温度预测模型研究.
温度变化对大气环境影响研究及其预测模型建立

温度变化对大气环境影响研究及其预测模型建立随着全球气候变化问题的引起人们的关注,温度和大气环境受到了广泛的关注。
温度变化会对大气环境产生什么样的影响?科学家已经做出了一系列的研究,并建立了一些预测模型。
本文将探讨温度变化对大气环境的影响以及相关的预测模型建立。
一、温度变化对大气环境的影响温度变化会对大气环境产生多方面的影响。
首先,温度升高将导致海平面上升,从而引发大规模的海岸侵蚀、海水入侵和低陆地淹没等影响。
其次,温度升高还会对生态系统产生影响,包括物种的分布和生态系统的稳定性。
此外,温度变化还会加剧自然灾害的发生频率和严重程度。
其中,最为重要的是温度变化对大气环境的影响。
温度的升高将导致大气层的热量分配发生改变,温度梯度增加,从而导致风的强度和方向发生变化。
此外,温度的升高还可以加剧干旱、风暴、洪水等自然灾害的发生频率和严重程度,导致大气环境的混乱和不稳定。
因此,深入研究温度变化对大气环境的影响,对于减少大气环境的危害和保护人类安全具有非常重要的意义。
二、相关研究为深入了解温度变化对大气环境的影响,科学家们已经开展了大量的研究。
其中,复杂的气候模拟和长期的气候数据分析是其中的两个主要方法。
一方面,科学家们通过复杂的气候模拟来模拟大气环境的变化。
这些模拟模型基于空气动力学、热力学、化学物理等多种科学原理,并结合具体的地理位置、气象数据等因素,以预测未来气候趋势。
另一方面,科学家们通过长期的气候数据分析来研究温度变化对大气环境的影响。
他们收集来自全球各地长达数十年的气象数据,并使用各种数据分析技术进行处理和分析,以查看温度变化对大气环境的影响。
三、建立预测模型了解温度变化对大气环境的影响是非常重要的,但是如何建立一个准确的预测模型来预测未来的气候变化是更加关键的。
预测模型的建立需要考虑多种因素,包括大气环境的物理、化学、生态等因素。
目前,科学家们已经开发了各种预测模型,包括统计模型、物理模型、机器学习模型等。
ARIMA模型---时间序列分析---温度预测
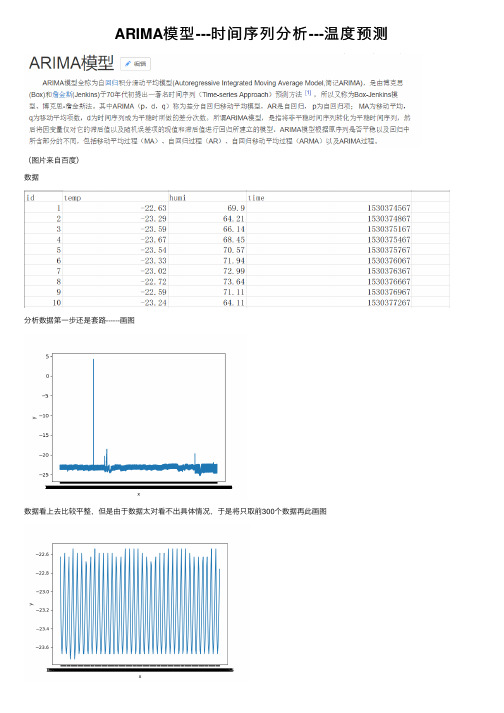
ARIMA模型---时间序列分析---温度预测(图⽚来⾃百度)数据分析数据第⼀步还是套路------画图数据看上去⽐较平整,但是由于数据太对看不出具体情况,于是将只取前300个数据再此画图这数据看上去很不错,感觉有隐藏周期的意思代码#coding:utf-8import csvimport matplotlib.pyplot as pltdef read_csv_data(aim_list_1, aim_list_2, file_name):i = 0csv_file = csv.reader(open(file_name,'r'))for data in csv_file:if (i == 0):i += 1continueaim_list_1.append(float(data[1]))aim_list_2.append(data[3])returndef plot_picture(x, y):plt.xlabel('x')plt.ylabel('y')plt.plot(x, y)plt.show()returnif__name__ == '__main__':temp = []tim = []file_name = 'C:/Users/lichaoxing/Desktop/testdata.csv'read_csv_data(temp, tim, file_name)plot_picture(tim[:300], temp[:300])使⽤ARIMA模型(ARMA)第⼀步观察数据是否是平稳序列,通过上图可以看出是平稳的如果不平稳,则需要进⾏预处理,⽅法有对数变换差分对于平稳的时间序列可以直接使⽤ARMA(p, q)模型进⾏拟合ARMA (p, q) : AR(p) + MA(q)此时参数p和q的确定可以通过观察ACF和PACF图来确定通过观察PACF图可以看出,阶数为9也就是p=9,这⾥ACF图看出⾃相关呈现震荡下降收敛,但是怎么决定出q,我没太明⽩,这⾥姑且拍脑袋才⼀个吧就q=3但是这⾥我遇到了⼀个问题,没有搞懂,就是平稳的序列,如果我进⾏⼀阶差分后应该仍然是平稳的序列,但是这个时候我⼜画了⼀个ACF 与PACF图,竟然是下图这样,lag的范围是-0.04到0.04(不懂)lag的范围是-0.04到0.04的问题原因(修改于再次使⽤此模型)原因:当时,我使⽤的是⼀阶差分,也就是让数据的后⼀个值减去前⼀个值得到新的值,这样就会导致第⼀个值变为缺失值(下⾯的数据是再此使⽤此模型时的数据,与原博客数据⽆关)就是因为此处的值为缺失值,导致绘制ACF与PACF时数据有问题⽽⽆法成功显⽰解决办法,在绘制上述图形前,将第⼀个数据去除:dta= dta.diff(1)dta = dta.truncate(before= ym[1])#删除第⼀个缺失值其实还有就是使⽤ADF检验,得到的结果如图,这个p值很⼩===》平稳画图代码def acf_pacf(temp, tim):x = timy = tempdta = pd.Series(y, index = pd.to_datetime(x))fig = plt.figure(figsize=(9,6))ax1 = fig.add_subplot(211)fig = sm.graphics.tsa.plot_acf(dta,lags=50,ax=ax1)ax2 = fig.add_subplot(212)fig = sm.graphics.tsa.plot_pacf(dta,lags=50,ax=ax2)show()ADF检验代码def test_stationarity(timeseries):dftest = adfuller(timeseries, autolag='AIC')return dftest[1]这⾥先使⽤ARMA(9,3)来实验测试⼀下效果,取前300个数据中的前250个作为train,后⾯的作为test 效果可以说这个模型是真的强⼤,预测的还是⼗分准确的代码def test_300(temp, tim):x = tim[0:300]y = temp[0:300]dta = pd.Series(y[0:249], index = pd.to_datetime(x[0:249]))fig = plt.figure(figsize=(9,6))ax1 = fig.add_subplot(211)fig = sm.graphics.tsa.plot_acf(dta,lags=30,ax=ax1)ax2 = fig.add_subplot(212)fig = sm.graphics.tsa.plot_pacf(dta,lags=30,ax=ax2)arma_mod = sm.tsa.ARMA(dta, (9, 3)).fit(disp = 0)predict_sunspots = arma_mod.predict(x[200], x[299], dynamic=True)fig, ax = plt.subplots(figsize=(9, 6))ax = dta.ix[x[0]:].plot(ax=ax)predict_sunspots.plot(ax=ax)show()其实,可以通过代码来⾃动的选择p和q的值,依据BIC准则,⽬标就是bic越⼩越好代码def proper_model(timeseries, maxLag):init_bic = 100000000init_properModel = Nonefor p in np.arange(maxLag):for q in np.arange(maxLag):model = ARMA(timeseries, order=(p, q))try:results_ARMA = model.fit(disp = 0, method='css')except:continuebic = results_ARMA.bicif bic < init_bic:init_properModel = results_ARMAinit_bic = bicreturn init_properModel遇到的问题,预测时predict函数没怎么使⽤明⽩当写于某些预测区间的时候,会报 “start”或“end”的相关错误,还有⼀个函数forcast,这个函数使⽤就是forcast(N):预测后⾯N个值返回的是预测值(array型)标准误差(array型)置信区间(array型)还有:对于构造时间序列,时间可以是时间格式:如 “2018-01-01” 或者就是个时间戳,在⽤时间戳的时候,其实在序列⾥它会⾃动识别时间戳,并加上起始时间1970-01-01 00:00:01形式附录(代码)预测⼀序列中某⼀点的值#coding:utf-8import csvimport timeimport pandas as pdimport numpy as npfrom statsmodels.tsa.arima_model import ARMAimport argparseimport warningswarnings.filterwarnings('ignore')def timestamp_datatime(value):value = time.localtime(value)dt = time.strftime('%Y-%m-%d %H:%M',value)return dtdef time_timestamp(my_date):my_date_array = time.strptime(my_date,'%Y-%m-%d %H:%M')my_date_stamp = time.mktime(my_date_array)return my_date_stampdef read_csv_data(aim_list_1, aim_list_2, file_name):i = 0csv_file = csv.reader(open(file_name,'r'))for data in csv_file:if (i == 0):i += 1continueaim_list_1.append(float(data[1])) #1:温度 2:湿度dt = int(data[3])aim_list_2.append(dt)returndef proper_model(timeseries, maxLag):init_bic = 100000000init_properModel = Nonefor p in np.arange(maxLag):for q in np.arange(maxLag):model = ARMA(timeseries, order=(p, q)) #bugtry:results_ARMA = model.fit(disp = 0, method='css')except:continuebic = results_ARMA.bicif bic < init_bic:init_properModel = results_ARMAinit_bic = bicreturn init_properModeldef test_300(temp, tim, time_in):x = []y = []end_index = len(tim)for i in range(0, len(tim)):if (time_in - (tim[i]) < 300):end_index = ibreakif (end_index < 100):x = tim[0: end_index]y = temp[0: end_index]else:x = tim[end_index - 100: end_index]y = temp[end_index - 100: end_index]tidx = pd.DatetimeIndex(x, freq='infer')dta = pd.Series(y, index = tidx)print(dta)arma_mod = proper_model(dta, 9)predict_sunspots = arma_mod.forecast(1)return predict_sunspots[0]def predict_temperature(file_name, time_in):temp = []tim = []read_csv_data(temp, tim, file_name)result_temp = test_300(temp, tim, time_in)return result_tempif__name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('-f', action='store', dest='file_name')parser.add_argument('-t', action='store', type = int, dest='time_')args = parser.parse_args()file_name = args.file_nametime_in = args.time_result_temp = predict_temperature(file_name, time_in)print ('the temperature is %f ' % result_temp)在上⾯的代码中,预测某⼀点的值我采⽤序列中此点的前100个点作为训练集如果给出待预测的多个点,由于每次都要计算模型的p和q以及拟合模型,时间会很慢,于是考虑将给定的待预测时间点序列切割成⼩段,使每⼀段中最⼤与最⼩的时间间隔在某⼀范围内在使⽤forcast(n)函数⼀次预测多点,然后在预测值中找到与待预测的时间值相近的值,速度⼤⼤提升,思路如图代码#coding:utf-8import csv#import timeimport pandas as pdimport numpy as npfrom statsmodels.tsa.arima_model import ARMAimport warningswarnings.filterwarnings('ignore')def proper_model(timeseries, maxLag):init_bic = 1000000000init_p = 1init_q = 1for p in np.arange(maxLag):for q in np.arange(maxLag):model = ARMA(timeseries, order=(p, q))try:results_ARMA = model.fit(disp = 0, method='css')except:continuebic = results_ARMA.bicif bic < init_bic:init_p = pinit_q = qinit_bic = bicreturn init_p, init_qdef read_csv_data(file_name, clss = 1):i = 0aim_list_1 = [] #temperature(1) or humidity(2)aim_list_2 = [] #timecsv_file = csv.reader(open(file_name,'r'))for data in csv_file:if (i == 0):i += 1continueaim_list_1.append(float(data[clss]))dt = int(data[3])aim_list_2.append(dt)tidx = pd.DatetimeIndex(aim_list_2, freq = None)dta = pd.Series(aim_list_1, index = tidx)init_p, init_q = proper_model(dta[:aim_list_2[100]], 9)return init_p, init_q, aim_list_2, dtadef for_kernel(p, q, tim, dta, tmp_time_list, result_dict):interval = 20end_index = len(tim) - 1for i in range(0, len(tim)):if (tmp_time_list[0]["time"] - tim[i] < tim[1] - tim[0]):end_index = ibreakif (end_index < 100):dta = dta.truncate(after = tim[end_index])else:dta = dta.truncate(before= tim[end_index - 101], after = tim[end_index])arma_mod = ARMA(dta, order=(p, q)).fit(disp = 0, method='css')#为未来interval天进⾏预测,返回预测结果,标准误差,和置信区间predict_sunspots = arma_mod.forecast(interval)####################################for tim_i in tmp_time_list:for tim_ in tim:if tim_i["time"] - tim_ >= 0 and tim_i["time"] - tim_ < tim[1] - tim[0]:result_dict[tim_i["time"]] = predict_sunspots[0][tim.index(tim_) - end_index] returndef kernel(p, q, tim, dta, time_in_list):interval = 20time_first = time_in_list[0]det_time = tim[1] - tim[0]result_dict = {}tmp_time_list = []for time_ in time_in_list:if time_first["time"] + det_time * interval > time_["time"]:tmp_time_list.append(time_)continuetime_first = time_for_kernel(p, q, tim, dta, tmp_time_list, result_dict)tmp_time_list = []tmp_time_list.append(time_first)for_kernel(p, q, tim, dta, tmp_time_list, result_dict)return result_dictdef predict_temperature(file_name, time_in_list, clss = 1):p, q, tim, dta = read_csv_data(file_name, clss)result_temp_dict = kernel(p, q, tim, dta, time_in_list)return result_temp_dictdef predict_humidity(file_name, time_in_list, clss = 2):p, q, tim, dta = read_csv_data(file_name, clss)result_humi_dict = kernel(p, q, tim, dta, time_in_list)return result_humi_dictif__name__ == '__main__':file_name = "testdata.csv"time_in = [{"time":1530419271,"temp":"","humi":""},{"time":1530600187,"temp":"","humi":""},{"time":1530825809,"temp":"","humi":""}] #time_in = [{"time":1530600187,"temp":"","humi":""},]result_temp = predict_temperature(file_name, time_in)print(result_temp)由于后续⼜改动了需求,需要预测温度以及湿度,完成了项⽬在github。
转子温度模型估算精度和意义-概述说明以及解释

转子温度模型估算精度和意义-概述说明以及解释1.引言1.1 概述转子温度模型估算是一种重要的技术手段,用于预测和估计转子在工作过程中的温度变化。
随着工业技术的不断发展,转子的温度变化对于机械设备的性能和寿命有着重要的影响。
因此,精确地估算转子的温度变化对于设备的正常运行和维护具有重要的意义。
在本文中,我们将介绍转子温度模型估算方法的基本原理和流程。
首先,我们会对不同的转子温度模型进行介绍,并分析它们的优缺点。
然后,我们将详细说明转子温度模型的估算方法和步骤,包括输入数据的获取、数学模型的建立以及模型参数的优化等。
为了评估转子温度模型的估算精度,我们将进行数值模拟和实际测试。
通过与实际测量数据进行对比,我们可以对转子温度模型的估算精度进行评估和分析。
同时,我们还会探讨不同因素对温度模型估算精度的影响,以及如何进一步提高模型的准确性和可靠性。
转子温度模型的估算具有重要的工程应用意义。
首先,它可以帮助监测和预测机械设备的性能和寿命,提前发现潜在的故障和问题。
其次,它可以指导设备的运行和维护,合理调整工作参数,提高设备的运行效率和安全性。
最后,转子温度模型的估算结果可以为设计优化提供参考,改进设备结构和材料的选取,提高设备的整体性能和可靠性。
总结而言,本文将重点介绍转子温度模型估算的方法和精度分析,探讨其在工程实践中的意义和应用。
通过深入研究和分析,我们希望能够提供有关转子温度模型估算精度和应用的全面理解,为转子温度模型估算和相关领域的研究工作提供有益的参考和启示。
1.2 文章结构本文将以转子温度模型的估算精度和意义为主题,分为引言、正文和结论三个部分。
引言部分将概述转子温度模型估算的背景和意义,介绍转子温度模型估算方法的重要性和现状。
同时,明确本文的目的,即通过对转子温度模型估算精度和意义的分析,为相关领域的研究和应用提供参考和指导。
正文部分将分为三个小节。
首先,介绍转子温度模型估算方法的基本原理和常用方法,包括传统的热传导模型和基于机器学习的模型等。
基于线性逐步回归的夏季草莓大棚内地温预测模型研究

Journal of Agricultural Catastrophology 2023, Vol.13 No.9基于线性逐步回归的夏季草莓大棚内地温预测模型研究黄龙斐1,王 忠1,张 靓2,王 涛1,周志恒31.阿坝州气象探测中心,四川马尔康 624000;2.阿坝州气象局,四川马尔康624000;3.阿坝州气象台,四川马尔康 624000摘要 收集2018年8—9月塑料大棚内观测的气象数据,构建了基于线性逐步回归的草莓生产大棚内的地温预测模型,采用1号大棚内的地面温度、气温、风速、总辐射,构建1个模拟方程,在构建的过程中,逐一剔除不显著的自变量。
将通过信度为0.05水平的显著性检验的要素模拟出地温模型。
通过2号棚的相应数据验证模型。
该模型所需参数少,实用性强,模拟精度较好,可为设施夏季草莓气象服务和环境调控提供数据依据。
关键词 线性逐步回归;地温;模拟模型;夏季草莓中图分类号:S625.3 文献标识码:B 文章编号:2095–3305(2023)09–0112-03草莓为蔷薇科,属多年生草本植物,有“水果皇后”的美誉,营养价值、经济价值都较高。
作为短日照、喜冷凉气候作物,我国出产的草莓主要为冬春草莓,出产时间为每年12月—翌年5月,批发价格20~40元/kg。
每年6—11月是我国草莓生产空白期,只有南半球可出产优质草莓,但受限于交通运输,目前国内优质夏季鲜食草莓市场暂为空白[1]。
川西北高原位于四川省西北部的阿坝藏族羌族自治州、甘孜藏族自治州境内,平均海拔在3 000~4 000 m以上,是四川省地势最高地区;大部分地区年均温为0~6 ℃,极端最低温在-20 ℃以下,10 ℃以上活动积温1 000~1 500 ℃·d,全年长冬无夏,春秋相连,为四川热量最低地区。
而太阳年辐射量和年日照时数均为四川省最高值,丰富的光能资源在一定程度上弥补了地高天寒、热量不足的缺陷[2-6]。
通过利用高原的夏季模拟平原冬季气候,“蓝迦梅朵”团队前期经不同栽培试验,目前已成功在6—10月产出了优质鲜食草莓,并于松潘高原种植基地成功投入生产。
小井眼超深井井筒温度预测模型及降温方法研究

小井眼超深井井筒温度预测模型及降温方法研究
刘涛;何淼;张亚;陈鑫;阚正玉;王世鸣
【期刊名称】《钻采工艺》
【年(卷),期】2024(47)3
【摘要】顺北区块超深小井眼钻井井底高温问题突出,明确井筒温度场分布规律并探讨高效降温方法对于保障该地区钻井安全具有重要工程意义。
文章基于超深小井眼钻井工艺,综合考虑钻井液黏性耗散、钻柱偏心和旋转及钻头破岩等多种热源项对井筒温度的影响,建立了适用于小井眼超深井的井筒瞬态传热模型,并提出针对性的降温方法,然后采用MWD实测数据及商业软件Drillbench进行对比验证,本模型预测值与随钻数据更为吻合,误差在2%以内;钻柱隔热可降低井底温度33℃,钻井提速、增加排量等其它方法可使井底温度降低3~10℃,采用地面降温法的降温效率呈现显著的边际递减效应,即井越深其降温能力越有限。
针对单一降温方法降温效果不够显著,建议综合多种降温方法有效降低井筒温度。
本研究成果可为小井眼超深井的井筒温度准确预测和降温方法优选提供理论指导。
【总页数】8页(P65-72)
【作者】刘涛;何淼;张亚;陈鑫;阚正玉;王世鸣
【作者单位】长江大学石油工程学院;油气钻采工程湖北省重点实验室•长江大学;荆州嘉华科技有限公司;天津汇铸石油设备科技有限公司;天津市油气与地热完井工具重点实验室
【正文语种】中文
【中图分类】TE2
【相关文献】
1.超深井掺稀降黏井筒温度分布模拟研究
2.深水超深井钻井井筒温度剖面预测
3.顺北一区小井眼超深井井筒温度场特征研究与应用
4.超深井井筒温度数值模型与解析模型计算精度对比研究
5.深井超深井注入过程井筒温度场模型研究及应用
因版权原因,仅展示原文概要,查看原文内容请购买。
转炉炼钢终点温度预报模型的研究

转炉炼钢终点温度预报模型的研究转炉炼钢是一种重要的钢铁生产过程,其终点温度的预报是关键的决策因素之一。
为了提高转炉炼钢的质量和效率,研究转炉炼钢终点温度预报模型已成为研究的热点。
本文将介绍转炉炼钢终点温度预报模型的研究内容和研究现状,探讨其应用价值和未来发展方向。
一、研究内容转炉炼钢终点温度预报模型的研究内容主要包括以下几个方面:1、数据采集和处理:利用物理、化学参数和历史数据等信息,建立炉内温度、氧气含量、碳含量等变量的数据采集系统,并进行数据预处理,以保证数据的质量和可靠性。
2、模型建立:基于数据采集和处理的结果,建立转炉炼钢终点温度预报模型,以实现对炉内不同区域温度的预测和控制。
常见的预测模型包括神经网络、支持向量机和逻辑回归等。
3、模型评估:通过比较不同模型的预测结果,评估模型的准确性、稳定性和实用性,确定最优模型并进行后续验证。
4、应用实践:利用建立的预报模型,实现对转炉炼钢过程中终点温度的预测和控制。
通过实践应用,逐步提高模型的适应性和预测精度,为钢铁生产提供可靠的技术支持。
二、研究现状目前,国内外对于转炉炼钢终点温度预报模型的研究已经取得了一定的成果。
国内一些钢铁企业对于该问题进行了探索和应用,开展了一些基于统计学和人工智能算法的研究。
例如,多个钢铁企业采用了支持向量机算法来预测炉内温度,取得了良好的预测效果。
国际上,美国、日本等国家也在该领域进行了长期的研究,目前已有许多文献探讨了转炉炼钢终点温度预测的基础理论、实验研究以及预测模型的应用等方面。
以美国为例,该国的许多大型钢铁企业都在转炉炼钢领域具有深厚的技术积累和应用经验,其预测模型的准确性已经达到了相当高的水平。
三、应用价值转炉炼钢终点温度预报模型的研究具有重要的应用价值。
首先,该模型可以预测炉内不同区域的温度分布,实现对炉温的精准控制,提高炼钢的质量和效率。
其次,该模型可以帮助钢铁企业降低生产成本,减少资源浪费,提高经济效益。
航空高速齿轮服役温度预测模型研究

2024年第48卷第2期Journal of Mechanical Transmission航空高速齿轮服役温度预测模型研究陈玉灵1朱加赞2陈泰民1朱才朝1魏沛堂1徐永强2(1 重庆大学高端装备机械传动全国重点实验室,重庆400044)(2 中国航发四川燃气涡轮研究院机械系统技术研究室,四川成都610500)摘要随着高速重载下航空传动服役温度的不断提高,齿轮胶合失效成为制约飞行器性能的关键因素。
为高效预测航空齿轮服役温度,针对某航空发动机齿轮提出了一种基于顺序耦合的齿轮温度仿真分析方法,考虑固-液-气多相对流换热及不同齿面散热系数等因素,模拟了航空齿轮在不同工况下的本体温度和齿面闪温。
经验证说明,该数值方法与ISO/TS 6336-20闪温法标准计算结果吻合良好,不同工况下接触温度最大偏差控制在10%以内;当传动系统输入转速为22 400 r/min、转矩为119.4 N·m时,分流大齿轮的接触温度达到242.6 ℃,齿轮胶合安全系数为1.22,存在胶合失效风险。
所提出的仿真分析方法能有效预测航空等领域高速齿轮服役温度,为评估航空齿轮胶合失效风险提供了高效可靠的方法。
关键词航空齿轮齿轮胶合温度仿真本体温度接触温度Study on Operating Temperature Prediction Model of Aero High-speed GearsChen Yuling1Zhu Jiazan2Chen Taimin1Zhu Caichao1Wei Peitang1Xu Yongqiang2(1 State Key Laboratory of Mechanical Transmission for Advanced Equipment, Chongqing University, Chongqing 400044, China)(2 Laboratory of Mechanical Systems Technology, AEEC Sichuan Gas Turbine Establishment, Chengdu 610500, China)Abstract With the continuous improvement of the operating temperature of aero transmission under the high-speed and high load, gear scuffing failure has become a key factor restricting the performance of aircrafts. To efficiently predict the operating temperature of aero gears, a sequential coupling numerical analysis method of the gear temperature is proposed for an aero engine gear, which simulates the bulk temperature and flash tem⁃perature under different working conditions, considering factors such as solid-liquid-gas multi-state flow heat exchange and heat dissipation coefficients of different tooth surfaces. The simulated gear contact temperature is compared with calculation results of ISO/TS 6336-20 and shows consistency, the largest deviation between which under different working conditions is controlled within 10%. When the input speed is 22 400 r/min and the torque is 119.4 N∙m, the split large gear contact temperature reaches 242.6 ℃, the scuffing safety factor is 1.22, and there is a risk of scuffing failure. The proposed simulation analysis method can effectively predict the operating temperature of aero high-speed gears, and provide an efficient and reliable method for assessing the risk of aero gear scuffing failure.Key words Aero gear Gear scuffing Temperature simulation Bulk temperature Contact tempera⁃ture0 引言航空发动机朝着高马赫数、高推重比、高可靠性和长寿命方向发展,这给航空发动机机械传动系统研制带来了更加严峻的挑战。
基于GA-BP神经网络的温室温度预测研究

第13卷㊀第9期Vol.13No.9㊀㊀智㊀能㊀计㊀算㊀机㊀与㊀应㊀用IntelligentComputerandApplications㊀㊀2023年9月㊀Sep.2023㊀㊀㊀㊀㊀㊀文章编号:2095-2163(2023)09-0168-04中图分类号:S625;TP183文献标志码:A基于GA-BP神经网络的温室温度预测研究李其操,董自健(江苏海洋大学电子工程学院,江苏连云港222005)摘㊀要:温度对于温室内作物的生长起着重要的作用,为了更精准的管理和控制温室内的温度,提出了基于遗传算法优化的BP神经网络预测模型(GA-BP),对温室内温度进行预测㊂本文利用遗传算法对BP神经网络的权值和阈值进行优化,使模型避免出现局部最优,有效改善了传统BP神经网络预测模型的性能,使预测出的温度更加精准㊂实验证明,选择隐藏层节点数为7时,GA-BP神经网络预测模型的预测结果最佳,平均绝对误差(MAE)㊁均方误差(MSE)和平均绝对百分比误差(MAPE)分别为0.441㊁0.276㊁0.525㊂与传统BP神经网络预测模型相比分别提升了13.2%㊁38.4%㊁21.5%㊂关键词:遗传算法;BP神经网络;温室温度;预测模型GreenhousetemperaturepredictionbasedonGA-BPneuralnetworkLIQicao,DONGZijian(SchoolofElectronicEngineering,JiangsuOceanUniversity,LianyungangJiangsu222005,China)ʌAbstractɔTemperatureplaysanimportantroleinthegrowthofcropsinthegreenhouse.Inordertomanageandcontrolthetemperatureinthegreenhousemoreaccurately,ageneticalgorithm-optimizedBPneuralnetworkpredictionmodel(GA-BP)wasproposedtopredictthetemperatureinthegreenhouse.Inthispaper,thegeneticalgorithmisusedtooptimizetheweightsandthresholdsoftheBPneuralnetwork,sothatthemodelavoidslocaloptimization,effectivelyimprovestheperformanceofthetraditionalBPneuralnetworkpredictionmodel,andmakesthepredictedtemperaturemoreaccurate.Experimentsshowthatwhenthenumberofhiddenlayernodesisselectedtobe7,thepredictionresultoftheGA-BPneuralnetworkpredictionmodelisthebest,andthemeanabsoluteerror(MAE),meansquareerror(MSE)andmeanabsolutepercentageerror(MAPE)are0.441,0.276,and0.525respectively.ComparedwiththetraditionalBPneuralnetworkpredictionmodel,ithasincreasedby13.2%,38.4%,and21.5%respectively.ʌKeywordsɔgeneticalgorithm;BPneuralnetwork;greenhousetemperature;predictionmodel作者简介:李其操(1997-),男,硕士研究生,主要研究方向:农业物联网;董自健(1973-),男,博士,教授,主要研究方向:检测与控制㊁通信技术㊂通讯作者:董自健㊀㊀Email:dzjian@126.com收稿日期:2022-10-200㊀引㊀言中国是排在世界前列的农业生产大国,温室的面积占据着世界首位㊂温室内的环境因素对于作物的生长有着至关重要的影响[1-2]㊂目前,温室的调控方式大多是凭借工人的生产经验,通过获得的传感器数据,进行预判性的调控㊂因此,能够精准的预测出温室内的温度情况,对温室调控系统有很大的帮助㊂近年来,许多学者提出了针对温度预测的方法㊂如:左志宇[3]提出采用时序分析法建立温度预测模型的方法;徐意[4]构建了基于RBF神经网络的温室温度预测模型;徐宇[5]构建了基于复数神经网络的温室温度预测模型;王红君[6]利用贝叶斯正则化算法对BP神经网络进行改进,降低了影响温度的因子之间的耦合度等㊂但是,上述预测模型都容易出现陷入局部最优的情况㊂因此,本文利用遗传算法,对BP神经网络的初始权值和阈值进行优化,使预测模型避免出现局部最优的情况,从而对温室内温度进行更精准的预测㊂1㊀GA-BP神经网络预测模型的构建1.1㊀BP神经网络BP神经网络的主要思想是:训练数据通过前馈网络训练后得到输出数据,将输出数据与期望数据进行对比得到误差,反向传播网络将得到的误差反向输入输出层,对网络的连接权值和阈值进行反复训练,缩小网络输出和期望输出之间的误差㊂输入㊁输出层为单层结构,而隐藏层可以是单层或多层㊂输入层㊁隐藏层㊁输出层之间的神经元都是相互连接的,为全连接㊂BP神经网络结构如图1所示㊂uy输入层节点隐藏层节点输出层节点图1㊀BP神经网络结构图Fig.1㊀StructureofBPneuralnetwork㊀㊀假设输入层节点数为n,隐藏层节点数为l,输出层节点数为m,输入层到隐藏层的权重为ωij,隐藏层到输出层的权重为ωjk,输入层到隐藏层的阈值为aj,隐藏层到输出层的阈值为bk,学习速率为η,激励函数为g(x)㊂其中,激励函数为g(x)取sigmoid函数㊂形式如式(1)所示:gx()=11+e-x(1)㊀㊀隐藏层的输出如式(2)所示:Hj=gðni=1ωijxi+aj()(2)㊀㊀输出层的输出如式(3)所示:Ok=ðlj=1Hjωjk+bk(3)㊀㊀网络误差如式(4)所示:ek=Yk-Ok(4)㊀㊀其中,Yk为期望输出㊂输入层到隐藏层权值的更新公式如式(5)所示:㊀㊀ωij=ωij+ηHj1-Hj()xiðmk=1ωjkek(5)隐藏层到输出层权值的更新公式如式(6)所示:ωjk=ωjk+ηHjek(6)㊀㊀隐藏层节点阈值的更新公式如式(7)所示:aj=aj+ηHj1-Hj()ðmk=1ωjkek(7)㊀㊀输出层节点阈值的更新公式如式(8)所示:bk=bk+ηek(8)㊀㊀由于BP神经网络的初始连接权值和阈值是随机选定,可能会使网络陷入局部极值,权值收敛到局部最小值,从而出现网络训练失败,模型的预测精度不高的结果㊂因此,本文采用遗传算法对BP神经网络进行优化,得到权值和阈值的最优解,使模型能够更高效的训练和更精准的预测㊂1.2㊀遗传算法(1)初始化种群㊂种群中的个体由BP神经网络中输入层到隐藏层的权值㊁隐藏层的阈值㊁隐藏层到输出层的权值和输出层的阈值编码而成㊂(2)适应度函数㊂适应度函数用于表明BP神经网络中权值和阈值的优劣性,个体适应度值为训练数据预测误差绝对值之和㊂适应度函数的计算公式如式(9)所示:Fi=kðni=1absyi-oi()()(9)式中:k为系数,n为神经网络输出节点数量,yi为神经网络第i个节点的期望输出,oi为神经网络第i个节点的预测输出㊂(3)选择操作㊂选择操作从旧群体中以一定概率选择优良个体组成新的种群,以繁殖得到下一代个体,本文采用轮盘赌法,每个个体i被选择的概率pi如式(10)所示:pi=FiðNj=1Fi(10)式中:N为种群规模,Fi为第i个个体适应度值㊂(4)交叉操作㊂交叉操作是指从种群中随机选择两个个体,通过两个染色体的交换组合,把父串的优秀特征遗传给子串,从而产生新的优秀个体,由于个体采用实数编码,所以交叉操作采用实数交叉法[7]㊂第j个个体Sj和k个个体Sk在i位的交叉过程如式(11)所示:Sj,i=Sj,i1-b()+Sk,i㊃bSk,i=Sk,i1-b()+Sj,i㊃b{(11)式中b为[0,1]区间内的随机数㊂(5)变异操作㊂为了防止遗传算法在优化过程中陷入局部最优解,在搜索过程中,需要对个体进行变异㊂经过交叉操作后得到新的染色体后,随机选择染色体上的若干个基因,将这若干个基因的值进行随机修改,从而更新了染色体的基因,突破了搜索的限制,更有利于获取全局最优解[8]㊂选择第i个961第9期李其操,等:基于GA-BP神经网络的温室温度预测研究个体的第j个基因aij进行变异,操作过程如式(12)㊁式(13)所示:aij=aij+amax-aij()㊃fs()r>0.5aij-aij-amin()㊃fs()rɤ0.5{(12)fs()=r1-sGmaxæèçöø÷(13)式中:amax㊁amin分别是个体i的最大值和最小值,s是迭代次数,Gmax是最大进化次数,r为[0,1]区间内的随机数㊂1.3㊀GA-BP神经网络预测模型GA-BP神经网络预测模型由遗传算法(GeneticAlgorithms,GA)优化部分和BP神经网络两部分组成㊂由于种群中的每个个体都包含了BP神经网络的初始权值和阈值,遗传算法部分的作用是优化BP神经网络的权值和阈值㊂通过计算BP神经网络的误差,得到个体适应度值㊂经过遗传算法的选择㊁交叉和变异操作找到最优适应度值的个体㊂对最优个体进行解码,得到权值和阈值,赋值给BP神经网络,再使用反向传播进行训练㊂GA-BP神经网络预测模型的执行过程如图2所示㊂输出预测结果满足终止条件更新权值和阈值计算误差获取最优权值和阈值确定B P 神经网络初始权值和阈值满足终止条件选择、交叉、变异计算适应度值初始化种群对权值和阈值编码YNNY图2㊀遗传算法优化BP神经网络流程图Fig.2㊀FlowchartofgeneticalgorithmtooptimizeBPneuralnetwork2㊀实验与结果分析2.1㊀样本数据采集本文实验数据采集自连云港赣榆葡萄园第6号温室,选用温度㊁湿度㊁二氧化碳浓度㊁土壤氮含量㊁土壤磷含量和土壤钾含量作为样本数据㊂每15min采集一次数据,共采集了2292组样本数据㊂为了实验测试更方便,本文选用其中2000组数据,并将前80%的样本数据作为训练样本,剩余的20%样本数据作为测试样本㊂部分样本数据见表1㊂表1㊀部分样本数据Tab.1㊀Partialsampledata日期时间温度/ħ湿度/%二氧化碳浓度/(ppm)土壤氮含量/%土壤磷含量/%土壤钾含量/%2022/8/2118:40:3828.28736125.226702022/8/2119:19:4127.88635925.225702022/8/2119:34:5527.88636025.126702022/8/2119:50:1027.68635925.225702022/8/2120:05:2427.68635825.225702022/8/2120:20:3927.58635825.225682.2㊀模型参数设定2.2.1㊀BP神经网络结构根据所获得的样本数据,将输入层节点设定为5,即5个特征,分别为湿度㊁二氧化碳浓度㊁土壤氮含量㊁土壤磷含量和土壤钾含量数据;输出层节点为1个,特征为温度数据;通过试凑法确定隐藏层节点为7个㊂因此,BP神经网络的结构为5-7-1㊂2.2.2㊀遗传算法参数设定由于过多的迭代次数会影响模型的训练效率,且适应度曲线在迭代50次后的变化幅度不大,因此本实验将进化迭代次数设定为50次,种群规模为30,交叉概率为0.3,变异概率为0.1㊂图3为遗传算法的适应度曲线㊂10410310210110099980102030405060进化代数适应度平均适应度适应度曲线终止代数=50图3㊀遗传算法适应度曲线Fig.3㊀Geneticalgorithmfitnesscurve071智㊀能㊀计㊀算㊀机㊀与㊀应㊀用㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀第13卷㊀2.3㊀模型评价标准为了评定预测模型的性能,本文以平均绝对误差(MAE)㊁均方误差(MSE)和平均绝对百分比误差(MAPE)作为评判预测模型性能优劣的标准㊂各评估误差指标的计算公式如式(14) 式(16)所示:MAE=1nðni=1y^i-yi(14)MSE=1nðni=1y^i-yi()2(15)MAPE=1nðni=1y^i-yiyi(16)式中:y^i为模型的预测值,yi为真实值,n为样本数㊂所得的值越小,则模型的性能越优异㊂2.4㊀预测结果及分析通过MATLAB软件对GA-BP神经网络预测模型和传统BP神经网络预测模型进行验证,得到的预测对比结果如图4所示㊂预测结果实际值282726252423222120050100150200250300350400样本编号温度(a)GA-BP网络预测输出预测结果实际值282726252423222120050100150200250300350400样本编号温度(b)BP网络预测输出图4㊀GA-BP与BP训练效果对比图Fig.4㊀ComparisonofGA-BPandBPtrainingeffects㊀㊀由图4可知,GA-BP神经网络预测模型与传统BP神经网络预测模型相比,GA-BP的预测效果更优,预测结果更贴近实际值㊂评价结果见表2㊂可以看出,GA-BP预测模型的各项误差指标均小于传统BP预测模型㊂实验证明,GA-BP神经网络预测模型具有更好的预测效果㊂表2㊀模型的评价指标对比Tab.2㊀Comparisonofevaluationindicatorsofthemodels评价指标GA-BPBPMAE0.4410.508MSE0.2760.448RMSE0.5250.6693㊀结束语本文以温室内湿度㊁二氧化碳浓度和土壤氮磷钾含量与温度有关的影响因子作为输入量,以温度作为输出量,通过遗传算法优化BP神经网络的权值和阈值,构建了GA-BP神经网络预测模型㊂实验证明,GA-BP神经网络预测模型能够更精准的进行温室内温度预测,对于温室管理有一定的参考价值㊂参考文献[1]王军伟.苏北地区日光温室构型优化㊁室内温湿度分析及应用效果初探[D].南京:南京农业大学,2015.[2]王克安,李絮花,吕晓惠,等.不同结构日光温室温湿度变化规律及其对番茄产量和病害的影响[J].山东农业科学,2011,235(3):33-36.[3]左志宇,毛罕平,张晓东,等.基于时序分析法的温室温度预测模型[J].农业机械学报,2010,41(11):173-177,182.[4]徐意,项美晶.基于RBF神经网络的温室温度调控研究[J].农机化研究,2010,32(3):74-76.[5]徐宇,冀荣华.基于复数神经网络的智能温室温度预测研究[J].中国农机化学报,2019,40(4):174-178.[6]王红君,史丽荣,赵辉,等.基于贝叶斯正则化BP神经网络的日光温室温度预测模型[J].湖北农业科学,2015,54(17):4300-4303.[7]曹雪丽.配送中心订单分批处理随机服务系统模型与优化研究[D].北京:北京物资学院,2012.[8]高基旭,王珺.一种基于遗传算法的多边缘协同计算卸载方案[J].计算机科学,2021,48(1):72-80.171第9期李其操,等:基于GA-BP神经网络的温室温度预测研究。
3500mm轧机层流冷却控制终冷温度预测模型的探讨

3500mm轧机层流冷却控制终冷温度预测模型的探讨摘要:由于钢板在轧后层流冷却能够提高钢板的性能,而且还可以省去钢板轧后专门的热处理,节约成本,提高钢厂的效益,因此越来越多的钢厂纷纷安装了冷却控制装置,然由于层流冷却过程是非常复杂的生产过程,因此数学模型的精度受到了限制,本文针对这种情况,本文采用BP神经网络结合数学模型来提高钢板的终冷温度控制精度。
关键词:数学模型神经网络换热系数1 层流冷却控制技术研究的意义随着各国成功地使用层流冷却控制技术,我国也紧随其后开始在国内投入大量的研究工作。
目前我国各钢厂使用的层流冷却控制装置大部分都是在国外引进的。
然而,由于国外的技术保密,国内中厚板层流冷却控制技术的成功应用受到了限制,因此,开展中厚板层流冷却控制技术的研究是一个挑战性的课题。
2 数学模型的建立钢板在冷却过程中主要的传热有:钢板内部的导热、钢板与空气的对流传热和钢板自身的热辐射、钢板与水的对流传热、钢板内部的相变产生热、钢板和辊道之间热传导等部分组成。
忽略钢板在长度方向的传热,针对南钢3500mm轧机层流冷却建立二维导热终冷温度预测数学模型。
根据傅里叶导热微分方程得:=λ(t)(+)其中,X,Y—钢板的宽和厚度方向的坐标,λ—钢板的导热系数,c—钢板的比热,ρ—钢板的密度。
式中的ρ随温度变化不大,所以本文确定其为常数7800kg/m3[4],比热c(t)和导热系数λ(t)都随温度的变化较大,根据下表1,2各个钢种的导热系数和比热系数在不同温度下的值,用线性插值法求所需要的比热和导热系数。
只考虑钢板的辐射换热,根据斯蒂芬—波尔兹曼定律:钢板的辐射能力和绝对温度的四次方成正比得如下方程:Q=εσ(Ts4-T04)A其中,A—钢板辐射面积m2σ—黑体的辐射常数,其值为5.67W/m2·K4,ε—钢板的黑度。
Ts—钢板出轧机时的温度(K)T0—钢板进入水冷时的温度(K)3 水冷综合换热系数的确定水冷综合换热系数受钢板的规格、冷却水的温度、水流量、钢板表面温度、目标终冷温度、实际终冷温度、水冷时间等很多因素的影响,BP神经网络的优点是只要有足够多的隐层和隐层节点它就可以逼近任意的非线性函数,鉴于此,本文建立三层BP神经网络,一个具有Sigmoid非线性函数的三层BP神经网络可以在空间上逼近任意维的函数。
基于灰色预测与BP神经网络的全球温度预测研究

基于灰色预测与BP神经网络的全球温度预测研究全球气候变化是当前全球关注的热点问题之一,预测全球温度变化趋势对于应对气候变化、制定相关政策具有重要意义。
本文将基于灰色预测和BP神经网络的方法,对全球温度进行预测研究。
介绍一下灰色预测模型。
灰色预测是一种非线性动态系统预测方法,该方法主要适用于时间序列较短、数据质量较差的情况。
灰色预测模型基于灰度关联度的原理,通过建立灰色微分方程,对非确定性的系统进行建模和预测。
灰色预测模型的关键是建立灰色微分方程。
灰色微分方程包括GM(1,1)模型和其它高阶模型。
其中GM(1,1)模型是最简单的一种,也是应用最广泛的一种。
GM(1,1)模型通过对原始数据进行累加生成累加生成数列,然后通过一次累加生成数列得到一次累加数列,通过两次累加生成数列得到两次累加数列,依此类推,直到累加生成数列的相关系数满足精度要求。
通过差分方程对一次累加数列进行逆向累加生成数列即可得到灰色模型的预测结果。
然后,介绍BP神经网络模型。
BP神经网络是一种基于反向传播算法的多层前馈网络,广泛应用于模式识别、数据建模、预测等领域。
BP神经网络模型通过调整网络的连接权值和偏置值,使得网络的输出与期望输出之间的误差最小化。
通过多次迭代训练,不断优化网络结构和参数,以提高模型的预测能力。
在本文的研究中,首先收集全球温度数据,建立时间序列。
然后,将数据分为训练集和测试集。
使用灰色预测模型和BP神经网络模型对训练集进行训练,并在测试集上进行预测。
对于灰色预测模型,将原始温度数据应用于GM(1,1)模型。
对原始数据进行累加生成数列,然后通过相关系数检验确定最优累加次数。
根据差分方程对数据进行逆向累加生成数列,得到预测结果。
对比灰色预测模型和BP神经网络模型的预测结果,并评估两种模型的预测能力。
通过对比分析,选择较为准确的预测模型,并对全球温度的未来变化趋势进行预测。
基于LSTM的气温数据建模研究

技术交流|丿Technology Discussion 2021.2数据通信基于LSTM的气温数据建模研究----------------------------------------武双新(昆明理工大学信息工程与自动化学院云南昆明650500)摘要:气温数据是一种时间序列数据,具有明显非平稳波动特征。
对气温数据进行建模可以对气温变化进行分析。
针对时间序列模型预测精度不高的问题,提出了一种长短时记忆网络%Long Shoo-Term Memore Recurrent Neurae Network,LSTM)气温预测模型对昆明每天的最高温度进行预测,对不同模型进行实验并对预测结果进行对比分析。
实验结果表明,该模型对昆明日最高气温数据预测的平均相对误差比ARIMA模型低55.75%。
本文提出的长短时记忆网络模型相比于传统的差分自回归移动平均模型(ARIMA)对昆明的日最高气温数据预测有良好的表现。
因此,该模型可以作为昆明日最高气温数据预测的一种有效方法。
利用该模型对气温进行预测分析可以为气象工作者提供有价值的参考,具有指导意义。
关键词:时间序列模型;长短时记忆网络模型;气温数据中图分类号:TP18文献标识码:A0引言随着全球气候变化研究的深入,人们逐渐认识到极端天气变化对人类和周边环境的来越大,在极端天气现来的中,极端高极端低来的损失是其中重要的一方面,所以,目地的研究引起人们的广泛关注[1]#在全球变暖,生态气候发生变化的情[2],研究气温的变化也变得越来越重要,因为气系着我们的方方面面,我们要能够用气温数挖掘其中有价值的信息)3,4*#气象变化是一个很的过程,同时气温时刻都在变化并且受到素的影响,的考虑各素,才可以更加准确地对气温进行预测,达到预期J#科技的进步,我们数据时代,通过数据挖掘技术,挖掘其中蕴含的信息指导我们的日常生活[5]#在气象领域也产量的数据,们可用气象大数据,建立气温的预测模型,未来的天气现象进行预测分析[6,7]#在大数据时代来的[8],通过对数据的拟合,在同领域到应用。
路面温度场预报模型研究

路面温度场预报模型研究第一章:前言随着人们对交通安全和效率的不断需求,路面温度场预报已成为一个热门话题。
在寒冷地区,道路结冰是一个常见的问题,而在炎热地区,高温对道路的影响也是不可忽视的。
因此,能够准确预测道路表面温度场对交通管理和路面维护具有重要意义。
本文旨在研究路面温度场预报模型,以及其在实际应用中的价值和挑战。
第二章:路面温度场预报模型的原理路面温度场的预报需要建立一个基于气象因素和路面特性的预报模型。
这个模型通常由以下几个方面的数据组成:气象数据、路面材料和路面结构参数、路面状态数据。
具体的原理如下:2.1 气象因素气象数据是预测路面表面温度的主要输入变量。
该数据集包括空气温度、风速、相对湿度和太阳辐射等。
这些数据可以通过气象站和其他传感器来进行采集。
其中,太阳辐射是一个特别重要的变量,因为它可以通过扩散和反射,影响路面表面的温度。
2.2 路面材料和路面结构参数路面材料和路面结构参数也对路面温度的预测起到重要作用。
常见的路面材料有沥青混凝土、水泥混凝土、沙石路面等。
每种材料都有不同的热导率和热容量,因此对于每种材料,需要确定其特定的热学参数。
路面结构参数包括路面的厚度和层数。
这对于研究路面的热传递和储能过程非常重要。
2.3 路面状态数据路面的状态数据通常由温度数据和含水量数据组成。
路面温度可以通过测量涂层表面的温度来获得。
由于路面表面温度和路面内部温度的温差比较大,因此需要建立一个温度场模型来计算路面的内部温度。
含水量数据对冬季道路结冰的预测非常重要,因为当路面温度低于冰点时,含水量较高的路面更容易结冰。
第三章:路面温度场预报模型的应用3.1 预测道路冰雪当气温低于冰点时,路面易于结冰。
因此,预测道路冰雪是公路交通管理的一个重要组成部分。
道路冰雪的预测将会提前至少几小时,使道路工作人员采取措施来避免或减轻冰雪带来的影响。
3.2 预测道路酷热在炎热的夏季,道路表面的温度经常达到非常高的水平,这可能会导致许多问题,例如车辆气压变化,甚至引发轮胎爆炸的风险。
基于模型预测控制算法的温控技术研究

基于模型预测控制算法的温控技术研究随着科技的不断发展,温控技术已经成为现代生产和生活中不可或缺的一部分。
目前市面上普遍采用的温控技术有PID控制器、ON/OFF控制器、自适应控制器等,它们都存在着一定的局限性。
因此,如何提高温控系统的精度和稳定性,成为了研究的焦点。
在这个背景下,基于模型预测控制算法的温控技术应运而生。
一、基于模型预测控制算法的原理模型预测控制算法是一种基于预测模型的控制算法。
它通过解决优化问题来寻找未来一段时间内的最优控制方案,并进行实时控制。
与传统的反馈控制算法不同,模型预测控制算法是一种前瞻性的控制方式,它可以更准确地预测系统的未来状态,从而提高控制的精度和稳定性。
在温控系统中,模型预测控制算法可以通过建立数学模型,预测系统的温度变化趋势。
由于温度变化具有时序性,因此模型预测控制算法也需要考虑时间因素。
它通过预测未来一段时间内的温度变化趋势,实现精确的温度控制。
二、基于模型预测控制算法的温控技术的优势1. 高精度基于模型预测控制算法的温控技术能够准确预测未来温度变化趋势,从而实现更加精确的温度控制。
与传统的PID控制器相比,它能够更加准确地控制温度波动范围,从而提高系统的控制精度。
2. 稳定性好模型预测控制算法能够更好地控制系统的稳定性,减少温度的波动,从而提高系统的稳定性。
通过建立动态数学模型,预测未来温度变化趋势,实现实时控制,减少了控制误差,避免了系统产生过度振荡的情况。
3. 适应性强模型预测控制算法具有较强的适应性,能够适应不同的控制场景。
它能够自主识别系统的动态特性,根据调节参数,针对不同的系统特性进行控制。
三、基于模型预测控制算法的温控技术的应用场景基于模型预测控制算法的温控技术已经被广泛应用于各种领域,特别是在工业自动化、生物医疗、航空航天等领域有着广泛的应用。
下面针对几种典型的应用场景进行具体介绍。
1. 工业自动化在工业生产过程中,温度控制是非常关键的一环。
高速公路路面温度分布与预测模型研究

高速公路路面温度分布与预测模型研究高速公路是连接城市之间的重要交通通道之一,其良好的路面状态能够保障行车的安全性和舒适性。
而路面温度的变化对路面状况和行车舒适度产生着巨大影响。
因此,对路面温度分布及其预测模型的研究具有重要的意义。
一、路面温度分布高速公路路面温度是由多种因素综合作用的结果。
其中影响最大的因素是天气条件和太阳辐射强度。
在晴天和降雨天气下,路面温度分布规律不同。
由于直接受到阳光照射,太阳辐射强度是影响路面温度的一个关键因素,也是驾驶员需注意的一个因素。
通常情况下,高速公路太阳辐射强度较大,导致路面温度较高,而反之,天气阴沉,太阳辐射强度较小,路面温度也相应下降。
此外,路段的地势、路面的材料、颜色、湿度等因素都会对路面温度产生影响。
例如,路段的海拔高度高、地势平缓、道路旁边有高大建筑环绕,这些都是造成路面温度升高的因素。
不同材料的路面吸收太阳辐射的能力也不同,较暗色的路面吸收太阳辐射能力更强,导致路面温度升高的可能性更大。
二、预测模型研究为了预测高速公路路面温度的变化,建立准确、可靠的预测模型是必不可少的。
目前,较为常见的预测模型有基于神经网络、基于物理模型、基于统计学方法等几种。
神经网络模型是利用多个神经元相互联系的模型,通过大量的数据训练后能够准确地预测未来的路面温度,其优点是能将数据中不规则性的特征准确地捕捉出来。
而物理模型则是基于热传导方程等基本自然规律构建的数学模型,其能够精确地反映路面温度的变化规律。
但是由于个别因素的影响很难被考虑进去,这种方法的预测精度受到一定的限制。
统计学方法是将历史数据与天气预报等因素结合,利用统计学模型来预测未来时间点的路面温度。
这种方法简单易行,但是对数据的质量和数量有较高的要求。
三、实际使用情况在实际高速公路建设中,一些技术手段被广泛应用于路面温度的监测与预测。
如利用红外测温仪实现路面温度的实时监测;采用气象观测站等设备测量天气因素的数值;利用上述的预测模型进行预测。
烟台地区土壤温度变化特征及预测模型研究

王 选耀 (鲁 东 大 学 资 产 与后 勤 管 理 处 , :根 据烟 台某一 气象站提供 的 2003年 与 2005年气 象资料及 土壤温度数 据 ,对此 地 区土壤 温度 的变化特征 及其 预报
模型进行 了研究 。结果表 明:各 个土层 土壤 温度 变化规律基 本一致 ,1月份土壤 温度 最低 ,到 7月份 达到 最 高值 ,同时也
第 26卷 第 4期 2010年 11月
农 业 系 统 科 学 与 综 合 研 究
SYsTEM SCIENCES AND COM PREHENSIVE STUDIES IN AGRICULTURE
Vo1.26. No.4 NOV., 2010
烟 台地 区土 壤 温 度 变 化 特 征 及 预测 模 型研 究
1 材 料 和 方 法
所用 数 据为 烟 台某 一气 象 站提供 ,包括 2003、2005年全 年 每天 平 均气 温 ( )、最 高气 温 (℃ )、最 低 气温 (℃ )、相 对湿 度 、绝对 湿 度 、平 均 地 面 温 度 (℃ )、最 高地 面温 度 (℃ )、最 低 地 面温 度 ( )、 El照 时数 (h)、风 速 (In·s )、5cm 土 层 温 度 (℃ )、10cm 土 层 温 度 (oC)、15cm 土 层 温 度 (cIC) 和
基于长短时记忆网络的恒温水浴锅温度模型预测

河南科技Henan Science and Technology计算机与人工智能总第873期第2期2024年1月收稿日期:2023-09-28基金项目:吉林省教育厅“十三五”科学技术项目“基于微分平坦的多容耦联水罐液位系统优化控制方法研究”(JJKH20200252K )。
作者简介:高兴泉(1976—),男,博士,教授,研究方向:复杂系统仿真与控制;俞文博(1996—),男,硕士生,研究方向:先进控制技术及控制系统集成;段虹州(1998—),男,硕士生,研究方向:先进控制技术及控制系统集成。
基于长短时记忆网络的恒温水浴锅温度模型预测高兴泉1,2俞文博1段虹州1(1.吉林化工学院,吉林吉林132022;2.吉林工业职业技术学院,吉林吉林132013)摘要:【目的】由于恒温水浴锅温度系统存在强非线性及大滞后性,本研究提出一种基于长短时记忆网络的恒温水浴锅温度模型预测方法。
【方法】首先,对采集到的数据进行标准化处理,寻找长短时记忆网络的最优结构及超参数,用来拟合出最佳的数据映射特征,并构建恒温水浴锅温度的动态数学模型。
其次,通过模型对未来一段时间内的温度趋势进行预测。
最后,使用本研究提出的方法与最小二乘法所预测的结果进行对比分析。
【结果】本研究所提方法构建的模型的拟合度达到了98.2%,预测结果的MSE 及MAE 比最小二乘法模型分别降低了4.616、0.823。
【结论】本研究所提方法具有更高的预测精度,对提高恒温水浴锅的生产效率及控制精度具有重要意义。
关键词:恒温水浴锅;长短时记忆网络;温度预测;数学模型中图分类号:TP273文献标志码:A文章编号:1003-5168(2024)02-0034-06DOI :10.19968/ki.hnkj.1003-5168.2024.02.006Temperature Model Prediction of Thermostatic Water Bath Based onLong Short-term Memory NetworkGAO Xingquan 1,2YU Wenbo 2DUAN Hongzhou 2(1.Jilin Institute of Chemical Technology,Jilin 132022,China;2.Jilin Industrial Vocational and TechnicalCollege,Jilin 132013,China)Abstract:[Purposes ]Since the temperature system of thermostatic water bath has the characteristics ofstrong nonlinearity and large lag,this study proposes a temperature model prediction method of thermo⁃static water bath based on long short-term memory network.[Methods ]Firstly,the collected data were stan⁃dardized to find the optimal structure and hyperparameters of the long short-term memory network,which were used to fit the best data mapping characteristics and construct a dynamic mathematical model of the temperature of the thermostatic water bath.Secondly,the temperature trend in the future is predicted by the model.Finally,the results predicted by the method proposed in this study are compared with those predicted by the least squares method.[Findings ]The fitting degree of the model constructed by themethod proposed in this study reached 98.2%,and the MSE and MAE of the prediction results were 4.616and 0.823lower than those of the least squares model,respectively.[Conclusions ]The methodproposed in this study has higher prediction accuracy,which is of great significance to improvethe production efficiency and control accuracy of thermostatic water bath.Keywords:thermostatic water bath;LSTM;temperature prediction;mathematical model0引言恒温水浴锅由内外锅体、加热棒、搅拌器、温度传感器组成,被广泛应用于医疗机构、高等院校等的实验室中的试剂蒸馏、浓缩等加热工艺中[1-5]。
高速公路路面温度预测模型及实现技术研究

高速公路路面温度预测模型及实现技术研究第一章绪论近年来,高速公路交通事故频繁发生,其中很大一部分与路面温度异常有关。
因此,对高速公路路面温度进行预测和监测非常必要。
本文主要针对高速公路路面温度预测模型及实现技术展开研究,以期对交通运输事业的发展做出一定的贡献。
第二章相关技术介绍2.1 高速公路路面温度检测技术为了了解高速公路路面温度变化,需要对温度进行检测。
目前,最常用的方法是使用红外线技术检测路面温度。
该技术可以快速而准确地获得温度数据,并且可以实现自动化检测。
2.2 温度预测模型为了更好地预测高速公路路面温度,需要选用合适的预测模型。
常见的预测模型包括传统的回归模型、时间序列模型以及机器学习模型等。
目前,较为常用的是卷积神经网络(CNN)模型和长短期记忆网络(LSTM)模型等。
第三章预测模型研究及实现3.1 数据处理在进行路面温度预测前,需要对数据进行处理,包括数据清洗、特征选择、数据归一化等。
这些处理步骤的目的是为了消除数据中的噪声和异常,并且降低数据的复杂度,使得机器学习算法能够更好地训练和预测。
3.2 CNN模型CNN模型是一种基于图像处理技术的深度学习模型,该模型可以用于时间序列预测问题。
该模型是通过卷积、池化和全连接等操作构建神经网络结构的,可以有效地捕捉数据的空间和时间特征。
在实际应用中,通过CNN模型预测高速公路路面温度的精度较高,具有很好的实际应用价值。
3.3 LSTM模型LSTM模型是一种在建模时考虑时间序列因素的循环神经网络模型。
该模型可以考虑到不同时刻的数据之间的相互关系,并且可以记忆之前的数据,从而更好地预测未来的温度变化。
该模型在高速公路路面温度预测中的精度也较高。
第四章实验及结果分析为了验证模型的预测能力和准确性,本文对实际数据进行了实验。
实验结果表明,CNN和LSTM模型在预测高速公路路面温度时表现出了较高的准确性和预测能力,并且可以准确预测温度变化趋势。
第五章结论本文针对高速公路路面温度预测模型进行了研究,从数据处理、预测模型选择及实验结果分析等角度对该问题进行了探讨。
线圈温度预测模型建立及其定性分析

线圈温度预测模型建立及其定性分析一、研究背景线圈是电机、变压器等电力设备的重要组成部分,其温度是衡量设备运行状态的重要指标之一。
在电机、变压器等设备运行过程中,由于线圈运行时会受到过电流、磁场等因素的影响,进而导致线圈的温度升高。
因此,如何准确地预测线圈的温度变化,对于保证设备的运行安全和稳定,具有非常重要的意义。
二、相关研究预测线圈温度的方法主要有三类:基于理论模型的方法、基于统计学习的方法以及基于神经网络的方法。
(一)基于理论模型的方法基于理论模型的方法是采用数学模型对线圈温度进行数值仿真预测,其核心是建立线圈的数学模型,通过模型求解,可以预测出线圈的温度变化。
但是,由于模型假设和模型参数的选择存在一定的难度,因此该方法在实际应用中存在一定的局限性。
(二)基于统计学习的方法基于统计学习的方法是基于历史数据对线圈温度进行预测。
该方法首先需要建立一定的数学模型,然后利用历史数据对模型进行训练,最终得到线圈温度的预测结果。
该方法针对不同的问题和数据集选择不同的算法,如回归分析、支持向量机、决策树等。
但该方法需要大量的历史数据进行训练,且对数据的质量和特征提取有较高的要求。
(三)基于神经网络的方法基于神经网络的方法是利用神经网络的自适应能力,通过输入历史数据,建立神经网络预测模型,对线圈的温度变化进行预测。
该方法具有较强的自适应性和鲁棒性,可以较好地应对非线性、时变等复杂问题。
同时,该方法还可以通过网络结构的调整和学习算法的选取等手段不断提高预测精度。
因此,在工程实际应用中,基于神经网络的方法被广泛采用。
三、模型建立和定性分析基于神经网络的线圈温度预测模型有两个重要的组成部分:神经网络模型和数据预处理。
(一)神经网络模型神经网络模型是模型的核心部分,其建立过程可以分为以下步骤:1.确定神经网络的网络结构,包括输入层、隐藏层和输出层,并确定神经元数量。
2.通过网络结构的优化和参数调整,选取合适的学习算法,提高网络的预测精度。
物联网环境下基于机器学习的温湿度预测模型研究

物联网环境下基于机器学习的温湿度预测模型研究随着物联网技术的快速发展,我们日常生活中越来越多的设备通过互联网相互连接,并形成一个庞大的网络。
这些设备能够实时收集、传输和处理大量的数据,为我们提供了更多的信息和便利。
其中,温湿度是重要的环境参数之一,在许多领域中都有重要的应用价值。
因此,基于机器学习的温湿度预测模型的研究具有重要的意义。
机器学习是一种能够从数据中自动学习并生成模型的技术。
通过对大量的历史数据进行分析和学习,机器学习算法能够发现数据中的潜在规律,并根据这些规律进行预测。
在物联网环境下,温湿度数据可以通过传感器实时采集,并通过互联网传输到中央服务器进行处理和分析。
通过对这些数据进行机器学习,可以构建出一个准确的预测模型,用来预测未来一段时间内的温湿度变化。
在构建基于机器学习的温湿度预测模型时,首先需要收集大量的温湿度数据。
这些数据应包含各种不同的环境参数,如时间、季节、地理位置等,以便更好地描述不同环境条件下的温湿度变化。
然后,需要对数据进行预处理,包括数据清洗、缺失值处理和特征选择等。
清洗数据能够去除噪声和异常值,从而提高模型的可靠性和准确性。
缺失值处理可以通过插值等方法进行,以保证数据的完整性。
特征选择可以选取与温湿度变化密切相关的特征,以减少模型的复杂度和计算量。
接下来,选择合适的机器学习算法进行建模。
常用的机器学习算法包括线性回归、支持向量机、决策树和神经网络等。
根据温湿度数据的特点和需求,可以选择适合的算法进行模型训练和预测。
在训练模型时,将数据集分为训练集和测试集,使用训练集对模型进行训练,并使用测试集评估模型的性能。
通过不断调整模型的参数和结构,可以得到更准确的预测模型。
为了提高机器学习模型的预测能力,可以结合其他技术进行改进。
例如,可以使用时间序列分析和深度学习方法来处理温湿度数据中的时序关系和非线性关系。
时间序列分析能够识别数据中的周期性和趋势性,从而更好地预测未来的温湿度变化。
基于LSTM模型的日光温室温湿度预测技术研究

基于LSTM模型的日光温室温湿度预测技术研究基于LSTM模型的日光温室温湿度预测技术研究一、引言近年来,农业生产技术的快速发展,越来越多的农业生产过程向智能化方向转型。
作为现代农业的重要组成部分,日光温室的温湿度预测技术对于农作物的生长和产量具有重要影响。
本文旨在研究基于LSTM(Long Short-Term Memory)模型的日光温室温湿度预测技术,提高农业生产效率,实现智能化温室管理。
二、LSTM模型简介LSTM模型是一种用于处理时间序列数据的循环神经网络(RNN)的变种。
相比于传统的RNN,LSTM网络结构更加复杂,具有更强的记忆和长期依赖能力。
LSTM通过门控单元的设计,有效解决了传统RNN模型中的梯度消失和梯度爆炸问题,使得其在时间序列预测任务中具有优秀的性能。
三、数据收集与预处理日光温室温湿度预测需要大量的历史温湿度数据作为输入,以建立预测模型。
本研究选择了某个日光温室作为实验对象,使用传感器采集温湿度数据。
数据预处理包括数据清洗、异常值处理和特征提取。
清洗过程中,剔除了异常值和缺失值;异常值处理采用线性插值法进行补充;特征提取主要采用滑动窗口的方式,构建以前n天的温湿度数据作为模型的输入特征。
四、LSTM模型设计与训练本文将LSTM模型应用于日光温室温湿度预测任务,并对模型进行了详细设计与训练。
模型采用了两层的LSTM结构,并引入了Dropout层以防止过拟合。
模型的损失函数采用均方误差(MSE),使用Adam优化器进行参数更新。
为了避免过拟合,使用早停机制进行训练停止的判断。
五、实验结果与分析本文将所提出的基于LSTM模型的日光温室温湿度预测技术与传统的ARIMA模型进行对比实验。
结果表明,基于LSTM模型的温湿度预测技术在预测精度上显著优于传统ARIMA模型。
通过对预测结果的误差分析,发现模型对于温度预测具有较高的准确性,但对于湿度预测存在一定的偏差。
六、实际应用与展望基于LSTM模型的日光温室温湿度预测技术具有广泛的应用前景。