正则表达式15
正则表达式

IP 地址:/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
HTML 标签:/^<([a-z]+)([^<]+)*(?:>(.*)<\/\1>|\s+\/>)$/
评注:表单验证时很实用
匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}
评注:匹配形式如 0511-4405222 或 021-87888822
匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
匹配中国大陆邮政编码:[1-9]\d{5}(?!\d)
中国大陆固定电话号码 (\d{4}-|\d{3}-)?(\d{8}|\d{7})
中国大陆手机号码 1\d{10}
中国大陆邮政编码 [1-9]\d{5}
中国大陆身份证号(15位或18位) \d{15}(\d\d[0-9xX])?
非负整数(正整数或零) \d+
正整数 [0-9]*[1-9][0-9]*
^-?[1-9]\d*$ //匹配整数
^[1-9]\d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]\d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ //匹配正浮点数
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ //匹配负浮点数
^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$ //匹配浮点数
身份证正则表达式

⾝份证正则表达式//⾝份证正则表达式(15位)isIDCard1=/^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$/;//⾝份证正则表达式(18位)isIDCard2=/^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}([0-9]|X)$/;地区、性别和⾝份证进⾏判断的正则表达式:<script>varaCity={11:"北京",12:"天津",13:"河北",14:"⼭西",15:"内蒙古",21:"辽宁",22:"吉林",23:"⿊龙江",31:"上海",32:"江苏",33:"浙江",34:" 安徽",35:"福建",36:"江西",37:"⼭东",41:"河南",42:"湖北",43:"湖南",44:"⼴东",45:"⼴西",46:"海南",50:"重庆",51:"四川",52:"贵州" ,53:"云南",54:"西藏",61:"陕西",62:"⽢肃",63:"青海",64:"宁夏",65:"新疆",71:"台湾",81:"⾹港",82:"澳门",91:"国外"}function cidInfo(sId){var iSum=0var info=""if(!/^\d{17}(\d|x)$/i.test(sId))return false;sId=sId.replace(/x$/i,"a");if(aCity[parseInt(sId.substr(0,2))]==null)return "Error:⾮法地区";sBirthday=sId.substr(6,4)+"-"+Number(sId.substr(10,2))+"-"+Number(sId.substr(12,2));var d=new Date(sBirthday.replace(/-/g,"/"))if(sBirthday!=(d.getFullYear()+"-"+ (d.getMonth()+1) + "-" + d.getDate()))return "Error:⾮法⽣⽇";for(var i = 17;i>=0;i --) iSum += (Math.pow(2,i) % 11) * parseInt(sId.charAt(17 - i),11)if(iSum%11!=1)return "Error:⾮法证号";return aCity[parseInt(sId.substr(0,2))]+","+sBirthday+","+(sId.substr(16,1)%2?"男":"⼥")}</script>-------------正则表达式全集 中国电话号码验证 匹配形式如:0511-******* 或者021-******** 或者 021-********-555 或者 (0511)4405222 正则表达式 "((d{3,4})|d{3,4}-)?d{7,8}(-d{3})*" 中国邮政编码验证 匹配形式如:215421 正则表达式 "d{6}" 电⼦邮件验证 匹配形式如:justali@ 正则表达式 "w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*" ⾝份证验证 匹配形式如:15位或者18位⾝份证 正则表达式 "d{18}|d{15}" 常⽤数字验证 正则表达式 "d{n}" n为规定长度 "d{n,m}" n到m的长度范围 ⾮法字符验证 匹配⾮法字符如:< > & / ' | 正则表达式 [^<>&/|'\]+ ⽇期验证 匹配形式如:20030718,030718 范围:1900--2099 正则表达式((((19){1}|(20){1})d{2})|d{2})[01]{1}d{1}[0-3]{1}d{1} 正则表达式是⼀个好东西,但是⼀般情况下,我们需要验证的内容少之⼜少。
常用正则表达式大全!(例如:匹配中文、匹配html)

常⽤正则表达式⼤全!(例如:匹配中⽂、匹配html)⼀、常见正则表达式 匹配中⽂字符的正则表达式: [u4e00-u9fa5] 评注:匹配中⽂还真是个头疼的事,有了这个表达式就好办了 匹配双字节字符(包括汉字在内):[^x00-xff] 评注:可以⽤来计算字符串的长度(⼀个双字节字符长度计2,ASCII字符计1) 匹配空⽩⾏的正则表达式:ns*r 评注:可以⽤来删除空⽩⾏ 匹配HTML标记的正则表达式:<(S*?)[^>]*>.*?|<.*? /> 评注:⽹上流传的版本太糟糕,上⾯这个也仅仅能匹配部分,对于复杂的嵌套标记依旧⽆能为⼒ 匹配⾸尾空⽩字符的正则表达式:^s*|s*$ 评注:可以⽤来删除⾏⾸⾏尾的空⽩字符(包括空格、制表符、换页符等等),⾮常有⽤的表达式 匹配Email地址的正则表达式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)* 评注:表单验证时很实⽤ 匹配⽹址URL的正则表达式:^(http|https):\/\/[\w\-_]+(\.[\w\-_]+)+([\w\-\.,@?^=%&:/~\+#]*[\w\-\@?^=%&/~\+#])?$ 评注:⽹上流传的版本功能很有限,上⾯这个基本可以满⾜需求匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$ 评注:表单验证时很实⽤ 匹配国内电话号码:d{3}-d{8}|d{4}-d{7} 评注:匹配形式如 0511-******* 或 021-******** 匹配腾讯QQ号:[1-9][0-9]{4,} 评注:腾讯QQ号从10000开始 匹配中国邮政编码:[1-9]d{5}(?!d) 评注:中国邮政编码为6位数字 匹配⾝份证:d{15}|d{18} 评注:中国的⾝份证为15位或18位 匹配ip地址:d+.d+.d+.d+ 评注:提取ip地址时有⽤ 匹配特定数字: ^[1-9]d*$ //匹配正整数 ^-[1-9]d*$ //匹配负整数 ^-?[1-9]d*$ //匹配整数 ^[1-9]d*|0$ //匹配⾮负整数(正整数 + 0) ^-[1-9]d*|0$ //匹配⾮正整数(负整数 + 0) ^[1-9]d*.d*|0.d*[1-9]d*$ //匹配正浮点数 ^-([1-9]d*.d*|0.d*[1-9]d*)$ //匹配负浮点数 ^-?([1-9]d*.d*|0.d*[1-9]d*|0?.0+|0)$ //匹配浮点数 ^[1-9]d*.d*|0.d*[1-9]d*|0?.0+|0$ //匹配⾮负浮点数(正浮点数 + 0) ^(-([1-9]d*.d*|0.d*[1-9]d*))|0?.0+|0$ //匹配⾮正浮点数(负浮点数 + 0) 评注:处理⼤量数据时有⽤,具体应⽤时注意修正 匹配特定字符串: ^[A-Za-z]+$ //匹配由26个英⽂字母组成的字符串 ^[A-Z]+$ //匹配由26个英⽂字母的⼤写组成的字符串 ^[a-z]+$ //匹配由26个英⽂字母的⼩写组成的字符串 ^[A-Za-z0-9]+$ //匹配由数字和26个英⽂字母组成的字符串 ^w+$ //匹配由数字、26个英⽂字母或者下划线组成的字符串 在使⽤RegularExpressionValidator验证控件时的验证功能及其验证表达式介绍如下: 只能输⼊数字:“^[0-9]*$” 只能输⼊n位的数字:“^d{n}$” 只能输⼊⾄少n位数字:“^d{n,}$” 只能输⼊m-n位的数字:“^d{m,n}$” 只能输⼊零和⾮零开头的数字:“^(0|[1-9][0-9]*)$” 只能输⼊有两位⼩数的正实数:“^[0-9]+(.[0-9]{2})?$” 只能输⼊有1-3位⼩数的正实数:“^[0-9]+(.[0-9]{1,3})?$” 只能输⼊⾮零的正整数:“^+?[1-9][0-9]*$” 只能输⼊⾮零的负整数:“^-[1-9][0-9]*$” 只能输⼊长度为3的字符:“^.{3}$” 只能输⼊由26个英⽂字母组成的字符串:“^[A-Za-z]+$” 只能输⼊由26个⼤写英⽂字母组成的字符串:“^[A-Z]+$” 只能输⼊由26个⼩写英⽂字母组成的字符串:“^[a-z]+$” 只能输⼊由数字和26个英⽂字母组成的字符串:“^[A-Za-z0-9]+$” 只能输⼊由数字、26个英⽂字母或者下划线组成的字符串:“^w+$” 验证⽤户密码:“^[a-zA-Z]w{5,17}$”正确格式为:以字母开头,长度在6-18之间,只能包含字符、数字和下划线。
常用的正则表达式

常用的正则表达式整理1、非负整数:^\d+$2、正整数:^[0-9]*[1-9][0-9]*$3、非正整数:^((-\d+)|(0+))$4、负整数:^-[0-9]*[1-9][0-9]*$5、整数:^-?\d+$6、非负浮点数:^\d+(\.\d+)?$7、正浮点数:^((0-9)+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)) $8、非正浮点数:^((-\d+\.\d+)?)|(0+(\.0+)?))$9、负浮点数:^(-((正浮点数正则式)))$10、英文字符串:^[A-Za-z]+$11、英文大写串:^[A-Z]+$12、英文小写串:^[a-z]+$13、英文字符数字串:^[A-Za-z0-9]+$14、英数字加下划线串:^\w+$15、E-mail地址:^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$16、URL:^[a-zA-Z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\s*)?$或:^http:\/\/[A-Za-z0-9]+\.[A-Za-z0-9]+[\/=\?%\-&_~`@[\]\':+!]*([^<>\"\"])*$17、邮政编码:^[1-9]\d{5}$18、中文:^[\u0391-\uFFE5]+$19、电话号码:^((\(\d{2,3}\))|(\d{3}\-))?(\(0\d{2,3}\)|0\d{2,3}-)?[1-9]\d{6,7}(\-\d{1,4})?$ 20、手机号码:^((\(\d{2,3}\))|(\d{3}\-))?13\d{9}$21、双字节字符(包括汉字在内):^\x00-\xff22、匹配首尾空格:(^\s*)|(\s*$)(像vbscript那样的trim函数)23、匹配HTML标记:<(.*)>.*<\/\1>|<(.*) \/>24、匹配空行:\n[\s| ]*\r25、提取信息中的网络链接:(h|H)(r|R)(e|E)(f|F) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?26、提取信息中的邮件地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*27、提取信息中的图片链接:(s|S)(r|R)(c|C) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?28、提取信息中的IP地址:(\d+)\.(\d+)\.(\d+)\.(\d+)29、提取信息中的中国手机号码:(86)*0*13\d{9}30、提取信息中的中国固定电话号码:(\(\d{3,4}\)|\d{3,4}-|\s)?\d{8}31、提取信息中的中国电话号码(包括移动和固定电话):(\(\d{3,4}\)|\d{3,4}-|\s)?\d{7,14}32、提取信息中的中国邮政编码:[1-9]{1}(\d+){5}33、提取信息中的浮点数(即小数):(-?\d*)\.?\d+34、提取信息中的任何数字:(-?\d*)(\.\d+)?35、IP:(\d+)\.(\d+)\.(\d+)\.(\d+)36、电话区号:/^0\d{2,3}$/37、腾讯QQ号:^[1-9]*[1-9][0-9]*$38、帐号(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$匹配中文字符的正则表达式:[\u4e00-\u9fa5]匹配双字节字符(包括汉字在内):[^\x00-\xff]匹配空行的正则表达式:\n[\s| ]*\r匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/ 匹配首尾空格的正则表达式:(^\s*)|(\s*$)匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*匹配网址URL的正则表达式:^[a-zA-z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S *)?$匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$匹配国内电话号码:(\d{3}-|\d{4}-)?(\d{8}|\d{7})?匹配腾讯QQ号:^[1-9]*[1-9][0-9]*$下表是元字符及其在正则表达式上下文中的行为的一个完整列表:\将下一个字符标记为一个特殊字符、或一个原义字符、或一个后向引用、或一个八进制转义符。
10个(含10)以内字母或字母数字的正则表达式

正则表达式是一种用来描述字符模式的工具,它可以帮助我们在文本中搜索、替换和匹配特定的内容。
在实际应用中,常常会遇到需要匹配特定字母或字母数字组合的情况。
本文将介绍10个以内字母或字母数字的正则表达式,帮助读者更好地理解和运用这一强大的工具。
1. 匹配单个小写字母:正则表达式:[a-z]解释:这个正则表达式可以匹配任意一个小写字母,包括a、b、c等。
2. 匹配单个大写字母:正则表达式:[A-Z]解释:这个正则表达式可以匹配任意一个大写字母,包括A、B、C等。
3. 匹配单个数字:正则表达式:[0-9]解释:这个正则表达式可以匹配任意一个数字,包括0、1、2等。
4. 匹配字母数字组合:正则表达式:[a-zA-Z0-9]解释:这个正则表达式可以匹配任意一个字母或数字,包括大小写字母和数字。
5. 匹配特定数量的字母或数字:正则表达式:[a-zA-Z0-9]{n}解释:这个正则表达式可以匹配包含n个字母或数字的字符。
6. 匹配至少一个字母或数字:正则表达式:[a-zA-Z0-9]+解释:这个正则表达式可以匹配至少一个字母或数字的字符,包括单个字母或数字、字母数字组合等。
7. 匹配不超过m个字母或数字:正则表达式:[a-zA-Z0-9]{,m}解释:这个正则表达式可以匹配不超过m个字母或数字的字符。
8. 匹配字母开头的字母数字组合:正则表达式:[a-zA-Z][a-zA-Z0-9]*解释:这个正则表达式可以匹配以字母开头的任意字母数字组合,包括单个字母、字母数字组合等。
9. 匹配以字母或数字结尾的字母数字组合:正则表达式:[a-zA-Z0-9]*[a-zA-Z0-9]解释:这个正则表达式可以匹配以字母或数字结尾的任意字母数字组合,包括单个字母、字母数字组合等。
10. 匹配不包含特定字符的字母或数字组合:正则表达式:[^特定字符]解释:这个正则表达式可以匹配不包含特定字符的任意字母或数字组合,可以根据实际需求替换"特定字符"。
正则表达式150种表达方式

正则表达式150种表达方式1、删除所有数字。
只要查找:\d就OK。
为了不留空行:替换处:\d2、删除所有英文字母。
只要查找:\a就OK。
为了不留空行:替换处:\d3、删除除换行符以外的所有。
只要查找:. 为了不留空行:替换处:\d4、既删除英文字母又删除数字。
只要查找:\w。
为了不留空行:替换处:\d5、删除数字加字母加等于(如:3a=或3zz=)只要查找:\d+\a+\=。
为了不留空行:替换处:\d6、删除换行。
只要查找:$。
替换处:\d(还原查找:\a+=\f。
替换:\0\n)。
如在换行后加一空格,查找:(\a)$。
替换:\0 \d。
7、删除空行只要查找:^$。
为了不留空行:替换处:\d8、删除首尾空格。
只要查找:^\s*|\s*$就OK9、删除行前数字及顿号。
只要查找:\d+、替换为空10、删除末尾标点符号。
只要查找:\P+$|\P+\s+$,“|”前面是没有空格的,“|”后面有空格,P后的加是为了……而用的。
11、删除末尾空格。
只要查找:\s+$。
替换为空。
12、删除第一个字如:“的我们”中的“的”只要查找:^\的。
13、删除第几个字。
查找:查找:^().(.+)。
替换:\1\2。
去掉前面的拼音:查找:^\a+替换为空。
第一个括号里可加“.”且可变。
14、删含的。
查:.*的.*替:\d。
的头查:.*=的.*替:\d。
的尾查:\a.*\c.*的$替:\d(留它不匹配)●删非的行查:^[^的]+$替:\d15、删除几码以上的码查:^(...)...替:\1。
删第几位码。
查:^(...).(.+)替:\1\2(变成\1,\2则其位则改成,了)首括号的.可变。
16、删除各类型的几字词,但必须是码前词后或纯词。
三字词:查找:^\~f{}\f{3}$替换:\d。
替换:\d “3”可以改。
17、删除11字词及其以上的词条查找(自定义格式):\a{}\=(\c|\P|\p){11,}。
替换:\d。
11可改。
常用正则式

61.
62. (?:pattern) 匹配pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。
63.
64. (?=pattern) 正向预查,在任何匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。
119.
120. 匹配双字节字符(包括汉字在内):[^x00-xff]
121.
122. 匹配空行的正则表达式:n[s| ]*r
123.
124. 匹配HTML标记的正则表达式:/<(.*)>.*</1>|<(.*) />/
125.
126. 匹配首尾空格的正则表达式:(^s*)|(s*$)
75.
76. [^a-z] 负值字符范围,匹配任何不在指定范围内的任意字符。
77.
78. \b 匹配一个单词边界,也就是指单词和空格间的位置。
79.
80. \B 匹配非单词边界。
81.
82. \cx 匹配由x指明的控制字符。
83.
36.
37. 元字符及其在正则表达式上下文中的行为:
38.
39. \ 将下一个字符标记为一个特殊字符、或一个原义字符、或一个后向引用、或一个八进制转义符。
40.
41. ^ 匹配输入字符串的开始位置。如果设置了 RegExp 对象的Multiline 属性,^ 也匹配 ’\n’ 或 ’\r’ 之后的位置。
91.
92. \r 匹配一个回车符。等价于 \x0d 和 \cM。
python常用的正则表达式大全
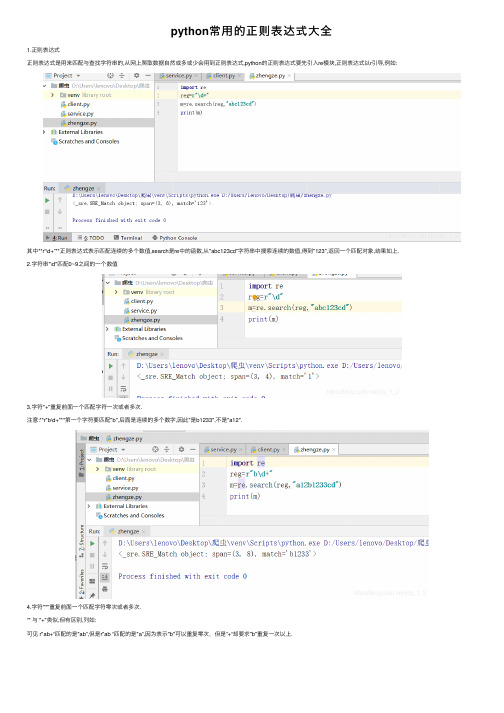
python常⽤的正则表达式⼤全1.正则表达式正则表达式是⽤来匹配与查找字符串的,从⽹上爬取数据⾃然或多或少会⽤到正则表达式,python的正则表达式要先引⼊re模块,正则表达式以r引导,例如:其中**r“\d+”**正则表达式表⽰匹配连续的多个数值,search是re中的函数,从"abc123cd"字符串中搜索连续的数值,得到"123",返回⼀个匹配对象,结果如上.2.字符串"\d"匹配0~9之间的⼀个数值3.字符"+"重复前⾯⼀个匹配字符⼀次或者多次.注意:**r"b\d+"**第⼀个字符要匹配"b",后⾯是连续的多个数字,因此"是b1233",不是"a12".4.字符"*"重复前⾯⼀个匹配字符零次或者多次.“" 与 "+"类似,但有区别,列如:可见 r"ab+“匹配的是"ab”,但是r"ab “匹配的是"a”,因为表⽰"b"可以重复零次,但是”+“却要求"b"重复⼀次以上.5.字符"?"重复前⾯⼀个匹配字符零次或者⼀次.匹配结果"ab”,重复b⼀次.6.字符".“代表任何⼀个字符,但是没有特别声明时不代表字符”\n".结果“.”代表了字符"x".7."|"代表把左右分成两个部分 .结果匹配"ab"或者"ba"都可以.8.特殊字符使⽤反斜杠"“引导,例如”\r"、"\n"、"\t"、"\"分别表⽰回车、换⾏、制表符号与反斜线⾃⼰本⾝.9.字符"\b"表⽰单词结尾,单词结尾包括各种空⽩字符或者字符串结尾.结果匹配"car",因为"car"后⾯是⼀个空格.10."[]中的字符是任选择⼀个,如果字符ASCll码中连续的⼀组,那么可以使⽤"-"字符连接,例如[0-9]表⽰0-9的其中⼀个数字,[A-Z]表⽰A-Z的其中⼀个⼤写字符,[0-9A-z]表⽰0-9的其中⼀个数字或者A-z的其中⼀个⼤写字符.11."^"出现在[]的第⼀个字符位置,就代表取反,例如[ ^ab0-9]表⽰不是a、b,也不是0-9的数字.12."\s"匹配任何空⽩字符,等价"[\r\n 20\t\f\v]"13."\w"匹配包括下划线⼦内的单词字符,等价于"[a-zA-Z0-9]"14."$"字符⽐配字符串的结尾位置匹配结果是最后⼀个"ab",⽽不是第⼀个"ab"15.使⽤括号(…)可以把(…)看出⼀个整体,经常与"+"、"*"、"?"的连续使⽤,对(…)部分进⾏重复.结果匹配"abab","+“对"ab"进⾏了重复16.查找匹配字符串正则表达式re库的search函数使⽤正则表达式对要匹配的字符串进⾏匹配,如果匹配不成功返回None,如果匹配成功返回⼀个匹配对象,匹配对象调⽤start()函数得到匹配字符的开始位置,匹配对象调⽤end()函数得到匹配字符串的结束位置,search虽然只返回匹配第⼀次匹配的结果,但是我们只要连续使⽤search函数就可以找到字符串全部匹配的字符串.匹配找出英⽂句⼦中所有单词我们可以使⽤正则表达式r”[A-Za-z]+\b"匹配单词,它表⽰匹配由⼤⼩写字母组成的连续多个字符,⼀般是⼀个单词,之后"\b"表⽰单词结尾.程序开始匹配到⼀个单词后m.start(),m.end()就是单词的起始位置,s[start:end]为截取的单词,之后程序再次匹配字符串s=s[end:],即字符串的后半段,⼀直到匹配完毕为⽌就找出每个单词.总结到此这篇关于python常⽤正则表达式的⽂章就介绍到这了,更多相关python正则表达式内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
常用正则表达式,手机号、固话号、身份证号等

常⽤正则表达式,⼿机号、固话号、⾝份证号等⼿机号码正则表达式验证function checkPhone(){var phone = document.getElementById('phone').value;if(!(/^1[34578]\d{9}$/.test(phone))){alert("⼿机号码有误,请重填");return false;}}或者是function checkPhone(){var phone = document.getElementById('phone').value;if(!(/^1(3|4|5|7|8)\d{9}$/.test(phone))){alert("⼿机号码有误,请重填");return false;}}注:⼩括号就是括号内看成⼀个整体 ,中括号就是匹配括号内的其中⼀个正则⾥⾯的中括号[]只能匹配其中⼀个,如果要匹配特定⼏组字符串的话,那就必须使⽤⼩括号()加或|,我还以为在中括号中也能使⽤或|符号,原来|在中括号⾥⾯也是⼀个字符,并不代表或。
[3457]匹配3或者4或者5或者7,⽽(3457)只匹配3457,若要跟前⾯⼀样可以加或(3|4|5|7)。
[34|57]匹配3或者4或者|或者5或者7.⽽(34|57)能匹配34或者57。
固定电话号码正则表达式:function checkTel(){var tel = document.getElementById('tel').value;if(!/^(\(\d{3,4}\)|\d{3,4}-|\s)?\d{7,14}$/.test(tel)){alert('固定电话有误,请重填');return false;}}⾝份证校验//⾝份证正则表达式(15位)isIDCard1=/^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$/;//⾝份证正则表达式(18位)isIDCard2=/^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{4}$/;⾝份证正则合并:(^\d{15}$)|(^\d{17}([0-9]|X)$)提取信息中的⽹络链接:(h|H)(r|R)(e|E)(f|F) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?提取信息中的邮件地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*提取信息中的图⽚链接:(s|S)(r|R)(c|C) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?提取信息中的IP地址:(\d+)\.(\d+)\.(\d+)\.(\d+)提取信息中的中国电话号码(包括移动和固定电话):(\(\d{3,4}\)|\d{3,4}-|\s)?\d{7,14}提取信息中的中国邮政编码:[1-9]{1}(\d+){5}提取信息中的中国⾝份证号码:\d{18}|\d{15}提取信息中的整数:\d+提取信息中的浮点数(即⼩数):(-?\d*)\.?\d+提取信息中的任何数字:(-?\d*)(\.\d+)?提取信息中的中⽂字符串:[\u4e00-\u9fa5]*提取信息中的双字节字符串 (汉字):[^\x00-\xff]*使⽤⽅法:test()⽅法在字符串中查找是否存在指定的正则表达式,并返回布尔值,如果存在则返回true,否则返回false。
正则表达式15个常用实例

正则表达式15个常用实例正则表达式是一种文本模式语言,它允许用户通过指定模式来查找或替换文本。
它在编程语言和许多计算机应用程序中都有用,特别是在解析和处理文本时。
下面我们就来看看正则表达式的15个常用实例。
1.匹配字符串中的数字:\d+ 。
2.匹配字符串中的小写字母:[a-z] 。
3.匹配字符串中的大写字母:[A-Z] 。
4.匹配字符串中的所有单词字符:\w+ 。
5.匹配字符串中的空格字符:\s+ 。
6.匹配字符串中的日期:\d{4}-\d{2}-\d{2} 。
7.匹配字符串中的邮箱地址:[a-zA-Z0-9]+@[a-z]+\.[a-z]+ 。
8.匹配字符串中的URL:https?:\/\/[a-zA-Z0-9]+\.[a-z]+ 。
9.匹配字符串中的IP地址:\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3} 。
10.匹配字符串中的HTML标签:<[a-zA-Z0-9]+> 。
11.匹配字符串中的HTML属性:\w+=".*?" 。
12.匹配字符串中的中文字符:[\u4e00-\u9fa5] 。
13.匹配字符串中的特殊字符:[\^\.\?\*\+\$\[\]\(\)\{\}\\\/\|] 。
14.匹配字符串中的任意字符:. 。
15.匹配字符串中的任意位置:^$ 。
正则表达式非常强大,它可以用来检测字符串中的任何模式,并执行替换或提取操作。
正则表达式的15个常用实例只是用来提醒用户,它们只是正则表达式的一小部分。
正则表达式的应用种类很多,可以用来检测文本格式、搜索特定字符串、数据验证和替换文本。
有了正则表达式,开发者可以更有效地处理文本,从而大大提高工作效率。
正则表达式(正则表达式括号的作用)

正则表达式(正则表达式括号的作⽤)正则表达式之前学习的时候,因为很久没怎么⽤,或者⽤的时候直接找⽹上现成的,所以都基本忘的差不多了。
所以这篇⽂章即是笔记,也让⾃⼰再重新学习⼀遍正则表达式。
其实平时在操作⼀些字符串的时候,⽤正则的机会还是挺多的,之前没怎么重视正则,这是⼀个错误。
写完这篇⽂章后,发觉⼯作中很多地⽅都可以⽤到正则,⽽且⽤起来其实还是挺爽的。
正则表达式作⽤ 正则表达式,⼜称规则表达式,它可以通过⼀些设定的规则来匹配⼀些字符串,是⼀个强⼤的字符串匹配⼯具。
正则表达式⽅法基本语法,正则声明js中,正则的声明有两种⽅式1. 直接量语法:1var reg = /d+/g/2. 创建RegExp对象的语法1var reg = new RegExp("\\d+", "g");这两种声明⽅式其实还是有区别的,平时的话我⽐较喜欢第⼀种,⽅便⼀点,如果需要给正则表达式传递参数的话,那么只能⽤第⼆种创建RegExp的形式格式:var pattern = new RegExp('regexp','modifier');regexp:匹配的模式,也就是上⽂指的正则规则。
modifier: 正则实例的修饰符,可选值有:i : 表⽰区分⼤⼩写字母匹配。
m :表⽰多⾏匹配。
g : 表⽰全局匹配。
传参的形式如下:我们⽤构造函数来⽣成正则表达式1var re = new RegExp("^\\d+$","gim");这⾥需要注意,反斜杠需要转义,所以,直接声明量中的语法为\d,这⾥需要为\\d那么,给它加变量,就和我们前⾯写的给字符串加变量⼀样了。
1 2var v = "bl";var re =new RegExp("^\\d+" + v + "$","gim"); // re为/^\d+bl$/gim⽀持正则的STRING对象⽅法1. search ⽅法作⽤:该⽅法⽤于检索字符串中指定的⼦字符串,或检索与正则表达式相匹配的字符串基本语法:stringObject.search(regexp);返回值:该字符串中第⼀个与regexp对象相匹配的⼦串的起始位置。
20个常用的正则表达式 单字母

正则表达式(Regular Expression)是一种用于匹配字符串的强大工具。
它通过使用特定的符号和字符来描述和匹配一系列字符串,能够满足我们在处理文本时的各种需求。
在这篇文章中,我们将深入探讨20个常用的单字母正则表达式,并通过实例来展示它们的使用方法。
1. \b在正则表达式中,\b表示单词的边界。
它可以用来匹配单词的开头或结尾,用于查找特定单词而不是单词的一部分。
2. \d\d表示任意一个数字字符。
它可以用来匹配任何数字,例如\d+可以匹配一个或多个数字字符。
3. \w\w表示任意一个字母、数字或下划线字符。
它可以用来匹配单词字符,例如\w+可以匹配一个或多个单词字符。
4. \s\s表示任意一个空白字符,包括空格、制表符、换行符等。
它可以用来匹配空白字符,例如\s+可以匹配一个或多个空白字符。
5. \.\.表示匹配任意一个字符,包括标点符号和空格等。
它可以用来匹配任意字符,例如\.可以匹配任意一个字符。
6. \A\A表示匹配字符串的开始。
它可以用来确保匹配发生在字符串的开头。
7. \Z\Z表示匹配字符串的结束。
它可以用来确保匹配发生在字符串的结尾。
8. \b\b表示单词的边界。
它可以用来匹配单词的开头或结尾,用于查找特定单词而不是单词的一部分。
9. \D\D表示任意一个非数字字符。
它可以用来匹配任何非数字字符。
10. \W\W表示任意一个非单词字符。
它可以用来匹配任何非单词字符。
11. \S\S表示任意一个非空白字符。
它可以用来匹配任何非空白字符。
12. \[\[表示匹配方括号。
它可以用来匹配包含在方括号内的字符。
13. \]\]表示匹配方括号。
它可以用来匹配包含在方括号内的字符。
14. \(\(表示匹配左括号。
它可以用来匹配包含在左括号内的字符。
15. \)\)表示匹配右括号。
它可以用来匹配包含在右括号内的字符。
16. \{\{表示匹配左花括号。
它可以用来匹配包含在左花括号内的字符。
17. \}\}表示匹配右花括号。
史上最全的正则表达式-匹配中英文、字母和数字

史上最全的正则表达式-匹配中英⽂、字母和数字在做项⽬的过程中,使⽤正则表达式来匹配⼀段⽂本中的特定种类字符,是⽐较常⽤的⼀种⽅式,下⾯是对常⽤的正则匹配做了⼀个归纳整理。
匹配中⽂:[\u4e00-\u9fa5]英⽂字母:[a-zA-Z]数字:[0-9]匹配中⽂,英⽂字母和数字及_:^[\u4e00-\u9fa5_a-zA-Z0-9]+$同时判断输⼊长度:[\u4e00-\u9fa5_a-zA-Z0-9_]{4,10}^[\w\u4E00-\u9FA5\uF900-\uFA2D]*$ 1、⼀个正则表达式,只含有汉字、数字、字母、下划线不能以下划线开头和结尾:^(?!_)(?!.*?_$)[a-zA-Z0-9_\u4e00-\u9fa5]+$其中:^与字符串开始的地⽅匹配(?!_) 不能以_开头(?!.*?_$) 不能以_结尾[a-zA-Z0-9_\u4e00-\u9fa5]+ ⾄少⼀个汉字、数字、字母、下划线$ 与字符串结束的地⽅匹配放在程序⾥前⾯加@,否则需要\\进⾏转义 "^(?!_)(?!.*?_$)[a-zA-Z0-9_\u4e00-\u9fa5]+$"(或者:"^(?!_)\w*(?2、只含有汉字、数字、字母、下划线,下划线位置不限:^[a-zA-Z0-9_\u4e00-\u9fa5]+$3、由数字、26个英⽂字母或者下划线组成的字符串^\w+$4、2~4个汉字"^[\u4E00-\u9FA5]{2,4}$";5、^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$⽤:(Abc)+ 来分析:XYZAbcAbcAbcXYZAbcAbXYZAbcAbcAbcXYZAbcAb6、[^\u4E00-\u9FA50-9a-zA-Z_]34555#5' -->34555#5'publicbool RegexName(string str){bool flag=Regex.IsMatch(str,@"^[a-zA-Z0-9_\u4e00-\u9fa5]+$");returnflag;}Regex reg=new Regex("^[a-zA-Z_0-9]+$");if(reg.IsMatch(s)){\\符合规则}else{\\存在⾮法字符}最长不得超过7个汉字,或14个字节(数字,字母和下划线)正则表达式^[\u4e00-\u9fa5]{1,7}$|^[\dA-Za-z_]{1,14}$常⽤正则表达式⼤全!(例如:匹配中⽂、匹配html)匹配中⽂字符的正则表达式: [u4e00-u9fa5]评注:匹配中⽂还真是个头疼的事,有了这个表达式就好办了匹配双字节字符(包括汉字在内):[^x00-xff]评注:可以⽤来计算字符串的长度(⼀个双字节字符长度计2,ASCII字符计1)匹配空⽩⾏的正则表达式:ns*r评注:可以⽤来删除空⽩⾏匹配HTML标记的正则表达式:<(S*?)[^>]*>.*?|<.*? />评注:⽹上流传的版本太糟糕,上⾯这个也仅仅能匹配部分,对于复杂的嵌套标记依旧⽆能为⼒匹配⾸尾空⽩字符的正则表达式:^s*|s*$评注:可以⽤来删除⾏⾸⾏尾的空⽩字符(包括空格、制表符、换页符等等),⾮常有⽤的表达式匹配Email地址的正则表达式:^[a-zA-Z0-9][\w\.-]*[a-zA-Z0-9]@[a-zA-Z0-9][\w\.-]*[a-zA-Z0-9]\.[a-zA-Z][a-zA-Z\.]*[a-zA-Z]$评注:表单验证时很实⽤⼿机号:^((13[0-9])|(14[0-9])|(15[0-9])|(17[0-9])|(18[0-9]))\d{8}$⾝份证:(^\d{15}$)|(^\d{17}([0-9]|X|x)$)⽤正则表达式限制只能输⼊数字和英⽂:onkeyup="value=value.replace(/[W]/g,')"onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^d]/g,'。
最全的常用正则表达式大全(校验数字,字符,号码等)

最全的常⽤正则表达式⼤全(校验数字,字符,号码等)⼀、校验数字的表达式1 数字:^[0-9]*$2 n位的数字:^\d{n}$3 ⾄少n位的数字:^\d{n,}$4 m-n位的数字:^\d{m,n}$5 零和⾮零开头的数字:^(0|[1-9][0-9]*)$6 ⾮零开头的最多带两位⼩数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$7 带1-2位⼩数的正数或负数:^(\-)?\d+(\.\d{1,2})?$8 正数、负数、和⼩数:^(\-|\+)?\d+(\.\d+)?$9 有两位⼩数的正实数:^[0-9]+(.[0-9]{2})?$10 有1~3位⼩数的正实数:^[0-9]+(.[0-9]{1,3})?$11 ⾮零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$12 ⾮零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$13 ⾮负整数:^\d+$ 或 ^[1-9]\d*|0$14 ⾮正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$15 ⾮负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$16 ⾮正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$17 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$18 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$19 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$⼆、校验字符的表达式1 汉字:^[\u4e00-\u9fa5]{0,}$2 英⽂和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$3 长度为3-20的所有字符:^.{3,20}$4 由26个英⽂字母组成的字符串:^[A-Za-z]+$5 由26个⼤写英⽂字母组成的字符串:^[A-Z]+$6 由26个⼩写英⽂字母组成的字符串:^[a-z]+$7 由数字和26个英⽂字母组成的字符串:^[A-Za-z0-9]+$8 由数字、26个英⽂字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$9 中⽂、英⽂、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$10 中⽂、英⽂、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$11 可以输⼊含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+12 禁⽌输⼊含有~的字符:[^~\x22]+三、特殊需求表达式1 Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$2 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?3 InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$4 ⼿机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$5 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$6 国内电话号码(0511-*******、021-********):\d{3}-\d{8}|\d{4}-\d{7}7 ⾝份证号(15位、18位数字):^\d{15}|\d{18}$8 短⾝份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$9 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$10 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$11 强密码(必须包含⼤⼩写字母和数字的组合,不能使⽤特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$12 ⽇期格式:^\d{4}-\d{1,2}-\d{1,2}13 ⼀年的12个⽉(01~09和1~12):^(0?[1-9]|1[0-2])$14 ⼀个⽉的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$15 钱的输⼊格式:16 1.有四种钱的表⽰形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$17 2.这表⽰任意⼀个不以0开头的数字,但是,这也意味着⼀个字符"0"不通过,所以我们采⽤下⾯的形式:^(0|[1-9][0-9]*)$18 3.⼀个0或者⼀个不以0开头的数字.我们还可以允许开头有⼀个负号:^(0|-?[1-9][0-9]*)$19 4.这表⽰⼀个0或者⼀个可能为负的开头不为0的数字.让⽤户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下⾯我们要加的是说明可能的⼩数部分:^[0-9]+(.[0-9]+)?$20 5.必须说明的是,⼩数点后⾯⾄少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$21 6.这样我们规定⼩数点后⾯必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$22 7.这样就允许⽤户只写⼀位⼩数.下⾯我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$23 8.1到3个数字,后⾯跟着任意个逗号+3个数字,逗号成为可选,⽽不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$24 备注:这就是最终结果了,别忘了"+"可以⽤"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在⽤函数时去掉去掉那个反斜杠,⼀般的错误都在这⾥25 ⽂件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$26 中⽂字符的正则表达式:[\u4e00-\u9fa5]27 双字节字符:[^\x00-\xff] (包括汉字在内,可以⽤来计算字符串的长度(⼀个双字节字符长度计2,ASCII字符计1))28 空⽩⾏的正则表达式:\n\s*\r (可以⽤来删除空⽩⾏)29 标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? /> (⽹上流传的版本太糟糕,上⾯这个也仅仅能部分,对于复杂的嵌套标记依旧⽆能为⼒)30 ⾸尾空⽩字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以⽤来删除⾏⾸⾏尾的空⽩字符(包括空格、制表符、换页符等等),⾮常有⽤的表达式)31 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)32 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字) 33 IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有⽤) 34 IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))。
正则表达式_email_数字_字母_下划线_汉字

email和数字,字母,下划线还有汉字的正则表达式关键字: 正则表达式 email 数字字母下划线汉字自己总结的正则表达式:绝对正确的,本人已经验证通过了。
Java代码1.1. 只有字母、数字和下划线且不能以下划线开头和结尾的正则表达式:^(?!_)(?!.*?_$)[a-zA-Z0-9_]+$2.只有字母和数字的: ^[a-zA-Z0-9_]+$3.2. 至少一个汉字、数字、字母、下划线: "[a-zA-Z0-9_\u4e00-\u9fa5]+"4.3. 至少一个汉字的正则表达式:"^[\u4e00-\u9fa5]"5.4. 最多10个汉字: ValidationExpression="^[\u4e00-\u9fa5]{0,10}"6.5. 只含有汉字、数字、字母、下划线不能以下划线开头和结尾:^(?!_)(?!.*?_$)[a-zA-Z0-9_\u4e00-\u9fa5]+$7.解释:8. ^ 与字符串开始的地方匹配9. (?!_) 不能以_开头10. (?!.*?_$) 不能以_结尾11. [a-zA-Z0-9_\u4e00-\u9fa5]+ 至少一个汉字、数字、字母、下划线12. $ 与字符串结束的地方匹配13.14.6. email正则表达式:两种方式都可以15. (1) \w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*16. (2) ^[_A-Za-z0-9-]+(\\.[_A-Za-z0-9-]+)*@[A-Za-z0-9-]+(\\.[A-Za-z0-9-]+)*((\\.[A-Za-z]{2,}){1}$)下面是转载的(但我验证了下怎么没有成功?又期待性):Java代码1.完美E-Mail正则表达式:2.国际域名格式如下:3.域名由各国文字的特定字符集、英文字母、数字及“-”(即连字符或减号)任意组合而成, 但开头及结尾均不能含有“-”,“-”不能连续出现。
最全的常用正则表达式大全

最全的常⽤正则表达式⼤全⼀、校验数字的表达式1 数字:^[0-9]*$2 n位的数字:^\d{n}$3 ⾄少n位的数字:^\d{n,}$4 m-n位的数字:^\d{m,n}$5 零和⾮零开头的数字:^(0|[1-9][0-9]*)$6 ⾮零开头的最多带两位⼩数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$7 带1-2位⼩数的正数或负数:^(\-)?\d+(\.\d{1,2})?$8 正数、负数、和⼩数:^(\-|\+)?\d+(\.\d+)?$9 有两位⼩数的正实数:^[0-9]+(.[0-9]{2})?$10 有1~3位⼩数的正实数:^[0-9]+(.[0-9]{1,3})?$11 ⾮零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$12 ⾮零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$13 ⾮负整数:^\d+$ 或 ^[1-9]\d*|0$14 ⾮正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$15 ⾮负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$16 ⾮正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$17 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$18 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$19 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$⼆、校验字符的表达式1 汉字:^[\u4e00-\u9fa5]{0,}$2 英⽂和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$3 长度为3-20的所有字符:^.{3,20}$4 由26个英⽂字母组成的字符串:^[A-Za-z]+$5 由26个⼤写英⽂字母组成的字符串:^[A-Z]+$6 由26个⼩写英⽂字母组成的字符串:^[a-z]+$7 由数字和26个英⽂字母组成的字符串:^[A-Za-z0-9]+$8 由数字、26个英⽂字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$9 中⽂、英⽂、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$10 中⽂、英⽂、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$11 可以输⼊含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+12 禁⽌输⼊含有~的字符:[^~\x22]+三、特殊需求表达式1 Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$2 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?3 InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$4 ⼿机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$5 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$6 国内电话号码(0511-*******、021-********):\d{3}-\d{8}|\d{4}-\d{7}7 ⾝份证号(15位、18位数字):^\d{15}|\d{18}$8 短⾝份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$9 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$10 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$11 强密码(必须包含⼤⼩写字母和数字的组合,不能使⽤特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$12 ⽇期格式:^\d{4}-\d{1,2}-\d{1,2}13 ⼀年的12个⽉(01~09和1~12):^(0?[1-9]|1[0-2])$14 ⼀个⽉的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$15 钱的输⼊格式:16 1.有四种钱的表⽰形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$17 2.这表⽰任意⼀个不以0开头的数字,但是,这也意味着⼀个字符"0"不通过,所以我们采⽤下⾯的形式:^(0|[1-9][0-9]*)$18 3.⼀个0或者⼀个不以0开头的数字.我们还可以允许开头有⼀个负号:^(0|-?[1-9][0-9]*)$19 4.这表⽰⼀个0或者⼀个可能为负的开头不为0的数字.让⽤户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下⾯我们要加的是说明可能的⼩数部分:^[0-9]+(.[0-9]+)?$20 5.必须说明的是,⼩数点后⾯⾄少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$21 6.这样我们规定⼩数点后⾯必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$22 7.这样就允许⽤户只写⼀位⼩数.下⾯我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$23 8.1到3个数字,后⾯跟着任意个逗号+3个数字,逗号成为可选,⽽不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$24 备注:这就是最终结果了,别忘了"+"可以⽤"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在⽤函数时去掉去掉那个反斜杠,⼀般的错误都在这⾥25 xml⽂件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$26 中⽂字符的正则表达式:[\u4e00-\u9fa5]27 双字节字符:[^\x00-\xff] (包括汉字在内,可以⽤来计算字符串的长度(⼀个双字节字符长度计2,ASCII字符计1))28 空⽩⾏的正则表达式:\n\s*\r (可以⽤来删除空⽩⾏)29 HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? /> (⽹上流传的版本太糟糕,上⾯这个也仅仅能部分,对于复杂的嵌套标记依旧⽆能为⼒)30 ⾸尾空⽩字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以⽤来删除⾏⾸⾏尾的空⽩字符(包括空格、制表符、换页符等等),⾮常有⽤的表达式)31 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)32 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字) 33 IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有⽤) 34 IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))20个正则表达式必知(能让你少写1,000⾏代码)正则表达式(regular expression)描述了⼀种字符串匹配的模式,可以⽤来检查⼀个串是否含有某种⼦串、将匹配的⼦串做替换或者从某个串中取出符合某个条件的⼦串等。
常用正则表达式

1.平时做网站经常要用正则表达式,下面是一些讲解和例子,仅供大家参考和修改使用:2."^\d+$"d+)$"0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$"d+))|(0+(\.0+)))$"0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$"d+)$"\w-]+)*@[\ w-]+(\.[\w-]+)+$"\w+(-\w+)*))*(\\S*)$"+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-z A-Z]{2,4}|[0-9]{1,3})(])$" d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|2 5[0-5])$" >.*<\/\1>|<(.*) \/>/3.匹配首尾空格的正则表达式:(^\s*)|(\s*$)4.匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*5.匹配网址URL的正则表达式:^[a-zA-z]+:\\w+(-\\w+)*))*(\\\\S*)$6.匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$7.匹配国内电话号码:(\d{3}-|\d{4}-)(\d{8}|\d{7})8.匹配腾讯QQ号:^[1-9]*[1-9][0-9]*$9.10.11.元字符及其在正则表达式上下文中的行为:12.13.\ 将下一个字符标记为一个特殊字符、或一个原义字符、或一个后向引用、或一个八进制转义符。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
反向引用 \n Whatever the nth capturing group matched Quotation \ 引用后面的字符 \Q 引用所有的字符直到 \E 出现 \E 结束以 \Q 开始的引用 Special constructs (non-capturing) (?:X) X, as a non-capturing group 匹配标志开关 (?idmsux-idmsux)
Reluctant quantifiers X?? X*? X+? X{n}? X{n,}? X{n,m}? X, 不出现或出现一次 X, 不出现或出现多次 X, 至少出现一次 X, 出现 n 次 X, 至少出现 n 次 X, 至少出现 n 次,但不会超过 m 次
Possessive quantifiers X?+ X*+ X++ X{n}+ X{n,}+ X{n,m}+ 逻辑运算符 XY Y 跟在 X 后面 X|Y (X) X 或 Y X, as a capturing group X, 不出现或出现一次 X, 不出现或出现多次 X, 至少出现一次 X, 出现 n 次 X, 至少出现 n 次 X, 至少出现 n 次,但不会超过 m 次
Backslashes, escapes, and quoting 反斜杠字符('\')用来转义,就像上面的表中定义的那样,如果不这样做的话可能会产生 歧义。因此,表达式\\匹配 单个反斜杠,表达式\{匹配单个左花括号。 如果把反斜杠放在没有定义转移构造的任何字母符号前面都会发生错误,这些将被保留 到以后的正则表达式中扩展。反斜杠可以放在任何 非字母符号前面,即使它没有定义转义构造也不会发生错误。 在 java 语言规范中指出,在 java 代码中自符串中的反斜杠是必要的,不管用于 Unicode 转 义,还是用于普通的字符转义。因此, 为了保持正则表达式的完整性,在 java 字符串中要写两个反斜杠。例如,在正则表达式 中字符'\b'代表退格,'\\b'则代表单词边界。'\(helቤተ መጻሕፍቲ ባይዱo\)'是无效的,并且会产生编译 时错误,你必须用 '\\(hello\\)'来匹配(hello)。 Character Classes 字符类可以出现在其他字符类内部,并且可以由并操作符和与操作符(&&)组成。并集操 作结果是,其中的任意字符,肯定在至少其中操作数中至少出现过一次。 交集的结果包括各个操作数中同时出现的任意字符。 字符类操作符的优先级如下: (从高到低) 1 2 3 4 5 文字转义 集合 范围 并集 交集 [...] a-z [a-e][i-u] [a-z&&[aeiou]] \x
0 组代表整个表达式。 分组捕获之所以如此命名,是因为在匹配过程中,输入序列的每一个与分组匹配的子序 列都会被保存起来。通过向后引用,被捕获的子序列可以在后面的表达式中被再次使用 。 而且,在匹配操作结束以后还可以通过匹配器重新找到。 与一个分组关联的被捕获到的输入通常是被保存的最近与这个分组相匹配的队列的子队 列。如果一个分组被第二次求值,即使失败,它的上一次被捕获的值也会被保存起来。 例如, 表达式(a(b)?)+匹配"aba","b"设为子分组。在开始匹配的时候,以前被捕获的输入都 将被清除。 以(?开始的分组是完全的,无需捕获的分组不会捕获任何文本,也不会计算分组总数。 Unicode support Unicode Technical Report #18: Unicode Regular Expression Guidelines 通过轻微的语法改变实现了更深层 次的支持。 在 java 代码中,像\u2014 这样的转义序列,java 语言规范中?3.3 提供了处理方法 。 为了便于使用从文件或键盘读取的 unicode 转义字符,正则表达式解析器也直接实现了这 种转移。因此,字符串"\u2014"与"\\u2014"虽然不相等,但是编译进同一种模式,可以 匹配
[\p{L}&&[^\p{Lu}]] 除大写字母外的任意字符 (subtraction) 边界匹配器 ^ $ 一行的开始 一行的结束
\b 单词边界 \B 非单词边界 \A 输入的开始 \G 当前匹配的结束
\Z The end of the input but for the final terminator, if any \z 输入的结束 Greedy quantifiers 贪婪匹配量词(Greedy quantifiers ) (不知道翻译的对不对) X? X* X+ X{n} X{n,} X{n,m} X 不出现或出现一次 X 不出现或出现多次 X 至少出现一次 X 出现 n 次 X 至少出现 n 次 X 至少出现 n 次,但不会超过 m 次
正则表达式通常以字符串的形式出现,它首先必须被编译为 Pattern 类的一个实例。 结果模型可以用来生成一个 Matcher,它(生成的 Macher 实例)可以匹配根据 这个正则表达式生成的任意字符序列。在实现一个匹配器中的匹配时包括了 任意多的情况,并且多个匹配器可以共享同一个匹配模式。 下面是一个典型的调用次序: Pattern p = pile("a*b"); Matcher m = p.matcher("aaaaab"); boolean b = m.matches(); 为了方便使用,Pattern 类也定义了 matches()方法, 因为有时候一个正则表达使只用到一次。 在一次调用中,这个方法首先编译表达式,然后匹配输入的序列。 下面这个句子: boolean b = Pattern.matches("a*b", "aaaaab"); 等价于上面的三个句子。但是由于它不允许便以后的模式被重用,所以在需要重复匹配 时显然比上面的方法效率要低。 Pattern 类的实例不能被改变,并且是线程安全的。注意,Matcher 类并不是线程安全的 。 正则表达式结构简介: 字符: x \0n \0nn \0mnn \xhh 字符 x 十进制数 (0 <= n <= 7) 十进制数 0nn (0 <= n <= 7) 十进制数 0mnn (0 <= m <= 3, 0 <= n <= 7) 十六进制数 0xhh \\ 反斜杠
\p{XDigit} 十六进制数: [0-9a-fA-F]
Unicode 字符类 \p{InGreek} \p{Lu} \p{Sc} 希腊语种的字符 (simple block) 大写字母 (simple category) 货币符号 除希腊语种字符外的任意字符 (negation)
\P{InGreek}
\uhhhh 十六进制数 0xhhhh \t 制表符 ('\u0009') \n 换行符 ('\u000A') \r 回车符 ('\u000D') \f The form-feed character ('\u000C') \a The alert (bell) character ('\u0007') \e esc 符号 ('\u001B') \cx 字符类 [abc] [^abc] a, b, 或 c (简单字符串) 除了 a, b, 或 c 之外的任意字符(否定) x 对应的控制符
回车换行符 ("\r\n"),
如果激活了 UNIX_LINES 模式,唯一的行结束符就是换行符。 除非你指定了 DOTALL 标志,否则正则表达式.匹配任何字符,只有行结束符除外。 确省情况时,在整个输入队列中,正则表达式^和$忽略行结束符,只匹配开始和结束。 如果激活了 MULTILINE 模式,则^匹配输入的开始和所有行结束符之后,除了整个输入 的结束。 在 MULTILINE 模式下,$匹配所有行结束符之前,和整个输入的结束。 Groups and capturing 分组捕获通过从左到右的顺序,根据括号的数量类排序。例如,在表达式((A)(B(C)))中 ,有四个组: 1 2 3 4 ((A)(B(C))) (A) (B(C)) (C)
(?idmsux-idmsux:X) - off (?=X) (?!X) (?<=X) (?<!X) (?>X)
X, as a non-capturing group with the given flags on
X, via zero-width positive lookahead X, via zero-width negative lookahead X, via zero-width positive lookbehind X, via zero-width negative lookbehind X, as an independent, non-capturing group
请注意各个字符类的有效字符集。例如,在字符类中,正则表达式.失去了它的特别含义 ,而-变成了元字符的范围指示。 Line terminators 行结束符是一个或两个字符序列,用来标识输入字符序列的一行的结束。下列都被认为 是行结束符:
换行符 回车符 下一行 行分隔符 段分隔符
('\n'), ('\r'), ('\u0085'), ('\u2028'), 或 ('\u2029).
十六进制数 0x2014。 在 Perl 中,unicode 块和分类被写入\p,\P。如果输入有 prop 属性,\p{prop}将会匹配, 而\P{prop}将不会匹配。块通过前缀 In 指定,作为在 nMongolian 之中。 分类通过任意的前缀 Is 指定: \p{L} 和 \p{IsL} 都引用 Unicode 字母。块和分类可以 被使用在字符类的内部或外部。 The Unicode Standard, Version 3.0 指出了支持的块和分类。块的名字在第 14 章和 Unicode Character Database 中的 Blocks-3.txt 文件定义, 但空格被剔除了。例如 Basic Latin"变成了 "BasicLatin"。分类的名字被定义在 88 页 ,表 4-5。 Comparison to Perl 5 Pattern 类不支持的 Perl 构造: 条件构造 (?{X}) 和 (?(condition)X|Y), (?{code}) 和 (??{code}), (?#comment), 和 \l \u, \L, and \U.