机器学习十大算法的每个算法的核心思想、工作原理、适用情况及优缺点
机器学习常见算法优缺点汇总
机器学习的算法很多。
很多时候困惑人们都是,很多算法是一类算法,而有些算法又是从其他算法中延伸出来的。
这里,我们从两个方面来给大家介绍,第一个方面是学习的方式,第二个方面是算法的类似性。
学习方式根据数据类型的不同,对一个问题的建模有不同的方式。
在机器学习或者人工智能领域,人们首先会考虑算法的学习方式。
在机器学习领域,有几种主要的学习方式。
将算法按照学习方式分类是一个不错的想法,这样可以让人们在建模和算法选择的时候考虑能根据输入数据来选择最合适的算法来获得最好的结果。
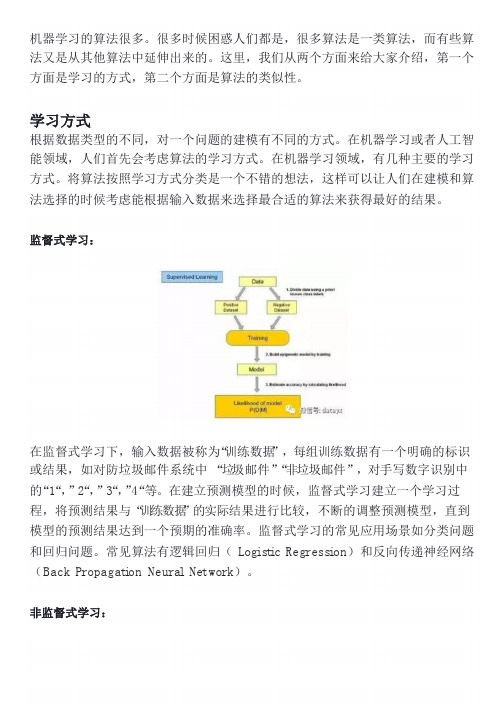
监督式学习:在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。
在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。
监督式学习的常见应用场景如分类问题和回归问题。
常见算法有逻辑回归( Log is t ic Regress i on)和反向传递神经网络(Back Propagat i on Neura l Network)。
非监督式学习:在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。
常见的应用场景包括关联规则的学习以及聚类等。
常见算法包括Apr ior i 算法以及k-Means算法。
半监督式学习:在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。
应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。
如图论推理算法( Graph In ference)或者拉普拉斯支持向量机( Laplac ian S V M.)等。
机器学习算法解析

机器学习算法解析机器学习算法是指一类可以从数据中学习模型并进行预测和决策的算法。
这些算法基于统计学原理和数据模式识别,通过训练数据集来对未知数据进行预测和分类。
以下是对几种常见机器学习算法的解析。
一、线性回归算法线性回归算法是一种最简单、最经典的机器学习算法。
它的目标是找到一条直线来最好地拟合数据点。
算法基于输入特征与输出目标之间的线性关系,通过最小二乘法来估计回归模型的参数,从而进行预测和分析。
二、决策树算法决策树算法是一种基于树形结构的机器学习算法。
它通过一系列的判断条件来对输入数据进行分类和预测。
决策树算法的构建过程中,根据特征的重要性和不纯度来选择最佳的分裂点,从而构建出一棵具有最好分类性能的决策树模型。
三、支持向量机算法支持向量机算法是一种用于分类和回归的机器学习算法。
它通过构建一个或多个超平面来实现对数据的二元分类或多元分类。
支持向量机算法的关键思想是找到能够将不同类别的样本分隔开的最优超平面。
在构建模型的过程中,支持向量机算法会根据样本点与超平面的距离来选择最佳的分割点,从而实现对未知数据的分类。
四、朴素贝叶斯算法朴素贝叶斯算法是一种基于贝叶斯定理的机器学习算法。
它通过统计特征之间的条件概率来对数据进行分类。
朴素贝叶斯算法的核心假设是所有特征之间相互独立。
在模型的训练过程中,朴素贝叶斯算法会根据训练数据集来估计不同类别的联合概率分布,从而实现对未知数据的分类。
五、聚类算法聚类算法是一种无监督学习的机器学习算法。
它通过将相似的数据点聚集在一起来实现对数据的分组和分类。
聚类算法的目标是找到数据之间的内在模式和结构,从而对数据进行分组和簇的形成。
常见的聚类算法有K均值聚类算法、层次聚类算法等。
六、神经网络算法神经网络算法是一种模拟人脑神经网络结构和功能的机器学习算法。
它通过层层连接的神经元和反向传播算法来学习和处理数据。
神经网络算法的核心思想是通过不断调整神经元之间的连接权重来实现对数据的学习和判断。
机器学习算法的原理及应用分析

机器学习算法的原理及应用分析机器学习一直是人工智能研究领域中的热门话题。
随着互联网的发展和智能设备的普及,机器学习的应用范围越来越广泛。
机器学习算法是机器学习的关键组成部分。
本文将介绍机器学习算法的原理和应用分析。
一、机器学习算法的原理机器学习算法指的是用于从数据中提取模式和规律的计算机程序,其基本原理是通过将输入数据与所需输出数据进行比对,找到相应的规律和模式。
机器学习算法主要分为三种类型:监督学习、无监督学习和强化学习。
1.监督学习监督学习是指通过给算法提供已知数据来进行训练,从而让算法能够进行推断和预测。
常见的监督学习算法有决策树、朴素贝叶斯、支持向量机和神经网络等。
决策树是一种基于树状结构进行决策的算法,它的每个节点都表示一个属性,每个叶子节点都表示一个分类。
通过将样本集递归地进行划分,最终得到一个决策树。
朴素贝叶斯算法是一种基于贝叶斯定理和特征条件独立假设的算法。
它通过统计每个特征的类别和条件概率来计算分类概率。
支持向量机是一种基于间隔最大化的分类算法。
它通过寻找一个最优的超平面将数据进行分类。
神经网络算法是一种模仿人类神经系统进行学习和推断的算法。
它通过一系列神经元的相互连接来实现数据的分类和预测。
2.无监督学习无监督学习是指在没有给定数据的类别标签的情况下,通过对数据的统计特征进行分析,来获取数据内在的结构和模式。
常见的无监督学习算法有聚类和降维等。
聚类算法是一种基于相似度度量的算法,它将数据集划分为若干个簇,每个簇内的数据相似度较高,而簇间的相似度较低。
降维算法是一种将高维数据投影到低维空间的算法,它可以帮助我们在不损失重要信息的前提下,降低计算复杂度。
3.强化学习强化学习是一种通过试错的方法来学习和优化策略的机器学习算法。
它通常工作在环境和智能体的交互中,智能体在环境中采取不同的动作,从而获得奖励或惩罚。
常见的强化学习算法有Q-learning和Deep Q-network等。
机器学习的常见算法

机器学习的常见算法机器学习(Machine Learning)是人工智能领域中的一个重要分支,其主要研究如何让机器通过经验不断提升自身的性能,进而自主地完成各种任务。
在这个领域中,算法是最为重要的一环,不同的算法可以用于不同的问题,选择合适的算法可以提高机器学习的准确率和效率。
现在我们来讨论一下机器学习中常见的算法。
一、监督学习算法监督学习算法是指从带有标记的数据(即已知结果)中学习出一个函数,然后将其应用于未知数据上,以预测其结果。
其中最常见的算法包括:1.1 k-NN算法k-NN算法是一种基于实例的学习方法,其核心思想是通过“找到最相似的事物”来进行预测。
具体来说,它通过计算待预测样本与所有已知样本之间的距离(通常使用欧氏距离或曼哈顿距离等),并选取k个距离最近的已知样本作为待预测样本的“邻居”,再利用这k个邻居的标记结果来预测待预测样本的标记。
1.2 决策树算法决策树算法是一种基于树形结构的分类器,其构建过程类似于问答游戏。
具体来说,我们从根节点开始,选择一些特征进行问题的提问,然后根据回答将样本逐步分类,最终得到一个叶节点作为预测结果。
1.3 朴素贝叶斯算法朴素贝叶斯算法是一种基于概率统计的分类方法,其核心思想是利用贝叶斯公式计算出待预测样本属于各个类别的概率,然后选取最大概率的类别作为预测结果。
与其他算法相比,它在训练数据较少时表现优秀,在文本分类、垃圾邮件过滤等领域中得到了广泛应用。
二、无监督学习算法无监督学习算法是指从不带标记的数据中学习出一种概括性的结构或特征,以更好地理解数据。
其中常见的算法包括:2.1 聚类算法聚类算法是一种将数据点分组的方法,其本质是通过相似性度量将相似的数据点划分到同一组中,从而得到一些潜在的类别。
K-Means算法是聚类算法中最常用的一种方法,其步骤包括初始化聚类中心、计算每个数据点到聚类中心的距离并分配到最近的聚类中心、更新聚类中心。
2.2 主成分分析算法(PCA)主成分分析算法是一种在多元统计分析中经常使用的技术,其目的是将高维数据降到低维(通常是二维或三维)并保留尽可能多的信息。
机器学习中使用的最佳算法

机器学习中使用的最佳算法机器学习是当下非常火热的技术领域,而算法作为机器学习的核心,能够直接影响到机器学习的效果。
在机器学习中,有许多不同的算法可以使用,但是哪一种算法才是最佳的呢?本文将对机器学习中使用的最佳算法进行探讨。
一、什么是最佳算法?在机器学习中,最佳算法是指能够最大限度地提高模型的准确性和效率的算法。
也就是说,最佳算法能够让机器学习的模型在预测新数据时具有最高的精确性和最快的速度。
这需要考虑算法的复杂度,可解释性,适用场景,数据规模和模型精度等因素。
二、机器学习中的最佳算法1.决策树算法决策树是一种非常常见的机器学习算法,能够处理分类和回归问题。
它的原理是将数据集划分成不同的子集,直到所有的数据被正确分类为止。
决策树算法具有可解释性,能够生成易于理解的规则,并且可以处理多种不同类型的数据。
但是,它容易出现过拟合现象,并且不能很好地处理连续变量。
2.支持向量机算法支持向量机算法是一种二元分类算法,旨在找到一个将数据集划分为两个类别的超平面。
它具有很好的适应性和较高的精度,能够处理高维数据。
但是,SVM算法对于噪声和离群值比较敏感。
3.随机森林算法随机森林算法是一种集成学习算法,将多个决策树组合在一起以提高准确性。
它具有更好的泛化能力和可靠性,并且能够有效地处理缺失或多余的特征。
但是,随机森林在处理具有大量数据时性能较差。
4.神经网络算法神经网络算法是一种模仿人类大脑的算法,可以用于分类和回归问题。
它能够从大量数据中提取特征,并且能够处理连续变量。
但是,神经网络算法非常复杂,训练时间很长,并且很难解释。
5.K近邻算法K近邻算法是一种基于相似度度量的分类方法,它的原理是将一个新数据点与其最接近的K个数据点取平均值。
它具有简单的实现和较高的精度,对于分类不平衡的问题也有很好的表现。
但是,K近邻算法需要处理大量的距离计算和内存存储,时间复杂度较高。
三、如何选择最佳算法?选择最佳算法需要考虑多个因素,包括数据的大小,目标变量的类型,数据类型,算法的可解释性,算法的参数和模型的计算效率等。
11种最常见的机器学习算法简介

11种最常见的机器学习算法简介常见机器学习算法的摘要。
> Photo by Santiago Lacarta on Unsplash近年来,由于对技术的高需求和进步,机器学习的普及已大大增加。
机器学习可以从数据中创造价值的潜力使其吸引了许多不同行业的企业。
大多数机器学习产品都是使用现成的机器学习算法进行设计和实现的,并且需要进行一些调整和细微更改。
机器学习算法种类繁多,可分为三大类:· 监督学习算法在给定一组观察值的情况下,对特征(独立变量)和标签(目标)之间的关系进行建模。
然后,使用该模型使用特征预测新观测的标签。
根据目标变量的特性,它可以是分类(离散目标变量)或回归(连续目标变量)任务。
· 无监督学习算法试图在未标记的数据中找到结构。
· 强化学习基于行动奖励原则。
代理通过迭代计算其行为的报酬来学习达到目标。
在本文中,我将介绍前两类中最常见的算法。
注意:尽管深度学习是机器学习的一个子领域,但我不会在本文中包含任何深度学习算法。
我认为深度学习算法由于复杂性和动态性而应分开讨论。
此外,我会犹豫地使这篇文章过长,使读者感到厌烦。
开始吧。
1.线性回归线性回归是一种有监督的学习算法,它通过对数据拟合线性方程,尝试对连续目标变量和一个或多个自变量之间的关系进行建模。
为了使线性回归成为一个不错的选择,自变量和目标变量之间必须存在线性关系。
有许多工具可以探索变量之间的关系,例如散点图和相关矩阵。
例如,下面的散点图显示了自变量(x轴)和因变量(y 轴)之间的正相关。
随着一个增加,另一个也增加。
线性回归模型试图使回归线适合最能表示关系或相关性的数据点。
最常用的技术是普通最小二乘(OLE)。
使用此方法,可以通过最小化数据点和回归线之间距离的平方和来找到最佳回归线。
对于上面的数据点,使用OLE获得的回归线看起来像:2.支持向量机支持向量机(SVM)是一种监督学习算法,主要用于分类任务,但也适用于回归任务。
机器学习算法解析

机器学习算法解析机器学习算法是计算机科学和人工智能领域中的重要组成部分,它通过分析和理解大量的数据,使计算机能够自动学习并做出决策。
不同的机器学习算法适用于不同的问题和数据类型,本文将对几种常见的机器学习算法进行解析。
一、线性回归算法线性回归算法是最简单的机器学习算法之一,它通过建立一个线性模型来预测连续型变量的值。
该算法通过找到最佳拟合直线来描述变量之间的线性关系。
它使用最小二乘法来计算误差,并进行参数估计。
线性回归算法广泛应用于房价预测、销售预测等实际问题中。
二、决策树算法决策树算法是一种基于树形结构的分类和回归算法。
它通过将数据集按照属性特征进行划分,并生成一棵决策树。
决策树的每个节点代表一个属性,边代表属性的取值,叶子节点代表最终的分类或回归结果。
决策树算法具有可解释性强、计算复杂度低等优点,被广泛应用于金融风控、医疗诊断等领域。
三、支持向量机算法支持向量机算法是一种二分类算法,它通过构建超平面来将不同类别的数据分开。
该算法寻找离超平面最近的一些数据点,称为支持向量,以最大化分类间隔。
支持向量机算法具有良好的泛化能力,适用于处理高维数据和非线性问题。
它被广泛应用于文本分类、图像识别等领域。
四、聚类算法聚类算法是一种将数据集按照相似性进行分组的无监督学习算法。
它通过计算数据点之间的距离或相似性,将相似的数据点归为一类。
常见的聚类算法包括K均值聚类、层次聚类等。
聚类算法可以用于市场细分、推荐系统等领域。
五、深度学习算法深度学习算法是机器学习的一个分支,它模拟人脑神经网络的工作原理。
该算法通过多层神经网络进行学习和训练,可以自动提取高级特征和表示。
深度学习算法在图像识别、语音识别、自然语言处理等任务中取得了巨大的成功。
综上所述,机器学习算法在人工智能领域中扮演着重要的角色。
通过对不同算法的解析,我们能够更好地理解它们的原理和应用场景。
随着技术的进步和数据的不断增加,相信机器学习算法将在未来发挥更加重要的作用,为社会带来更多的价值。
人工智能十大算法总结(精选五篇)

人工智能十大算法总结(精选五篇)第一篇:人工智能十大算法总结5-1 简述机器学习十大算法的每个算法的核心思想、工作原理、适用情况及优缺点等。
1)C4.5 算法:ID3 算法是以信息论为基础,以信息熵和信息增益度为衡量标准,从而实现对数据的归纳分类。
ID3 算法计算每个属性的信息增益,并选取具有最高增益的属性作为给定的测试属性。
C4.5 算法核心思想是ID3 算法,是ID3 算法的改进,改进方面有:1)用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;2)在树构造过程中进行剪枝3)能处理非离散的数据4)能处理不完整的数据C4.5 算法优点:产生的分类规则易于理解,准确率较高。
缺点:1)在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
2)C4.5 只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
2)K means 算法:是一个简单的聚类算法,把n 的对象根据他们的属性分为k 个分割,k < n。
算法的核心就是要优化失真函数J,使其收敛到局部最小值但不是全局最小值。
其中N 为样本数,K 是簇数,rnk b 表示n 属于第k 个簇,uk 是第k 个中心点的值。
然后求出最优的uk优点:算法速度很快缺点是,分组的数目k 是一个输入参数,不合适的k 可能返回较差的结果。
3)朴素贝叶斯算法:朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。
算法的基础是概率问题,分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。
朴素贝叶斯假设是约束性很强的假设,假设特征条件独立,但朴素贝叶斯算法简单,快速,具有较小的出错率。
在朴素贝叶斯的应用中,主要研究了电子邮件过滤以及文本分类研究。
4)K 最近邻分类算法(KNN)分类思想比较简单,从训练样本中找出K个与其最相近的样本,然后看这k个样本中哪个类别的样本多,则待判定的值(或说抽样)就属于这个类别。
机器学习算法的原理与应用

机器学习算法的原理与应用机器学习算法是一种可以使计算机通过学习自动地改进性能的方法。
它是人工智能领域的重要分支,对于解决大规模数据问题和进行智能决策具有广泛应用。
本文将介绍机器学习算法的原理和主要的应用领域。
一、机器学习算法的原理机器学习算法的核心思想是通过训练模型从数据中学习规律,并利用学习到的规律对新的数据进行预测或分类。
机器学习算法可以分为监督学习、无监督学习和强化学习三种类型。
1. 监督学习在监督学习中,我们需要准备带有标签的训练数据。
算法通过对这些数据的学习,构建一个能够将输入映射到输出的函数。
常见的监督学习算法包括决策树、支持向量机和神经网络等。
例如,在垃圾邮件分类问题中,我们可以使用一个监督学习算法,通过训练一组已经被标记为垃圾邮件或非垃圾邮件的样本,来预测一封新邮件是否是垃圾邮件。
2. 无监督学习无监督学习是指从未标记的数据中学习隐藏的结构或模式。
与监督学习不同,无监督学习没有预定义的输出值。
常见的无监督学习算法包括聚类算法、主成分分析和关联规则挖掘等。
例如,在客户分群问题中,我们可以使用无监督学习算法将客户分成不同的群组,以便更好地了解他们的需求和行为。
3. 强化学习强化学习是一种通过与环境交互来寻求最优行动策略的学习方式。
在强化学习中,智能体通过观察环境的状态和接收奖励,学习采取行动以最大化累积奖励。
常见的强化学习算法包括Q-learning和深度强化学习等。
例如,在围棋游戏中,计算机可以通过与人类棋手对弈来学习最佳下棋策略。
二、机器学习算法的应用机器学习算法在各个领域都有广泛的应用。
以下是一些常见的应用领域:1. 图像识别机器学习算法在图像识别领域具有重要的应用价值。
通过使用深度学习算法,计算机可以自动学习图像中的特征,并准确地识别出物体或场景。
这一技术在人脸识别、车辆检测和医学影像分析等方面具有广泛的应用。
2. 自然语言处理自然语言处理是指使计算机能够理解和处理人类语言的技术。
常见的机器学习算法解析

常见的机器学习算法解析机器学习是一门利用统计学和数学模型来让计算机从数据中学习的学科。
在实践中,我们常常使用各种机器学习算法来解决现实生活中的问题。
本文将对一些常见的机器学习算法进行解析,帮助读者了解它们的原理和应用。
一、线性回归算法(Linear Regression)线性回归是一种用于预测数值型目标变量的简单机器学习算法。
它通过拟合一个线性模型来建立自变量(输入特征)和因变量(输出)之间的关系。
线性回归的基本思想是找到一条能够最好地拟合数据的直线或超平面。
二、逻辑回归算法(Logistic Regression)逻辑回归是一种用于分类问题的机器学习算法。
它通过对数据进行二分类(或多分类)来预测离散型目标变量。
逻辑回归使用了一个逻辑函数(通常是Sigmoid函数)来建立自变量和因变量之间的关系。
三、决策树算法(Decision Tree)决策树是一种基于树形结构的机器学习算法。
它通过一系列的问题和决策节点来预测目标变量。
每个决策节点都代表一个特征,每个分支代表该特征的不同取值,最终的叶节点表示预测的结果。
四、随机森林算法(Random Forest)随机森林是一种集成学习方法,它通过构建多个决策树来进行预测。
每个决策树都是独立构建的,通过对每个决策树的预测结果进行投票或平均来得出最终的预测结果。
随机森林算法可以有效地减少过拟合问题。
五、支持向量机算法(Support Vector Machine)支持向量机是一种二分类机器学习算法。
它通过在特征空间中找出一个最优的超平面来分隔不同类别的样本。
支持向量机可以处理线性可分的数据,也可以通过核函数来处理线性不可分的数据。
六、朴素贝叶斯算法(Naive Bayes)朴素贝叶斯算法是一种基于贝叶斯定理的分类算法。
它假设特征之间条件独立,通过计算后验概率来进行分类。
朴素贝叶斯算法在文本分类和垃圾邮件过滤等领域有广泛的应用。
七、聚类算法(Clustering)聚类算法是一种无监督学习算法,它将相似的样本分为一组,不同组之间的样本应该有较大的差异。
人工智能的常用十种算法

人工智能的常用十种算法
一、朴素贝叶斯算法
朴素贝叶斯算法是一种基于概率的分类方法,在贝叶斯理论基础之上,假设特征之间相互独立,它根据样本特征出现的概率来判断样本的类别,
可以解决离散特征存在的分类问题,在文本分类、垃圾邮件的过滤等方面
有着广泛的应用。
二、决策树算法
决策树算法是一种使用树结构来表示一个决策过程的算法,决策树可
以用来表示一组除规则,每个内部节点表示一个属性测试、每个分支表示
一个满足属性测试的值,每个叶子节点表示一类结果。
它的应用非常广泛,可以用来解决连续和离散特征的分类问题,并且可以处理不相关的特征,
在许多实际场景中,它都表现出较好的性能。
三、K-Means聚类算法
K-Means聚类算法是一种基于划分的无监督学习算法,它可以对数据
集中的对象分到K个不同的簇中,其中每个簇都有共同的属性。
K-Means
聚类算法需要指定K,它有一个基本假设,即K个簇的质心相互离散,这
样可以尽可能的用质心来描述每个簇。
K-Means算法用来对数据进行分类,它的应用比较广泛,可以用在文本分类、图像分类等问题上。
四、Apriori算法
Apriori算法是一种关联规则算法。
常见机器学习算法的原理和应用分析

常见机器学习算法的原理和应用分析机器学习(Machine Learning, ML)是人工智能(Artificial Intelligence, AI)的核心领域之一,是一种通过样本数据对机器进行训练、自主探索特征规律及进行预测、判断等任务的方法。
机器学习算法是机器学习的核心内容,针对不同的问题和数据,具有不同的算法模型。
本文将针对常见机器学习算法的原理和应用进行分析。
一、监督学习算法监督学习算法是最为常见的机器学习算法,它的训练样本包含输入和输出的对应关系。
在监督学习算法中,常用的模型有决策树、随机森林、朴素贝叶斯、支持向量机等。
1. 决策树决策树(Decision Tree)是一种基于树形结构进行决策分析的算法。
通过将数据样本划分成多个类别,并形成一颗树状结构,确定样本通过树状结构的哪个分支可归属于哪个类别。
在决策树的构建过程中,通常采用递归的形式,对样本数据进行分裂。
具体地,根据所有属性的每个划分,都计算一个信息增益,并选择信息增益最大的属性作为当前节点的划分属性,对该属性进行划分。
直到叶子节点的样本属于同一类,或者节点所代表的属性集合为空时迭代结束。
2. 随机森林随机森林(Random Forest)是一种基于多个决策树构建的集成模型,以降低模型方差,提高模型精度。
随机森林的构建方式是通过对多个决策树在选择属性、分裂点时采用随机方法,形成多个弱分类器,共同进行综合决策。
随机森林的训练过程中,先利用自助式(Bootstrap)采样原始数据形成数据集,再分别随机选择每棵树的属性和分裂点,构建决策树。
最后,通过投票方式将多个决策树的结果进行集成,形成一个最终的整体结果。
3. 朴素贝叶斯朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理而来的分类算法,其基本思想是通过先验概率和概率密度函数,通过样本数据推导后验概率,最后对样本进行分类。
朴素贝叶斯算法假设所有特征都是相互独立的,并把各个特征的概率合成后,再根据贝叶斯公式计算后验概率,进行分类。
数据挖掘十大经典算法,详细解释数据挖掘中的10大算法,机器学习常见算法总结

数据挖掘⼗⼤经典算法,详细解释数据挖掘中的10⼤算法,机器学习常见算法总结⼗⼤数据挖掘算法及各⾃优势国际权威的学术组织the IEEE International Conference on Data Mining (ICDM) 2006年12⽉评选出了数据挖掘领域的⼗⼤经典算法:C4.5, k-Means, SVM, Apriori, EM, PageRank, AdaBoost, kNN, Naive Bayes, and CART.不仅仅是选中的⼗⼤算法,其实参加评选的18种算法,实际上随便拿出⼀种来都可以称得上是经典算法,它们在数据挖掘领域都产⽣了极为深远的影响。
1. C4.5C4.5算法是机器学习算法中的⼀种分类决策树算法,其核⼼算法是ID3算法. C4.5算法继承了ID3算法的优点,并在以下⼏⽅⾯对ID3算法进⾏了改进:1) ⽤信息增益率来选择属性,克服了⽤信息增益选择属性时偏向选择取值多的属性的不⾜;2) 在树构造过程中进⾏剪枝;3) 能够完成对连续属性的离散化处理;4) 能够对不完整数据进⾏处理。
C4.5算法有如下优点:产⽣的分类规则易于理解,准确率较⾼。
其缺点是:在构造树的过程中,需要对数据集进⾏多次的顺序扫描和排序,因⽽导致算法的低效。
2. The k-means algorithm 即K-Means算法k-means algorithm算法是⼀个聚类算法,把n的对象根据他们的属性分为k个分割,k < n。
它与处理混合正态分布的最⼤期望算法很相似,因为他们都试图找到数据中⾃然聚类的中⼼。
它假设对象属性来⾃于空间向量,并且⽬标是使各个群组内部的均⽅误差总和最⼩。
3. Support vector machines⽀持向量机,英⽂为Support Vector Machine,简称SV机(论⽂中⼀般简称SVM)。
它是⼀种監督式學習的⽅法,它⼴泛的应⽤于统计分类以及回归分析中。
常见机器学习算法优缺点小结

常见机器学习算法优缺点⼩结常见机器学习算法⼀、最近邻算法(KNN)1. 概述KNN的主要过程如下:Step 1: 计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马⽒距离等);Step 2: 对上⾯所有的距离值进⾏排序;Step 3: 选前k个最⼩距离的样本;Step 4: 根据这k个样本的标签进⾏投票,得到最后的分类类别;如何选择⼀个最佳的K值,这取决于数据。
⼀般情况下,在分类时较⼤的K值能够减⼩噪声的影响。
但会使类别之间的界限变得模糊。
⼀个较好的K值可通过各种启发式技术来获取,⽐如,交叉验证。
另外噪声和⾮相关性特征向量的存在会使K近邻算法的准确性减⼩。
近邻算法具有较强的⼀致性结果。
随着数据趋于⽆限,算法保证错误率不会超过贝叶斯算法错误率的两倍。
对于⼀些好的K 值,K近邻保证错误率不会超过贝叶斯理论误差率。
2. 优点(1) 理论成熟,思想简单,既可以⽤来做分类也可以⽤来做回归;(2) 可⽤于⾮线性分类;(3) 训练时间复杂度为O(n);(4) 对数据没有假设,准确度⾼,对outlier不敏感;(5) KNN是⼀种在线技术,新数据可以直接加⼊数据集⽽不必进⾏重新训练3. 缺点(1) 对于样本容量⼤的数据集计算量⽐较⼤。
(2) 样本不平衡时,预测偏差⽐较⼤。
如:某⼀类的样本⽐较少,⽽其它类样本⽐较多。
(3) KNN每⼀次分类都会重新进⾏⼀次全局运算。
(4) k值⼤⼩的选择。
(5) 需要⼤量的内存;4. 应⽤领域⽂本分类、模式识别、聚类分析,多分类领域⼆、朴素贝叶斯(Na?ve Bayes, NB)1. 概述朴素贝叶斯属于⽣成式模型(关于⽣成模型和判别式模型,主要还是在于是否是要求联合分布),⾮常简单,你只是做了⼀堆计数。
如果注有条件独⽴性假设(⼀个⽐较严格的条件),朴素贝叶斯分类器的收敛速度将快于判别模型,如逻辑回归,所以你只需要较少的训练数据即可。
即使NB条件独⽴假设不成⽴,NB分类器在实践中仍然表现的很出⾊。
快速入门机器学习:10个常用算法简介

快速入门机器学习:10个常用算法简介1. 引言1.1 概述:机器学习是一门涉及分析数据和构建预测模型的领域,它能够让计算机通过从数据中学习规律、模式和知识,作出智能决策或预测。
随着人工智能和大数据的快速发展,机器学习在各个领域都获得了广泛应用。
本篇文章将给读者带来关于机器学习中最常用的10种算法的简介。
无论你是刚刚开始接触机器学习还是想要巩固自己对这些算法的理解,这篇文章都会为你提供一个快速入门的指南。
1.2 文章结构:本文将按照以下结构展开内容:- 引言:简要介绍文章背景和目标。
- 机器学习简介:第二节将讨论机器学习的定义、应用领域以及发展历程。
- 常用算法类型:第三节将解释三种常见的机器学习算法类型:监督学习、无监督学习、半监督学习。
- 常用机器学习算法简介:第四节将深入探讨三种常见的监督学习算法:线性回归模型、逻辑回归模型和决策树算法。
- 其他常用算法简介:第五节将介绍三种其他常用的机器学习算法:支持向量机(SVM)、K均值聚类算法(K-means)和随机森林(Random Forest)。
通过这样的文章结构,读者们将能够对不同类型的算法有一个清晰的概念,并且了解每个算法的基本原理和应用场景。
1.3 目的:本文的目标是帮助读者快速了解机器学习中最常用的十种算法。
通过这篇文章,读者可以获得对于这些算法的基本认知,并且能够判断何时使用某个特定的算法以及如何开始在实际问题中应用它们。
我们相信,通过阅读本文,您将收获关于机器学习算法的全面理解,并且为进一步学习和探索领域打下坚实基础。
让我们一起开始这个令人兴奋而又有趣的旅程吧!2. 机器学习简介2.1 定义机器学习是一种人工智能领域的研究分支,旨在通过计算机系统从数据中学习模式和规律,以便能够做出准确预测或自动决策,而无需明确编程。
机器学习的目标是建立能够自动进行学习和推断的算法和模型。
2.2 应用领域机器学习在许多领域都得到了广泛的应用。
例如,在医疗保健领域,机器学习可用于诊断疾病、制定治疗方案和预测患者病情。
机器学习和十大机器学习算法

15
Autoencoder
01.
自编码器是一种用于数据降维和异常检测的神经网络模型。它通过编码和解 码两个步骤来学习数据的低维表示,并用于数据压缩和异常检测等任务
02.
以上是一些常见的机器学习算法,它们在不同的任务和应用领域中都有广泛的应用。然而,机器学习 领域仍在快速发展,新的算法和技术不断涌现,为解决复杂的问题提供了更多的可能性
朴素贝叶斯是一种基于贝叶斯定理的分类器
x
它假设输入数据的每个特征之间是独立的,并使用这 个假设来计算输入数据属于每个类别的概率
6
逻辑回归
7
神经网络
8
01
梯度提升树是一 种通过迭代地添 加简单模型(如决 策树)来构建复杂 模型的方法
梯度提升树
02
这种方法在处理 大量特征和复杂 关系时特别有效
-
请各位老师批评指正!
THESIS DEFENSE POWERPOINT
XXXXXXXXXX
指导老师:XXX
答 辩 人 :XXX
以上就是常见的十大机器学习算法。然而,这只是冰 山一角,机器学习领域正在快速发展,每天都会有新 的算法和技术被提出
除了上述十大机器学习算法,还有一些其他的机器学 习算法也值得关注,例如
11
卷积神经网络(CNN)
卷积神经网络是一种专门用于处理图像数据的 神经网络
它通过使用卷积层、池化层和全连接层等组件 来学习图像中的特征,并用于图像分类、目标
1 线性回归 3 决策树和随机森林 5 朴素贝叶斯 7 神经网络 9 集成方法
-
2 支持向量机 4 K-近邻算法 6 逻辑回归 8 梯度提升树
10 贝叶斯网络
机器学习和十大机器学习算法
机器学习算法的原理和使用方法

机器学习算法的原理和使用方法机器学习是人工智能领域的一个重要分支,通过利用统计学和计算机科学的方法,让机器能够自主学习和改进算法。
机器学习算法的原理和使用方法是理解和应用机器学习的关键所在。
一、机器学习算法的原理1. 数据预处理:在机器学习中,数据预处理是非常重要的一步。
它包括数据清洗、数据变换和数据规范化等过程,目的是为了提高模型的准确性和可靠性。
数据清洗主要是处理缺失值、异常值和离群值等,数据变换则是对数据进行标准化、归一化或者离散化等处理,数据规范化是将数据转换为一定范围内的标准分布。
2. 特征选择:在机器学习中,特征选择是选择最相关和最重要的特征,以便构建模型。
常用的特征选择方法有过滤式选择、包裹式选择和嵌入式选择等。
过滤式选择通过计算特征和目标变量之间的相关性来选择特征,包裹式选择则通过构建模型来选择特征,嵌入式选择是将特征选择作为模型训练过程的一部分。
3. 模型选择和评估:在机器学习中,选择合适的模型是至关重要的。
常见的机器学习模型包括决策树、朴素贝叶斯、支持向量机和神经网络等。
模型的选择要考虑数据类型、问题类型和需求等因素。
在模型选择之后,还需要对模型进行评估,常见的评估指标包括准确率、精确率、召回率和F1值等。
模型评估可以帮助我们了解模型的性能和表现。
4. 训练和优化:机器学习的核心就是训练模型。
训练模型的过程是通过使用已有的训练数据来调整模型的参数,使其能够更好地拟合数据和预测结果。
训练过程可以使用不同的优化算法,例如梯度下降算法和遗传算法等。
优化算法的选择要考虑时间效率和收敛性等因素。
5. 预测和应用:经过训练的模型可以用来进行预测和应用。
预测是利用模型来对未知数据进行预测和分类,应用则是将模型应用于实际的问题和场景中。
预测结果可以用来辅助决策和优化,应用则可以帮助解决实际问题并提高工作效率。
二、机器学习算法的使用方法1. 确定问题和目标:在使用机器学习算法之前,首先要明确问题和目标。
10种机器学习算法介绍

线性回归
针对线性回归容易出现欠拟合的问题,采取局部加权线性回归。
在该算法中,赋予预测点附近每一个点以一定的权值,在这上面基于波长函数来进行普通的线
性回归.可以实现对临近点的精确拟合同时忽略那些距离较远的点的贡献,即近点的权值大,远 点的权值小,k为波长参数,控制了权值随距离下降的速度,越大下降的越快。
缺点:
(1) SVM算法对大规模训练样本难以实施
(2) 用SVM解决多分类问题存在困难
经典的支持向量机算法只给出了二类分类的算法,而在数据挖掘的实际应用中,一般要解决多类 的分类问题。
朴素贝叶斯
#Import Library from sklearn.naive_bayes import GaussianNB #Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset # Create SVM classification object model = GaussianNB() # there is other distribution for multinomial classes like Bernoulli Naive Bayes, Refer link # Train the model using the training sets and check score model.fit(X, y) #Predict Output predicted= model.predict(x_test)
终止树
(1)节点达到完全纯性; (2)树的深度达到用户指定的深度; (3)节点中样本的个数少于用户指定的个数; (4) 异质性指标下降的最大幅度小于用户指定的幅度。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
5-1简述机器学习十大算法的每个算法的核心思想、工作原理、适用情况及优缺点等。
1)C4.5算法:
ID3算法是以信息论为基础,以信息熵和信息增益度为衡量标准,从而实现对数据的归纳分类。
ID3算法计算每个属性的信息增益,并选取具有最高增益的属性作为给定的测试属性。
C4.5算法核心思想是ID3算法,是ID3算法的改进,改进方面有:1)用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;
2)在树构造过程中进行剪枝
3)能处理非离散的数据
4)能处理不完整的数据
C4.5算法优点:产生的分类规则易于理解,准确率较高。
缺点:
1)在构造树的过程中,需要对数据集进行多次的顺序扫描
和排序,因而导致算法的低效。
2)C4.5只适合于能够驻留于内存的数据集,当训练集大得
无法在内存容纳时程序无法运行。
2)K means算法:
是一个简单的聚类算法,把n的对象根据他们的属性分为k个分割,k<n。
算法的核心就是要优化失真函数J,使其收敛到局部最小值但不是全局最小值。
,其中N为样本数,K是簇数,rnk b表示n属于第k个簇,uk是第k个中心点的值。
然后求出最优的uk
优点:算法速度很快
缺点是,分组的数目k是一个输入参数,不合适的k可能返回较差的结果。
3)朴素贝叶斯算法:
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。
算法的基础是概率问题,分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。
朴素贝叶斯假设是约束性很强的假设,假设特征条件独立,但朴素贝叶斯算法简单,快速,具有较小的出错率。
在朴素贝叶斯的应用中,主要研究了电子邮件过滤以及文本分类研究。
4)K最近邻分类算法(KNN)
分类思想比较简单,从训练样本中找出K个与其最相近的样本,然后看这k个样本中哪个类别的样本多,则待判定的值(或说抽样)就属于这个类别。
缺点:
1)K值需要预先设定,而不能自适应
2)当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
该算法适用于对样本容量比较大的类域进行自动分类。
5)EM最大期望算法
EM算法是基于模型的聚类方法,是在概率模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量。
E步估计隐含变量,M步估计其他参数,交替将极值推向最大。
EM算法比K-means算法计算复杂,收敛也较慢,不适于大规模数据集和高维数据,但比K-means算法计算结果稳定、准确。
EM经常用在机器学习和计算机视觉的数据集聚(Data Clustering)领域。
6)PageRank算法
是google的页面排序算法,是基于从许多优质的网页链接过来的网页,必定还是优质网页的回归关系,来判定所有网页的重要性。
(也就是说,一个人有着越多牛X朋友的人,他是牛X的概率就越大。
)优点:
完全独立于查询,只依赖于网页链接结构,可以离线计算。
缺点:
1)PageRank算法忽略了网页搜索的时效性。
2)旧网页排序很高,存在时间长,积累了大量的in-links,拥有最新资讯的新网页排名却很低,因为它们几乎没有in-links。
7)AdaBoost
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个
更强的最终分类器(强分类器)。
其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。
将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。
整个过程如下所示:
1.先通过对N个训练样本的学习得到第一个弱分类器;
2.将分错的样本和其他的新数据一起构成一个新的N个的训练样本,通过对这个样本的学习得到第二个弱分类器;
3.将和都分错了的样本加上其他的新样本构成另一个新的N 个的训练样本,通过对这个样本的学习得到第三个弱分类器;
4.如此反复,最终得到经过提升的强分类器。
目前AdaBoost算法广泛的应用于人脸检测、目标识别等领域。
8)Apriori算法
Apriori算法是一种挖掘关联规则的算法,用于挖掘其内含的、未知的却又实际存在的数据关系,其核心是基于两阶段频集思想的递推算法。
Apriori算法分为两个阶段:
1)寻找频繁项集
2)由频繁项集找关联规则
算法缺点:
1)在每一步产生侯选项目集时循环产生的组合过多,没有排除不应该参与组合的元素;
2)每次计算项集的支持度时,都对数据库中的全部记录进行了一遍扫描比较,需要很大的I/O负载。
9)SVM支持向量机
支持向量机是一种基于分类边界的方法。
其基本原理是(以二维数据为例):如果训练数据分布在二维平面上的点,它们按照其分类聚集在不同的区域。
基于分类边界的分类算法的目标是,通过训练,找到这些分类之间的边界(直线的――称为线性划分,曲线的――称为非线性划分)。
对于多维数据(如N维),可以将它们视为N维空间中的点,而分类边界就是N维空间中的面,称为超面(超面比N 维空间少一维)。
线性分类器使用超平面类型的边界,非线性分类器使用超曲面。
支持向量机的原理是将低维空间的点映射到高维空间,使它们成为线性可分,再使用线性划分的原理来判断分类边界。
在高维空间中是一种线性划分,而在原有的数据空间中,是一种非线性划分。
SVM在解决小样本、非线性及高维模式识别问题中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
10)CART分类与回归树
是一种决策树分类方法,采用基于最小距离的基尼指数估计函数,用来决定由该子数
据集生成的决策树的拓展形。
如果目标变量是标称的,称为分类树;如果目标变量是连续的,称为回归树。
分类树是使用树结构算法将数据分成离散类的方法。
优点
1)非常灵活,可以允许有部分错分成本,还可指定先验概率分布,可使用自动的成本复杂性剪枝来得到归纳性更强的树。
2)在面对诸如存在缺失值、变量数多等问题时CART显得非常稳健。