SPSS--logistic回归分析
多因素logistic回归分析spss

多因素logistic回归分析spssLogistic回归分析是一种用来研究影响离散变量的因素的方法,该方法的输出是一个logistic模型,这一模型可以用于预测变量的值,即预测该变量的值有多高的概率会取各种可能的取值。
简言之,logistic回归分析的主要目的是把客观的结果(例如,是否改变某个政策,是否感染某种疾病等)变成可预测的离散变量,以便分析影响客观结果的各种因素。
Spss可以提供多因素logistic回归分析,这种分析可用于识别影响离散变量(例如,是否改变某个政策,是否感染某种疾病等)的多个因素之间的关联。
该分析需要有一个组合变量作为自变量,以及一个离散变量作为因变量。
例如,如果您要研究性别和年龄两个因素如何影响某种疾病的发生率,那么性别和年龄两个因素就是组合变量,而疾病的发生率则是因变量。
1.建立变量和分类(上述示例中需要建立性别和年龄两个变量,以及分类变量的可能的取值)。
2.执行logistic回归分析。
打开spss,并在“分析”菜单中打开多元分析,然后点击“逻辑回归”,并选择您要研究的变量和分类。
3.生成回归模型和检验其统计学意义。
在spss中,您可以使用类似“回归系数”之类的描述性统计学方法来估算回归模型,并可以使用“p-值”来判断回归模型中各变量的统计学意义。
4.Interpret模型。
根据p值判断各变量的统计学意义,进而分析影响离散变量的多个因素之间的关联。
四、总结Logistic回归分析是一种用来研究影响离散变量的因素的方法,spss可以提供多因素logistic回归分析,这种分析可用于识别影响离散变量的多个因素之间的关联,spss中步骤:建立变量和分类,执行logistic回归分析,生成回归模型和检验其统计学意义,Interpret模型。
利用SPSS进行logistic回归分析(二元、多项)

线性回归是很重要的一种回归方法,但是线性回归只适用于因变量为连续型变量的情况,那如果因变量为分类变量呢?比方说我们想预测某个病人会不会痊愈,顾客会不会购买产品,等等,这时候我们就要用到logistic回归分析了。
Logistic回归主要分为三类,一种是因变量为二分类得logistic回归,这种回归叫做二项logistic回归,一种是因变量为无序多分类得logistic回归,比如倾向于选择哪种产品,这种回归叫做多项logistic回归。
还有一种是因变量为有序多分类的logistic回归,比如病重的程度是高,中,低呀等等,这种回归也叫累积logistic回归,或者序次logistic回归。
二值logistic回归:选择分析——回归——二元logistic,打开主面板,因变量勾选你的二分类变量,这个没有什么疑问,然后看下边写着一个协变量。
有没有很奇怪什么叫做协变量?在二元logistic回归里边可以认为协变量类似于自变量,或者就是自变量。
把你的自变量选到协变量的框框里边。
细心的朋友会发现,在指向协变量的那个箭头下边,还有一个小小的按钮,标着a*b,这个按钮的作用是用来选择交互项的。
我们知道,有时候两个变量合在一起会产生新的效应,比如年龄和结婚次数综合在一起,会对健康程度有一个新的影响,这时候,我们就认为两者有交互效应。
那么我们为了模型的准确,就把这个交互效应也选到模型里去。
我们在右边的那个框框里选择变量a,按住ctrl,在选择变量b,那么我们就同时选住这两个变量了,然后点那个a*b的按钮,这样,一个新的名字很长的变量就出现在协变量的框框里了,就是我们的交互作用的变量。
然后在下边有一个方法的下拉菜单。
默认的是进入,就是强迫所有选择的变量都进入到模型里边。
除去进入法以外,还有三种向前法,三种向后法。
一般默认进入就可以了,如果做出来的模型有变量的p值不合格,就用其他方法在做。
再下边的选择变量则是用来选择你的个案的。
spsslogistic回归分析结果解读

spsslogistic回归分析结果解读
本文分析了使用SPSS Logistic回归分析的结果,以了解不同变量之间
是否存在潜在关系。
Logistic回归是一种用于预测调查中的变量组合能够预测调查的结果的
机器学习技术。
在这种情况下,我们使用Logistic回归来预测一个变量
(假设为购买行为)和其他变量(价格,品牌认知度等)之间的关系。
特别是,我们可以评估价格是否是客户决定购买商品的重要影响因素。
SPSS Logistic回归分析的结果表明,在本例中,我们发现价格是一个
重要的影响因素。
我们看到,价格的变化程度会影响客户购买商品的可能性:客户可能更愿意购买相对较低的价格,而对于较高的价格则更不可能购买。
此外,品牌认知度也会影响客户是否愿意购买:客户对品牌认知度越高,购
买概率越高。
这可能是因为客户更倾向于信任已经熟悉的品牌而忽略未熟悉
的品牌,或者可能是因为客户更了解该品牌的商品及其优缺点,因此可以作
出的更明智的购买决策。
因此,本次分析表明,价格和品牌认知度在客户决定购买商品时都有重
要的影响。
商家应考虑这些因素,以确保它们的产品在客户面前具有足够的
吸引力和优势,使其愿意购买。
spss二元logistic回归分析结果解读

spss的二元logistic回归
SPSS(Statistical Product and Service Solutions)是一款数据统计与分析软件。
SPSS软件可以提供全面高级的统计分析,方便易用可快速操作,可缩小数据科学与数据理解之间的差距;在具体的应用方向方面,SPSS提供了高级统计分析、大量机器学习算法、文本分析等功能,具备开源可扩展性,可与大数据的集成,并能够无缝部署到应用程序中。
Logistic回归:主要用于因变量为分类变量(如疾病的缓解、不缓解,评比中的好、中、差等)的回归分析,自变量可以为分类变量,也可以为连续变量。
变量为二分类的称为二项logistic回归,因变量为多分类的称为多元logistic回归。
Odds:称为比值、比数,是指某事件发生的可能性(概率)与不发生的可能性(概率)之比。
OR(OddsRatio):比值比,优势比。
二元logistic回归是研究二分类反应变量和多个解释变量间回归关系的统计学分析方法。
详解利用SPSS进行Logistic_回归分析
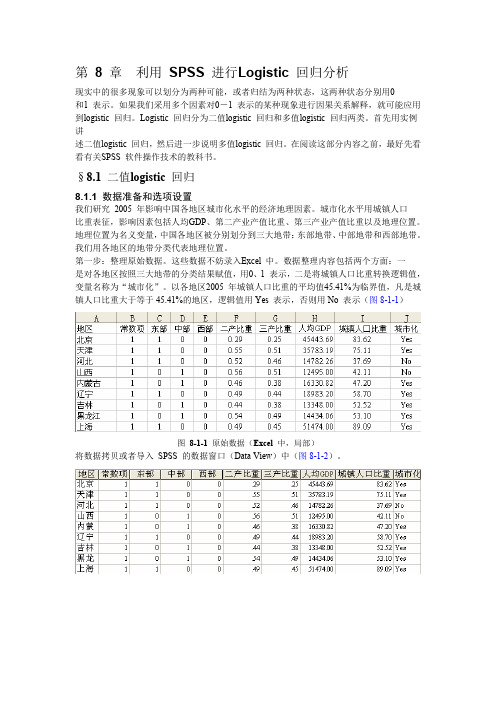
第8 章利用SPSS 进行Logistic 回归分析现实中的很多现象可以划分为两种可能,或者归结为两种状态,这两种状态分别用0和1 表示。
如果我们采用多个因素对0-1 表示的某种现象进行因果关系解释,就可能应用到logistic 回归。
Logistic 回归分为二值logistic 回归和多值logistic 回归两类。
首先用实例讲述二值logistic 回归,然后进一步说明多值logistic 回归。
在阅读这部分内容之前,最好先看看有关SPSS 软件操作技术的教科书。
§8.1 二值logistic 回归8.1.1 数据准备和选项设置我们研究2005 年影响中国各地区城市化水平的经济地理因素。
城市化水平用城镇人口比重表征,影响因素包括人均GDP、第二产业产值比重、第三产业产值比重以及地理位置。
地理位置为名义变量,中国各地区被分别划分到三大地带:东部地带、中部地带和西部地带。
我们用各地区的地带分类代表地理位置。
第一步:整理原始数据。
这些数据不妨录入Excel 中。
数据整理内容包括两个方面:一是对各地区按照三大地带的分类结果赋值,用0、1 表示,二是将城镇人口比重转换逻辑值,变量名称为“城市化”。
以各地区2005 年城镇人口比重的平均值45.41%为临界值,凡是城镇人口比重大于等于45.41%的地区,逻辑值用Yes 表示,否则用No 表示(图8-1-1)图8-1-1 原始数据(Excel 中,局部)将数据拷贝或者导入SPSS 的数据窗口(Data View)中(图8-1-2)。
图8-1-2 中国31 个地区的数据(SPSS 中,局部)第二步:打开“聚类分析”对话框。
沿着主菜单的“Analyze→Regression→Binary Logistic K”的路径(图8-1-3)打开二值Logistic 回归分析选项框(图8-1-4)。
图8-1-3 打开二值Logistic 回归分析对话框的路径对数据进行多次拟合试验,结果表明,像二产比重、三产比重等对城市化水平影响不显著。
SPSS中logistics回归分析哑变量设置及结果解读

SPSS中logistics回分析哑变量设置及结果解读
一、SPSS 两分类logistics回归分析:分析—回归—二元logistic
二、在进行回归分析时,如果要分析的变量为分类变量(尤其是无序多分类变
量)时,通常会将原始的多分类变量转化为哑变量,通过构建回归模型,每一个哑变量都能得出一个估计的回归系数,从而使得回归的结果更易于解释,更具有实际意义。
在SPSS中的实现过程如下:
默认的参考值为最后一个,即:赋值最大的数;如果想要更改将第一个作为参照则需要点击:“第一个(F)” – “变化量(H)”,
如下图:出现“x7(指示符(first))”时,则说明x7变量是以第一个(最小的)作为参照。
三、结果:
在输出结果中有“分类变量编码”,即展示了分类变量设置为哑变量的编码;
最后结果中,需对照“分类变量编码”进行结果解释,在“方程中变量” 的“铂种类
(1)”则代表的是“顺铂”相对于“其他”的OR 值是0.483;“铂种类(2)”则代表的是“奥沙利铂”相对于“其他”的OR 值是0.852;…… “肝功能(1)”则代表肝功能异常相对于正常的OR 是3.634。
SPSS学习笔记之——二项Logistic回归分析

SPSS学习笔记之——二项Logistic回归分析一、概述Logistic回归主要用于因变量为分类变量(如疾病的缓解、不缓解,评比中的好、中、差等)的回归分析,自变量可以为分类变量,也可以为连续变量。
他可以从多个自变量中选出对因变量有影响的自变量,并可以给出预测公式用于预测。
因变量为二分类的称为二项logistic回归,因变量为多分类的称为多元logistic回归。
下面学习一下Odds、OR、RR的概念:在病例对照研究中,可以画出下列的四格表:------------------------------------------------------暴露因素病例对照-----------------------------------------------------暴露 a b非暴露 c d-----------------------------------------------Odds:称为比值、比数,是指某事件发生的可能性(概率)与不发生的可能性(概率)之比。
在病例对照研究中病例组的暴露比值为:odds1 = (a/(a+c))/(c(a+c)) = a/c,对照组的暴露比值为:odds2 = (b/(b+d))/(d/(b+d)) = b/dOR:比值比,为:病例组的暴露比值(odds1)/对照组的暴露比值(odds2) = ad/bc换一种角度,暴露组的疾病发生比值:odds1 = (a/(a+b))/(b(a+b)) = a/b非暴露组的疾病发生比值:odds2 = (c/(c+d))/(d/(c+d)) = c/dOR = odds1/odds2 = ad/bc与之前的结果一致。
OR的含义与相对危险度相同,指暴露组的疾病危险性为非暴露组的多少倍。
OR>1说明疾病的危险度因暴露而增加,暴露与疾病之间为“正”关联;OR<1说明疾病的危险度因暴露而减少,暴露与疾病之间为“负”关联。
用SPSS做logistic回归分析解读

如何用SPSS做logistic回归分析解读————————————————————————————————作者:————————————————————————————————日期:如何用进行二元和多元logistic回归分析一、二元logistic回归分析二元logistic回归分析的前提为因变量是可以转化为0、1的二分变量,如:死亡或者生存,男性或者女性,有或无,Yes或No,是或否的情况。
下面以医学中不同类型脑梗塞与年龄和性别之间的相互关系来进行二元logistic回归分析。
(一)数据准备和SPSS选项设置第一步,原始数据的转化:如图1-1所示,其中脑梗塞可以分为ICAS、ECAS和NCAS三种,但现在我们仅考虑性别和年龄与ICAS的关系,因此将分组数据ICAS、ECAS和NCAS转化为1、0分类,是ICAS赋值为1,否赋值为0。
年龄为数值变量,可直接输入到spss中,而性别需要转化为(1、0)分类变量输入到spss当中,假设男性为1,女性为0,但在后续分析中系统会将1,0置换(下面还会介绍),因此为方便期间我们这里先将男女赋值置换,即男性为“0”,女性为“1”。
图 1-1第二步:打开“二值Logistic 回归分析”对话框:沿着主菜单的“分析(Analyze)→回归(Regression)→二元logistic(Binary Logistic)”的路径(图1-2)打开二值Logistic 回归分析选项框(图1-3)。
如图1-3左侧对话框中有许多变量,但在单因素方差分析中与ICAS 显著相关的为性别、年龄、有无高血压,有无糖尿病等(P<),因此我们这里选择以性别和年龄为例进行分析。
在图1-3中,因为我们要分析性别和年龄与ICAS的相关程度,因此将ICAS选入因变量(Dependent)中,而将性别和年龄选入协变量(Covariates)框中,在协变量下方的“方法(Method)”一栏中,共有七个选项。
Spss软件之logistic回归分析

Logistic regression analysis
(二) 模型参数的意义 如果把logistic模型中的 P看作是在某一暴露状态下发
病的概率,则 β0:表示所有暴露剂量为0时发病与不发病概率之比的 自然对数,反映了疾病的基准状态。 βj :表示当因素 Xj 改变一个单位时logit(P)的改变量。
G 2(ln L1 ln L0)
当样本含量较大时,在零假设下得到的G统计量
近似服从自由度为d(d=p-l)的
2
分布。
由例13-1可以算得
lnL(X1 ) 585.326
•对于 H0:β1=0和 H0:β2=0
lnL(X1 , X2 ) 579.711
Hypothesis test
lnL(X2 ) 597.436
G1 2[lnL(X1 , X2 ) lnL(X2 )]=35.45>3.84 G2 2[lnL(X1 , X2 ) lnL(X1 )]=11.23>3.84
Hypothesis test
上面计算结果说明:在α=0.05检验水准上拒绝H0, 接受H1,说明平衡了饮酒因素的影响后,食管癌 与吸烟有显著性关系;同理,平衡了吸烟因素的 影响后,食管癌与饮酒有显著性关系。
Hypothesis test
2.Wald检验
z bj , Sbj
2
bj Sbj
2
对于大样本资料,在零假设下z 近似
服从标准正态分布,而 则近似服从
自由度=1的 分布。
2
2
Abraham Wald
Hypothesis test
似然比检验可以对自变量增减时所得到的不同回 归模型进行比较,既适合单个自变量的假设检验, 又适合多个自变量的同时检验。Wald检验比较适 合单个自变量的检验,但结果略为保守。
SPSS Logistic回归分析及其应用 图文

gi
ln(
p(y i) ) p(y J)
bi0
bi1x1
bi2 x2
bip xp
•而对于参考类别, 其模型中的所有系数均为0。
•最后,求得第i类的概率值:
p( yi )
exp( gi )
J
exp( gk )
k 1
•另:参数估计表(Parameter Estimates) 中的Exp(B) 表示某 因素(自变量) 内该类别是其相应参考类别具有某种倾向性的 倍数。
分析的一般步骤
• 变量的编码 • 哑变量的设置和引入(设置参照类) • 各个自变量的单因素分析 • 变量的筛选 • 交互作用的引入 • 建立多个模型 • 选择较优的模型 • 模型应用条件的评价 • 输出结果的解释
Logistic回归的分类
• 二项Logistic回归 (Binary Regression)
•
log it( p)
ln( p ) 1 p
b0
b1x1
bpxp
ez
eb0 b1x1 bp x p
p 1 e z 1 eb0 b1x1 bp x p
建立回归模型:
ln( p 1
p
)
b0
b1x
其中,p=p(y=1)
1 拥有住房 y=
0 其它情况
5
4.909
4
5.548
5
4.281
6
4.406
2
1.816
0
1.313
1
1.011
1
.537
0
.179
住房Y = 1
应用SPSS软件进行多分类Logistic回归分析

应用SPSS软件进行多分类Logistic回归分析应用SPSS软件进行多分类Logistic回归分析一、简介Logistic回归是一种常用的统计分析方法,在很多领域中都有广泛的应用。
它主要用于预测一个分类变量的可能性或概率,例如判断一个疾病的患病风险、判断学生成绩的优劣、预测金融市场的涨跌等。
本文将介绍如何使用SPSS软件进行多分类Logistic回归分析,并以一个具体案例来说明其应用。
二、SPSS软件介绍SPSS软件是统计分析的常用工具之一,它具有友好的用户界面和丰富的分析功能。
在进行Logistic回归分析时,SPSS可以帮助我们进行数据处理、模型建立、模型拟合、模型评估等步骤,并输出详细的分析结果。
三、案例描述我们假设有一份数据集,包含了500个样本和5个自变量,要根据这些自变量对样本进行多分类。
自变量包括性别、年龄、教育水平、收入和职业。
而多分类的目标变量是购买冰淇淋的偏好,包括三个分类:喜欢巧克力口味、喜欢草莓口味和喜欢香草口味。
四、数据处理首先,我们需要对数据进行处理。
SPSS可以读取各种文件格式,如Excel、CSV等。
我们将数据导入SPSS后,可以进行缺失值处理、异常值处理等预处理步骤。
这些步骤是为了保证后续的分析结果的准确性和可靠性。
五、模型建立在SPSS中,我们可以使用多分类Logistic回归模型进行建模。
它采用最大似然估计方法来估计模型参数,以便进行分类预测。
我们需要将自变量和目标变量进行指定,SPSS会自动计算出各个自变量对目标变量的系数和统计学意义。
六、模型拟合在模型拟合阶段,SPSS会对模型进行拟合优度的检验,包括卡方拟合优度检验、Hosmer-Lemeshow检验等。
这些检验可以帮助我们评估模型的拟合程度和可靠性。
如果模型的拟合程度不好,我们可以对模型进行进一步调整和改进。
七、模型评估在模型评估阶段,SPSS提供了一系列的统计指标和图表,用于评估多分类Logistic回归模型的性能。
如何用SPSS做logistic回归分析

如何用spss17.0进行二元和多元logis tic回归分析一、二元logis tic回归分析二元logis tic回归分析的前提为因变量是可以转化为0、1的二分变量,如:死亡或者生存,男性或者女性,有或无,Yes或No,是或否的情况。
下面以医学中不同类型脑梗塞与年龄和性别之间的相互关系来进行二元logist ic回归分析。
(一)数据准备和SP SS选项设置第一步,原始数据的转化:如图1-1所示,其中脑梗塞可以分为ICAS、ECAS和NC AS三种,但现在我们仅考虑性别和年龄与ICAS的关系,因此将分组数据ICAS、ECAS和NC AS转化为1、0分类,是ICAS赋值为1,否赋值为0。
年龄为数值变量,可直接输入到s pss中,而性别需要转化为(1、0)分类变量输入到spss当中,假设男性为1,女性为0,但在后续分析中系统会将1,0置换(下面还会介绍),因此为方便期间我们这里先将男女赋值置换,即男性为“0”,女性为“1”。
图1-1第二步:打开“二值Logis tic 回归分析”对话框:沿着主菜单的“分析(Analyze)→回归(Regress ion)→二元logis tic (BinaryLogisti c)”的路径(图1-2)打开二值Log istic回归分析选项框(图1-3)。
如图1-3左侧对话框中有许多变量,但在单因素方差分析中与IC AS 显著相关的为性别、年龄、有无高血压,有无糖尿病等(P<0.05),因此我们这里选择以性别和年龄为例进行分析。
在图1-3中,因为我们要分析性别和年龄与ICAS的相关程度,因此将ICAS选入因变量(Depende nt)中,而将性别和年龄选入协变量(Covaria tes)框中,在协变量下方的“方法(Method)”一栏中,共有七个选项。
利用SPSS进行logistic回归分析(二元、多项)

线性回归是很重要的一种回归方法,但是线性回归只适用于因变量为连续型变量的情况,那如果因变量为分类变量呢?比方说我们想预测某个病人会不会痊愈,顾客会不会购买产品,等等,这时候我们就要用到logistic回归分析了。
Logistic回归主要分为三类,一种是因变量为二分类得logistic回归,这种回归叫做二项logistic回归,一种是因变量为无序多分类得logistic回归,比如倾向于选择哪种产品,这种回归叫做多项logistic回归。
还有一种是因变量为有序多分类的logistic回归,比如病重的程度是高,中,低呀等等,这种回归也叫累积logistic回归,或者序次logistic回归。
二值logistic回归:选择分析——回归——二元logistic,打开主面板,因变量勾选你的二分类变量,这个没有什么疑问,然后看下边写着一个协变量。
有没有很奇怪什么叫做协变量?在二元logistic回归里边可以认为协变量类似于自变量,或者就是自变量。
把你的自变量选到协变量的框框里边。
细心的朋友会发现,在指向协变量的那个箭头下边,还有一个小小的按钮,标着a*b,这个按钮的作用是用来选择交互项的。
我们知道,有时候两个变量合在一起会产生新的效应,比如年龄和结婚次数综合在一起,会对健康程度有一个新的影响,这时候,我们就认为两者有交互效应。
那么我们为了模型的准确,就把这个交互效应也选到模型里去。
我们在右边的那个框框里选择变量a,按住ctrl,在选择变量b,那么我们就同时选住这两个变量了,然后点那个a*b的按钮,这样,一个新的名字很长的变量就出现在协变量的框框里了,就是我们的交互作用的变量。
然后在下边有一个方法的下拉菜单。
默认的是进入,就是强迫所有选择的变量都进入到模型里边。
除去进入法以外,还有三种向前法,三种向后法。
一般默认进入就可以了,如果做出来的模型有变量的p值不合格,就用其他方法在做。
再下边的选择变量则是用来选择你的个案的。
SPSS-二元Logistic回归案例分析

二元Logistic回归案例分析二元Logistic,从字面上其实就可以理解大概是什么意思,Logistic中文意思为“逻辑”但是这里,并不是逻辑的意思,而是通过logit变换来命名的,二元一般指“两种可能性”就好比逻辑中的“是”或者“否”一样,Logistic 回归模型的假设检验——常用的检验方法有似然比检验(likelihood ratio test)和 Wald检验)似然比检验的具体步骤如下:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL02:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InL13: 最后比较两个对数似然函数值的差异,若两个模型分别包含l个自变量和P个自变量,记似然比统计量G的计算公式为 G=2(InLP - InLl). 在零假设成立的条件下,当样本含量n较大时,G统计量近似服从自由度为 V = P-l 的 x平方分布,如果只是对一个回归系数(或一个自变量)进行检验,则 v=1.wald 检验,用u检验或者X平方检验,推断各参数βj是否为0,其中u= bj / Sbj, X的平方=(bj / Sbj), Sbj 为回归系数的标准误这里的“二元”主要针对“因变量”所以跟“曲线估计”里面的Logistic曲线模型不一样,二元logistic回归是指因变量为二分类变量是的回归分析,对于这种回归模型,目标概率的取值会在(0-1),但是回归方程的因变量取值却落在实数集当中,这个是不能够接受的,所以,可以先将目标概率做 Logit变换,这样它的取值区间变成了整个实数集,再做回归分析就不会有问题了,采用这种处理方法的回归分析,就是Logistic回归设因变量为y, 其中“1” 代表事件发生,“0”代表事件未发生,影响y的 n个自变量分别为 x1, x2 ,x3 xn 等等记事件发生的条件概率为 P那么P= 事件未发生的概理为 1-P事件发生跟”未发生的概率比为( p / 1-p ) 事件发生比,记住Odds将Odds做对数转换,即可得到Logistic回归模型的线性模型:还是以教程“blankloan.sav"数据为例,研究银行客户贷款是否违约(拖欠)的问题,数据如下所示:上面的数据是大约700个申请贷款的客户,我们需要进行随机抽样,来进行二元Logistic回归分析,上图中的“0”表示没有拖欠贷款,“1”表示拖欠贷款,接下来,步骤如下:1:设置随机抽样的随机种子,如下图所示:选择“设置起点”选择“固定值”即可,本人感觉200万的容量已经足够了,就采用的默认值,点击确定,返回原界面、2:进行“转换”—计算变量“生成一个变量(validate),进入如下界面:在数字表达式中,输入公式:rv.bernoulli(0.7),这个表达式的意思为:返回概率为0.7的bernoulli分布随机值如果在0.7的概率下能够成功,那么就为1,失败的话,就为"0"为了保持数据分析的有效性,对于样本中“违约”变量取缺失值的部分,validate变量也取缺失值,所以,需要设置一个“选择条件”点击“如果”按钮,进入如下界面:如果“违约”变量中,确实存在缺失值,那么当使用"missing”函数的时候,它的返回值应该为“1”或者为“true",为了剔除”缺失值“所以,结果必须等于“0“也就是不存在缺失值的现象点击”继续“按钮,返回原界面,如下所示:将是“是否曾经违约”作为“因变量”拖入因变量选框,分别将其他8个变量拖入“协变量”选框内,在方法中,选择:forward.LR方法将生成的新变量“validate" 拖入"选择变量“框内,并点击”规则“设置相应的规则内容,如下所示:设置validate 值为1,此处我们只将取值为1的记录纳入模型建立过程,其它值(例如:0)将用来做结论的验证或者预测分析,当然你可以反推,采用0作为取值记录点击继续,返回,再点击“分类”按钮,进入如下页面在所有的8个自变量中,只有“教育水平”这个变量能够作为“分类协变量” 因为其它变量都没有做分类,本例中,教育水平分为:初中,高中,大专,本科,研究生等等, 参考类别选择:“最后一个”在对比中选择“指示符”点击继续按钮,返回再点击—“保存”按钮,进入界面:在“预测值"中选择”概率,在“影响”中选择“Cook距离” 在“残差”中选择“学生化”点击继续,返回,再点击“选项”按钮,进入如下界面:点击继续,再点击确定,可以得出分析结果了分析结果如下:1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别用值“1“和“0”代替,在“分类变量编码”中教育水平分为5类,如果选中“为完成高中,高中,大专,大学等,其中的任何一个,那么就取值为 1,未选中的为0,如果四个都未被选中,那么就是”研究生“ 频率分别代表了处在某个教育水平的个数,总和应该为 489个1:在“分类表”中可以看出:预测有360个是“否”(未违约)有129个是“是”(违约)2:在“方程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为-1.026,标准误差为:0.103那么wald =( B/S.E)²=(-1.026/0.103)² = 99.2248, 跟表中的“100.029几乎接近,是因为我对数据进行的向下舍入的关系,所以数据会稍微偏小,B和Exp(B) 是对数关系,将B进行对数抓换后,可以得到:Exp(B) = e^-1.026 = 0.358, 其中自由度为1, sig为0.000,非常显著1:从“不在方程中的变量”可以看出,最初模型,只有“常数项”被纳入了模型,其它变量都不在最初模型内表中分别给出了,得分,df , Sig三个值, 而其中得分(Score)计算公式如下:(公式中(Xi- X¯) 少了一个平方)下面来举例说明这个计算过程:(“年龄”自变量的得分为例)从“分类表”中可以看出:有129人违约,违约记为“1”则违约总和为 129,选定案例总和为489那么: y¯ = 129/489 = 0.2638036809816x¯ = 16951 / 489 = 34.664621676892所以:∑(Xi-x¯)² = 30074.9979y¯(1-y¯)=0.2638036809816 *(1-0.2638036809816 )则:y¯(1-y¯)* ∑(Xi-x则:[∑Xi(yi - y¯)]^2 = 43570.8所以:=43570.8 / 5 840.9044060372 = 7.4595982010876 = 7.46 (四舍五入)计算过程采用的是在 EXCEL 里面计算出来的,截图如下所示:从“不在方程的变量中”可以看出,年龄的“得分”为7.46,刚好跟计算结果吻合!!答案得到验证~!!!!1:从“块1” 中可以看出:采用的是:向前步进的方法,在“模型系数的综合检验”表中可以看出:所有的SIG 几乎都为“0”而且随着模型的逐渐步进,卡方值越来越大,说明模型越来越显著,在第4步后,终止,根据设定的显著性值和自由度,可以算出卡方临界值,公式为:=CHIINV(显著性值,自由度) ,放入excel就可以得到结果2:在“模型汇总“中可以看出:Cox&SnellR方和 Nagelkerke R方拟合效果都不太理想,最终理想模型也才:0.305 和 0.446,最大似然平方的对数值都比较大,明显是显著的似然数对数计算公式为:计算过程太费时间了,我就不举例说明计算过程了Cox&SnellR方的计算值是根据:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL0 (指只包含“常数项”的检验)2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InLB (包含自变量的检验)再根据公式:即可算出:Cox&SnellR方的值!提示:将Hosmer 和 Lemeshow 检验和“随机性表” 结合一起来分析1:从 Hosmer 和 Lemeshow 检验表中,可以看出:经过4次迭代后,最终的卡方统计量为:11.919,而临界值为:CHINV(0.05,8) = 15.507卡方统计量< 临界值,从SIG 角度来看: 0.155 > 0.05 , 说明模型能够很好的拟合整体,不存在显著的差异。
SPSS—二元Logistic回归结果分析

SPSS—二元Logistic回归结果分析2011-12-02 16:48身心疲惫,睡意连连,头不断往下掉,拿出耳机,听下歌曲,缓解我这严重的睡意吧!今天来分析二元Logistic回归的结果分析结果如下:1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别用值“1“和“0”代替,在“分类变量编码”中教育水平分为5类,如果选中“为完成高中,高中,大专,大学等,其中的任何一个,那么就取值为 1,未选中的为0,如果四个都未被选中,那么就是”研究生“ 频率分别代表了处在某个教育水平的个数,总和应该为489个1:在“分类表”中可以看出:预测有360个是“否”(未违约)有129个是“是”(违约)2:在“方程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为,标准误差为:那么wald =( B/²=² = , 跟表中的“几乎接近,是因为我对数据进行的向下舍入的关系,所以数据会稍微偏小,B和Exp(B) 是对数关系,将B进行对数抓换后,可以得到:Exp(B) = e^ = , 其中自由度为1, sig为,非常显著1:从“不在方程中的变量”可以看出,最初模型,只有“常数项”被纳入了模型,其它变量都不在最初模型内表中分别给出了,得分,df , Sig三个值, 而其中得分(Score)计算公式如下:(公式中(Xi- X¯) 少了一个平方)下面来举例说明这个计算过程:(“年龄”自变量的得分为例)从“分类表”中可以看出:有129人违约,违约记为“1”则违约总和为 129,选定案例总和为489那么: y¯ = 129/489 =x¯ = 16951 / 489 =所以:∑(Xi-x¯)² =y¯(1-y¯)= *()=则:y¯(1-y¯)* ∑(Xi-x¯)² = * = 5则:[∑Xi(yi - y¯)]^2 =所以:= / 5 = = (四舍五入)计算过程采用的是在 EXCEL 里面计算出来的,截图如下所示:从“不在方程的变量中”可以看出,年龄的“得分”为,刚好跟计算结果吻合!!答案得到验证~!!!!1:从“块1” 中可以看出:采用的是:向前步进的方法,在“模型系数的综合检验”表中可以看出:所有的SIG 几乎都为“0”而且随着模型的逐渐步进,卡方值越来越大,说明模型越来越显著,在第4步后,终止,根据设定的显著性值和自由度,可以算出卡方临界值,公式为:=CHIINV(显著性值,自由度) ,放入excel就可以得到结果2:在“模型汇总“中可以看出:Cox&SnellR方和 Nagelkerke R方拟合效果都不太理想,最终理想模型也才:和,最大似然平方的对数值都比较大,明显是显著的似然数对数计算公式为:计算过程太费时间了,我就不举例说明计算过程了Cox&SnellR方的计算值是根据:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL0 (指只包含“常数项”的检验)2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InLB (包含自变量的检验)再根据公式:即可算出:Cox&SnellR 方的值!提示:将Hosmer 和 Lemeshow 检验和“随机性表” 结合一起来分析1:从Hosmer 和 Lemeshow 检验表中,可以看出:经过4次迭代后,最终的卡方统计量为:,而临界值为:CHINV,8) =卡方统计量< 临界值,从SIG 角度来看: > , 说明模型能够很好的拟合整体,不存在显著的差异。
spss logistic回归分析

附录:Logistic回归分析的其他应用
回顾:
分类变量的假设检验——完全随机设计的多个样本比较
假设检验的目的 推断多个总体率是否相等
结果解释 当P≤0.05,拒绝H0时,总的说来各组有差别,但并不意味着 任何两组都有差别:可能是任何两者间都有差别,也可能其 中某两者间有差别,而其它组间无差别。目前尚无公认的进 一步两两比较的方法(可考虑采用Logistic回归)。
+ ...... +
βm xm
P=P(y=1|x),为发病概率;1-P=P(y=0|x),为不发
病概率。β0为常数项, β1 , β2 ….. βm分别为m个
自变量的回归系数。
模型估计方法:最大似然法(Maximum Likelihood
Method)。构造似然函数( Likelihood function ) L=∏ P(y=1|x) P(y=0|x),通过迭代法估计一组参数
6.OR与RR
Logistic回归模型中,OR=EXP(β)。
当某种疾病的发病率或死亡率很低时,OR≈RR
(三)Logistic回归分析的适用条件
1.经典的Logistic回归分析,要求因变量为二分类变量。但是 其因变量也可以为多分类变量(SPSS中Multinomial Logistic 菜单)。
例:某省从3个水中氟含量不同的地区随机抽取10~12 岁儿童,进行第一恒齿患病率的调查(见数据文件 p231.sav),问3个地区儿童第一恒齿患病率是否不 同?
变量说明:group:组别,1=高氟区,2=干预区,3=低 氟区;effect:1=患龋,2=未患龋;freq:频数 。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
小结
谢谢大家!
基础知识
通过下例复习相关概念 如:研究患某疾病与饮酒的关联性
患病率 P1=? P2=?
基础知识
二分类logistic回归模型
回归系数的意义
多因素logistic回归分析时,对回归系数 的解释都是指在其他所有自变量固定的 情况下的优势比。 存在因素间交互作用时,logistic回归系 数的解释变得更为复杂,应特别小心。
适用条件
因变量为二分类变量或某事件的发生率 自变量与Logit(P)之间为线性关系 残差合计为0,且服从二项分布 各观测间相互独立 参数估计方法:最大似然法
例1
研究急性心肌梗塞(AMI)患病与饮酒的关 系,采用横断面调查。
SPSS基本操作
哑变量设置
为了便于解释,对二分类变量按0、1编码 如果对二项分类变量按+1、-1编码,结果? 分类变量必须转化。如地区对血压的影响。 等级资料,当等级之间量度不一时必须转化。 连续资料不宜直接进入方程时,转化为等级 资料或分类资料。
多因素统计分析 1. 因变量为计量资料,多重现性回归 2. 因变量为分类变量,logistic回归
பைடு நூலகம்
Logistic回归模型
按研究设计分类: 1. 非配对设计:非条件logistic回归模型 2. 配对病例对照:条件logistic回归模型
按反应变量分类: 1. 二分类logistic回归模型(常用) 2. 多分类无序logistic回归模型(常用) 3. 多分类有序logistic回归模型(常用)
logistic 回归
海南医学院公共卫生学院 卫生统计学教研室 赵婵娟
chanjuan850@
内容
基本概念 基本步骤 基本操作 基本结果解释
数据分析思路
单因素统计分析 1. 计量资料的比较,t检验,方差分析或秩和检验 2. 两个变量的相关分析,Pearson相关或spearman相关 3. 分类资料的比较,Pearson卡方检验 4. 分类资料的相关,OR值及其CI或列联系数
SPSS哑变量设置
矫正混杂作用
例2:上例没有考虑吸烟情况,故将吸烟作为 分层加入,资料如下:操作同例1
逐步回归分析
逐步回归
逐步logistic回归
条件logistic回归
条件logistic回归
logistic回归模型小结
logistic回归模型小结
logistic回归模型小结