信息论三种编码
信息论总结与复习

(3)稳态符号概率: (4)稳态信息熵:
结论:N阶马氏信源稳态信息熵(即极限熵)等于N+1阶条件熵。
第一部分、信息论基础
1.1 信源的信息理论
[例1] 已知二阶马尔可夫信源的条件概率:
p(0|00)=p(1|11)=0.8;p(0|01)=p(1|10)=0.6;
(2)联合熵:
H(XY)= -0.21log0.21 –0.14log0.14 –0.35log0.35 –0.12log0.12 –0.09log0.09–0.09log0.09 =2.3924 bit/符号
第一部分、信息论基础
1.2 信道的信息理论
(3)噪声熵:
由 和
H(Y | X)= – 0.21log0.3 –0.14log0.2 –0.35log0.5
(4)无噪有损信道:分组多对一(归并),其传输矩阵应具 有多行一列的分块对角化形式。
(5)对称信道:传输矩阵的各行都是一些相同元素的重排, 各列也是一些相同元素的重排。
第一部分、信息论基础
1.2 信道的信息理论
3、信道有关的信息熵:
(1)信源熵 (先验熵):
(2)噪声熵 (散布度):
(3)联合熵: (4)接收符号熵:
–0.12log0.4 –0.09log0.3–0.09log0.3
==(0.21+0.12,0.14+0.09,0.35+0.09) = (0.33, 0.23, 0.44)
H(Y)= -0.33log0.33 -0.23log0.23 -0.44log0.44
[例3]求对称信道 解:C =log4-H(0.2,0.3,0.2,0.3) =2+(0.2log0.2+0.3log0.3)×2 = 0.03 bit/符号; 的信道容量。
信息论与编码知识点总结

信息论与编码知识点总结信息论与编码随着计算机技术的发展,人类对信息的传输、存储、处理、交换和检索等的研究已经形成一门独立的学科,这门学科叫做信息论与编码。
我们来看一下信息论与编码知识点总结。
二、决定编码方式的三个主要因素1。
信源—信息的源头。
对于任何信息而言,它所包含的信息都是由原始信号的某些特征决定的。
2。
信道—信息的载体。
不同的信息必须有不同的载体。
3。
编码—信息的传递。
为了便于信息在信道中的传输和解码,就需要对信息进行编码。
三、信源编码(上) 1。
模拟信号编码这种编码方式是将信息序列变换为电信号序列的过程,它能以较小的代价完成信息传送的功能。
如录音机,就是一种典型的模拟信号编码。
2。
数字信号编码由0和1表示的数字信号叫做数字信号。
在现实生活中,数字信号处处可见,像电话号码、门牌号码、邮政编码等都是数字信号。
例如电话号码,如果它用“ 11111”作为开头,那么这串数字就叫做“ 11”位的二进制数字信号。
数字信号的基本元素是0和1,它们组成二进制数,其中每一个数码都是由两个或更多的比特构成的。
例如电话号码就是十一位的二进制数。
我们平常使用的编码方法有: A、首部-----表明发送者的一些特征,如发送者的单位、地址、性别、职务等等B、信源-----表明信息要发送的内容C、信道-----信息要通过的媒介D、信宿-----最后表明接受者的一些特征E、加密码----对信息进行加密保护F、均匀量化----对信息进行量化G、单边带----信号只在一边带宽被传输H、调制----将信息调制到信号载波的某一特定频率上I、检错----信息流中若发生差错,则输出重发请求消息,比如表达公式时,可写成“ H=k+m-p+x”其中H=“ X+m-P-k”+“ y+z-p-x”+“ 0-w-k-x”,这样通过不断积累,就会发现:用无限长字符可以表达任意长度的字符串;用不可再分割的字符串表达字符串,且各字符之间没有空格等等,这些都表明用无限长字符串表达字符串具有很大的优越性,它的许多优点是有限长字符串不能取代的。
信息论霍夫曼、香农-费诺编码

信息论霍夫曼、香农-费诺编码LT二、实验原理:1、香农-费诺编码首先,将信源符号以概率递减的次序排列进来,将排列好的信源符号划分为两大组,使第组的概率和近于相同,并各赋于一个二元码符号”0”和”1”.然后,将每一大组的信源符号再分成两组,使同一组的两个小组的概率和近于相同,并又分别赋予一个二元码符号。
依次下去,直至每一个小组只剩下一个信源符号为止。
这样,信源符号所对应的码符号序列则为编得的码字。
译码原理,按照编码的二叉树从树根开始,按译码序列进行逐个的向其叶子结点走,直到找到相应的信源符号为止。
之后再把指示标记回调到树根,按照同样的方式进行下一序列的译码到序列结束。
如果整个译码序列能够完整的译出则返回成功,否则则返回译码失败。
2、霍夫曼编码霍夫曼编码属于码词长度可变的编码类,是霍夫曼在1952年提出的一种编码方法,即从下到上的编码方法。
同其他码词长度可变的编码一样,可区别的不同码词的生成是基于不同符号出现的不同概率。
生成霍夫曼编码算法基于一种称为“编码树”(coding tree)的技术。
算法步骤如下:(1)初始化,根据符号概率的大小按由大到小顺序对符号进行排序。
(2)把概率最小的两个符号组成一个新符号(节点),即新符号的概率等于这两个符号概率之和。
(3)重复第2步,直到形成一个符号为止(树),其概率最后等于1。
(4)从编码树的根开始回溯到原始的符号,并将每一下分枝赋值为1,上分枝赋值为0。
三、实验环境matlab7.1四、实验内容1、对于给定的信源的概率分布,用香农-费诺编码实现图像压缩2、对于给定的信源的概率分布,用霍夫曼编码实现图像压缩五、实验过程1.香农-费诺编码编码1function c=shannon(p)%p=[0.2 0.15 0.15 0.1 0.1 0.1 0.1 0.1] %shannon(p)[p,index]=sort(p)p=fliplr(p)n=length(p)pa=0for i=2:npa(i)= pa(i-1)+p(i-1) endk=ceil(-log2(p))c=cell(1,n)for i=1:nc{i}=”tmp=pa(i)for j=1:k(i)tmp=tmp*2if tmp>=1tmp=tmp-1 c{i(j)='1'elsec{i}(j) = '0' endendendc = fliplr(c)c(index)=c编码2clc;clear;A=[0.4,0.3,0.1,0.09,0.07,0.04]; A=fliplr(sort(A));%降序排列[m,n]=size(A);for i=1:nB(i,1)=A(i);%生成B的第1列end%生成B第2列的元素a=sum(B(:,1))/2;for k=1:n-1ifabs(sum(B(1:k,1))-a)<=abs(sum(B(1:k+1, 1))-a)break;endendfor i=1:n%生成B第2列的元素if i<=kB(i,2)=0;elseB(i,2)=1;endend%生成第一次编码的结果END=B(:,2)';END=sym(END);%生成第3列及以后几列的各元素j=3;while (j~=0)p=1;while(p<=n)x=B(p,j-1);for q=p:nif x==-1break;elseif B(q,j-1)==xy=1;continue;elsey=0;break;endendif y==1q=q+1;endif q==p|q-p==1B(p,j)=-1;elseif q-p==2B(p,j)=0;END(p)=[char(END(p)),'0'];B(q-1,j)=1;END(q-1)=[char(END(q-1)),'1']; elsea=sum(B(p:q-1,1))/2;for k=p:q-2abs(sum(B(p:k,1))-a)<=abs(sum(B(p:k+1, 1))-a);break;endendfor i=p:q-1if i<=kB(i,j)=0;END(i)=[char(END(i)),'0'];elseB(i,j)=1;END(i)=[char(END(i)),'1'];endendendendendC=B(:,j);D=find(C==-1);[e,f]=size(D);if e==nj=0;elsej=j+1;endendBAENDfor i=1:n[u,v]=size(char(END(i))); L(i)=v;avlen=sum(L.*A)2. 霍夫曼编码function c=huffman(p)n=size(p,2)if n==1c=cell(1,1)c{1}=''returnend[p1,i1]=min(p)index=[(1:i1-1),(i1+1:n)] p=p(index)n=n-1[p2,i2]=min(p)index2=[(1:i2-1),(i2+1:n)] p=p(index2);i2=index(i2)index=index(index2)p(n)=p1+p2c=huffman(p)c{n+1}=strcat(c{n},'1')c{n}=strcat(c{n},'0') index=[index,i1,i2]c(index)=c。
信息论与编码3

(2) 增强通信的可靠性 如何增加信号的抗干扰能力,提 高传输的可靠性,这是信道编码 主要考虑的问题。解决这一问题 ,一般是采用冗余编码法,赋予 信码自身一定的纠错和检错能力 ,只要采取适当的信道编码和译 码措施,就可使信道传输的差错 概率降到允许的范围之内。
综上所述,提高抗干扰能力往往是以降低信息传输效率为 代价的,而为了提高传输效率又往往削弱了其抗干扰能力。 这样,设计者在取舍之间就要作均衡考虑。
3.2 等长码及等长编码定理
考虑对一简单信源S进行等长编码,信源符号集有K个符号, 码符号集含D个符号,码字长度记为n。要得到惟一可译码, 必须满足下式 K≤Dn 对单符号信源S的L次扩展信源S(L) 进行等长编码,要得到长为n 的惟一可译码,必须满足 KL≤Dn (3-5) 对式(3-5)两边取对数,得 n log K (3-6) L log D 对于那些出现概率极小的字符序列不予编码,这样可以减小平 均码长,当然这样会带来一定的失真。下面的[定理3.1] 将证明, 当满足一定的条件时,在L →∞时,失真pe →0
7.惟一可译码 定义3.1 如果码的任意N次扩展码都是非奇异码,则称该码为 惟一可译码。 对于定长码,若原码是惟一可译码,则它的N次扩展码也是惟一可译 的,而对于变长码则不尽然,见表3-2。
表3-2 同一信源的几种不同变长编码 各消息概 码2 码1 信源消息 率 u1 0 1 q(u1)
u2 u3 u4 q(u2) q(u3) q(u4) 1 00 11 10 100 1000
扩展信源
信源符号 {a1,a2, …, aK} 图3-2
信源编码器
信道符号(码符号){b1, b2, …, bD} N次扩展信源编码器模型
原码的N次扩展码是将信源作N次扩展得到的
信息论与编码原理信源编码

信息论与编码原理信源编码
信息论是一门涉及了信息处理的学科,它研究信息生成、传输、接收、存储、利用等过程的一般性理论。
它探讨涉及信息的一切问题,强调掌握
信息所必需的体系性的体系知识,其主要内容有:信息的定义、信息测度,信息的熵,信息编码,信息的可计量性,信息传输,信息和随机性,信息
编译,信息安全,信息认证,解码准确性,信息的保密,校验,系统复杂性,信息的加密等。
信源编码是一种在信息论中常用的编码技术,其目的是用最少的信息
量表示最多的信息内容,以提高信息发送效率。
它主要包括概率信息源编
码和确定性信息源编码两种。
概率信息源编码是根据一个信息源的发生概率来编码,是根据发出信
息的概率来决定编码方式的。
它根据一个消息源中发出的不同信息的概率
来决定信息的编码,并确定每种信息的编码长度。
在这种情况下,越高概
率的信息,编码长度越短。
确定性信息息源编码,是根据一个消息源中出现特定信息的概率确定
编码方式的。
在这种情况下,编码长度取决于消息源的熵,也就是期望的
信息量。
信源编码的基本思想是以最小的编码来传输最多的信息量。
信息论与编码

信息论与编码
信息论是一门研究信息传输、存储和处理的学科。
它的基本概念是由克劳德·香农于20世纪40年代提出的。
信息论涉及了许多重要的概念和原理,其中之一是编码。
编码是将信息从一种形式转换为另一种形式的过程。
在信息论中,主要有两种编码方式:源编码和信道编码。
1. 源编码(Source Coding):源编码是将信息源中的符号序列转换为较为紧凑的编码序列的过程。
它的目标是减少信息的冗余度,实现信息的高效表示和传输。
著名的源编码算法有霍夫曼编码和算术编码等。
2. 信道编码(Channel Coding):信道编码是为了提高信息在信道传输过程中的可靠性而进行的编码处理。
信道编码可以通过添加冗余信息来使原始信息转换为冗余编码序列,以增加错误检测和纠正的能力。
常见的信道编码算法有海明码、卷积码和LDPC码等。
编码在通信中起着重要的作用,它可以实现对信息的压缩、保护和传输的控制。
通过合理地选择编码方式和算法,可以在信息传输过程中提高传输效率和可靠性。
信息论和编码理论为信息传输和存储领域的发展提供了理论基础和数学工具,广泛应用于通信系统、数据压缩、加密解密等领域。
信息论三种编码
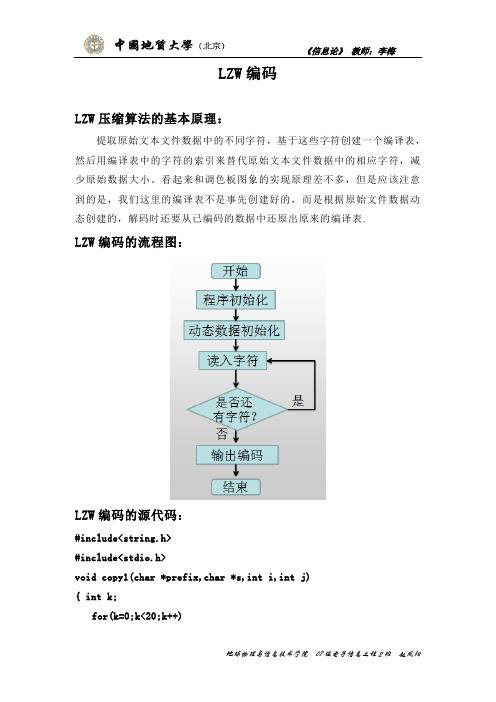
LZW编码LZW压缩算法的基本原理:提取原始文本文件数据中的不同字符,基于这些字符创建一个编译表,然后用编译表中的字符的索引来替代原始文本文件数据中的相应字符,减少原始数据大小。
看起来和调色板图象的实现原理差不多,但是应该注意到的是,我们这里的编译表不是事先创建好的,而是根据原始文件数据动态创建的,解码时还要从已编码的数据中还原出原来的编译表.LZW编码的流程图:LZW编码的源代码:#include<string.h>#include<stdio.h>void copy1(char *prefix,char *s,int i,int j){ int k;for(k=0;k<20;k++)prefix[k]=0;for(k=i;k<i+j;k++)prefix[k-i]=s[k];}void main(){int i ,j,k,n,t,m;char s[30],prefix[30],dic[20][30]={"A","B","C"},c[20]; k=3;m=0;j=1;i=0;printf(“Please input some words:\n");gets(s);while(i<strlen(s)){copy1(prefix,s,i,j);for(n=0;n<k;n++){if(strcmp(prefix,dic[n])==0) //比较两字符串{ j++; m=n;if( (i+j)<=strlen(s) )copy1(prefix,s,i,j);elsestrcpy(prefix,"");}}printf(“%d\n",m);if(strlen(prefix)!=0)//求字符串长度{strcpy(dic[k],prefix);//把后面的字符复给到前面printf("%s\n",dic[k]);}k=k+1;i=i+j-1;j=1;}getch();}实验结果:Huffman编码Huffman编码原理简介:霍夫曼(Huffman)编码是1952年为文本文件而建立,是一种统计编码。
信息论与编码总结

信息论与编码1. 通信系统模型信源—信源编码—加密—信道编码—信道—信道解码—解密—信源解码—信宿 | | |(加密密钥) 干扰源、窃听者 (解密秘钥)信源:向通信系统提供消息的人或机器信宿:接受消息的人或机器信道:传递消息的通道,也是传送物理信号的设施干扰源:整个系统中各个干扰的集中反映,表示消息在信道中传输受干扰情况 信源编码:编码器:把信源发出的消息变换成代码组,同时压缩信源的冗余度,提高通信的有效性 (代码组 = 基带信号;无失真用于离散信源,限失真用于连续信源)译码器:把信道译码器输出的代码组变换成信宿所需要的消息形式基本途径:一是使各个符号尽可能互相独立,即解除相关性;二是使各个符号出现的概率尽可能相等,即概率均匀化信道编码:编码器:在信源编码器输出的代码组上增加监督码元,使之具有纠错或检错的能力,提高通信的可靠性译码器:将落在纠检错范围内的错传码元检出或纠正基本途径:增大码率或频带,即增大所需的信道容量2. 自信息:()log ()X i i I x P x =-,或()log ()I x P x =-表示随机事件的不确定度,或随机事件发生后给予观察者的信息量。
条件自信息://(/)log (/)X Y i j X Y i j I x y P x y =-联合自信息:(,)log ()XY i j XY i j I x y P x y =-3. 互信息:;(/)()(;)log log ()()()i j i j X Y i j i i j P x y P x y I x y P x P x P y ==信源的先验概率与信宿收到符号消息后计算信源各消息的后验概率的比值,表示由事件y 发生所得到的关于事件x 的信息量。
4. 信息熵:()()log ()i iiH X p x p x =-∑ 表示信源的平均不确定度,或信源输出的每个信源符号提供的平均信息量,或解除信源不确定度所需的信息量。
信息论与编码原理信道编码

合码等
差错控制系统分类
前向纠错(FEC):发端信息经纠错编码 后传送,收端通过纠错译码自动纠正传递 过程中的差错
反馈重发(ARQ):收端通过检测接收码 是否符合编码规律来判断,如判定码组有 错,则通过反向信道通知发端重发该码
生成的码字C
前k位由单位矩阵Ik决定,等于把信息组m原封不 动搬到码字的前k位;
其余的n-k位叫冗余位或一致校验位,是前k个信 息位的线性组合。
这样生成的(n,k)码叫做系统码。 若生成矩阵G不具备系统形式,则生成的码叫做
非系统码。 系统化不改变码集,只是改变了映射规则。
校验矩阵
将H空间的n-k个基底排列起来可构成一个(nk)×n矩阵,称为校验矩阵H。用来校验接收到 的码字是否是正确的;
用这种方法不能得知最优码是如何具体编 出来的,却能得知最优码可以好到什么程 度,并进而推导出有扰离散信道的编码定 理,对指导编码技术具有特别重要的理论 价值。
6.1.3随机编码
在(N,K)分组编码器中随机选定的码集有qNM种 第m个码集(记作{c}m )被随机选中的概率是
P({c}m)q(NM)
qk
<
qn
构造线性分组码的方法就是构造子空间的方法,即 在n维n重矢量空间的n个基底中选取k个基底张 成一个k维n重子空间
空间构成
n维n重空间有相互 正交的n个基底
选择k个基底构成码 空间C
选择另外的(n-k)个 基底构成空间H
C和H是对偶的
CHT=0,码的生成矩阵,H是它的校验矩阵; H是(n,n-k)对偶码的生成矩阵,它的每一行是
一个基底。 G则是它的校验矩阵。 GHT=0 ,H=[- PT In-k ],二进制时,负号
信息论中的信息传输与信道编码

信息论中的信息传输与信道编码信息论是一门研究信息传输与编码的学科,它的产生与发展始于20世纪40年代,其核心理论是由克劳德·香农于1948年提出的。
信息传输是指将信息从一个地方传递到另一个地方的过程,而信道编码则是指在信息传输的过程中,通过采用适当的编码方式来提高传输的可靠性以及效率。
1. 信息传输的基本原理信息传输是通过信号或消息的传递来实现的。
在信息论中,消息是指所要传递的信息内容,而信号则是指用来携带消息的物理量或波形。
信息传输的基本原理可概括为三个步骤:信源编码、信道传输和信宿解码。
1.1 信源编码信源编码是将待传输的消息进行编码,以便在信道传输中降低传输所需的带宽。
常用的信源编码方式包括香农-福普编码和哈夫曼编码等。
1.2 信道传输信道传输是指将编码后的信号通过信道传递到接收端。
信道可以是有线或无线的媒介,如光纤、电缆或无线电波等。
在信道传输过程中,信号可能会受到噪声的干扰,从而导致信息的丢失或错误。
1.3 信宿解码信宿解码是指在接收端对传输过来的信号进行解码,以恢复出原始的消息。
解码过程需要考虑信道传输过程中可能引入的噪声和误码等问题,并通过适当的解码算法进行纠正。
2. 信道编码的作用信道编码是信息论中的重要概念,它的主要作用是提高信道传输的可靠性和效率。
信道编码通过向待传输的消息添加冗余信息,使得在信道传输过程中能够检测和纠正部分错误,从而提高系统的抗干扰能力。
2.1 基本概念在信道编码中,常用的两个重要概念是编码率和纠错能力。
编码率是指在给定的信道条件下,传输的有效信息所占的比例。
纠错能力是指编码算法能够对传输过程中的错误进行检测和纠正的能力。
2.2 常用的信道编码方式常见的信道编码方式包括前向纠错编码(FEC)和自动重传请求(ARQ)等。
前向纠错编码通过在消息中添加冗余信息,使接收端能够检测和纠正部分错误。
而自动重传请求则是在接收端检测到错误时,向发送端请求重新发送丢失或错误的信息。
信息论与编码 钢束

信息论与编码钢束随着现代通讯技术的飞速发展,信息论与编码(Information Theory and Coding)已成为热门的学术研究领域之一。
信息论是一个定量描述信息量与信息传输的学科,而编码则是将信息按照一定规则进行编码和解码的过程。
本文将从以下三个方面对信息论与编码进行深入探讨。
一、信息的度量与编码信息作为计算机科学中一个重要的概念,主要涉及到“信息的度量”和“数据的编码”两个方面。
信息量的度量是通过信息熵来进行度量的,而数据编码则是将信息组织成一定的格式,以便于传输和处理。
对于信息的编码,有源编码(Source Coding)和信道编码(Channel Coding)两种编码方式。
源编码是指将原始数据进行压缩以减少传输数据量,而信道编码则是通过添加纠错码以确保数据传输过程中的完整性和准确性。
二、信息的传输与解码针对信息的传输和解码过程,需要考虑信道带宽、传输距离、传输速率、信噪比等因素。
同时,在信号传输过程中往往会出现数据传输错误的情况,需要通过差错控制和纠错码等技术进行修正和纠正。
此外,在信号解码方面,根据信道编码的方式,可以进行硬决策(Hard Decision)和软决策(Soft Decision)两种方式解码。
三、信息论与编码在实际应用中的应用作为一个基础学科,信息论与编码在现代通讯领域中得到了广泛应用,如电话、电视、互联网、移动通信等。
其中,无线通信领域的发展速度最快,主要涉及到无线传感器网络、物联网、车联网等。
此外,在通讯安全领域中,信息论与编码也发挥着重要作用,如公钥密码学、哈希函数等安全算法等。
综上所述,信息论与编码作为计算机科学中关键性的学科,发挥着重要的作用,涉及到多种技术和应用。
未来,信息论与编码将继续发展壮大,不断为通讯技术的发展提供强有力的支持。
信息论与编码

信息论与编码信息论与编码是一个涉及信息传输和存储的学科领域,它涵盖了多个核心概念和技术。
下面是一些与信息论与编码相关的知识:1.信息熵:信息熵是信息的不确定性度量,用于衡量随机变量的平均信息量。
当一个事件的发生概率较低时,它包含的信息量较大,而当一个事件的发生概率较高时,它包含的信息量较少。
信息熵越高,表示信息的不确定性越大。
2.哈夫曼编码:哈夫曼编码是一种无损编码方法,它通过将频率较高的符号表示为短码,而将频率较低的符号表示为长码,从而达到压缩数据的目的。
哈夫曼编码的核心思想是用较少的比特表示常见的符号,用较多的比特表示不常见的符号,以实现数据压缩。
3.纠错码:纠错码是一种编码技术,旨在通过引入冗余信息来检测和纠正在传输过程中出现的错误。
纠错码能够通过添加校验位或冗余比特,在接收端对数据进行恢复和纠正,从而提高通信的可靠性。
4.调制技术:调制技术是将数字信号转换为模拟信号或其他形式的信号,以适应不同的通信媒介和传输条件。
调制技术能够将数字信号转换为能够在传输介质上传输的模拟信号,如调幅调制(AM)、调频调制(FM)和相移键控调制(PSK)等。
5.信道容量:信道容量是信息论中的一个重要概念,表示信道在理论上可以达到的最高传输速率。
信道容量取决于信道的带宽、信噪比以及任何潜在的干扰,它描述了信道所能达到的最高信息传输速率的界限。
6.数据压缩:数据压缩是利用信息论和编码技术来减少数据存储和传输所需的比特数。
数据压缩分为无损压缩和有损压缩两种方式。
无损压缩能够完全还原原始数据,如ZIP压缩算法;而有损压缩则会在一定程度上减少数据的质量,如JPEG图像压缩。
了解这些信息论与编码的相关知识,能够帮助我们更好地理解信息的传输和存储过程,以及如何进行数据的压缩和错误纠正,为技术和应用提供基础和指导。
信息论、编码与密码学

信息论、编码与密码学
1. 信息论:
信息论是由克劳德·香农于20世纪40年代提出的一门学科,
它研究信息的量、传输和处理。
信息论的核心概念是信息熵,用来
衡量一个随机变量的不确定性。
信息熵越高,表示信息的不确定性
越大。
信息论还研究了信道容量、编码理论、误差校正等问题,为
通信系统的设计和优化提供了理论基础。
2. 编码:
编码是将信息转换为特定的形式或规则的过程。
编码既可以用
于数据的压缩,以减少存储和传输的成本,也可以用于数据的加密,以保护数据的安全性。
在信息论中,编码理论研究如何使用更少的
比特来传输信息,以达到更高的传输效率。
常见的编码方法包括霍
夫曼编码、熵编码、哈夫曼编码等。
3. 密码学:
密码学是研究如何保护信息安全的学科。
它涉及到加密算法、
解密算法、密钥管理等内容。
密码学可以分为对称密码学和公钥密码学两大分支。
对称密码学使用相同的密钥进行加密和解密,而公钥密码学使用一对密钥,即公钥和私钥,来进行加密和解密。
密码学的应用包括数据加密、数字签名、身份验证等,它在保护个人隐私和保障信息安全方面起着重要的作用。
综上所述,信息论、编码与密码学是三个相互关联的领域。
信息论研究信息的量和传输,编码研究如何将信息转换为特定形式,密码学研究如何保护信息的安全。
它们在通信、网络安全、数据存储等领域都有广泛的应用。
信息论中的编码理论与纠错码

信息论中的编码理论与纠错码信息论是一门研究信息传输和处理的学科,它的核心是信息的编码与解码。
编码理论和纠错码是信息论中的重要内容,它们在保证信息传输可靠性和效率方面起着至关重要的作用。
一、编码理论的基本概念编码理论是指将信息转化为特定的编码形式,以便在传输和存储过程中能够更加高效地进行处理和传递。
编码理论的基本概念包括源编码和信道编码。
源编码是将信息源中的符号转化为编码序列的过程。
常见的源编码方法有霍夫曼编码、香农-费诺编码等。
这些编码方法通过对出现频率较高的符号进行较短的编码,从而提高信息的传输效率。
信道编码是为了提高信息传输在信道中的可靠性而进行的编码。
信道编码通过在发送端添加冗余信息,使得接收端能够在一定程度上纠正错误。
常见的信道编码方法有奇偶校验码、循环冗余校验码等。
二、纠错码的原理与应用纠错码是一种能够在传输过程中检测和纠正错误的编码方式。
它通过在发送端添加冗余信息,并在接收端利用这些冗余信息对接收到的信息进行纠错。
纠错码的原理是利用冗余信息进行错误检测和纠正。
常见的纠错码包括海明码、RS码等。
海明码通过在原始信息中添加冗余位,使得接收端能够检测到错误的位置,并进行纠正。
RS码则通过在原始信息中添加多余的校验位,使得接收端能够纠正一定数量的错误。
纠错码在通信领域中有着广泛的应用。
在无线通信中,由于信道的干扰和噪声,信息传输容易出现错误。
纠错码的应用可以提高信道传输的可靠性,保证信息的正确接收。
在存储介质中,纠错码也被广泛应用于磁盘、闪存等存储设备,以保证数据的完整性和可靠性。
三、编码理论与纠错码的发展编码理论和纠错码的发展经历了多个阶段。
早期的编码方法主要是基于统计学的方法,如霍夫曼编码。
随着信息论的发展,信息熵的概念被引入到编码理论中,使得编码方法更加高效和优化。
纠错码的发展也经历了多个阶段。
早期的纠错码主要是基于奇偶校验码的原理,但其纠错能力有限。
后来,海明码的提出使得纠错码的纠错能力得到了大幅提升。
信息论与编码教案

教案信息论与编码课程目标:本课程旨在帮助学生理解信息论的基本原理,掌握编码技术的基本概念和方法,并能够应用这些知识解决实际问题。
教学内容:1.信息论的基本概念:信息、熵、信源、信道、编码等。
2.熵的概念及其计算方法:条件熵、联合熵、互信息等。
3.信源编码:无失真编码、有失真编码、哈夫曼编码等。
4.信道编码:分组码、卷积码、汉明码等。
5.编码技术的应用:数字通信、数据压缩、密码学等。
教学方法:1.讲授:通过讲解和示例,向学生介绍信息论与编码的基本概念和原理。
2.案例分析:通过分析实际问题,让学生了解信息论与编码的应用。
3.实践操作:通过实验和练习,让学生掌握编码技术的具体应用。
1.引入:介绍信息论与编码的基本概念和重要性,激发学生的学习兴趣。
2.讲解:详细讲解信息论的基本原理和编码技术的基本方法,包括信源编码和信道编码。
3.案例分析:通过分析实际问题,让学生了解信息论与编码的应用,如数字通信、数据压缩等。
4.实践操作:通过实验和练习,让学生亲自动手实现编码过程,加深对知识点的理解。
5.总结:回顾本课程的内容,强调重点和难点,提供进一步学习的建议。
教学评估:1.课堂参与度:观察学生在课堂上的表现,包括提问、回答问题、参与讨论等。
2.作业完成情况:评估学生对作业的完成情况,包括正确性、规范性和创新性。
3.实验报告:评估学生的实验报告,包括实验结果的正确性、实验分析的深度和实验报告的写作质量。
1.教材:选用一本适合初学者的教材,如《信息论与编码》。
2.参考文献:提供一些参考文献,如《信息论基础》、《编码理论》等。
3.在线资源:提供一些在线资源,如教学视频、学术论文等。
教学建议:1.鼓励学生积极参与课堂讨论和提问,提高他们的学习兴趣和主动性。
2.在讲解过程中,尽量使用简单的语言和生动的例子,帮助学生更好地理解复杂的概念。
3.鼓励学生进行实践操作,通过实验和练习,加深对知识点的理解。
4.提供一些实际问题,让学生运用所学知识解决,培养他们的应用能力。
信息论发展的三个阶段,各阶段的主要研究内容

信息论是研究信息传输、储存和处理的一门跨学科科学。
信息论的发展可以大致分为三个阶段,每个阶段都有其独特的特点和主要的研究内容。
一、第一个阶段:信源编码与信道编码1. 信源编码信源编码是信息论发展的最早阶段,主要研究如何有效地表示和压缩信息。
在这个阶段,研究者通过数学方法和算法设计来实现对信息的高效表示和存储,使得信息可以以最小的成本传输和储存。
其中,香农在1948年提出了信息熵的概念,将信息的不确定性用数学语言进行了描述,成为信息论的重要里程碑。
2. 信道编码信道编码是对信息传输过程中出现的误差进行纠正和控制的研究领域。
在这个阶段,研究者主要关注信息在传输过程中受到的干扰和失真问题,设计各种编码方式和技术来提高信道的可靠性和容错能力。
汉明码、卷积码、纠错码等技术都是在这个阶段提出并得到了深入研究和应用。
二、第二个阶段:网络信息论1. 信息网络结构随着互联网的迅猛发展,人们开始关注如何在复杂的信息网络环境中进行信息传输和处理。
信息网络结构的研究成为信息论的重要方向之一,其中包括网络拓扑结构、信息传输路由原理、网络流量控制等内容。
2. 信息网络安全随着信息技术的飞速发展,信息安全问题日益成为人们关注的焦点。
网络信息论在这一阶段开始关注如何在信息传输和处理的过程中保障信息的安全性和隐私性。
密码学、加密技术、数字水印等安全技术在这一阶段得到了广泛的研究和应用。
三、第三个阶段:量子信息论1. 量子信息传输随着量子力学的发展,量子信息论成为信息论研究的新的前沿领域。
量子信息论着眼于利用量子力学的特性来实现更加安全、高效的信息传输。
量子隐形传态、量子纠缠、量子密钥分发等技术成为了量子信息论研究的热点。
2. 量子计算机量子计算机作为量子信息论的重要应用领域,成为信息技术的新的突破方向。
量子计算机以量子比特为基本计算单元,利用量子叠加和量子纠缠的特性来进行信息处理,有望实现传统计算机无法完成的任务。
量子信息论的发展也为量子计算机的实现提供了理论基础和技术支持。
信息论与编码 管程

信息论与编码一、引言信息论与编码是现代通信领域中的重要概念和技术。
信息论研究的是信息的度量和传输,而编码则是将信息转换为可传输的信号的过程。
本文将从信息论和编码的基本原理、应用领域以及未来发展方向等方面进行探讨。
二、信息论的基本原理信息论是由克劳德·香农在1948年提出的一种数学理论,用于研究信息的度量和传输。
其核心概念是“信息熵”,用于衡量信息的不确定性。
信息熵越高,表示信息越不确定,越需要传输的信道容量;而信息熵越低,表示信息越确定,传输的信道容量要求越低。
在信息论中,还有一个重要的概念是“信道容量”。
信道容量指的是在给定的信噪比条件下,信道能够传输的最大信息速率。
通过对信道容量的研究,可以确定传输系统的性能极限,并优化编码方案以逼近这个极限。
三、编码的基本原理编码是将信息转换为可传输的信号的过程。
在通信领域中,常用的编码方式有三种:源编码、信道编码和调制编码。
1. 源编码源编码是将源信息进行压缩,以减少传输所需的带宽或存储空间。
常见的源编码方式有哈夫曼编码、算术编码等。
这些编码方式通过利用源信息的统计特性,将出现频率较高的符号用较短的编码表示,从而减少传输的数据量。
2. 信道编码信道编码是在传输过程中对信号进行编码,以提高传输的可靠性。
常见的信道编码方式有前向纠错编码(如海明码、卷积码)和调制码(如调制解调器中的调制方式)。
这些编码方式通过在信号中引入冗余信息,使接收端能够检测和纠正传输过程中的错误,提高传输的可靠性。
3. 调制编码调制编码是将数字信号转换为模拟信号的过程,以适应不同的传输介质和信道特性。
常见的调制编码方式有振幅调制(AM)、频率调制(FM)和相位调制(PM)等。
这些编码方式通过改变信号的振幅、频率或相位来表示数字信息,从而适应不同的传输介质和信道。
四、信息论与编码的应用领域信息论与编码在通信领域有着广泛的应用。
以下是一些常见的应用领域:1. 无线通信在无线通信中,由于信道的不稳定性和带宽限制,信息的传输和编码变得尤为重要。
信息论与编码知识点分布

信息论与编码知识点分布1.信息:信息论与编码的核心概念就是信息。
信息是一种度量,用来衡量不确定性的消除量。
在信息论中,我们用信息熵来度量不确定性的量,信息熵越大,表示不确定性越高。
2.信息熵:信息熵是信息论中的重要概念,用来度量一个随机事件的不确定性。
信息熵的定义是随机变量的平均不确定性。
信息熵越大,表示事件的不确定性越高。
3.香农编码:香农编码是一种无损数据压缩算法,它通过对频繁出现的符号使用较短的编码,对不频繁出现的符号使用较长的编码,从而实现数据的压缩。
香农编码是一种最优编码,可以达到信息熵的下界。
4.哈夫曼编码:哈夫曼编码也是一种无损数据压缩算法,它通过构建哈夫曼树来实现数据的压缩。
哈夫曼编码是一种树形编码,通过将出现频率高的符号放在较短的编码路径上,出现频率低的符号放在较长的编码路径上,从而实现数据的压缩。
5.信道容量:信道容量是指在给定信道条件下,能够传输的最大有效信息的速率。
信道容量取决于信道的带宽和信道的噪声,可以通过香农公式来计算。
6.信息编码:信息编码是指将信息转换成一串编码的过程。
在信息论与编码中,我们可以使用各种编码技术来实现信息的传输和存储,如香农编码、哈夫曼编码、循环冗余码等。
7.循环冗余码(CRC):CRC是一种常用的错误检测码,通过添加冗余位来检测数据传输中的错误。
CRC码能够在接收端检测出出现在传输过程中的任何误码。
8.线性分组码:线性分组码是一种常用的错误检测和纠错码,具有良好的性能和编码效率。
线性分组码的编码和解码过程可以用矩阵运算来表示,其性质可以通过线性代数的方法进行研究。
9.噪声模型:在信息论与编码中,我们经常需要考虑信道的噪声对信息传输的影响。
常见的噪声模型有加性高斯白噪声模型、二进制对称信道模型等。
10.噪声信道容量:噪声信道容量是指在给定信道条件下,能够传输的最大有效信息的速率。
噪声信道容量取决于信道的带宽、信道的噪声以及信号的功率等因素。
11.码率:码率是指在通信过程中,单位时间内传输的比特数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
LZW编码LZW压缩算法的基本原理:提取原始文本文件数据中的不同字符,基于这些字符创建一个编译表,然后用编译表中的字符的索引来替代原始文本文件数据中的相应字符,减少原始数据大小。
看起来和调色板图象的实现原理差不多,但是应该注意到的是,我们这里的编译表不是事先创建好的,而是根据原始文件数据动态创建的,解码时还要从已编码的数据中还原出原来的编译表.LZW编码的流程图:LZW编码的源代码:#include<string.h>#include<stdio.h>void copy1(char *prefix,char *s,int i,int j){ int k;for(k=0;k<20;k++)prefix[k]=0;for(k=i;k<i+j;k++)prefix[k-i]=s[k];}void main(){int i ,j,k,n,t,m;char s[30],prefix[30],dic[20][30]={"A","B","C"},c[20]; k=3;m=0;j=1;i=0;printf(“Please input some words:\n");gets(s);while(i<strlen(s)){copy1(prefix,s,i,j);for(n=0;n<k;n++){if(strcmp(prefix,dic[n])==0) //比较两字符串{ j++; m=n;if( (i+j)<=strlen(s) )copy1(prefix,s,i,j);elsestrcpy(prefix,"");}}printf(“%d\n",m);if(strlen(prefix)!=0)//求字符串长度{strcpy(dic[k],prefix);//把后面的字符复给到前面printf("%s\n",dic[k]);}k=k+1;i=i+j-1;j=1;}getch();}实验结果:Huffman编码Huffman编码原理简介:霍夫曼(Huffman)编码是1952年为文本文件而建立,是一种统计编码。
属于无损压缩编码。
霍夫曼编码的码长是变化的,对于出现频率高的信息,编码的长度较短;而对于出现频率低的信息,编码长度较长。
这样,处理全部信息的总码长一定小于实际信息的符号长度。
Huffman编码过程的几个步骤:l)将信号源的符号按照出现概率递减的顺序排列。
2)将最下面的两个最小出现概率进行合并相加,得到的结果作为新符号的出现概率。
3)重复进行步骤1和2直到概率相加的结果等于1为止。
4)在合并运算时,概率大的符号用编码0表示,概率小的符号用编码1表示。
5)记录下概率为1处到当前信号源符号之间的0,l序列,从而得到每个符号的编码。
Huffman编码源代码:#include <stdio.h>#include <math.h>#define sy_max 100#define sy_max2 30#define sy_max3 59#define DEEP 10 /*定义sycode1类*/typedef struct{float weight;int flag;int father;int leftchilde;int rightchilde;}sycode1; /*定义类sycode2类*/typedef struct{ int sy_array[sy_max2];int start;}sycode2; int main(void){sycode1 sy1[sy_max3];sycode2 sy2[sy_max2],cd;int i,j,x1,x2,n,c,p;float m1,m2,temp,hx=0,KL=0;printf("please input the signal's length\n");scanf("%d",&n); /*根据输入长度,初始化编码变量*/for(i=0;i<=2*n-1;i++){sy1[i].weight=0;sy1[i].father=0;sy1[i].flag=0;sy1[i].leftchilde=-1;sy1[i].rightchilde=-1;}printf("input the probability for every signal:\n");/*根据输入长度,接收相应数目的概率数*/for(i=0;i<n;i++){ printf("input %dth probability:",i+1);scanf("%f",&temp);sy1[i].weight=temp;hx=hx-temp*3.332*log10(temp);}for(i=0;i<n-1;i++){m1=m2=sy_max;x1=x2=0;for(j=0;j<n+i;j++)if(sy1[j].weight<m1&&sy1[j].flag==0){m2=m1;x2=x1;m1=sy1[j].weight;x1=j;}elseif(sy1[j].weight<m2&&sy1[j].flag==0){m2=sy1[j].weight;x2=j;}}sy1[x1].father=n+i;sy1[x2].father=n+i; /*将找出的两棵子树合并为一棵子树*/ sy1[x1].flag=1;sy1[x2].flag=1;sy1[n+i].weight=sy1[x1].weight+sy1[x2].weight;sy1[n+i].leftchilde=x1;sy1[n+i].rightchilde=x2;}for(i=0;i<n;i++){cd.start=n;c=i;p=sy1[c].father;while(p!=0)if(sy1[p].leftchilde==c) cd.sy_array[cd.start]=1;else cd.sy_array[cd.start]=0;cd.start=cd.start-1;c=p;p=sy1[p].father;}cd.start++;for(j=cd.start;j<=n;j++){sy2[i].sy_array[j]=cd.sy_array[j];sy2[i].start=cd.start;}}printf("\nweight\thuffmancode\n");for(i=0;i<n;i++){printf("%2.3f:\t",sy1[i].weight);for(j=sy2[i].start;j<=n;j++)printf("%d",sy2[i].sy_array[j]);/*计算平均码长以及信源熵*/ KL=KL+(n-sy2[i].start+1)*sy1[i].weight;printf("\n");}printf("\nH(X)=%f\tKL=%f\nR=%f",hx,KL,hx/KL);getch();}实验结果:Shannon编码Shannon编码源代码#include <stdio.h>#include <math.h>#include <stdlib.h>#define sy_CL 10 /*最大码长*/#define sy_PN 100 /*最大码数*/typedef float sy_type;typedef struct SHNODE {sy_type pb;sy_type sy_sum;int kl;intcode[sy_CL];struct SHNODE *next;}sy_class;sy_type sym_arry[sy_PN]; /*序列的概率*/int sy; /*定义全局变量sy代表码数也就是符号数*/void sy_pb_scan(){int i;sy_type sum=0;printf("Think you for using this Shannon program!\nPlease input length\n");scanf("%d",&sy);printf("input%dsignal's probability:\n",sy);printf(">>");for(i=0;i<sy;i++){scanf("%f",&sym_arry[i]);sum=sum+sym_arry[i];}if(sum>1.0001||sum<0.99){printf("sum=%f,sum must(<0.999<sum<1.0001)",sum);sy_pb_scan();}} /*定义函数sy_pb_scan(),输入数据,并且检验输入概率和是否等于1*/void sy_sort(){ int i,j,pos;sy_type max;for(i=0;i<sy-1;i++){max=sym_arry[i];pos=i;for(j=i+1;j<sy;j++)if(sym_arry[j]>max){max=sym_arry[j];pos=j;}sym_arry[pos]=sym_arry[i];sym_arry[i]=max;}} /*定义函数sy_sort(),对输入概率进行由小到大排序*/void valuelist(sy_class *L){sy_class *head,*p;int j=0;int i;sy_type temp,s;head=L; temp=0;p=head->next;while(j<sy){p->sy_sum=temp;temp=temp+p->pb;p->kl=-3.322*log10(p->pb)+1;{s=p->sy_sum;for(i=0;i<p->kl;i++)p->code[i]=0;for(i=0;i<p->kl;i++){p->code[i]=2*s;if(2*s>=1)s=2*s-1;elseif(2*s==0)break;else s=2*s;}}j++;p=p->next;}} /*算法函数*/void codedisp(sy_class *L){int i,j;sy_class *p;sy_type hx=0,KL=0;p=L->next;printf("num\tgailv\tsum\t-lb(p(ai))\tlenth\tcode\n");printf("\n");for(i=0;i<sy;i++){printf("a%d\t%1.3f\t%1.3f\t%f\t%d\t",i,p->pb,p->sy_sum,-3.332*l og10(p->pb),p->kl);j=0;for(j=0;j<p->kl;j++)printf("%d",p->code[j]);printf("\n");hx=hx-p->pb*3.332*log10(p->pb); /*计算信源序列的熵*/ KL=KL+p->kl*p->pb; /*计算平均码字*/p=p->next;}printf("H(x)=%f\tKL=%f\nR=%fbit/code",hx,KL,hx/KL);/*计算编码效率*/ }sy_class *setnull(){ sy_class *head;head=(sy_class *)malloc(sizeof(sy_class));head->next=NULL;return(head);}sy_class *my_creat(sy_type a[],int n){sy_class *head,*p,*r;int i;head=setnull();r=head;for(i=0;i<n;i++){ p=(sy_class *)malloc(sizeof(sy_class));p->pb=a[i];p->next=NULL;r->next=p;r=p;}return(head);}int main(void) /*主函数*/{sy_class *head;sy_pb_scan();sy_sort();head=my_creat(sym_arry,sy); valuelist(head);codedisp(head);getch();}实验结果。