在MyEclipse中搭建Nutch开发环境
MyEclipse+Tomcat+MySQL的环境搭建

java环境安装,主要分为三大部分:1、下载并安装java_jdk2、下载并安装。
MyEclipse 10_xx3、数据库及服务器安装(mysql(数据库)、Tomcat(服务器))第一部分:java_jdk的安装1、在oracle官网找到最新java_jdk(EE及SE版本自选,并看清windows32位或64位)下载。
2、双击名为jdk的exe文件,进行安装到C:\Program Files\Java\jdk1.6.0_22(一路next,如不想安装在c盘,在路径选择处修改即可,此处以D盘为例)。
3、环境变量的设置(此为重要的一步):windows7下java 环境变量配置方法:1.用鼠标右击“我的电脑”->属性继续选择右下角的“环境变量”选项2.进行win7下Java 环境变量配置在"系统变量"下进行如下配置:(1)新建->变量名:JA VA_HOME 变量值:C:\Program Files\Java\jdk1.6.0_22 (这只是我的JDK安装路径)(2)编辑->变量名:Path 在变量值的最前面加上:%JA V A_HOME%/bin;%JA V A_HOME%/jre/bin(3)新建->变量名:CLASSPATH 变量值:.;%JA V A_HOME%/lib;%JA V A_HOME%/lib/dt.jar;%JA V A_HOME%/lib/tools.jar3.测试下环境变量是否设置成功在左下角的搜索框中键入cmd或者按下“WIN+R”键,“WIN”键就是"CTRL"和“ALT””中间那个微软图标那个键;分别输入java,javac,java -version 命令如果出现如下信息:4.你的Java环境变量配置成功!注意:若出现'javac' 不是内部或外部命令,也不是可运行的程序或批处理文件。
jdk-myeclipse-tomcat配置

程序部署说明一、安装并配置JDK(1)双击运行JDK安装程序jdk-6u10-rc2-bin-b32-windows-i586-p-12_sep_2008.exe。
(2)默认选择下一步,直到完成。
(3)设置环境变量。
在操作系统桌面右击“我的电脑”,在快捷菜单中选“属性”,此时将弹出“系统属性”对话框。
选择“高级”选项卡,点击“环境变量”按钮,将弹出“环境变量”对话框。
点击“系统变量”栏目中的“新建”按钮,在弹出的“新建系统变量”对话框的“变量名”中输入“JAVA_HOME”,“变量值”中输入JDK的安装路径,默认为“C:\ProgramFiles\Java\jdk1.6.0_10”,点击“确定”。
再到“系统变量”栏目中选中变量“Path”,并点击“修改”按钮,在弹出的“修改系统变量”对话框的“变量值”的最前端添加JDK安装路径,如“C:\ProgramFiles\Java\jdk1.6.0_10\bin;”,点击“确定”即可。
注意该路径比上面的多了“\bin;”,其中分号“;”是必不可少的。
(4)验证JDK是否安装成功。
打开Dos命令窗体,输入命令Java -version,若出现以下信息则表示安装成功。
图18.1 Java版本信息二、安装并配置Tomcat(1)将apache-tomcat-7.0.11-windows-x86.zip 解压,然后直接将该文件夹拷贝到目标位置,如“F:\”。
(2)运行“F:\apache-tomcat-7.0.11\bin”文件夹中的“startup.bat”文件,将弹出Tomcat 窗口,并显示服务启动信息,这说明Tomcat启动成功。
(3)在浏览器中输入http://localhost:8080/,会进入到Tomcat管理界面,如图18.2所示。
图18.2 Tomcat管理界面三、安装并配置MyEclipse(1)通过MyEclipse官方网站的地址/downloads/products/eworkbench/galileo/myeclipse-8.5.0-win32.exe下载MyEclipse安装程序myeclipse-8.5.0-win32.exe。
安装Nutch步骤

header and User-Agent header. A good practice is to mangle this
address (e.g. 'info at example dot com') to avoid spamming.
</description>
在Windows下面配置Nutch有两种方法,一种是使用cygwin模拟Linux环境,另一种是配置到Eclipse中运行。因为linux环境不熟悉,所以还是决定使用eclipse了。
在Eclipse中配置Nutch的步骤:(Eclipse3.4, Nutch0.9)
第一步:下载release版本的nutch-0.9.tar.gz.解压到d盘.保证下载的nutch中没有.classpath和.projsect.即d:/nutch-0.9。注意解压路径中最好不要包含中文,因为将爬行结果在Tomcat中配置时,就可以直接指向保存结果的文件夹。
8. 配置web search服务. 把nutch*.war考到tomcat的webapps下, 运行tomcat, 这时tomcat会自动解压nutch*.war到nutch*目录
9. 进入nutch*目录, 修改web-inf/classes下的nutch-default.xml文件, 找到searcher.dir项, 改为你的index目录, 例如crawl.test
下一步
把conf目录添加到classpath(选择在项目的build选项里面)
把"src/java", "src/test" 还有所有的扩展(plugin)中的 "src/java" 和 "src/test" 添加到源代码目录( source folders)
eclipse以及myeclipse开发工具开发环境设置
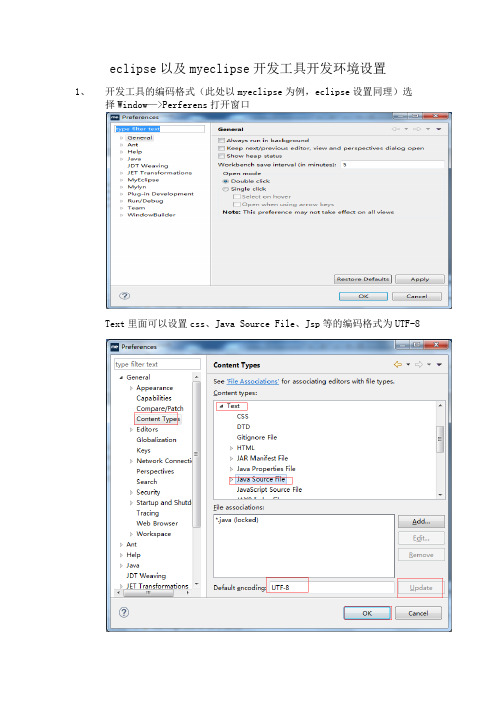
eclipse以及myeclipse开发工具开发环境设置1、开发工具的编码格式(此处以myeclipse为例,eclipse设置同理)选择Window—>Perferens打开窗口Text里面可以设置css、Java Source File、Jsp等的编码格式为UTF-82、配置开发工具的jdk环境点击Add添加,选择Standard VM,然后点击next选择相应的jdk安装目录,同时操作这一步时确保maven环境配置正确,并且安装目录环境变量名为M2_HOMEDefaule VM arguments出填写:-Dmaven.multiModuleProjectDirectory=$M2_HOME3、配置开发工具需要使用的maven之后点击Apply—>点击OK.4、为开发工具设置运行服务器环境(Tomcat)点击Finish之后自动回到了上个页面,选择刚才设置的tomcat点击OK.5、设置工具是否使用代理如果开启代理的情况下最好看下此设置6、取消检出项目的验证(本人比较懒全部取消验证)7、工具内SVN 设置<1>、这种设置时(默认采取这种设置)更改用户名和密码操作,进入C:\Users\Administrator\AppData\Roaming\Subversion\auth,并且删除里面的所有内容。
<2>、如果采用下面这中设置时修改用户名和密码操作,找到myeclipse或者eclipse安装目录E:\MyEclipse\configuration找到里面的org.eclipse.core.runtime文件夹并且删除里面的所有内容8、开发工具环境设置后之后,接下里就是项目的自身环境的设置<1>、项目编码格式设置<2>、项目运行的jdk环境设置,以及web项目支持的版本设置。
MyEclipse配置tomcat环境

MyEclipse配置tomcat环境
⼀、MyEclipse配置JDK
1、依次点击菜单栏中Window -- preferences,弹出preferences设置对话框。
2、依次点击左侧选项框中的 Java -- Installed JREs 后会出现以下界⾯:
3、点击右侧 Add 进⼊ JRE Type 选择界⾯,选择 Standard VM 后点击 Next 进⼊如下界⾯:
4、点击 JRE home 右侧的 Directory... 选择jdk的安装路径,选择成功后会进⼊如下界⾯:
5、点击 Finish 进⼊如下界⾯,选中新添加的 jdk 后点击 OK,配置成功:
⼆、MyEclipse配置Tomcat
1、打开MyEclipse并依次点击 Window -- preferences -- myeclipse -- server -- tomcat -- configure tomcat 7.x 后会进⼊到如下界⾯:
2、选择左边选项框 Tomcat 7.x 下的JDK后,会进⼊如下界⾯:
点击红框内的下拉键,选择⼀个jdk即可(如果下来后没有jdk,可以点击右边的 Add 键添加对应jdk即可),最后点击OK,运⾏tomcat 在浏览器输⼊localhost:8080 成功显⽰。
MyEclipse开发环境的搭建

MyEclipse开发环境的搭建e+MyEclipse开发环境一、安装JDK下载JDK 5.0(JDK 5.0的下载页面为:/j2se/1.5.0/download.jsp);然后运行JDK 5.0安装程序jdk-1_5_0_06-windows-i586-p.exe,安装过程中所有选项保持默认;最后配置JDK的环境变量:在“我的电脑”上点右键—>“属性”—>“高级”—> “环境变量(N)”。
二、安装Tomcat下载jakarta-tomcat-5.0.30.zip,之所以下载免安装版的好处是可以使用多个Tomcat(jakarta-tomcat-5.0.30.zip的下载页面为:/tomcat/tomcat-5/v5.0.30/bin/);然后将jakarta-tomcat-5.0.30.zip直接解压到D盘根目录:三、安装Eclipse下载eclipse-SDK-3.1.2-win32.zip下载地址为:/downloads/);然后将eclipse-SDK-3.1.2-win32.zip直接解压到D盘根目录:四、安装MyEclipse五、指定Eclipse+MyEclipse的JRE 和Tomcat 服务器六、新建一个项目来测试一下Eclipse+MyEclipse开发环境是否搭建成功实验完成情况学员对以上实验内容基本完成,能对实验结果或实验中出现的问题进行分析,并把实验中遇到的故障及排除方法记录下来。
能按实验内容完成所有的操作,结果的基本准确。
实验内容基本完成。
开发Java Project实验内容开发步骤: 将开发第一个Java Project。
运行结果为在控制台打印“Hello World”:在MyEclipse的工具栏点击“start stop/restart MyEclipse Server”按钮,选择Tomcat 6.x Start。
在控制台会出现启动Tomcat的信息。
j2ee环境配置

Myeclipse + tomcat + jdk的j2ee开发环境配置一直在想我到底要不要写这个小文章,但想了想当初的我在配置j2ee环境的时候都找了好多的资料,不是不够全,就是不够详细。
所以为了大家不要花那么多时间在配置环境的时候蛋疼,于是我就硬着头皮以新手的身份写了这个小文章。
进入正题吧。
好明显,Step_1(下载各自东西):Step_2(配置好jdk和tomcat各自的环境,配置不分先后):Step_2.1:按下图的顺序打开系统环境设置(是在这里配置的): 右击“我的电脑“→选择”属性“→选择”高级“→选择”环境变量“最后会看到这个图片:Step_2.2(jdk的配置--------3步):Step_2.2.1(修改Path变量):打开Path这个变量,在最后加;E:\myJ2ee\inSize\jdk\bin 这个E:\myJ2ee\inSize\jdk\bin是我的jdk的bin这个文件夹的路径换成你的jdk的bin这个文件路径变可以了,还有那个在路径前的分号(一定要英文的分号)是不可以少的。
如图:Step_2.2.2(新增Classpath变量):点击“新建“→”变量名“设为Classpath→”变量值“设为.;E:\myJ2ee\inSize\jdk\lib同理把路径换成你的lib这个文件的路径,其中路径前的点号和分号不能少(一定要英文的点号和分号)如图:Step_2.2.3(新增JA V A_HOME变量):点击“新建“→”变量名“设为JA V A_HOME→”变量值“设为E:\myJ2ee\inSize\jdk同理换成你的jdk的安装路径,这个路径下包含lib和bin两个文件。
如图:这样jdk的配置就0k了,好,去测试一下正不正确:在c盘下有记事本写下一个java类,如:保存,修改后缀名为.java,之后打开cmd,(在“开始“→”运行“→输入”cmd“)如下图输入dos命令:(如果全部通过就ok了)其中javac Test.java这个命令在c盘下生成一个Test.class的文件。
Eclipse配置Nutch源码-适用于nutch任何版本-在网上找了很久,这是自己总结出来的
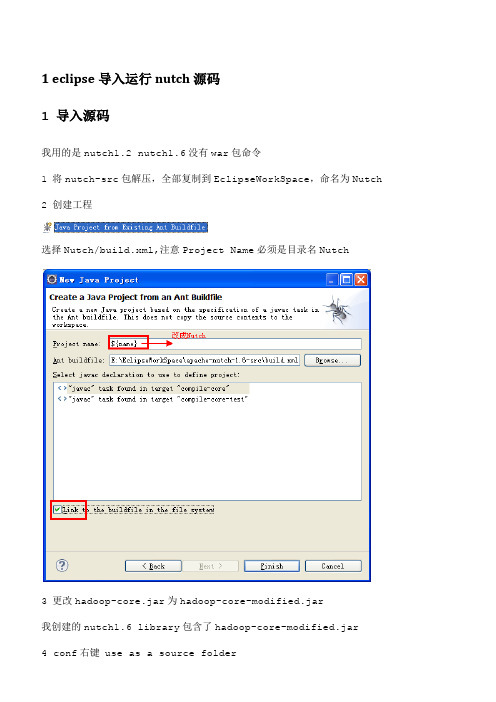
1 eclipse导入运行nutch源码1 导入源码我用的是nutch1.2 nutch1.6没有war包命令1 将nutch-src包解压,全部复制到EclipseWorkSpace,命名为Nutch2 创建工程选择Nutch/build.xml,注意Project Name必须是目录名Nutch3 更改hadoop-core.jar为hadoop-core-modified.jar我创建的nutch1.6 library包含了hadoop-core-modified.jar4 conf右键 use as a source folder项目编码改为utf-85 修改conf下的nutch-site.xml,在configuration标签对中添加如下代码:<property><name></name><value>My Agent</value></property>6 在conf下的nutch-default.xml中找到plugin.folders,原来的值是plugins,这个是build.xml编译之后,生成的目录,所以不用改7 ant编译build.xml,勾选jar job war有的src源码中的java文件扩展名改为了jav,不多,都要改过来8 将生成的build/ jar job plugins复制到根目录下面注意,每次修改了conf目录中的配置文件,必须重新编译,重新把jar job plugins复制一份,修改才能生效9在工程的根目录下建立urls文件夹,其中新建一个url.txt文件注意,最后由一个/,否则,会出错10 修改crawl-urlfilter.txt,只过滤我们想要的网站11在Crawl.java上配置java项目的运行参数: urls -dir mycrawls -depth 5 -threads4urls表示去爬那个网站,就是创建的urls目录名,不是命令参数名,就是一个参数值-dir参数,表示爬的数据放在mycrawls目录中,-depth 5表示深度为5 可以理解成/ 后面跟了几个/就是目录的深度,-threads 4就是几个线程11 运行中碰到的问题可以查看根目录中的hadoop.log详细信息2 问题1 fail to set permissions of path\ staging 0700nutch1.4往上的版本会有这个问题,hadoop设置的文件权限问题,linux下没有问题,方法,将nutch library中的hadoop-core-1.3.jar中的一个FileUtil文件修改一下,重新打包,我下载了一个,在libs_plugins/libs/hadoop-core-modified.1.0.2.jar2 OutofMem-Xms512m -Xmx1024m -XX:MaxPermSize=256m3 Error in configuring object应该是没有ant编译,plugins不是程序需要的。
图文详解win8系统下Myeclipse Tomcat MySQL Navicat的jsp网站开发环境配置汇总

图文详解win8系统下Myeclipse+Tomcat+MySQL+Navicat的jsp网站开发环境配置1、安装Tomcat首先必须安装Tomcat,不然点Myeclipse新建web project时,你会发现怎么也点不开,你还会以为Myeclipse是不是有什么问题的。
因此我建议先装Tomcat再装Myeclipse。
(1)在Tomcat官网下载Tomcat,我下载的是apache-tomcat-6.0.37-windows-x64.zip,建议新手选择zip文件,不要用安装版本,以后等熟练掌握tomcat的基本使用方法后,再慢慢打开里面的资源,查询其源码,便于更深入的了解掌握tomcat的运行原理。
(2)将tomcat直接解压缩到指定文件夹。
我放在了D:\Java\tomcat下。
(3)配置JA V A_HOME。
(首先要配置jdk运行环境设置,请参考我前面写过的“图文详解Win8系统安装最新JA V A、Android、Eclipse开发环境”,在百度文库里有)在环境变量中的用户变量中新建JA V A_HOME请注意,在JA V A_HOME的变量值后面不要加“;”,否则tomcat启动不了,会出现如下错误,那是因为tomcat会把“;”当做一个路径去理解。
配置完毕后,在cmd中转入到tomcat的bin目录下,输入startup,看到下面的东东你就成功了。
(4)测试tomcat。
打开浏览器,在地址栏输入:http://localhost:8080,如下图就ok了2、安装与配置myeclipse(1)Myeclipse的安装在这就不多讲了,因为myeclipse是需要付费,所以我找的是8.5低版本可以破解的,用于开发基本够了。
如果你一定要用最新版本,请去myeclipse购买或者申请试用序列号。
个人体会,如果你认真学习,试用序列号就可以满足学习的需要,说不定还能开发出一个比较挣钱的东东,那时候就有足够的钱去付费了。
Eclipse+Tomcat+MySql搭建java web开发环境

对于初学者来说,如果没有接触过java web开发的话,搭建开发环境将是一个门槛。
以前一直用进行web开发,基本不需要搭建环境,因为Visual Studio已经把开发需要的环境都集成好了,所以对新手来说很容易上手。
最近因为项目需要,必须得用j2ee架构进行开发,所以将配置环境过程中遇到的问题记录下来。
一.准备工作系统环境:Windows xp先下载相关的工具JDK1.6 官网下载:/download/jdk6/6u10/promoted/b32/binaries/jdk-6u10-r c2-bin-b32-windows-i586-p-12_sep_2008.exeEclipse Galileo 3.5.0 Classic 官网下载:/downloads/packages/release/galileo/r(注意,Eclipse有很多版本的,这里下载的是伽利略3.5标准版的,其它版本都是在标准版的基础上集成一些插件而成的,如Eclipse IDEfor Java EE Developers则集成了进行java ee开发所需要的插件,Eclipse IDE forC/C++ Developers则集成了C/C++开发所需要的插件)Tomcat 6.X 官网下载:/download-60.cgi(注意,Tomcat有压缩版的和安装版之分,压缩版的解压之后,需要配置一些环境变量,安装版的安装完毕之后可以直接使用,不用配置环境,对于新手方便很多,在这里我们下载安装版本的,32-bit/64-bit Windows Service Installer)MySql5.5 官网下载:/downloads/mysql/(MySql是一款轻巧开源的数据库引擎,它的Community Server是免费使用的,Enterprise(企业版)需要付费)MySql-Front 5.1.4 官网下载:http://www.mysqlfront.de/wp/download/(MySql-Front是针对MySql数据库引擎开发的一套图形管理工具,不过可惜需要付费。
JAVA环境搭建之MyEclipse10+jdk1.8+tomcat8环境搭建详解
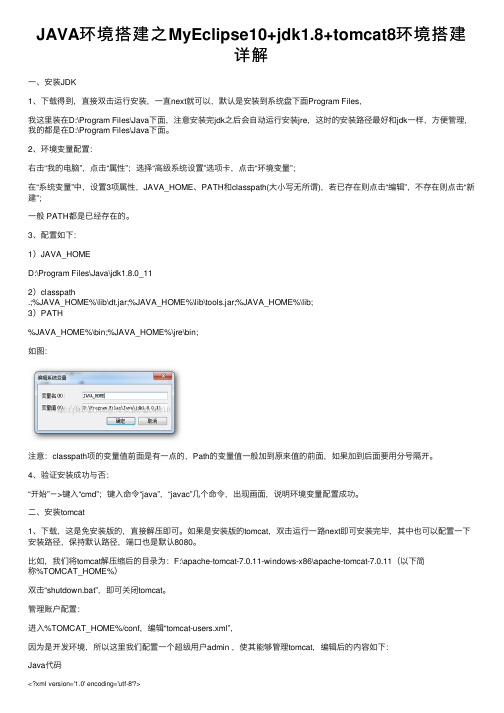
JAVA环境搭建之MyEclipse10+jdk1.8+tomcat8环境搭建详解⼀、安装JDK1、下载得到,直接双击运⾏安装,⼀直next就可以,默认是安装到系统盘下⾯Program Files,我这⾥装在D:\Program Files\Java下⾯,注意安装完jdk之后会⾃动运⾏安装jre,这时的安装路径最好和jdk⼀样,⽅便管理,我的都是在D:\Program Files\Java下⾯。
2、环境变量配置:右击“我的电脑”,点击“属性”;选择“⾼级系统设置”选项卡,点击“环境变量”;在“系统变量”中,设置3项属性,JAVA_HOME、PATH和classpath(⼤⼩写⽆所谓),若已存在则点击“编辑”,不存在则点击“新建”;⼀般 PATH都是已经存在的。
3、配置如下:1)JAVA_HOMED:\Program Files\Java\jdk1.8.0_112)classpath.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;%JAVA_HOME%\lib;3)PATH%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;如图:注意:classpath项的变量值前⾯是有⼀点的,Path的变量值⼀般加到原来值的前⾯,如果加到后⾯要⽤分号隔开。
4、验证安装成功与否:“开始”->键⼊“cmd”;键⼊命令“java”,“javac”⼏个命令,出现画⾯,说明环境变量配置成功。
⼆、安装tomcat1、下载,这是免安装版的,直接解压即可。
如果是安装版的tomcat,双击运⾏⼀路next即可安装完毕,其中也可以配置⼀下安装路径,保持默认路径,端⼝也是默认8080。
⽐如,我们将tomcat解压缩后的⽬录为:F:\apache-tomcat-7.0.11-windows-x86\apache-tomcat-7.0.11(以下简称%TOMCAT_HOME%)双击“shutdown.bat”,即可关闭tomcat。
MyEclipse+Tomcat+JSP开发环境配置
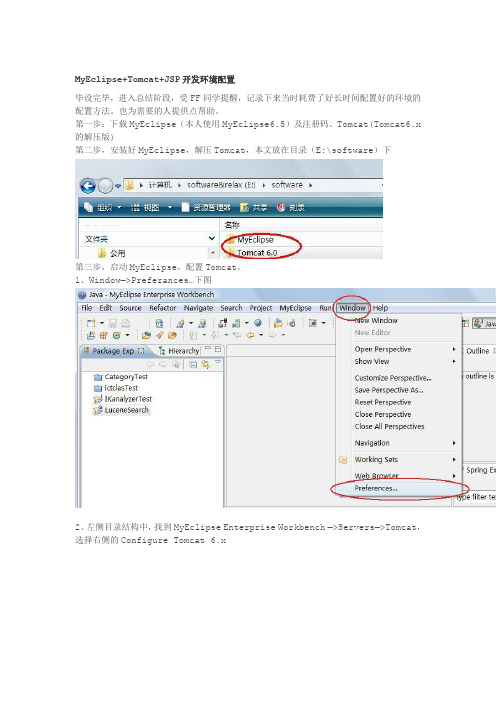
MyEclipse+Tomcat+JSP开发环境配置毕设完毕,进入总结阶段,受FF同学提醒,记录下来当时耗费了好长时间配置好的环境的配置方法。
也为需要的人提供点帮助。
第一步:下载MyEclipse(本人使用MyEclipse6.5)及注册码、Tomcat(Tomcat6.x 的解压版)第二步,安装好MyEclipse,解压Tomcat,本文放在目录(E:\software)下第三步,启动MyEclipse,配置Tomcat。
1、Window—>Preferances…下图2、左侧目录结构中,找到MyEclipse Enterprise Workbench —>Servers—>Tomcat,选择右侧的Configure Tomcat 6.x3、将Tomcat Server设为Enable,设置Tomcat目录home directory,下面的base、temp directory 好像是自动设置的。
应用一下,Apply。
4、左侧目录中,找到Java—>Installed JREs,添加一个自己安装的JDK的jre,名字任意(本人命名为jre,本人的jdk安装在C:\ProgramFiles\Java\jdk1.5.0_07)。
5、回到MyEclipse Enterprise Workbench—>Servers—>Tomcat—>Tomcat6.x—>JDK,在下拉列表中选择刚才建的jre,好像这个jre也可以直接在这里Add...然后点最下面的"OK”,就配好了Tomcat。
第四步,建立Web工程,部署工程,运行1、新建Web Project本文示例,命名为WebTest ,J2EE 改为5.0,完成。
2、部署工程,选中WebTest工程,点击工具栏中的部署按钮,如图所示。
3、确认部署的是WebTest,添加Add4、在下拉列表中选择Tomcat 6.x,完成Finish该对话框,上一级对话框也点"OK”,完成确认,部署完成。
MyEclipse+tomcat搭建J2EE开发环境

Eclipse+MyEclipse+tomcat搭建J2EE开发环境1,下载并安装JDK目前JDK最新版本为1.7,我装机用的是1.6,其实差别不大,下载并安装,记住目录:E:\Program Files\Java\jdk1.6.0_202 并置JDK的环境变量在“计算机”上右击,选择“属性”—>“高级”—> “环境变量(N)”新建系统变量JAVA_HOME:E:\Program Files\Java\jdk1.6.0_20新建系统变量CLASSPATH:.;%JAVA_HOME%\lib;(注意:点号表示当前目录,不能省略)系统变量Path的值的前面加入以内容:%JAVA_HOME%\bin;(注意:这里的分号不能省略)注意:以上变量均为系统变量,不是用户变量3 测试JDK是否安装成功将以下内容复制到记事本中:public class Hello{public static void main(String args[]){System.out.println("Hello Java");}}另存为“Hello.java”(不含引号,下同),并保存到D盘根目录下。
在命令行依次输入下图中对应的命令:如果出现上图中“Hello Java”,则说明JDK安装成功!注意:如果以后要安装诸如Eclipse、Borland JBuilder、JCreator、IntelliJ IDEA 等集成开发环境(IDE,Integrated Development Environment),应该在IDE中编译运行一个简单的HelloWorld程序,以保证IDE可以识别出JDK的位置。
4 安装Eclipse+MyEclipse鉴于网上现行版本的MyEclipse均附内置有Eclipse,所以只要装MyEclipse 即可,如果是不附带Eclipse的MyEclipse,在装机过程会提示你Eclipse的安装路径在哪?MyEclipse 9 以上版本甚至内置有Tomcat.连服务器都不用装。
myeclipse+tomcat+JDK安装示意图

在开始安装之前,需准备的软件:1、jdk-1.62、tomcat-5.5.283、MyEclipse 7.0如果已经安装了JDK环境,则只需安装tomcat即可。
各软件的下载地址如下:jdk-1.6 -- :/javase/downloads/index.jsptomcat-5.5.28 -- :/tomcat/tomcat-6/v6.0.26/bin/apache-tomcat-6.0.26.zip一、安装jdk环境JDK-1.6的安装,我们使用Exe版本的安装文件,除了选择目录外,其他的都默认好了,这里安装到D:\Tomcat5.5,注意中间的空格去掉了,因为有时候有空格会很麻烦。
jdk-1.6 安装图解类似于链接: /529901956/blog/1270804791二、安装tomcatTomcat的安装,我们使用Exe版本的安装文件,除了选择目录外,其他的都默认好了,这里安装到D:\Tomcat5.5,注意中间的空格去掉了,因为有时候有空格会很麻烦。
tomcat-5.5.28 安装图解链接:/529901956/blog/1270043200三、安装并配置MyEclipse运行JSP1.首先安装Java的Jdk1.6和Tomcat-5.5.28到指定位置并测试成功2.安装MyEclipse7.0 (一般默认安装),MyEclipse是一个Exe安装文件,有安装向导,直接双击安装,选择完MyEclipse7.0 安装目录和自身的安装目录,然后一路next就行了。
最后需要输入MyEclipse的注册码,打开菜单window->preferences,在对话框的菜单树中打开MyEclipse->Subscription项,点击Enter Subscription…按钮,然后输入注册用户名和密码即可。
3. 配置MyEclipse7.0运行MyEclipse7.0.exe,同样,将检测到更新。
确定,然后再重新启动MyEclipse7.0.exe1)添加jdk路径Menu(主菜单)->Window(窗口)-> references(首选项)->java->Installed JREs(已安装的jre),点Add(添加)。
tomcat6.0 + myeclipse8.5 + jdk 完整配置环境(很详细)

13)打开浏览器输入地址:http://localhost:8080/Test1/index.jsp将出现下图所示界面,表示部署运行成功。
14)同样,在server面板下面可以关闭Tomcat服务器,如下图:
7)单击“系统变量”区域的“新建”按钮,出现“新建环境变量”对话框,在其中新建环境变量:JAVA_HOME=JDK的安装目录。
8)用同样的方法新建环境变量:
CLASSPATH=.;%JAVA_HOME%\lib)在系统区域中选择环境变量:Path。单击编辑按钮进入编辑对话框,对其进行编辑如下:
8)WEB项目建立成功后,在左侧的项目面板中将出现新建的项目,如下图:
9)双击上图中的index.jsp文件,文件内容如下图:
10)右击要部署web应有的Tomcat服务器,选择Add Deployment,打开部署对话框,如下图:
11)从Project选项中选择要部署的WEB应有程序的名称,单击Finishi完成部署。并单击服务器左侧小三角,可看到刚部署的应用程序。
2)Tomcat
Tomcat是一款开源的WEB服务器。目前符合一定工业标准的商业WEB应用服务产品有BEA公司的Weblogic服务器、IBM公司的Websphere服务器、Jakarta项目组的Apache Tomcat服务器、开源项目SourceForge的JBoss服务器等。
3)文本编辑工具或集成开发环境(MyEclipse)
1.MyElipse配置与使用
首先,安装并启动MyEclipse(这里已MyEclipse8.5为例),第一步设置MyEclipse所适用使用的JDK的版本;第二步设置在MyEclipse下如何配置和使用Tomcat;第三步学习如何利用MyEclipse建立,部署和调试一个简单的WEB应用程序。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
在MyEclipse中搭建Nutch开发环境
1以Java Project形式搭建
1.1第一步:下载Nutch的压缩包
到Nutch的网站上下载Nutch的压缩包,这里以Nutch1.1为例。
Nutch各版本的下载地址为/dist/nutch/,进入该网页后,找到apache-nutch-1.1-bin.tar.gz 文件,将其下载到自己的电脑里。
1.2第二步:新建一个Java项目
打开MyEclipse,点击File→New→Java Project新建一个Java项目,输入Project Name 如Nutch1.1,点击Finish按钮。
如下图所示。
1.3第三步:导入Nutch的代码
将第一步下载的Nutch压缩包解压,解压后的目录结构如下图所示。
将src/java目录下的整个org文件夹copy到Nutch1.1项目的src目录下。
1.4第四步:导入Nutch的配置文件、Jar包、插件
在第三步解压后的目录下,找到conf、lib、plugins三个文件夹,将这三个文件夹copy 到Nutch1.1项目的根目录下(即与src目录同级)。
Copy完后,Nutch1.1项目的目录结构如图所示。
1.5第五步:替换Nutch中Hadoop的核心包
官方版本的Hadoop是不支持Windows下的存取操作的,我们需要将其替换为自己修改过的Jar包。
在Nutch1.1项目的lib目录下,找到Hadoop的核心包(如:hadoop-0.20.2-core.jar),将其删除,然后将自己的Jar包(hadoop-0.21.0-core.jar)copy到该目录下。
1.6第六步:在MyEclipse中为项目加载Jar包
在MyEclipse中刷新Nutch1.1项目,可以看到如下所示的目录结构。
我们会发现src目录下有错误存在,这是因为尽管该项目的lib目录下有Jar包,但是没有将其加入到ClassPath变量中。
下面来解决这个问题。
在Nutch1.1目录上单击右键→Build Path→Configure Build Path…将打开如下所示的对话框。
在Libraries选项卡里,点击Add JARs…按钮,将出现如下所示的对话框。
展开Nutch1.1目录,展开lib目录,将lib文件夹及其子文件夹下的全部Jar包选中,然后单击OK按钮,如下图所示。
单击OK按钮后,将回到Libraries选项卡,此时该选项卡将如下所示。
最后,单击Libraries选项卡里的OK按钮,回到MyEclipse的主页面,看看src目录上的错误是不是消失了。
1.7第七步:在MyEclipse中为项目加载配置文件
同理,虽然conf目录下已经有配置文件了,但Java虚拟机仍不能识别它们,因为它们也没有加入到ClassPath变量中。
下面我们来将其加入。
在conf目录上单击右键→Build Path→Use as Source Folder。
然后我们会发现conf 目录变成了一个“Source Folder”,这样conf目录下的配置文件就被中加入到ClassPath 变量中了。
1.8第八步:修改Nutch中的配置
Nutch中默认的配置并不能使Nutch正常运行,需要修改几个地方后才能使Nutch运行起来。
1.8.1修改nutch-default.xml
在conf目录下找到nutch-default.xml文件,将其打开,找到配置项,如果该项的value值为空,则随便加入一个值,然后保存。
如下图所示。
1.8.2修改crawl-urlfilter.txt
在conf目录下找到crawl-urlfilter.txt文件,将其打开,找到# accept hosts in
配置项,将其下面的正则表达式+^http://([a-z0-9]*\.)*/改为+^http://([a-z0-9]*\.)*。
找到# skip URLs containing certain characters as probable queries, etc. 配置项,如果其下面有-[?*!@=]形式的正则表达式,将其删除,或将-号改为+号。
最后,保存所作的修改。
如下图所示。
此外,还可以修改nutch-site.xml这个文件的配置。
(这里略去,不作修改)
1.9第九步:测试Crawl类,修正运行中的各种错误
经过以上的操作,Nutch的开发环境的搭建就有可能大功告成了,现在我们就可以开始运行Nutch了。
我们通过Crawl类来运行Nutch,运行时将出现两种结果,一是顺利地运行完成,二是程序被各种异常终止(即运行失败)。
如果出现第一种结果,恭喜你,Nutch的开发环境搭建成功;如果出现第二种结果,很抱歉,你可能离成功还有很远,不过没关系,你可以一步一个脚印,修正运行中的各个错误。
下面,按如下步骤来运行Nutch,修正运行中的各种错误。
1.9.1运行前的准备工作
Nutch爬虫运行时需要一个入口,即一个或若干个url,通常将url存放在一个txt文件中。
因此,运行前需要有这样的txt文件。
在Nutch1.1项目的根目录下新建一个名为“testData”的文件夹,在该文件夹下新建一个名为“urls.txt”的文件,在urls.txt文件中写入若干url,如下图所示。
1.9.2打开Crawl类,配置运行参数
在MyEclipse中,展开src目录,找到org/apache/nutch/crawl包下的Crawl.java类,双击打开。
在MyEclipse的工具栏上找到,点击右边的黑色小三角,再点击Run Configurations…,将打开一个对话框,如下图所示。
点击Arguments选项卡,如下图所示输入运行参数和虚拟内存,点击Apply按钮,再点击Close按钮,返回主界面。
1.9.3运行Crawl类
打开Crawl类,点击工具栏上左边的小三角,程序开始运行起来,耐心等待程序执行完成。
如果程序运行后,满足以下几个条件则认为程序运行正常,开发环境搭建成功。
如果不满足以下的条件,则认为程序运行失败,需要修正各种错误。
①程序没有被异常终止
②运行中没有抛出较严重的异常
③运行结束时,控制台出现类似以下的信息
④运行结束后,testData目录下出现out文件夹,且out目录下出现如下所示的子文件夹,并且各子文件夹中的文件要有数据
1.9.4修正错误,直至运行成功
如果上一步中,Crawl类运行成功,则此步可以跳过。
如果上一步中,Crawl类运行失败,则要根据实际情况,一步一个脚印,碰到一个错误修正一个错误,直到Crawl类运行成功。
下面给出运行中常见的错误及其解决方法。
①ng.NoClassDefFoundError
这类异常是因为没有找到相应的类文件,通常是缺少Jar包。
以下图的异常为例,该异常是因为缺少jackson的Jar包,因而找不到相应的类文件。
解决方法是:将jackson-core-asl-1.4.2.jar和jackson-mapper-asl-1.4.2.jar文件加入到lib目录下,再通过MyEclipse加入Jar包的方法将这两个Jar包加入到ClassPath变量中。
②Job failed!
Job failed是Nutch中最常见也是最复杂的问题,引发该异常的原因数不胜数,解决方法应视具体情况而定。
遇到该问题时,通常可以按以下步骤来解决。
第一:检查Hadoop的核心包是否替换,没有则替换为自己修改过的Jar包,如:hadoop-0.21.0-core.jar。
第二:检查nutch-defult.xml是否修改,以及是否修改正确。
第三:检查crawl-urlfilter.txt是否修改,以及是否修改正确。
第四:以上三种方法仍然不能解决时,需要查看Hadoop的日志文件hadoop.log(该文件通常在项目的根目录下,也可能在其他地方),来找出出现问题的具体原因。
下面是hadoop.log的一个片段,该片段说明了引起Job failed的一个原因:avro的某些类文件未找到。
因此,说明我们还要在项目中加入avro的Jar包,如:avro-1.3.2.jar。
下面是hadoop.log的另一个片段,该片段说明了引起Job failed的另一个原因:OutOfMemoryError(内存溢出错误)。
这个错误说明运行的虚拟内存太小或者根本就没设置虚拟内存,解决方法是在配置Crawl运行参数的对话框中正确设置虚拟内存的大小。
③Input path does not exist
这个异常说明输入路径不存在,即含有url的txt文件不存在。
引起这个异常的原因有两个,一个是没有所需的txt文件,另一个是运行参数配置错误。
解决的方法是首先检查txt 文件是否存在,然后检查Crawl的运行参数是否如下图的形式配置(注意斜杠和空格)。
④Too small initial heap
Crawl运行时直接输出上图的信息时,说明虚拟内存太小了,同时检查虚拟内存的配置,将其配置正确。
(此时多为数字后面掉了m)
⑤⑥
1.10第十步:搭建完成,运行Nutch
经过上面的操作,相信Crawl类可以成功运行了,直至Nutch开发环境的搭建终于大功告成了。
现在,就可以利用Nutch来爬行互联网了。