知识点串的模式匹配
串的模式匹配

串的模式匹配串的模式匹配⼀般分为两种:简单模式匹配和KMP算法#include <stdio.h>#include <stdlib.h>#define MaxSize 100typedef struct{char str[MaxSize+1];int length;}Str;//串的存储结构int index1(Str *str1,Str *str2){int i=1,j=1;int pos=i;//记录当前主串开始匹配的起始位置while(i<=str1->length&&j<=str2->length){if(str1->str[i]==str2->str[j]){i++;j++;}else{j=1;i=++pos;//若匹配失败,则将起始位置的下⼀个位置开始}}if(j>str2->length){printf("模式串在主串中的位置:%d\n",pos);return pos;}else return0;}//简单模式匹配int GetLength(Str *str1){int i=0;while(str1->str[i+1]){i++;}return i;}//获得串的长度void get_next(Str *str2,int next[]){int i=1,j=0;next[1]=0;while(i<str2->length){if(j==0||str2->str[i]==str2->str[j]){i++;j++;next[i]=j;}else {j=next[j];}}}//构造next数组int index_KMP(Str *str1,Str *str2,int next[]){int i=1,j=1;while(i<=str1->length&&j<=str2->length){if(j==0||str1->str[i]==str2->str[j]){i++;j++;}else j=next[j];}if(j>str2->length){printf("模式串在主串中的位置:%d\n",i-str2->length);return i-str2->length;}else return0;}//KMP算法void main(){Str str1;Str str2;int next[MaxSize];//kmp算法中的next数组scanf("%s",str1.str);//0ababcabcacbabscanf("%s",str2.str);//0abcstr1.length=GetLength(&str1);str2.length=GetLength(&str2);index1(&str1,&str2);get_next(&str2,next);index_KMP(&str1,&str2,next);}。
关于串的模式匹配的叙述中

关于串的模式匹配的叙述中
摘要:
1.串的模式匹配的概述
2.串的模式匹配的基本算法
3.串的模式匹配的实际应用
正文:
一、串的模式匹配的概述
串的模式匹配是在计算机科学和信息处理领域中常见的一种技术,其目的是在给定的文本中查找与某种模式相匹配的子串。
在实际应用中,这种技术被广泛应用于数据挖掘、信息检索、文本分析等领域。
二、串的模式匹配的基本算法
在串的模式匹配中,最基本的算法是朴素匹配算法(Brute Force)。
这种算法的基本思想是逐个字符地比较给定的文本和模式,直到找到匹配的子串或者到达文本的末尾。
另外,还有一种算法是KMP 算法,它是在朴素匹配算法的基础上,利用模式自身的特点,避免重复比较,从而提高匹配效率。
三、串的模式匹配的实际应用
在实际应用中,串的模式匹配技术被广泛应用在文本处理、数据分析、信息检索等领域。
例如,在搜索引擎中,通过串的模式匹配技术,可以在海量的网页中快速找到与用户输入的关键词相匹配的内容;在文本分析中,通过串的模式匹配技术,可以找到文本中的关键词或者特定的语句,从而对文本进行分类或者分析。
串的模式匹配问题实验总结(用C实现)

串的模式匹配问题实验总结(用C实现)第一篇:串的模式匹配问题实验总结(用C实现)串的模式匹配问题实验总结1实验题目:实现Index(S,T,pos)函数。
其中,Index(S,T,pos)为串T在串S的第pos个字符后第一次出现的位置。
2实验目的:熟练掌握串模式匹配算法。
3实验方法:分别用朴素模式匹配和KMP快速模式匹配来实现串的模式匹配问题。
具体方法如下:朴素模式匹配:输入两个字符串,主串S和子串T,从S串的第pos个位置开始与T的第一个位置比较,若不同执行i=i-j+2;j=1两个语句;若相同,则执行语句++i;++j;一直比较完毕为止,若S中有与T相同的部分则返回主串(S字符串)和子串(T字符串)相匹配时第一次出现的位置,若没有就返回0。
KMP快速模式匹配:构造函数get_next(char *T,int *next),求出主串S串中各个字符的next值,然后在Index_KMP(char *S,char *T,int pos)函数中调用get_next(char *T,int *next)函数并调用next值,从S串的第pos 位置开始与T的第一个位置进行比较,若两者相等或j位置的字符next值等于0,则进行语句++i;++j;即一直向下进行。
否则,执行语句j=A[j];直到比较完毕为止。
若S中有与T相同的部分则返回主串(S字符串)和子串(T字符串)相匹配时第一次出现的位置,若没有就返回04实验过程与结果:(1)、选择1功能“输入主串、子串和匹配起始位置”,输入主串S:asdfghjkl, 输入子串T:gh,输入pos的值为:2。
选择2功能“朴素的模式匹配算法”,输出结果为 5;选择3功能“KMP快速模式匹配算法”,输出结果为 5;选择0功能,退出程序。
截图如下:(2)、选择1功能“输入主串、子串和匹配起始位置”,输入主串S:asdfghjkl, 输入子串T:wp, 输入pos的值为:2。
02-第4章串第2讲-串的模式匹配概念

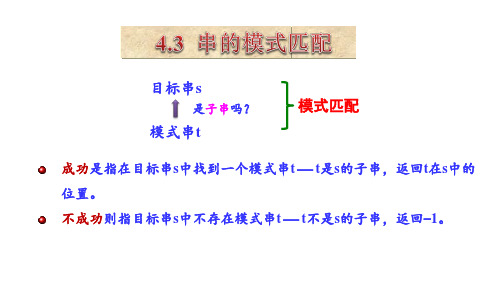
L4.3 串的模式匹配算法⏹定义子串的定位操作通常称做串的模式匹配(其中P、T称为模式串,P a T tern),是各种串处理系统中最重要的操作之一。
⏹名词在串的模式匹配中,子串P称为模式,主串S称为目标。
【示例】目标S : “Beijing”模式P : “jin”匹配结果= 3(匹配位置从0 开始)☐讨论两种匹配算法:BF 算法和KMP 算法。
4.3.1 求子串位置的定位函数初始时让目标S 的第0 位与模式P 的第0 位对齐;顺序比对目标S 与模式P 中的对应字符:❒若P 与S 比对发现对应位不匹配,则本趟失配。
将P 右移一位与S 对齐,进行下一趟比对;❒若P 与S 对应位都相等,则匹配成功,返回S 当前比较指针停留位置减去P 的长度,即目标S 中匹配成功的位置,算法结束。
❒若P 与S 比对过程中,S 后面所剩字符个数少于P 的长度,则模式匹配失败。
Brute-Force 简称为BF 算法,亦称简单匹配算法。
采用穷举的思路。
LBF 算法匹配过程的示例第1趟S a b b a b aP a b a 第2趟S a b b a b aP a b ai=2j=2i=1j=0第3趟S a b b a b a P a b a第4趟S a b b a b a P a b ai=2j=0i=6j=3这是最简单的模式匹配算法。
Lint index(SqString S, SqString P, int pos)L{int i = pos -1, j = 0;while(i < S.length && j < P.length) {if(S.SString[i] == P.SString[j]) {i++;//主串和子串依次匹配下一个字符j++;}else { //主串、子串指针回溯重新开始下一次匹配i = i -j + 1; //主串从下一个位置开始匹配j = 0; //子串从头开始匹配}}if(j >= P.length)return(i -P.length);//返回匹配的第一个字符的下标elsereturn -1;//模式匹配不成功}☐若设n 为目标S 的长度,m 为模式P 的长度,匹配算法最多比较n -m +1趟。
计算机基础知识:串的模式匹配之求子串位置的定位函数

计算机基础知识:串的模式匹配之求子串位置的定位函数【导语】在事业单位考试中,计算机专业知识的复习向来是考生复习备考阶段的一大重点,其中中公事业单位考试网为计算机基础知识的复习为考生提供知识点梳理,帮助考生备考!
在串匹配中,假设S为目标串,P为模式串:
S=‘s1s2...sn’ P=‘p1p2…pm’
串的匹配实际上是根据 1≤i≤n-m+1 依次将 S 的子串 S’[i..i+m-1] 和 P[1..m] 进行比较,若 S’[i..i+m-1] = P[1..m],则称从位置i开始的匹配成功;反之,匹配失败。
上述的位置i又称为位移,
当S’[i..i+m-1] = P[1..m]时,i称有效位移;
当S’[i..i+m-1]≠ P[1..m]时,i称无效位移。
这样,串匹配问题可简化为是找出某给定模式串 P 在给定目标串 S 中首次出现的有效位移。
以上是中公事业单位考试网为考生梳理计算机基础知识点,供大家学习识记!
中公教育新疆事业单位/xinjiang/。
串的知识点总结

串的知识点总结1. 串的基本概念串是由零个或多个字符组成的有限序列,通常用来表示文本数据。
在编程语言中,串通常被定义为一个字符数组或字符串变量。
例如,在C语言中,字符串通常被定义为char类型的数组,而在Java语言中,字符串则是一个类对象。
2. 串的存储结构串的存储结构有两种常见形式:一是定长顺序存储结构,二是链式存储结构。
定长顺序存储结构是将串的字符按照顺序存储在一块连续的存储空间中,这种方式可以通过下标来访问任意位置的字符,但是需要预先分配足够的存储空间。
链式存储结构则是使用链表来存储串的字符,这种方式可以动态分配内存空间,但是访问任意位置的字符需要从链表头开始遍历,效率较低。
3. 串的基本操作串的基本操作包括串的创建、复制、连接、比较、插入和删除等。
创建串是指将一组字符转换成串的操作;复制是指将一个串的内容复制到另一个串中;连接是指将两个串连接在一起形成一个新的串;比较是指比较两个串的大小关系;插入是指在一个串中的指定位置插入一个子串;删除是指删除一个串中的指定子串。
这些操作都是串的基本操作,它们在实际应用中有着重要的作用。
4. 串的模式匹配串的模式匹配是指在一个主串中查找与给定模式串相匹配的子串的过程。
常见的模式匹配算法有暴力匹配算法、KMP算法和Boyer-Moore算法等。
暴力匹配算法是最简单的模式匹配算法,它的时间复杂度为O(m*n),其中m为主串长度,n为模式串长度;KMP算法是一种高效的模式匹配算法,它的时间复杂度为O(m+n),其中m为主串长度,n为模式串长度;Boyer-Moore算法是一种更加高效的模式匹配算法,它的时间复杂度为O(m*n),其中m为主串长度,n为模式串长度。
5. 串的应用串在计算机科学中有着广泛的应用,它在各种应用中都有着重要的作用。
例如,在文本编辑器中,串被用来表示文本文件的内容;在数据库系统中,串被用来表示数据的各种属性;在网络通信中,串被用来表示网页的URL地址等。
第5周串第2讲-串的模式匹配
例如,设目标串s=“aaaaab”,模式串t=“aaab”。s的长度为n (n=6),t的长度为m(m=4)。BF算法的匹配过程如下。
i
s: a a a a a b
t a a a b 匹配失败:
:
i=i-j+1=1 (回退)
j
j=0 (从头开始)
i=1,j=0
i
s aaaaab
t:: a a a b
开头的k个字符 后面的k个字符
next[j]=
MAX{ k | 0<k<j,且“t0t1…tk-1” = “tj-ktj-k+1…tj-1”}
当此集合非空时
-1
当j=0时
0
其他情况
t=“aaab”对应的next数组如下:
j
0
1
t[j]
a
a
next[j]
-1
0
2
3
a
b
1
2
t0=t1="a"t0t1=t1t2="aa"
匹配失败: i=i-j+1=2(回退)
j
j=0(从头开始)
i=2,j=0
i
s a a aaa b t:: a a a b
j
匹配成功:
i=6,j=4
返回i-t.length=2
对应的BF算法如下:
int index(SqString s,SqString t)
{ int i=0, j=0;
while (i<s.length && j<t.length)
模式串t存在某个k(0<k<j),使得以下成立:
“t0t1…tk
串的两种模式匹配算法

串的两种模式匹配算法 模式匹配(模范匹配):⼦串在主串中的定位称为模式匹配或串匹配(字符串匹配) 。
模式匹配成功是指在主串S中能够找到模式串T,否则,称模式串T在主串S中不存在。
以下介绍两种常见的模式匹配算法:1. Brute-Force模式匹配算法暴风算法,⼜称暴⼒算法。
算法的核⼼思想如下: 设S为⽬标串,T为模式串,且不妨设: S=“s0s1s2…sn-1” , T=“t0t1t2 …tm-1” 串的匹配实际上是对合法的位置0≦i≦n-m依次将⽬标串中的⼦串s[i…i+m-1]和模式串t[0…m-1]进⾏⽐较:若s[i…i+m-1]=t[0…m-1]:则称从位置i开始的匹配成功,亦称模式t在⽬标s中出现;若s[i…i+m-1]≠t[0…m-1]:从i开始的匹配失败。
位置i称为位移,当s[i…i+m-1]=t[0…m-1]时,i称为有效位移;当s[i…i+m-1] ≠t[0…m-1]时,i称为⽆效位移。
算法实现如下: (笔者偷懒,⽤C#实现,实际上C# String类型已经封装实现了该功能)1public static Int32 IndexOf(String parentStr, String childStr)2 {3 Int32 result = -1;4try5 {6if (parentStr.Length > 1 && childStr.Length > 1)7 {8 Int32 i = 0;9 Int32 j = 0;10while (i < parentStr.Length && j < childStr.Length)11 {12if (parentStr[i] == childStr[j])13 {14 i++;15 j++;16 }17else18 {19 i = i - j + 1;20 j = 0;21 }22 }23if (i < parentStr.Length)24 {25 result = i - j;26 }27 }28 }29catch (Exception)30 {31 result = -1;32 }33return result;34 } 该算法的时间复杂度为O(n*m) ,其中n 、m分别是主串和模式串的长度。
简述串的模式匹配原理

简述串的模式匹配原理嘿,咱聊聊串的模式匹配原理呗!这串的模式匹配,听着挺神秘,其实也不难理解。
就像在一堆宝藏里找宝贝。
啥是串的模式匹配呢?简单说,就是在一个大字符串里找一个小字符串。
这就像在一片大海里找一条小鱼。
你得有办法才能找到它。
比如说,你想在一篇文章里找一个特定的词,这就是串的模式匹配。
那怎么找呢?有好几种方法呢。
一种是暴力匹配。
这就像一个愣头青,一个一个地比对。
从大字符串的开头开始,一个字符一个字符地和小字符串比对。
如果不一样,就往后移一个字符,继续比对。
这就像在一堆沙子里找一颗小石子,得一颗一颗地找。
虽然有点笨,但是有时候也能管用。
还有一种是KMP 算法。
这就像一个聪明的侦探,有自己的一套方法。
它会先分析小字符串的特点,然后根据这些特点来快速匹配。
比如说,如果在比对的过程中发现不一样了,它不会像暴力匹配那样从头开始,而是根据之前的分析,直接跳到合适的位置继续比对。
这就像你知道了宝藏的线索,就能更快地找到宝藏。
串的模式匹配有啥用呢?用处可大了。
比如说,在文本编辑软件里,你想查找一个特定的词或者句子,就用到了串的模式匹配。
还有在搜索引擎里,也是用串的模式匹配来找到你想要的信息。
这就像你有一把神奇的钥匙,能打开知识的大门。
你说要是没有串的模式匹配,那会咋样呢?那找东西可就麻烦了。
就像在一个乱七八糟的房间里找东西,没有头绪,得翻个底朝天。
有了串的模式匹配,就像有了一个指南针,能让你更快地找到你想要的东西。
总之,串的模式匹配就像一个神奇的工具,能在大字符串里找到小字符串。
咱可得好好理解它,让它为我们的生活带来更多的便利。
串的模式匹配串的模式匹配

实验题目:串的模式匹配一、实验目的1、加深理解串的基本操作;2、理解并实现串的朴素模式匹配算法。
二、实验内容输入主串S和模式T,在S中查找T出现的第一个位置。
三、设计与编码1、基本思想1,在串S和串T中设置比较的起始下标i和j;2,如果S[i]=T[j],继续比较S和T的下一对字符,否则将下标i,j回溯,准备下一趟比较;3,如果T中所有字符都比较完,则匹配成功,返回匹配的开始位置,否则返回0;2、编码#include<iostream>#include<string>using namespace std;class BF{private:char *s,*t;public:BF(char a[],char b[]){s=a;t=b;}int bf(){int i=0,j=0;while((s[i]!='\0')&&(t[j]!='\0')){if(s[i]==t[j]){i++;j++;}else{i=i-j+1;j=0;}}if(t[j]=='\0')return i-j+1;}};int main(){char s[100],t[100];cin>>s>>t;BF A(s,t);cout<<"主串S:"<<s<<'\n'<<"模式T:"<<t<<endl;cout<<A.bf()<<endl;return 0;}四、调试与运行1、调试时遇到的主要问题及解决答:基本没有大的错误,大多是一些细节问题,就是字符串的上传问题,我最后直接用指针搞定。
2、运行结果(输入及输出,可以截取运行窗体的界面)输入:abcdefgh defg;输出:五、实验心得答:通过本次的实验,让我加深了理解了串的操作。
数据结构—串的模式匹配

数据结构—串的模式匹配数据结构—串的模式匹配1.介绍串的模式匹配是计算机科学中的一个重要问题,用于在一个较长的字符串(称为主串)中查找一个较短的字符串(称为模式串)出现的位置。
本文档将详细介绍串的模式匹配算法及其实现。
2.算法一:暴力匹配法暴力匹配法是最简单直观的一种模式匹配算法,它通过逐个比较主串和模式串的字符进行匹配。
具体步骤如下:1.从主串的第一个字符开始,逐个比较主串和模式串的字符。
2.如果当前字符匹配成功,则比较下一个字符,直到模式串结束或出现不匹配的字符。
3.如果匹配成功,返回当前字符在主串中的位置,否则继续从主串的下一个位置开始匹配。
3.算法二:KMP匹配算法KMP匹配算法是一种改进的模式匹配算法,它通过构建一个部分匹配表来减少不必要的比较次数。
具体步骤如下:1.构建模式串的部分匹配表,即找出模式串中每个字符对应的最长公共前后缀长度。
2.从主串的第一个字符开始,逐个比较主串和模式串的字符。
3.如果当前字符匹配成功,则继续比较下一个字符。
4.如果当前字符不匹配,则根据部分匹配表的值调整模式串的位置,直到模式串移动到合适的位置。
4.算法三:Boyer-Moore匹配算法Boyer-Moore匹配算法是一种高效的模式匹配算法,它通过利用模式串中的字符出现位置和不匹配字符进行跳跃式的匹配。
具体步骤如下:1.构建一个坏字符规则表,记录模式串中每个字符出现的最后一个位置。
2.从主串的第一个字符开始,逐个比较主串和模式串的字符。
3.如果当前字符匹配成功,则继续比较下一个字符。
4.如果当前字符不匹配,则根据坏字符规则表的值调整模式串的位置,使模式串向后滑动。
5.算法四:Rabin-Karp匹配算法Rabin-Karp匹配算法是一种基于哈希算法的模式匹配算法,它通过计算主串和模式串的哈希值进行匹配。
具体步骤如下:1.计算模式串的哈希值。
2.从主串的第一个字符开始,逐个计算主串中与模式串长度相同的子串的哈希值。
简述串的模式匹配算法概念 -回复

简述串的模式匹配算法概念-回复串的模式匹配算法是指在一个文本串中寻找一个模式串出现的位置的算法。
它是计算机科学领域中的经典问题,应用广泛。
不论是搜索引擎中的关键词匹配,还是代码编辑器中的查找替换功能,在实际的编程开发中都需要用到串的模式匹配算法。
在深入理解串的模式匹配算法之前,我们需要先了解什么是串。
串是指由零个或多个字符组成的有限序列。
在计算机中,串通常是以字符串的形式存在,它是一种非常基础的数据结构,用于表示文本。
在串的模式匹配算法中,有几种常见的思想和算法。
1.暴力匹配算法暴力匹配算法也被称为朴素匹配算法,它是最简单直接的模式匹配算法。
它的思想是从文本串的第一个字符开始,逐个与模式串进行匹配,如果匹配失败,则将文本串向后移动一个字符,再次与模式串进行匹配。
这个过程会一直重复,直到找到匹配的位置或者搜索到文本串的末尾。
暴力匹配算法的时间复杂度为O(n*m),其中n为文本串的长度,m为模式串的长度。
虽然时间复杂度较高,但暴力匹配算法是一种简单易懂、实现容易的模式匹配算法。
2.KMP算法KMP算法是一种高效的模式匹配算法,它的核心思想是通过利用已经匹配过的信息,避免不必要的重复匹配。
KMP算法首先构建模式串的最长前缀后缀表,该表记录了模式串中每个位置之前的字符串中,最长的既是前缀又是后缀的子串的长度。
通过这个表,可以在匹配过程中根据已经匹配的部分直接跳跃到下一个可能匹配的位置,从而避免了重复匹配。
KMP算法的时间复杂度为O(n+m),其中n为文本串的长度,m为模式串的长度。
相比于暴力匹配算法,KMP算法在匹配过程中减少了不必要的比较次数,大大提高了匹配效率。
3.Boyer-Moore算法Boyer-Moore算法是一种根据字符在模式串中出现的位置进行跳跃匹配的算法。
它的核心思想是从模式串的末尾开始,逐个比较模式串和文本串的字符,并根据预处理的跳跃表进行匹配位置的选择。
Boyer-Moore算法分别预处理了两个跳跃表:bad character表和good suffix表。
串的模式匹配

串的模式匹配(1)、Brute-Force 暴风(Brute Force)算法是普通的模式匹配算法,BF算法的思想就是将⽬标串S的第⼀个字符与模式串T的第⼀个字符进⾏匹配,若相等,则继续⽐较S的第⼆个字符和 T的第⼆个字符;若不相等,则⽐较S的第⼆个字符和T的第⼀个字符,依次⽐较下去,直到得出最后的匹配结果。
BF算法是⼀种蛮⼒算法。
如⽬标串:"caatcat",t="cat",pos=1,匹配过程如图程序如下:#include<stdio.h>#include<stdlib.h>#define MAXNUM 100//顺序串的存储结构,即串中的字符被依次存放在⼀组连续的存储单元中typedef struct St{char *ch; //存放串的起始地址,串中的第i个元素存储在ch[i-1]中int length; //串的长度int strsize;//分配给串的存储空间⼤⼩,若不够,通过realloc()再分配,增加存储空间}String;String CreateNullString(){String s;s.ch=(char *)malloc(MAXNUM*sizeof(char)); //初始化串的存储空间s.length=0;s.strsize=MAXNUM;return s;}//为字符串赋值void Stringassign(String *s,char s2[]){int i=0;//统计串s2的长度,若不够,然后再通过realloc去增加存储空间while(s2[i]!='\0')i++;if(i>s->strsize){s->ch=(char *)realloc(s->ch,i*sizeof(char));s->strsize=i;}s->length=i;for(i=0;i<s->length;i++)s->ch[i]=s2[i];}/*s:⽬标字符串t:匹配字符串pos:索引*/int index(String s,String t,int pos){int i,j;if(pos<1 || s.length<pos || s.length-t.length+1<pos){printf("输⼊参数不合理\n");exit(0);}i=pos-1;j=0;while(i<s.length && j<t.length){if(s.ch[i]==t.ch[j]){i++; //第i个字符相等,继续匹配j++;}else{i=i-j+1; //匹配失败,初始i的后⼀个位置继续开始匹配j=0;}}if(j>=t.length)return i-t.length+1; //匹配成功,返回第匹配成功的字符串的起始地址elsereturn 0; //未匹配成功}void main(){String s,t;int i;char ch[MAXNUM];s=CreateNullString();t=CreateNullString();printf("请输⼊主字符串:");gets(ch);Stringassign(&s,ch);printf("输⼊⼦串:");gets(ch);Stringassign(&t,ch);printf("输⼊匹配的起始地址:");scanf("%d",&i);i=index(s,t,i);printf("%d\n",i);}运⾏结果如下:备注:关于get()和scanf()函数的区别gets() : gets从标准输⼊设备读字符串函数。
串的模式匹配PPT教案学习

第3页/共38页
串的ADT定义—引用型操作
StrLength(S)
SubString( sub, commander, 4, 3) 求得sub= man SubString(sub,c om m a nde r,1,9)求得sub= c om m a nde r SubString( sub, commander, 9, 1)求得 sub = r; SubString(sub,student,5,0)求得sub= φ或 SubString(sub, beijing, 7, 2)求得sub = ?
} HString; //定长顺序存储结构下数组首元素存放串长 ,堆分配存储结构下数组各元素均存放有 效字符
第14页/共38页
Status StrAssign(HString &T, char *chars){ //chars为 常 量 char *p=chars,q; int i=0; if(T.ch) free(T.ch); while(*p++)i++; //求 chars的 长 度 T.length=i; if (!i) T.ch=NULL; else { T.ch=(char *)malloc(i*sizeof(char)); if (!(T.ch)) exit OVERFLOW; p=chars; q=T.ch; while(*p)*q++=*p++; } return OK;
第5页/共38页
2、串的最小操作子集
除串清空和销毁外StrAssign、Strcopy、Concat 、 StrLength、 SubString、StrCompare六种操 作构成一个最小操作子集。其他串操作可在这个 最小操作子集上实现,如Index(S,T,pos)
串的模式匹配

进行10次比较运算呢?
分析
不然。 因为通过计算extend[1]=10,我们可以得到这样的信息:
S[1..10]=T[1..10]S[2..10]=T[2..10]。 计算extend[2]的时候,实际上是S[2]开始匹配T。因为 S[2..10]=T[2..10],所以在匹配的开头阶段是“以T[2..10]为 母串,T为子串”的匹配。 不妨设辅助函数next[i]表示T[i..m]与T的最长公共前缀长度。 对于这个例子,next[2]=10。也就是说: T[2..11]=T[1..10]T[2..10]=T[1..9]S[2..10]=T[1..9]。 这就是说前9位的比较是完全可以避免的!我们直接从 S[11]T[10]开始比较。这时候一比较就发现失配,因此 extend[2]=9。
DNA病毒
科学家最近发现了某种病毒,通过对该病毒的分析,
它的DNA是是环状的,科学家为了方便研究,将病 毒DNA表示成由一些字母组成的字符串,现在科学 家怀疑有人中了这种病毒,如何判断是否中了病毒 呢?主要是看这种病毒代码是不是在人的DNA中出 现过,如果出现过,则此人中了病毒,否则没有中 病毒。例如,假设人的DNA代码为abcddcba,而 病毒代码为ccdd,则abcddcba的下划线部分为病 毒部分,该人中了毒。 科学家有一些任务,他们已找出了病毒的DNA和人 的DNA,现在要你提供帮助,看看哪些是否中了毒。
第一行一个数n,表示有n个任务,(k<=300)。
接下来的每个任务都包括两行,第2i行的字符串表示第i 个人的DNA (长度<=8000) ,第2i+1行的字符串,表示 第i个病毒的DNA。(长度<=8000)。 (注意,人的DNA是线性的,而病毒DNA是环状的) 输出:DNA.out n行,每行一个词”YES”或者“NO”。分别所对应那个 任务的判断情况。 样例: DNA.IN DNA.OUT 2 YES bbab YES abb ababab ab
数据结构—串的模式匹配

数据结构—串的模式匹配数据结构—串的模式匹配1:引言1.1 背景在计算机科学中,模式匹配是一个常见的问题,涉及到在给定的文本字符串中查找特定的模式串。
串的模式匹配是一种重要的算法,广泛应用于字符串处理、数据查询和自然语言处理等领域。
1.2 目的本文档旨在介绍串的模式匹配算法的基本原理和常用的实现方法,以及其在实际应用中的一些应用场景。
通过阅读本文档,读者将能够理解串的模式匹配算法的工作原理,并能够根据具体的应用需要选择合适的算法进行实现。
2:基本概念2.1 字符串字符串是由字符组成的有限序列,在计算机中通常以字符数组或字符指针的形式来表示。
字符串是计算机科学中常用的数据类型之一,用于表示文本数据。
2.2 模式串模式串是在字符串匹配中需要查找的特定模式,它是一个想要在文本串中查找的子串。
3:算法实现3.1 简单匹配算法简单匹配算法,也称为朴素匹配算法,是最简单直观的一种模式匹配算法。
它的基本思想是,从文本串的第一个字符开始,逐个字符地与模式串进行匹配,如果匹配失败,则从文本串的下一个字符重新开始匹配。
3.2 KMP算法KMP算法是一种高效的模式匹配算法,它利用了模式串本身的信息来加速匹配过程。
该算法基于一个重要观察结果,即当模式串在某一位置匹配失败时,它的前缀与后缀可能存在一定的重叠,从而可以避免无效的匹配。
3.3 Boyer-Moore算法Boyer-Moore算法是一种高效的模式匹配算法,它利用了模式串和文本串的不同之处来加速匹配过程。
该算法在匹配失败时,根据坏字符规则和好后缀规则,可以跳过一定数量的字符,从而避免无效的匹配。
4:应用场景4.1 文本搜索串的模式匹配算法可以应用于文本搜索中,用于在大量文本数据中查找特定模式的出现位置。
4.2 数据处理串的模式匹配算法可以应用于数据处理中,用于对字符串数据进行匹配处理、替换等操作。
4.3 自然语言处理串的模式匹配算法可以应用于自然语言处理中,用于识别特定语义模式或词组的出现。
串的模式匹配的几种方法

串的模式匹配1. Brute Force(BF或蛮力搜索)算法:首先将匹配串和模式串左对齐,然后从左向右一个一个进行比较,如果不成功则模式串向右移动一个单位。
速度最慢。
2.KMP算法利用不匹配字符的前面那一段字符的最长前后缀来尽可能地跳过最大的距离比如模式串ababac 这个时候我们发现在c 处不匹配,然后我们看c 前面那串字符串的最大相等前后缀,然后再来移动下面的两个都是模式串,没有写出来匹配串原始位置 ababa c移动之后 aba bac因为后缀是已经匹配了的,而前缀和后缀是相等的,所以直接把前缀移动到原来后缀处,再从原来的c 处,也就是现在的第二个b 处进行比较。
这就是KMP 。
3.Horspool算法Horspool 算法的思想很简单的。
不过有个创新之处就是模式串是从右向左进行比较的。
很好很强大,为后来的算法影响很大。
匹配串:abcbc sdxzcxx模式串:cbcac这个时候我们从右向左进行对暗号,c-c ,对上了,第二个b-a ,不对,于是,模式串从不匹配的那个字符开始从右向左寻找匹配串中不匹配的字符b 的位置,发现有,赶快对上匹配串:abcbcsd xzcxx模式串: cbcac然后继续从最右边的字符从右向左进行比较。
这时候,我们发现了,d-c 不匹配,而且模式穿里面没有,没办法,只好移动一个模式串长度的单位了。
匹配串:abcbcsdxzcxx模式串: cbcac4.Boyer-Moore算法是一个很复杂的算法,当然,虽然理论上时间复杂度和KMP 差不多,但是实际上却比KMP 快数倍。
分为两步预处理,第一个是bad-character heuristics ,也就是当出现错误匹配的时候,移位,基本上就是做的Horspool 那一套。
第二个就是good-suffix heuristics ,当出现错误匹配的时候,还要从不匹配点向左看,以前匹配的那段子字符串是不是在模式串本身中还有重复的,有重复的话,那么就直接把重复的那段和匹配串中已经匹配的那一段对齐就是了。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
主串s="ababcabcacbab",模式T="abcac"
主串s
模式串T ="abcac" 模式串T ="abcac"
模式串T ="abcac"
核心语句
if
(Se[2il]s0e=2={0Ti =/[8j]i)/-2j{+0+2+; i;j
++j; = 1;
} }
// 继续比较后继字符
i=6 返回值为11-5=6
∴t1≠s5
j
第 aba
6 趟
2020/8/20
bcab ca cb ab a b c a c 匹配成功
KMP模式匹配算法小结-1
(1)结论: i可以不回溯 ,模式向右滑动到的新比 较起点k ,并且k 仅与模 式串T有关!
2020/8/20
(1)模式滑动到第k个字符,有p1~pk-1 =Si-(k-1) ~ Si-1
第 aba b cabc a cbab
3 趟
2020/8/20
abc ac
KMP模式匹配算法图示-2
i
第 aba bca bcac ba b
3
趟
abc ac
i=7,j=5失败s4=t2;t1≠t2
∴t1≠s4
j
第 ab ab cabc acba b
4 趟
2020/8/20
abc ac
KMP模式匹配算法图示-3
(2)再观察失配时,有pj-(k-1) ~ pj-1 =Si-(k-1) ~ Si-1
两式联立可得:p1~pk-1=pj-(k-1) ~pj-1
i
S="a b a b c a a b c c b a b"
Si-(k-1)... si-1
j
p="a b c a a b a b c"
P1 --pk-1
Pj-(k-1)
i=11
b
J=6
算法4.5 Index(S,T,pos) 即模式匹配的特点:
特点一: Index(S,T,pos) 算法的匹配方法简单,理解方便,适合一些文本编辑,效 率较高;
特点二: Index(S,T,pos) 算法的匹配方法简单,理解方便,适合一些文本编辑,效 率较高;正常情况下,时间复杂度为O(M+N);
KMP算法优点:可以在O(M+N)的时间复杂度内完成模式匹配操作,即对 Index(S,T,pos)模式匹配算法的改进,取消了主串的回溯 。
KMP算法基本思想:每当匹 20配20/8/2过0 程中出现字符比较不
KMP模式匹配算法图示-1
i
第 aba bc abcac bab
1
趟 abc ac
j
i=3,j=3时,失败即 s3 ≠ t3 ;; S1=t1 ; s2=t2; 因为t1≠t2;所以t1≠s2
Pj-1
当 si ≠ pj失匹时
2020/8/20
小结-2
关注部分匹配时的重要特征——
i
S="ap=b"aa
b b
c c
a a
a a
b b
cc b a a b c"
b"
j
i
S="a b a b cpa="aabbcccabca"b"
特点 三: 如果主串和子串存在多个零时,如: S=‘0000…1’{总共52个零};T=‘00000001’, 则出现多次重复的比较,即出现不等时, I 指针每次都回朔到i-1位置,这样 浪费了大量的比较时间,整个匹配需要回朔45次,While循环语句的执行次 数为46*8(index*m).
2020/8/20
算法4.5 Index(S,T,pos) 即模式匹配的时间复杂性分析 因为Index(S,T,pos)是一种有回溯的模式匹配算法 ; 所以,在最坏情况下的时间复杂度是O(n*m)。
2020/8/20
• 4. 3.2 模式匹配的一种改进算法
模式匹配的一种改进算法是D.E.Knuth 与V.R.Pratt和J.H.Morris同时发现的, 因此,称该算法为克努特-莫里斯-普拉特算法(简称为KMP算法)。在串匹 配算法中又称 KMP模式匹配算法。
2020/8/20
p79算法4.5
int Index (SString S, SString T, int pos) { // 返回子串T在主串S中第pos个字符之后的位置。若不存在,
// 则函数值为0。其中,T非空,1≤pos≤StrLength(S)。 i = pos; j = 1; while (i <= S[0] && j <= T[0]) { if (S[i] == T[j]) { ++i; ++j; } // 继续比较后继字符 else { i = i-j+2; j = 1; } // 指针后退重新开始匹配 } if (j > T[0]) return i-T[0]; else return 0; } // 2In0d2e0x/8/20
这是串的一种重要操作,很多软件,若有“编辑”菜单 项的话,则其中必有“查找”子菜单项。
2020/8/20
• 4. 3.1 求子串位置的定位函数 Index(S,T,pos)
Index(S,T,pos)称为模式匹配(S为主串, T为模式串 ); 初始条件:S和T存在,T是非空串, 1 <= pos <= (S的长度)。 操作结果:若主串S中存在和串T相同的(模式串 )子串,则返回它在 主串S中第pos个字符之后第一次出现的位置;否则返回0。
i
第 ababcabcacbab
3
趟
abc ac
i=7,j=5失败s5=t3;t1≠t3
∴t1≠s5
j
第 aba
5 趟
2020/8/20
bc a bcacba b abc a c
KMP模式匹配算法图示-4
i
第 ab abca bcac bab
3
趟
ab cac
i=7,j=5失败s5=t3;t1≠t3
• 4. 3 串的模式匹配算法( 知识点三) • 子串定位运算又称为模式匹配或串匹配,此运算的应
用非常广泛。例如,文本编辑程序中,经常要查找某 一特定单词出现的位置。解此问题的有效算法能极大 地提高文本编辑程序的响应性能。 串的模式匹配定义:在主串中寻找子串在串中的位置。 在模式匹配中,子串称为模式串,主串称为目标串。
例如:对某文本进行编辑时,可以运用如下步骤: (1)编辑;(2)查找 ——“输入查找文本(字符串)”;(3)找出对应 的串
2020/8/20
T串
defghijk
pos=4
Abcdefghijklmnopqrstuvw
S串
按照上述主串S和子串T求子串位置的定位函数 Index(S,T,pos)的返回值是4