6_第六讲(关联规则分析)
关联规则

C3 itemset
{2 3 5}
扫描 D
L3 itemset sup
{2 3 5} 2
{2,3}->{5}
21
Apriori 够快了吗? — 性能瓶颈
Apriori算法的核心:
用频繁的(k – 1)-项集生成候选的频繁 k-项集 用数据库扫描和模式匹配计算候选集的支持度 巨大的候选集: 多次扫描数据库:
给定数据库D,关联规则的挖掘就是找出所有存 在于数据库D中的强关联规则。因此整个关联规 则挖掘过程可以分解为以下两个子问题:
找出所有的频繁项目集; 根据找到的频繁项目集导出所有的强关联规则。
13
强关联规则的产生
第一个子问题的求解,需要多次扫描数据库D,这意味着 关联规则挖掘算法的效率将主要取决于数据库扫描、I/O操 作和频繁项目集的计算上。因此如何迅速、高效地找出所 有的频繁项目集是关联规则挖掘的中心问题 第二个子问题的求解比较容易,R. Agrawal等人已提出了 有效的解决办法,具体过程如下: 对每个频繁项目集I,产生所有的非空真子集:对I的任意 非空真真子集m,若support(I)/Support(m) minconfidence,则产生强关联规则m->(l-m)。
第二步: 修剪
forall itemsets c in Ck do
forall (k-1)-subsets s of c do if (s is not in Lk-1) then delete c from Ck
19
生成候选集的例子
L3={abc, abd, acd, ace, bcd} 自连接 : L3*L3
关联规则 PPT

2. 2 挖掘过程
第一阶段 找出所有频繁项集 (Large Itemsets) 第二阶段 由频繁项集产生强关联规则(Association Rules )
3. 1 相关算法
Apriori算法 基于划分的算法 FP-Grow算法
3.2 Apriori算法
思想:
首先,找出频繁1-项集,以L1表示.L1用来寻找L2,即频繁2-项集 的集合.L2用来寻找L3,以此类推,直至没有新的频繁k-项 集被发现.每个Lk都要求对数据库作一次完全扫描.
2.1 基本概念
交易数据库(D) 交易/事务 (T)
T I
交易标识符(TID) 项集(I)
I {i1,i2,..i.m},
规则 i1 i2
支持度support: D中包含i1和 i2 的事务数与总的事务数的比值
s(A B)|{ | TD| |AD| |B|T}||
可信度 confidence: D中同时包含i1和i2的事务数与包含i1的事务数的比值
2.1 基本概念
阈值 最小支持度 – 表示规则中的所有项在事务中出现的频度 最小可信度 - 表示规则中左边的项(集)的出现暗示着右
边的项(集)出现的频度
项集 – 任意项的集合 k-项集 – 包含k个项的项集 频繁 (或大)项集 – 满足最小支持度的项集 强规则:那些满足最小支持度和最小可信度的规则.
Apriori算法
候选项集生成的示例 L3={ abc, abd, acd, ace, bcd } 自连接: L3*L3 由abc 和abd 连接得到abcd 由acd 和ace 连接得到acde 剪枝: 因为ade 不在L3中acde 被剪除
Apriori算法
挑战: 多次扫描事务数据库 巨大数量的候选项集 繁重的计算候选项集的支持度工作 改进 Apriori: 大体的思路 减少事务数据库的扫描次数 缩减候选项集的数量 使候选项集的支持度计算更加方便
06第5章-关联规则

<I2:4>
{I2 I1:4}
第22页,共88页。
输入:D:事务数据库; min_sup:最小支持度计数阀值 输出:频繁模式的完全集。
第五章 挖掘频繁模式、关联和相关
5.1 基本概念和线路图
5.1.1 购物篮分析:引发性例子
5.1.2 频繁项集、闭项集和关联规则
5.1.3频繁模式挖掘:路线图
第1页,共88页。
5.1.1 购物篮分析:引发性例子
频繁项集挖掘的一个典型例子是购物篮分 析。
例如:如果顾客在超市购物时购买了牛奶,他们有多大的可 能同时购买面包?
T500 T600 T700
T800
T900
商品ID的列表
I1,I2,I5 I2,I4 I2,I3 I1,I2,I4
I1,I3 I2,I3
I1,I3
I1,I2,I3,I5
I1,I2,I3
表5-1 AllElectronics某分店的是事务数据
第9页,共88页。
D
C1
项集
扫 {I1} 描
对 {I2}
for(k=2; Lk-1≠空集; k++) //由(k-1)项频繁项集产生第k项侯选项集;
Ck= apriori_gen(Lk-1); //产生的第k项侯选项集;
for each 事务 t∈D
//扫描数据库D中的每一个事务t;
{
Ct= subset(Ck,t); //对事务t,产生具有K项的子集赋给Ct; for each 侯选c∈Ct // 检查侯选项集中的某一项是否属于Ct;
1.它可能需要产生大量侯选项集;
2.它可能需要重复地扫描数据库,通过模式匹配检查一个很
大的侯选集合。
关联规则简介与Apriori算法课件

评估关联规则的置信度,以确定规则是否具有可信度 。
剪枝
根据规则的置信度和支持度进行剪枝,去除低置信度 和低支持度的规则。
04 Apriori算法的优化策略
基于散列的技术
散列技术
通过散列函数将数据项映射到固定大小的桶中,具有相同散列值的数据项被分配 到同一个桶中。这种方法可以减少候选项集的数量,提高算法效率。
散列函数选择
选择合适的散列函数可以减少冲突,提高散列技术的效率。需要考虑散列函数的 均匀分布性和稳定性。
基于排序的方法
排序技术
对数据项按照某种顺序进行排序,如 按照支持度降序排序,优先处理支持 度较高的数据项,减少不必要的计算 和比较。
排序算法选择
选择高效的排序算法可以提高算法效 率,如快速排序、归并排序等。
关联规则的分类
关联规则可以根据不同的标准进行分类。
根据不同的标准,关联规则可以分为多种类型。根据规则中涉及的项的数量,可以分为单维关联规则和多维关联规则。根据 规则中项的出现顺序,可以分为无序关联规则和有序关联规则。根据规则的置信度和支持度,可以分为强关联规则和弱关联 规则。
关联规则挖掘的步骤
关联规则挖掘通常包括以下步骤:数据预处理、生成 频繁项集、生成关联规则。
关联规则简介与 Apriori算法课件
目录
• 关联规则简介 • Apriori算法简介 • Apriori算法的实现过程 • Apriori算法的优化策略 • 实例分析 • 总结与展望
01 关联规则简介
关联规则的定义
关联规则是数据挖掘中的一种重要技术,用于发现数据集中 项之间的有趣关系。
关联规则是一种在数据集中发现项之间有趣关系的方法。这 些关系通常以规则的形式表示,其中包含一个或多个项集, 这些项集在数据集中同时出现的频率超过了预先设定的阈值 。
关联规则分析

超市例子
例3.1 (Groceries.txt) 这是一个超市购物例子(Hahsler et al., 2006),数据中有9835笔交易,涉及169种商品。每个交易 为一个顾客的购买记录,而每种商品是一个二分变量,比 如,购买用1代表,未购买用0代表。通过对数据的初步计 算,我们发现在单项计数中,全牛奶(whole milk)的频数最 高,为2513(频率接近26%),而其次为:其它蔬菜(other vegetables)为1903,面包(rolls/buns)为1809,苏打(soda)为 1715,酸奶(yogurt)为1372等等。超过5%的顾客购买的商 品频率显示在图3.1中。此外,还可以知道分别买不同数 量商品的顾客人数,购买1至9种商品的人数展示在下表中:
library(arules) data(Groceries) summary(Groceries) itemFrequencyPlot(Groceries, support = 0.05, s = 0.8) #图3.1 图
0.00
0.05
0.10
0.15
0.20
0.25
超过5%的顾客购买的商品名字和频率 超过 的顾客购买的商品名字和频率
支持度(support) 支持度 信息 • X=>Y的支持度
表示事务Ζ 表示事务包含X的 记σ(Z)表示事务Ζ在包含Ν个事务的整个事务数据集中的频数,用A表示事务包含 的 表示事务 在包含Ν个事务的整个事务数据集中的频数, 表示事务包含 事件, 表示事务包含Y的事件 没有交) 事件,而B表示事务包含 的事件 和Y没有交 ,则: 表示事务包含 的事件(X和 没有交
fra nk fu sa rter us ag e po rk b cit e e f ru tro s fr pi uit ca lf ru ro pi it ot p ve fru ot ge it he r v tab eg le s et a wh b le s ol e m i lk bu tte r wh cu ip rd pe y d/ so ogu do ur c r t r m e s eam t ic e ro ggs lls /b br ow un s n br ea d pa s m ar try ga rin e bo co ff ttl ed ee wa fru te it/ ve r ge s ta od bl a e ju bo ic ttl ed e ca b nn ee ed r be na er ne pk w in sh sp s op ap e pi ng rs ba gs
关联分析基本概念与算法ppt课件
2/5 频繁项集(Frequent Itemset) – 满足最小支持度阈值( minsup )的
先验原理( Apriori principle)
先验原理:
– 如果一个项集是频繁的,则它的所有子集一定也是频繁 的
相反,如果一个项集是非频繁的,则它的所有超集 也一定是非频繁的:
– 这种基于支持度度量修剪指数搜索空间的策略称为基于 支持度的剪枝(support-based pruning)
– 这种剪枝策略依赖于支持度度量的一个关键性质,即一 个项集的支持度决不会超过它的子集的支持度。这个性 质也称为支持度度量的反单调性(anti-monotone)。
4
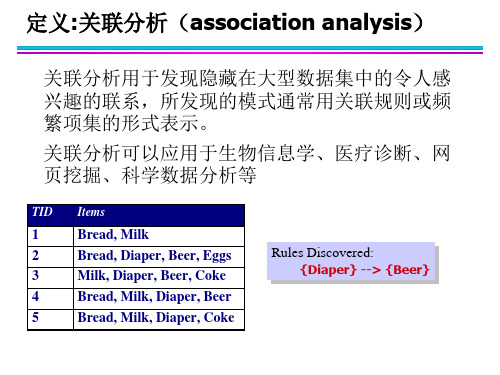
Bread, Milk, Diaper, Beer
关联规则的强度
5
Bread, Milk, Diaper, Coke
– 支持度 Support (s) 确定项集的频繁程度
Example:
{M,iD lkia}p e Bree
– 置信度 Confidence (c) 确定Y在包含X的事 务中出现的频繁程度
Brute-force 方法:
– 把格结构中每个项集作为候选项集
– 将每个候选项集和每个事务进行比较,确定每个候选项集 的支持度计数。
Transactions
TID Items
1 Bread, Milk
2 Bread, Diaper, Beer, Eggs
关联规则

内部资料 泰迪科技()
4
关联规则——Apriori算法介绍
以超市销售数据为例,提取关联规则的最大困难在于当存在
很多商品时,可能的商品的组合(规则的前项与后项)的数
目会达到一种令人望而却步的程度。因而各种关联规则分析 的算法从不同方面入手减小可能的搜索空间的大小以及减小 扫描数据的次数。 Apriori算法是最经典的挖掘频繁项集的算法,第一次实现了 在大数据集上可行的关联规则提取,其核心思想是通过连接 产生候选项与其支持度然后通过剪枝生成频繁项集。
内部资料 泰迪科技()
5
关联规则——Apriori算法介绍
1、关联规则和频繁项集
,
(1)关联规则的一般形式 项集A、B同时发生的概率称为关联规则的支持度:
Support ( A B) P( A B)
项集A发生,则项集B也同时发生的概率为关联规则的置信度:
Confidence( A B) P( B|A)
订单号 1 2 3 4 5 6 7 8 9 10 菜品id 18491, 8693,8705 8842,7794 8842,8693 18491,8842,8693,7794 18491,8842 8842,8693 18491,8842 18491,8842,8693,8705 18491,8842,8693 18491,8693 菜品id a,c,e b,d b,c a,b,c,d a,b b,c a,b a,b,c,e a,b,c a,c,e
项集将不会存在于 Ck ,该过程就是剪枝。
内部资料 泰迪科技()
13
关联规则——Apriori算法实现
Apriori算法的实现的两个过程 过程一:找出所有的频繁项集。 过程二:由频繁项集产生强关联规则 由过程一可知未超过预定的最小支持度阈值的项集已被剔除, 如果剩下这些规则又满足了预定的最小置信度阈值,那么就挖 掘出了强关联规则。
关联规则分析

市场购物篮分析
事务 ID A B C D 购物篮 Chips, Salsa, Cookies, Crackers, Coke, Beer Lettuce, Spinach, Oranges, Celery, Apples, Grapes Chips, Salsa, Frozen Pizza, Frozen Cake Lettuce, Spinach, Milk, Butter, Chips
36
生成频繁项集
naïve algorithm的分析
I 的子集: O(2m)
为每一个子集扫描n个事务 测试s为T的子集: O(2mn)
随着项的个数呈指数级增长! 我们能否做的更好?
37
Apriori 性质
定理(Apriori 性质): 若A是一个频繁项集,则A 的每一个子集都是一个频繁项集. 证明:设n为事务数.假设A是l个事务的子集,若 A’ ⊂ A , 则A’ 为l’ (l’ ≥ l )个事务的子集.因此, l/n ≥s(最小支持度), l’/n ≥s也成立.
关联规则的最小支持度也就是衡量频繁 集的最小支持度 (Minimum Support) , 记为supmin,它用于衡量规则需要满足 的最低重要性。 规 则 的 最 小 可 信 度 (Minimum Confidence )记为confmin,它表示关 联规则需要满足的最低可靠性。
32
定义9 强关联规则
35
生成频繁项集
Naïve algorithm
n <- |D| for each subset s of I do l <- 0 for each transaction T in D do if s is a subset of T then l <- l + 1 if minimum support <= l/n then add s to frequent subsets
关联规则分析

关联规则分析近年来,数据挖掘技术越来越受到业界的关注,其中具有代表性的一项技术就是关联规则分析。
关联规则分析是一种可以挖掘数据中存在的关联关系的技术,通过挖掘数据中的规律,从而为企业的决策制定提供支持。
本文将对关联规则分析技术进行深入的阐述,并探讨其在实际应用中的意义和价值。
一、关联规则分析的原理关联规则分析的核心就是寻找数据集中项之间存在的频繁集合和规则。
所谓频繁集合,就是指出现频率达到一定阈值的项组合。
在寻找频繁项时,通常需要依靠支持度和置信度来作为衡量指标。
支持度是指该项集在整个数据集中出现的频率,而置信度则是指该项集中的某些项出现时,另一项也很可能出现的概率。
举个例子,假设我们有一组销售记录,其中有许多顾客购买了商品A,并且部分顾客还购买了商品B。
为了进一步挖掘数据集中的关联关系,我们可以通过关联规则分析来寻找商品A和商品B之间的关联关系。
我们可以设置一个支持度的阈值(比如说10%),并且只分析那些出现频率超过这一阈值的数据集合。
这样就可以找到所有同时购买A和B的顾客,也就是频繁项集。
在这个过程中,我们可以计算A和B同时出现的置信度,即出现A 就很可能会出现B的概率,这可以为我们后续的销售战略制定做出重要贡献。
二、关联规则分析的应用领域关联规则分析在实际应用中有着广泛的应用领域,其中最为显著的一个应该就是电子商务领域。
在电子商务平台中,很多商家会通过关联规则分析技术来寻找不同商品之间的关联关系,从而制定出更为有效的销售策略。
例如通过寻找数据中的频繁项集,我们可以找到顾客们在购买某件商品时,最可能还需要购买哪些其他商品,进而为顾客提供更加便捷的购物体验。
除此之外,在金融领域、医疗领域以及网络推荐系统等领域中,也都可以使用关联规则分析技术来寻找业务中的关联关系。
例如在医疗领域,我们可以通过关联规则分析找出不同疾病之间的关联关系,这对于医生的诊疗决策具有重要帮助。
三、关联规则分析技术的局限性虽然关联规则分析技术在应用中具有很大的价值,但是它也存在着一定的局限性。
第六讲 关联规则Apriori算法与应用

--ASSOCIATION(APRIORI)
关联规则APRIORI介绍
Agrawal 等于1993 年首先提出了挖掘顾客交易数 据库中项集间的关联规则问题,并设计 Apriori 算法, 以后诸多的研究人员对关联规则的挖掘问题进行了大 量的研究。
Apriori 算法是单维单层次布尔关联规则挖掘的一 种经典算法,是挖掘产生布尔关联规则所需频繁项集 的基本算法;Apriori 算法就是根据有关频繁项集特性 的先验知识 (prior knowledeg ) 而命名的。
Antecedent beer beer beer cannedmeat cannedmeat cannedmeat cannedveg cannedveg cannedveg confectionery confectionery fish fish fish frozenmeal frozenmeal fruitveg wine wine
减慢,但是节约内存。
软件操作(III)
专家选项操作:
(性度似或此给此防)差,准对定来选止相此确于水评项出会现 估方平偏规法的差则会置,。即 对考信结于虑度果此不,分布 评均它不估匀倾均尺分向匀。 度布于因,。覆此评此盖有助
标准化估下方其卡更录于留尺限法适多的防方“度为尤用记规止很保明
这项度禁于量则显用找是。的状出请” 规 Antecedent态预(将则,测前该。因不项评请)将 条关件 性与 的结 统论 计为项“常事规估下置之 指该度置此对模发件则尺限为评下为间 数选于型生的。度设您估限您相 。”尺设希 这项度量经选请希过望项将望保标卡该保留准的 化,取值为上评留0规的估到的则最尺1规的。置
2.执行时必须经常扫瞄整个数据库,造成执行效率 不佳。
数据挖掘关联规则

数据挖掘关联规则简介数据挖掘是一种通过对大量数据进行分析和挖掘,发现其中隐藏的有价值信息的过程。
在数据挖掘的过程中,关联规则是其中一种重要的技术。
关联规则分析可以帮助我们发现数据集中不同项之间的相关性,从而帮助我们做出更好的业务决策。
关联规则挖掘的核心目标是发现数据集中的频繁项集和关联规则。
频繁项集指的是数据集中经常出现在一起的项的集合,而关联规则所描述的是这些项之间的关系,例如”如果买了A商品,那么也可能买B商品”。
关联规则的基本概念关联规则由两部分组成:前项和后项。
前项和后项分别是一个或多个项的集合。
•支持度(support):支持度是指某个项集在数据集中出现的频率。
支持度越高表示该项集出现的频率越大。
•置信度(confidence):置信度是指规则的前项和后项同时出现的概率,即在前项出现的情况下,后项也出现的概率。
根据支持度和置信度,可以使用以下公式计算关联规则的重要度:•支持度:support(A->B) = (出现A和B的次数) / (总事务数)•置信度:confidence(A->B) = (出现A和B的次数) / (出现A的次数)如何挖掘关联规则挖掘关联规则的过程通常分为以下几个步骤:1. 数据预处理在进行关联规则挖掘之前,需要对数据进行预处理。
预处理的步骤包括数据清洗(去除重复项、缺失值等),数据转换(将数据转换为适合关联规则挖掘的形式)等。
2. 挖掘频繁项集频繁项集指的是在数据集中出现频率较高的项集。
挖掘频繁项集的常用算法有Apriori算法和FP-growth算法。
Apriori算法是一种生成候选项集的算法。
它从频繁的1项集开始,通过逐层连接和剪枝的方式生成候选项集,最后得到频繁项集。
Apriori算法的思想是基于Apriori原理:如果一个项集是频繁的,那么它的所有子集也是频繁的。
FP-growth算法是一种利用频繁模式树进行挖掘的算法。
它通过构建一个树状结构(FP树)来存储频繁项集的信息,并利用树的性质来高效挖掘频繁项集。
关联规则分析及应用课件

目录
基本概念
关联规则挖掘过程
分类
关联规则的价值衡量
4
1
2
3
挖掘算法
关联规则的应用
5
6
绪论
在购买铁锤的顾客当中,有70%的人同时购买了铁钉。 年龄在40 岁以上,工作在A区的投保人当中,有45%的人曾经向保险公司索赔过。 在超市购买面包的人有70%会购买牛奶
绪论
一、基本概念
设 I={I1,I2,…,In} 是项的集合。 任务相关数据D:是事务(或元组)的集合。 事务T:是项的集合,且每个事务具有事务标识符TID。 项集A:是T 的一个子集,加上TID 即事务。 项集(Items):项的集合,包含k个项的项集称为k-项集,如二项集{I1,I2}。 支持度计数(Support count):一个项集的出现次数就是整个数据集中包含该项集的事务数。
三、关联规则的分类
基于规则中处理的变量的类别 布尔型:布尔型关联规则处理的值都是离散的、种类化的,它显示了这些变量之间的关系; B. 数值型 :数值型关联规则可以和多维关联或多层 关联规则结合起来,对数值型字段进行处理。 eg: 性别=“女”=>职业=“秘书” 性别=“女”=>avg(收入)=2300
I(A B)=
三、关联规则的分类
基于规则中处理的变量的类别 布尔型:布尔型关联规则处理的值都是离散的、种类化的,它显示了这些变量之间的关系; B. 数值型:数值型关联规则可以和多维关联或多层 关联规则结合起来,对数值型字段进行处理。 eg: 性别=“女”=>职业=“秘书” 性别=“女”=>avg(收入)=2300
关联规则分析及应用ppt课件

❖ 强关联规则:同时满足用户定义的最小支持度阈值 (min_sup)和最小置信度阈值(min_conf)的规则 称为强规则。
9
8
2012-10-12
二、关联规则挖掘过程
两个步骤: ▪ 找出所有频繁项集。 ▪ 由频繁项集生成满足最小信任度阈值的规则。
挖掘模式:
Database
产生频繁项集
min_sup
3
2012-10-12
绪论
4
2012-10-12
一、基本概念
设 I={I1,I2,…,In} 是项的集合。
❖任务相关数据D:是事务(或元组)的集合。
❖事务T:是项的集合,且每个事务具有事务标识 符TID。
❖项集A:是T 的一个子集,加上TID 即事务。
❖项集(Items):项的集合,包含k个项的项集称为 k-项集,如二项集{I1,I2}。 ❖支持度计数(Support count):一个项集的出现次
Support(A B)=P ( A ∩ B )
= support _ count(A∩B)
count (T) ❖ 频繁项集:若一个项集的支持度大于等于某个阈值。
7
2012-10-12
一、基本概念
❖ 置信度c:是包含A的事务中同时又包含B的百分比, 即条件概率。[规则准确性衡量]
confidence ( A B ) = P ( B | A) = support _ count ( A U B ) support_count ( A)
啤酒=>尿布
职业 秘书 工程师
购买物品 月工资
尿布
3000
啤酒、尿布 5000
性别=“女”=>职业=“秘书”
20
2012-10-12
关联规则专题知识专业知识讲座

? 关联规则
– 关联规则是形如 X ? Y的蕴含表达 式, 其中 X 和 Y 是不相交的项集
– 例子: {Milk, Diaper} ? {Beer}
TID Items
1
Bread, Milk
2
Bread, Diaper, Beer, Eggs
3
? 先验原理:
? 如果一个项集是频繁的,则它的所有子集一定也是 频繁的
? 相反,如果一个项集是非频繁的,则它的所有超 集也一定是非频繁的 :
? 这种基于支持度度量修剪指数搜索空间的策略称为 基于支持度的剪枝(support-based pruning)
? 这种剪枝策略依赖于支持度度量的一个关键性质, 即一个项集的支持度决不会超过它的子集的支持度。 这个性质也称为支持度度量的反单调性(antimonotone)。
4
Bread, Milk, Diaper, Beer
5
Bread, Milk, Diaper, Coke
本文档所提供的信息仅供参考之用,不能作为科学依据,请勿模仿。文档如有不
当之处,请联系本人或网站删除。
Apriori算法的频繁项集产生
Item
Count Items (1-itemsets)
Bread
5 Bread, Milk, Diaper, Coke
w
List of Candidates
M
? 时间复杂度 ~ O(NMw),这种方法的开销可能非常大。
本文档所提供的信息仅供参考之用,不能作为科学依据,请勿模仿。文档如有不 当之处,请联系本人或网站删除。
降低产生频繁项集计算复杂度的方法
? 减少候选项集的数量 (M)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
每个关联规则可由如下过程产生:
对于每个频繁项集 l,产生 l 的所有非空子集; sup port _ count(l ) 对于每个非空子集s,如果 sup port _ count( s) min_conf 则输出规则“ ” s (l s)
Apriori算法—用伪码表示其形式00 5000
购买的item A,B,C A,C A,D B,E,F
假设最小支持度为50%, 最小置信度为50%,则有 如下关联规则
A C (50%, 66.6%) C A (50%, 100%)
大型数据库关联规则挖掘中如何降低计 算复杂度,提高关联规则效率
由事务数据库挖掘单维布尔关联规则
最简单的关联规则挖掘,即单维、单层、布尔关联规 则的挖掘,而且我们的举例尽量不涉及概念分层。
Items Bought A,B,C A,C A,D B,E,F
首先挖掘频繁项集,其前提条件是: 最小支持度 50%,且最小置信度 50%
Transaction ID 2000 1000 4000 5000
Apriori算法(计算大型数据库时挖掘关联规则的常用算法之一)
Apriori算法利用频繁项集性质的先验知识(prior knowledge),通过逐层搜索的迭代方法,即将k-项 集用于探察(k+1)-项集,来穷尽数据集中的所有频繁 项集(通过先验知识挖掘未知知识)。
Apriori性质:频繁项集的所有非空子集也必须是频繁 的。( A B 模式不可能比A更频繁的出现,即A与
先找到频繁1-项集集合(即单个项出现的频率)L1,然后用L1 找到频繁2-项集集合L2,接着用L2找L3,直到找不到频繁k项集,找每个Lk需要一次数据库扫描,过程用到下面性质。
B的非空交集不可能比A大,只能被包含)
Apriori算法是反单调的,即一个集合如果不能通过测试,则 该集合的所有超集(注意超集与真超集概念是怎么样的?其 定义与子集相对!)也不能通过相同的测试。
Frequent Itemset Support {A} 75% {B} 50% {C} 50% {A,C} 50%
对规则A C,其支持度 support(A C ) P(A C ) =50% 置信度分A推导C和由C推导A,以A推导C为例:
confidence (A C ) P(C | A) P(A C ) / P(A) support(A C ) / support(A) 66.6%
关联规则的两个兴趣度度量
支持度 置信度
关联规则:基本概念
给定:
项的集合(进行关联分析时问题的邻域所包含的项的集合):
I={i1,i2,...,in}
任务相关数据D是数据库事务的集合,每个事务T则是项的集合, 使得T I 。例如每个事务就是购买的一个订单,每个订单记录的 是购买的哪些商品的信息,项的集合就是商店里所有商品种类的集 合,每个订单就是关于这个订单中购买的商品种类的集合。 这样, 一个订单中购买商品种类总是被商场所有商品种类的集合所包含。 为了进行关联规则分析,我们将每个事务由事务标识符TID标识; A,B为两个项集,事务T包含A当且仅当A T ,一般分析两个项 集。
C2 2rd scan
Itemset {A, B} {A, C} {A, E} {B, C}
{A,E}
{B, E}
{C, E}
最终,挖掘出2项集中4个 和3项集中1个频繁项集!
C3
Itemset {B, C, E}
3rd
scan
L3
Itemset {B, C, E}
注意:我们假设最小支持度是50%,则最小支持计数是2个,则L1时删除D,则 任何包含D的超集其出现次数都不可能再超过1次,即Apriori性质所讲的内容。
Ck是Lk的超集,即它的成员可能不是频繁的,但是所 有频繁的k-项集都在Ck中(为什么?)。因此可以通 过扫描数据库,通过计算每个k-项集的支持度来得到 Lk 。
为了减少计算量,可以使用Apriori性质,即如果一个k-项集 的(k-1)-子集不在Lk-1中,则该候选不可能是频繁的,可以直 接从Ck删除。
2.使用Apriori性质剪枝:频繁项集的所有子集必须是频繁 的,对候选项C3,我们可以删除其子集为非频繁的选项: {A,B,C}的2项子集是{A,B},{A,C},{B,C},其中{A,B}不是L2的元素,
所以删除这个选项; {A,C,E}的2项子集是{A,C},{A,E},{C,E},其中{A,E} 不是L2的元素, 所以删除这个选项; {B,C,E}的2项子集是{B,C},{B,E},{C,E},它的所有2-项子集都是L2 的元素,因此保留这个选项。
Apriori算法—示例
使用Apiori性质由L2产生C3
1 .连接:至少有一个元素相同时,才能进行两两连接 C3=L2 L2= {{A,C},{B,C},{B,E}{C,E}} {{A,C},{B,C},{B,E}{C,E}} = {{A,B,C},{A,C,E},{B,C,E}}, 我们认为任何频繁的三项集都包含在此C3中!
Apriori算法—示例(如何挖掘满足最小支持度的关联的频繁项集)
Database TDB
Tid 10 20 30 40 Items A, C, D B, C, E A, B, C, E B, E
不在 L2中
Itemset
sup
C1 1st scan
{A}
{B} {C}
2
3 3
L1
Itemset
{A} {B} {C} {E}
基本概念
k-项集:包含k个项的集合
{牛奶,面包,黄油}是个3-项集
项集的频率是指包含项集的事务数占总的事务数的百分比
如果项集的频率大于(最小支持度×D中的事务总数),则 称该项集为频繁项集(即满足最小支持度要求的项集) 找出所有频繁项集
大型数据库中的关联规则挖掘包含两个过程:
涉及到大量数据读取和计算,所以大部分的计算都集中在这一 步,完成后找到的项集其本身已经满足了最小支持度规则
举例二:购物篮分析
如果问题的全域是商店中所有商品的集合,则 对每种商品都可以用一个布尔量来表示该商品 是否被顾客购买,则每个购物篮都可以用一个 布尔向量表示(0001001100);而通过分析布尔 向量则可以得到商品被频繁关联或被同时购买 的模式,这些模式就可以用关联规则表示。
思考:这种布尔购物篮有什么缺陷?影响挖掘结果吗?
用DMQL深入学习各种数据挖掘功能之二
关联规则分析--大型数据库中关联规则挖掘
(概念描述、关联规则分析、分类、预测、聚类及孤立点分析等等)
什么是关联规则挖掘?
关联规则挖掘:
从事务数据库,关系数据库和其他信息存储中的大 量数据的项集之间发现有趣的、频繁出现的模式、 关联和相关性。 主要的兴趣度度量指标有两个:置信度、支持度, 如果一个模式既满足支持度和置信度要求,则称这 个模式为强关联规则。
age( X , "30...39" ) buys( X , " laptop_ computer ")
age( X , "30...39" ) buys( X , " computer ")
4、根据关联挖掘的各种扩充 挖掘最大的频繁模式(该模式的任何真超模式都是非 频繁的,意味着这个模式是最大的频繁模式) 挖掘频繁闭项集(一个项集c是频繁闭项集,如果不 存在其真超集c`,使得每个包含c的事务也包含c`, 意味着c的任何一个真超集都不可能是频繁的,我们 就说c是频繁闭项集)
support(A B ) P(A B )
支持度s是指事务集D中包 含 A B 的百分比
注意: 不是或,是模式间的连接,是
union
Customer buys beer
confidence( A B) P( B | A) P( A B) / P( A)
置信度c是指D中包含A的 事务同时也包含B的百分比
基本思路步骤为:
算法:Apriori使用根据候选生成的逐层迭代找出频繁项表
输入:与任务相关的事务数据库D;最小支持临界值 min_sup 输出:D中的频繁项集L
具体代码,略。代码了解即可,但要掌握Apriori算法的计算思想。
提高Apriori算法的有效性(1)
Apriori算法主要的挑战
3.这样,剪枝后得到C3={{B,C,E}}
Apriori算法—示例
由频繁项集产生关联规则
同时满足最小支持度和最小置信度的才是强关 联规则,从频繁项集产生的规则都满足支持度 要求,而其置信度则可由一下公式计算:
confidence (A B ) P(A | B )
sup port _ count(A B ) sup port _ count(A )
sup
2 3 3 3
{D}
{E}
1
3 Itemset {A, B} {A, C} {A, E} {B, C} {B, E} {C, E} sup 2 sup 1 2 1 2 3 2
连接!
C3
Itemset {A,B,C} {B,C,E} {A,C,E}
剪 枝 结 果
{A,B}
都在
L2
连接!
C2
Itemset {A, C} {B, C} {B, E} {C, E} sup 2 2 3 2