图像语义自动标注介绍
基于多媒体融合的图像检索的技术
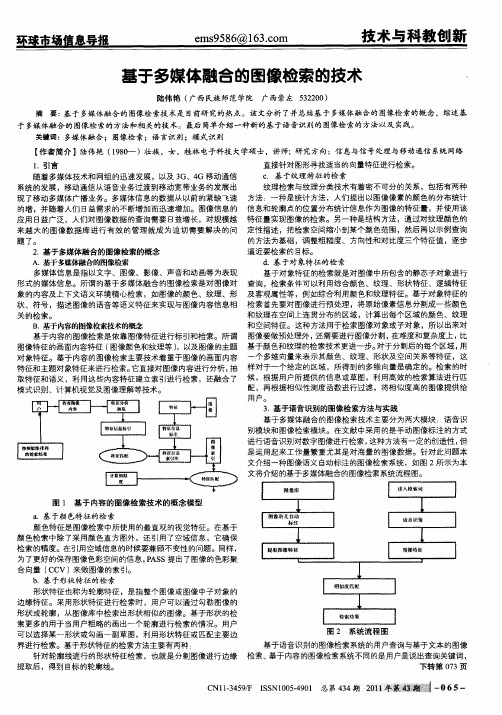
用 户。 3 基 于语音识别的图像检 索方法与实践 . 基于 多媒体 融合 的图像检 索技术主要分为两大模块 :语音识
别模块和图像检 索模块。在文献中采用的是手动 图像标注的方式 进行语音识 别对数字图像进行检 索, 这种方法有一定的创造性 , 但 是运用起来工作 量繁重尤其是对海量的图像数据。针对此问题本 文介绍一种图像语义 自动标注 的图像检 索系统 ,如 图 2所示为本 文将介绍的基于多媒体融合的图像检索系统流程图。
es 8 ̄1 .m m9 6 பைடு நூலகம் c 5 30
技术与科教创新
基于 多媒体 融合的图像检索 的技术
陆伟 艳 ( 广西民族师范学院 广 西崇左 5 2 0 3 2 0)
摘 要: 基于 多媒体融合 的图像检 索技 术是 目前研 究的热点。该文分析 了并 总结基 于 多媒 体融合的 图像检 索的概念 ,综述基 于多媒体 融合 的图像检 索的方法和相关的技术 。最后 简单介 绍一种 新的基于语音识别的 图像检索的方法 以及 实践 。 关键词:多媒 体融合 ;图像 检 索;语言识别 ;模式识 别
【 作者简介】陆伟艳 (9o_ 18- )壮族,女,桂林电子科技大学硕士,讲师; 研究方向:信息与信号处理与移动通信系统网络
1 .引言
随着多媒体 技术和 网组的迅速发展 ,以及 3 G、4 G移动通信 系统的发展 ,移动通信从语 音业务过渡到移动 宽带业务的发展 出 现 了移动多媒体 广播业务。多媒体信息的数据从 以前的紧缺 飞速 的增 ,并随着人们 目益需求的不断增加而迅速增加 。图像信 息的 应用 日益广泛 ,人们对图像数据 的查询需要 日益增长 ,对规模越 来越 大 的图像 数据库进行 有效的管理就成 为迫切 需要解决 的问
基于MPEG-7和MM混合模型的图像自动标注算法

计算机工程与设计
C OMP UT E R E NG I N E E R I NG AN D D E S I GN
D e c . 2 0 1 2 V o l . 3 3 N o . 1 2
A l o r i t h m o f a u t o m a t i c i m a e a n n o t a t i o n b a s e d o n MP E G- 7a n d g g MM m i x t u r e m o d e l
1 12 12 1 , , L UO X i a o a n OUYANG N i n J i a n e n L I Y a n -y -w g ,MO ,,
基于 MP 7 和 MM 混合模型的图像自动标注算法 E G-
2 2 , 莫建文1, , 李 雁1 罗晓燕1 , 欧阳宁1,
( 1. 桂林电子科技大学 信息与通信学院 , 广西 桂林 5 4 1 0 0 4; ) 2. 桂林电子科技大学 图像信息研究所 , 广西 桂林 5 4 1 0 0 4
,改 善 图 像 自 动 标 注 的 性 能,提 出 了 基 于 多 媒 体 描 述 摘 要 : 为了弥补图像低层视觉特征和高层语义 之 间 的 “ 语义鸿沟” ) 和 MM ( ) 混合模型的图像标注算法 。 该算法采用 MP 接口 ( MP E G 7 M i x t u r e M o d e l E G 7 标准 推 荐 的 颜 色 和 纹 理 描 述 子 - - 提取图像的低层视觉特征 , 通过 MM 混合模型建立低层特征到高层语义空间的映射 , 实现了基于图像整体低 层 特 征 的 多 标 签图像自动标注 。 通过在 c o r e l图像数据集上的一系列实验测试验证了该方法的可行性和有效性 。 关键词 : 图像自动标注 ; MP E G 7 描述子 ; MM 混合模型 ; 语义鸿沟 ; 多标签 - )1 中图法分类号 : T P 3 9 1 文献标识号 :A 文章编号 : 1 0 0 0 7 0 2 4( 2 0 1 2 2 4 7 0 7 0 4 - - -
图像自动标注

人工智能发展
自动图像标注作为人工智能领域的 重要分支,对于图像识别、自然语 言处理等任务具有重要意义。
社会价值
图像自动标注技术能够广泛应用于 各个领域,如医疗、安防、交通等 ,为社会带来巨大的经济价值和社 会价值。
图像自动标注的定义
01
02
03
自动标注
指利用计算机视觉、自然 语言处理等技术,自动为 图像添加描述性标签或注 释的过程。
上下文信息融合策略
空间上下文信息
利用图像中物体之间的 空间关系进行标注。
语义上下文信息
结合图像中的文本、语 音等多模态信息进行综 合标注。
时序上下文信息
考虑视频等时序数据中 的上下文关系进行标注 。
多模态数据联合标注方法
多模态数据对齐
将不同模态的数据进行时间或空间上的对齐。
跨模态特征融合
将不同模态的特征进行有效融合,提高标注准确性。
通过调整学习率、批次大小等超参数,进一 步优化模型训练效果。
评估指标选择及性能对比分析
评估指标选择
根据任务需求选择合适的评估指标, 如准确率、召回率、F1值等,以全面 评估模型的性能。
性能对比分析
将所提算法与其他先进算法进行对比 分析,包括定量指标对比和可视化结 果展示,以验证所提算法的有效性和 优越性。
05
图像自动标注系统设 计与实现
系统架构设计原则及功能模块划分
设计原则
遵循高内聚低耦合、可扩展性、可维 护性等原则进行系统架构设计。
功能模块划分
将系统划分为数据预处理、特征提取 、标注模型训练、标注结果生成等模 块,每个模块负责相应的功能实现。
数据预处理与扩充策略
数据预处理
《2024年数据标注研究综述》范文

《数据标注研究综述》篇一一、引言随着人工智能()和机器学习(ML)技术的快速发展,数据标注作为训练高精度、高效率的模型的关键环节,日益受到学术界和工业界的广泛关注。
数据标注是通过将原始数据转换为有标签的数据集,为算法提供训练所需的特征表示。
本文将对近年来数据标注的相关研究进行全面的综述,以展现该领域的最新进展与未来发展方向。
二、数据标注的重要性与基本原理数据标注是构建人工智能系统的核心步骤之一。
其基本原理在于通过为原始数据添加相关的标签或特征,使得模型能够理解并学习数据的特性。
数据标注广泛应用于图像识别、自然语言处理、语音识别等各个领域,对提升模型的性能具有重要作用。
三、数据标注的研究现状(一)研究领域目前,数据标注的研究领域主要包括图像标注、文本标注、语音标注等。
其中,图像标注研究旨在通过添加对象标签、属性标签等方式为图像提供语义信息;文本标注研究主要涉及情感分析、关键词提取等方面;语音标注则致力于通过语种、口音等因素提升语音识别率。
(二)研究方法在数据标注的研究方法上,学者们主要采用自动化标注和人工标注两种方式。
自动化标注利用算法自动为数据添加标签,具有速度快、成本低的优势;而人工标注则依赖于专业人员对数据进行手动标注,其准确性较高,但成本相对较高。
此外,还有半自动化标注和混合标注等方法,旨在结合两种方法的优点。
四、数据标注的挑战与机遇(一)挑战当前,数据标注面临的主要挑战包括:1. 数据质量与准确性问题;2. 人工成本高昂;3. 缺乏标准化和规范化的标注流程;4. 面对海量数据的处理能力不足等。
这些挑战限制了数据标注的效率和准确性,影响了模型的性能。
(二)机遇随着技术的发展,数据标注也面临着诸多机遇:1. 自动化标注技术的不断提升,提高标注效率和准确性;2. 大数据技术的快速发展为处理海量数据提供了可能;3. 深度学习技术的广泛应用为跨领域、跨模态的数据标注提供了新思路;4. 数据标准化和规范化有望推动产业协同创新发展等。
视觉和文本领域的跨模态算法

视觉和文本领域的跨模态算法全文共四篇示例,供读者参考第一篇示例:视觉和文本领域的跨模态算法是近年来人工智能领域中备受关注的一个课题。
随着计算机视觉和自然语言处理技术的不断发展,研究者们开始探索将这两个领域结合起来,通过跨模态算法实现视觉与文本之间的有效交互与融合。
跨模态算法的发展为许多领域提供了新的可能性,如图像标注、图像检索、视频内容分析等。
在本文中,我们将详细介绍视觉和文本领域的跨模态算法的原理、方法和应用。
一、跨模态算法的基本概念跨模态算法是指将不同领域的信息进行融合和交互,实现跨模态数据之间的有效转换和学习。
在视觉和文本领域中,跨模态算法可以实现图像和文本之间的相互关联和推理,从而为未来智能系统的发展提供技术支持。
在跨模态算法中,通常会涉及到视觉和文本之间的特征提取、表示学习、匹配与融合等过程。
1. 特征提取:在跨模态算法中,视觉和文本数据通常会通过特征提取的方式将数据转换为机器可识别的表示形式。
对于视觉数据,可以通过卷积神经网络(CNN)等深度学习方法提取图像的特征;对于文本数据,可以采用词袋模型(Bag of Words)等方法进行文本特征的提取。
2. 表示学习:得到数据的特征表示后,跨模态算法会尝试学习不同数据模态之间的关联和共享信息。
通过表示学习的过程,算法可以发现图像和文本之间的相关性和相似性,为后续的任务提供支持。
3. 匹配与融合:跨模态算法会通过匹配与融合的方式将不同数据模态之间的信息进行整合。
通过匹配和融合的过程,算法可以实现视觉与文本之间的内容对齐、情感融合等任务,为图像标注、图像检索等应用提供支持。
二、视觉和文本领域的跨模态算法1. 图像标注:图像标注是指通过文本描述的方式为图像内容添加语义标签。
跨模态算法可以将图像的视觉信息与文本的语义信息进行融合,实现图像标注的自动化过程。
在图像标注任务中,跨模态算法可以通过图像特征与文本特征的匹配与融合,将图像与对应的语义标签进行关联。
图像自动分类在数字化图书馆中的应用

图 1 图 书馆 分 类 体 系
根据 某 个分类 图像 的底 层 特征 的概率 分 布映 射
到该 分类 。 比如 , 过 某 一 图像 提 取 到 的底 层 特 征 通
与花 草类 图像 的底 层 特 征 相 比较 , 果 相 似度 达 到 如
了一定程度 , 则可 以将该图像划人花草类图像。从 而在一定程度上解决 了语义鸿沟的问题 。 图像 自动分类 的流程为 : 首先提取图像 的视觉 特 征作 为 图像 的语 义 描 述 , 然后 根据 某 种 特 征 匹 配 模型, 用示例查询的方法进行基于内容的图像检索 , 最后 根 据 检 索 结 果 对 示 例 图 像 进 行 分类 J 。算 法
从 图像 中抽 取 低 层 的视 觉 特 征 ( , 色 、 如 颜 纹理 、 形
状 等 ), 后基 于这 些 特征 将 用 户查 询 的 图像 与 数 然 据库 中的图像进 行相 似 程度 衡 量 。图像 的相 似性 判
断建立 在视 觉特 征 的相 似性 上 。这 种方 法在某 些 特
类 对 自身 的等 视觉 和 图像 理 解机 理 尚不 清 楚 , 没 还 有 找 到 同机 理 的机器 识 别方 法 。从 而在 第 一层 与第 二 层之 间 产 生 了 “ 义 鸿 沟 ” 语 。所 讨 论 的 自动 分 类 是 根据 图像 的语 义特 征进 行分 类 的 。图书馆 现有 分 类体 系 如 图 1所示 。
一
别 图像 中描绘 的 对 象 ( “ 阳 ” “ 球 ” ) 如 太 、篮 等 。对 应 于 图像 的对 象语义 ; 三层 是抽 象属 性层 , 第 包括 对
对 象 和场 景 进 行 更 高层 的 推 理 而 得 到 的抽 象 属 性
。
如何应对计算机视觉中的语义分析与语义理解问题

如何应对计算机视觉中的语义分析与语义理解问题计算机视觉中的语义分析与语义理解是近年来人工智能领域的热门课题之一。
通过对图像或视频进行深度学习和自然语言处理等技术的应用,计算机能够理解并解释出图像中所包含的语义信息。
在实际应用中,这种能力可以帮助计算机实现自动化的图像识别、场景分析和智能决策等功能。
本文将从语义分析和语义理解两个方面入手,介绍如何应对计算机视觉中的语义分析与语义理解问题。
一、语义分析在计算机视觉中,语义分析的目标是从图像中提取出包含诸如物体、场景、行为等语义内容的信息。
通常情况下,语义分析可以分为以下几个步骤:1. 物体识别:通过训练深度神经网络模型,将图像分成若干个区域,然后对每个区域进行物体识别。
这一步骤需要使用大量标注好的图像数据进行训练,以提高算法的准确性和鲁棒性。
2. 场景理解:通过对图像中包含的各种物体进行分析和推理,识别出图像所展示的场景信息。
场景理解可以帮助计算机更好地理解并处理复杂的现实场景,从而提供更准确的分析结果。
3. 行为分析:通过对图像中人体或其他物体的姿态、动作等特征进行分析,推测出其所代表的行为。
行为分析在安防监控、视频分析等领域有着广泛的应用,可以提供实时的行为检测和警报功能。
针对计算机视觉中的语义分析问题,我们可以采取以下策略:1. 数据标注与模型训练:为了获取高质量的语义信息,需要构建标注好的图像数据集,并基于这些数据集训练优秀的深度学习模型。
数据的质量和数量对于模型的准确性至关重要,因此需要花费充分的时间和人力资源来完成这一步骤。
2. 特征提取与表达:在语义分析过程中,如何提取出关键的特征并进行有效的表示是一个关键问题。
可以通过使用卷积神经网络(CNN)等技术,从原始图像中提取出物体检测和场景理解等方面所需要的特征。
3. 深度学习与模型优化:采用深度学习技术来实现语义分析是目前最为常见的方法。
在模型训练过程中,可以通过调整网络结构、优化算法和增加训练数据来提高模型的准确性和泛化能力。
目标识别 语义分割 变化检测 场景分类 逻辑回归-概述说明以及解释

目标识别语义分割变化检测场景分类逻辑回归-概述说明以及解释1.引言1.1 概述目标识别、语义分割、变化检测、场景分类以及逻辑回归是计算机视觉领域中重要的研究方向。
随着人工智能的快速发展,这些技术在图像处理、视频分析以及自动驾驶等应用中发挥着关键作用。
目标识别是指通过图像或视频中的特征提取和模式匹配技术,将感兴趣的目标从背景中准确定位和识别出来。
它在实时监控、人脸识别和图像检索等领域中有着广泛的应用。
语义分割是将图像分割成语义上有意义的区域,即将每个像素点分配给特定的类别。
通过语义分割,我们可以更好地理解图像中的场景以及不同目标的位置与形状,在自动驾驶、医学影像分析等领域具有很高的研究价值。
变化检测是指通过比较图像序列之间的差异,来检测图像中发生的变化。
变化检测在遥感图像分析、环境监测以及视频监控中具有重要意义,它可以帮助我们及时发现异常情况和变化事件。
场景分类是将图像或视频分为不同的场景类别,例如室内、室外、山地、海滩等。
场景分类在图像检索、智能监控和图像自动标注等方面有广泛的应用,通过对图像的场景分类可以更好地理解图像的语义和内容。
逻辑回归是一种常用的分类算法,通过建立逻辑回归模型,将输入样本映射为一个概率值,并根据概率值进行分类决策。
逻辑回归在广告推荐、信用风险评估以及医疗诊断等领域有着广泛的应用。
本篇文章将重点介绍目标识别、语义分割、变化检测、场景分类和逻辑回归这几个研究方向的要点和方法,并对其在实际应用中的挑战和发展前景进行讨论。
通过对这些技术的深入了解,我们可以更好地理解计算机视觉领域的最新研究动态,并为相关实际问题提供有效的解决方案。
1.2 文章结构文章结构部分的内容可以是对整篇文章的组织和结构进行介绍和概述。
以下是一个可能的编写内容:文章结构本文主要围绕目标识别、语义分割、变化检测、场景分类和逻辑回归这五个主题展开深入研究和讨论。
为了更好地分析和理解这些主题,文章按照以下结构进行组织和呈现。
人工智能初级工数据标注知识点

人工智能初级工数据标注知识点一、数据标注的定义和意义数据标注是指对原始数据进行标记和注释,以便于机器学习算法能够理解和处理这些数据。
数据标注在人工智能领域中起着至关重要的作用,它为机器学习提供了有标签的训练数据,使得模型能够通过学习这些数据来进行预测和决策。
二、数据标注的常见任务数据标注涵盖了多个任务,常见的包括:1. 分类标注分类标注是将数据分为不同的类别或类别集合,例如将一组图片标注为猫、狗和鸟等。
2. 实体标注实体标注是在文本中标注出特定的实体,例如人名、地名、组织机构等。
3. 关系标注关系标注是在数据中标注出不同实体之间的关系,例如人物之间的亲属关系、产品之间的竞争关系等。
4. 语义标注语义标注是对数据进行语义解析和标注,例如将自然语言文本转换成语义表示形式。
5. 图像标注图像标注是对图像中的不同部分进行标注,例如标注出图像中的物体、场景和动作等。
三、数据标注的流程数据标注通常包括以下几个步骤:1. 数据准备在数据标注之前,需要对原始数据进行清洗和预处理,包括去除噪声、处理缺失值等。
2. 标注方案设计根据任务需求,设计标注方案,明确需要标注的内容和标注方式。
3. 标注工具选择选择适合的标注工具,常见的标注工具包括LabelImg、RectLabel、VGG Image Annotator等。
4. 标注过程根据标注方案,使用标注工具对数据进行标注,确保标注的准确性和一致性。
5. 质量控制对已标注的数据进行质量控制,包括人工复核和自动化检查等,确保标注的质量和准确性。
6. 数据集划分将标注好的数据集划分为训练集、验证集和测试集,用于机器学习模型的训练和评估。
四、数据标注的挑战和注意事项数据标注虽然重要,但也面临一些挑战和注意事项:1. 主观性数据标注往往涉及主观判断,不同标注人员可能有不同的看法和标准,需要进行统一的标注规范和培训。
2. 标注错误标注过程中可能会出现错误,例如标注遗漏、错误标注等,需要进行质量控制和纠正。
基于DBNMI模型的海洋遥感影像自动标注方法

基于DBNMI模型的海洋遥感影像自动标注方法黄冬梅;许琼琼;杜艳玲;贺琪【期刊名称】《中国科学技术大学学报》【年(卷),期】2017(047)007【摘要】研究大规模海洋遥感影像管理的关键是缩小影像低层视觉特征与高层语义之间的鸿沟.针对海洋遥感影像中不同区域对语义相似性度量的贡献程度不同,提出一种基于深度信念网络多示例(deep belief networks multi-instance,DBNMI)的遥感影像语义自动标注模型.模型对初始输入遥感影像进行自适应分割,粗粒度划分海洋遥感影像背景区域和对象区域;对影像对象区域的低层视觉特征和高层语义概念间关系,利用深度信念网络模型进行自动建模;定量计算标注词间共现和对立的语义关系,改善图像标注结果.在公开遥感影像数据集上进行验证,实验表明所提出方法在标注精度上取得了较好效果.%Bridge the semantic gap between low-level visual feature and high-level semantic concepts has been the subject of intensive investigation on large scale remote sensing image management for years in order to improve the accuracy of automatic image annotation.An ocean remote sensing image auto-annotation method based on DBNMI model was proposed for contributions of semantic similarity about different regions of ocean remote sensing images.Initial remote sensing images were adaptively segmented, ocean remote sensing images were divided into background and the object region by means of a coarse-grained method,the relationship between low-level visual feature and high-level semantics label of the object region was modeledautomatically, using DBN model, and the co-occurrence relations and adversarial relations between semantic concepts for improving image annotation results were calculated. The proposed approach is evaluated on a public remote sensing image dataset.The experimental results show a satisfactory improvement on accuracy.【总页数】6页(P541-546)【作者】黄冬梅;许琼琼;杜艳玲;贺琪【作者单位】上海海洋大学信息学院,上海 201306;上海海洋大学信息学院,上海201306;上海海洋大学信息学院,上海 201306;上海海洋大学信息学院,上海201306【正文语种】中文【中图分类】TP391【相关文献】1.基于扩展生成语言模型的图像自动标注方法 [J], 王梅;周向东;张军旗;许红涛;施伯乐2.基于自适应高斯混合模型的遥感影像分类方法研究——以武汉地区遥感影像分类为例 [J], 李登朝;吴健;许凯3.基于高斯混合模型的现代汉语构式成分自动标注方法 [J], 黄海斌;常宝宝;詹卫东4.一种基于多模态主题模型的图像自动标注方法 [J], 田璟;郭智;黄宇;黄廷磊;付琨5.基于异构描述子的新型高斯混合模型图像自动标注方法 [J], 陈利琴;金聪因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于内容的检索结果 2
此概念于1992年由T.Kato在论文“Query by Visual Example
- Content based Image Retrieval”中提出。最早应用是IBM的 QBIC系统,是为一个俄国博物馆制作的绘画作品查询系统。
目前基于内容的图像检索系统,例如:谷歌搜图、9 标注的评价指标相关
检索到 未检索到 A C
不相关
B D
(1)查全率 = A/(A+C)
(2)查准率 = A/(A+B) 该评价指标主要借鉴于文本检索领域的查全率和查准率,针对图 像的非精确度匹配原则,有待于寻找一种更适合的评价标准。
10 WordNet在标注中的作用
WordNet是由Princeton大学的心理学家、语言学家和计算 机工程师联合设计的一种基于认知语言学的英语词典。它按
6 特征提取的主要方法
(1)基于颜色的特征提取
由于颜色特征具有对尺度、平移和旋转等不变的特性, 同时颜色特征是我们辨别物体的主要方法,所以基于颜色的 特征提取是目前图像特征提取的最常用方法。 常用的颜色特征提取方法有:
●颜色直方图法 ●颜色相关图法 ●颜色矩法 ●颜色集法 ●颜色聚合向量法 ● ……
电脑)。
11 课题研究可能的切入点
(1)颜色、纹理、形状这些底层特征间的权重、优先序。 (2)文本检索比较成熟,从文本检索中找一些启发。 (3)基于区域的不均匀块分割(快速、易分割、位置相关) (4)基于视觉权重的图像特征提取(基于心理学的视觉焦点) (5)从图像+相关文本+人反馈的综合角度提出新的方法思路,从质上 改变鸿沟现状。
12 问题与疑惑
(1)“语义鸿沟”似乎永远无法逾越,目前所有工作只是缩小“鸿沟”而 已。人工标注的训练集也不是最客观、无“鸿沟”的。
(特征语义,对象语义,空间关系语义,场景语义,行为语义以及情感语义)
(2)若训练集共有500个标注词,那么构造出的分类器给出的词也就是那
500个,这如何足够去描绘丰富的现实呢?
作量巨大,且缺乏一定的客观性。
2 目前图像检索方式
(1)基于文本的图像检索(Text-based Image Retrieval——TBIR)
通过关键字检索,图像库中的关键字由人工标注,现有互联网搜索 引擎主要使用此方式。
优点:将图的检索问题转为文本的检索问题,效率高,技术成熟。
缺点:需要人工给每幅图片标注对应的若干个语义词,工作量巨大。
6 特征提取的主要方法
(3)基于形状的特征提取
形状是刻画物体的基本特征之一,用形状区别物体非 常直观。通过形状特征的提取可以识别图像中所包含的事 物或对象,从而提取出其中感兴趣的目标。 常用的形状特征提取方法有:
●边界特征值法 ●形状不变矩法 ● …… ●几何参数法 ●傅里叶形状描述法
6 特征提取的主要方法
照单词的语义将其组成一个“单词网络”,体现了不同单词
间的语义层次和关系(相近、对立、包容等)。在自然语言 理解和人工智能的应用研究上都具有重要的价值。 在图像语义自动标注中,可以借助WordNet的结构化语 义信息来衡量词汇之间的关系,从而更好的选取适当的语义
词(生物、鸟类、白鸽),以及剔除冗余的语义词(计算机、
6 特征提取的主要方法
(2)基于纹理的特征提取
纹理是物体表面固有的一种特性,它具有区域特性和 旋转不变性,反映了不同对象之间的区分。所以纹理也是 图像的主要提取特征。 常用的纹理特征提取方法有:
●局部二值模式法 ●灰度共生矩阵法 ●随机场模型法法
●基于小波变化法 ●基于Gabor滤波器法 ●自回归纹理模型法 ●结构法 ● ……
识图等,因为“语义鸿沟”的原因,都不能很好的匹配用户
的检索意图。
所谓“语义鸿沟”是指基于图像底层可视特征(颜色、
纹理、形状等)的匹配,并不能完全反映用户更高层次的语
义查询,例如:生命、呵护、沉思…
图像检索问题的思考?
(1)如何克服方式1中人工标注的难题?
答案:让机器代替人去做。
(2)如何克服方式2中“语义鸿沟问题”?
它是图像语义理解研究领域的一个热点。由Mori等人在1999年提出。
涉及技术:图像处理(增强、去噪、分割等)、计算机视觉(特征提取)、模式 识别(分类和理解)、机器学习(建立分类器)等。
4自动标注方法原理
利用已标注图像集或其他可获得的信息自动学习语义概念
空间与视觉特征空间的关系模型,并用此模型标注未知语义的
图像。即试图在图像的高层语义和低层视觉特征之间建立一种 映射关系,一定程度上解决“语义鸿沟”问题。
(1)基于整幅图特征的语义映射;(自然场景、纹理、建筑,不区分前后景) (2)基于规则块或同质区域的语义映射;
(比(1)多了位置区分)
(3)基于图中物体识别的语义词射;(语义更准确、更丰富)
5 用于标注实验的数据集
(3)目前的训练集是否具有一般性? (4)大众标注与专家标注差异较大。(提出两者互为补充)
困难?机遇? 现有的自动图像标注方法多数停留在理论研究上,还无法进行具体应用,甚至目前还 没有一个被学界普遍接受的已标注图像库。
感谢各位的聆听!
由于查阅文献资料的有限性,以及个人水 平所限,报告中必然有不妥或错误之处,恳请
图像语义自动标注 课题介绍
介绍人:李思辉
1 问题提出背景
随着数字影像技术与互联网技术的迅速发展,
互联网上有约数以百亿记的图像,如何快速的检
索到用户需要的图片成为一个关键问题。
目 前 商 是以文本关键字的形式来查
询,其关键字主要依靠人工标注及 Web 文本,工
(2)基于内容的图像检索(Content-based Image Retrieval—— CBIR)
输一幅图像,通过计算图像的可视特征(如颜色、纹理、形状等) 来实现图像的匹配与检索。
优点:无需人工标注,由计算机自动计算特征并匹配。 缺点:“语义鸿沟”使检索出的结果不能完全反映检索者的意图。
基于内容的检索结果 1
目前较为公认的图像集是Corel-5k
◆它由科雷尔公司收集整理,分成三部分:
(1)4000张像作为训练集;
(2)500张作为验证集用来估计模型参数;
(3)500张作为测试集评价算法性能; ◆5000张图片按照每100张一个主题,共分为50个主题。 ◆图像库中的每张图片被标注3∽5个标注词,训练集中 总共有374个标注词,在测试集中总共使用了263个标注词。
批评与指正。
(4)基于空间关系的特征提取
空间关系是指图Leabharlann 中多个目标之间的相互位置或方向 关系。这些关系可分为连接、邻接、交叠、包含等。空间 关系加强了图像内容的描述和区分能力。
空间关系特征提取方法:
●基于图像的规则子块分割,建立子块索引法。
●基于图像中对象或区域的分割,建立对象索引。
7 图像相似度的计算
判断两幅图像是否相似,就是计算两幅图像的特征向量, 然后将特征向量看做多维空间中的点,然后计算两点之间的
距离,距离越短越相似。常用的距离度量公式有:
Minkkowsky 距 离 , Manhattan 距 离 , Euclidean 距 离 , 加 权 Euclidean距离,Chebyshev距离,Mahalanobis距离等。 当然还有其它方法,例如:支持向量机的分类学习方法, 它将图像的匹配过程看成是相似图像的分类过程。
8 图像标注的主要方法
(3)基于图学习的标注算法
将已标注图像和未标注图像放在一起,将每一幅图像 视为一个图节点,以图像间的相似关系作为边,实现标注 信息从已标注图像到未知图像的传播,从而完成对待标注
图像的标注任务。
同样的方法也可用于标注词,并依据标注词之间的语 义相关性进一步改善基于图学习生成的标注。
(具体方法模型:多示例学习、SVM、语言索引法、多样性密度法、高斯混合模型等)
8 图像标注的主要方法
(2)基于概率关联模型的标注算法
在概率统计模型的基础上,分析图像区域特征与语义关键 词之间的共生概率关系,并以此为待标注图像进行语义标注。
(两篇内容最相似的文章,其相同单词出现的概率就最高)
①将训练集中每幅图像进行区域分割;(每个区域可为一个视觉单词)
②提取每幅图像的区域视觉特征;(颜色、纹理、形状等;即提取视觉单词) ③将所有图像的区域视觉特征聚类; (即建立视觉单词字典) ④用统计方法计算每个区域视觉特征与标注词的相关概率; (?) ⑤根据待标注图像的区域视觉特征对其标注最相关的几个标注词;
(具体方法模型:Co-occurrence模型、翻译模型、LDA、CMRM、CRM、MBRM模型)
8 图像标注的主要方法
(1)基于分类的标注算法
将标注问题看成是图像语义分类问题。将每个语义关键词 都看成是一个类别标记,则图像标注问题就转化为图像分类问 题。
①按照每个标注词将训练集分为正例和反例;
②提取所有正例的全局特征和反例的全局特征; ③根据正反例特征值构造分类器; ④用每个标注词分类器为待标注图像分类; ⑤在所有标注词中选取分类值最高的几个作为标注词;
答案:让机器进行多示例学习。
结论: 让机器通过多示例学习后自动完成图像内容 语义的标注,即图像语义自动标注。
3 什么是图像语义自动标注
图像自动标注(Automatic
Image Annotation,AIA)就是让计算机自动地给
图像加上能够反映其内容的语义关键词。自动标注的使用可以有效改善目前
的图像检索困境。使检索在保留基于文本关键词搜索的同时,免去了人工标 注的巨大工作量,也一定程度的跨越了“语义鸿沟”。