实验三香农编码
编码理论实验报告

一、实验目的1. 理解编码理论的基本概念和原理;2. 掌握哈夫曼编码和香农编码的方法;3. 熟悉编码效率的计算方法;4. 培养编程能力和实践操作能力。
二、实验原理1. 编码理论:编码理论是研究信息传输、存储和处理中信息压缩和编码的理论。
其目的是在保证信息传输质量的前提下,尽可能地减少传输或存储所需的数据量。
2. 哈夫曼编码:哈夫曼编码是一种根据字符出现频率进行编码的方法,字符出现频率高的用短码表示,频率低的用长码表示,从而达到压缩数据的目的。
3. 香农编码:香农编码是一种基于信息熵的编码方法,根据字符的概率分布进行编码,概率高的字符用短码表示,概率低的字符用长码表示。
4. 编码效率:编码效率是指编码后数据长度与原始数据长度的比值。
编码效率越高,表示压缩效果越好。
三、实验内容1. 使用MATLAB软件实现哈夫曼编码和香农编码;2. 对给定信源进行编码,并计算编码效率;3. 对比哈夫曼编码和香农编码的效率。
四、实验步骤1. 编写哈夫曼编码程序:首先,统计信源中各个字符的出现频率;然后,根据频率构造哈夫曼树;最后,根据哈夫曼树生成编码。
2. 编写香农编码程序:首先,计算信源熵;然后,根据熵值生成编码。
3. 编码实验:对给定的信源进行哈夫曼编码和香农编码,并计算编码效率。
4. 对比分析:对比哈夫曼编码和香农编码的效率,分析其优缺点。
五、实验结果与分析1. 哈夫曼编码实验结果:信源:'hello world'字符频率:'h' - 2, 'e' - 1, 'l' - 3, 'o' - 2, ' ' - 1, 'w' - 1, 'r' - 1, 'd' - 1哈夫曼编码结果:'h' - 0'e' - 10'l' - 110'o' - 1110' ' - 01'w' - 101'r' - 100'd' - 1001编码效率:1.52. 香农编码实验结果:信源:'hello world'字符频率:'h' - 2, 'e' - 1, 'l' - 3, 'o' - 2, ' ' - 1, 'w' - 1, 'r' - 1, 'd' - 1香农编码结果:'h' - 0'e' - 10'l' - 110'o' - 1110' ' - 01'w' - 101'r' - 100'd' - 1001编码效率:1.53. 对比分析:哈夫曼编码和香农编码的效率相同,均为1.5。
实验四_香农编码
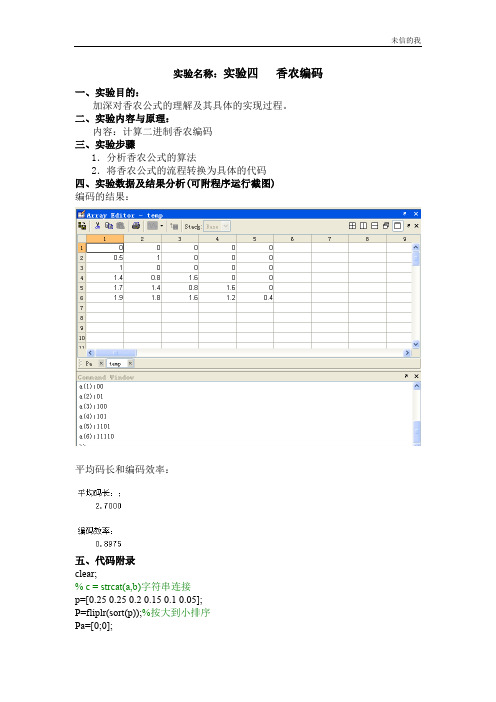
实验名称:实验四香农编码一、实验目的:加深对香农公式的理解及其具体的实现过程。
二、实验内容与原理:内容:计算二进制香农编码三、实验步骤1.分析香农公式的算法2.将香农公式的流程转换为具体的代码四、实验数据及结果分析(可附程序运行截图)编码的结果:平均码长和编码效率:五、代码附录clear;% c = strcat(a,b)字符串连接p=[0.25 0.25 0.2 0.15 0.1 0.05];P=fliplr(sort(p));%按大到小排序Pa=[0;0];%累加和的定义----第一行为累加和,第二行为Ki %求累加和for x=1for y=1:1:5%Pa(x,y)=1;Pa(x,y+1)=P(x,y)+ Pa(x,y);endend%ceil 是取向离它最近的大整数圆整for i=2for j=1:1:6Pa(i,j)=ceil( -log2(P(1,j)) );endend%信源熵H=0;L=0;for i=1:1:6H=H-P(i)*log2(P(i));L=L+P(i)*Pa(2,i);endu=H/L;disp('平均码长:;');disp(L);disp('编码效率:');disp(u);%求各符号的编码temp=[];%临时的编码值:1:6for m=1:1:6fprintf('a(%d):',m);for n=1:1:abs(Pa(2,m))temp(m,n)=Pa(1,m)*2;if temp(m,n)>=1O(m,n)=1;Pa(1,m)=temp(m,n)-1;elseO(m,n)=0;Pa(1,m)=temp(m,n);endfprintf('%d',O(m,n));endfprintf('\n');end六、其他:实验总结、心得体会及对本实验方法、手段及过程的改进建议等。
实验起初是想把累加和及Ki和编码放在一个二维矩阵中,但具体的实现较为复杂,所以最后改为逐行存放并成功完成了实验。
数字图像处理实验报告 (图像编码)

实验三图像编码一、实验内容:用Matlab语言、C语言或C++语言编制图像处理软件,对某幅图像进行时域和频域的编码压缩。
二、实验目的和意义:1. 掌握哈夫曼编码、香农-范诺编码、行程编码2.了解图像压缩国际标准三、实验原理与主要框架:3.1实验所用编程环境:Visual C++6.0(简称VC)3.2实验处理的对象:256色的BMP(BIT MAP )格式图像BMP(BIT MAP )位图的文件结构:(如图3.1)图3.1 位图的文件结构具体组成图:单色DIB 有2个表项16色DIB 有16个表项或更少 256色DIB 有256个表项或更少 真彩色DIB 没有调色板每个表项长度为4字节(32位) 像素按照每行每列的顺序排列每一行的字节数必须是4的整数倍biSize biWidth biHeight biPlanes biBitCount biCompression biSizeImagebiXPelsPerMeter biYPelsPerMeter biClrUsedbiClrImportantbfType=”BM ” bfSizebfReserved1 bfReserved2 bfOffBits BITMAPFILEHEADER位图文件头 (只用于BMP 文件)BITMAPINFOHEADER位图信息头Palette 调色板DIB Pixels DIB 图像数据3.3 数字图像基本概念数字图像是连续图像(,)f x y 的一种近似表示,通常用由采样点的值所组成的矩阵来表示:(0,0)(0,1)...(0,1)(1,0)(1,1)...(1,1).........(1,0)(1,1)...(1,1)f f f M f f f M f N f N f N M -⎡⎤⎢⎥-⎢⎥⎢⎥⎢⎥----⎣⎦每一个采样单元叫做一个像素(pixel ),上式(2.1)中,M 、N 分别为数字图像在横(行)、纵(列)方向上的像素总数。
信源编译码实验报告

一、实验目的1. 理解信源编译码的基本概念和原理。
2. 掌握信源编译码的基本方法和技术。
3. 通过实验加深对信源编译码理论的理解和应用。
二、实验原理信源编译码是信息论中的一个重要分支,其主要目的是提高通信系统的效率和可靠性。
信源编译码的基本原理是将原始信源符号序列转换为具有更好统计特性的编码序列,从而降低编码后的序列长度,提高传输效率;同时,通过引入冗余信息,提高编码序列的纠错能力,提高通信系统的可靠性。
三、实验设备与软件1. 实验设备:计算机、编译码软件2. 实验软件:Matlab、C++等四、实验步骤1. 信源符号生成根据实验要求,生成信源符号序列。
例如,生成一个长度为1000的随机二进制序列。
2. 信源符号统计对生成的信源符号序列进行统计,计算每个符号的概率。
3. 信源编译码根据信源符号的概率分布,选择合适的编译码方法。
本实验采用霍夫曼编译码和香农-费诺编译码两种方法。
a. 霍夫曼编译码根据信源符号的概率分布,构建霍夫曼树,生成霍夫曼编码表。
将信源符号序列转换为霍夫曼编码序列。
b. 香农-费诺编译码根据信源符号的概率分布,构建香农-费诺树,生成香农-费诺编码表。
将信源符号序列转换为香农-费诺编码序列。
4. 编译码性能分析对编译码后的序列进行性能分析,包括编码效率、纠错能力等。
5. 结果对比对比霍夫曼编译码和香农-费诺编译码的性能,分析其优缺点。
五、实验结果与分析1. 信源符号统计假设生成的信源符号序列中,0和1的出现概率分别为0.6和0.4。
2. 编译码结果a. 霍夫曼编译码编码效率:0.6 1 + 0.4 2 = 1.2纠错能力:1位b. 香农-费诺编译码编码效率:0.6 1 + 0.4 2 = 1.2纠错能力:2位3. 结果对比霍夫曼编译码和香农-费诺编译码在编码效率上相同,但在纠错能力上有所不同。
香农-费诺编译码的纠错能力更强。
六、实验结论1. 信源编译码可以提高通信系统的效率和可靠性。
《信息论与编码技术》实验教案

技术选型
根据实际需求选择合适的差错控制编码技术, 包括线性分组码、卷积码等。
实现与测试
通过编程实现所选差错控制编码技术的编码和解码过程,并进行测试和性能分 析。
04
现代编码技术实验
Turbo码编译码原理及性能评估
Turbo码基本原理
介绍Turbo码的结构、编码原理、迭代译码原理等基本概念。
编译码算法实现
《信息论与编码技术》实验教案
目录
• 课程介绍与实验目标 • 信息论基础实验 • 编码技术基础实验 • 现代编码技术实验 • 信息论与编码技术应用案例分析 • 课程总结与展望
01
课程介绍与实验目标
信息论与编码技术课程概述
课程背景
信息论与编码技术是通信工程、 电子工程等专业的核心课程,主 要研究信息的传输、存储和处理 过程中的基本理论和方法。
2. 根据概率分布生成模拟信源序列;
03
离散信源及其数学模型
3. 计算信源熵、平均符号长度等参数;
4. 分析实验结果,理解信源熵的物理 意义。
信道容量与编码定理验证
实验目的
理解信道容量的概念、计算方法和物理意义,验证香农编码定理的正确性。
实验内容
设计并实现一个信道模拟器,通过输入不同的信道参数和编码方案,计算并输出信道容量、误码率等关键参数。
数据存储系统中纠删码技术应用
纠删码基本原理
阐述纠删码的基本概念、原理及其在数据存储系统中的应用价值。
常用纠删码技术
介绍常用的纠删码技术,如Reed-Solomon码、LDPC码等,并分 析其性能特点。
纠删码技术应用实践
通过实验,将纠删码技术应用于数据存储系统中,评估其对系统可 靠性、数据恢复能力等方面的提升效果。
信源熵的计算

桂林电子科技大学数学与计算科学学院实验报告 实验室: 实验日期: 2010年 11月 11日院(系) 数学与计算科学学院 年级、专业、班 0800710310 姓名 何帅 成绩课程名称 信息与编码 实验项目名 称 信源熵的计算 指导教师一 实验目的1、掌握香农编码的原理2、掌握二进制小数的输出方法二 实验内容与步骤Shannon 码编码步骤为:1、将信源S 的所有符号按概率从大到小排列:12q P P P ≥≥≥ 2、对第i 个信源符号i s 取整数码长[]1log 1,i i l P ⎡⎤=+⎢⎥⎣⎦为取整运算 3、计算累加概率111,0,(2)i i i k k R R R P i -===≥∑ 4、将i R 变换成二进制数12j i j j R x ∞-==∑,并按步骤2中计算的长度i l 取i R 的二进制系数j x ,组合起来即为i s的香农码字i W 程序:#include<stdio.h>#include<iostream.h>#include<math.h>double P[6]={0.25,0.1,0.2,0.25,0.15,0.05},Pax[6],machang[6];void main(){double temp;for(int a=1;a<6;a++){for(int i=0;i<6-a;i++)if(P[i]<P[i+1]){temp=P[i];P[i]=P[i+1];P[i+1]=temp;}}for(int i=0;i<6;i++)cout<<P[i]<<" ";cout<<endl;for(i=0;i<6;i++){Pax[0]=0.0;Pax[i+1]=Pax[i]+P[i];}cout<<"概率累加和为:"<<endl;for(i=0;i<6;i++)cout<<Pax[i]<<" ";cout<<endl;for(i=0;i<6;i++){double m=log(1/P[i]/log(2));if(m-int(m)==0)machang[i]=log(1/P[i])/log(2);elsemachang[i]=int(m)+1;cout<<P[i]<<"的码长为:"<<machang[i]<<endl;}for(i=0;i<6;i++){for(int j=0;j<machang[i];j++){int n=int(Pax[i]*2);cout<<n;if((Pax[i]*2-1)>0){Pax[i]=Pax[i]*2-1;continue;}if((Pax[i]*2-1)==0)Pax[i]=Pax[i]*2-1;elsePax[i]=Pax[i]*2;}cout<<endl;}}运行结果:三实验体会心得通过本次实验学习了求香农编码的基本步骤,同时学习了如何在C++下实现,在编程中主要是注意求二进制数是通过乘2取整得到的。
信息论与编码实验报告

实验一:计算离散信源的熵一、实验设备:1、计算机2、软件:Matlab二、实验目的:1、熟悉离散信源的特点;2、学习仿真离散信源的方法3、学习离散信源平均信息量的计算方法4、熟悉 Matlab 编程;三、实验内容:1、写出计算自信息量的Matlab 程序2、写出计算离散信源平均信息量的Matlab 程序。
3、将程序在计算机上仿真实现,验证程序的正确性并完成习题。
四、求解:1、习题:A 地天气预报构成的信源空间为:()⎥⎦⎤⎢⎣⎡=⎥⎦⎤⎢⎣⎡6/14/14/13/1x p X 大雨小雨多云晴 B 地信源空间为:17(),88Y p y ⎡⎤⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦⎣⎦ 小雨晴 求各种天气的自信息量和此两个信源的熵。
2、程序代码:p1=[1/3,1/4,1/4,1/6];p2=[7/8,1/8];H1=0.0;H2=0.0;I=[];J=[];for i=1:4H1=H1+p1(i)*log2(1/p1(i));I(i)=log2(1/p1(i));enddisp('自信息I分别为:');Idisp('信息熵H1为:');H1for j=1:2H2=H2+p2(j)*log2(1/p2(j));J(j)=log2(1/p2(j));enddisp('自信息J分别为');Jdisp('信息熵H2为:');H23、运行结果:自信息量I分别为:I = 1.5850 2.0000 2.0000 2.5850信源熵H1为:H1 = 1.9591自信息量J分别为:J =0.1926 3.0000信源熵H2为:H2 =0.54364、分析:答案是:I =1.5850 2.0000 2.0000 2.5850 J =0.1926 3.0000H1 =1.9591; H2 =0.5436实验2:信道容量一、实验设备:1、计算机2、软件:Matlab二、实验目的:1、熟悉离散信源的特点;2、学习仿真离散信源的方法3、学习离散信源平均信息量的计算方法4、熟悉 Matlab 编程;三、实验内容:1、写出计算自信息量的Matlab 程序2、写出计算离散信源平均信息量的Matlab 程序。
信息论与编码-曹雪虹-课后习题参考答案

《信息论与编码》-曹雪虹-课后习题答案第二章错误!未定义书签。
2.1一个马尔可夫信源有3个符号{}1,23,uu u ,转移概率为:()11|1/2p u u =,()21|1/2p u u =,()31|0p u u =,()12|1/3p u u =,()22|0p u u =,()32|2/3p u u =,()13|1/3p u u =,()23|2/3p u u =,()33|0p u u =,画出状态图并求出各符号稳态概率。
W 2、W 31231025925625W W W ⎧=⎪⎪⎪=⎨⎪⎪=⎪⎩ 2.2(0|p (0|01)p =0.5,(0|10)p 解:(0|00)(00|00)0.8p p ==(0|01)(10|01)0.5p p ==于是可以列出转移概率矩阵:0.80.200000.50.50.50.500000.20.8p ⎛⎫ ⎪ ⎪= ⎪ ⎪⎝⎭ 状态图为:设各状态00,01,10,11的稳态分布概率为W1,W2,W3,W4有411iiWP WW==⎧⎪⎨=⎪⎩∑得13113224324412340.80.50.20.50.50.20.50.81W W WW W WW W WW W WW W W W+=⎧⎪+=⎪⎪+=⎨⎪+=⎪+++=⎪⎩计算得到12345141717514WWWW⎧=⎪⎪⎪=⎪⎨⎪=⎪⎪⎪=⎩2.31/6,求:(1)“3和5(2)“两个1(3)1的自信息量。
11 12 13 14 15 1621 22 23 24 25 2631 32 33 34 35 3641 42 43 44 45 4651 52 53 54 55 5661 62 63 64 65 66共有21种组合:其中11,22,33,44,55,66的概率是3616161=⨯ 其他15个组合的概率是18161612=⨯⨯ (4)x p x p X H X P X i i i 1212181log 1812361log 3612 )(log )()(1211091936586173656915121418133612)( ⎝⎛⨯+⨯+⨯-=-=⎪⎩⎪⎨⎧=⎥⎦⎤⎢⎣⎡∑2.575%是身高160厘米以上的占总数的厘米以上的某女孩是大学生”的设随机变量X 代表女孩子学历X x 1(是大学生) x 2(不是大学生)P(X) 0.25 0.75设随机变量Y 代表女孩子身高Y y1(身高>160cm)y2(身高<160cm)P(Y) 0.5 0.5已知:在女大学生中有75%是身高160厘米以上的即:bitxyp75.0)/(11=求:身高160即:ypxypxpyxpyxI5.075.025.0log)()/()(log)/(log)/(11111111⨯-=-=-=2.6掷两颗骰子,1()(1,2)(2,1)18p x p p=+=log()log18 4.170p x bit=-==7的概率log()log6 2.585p x bit=-==341231/41/8x x===⎫⎪⎭(1)求每个符号的自信息量(2)信源发出一消息符号序列为{202120130213001203210110321010021032011223210},求该序列的自信息量和平均每个符号携带的信息量解:122118()log log 1.415()3I x bit p x === 同理可以求得233()2,()2,()3I x bit I x bit I x bit === 因为信源无记忆,所以此消息序列的信息量就等于该序列中各个符号的信息量之和就有:123414()13()12()6()87.81I I x I x I x I x bit =+++= 平均每个符号携带的信息量为87.81 1.9545=bit/符号 2.8试问四进制、八进制脉冲所含信息量是二进制脉冲的多少倍?解:四进制脉冲可以表示4个不同的消息,例如:{0,1,2,3}八进制脉冲可以表示8个不同的消息,例如:{0,1,2,3,4,5,6,7}二进制脉冲可以表示2个不同的消息,例如:{0,1}假设每个消息的发出都是等概率的,则:四进制脉冲的平均信息量symbol bit n X H / 24log log )(1=== 八进制脉冲的平均信息量symbol bit n XH / 38log log )(2=== 二进制脉冲的平均信息量symbol bit n X H / 12log log )(0===所以:四进制、八进制脉冲所含信息量分别是二进制脉冲信息量的2倍和3倍。
克劳德·香农

生平介绍:
克劳德•香农(Claude
Elwood Shannon, 1916-2001) 1916年4月30日诞生于美国 密西根州的加洛德,父亲为该镇法官, 母亲是中学校长,身为农场兼发明家 的祖父给予他很大的科学影响,此外 香农的家庭与大发明家爱迪生还有远 亲关系。
1936年毕业于密歇根大学并获得数学和 电子工程学士学位,1940年获得麻省理 工学院数学博士学位和电子工程硕士学 位。1941年他加入贝尔实验室数学部, 工作到1972年。1956年他成为麻省理工 学院客座教授,并于1958年成为终生教 授,1978年成为名誉教授。香农博士于 2001年2月26日去世,享年84岁。
在传播学中的主要贡献:
香农三大定理 信息熵(entropy)的概念的提出 香农—韦弗传播模式
香农定理:香农定理描述了有限带宽、有
随机热噪声信道的最大传输速率与信道带宽、 信号噪声功率比之间的关系. 香农三大定理是信息论的基础理论。香农三 大定理是存在性定理,虽然并没有提供具体 的编码实现方法,但为通信信息的研究指明 了方向。香农第一定理是可变长无失真信源 编码定理。香农第二定理是有噪信道编码定 理。香农第三定理是保失真度准则下的有失 真信源编码定理。
优点:
与拉斯韦尔模式相比,香农—韦弗模 式多了“干扰”因素。这也是香 农—韦弗模式的一大优点。这样,传 播的信息中就不仅仅包括“有效信 息”,还包括重复的那部分信息即 “冗余”。传播过程中出现噪音时, 要力争处理好有效信息和冗余信息之 间的平衡。冗余信息的出现会使一定 时间内所能传递的有效信息有所减少。
信息熵(entropy)的概念的提出
· 19论正式诞生的里程碑。在他的 通信数学模型中,清楚地提出信息的度量问题。
信息论与编码实验报告

信息论与编码实验报告一、实验目的信息论与编码是一门涉及信息的度量、传输和处理的学科,通过实验,旨在深入理解信息论的基本概念和编码原理,掌握常见的编码方法及其性能评估,提高对信息处理和通信系统的分析与设计能力。
二、实验原理(一)信息论基础信息熵是信息论中用于度量信息量的重要概念。
对于一个离散随机变量 X,其概率分布为 P(X) ={p(x1), p(x2),, p(xn)},则信息熵H(X) 的定义为:H(X) =∑p(xi)log2(p(xi))。
(二)编码原理1、无失真信源编码:通过去除信源中的冗余信息,实现用尽可能少的比特数来表示信源符号,常见的方法有香农编码、哈夫曼编码等。
2、有噪信道编码:为了提高信息在有噪声信道中传输的可靠性,通过添加冗余信息进行纠错编码,如线性分组码、卷积码等。
三、实验内容及步骤(一)信息熵的计算1、生成一个离散信源,例如信源符号集为{A, B, C, D},对应的概率分布为{02, 03, 01, 04}。
2、根据信息熵的定义,使用编程语言计算该信源的信息熵。
(二)香农编码1、按照香农编码的步骤,首先计算信源符号的概率,并根据概率计算每个符号的编码长度。
2、确定编码值,生成香农编码表。
(三)哈夫曼编码1、构建哈夫曼树,根据信源符号的概率确定树的结构。
2、为每个信源符号分配编码,生成哈夫曼编码表。
(四)线性分组码1、选择一种线性分组码,如(7, 4)汉明码。
2、生成编码矩阵,对输入信息进行编码。
3、在接收端进行纠错译码。
四、实验结果与分析(一)信息熵计算结果对于上述生成的离散信源,计算得到的信息熵约为 184 比特/符号。
这表明该信源存在一定的不确定性,需要一定的信息量来准确描述。
(二)香农编码结果香农编码表如下:|信源符号|概率|编码长度|编码值|||||||A|02|232|00||B|03|174|10||C|01|332|110||D|04|132|111|香农编码的平均码长较长,编码效率相对较低。
香农编码

cin>>p[i];
}
排序函数:void sort(double p[])
{
double t;
for (int i=0;i<f;i++)
{
for(int j=f-1;j>i;j--)
{
if (p[j]>p[j-1])
{t=p[j];p[j]=p[j-1];p[j-1]=t;}
{
x=pp[i];
for(int m=1;m<l[i]+1;m++)
{
x=x*2.0;
if(x>=1.0){c[j]=1;x=x-1.0;}
else{c[j]=0;}
j++;
}
}
}
输出函数:
void output(int l[],int c[],double p[],double pp[])
{
int m=0;
cout<<endl;
m=m+j;
}}
求解结果:
例5.1.2的求解结果
五、总结
一上机才发现,自己C和C++又该复习了,主要是很多语法怎么使用都记不太清楚了,但是以前通过复习的资料,自己还是很快很够把握一些基本的知识了,所以编写程序不是特别的难了,对于香农编码而言,主要是弄清楚各个步骤,像求码长、累加和、概率排序,每个模块建立一个函数,使得程序简单易读,自己的思路也更清晰明了。编码的原理我们都很清楚,主要就是在一些C和C++基本知识上的巩固才能做好这次的实验。
二进制香农编码的步骤如下:(1)、将信源符号按概率从大到小的顺序排列(2)、对第j个前的概率进行累加得到pa(aj)(3)、由-logp(ai) ki<1-logp(ai)求得码字长度ki (4)、将pa(aj)用二进制表示,并取小数点后ki位作为符号ai的编码。
信息论与编码实验指导书

没实验一 绘制二进熵函数曲线(2个学时)一、实验目的:1. 掌握Excel 的数据填充、公式运算和图表制作2. 掌握Matlab 绘图函数3. 掌握、理解熵函数表达式及其性质 二、实验要求:1. 提前预习实验,认真阅读实验原理以及相应的参考书。
2. 在实验报告中给出二进制熵函数曲线图 三、实验原理:1. Excel 的图表功能2. 信源熵的概念及性质()()[]()[]())(1)(1 .log )( .)( 1log 1log )(log )()(10 , 110)(21Q H P H Q P H b nX H a p H p p p p x p x p X H p p p x x X P X ii i λλλλ-+≥-+≤=--+-=-=≤≤⎩⎨⎧⎭⎬⎫-===⎥⎦⎤⎢⎣⎡∑四、实验内容:用Excel 或Matlab 软件制作二进熵函数曲线。
具体步骤如下:1、启动Excel 应用程序。
2、准备一组数据p 。
在Excel 的一个工作表的A 列(或其它列)输入一组p ,取步长为0.01,从0至100产生101个p (利用Excel 填充功能)。
3、取定对数底c ,在B 列计算H(x) ,注意对p=0与p=1两处,在B 列对应位置直接输入0。
Excel 中提供了三种对数函数LN(x),LOG10(x)和LOG(x,c),其中LN(x)是求自然对数,LOG10(x)是求以10为底的对数,LOG(x,c)表示求对数。
选用c=2,则应用函数LOG(x,2)。
在单元格B2中输入公式:=-A2*LOG(A2,2)-(1-A2)*LOG(1-A2,2) 双击B2的填充柄,即可完成H(p)的计算。
4、使用Excel 的图表向导,图表类型选“XY 散点图”,子图表类型选“无数据点平滑散点图”,数据区域用计算出的H(p)数据所在列范围,即$B$1:$B$101。
在“系列”中输入X值(即p值)范围,即$A$1:$A$101。
信息论与编码实验报告

实验报告课程名称:信息论与编码姓名:系:专业:年级:学号:指导教师:职称:年月日目录实验一信源熵值的计算 (1)实验二 Huffman信源编码 (5)实验三 Shannon编码 (9)实验四信道容量的迭代算法 (12)实验五率失真函数 (15)实验六差错控制方法 (20)实验七汉明编码 (22)实验一 信源熵值的计算一、 实验目的1 进一步熟悉信源熵值的计算 2熟悉 Matlab 编程二、实验原理熵(平均自信息)的计算公式∑∑=--==qi i i qi i i p p p p x H 1212log 1log )(MATLAB 实现:))(log *.(2x x sum HX -=;或者))((log *)(2i x i x h h -= 流程:第一步:打开一个名为“nan311”的TXT 文档,读入一篇英文文章存入一个数组temp ,为了程序准确性将所读内容转存到另一个数组S ,计算该数组中每个字母与空格的出现次数(遇到小写字母都将其转化为大写字母进行计数),每出现一次该字符的计数器+1;第二步:计算信源总大小计算出每个字母和空格出现的概率;最后,通过统计数据和信息熵公式计算出所求信源熵值(本程序中单位为奈特nat )。
程序流程图:三、实验内容1、写出计算自信息量的Matlab 程序2、已知:信源符号为英文字母(不区分大小写)和空格。
输入:一篇英文的信源文档。
输出:给出该信源文档的中各个字母与空格的概率分布,以及该信源的熵。
四、实验环境Microsoft Windows 7Matlab 6.5五、编码程序#include"stdio.h"#include <math.h>#include <string.h>#define N 1000int main(void){char s[N];int i,n=0;float num[27]={0};double result=0,p[27]={0};FILE *f;char *temp=new char[485];f=fopen("nan311.txt","r");while (!feof(f)) {fread(temp,1, 486, f);}fclose(f);s[0]=*temp;for(i=0;i<strlen(temp);i++){s[i]=temp[i];}for(i=0;i<strlen(s);i++){if(s[i]==' ')num[26]++;else if(s[i]>='a'&&s[i]<='z')num[s[i]-97]++;else if(s[i]>='A'&&s[i]<='Z')num[s[i]-65]++;}printf("文档中各个字母出现的频率:\n");for(i=0;i<26;i++){p[i]=num[i]/strlen(s);printf("%3c:%f\t",i+65,p[i]);n++;if(n==3){printf("\n");n=0;}}p[26]=num[26]/strlen(s);printf("空格:%f\t",p[26]);printf("\n");for(i=0;i<27;i++){if (p[i]!=0)result=result+p[i]*log(p[i]);}result=-result;printf("信息熵为:%f",result);printf("\n");return 0;}六、求解结果其中nan311.txt中的文档如下:There is no hate without fear. Hate is crystallized fear, fear’s dividend, fear objectivized. We hate what we fear and so where hate is, fear is lurking. Thus we hate what threatens our person, our vanity andour dreams and plans for ourselves. If we can isolate this element in what we hate we may be able to cease from hating.七、实验总结通过这次实验,我们懂得了不必运行程序时重新输入文档就可以对文档进行统计,既节省了时间而且也规避了一些输入错误。
实验三哈夫曼编码

实验三哈夫曼编码一、实验目的和任务1、 理解信源编码的意义;2、 熟悉 MATLAB 程序设计;3、 掌握哈夫曼编码的方法及计算机实现;4、 对给定信源进行香农编码,并计算编码效率;二、实验原理介绍1、把信源符号按概率大小顺序排列, 并设法按逆次序分配码字的长度;12.......n p p p ≥≥≥2、在分配码字长度时,首先将出现概率 最小的两个符号的概率相加合成一个概率;3、把这个合成概率看成是一个新组合符号地概率,重复上述做法直到最后只剩下两个符号概率为止;4、完成以上概率顺序排列后,再反过来逐步向前进行编码,每一次有二个分支各赋予一个二进制码,可以对概率大的赋为零,概率小的赋为1;5、从最后一级开始,向前返回得到各个信源符号所对应的码元序列,即相应的码字。
三、实验设备介绍1、计算机2、编程软件MATLAB6.5以上四、实验内容和步骤对如下信源进行哈夫曼编码,并计算编码效率。
12345670.200.190.180.170.150.100.01X a a a a a a a P ⎡⎤⎡⎤=⎢⎥⎢⎥⎣⎦⎣⎦(1)计算该信源的信源熵,并对信源概率进行排序;(2)首先将出现概率最小的两个符号的概率相加合成一个概率,把这个合成 概率与其他的概率进行组合,得到一个新的概率组合,重复上述做法,直到只剩下两个概率为止。
之后再反过来逐步向前进行编码,每一次有两个分支各赋予一个二进制码。
对大的概率赋“1”,小的概率赋“0”。
(3)从最后一级开始,向前返回得到各个信源符号所对应的码元序列,即相应的码字。
(4)计算码字的平均码长得出最后的编码效率。
实验代码:。
香农三大定理[宝典]
![香农三大定理[宝典]](https://img.taocdn.com/s3/m/71be0b29b80d6c85ec3a87c24028915f804d8499.png)
香农三大定理首先我们要知道香农三大定理,这样有助于我们理解香农极限。
香农第一定理(可变长无失真信源编码定理)设信源S的熵H(S),无噪离散信道的信道容量为C,于是,信源的输出可以进行这样的编码,使得信道上传输的平均速率为每秒(C/H(S)-a)个信源符号.其中a可以是任意小的正数, 要使传输的平均速率大于(C/H(S))是不可能的。
于是,C/H(S)便是可变长无失真信源编码的香农极限。
香农第二定理(有噪信道编码定理)设某信道有r个输入符号,s个输出符号,信道容量为C,当信道的信息传输率R码长N足够长,总可以在输入的集合中(含有r^N个长度为N 的码符号序列),找到M (M<=2^(N(C-a))),a为任意小的正数)个码字,分别代表M个等可能性的消息,组成一个码以及相应的译码规则,使信道输出端的最小平均错误译码概率Pmin达到任意小,此时的信道容量即为信道的香农极限。
香农第三定理(保失真度准则下的有失真信源编码定理)设R(D)为一离散无记忆信源的信息率失真函数,并且选定有限的失真函数,对于任意允许平均失真度D>=0,和任意小的a>0,以及任意足够长的码长N,则一定存在一种信源编码W,其码字个数为M<=EXP{N[R(D)+a]},而编码后码的平均失真度D'(W)<=D+a。
D'(W)即为平均失真度的香农极限。
总而言之,香农极限是在香农三大定理的极值,也就是其极限情况。
2001年2月24日,当代最伟大的数学家和贝尔实验室最杰出的科学家之一,84岁的香农(Claude Elwood Shannon)博士不幸去世。
香农1916年生于美国,1940年获得麻省理工学院数学博士学位和电子工程硕士学位。
1941年他加入了贝尔实验室数学部,在此工作了15年。
1948年6月和10月,由贝尔实验室出版的《贝尔系统技术》杂志连载了香农博士的文章《通讯的数学原理》,该文奠定了香农信息基本理论的基础。
最新《信息论基础》实验报告-实验1

最新《信息论基础》实验报告-实验1实验目的:1. 理解信息论的基本概念,包括信息熵、互信息和编码理论。
2. 通过实验掌握香农信息熵的计算方法。
3. 学习并实践简单的数据压缩技术。
实验内容:1. 数据集准备:选择一段英文文本作为实验数据集,统计各字符出现频率。
2. 信息熵计算:根据字符频率计算整个数据集的香农信息熵。
3. 编码设计:设计一种基于频率的霍夫曼编码方案,为数据集中的每个字符分配一个唯一的二进制编码。
4. 压缩与解压缩:使用设计的霍夫曼编码对原始文本进行压缩,并验证解压缩后能否恢复原始文本。
5. 性能评估:比较压缩前后的数据大小,计算压缩率,并分析压缩效果。
实验步骤:1. 从文本文件中读取数据,统计每个字符的出现次数。
2. 利用统计数据计算字符的相对频率,并转换为概率分布。
3. 应用香农公式计算整个数据集的熵值。
4. 根据字符频率构建霍夫曼树,并为每个字符生成编码。
5. 将原始文本转换为编码序列,并记录压缩后的数据大小。
6. 实现解压缩算法,将编码序列还原为原始文本。
7. 分析压缩前后的数据大小差异,并计算压缩率。
实验结果:1. 原始文本大小:[原始文本大小]2. 压缩后大小:[压缩后大小]3. 压缩率:[压缩率计算结果]4. 霍夫曼编码表:[字符与编码的对应表]实验讨论:- 分析影响压缩效果的因素,如字符集大小、字符频率分布等。
- 讨论在实际应用中,如何优化编码方案以提高压缩效率。
- 探讨信息论在数据压缩之外的其他应用领域。
实验结论:通过本次实验,我们成功地应用了信息论的基本原理,通过霍夫曼编码技术对文本数据进行了有效压缩。
实验结果表明,基于字符频率的霍夫曼编码能够显著减少数据的存储空间,验证了信息论在数据压缩领域的有效性和实用性。
实验三 费诺编码

第 N=input('输入信源符号 的个数:'); s=0; l=0; H=0; for i=1:N fprintf('第%d 个',i); p(i)=input('p='); if (p(i)<=0)||(p(i)>=1) error('不符合分布概率'); end s=s+p(i); H=H+(- p(i)*log2(p(i))); end if (s<=0.999999||s>=1.000001) error('不符合分布概率') end for i=1:N-1 for j=i+1:N if p(i)<p(j) m=p(j); p(j)=p(i); p(i)=m; end end end x=f1(1,N,p,1); for i=1:N L(i)=length(find(x(i,:))); l=l+p(i)*L(i); end n=H/l; fprintf(' 按 概 率 降 序 排 列 的 码 子:\n'); disp(x) fprintf('平均码长:\n'); disp(l) fprintf('编码效率:\n'); disp(n) function x=f1(i,j,p,r) global x; x=char(x); if(j<=i) return; else q=0; for t=i:j q=p(t)+q; y(t)=q; end for t=i:j v(t)=abs(y(t)-(q-y(t))); end for t=i:j if(v(t)==min(v)) for k=i:t x(k,r)='0'; end for k=(t+1):j x(k,r)='1'; end d=t; f1(i,d,p,r+1); f2(d+1,j,p,r+1); f1(d+1,j,p,r+1); f2(i,d,p,r+1); else end end end return; function x=f2(i,j,p,r) global x; x=char(x); if(j<=i) return; else q=0; for t=i:j q=p(t)+q;y(t-i+1)=q; end for t=1:j-(i-1) v(t)=abs(y(t)-(q-y(t))); end for t=1:j-(i-1) if(v(t)==min(v)) d=t+i-1;
信息论与编码(第二版)曹雪虹(版本)答案
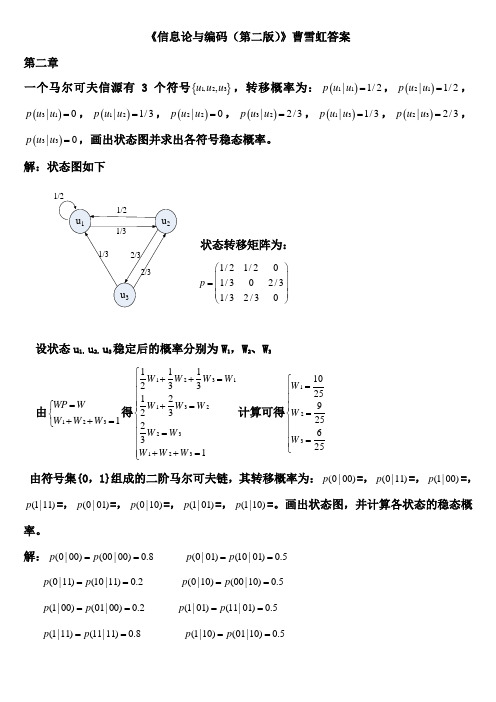
《信息论与编码(第二版)》曹雪虹答案第二章一个马尔可夫信源有3个符号{}1,23,u u u ,转移概率为:()11|1/2p u u =,()21|1/2p u u =,()31|0p u u =,()12|1/3p u u =,()22|0p u u =,()32|2/3p u u =,()13|1/3p u u =,()23|2/3p u u =,()33|0p u u =,画出状态图并求出各符号稳态概率。
解:状态图如下状态转移矩阵为:1/21/201/302/31/32/30p ⎛⎫ ⎪= ⎪ ⎪⎝⎭设状态u 1,u 2,u 3稳定后的概率分别为W 1,W 2、W 3由1231WP W W W W =⎧⎨++=⎩得1231132231231112331223231W W W W W W W W W W W W ⎧++=⎪⎪⎪+=⎪⎨⎪=⎪⎪⎪++=⎩计算可得1231025925625W W W ⎧=⎪⎪⎪=⎨⎪⎪=⎪⎩ 由符号集{0,1}组成的二阶马尔可夫链,其转移概率为:(0|00)p =,(0|11)p =,(1|00)p =,(1|11)p =,(0|01)p =,(0|10)p =,(1|01)p =,(1|10)p =。
画出状态图,并计算各状态的稳态概率。
解:(0|00)(00|00)0.8p p == (0|01)(10|01)0.5p p ==(0|11)(10|11)0.2p p == (0|10)(00|10)0.5p p == (1|00)(01|00)0.2p p == (1|01)(11|01)0.5p p == (1|11)(11|11)0.8p p == (1|10)(01|10)0.5p p ==于是可以列出转移概率矩阵:0.80.200000.50.50.50.500000.20.8p ⎛⎫ ⎪⎪= ⎪ ⎪⎝⎭状态图为:设各状态00,01,10,11的稳态分布概率为W 1,W 2,W 3,W 4 有411i i WP W W ==⎧⎪⎨=⎪⎩∑ 得 13113224324412340.80.50.20.50.50.20.50.81W W W W W W W W W W W W W W W W +=⎧⎪+=⎪⎪+=⎨⎪+=⎪+++=⎪⎩ 计算得到12345141717514W W W W ⎧=⎪⎪⎪=⎪⎨⎪=⎪⎪⎪=⎩同时掷出两个正常的骰子,也就是各面呈现的概率都为1/6,求: (1) “3和5同时出现”这事件的自信息; (2) “两个1同时出现”这事件的自信息;(3) 两个点数的各种组合(无序)对的熵和平均信息量; (4) 两个点数之和(即2, 3, … , 12构成的子集)的熵; (5) 两个点数中至少有一个是1的自信息量。
信息论与编码-曹雪虹-课后习题答案 (2)

《信息论与编码》-曹雪虹-课后习题答案第二章2.1一个马尔可夫信源有3个符号{}1,23,u u u ,转移概率为:()11|1/2p u u =,()21|1/2p u u =,()31|0p u u =,()12|1/3p u u =,()22|0p u u =,()32|2/3p u u =,()13|1/3p u u =,()23|2/3p u u =,()33|0p u u =,画出状态图并求出各符号稳态概率。
解:状态图如下状态转移矩阵为:1/21/201/302/31/32/30p ⎛⎫ ⎪= ⎪ ⎪⎝⎭设状态u 1,u 2,u 3稳定后的概率分别为W 1,W 2、W 3由1231WP W W W W =⎧⎨++=⎩得1231132231231112331223231W W W W W W W W W W W W ⎧++=⎪⎪⎪+=⎪⎨⎪=⎪⎪⎪++=⎩计算可得1231025925625W W W ⎧=⎪⎪⎪=⎨⎪⎪=⎪⎩2.2 由符号集{0,1}组成的二阶马尔可夫链,其转移概率为:(0|00)p =0.8,(0|11)p =0.2,(1|00)p =0.2,(1|11)p =0.8,(0|01)p =0.5,(0|10)p =0.5,(1|01)p =0.5,(1|10)p =0.5。
画出状态图,并计算各状态的稳态概率。
解:(0|00)(00|00)0.8p p == (0|01)(10|01)0.5p p ==(0|11)(10|11)0.2p p == (0|10)(00|10)0.5p p == (1|00)(01|00)0.2p p == (1|01)(11|01)0.5p p ==(1|11)(11|11)0.8p p == (1|10)(01|10)0.5p p ==于是可以列出转移概率矩阵:0.80.200000.50.50.50.500000.20.8p ⎛⎫ ⎪⎪= ⎪ ⎪⎝⎭状态图为:设各状态00,01,10,11的稳态分布概率为W 1,W 2,W 3,W 4 有411i i WP W W ==⎧⎪⎨=⎪⎩∑ 得 13113224324412340.80.50.20.50.50.20.50.81W W W W W W W W W W W W W W W W +=⎧⎪+=⎪⎪+=⎨⎪+=⎪+++=⎪⎩ 计算得到12345141717514W W W W ⎧=⎪⎪⎪=⎪⎨⎪=⎪⎪⎪=⎩2.3 同时掷出两个正常的骰子,也就是各面呈现的概率都为1/6,求:(1) “3和5同时出现”这事件的自信息; (2) “两个1同时出现”这事件的自信息;(3) 两个点数的各种组合(无序)对的熵和平均信息量; (4) 两个点数之和(即2, 3, … , 12构成的子集)的熵; (5) 两个点数中至少有一个是1的自信息量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
信息论与编码实验报告
院系:哈尔滨理工大学荣成校区专业:电子信息工程
学号:
姓名:
日期: 2015年6月16日
香农编码 信息论与编码第三次实验报告
一、实验目的和任务
1、 理解信源编码的意义;
2、 熟悉 MATLAB 程序设计;
3、 掌握香农编码的方法及计算机实现;
4、 对给定信源进行香农编码,并计算编码效率; 二、实验原理介绍
给定某个信源符号的概率分布,通过以下的步骤进行香农编码
1、信源符号按概率从大到小排列;
n p p p ≥≥≥ (21)
2、确定满足下列不等式的整数码长i K 为
1)(K )lb(p -i i +-<≤i p lb
3、为了编成唯一可译码,计算第i 个消息的累加概率:
∑--=
11)(l K K i a p p 4、将累加概率i P 变换成二进制数;
5、取i P 二进制数的小数点后i K 位即为该消息符号的二进制码字。
三、实验设备
1、计算机
2、Matlab2014
四、编码程序
N=input('N='); %输入信源符号的个数 s=0; %对行的概率进行初始化 l=0; %对列的概率初始化。