正态总体参数的置信区间及显著性检验一览表(2020)
概率论第八章 置信区间

试问机器是否正常 (给定显著性水平 0.05)
解 : 设X ~ N ( , ), 此是在 0.015已知条件下 ,
2
判断均值 0.5
还是 0.5的问题, 为此
1)提出假设 H 0 : 0.5; H1 : 0.5;
2)显著性水平 0.05, 样本容量 n9
装糖重总体 X 的均值和标准差, 已知 0.015, 则 X ~ N ( , 0.0152 ), 其中 未知.
问题: 根据样本值判断 0.5 还是 0.5 .
提出两个对立假设H 0 : 0 0.5 和 H1 : 0 . 再利用已知样本作出判断是接受假设 H0 ( 拒绝 假设 H1 ) , 还是拒绝假设 H0 (接受假设 H1 ). 如果作出的判断是接受 H0, 则 0 ,
又如, 对于正态总体提出数学期望等于 0 的 假设等. 假设检验就是根据样本对所提出的假设作 出判断: 是接受, 还是拒绝.
假设检验问题是统计推断的另一类重要问题. 如何利用样本值对一个具体的假设进行检验?
通常借助于直观分析和理论分析相结合 的做法,其基本原理就是人们在实际问题中经 常采用的所谓实际推断原理:“一个小概率事 件在一次试验中几乎是不可能发生的”.
对实际中需作出判断的 问题, 提出适当的 统计假设, 根据来自总体的样本 X 1 , X 2 , , X n , 选择适当的统计量 , 此统计量需服从熟知的 分 布, 据此分布由小概率原理 可以确定原假设的 拒绝域, 若样本值落入此拒绝域 中, 则拒绝原假 设, 否则接受原假设。
二、假设检验的相关概念
H0:0 H0: 0 H 0: = 0
vs vs vs
H 1: > 0 H 1: < 0 H1: 0
04 第四节 正态总体的置信区间

第四节 正态总体的置信区间与其他总体相比, 正态总体参数的置信区间是最完善的,应用也最广泛。
在构造正态总体参数的置信区间的过程中,t 分布、2χ分布、F 分布以及标准正态分布)1,0(N 扮演了重要角色.本节介绍正态总体的置信区间,讨论下列情形: 1. 单正态总体均值(方差已知)的置信区间; 2. 单正态总体均值(方差未知)的置信区间; 3. 单正态总体方差的置信区间;4. 双正态总体均值差(方差已知)的置信区间;5. 双正态总体均值差(方差未知但相等)的置信区间;6. 双正态总体方差比的置信区间.注: 由于正态分布具有对称性, 利用双侧分位数来计算未知参数的置信度为α-1的置信区间, 其区间长度在所有这类区间中是最短的.内容分布图示★ 引言★ 单正态总体均值(方差已知)的置信区间★ 例1 ★ 例2★ 单正态总体均值(方差未知)的置信区间 ★ 例3 ★ 例4★ 单正态总体方差的置信区间 ★ 例5 ★ 双正态总体均值差(方差已知)的置信区间 ★ 例6 ★ *双正态总体均值差(方差未知)的置信区间★ 例7 ★ 例8★ *双正态总体方差比的置信区间 ★ 例9 ★ 内容小结 ★ 课堂练习 ★ 习题6-4内容要点:一、单正态总体均值的置信区间(1)设总体),,(~2σμN X 其中2σ已知, 而μ为未知参数, n X X X ,,,21 是取自总体X 的一个样本. 对给定的置信水平α-1, 由上节例1已经得到μ的置信区间,,2/2/⎪⎪⎭⎫⎝⎛⋅+⋅-n u X n u X σσαα二、单正态总体均值的置信区间(2)设总体),,(~2σμN X 其中μ,2σ未知, n X X X ,,,21 是取自总体X 的一个样本. 此时可用2σ的无偏估计2S 代替2σ, 构造统计量n S X T /μ-=,从第五章第三节的定理知).1(~/--=n t nS X T μ对给定的置信水平α-1, 由αμαα-=⎭⎬⎫⎩⎨⎧-<-<--1)1(/)1(2/2/n t n S X n t P ,即 ,1)1()1(2/2/αμαα-=⎭⎬⎫⎩⎨⎧⋅-+<<⋅--n S n t X n S n t X P 因此, 均值μ的α-1置信区间为.)1(,)1(2/2/⎪⎪⎭⎫ ⎝⎛⋅-+⋅--n S n t X n S n t X αα三、单正态总体方差的置信区间上面给出了总体均值μ的区间估计,在实际问题中要考虑精度或稳定性时,需要对正态总体的方差2σ进行区间估计.设总体),,(~2σμN X 其中μ,2σ未知,n X X X ,,,21 是取自总体X 的一个样本. 求方差2σ的置信度为α-1的置信区间. 2σ的无偏估计为2S , 从第五章第三节的定理知,)1(~1222--n S n χσ, 对给定的置信水平α-1, 由,1)1()1()1()1(,1)1(1)1(22/12222/222/2222/1αχσχαχσχαααα-=⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧--<<---=⎭⎬⎫⎩⎨⎧-<-<---n S n n Sn P n S n n P 于是方差2σ的α-1置信区间为⎪⎪⎭⎫ ⎝⎛-----)1()1(,)1()1(22/1222/2n S n n S n ααχχ而方差σ的α-1置信区间.)1()1(,)1()1(22/1222/2⎪⎪⎭⎫ ⎝⎛-----n S n n S n ααχχ四、双正态总体均值差的置信区间(1)在实际问题中,往往要知道两个正态总体均值之间或方差之间是否有差异,从而要研究两个正态总体的均值差或者方差比的置信区间。
置信区间(详细定义及计算)

可见,对参数 作区间估计,就是要设法找出两个 只依赖于样本的界限(构造统计量) (ˆ1 ˆ2 )
[ˆ1 ,ˆ2 ] 内.
1. 要求 很大的可能被包含在区间 [ˆ1 , ˆ2 ] 内,
就是说,概率 P {ˆ1 ˆ2 } 要尽可能大. 即要求估计尽量可靠.
ˆ ˆ 2. 估计的精度要尽可能的高.如要求区间长度 2 1 尽可能短,或能体现该要求的其它准则.
查正态分布表得临界值 Z 1.96,由此得置信区间:
18
当总体X的方差未知时, 容易想到用样本方差Ѕ 2代替σ2。 X T ~ t (n 1) 已知 2 S n X t (n 1)} 1 则对给定的α,令 P{ S 2 2 n 查t 分布表,可得 t (n 1) 的值。 2 S S P{ X t 2 ( n 1) X t 2 ( n 1)} 1 n n
有时我们嫌置信度0.95偏低或偏高, 也可采用0.99或
0.9. 对于 1- α不同的值, 可以得到不同的置信区间。
15
ˆ1 ˆ1 ( X 1 , X 2 , X n ) ˆ2 ˆ2 ( X 1 , X 2 , X n )
一旦有了样本,就把 估计在区间 这里有两个要求:
[96.05 , 113.95]
用某仪器间接测量温度,重复测量5次得 1250 0 12650 1245 0 1260 0 12750 求温度真值的置信度为 0.99 的置信区间。
解
设μ为温度的真值,X表示测量值,通常是一个 正态随机变量 EX .
问题是在未知方差的条件下求μ的置信区间。 由公式 1 x 1250 [0 15 5 10 25] 1259 5 1 570 2 2 2 s [(1250 1259) (1275 1259) ] 5 1 4 2 s n 1 4 0.01 28.5 5.339 5 S [X t 2 ( n 1)] t ( 4 ) t ( 4 ) 4 . 6041 查表 0.01 0.005 n 则所求μ的置信区间为 [1259 24 .58 , 1259 24 .58]
第二节 正态总体均值的假设检验

σ
~ N(0,1)
n
(σ 2 已知)
原假设 备择假设 检验统计量及其在 H0为真时的分布 H0 H1
=0 ≠0
X 0 T= ~ T(n 1) S n
接受域
x 0 s n
≤ tα
(σ 2未知)
2
待估参数
枢轴量及其分布 置信区间
X 0 T= ~ T(n 1) S n
( x tα
2
= 0 ≥ 0 ≤ 0
≠ 0 < 0 > 0
U=
X 0
σ
U ≥ zα
2
n
U ≤ zα
N(0,1)
U ≥ zα
未知) T 检验法 (σ2 未知) 原假设 备择假设 检验统计量及其 H0 H1 H0为真时的分布 拒绝域
= 0 ≥ 0 ≤ 0
≠ 0 < 0 > 0
X 0 T= S n ~ t(n 1)
(2)关于 σ
2
χ2检验法 的检验
拒绝域
原假设 备择假设 检验统计量及其在 H1 H0为真时的分布 H0
σ
2=σ 2 0
σ
2≠σ 2 0
χ =
2
∑(X )
i=1 i
n
χ ≤ χ (n)
2 2 1α 2
2
或 χ 2 ≥ χα2 (n)
2
σ 2≥σ 02 σ 2<σ 02
σ
2 0
~ χ (n)
2
χ ≤ χ (n)
(1) 关于均值差 1 – 2 的检验
原假设 备择假设 检验统计量及其在 H0为真时的分布 H0 H1
1 – 2 = δ 1 – 2 ≠ δ 1 – 2 ≥ δ 1 – 2 < δ 1 – 2 ≤ δ 1 – 2 > δ
置信度(置信区间计算方法)

推导
选取枢轴量 T X ~ T (n 1)
S
n X 由P t (n 1) 确定t ( n 1) 2 S 2 n
这时, T2 T1 往往增大, 因而估计精度降低.
确定后, 置信区间 的选取方法不唯一,
ch73
常选最小的一个.
75
处理“可靠性与精度关系”的原 则
先
求参数 置信区间 保 证 可靠性
再
提 高 精 度
ch73
76
求置信区间的步骤
寻找一个样本的函数
— 称为枢轴量 它含有待估参数, 不含其它未知参数, 它的分布已知, 且分布不依赖于待估参 数 (常由 的点估计出发考虑 ). 例如 X~N ( , 1 / 5)
P(T1 T2 ) 1
则称 [ T1 , T2 ]为 的置信水平为1 - 的
置信区间或区间估计. T1 置信下限 T2 置信上限
ch73
几点说明
置信区间的长度 T2 T1 反映了估计精度 T2 T1 越小, 估计精度越高.
反映了估计的可靠度, 越小, 越可靠. 越小, 1- 越大, 估计的可靠度越高,但
( 引例中 a 1.96, b 1.96 )
由 a g ( X1, X 2 , X n , ) b 解出 T1 , T2
得置信区间 ( T1 , T2 ) 引例中
( T1 , T2 ) ( X 1.96 1 , X 1.96 1 ) 5 5
ch73 78
置信区间常用公式
复习资料(医学统计)

复习资料第一大题:单项选择题1、欲了解某市8岁小学生的身高情况,该市某小学二年级8岁小学生是:()∙ A. 样本∙ B. 有限总体∙ C. 无限总体∙ D. 个体2、抽样调查了某地4岁男孩的生长发育情况,得到身高均数为98.67cm,标准差为4.63cm,头围均数为46.23cm,标准差为3.16cm,欲比较两者的变异程度,下列结论正确的是:()∙ A. 身高变异程度大∙ B. 头围变异程度大∙ C. 身高和头围的变异程度相同∙ D. 由于两者的均数相差很大,无法比较两者的变异程度3、在计算方差时,若将各观察值同时减去某一常数后求得的方差:( )∙ A. 会变小∙ B. 会变大∙ C. 不变∙ D. 会出现负值4、某地2006年肝炎发病人数占当年传染病发病人数的10.1%,该指标为( )∙ A. 概率∙ B. 构成比∙C. 发病率∙D. 相对比5、两个分类变量的频数表资料作关联性分析,可用( )∙A. 积距相关或等级相关∙B. 积距相关或列联系数∙C. 列联系数或等级相关∙D. 只有等级相关6、对于服从双变量正态分布的资料,如果直线相关分析算出的值越大,则经回归分析得的相应的b 值:∙A. 越大∙B. 越小∙C. 比r小∙D. 可能较大也可能较小7、多组均数的两两比较中,若不用q检验而用t 检验,则:()∙A. 结果更合理∙B. 结果一样∙C. 会把一些无差别的总体判断为有差别∙D. 会把一些有差别的总体判断为无差别8、在比较甲、乙两种监测方法测量结果是否一直时,若采用配对设计秩和检验,甲、乙两法测量值之差中有-0.02、0.02,若差值绝对值的位次为3、4,则这两个差值的秩次分别为:()∙A. -3.5,3.5∙ B. -3.5,-3.5∙ C. 3.5,3.5∙ D. -3,49、Y=14+4X是1~7岁儿童以年龄(岁)估计体重(市斤)回归方程,若体重换成国际单位kg,则此方程:()∙ A. 截距改变∙ B. 回归系数改变∙ C. 两者都改变∙ D. 两者都不变10、某卫生局对其辖区内甲、乙两医院医疗技术人员的业务素质进行考核,在甲医院随机抽取100人,80人考核结果为优良;乙医院随机抽取150人,100人考核结果为优良。
6-5 两个正态总体均值及方差比的置信区间

6.5 两个正态总体均值差及 方差比的置信区间
1. 两正态总体均值差 µ1 − µ 2的置信区间
2 σ1 2. 两个总体方差比 2 的置信区间 σ2
3. 小结
设给定置信度为1 − α , 并设 X 1 , X 2 ,⋯, X n 为 第一个总体 N ( µ1 ,σ 1 )的样本 , Y1 ,Y2 ,⋯,Yn 为第二
要点回顾
无偏性 1. 估计量的评选的三个标准 有效性 相合性 2. 置信区间是一个随机区 (θ , θ ), 它覆盖未知参 间 ( 数具有预先给定的概率置信水平) , 即对于任
意的θ ∈Θ, 有 P{θ < θ < θ } ≥ 1−α. 求置信区间的一般步骤(分三步 分三步). 求置信区间的一般步骤 分三步
例4 分别由工人和机器人操作钻孔机在纲部件 上钻孔,今测得所钻的孔的深度(以cm计)如下 上钻孔,今测得所钻的孔的深度( 计
工人 操作 机器人 操作 4.02 3.64 4.03 4.02 3.95 4.06 4.00 4.01 4.03 4.02 4.01 4.00 3.99 4.02 4.00
2 σ1 , 由 X , Y 的独立性及 X ~ N µ1 , n1 2 2 σ1 σ 2 , + 可知 X − Y ~ N µ1 − µ 2 , n1 n2
2 σ2 , Y ~ N µ2 , n2
或
( X − Y ) − (µ1 − µ 2 ) ~ N (0, 1),
2 s1 s12 1 1 2 , 2 s F (6,7) s F (6,7) = ( 2.87,46.81). 0.95 2 2 0.05
这个区间的下限大于1,在实际中, 这个区间的下限大于 ,在实际中,我们就认为
伍德里奇《计量经济学导论》(第6版)复习笔记和课后习题详解-多元回归分析:推断【圣才出品】

伍德⾥奇《计量经济学导论》(第6版)复习笔记和课后习题详解-多元回归分析:推断【圣才出品】第4章多元回归分析:推断4.1复习笔记考点⼀:OLS估计量的抽样分布★★★1.假定MLR.6(正态性)假定总体误差项u独⽴于所有解释变量,且服从均值为零和⽅差为σ2的正态分布,即:u~Normal(0,σ2)。
对于横截⾯回归中的应⽤来说,假定MLR.1~MLR.6被称为经典线性模型假定。
假定下对应的模型称为经典线性模型(CLM)。
2.⽤中⼼极限定理(CLT)在样本量较⼤时,u近似服从于正态分布。
正态分布的近似效果取决于u中包含多少因素以及因素分布的差异。
但是CLT的前提假定是所有不可观测的因素都以独⽴可加的⽅式影响Y。
当u是关于不可观测因素的⼀个复杂函数时,CLT论证可能并不适⽤。
3.OLS估计量的正态抽样分布定理4.1(正态抽样分布):在CLM假定MLR.1~MLR.6下,以⾃变量的样本值为条件,有:∧βj~Normal(βj,Var(∧βj))。
将正态分布函数标准化可得:(∧βj-βj)/sd(∧βj)~Normal(0,1)。
注:∧β1,∧β2,…,∧βk的任何线性组合也都符合正态分布,且∧βj的任何⼀个⼦集也都具有⼀个联合正态分布。
考点⼆:单个总体参数检验:t检验★★★★1.总体回归函数总体模型的形式为:y=β0+β1x1+…+βk x k+u。
假定该模型满⾜CLM假定,βj的OLS 量是⽆偏的。
2.定理4.2:标准化估计量的t分布在CLM假定MLR.1~MLR.6下,(∧βj-βj)/se(∧βj)~t n-k-1,其中,k+1是总体模型中未知参数的个数(即k个斜率参数和截距β0)。
t统计量服从t分布⽽不是标准正态分布的原因是se(∧βj)中的常数σ已经被随机变量∧σ所取代。
t统计量的计算公式可写成标准正态随机变量(∧βj-βj)/sd(∧βj)与∧σ2/σ2的平⽅根之⽐,可以证明⼆者是独⽴的;⽽且(n-k-1)∧σ2/σ2~χ2n-k-1。
国开(电大)《统计学原理》形成性考核参考答案

国开(电大)《统计学原理》形成性考核1-4参考答案形考任务1一、单项选择题(每小题2分,共计20分)1.在某个或某些属性上的属性表现相同的诸多实体构成的集合称为()。
A.同类实体B.异类实体C.总体D.同类集合2.不能自然地直接使用数字表示的属性称为()。
A.数量属性B.质量属性C.水平属性D.特征属性3.下列选项中,属于总体边界清晰,个体边界不清晰的是()。
A.一列车的煤炭B.滇金丝猴种群C.大兴安岭的树D.工业流水线上的一批产品4.()是选择个体和采集个体属性值的途径。
A.调查方法B.调查工具C.调查准则D.调查程序5.从某生产线上每隔25min抽取5min的产品进行检验,这种抽样方式属于()。
A.简单随机抽样B.等距抽样C.整群抽样D.分层抽样6.抽样调查和重点调查都是非全面调查,两者根本区别是()。
A.灵活程度不同B.组织方式不同C.作用不同D.抽取样本的方式不同7.按随机原则进行的抽样称为()。
A.问卷设计B.调查C.抽样设计D.随机抽样8.统计学将由许多个小实体构成的同类实体看作集合,称为()。
A.总体B.个体C.总量D.变量9.根据总体的形态,可将其分为()。
A.时间总体和空间总体B.实在总体和想象总体C.时点总体和时期总体D.平面总体和线性总体10.统计工作过程由()两个步骤构成。
A.统计设计和统计实施B.统计实施和调查设计C.现场调查和调查设计D.统计设计和调查设计二、多项选择题(每小题2分,共计10分)1.按信息科学和数据库理论,信息的构成要素主要包括()。
A.实体B.属性C.调查D.情况2.属性的基本类别包括()。
A.数量属性B.质量属性C.水平属性D.特征属性3.下列选项中,属于总体边界清晰,个体边界不清晰的是()。
A.一艘石油巨轮的石油B.一列车的煤炭C.公园里的一片草地D.大兴安岭的树4.现场调查方法的方式有()。
A.访问B.观察C.实验D.测量5.按调查的范围,可将调查分为()。
正态分布总体的区间估计与假设检验汇总表
(单侧检验)
2
(n
1)S 2
2 0
~2n1
2
2 /2
n
1
或
2
2 1- / 2
n 1
2 2 n 1
2
≥
2 0
2
<
2 0
(单侧检验)
2
2 1-
n
1
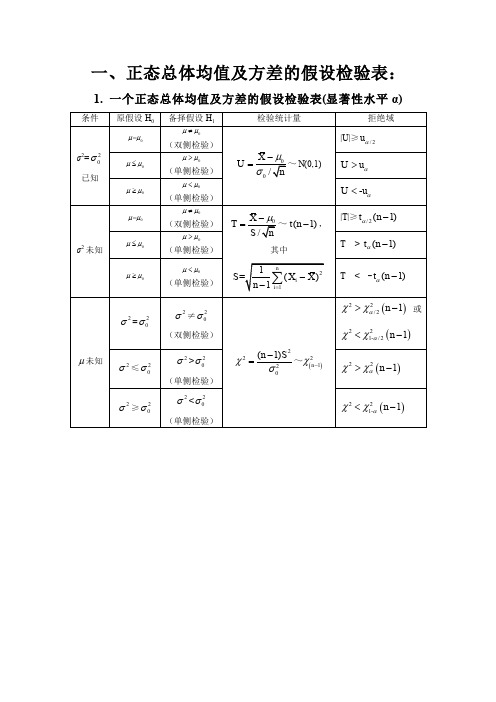
2. 两个正态总体均值及方差的假设检验表(显著性水平 α)
条件 原假设 H0 备择假设 H1
检验统计量
拒绝域
12
,
2 2
已知
1 =2 1 2 1 2
1 2
1 2
(单侧检验)
SW
(n1 1)S12 (n2 1)S22 n1 n2 2
T < - t (n1 n2 2)
1,2
未知
2 1
=
2 2
2 1
≤
2 2
2 1
≠
2 2
(双侧检验)
2 1
>
2 2
(单侧检验)
F
S12 S22
~
F ( n1 - 1, n2 - 1)
F ≥ F /2 n1 1, n2 1
已知
0 / n
X
0 n
u
/2,
X
0 n
u
/2
2 未知 T X 0 ~ t(n 1) S/ n
X
S n 1
t / 2
n
1 ,
X
S n
1
t
/
2
n
1
方差 2
未知
2
(n 1)S 2
2 0
~2n1
(n 2 /
1)S 2
7-2正态总体参数的检验

一、单个正态总体均值的检验 二、两个正态总体均值差的检验 三、正态总体方差的检验
同上节) 标准要求长度是32.5毫米 毫米. 例2(同上节 某工厂生产的一种螺钉 标准要求长度是 同上节 某工厂生产的一种螺钉,标准要求长度是 毫米
实际生产的产品,其长度 假定服从正态分布N( σ 未知, 实际生产的产品,其长度X 假定服从正态分布 µ,σ2 ) ,σ2 未知, 现从该厂生产的一批产品中抽取6件 得尺寸数据如下: 现从该厂生产的一批产品中抽取 件, 得尺寸数据如下
(1)与(4); (2)与(5)的拒绝域形式相同 与 的拒绝域形式相同. 与 的拒绝域形式相同
一、单个正态总体均值的检验
是来自N( σ 的样本 的样本, 设x1,…,xn是来自 µ,σ2)的样本 关于µ的三种检验问题是 (µ0是个已知数 是个已知数)
(1) H0 : µ ≤ µ0 vs H1 : µ > µ0 (2) H0 : µ ≥ µ0 vs H1 : µ < µ0 (3) H0 : µ = µ0 vs H1 : µ ≠ µ0
对于检验问题 对于检验问题
(2) H0 : µ ≥ µ0 vs H1 : µ < µ0
x − µ0
仍选用u统计量 u = 选用 统计量 相应的拒绝域的形式为: 相应的拒绝域的形式为
取显著性水平为α 取显著性水平为α,使c满足 P 0 (u ≤ c) = α 满足 µ
由于μ = μ 0时,u ~ N(0,1),故 c = uα,如图 故 , 因此拒绝域为: 因此拒绝域为 或等价地: 或等价地 φ(x)
检 H0 : µ = µ0 vs H1 : µ ≠ µ0 验
x − µ0 s/ n
接受域为: 接受域为
正态总体参数的区间估计

总体均值μ的区间估计是一种基于抽样 调查的方法,通过样本均值和标准差 来估计总体均值的范围,常用t分布或z 分布计算置信区间。
详细描述
在进行总体均值μ的区间估计时,首先 需要收集样本数据,计算样本均值和 标准差。然后,根据样本数据的大小 和置信水平,选择适当的分布(如t分 布或z分布)来计算置信区间。最后, 根据置信区间的大小和分布特性,可 以得出总体均值μ的可能取值范围。
正态分布的性质
集中性
正态分布的曲线关于均值μ对称。
均匀变动性
随着x的增大,f(x)逐渐减小,但速 度逐渐减慢。
随机变动性
在μ两侧对称的位置上,离μ越远, f(x)越小。
正态分布在生活中的应用
金融
正态分布在金融领域的应用十分 广泛,如股票价格、收益率等金 融变量的分布通常被假定为正态 分布。
生物医学
THANKS
感谢观看
实例二:总体方差的区间估计
总结词
在正态分布下,总体方差的区间估计可以通过样本方 差和样本大小来计算。
详细描述
当总体服从正态分布时,根据中心极限定理,样本方差 近似服从卡方分布。因此,总体方差σ²的置信区间可以 通过以下公式计算:$[s^2 cdot frac{n - 1}{n} cdot F^{-1}(1 - frac{alpha}{2}), s^2 cdot frac{n - 1}{n} cdot F^{-1}(1 - frac{alpha}{2})]$,其中$s^2$是样本 方差,$n$是样本容量,$F^{-1}$是自由度为1的卡方 分布的逆函数,$alpha$是显著性水平。
详细描述
当总体服从正态分布时,根据中心极限定理,样本均值 近似服从正态分布。因此,总体均值μ的置信区间可以通 过以下公式计算:$[bar{x} - frac{s}{sqrt{n}} cdot Phi^{-1}(1 - frac{alpha}{2}), bar{x} + frac{s}{sqrt{n}} cdot Phi^{-1}(1 - frac{alpha}{2})]$,其中$bar{x}$是样 本均值,$s$是样本标准差,$n$是样本容量,$Phi^{1}$是标准正态分布的逆函数,$alpha$是显著性水平。
假设检验和区间估计
第7章 假设检验和区间估计7.1 内容框图7.2 基本要求(1) 理解假设检验的基本思想及两类错误的含义.(2) 掌握有关正态总体参数的假设检验的基本步骤和方法. (3) 理解单侧检验与双侧检验的异同.(4) 理解并掌握正态总体参数区间估计的的基本方法. (5) 了解总体分布的检验和独立性检验的基本方法.7.3 内容概要1)假设检验下面把各种情形列一个表:∈U 接受域0W ,接受0H∈U 拒绝域1W ,拒绝0H0H 为真,1H 不真 正确 犯第一类错误0H 不真,1H 为真犯第二类错误正确α值为显著水平。
然后,根据显著水平 α来确定临界值,用临界值来划分接受域 0W 假设检验 区间估计参数检验 分布的检验正态总体参数的检验独立性检验和拒绝域 1W 。
这样的检验,称为显著性检验。
假设检验的一般步骤是: (1)提出原假设 0H ;(2)选取合适的检验统计量 U ,从样本求出 U 的值;(3)对于给定的显著水平α,查 U 的分布表,求出临界值,用它划分接受域 0W 和拒绝域 1W ,使得当 0H 为真时,有 α=∈}{1W U P ;(4)若 U 的值落在拒绝域 1W 中,就拒绝 0H ,若 U 的值落在接受域 0W 中,就接受 0H 。
假设检验的理论依据是所谓的小概率事件原理,即一个概率很小的事件在一次试验中几乎是不可能发生的.要检验一个根据实际问题提出的原假设0H 是否成立,如果已知在0H 成立时,某个事件发生的可能性很小,而试验的结果却是这个事件发生了,那么根据小概率事件原理,我们就可以认为所提出的这个假设0H 是不成立的,即拒绝0H ;反之,则接受0H .这里的原假设0H 可以根据实际问题提出,事件是否发生可根据试验观测值判断,因此假设检验的关键问题就是要确定在0H 成立时,发生可能性很小的某个事件.我们知道,正态分布有个3σ原则,即ξ若服从正态分布,那么ξ的取值会大多集中在其均值附近,落入两侧的可能性很小.事实上,当ξ服从t 分布,2x 分布,F 分布时,其取值落入两侧的可能性也都相对很小.因此,我们要确定0H 成立时一个发生可能性很小的事件,只需根据样本构造出服从正态分布,t 分布,2x 分布或F 分布的随机变量(统计量)就可以了. 根据上述分析,正态总体参数的假设检验可概括为如下步骤。
正态总体参数假设检验

嘉兴学院
第七章 假设检验
第18页
7.2.2 两个正态总体均值差的检验 检验 法 u检 验 t检 验 条 件 原假 设 备择 假设 检验统 计量 拒绝域
已 知
未 知
嘉兴学院
16 July 2012
第七章 假设检验
第19页
大样 本检 u验 近似 t检 验
未知 m,n充 分大 未知 m,n不 很大
16 July 2012
嘉兴学院
第七章 假设检验
第4页
(a)
16 July 2012
(b)
(c)
嘉兴学院
第七章 假设检验
第5页
该检验用 u 检验统计量,故称为u 检验。 下面以 由 为例说明: 可推出具体的拒绝域为
该检验的势函数是 的函数,它可用正态分布 写出,具体为
16 July 2012
16 July 2012
16.2 16.4 15.8 15.5 16.7 15.6 15.8 15.9 16.0 16.4 16.1 16.5 15.8 15.7 15.0
嘉兴学院
第七章 假设检验
第30页
这是两正态总体方差之比的双侧假设检验问题, 待检假设为 此处 m=7,n=8,经计算
于是 查表知 ,若取 =0.05,
通常 , 均未知,记 , 分别是由 算得的 的无偏估计和由 算得的 的无偏估计.
16 July 2012
嘉兴学院
第七章 假设检验
第28页
可建立检验统计量: 三种检验问题对应的拒绝域依次为
或
16 July 2012
}。
嘉兴学院
第七章 假设检验
第29页
例7.2.5 甲、乙两台机床加工某种零件,零件 的直径服从正态分布,总体方差反映了加工 精度,为比较两台机床的加工精度有无差别, 现从各自加工的零件中分别抽取7件产品和8 件产品,测得其直径为 X (机 床甲) Y (机 床乙)
常用统计方法(SPSS)期末考试题型总结

SPSS期末考试题型总结一、单样本t检验(单个正态总体的均值检验与置信区间)(P48)1、题目类型:某糖厂打包机打包的糖果标准值为,给出一系列抽取值。
问:(1)这天打包机的工作是否正常?(2)这天打包机平均装糖量的置信区间是多少?2、操作:(1)Analyze Compare mean One—Sample T Test(2)将左边源变量X送入Test Variable(s)中,在Test Value中输入3、结果分析:若Sig。
>0.05,接受假设,即没有显著性差异若Sig。
<0。
05,拒绝假设,即有显著性差异置信区间(100+Lower,100+uppper)二、两个样本t检验(两个正态总体的均值检验与置信区间)(P50)1、题目类型:从A批导线抽取4根,从B批导线抽取5根。
问:这两批导线的平均电阻是否有显著差异?并求的置信区间。
2、操作:(1)Analyze Compare mean Indepvendent Sample T Test(2)将检验变量x送入Test Variable(s),将分组变量group送入Grouping Variable(3)选按钮define Groups Use specified values,分别输入1和2。
3、结果分析:(1)若F显著性概率Sig.>0.05,接受假设,两组方差没有显著性差异,即可认为两组方差是相等的(2)若t显著性概率Sig。
2—tailed>0。
05,可以得出A、B两批电线的电阻值没有显著差异.三、单因素方差分析(P54)1、题目类型:6种不同农药在相同条件下的杀虫率。
问:杀虫率是否因农药的不同而有显著性差异?2、操作:(1)Analyze Compare mean One-Way ANOV(2)将源变量x送入Dependent List(因变量),将类型变量kind送入Factor.3、结果分析:(1)若Sig.>0。
生物统计重要复习资料(畜牧兽医)

第一章绪论1.生物统计学的内容:统计原理、统计方法和试验设计。
2.生物统计的作用:a.科学地整理分析数据;b.判断试验结果的可能性;c.确定事物之间的相互关系;d.提供试验设计的原理。
3.样本容量常记为n,通常把n≤30的样本称为小样本,n.>30的样本称为大样本。
4.名解:(重)①生物统计:生物统计是应用概率论和数据统计的原理和方法来研究生物界数量变化的学科;②总体:是被研究对象的全体,据所含的个体的多少,总体分为有限总体和无限总体。
③样本:是指总体内随机抽取出来若干个体所组成的单位。
④随机误差:由于许多无法控制的内在和外在的偶然因素所造成的误差,内在如个体差异,外在如环境,它影响试验的精确性。
(了)①参数:从总体计算出来的数量特征值,它是一个真值,没有抽样变动的影响,一般用平均数u,标准差s。
②统计量:是从样本计算出来的数量特征值,它是参数的估计值,受样本变动的影响,一般用拉丁字母表示,如平均数。
③系统误差:主要是试验动物的初始条件不同,试验条件相差较大,仪器不准,标准试剂未经校正,药品批次不同,药品用量与种类不符合试验计划要求,以及观察,记录抄案,计算中的错误所引起的误差,它影响试验的准确性。
④准确性:指在试验或调查中某试验指标或形状的观测值与其真值接近的程度。
⑤精确性:指试验或调查中一试验指标或形状的重复观测值彼此接近的程度。
第二章资料的整理1.统计资按性质分为:计量资料、次数资料和半定量资料。
2.计量资料是指用量测方式获得的数量性状资料,即用度、量、衡等计量工具直接测量获得的数量性状资料。
计量资料整理的五步骤如下:(1)求全距,即资料中最大值和最小值之差R=Max(x)—Min(x);(2)确定组数即按样本大小而定;样本含量与组数样本含量组数30~60 6~860~100 8~10100~200 10~12200~500 12~17500以上17~30(3)确定组距,每组最大值与最小值之差记为i ,公式:组距(i)=全距(R)/组数k ;(4)确定组中值及组限,各组的最大值和最小值称为组限,最小值为下限,最大值为上限,每组的中点值称为组中值,组中值=(下限+上限)/2=下限+组距/2=上限-组距/2;(5)归组划线计数,作次数分布表。
正态总体的置信区间

(Xi
X )2
来代替2
统计量
X X
Z
S2
S
~ t(n 1)
n
n
服从自由度为n-1的t分布
P{t (n 1) 2
X
S
t (n 1)} 1 2
n
P{t (n 1) 2
X S
t (n 1)} 1 2
n
即P{ X S t (n 1) X S t (n 1)} 1
(2)总体标准差的置信度为0.95的置信区间。
解(1) 1- =0.95 /2=0.025 n-1=15
t0.025(15)=2.1315 x 503.75 s=6.2022
2未知, 的置信度为1- 的置信区间为
S ( X t (n 1))
n2
则 的置信度为0.95的置信区间为(500.4,507.1).
(11)
21.9
2 (11) 3.82 2
所以1549467 2 1549467
21.9
3.82
总体方差2的置信区间为(70752,405620)。
二.两个正态总体的情况
在实际应用中经常会遇到两个正态总体的区间估 计问题.例如:考察一项新技术对提高产品的某项质 量指标的作用──把实施新技术前产品的质量指标 看成一个正态总体 N(1,12),而把实施新技术后产 品质量指标看成另一个正态总体N(2,22).
于是,评价此新技术的效果问题,就归结为研究两 个正态总体均值之差1-2的问题.
比较甲乙两厂生产某种药物的治疗效果──把两个 厂的药效分别看成服从正态分布的两个总体
N(1,12)和 N(2,22). 于是,评价两厂生产的药物的差异,就归结为研究