史上最全资料(oracle全文检索说明(全))
使用Oracle全文索引搜索文本

使用Oracle全文索引搜索文本不使用Oracle text功能,也有很多方法可以在Oracle数据库中搜索文本.可以使用标准的INSTR 函数和LIKE操作符实现。
SELECT *FROM mytext WHERE INSTR (thetext, 'Oracle') > 0;SELECT * FROM mytext WHERE thetext LIKE '%Oracle%';有很多时候,使用instr和like是很理想的, 特别是搜索仅跨越很小的表的时候.然而通过这些文本定位的方法将导致全表扫描,对资源来说消耗比较昂贵,而且实现的搜索功能也非常有限,因此对海量的文本数据进行搜索时,建议使用oralce提供的全文检索功能建立全文检索的步骤步骤一检查和设置数据库角色首先检查数据库中是否有CTXSYS用户和CTXAPP脚色。
如果没有这个用户和角色,意味着你的数据库创建时未安装intermedia功能。
你必须修改数据库以安装这项功能。
默认安装情况下,ctxsys用户是被锁定的,因此要先启用ctxsys 的用户。
步骤二赋权在ctxsys用户下把ctx_ddl的执行权限赋于要使用全文索引的用户,例:grant execute on ctx_ddl to pomoho;步骤三设置词法分析器(lexer)Oracle实现全文检索,其机制其实很简单。
即通过Oracle专利的词法分析器(lexer),将文章中所有的表意单元(Oracle 称为term)找出来,记录在一组以dr$开头的表中,同时记下该term 出现的位置、次数、hash 值等信息。
检索时,Oracle 从这组表中查找相应的term,并计算其出现频率,根据某个算法来计算每个文档的得分(score),即所谓的‘匹配率’。
而lexer则是该机制的核心,它决定了全文检索的效率。
Oracle 针对不同的语言提供了不同的lexer, 而我们通常能用到其中的三个:n basic_lexer: 针对英语。
基于Oracle Text的信息系统资料库全文检索技术

( )过滤 器 提取 文 档 数 据 并 将其 转换 为文 本 表 示 方 式 。存 储 二进 制 文 档 ( wod 2 如 r
或 ar b t co a 文件 )时需 要 这样 做 。过滤器的输 出不 必是 纯 文本 格 式 , 可 以是 x 或 h — 它 ml t
ml 之类 的文 本 格式 。
O al Te t rce x 的原 理及 其 在信 息 系统 中的使 用 。
关 键词 : a l Te t 资料库 ; 文检 索 0rce x ; 全
1 引 言
OrceT x 是 Orce al e t a l 提供 的一 个服务 集 , 功能 十分 强大 , 可 以 为文 档 提 供索 引 方 它 法 、 行检 索 , 可 以对 文 档进 行格式 转换 、 进 还 存储 和 管理等 。它 不仅 支 持 TXT、 HTML等 纯文 本格 式 , 支持 很 多种 二进 制格 式的 文档 , D C、 P P F等等 。OrceTe t 还 如 O P T、 D al x 还 可用来 对 不 同语 种 的 文档进 行 检索 。Orc x 是完 全集 成在 数据 库 核心 内的 , 对 数 a l Te t e 它 据 库 中的 文档 进 行检 索 的效 率很 高 。
( )分段 器 提取 过 滤器 的输 出信息 , 3 并将 其转 换为 纯文 本 。包 括 x 和 h ml 内的 ml t 在
不 同 文本 格式 有 不 同的分 段器 。转换 为纯 文本 涉 及检 测 重要 文档 段标 记 、 移去 不 可 见 的 信 息 和文本 重新 格式化 。
( )词 法 分析 器提 取 分段器 中的纯 文本 , 将 其拆 分 为不 连 续 的标 记 。既 存在 空 白 4 并 字 符 分 隔语 言使 用 的词 法分 析器 , 也存在分 段复 杂的亚 洲语 言使用 的专 门词法 分析器 。 ( )索 引引 擎提 取词 法分 析器 中的所 有标 记 、 档 段在 分段 器 中的偏 移 量 以及 被 称 5 文 为 非索 引字 的 低 信息含 量字 列表 , 并构 建反 向索 引 。倒排 索 引 存 储标 记和 含有 这 些 标 记
[转载]oracleText全文检索功能对中文分词的支持情况
![[转载]oracleText全文检索功能对中文分词的支持情况](https://img.taocdn.com/s3/m/8df837d72dc58bd63186bceb19e8b8f67c1ceff2.png)
[转载]oracleText全⽂检索功能对中⽂分词的⽀持情况下⾯例⼦在XE中测试通过。
准备⼯作:CREATE TABLE issues (ID NUMBER,summary VARCHAR(120),description CLOB,author VARCHAR(80),ot_version VARCHAR(10));INSERT INTO issuesVALUES (1, 'Jane', 'Text does not make tea','Oracle Text is unable to make morning tea', 1);INSERT INTO issuesVALUES (2, 'John', 'It comes in the wrong color','I want to have Text in pink', 1);INSERT INTO issuesVALUES (3, 'Mike', 'I come from china', '所以我讲中⽂', 1);--下⾯两句话很难解析的INSERT INTO issuesVALUES (4, 'Mike', 'I come from china', '吉林省长春市的⼈民', 1);INSERT INTO issuesVALUES (5, 'Mike', 'I come from china','我们要积极地主动作好计划⽣育⼯作', 1);-- define datastore preference for issuesBEGIN--ctx_ddl.drop_preference ('issue_lexer');ctx_ddl.set_attribute ('issue_store', 'output_type', 'CLOB');ctx_ddl.create_preference ('issue_lexer', 'CHINESE_LEXER');END;/-- index issues 没有指定任何lexerCREATE INDEX issue_index ON issues(author) INDEXTYPE IS ctxsys.CONTEXT;--进⾏查询SELECT *FROM issuesWHERE contains (author, '中⽂', 1) > 0;会返回no rows selected。
Oracle中文使用手册

1.Oracle的使用1.1. SQLPLUS的命令初始化表的位置:set NLS_LANG=american_7ascii (设置编码才可以使用下面脚本)cd $ORACLE_HOME/rdbms cd demo summit2.sql*********************************我们目前使用的是oralce 9i 9201 版本select * from v$version;恢复练习表命令:sqlplus **/** @summit2.sql //shell要在这个文件的位置。
登陆oracle的命令:sqlplus 用户名/密码show user 显示当前登陆的身份.set pause onset pause off 分页显示.oracle中默认日期和字符是左对齐,数字是右对齐table or view does not exist ; 表或示图不存在edit 命令用于自动打开vi修改刚修执行过的sql的命令。
修改方法二:l 3 先定位到行 c /旧串/新串执行出错时,利用错误号来查错误:!oerr ora 942 (装完系统后会装一个oerr工具,用于通过错误号来查看错误的具体信息)想在sql中执行unix命令时,把所有的命令前加一个!就可以,或者host( 用于从sql从切换至unix环境中去)/*** 初次使用时注意 ****运行角本时的命令:先切换到unix环境下,cd $oracle_home cd sqlplus cd demo 下面有两个角本建表语句。
@demobld.sqlsqlplus nanjing/nanjing @demobid.sql 直接运行角本,后面跟当前目录或者是绝对路径保存刚才的sql语句:save 命令第二次保存时要替换之前的角本 save 文件名 replace把刚才保的sql重新放入 buffer中spool on 开启记录spool off 关闭记录spool 文件名此命令会把所有的操作存在某个文件中去常见缩写:nls national language support 国家语言支持1.2. SQL的结构|DDL 数据库定义|DML 数据库管理SQL――Commit rollback|DCL 数据库控制|grant+revoke 权限管理表分为:系统表(数据字典),用户表注:知道数据字典可以更便于使用数据库。
ORACLE CMD命令(最全的)

SQL*Plus: Release 9.0.1.0.0 - Production on Mon Jul 14 17:01:09 2003
(c) Copyright 2001 Oracle Corporation. All rights reserved.
su -root
date -u 08010000
21. 在ORACLE TABLE中如何抓取MEMO类型字段为空的数据记录?
select remark from om39; from remark) is not null ;
22. 如何用BBB表的数据去更新AAA表的数据(有关联的字段)
sum(nvl(a.bytes,0)) 剩余空间,
sum(nvl(a.bytes,0))/(b.bytes)*100 剩余百分比
from dba_free_space a,dba_data_files b
where a.file_id=b.file_id
SQL>
SQL> show parameter processes
NAME TYPE VALUE
------------------------------------ ------- ------------------------------
aq_tm_processes integer 1
Connected to:
Oracle9i Enterprise Edition Release 9.0.1.0.0 - Production
With the Partitioning option
JServer Release 9.0.1.0.0 - Production
oracle 全文检索 索引类型

Oracle支持多种全文检索索引类型,包括:
1. 简单全文索引(Basic Text Index):适用于常规的全文搜索需求,将文本内容分解为单词,存储在索引中,并提供搜索、排序和过滤功能。
2. 范围索引(Range Index):针对XML数据类型的索引,用于对XML文档的路径进行全文搜索,支持基于XSLT风格模式的查询和范围搜索。
3. 空间索引(Spatial Index):用于支持基于空间关系的查询,例如地理位置或几何形状的搜索,可以加速地理信息系统(GIS)或位置相关应用的查询操作。
Oracle索引类型按照物理可划分为分区索引和非分区索引,按照索引结构可划分为正常索引、Bitmap索引、Reverse索引和Domain 索引。
oracle中文使用手册

oracle中文使用手册Oracle是一款功能强大的关系型数据库管理系统,广泛应用于企业数据管理和应用开发领域。
本手册将详细介绍Oracle数据库的基本概念、常用命令和操作方法,以帮助初学者快速上手和熟练使用Oracle。
1. Oracle简介Oracle是美国Oracle公司开发的一种关系型数据库管理系统。
它是目前企业级应用系统首选的数据库产品之一,被广泛应用于各个行业的数据管理和应用开发中。
Oracle具有可靠性高、性能优异、安全性强等特点,成为大型企业数据处理的首选。
2. 安装与配置在开始使用Oracle之前,首先需要进行安装和配置。
可以从Oracle官方网站下载安装程序,根据提示进行安装。
安装完成后,需要进行一些基本的配置,如创建数据库实例、设置监听器等。
详细的安装和配置过程可以参考Oracle官方提供的文档或手册。
3. 数据库连接与登录使用Oracle数据库前,需要先进行数据库连接和登录。
可以使用SQL*Plus命令行工具或Oracle SQL Developer等图形化界面工具来进行连接和登录。
在连接时需要提供数据库的主机名、端口号和SID等信息,以及合法的用户名和密码。
连接成功后,即可开始对数据库进行操作。
4. SQL基本操作SQL是结构化查询语言,用于在关系型数据库中进行数据的增删改查等操作。
下面介绍一些常用的SQL命令:- 创建表: 使用CREATE TABLE语句可以创建数据表,并指定表的字段、数据类型、约束等信息。
- 插入数据: 使用INSERT INTO语句可以向表中插入数据。
- 更新数据: 使用UPDATE语句可以更新表中的数据。
- 删除数据: 使用DELETE FROM语句可以删除表中的数据。
- 查询数据: 使用SELECT语句可以查询表中的数据。
5. 数据库事务和锁机制数据库事务是指对数据库进行的一系列操作,要么全部执行成功,要么全部不执行。
Oracle提供了事务管理机制,可以确保数据库的一致性和完整性。
Oracle-Text-组件-说明

2.1 Oracle 10g中重建2.1.1 Manualinstallation of Text 10gR1 (10.1.0.x)--安装Text 组件
1. Text dictionary, schema name CTXSYS, iscreated by calling following script from SQL*Plus connected as SYSDBA:
CATALOG Oracle Database Catalog Views 11.2.0.3.0
ห้องสมุดไป่ตู้
COMP_ID COMP_NAME VERSION
--------------- ---------------------------------------------
CATPROC Oracle Database Packages and T11.2.0.3.0
APS OLAP Analytic Workspace 11.2.0.3.0
17 rows selected.
MOS上的说明:
Oracle 8i/9i/10g/11g 组件(Components) 说明
/tianlesoftware/article/details/5937382
Oracle Text 组件 说明Oracle Text 组件 说明
一.OracleText 组件说明
在说明之前,我们先用如下SQL 查看一下DB中的组件:
SQL> col comp_id for a15
SQL> col version for a15
SQL> col comp_name for a30
Oracle官方文档一览

包含了 oracle 数据库里面的一些基本概念和原理, 比如 数据库逻辑结构, 物理结构, 实例结构, 优化器, 事务等. PDF 460页
Reference
包含了动态性能视图, 数据字典, 初始化参数等, 如果有参数不知道意思, 或者 v$视图字段信息模糊, 都可以从这里找到描述, 使用 html版的进去 ctrl+f查找比较快.还包含一些其他比如数据库的硬性限制, 等待事件的名称, 后台进程的描述等.
包括各种 oracle 自建的包和函数的功能, 参数描述. 如果有不了解的包, 可以在这里找到, 比如 dbms_stats.
PL/SQL language Reference
plsql 编程的基础概念, 语法等.
SQLJ Developer’s Guide
SQLJ, JAVA相关的内容
Automatic Storage Management Administrator’s Guide
Asm 相关文档
Real Application Clusters Administration and Development Guide
包括 RAC 环境下的数据库管理和维护的内容
Clusterware Administration and Deployment Guide
数据仓库和商业智能的相关技术
VLDB and Partitioning Guide
very large database, … partition 和 parallel 相关的内容
utilities
imp, expdp, sql*loader, 外部表, dbv, adrci, logminer
oracle索引。其中全文检索最变态

oracle索引。
其中全⽂检索最变态全⽂检索位图索引B全⽂检索很少使⽤,如果产品上使⽤⼤家可以⽤Lcunce这些应⽤如果⾮要在数据库做这个采⽤就把⽤⼀个全⽂检索索引检索索引不会像其他的索引创建⼀个对象他会创建⼗个相关的对象。
⼗张的其中⼀张表存在形式如下Dtaken_text token_last tokent_count是 1 1是⼀个 1 1我是 1 1我是⼀个 1 1通过形式就猜到冗余存储如果表数据10M 索引表估计要50m⼤家会想问like 会⽤全⽂索引实际是不会的下⾯⽅法使⽤select * form t where contains("name","DBA")>0我插⼊⼀条sql 会直接有索引吗答案可能你猜错了没有的需要⼿⼯同步alter index t_idx_rebuild parameters('sync');⼿⼯同步有时间也是优势,以后讲sql优化⽅案会讲到的。
删除更新同样需要公共同步当然oracle 可以⾃动同步,只是默认没有开启。
全⽂索引操作量太⼤。
位图索引在⼤量相同数据时B树索引是⾮常低效的。
位图索引存款空间⼩对 or⽐较⾼效。
位图索引适合数据仓库不适合 oltp位图索引⽤在下⾯情况1.重复率⾼的数据2.特定类型的查询。
对 or⽐较⾼效。
3.联合索引B树索引唯⼀索引和主键的区别。
主键侧重的外键,唯⼀索引强调索引。
采⽤数据结构B树索引。
⼤量插⼊压⼒很⼤。
Hive索引的弊端:– 每次查询时候都要先⽤⼀个job扫描索引表,如果索引列的值⾮常稀疏,那么索引表本⾝也会⾮常⼤– 索引表不会⾃动rebuild,如果表有数据新增或删除,那么必须⼿动rebuild索引表数据索引是传统RDBMS的标准技术,⽤来加速查询Hive⾃0.7版本开始⽀持索引,但提供的功能很有限,效率也并不⾼,因此Hive索引很少使⽤Hive索引原理:– 在指定列上建⽴索引,⽣成⼀张索引表(Hive的⼀张物理表),记录以下三个字段:索引列的值、该值对应的HDFS⽂件路径、该值在⽂件中的偏移量– 在执⾏索引字段查询时候,⾸先额外⽣成⼀个MapReduce job,根据对索引列的过滤条件,从索引表中过滤出索引列的值对应的hdfs⽂件路径及偏移量,输出到hdfs上的⼀个⽂件中,然后根据这些⽂件中的hdfs路径和偏移量,筛选原始input⽂件,⽣成新的split,作为整个job的split,达到不⽤全表扫描的⽬的。
oracle all用法

Oracle ALL用法1. 概述在Oracle数据库中,ALL是一个关键字,可用于查询和过滤数据。
它可以与其他SQL语句一起使用,如SELECT、UPDATE和DELETE等。
使用ALL关键字可以对表中的所有行或特定条件下的所有行进行操作。
2. SELECT语句中的ALL用法2.1 查询所有行要查询表中的所有行,可以使用以下语法:SELECT * FROM table_name;这将返回指定表中的所有行。
2.2 查询满足特定条件的所有行要查询满足特定条件的所有行,可以使用以下语法:SELECT * FROM table_name WHERE condition;其中,condition是用于筛选数据的条件表达式。
例如,要查询年龄大于30岁的员工信息:SELECT * FROM employees WHERE age > 30;这将返回年龄大于30岁的员工信息。
2.3 使用ALL关键字进行比较在某些情况下,我们可能需要对结果集进行比较。
此时,可以使用ALL关键字来执行比较操作。
2.3.1 大于ALL子查询结果要查询大于某个子查询结果集中所有值的行,可以使用以下语法:SELECT column_name FROM table_name WHERE column_name > ALL (subquery);例如,要查询工资高于所有员工的经理信息:SELECT * FROM managers WHERE salary > ALL (SELECT salary FROM employees);这将返回工资高于所有员工的经理信息。
2.3.2 小于ALL子查询结果要查询小于某个子查询结果集中所有值的行,可以使用以下语法:SELECT column_name FROM table_name WHERE column_name < ALL (subquery);例如,要查询工资低于所有员工的经理信息:SELECT * FROM managers WHERE salary < ALL (SELECT salary FROM employees);这将返回工资低于所有员工的经理信息。
Oracle从入门到精通-经典资料

用于存储从磁盘数据文件中读入的数据,所有用户共享。 服务器进程将读入的数据保存在数据缓冲区中,当后续的请求需要这些数
据时可以在内存中找到,不需要再从磁盘读取,提高了读取速度。 数据缓冲区的大小对数据库的读取速度有直接的影响。
日志缓冲区
日志记录数据库的所有修改信息,日志信息首先产生于日志缓冲区。 当日志缓冲区的日志数据达到一定数量时,由后台进程将日志数据写入日
5
Oracle 数据库简介 2-2
Oracle数据库基于客户端/服务器技术
网络
请求
服务器
响应
数据库服务器对数据库表进行最佳管理,处理多个客户端对 客同户一端数应据用的程并序发通 访过 问向 。服 全务 面器 地请 保求 持并 数接 据收 完信 整息 性的 ,方并式控与制数数据据
库进行交互库。访它问充权当限用等户安与全数性据需库求之间的接口
Oracle 客户端
Oracle 服务器
tnsnames.ora
25
listener.ora
Oracle 网络配置 2-2
服务器端监听器配置信息包括监听协议、地址及 其他相关信息。 配置信息保存在名为listener.ora 的文件中。在安装服务器软件时自动配置一个监 听器
客户端的网络服务名配置信息包括服务器地址、 监听端口号和数据库SID等,与服务器的监听器 建立连接。配置信息保存在名为tnsnames.ora的 文件中
目标
4
Oracle 数据库简介 2-1
对象关系型的数据库管理系统 (ORDBMS) 在管理信息系统、企业数据处理、因特网及电子
商务等领域使用非常广泛 在数据安全性与数据完整性控制方面性能优越 跨操作系统、跨硬件平台的数据互操作能力
oracle全文检索
全文检索(oracle text)Oracle Text使Oracle9i具备了强大的文本检索能力和智能化的文本管理能力,Oracle Text是Oracle9i采用的新名称,在oracle8/8i中被称为oracle intermedia text,oracle8以前是oracle context cartridge。
Oracle Text的索引和查找功能并不局限于存储在数据库中的数据。
它可以对存储于文件系统中的文档进行检索和查找,并可检索超过150种文档类型,包括Microsoft Word、PDF和XML。
Oracle Text查找功能包括模糊查找、词干查找(搜索mice 和查找mouse)、通配符、相近性等查找方式,以及结果分级和关键词突出显示等。
你甚至可以增加一个词典,以查找搭配词,并找出包含该搭配词的文档。
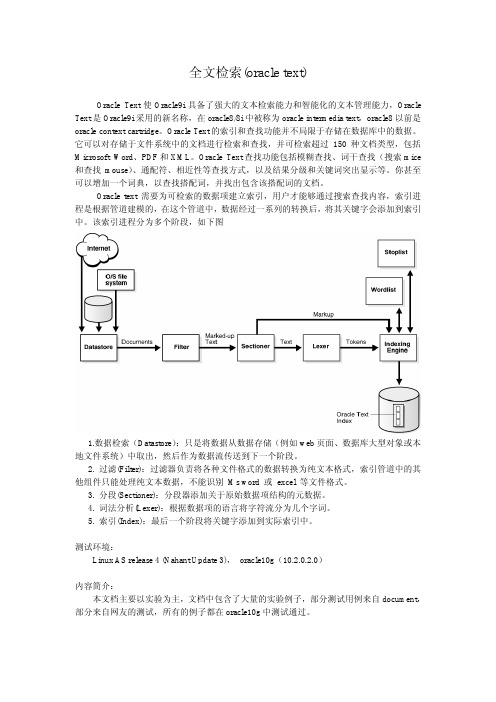
Oracle text 需要为可检索的数据项建立索引,用户才能够通过搜索查找内容,索引进程是根据管道建模的,在这个管道中,数据经过一系列的转换后,将其关键字会添加到索引中。
该索引进程分为多个阶段,如下图1.数据检索(Datastore):只是将数据从数据存储(例如web页面、数据库大型对象或本地文件系统)中取出,然后作为数据流传送到下一个阶段。
2. 过滤(Filter):过滤器负责将各种文件格式的数据转换为纯文本格式,索引管道中的其他组件只能处理纯文本数据,不能识别 Ms word 或 excel 等文件格式。
3. 分段(Sectioner):分段器添加关于原始数据项结构的元数据。
4. 词法分析(Lexer):根据数据项的语言将字符流分为几个字词。
5. 索引(Index):最后一个阶段将关键字添加到实际索引中。
测试环境:Linux AS release 4 (Nahant Update 3), oracle10g(10.2.0.2.0)内容简介:本文档主要以实验为主,文档中包含了大量的实验例子,部分测试用例来自document,部分来自网友的测试,所有的例子都在oracle10g中测试通过。
验收文档--Oracle产品说明、配置、维护

Oracle 技术说明随着计算机技术、通信技术和网络技术的发展,人类社会已经进入了信息化时代。
信息资源已经成为最重要和宝贵的资源之一,确保信息资源的存储,以及其有效性就变得非常重要,而保存信息的核心就是数据库技术。
对于数据库技术,当前应用最为广泛的是关系型数据库,而在关系型数据库中,Oracle公司推出的Oracle数据库是其中佼佼者。
到目前为止,Oracle数据库的最新版本为11g,这也是本系统所基于的数据库。
Oracle数据库11g产品具有丰富的功能以满足当前业务需求。
此外,Oracle还提供了一系列选件来满足某些特殊需求,比如确保关键业务可靠性,数据仓库等复杂需求等。
1.活动数据卫士选件(Actvie Data Guard)Oracle活动数据卫士属于Oracle数据库11g企业版选件,通过将负载压力从一个生产数据库上分担到一个或者多个容灾数据库的方式,加强了数据库对外服务的质量。
Oracle活动数据卫士增强了对物理备用数据库只读访问处理能力,让其可以很好的用来查询,排序,出报表等,同时还可以接受来自主点数据库传输过来的数据变更日志。
Oracle活动数据卫士也支持备用数据库的快速增量备份。
这可以提供更好的可靠性能和容灾保护以应对计划停机和非计划停机。
2.高级压缩选件(Advanced Compression)Oracle数据库11g企业版的高级压缩选件可以管理不断增长的数据。
Oracle高级压缩选件可以压缩不同的数据,无论是结构化数据,还是像文件,图片这样的非结构化数据,甚至是网络传输的备份数据都可以很好的压缩。
如此一来就可以充分的利用资源,减少在存储上面的开支。
3.高级安全选件(Advanced Security)Oracle高级安全选件提供透明数据加密,可以对数据库里存储的数据和网络传输的数据进行加密。
此外它提供一个完整的安全认证服务套件。
网络加密使用的是工业标准的数据加密算法。
该选件提供一系列的算法加强安全性。
ORACLECMD命令(最全的)

ORACLECMD命令(最全的)启动Oracle,在cmd模式下依次启动:net start oracleservice服务名lsnrctl start 启动监听程序关闭服务为:lsnrctl stopnet stop oracleserviceData1. Oracle安装完成后的初始口令?internal/oraclesys/change_on_installsystem/managerscott/tigersysman/oem_temp2. ORACLE9IAS WEB CACHE的初始默认用户和密码?administrator/administrator3. oracle 8.0.5怎么创建数据库?用orainst。
如果有motif界面,可以用orainst /m4. oracle 8.1.7怎么创建数据库?dbassist5. oracle 9i 怎么创建数据库?dbca6. oracle中的裸设备指的是什么?裸设备就是绕过文件系统直接访问的储存空间7. oracle如何区分 64-bit/32bit 版本$ sqlplus '/ AS SYSDBA'SQL*Plus: Release 9.0.1.0.0 - Production on Mon Jul 14 17:01:09 2003(c) Copyright 2001 Oracle Corporation. All rights reserved.Connected to:Oracle9i Enterprise Edition Release 9.0.1.0.0 - ProductionWith the Partitioning optionJServer Release 9.0.1.0.0 - ProductionSQL> select * from v$version;BANNER---------------------------------------------------------------- Oracle9i Enterprise Edition Release 9.0.1.0.0 - ProductionPL/SQL Release 9.0.1.0.0 - ProductionCORE 9.0.1.0.0 ProductionTNS for Solaris: Version 9.0.1.0.0 - ProductionNLSRTL Version 9.0.1.0.0 - ProductionSQL>8. SVRMGR什么意思?svrmgrl,Server Manager.9i下没有,已经改为用SQLPLUS了sqlplus /nolog变为归档日志型的9. 请问如何分辨某个用户是从哪台机器登陆ORACLE的?SELECT machine , terminal FROM V$SESSION;10. 用什么语句查询字段呢?desc table_name 可以查询表的结构select field_name,... from ... 可以查询字段的值select * from all_tables where table_name like '%'select * from all_tab_columns where table_name='??'11. 怎样得到触发器、过程、函数的创建脚本?desc user_sourceuser_triggers12. 怎样计算一个表占用的空间的大小?select owner,table_name,NUM_ROWS,BLOCKS*AAA/1024/1024 "Size M",EMPTY_BLOCKS,LAST_ANALYZEDfrom dba_tableswhere table_name='XXX';Here: AAA is the value of db_block_size ;XXX is the table name you want to check13. 如何查看最大会话数?SELECT * FROM V$PARAMETER WHERE NAME LIKE 'proc%';SQL>SQL> show parameter processesNAME TYPE VALUE------------------------------------ ------- ------------------------------aq_tm_processes integer 1db_writer_processes integer 1job_queue_processes integer 4log_archive_max_processes integer 1processes integer 200这里为200个用户。
甲骨文数据库oracle个人学习资料(pdf 34页)

甲骨文数据库oracle个人学习(OCP-042)by bingosummer一、创建oracle数据库1.数据库制定计划1)组成表空间的多个数据文件实际存储在哪些磁盘驱动器上。
2)制定备份策略,通过变更数据库的逻辑存储结构或设计可以提高备份效率。
2.典型的数据库类型:1)数据仓库:长期存放数据2)事务处理数据库:处理数量很多但规模通常较小的事务。
ATM.结账收款系统3)通过数据库3.删除数据库1)数据库必须装载且已关闭2)必须以独占方式而不是以共享模式装载数据库3)数据必须装载为Restricted4)删除语句Drop database,会删除数据文件、重做日志文件、控制文件和初始化参数文件。
对归档日志、数据库副本或备份不起作用。
5)如果数据文件保存在RAW设备中,则不会删除RAW设备专用文件。
二、管理ORACLE实例1.启动和停止dababase control1)emctl start|stop|status dbconsole2)执行程序emctl在$oracle_home/bin 路径下2.从SQL*PLUS 下调用SQL脚本1)sqlplus hr/hr @script.sql2)sql> @script.sql3.初始化参数文件1)服务器参数文件spfile<sid>.ora 路径:$ORACLE_HOME/dbs2)文本初始化文件init<sid>.ora 路径:$ORACLE_HOME/dbs4.关闭数据库1)sql> shutdown abort| immediate | transactional | normal5.启动数据库1)sql> startup force | restrict | mount |open |nomount6.预警日志记录:/u01/app/oracle/admin/orcl/bdump/alert_<sid>.log7.动态性能视图1)建立在根据数据库服务器内的内存结构构建的虚拟表基础上。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
oracle context cartridge 。Oracle Text 的索引和查找功能并不局限于存储在数据库中的数据。
它可以对存储于文件系统中的文档进行检索和查找,并可检索超过 150 种文档类型,包括
这表示 dog 在文档 doc1,doc3,doc5 中都出现过。索引建好之后,系统中会自动产生
如下 DR$MYINDEX$I,DR$MYINDEX$K,DR$MYINDEX$R,DR$MYINDEX$X,MYTABLE5 个表(假设表为
mytable,索引为 myindx)。Dml 操作后,context 索引不会自动同步,需要利用
他组件只能处理纯文本数据,不能识别 Ms word 或 excel 等文件格式。
3. 分段(Sectioner):分段器添加关于原始数据项结构的元数据。
4. 词法分析(Lexer):根据数据项的语言将字符流分为几个字词。
5. 索引(Index):最后一个阶段将关键字添加到实际索引中。
ctx_ddl.sync_index 手工同步索引。
----------------------- Page 4-----------------------
例子:
Create table docs (id number primary key, text varchar2 (200));
----------------------- Page 1-----------------------
全文检索(oracle text)
Oracle Text 使 Oracle9i 具备了强大的文本检索能力和智能化的文本管理能力,Oracle
SQL>Create user oratext identified by oratext default tablespace oratext temporary
tablespace temp;
Grant resource, connect, ctxapp to oratext;
--创建 ctxsys 用户
SQL> @?/ctx/admin/dr0csys password default_tablespace_name temporary_tablespace_name
SQL> connect ctxsys/password
--创建数据字典
SQL> @?/ctx/admin/dr0inst @?/ctx/lib/libctxx9.so
SQL> @?/ctx/admin/defaults/drdefus.sql ;
Oracl0g 安装 text:
SQL> connect / as sysdba
SQL> @?/ctx/admin/catctx.sql ctxsys TBS_DRSYS temp unlock
Conn ctxsys/ctxsys
SQL> @?/ctx/admin/defaults/drdefel.sql
(2).
创建测试用户 oratext
合于查询较小的具有一定结构的文本段。
具有事务性。DML操作后,索引会自动进行同步。
操作符:and,or,>,<, =,between,in
CTXRULE Use CTXRULE index to build a document classification or routing MATCHES
DML 操作后,需要CTX_DDL.SYNC_INDEX 手工同步索引
如果有查询包含多个词语,直接用空格隔开(如 oracle itpub)
CTXCAT 适用于混合查询语句(如查询条件包括产品id,价格,描述等)。适 CATSEARCH
Alter user ctxsys identified by ctxsys account unlock (10g默认安装,帐号被锁定);
Create tablespace oratext datafile '/opt/oracle10g/oradata/10gtest/oratext01.dbf' size
索引类型 描述 查询操作符
CONTEXT 用于对含有大量连续文本数据进行检索。支持 word、html、xml、text CONTAINS
Insert into docs values (1, '<html>california is a state in the us.</html>');
Insert into docs values (2, '<html>paris is a city in france.</html>');
1.
Context 索引
Oracle text 索引把全部的 word 转化成记号,context 索引的架构是反向索引(inverted
index ),每个记号都映射着包含它自己的文本位置,如单词 dog 可能会有如下的条目
Dog Doc1 Doc3 Doc5
----------------------- Page 2-----------------------
(1).
配置 oracle text
9i 之前,Oracle Text 不是默认安装的,必须手工安装。检查数据库中是否有 ctxsys 用户
和 ctxapp 脚色,如果没有这个用户和角色,这意味着你在创建数据库时没有安装 oracle text
Microsoft Word 、PDF 和 XML 。Oracle Text 查找功能包括模糊查找、词干查找(搜索 mice
和查找 mouse )、通配符、相近性等查找方式,以及结果分级和关键词突出显示等。你甚至
可以增加一个词典,以查找搭配词,并找出包含该搭配词的文档。
Oracle text 需要为可检索的数据项建立索引,用户才能够通过搜索查找内容,索引进
2000m ;
Create user oratext identified by oratect default tablespace oratext temporary tablespace
temp;
Alter database tempfile '/opt/oracle10g/oradata/10gtest/temp01.dbf' resize 2000m;
等很多数据格式。支持范围(range)分区,支持并行创建索引(Parallel
indexing)的索引类型。支持类型:VARCHAR2, CLOB, BLOB, CHAR, BFILE,
XMLType, and URIType.
Grant execute on ctxsys.ctx_cls to oratext;
Grant execute on ctxsys.ctx_ddl to oratext;
Grant execute on ctxsys.ctx_doc to oratext;
Grant execute on ctxsys.ctx_output to oratext;
Insert into docs values (3, '<html>france is in europe.</html>');
Commit;
application. The CTXRULE index is an index created on a table
of queries, where the queries define the classification or
测试环境:
Linux AS release 4 (Nahant Update 3) , oracle10g (10.2.0.2.0)
内容简介:
本文档主要以实验为主,文档中包含了大量的实验例子,部分测试用例来自 document,
部分来自网友的测试,所有的例子都在 oracle10g 中测试通过。
功能,需要先配置上该功能。
9i 安装 text
--创建表空间
SQL>create tablespace drsys datafile '/opt/oracle10g/oradata/10gtest/drsys01.dbf' size
100m;
SQL> connect / as sysdba
routing criteria.
CTXXPATH Create this index when you need to speed up existsNode() queries
on an XMLType column.
Grant execute on ctxsys.ctx_query to oratext;
Grant execute on ctxsys.ctx_report to oratext;
Grant execute on ctxsys.ctx_thes to oratext;
程是根据管道建模的,在这个管道中,数据经过一系列的转换后,将其关键字会添加到索引
中。该索引进程分为多个阶段,如下图
1.数据检索(Datastore ):只是将数据从数据存储(例如web 页面、数据库大型对象或本
地文件系统)中取出,然后作为数据流传送到下一个阶段。
2. 过滤(Filter) :过滤器负责将各种文件格式的数据转换为纯文 execute on ctxsys.ctx_ulexer to oratext;