不断增长的数据。
Oracle高级压缩选件可以压缩不同的数据,无论是结构化数据,还是像文件,图片这样的非结构化数据,甚至是网络传输的备份数据都可以很好的压缩。
如此一来就可以充分的利用资源,减少在存储上面的开支。
3.高级安全选件(Advanced Security)Oracle高级安全选件提供透明数据加密,可以对数据库里存储的数据和网络传输的数据进行加密。
此外它提供一个完整的安全认证服务套件。
网络加密使用的是工业标准的数据加密算法。
该选件提供一系列的算法加强安全性。
oracle 索引类型大全

行
值 1 2 3 4 5 6 7 8 9 10
Male 1 0 0 0 0 0 0 0 1 1
Female 0 1 1 1 0 0 1 1 0 0
Null 0 0 0 0 1 1 0 0 0 0
如果搜索where gender=’Male’,要统计性别是”Male”的列行数的话,Oracle很快就能从位图中找到共3行即第1,9,10行是符合条件的;如果要搜索where gender=’Male’ or gender=’Female’的列的行数的话,也很容易从位图中找到共8行即1,2,3,4,7,8,9,10行是符合条件的。如果要搜索表的值的话,那么Oracle会用内部的转换函数将位图中的相关信息转换成rowid来访问数据块。
2 union all select 'number',dump(reverse(2),16) from dual
3 union all select 'number',dump(reverse(3),16) from dual;
'NUMBE DUMP(REVERSE(1),1
------ -----------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=100 Bytes=400)
1 0 INDEX (RANGE SCAN) OF 'IND_DESC' (NON-UNIQUE) (Cost=2 Card=100 Bytes=400)
我们看到排序过程消失了,这是因为创建降序索引时Oracle已经把数据都按降序排好了。
提交完成。
SQL> select /*+ RULE*/* FROM test.testindex where upper(a)='A';
Oracle B-tree、位图、全文索引三大索引性能比较及优缺点汇总

引言:大家都知道“效率”是数据库中非常重要的一个指标,如何提高效率大家可能都会想起索引,但索引又这么多种,什么场合应该使用什么索引呢?哪种索引可以提高我们的效率,哪种索引可以让我们的效率大大降低(有时还不如全表扫描性能好)下面要讲的“索引”如何成为我们的利器而不是灾难!多说一点,由于不同索引的存储结构不同,所以应用在不同组织结构的数据上,本篇文章重点就是:理解不同的技术都适合在什么地方应用!B-Tree索引场合:非常适合数据重复度低的字段例如身份证号码手机号码 QQ号等字段,常用于主键唯一约束,一般在在线交易的项目中用到的多些。
原理:一个键值对应一行(rowid)格式:【索引头|键值|rowid】优点:当没有索引的时候,oracle只能全表扫描where qq=40354446 这个条件那么这样是灰常灰常耗时的,当数据量很大的时候简直会让人崩溃,那么有个B-tree索引我们就像翻书目录一样,直接定位rowid 立刻就找到了我们想要的数据,实质减少了I/O操作就提高速度,它有一个显著特点查询性能与表中数据量无关,例如查2万行的数据用了3 consistent get,当查询1200万行的数据时才用了4 consistent gets。
当我们的字段中使用了主键or唯一约束时,不用想直接可以用B-tree索引缺点:不适合键值重复率较高的字段上使用,例如第一章1-500page 第二章501-1000page实验:alter system flush shared_pool; 清空共享池alter system flush buffer_cache; 清空数据库缓冲区,都是为了实验需要创建leo_t1 leo_t2 表leo_t1 表的object_id列的数据是没有重复值的,我们抽取了10行数据就可以看出来了。
LS@LEO> create table leo_t1 as select object_id,object_name from dba_objects;LS@LEO> select count(*) from leo_t1;COUNT(*)----------9872LS@LEO> select * from leo_t1 where rownum <= 10;OBJECT_ID OBJECT_NAME---------- -----------20 ICOL$44 I_USER128 CON$15 UNDO$29 C_COBJ#3 I_OBJ#25 PROXY_ROLE_DATA$39 I_IND151 I_CDEF226 I_PROXY_ROLE_DATA$_1leo_t2 表的object_id列我们是做了取余操作,值就只有0,1两种,因此重复率较高,如此设置为了说明重复率对B树索引的影响LS@LEO> create table leo_t2 as select mod(object_id,2) object_ID ,object_name from dba_objects;LS@LEO> select count(*) from leo_t2;COUNT(*)----------9873LS@LEO> select * from leo_t2 where rownum <= 10;OBJECT_ID OBJECT_NAME---------- -----------0 ICOL$0 I_USER10 CON$1 UNDO$1 C_COBJ#1 I_OBJ#1 PROXY_ROLE_DATA$1 I_IND11 I_CDEF20 I_PROXY_ROLE_DATA$_1LS@LEO> create index leo_t1_index on leo_t1(object_id); 创建B-tree索引,说明默认创建的都是B-tree索引Index created.LS@LEO> create index leo_t2_index on leo_t2(object_ID); 创建B-tree索引Index created.让我们看一下leo_t1与leo_t2的重复情况LS@LEO> select count(distinct(object_id)) from leo_t1; 让我们看一下leo_t1与leo_t2的重复情况,leo_t1没有重复值,leo_t2有很多COUNT(DISTINCT(OBJECT_ID))--------------------------9872LS@LEO> select count(distinct(object_ID)) from leo_t2;COUNT(DISTINCT(OBJECT_ID))--------------------------2收集2个表统计信息LS@LEO> execute dbms_stats.gather_table_stats(ownname=>'LS',tabname=>'LEO_T1',method_opt=>'for all indexed columns size 2',cascade=>TRUE);LS@LEO> execute dbms_stats.gather_table_stats(ownname=>'LS',tabname=>'LEO_T2',method_opt=>'for all indexed columns size 2',cascade=>TRUE);参数详解:method_opt=>'for all indexed columns size 2' size_clause=integer 整型,范围1~254 ,使用柱状图[ histogram analyze ]分析列数据的分布情况cascade=>TRUE 收集表的统计信息的同时收集B-tree索引的统计信息显示执行计划和统计信息+设置autotrace简介序号命令解释1 SET AUTOTRACE OFF 此为默认值,即关闭Autotrace2 SET AUTOTRACE ON EXPLAIN 只显示执行计划3 SET AUTOTRACE ON STATISTICS 只显示执行的统计信息4 SET AUTOTRACE ON 包含2,3两项内容5 SET AUTOTRACE TRACEONLY 与ON相似,但不显示语句的执行结果结果键值少的情况set autotrace trace exp stat; (SET AUTOTRACE OFF 关闭执行计划和统计信息)LS@LEO> select * from leo_t1 where object_id=1;no rows selectedExecution Plan 执行计划----------------------------------------------------------Plan hash value: 3712193284--------------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |--------------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | 21 | 2 (0)| 00:00:01 || 1 | TABLE ACCESS BY INDEX ROWID| LEO_T1 | 1 | 21 | 2 (0)| 00:00:01 ||* 2 | INDEX RANGE SCAN索引扫描 | LEO_T1_INDEX | 1 | | 1 (0)| 00:00:01 |-------------------------------------------------------------------------------------------- Predicate Information (identified by operation id):---------------------------------------------------2 - access("OBJECT_ID"=1)Statistics 统计信息----------------------------------------------------------0 recursive calls0 db block gets2 consistent gets 我们知道leo_t1表的object_id没有重复值,因此使用B-tree索引扫描只有2次一致性读0 physical reads0 redo size339 bytes sent via SQL*Net to client370 bytes received via SQL*Net from client1 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)0 rows processed结果键值多的情况LS@LEO> select * from leo_t2 where object_ID=1; (select /*+full(leo_t2) */ * from leo_t2 where object_ID=1;hint方式强制全表扫描)4943 rows selected.Execution Plan 执行计划----------------------------------------------------------Plan hash value: 3657048469----------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |----------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 4943 | 98860 | 12 (0)| 00:00:01 ||* 1 | TABLE ACCESS FULL| LEO_T2 | 4943 | 98860 | 12 (0)| 00:00:01 | sql结果是4943row,那么全表扫描也是4943row----------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - filter("OBJECT_ID"=1)Statistics 统计信息----------------------------------------------------------1 recursive calls0 db block gets366 consistent gets 导致有366次一致性读0 physical reads0 redo size154465 bytes sent via SQL*Net to client4000 bytes received via SQL*Net from client331 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)4943 rows processed大家肯定会疑惑,为什么要用全表扫描而不用B-tree索引呢,这是因为oracle基于成本优化器CBO认为使用全表扫描要比使用B-tree索引性能更好更快,由于我们结果重复率很高,导致有366次一致性读,从cup使用率12%上看也说明了B-tree索引不适合键值重复率较高的列我们在看一下强制使用B-tree索引时,效率是不是没有全表扫描高呢?LS@LEO> select /*+index(leo_t2 leo_t2_index) */ * from leo_t2 where object_ID=1; hint 方式强制索引扫描4943 rows selected.Execution Plan 执行计划----------------------------------------------------------Plan hash value: 321706586--------------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |--------------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 4943 | 98860 | 46 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| LEO_T2 | 4943 | 98860 | 46 (0)| 00:00:01 ||* 2 | INDEX RANGE SCAN | LEO_T2_INDEX | 4943 | | 10 (0)| 00:00:01 |-------------------------------------------------------------------------------------------- Predicate Information (identified by operation id):---------------------------------------------------2 - access("OBJECT_ID"=1)Statistics 统计信息----------------------------------------------------------1 recursive calls0 db block gets704 consistent gets 使用B-tree索引704次一致性读> 全表扫描366次一致性读,而且cpu 使用率也非常高,显然效果没有全表扫描高0 physical reads0 redo size171858 bytes sent via SQL*Net to client4000 bytes received via SQL*Net from client331 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)4943 rows processed小结:从以上的测试我们可以了解到,B-tree索引在什么情况下使用跟键值重复率高低有很大关系的,之间没有一个明确的分水岭,只能多测试分析执行计划后来决定。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
[Oracle全文索引技术] 使用说明文档金联万家(北京)电子支付科技发展有限公司修改记录目录1 前言 (3)1.1 编写目的 (3)1.2 名词解释 (3)1.3 参考资料 (3)2 oracle全文索引技术 (4)3 建立全文索引的操作步骤 (4)3.1 查看用户与角色 (4)3.2 开启目标用户全文索引权限 (4)3.3 设置语法分析器Lexer (5)3.4 建立索引 (5)3.5 使用索引 (6)4 全文索引的种类 (6)5 对多字段建立索引 (6)6 Oracle全文索引之 - CONTEXT (7)6.1 函数 CONTAINS 语法 (7)6.2 全文索引的维护 (7)6.2.1 同步数据 (8)6.3 单个中文字查询问题 (9)7 建立全文索引的完整脚本 (10)8 附录 (14)1前言1.1编写目的本文档主要说明Oracle全文索引技术的使用与维护,为数据库操作使用人员提供参考维护手册。
1.2名词解释表 1.术语表1.3参考资料表 2.参考资料列表2oracle全文索引技术全文检索:是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。
这个过程类似于通过字典中的检索字表查字的过程。
【Oracle Text 全文检索】Oracle一直致力于全文检索技术的研究,当Oracle9i Rlease2发布之时,Oracle数据库的全文检索技术已经非常完美,Oracle Text使Oracle9i具备了强大的文本检索能力和智能化的文本管理能力。
Oracle Text是Oracle9i 采用的新名称,在Oracle8/8i中它被称作Oracle interMedia Text,在Oracle8以前它的名称是Oracle ConText Cartridge。
使用Oracle9i和Oracle Text,可以方便而有效地利用标准的SQL工具来构建基于文本的新的开发工具或对现有应用程序进行扩展。
应用程序开发人员可以在任何使用文本的Oracle数据库应用程序中充分利用Oracle Text搜索,应用范围可以是现有应用程序中可搜索的注释字段,也可是实现涉及多种文档格式和复杂搜索标准的大型文档管理系统。
Oracle Text支持Oracle数据库所支持的大多数语言的基本全文搜索功能。
扩展阅读: /view/663956.htm3建立全文索引的操作步骤3.1查看用户与角色检查数据库中是否有CTXSYS 用户和CTXAPP 角色如果没有这个用户和角色,意味着你的数据库创建时未安装intermedia功能。
你必须修改数据库以安装这项功能。
默认安装情况下,ctxsys用户是被锁定的,因此要先启用ctxsys的用户。
-- 锁住用户ALTER USER ctxsys ACCOUNT LOCK PASSWORD EXPIRE;-- 解锁用户ALTER USER ctxsys ACCOUNT UNLOCK IDENTIFIED BY ctxsys;如果没有该用户,则需要打开dbca工具中选择configrue database options,然后选择所有数据库组件安装即可。
3.2开启目标用户全文索引权限赋权在ctxsys用户下把ctx_ddl的执行权限赋于要使用全文索引的用户,例:GRANT EXECUTE ON ctx_ddl TO username;3.3设置语法分析器LexerOracle实现全文检索,其机制其实很简单。
即通过Oracle专利的词法分析器(lexer),将文章中所有的表意单元(Oracle 称为 term)找出来,记录在一组以dr$开头的表中,同时记下该term出现的位置、次数、hash 值等信息。
检索时,Oracle 从这组表中查找相应的term,并计算其出现频率,根据某个算法来计算每个文档的得分(score),即所谓的‘匹配率’。
而lexer则是该机制的核心,它决定了全文检索的效率。
Oracle 针对不同的语言提供了不同的 lexer, 而我们通常能用到其中的三个:basic_lexer :针对英语(默认分析器)chinese_vgram_lexer:专门针对汉语,对汉字搜索准确性较高如:‘中国人民站起来了’这句话,会被它分析成如下几个term: ‘中’,‘中国’,‘国人’,‘人民’,‘民站’,‘站起’,起来’,‘来了’,‘了’chinese_lexer:新的汉语分析器,只支持 UTF8 字符集,可以将语句分词成常见的词组,能跟有效率的分析语句,对汉字解析搜索效率较高【指定语法分析器:】1.当前用户下下建立一个preference(例:在pomoho用户下执行以下语句)EXEC ctx_ddl.create_preference('my_lexer','chinese_vgram_lexer');2.在建立全文索引索引时,指明所用的lexer:CREATE INDEX myindex ON mytable(mycolumn) INDEXTYPE IS ctxsys.context PARAMETERS('lexer my_lexer');这样建立的全文检索索引,就会使用chinese_vgram_lexer作为分析器。
3.4建立索引通过以下语法建立全文索引3.5使用索引使用全文索引很简单,可以通过:SELECT * FROM PUBMENU WHERE CONTAINS(MENUNAME, '上传图片') > 0;4全文索引的种类建立的Oracle Text索引被称为域索引(domain index),包括4种索引类型:⏹CONTEXT用于对含有大量连续文本数据进行检索。
支持word、html、xml、text等很多数据格式。
支持中文字符集,支持分区索引,唯一支持并行创建索引(Parallel indexing)的索引类型。
对表进行DML操作后,并不会自动同步索引。
需要手工同步索引。
查询操作符:CONTAINS⏹CTXCAT当使用混合查询语句的时候可以带来很好的效率。
适合于查询较小的具有一定结构的文本段。
具有事务性,当更新主表的时候自动同步索引。
作符:CA TSEARCH⏹CTXRULE主要用于文档分类。
查询操作符:MATCHES⏹CTXXPATH快速查找XML文档NODE节点XPATH路径5对多字段建立索引很多时候需要从多个文本字段中查询满足条件的记录,这时就需要建立针对多个字段的全文索引,例如需要从作:--建议多字段索引的preference ,以ctxsys登录,并执行EXEC ctx_ddl.create_preference('ctx_idx_subject_pref','MULTI_COLUMN_DATASTORE');-- 建立 preference 对应的字段值(以ctxsys登陆)EXEC ctx_ddl.set_attribute('ctx_idx_subject_pref','columns','subjectname,briefintro'); --建立全文索引CREATE INDEX ctx_idx_subject ON pmhsubjects(subjectname) INDEXTYPE IS ctxsys.context PARAMETERS('DATASTORE ctxsys.ctx_idx_subject_pref lexer my_lexer');--使用索引SELECT * FROM pmhsubjects WHERE contains(subjectname,'李宇春');6Oracle全文索引之- CONTEXTCONTEXT:用于对含有大量连续文本数据进行检索。
支持word、html、xml、text等很多数据格式。
支持中文字符集,支持分区索引,唯一支持并行创建索引(Parallel indexing)的索引类型。
对表进行DML操作后,并不会自动同步索引。
需要手工同步索引。
查询操作符:CONTAINS6.1函数CONTAINS 语法使用contains时,主要查询语法有:contains([列名称],[查询关键字])Logical Operators:组合搜索条件,通过使用AND,OR等逻辑符号。
⏹AND(&),同时含有所有关键词,如:'cats AND dogs','cats & dogs'⏹OR(|),含有所有关键词中的任意一个,如:'cats | dogs','cats OR dogs's⏹NOT(~),不含该关键词,如:'animals ~ dogs'⏹ACCUM(,),与|类似,如:'dogs, cats, puppies'⏹EQUIV(=),如:'German shepherds=alsatians are big dogs'⏹ABOUT等【示例:】包含:“中国、安徽”关键字的“建设”或“农业”银行SELECT * FROM cn_common_data_bank_info t WHERE contains(t.ptcpt_nm,'( 建设 | 农业 ) & 安徽 & 中国')>0;6.2全文索引的维护对于CTXSYS.CONTEXT索引,当应用程序对基表进行DML操作后,对基表的索引维护是必须的。
索引维护包括索引myindex):DR$myindex$I、DR$myindex$K、DR$myindex$R、DR$myindex$N其中以I表最重要,可以查询一下该表,看看有什么内容:--IDX_CNDATABANKINFO_PKNMSELECT * FROM cn_common_data_bank_info;SELECT * FROM user_indexes;SELECT t.token_text,t.token_count FROM dr$idx_cndatabankinfo_pknm$i t;这里就不列出查询接过了。
可以看到,该表中保存的其实就是Oracle 分析你的文档后,生成的term记录在这里,包括term出现的位置、次数、hash值等。
当文档的内容改变后,可以想见这个I表的内容也应该相应改变,才能保证Oracle在做全文检索时正确检索到内容(因为所谓全文检索,其实核心就是查询这个表)。