pNN概率神经网络(基于C语言伪码和Matlab代码)
pNN概率神经网络(基于C语言伪码和Matlab代码)

号码与背景的程序,也就是车牌号图像的二值化。本文仅用这个程序作为 PNN 神经网络运 用的简单例子,因此对图像进行些处理以简化编程,采用8位 BMP 带调色板的图片格式存 储。
图4-1
车牌图像
人眼能够识别这个车牌号码是由于车牌的号码白色和它周围的背景蓝色有着鲜明的不 同。对于要完成的程序同样也可以运用颜色差来完成识别。计算机显示 bmp 图片时采用的 是 RBG 的值来描绘每一点的像素颜色,虽然看到图像车牌背景都是蓝色,但是如果放大来 看蓝色并不完全相同而且还有夹杂着些其他颜色, 同样车牌号也并非全部白色。 分析到这里 目标就清楚了,运用 PNN 神经网络采集图片中每个像素点的颜色 RBG 值,将接近蓝色或 者背景中出现的其他颜色分为 A 类,表示背景色;将接近白色的颜色分为 B 类,表示车牌 号色。再用0、1这两个数值来表示 A 类、B 类,重新设置图片中像素的颜色实现了车牌号 图像的二值化。 程序的流程可分为三步:第一步,选取背景色和号码色的样本图片,收集它们各自的颜 色样本数据;第二步,运用收集的颜色数据训练 PNN 神经网络;第三步,将需要识别的车 牌图片中每个像素的颜色数据输入 PNN 神经网络完成分类,然后重置图片颜色数据完成二 值化。 PNN 神经网络的设计:将 RBG 三个值作为输入数据,样本层里的每个神经元代表一种 样本颜色, 竞争层的两个单元分别代表背景色类和号码色类。 输入层和样本层之间的权重存 储在二维指针 **w 中,样本层到求和层的关系存储在**a 中,**a 中的值只能是0和1,每 个样本层里的神经元对应的类别有且仅有一条边值为1,用来说明该样本层神经元存储的样 本颜色属于该边连接的类别。 数据收集及神经网络结构实现的伪代码如下:
Gao Fei, Zhao Zhenzhen, Song Yan Abstract: The basic structure model of probabilistic neural network (PNN) is introduced in this paper, as well as the function of the model, the basic learning algorithm. The application of PNN in the field of Vehicle License Plate Recognition is interpreted in details. At the end of the paper,genetic algorithm( GA ) and its application in optimizing the PNN model are mainly focused on. Keywords: PNN; Parzen window estimate method; Genetic Algorithm
MATLAB程序代码 bp神经网络通用代码

实用标准文案MATLAB程序代码--bp神经网络通用代码matlab通用神经网络代码学习了一段时间的神经网络,总结了一些经验,在这愿意和大家分享一下,希望对大家有帮助,也希望大家可以把其他神经网络的通用代码在这一起分享感应器神经网络、线性网络、BP神经网络、径向基函数网络%通用感应器神经网络。
P=[-0.5 -0.5 0.3 -0.1 -40;-0.5 0.5 -0.5 1 50];%输入向量T=[1 1 0 0 1];%期望输出plotpv(P,T);%描绘输入点图像net=newp([-40 1;-1 50],1);%生成网络,其中参数分别为输入向量的范围和神经元感应器数量hold onlinehandle=plotpc(net.iw{1},net.b{1});net.adaptparam.passes=3;for a=1:25%训练次数[net,Y,E]=adapt(net,P,T);linehandle=plotpc(net.iw{1},net.b{1},linehandle);drawnow;end%通用newlin程序%通用线性网络进行预测time=0:0.025:5;T=sin(time*4*pi);Q=length(T);P=zeros(5,Q);%P中存储信号T的前5(可变,根据需要而定)次值,作为网络输入。
精彩文档.实用标准文案P(1,2:Q)=T(1,1:(Q-1));P(2,3:Q)=T(1,1:(Q-2));P(3,4:Q)=T(1,1:(Q-3));P(4,5:Q)=T(1,1:(Q-4));P(5,6:Q)=T(1,1:(Q-5));plot(time,T)%绘制信号T曲线xlabel('时间');ylabel('目标信号');title('待预测信号');net=newlind(P,T);%根据输入和期望输出直接生成线性网络a=sim(net,P);%网络测试figure(2)plot(time,a,time,T,'+')xlabel('时间');ylabel('输出-目标+');title('输出信号和目标信号');e=T-a;figure(3)plot(time,e)hold onplot([min(time) max(time)],[0 0],'r:')%可用plot(x,zeros(size(x)),'r:')代替hold offxlabel('时间');ylabel('误差');精彩文档.实用标准文案title('误差信号');%通用BP神经网络P=[-1 -1 2 2;0 5 0 5];t=[-1 -1 1 1];net=newff(minmax(P),[3,1],{'tansig','purelin'},'traingd');%输入参数依次为:'样本P范围',[各层神经元数目],{各层传递函数},'训练函数'%训练函数traingd--梯度下降法,有7个训练参数.%训练函数traingdm--有动量的梯度下降法,附加1个训练参数mc(动量因子,缺省为0.9)%训练函数traingda--有自适应lr的梯度下降法,附加3个训练参数:lr_inc(学习率增长比,缺省为1.05;% lr_dec(学习率下降比,缺省为0.7);max_perf_inc(表现函数增加最大比,缺省为1.04)%训练函数traingdx--有动量的梯度下降法中赋以自适应lr的方法,附加traingdm和traingda的4个附加参数%训练函数trainrp--弹性梯度下降法,可以消除输入数值很大或很小时的误差,附加4个训练参数:% delt_inc(权值变化增加量,缺省为1.2);delt_dec(权值变化减小量,缺省为0.5);% delta0(初始权值变化,缺省为0.07);deltamax(权值变化最大值,缺省为50.0)% 适合大型网络%训练函数traincgf--Fletcher-Reeves共轭梯度法;训练函数traincgp--Polak-Ribiere共轭梯度法;%训练函数traincgb--Powell-Beale共轭梯度法%共轭梯度法占用存储空间小,附加1训练参数searchFcn(一维线性搜索方法,缺省为srchcha);缺少1个训练参数lr %训练函数trainscg--量化共轭梯度法,与其他共轭梯度法相比,节约时间.适合大型网络% 附加2个训练参数:sigma(因为二次求导对权值调整的影响参数,缺省为5.0e-5);% lambda(Hessian阵不确定性调节参数,缺省为5.0e-7)% 缺少1个训练参数:lr精彩文档.实用标准文案%训练函数trainbfg--BFGS拟牛顿回退法,收敛速度快,但需要更多内存,与共轭梯度法训练参数相同,适合小网络%训练函数trainoss--一步正割的BP训练法,解决了BFGS消耗内存的问题,与共轭梯度法训练参数相同%训练函数trainlm--Levenberg-Marquardt训练法,用于内存充足的中小型网络net=init(net);net.trainparam.epochs=300; %最大训练次数(前缺省为10,自trainrp后,缺省为100)net.trainparam.lr=0.05; %学习率(缺省为0.01)net.trainparam.show=50; %限时训练迭代过程(NaN表示不显示,缺省为25)net.trainparam.goal=1e-5; %训练要求精度(缺省为0)%net.trainparam.max_fail 最大失败次数(缺省为5)%net.trainparam.min_grad 最小梯度要求(前缺省为1e-10,自trainrp后,缺省为1e-6)%net.trainparam.time 最大训练时间(缺省为inf)[net,tr]=train(net,P,t); %网络训练a=sim(net,P) %网络仿真%通用径向基函数网络——%其在逼近能力,分类能力,学习速度方面均优于BP神经网络%在径向基网络中,径向基层的散步常数是spread的选取是关键%spread越大,需要的神经元越少,但精度会相应下降,spread的缺省值为1%可以通过net=newrbe(P,T,spread)生成网络,且误差为0%可以通过net=newrb(P,T,goal,spread)生成网络,神经元由1开始增加,直到达到训练精度或神经元数目最多为止%GRNN网络,迅速生成广义回归神经网络(GRNN)P=[4 5 6];T=[1.5 3.6 6.7];精彩文档.实用标准文案net=newgrnn(P,T);%仿真验证p=4.5;v=sim(net,p)%PNN网络,概率神经网络P=[0 0 ;1 1;0 3;1 4;3 1;4 1;4 3]';Tc=[1 1 2 2 3 3 3];%将期望输出通过ind2vec()转换,并设计、验证网络T=ind2vec(Tc);net=newpnn(P,T);Y=sim(net,P);Yc=vec2ind(Y)%尝试用其他的输入向量验证网络P2=[1 4;0 1;5 2]';Y=sim(net,P2);Yc=vec2ind(Y)%应用newrb()函数构建径向基网络,对一系列数据点进行函数逼近P=-1:0.1:1;T=[-0.9602 -0.5770 -0.0729 0.3771 0.6405 0.6600 0.4609...0.1336 -0.2013 -0.4344 -0.500 -0.3930 -0.1647 -0.0988...0.3072 0.3960 0.3449 0.1816 -0.0312 -0.2189 -0.3201];%绘制训练用样本的数据点plot(P,T,'r*');title('训练样本');精彩文档.实用标准文案xlabel('输入向量P');ylabel('目标向量T');%设计一个径向基函数网络,网络有两层,隐层为径向基神经元,输出层为线性神经元%绘制隐层神经元径向基传递函数的曲线p=-3:.1:3;a=radbas(p);plot(p,a)title('径向基传递函数')xlabel('输入向量p')%隐层神经元的权值、阈值与径向基函数的位置和宽度有关,只要隐层神经元数目、权值、阈值正确,可逼近任意函数%例如a2=radbas(p-1.5);a3=radbas(p+2);a4=a+a2*1.5+a3*0.5;plot(p,a,'b',p,a2,'g',p,a3,'r',p,a4,'m--')title('径向基传递函数权值之和')xlabel('输入p');ylabel('输出a');%应用newrb()函数构建径向基网络的时候,可以预先设定均方差精度eg以及散布常数sceg=0.02;sc=1; %其值的选取与最终网络的效果有很大关系,过小造成过适性,过大造成重叠性net=newrb(P,T,eg,sc);%网络测试精彩文档.实用标准文案plot(P,T,'*')xlabel('输入');X=-1:.01:1;Y=sim(net,X);hold onplot(X,Y);hold offlegend('目标','输出')%应用grnn进行函数逼近P=[1 2 3 4 5 6 7 8];T=[0 1 2 3 2 1 2 1];plot(P,T,'.','markersize',30)axis([0 9 -1 4])title('待逼近函数')xlabel('P')ylabel('T')%网络设计%对于离散数据点,散布常数spread选取比输入向量之间的距离稍小一些spread=0.7;net=newgrnn(P,T,spread);%网络测试A=sim(net,P);hold onoutputline=plot(P,A,'o','markersize',10,'color',[1 0 0]);精彩文档.实用标准文案title('检测网络')xlabel('P')ylabel('T和A')%应用pnn进行变量的分类P=[1 2;2 2;1 1]; %输入向量Tc=[1 2 3]; %P对应的三个期望输出%绘制出输入向量及其相对应的类别plot(P(1,:),P(2,:),'.','markersize',30)for i=1:3text(P(1,i)+0.1,P(2,i),sprintf('class %g',Tc(i)))endaxis([0 3 0 3]);title('三向量及其类别')xlabel('P(1,:)')ylabel('P(2,:)')%网络设计T=ind2vec(Tc);spread=1;net=newgrnn(P,T,speard);%网络测试A=sim(net,P);Ac=vec2ind(A);%绘制输入向量及其相应的网络输出plot(P(1,:),P(2,:),'.','markersize',30)精彩文档.实用标准文案for i=1:3text(P(1,i)+0.1,P(2,i),sprintf('class %g',Ac(i)))endaxis([0 3 0 3]);title('网络测试结果')xlabel('P(1,:)')ylabel('P(2,:)')P=[13, 0, 1.119, 1, 26.3;22, 0, 1.135, 1, 26.3;-15, 0, 0.9017, 1, 20.4;-30, 0, 0.9172, 1, 26.7;24,0,1.238,0.9704,28.2;3,24,1.119,1,26.3;0,52,1.089,1,26.3;0,-73,1.0889,1,26.3;1,28,0.8748,1,2 6.3;-1,-39,1.1168,1,26.7;-2, 0, 1.495, 1, 26.3;0, -1, 1.438, 1, 26.3;4, 1,0.4964,0.9021, 26.3;3, -1, 0.5533, 1.2357, 26.7;-5, 0, 1.7368, 1, 26.7;1, 0, 1.1045, 0.0202,26.3;-2, 0, 1.1168, 1.3764, 26.7;-3, -1, 1.1655, 1.4418,27.5;3, 2, 1.0875, 0.748, 27.5;-3, 0, 1.1068, 2.2092, 26.3;4, 1, 0.9017, 1, 13.7;3, 2, 0.9017, 1, 14.9;-3, 1, 0.9172, 1, 13.7;-2, 0, 1.0198, 1.0809, 16.1;0, 1, 0.9172, 1, 13.7]T=[1, 0, 0, 0, 0 ;1, 0, 0, 0, 0 ;1, 0, 0, 0, 0 ;1, 0, 0, 0, 0 ;1, 0, 0, 0, 0;0, 1, 0, 0, 0;0, 1, 0, 0, 0;0, 1, 0, 0, 0;0, 1, 0, 0, 0;0, 1, 0, 0, 0;0, 0, 1, 0, 0;0, 0, 1, 0, 0;0, 0, 1, 0, 0;0, 0, 1, 0, 0;0, 0, 1, 0, 0;0, 0, 0, 1, 0 ;0, 0, 0, 1, 0 ;0, 0, 0, 1, 0 ;0, 0, 0, 1, 0 ;0, 0, 0, 1, 0 ;0, 0, 0, 0, 1;0, 0, 0, 0, 1;0, 0, 0, 0, 1;0, 0, 0, 0, 1;0, 0, 0, 0, 1 ];%期望输出plotpv(P,T);%描绘输入点图像精彩文档.。
概率神经网络的分类预测——基于PNN的变压器故障诊断

概率神经网络的分类预测——基于PNN的变压器故障诊断摘要:电力变压器故障诊断对变压器、电力系统的安全运行有着十分重要的意义,本文介绍了基于概率故障神经网络(PNN)在变压器故障诊断中的应用。
针对概率神经网络(PNN)模型强大的非线性分类能力,PNN能够很好地对变压器故障进行分类;文章通过对PNN神经网络的结构和原理的分析,应用PNN概率神经网络方法对变压器故障进行诊断。
关键词:变压器;概率神经网络;故障诊断0 引言变压器是电力系统中的一个重要设备,由于它对电能的经济传输、灵活分配和安全使用具有重要意义,因而它的维护检修就显得极为重要,特别是通过对其进行故障诊断为其正常运行提供可靠的依据。
故障诊断技术是借助于现代测试、监控和计算机分析等手段,研究设备在运行中或相对静止条件下的状态信息,分析设备的技术状态,诊断其故障的性质和起因,并预测故障趋势,进而确定必要对策的一种方法。
从本质上讲,故障诊断就是模式识别问题。
神经网络的出现,为故障诊断问题提供了一种新的解决途径,特别是对于实际中难以解决的数学模型的复杂系统,神经网络更显示出其独特的作用。
目前,在故障诊断方面虽然BP网络应用得最为广泛,但其网络层数及每层神经元的个数不易确定,而且在训练过程中网络容易陷入局部最小点。
本文引入一种新的人工神经网络模型——概率神经网络,使用该网络进行变压器的故障诊断,可以获得令人满意的故障诊断率,并能有效地克服BP神经网络的缺点。
本文采用概率神经网络(probabilistic neural networks)对变压器故障进行诊断。
概率神经网络结构简单、训练简洁,利用概率神经网络模型的强大的非线性分类能力,将故障样本空间映射到故障模式空间中,可形成一个具有较强容错能力和结构自适应能力的诊断网络系统,从而提高故障诊断的准确率。
在实际应用中,尤其是在解决分类问题的应用中,它的优势在于用线性学习算法来完成非线性学习算法所做的工作,同时保持非线性算法的高精度等特性。
MATLAB 神经网络概率神经网络的分类预测--基于PNN的变压器故障诊断
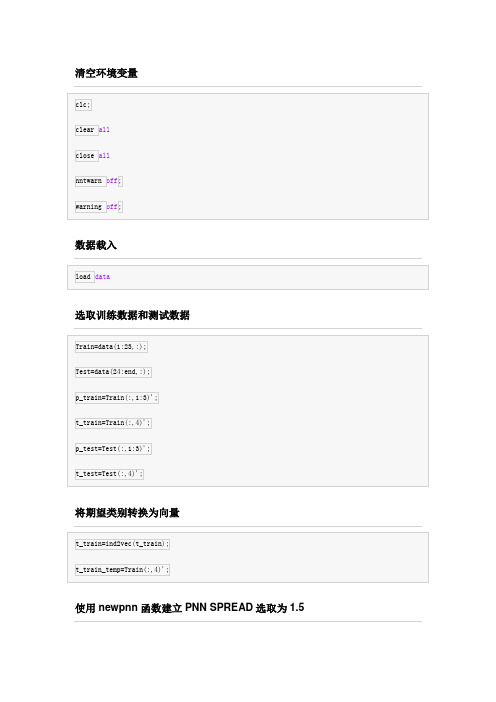
清空环境变量数据载入选取训练数据和测试数据将期望类别转换为向量使用newpnn函数建立PNN SPREAD选取为1.5net =Neural Networkname: 'Probabilistic Neural Network'efficiency: .cacheDelayedInputs, .flattenTime, .memoryReductionuserdata: (your custom info)dimensions:numInputs: 1numLayers: 2numOutputs: 1numInputDelays: 0numLayerDelays: 0numFeedbackDelays: 0numWeightElements: 207sampleTime: 1connections:biasConnect: [1; 0]inputConnect: [1; 0]layerConnect: [0 0; 1 0]outputConnect: [0 1]subobjects:inputs: {1x1 cell array of 1 input} layers: {2x1 cell array of 2 layers} outputs: {1x2 cell array of 1 output} biases: {2x1 cell array of 1 bias} inputWeights: {2x1 cell array of 1 weight} layerWeights: {2x2 cell array of 1 weight}functions:adaptFcn: (none)adaptParam: (none)derivFcn: 'defaultderiv'divideFcn: (none)divideParam: (none)divideMode: 'sample'initFcn: 'initlay'performFcn: 'mse'performParam: .regularization, .normalizationplotFcns: {}plotParams: {1x0 cell array of 0 params}trainFcn: (none)trainParam: (none)weight and bias values:IW: {2x1 cell} containing 1 input weight matrix LW: {2x2 cell} containing 1 layer weight matrix b: {2x1 cell} containing 1 bias vectormethods:adapt: Learn while in continuous useconfigure: Configure inputs & outputsgensim: Generate Simulink modelinit: Initialize weights & biasesperform: Calculate performancesim: Evaluate network outputs given inputstrain: Train network with examples view: View diagramunconfigure: Unconfigure inputs & outputs 训练数据回代查看网络的分类效果通过作图观察网络对训练数据分类效果网络预测未知数据效果。
两种截然不同的PNN

关于两个PNN杂七杂八关于PNN其实有两种说法,一种是概率神经网络(Probabilistic Neural Network),另一种是基于产品的神经网络Product-based Neural Network,所以在使用PNN的时候要格外注意,要不然你的领导你的导师都不知道你说的是哪一个,常用的是第一种PNN,概率神经网络,北京航空航天大学的王小川老师在其著作中提到的PNN也指代的是概率神经网络下面先说概率神经网络1 概率神经网络的原理概率神经网络(Probabilistic Neural Network)的网络结构类似于RBF神经网络,但不同的是,PNN是一个前向传播的网络,不需要反向传播优化参数。
这是因为PNN结合了贝叶斯决策,来判断测试样本的类别。
1.1关于贝叶斯决策1.2关于概率神经网络的结构其网络并不算很主流的3层,而是4层图中样本特征维度为3,由上图可知,PNN的网络结构分为四层:输入层,模式层、求和层、输出层。
假设训练样本为PNN各层的作用于相互之间关系描述如下:输入层:输入测试样本,节点个数等于样本的特征维度。
感觉根据实际含义输入层中节点个数的确定依据与理由也大都同BP中的相关说法相似。
模式层:计算测试样本与训练样本中的每一个样本的Gauss函数的取值,节点个数等于训练样本的个数。
机器学习模型中,超参数是在开始学习过程之前设置值的参数这个时候不得不设定一些合适的寻址算法,相关的能够使用的寻址算法其实有很多,可以是GA算法,可以是SA(模拟退火),可以是PSO(粒子群算法),可以是AFSA(人工鱼群算法),可以是萤火虫算法,相关套路很多。
求和层:求取相同类别测试样本对应的模式层节点输出之和,节点个数等于训练样本的类别个数。
训练样本的类别个数其实就是侧面反映的label的个数输出层:对上述求和层输出进行归一化处理求取测试样本对应不同类别的概率,根据概率大小判断测试样本的类别,节点个数为1。
神经网络及深度学习(包含matlab代码).pdf

神经网络及深度学习(包含matlab代码).pdf
神经网络可以使用中间层构建出多层抽象,正如在布尔电路中所做的那样。
如果进行视觉模式识别,那么第1 层的神经元可能学会识别边;第2 层的神经元可以在此基础上学会识别更加复杂的形状,例如三角形或矩形;第3 层将能够识别更加复杂的形状,以此类推。
有了这些多层抽象,深度神经网络似乎可以学习解决复杂的模式识别问题。
正如电路示例所体现的那样,理论研究表明深度神经网络本质上比浅层神经网络更强大。
《深入浅出神经网络与深度学习》PDF+代码分析
《深入浅出神经网络与深度学习》PDF中文,249页;PDF英文,292页;配套代码。
提取码: 6sgh
以技术原理为导向,辅以MNIST 手写数字识别项目示例,介绍神经网络架构、反向传播算法、过拟合解决方案、卷积神经网络等内容,以及如何利用这些知识改进深度学习项目。
学完后,将能够通过编写Python 代码来解决复杂的模式识别问题。
MATLAB程序代码--神经网络基础问题整理

MATLAB程序代码--神经网络基础问题整理所选问题及解答大部分来源于/bbs/资料大部分为江南一纪收集整理对其他参与整理的版友(不一一列举)及资料的原创者一并表示感谢因江南对神经网络的理解也不是很多错误之处难勉请谅解有什么问题可以来/bbs/的『人工神经网络专区』交流***************************************************************** 1神经网络的教材哪本比较经典神经网络原理Simon Haykin ? 叶世?史忠植译神经网络设计神经网络书籍神经网络模型及其matlab仿真程序设计周开利(对神经网络工具箱函数及里面神经网络工具箱的神经网络模型的网络对象及其属性做了详细的论述,后者在神经网络理论与matlab7实现那本书里面是没有的)神经网络理论与matlab7实现(这本书对初学这入门还是挺不错的,看过了,就对matlab神经网络工具箱有教好的了解)神经网络设计(我认为这是一本很好的书,讲理论不是很多,看过之后就会对神经网络的原理有更好的了解)神经网络结构设计的理论与方法(这本书对提高网络的泛化能力的一些方法做了讲述,并且书后有程序,对网络结构的设计应该是挺有帮助的)摘自给初学matlab神经网络的一点建议/bbs/read.php?tid=1111&keyword=2 神经网络理论的发展与前沿问题神经网络理论的发展与前沿问题刘永?摘要系统地论述了神经网络理论发展的历史和现状,在此基础上,对其主要发展趋向和所涉及的前沿问题进行了阐述.文中还作了一定的评论,并提出了新的观点.关键词神经网络理论,神经计算,进化计算,基于神经科学和数学的研?查看原文/bbs/read.php?tid=5374&keyword=%C9%F1%BE%AD%CD%F8%C2%E73 神经网络的权值和阈值分别是个什么概念??权值和阈值是神经元之间的连接,将数据输入计算出一个输出,然后与实际输出比较,误差反传,不断调整权值和阈值假如p1=[1 1 -1]';p2=[1 -1 -1]';属于不同的类须设计分类器将他们分开这里用单层神经元感知器初始权值w=[0.2 0.2 0.3] b=-0.3输出a1 a2a1=hardlims(w*p1+b)a2=hardlims(w*p2+b)如果不能分开,还须不断调整w,b这里说明一下权值w 阈值b 而已简单地说,阈值也可以看作一维权值,只不过它所对应的那一维样本永远是-1(也有的书上说是1),这样就把输入样本增加了一维,更有利于解决问题./bbs/read.php?tid=6078&keyword=%C9%F1%BE%AD %CD%F8%C2%E74 神经网络归一化看了研学和ai创业研发俱乐部神经网络版及振动论坛部分帖子内容,对归一化做一下整理,冒昧引用了一些他人的观点,有的未列出其名,请谅解-------------------------------------------------------------------------------------------------------关于神经网络归一化方法的整理由于采集的各数据单位不一致,因而须对数据进行[-1,1]归一化处理,归一化方法主要有如下几种,供大家参考:(by james)1、线性函数转换,表达式如下:y=(x-MinValue)/(MaxValue-MinValue)说明:x、y分别为转换前、后的值,MaxValue、MinValue分别为样本的最大值和最小值。
基于概率神经网络(PNN)的故障诊断

基于概率神经网络(PNN)的故障诊断概率神经网络PNN是一种结构简单、训练简洁、应用相当广泛的人工神经网络,在实际应用中,尤其是在解决分类问题的应用中,它的优势在于线性学习算法来完成以往非线性学习算法所做的工作,同时又能保持非线性算法的高精度等特性。
基于概率神经网络的故障诊断方法实质上是利用概率神经网络模型的强大的非线性分类能力,将故障样本空间映射到故障模式空间中,从而形成一个具有较强容错能力和结构自适应能力的诊断网络系统。
1 概述概率神经网络是一种可以用于模式分类的神经网络,其实只是基于贝叶斯最小风险准则发展而来的一种并行算法,目前已经在雷达、心电图仪等电子设备中获得了广泛的应用。
PNN与BP网络相比较,其主要优点为:快速训练,其训练时间仅仅大于读取数据的时间。
无论分类问题多么复杂,只要有足够多的训练数据,就可以保证获得贝叶斯准则下的最优解。
允许增加或减少训练数据而无需重新进行长时间的训练。
PNN层次模型是Specht根据贝叶斯分类规则与Parzen的概率密度函数提出的。
在进行故障诊断的过程中,求和层对模式层中间同一模式的输出求和,并乘以代价因子;决策层则选择求和层中输出最大者对应的故障模式为诊断结果。
当故障样本的数量增加时,模式层的神经元将随之增加。
而当故障模式多余两种时,则求和层神经元将增加。
所以,随着故障经验知识的积累,概率神经网络可以不断横向扩展,故障诊断的能力也将不断提高。
2基于PNN的故障诊断1.问题描述发动机运行过程中,油路和气路出现故障是最多的。
由于发动机结构复杂,很难分清故障产生的原因,所以接下来尝试利用PNN来实现对发动机的故障诊断。
在发动机运行中常选用的6种特征参数:AI、MA、DI、MD、TR和PR。
其中,AI为最大加速度指标;MA为平均加速度指标;DI为最大减速度指标;MD为平均减速度指标;TR为扭矩谐波分量比;PR为燃爆时的上升速度。
进行诊断时,首先要提取有关的特征参数,然后利用PNN进行诊断,诊断模型如图1所示。
基于Matlab的概率神经网络的实现及应用

Ke rs Poa iscN ua N tok P N) Ma a ;c s ctn f i e i ywod :rbblt erl ew r( N ; t b l i ao ; ag f ii l s i a f i t u le
0 引 言
概 率 神 经 网 络 ( rbblt N ua N tok Poaisc erl e r, ii w
苏 亮, 宋绪丁7 06 ) 陕 104 摘要 : 介绍概率神经 网络 ( N 的模型和基 本算 法, P N) 以及 利用 Maa t b神经 网络 工具箱设 计 P N网络 的方法和 步骤 , l N 实现 对网络的设计、 训练 、 仿真。针 对某水泥泵车臂 架细部 焊接 结构的疲劳寿命 实验数据 , 应用 P N的 分类功能对 实验数 据 N
I p e nt to n m l me a i n a d App i a i n o o biitc Ne a t r s d o a l b lc to fPr ba lsi ur lNe wo k Ba e n M ta
S in U L a g,S NG Xu dn O —ig
领域 中被广 泛应用 。
Ma a l f b是 由美 国 Mah rs公 司开 发 的集 数 值 t Wok
本 文将 以 Maa70 1 发 环境 , 绍 神 经 网络 l fb .. 开 介 工具 箱 及 其 相 关 函数 , 述 利 用 Maa 经 网络 工 论 db神 具箱 实现概 率神 经 网络 模型 的建立 步骤及 其应 用 。
1 概 率神 经 网络 的 模 型
进行 训练仿真处理 , 得到对臂 架细部结构疲 劳寿命的预测分类 结果 , 验证 了此方法的可靠性。 关键 词 : 概率神 经 网络( N ;M d b 分 类;疲劳寿命 P N) a a ;
【国家自然科学基金】_概率神经网络(pnn)_基金支持热词逐年推荐_【万方软件创新助手】_20140801

推荐指数 8 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
2008年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
科研热词 推荐指数 概率神经网络 6 故障诊断 2 非负矩阵分解 1 邻接谱 1 遥感傅里叶变换红外光谱 1 语音识别 1 蒙特卡罗分析 1 自适应概率神经网络(apnn) 1 自组织神经网络 1 自组织特征映射网络 1 能量特征向量 1 耳语音 1 粗集 1 神经网络 1 特征提取 1 模糊.仿射联合不变矩 1 模式识别 1 桥梁benchmark模型 1 易挥发性有机化合物 1 损伤识别 1 损伤模式识别 1 平滑因子 1 属性约简 1 容羞电路 1 容差 1 定性分析 1 多尺度 1 图谱 1 图像分类 1 反向传播人工神经网络 1 卫星云图 1 分割 1 全局k-均值算法 1 交通标志 1 云分类 1 主成分分析法 1 sar图像 1 mfcc参数 1 matlab 1
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
科研热词 概率神经网络 电能质量 扰动 分类 s变换 高光谱 辅助驾驶系统 脑-机接口 脉冲噪声 老油田 粗集 粒子群优化 相对小波能量 独立分量分析 特征提取 浅层气藏 正演 模式识别 概率神经网络(pnn) 核主元分析(kpca) 数据融合 故障辨识 损伤识别 快速傅里叶变换 径向基 属性约简 局部特征检测模板 多属性分析 多尺度信息融合 图像处理 噪声检测 去噪 关联故障 储层 交通标志识别 中值滤波 j-mean8算法
PNN神经网络

概率神经网络(PNN)一、引言概率神经网络它主要用于模式分类,是径向基网络的一个分支,是基于贝叶斯策略前馈神经网络。
它具有如下优点:学习过程简单、训练速度快;分类更准确,容错性好等。
从本质上说,它属于一种有监督的网络分类器,基于贝叶斯最小风险准则。
二、PNN结构该神经网络与GRNN类似由输入层、隐含层和输出层组成。
输入层将变量传递给隐含层,但不进行计算,因此该层只起传输数据的作用。
隐含层中的神经元个数等于训练集样本个数,该层的权值函数为欧式距离函数,用||dist||表示,其作用是计算出网络输入与输入层权重IW1,1之间的距离及阈值,阈值用b1表示。
隐含层传递函数为径向基函数,采用高斯函数作为网络的传递函数。
输出层为竞争输出,各神经元依据Parzen方法来球和估计各类的概率,从而竞争输入模式的响应机会,最后仅有一个神经元竞争获胜,这样获胜的神经元即表示对输入变量的分类。
在数学上,PNN结构的特性,可在高维数据空间中解决在低维空间不易解决的问题。
也因此其隐含神经元较多,但隐含层空间的维数和网络性能有着直接的关系,维数越高,网络的逼近精度越高,但带来的负面后果是网络复杂度也随之提高。
三、算法步骤(1)确定隐含层神经元径向基函数中心设训练集样本输入矩阵P和输出矩阵T111211112121222212221212P=,T=m m m m n n nm k k km p p p t t t p p p t t t p p p t t t ⎡⎤⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦⎣⎦ 其中,ij p 表示第j 个训练样本的第i 个输入变量;ij t 表示第j 个训练样本的第i个输出变量;n 为输入变量的维度;k 为输出变量的维度;m 为训练集样本数。
隐含层的每个神经元对应一个训练样本,即m 个隐含神经元对应的径向基函数中心C P '=(2)确定隐含层神经元阈值m 个隐含神经元对应的阈值为:111121[,,,]m b b b b =111210.8326m b b b spread==== spread 为径向基函数的扩展速度。
matlab中pnn算法原理

一、概述Matlab中的PNN算法,即概率神经网络(Probabilistic Neural Network),是一种基于概率理论的神经网络模型。
它具有较高的模式识别能力,在模式分类、函数逼近和数据建模等领域有着广泛的应用。
PNN算法通过统计学习方法,采用高效的概率密度函数估计技术,能够对输入数据进行快速分类和预测,是一种十分有效的分类器。
二、PNN算法原理1. Parzen 窗估计PNN算法的核心思想是采用Parzen 窗估计的方法,对概率密度函数进行估计。
Parzen 窗估计是一种非参数密度估计方法,通过对每个训练样本点周围的一个窗口进行加权求和,来估计概率密度函数。
这种方法不需要事先对密度函数的形状作出假设,能够较为准确地估计概率密度,具有较好的拟合性能。
2. 概率密度函数PNN算法中的隐藏层神经元使用径向基函数(RBF)作为激活函数,每个神经元对应一个样本类别,其输出对应了输入数据与该类别的概率密度。
PNN通过在每个样本点周围构建一个窗口,利用Parzen 窗估计方法得到每个类别对应的概率密度函数。
当有新的输入数据时,PNN算法计算输入数据与每个类别的概率密度,根据最大概率进行分类决策。
3. 模式分类PNN算法的模式分类过程包括训练和测试两个阶段。
在训练阶段,PNN通过对训练数据进行概率密度函数的估计,构建PNN模型。
在测试阶段,PNN算法通过计算输入数据与各类别的概率密度,选择概率密度最大的类别作为输入数据的类别。
三、PNN算法实现1. 训练阶段(1)输入训练数据将训练数据输入到PNN算法中。
训练数据应包括输入特征和对应的类别标签。
(2)估计概率密度函数PNN算法通过Parzen 窗估计方法,对每个类别的概率密度函数进行估计。
在训练数据上,对每个类别的样本点构建窗口,利用Parzen 窗估计方法计算概率密度函数。
2. 测试阶段(1)输入测试数据对于新的输入数据,将其输入到PNN算法中。
概率神经网络

概率神经网络概述概率神经网络(Probabilistic Neural Network,PNN)就是由D 、 F 、 Specht 在1990年提出得。
主要思想就是贝叶斯决策规则,即错误分类得期望风险最小,在多维输入空间内分离决策空间。
它就是一种基于统计原理得人工神经网络,它就是以Parazen 窗口函数为激活函数得一种前馈网络模型。
PNN 吸收了径向基神经网络与经典得概率密度估计原理得优点,与传统得前馈神经网络相比,在模式分类方面尤其具有较为显著得优势。
1、1 概率神经网络分类器得理论推导 由贝叶斯决策理论:ww w ijix then i j x p x p if ∈≠∀>→→→ , )|()|((1-1)其中)|()()|(w w w iiix p p x p →→=。
一般情况下,类得概率密度函数)|(→x p w i 就是未知得,用高斯核得Parzen 估计如下:)2exp(11)|(22122σσπ→→-∑-==→x x Nw ikN ik lliix p(1-2)其中,→x ik 就是属于第w i 类得第k 个训练样本,l 就是样本向量得维数,σ就是平滑参数,N i 就是第w i 类得训练样本总数。
去掉共有得元素,判别函数可简化为:∑-=→→→-=Nikik iiix x Nw g p x 122)2exp()()(σ(1-3)1、2 概率神经元网络得结构模型PNN 得结构以及各层得输入输出关系量如图1所示,共由四层组成,当进行并行处理时,能有效地进行上式得计算。
图1 概率神经网络结构如图1所示,PNN 网络由四部分组成:输入层、样本层、求与层与竞争层。
PNN 得工作过程:首先将输入向量→x 输入到输入层,在输入层中,网络计算输入向量与训练样本向量之间得差值|-|→→x ikx 得大小代表着两个向量之间得距离,所得得向量由输入层输出,该向量反映了向量间得接近程度;接着,输入层得输出向量→→xikx -送入到样本层中,样本层节点得数目等于训练样本数目得总与,∑===M i i iNN 1,其中M 就是类得总数。
【完整注释MATLAB版】PNN神经网络分类程序代码-带数据可运行

%% 清空环境变量clearclose allclcwarning off%% 数据载入data=xlsread('数据.xlsx');data=data(randperm(size(data,1)),:); %此行代码用于打乱原始样本,使训练集测试集随机被抽取,有助于更新预测结果,选取合适的数据集划分方式。
可以删掉这行代码,不影响程序。
%% 选取训练数据和测试数据input=data(:,1:end-1);output=data(:,end);m=100; %训练的样本数目input_train=input(1:m,:)';output_train=output(1:m)';input_test=input(m+1:end,:)';output_test=output(m+1:end)';%% 数据归一化%输入需要归一化|输出不须归一化需要转成向量格式[inputn,inputps]=mapminmax(input_train);%归一化到[-1,1]之间,inputps用来作下一次同样的归一化inputn_test=mapminmax('apply',input_test,inputps);% 对测试样本数据进行归一化%类别转换为向量T=ind2vec(output_train);%% 使用newpnn函数建立PNNSpread=0.8;net=newpnn(inputn,T,Spread);%% 训练数据回代查看网络的分类效果Y=sim(net,input_train);%网络输出向量转换为类别Yc=vec2ind(Y);Arightratio=sum(output_train==Yc)/length(output_train); %计算预测的确率%% 网络测试Y2=sim(net,inputn_test);Y2c=vec2ind(Y2);AArightratio=sum(output_test==Y2c)/length(output_test); %计算预测的确率%% 作图%网络对训练数据分类效果figurestem(1:length(Yc),Yc,'bo')hold onstem(1:length(Yc),output_train,'r*')title('PNN 网络训练后的效果')legend('预测类别','真实类别')xlabel('样本编号')ylabel('分类结果')set(gca,'fontsize',12)figureH=Yc-output_train;stem(H)title('PNN 网络训练后的误差图')xlabel('样本编号')ylabel('误差')set(gca,'fontsize',12)%网络对测试数据分类效果figurestem(1:length(Y2c),Y2c,'b^')hold onstem(1:length(Y2c),output_test,'r*')title({'PNN 网络的预测效果',['测试集正确率= ',num2str(rightratio*100),' %']}) xlabel('预测样本编号')ylabel('分类结果')legend('预测类别','真实类别')set(gca,'fontsize',12)%输出准确率disp('---------------------------测试准确率-------------------------')disp(rightratio)%% 算法咨询% 注可以删掉以下命令不影响本程序consult()将表格另存为“数据.xlsx”,与主程序同一文件夹。
pnn设计

for i=1:29,text(p(1,i),p(2,i),p(3,i),sprintf(' %g',Ac(i))),end
%以图形方式输出训练结果
hold off
f=Ac';
index1=find(f==1);
index2=find(f==2);
index3=find(f==3);
index4=find(f==4);
line(p(1,index1),p(2,index1),p(3,index1),'linestyle','none','marker','*','color','g');
line(p(1,index2),p(2,index2),p(3,index2),'linestyle','none','marker','*','color','r');
整理ppt
14
仿真结果
当训练数据为29组,测试数据为30组时 的仿真图:
Spread=30时的分类结果
整理ppt
15
仿真结果
当训练数据为29组,测试数据为30组时的 仿真图:
Spread=150时的分类结果
整理ppt
16
仿真结果
当训练数据为29组,测试数据为30组时 MATLAB仿真结果:
第四层是竞争层, 它接收从求和层输出的各类概 率密函数, 概率密度最大的那个神经元输出为1 , 即所对应的那一类即为整理待ppt 识别的样本模式类别, 5
PNN网络的优点
训练速度快,其训练时间仅仅略大于读取数 据的时间;
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1 p( x | wi ) Ni
Ni
k 1
1 (2 ) l
l 2
2 x xik exp( ) 2 2
(1-2)
其中, xik 是属于第 wi 类的第 k 个训练样本, l 是样本向量的维数, 是平滑参数,N i 是第 wi 类的训练样本总数。 去掉共有元素,判别函数可简化为:
d
1k
E E E
12 22
p2
2m E pm
1m
E E
(2-4) 第四步:样本层径向基函数的神经元被激活。学习样本与待识别样本被归一化后,通常 取标准差 =0.1的高斯型函数。激活后得到初始概率矩阵:
E11 e 2 2 E 21 P e 2 2 E p1 2 e 2
m
P
1l
S12 S 22 S p2
S1c S 2c S pc
(2-6) 在上式中, S 代表的意思是:将要被识别的样本中,第i个样本属于第j类的初始概率
ij
和。 第六步:计算概率 probij ,即第i个样本属于第j类的概率。
prob
ij
S S
ij c l 1
2 mk
C
mn
B 11 1
m 1
1 n
X
mn
=
1 2n 2 xmn Mm
1n
x11 M1 x21 M2 xm1 Mm
x M x M
12 22
1
2
m
x M x M
x M
m1
C11 C 21 C m1
1n
X X
(2-1)
从样本的矩阵如式(2-1)中可以看出,该矩阵的学习样本有m个,每一个样本的特征 属性有n个。在求归一化因子之前,必须先计算 B 矩阵:
T
B
然后计算:
T
1
n
1
2 1k n
...
2 2k
1
n
x
k 1
x
k 1
x
k 1
p2
2m P pm
1m
P P
(2-5)
第五步:假设样本有m个,那么一共可以分为c类,并且各类样本的数目相同,设为k, 则可以在网络的求和层求得各个样本属于各类的初始概率和:
k P1l 1 lk P2l S l 1 k P pl l 1
d 11 d D 21 d p1
d d d
12 22
p2
2n d pn
1n
d d
(2-3)
计算欧式距离:就是需要识别的样本向量,样本层中各个网络节点的中心向量,这两个 向量相应量之间的距离:
E
Gao Fei, Zhao Zhenzhen, Song Yan Abstract: The basic structure model of probabilistic neural network (PNN) is introduced in this paper, as well as the function of the model, the basic learning algorithm. The application of PNN in the field of Vehicle License Plate Recognition is interpreted in details. At the end of the paper,genetic algorithm( GA ) and its application in optimizing the PNN model are mainly focused on. Keywords: PNN; Parzen window estimate method; Genetic Algorithm
{ 读取号码颜色样本;
记录号码颜色样本的颜色,并统计总数 countHM; 读取背景颜色样本; 记录背景颜色样本的颜色,并统计总数 countBJ; w = (long double **)malloc((countBJ+countHM)*sizeof(long double *)); a = (int **)calloc((countBJ+countHM),sizeof(int *)); for(i=0; i<(countBJ+countHM); i++) { w[i]=(long double *)malloc(3*sizeof(long double)); //RBG 三个值 a[i]=(int *)calloc(2,sizeof(int)); } } PNN 神经网络训练伪代码: { FOR 记录到的每一种颜色也就是每个模式层单元 j Xr,b,g = Xr,b,g/ sqrt(Xr*Xr+Xb*Xb+Xg*Xg); //这里归一化时须采用这种方式 w[j][Xr,b,g]= Xr,b,g; IF 颜色属于车牌号码 a[j][1]=1; IF 颜色属于车牌背景 a[j][0]=1; } PNN 神经网络分类算法为代码: { FOR 每一行
E12 e 2 E 22 e 2 2 E p2 e 2 2
2
E1m e 2 2 P11 E 2m P 21 e 2 2 E pm P p1 e 2 2
P P P
12 22
2.基本学习算法
以下几步构成了PNN神经网络的算法: 第一步:首先必须对输入矩阵进行归一化处理,这样可以减小误差,避免较小的值被较 大的值“吃掉”。设原始输入矩阵为:
X 11 X X 21 ... X m1
X X X
12 22
...
m2
... ... ... ...
2n ... X mn
x x ik p ( wi ) N i g i ( x) exp( 2 2 N i k 1
1.2 概率神经元网络的结构模型
2
)
(1-3)
PNN 的结构以及各层的输入输出关系量如图 1 所示,共由四层组成,当进行并行处理 时,能有效地进行上式的计算。
图 1 概率神经网络结构(以3个类别为例) 如图1-1所示,PNN 网络由四部分组成:输入层、样本层、求和层和竞争层。PNN 的工 作过程:首先将输入向量 x 输入到输入层,在输入层中,网络计算输入向量与训练样本向量 之间的差值
2k l k 1 2k l k 1 2k
P
1l
P
2l
l k 1
P
pl
S11 l m k 1 m S 21 P 2l l m k 1 m S p1 P pl l m k 1
主要工作是:先判断哪些类别与输入向量有关,再将相关度高的类别集中起来,样本层的输 出值就代表相识度;然后,将样本层的输出值送入到求和层,求和层的结点个数是 M,每 个结点对应一个类, 通过求和层的竞争传递函数进行判决; 最后, 判决的结果由竞争层输出, 输出结果中只有一个1,其余结果都是0,概率值最大的那一类输出结果为1。
x xik x x ik , 差值绝对值 的大小代表这两个向量之间的距离, 所得的向量由
输入层输出,该向量反映了向量间的接近程度;接着,输入层的输出向量
iM
x x ik 送入到样本层中,
样本层结点的数目等于训练样本数目的总和, N
N
i 1
i
,其中 M 是类的总数。样本层的
n
d
k 1 n
1k
c1k c1k c1k
2
n
d
k 1 n
1k
c2 k c2 k c2 k
2
d
k 1 n
2
2k
d
k 1 n
2
2k
2
d
k 1
pk
d
k 1
2 pk
2 c mk k 1 E11 n 2 c mk E 21 d 2k k 1 n E p1 2 cmk d pk k 1 n
概率神经网络
摘 要:本文介绍了概率神经网络(PNN)的结构模型、功能、基本学习算法。基于 PNN 的模式分类功能, 介绍了它在车牌识别方面的具体应用。 论文的最后介绍了遗传算法以及用 遗传算法对 PNN 的优化。 关键词:概率神经网络;Parzen 窗估计法;遗传算法
Probabilistic Neural Networks
号码与背景的程序,也就是车牌号图像的二值化。本文仅用这个程序作为 PNN 神经网络运 用的简单例子,因此对图像进行些处理以简化编程,采用8位 BMP 带调色板的图片格式存 储。
图4-1
车牌图像
人眼能够识别这个车牌号码是由于车牌的号码白色和它周围的背景蓝色有着鲜明的不 同。对于要完成的程序同样也可以运用颜色差来完成识别。计算机显示 bmp 图片时采用的 是 RBG 的值来描绘每一点的像素颜色,虽然看到图像车牌背景都是蓝色,但是如果放大来 看蓝色并不完全相同而且还有夹杂着些其他颜色, 同样车牌号也并非全部白色。 分析到这里 目标就清楚了,运用 PNN 神经网络采集图片中每个像素点的颜色 RBG 值,将接近蓝色或 者背景中出现的其他颜色分为 A 类,表示背景色;将接近白色的颜色分为 B 类,表示车牌 号色。再用0、1这两个数值来表示 A 类、B 类,重新设置图片中像素的颜色实现了车牌号 图像的二值化。 程序的流程可分为三步:第一步,选取背景色和号码色的样本图片,收集它们各自的颜 色样本数据;第二步,运用收集的颜色数据训练 PNN 神经网络;第三步,将需要识别的车 牌图片中每个像素的颜色数据输入 PNN 神经网络完成分类,然后重置图片颜色数据完成二 值化。 PNN 神经网络的设计:将 RBG 三个值作为输入数据,样本层里的每个神经元代表一种 样本颜色, 竞争层的两个单元分别代表背景色类和号码色类。 输入层和样本层之间的权重存 储在二维指针 **w 中,样本层到求和层的关系存储在**a 中,**a 中的值只能是0和1,每 个样本层里的神经元对应的类别有且仅有一条边值为1,用来说明该样本层神经元存储的样 本颜色属于该边连接的类别。 数据收集及神经网络结构实现的伪代码如下: