随机前沿模型(SFA)-原理解读
物流业要素配置效率及区域异质性——基于SFA模型的实证检验

分析了 2005-2018 年全国各地区劳动、资本、技术三大生产要素资源配置效率。结果表明,全国物流业要素配置
效率大体呈波动变化的下降态势。资本和劳动力要素配置效率差异格局明显,总体呈现出“东强西弱”的异质性
格局,需要针对性地提升各区域生产要素的配置和利用水平,实现物流业多样化发展。
关键词:劳动力要素配置;物流业;随机前沿模型;异质性;实证分析
的产出模式,当 ui,t>0 时表示为产出导向型生产非效率项。
考虑物流业完全竞争要素市场下生产要素的自由流
动,在供求双方均拥有完全信息交换需求以保证竞争不受
到阻碍与干扰的前提下,要素配置便达到最优状态。参考
Kim(1992)的研究,有如下结论:
生产函数:Y=f (x1、x2…xj )
(2)
利润函数:π=TR-c=p·f (x1、x2…xj )-∑ j wj xj
中图分类号:F252
文献标识码:A
文章编号:2095-9397(2021)14-0111-04
文章著录格式:何纪翔,马晓琳 . 物流业要素配置效率及区域异质性——基于 SFA 模型的实证检验 [J]. 商业经
济研究,2021(14):111-114
引言
资本、劳动力均是维持生产活动不可或缺的物质基 础,为产业经济建设和发展提供了有力支撑。一直以来, 我国物流业粗放式发展格局依赖于生产要素无序的高投 入和高消耗,在很大程度上造成了要素配置扭曲,引起了 各类生产要素过度消耗、效率低下等严重阻碍经济可持 续发展的问题。而物流业不仅是服务业的重要组成部分, 在新常态经济格局下,物流业还是促进资源融通、加速 生产、带动消费发展的重要行业,物流业的发展需要更 多要素投入,要素资源约束也会更多地体现在物流业发 展过程中,以物流业提质增效为关键的第三产业发展方 式转型的要求同样迫切。因此,基于要素配置效率角度, 合理分析物流业发展质量,是加速物流经济整体发展水平 的关键。从物流业业务量来看,2020 年第一季度全国快 递单量累计 125.3 亿件,同比增长 3.2%;从市场规模来看, 伴随着存量消费市场持续向线上转移,多样化的物流形 态不断发展,以往的社会物流体系不断派生出市域物流、 短途快速物流等新业态,特别是移动互联网催生社区新 零售的发展,在很大程度上使得物流市场日益发展完善。 在物流经济可持续快速发展背景下,劳动力要素的稳定投 入不可或缺,2020 年 4 月,中共中央、国务院关于构建 更加完善的要素市场化配置体制机制的意见中指出要引 导劳动力要素合理畅通有序流动,这在一定程度上对于提
中国工业企业生产效率随机前沿模型分析

若TEC>1,则存在前沿效率的进步。 (3)规模效率变化(SEC) 一个厂商可以通过变动他的运营规模 使得该厂商运营与生产的技术最优规模 (TOPS)处,以提高其生产效率。 一个厂商在 某个时期的规模效率可以表示为:
均来源于2000 年~2 0 0 8年的 《中国统计年 鉴》 和 《科技统计年鉴》 , 部分年份的数据来 源于各年各地区的统计年鉴。 (1)实际工业总产值(Y)。 本文采用实际 工业总产值作为产出。 处理方式如下:将 《中国统计年鉴》 中规模以上工业企业的各 年名义工业总产值,经过各年各地区工业 品出厂价格指数平减, 得到实际的工业总 产值。 内资工业部门的实际工业总产值由 规模以上工业企业和规模以上三资企业的 实际工业总产值相减得到。 (2)固定资产净值(K)。 对于固定资产净 值的处理采用永续盘存法(PIM),以1999年 的 固 定 资 产 净 值 为 基 期, 以 相 邻 两 年 的 固 定资产年末余值之差作为当年的新增固定 资产投资。 公 式 如 下:
表2
+∑
n =1
N
n
InX nit +
1 N N ∑∑ 2 n =1 j =1
nj
InX nit InX njt +
∑
n =1
N
tn
tInX nit + t t +
1 2
tt
t 2 + D1 + D2 + D3 + Vit − U it (11)
(1)内 资 工 业 企 业 的 估 计 结 果 分 析:我 们将内资工业部门的估计结果统计如表1 所示。 (2)对 于 显 著 性 和 假 设 检 验 的 说 明:由 表3.1,除了δ4、 δ7之外,所有系数均通过 了1%的t检验;而γ=0.999,并且显著,这说 明 生 产 对 于 前 沿 的 偏 离, 主 要 是 由 于 技 术 无效率所引起的。 对于是否存在无效性的
空间面板随机前沿模型及技术效率估计.doc

空间面板随机前沿模型及技术效率估计空间面板随机前沿模型及技术效率估计林佳显, 龙志和, 林光平 1 12 ( 1. 华南理工大学经济与贸易学院, 广东广州510006; 摘要: 随机前沿模型是测算技术效率的重要方法之一。
通常,模型假设生产单元之间彼此独立,然而在技术扩散过程中,空间外部性起着重要作用。
文章结合随机前沿模型理论与空间经济计量分析方法,构建空间面板随机前沿模型, 同时考虑空间滞后因变量和空间误差自相关,并逐步放松模型设定条件, 首先考虑技术效率时变,接着引入技术无效率项的异方差性,之后考虑观察数据中潜在的截面异质性,分别以引入随机截面特有项和设定随机系数的形式来表示截面中图分类号: F064. 1 ----------------------------------- 精选公文范文,管理类,工作总结类,工作计划类文档,感谢阅读下载---------------------------------------- ~ 1 ~文献标识码: A 文章编号: 100022154 ( 2010 ) 05 20071 20 、引言随机前沿模型( SFM ) 的理论最初 A igne r、Love ll 和Schm id t (ALS) ( 1977 ) [ 2 ] [ 1 ] , Meeu sen 和V an den B roeck (MB ) ( 1977 ) 提出, 并很快成为计量经济学中一个引人注目的分支,被广泛应用于效率测算和生[ 3 ] 产率分析尤其是在Jond row 等( JLM S) ( 1982 )指出各个生产单元的技术无效率可以通过条件分布[ u |i vi - ui ] 的期望 E [ ui | vi - ui ] 或模M ode [ ui | vi - ui ] 来估算以后。
随机前沿分析( SFA ) 始于对生产最优化的研究, 经过30 多年的发展, 其在理论研究与实践应用方面都得到了深入的发展, 已被尝试性地应用于生产经济学以外的领域, 如劳动经济学、公共经济学以及金融经济学等。
【国家自然科学基金】_随机前沿方法(sfa)_基金支持热词逐年推荐_【万方软件创新助手】_20140802
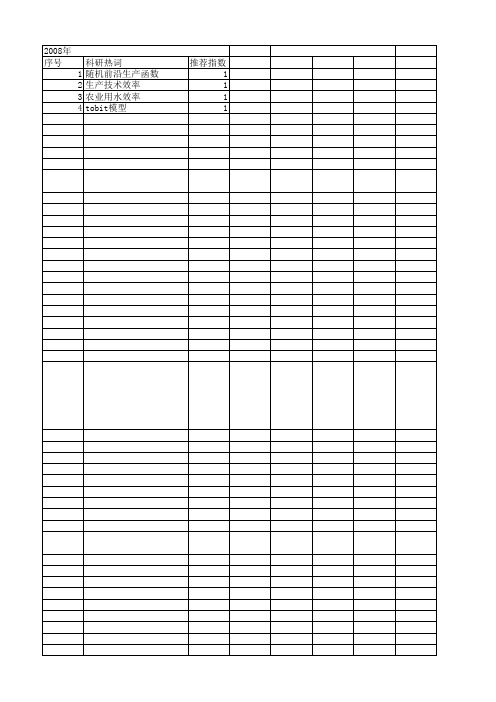
科研热词 随机前沿生产函数 生产技术效率 农业用水效率 tobit模型
推荐指数 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
科研热词 随机前沿分析 灌溉用水效率 sfa dea 面板数据 随机前沿生产函数 通径分析 跨国公司r&d投资 绩效 生产效率 玉米优势产区 玉米 溢出效应 投资效率 技术非效率模型 大股东控制 多层次/随机前沿分析 农户 全要素生产率 供应商 人力资源外包 主成分变量 c-d生产函数
推荐指数 3 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2011年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 随机前沿分析 技术效率 物流业 数据包络分析 全要素生产率 随机前沿方法 随机前沿主方程组方法 配置效率 能源消耗 股权结构 综合绩效 经济增长 空间相关性 空间收敛性 研究现状 研发技术效率 独立董事 影响因素 大型综合医院 复合残差项 地区差异 区域增长 全要素生产率变动分解 企业效率 代理成本 主成分分析 sfa
2014年 序号 1 2 3 4 5 6 7 8 9 10 11
科研热词 高技术产业 随机前沿函数 环境因素 旅游业 医疗服务 医疗卫生服务效率 医疗卫生服务 全要素生产率 专利产业化效率 sfa方法 malmquist指数
推荐指数 1 1 1 1 1 1 1 1 1 1 1
2013年 科研热词 推荐指数 随机前沿方法 4 随机前沿分析 4 技术效率 4 高校校办产业 2 随机前沿分析(sfa) 2 效率 2 投资来源 2 成本函数 2 全要素生产率 2 fdi 2 高校知识创新链 1 高校 1 随机前沿分析方法(sfa) 1 随机前沿 1 绩效评价 1 统计分析 1 科技创新 1 碳排放 1 湖北省 1 数据包络分析 1 政产学研用 1 技术转移效率 1 房地产上市公司 1 战略性新兴产业 1 成本效率 1 成本一效益效率 1 成本-效益效率 1 影响因素 1 当地政府支持 1 外部运营环境 1 国防科技工业 1 商业银行 1 参数法 1 协同 1 医疗卫生 1 区域市场需求规模不确定性 1 创新效率 1 创意经济 1 农地城市流转效率 1 军民融合 1 公交线路 1 企业规模 1 人力资本 1 产权类型 1 产业集聚 1 产业竞争力 1 交通运输系统工程 1 专利转化效率 1 x效率 1 malmquist指数 1
基于SFA方法的中国智能制造业全要素生产率研究

基于SFA方法的中国智能制造业全要素生产率研究*申丹虹 崔张鑫内容摘要:本文基于随机前沿分析(SFA)和Malmquist法对我国2010—2018年的智能制造业①上市公司的全要素生产率进行了测算和分解,以探寻智能制造业的发展现状及存在的问题,从而找到提升路径。
结果表明:智能制造业目前还处于规模递减的状态,但是发展潜力很大。
智能制造业的全要素生产率年均增长为 5%,主要归因于技术水平的落后,说明智能与制造业的融合并没有消除“信息技术生产率悖论”的存在。
我国依然要加大对技术创新的投入并加强对高素质人才和管理人才的投入,推进要素的优化配置以及增加资本的投入从而促进制造业的高质量发展。
关键词:智能制造业;全要素生产率;Malmquist;随机前沿函数中图分类号:C812 文献标识码:A 文章编号:1004-7794(2021)01-0048-06DOI: 10.13778/ki.11-3705/c.2021.01.006一、引言和文献综述在互联网、大数据、云计算等技术不断发展的基础上,人工智能催生了一批新技术,引领着新一轮的科技革命和产业变革,各领域对人工智能的应用加速推进,在此背景下,人工智能和制造业的融合,可以为制造业的高质量发展提供新动能。
米晋宏等(2020)运用上市公司的数据实证研究分析了人工智能技术的应用对制造业产业结构的升级有促进作用[1]。
付文宇等(2020)通过2003—2018年30个省份的面板数据实证分析表明人工智能通过技术的创新和人才资本的积累效应促进了了制造业的升级[2]。
智能制造业是人工智能和制造业的深度融合。
目前,对于智能制造业全要素生产率的研究是热点话题。
葛金田(2019)提出生产率是衡量竞争力和经济可持续发展的重要影响因素,因而提高智能制造业全要素生产率极其重要[3]。
一些学者认为智能促进制造业全要素生产率的提升,刘亮等(2020)证伪了“信息技术生产率悖论”的存在,指出人工智能对中高技术行业生产率的提升效应强[4]。
stata随机前沿模型sfa方法

stata随机前沿模型sfa方法随机前沿模型(Stochastic Frontier Analysis,简称SFA)是一种经济学方法,用于评估生产或效率的前沿水平和技术效率。
本文将介绍SFA方法的基本原理和应用领域,并探讨其在实际研究中的价值和局限性。
SFA方法最初由Aigner、Lovell和Schmidt在1977年提出,旨在解决生产要素利用效率评估中的随机误差和不可观测因素的问题。
该方法将生产函数分为两个部分:前沿函数和误差项。
前沿函数描述了理论上的最大产出水平,而误差项则捕捉了技术效率的偏差。
通过估计前沿函数和技术效率,SFA方法可以提供对生产效率的准确评估。
SFA方法的应用领域广泛,包括农业、制造业、金融业等。
在农业领域,SFA方法可以评估农民的生产效率,帮助政府制定农业政策和资源配置。
在制造业领域,SFA方法可以评估企业的生产效率,发现潜在的改进空间。
在金融业领域,SFA方法可以评估银行的效率和绩效,指导银行经营和监管。
然而,SFA方法也存在一些局限性。
首先,SFA方法基于对生产函数的假设,需要满足一定的假定条件。
如果这些假定条件不成立,SFA 方法的结果可能失真。
其次,SFA方法对数据的要求较高,需要大样本和高质量的数据。
如果数据质量差或样本量小,SFA方法的结果可能不可靠。
此外,SFA方法对模型的选择和参数的估计也存在一定的主观性和不确定性。
为了提高SFA方法的准确性和可靠性,研究者可以采取一些改进措施。
首先,可以使用更加灵活的模型来捕捉生产函数的非线性关系和异方差性。
其次,可以使用面板数据模型,以提高数据的效率和可靠性。
此外,还可以引入其他变量或控制变量,以更全面地评估生产效率。
SFA方法是一种评估生产效率的重要工具。
通过估计前沿函数和技术效率,SFA方法可以帮助研究者和决策者更好地理解和改进生产过程。
然而,使用SFA方法时需要注意其局限性,并采取相应的改进措施,以提高评估结果的准确性和可靠性。
随机前沿模型SFA原理解读

随机前沿模型(SFA )原理和软件实现一、SFA 原理在经济学中,常常需要估计生产函数或者成本函数。
生产函数f (x)的定义为:在给定投入x 情况下的最大产出。
但现实中的产商可能达不到最大产出的前沿,为了,假设产商i 的产量为:i i i y f (x ,)βξ= (1) 其中,β为待估参数;i ξ为产商i 的水平,满足i 01ξ<≤。
如果i =1ξ,则产商i 正好处于效率前沿。
同时,考虑生产函数还会受到随机冲击,故将方程(1)改写成:i v i i i y f (x ,)e βξ= (2) 其中,i v e 0>为随机冲击。
方程(2)意味着生产函数的前沿i v i f (x ,)e β是随机的,故此类模型称为“随机前沿模型”(stochastic frontier model )。
随机前沿模型最早由Aigner, Lovell and Schmidt(1977)提出,并在实证领域运用广泛,Kumbhakar and Lovell(2000)为该领域的研究写了一本著作,有兴趣的同学可以去参考。
假设o k 1i 1i ki f (x ,)e x x ββββ=(柯布道格拉斯生产函数,共有K 个投入品),则对方程(2)取对数可得:K i 0k ki i i k 1ln y =+ln x ln ββξν=++∑ (3)由于i 01ξ<≤,故i ln 0ξ≤。
定义i i u =-ln 0ξ≥,则方程3可以写成:Ki 0k ki i i k 1ln y =+ln x -u ββν=+∑ 其中,i u 0≥为“无效率”项,反映产商i 距离效率前沿面的距离。
混合扰动项i i i ενμ=-分布不对称,使用OLS 估计不能估计无效率项i u 。
为了估计无效率项i u ,必须对i i νμ、的分布作出假设,并进行更有效率的MLE (最大似然估计)估计。
一般,无效率项的分布假设有如下几种:(1) 半正态分布(2) 截断正态分布(3) 指数分布在一般的论文中,使用的最多的是半正态分布随机前沿模型可以很容易地用于估计成本函数,经过与生产函数的随机前沿模型类似的推导可得:Ki 0y i k ki i i k 1ln c =+lny ln P +u βββν=++∑其中,i c 为产商i 的成本,i y 为产出,ki P 为要素K 的价格,i u 为无效率项,i ν为成本函数的随机冲击。
随机前沿分析和包络数据分析SFA,DEA及运行结果

随机前沿分析和包络数据分析SFA,DEA及运⾏结果先推荐读这篇⽂章:邹志庄教授计量研究汇结,三部分总结经济研究经验(昨⽇,计量哥推荐出去之后,由于未能够把邹⾄庄教授名字校正正确,对此向各位读者和Chow教授表⽰抱歉).正⽂在经济学中,技术效率是指在既定的投⼊下产出可增加的能⼒或在既定的产出下投⼊可减少的能⼒。
常⽤度量技术效率的⽅法是⽣产前沿分析⽅法。
所谓⽣产前沿是指在⼀定的技术⽔平下,各种⽐例投⼊所对应的最⼤产出集合。
⽽⽣产前沿通常⽤⽣产函数表⽰。
前沿分析⽅法根据是否已知⽣产函数的具体的形式分为参数⽅法和⾮参数⽅法,前者以随机前沿分析(StochasticFrontierAnalysis,下⽂简称SFA)为代表,后者以数据包络分析(DataEnvelopeAnalysis,下⽂简称DEA)为代表。
⽬前,我国学者已将这两种⽅法⼴泛应⽤于各个领域,但在使⽤过程中也存在⼀些问题,尤其对于SFA。
⽽SFA与DEA各有其利弊,不能简单地认为⼀种⽐另⼀种好,必须根据具体问题和实际度量结果做出判断。
因此如何正确合理地使⽤这两种⽅法是⽬前⾯临的主要问题。
针对上述情况,本⽂将⾸先简要总结SFA与DEA中最常⽤的模型;然后分别指出使⽤中⼀些关键的地⽅和常见的问题;最后⽐较分析这种两种⽅法。
1 SFA模型在经济学中,技术效率的概念应⽤⼴泛。
Koopmans⾸先提出了技术效率的概念,他将技术有效定义为:在⼀定的技术条件下,如果不减少其它产出就不可能增加任何产出,或者不增加其它投⼊就不可能减少任何投⼊,则称该投⼊产出为技术有效的。
Farrell⾸次提出了技术效率的前沿测定⽅法,并得到了理论界的⼴泛认同,成为了效率测度的基础。
在实际应⽤中,前沿⾯是需要确定的。
其确定⽅法主要两种:⼀种是通过计量模型对前沿⽣产函数的参数进⾏统计估计,并在此基础上,对技术效率进⾏测定,这种⽅法被称为效率评价的“统计⽅法”或“参数⽅法”;另⼀种是通过求解数学中的线性规划来确定⽣产前沿⾯,并进⾏技术效率的测定,这种⽅法被称为“数学规划⽅法”或“⾮参数⽅法”。
【国家自然科学基金】_随机前沿分析(sfa)_基金支持热词逐年推荐_【万方软件创新助手】_20140801
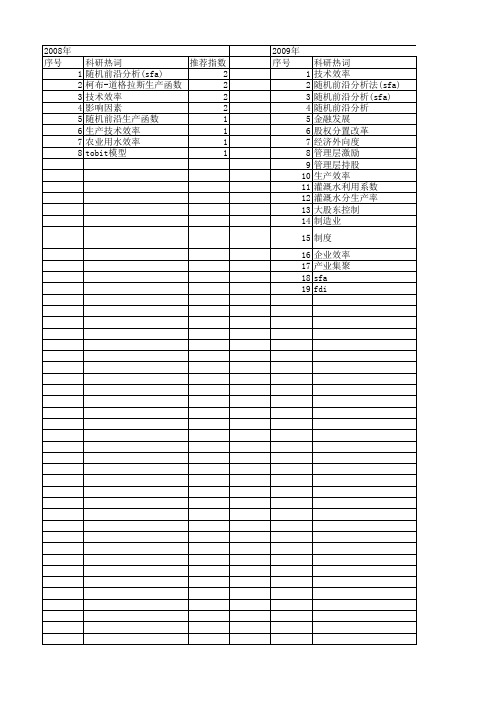
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
2014年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74
协同 区域市场需求规模不确定性 创意经济 出口贸易 农户技术效率 农地城市流转效率 农业产业化 军民融合 公交线路 企业规模 人力资源效率 人力资本 产权类型 产业集聚 产业竞争力 交通运输系统工程 主成分分析 专利转化效率 不良贷款 三阶段dea模型 x效率 malmquist指数
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51
科研热词 推荐指数 技术效率 8 随机前沿分析 7 随机前沿方法 4 随机前沿模型 3 随机前沿分析(sfa) 3 效率 3 影响因素 3 商业银行 3 sfa 3 高校校办产业 2 能源效率 2 投资来源 2 战略性新兴产业 2 成本效率 2 成本函数 2 创新效率 2 全要素生产率 2 fdi 2 高校知识创新链 1 高校 1 面板单位根 1 随机效应回归 1 随机性收敛 1 随机前沿生产函数 1 随机前沿分析方法(sfa) 1 长三角 1 自然因素 1 绿色经济 1 绩效评价 1 统计分析 1 空间差异 1 科技环境 1 科技创新 1 碳排放 1 知识溢出 1 滞后效应 1 湖北省 1 水资源利用效率 1 数据包络分析 1 政产学研用 1 技术转移效率 1 房地产上市公司 1 成本一效益效率 1 成本-效益效率 1 当地政府支持 1 外部运营环境 1 外资r&d 1 地区差异 1 国际比较 1 国防科技工业 1 国民健康 1 参数法 1
我国能源效率的地区差异及影响因素--基于异质性随机前沿边界模型的实证分析

我国能源效率的地区差异及影响因素--基于异质性随机前沿边界模型的实证分析张东辉;宋锋华【摘要】在异质性随机边界模型的分析框架下,基于我国大陆27个省、市、自治区1985—2012年的面板数据,对各省份能源利用的技术效率进行测算,并对能源效率地区差异、影响因素进行分析。
结果表明:我国的能源利用的技术效率整体水平不高,效率损失约为30%,但随着时间的推移呈现出技术效率逐渐上升的趋势;技术效率区域差距明显,东部区域最高,中部和西部区域的技术效率水平相近。
制定差异化产业结构、能源结构、产权结构和对外开放等目标,有利于技术效率水平的提高和缩小地区间的效率差距。
%Within the framework of heterogeneous random boundary models, this paper made an empirical study using the 1985 to 2012 panel data from the 27 provinces and regions to work out the technical efficiency of energy use of the regions,as well as the energy efficiency of regional differences and the influence factors. The results show that the technical efficiency of energy use in China is not high in general with a 30%efficiency loss, but rising gradually with the time. It varies considerably with region, with the eastern region having the best performance, and the central and western regions similarto each other. Differentiated goals in industrial structure, energy structure, property right structure and opening to the public is conducive to use the technical efficiency better and reduce the gap in efficiency between the regions.【期刊名称】《厦门理工学院学报》【年(卷),期】2015(000)002【总页数】8页(P52-59)【关键词】能源效率;地区差异;影响因素;技术效率;技术异质性;随机前沿模型【作者】张东辉;宋锋华【作者单位】新疆财经大学经济学院,新疆乌鲁木齐830012;新疆财经大学经济学院,新疆乌鲁木齐830012【正文语种】中文【中图分类】F124.5当前,我国的能源利用效率水平低于发达国家,甚至落后于巴西等部分发展中国家。
随机边界模型Stochastic Frontier Models

最大产出
SFA 的模型设定思想
TE(q, z) q 1 f (z)
(18.1)
q : 实际产出; f (z) : 理论产出; z : 要素投入
qi f (zi , ) TEi
qi f (zi , ) TEi exp(vi )
vi
~
N
(0,
2 v
)
(18.2) (18.3)
(18.60) (18.66)
Thanks
New Course: /Default.aspx?id=93
References 1
• Aigner, D., C. Lovell, P. Schmidt, 1977, Formulation and estimation of stochastic frontier production function models, Journal of Econometrics, 6 (1): 21-37.
u+it : 随时间变化的无效率项 (transient component)
Panel SFA: Pooled SFA model
yit 1 44x2i't 443vit uit ,
SF
vit :
iid
N
(0,
2 v
),
uit :
iid
N
(0,
2 u
)
(18.31)
Panel SFA:随机效应模型 (RE-SFA)
SF
inEff
(18.44)
• TE 的估计值将是有偏的
• 把那些个体异质性(公司文化, CEO特征等)影响产出的因素都归为“无 效率项”了
基于SFA模型的我国区域技术创新效率的实证研究

基于SFA模型的我国区域技术创新效率的实证研究一、本文概述本文旨在利用随机前沿分析(Stochastic Frontier Analysis,简称SFA)模型,对我国区域技术创新效率进行深入的实证研究。
技术创新是推动社会进步和经济发展的核心动力,而区域技术创新效率的高低直接影响着我国各地区的经济增长质量和速度。
因此,全面、准确地评估我国区域技术创新效率,对于优化创新资源配置、提升创新体系效能具有重要的理论和现实意义。
本文将简要介绍SFA模型的基本原理及其在技术创新效率研究中的应用。
随后,通过对我国各区域技术创新活动的数据收集与整理,运用SFA模型对区域技术创新效率进行量化分析。
研究将涵盖技术创新投入、产出以及环境因素等多个方面,以全面反映我国各区域技术创新效率的实际状况。
在实证研究中,本文将重点关注以下几个方面:一是我国各区域技术创新效率的总体水平及差异;二是影响区域技术创新效率的关键因素;三是如何优化创新资源配置,提升区域技术创新效率。
通过对这些问题的深入探讨,本文旨在为我国区域技术创新政策的制定和实施提供科学依据。
本文将对实证研究结果进行总结,并提出相应的政策建议。
通过提高区域技术创新效率,促进我国经济的持续、健康、快速发展,为实现创新型国家的战略目标贡献力量。
二、理论框架与模型构建技术创新效率是衡量一个区域技术创新能力和资源利用效果的重要指标。
在当前全球化和知识经济的背景下,技术创新已成为推动区域经济发展的核心动力。
基于随机前沿分析(SFA)模型,本研究旨在深入探究我国各区域技术创新效率的差异及其影响因素,为政策制定者提供决策参考。
SFA模型起源于经济学中的生产前沿理论,它假设每个生产单位都存在一个潜在的最大产出,而实际产出则受到各种非效率因素的影响,如技术无效、管理不善等。
通过估计生产单位的随机误差项和技术无效项,SFA模型能够准确地量化技术效率,并进一步分析影响技术效率的因素。
本研究采用SFA模型对我国各区域的技术创新效率进行实证研究。
【国家社会科学基金】_随机前沿分析方法(sfa)_基金支持热词逐年推荐_【万方软件创新助手】_20140808

2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
科研热词 随机前沿分析 技术效率 非参数方法 随机前沿分析方法 随机前沿分析(sfa) 营业税 空间计量 税收征管效率 测土配方施肥技术 本土技术转移 教育投入产出 技术效率损失模型 国际技术转移 全要素生产率 主成分分析 σ 收敛 β 收敛 tobit模型
推荐指数 3 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
科研热词 推荐指数 技术效率 2 影响因素 2 随机前沿生产函数 1 随机前沿分析方法(sfa) 1 随机前沿分析 1 进入退出 1 航空航天产业 1 生产率促进型投资 1 生产效率 1 湖北省 1 支出扩张 1 技术前沿 1 分位数回归分解 1 农地城市流转效率 1 农业技术 1 全要素生产率 1 sfa 1
2011年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
2011年 科研热词 随机前沿分析 技术效率 税收征管效率 sfa 能源消耗 股权结构 经济开放 效率评估 小麦生产 奶农 养殖方式 公共部门 企业效率 代理成本 中国粮食主产区 bc(1995)模型 推荐指数 3 3 2 2 1 1 1 1 1 1 1 1 1 1 1 1
科研热词 随机前沿方法 高科技产业 随机前沿分析法(sfa) 随机前沿分析 间接溢出效应 金融安全 经验分析 直接溢出效应 海外扩张 效率 技术效率 战略引资 外商直接投资 制造业 利润效率 创新效率 创新 创业板 ipo抑价
推荐指数 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
基于随机前沿分析的高校创新效率及差异研究

基于随机前沿分析的高校创新效率及差异研究
苏涛永;高琦
【期刊名称】《预测》
【年(卷),期】2012(031)006
【摘要】本文基于随机前沿分析(SFA)原理,以2004~2008年省际数据为样本,测算并分析中国高校创新效率及其区域差异.实证研究结论为:(1)中国高校创新效率平均水平较低,小于0.5,且呈下降趋势;(2)创新活动人员投入对创新效率的推动作用大于创新活动经费.(3)区域差异分析表明,中国高校创新投入存在规模不经济,高校在增加创新活动投入的同时,亟待加强创新能力的培养和科研管理水平的提升.
【总页数】5页(P61-65)
【作者】苏涛永;高琦
【作者单位】同济大学经济与管理学院,上海200092;同济大学经济与管理学院,上海200092
【正文语种】中文
【中图分类】G644
【相关文献】
1.长三角出口贸易的技术效率及其区域差异研究——基于随机前沿分析(SFA)技术的实证研究 [J], 郭际;叶卫美
2.中国地方政府公共服务成本效率的地区差异研究——基于多产出随机成本前沿模型 [J], 张蕊;王楠;冯鑫鑫
3.R&D影响下的工业行业技术效率部门差异研究——基于大中型工业企业37个
行业面板数据随机前沿分析 [J], 冯锋;李慧敏
4.不同规模稻谷种植的共同前沿技术效率分析——基于共同随机前沿生产函数的方法 [J], 王善高;王琪
5.高新技术产业创新效率地区差异研究——基于随机前沿生产函数 [J], 韩彦
因版权原因,仅展示原文概要,查看原文内容请购买。
中国科技成果转化效率及其影响因素研究_基于随机前沿函数的实证分析_董洁

收稿日期:2012-02-28基金项目:国家社会科学基金重点项目(10ATJ003);江苏统计应用研究基地基金项目(2012012)作者简介:董洁(1964-),女,辽宁沈阳人,博士、研究员、硕士生导师,研究方向为经济系统分析与管理;黄付杰(1987-),男,山东聊城人,硕士研究生,研究方向为科技统计。
中国科技成果转化效率及其影响因素研究———基于随机前沿函数的实证分析董洁a ,黄付杰b(江苏大学a.工商管理学院;b.财经学院,江苏镇江212013)摘要:通过收集2007 2010年我国31个省市科技成果转化的面板数据,采用因子分析法和随机前沿分析法,对我国科技成果转化效果和科技成果转化效率及其影响因素分别进行测度与比较分析。
研究发现:我国科技成果转化效率不高、各省市间存在较大差距;东部省市的科技成果转化效果和转化效率明显好于中西部省市;在影响科技成果转化的诸多因素中,政府支持起着最为关键的作用。
关键词:科技成果转化;因子分析;随机前沿分析中图分类号:F124.3文献标识码:A 文章编号:1001-8409(2012)10-0015-06Research on Transformation Efficiency ofSci -tech Achievements and Its Influencing Factors———An Empirical Analysis Based on Stochastic Frontier FunctionDONG Jie a ,HUANG Fu -jie b(a.School of Business and Management ;b.School of Financial and Economics ,Jiangsu University ,Zhenjiang 212013)Abstract :This paper compared and analyzed the efficiency of sci -tech achievements and its influencing factors through collecting the sci -tech Achievements of Chinese 31provinces panel data from 2007to 2010by factor analysis and stochastic frontier analysis.Result shows that china's scientific and technological achievements conversion efficiency is not high and there is a big gap between the provinces ;Effects and the conversion efficiency of scientific and technological achievements of the eastern is significantly better than the central and western provinces ;government support plays the most crucial role in the many factors that affect the scientific and technological achievements.Key words :transformation of sci -tech achievements ;factor analysis ;stochastic frontier analysis1引言近年来,随着高技术产业的发展日益成为经济发展的推动力,研发活动日益受到我国的重视,R&D 投入大幅增加,由此也引发了对R&D 推动经济增长效率的研究。
随机前沿分析(穆瑜秀11.27)

SFA
参数方法 是 存在无效率
技术效率、规模效
率、配置效率 投入产出的数量 截面数据 面板数据
技术效率、规模效率、配置
效率、技术进步、TFP的变化 投入产出的数量 截面数据 面板数据
所需要变量
所需要数据
随机前沿分析(SFA)与数据包络分析(DEA)的比较
SFA与DEA的优缺点比较
SFA
有统计特性; 有无统计特性 对参数进行t检验; 对模型本身进行LR检验 随机前沿面; 固定前沿面; 无统计特性
动的产出弹性); Translog 函数优点: 考虑了资本和劳动相互作用对于产出的影响,克服了C—D 函数 替代弹性固定为1的缺点。 如何选择使用哪种生产函数: 首先选择Translog函数,在参数估计后做β 3=β 4=β 5=0是否为0
的似然比检验(LR检验)。若不能拒绝β 3=β 4=β 5=0的原假设,
又分为随机性和确定性两种方法。
确定性前沿生产函数
是否考虑随 机因素影响 不考虑
随机前沿生产函数(SFA)
考虑
随机扰动项ε 应由v和u 组
把影响最优产出和平均 成; 误差项 产出的全部误差归入单 v是随机误差项/噪声(不可 侧的一个误差项,称为 控),计算系统非效率; 生产非效率。 计算技术非效率。
u是技术损失误差项(可控),
随机前沿生产函数模型
随机前沿生产函数模型: 在确定性生产函数的基础上提出了具有复合扰动项的随机前 沿模型。Aigner,Lovell和Schmidt(1977)以及Meeusen和 Broeck(1977)都分别提出了如下形式的随机前沿面生产函数:
式中, 代表第i家公司的产出; 是包含投入对数的K*1向
2 u
式1表明 是独立同分布的正态随机变量,服从期望为0,
基于SFA模型的我国旅游业效率估计与区域差异性分析

其中 , Y + . 代表第 t 年第 i 个地 区旅 游产
Байду номын сангаас
业的总产 出水平 ;L + . 代表第 t 年第 i 个地 区
旅游产业的劳动力要素投入量 ,K . + 表示第t
模 型 构 建 与 数 据 样 本
( 一 )模 型 设 定
年第 i 个地区旅 游产业的资本要素投入量 ; A表示旅 游业 的技术要素投入水平 ;1 3 和
Y=f ( x ;1 3) e x p( V—U) ( 1 ) 其中, y 表示产 出水平; x 表示投入量;
反映时间因素对技 术非效率的影响 , 其 中,
T 1 为模型 的参数 , 当T 1 >0 时, 随着 时间推
( 2 0 1 0) 利 用随机前沿 函数来评价 西班牙
旅游业 的资源利用效率 ,他 们认 为西班牙 应重视旅游 资源的可持续发展原 则 ,发展
在式 f 6) 中,y是待估 计参数 ,表示
随机误 差项 中技术 非效率所 占比重。若 y
值接近 1 ,则误 差项主要 由技术非效 率引 起 ;若 y接近 于 O ,则实 际产 出水平 与随
基 于 S F A 模 型 的 我 国 旅 游 业 效 率 估 计
与区 域差异 性分 析
■ 孟 涛 副教授 ( 青海 民族 大学工商管理 学院 西 宁 8 1 0 0 0 0)
◆ 中图分 类号 :F 0 6 2 . 9 文献标 识码 :A
我 国省域旅游 业的空间差异性 ,认为我 国
0 。当 u = 0时,有 Y=f ( x ;1 3) e x p( V) ,
国 内也有很 多学者对旅游业 的效 率进 行评 价, 但是大部分 学者 都采用 DE A评价 的方 法对 我 国旅 游 业 的效 率 进行 估计 ,采 用 S F A对我 国旅 游业 效率评价和 区域差 异性
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
随机前沿模型(SFA )原理和软件实现
一、SFA 原理
在经济学中,常常需要估计生产函数或者成本函数。
生产函数f (x)的定义为:在给定投入x 情况下的最大产出。
但现实中的产商可能达不到最大产出的前沿,为了,假设产商i 的产量为:
i i i y f (x ,)βξ= (1) 其中,β为待估参数;i ξ为产商i 的水平,满足i 01ξ<≤。
如果i =1ξ,则产商i 正好处于效率前沿。
同时,考虑生产函数还会受到随机冲击,故将方程(1)改写成:
i v i i i y f (x ,)e βξ= (2)
其中,i v e 0>为随机冲击。
方程(2)意味着生产函数的前沿i v i f (x ,)e β是随机的,故此类模型称为“随机前沿模型”(stochastic frontier model )。
随机前沿模型最早由Aigner, Lovell and Schmidt(1977)提出,并在实证领域运用广泛,Kumbhakar and Lovell(2000)为该领域的研究写了一本著作,有兴趣的同学可以去参考。
假设o k
1i 1i ki f (x ,)e x x ββββ=L (柯布道格拉斯生产函数,共有K 个投入品),则对方程(2)取对数可得:
K i 0k ki i i k 1ln y =+ln x ln ββξν=++∑ (3)
由于i 01ξ<≤,故i ln 0ξ≤。
定义i i u =-ln 0ξ≥,则方程3可以写成:
K
i 0k ki i i k 1ln y =+ln x -u ββν=+∑ 其中,i u 0≥为“无效率”项,反映产商i 距离效率前沿面的距离。
混合扰动项i i i ενμ=-分布不对称,使用OLS 估计不能估计无效率项i u 。
为了估计无效率项i u ,必须对i i νμ、的分布作出假设,并进行更有效率的MLE (最大似然估计)估计。
一般,无效率项的分布假设有如下几种:
(1)半正态分布
(2)截断正态分布
(3)指数分布
在一般的论文中,使用的最多的是半正态分布
随机前沿模型可以很容易地用于估计成本函数,经过与生产函数的随机前沿模型类似的推导可得:
K
i 0y i k ki i i k 1ln c =+lny ln P +u βββν=++∑ 其中,i c 为产商i 的成本,i y 为产出,ki P 为要素K 的价格,i u 为无效率项,i ν为成本函数的随机冲击。
注意混合误差项的形式(符号)。
对于成本函数,i u =0意味着产商达到最低成本的效率前沿;
反之,如果i u 0>,则产商需付出更高的成本。
i u 是否存在的检验
使用随机前沿模型的前提是无效率项i u 存在,此假定可以通过检验
“220u 1u H : =0 vs H : >0σσ”来判断是否成立。
使用单边的广义似然比检验。
二、软件实现
软件是由Tim Coelli 开发的一款专门用于完成随机前沿分析的软件,它可以用最大似然估计随机前沿成本模型和随机前沿生产模型,下面简单介绍一下该软件的使用方法,更加详细的说明可以参考英文指导《A Guide to FRONTIER Version : A Computer Program for Stochastic Frontier Production and Cost Function Estimation 》
用于输入数据,是一个纯文本文件,数据文件的格式必须是3+K[+p]列。
第一列是评价体系的序号;
第二列是时期t ;
第三列是因变量;
第四列之后是K个自变量;
[+p]仅当选择TE EFFECTS MODEL模型输入。
设置命令
11=ERROR COMPONENTS MODEL, 2=TE EFFECTS MODEL
选择模型
DATA FILE NAME
数据文件
OUTPUT FILE NAME
结果存储文件
2 1=PRODUCTION FUNCTION, 2=COST FUNCTION
选择生产模型(1)还是成本模型(2)
n LOGGED DEPENDENT VARIABLE (Y/N)
变量是不是已经进行了对数运算
25 NUMBER OF CROSS-SECTIONS
评价体系数目
1 NUMBER OF TIME PERIODS
时期数目
25 NUMBER OF OBSERVATIONS IN TOTAL
总记录数目
2 NUMBER OF REGRESSOR VARIABLES (Xs)
自变量个数
Y MU (Y/N) [OR DELTA0 (Y/N) IF USING TE EFFECTS MODEL]假设U的分布。
Y表示截断分布,N表示半正态分布
n ETA (Y/N) [OR NUMBER OF TE EFFECTS REGRESSORS (Zs)] y 表示时变模型,n表示非时变模型。
n STARTING VALUES (Y/N)选择n
其他设置保持不变。