信息论与编码课程大作业香农编码
香农编码--信息论大作业

信息论与编码课程大作业题目:香农编码学生姓名:******学号:&**********专业班级:*******************2013 年 5 月10 日香农编码1.香农编码的原理/步骤香农第一定理指出了平均码长与信源之间的关系,同时也指出了可以通过编码使平均码长达到极限值,这是一个很重要的极限定理。
如何构造这种码?香农第一定理指出,选择每个码字的长度K i将满足式I(x i)≤K i<I p(x i)+1就可以得到这种码。
这种编码方法就是香农编码。
香农编码步骤如下:(1)将信源消息符按从大到小的顺序排列。
(2)计算p[i]累加概率;(3)确定满足自身要求的整数码长;(4)将累加概率变为二进制数;(5)取P[i]二进制数的小数点后Ki位即为该消息符号的二进制码字。
2. 用C语言实现#include <stdio.h>#include <math.h>#include <stdlib.h>#define max_CL 10 /*maxsize of length of code*/#define max_PN 6 /*输入序列的个数*/typedef float datatype;typedef struct SHNODE {datatype pb; /*第i个消息符号出现的概率*/datatype p_sum; /*第i个消息符号累加概率*/int kl; /*第i个消息符号对应的码长*/int code[max_CL]; /*第i个消息符号的码字*/struct SHNODE *next;}shnolist;datatype sym_arry[max_PN]; /*序列的概率*/void pb_scan(); /*得到序列概率*/void pb_sort(); /*序列概率排序*/void valuelist(shnolist *L); /*计算累加概率,码长,码字*/void codedisp(shnolist *L);void pb_scan(){int i;datatype sum=0;printf("input %d possible!\n",max_PN);for(i=0;i<max_PN;i++){ printf(">>");scanf("%f",&sym_arry[i]);sum=sum+sym_arry[i];}/*判断序列的概率之和是否等于1,在实现这块模块时,scanf()对float数的缺陷,故只要满足0.99<sum<1.0001出现的误差是允许的*/if(sum>1.0001||sum<0.99){ printf("sum=%f,sum must (<0.999<sum<1.0001)",sum);pb_scan();}}/*选择法排序*/void pb_sort(){int i,j,pos;datatype max;for(i=0;i<max_PN-1;i++){max=sym_arry[i];pos=i;for(j=i+1;j<max_PN;j++)if(sym_arry[j]>max){max=sym_arry[j];pos=j;}sym_arry[pos]=sym_arry[i];sym_arry[i]=max;}}void codedisp(shnolist *L){int i,j;shnolist *p;datatype hx=0,KL=0; /*hx存放序列的熵的结果,KL存放序列编码后的平均码字的结果*/p=L->next;printf("num\tgailv\tsum\t-lb(p(ai))\tlenth\tcode\n");printf("\n");for(i=0;i<max_PN;i++){printf("a%d\t%1.3f\t%1.3f\t%f\t%d\t",i,p->pb,p->p_sum,-3.332*log10(p->pb),p ->kl);j=0;for(j=0;j<p->kl;j++)printf("%d",p->code[j]);printf("\n");hx=hx-p->pb*3.332*log10(p->pb); /*计算消息序列的熵*/KL=KL+p->kl*p->pb; /*计算平均码字*/p=p->next;}printf("H(x)=%f\tKL=%f\nR=%fbit/code",hx,KL,hx/KL); /*计算编码效率*/ }shnolist *setnull(){ shnolist *head;head=(shnolist *)malloc(sizeof(shnolist));head->next=NULL;return(head);}shnolist *my_creat(datatype a[],int n){shnolist *head,*p,*r;int i;head=setnull();r=head;for(i=0;i<n;i++){ p=(shnolist *)malloc(sizeof(shnolist));p->pb=a[i];p->next=NULL;r->next=p;r=p;}return(head);}void valuelist(shnolist *L){shnolist *head,*p;int j=0;int i;datatype temp,s;head=L;p=head->next;temp=0;while(j<max_PN){p->p_sum=temp;temp=temp+p->pb;p->kl=-3.322*log10(p->pb)+1;/*编码,*/{s=p->p_sum;for(i=0;i<p->kl;i++)p->code[i]=0;for(i=0;i<p->kl;i++){p->code[i]=2*s;if(2*s>=1)s=2*s-1;else if(2*s==0)break;else s=2*s;}}j++;p=p->next;}}int main(void){shnolist *head;pb_scan();pb_sort();head=my_creat(sym_arry,max_PN); valuelist(head);codedisp(head);}3.运行结果及分析(本程序先定义了码字长度的最大值和信源概率的个数,然后有设定了概率的和的范围。
信息论与编码实验2-实验报告

信息论与编码实验2-实验报告信息论与编码实验 2 实验报告一、实验目的本次信息论与编码实验 2 的主要目的是深入理解和应用信息论与编码的相关知识,通过实际操作和数据分析,进一步掌握信源编码和信道编码的原理及方法,提高对信息传输效率和可靠性的认识。
二、实验原理(一)信源编码信源编码的目的是减少信源输出符号序列中的冗余度,提高符号的平均信息量。
常见的信源编码方法有香农编码、哈夫曼编码等。
香农编码的基本思想是根据符号出现的概率来分配码字长度,概率越大,码字越短。
哈夫曼编码则通过构建一棵最优二叉树,为出现概率较高的符号分配较短的编码,从而实现平均码长的最小化。
(二)信道编码信道编码用于增加信息传输的可靠性,通过在发送的信息中添加冗余信息,使得在接收端能够检测和纠正传输过程中产生的错误。
常见的信道编码有线性分组码,如汉明码等。
三、实验内容与步骤(一)信源编码实验1、选取一组具有不同概率分布的信源符号,例如:A(02)、B (03)、C(01)、D(04)。
2、分别使用香农编码和哈夫曼编码对信源符号进行编码。
3、计算两种编码方法的平均码长,并与信源熵进行比较。
(二)信道编码实验1、选择一种线性分组码,如(7,4)汉明码。
2、生成一组随机的信息位。
3、对信息位进行编码,得到编码后的码字。
4、在码字中引入随机错误。
5、进行错误检测和纠正,并计算错误纠正的成功率。
四、实验结果与分析(一)信源编码结果1、香农编码的码字为:A(010)、B(001)、C(100)、D (000)。
平均码长为 22 比特,信源熵约为 184 比特,平均码长略大于信源熵。
2、哈夫曼编码的码字为:A(10)、B(01)、C(111)、D (00)。
平均码长为 19 比特,更接近信源熵,编码效率更高。
(二)信道编码结果在引入一定数量的错误后,(7,4)汉明码能够成功检测并纠正大部分错误,错误纠正成功率较高,表明其在提高信息传输可靠性方面具有较好的性能。
信息论与编码大作业

二
当前信息论发展日新月异,目前,世界正在谈论三种前沿科学,即生命科学、材料科学和信息科学。信息论是信息科学的理论基础,现在的人们虽然不通晓信息论,但是,在日常生活中的谈话、书信、报纸、书籍、电影、电话、电报、电视、电子计算机……都是信息传输和处理的方式。随着信息革命和信息科学的发展,信息技术(指通信、计算机和控制)的研究和使用,信息论研究范畴远远超出了通信及类似的学科,从一般认为“信息论即通信理论”的认识延伸到像生物学、生理学、人类学、物理学、化学、电子学、语言学、经济学和管理学等学科。人类社会正在走向一个以充分发挥人的创造力和创新精神,以智能、知识为核心的高度发展的信息社会。
左分支表示字符'0',右分支表示字符'1',则可以根结点到叶结点的路径上分支字符组成的串作为该叶结点的字符编码。因此可得到字符A、B、C、D的二进制前缀编码分别:0、10、110、111。假设每种字符在电文中出现的次数为Wi,编码长度为Li,电文中有n种字符,则电文编码总长为∑WiLi。若将此对应到二叉树上,Wi为叶结点的权,Li为根结点到叶结点的路径长度。那么,∑WiLi恰好为二叉树上带权路径长度。因此,设计电文总长最短的二进制前缀编码,就是以n种字符出现的频率作权,构造一棵霍夫曼树,此构造过程称为霍夫曼编码。
信息论与编码课程设计

信息论与编码课程设计报告设计题目:统计信源熵、香农编码与费诺编码专业班级:XXXXXXXXXXXX姓名:XXXXXXXXXXXX学号:XXXXXXXXXXXX指导老师:XXXXXXXXXXXX成绩:时间:2015年3月31日目录一、设计任务与要求 (2)二、设计思路 (2)三、设计流程图 (5)四、程序及结果 (7)五、心得体会 (11)六、参考文献 (12)附录 (13)一、 设计任务与要求1. 统计信源熵要求:统计任意文本文件中各字符(不区分大小写)数量,计算字符概率,并计算信源熵。
2. 香农编码要求:任意输入消息概率,利用香农编码方法进行编码,并计算信源熵和编码效率。
3. 费诺编码要求:任意输入消息概率,利用费诺编码方法进行编码,并计算信源熵和编码效率。
二、 设计思路1、统计信源熵:统计信源熵就是对一篇英文文章中的i 种字符(包括标点符号及空格,英文字母不区分大小写)统计其出现的次数count i (),然后计算其出现的概率()p i ,最后由信源熵计算公式:1()()log ()ni i n H x p x p x ==-∑算出信源熵()H x 。
所以整体步骤就是先统计出文章中总的字符数,然后统计每种字符的数目,直到算出所有种类的字符的个数,进而算出每种字符的概率,再由信源熵计算公式计算出信源熵。
在这里我选择用Matlab 来计算信源熵,因为Matlab 中系统自带了许多文件操作和字符串操作函数,其计算功能强大,所以计算信源熵很是简单。
2、香农编码信源编码模型:信源编码就是从信源符号到码符号的一种映射f ,它把信源输出的符号i a 变换成码元序列i x 。
1,2,...,,i i N f a i q x =→:1:{,...,}q S s a a ∈ 信源 12{,...,}li i i i i X x x x = 码元1{,...,}1,2,...,i q S a a i N ∈=1,2,...,N i q =1:{,...,}r X x x x ∈ 码符号N 次扩展信源无失真编码器凡是能载荷一定的信息量,且码字的平均长度最短,可分离的变长码的码字集合都可以称为最佳码。
中南大学信息论与编码编码部分实验报告

信息论与编码编码部分实验报告课程名称:信息论与编码实验名称:关于香农码费诺码Huffman码的实验学院:信息科学与工程学院班级:电子信息工程1201姓名:viga学号:指导老师:张祖平日期:2014年1月3日目录⊙实验目的及要求1.1 实验目的 (4)1.2 开发工具及环境 (4)1.3 需求分析与功能说明 (4)⊙实验设计过程2.1 用matlab实现香农码、费诺码和Huffman编码2.1.1 说明 (6)2.1.2 源代码 (7)2.1.3 运行结果(截图) (19)2.2 用C\C++ 实现香农码2.2.1 说明 (22)2.2.2 源代码 (23)2.2.3 运行结果(截图) (26)2.3 用C\C++ 实现Huffman码2.3.1 说明 (26)2.3.2 源代码 (29)2.3.3 运行结果(截图) (36)2.4 用C\C++ 实现费诺码2.4.1 说明 (37)2.4.2 源代码 (37)2.4.3运行结果结果(截图) (40)⊙课程设计总结 (42)⊙参考资料4.1 课程设计指导书 (43)实验目的及要求1.1 实验目的1.掌握香农码、费诺码和Huffman编码原理和过程。
2.熟悉matlab软件的基本操作,练习使用matlab实现香农码、费诺码和Huffman编码。
3.熟悉C/C++语言,练习使用C/C++实现香农码、费诺码和Huffman编码。
4.应用Huffman编码实现文件的压缩和解压缩。
1.2 开发工具及环境MATLAB 7.0、wps文字、红精灵抓图精灵2010Windows7 系统环境1.3 需求分析与功能说明1、使用matlab实现香农码、费诺码和Huffman编码,并自己设计测试案例。
2、使用C\C++实现香农码、费诺码和Huffman编码,并自己设计测试案例。
3、可以用任何开发工具和开发语言,尝试实现Huffman编码应用在数据文件的压缩和解压缩中,并自己设计测试案例。
《信息论与编码》第三章部分习题参考答案

第三章习题参考答案第三章习题参考答案3-1解:(1)判断唯一可译码的方法:①先用克劳夫特不等式判定是否满足该不等式;②若满足再利用码树,看码字是否都位于叶子结点上。
如果在叶节点上则一定是唯一可译码,如果不在叶节点上则只能用唯一可译码的定义来判断是不是。
可译码的定义来判断是不是。
其中C1,C2,C3,C6都是唯一可译码。
都是唯一可译码。
对于码C2和C4都满足craft 不等式。
但是不满足码树的条件。
但是不满足码树的条件。
就只能就只能举例来判断。
举例来判断。
对C5:61319225218ki i ---==+´=>å,不满足该不等式。
所以C5不是唯一可译码。
译码。
(2)判断即时码方法:定义:即时码接收端收到一个完整的码字后,就能立即译码。
特点:码集任何一个码不能是其他码的前缀,即时码必定是唯一可译码, 唯一可译码不一定是即时码。
唯一可译码不一定是即时码。
其中C1,C3,C6都是即时码。
都是即时码。
对C2:“0”是“01”的前缀,……,所以C2不是即时码。
不是即时码。
(1) 由平均码长61()i i i K p x k ==å得1236 3 1111712(3456) 241681111712(3456) 2416811152334 24162K bitK bit K bitK bit==´+´+´+++==´+´+´+++==´+´+´´=62111223366()()log () 2 /()266.7%3()294.1%178()294.1%178()280.0%52i i i H U p u p u H U K H U K H U K H U K h h h h ==-=============å比特符号3-7解:(1)信源消息的概率分布呈等比级数,按香农编码方法,其码长集合为自然数数列1, 2, 3, ···, i, ·, i, ····;对应的编码分别为:0, 10, 110, ···, 111…110 ( i 110 ( i –– 1个1), ·1), ····。
信息论与编码课后习题答案

1. 有一个马尔可夫信源,已知p(x 1|x 1)=2/3,p(x 2|x 1)=1/3,p(x 1|x 2)=1,p(x 2|x 2)=0,试画出该信源的香农线图,并求出信源熵。
解:该信源的香农线图为:1/3○ ○2/3 (x 1) 1 (x 2)在计算信源熵之前,先用转移概率求稳固状态下二个状态x 1和 x 2 的概率)(1x p 和)(2x p 立方程:)()()(1111x p x x p x p =+)()(221x p x x p=)()(2132x p x p +)()()(1122x p x x p x p =+)()(222x p x x p =)(0)(2131x p x p + )()(21x p x p +=1 得431)(=x p 412)(=x p马尔可夫信源熵H = ∑∑-IJi j i jix x p x xp x p )(log )()( 得 H=0.689bit/符号2.设有一个无经历信源发出符号A 和B ,已知4341)(.)(==B p A p 。
求:①计算该信源熵;②设该信源改成发出二重符号序列消息的信源,采纳费诺编码方式,求其平均信息传输速度; ③又设该信源改成发三重序列消息的信源,采纳霍夫曼编码方式,求其平均信息传输速度。
解:①∑-=Xiix p x p X H )(log )()( =0.812 bit/符号②发出二重符号序列消息的信源,发出四种消息的概率别离为1614141)(=⨯=AA p 1634341)(=⨯=AB p1634143)(=⨯=BA p 1694343)(=⨯=BB p用费诺编码方式 代码组 b i BB 0 1 BA 10 2 AB 110 3 AA 111 3无经历信源 624.1)(2)(2==X H X H bit/双符号 平均代码组长度 2B =1.687 bit/双符号BX H R )(22==0.963 bit/码元时刻③三重符号序列消息有8个,它们的概率别离为641)(=AAA p 643)(=AAB p 643)(=BAA p 643)(=ABA p 649)(=BBA p 649)(=BAB p 649)(=ABB p 6427)(=BBB p用霍夫曼编码方式 代码组 b iBBB 6427 0 0 1 BBA 649 0 )(6419 1 110 3BAB 649 1 )(6418 )(644 1 101 3ABB 649 0 0 100 3AAB 6431 )(6461 11111 5 BAA 643 0 1 11110 5ABA6431 )(6440 11101 5 AAA641 0 11100 5)(3)(3X H X H ==2.436 bit/三重符号序列 3B =2.469码元/三重符号序列3R =BX H )(3=0.987 bit/码元时刻3.已知符号集合{ 321,,x x x }为无穷离散消息集合,它们的显现概率别离为 211)(=x p ,412)(=x p 813)(=x p ···ii x p 21)(=···求: ① 用香农编码方式写出各个符号消息的码字(代码组); ② 计算码字的平均信息传输速度; ③ 计算信源编码效率。
信息论与编码-曹雪虹-课后习题参考答案

《信息论与编码》-曹雪虹-课后习题答案第二章错误!未定义书签。
2.1一个马尔可夫信源有3个符号{}1,23,uu u ,转移概率为:()11|1/2p u u =,()21|1/2p u u =,()31|0p u u =,()12|1/3p u u =,()22|0p u u =,()32|2/3p u u =,()13|1/3p u u =,()23|2/3p u u =,()33|0p u u =,画出状态图并求出各符号稳态概率。
W 2、W 31231025925625W W W ⎧=⎪⎪⎪=⎨⎪⎪=⎪⎩ 2.2(0|p (0|01)p =0.5,(0|10)p 解:(0|00)(00|00)0.8p p ==(0|01)(10|01)0.5p p ==于是可以列出转移概率矩阵:0.80.200000.50.50.50.500000.20.8p ⎛⎫ ⎪ ⎪= ⎪ ⎪⎝⎭ 状态图为:设各状态00,01,10,11的稳态分布概率为W1,W2,W3,W4有411iiWP WW==⎧⎪⎨=⎪⎩∑得13113224324412340.80.50.20.50.50.20.50.81W W WW W WW W WW W WW W W W+=⎧⎪+=⎪⎪+=⎨⎪+=⎪+++=⎪⎩计算得到12345141717514WWWW⎧=⎪⎪⎪=⎪⎨⎪=⎪⎪⎪=⎩2.31/6,求:(1)“3和5(2)“两个1(3)1的自信息量。
11 12 13 14 15 1621 22 23 24 25 2631 32 33 34 35 3641 42 43 44 45 4651 52 53 54 55 5661 62 63 64 65 66共有21种组合:其中11,22,33,44,55,66的概率是3616161=⨯ 其他15个组合的概率是18161612=⨯⨯ (4)x p x p X H X P X i i i 1212181log 1812361log 3612 )(log )()(1211091936586173656915121418133612)( ⎝⎛⨯+⨯+⨯-=-=⎪⎩⎪⎨⎧=⎥⎦⎤⎢⎣⎡∑2.575%是身高160厘米以上的占总数的厘米以上的某女孩是大学生”的设随机变量X 代表女孩子学历X x 1(是大学生) x 2(不是大学生)P(X) 0.25 0.75设随机变量Y 代表女孩子身高Y y1(身高>160cm)y2(身高<160cm)P(Y) 0.5 0.5已知:在女大学生中有75%是身高160厘米以上的即:bitxyp75.0)/(11=求:身高160即:ypxypxpyxpyxI5.075.025.0log)()/()(log)/(log)/(11111111⨯-=-=-=2.6掷两颗骰子,1()(1,2)(2,1)18p x p p=+=log()log18 4.170p x bit=-==7的概率log()log6 2.585p x bit=-==341231/41/8x x===⎫⎪⎭(1)求每个符号的自信息量(2)信源发出一消息符号序列为{202120130213001203210110321010021032011223210},求该序列的自信息量和平均每个符号携带的信息量解:122118()log log 1.415()3I x bit p x === 同理可以求得233()2,()2,()3I x bit I x bit I x bit === 因为信源无记忆,所以此消息序列的信息量就等于该序列中各个符号的信息量之和就有:123414()13()12()6()87.81I I x I x I x I x bit =+++= 平均每个符号携带的信息量为87.81 1.9545=bit/符号 2.8试问四进制、八进制脉冲所含信息量是二进制脉冲的多少倍?解:四进制脉冲可以表示4个不同的消息,例如:{0,1,2,3}八进制脉冲可以表示8个不同的消息,例如:{0,1,2,3,4,5,6,7}二进制脉冲可以表示2个不同的消息,例如:{0,1}假设每个消息的发出都是等概率的,则:四进制脉冲的平均信息量symbol bit n X H / 24log log )(1=== 八进制脉冲的平均信息量symbol bit n XH / 38log log )(2=== 二进制脉冲的平均信息量symbol bit n X H / 12log log )(0===所以:四进制、八进制脉冲所含信息量分别是二进制脉冲信息量的2倍和3倍。
信息论课程实验报告—Shannon编码

: 六、实验器材(设备、元器件) 实验器材(设备、元器件)
PC 机一台,装有 VC++6.0 或其它 C 语言集成开发环境。
七、实验步骤及操作: 实验步骤及操作:
1)排序; 2)计算码长; 3)递归调用香农算法得到相应的码字。
八、实验数据及结果分析: 实验数据及结果分析:
s 2 s3 s4 s5 s6 s 7 s8 S s1 题目:已知信源: = ,给出其一个 P 0.20, 0.18, 0.17, 0.15, 0.15, 0.05, 0.05, 0.05 香农码,并求其平均码长和编码效率。
else k[i]=temp+1; } } void code(int *k,double *pa,string *str,int n) { for(int i=0;i<n;i++) { double s=pa[i]; for(int j=0;j<k[i];j++) { s=2*s; if(s>=1) { str[i]+="1"; s=s-1; } else str[i]+="0"; } } } void main() { int n; cout<<"信源符号个数 n= "; cin>>n; double *p=new double[n]; cout<<"信源符号的概率依次为(以回车表示概率的结束): "; for(int i=0;i<n;i++) { cin>>p[i]; } bubble(p,n); double *pa=new double[n]; leijia(p,pa,n); int *k=new int[n]; length(p,k,n); string *str=new string[n]; code(k,pa,str,n); cout<<setw(10)<<"pa(i)"<<setw(10)<<"Pa(a,j)"<<setw(10)<<"Ki"<<setw(10)<<"码字"<<endl; for(i=0;i<n;i++) { cout<<setw(10)<<p[i]<<setw(10)<<pa[i]<<setw(10)<<k[i]<<setw(10)<<str[i]<<endl; } }
信息论与编码课程设计报告统计信源熵与香农编码

信息论与编码课程设计报告统计信源熵与香农编码信息论与编码课程设计报告设计题目:统计信源熵与香农编码专业班级电信 12-06学号学生姓名指导教师教师评分3 月 30日目录一、设计任务与要求 (2)二、设计思路 (2)三、设计流程图 (3)四、程序运行及结果 (4)五、心得体会 (6)参考文献 (7)附录:源程序 (8)一、设计任务与要求1.统计信源熵要求:统计任意文本文件中各字符(不区分大小写)数量,计算字符概率,并计算信源熵。
2.香农编码要求:任意输入消息概率,利用香农编码方法进行编码,并计算信源熵和编码效率。
二、设计思路本次课程设计中主要运用C 语言编程以实现任务要求,分析所需要的统计量以及相关变量,依据具体公式和计算步骤编写语句,组成完整C 程序。
1、信源熵定义:信源各个离散消息的自信息量的数学期望为信源的平均信息量,一般称为信源的信息熵,也叫信源熵或香农熵,有时称为无条件熵或熵函数,简称熵,记为H ()。
计算公式:)(log )(-)x (i i i x p x p H ∑=2、香农编码过程:(1)将信源消息符号按其出现的概率大小依次排列为n p p ≥⋅⋅⋅≥≥21p(2)确定满足下列不等式的整数码长i K 为1)()(+-<≤-i i i p lb K p lb(3)为了编成唯一可译码,计算第i 个消息的累加概率∑-==11)(i k k i a p P(4)将累计概率i P 变换成二进制数。
(5)取i P 二进制数的小数点后i K 位即为该消息符号的二进制码字。
三、设计流程图1、统计信源熵开始计算字符概率输出结束2、香农编码开始计算信源熵计算编码效率输出结束四、程序运行及结果1、统计信源熵2、香农编码五、心得体会经过这次课程设计明显的体会到知识匮乏所带来的种种问题,首先是对C语言编程的不熟练,课程知识在与C语言的结合中没有清晰的思路,具体实现程序语言的编写较为困难。
在程序的调试中出现的问题无法及时快速的解决,有些错误甚至无法找到合适的解决方法,以至于不断的修改程序,浪费了大量的时间。
信息论编码实验四香农编码(可打印修改)

事也掌握香农编码的一般算法和香农编码算法中的二进制编码算法。 一开始做实验的时候,如果任意给定一个信源模型,要求编程实现其二进制香农编码,
输出编码结果对我而言有很大的难度,但是通过这次的实验,这些操作对我而言驾轻就熟 不在话下了。这次实验让我学到了很多,很有意义。
Hale Waihona Puke D(:,1)=y';%把 y 赋给零矩阵的第一列 for i=2:n
D(1,2)=0;%令第一行第二列的元素为 0 D(i,2)=D(i-1,1)+D(i-1,2);%第二列其余的元素用此式求得,即为累加概率 end for i=1:n D(i,3)=-log2(D(i,1));%求第三列的元素 D(i,4)=ceil(D(i,3));%求第四列的元素,对 D(i,3)向无穷方向取最小正整数 end D A=D(:,2)';%取出 D 中第二列元素 B=D(:,4)';%取出 D 中第四列元素 for j=1:n C=deczbin(A(j),B(j))%生成码字 function [C]=deczbin(A,B)%对累加概率求二进制的函数 C=zeros(1,B);%生成零矩阵用于存储生成的二进制数,对二进制的每一位进行操作 temp=A;%temp 赋初值 for i=1:B%累加概率转化为二进制,循环求二进制的每一位,A 控制生成二进制的位数 temp=temp*2; if temp>=1 temp=temp-1; C(1,i)=1; else C(1,i)=0; end end
实验四 香农编码
一、实验目的
1、理解香农编码的概念。 2、掌握香农编码的一般算法 3、掌握香农编码算法中的二进制编码算法。 4、任意给定一个信源模型,编程实现其二进制香农编码,输出编码结果。
信息论与编码(第二版)曹雪虹(最全版本)答案

《信息论与编码(第二版)》曹雪虹答案第二章2.1一个马尔可夫信源有3个符号{}1,23,u u u ,转移概率为:()11|1/2p u u =,()21|1/2p u u =,()31|0p u u =,()12|1/3p u u =,()22|0p u u =,()32|2/3p u u =,()13|1/3p u u =,()23|2/3p u u =,()33|0p u u =,画出状态图并求出各符号稳态概率。
解:状态图如下状态转移矩阵为:1/21/201/302/31/32/30p ⎛⎫ ⎪= ⎪ ⎪⎝⎭设状态u 1,u 2,u 3稳定后的概率分别为W 1,W 2、W 3由1231WP W W W W =⎧⎨++=⎩得1231132231231112331223231W W W W W W W W W W W W ⎧++=⎪⎪⎪+=⎪⎨⎪=⎪⎪⎪++=⎩计算可得1231025925625W W W ⎧=⎪⎪⎪=⎨⎪⎪=⎪⎩ 2.2 由符号集{0,1}组成的二阶马尔可夫链,其转移概率为:(0|00)p =0.8,(0|11)p =0.2,(1|00)p =0.2,(1|11)p =0.8,(0|01)p =0.5,(0|10)p =0.5,(1|01)p =0.5,(1|10)p =0.5。
画出状态图,并计算各状态的稳态概率。
解:(0|00)(00|00)0.8p p == (0|01)(10|01)0.5p p ==(0|11)(10|11)0.2p p == (0|10)(00|10)0.5p p == (1|00)(01|00)0.2p p == (1|01)(11|01)0.5p p == (1|11)(11|11)0.8p p == (1|10)(01|10)0.5p p ==于是可以列出转移概率矩阵:0.80.200000.50.50.50.500000.20.8p ⎛⎫ ⎪⎪= ⎪ ⎪⎝⎭状态图为:设各状态00,01,10,11的稳态分布概率为W 1,W 2,W 3,W 4 有411i i WP W W ==⎧⎪⎨=⎪⎩∑ 得 13113224324412340.80.50.20.50.50.20.50.81W W W W W W W W W W W W W W W W +=⎧⎪+=⎪⎪+=⎨⎪+=⎪+++=⎪⎩ 计算得到12345141717514W W W W ⎧=⎪⎪⎪=⎪⎨⎪=⎪⎪⎪=⎩2.3 同时掷出两个正常的骰子,也就是各面呈现的概率都为1/6,求: (1) “3和5同时出现”这事件的自信息; (2) “两个1同时出现”这事件的自信息;(3) 两个点数的各种组合(无序)对的熵和平均信息量; (4) 两个点数之和(即2, 3, … , 12构成的子集)的熵; (5) 两个点数中至少有一个是1的自信息量。
信息论与编码课后作业

第三章3.8 证明长为N的D元不等长码至多有D(D N-1)/(D-1)个码字。
证:已知长为N的不等长码D元可得此不等长为D进制,最大长为N所以例:N=2,D=2 {0,1}推出 {0,1,00,01,10,11}……可知码字数量n=D+D2+……D N即为等比数列求和:n=a1(1−q n)1−q =D(1−Dn)1−D=D(Dn−1)D−13.12 信源符号消息X={x1,x2,…x M},信源熵H(X),若对该信源能找到一个平均码长为⎺n=H(X)/log3的三元即时码,证明对每个x i∈X,其概率满足p(x i)=3−n i,式中n i为整数。
证:由题意已知:信源熵H(x)和平均码长,三元即时码设每个信源符号信息x1,x2,x3…x M ,对应的概率q1,q2,q3,q MH(x)=-q1logq1-q2logq2-q3logq3…-q M logq M平均码长:⎺n=q1+2*q2+2*q3+3*q4+…又因为⎺n=H(x)/log3⎺nlog3=( q1+2*q2+2*q3+3*q4+…)log3=-log(1/3)*( q1+2*q2+2*q3+3*q4+…)H(x)=-log(q1q1*q2q2*q3q3*q4q4…)因为H(x)= nlog3 所以-log(q1q1*q2q2*q3q3*q4q4…)=-log13q1+2∗q2+2∗q3+3∗q4+⋯得到:q1=1/3,q2=(1/3)2 ,q3=(1/3)2, q4=(1/3)3…q M=(1/3)ni概率满足P(x i)=3−ni (ni∈Z)3.16 某一信源有M 个消息,并且每个消息等概分布,对该信源进行二元霍夫曼编码,问当M=2i 和M=2i +1(i 为正整数)时,每个码字的长度n i 等于多少?平均码长⎺n 又为多少?答:当M=2i 时,得到等长码,码长为i ; 当M=2i+1时,平均码长为 :⎺n=2i −12i +1*i+22i +1*(i+1)=i+22i +13.17 信源分布[xq(x)]=[x 1x 2x 3x 41/31/31/41/12],(1) 对该信源进行二元霍夫曼编码;(2)证明存在两个不同的最佳码长集合,即证明码长集合{1,2,3,4}和{2,2,2,2}都是最佳的。
信息论编码作业

信息论编码一.信息论的认识1.消息是信息的载荷者。
信息是抽象的,消息是具体的。
要研究信息,还得从研究消息入手。
2.由于信源发送什么消息预先是不可知的,只能用概率空间来描述信源3.单符号信源:输出是单个符号(代码)的消息⏹ 离散信源 ⏹ 连续信源4.平稳随机序列信源:信源输出的消息由一系列符号序列所组成,可用N 维随机矢量 X =(X1,X2,…,XN)描述,且随机矢量X 的各维概率分布都与时间起点无关----平稳!⏹ 离散平稳信源 ⏹ 连续平稳信源⏹ 无记忆(独立)离散平稳信源 ⏹ 有记忆信源⏹ m 阶马尔可夫信源5.随机波形信源● 信息是信息论中最基本、最重要的概念,既抽象又复杂● 信息在日常生活中被认为是“消息”、“知识”、“情报”等● “信息”不同于消息(在现代信息论形成之前,信息一直被看作是通信中消息的同义词,没有严格的数学含义),消息是表现形式,信息是实质; ● “信息”不同于情报,情报的含义比“信息”窄的多,一般只限于特殊的领域,是一类特殊的信息;● 信息不同于信号,信号是承载消息的物理量;● 信息不同于知识,知识是人们根据某种目的,从自然界收集得来的数据中整理、概括、提取得到的有价值的信息,是一种高层次的信息。
6.互信息量 I(xi ; yj):收到消息yj 后获得关于xi 的信息量)()|(log )|(1log )(1log )/()();(i j i j i i j i x p y x p y x p x p y x I x I y x I =-=-=即:互信息量表示先验的不确定性减去尚存的不确定性,这就是收信者获得的信息量对于无干扰信道,I(xi ; yj) = I(xi);二.我们学到了1.离散信源熵和互信息定义具有概率为p(xi)的符号xi的自信息量为I(xi)=-logp(xi)信源输出的整体特征用平均自信息量,表示本身的特征用信源熵。
2.信道与信道容量信道分类:根据用户数量可分为单用户信道和多用户信道根据信道输入端和输出端的关系可分为无反馈信道和反馈信道。
信息论与编码基础--香浓三大定理

1-p
b2=1
PE = P(a1)P(b2|a1)+P(a2)P(b1|a2) = ωp + (1-ω)p = 0.01
信息论与编码基础
2、常用判决准则
香农三大定理 简介
a、MAP准则(Maximum a Posteriori) 对于所有的 C ′
P (C * | R) ≥ P (C ′ | R)
香农三大定理 简介
H(S) = H(3/4,1/4) = 0.811(bit/sign)
N=1
L1 = 1 (code/sign) H (S ) R1 = = 0.811 (bit/code) L1 H (S ) η1 = = 0.811 L1 ⋅ log 2
信息论与编码基础
例:二元DMS进行无失真编码
−4
PE = p + C pp = 3 × 10 < p = 0.01
3 1 3 2
信息论与编码基础
例1 重复编码 (n,1)
3 1 3 2 −4
香农三大定理 简介
PE = p + C pp ≈ 3 × 10 < p = 0.01
R = logM/n bit/code
n=5 n=7 n=9
可靠性增强
N次扩展信源无失真编码器
信息论与编码基础
1、信源编码器 b、举例
1)ASCII信源编码器
香农三大定理 简介
{英文字母/符号/命令}
二进代码
ASCII编码器
码符号集{0,1}
信息论与编码基础
1、信源编码器 符号 点 划 b 、举例 b、举例
二进代码 +— +++— 2 )摩尔斯电码 2)摩尔斯信源编码器 电平 10 1110 字母间隔 ——— 000
信息论实验报告(实验三、香农编码)
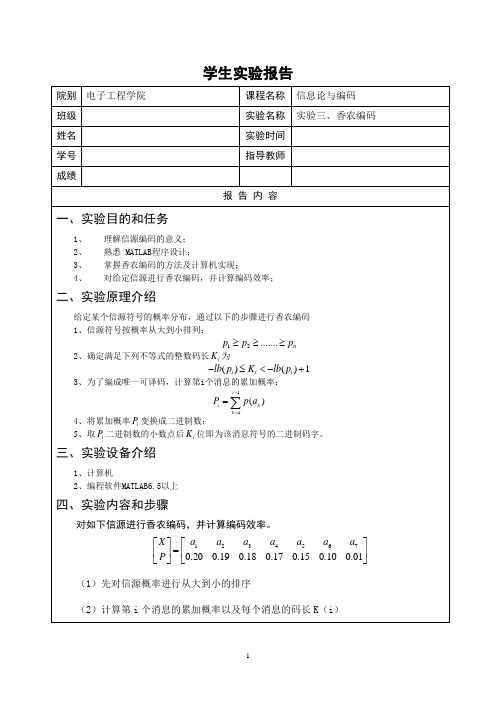
学生实验报告 院别 电子工程学院课程名称 信息论与编码 班级实验名称 实验三、香农编码 姓名实验时间 学号指导教师 成绩报 告 内 容 一、实验目的和任务1、理解信源编码的意义; 2、熟悉 MATLAB 程序设计; 3、掌握香农编码的方法及计算机实现; 4、 对给定信源进行香农编码,并计算编码效率;二、实验原理介绍给定某个信源符号的概率分布,通过以下的步骤进行香农编码1、信源符号按概率从大到小排列;12.......n p p p ≥≥≥2、确定满足下列不等式的整数码长i K 为()()1i i i lb p K lb p -≤<-+3、为了编成唯一可译码,计算第i 个消息的累加概率:4、将累加概率i P 变换成二进制数;5、取i P 二进制数的小数点后i K 位即为该消息符号的二进制码字。
三、实验设备介绍1、计算机2、编程软件MATLAB6.5以上四、实验内容和步骤对如下信源进行香农编码,并计算编码效率。
12345670.200.190.180.170.150.100.01X a a a a a a a P ⎡⎤⎡⎤=⎢⎥⎢⎥⎣⎦⎣⎦(1)先对信源概率进行从大到小的排序(2)计算第i 个消息的累加概率以及每个消息的码长K (i )11()i i k k P p a -==∑(3)调用子函数将累加概率的十进制表示转换成二进制(4)取第i个累加概率二进制的小数点后的K(i)位,即为该消息符号的二进制码字。
五、实验数据记录六、实验结论与心得通过本次实验,加强了对matlab程序的学习,进一步提高了我的编程能力。
信息论与编码(第3版)第3章部分习题答案

3.1设信源()12345670.20.190.180.170.150.10.01X a a a a a a a P X ⎛⎫⎧⎫=⎨⎬ ⎪⎩⎭⎝⎭ (1) 求信源熵()H X (2) 编二进制香农码(3) 计算平均码长及编码效率。
答:(1)根据信源熵公式()()()()21log 2.6087bit/symbol i i i H X p a p a ==−=∑(2)利用到3个关键公式:①根据()()()100,0i a i k k p a p a p a −===∑计算累加概率;②根据()()*22log 1log ,i i i i p a k p a k N −≤<−∈计算码长;③根据()a i p a 不断地乘m 取整(m 表示编码的进制),依次得到的i k 个整数就是i a 对应的码字根据①②③可得香农编码为(3)平均码长公式为()13.14i i i K p a k ===∑单符号信源L =1,以及二进制m =2, 根据信息率公式()2log bit/symbol m KR K L==编码效率()83.08%H X Rη==3.2对习题3.1的信源编二进制费诺码,计算其编码效率答:将概率从大到小排列,且进制m=2,因此,分成2组(每一组概率必须满足最接近相等)。
根据平均码长公式为()12.74i iiK p a k===∑单符号信源L=1,以及二进制m=2, 根据信息率公式()2log bit/symbolmKR KL==编码效率(信源熵看题3.1)()95.21%H XRη==3.3对习题3.1的信源编二进制赫夫曼码,计算平均码长和编码效率答:将n个信源符号的概率从大到小排列,且进制m=2。
从m个最小概率的“0”各自分配一个“0”和“1”,将其合成1个新的符号,与其余剩余的符号组成具有n-1个符号的新信源。
排列规则和继续分配码元的规则如上,直到分配完所有信源符号。
必须保证两点:(1)当合成后的信源符号与剩余的信源符号概率相等时,将合并后的新符号放在靠前的位置来分配码元【注:“0”位表示在前,“1”表示在后】,这样码长方差更小;(2)读取码字时是从后向前读取,确保码字是即时码。
信息论与编码理论(最全试题集+带答案+各种题型)

答:抗干扰能力强,中继时可再生,可消除噪声累计;差错可控制,可改善通信质量;便于加密和使用DSP处理技术;可综合传输各种信息,传送模拟系统时,只要在发送端增加莫属转换器,在接收端增加数模转换器即可。
7.简述信息的性质。
答:存在普遍性;有序性;相对性;可度量性;可扩充性;可存储、传输与携带性;可压缩性;可替代性;可扩散性;可共享性;时效性;
A.形式、含义和安全性
B.形式、载体和安全性
C.形式、含义和效用
D.内容、载体和可靠性
20.(D)是香农信息论最基本最重要的概念
A.信源B.信息C.消息D.熵
三.简答(
1.通信系统模型如下:
2.信息和消息的概念有何区别?
答:消息有两个特点:一是能被通信双方所理解,二是能够互相传递。相对于消息而言,信息是指包含在消息中的对通信者有意义的那部分内容,所以消息是信息的载体,消息中可能包含信息。
31.简单通信系统的模型包含的四部分分别为信源、有扰信道、信宿、干扰源。
32. 的后验概率与先念概率的比值的对数为 对 的互信息量。
33.在信息论中,互信息量等于自信息量减去条件自信息量。
34.当X和Y相互独立时,互信息为0。
35.信源各个离散消息的自信息量的数学期望为信源的平均信息量,也称信息熵。
第一章
一、填空(
1.1948年,美国数学家香农发表了题为“通信的数学理论”的长篇论文,从而创立了信息论。
2.按照信息的性质,可以把信息分成语法信息、语义信息和语用信息。
3.按照信息的地位,可以把信息分成客观信息和主观信息。
4.人们研究信息论的目的是为了高效、可靠、安全地交换和利用各种各样的信息。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
信息论与编码课程大作业
题目:香农编码
学生姓名:
学号:2010110100
专业班级:电子信息工程班
2013年5月17日
香农编码
一、实验目的
(1) 进一步熟悉Shannon 编码过程。
(2) 掌握高级语言程序的设计和调试技术。
二、实验要求
输入:信源符号个数n 、信源的概率分布P={p(s i )},i=1,…..,n 。
输出:每个信源符号对应的香农编码的码字。
三、实验原理
香农第一定理指出了平均码长与信源之间的关系,同时也指出了可以通过编码使平均码长达到极限值,这是一个很重要的极限定理。
如何构造这种码?香农第一定理指出,选择每个码字的长度K i 满足下式
I(x i )≤K ﹤I(x i )+1, 就可以得到这种码。
这种编码方法就是香农编码。
编码步骤
香农编码法冗余度稍大,实用性不大,但有重要的理论意义。
编码步骤如下: (1) 将信源消息符号按其出现的概率大小依次排列 p (x 1)≥p (x 2)≥…≥p (x n ) (2) 确定满足下列不等式整数码长K i :
-log 2p(x i )≤K i <-log 2p(x i )+1 (3) 为了编成唯一可译码,计算第i 个消息的累加概率 P i =∑-+1
1i k p(x k )
(4) 将累加概率P i 变成二进制数。
(5) 取P i 二进制数的小数点后K i 位即为该消息符号的二进制码字
四、用Matlab实现
1、编码主程序
n=input('输入单符号信源个数n=')
p=zeros(1,n);
for i=1:n
p(1,i)=input('输入单符号信源的概率:');
end
if sum(p)<1||sum(p)>1
error('不符合概率分布无效')
end
y=fliplr(sort(p));%大到小排序
D=zeros(n,4);%生成n*4的零矩阵
D(:,1)=y';%把y赋给零矩阵的第一列
for i=2:n
D(1,2)=0;%令第一行第二列的元素为0
D(i,2)=D(i-1,1)+D(i-1,2);%求累加概率
end
for i=1:n
D(i,3)=-log2(D(i,1));%求第三列的元素
D(i,4)=ceil(D(i,3));%求第四列的元素,对D(i,3)向无穷方向取最小正整数
end
D
A=D(:,2)';%取出D中第二列元素
B=D(:,4)';%取出D中第四列元素
for j=1:n
C=binary(A(j),B(j))%生成码字
end 2、含有的子函数binary
function [C]=binary(A,B)%对累加概率求二进制的函数
C=zeros(1,B);%生成零矩阵用于存储生成的二进制数,对二进制的每一位进行操作
temp=A;%temp赋初值
for i=1:B%累加概率转化为二进制,循环求二进制的每一位,A控制生成二进制的位数
temp=temp*2;
if temp>1
temp=temp-1;
C(1,i)=1;
else
C(1,i)=0;
end
end
五、运行结果及分析(宋体四号,加粗)
输入信源符号个数n=5
输入信源符号概率:0.21
输入信源符号概率:0.19
输入信源符号概率:0.18
输入信源符号概率:0.17
输入信源符号概率:0.25
得到结果为:
六、心得体会(宋体四号,加粗)
本次大作业之前我对信息论香农编码的理解还只是停留在以前通信课本和信息论课本理论知识,这两周时间主要是通过看课本和通过网络资源完成了本次大作业,运行程序只对于正确输入情况下可以出来结果,若输入信号概率之和不为1也能运行,出来的编码是错误的,这点没有考虑到。
通过运用香农编码方法进行计算和对香农编码Matlab的运行,可知,香农编码方法多余度稍大,相较于其他编码方法实用性不大,例如:后面课本上所学的费诺编码,但香农编码法有重要的理论意义。