BP神经网络整定的PID算法 matlab源程序
BP神经网络预测的matlab代码

BP神经网络预测的matlab代码附录5:BP神经网络预测的matlab代码: P=[ 00.13860.21970.27730.32190.35840.38920.41590.43940.46050.47960.49700.52780.55450.59910.60890.61820.62710.63560.64380.65160.65920.66640.67350.72220.72750.73270.73780.74270.74750.75220.75680.76130.76570.7700]T=[0.4455 0.323 0.4116 0.3255 0.4486 0.2999 0.4926 0.2249 0.48930.2357 0.4866 0.22490.4819 0.2217 0.4997 0.2269 0.5027 0.217 0.5155 0.1918 0.5058 0.2395 0.4541 0.2408 0.4054 0.2701 0.3942 0.3316 0.2197 0.2963 0.5576 0.1061 0.4956 0.267 0.5126 0.2238 0.5314 0.2083 0.5191 0.208 0.5133 0.18480.5089 0.242 0.4812 0.2129 0.4927 0.287 0.4832 0.2742 0.5969 0.24030.5056 0.2173 0.5364 0.1994 0.5278 0.2015 0.5164 0.2239 0.4489 0.2404 0.4869 0.2963 0.4898 0.1987 0.5075 0.2917 0.4943 0.2902 ]threshold=[0 1]net=newff(threshold,[11,2],{'tansig','logsig'},'trainlm');net.trainParam.epochs=6000net.trainParam.goal=0.01LP.lr=0.1;net=train(net,P',T')P_test=[ 0.77420.77840.78240.78640.79020.7941 ] out=sim(net,P_test')友情提示:以上面0.7742为例0.7742=ln(47+1)/5因为网络输入有一个元素,对应的是测试时间,所以P只有一列,Pi=log(t+1)/10,这样做的目的是使得这些数据的范围处在[0 1]区间之内,但是事实上对于logsin命令而言输入参数是正负区间的任意值,而将输出值限定于0到1之间。
BP神经网络整定的PID算法_matlab源程序

%BP based PID Controlclear all;close all;xite=0.28; % 学习速率alfa=0.001; %惯性系数IN=4;H=5;Out=3; %NN Structure(构造,神经网络结构)wi=0.50*rands(H,IN);wi_1=wi;wi_2=wi;wi_3=wi;wo=0.50*rands(Out,H);wo_1=wo;wo_2=wo;wo_3=wo;%构成变量Oh=zeros(H,1); %Output from NN middle layerI=Oh; %Input to NN middle layererror_2=0;error_1=0;ts=0.01;sys=tf(2.6126,[1,3.201,2.7225]); %建立被控对象传递函数(LTI Viewer对象模型sys=tf(num,den)将由传递函数模型所描述系统封装成对应的系统对象模型。
dsys=c2d(sys,ts,'z'); %把传递函数离散化(零阶保持器法离散化)[num,den]=tfdata(dsys,'v'); %离散化后提取分子、分母(提取每项的常数)for k=1:1:2000 %频率参数,构成一维数组time(k)=k*ts;rin(k)= 40;yout(k)=-den(2)*y_1-den(3)*y_2+num(2)*u_2+num(3)*u_3;error(k)=rin(k)-yout(k);xi=[rin(k),yout(k),error(k),1];x(1)=error(k)-error_1; %计算Px(2)=error(k);%计算Ix(3)=error(k)-2*error_1+error_2;%计算Depid=[x(1);x(2);x(3)];I=xi*wi'; %the output of the input layer , and 1*5for j=1:1:HOh(j)=(exp(I(j))-exp(-I(j)))/(exp(I(j))+exp(-I(j))); %Middle layer's outputendK=wo*Oh; %Output Layer(the input of output layer)for l=1:1:OutK(l)=exp(K(l))/(exp(K(l))+exp(-K(l))); %Getting kp,ki,kdendkp(k)=K(1);ki(k)=K(2);kd(k)=K(3);Kpid=[kp(k),ki(k),kd(k)];du(k)=Kpid*epid; % the increment(增加) of the output "u"u(k)=u_1+du(k); % the output of the value of controllingif u(k)>=45 % Restricting(限制)the output of controller u(k)=45;endif u(k)<=-45u(k)=-45;enddyu(k)=sign((yout(k)-y_1)/(u(k)-u_1+0.0000001)); %当x<0时,sign(x)=-1当x=0时,sign(x)=0;当x>0时,sign(x)=1。
BP神经网络matlab源程序代码

close allclearecho onclc% NEWFF——生成一个新的前向神经网络% TRAIN——对 BP 神经网络进行训练% SIM——对 BP 神经网络进行仿真% 定义训练样本% P为输入矢量P=[0.7317 0.6790 0.5710 0.5673 0.5948;0.6790 0.5710 0.5673 0.5948 0.6292; ... 0.5710 0.5673 0.5948 0.6292 0.6488;0.5673 0.5948 0.6292 0.6488 0.6130; ...0.5948 0.6292 0.6488 0.6130 0.5654; 0.6292 0.6488 0.6130 0.5654 0.5567; ...0.6488 0.6130 0.5654 0.5567 0.5673;0.6130 0.5654 0.5567 0.5673 0.5976; ...0.5654 0.5567 0.5673 0.5976 0.6269;0.5567 0.5673 0.5976 0.6269 0.6274; ...0.5673 0.5976 0.6269 0.6274 0.6301;0.5976 0.6269 0.6274 0.6301 0.5803; ...0.6269 0.6274 0.6301 0.5803 0.6668;0.6274 0.6301 0.5803 0.6668 0.6896; ...0.6301 0.5803 0.6668 0.6896 0.7497];% T为目标矢量T=[0.6292 0.6488 0.6130 0.5654 0.5567 0.5673 0.5976 ...0.6269 0.6274 0.6301 0.5803 0.6668 0.6896 0.7497 0.8094];% Ptest为测试输入矢量Ptest=[0.5803 0.6668 0.6896 0.7497 0.8094;0.6668 0.6896 0.7497 0.8094 0.8722; ...0.6896 0.7497 0.8094 0.8722 0.9096];% Ttest为测试目标矢量Ttest=[0.8722 0.9096 1.0000];% 创建一个新的前向神经网络net=newff(minmax(P'),[12,1],{'logsig','purelin'},'traingdm');% 设置训练参数net.trainParam.show = 50;net.trainParam.lr = 0.05;net.trainParam.mc = 0.9;net.trainParam.epochs = 5000;net.trainParam.goal = 0.001;% 调用TRAINGDM算法训练 BP 网络[net,tr]=train(net,P',T);% 对BP网络进行仿真A=sim(net,P');figure;plot((1993:2007),T,'-*',(1993:2007),A,'-o');title('网络的实际输出和仿真输出结果,*为真实值,o为预测值');xlabel('年份');ylabel('客运量');% 对BP网络进行测试A1=sim(net,Ptest');figure;plot((2008:2010),Ttest','-*',(2008:2010),A1,'-o');title('测试后网络的实际输出和仿真输出结果,*为真实值,o为预测值'); xlabel('年份');ylabel('客运量');% 计算仿真误差errorE = T - A;MSE=mse(E);figure;plot(1:length(E),E,'-.');title('误差变化图')如有侵权请联系告知删除,感谢你们的配合!。
基于BP神经网络的PID控制器及其MATLAB仿真

(4)
( =1,2,...n)
(5)
图 2 基于 BP 网络的 PID 控制框图
中国新技术新产品
- 13 -
由于输出层的神经元的活化函数不能为负数, 取非负的 Sigmoid 函数:
性能指标函数为: (6)
由梯度下降法,我们取加权系数的修整量为:
(7) 其中, 为学习效率; 为惯性系数。
(8)
这里,
未知,为表示其变化轨迹,
用符号函数
取代。
在 PID 控制器的应用中,使神经元的输出状
态对应于 PID 控制器的三个可调参数 Kp、Ki、Kd,
高新技术
中国新技术新产品 2009 NO.10
China New Technologies and Products
基于 BP 神经网络的 PID 控制器及其 MATLAB 仿真
谢利英 (衡阳财经工业职业技术学院,湖南 衡阳 421008)
摘 要: PID 控制算法简单、应用广泛,既能消除余差,又能提高系统的稳定性,但其 P 环节、I 环节、D 环节的控制参数却参数难以整定;BP 神经 网络算法具有很强的数字运算能力,因此,可通过 BP 神经网络自学习、加权系数调整,实现 PID 的最优调整,本文以小车控制为例,利用 BP 神 经网络的学习能力进行 PID 参数的在线整定,并进行了 MATLAB 仿真,结果表明,利用 BP 神经网络可很快的找到 PID 的控制参数。 关键词:BP 网络;PID 控制;MATLAB 仿真
行 PID 控制器的调整。通过仿真可以看出,利用
BP 神经网络进行 PID 控制,能很快得到最佳的
kp、ki、kd 值,从而有效控制被控对象,为工业
应用提供了一种快速控制手段。由于基于 BP 网络
基于神经网络的PID自整定实验及其源程序

实验原理PID控制要取得较好的控制效果,就必须通过调整好比例、积分和微分三种控制作用,形成控制量中既相互配合又相互制约的关系,这种关系不一定是简单的“线性组合”,从变化无穷的非线性组合中可以找到最佳的。
神经网络所具有的任意非线性表达能力,可以通过对系统性能的学习来实现具有最佳组合的PID控制。
采用BP网络,可以建立参数Kp,Ki,Kd自学习的PID控制器。
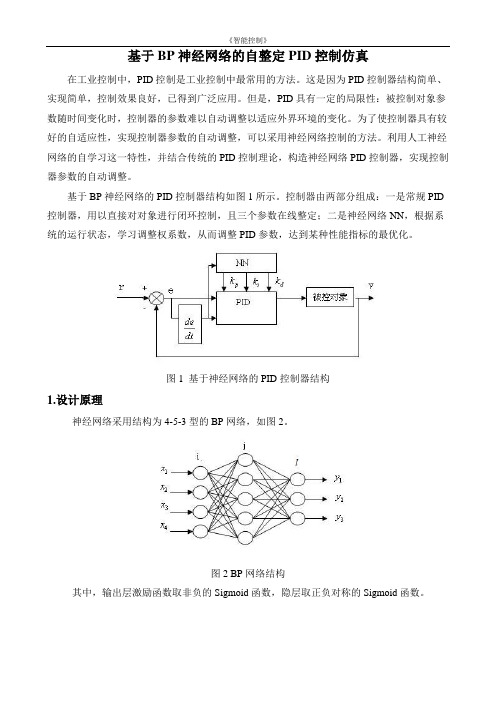
基于BP网络的PID控制系统如图1所示,控制器由两部分构成:(1)经典的PID控制器,直接对被控对象进行闭环控制,并且三个参数Kp,Ki,Kd 为在线调整方式。
(2)神经网络,根据系统的运行状态,调节PID控制器的参数,以达到某种性能指标的最优化,使输出层神经元的输出状态对应于PID控制器的三个可调参数Kp,Ki,Kd通过神经网络的自学习、加权系数的调整,使神经网络输出对应于某种最优控制律下的PID控制器参数。
图1 基于神经网络的PID控制器结构图1中神经网络采用结构为三层的BP网络。
BP网络是一种单向传播的多层前向网络。
输入节点对应系统的运行状态量,如系统的偏差与偏差变化率,必要时要进行归一化处理。
输入变量的个数取决于被控系统的复杂程度;输出节点对应的是PID的三个可调参数。
由于输出不能为负,所以输出层活化函数取非负的Sigmoid函数,隐层取正负对称的Sigmoid函数。
本系统取BP网络的如图2所示。
图2 BP网络结构经典增量式数字PID的控制算法为:(1)网络的学习过程由正向和反向传播两部分组成。
如果输出层不能得到期望输出,那么转入反向传播过程,通过修改各层神经元的权值,使得输出误差信号最小。
输出层节点分别对应三个可调参数、、。
取性能指标函数为:按照梯度下降法修正网络的权系数,即按E(k)对加权系数的负梯度方向搜索调整,并附加一使快速收敛全局极小的惯性项式中,η为学习速率;α为惯性系数。
又基于BP 网络的PID 控制器控制算法如下:(1) 确定BP 网络的结构,即确定输入层节点数M 和隐含层节点数Q ,并给出各层加权系数的初值W 1ij(0)和W 2li(0),选定学校数率η和惯性系数α,此时K=1;(2) 采样得到rin(k)和yout(k),计算该时刻误差error(k)=rin(k)-yout(k); (3) 计算神经网络NN 各层神经元的输入、输出,NN 输出层的输出即为PID 控制器的三个可调参数Kp ,Ki ,Kd ;(4) 根据式()计算PID 控制器的输出u(k); (5) 进行神经网络学习,在线调整加权系数W 1ij(k)和W 2li(k),实现PID 控制参数的自适应调整;(6) 置k=k+1,返回(1)。
MATLAB程序代码--BP神经网络的设计实例

MATLAB程序代码-—BP神经网络的设计实例例1 采用动量梯度下降算法训练BP 网络。
训练样本定义如下:输入矢量为p =[—1 -2 3 1-1 1 5 —3]目标矢量为t = [-1 —1 1 1]解:本例的MA TLAB 程序如下:close allclearecho onclc% NEWFF--生成一个新的前向神经网络% TRAIN——对BP 神经网络进行训练% SIM—-对BP 神经网络进行仿真pause% 敲任意键开始clc% 定义训练样本% P 为输入矢量P=[-1,—2,3,1; -1, 1,5, -3];% T 为目标矢量T=[-1,—1,1,1];pause;clc%创建一个新的前向神经网络net=newff(minmax(P),[3,1],{'tansig’,'purelin'},'traingdm')%当前输入层权值和阈值inputWeights=net。
IW{1,1}inputbias=net.b{1}% 当前网络层权值和阈值layerWeights=net。
LW{2,1}layerbias=net。
b{2}pauseclc% 设置训练参数net.trainParam.show = 50;net.trainParam。
lr = 0.05;net。
trainParam.mc = 0。
9;net。
trainParam.epochs = 1000;net.trainParam。
goal = 1e—3;pauseclc%调用TRAINGDM 算法训练BP 网络[net,tr]=train(net,P,T);pauseclc%对BP 网络进行仿真A = sim(net,P)% 计算仿真误差E = T — AMSE=mse(E)pauseclcecho off例2 采用贝叶斯正则化算法提高BP 网络的推广能力。
在本例中,我们采用两种训练方法,即L—M 优化算法(trainlm)和贝叶斯正则化算法(trainbr),用以训练BP 网络,使其能够拟合某一附加有白噪声的正弦样本数据。
(完整版)BP神经网络matlab实例(简单而经典)

p=p1';t=t1';[pn,minp,maxp,tn,mint,maxt]=premnmx(p,t); %原始数据归一化net=newff(minmax(pn),[5,1],{'tansig','purelin'},'traingdx');%设置网络,建立相应的BP网络net.trainParam.show=2000; % 训练网络net.trainParam.lr=0.01;net.trainParam.epochs=100000;net.trainParam.goal=1e-5;[net,tr]=train(net ,pn,tn); %调用TRAINGDM算法训练BP 网络pnew=pnew1';pnewn=tramnmx(pnew,minp,maxp);anewn=sim(net,pnewn); %对BP网络进行仿真anew=postmnmx(anewn,mint,maxt); %还原数据y=anew';1、BP网络构建(1)生成BP网络=net newff PR S S SNl TF TF TFNl BTF BLF PF(,[1 2...],{ 1 2...},,,)PR:由R维的输入样本最小最大值构成的2R⨯维矩阵。
S S SNl:各层的神经元个数。
[ 1 2...]{ 1 2...}TF TF TFNl:各层的神经元传递函数。
BTF:训练用函数的名称。
(2)网络训练[,,,,,] (,,,,,,)=net tr Y E Pf Af train net P T Pi Ai VV TV(3)网络仿真=[,,,,] (,,,,)Y Pf Af E perf sim net P Pi Ai T{'tansig','purelin'},'trainrp'2、BP网络举例举例1、%traingdclear;clc;P=[-1 -1 2 2 4;0 5 0 5 7];T=[-1 -1 1 1 -1];%利用minmax函数求输入样本范围net = newff(minmax(P),T,[5,1],{'tansig','purelin'},'trainrp');net.trainParam.show=50;%net.trainParam.lr=0.05;net.trainParam.epochs=300;net.trainParam.goal=1e-5;[net,tr]=train(net,P,T);net.iw{1,1}%隐层权值net.b{1}%隐层阈值net.lw{2,1}%输出层权值net.b{2}%输出层阈值sim(net,P)举例2、利用三层BP神经网络来完成非线性函数的逼近任务,其中隐层神经元个数为五个。
bp神经网络matlab实例(bp神经网络matlab实例)

bp神经网络matlab实例(bp神经网络matlab实例)Case 1 training BP network by momentum gradient descent algorithm.Training samples are defined as follows:Input vector asP =[-1 -2 31-1 15 -3]The target vector is t = [-1 -1 1 1]Solution: the MATLAB program of this example is as follows:Close allClearEcho onCLC% NEWFF - generating a new feedforward neural network% TRAIN -- training BP neural network% SIM -- Simulation of BP neural networkPauseStart by hitting any keyCLCPercent defines training samples% P as input vectorP=[-1, -2, 3, 1; -1, 1, 5, -3];% T is the target vectorT=[-1, -1, 1, 1];Pause;CLC% create a new feedforward neural networkNet=newff (minmax (P), [3,1],{'tansig','purelin'},'traingdm')The current input layer weights and thresholds InputWeights=net.IW{1,1}Inputbias=net.b{1}The current network layer weights and thresholdsLayerWeights=net.LW{2,1}Layerbias=net.b{2}PauseCLC% set training parametersNet.trainParam.show = 50;Net.trainParam.lr = 0.05;Net.trainParam.mc = 0.9;Net.trainParam.epochs = 1000;Net.trainParam.goal = 1e-3;PauseCLC% call TRAINGDM algorithm to train BP network [net, tr]=train (net, P, T);PauseCLCSimulation of BP network by%A = sim (net, P)Calculate the simulation errorE = T - AMSE=mse (E)PauseCLCEcho offExample 2 adopts Bayesian regularization algorithm to improve the generalization ability of BP network. In this case, we used two kinds of training methods, namely L-M algorithm (trainlm) and the Bias regularization algorithm (trainbr), is used to train the BP network, so that it can fit attached to a white noise sine sample data. Among them, the sample data can be generated as follows MATLAB statements:Input vector: P = [-1:0.05:1];Target vector: randn ('seed', 78341223);T = sin (2*pi*P) +0.1*randn (size (P));Solution: the MATLAB program of this example is as follows: Close allClearEcho onCLC% NEWFF - generating a new feedforward neural network% TRAIN -- training BP neural network% SIM -- Simulation of BP neural networkPauseStart by hitting any keyCLC% define training sample vector% P as input vectorP = [-1:0.05:1];% T is the target vectorRandn ('seed', 78341223); T = sin (2*pi*P) +0.1*randn (size (P));Draw the sample data pointsPlot (P, T, +);Echo offHold on;Plot (P, sin (2*pi*P), ':');Draw sine curves without noiseEcho onCLCPauseCLC% create a new feedforward neural networkNet=newff (minmax (P), [20,1], {'tansig','purelin'});PauseCLCEcho offCLCDisp ('1. L-M optimization algorithm TRAINLM'); disp ('2. Bayesian regularization algorithm TRAINBR');Choice=input (\ "please select training algorithm (1,2): ');Figure (GCF);If (choice==1)Echo onCLC% using L-M optimization algorithm TRAINLMNet.trainFcn='trainlm';PauseCLC% set training parametersnet.trainparam.epochs = 500;net.trainparam.goal = 1e-6;NET(.NET);%重新初始化暂停中图分类号“(选择= = 2)回声中图分类号%采用贝叶斯正则化算法trainbr trainfcn = 'trainbr”网;暂停中图分类号%设置训练参数net.trainparam.epochs = 500;randn(“种子”,192736547);NET(.NET);%重新初始化暂停中图分类号结束调用相应算法训练BP网络% [净额],列车=(净额,P,T);暂停中图分类号对BP网络进行仿真%a = sim(NET,p);%计算仿真误差e = a;MSE=MSE(e)暂停中图分类号%绘制匹配结果曲线关闭所有;图(p,a,p,t,+,p,p,p(2),“,”;暂停;中图分类号回音通过采用两种不同的训练算法,我们可以得到如图1和图2所示的两种拟合结果。
(整理)BP神经网络matlab实现和matlab工具箱使用实例.

(整理)BP神经网络matlab实现和matlab工具箱使用实例.BP神经网络matlab实现和matlab工具箱使用实例经过最近一段时间的神经网络学习,终于能初步使用matlab实现BP网络仿真试验。
这里特别感谢研友sistor2004的帖子《自己编的BP算法(工具:matlab)》和研友wangleisxcc的帖子《用C++,Matlab,Fortran实现的BP算法》前者帮助我对BP算法有了更明确的认识,后者让我对matlab下BP函数的使用有了初步了解。
因为他们发的帖子都没有加注释,对我等新手阅读时有一定困难,所以我把sistor2004发的程序稍加修改后加注了详细解释,方便新手阅读。
%严格按照BP网络计算公式来设计的一个matlab程序,对BP网络进行了优化设计%yyy,即在o(k)计算公式时,当网络进入平坦区时(<0.0001)学习率加大,出来后学习率又还原%v(i,j)=v(i,j)+deltv(i,j)+a*dv(i,j); 动量项clear allclcinputNums=3; %输入层节点outputNums=3; %输出层节点hideNums=10; %隐层节点数maxcount=20000; %最大迭代次数samplenum=3; %一个计数器,无意义precision=0.001; %预设精度yyy=1.3; %yyy是帮助网络加速走出平坦区alpha=0.01; %学习率设定值a=0.5; %BP优化算法的一个设定值,对上组训练的调整值按比例修改字串9error=zeros(1,maxcount+1); %error数组初始化;目的是预分配内存空间errorp=zeros(1,samplenum); %同上v=rand(inputNums,hideNums); %3*10;v初始化为一个3*10的随机归一矩阵; v表输入层到隐层的权值deltv=zeros(inputNums,hideNums); %3*10;内存空间预分配dv=zeros(inputNums,hideNums); %3*10;w=rand(hideNums,outputNums); %10*3;同Vdeltw=zeros(hideNums,outputNums);%10*3dw=zeros(hideNums,outputNums); %10*3samplelist=[0.1323,0.323,-0.132;0.321,0.2434,0.456;-0.6546,-0.3242,0.3255]; %3*3;指定输入值3*3(实为3个向量)expectlist=[0.5435,0.422,-0.642;0.1,0.562,0.5675;-0.6464,-0.756,0.11]; %3*3;期望输出值3*3(实为3个向量),有导师的监督学习count=1;while (count<=maxcount) %结束条件1迭代20000次c=1;while (c<=samplenum)for k=1:outputNumsd(k)=expectlist(c,k); %获得期望输出的向量,d(1:3)表示一个期望向量内的值endfor i=1:inputNumsx(i)=samplelist(c,i); %获得输入的向量(数据),x(1:3)表一个训练向量字串4end%Forward();for j=1:hideNumsnet=0.0;for i=1:inputNumsnet=net+x(i)*v(i,j);%输入层到隐层的加权和∑X(i)V(i)endy(j)=1/(1+exp(-net)); %输出层处理f(x)=1/(1+exp(-x))单极性sigmiod函数endfor k=1:outputNumsnet=0.0;for j=1:hideNumsnet=net+y(j)*w(j,k);endif count>=2&&error(count)-error(count+1)<=0.0001o(k)=1/(1+exp(-net)/yyy); %平坦区加大学习率else o(k)=1/(1+exp(-net)); %同上endend%BpError(c)反馈/修改;errortmp=0.0;for k=1:outputNumserrortmp=errortmp+(d(k)-o(k))^2; %第一组训练后的误差计算enderrorp(c)=0.5*errortmp; %误差E=∑(d(k)-o(k))^2 * 1/2%end%Backward();for k=1:outputNumsyitao(k)=(d(k)-o(k))*o(k)*(1-o(k)); %输入层误差偏导字串5endfor j=1:hideNumstem=0.0;for k=1:outputNumstem=tem+yitao(k)*w(j,k); %为了求隐层偏导,而计算的∑endyitay(j)=tem*y(j)*(1-y(j)); %隐层偏导end%调整各层权值for j=1:hideNumsfor k=1:outputNumsdeltw(j,k)=alpha*yitao(k)*y(j); %权值w的调整量deltw(已乘学习率)w(j,k)=w(j,k)+deltw(j,k)+a*dw(j,k);%权值调整,这里的dw=dletw(t-1),实际是对BP算法的一个dw(j,k)=deltw(j,k); %改进措施--增加动量项目的是提高训练速度endendfor i=1:inputNumsfor j=1:hideNumsdeltv(i,j)=alpha*yitay(j)*x(i); %同上deltwv(i,j)=v(i,j)+deltv(i,j)+a*dv(i,j);dv(i,j)=deltv(i,j);endendc=c+1;end%第二个while结束;表示一次BP训练结束double tmp;tmp=0.0; 字串8for i=1:samplenumtmp=tmp+errorp(i)*errorp(i);%误差求和endtmp=tmp/c;error(count)=sqrt(tmp);%误差求均方根,即精度if (error(count)<precision)%另一个结束条件< p="">break;endcount=count+1;%训练次数加1end%第一个while结束error(maxcount+1)=error(maxcount);p=1:count;pp=p/50;plot(pp,error(p),"-"); %显示误差然后下面是研友wangleisxcc的程序基础上,我把初始化网络,训练网络,和网络使用三个稍微集成后的一个新函数bpnet %简单的BP神经网络集成,使用时直接调用bpnet就行%输入的是p-作为训练值的输入% t-也是网络的期望输出结果% ynum-设定隐层点数一般取3~20;% maxnum-如果训练一直达不到期望误差之内,那么BP迭代的次数一般设为5000% ex-期望误差,也就是训练一小于这个误差后结束迭代一般设为0.01% lr-学习率一般设为0.01% pp-使用p-t虚拟蓝好的BP网络来分类计算的向量,也就是嵌入二值水印的大组系数进行训练然后得到二值序列% ww-输出结果% 注明:ynum,maxnum,ex,lr均是一个值;而p,t,pp,ww均可以为向量字串1% 比如p是m*n的n维行向量,t那么为m*k的k维行向量,pp为o*i的i维行向量,ww为o* k的k维行向量%p,t作为网络训练输入,pp作为训练好的网络输入计算,最后的ww作为pp经过训练好的BP训练后的输出function ww=bpnet(p,t,ynum,maxnum,ex,lr,pp)plot(p,t,"+");title("训练向量");xlabel("P");ylabel("t");[w1,b1,w2,b2]=initff(p,ynum,"tansig",t,"purelin"); %初始化含一个隐层的BP网络zhen=25; %每迭代多少次更新显示biglr=1.1; %学习慢时学习率(用于跳出平坦区)litlr=0.7; %学习快时学习率(梯度下降过快时)a=0.7 %动量项a大小(△W(t)=lr*X*ん+a*△W(t-1))tp=[zhen maxnum ex lr biglr litlr a 1.04]; %trainbpx[w1,b1,w2,b2,ep,tr]=trainbpx(w1,b1,"tansig",w2,b2,"purelin", p,t,tp);ww=simuff(pp,w1,b1,"tansig",w2,b2,"purelin"); %ww就是调用结果下面是bpnet使用简例:%bpnet举例,因为BP网络的权值初始化都是随即生成,所以每次运行的状态可能不一样。
BP神经网络matlab源程序代码

BP神经网络matlab源程序代码)%******************************%学习程序%******************************%%======原始数据输入========p=[2845 2833 4488;2833 4488 4554;4488 4554 2928;4554 2928 3497;2928 3497 2261;...3497 2261 6921;2261 6921 1391;6921 1391 3580;1391 3580 4451;3580 4451 2636;...4451 2636 3471;2636 3471 3854;3471 3854 3556;3854 3556 2659;3556 2659 4335;...2659 4335 2882;4335 2882 4084;4335 2882 1999;2882 1999 2889;1999 2889 2175;...2889 2175 2510;2175 2510 3409;2510 3409 3729;3409 3729 3489;3729 3489 3172;...3489 3172 4568;3172 4568 4015;]';%===========期望输出=======t=[4554 2928 3497 2261 6921 1391 3580 4451 2636 3471 3854 3556 2659 ... 4335 2882 4084 1999 2889 2175 2510 3409 3729 3489 3172 4568 4015 ... 3666];ptest=[2845 2833 4488;2833 4488 4554;4488 4554 2928;4554 2928 3497;2928 3497 2261;...3497 2261 6921;2261 6921 1391;6921 1391 3580;1391 3580 4451;3580 4451 2636;...4451 2636 3471;2636 3471 3854;3471 3854 3556;3854 3556 2659;3556 2659 4335;...2659 4335 2882;4335 2882 4084;4335 2882 1999;2882 1999 2889;1999 2889 2175;...2889 2175 2510;2175 2510 3409;2510 3409 3729;3409 3729 3489;3729 3489 3172;...3489 3172 4568;3172 4568 4015;4568 4015 3666]';[pn,minp,maxp,tn,mint,maxt]=premnmx(p,t); %将数据归一化NodeNum1 =4; % 隐层第一层节点数NodeNum2=7; % 隐层第二层节点数TypeNum = 5; % 输出维数TF1 = 'tansig';TF2 = 'tansig';TF3 = 'tansig';net=newff(minmax(pn),[NodeNum1,NodeNum2,TypeNum],{TF1 TF2 TF3},'traingdx');%网络创建traingdmnet.trainParam.show=50;net.trainParam.epochs=50000; %训练次数设置net.trainParam.goal=1e-5; %训练所要达到的精度net.trainParam.lr=0.01; %学习速率net.trainParam.mc=0.9;net.trainParam.lr_inc=1.05;net.trainParam.lr_dec=0.7;net.trainParam.max_perf_inc=1.04;net=train(net,pn,tn);p2n=tramnmx(ptest,minp,maxp);%测试数据的归一化an=sim(net,p2n);[a]=postmnmx(an,mint,maxt) %数据的反归一化,即最终想得到的预测结果plot(1:length(ttest),ttest,'o',1:length(ttest),a,'+');title('o表示预测值--- *表示实际值')grid on%m=length(a); %向量a的长度%t1=[t,a(m)];error=ttest-a; %误差向量figureplot(1:length(error),error,'-.')title('误差变化图')grid on[pn,minp,maxp,tn,mint,maxt]=premnmx(p,t); %½«Êý¾Ý¹éÒ»»¯NodeNum1 =4; % Òþ²ãµÚÒ»²ã½ÚµãÊýNodeNum2=7; % Òþ²ãµÚ¶þ²ã½ÚµãÊýTypeNum = 5; % Êä³öάÊýTF1 = 'tansig';TF2 = 'tansig';TF3 = 'tansig';net=newff(minmax(pn),[NodeNum1,NodeNum2,TypeNum],{TF1 TF2 TF3},'trainrp');%ÍøÂç´´½¨traingdmnet.trainParam.show=50;net.trainParam.epochs=50000; %ѵÁ·´ÎÊýÉèÖÃnet.trainParam.goal=1e-5; %ѵÁ·ËùÒª´ïµ½µÄ¾«¶Ènet.trainParam.lr=0.01; %ѧϰËÙÂÊ%net.trainParam.mc=0.9;%net.trainParam.lr_inc=1.05;%net.trainParam.lr_dec=0.7;%net.trainParam.max_perf_inc=1.04;%trainrpnet.trainParam.delt_inc=1.2;net.trainParam.delt_dec=0.5;net.trainParam.delta0=0.07;net.trainParam.deltamax=50.0;net=train(net,pn,tn);p2n=tramnmx(p,minp,maxp);%²âÊÔÊý¾ÝµÄ¹éÒ»»¯an=sim(net,p2n);[a]=postmnmx(an,mint,maxt) %Êý¾ÝµÄ·´¹éÒ»»¯ £¬¼´×îÖÕÏëµÃµ½µÄÔ¤²â½á¹ûplot(1:length(t),t,'o',1:length(a),a,'+');title('o±íʾԤ²âÖµ--- *±íʾʵ¼ÊÖµ')grid on%m=length(a); %ÏòÁ¿aµÄ³¤¶È%t1=[t,a(m)];error=t-a; %Îó²îÏòÁ¿figureplot(1:length(error),error,'-.')title('Îó²î±ä»¯Í¼')grid on%输入参数依次为:'样本P范围',[各层神经元数目],{各层传递函数},'训练函数'%训练函数traingd--梯度下降法,有7个训练参数.%训练函数traingdm--有动量的梯度下降法,附加1个训练参数mc(动量因子,缺省为0.9)%训练函数traingda--有自适应lr的梯度下降法,附加3个训练参数:lr_inc(学习率增长比,缺省为1.05;% lr_dec(学习率下降比,缺省为0.7);max_perf_inc(表现函数增加最大比,缺省为1.04)%训练函数traingdx--有动量的梯度下降法中赋以自适应lr的方法,附加traingdm和traingda 的4个附加参数%训练函数trainrp--弹性梯度下降法,可以消除输入数值很大或很小时的误差,附加4个训练参数:% delt_inc(权值变化增加量,缺省为1.2);delt_dec(权值变化减小量,缺省为0.5);% delta0(初始权值变化,缺省为0.07);deltamax(权值变化最大值,缺省为50.0) % 适合大型网络%训练函数traincgf--Fletcher-Reeves共轭梯度法;训练函数traincgp--Polak-Ribiere共轭梯度法;%训练函数traincgb--Powell-Beale共轭梯度法%共轭梯度法占用存储空间小,附加1训练参数searchFcn(一维线性搜索方法,缺省为srchcha);缺少1个训练参数lr%训练函数trainscg--量化共轭梯度法,与其他共轭梯度法相比,节约时间.适合大型网络% 附加2个训练参数:sigma(因为二次求导对权值调整的影响参数,缺省为5.0e-5);% lambda(Hessian阵不确定性调节参数,缺省为5.0e-7)% 缺少1个训练参数:lr%训练函数trainbfg--BFGS拟牛顿回退法,收敛速度快,但需要更多内存,与共轭梯度法训练参数相同,适合小网络%训练函数trainoss--一步正割的BP训练法,解决了BFGS消耗内存的问题,与共轭梯度法训练参数相同%训练函数trainlm--Levenberg-Marquardt训练法,用于内存充足的中小型网络net=init(net);net.trainparam.epochs=20000; %最大训练次数(前缺省为10,自trainrp后,缺省为100) net.trainparam.lr=0.05; %学习率(缺省为0.01)net.trainparam.show=25; %限时训练迭代过程(NaN表示不显示,缺省为25)net.trainparam.goal=1e-8; %训练要求精度(缺省为0)%net.trainparam.max_fail 最大失败次数(缺省为5)%net.trainparam.min_grad 最小梯度要求(前缺省为1e-10,自trainrp后,缺省为1e-6) %net.trainparam.time 最大训练时间(缺省为inf)[net,tr]=train(net,P,t); %网络训练a=sim(net,H) %网络仿真。
基于BP算法的神经网络PID控制器设计及仿真
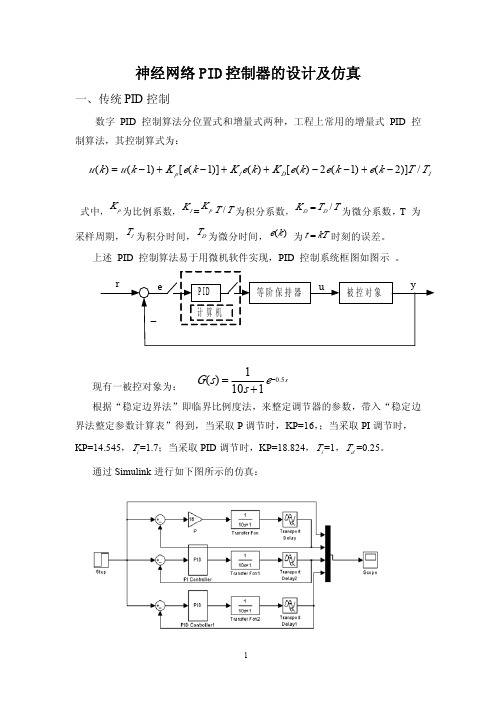
se s s G 5.01101)(−+=()(1)[(1)]()[()2(1)(2)]/p I D Iu k u k K e k K e k K e k e k e k T T =−+−++−−+−神经网络PID 控制器的设计及仿真一、传统PID 控制数字PID 控制算法分位置式和增量式两种,工程上常用的增量式PID 控制算法,其控制算式为:式中,pK 为比例系数,I K =p K /T T为积分系数,/D D K T T =为微分系数,T 为采样周期,IT 为积分时间,DT 为微分时间,()e k 为t kT =时刻的误差。
上述PID 控制算法易于用微机软件实现,PID 控制系统框图如图示。
现有一被控对象为:根据“稳定边界法”即临界比例度法,来整定调节器的参数,带入“稳定边界法整定参数计算表”得到,当采取P 调节时,KP=16,;当采取PI 调节时,KP=14.545,i T =1.7;当采取PID 调节时,KP=18.824,i T =1,d T =0.25。
通过Simulink 进行如下图所示的仿真:仿真结果如下图所示:二、基于BP算法的PID控制基于BP神经网络的PID控制系统结构如下图所示,控制器由两个部分组成:①经典的PID控制器:直接对被控对象进行闭环控制,并且KP,KI,KD三个参数为在线P,I,D整定;②神经网络NN:根据系统的运行状态,调节PID控制器的参数,以期达到某种性能指标的最优化。
即使神经网络的输出层神经元的输出状态对应于PID控制器的三个可调参数KP,KI,KD,通过神经网络的自学习、调整权系数,从而使其稳定P,I,D状态对应于某种最优控制规律下的PID控制器参数。
在这里设计的BP网络采用结构简单的三层BP神经网络,其结构如下图所示,有m个输入节点、Q个隐含层节点、3个输出节点。
输入节点对应所选的系统运行状态量,如系统不同时刻的输入量和输出量等,必要时要进行归一化K K K。
MATLAB程序代码 bp神经网络通用代码

实用标准文案MATLAB程序代码--bp神经网络通用代码matlab通用神经网络代码学习了一段时间的神经网络,总结了一些经验,在这愿意和大家分享一下,希望对大家有帮助,也希望大家可以把其他神经网络的通用代码在这一起分享感应器神经网络、线性网络、BP神经网络、径向基函数网络%通用感应器神经网络。
P=[-0.5 -0.5 0.3 -0.1 -40;-0.5 0.5 -0.5 1 50];%输入向量T=[1 1 0 0 1];%期望输出plotpv(P,T);%描绘输入点图像net=newp([-40 1;-1 50],1);%生成网络,其中参数分别为输入向量的范围和神经元感应器数量hold onlinehandle=plotpc(net.iw{1},net.b{1});net.adaptparam.passes=3;for a=1:25%训练次数[net,Y,E]=adapt(net,P,T);linehandle=plotpc(net.iw{1},net.b{1},linehandle);drawnow;end%通用newlin程序%通用线性网络进行预测time=0:0.025:5;T=sin(time*4*pi);Q=length(T);P=zeros(5,Q);%P中存储信号T的前5(可变,根据需要而定)次值,作为网络输入。
精彩文档.实用标准文案P(1,2:Q)=T(1,1:(Q-1));P(2,3:Q)=T(1,1:(Q-2));P(3,4:Q)=T(1,1:(Q-3));P(4,5:Q)=T(1,1:(Q-4));P(5,6:Q)=T(1,1:(Q-5));plot(time,T)%绘制信号T曲线xlabel('时间');ylabel('目标信号');title('待预测信号');net=newlind(P,T);%根据输入和期望输出直接生成线性网络a=sim(net,P);%网络测试figure(2)plot(time,a,time,T,'+')xlabel('时间');ylabel('输出-目标+');title('输出信号和目标信号');e=T-a;figure(3)plot(time,e)hold onplot([min(time) max(time)],[0 0],'r:')%可用plot(x,zeros(size(x)),'r:')代替hold offxlabel('时间');ylabel('误差');精彩文档.实用标准文案title('误差信号');%通用BP神经网络P=[-1 -1 2 2;0 5 0 5];t=[-1 -1 1 1];net=newff(minmax(P),[3,1],{'tansig','purelin'},'traingd');%输入参数依次为:'样本P范围',[各层神经元数目],{各层传递函数},'训练函数'%训练函数traingd--梯度下降法,有7个训练参数.%训练函数traingdm--有动量的梯度下降法,附加1个训练参数mc(动量因子,缺省为0.9)%训练函数traingda--有自适应lr的梯度下降法,附加3个训练参数:lr_inc(学习率增长比,缺省为1.05;% lr_dec(学习率下降比,缺省为0.7);max_perf_inc(表现函数增加最大比,缺省为1.04)%训练函数traingdx--有动量的梯度下降法中赋以自适应lr的方法,附加traingdm和traingda的4个附加参数%训练函数trainrp--弹性梯度下降法,可以消除输入数值很大或很小时的误差,附加4个训练参数:% delt_inc(权值变化增加量,缺省为1.2);delt_dec(权值变化减小量,缺省为0.5);% delta0(初始权值变化,缺省为0.07);deltamax(权值变化最大值,缺省为50.0)% 适合大型网络%训练函数traincgf--Fletcher-Reeves共轭梯度法;训练函数traincgp--Polak-Ribiere共轭梯度法;%训练函数traincgb--Powell-Beale共轭梯度法%共轭梯度法占用存储空间小,附加1训练参数searchFcn(一维线性搜索方法,缺省为srchcha);缺少1个训练参数lr %训练函数trainscg--量化共轭梯度法,与其他共轭梯度法相比,节约时间.适合大型网络% 附加2个训练参数:sigma(因为二次求导对权值调整的影响参数,缺省为5.0e-5);% lambda(Hessian阵不确定性调节参数,缺省为5.0e-7)% 缺少1个训练参数:lr精彩文档.实用标准文案%训练函数trainbfg--BFGS拟牛顿回退法,收敛速度快,但需要更多内存,与共轭梯度法训练参数相同,适合小网络%训练函数trainoss--一步正割的BP训练法,解决了BFGS消耗内存的问题,与共轭梯度法训练参数相同%训练函数trainlm--Levenberg-Marquardt训练法,用于内存充足的中小型网络net=init(net);net.trainparam.epochs=300; %最大训练次数(前缺省为10,自trainrp后,缺省为100)net.trainparam.lr=0.05; %学习率(缺省为0.01)net.trainparam.show=50; %限时训练迭代过程(NaN表示不显示,缺省为25)net.trainparam.goal=1e-5; %训练要求精度(缺省为0)%net.trainparam.max_fail 最大失败次数(缺省为5)%net.trainparam.min_grad 最小梯度要求(前缺省为1e-10,自trainrp后,缺省为1e-6)%net.trainparam.time 最大训练时间(缺省为inf)[net,tr]=train(net,P,t); %网络训练a=sim(net,P) %网络仿真%通用径向基函数网络——%其在逼近能力,分类能力,学习速度方面均优于BP神经网络%在径向基网络中,径向基层的散步常数是spread的选取是关键%spread越大,需要的神经元越少,但精度会相应下降,spread的缺省值为1%可以通过net=newrbe(P,T,spread)生成网络,且误差为0%可以通过net=newrb(P,T,goal,spread)生成网络,神经元由1开始增加,直到达到训练精度或神经元数目最多为止%GRNN网络,迅速生成广义回归神经网络(GRNN)P=[4 5 6];T=[1.5 3.6 6.7];精彩文档.实用标准文案net=newgrnn(P,T);%仿真验证p=4.5;v=sim(net,p)%PNN网络,概率神经网络P=[0 0 ;1 1;0 3;1 4;3 1;4 1;4 3]';Tc=[1 1 2 2 3 3 3];%将期望输出通过ind2vec()转换,并设计、验证网络T=ind2vec(Tc);net=newpnn(P,T);Y=sim(net,P);Yc=vec2ind(Y)%尝试用其他的输入向量验证网络P2=[1 4;0 1;5 2]';Y=sim(net,P2);Yc=vec2ind(Y)%应用newrb()函数构建径向基网络,对一系列数据点进行函数逼近P=-1:0.1:1;T=[-0.9602 -0.5770 -0.0729 0.3771 0.6405 0.6600 0.4609...0.1336 -0.2013 -0.4344 -0.500 -0.3930 -0.1647 -0.0988...0.3072 0.3960 0.3449 0.1816 -0.0312 -0.2189 -0.3201];%绘制训练用样本的数据点plot(P,T,'r*');title('训练样本');精彩文档.实用标准文案xlabel('输入向量P');ylabel('目标向量T');%设计一个径向基函数网络,网络有两层,隐层为径向基神经元,输出层为线性神经元%绘制隐层神经元径向基传递函数的曲线p=-3:.1:3;a=radbas(p);plot(p,a)title('径向基传递函数')xlabel('输入向量p')%隐层神经元的权值、阈值与径向基函数的位置和宽度有关,只要隐层神经元数目、权值、阈值正确,可逼近任意函数%例如a2=radbas(p-1.5);a3=radbas(p+2);a4=a+a2*1.5+a3*0.5;plot(p,a,'b',p,a2,'g',p,a3,'r',p,a4,'m--')title('径向基传递函数权值之和')xlabel('输入p');ylabel('输出a');%应用newrb()函数构建径向基网络的时候,可以预先设定均方差精度eg以及散布常数sceg=0.02;sc=1; %其值的选取与最终网络的效果有很大关系,过小造成过适性,过大造成重叠性net=newrb(P,T,eg,sc);%网络测试精彩文档.实用标准文案plot(P,T,'*')xlabel('输入');X=-1:.01:1;Y=sim(net,X);hold onplot(X,Y);hold offlegend('目标','输出')%应用grnn进行函数逼近P=[1 2 3 4 5 6 7 8];T=[0 1 2 3 2 1 2 1];plot(P,T,'.','markersize',30)axis([0 9 -1 4])title('待逼近函数')xlabel('P')ylabel('T')%网络设计%对于离散数据点,散布常数spread选取比输入向量之间的距离稍小一些spread=0.7;net=newgrnn(P,T,spread);%网络测试A=sim(net,P);hold onoutputline=plot(P,A,'o','markersize',10,'color',[1 0 0]);精彩文档.实用标准文案title('检测网络')xlabel('P')ylabel('T和A')%应用pnn进行变量的分类P=[1 2;2 2;1 1]; %输入向量Tc=[1 2 3]; %P对应的三个期望输出%绘制出输入向量及其相对应的类别plot(P(1,:),P(2,:),'.','markersize',30)for i=1:3text(P(1,i)+0.1,P(2,i),sprintf('class %g',Tc(i)))endaxis([0 3 0 3]);title('三向量及其类别')xlabel('P(1,:)')ylabel('P(2,:)')%网络设计T=ind2vec(Tc);spread=1;net=newgrnn(P,T,speard);%网络测试A=sim(net,P);Ac=vec2ind(A);%绘制输入向量及其相应的网络输出plot(P(1,:),P(2,:),'.','markersize',30)精彩文档.实用标准文案for i=1:3text(P(1,i)+0.1,P(2,i),sprintf('class %g',Ac(i)))endaxis([0 3 0 3]);title('网络测试结果')xlabel('P(1,:)')ylabel('P(2,:)')P=[13, 0, 1.119, 1, 26.3;22, 0, 1.135, 1, 26.3;-15, 0, 0.9017, 1, 20.4;-30, 0, 0.9172, 1, 26.7;24,0,1.238,0.9704,28.2;3,24,1.119,1,26.3;0,52,1.089,1,26.3;0,-73,1.0889,1,26.3;1,28,0.8748,1,2 6.3;-1,-39,1.1168,1,26.7;-2, 0, 1.495, 1, 26.3;0, -1, 1.438, 1, 26.3;4, 1,0.4964,0.9021, 26.3;3, -1, 0.5533, 1.2357, 26.7;-5, 0, 1.7368, 1, 26.7;1, 0, 1.1045, 0.0202,26.3;-2, 0, 1.1168, 1.3764, 26.7;-3, -1, 1.1655, 1.4418,27.5;3, 2, 1.0875, 0.748, 27.5;-3, 0, 1.1068, 2.2092, 26.3;4, 1, 0.9017, 1, 13.7;3, 2, 0.9017, 1, 14.9;-3, 1, 0.9172, 1, 13.7;-2, 0, 1.0198, 1.0809, 16.1;0, 1, 0.9172, 1, 13.7]T=[1, 0, 0, 0, 0 ;1, 0, 0, 0, 0 ;1, 0, 0, 0, 0 ;1, 0, 0, 0, 0 ;1, 0, 0, 0, 0;0, 1, 0, 0, 0;0, 1, 0, 0, 0;0, 1, 0, 0, 0;0, 1, 0, 0, 0;0, 1, 0, 0, 0;0, 0, 1, 0, 0;0, 0, 1, 0, 0;0, 0, 1, 0, 0;0, 0, 1, 0, 0;0, 0, 1, 0, 0;0, 0, 0, 1, 0 ;0, 0, 0, 1, 0 ;0, 0, 0, 1, 0 ;0, 0, 0, 1, 0 ;0, 0, 0, 1, 0 ;0, 0, 0, 0, 1;0, 0, 0, 0, 1;0, 0, 0, 0, 1;0, 0, 0, 0, 1;0, 0, 0, 0, 1 ];%期望输出plotpv(P,T);%描绘输入点图像精彩文档.。
基于BP神经网络PID整定原理和算法步骤-精品

虽然人工神经网络存在着以上的许多优点及广泛的应用,但同时也存在着一些不足,由于神经网络的不足阻碍了神经网络的发展,在现实应用中BP神经网络是最为广泛的神经网络模型,BP神经网络是在1986年被提出的,因其系统地解决了多层网络中隐含单元连接权的学习问题,它同样具有人工神经网络所具有的特点。本课题是以BP神经网络模型研究为主。BP神经网络的缺点主要表现在以下几个方面:
Nowadays, the neural network has wide application fields and prospects in the national economy and modernization of national defense science.It mainly applies in information, automation, economical and so on.
90年代初,对神经网络的发展产生了很大的影响是诺贝尔奖获得者Edelamn提出Darwinism模型。他建立了一种神经网络系统理论,例如,Darwinism的结构包括Dawin网络和Nallance网络,并且这两个网络是并行的,而他们又包含了不同功能的一些子网络。他采用了Hebb权值修正规则,当一定的运动刺激模式作用后,系统通过进化,学会扫描跟踪目标。Narendra和Parthasarathy(1990年)提出了一种推广的动态神经网络系及其连接权的学习算法,它可表示非线性特性,增强了鲁棒性。神经网络理论有较强的数学性质和生物学特性,尤是神经科学、心理学和认识科学等方面提出一些重大问题,是向神经网络理论研究的新挑战,因而也是它发展的最好的机会。
MATLAB基于BP神经网络PID控制程序.pdf

MATLAB基于BP神经网络PID控制程序>> %BP based PID Controlclear all;close all;xite=0.20; %学习速率alfa=0.01; %惯性因子IN=4;H=5;Out=3; %NN Structurewi=[-0.6394 -0.2696 -0.3756 -0.7023;-0.8603 -0.XXXX -0.5024 -0.2596;-1.0749 0.5543 -1.6820 -0.5437;-0.3625 -0.0724 -0.6463 -0.2859;0.1425 0.0279 -0.5406 -0.7660];%wi=0.50*rands(H,IN); %隐含层加权系数wi初始化wi_1=wi;wi_2=wi;wi_3=wi;wo=[0.7576 0.2616 0.5820 -0.1416 -0.1325;-0.1146 0.2949 0.8352 0.2205 0.4508;0.7201 0.4566 0.7672 0.4962 0.3632];%wo=0.50*rands(Out,H); %输出层加权系数wo初始化wo_1=wo;wo_2=wo;wo_3=wo;ts=20; %采样周期取值x=[0,0,0]; %比例,积分,微分赋初值u_1=0;u_2=0;u_3=0;u_4=0;u_5=0;y_1=0;y_2=0;y_3=0;Oh=zeros(H,1); %Output from NN middle layer 隐含层的输出I=Oh; %Input to NN middle layer 隐含层输入error_2=0;error_1=0;for k=1:1:500 %仿真开始,共500步time(k)=k*ts;rin(k)=1.0;%Delay plantsys=tf(1.2,[208 1],'inputdelay',80); %建立被控对象传递函数? dsys=c2d(sys,ts,'zoh'); %把传递函数离散化? [num,den]=tfdata(dsys,'v'); %离散化后提取分子、分母yout(k)=-den(2)*y_1+num(2)*u_5;error(k)=rin(k)-yout(k);xi=[rin(k),yout(k),error(k),1];%经典增量式数字PID 的控制算式为:()(1)(()(1))()(()2(1)(2))p i d u k u k k e k e k ke k k e k e k e k =−+−−++−−+− BP 神经网络PID 的控制算式为:()()()333123()(1)(()(1))()(()2(1)(2))u k u k o e k e k o e k o e k e k e k =−+−−++−−+− x(1)=error(k)-error_1; %比例输出x(2)=error(k); %积分输出x(3)=error(k)-2*error_1+error_2; %微分输出 epid=[x(1);x(2);x(3)];I=xi*wi';% 隐含层的输入,即:输入层输入*权值 for j=1:1:H Oh(j)=(exp(I(j))-exp(-I(j)))/(exp(I(j))+exp(-I(j))); %Middle Layer 在激活函数作用下隐含层的输出endK=wo*Oh; %Output Layer 输出层的输入,即:隐含层的输出*权值 for l=1:1:OutK(l)=exp(K(l))/(exp(K(l))+exp(-K(l))); %Getting kp,ki,kd 输出层的输出,即三个pid 控制器的参数end kp(k)=K(1);ki(k)=K(2);kd(k)=K(3);Kpid=[kp(k),ki(k),kd(k)];du(k)=Kpid*epid;u(k)=u_1+du(k);if u(k)>=10 % Restricting the output of controller 控制器饱和环节 u(k)=10; endif u(k)<=-10u(k)=-10;end%以下为权值wi 、wo 的在线调整,参考刘金琨的《先进PID 控制》dyu(k)=sign((yout(k)-y_1)/(u(k)-u_1+0.0000001));%Output layer 输出层for j=1:1:OutdK(j)=2/(exp(K(j))+exp(-K(j)))^2;endfor l=1:1:Outdelta3(l)=error(k)*dyu(k)*epid(l)*dK(l); endfor l=1:1:Outfor i=1:1:Hd_wo=xite*delta3(l)*Oh(i)+alfa*(wo_1-wo_2); endendwo=wo_1+d_wo+alfa*(wo_1-wo_2);%Hidden layerfor i=1:1:HdO(i)=4/(exp(I(i))+exp(-I(i)))^2;endsegma=delta3*wo;for i=1:1:Hdelta2(i)=dO(i)*segma(i);endd_wi=xite*delta2'*xi;wi=wi_1+d_wi+alfa*(wi_1-wi_2);%Parameters Update 参数更新u_5=u_4;u_4=u_3;u_3=u_2;u_2=u_1;u_1=u(k); y_2=y_1;y_1=yout(k);wo_3=wo_2;wo_2=wo_1;wo_1=wo;wi_3=wi_2;wi_2=wi_1;wi_1=wi;error_2=error_1;error_1=error(k);end%仿真结束,绘图figure(1);plot(time,rin,'r',time,yout,'b'); xlabel('time(s)');ylabel('rin,yout'); figure(2);plot(time,error,'r');xlabel('time(s)');ylabel('error'); figure(3);plot(time,u,'r');xlabel('time(s)');ylabel('u');figure(4);subplot(311);plot(time,kp,'r');xlabel('time(s)');ylabel('kp'); subplot(312);plot(time,ki,'g');xlabel('time(s)');ylabel('ki'); subplot(313);plot(time,kd,'b');xlabel('time(s)');ylabel('kd');。
基于BP神经网络的自整定PID控制的MATLAB程序代码
基于BP神经网络的自整定PID控制仿真在工业控制中,PID控制是工业控制中最常用的方法。
这是因为PID控制器结构简单、实现简单,控制效果良好,已得到广泛应用。
但是,PID具有一定的局限性:被控制对象参数随时间变化时,控制器的参数难以自动调整以适应外界环境的变化。
为了使控制器具有较好的自适应性,实现控制器参数的自动调整,可以采用神经网络控制的方法。
利用人工神经网络的自学习这一特性,并结合传统的PID控制理论,构造神经网络PID控制器,实现控制器参数的自动调整。
基于BP神经网络的PID控制器结构如图1所示。
控制器由两部分组成:一是常规PID 控制器,用以直接对对象进行闭环控制,且三个参数在线整定;二是神经网络NN,根据系统的运行状态,学习调整权系数,从而调整PID参数,达到某种性能指标的最优化。
图1 基于神经网络的PID控制器结构1.设计原理神经网络采用结构为4-5-3型的BP网络,如图2。
图2 BP网络结构其中,输出层激励函数取非负的Sigmoid函数,隐层取正负对称的Sigmoid函数。
被控对象为一时变非线性对象,数学模型可表示为: 2()(1)()(1)1(1)a k y k y k u k y k -=+-+- 式中,系数a(k)是慢时变的,。
为保证控制器有一定的动态跟踪能力,选定神经网络的输入层输入为[(),(1),(2),1]T in X e k e k e k =--网络的学习过程由正向和反向传播两部分组成。
如果输出层不能得到期望输出,那么转入反向传播过程,通过修改各层神经元的权值,使得输出误差信号最小。
输出层节点分别对应三个可调参数(3)1(3)2(3)3p I D O K O K O K ⎫=⎪=⎬⎪=⎭取性能指标函数为: 21()(()())2E k r k y k =-设其中:()()()r k y k e k -=若PID 控制器采用采用增量式数字PID 控制算法,则有(3)1(3)2(3)3()()(1)()()()()2(1)(2)u k e k e k O u k e k O u k e k e k e k O ⎫∂=--⎪∂⎪⎪∂=⎬∂⎪⎪∂=--+-⎪∂⎭2.网络权系数调整网络权系数的修正采用梯度下降法。
BP神经网络逼近(matlab程序)

BP神经网络逼近y=1/x,MATLAB程序%BP神经网络逼近y=1/x;%----------------定义必要的变量方便调试--------------------clear;clc;q=8; %神经元个数max_epoch=100000; %最大训练次数err_goal=0.01; %期望误差最小值alpha =0.01; %学习率X = 1:0.5:10; %样本D=1./X; %期望值[m,n] = size(X); %m为输入个数,n为样本数量l=1; %单输出wjk = rand(l,q); %隐层到输出层的初始权值vij = rand(q,m); %输入层到隐层的初始权值for epoch=1:max_epoch%-------------------------前向传播求输入--------------------NETj=vij*X; %隐层净输入Yj=1./(1+exp(-NETj)); %计算隐层输出NETk=wjk*Yj; %输出层净输入Ok=1./(1+exp(-NETk));%计算输出层输出e=((D-Ok)*(D-Ok)')/2; %计算误差函数E(epoch)=e;if(e<err_goal)char='达到输出误差要求学习结束'break;end%-------------------反向传播调权值-------------------------------%调整输出层权值deltak=Ok.*(1-Ok).*(D-Ok);wjk=wjk+alpha*deltak*Yj';%调整隐含层权值deltai=Yj.*(1-Yj).*(deltak'*wjk)';vij=vij+alpha*deltai*X';end%-----------------取样本测试---------------------------------Xx = 1:3:66;D1 = 1./Xx; %期望输出[m1,n1] = size(Xx);NETj1=vij*Xx; %隐层净输入Yj1=1./(1+exp(-NETj1)); %计算隐层输出NETk1=wjk*Yj1; %输出层净输入Ok1=1./(1+exp(-NETk1));%计算输出层输出%-----------------------显示与绘图---------------------------------epoch %显示样本集计算次数Ok %显示训练集输出层输出Ok1 %显示测试集输出层输出subplot(2,2,1);plot(X,D,'b-o'); %样本与期望值title('训练集网络样本')subplot(2,2,2);plot(X,Ok,'b-o',X,D,'r-x');%训练集网络输出与期望值title('训练集网络输出与期望值')subplot(2,2,3);plot(1:1:epoch,E,'k*'); %显示误差title('训练集输出误差')subplot(2,2,4);plot(Xx,Ok1,'b-o',Xx,D1,'r-x'); %绘制样本及网络输出title('测试集网络输出与期望值')运行结果当隐层神经元个数q=8时char =达到输出误差要求学习结束epoch =86197Ok =Columns 1 through 100.8717 0.7039 0.5349 0.4121 0.3313 0.2775 0.2398 0.2120 0.1908 0.1741Columns 11 through 190.1608 0.1499 0.1410 0.1337 0.1276 0.1225 0.1183 0.1147 0.1117Ok1 =Columns 1 through 100.8717 0.2398 0.1410 0.1117 0.1013 0.0972 0.0956 0.0950 0.0947 0.0946Columns 11 through 200.0945 0.0945 0.0945 0.0945 0.0945 0.0945 0.0945 0.0945 0.0945 0.0945Columns 21 through 220.0945 0.0945当隐层神经元个数q=2时epoch =100000Ok =Columns 1 through 100.3222 0.3112 0.3007 0.2910 0.2821 0.2741 0.2668 0.2603 0.2546 0.2495Columns 11 through 190.2451 0.2413 0.2379 0.2351 0.2326 0.2305 0.2287 0.2271 0.2258Ok1 =Columns 1 through 100.3222 0.2668 0.2379 0.2258 0.2211 0.2194 0.2187 0.2185 0.2184 0.2184Columns 11 through 200.2184 0.2184 0.2184 0.2184 0.2184 0.2184 0.2184 0.2184 0.2184 0.2184Columns 21 through 220.2184 0.2184结果分析由运行结果和图形可以看出隐层神经元个数q=8时,网络训练86197次就能使误差达到0.01q=2时,网络训练次数达到最大值100000次还没有达到误差允许的范围。
MATLAB程序代码BP神经网络的设计实例

MATLAB程序代码--BP神经网络的设计实例例1 采用动量梯度下降算法训练BP 网络。
训练样本定义如下:输入矢量为p =[-1 -2 3 1-1 1 5 -3]目标矢量为t = [-1 -1 1 1]解:本例的MA TLAB 程序如下:close allclearecho onclc% NEWFF——生成一个新的前向神经网络% TRAIN——对BP 神经网络进行训练% SIM——对BP 神经网络进行仿真pause% 敲任意键开始clc% 定义训练样本% P 为输入矢量P=[-1, -2, 3, 1; -1, 1, 5, -3];% T 为目标矢量T=[-1, -1, 1, 1];pause;clc% 创建一个新的前向神经网络net=newff(minmax(P),[3,1],{'tansig','purelin'},'traingdm')% 当前输入层权值和阈值inputWeights=net.IW{1,1}inputbias=net.b{1}% 当前网络层权值和阈值layerWeights=net.LW{2,1}layerbias=net.b{2}pauseclc% 设置训练参数net.trainParam.show = 50;net.trainParam.lr = 0.05;net.trainParam.mc = 0.9;net.trainParam.epochs = 1000;net.trainParam.goal = 1e-3;pauseclc% 调用TRAINGDM 算法训练BP 网络[net,tr]=train(net,P,T);pauseclc% 对BP 网络进行仿真A = sim(net,P)% 计算仿真误差E = T - AMSE=mse(E)pauseclcecho off例2 采用贝叶斯正则化算法提高BP 网络的推广能力。
在本例中,我们采用两种训练方法,即L-M 优化算法(trainlm)和贝叶斯正则化算法(trainbr),用以训练BP 网络,使其能够拟合某一附加有白噪声的正弦样本数据。
神经pid,模糊pid,常规pid的matlab比较

图4.BP神经网络PID系统输出响应曲线图6. PID 参数自适应模糊控制器系统框图图7.e,ec,Kp,Ki,Kd的隶属度函数通过不断进行仿真实验和借鉴专家经验可以得到如下的49条规则:图8.模糊PID控制系统输出曲线图9.模糊PID控制系统误差曲线图中1为常规整定PID 阶跃响应曲线,2为BP 神经网络PID 阶跃响应曲线,3为模糊自适应整定PID 阶跃响应曲线。
从曲线中以看出,三种PID控制方式中模糊PID几乎没有超调,调节时间短,控制效果最好;BP 网络PID效果次之;都比常规PID 效果好。
比较图5神经PID与图9模糊PID的误差曲线可以看出,模糊PID具有更短的学习时间。
仿真和实验结果均证明了神经网络PID 控制算法能有效地控制大时滞大惯性的温控系统,将神经网络与PID控制相结合,可以在线调整PID控制器的各个参数,减少了凭经验整定参数带来的误差,提高了温控系统的鲁棒性和自适应性。
此外,神经网络PID控制器还能有效的抑制干扰,而且对对象模型要求不高,具有较好的抗干扰性。
同时也可以进一步优化BP神经网络的结构和算法,使温度控制最终趋于最优,更好地满足实际生产对温度控制的要求。
但是由于该控制器的初始权值是随机值,控制输出在开始时波动很大,随着网络的自学习,不断调整权值控制输出来跟踪输入。
由于神经网络收敛速度慢,回到稳定状态所需时间较长,这个问题有待进一步研究解决。
,模糊PID控制响应几乎没有超调,但是响应速度较慢;在模型失配的情况下,模糊PID虽然产生了震荡,超调量也有所增加,但总体来说还能够保持稳定;在添加干扰后,系统持续产生小幅震荡,但超调量很小,系统整体还是稳定的,抗干扰能力强。
参考文献:1、陶永华.新型PID控制及其应用(第二版) [ M].北京:机械工业出版社,2002.2、杨智,朱海锋,黄以华.PID控制器设计与参数整定方法综述[ J ].化工自动化及仪表,2 005,32 ( 5 ):1-7 .3、杨智.工业自整定P ID调节器关键设计技术综述[J].化工自动化及仪表,2000,27 ( 2 ):5-10.4、王伟,张晶涛,柴天佑.PID参数先进整定方法综述[ J ].自动化学报,2000,26 (5):347-355.5、何宏源,徐进学,金妮.PID继电自整定技术的发展综述[ J ].沈阳工业大学学报,2005,27 (4):4 09-413.6、叶岚.基于继电反馈的PI D控制器的参数整定[ D].上海:上海交通大学自动化系,2007.7、李少远.基于继电反馈的PID控制器的参数整定[D].上海:上海交通大学自动化系,2007.8、吴泽宁等.BP神经网络的改进及应用[J ].河南科学,2003-4:202 -2069、李遵基编著.热工自动控制系统[M].中国电力出版社,1997.1010、俞海斌,褚健.CFB锅炉汽包水位的专家PID控制[J].机电工程,2000(3):103~10611、潘祥高等.模糊PID控制在工业锅炉控制系统中的应用[J].工业出版社,200412、刘金琨.先进PID 控制MA TLAB仿真M7.2 版.北京电子工业出版社,200413、薛定宇.控制系统计算机辅助设计MA TLAB 语言与应用M7.2 版.北京清华大学出版社,2006常规PID实现程序:clear all;close all;ts=10;sys=tf([1],[150,1],'inputdelay',50);dsys=c2d(sys,ts,'z oh');[num,den]=tfdata(dsys,'v');u_1=0;u_2=0;u_3=0;u_4=0;u_5=0;u_6=0;y_1=0;y_2=0;y_3=0;error_1=0;error_2=0;ei=0;for k=1:1:1000time(k)=k*ts;yout(k)=-den(2)*y_1+num(2)*u_6;rin(k)=1;error(k)=rin(k)-yout(k);ei=ei+error(k)*ts;kp=0.03;kd=1;ki=0.004;u(k)=kp*error(k)+kd*(error(k)-error_1)/ts+ki*ei; if u(k)>=10u(k)=10;endif u(k)<=-10u(k)=-10;endif k==200u(k)=u(k)+1;endu_6=u_5;u_5=u_4;u_4=u_3;u_3=u_2;u_2=u_1;u_1=u(k); y_3=y_2;y_2=y_1;y_1=yout(k);error_2=error_1;error_1=error(k);endfigure(1);plot(time,rin,'b',time,yout,'r');xlabel('time(s)');ylabel('rin,yout');figure(2);plot(time,u,'r');xlabel('time(s)');ylabel('u');BP神经网络PID程序:%BP based PID Controlclear all;close all;xite=0.9;IN=4;H=5;Out=3; %NN Structurewi=[-0.6394 -0.2696 -0.3756 -0.7023;-0.8603 -0.2013 -0.5024 -0.2596;-1.0749 0.5543 -1.6820 -0.5437;-0.3625 -0.0724 -0.6463 -0.2859;0.1425 0.0279 -0.5406 -0.7660];%wi=0.50*rands(H,IN);wi_1=wi;wi_2=wi;wi_3=wi;wo=[0.7576 0.2616 0.5820 -0.1416 -0.1325;-0.1146 0.2949 0.8352 0.2205 0.4508;0.7201 0.4566 0.7672 0.4962 0.3632];%wo=0.50*rands(Out,H);wo_1=wo;wo_2=wo;wo_3=wo;x=[0,0,0];du_1=0;u_1=0;u_2=0;u_3=0;u_4=0;u_5=0;u_6=0;y_1=0;y_2=0;Oh=zeros(H,1); %Output from NN middle layerI=Oh; %Input to NN middle layererror_2=0;error_1=0;ts=10;for k=1:1:1000time(k)=k*ts;rin(k)=1.0;%Unlinear modelyout(k)=0.9355*y_1+0.0645*u_6;error(k)=rin(k)-yout(k);xi=[rin(k),yout(k),error(k),1];x(1)=error(k)-error_1;x(2)=error(k);x(3)=error(k)-2*error_1+error_2;epid=[x(1);x(2);x(3)];I=xi*wi';for j=1:1:HOh(j)=(exp(I(j))-exp(-I(j)))/(exp(I(j))+exp(-I(j))); %Middle Layer endK=wo*Oh; %Output Layerfor l=1:1:OutK(l)=exp(K(l))/(exp(K(l))+exp(-K(l))); %Getting kp,ki,kd endkp(k)=K(1);ki(k)=K(2);kd(k)=K(3);Kpid=[kp(k),ki(k),kd(k)];du(k)=Kpid*epid;u(k)=u_1+du(k);dyu(k)=sign((yout(k)-y_1)/(du(k)-du_1+0.0001));%Output layerfor j=1:1:OutdK(j)=2/(exp(K(j))+exp(-K(j)))^2;endfor l=1:1:Outdelta3(l)=error(k)*dyu(k)*epid(l)*dK(l);endfor l=1:1:Outfor i=1:1:Hd_wo=xite*delta3(l)*Oh(i)+alfa*(wo_1-wo_2);endendwo=wo_1+d_wo+alfa*(wo_1-wo_2);%Hidden layerfor i=1:1:HdO(i)=4/(exp(I(i))+exp(-I(i)))^2;endsegma=delta3*wo;for i=1:1:Hdelta2(i)=dO(i)*segma(i);endif k==200u(k)=u(k)+1;endd_wi=xite*delta2'*xi;wi=wi_1+d_wi+alfa*(wi_1-wi_2);%Parameters Updatedu_1=du(k);u_6=u_5;u_5=u_4;u_4=u_3;u_3=u_2;u_2=u_1;u_1=u(k);y_2=y_1;y_1=yout(k);wo_3=wo_2;wo_2=wo_1;wo_1=wo;wi_3=wi_2;wi_2=wi_1;wi_1=wi;error_2=error_1;error_1=error(k);endfigure(1);plot(time,rin,'r',time,yout,'b');xlabel('time(s)');ylabel('rin,yout');figure(2);plot(time,error,'r');xlabel('time(s)');ylabel('error');figure(3);plot(time,u,'r');xlabel('time(s)');ylabel('u');figure(4);subplot(311);plot(time,kp,'r');xlabel('time(s)');ylabel('kp');subplot(312);plot(time,ki,'g');xlabel('time(s)');ylabel('ki');subplot(313);plot(time,kd,'b');xlabel('time(s)');ylabel('kd');模糊PID程序:clear all;close all;a=newfis('fuzzpid');a=addvar(a,'input','e',[-3,3]); %Parameter e a=addmf(a,'input',1,'NB','zmf',[-3,-1]);a=addmf(a,'input',1,'NM','t rimf',[-3,-2,0]);a=addmf(a,'input',1,'NS','trimf',[-3,-1,1]);a=addmf(a,'input',1,'Z','t rimf',[-2,0,2]);a=addmf(a,'input',1,'PS','trimf',[-1,1,3]);a=addmf(a,'input',1,'PM','t rimf',[0,2,3]);a=addmf(a,'input',1,'PB','smf',[1,3]);a=addvar(a,'input','ec',[-3,3]); %Parameter ec a=addmf(a,'input',2,'NB','zmf',[-3,-1]);a=addmf(a,'input',2,'NM','t rimf',[-3,-2,0]);a=addmf(a,'input',2,'NS','trimf',[-3,-1,1]);a=addmf(a,'input',2,'Z','t rimf',[-2,0,2]);a=addmf(a,'input',2,'PS','trimf',[-1,1,3]);a=addmf(a,'input',2,'PM','t rimf',[0,2,3]);a=addmf(a,'input',2,'PB','smf',[1,3]);a=addvar(a,'output','kp',[-0.3,0.3]); %Parameter kp a=addmf(a,'output',1,'NB','zmf',[-0.3,-0.1]);a=addmf(a,'output',1,'NM','t rimf',[-0.3,-0.2,0]);a=addmf(a,'output',1,'NS','trimf',[-0.3,-0.1,0.1]);a=addmf(a,'output',1,'Z','t rimf',[-0.2,0,0.2]);a=addmf(a,'output',1,'PS','trimf',[-0.1,0.1,0.3]);a=addmf(a,'output',1,'PM','t rimf',[0,0.2,0.3]);a=addmf(a,'output',1,'PB','smf',[0.1,0.3]);a=addvar(a,'output','ki',[-0.06,0.06]); %Parameter kia=addmf(a,'output',2,'NB','zmf',[-0.06,-0.02]);a=addmf(a,'output',2,'NM','t rimf',[-0.06,-0.04,0]);a=addmf(a,'output',2,'NS','trimf',[-0.06,-0.02,0.02]);a=addmf(a,'output',2,'Z','t rimf',[-0.04,0,0.04]);a=addmf(a,'output',2,'PS','trimf',[-0.02,0.02,0.06]);a=addmf(a,'output',2,'PM','t rimf',[0,0.04,0.06]);a=addmf(a,'output',2,'PB','smf',[0.02,0.06]);a=addvar(a,'output','kd',[-3,3]); %Parameter kpa=addmf(a,'output',3,'NB','zmf',[-3,-1]);a=addmf(a,'output',3,'NM','t rimf',[-3,-2,0]);a=addmf(a,'output',3,'NS','trimf',[-3,-1,1]);a=addmf(a,'output',3,'Z','t rimf',[-2,0,2]);a=addmf(a,'output',3,'PS','trimf',[-1,1,3]);a=addmf(a,'output',3,'PM','t rimf',[0,2,3]);a=addmf(a,'output',3,'PB','smf',[1,3]);rulelist=[1 1 7 1 5 1 1;1 2 7 1 3 1 1;1 3 6 2 1 1 1;1 4 6 2 1 1 1;1 5 5 3 1 1 1;1 6 4 4 2 1 1;1 7 4 4 5 1 1;2 1 7 1 5 1 1;2 2 7 1 3 1 1;2 3 6 2 1 1 1;2 4 5 3 2 1 1;2 5 5 3 2 1 1;2 6 4 43 1 1;2 7 34 4 1 1;3 1 6 1 4 1 1;3 2 6 2 3 1 1;3 3 6 3 2 1 1;3 45 3 2 1 1;3 5 4 4 3 1 1;36 3 5 3 1 1;37 3 5 4 1 1;4 1 6 2 4 1 1;4 2 6 2 3 1 1;4 3 5 3 3 1 1;4 4 4 4 3 1 1;4 5 3 5 3 1 1;4 6 2 6 3 1 1;4 7 2 6 4 1 1;5 1 5 2 4 1 1;5 2 5 3 4 1 1;5 3 4 4 4 1 1;5 4 3 5 4 1 1;5 5 3 5 4 1 1;5 6 2 6 4 1 1;5 7 2 7 4 1 1;6 1 5 4 7 1 1;6 2 4 4 5 1 1;6 3 3 5 5 1 1;6 4 2 5 5 1 1;6 5 2 6 5 1 1;6 6 27 5 1 1;6 7 1 7 7 1 1;7 1 4 4 7 1 1;7 2 4 4 6 1 1;7 3 2 5 6 1 1;7 4 2 6 6 1 1;7 5 2 6 5 1 1;7 6 1 7 5 1 1;7 7 1 7 7 1 1];a=addrule(a,rulelist);a=setfis(a,'DefuzzMethod','centroid');writefis(a,'fuzzpid');a=readfis('fuzzpid');%PID Controllerts=10;sys=tf([1],[150,1],'inputdelay',50);dsys=c2d(sys,ts,'t ustin');[num,den]=tfdata(dsys,'v');u_1=0.0;u_2=0.0;u_3=0.0;u_4=0.0;u_5=0.0;u_6=0.0;y_1=0;y_2=0;x=[0,0,0]';error_2=0;error_1=0;e_1=0.0;ec_1=0.0;kp0=0.0929;kd0=0.0078;ki0=0.0518;for k=1:1:1000time(k)=k*ts;rin(k)=1;%Using fuzzy inference to tunning PIDk_pid=evalfis([e_1,ec_1],a);kp(k)=kp0+k_pid(1);ki(k)=ki0+k_pid(2);kd(k)=kd0+k_pid(3);u(k)=kp(k)*x(1)+kd(k)*x(2)+ki(k)*x(3);if u(k)>=10u(k)=10;endif u(k)<=-10u(k)=-10;endif k==200u(k)=u(k)+1;endyout(k)=-den(2)*y_1+num(2)*u_6;error(k)=rin(k)-yout(k);%%%%%%%%%%%%%%Return of PID parameters%%%%%%%%%%%%%%% u_6=u_5;u_5=u_4;u_4=u_3;u_3=u_2;u_2=u_1;u_1=u(k);y_2=y_1;y_1=yout(k);x(1)=error(k); % Calculating Px(2)=error(k)-error_1; % Calculating Dx(3)=x(3)+error(k); % Calculating Ie_1=x(1);ec_1=x(2);error_2=error_1;error_1=error(k);endshowrule(a)figure(1);plot(time,rin,'b',time,yout,'r');xlabel('time(s)');ylabel('rin,yout');figure(2);plot(time,error,'r');xlabel('time(s)');ylabel('error');figure(3);plot(time,u,'r');xlabel('time(s)');ylabel('u');。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
BP神经网络整定的PID控制算法matlab源程序,系统为二阶闭环系统。
%BP based PID Control
clear all;
close all;
xite=0.28;
alfa=0.001;
IN=4;H=5;Out=3; %NN Structure
wi=0.50*rands(H,IN);
wi_1=wi;wi_2=wi;wi_3=wi;
wo=0.50*rands(Out,H);
wo_1=wo;wo_2=wo;wo_3=wo;
x=[0,0,0];
u_1=0;u_2=0;u_3=0;u_4=0;u_5=0;
y_1=0;y_2=0;y_3=0;
Oh=zeros(H,1); %Output from NN middle layer
I=Oh; %Input to NN middle layer
error_2=0;
error_1=0;
ts=0.01;
sys=tf(2.6126,[1,3.201,2.7225]); %建立被控对象传递函数
dsys=c2d(sys,ts,'z'); %把传递函数离散化
[num,den]=tfdata(dsys,'v'); %离散化后提取分子、分母
for k=1:1:2000
time(k)=k*ts;
rin(k)=40;
yout(k)=-den(2)*y_1-den(3)*y_2+num(2)*u_2+num(3)*u_3;
error(k)=rin(k)-yout(k);
xi=[rin(k),yout(k),error(k),1];
x(1)=error(k)-error_1;
x(2)=error(k);
x(3)=error(k)-2*error_1+error_2;
epid=[x(1);x(2);x(3)];
I=xi*wi';
for j=1:1:H
Oh(j)=(exp(I(j))-exp(-I(j)))/(exp(I(j))+exp(-I(j))); %Middle Layer end
K=wo*Oh; %Output Layer
for l=1:1:Out
K(l)=exp(K(l))/(exp(K(l))+exp(-K(l))); %Getting kp,ki,kd end
kp(k)=K(1);ki(k)=K(2);kd(k)=K(3);
Kpid=[kp(k),ki(k),kd(k)];
du(k)=Kpid*epid;
u(k)=u_1+du(k);
if u(k)>=45 % Restricting the output of controller u(k)=45;
end
if u(k)<=-45
u(k)=-45;
end
dyu(k)=sign((yout(k)-y_1)/(u(k)-u_1+0.0000001));
%Output layer
for j=1:1:Out
dK(j)=2/(exp(K(j))+exp(-K(j)))^2;
end
for l=1:1:Out
delta3(l)=error(k)*dyu(k)*epid(l)*dK(l);
end
for l=1:1:Out
for i=1:1:H
d_wo=xite*delta3(l)*Oh(i)+alfa*(wo_1-wo_2);
end
end
wo=wo_1+d_wo+alfa*(wo_1-wo_2);
%Hidden layer
for i=1:1:H
dO(i)=4/(exp(I(i))+exp(-I(i)))^2;
end
segma=delta3*wo;
for i=1:1:H
delta2(i)=dO(i)*segma(i);
end
d_wi=xite*delta2'*xi;
wi=wi_1+d_wi+alfa*(wi_1-wi_2);
%Parameters Update
u_5=u_4;u_4=u_3;u_3=u_2;u_2=u_1;u_1=u(k); y_2=y_1;y_1=yout(k);
wo_3=wo_2;
wo_2=wo_1;
wo_1=wo;
wi_3=wi_2;
wi_2=wi_1;
wi_1=wi;
error_2=error_1;
error_1=error(k);
end
figure(1);
plot(time,rin,'r',time,yout,'b');
xlabel('time(s)');ylabel('rin,yout');
figure(2);
plot(time,error,'r');
xlabel('time(s)');ylabel('error');
figure(3);
plot(time,u,'r');
xlabel('time(s)');ylabel('u');
figure(4);
subplot(311);
plot(time,kp,'r');
xlabel('time(s)');ylabel('kp');
subplot(312);
plot(time,ki,'g');
xlabel('time(s)');ylabel('ki');
subplot(313);
plot(time,kd,'b');
xlabel('time(s)');ylabel('kd');。