第七章模糊聚类分析
模糊聚类的分析

模糊聚类的分析模糊聚类分析是一种在统计分析领域中的方法。
它的主要思想是将客观数据更好地分类和分析。
模糊聚类是一种简单的数据挖掘技术,它可以从客观数据中挖掘出有价值的信息,以帮助我们分析和探索数据。
模糊聚类分析的本质是根据相似度度量算法来确定数据点之间的相似性,并将它们聚类为一个或多个类别。
它可以用于更好地加深对数据挖掘结果的理解,分析和发现数据中的结构和关系。
模糊聚类的优点1、可以更好地发现数据挖掘的结果和有价值的信息。
2、可以用于分析和发现客观数据中的结构和关系。
3、可以很好地分析大数据集。
4、可以使数据分类更有效率。
模糊聚类的应用1、金融领域:模糊聚类可用于金融分析,如风险识别、客户分析、金融监管等,可以显著提高对金融市场的了解,并帮助金融市场制定更有效的策略。
2、医学领域:模糊聚类可以更好地理解大量的临床资料,并为医生提供更有效的诊断建议。
它还可以应用于医疗和病理图像分析,以有效管理和指导患者的治疗过程。
3、气象领域:模糊聚类可以有效地识别气象 sensor卫星数据中的关键结构和特征,并用于气象研究和气象预报中。
4、人工智能:模糊聚类可以作为机器学习算法的基础,用于建模不同环境和情景。
它还可以用于自然语言处理,提供更有意义的信息,例如情感分析。
模糊聚类的局限性1、模糊聚类的结果很大程度上取决于人为干预,且模糊聚类的结果可能会受到相似度测量的影响,这可能会导致结果的不稳定性。
2、除此之外,由于模糊聚类是基于数据预处理后的假设来实施的,所以对数据预处理的要求较高,对数据准备质量和格式有较高的要求,这也是模糊聚类的一大局限性。
模糊聚类的发展前景模糊聚类分析技术在各个领域的应用及其发展前景均越来越广泛。
模糊聚类技术在人工智能、机器学习、大数据和自动化领域等方面都有广泛的应用,而且随着 AI 、Bigdata术的发展,模糊聚类在预测建模、数据挖掘和自然语言处理等方面也都有了重要的应用。
此外,模糊聚类技术还可以应用于声学识别、计算机视觉和实时处理等领域,进一步拓展模糊聚类技术的应用前景。
模糊聚类分析

模糊聚类分析是一种数学方法,它使用模糊数学语言根据某些要求对事物进行描述和分类。
模糊聚类分析通常是指根据研究对象的属性构造模糊矩阵,并在此基础上根据一定隶属度确定聚类关系,即样本之间的模糊关系由样本的数量来确定。
模糊数学方法,以客观,准确地聚类。
聚类是将数据集划分为多个类或群集,以便每个类之间的数据差异应尽可能大,并且该类内的数据差异应尽可能小基本覆盖当涉及事物之间的模糊边界时,模糊聚类分析是一种根据某些要求对事物进行分类的数学方法。
聚类分析是数学统计中的一种多元分析方法是利用数学方法定量确定样品之间的关系,从而客观地分类类型。
事物之间的某些界限是精确的,而其他界限则是模糊的。
人群中人脸的相似度之间的界限是模糊的,多云和晴天之间的界限也是模糊的。
当聚类涉及事物之间的模糊界限时,应使用模糊聚类分析方法。
模糊聚类分析广泛应用于气象预报,地质,农业,林业等领域。
通常,聚类的事物称为样本,一组事物称为样本集。
模糊聚类分析有两种基本方法:系统聚类和逐步聚类。
基本方法基本流程(1)通过计算样本或变量之间的相似系数,建立模糊相似矩阵;(2)通过对模糊矩阵进行一系列综合变换,生成模糊等效矩阵。
(3)最后,根据不同的截获水平λ对模糊等效矩阵进行分类系统聚类方法系统聚类方法是一种基于模糊等价关系的模糊聚类分析方法。
在经典聚类分析方法中,经典等价关系可用于对样本集X进行聚类。
令R为X上的经典等价关系。
对于X中的两个元素x和Y,如果XRY或(x,y)∈R ,然后x和y,否则X和y不属于同一类。
[3]使用这种方法,分类的结果与α的值有关。
α的值越大,划分的类别越多。
当α小于某个值时,X中的所有样本将被归为一类。
该方法的优点是可以根据实际需要选择α值,以获得正确的分类。
系统聚类的步骤如下:①用数字描述样品的特性。
设要聚类的样本为x = {x1,xn}。
每个样本具有p个特征,记录为Xi =(Xi1,xip);i = 1,2,…,N;XIP是描述样本Xi的第p个特征的编号。
数据挖掘第七章__聚类分析

Chapter 7. 聚类分析
• 聚类分析概述 • 聚类分析的数据类型
• 主要聚类分析方法分类
划分方法(Partitioning Methods)
分层方法
基于密度的方法
基于网格的方法
基于模型(Model-Based)的聚类方法
火龙果 整理
• 差异度矩阵
– (one mode)
0 d(2,1) 0 d(3,1 ) d ( 3, 2 ) : : d ( n,1) d ( n,2)
0 : ... ... 0
火龙果 整理
1.数据矩阵 数据矩阵是一个对象—属性结构。它是n个对象组
6.3 聚类分析中的数据类型
假设一个要进行聚类分析的数据集包含 n
个对象,这些对象可以是人、房屋、文件等。
聚类算法通常都采用以下两种数据结构:
火龙果 整理
两种数据结构
• 数据矩阵
– (two modes)
x11 ... x i1 ... x n1 ... x1f ... ... ... xif ... ... ... xnf ... x1p ... ... ... xip ... ... ... xnp
• 保险: 对购买了汽车保险的客户,标识那些有较高平均赔偿 成本的客户;
• 城市规划: 根据类型、价格、地理位置等来划分不同类型的 住宅; • 地震研究: 根据地质断层的特点把已观察到的地震中心分成 不同的类;
火龙果 整理
生物方面,聚类分析可以用来对动物或植物分类,或 根据基因功能对其进行分类以获得对人群中所固有的
(6.2)
火龙果 整理
模糊聚类分析实验报告
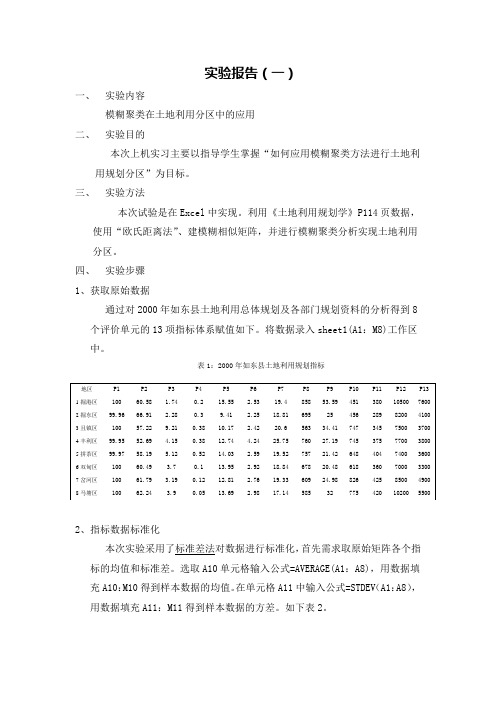
实验报告(一)一、实验内容模糊聚类在土地利用分区中的应用二、实验目的本次上机实习主要以指导学生掌握“如何应用模糊聚类方法进行土地利用规划分区”为目标。
三、实验方法本次试验是在Excel中实现。
利用《土地利用规划学》P114页数据,使用“欧氏距离法”、建模糊相似矩阵,并进行模糊聚类分析实现土地利用分区。
四、实验步骤1、获取原始数据通过对2000年如东县土地利用总体规划及各部门规划资料的分析得到8个评价单元的13项指标体系赋值如下。
将数据录入sheet1(A1:M8)工作区中。
表1:2000年如东县土地利用规划指标2、指标数据标准化本次实验采用了标准差法对数据进行标准化,首先需求取原始矩阵各个指标的均值和标准差。
选取A10单元格输入公式=AVERAGE(A1:A8),用数据填充A10:M10得到样本数据的均值。
在单元格A11中输入公式=STDEV(A1:A8),用数据填充A11:M11得到样本数据的方差。
如下表2。
表2:13个指标值得均值和标准差选取A13单元格输入公式=(A1-A$10)/A$11,并用数据填充A13:M20区域得到标准化矩阵如下表3。
表3:标准化数据矩阵3、求取模糊相似矩阵本次试验是通过欧氏距离法求取模糊相似矩阵。
其数学模型为:mr ij=1−c√∑(x ik−x jk)2k=1选取A23单元格输入公式=SQRT((A$13-A13)^2+(B$13-B13)^2+(C$13-C13)^2+(D$13-D13)^2+(E$13-E13)^2+(F$13-F13)^2+(G$13-G13)^2+(H$13-H13)^2+(I$13-I13)^2+(J$13-J13)^2+(K$13-K13)^2+(L$13-L13)^2+(M$13-M13)^2)求的d11,B23中输入公式=SQRT((A$14-A13)^2+(B$14-B13)^2+(C$14-C13)^2+(D$14-D13)^2+(E$14-E13)^2+(F$14-F13)^2+(G$14-G13)^2+(H$14-H13)^2+(I$14-I13)^2+(J$14-J13)^2+(K$14-K13)^2+(L$14-L13)^2+(M$14-M13)^2)q 求的d12。
模糊聚类分析

模糊聚类分析是根据客观事物的特征、亲和度和相似度建立模糊相似关系,对客观事物进行聚类的一种分析方法。
当涉及到事物之间的模糊边界时,根据一定的要求对事物进行分类的一种数学方法。
聚类分析是数理统计中的一种多元分析方法,它利用数学方法定量地确定样本之间的亲和力,从而客观地对类型进行分类。
一些事物之间的界限是精确的,而另一些则是模糊的。
人与人之间脸部相似的界限是模糊的,天气之间的界限也是模糊的。
当聚类涉及到事物之间的模糊边界时,应使用模糊聚类分析方法。
模糊聚类分析在天气预报、地质、农业、林业等领域有着广泛的应用。
通常,聚类物称为样本,一组聚类物称为样本集。
模糊聚类分析的基本方法有两种:系统聚类法和逐步聚类法。
概述。
在数据分类中,常用的分类方法包括多元统计中的系统聚类、模糊聚类分析等;在模糊聚类分析中,首先要计算模糊相似矩阵,不同的模糊相似矩阵会产生不同的分类结果;即使使用相同的模糊相似矩阵,不同的阈值也会产生不同的分类结果。
“如何确定这些分类的有效性”成为模糊聚类的关键点。
这是识别研究中的一个重要问题。
在文献中,不能令人满意的有效性归因于数据集的几何结构不令人满意。
但笔者认为,不同的几何结构反映了实际需要。
我们不能排除实际需要,追求所谓的“理想几何结构”。
分类不理想不能归因于数据集的几何结构。
对于相同的模糊相似矩阵,文献建立了一种判断模糊聚类有效性的方法。
在有固定显著性水平的情况下,在不同分类中选择F统一测量临界值与F检验临界值之间的最大差值是一种有效的分类方法。
但是,当显著性水平发生变化时,该方法的结果也会发生变化。
文献引入模糊划分办公室来评价模糊聚类的有效性,并人为规定当两个类别的办公室大于1时,两个类别可以合并,最终通过逐次合并得到有效的分类。
这种方法有较多的人为干预,当指定的数量不同时,会得到不同的结果。
系统聚类法。
系统聚类法是一种基于模糊等价关系的模糊聚类分析方法。
在经典的聚类分析方法中,样本集可以通过经典的等价关系进行聚类。
7第七章地理系统的聚类分析

第七章地理系统的聚类分析与判别分析§1 地理系统的聚类分析一概述聚类分析又叫群分析,它是研究分类的一种统计方法。
这种方法与判别分析的分类方法不同,它并不要求事先知道划分的类型与数目,而是根据研究对象(标本或变量)的相似程度进行聚合分类。
分类时首先将相互间关系密切的标本(或变量)各自聚合成一个小的分类单位,然后将关系比较疏远的聚合到一个大的分类单位中去。
这样就形成一个由小到大的分类系统。
通常对标本的分类叫做Q型聚类分析。
对变量的分类叫做R型聚类分析,这二种分析的基本作法都是一样的,都是选择一个“分类统计量”来表示标本或变量的相似程度,再按相似程度的大小逐步连结,最后作成一张“分类图”,用以表示标本的亲疏关系。
二、数据的规格化在根据相似程度(相似性统计量)进行聚合分类以前,有时需要对观测数据进行规格化变换。
因为各变量的观测数据,在数值上可能相差很大,当采用不同单位时,各变量的数据可以相差几个数量级。
所以如果直接采用原始数据进行计算。
就会突出那些绝对值大的变量而降低了那些绝对值小的变量的作用。
因此一般在计算前需对变量进行变换,使数据标准化。
此外,标准化的数据也便于计算。
一般在标准化之前,先进行对数变换,以使数据变幅减少且变均匀。
常用的数据标准化方法有如下二种。
1.标准差标准化数据标准化也称做数据的标准差规格化。
设有n 个标本,每个标本观测p 个变量。
得原始数据矩阵:n p ik x X ⨯=][⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=pn p p n n x x x x x xx x x 212222111211 (1)标准化时,将数据作如下变换:='ik w iiik s x x - ………………………………………………(2) 式中:i x ∑==nk ik x n 11=i s )(111i nk ik x x n --∑= 对标准变量而言,标本的均值为零)0(=μ,标准差为一)1(=s 。
模糊聚类的原理和应用

模糊聚类的原理和应用1. 简介模糊聚类是一种聚类分析方法,它通过考虑数据点属于不同聚类的程度,使得数据点可以同时属于多个聚类。
与传统的硬聚类方法不同,模糊聚类能够更好地处理实际问题中的复杂性和不确定性。
本文将介绍模糊聚类的原理和应用。
2. 模糊聚类的原理在传统的硬聚类方法中,每个数据点只能隶属于一个聚类,而在模糊聚类中,每个数据点可以属于多个聚类,且属于不同聚类的程度可以从0到1之间的任意值。
这种程度被称为隶属度,用来表示数据点与聚类的关联程度。
模糊聚类的原理可以通过以下步骤来解释:1.初始化聚类中心:首先随机选择一些数据点作为聚类中心。
2.计算隶属度:计算每个数据点与每个聚类中心的隶属度,可以使用模糊C均值(FCM)算法来计算。
3.更新聚类中心:根据隶属度计算出每个聚类的中心点,更新聚类中心。
4.重复步骤2和3,直到聚类中心不再变化或达到预设的迭代次数。
模糊聚类的核心是通过计算隶属度来确定每个数据点对每个聚类的归属程度,从而实现多类别的聚类。
3. 模糊聚类的应用模糊聚类在许多领域中具有广泛的应用,包括数据挖掘、模式识别、图像处理和生物信息学等。
以下是几个常见的应用领域:3.1 数据挖掘在数据挖掘中,模糊聚类可以帮助找到数据集中的隐藏模式和关联规则。
通过将数据点划分到不同的聚类中,可以更好地理解数据的结构和特征。
模糊聚类还可以用作预测分析和聚类分析的基础。
3.2 模式识别在模式识别中,模糊聚类可以帮助将输入数据分类到模式类别中。
通过考虑隶属度,模糊聚类可以更好地处理模糊和不确定性的输入数据。
这在人脸识别、手写体识别等任务中非常有用。
3.3 图像处理在图像处理中,模糊聚类被广泛应用于图像分割和图像压缩等任务。
通过将图像像素划分到不同的聚类中,可以实现图像的分割和压缩。
模糊聚类还可以用于图像特征提取和图像检索等应用。
3.4 生物信息学在生物信息学中,模糊聚类被用于处理基因表达数据和蛋白质序列数据等。
模糊聚类分析方法

模糊聚类分析方法对所研究的事物按一定标准进行分类的数学方法称为聚类分析,它是多元统 计“物以类聚”的一种分类方法。
载科学技术、经济管理中常常要按一定的标准 (相似程度或亲疏关系)进行分类。
例如,根据生物的某些性状可对生物分类, 根据土壤的性质可对土壤分类等。
由于科学技术、经济管理中的分类界限往往不 分明,因此采用模糊聚类方法通常比较符合实际。
一、模糊聚类分析的一般步骤1、第一步:数据标准化[9](1)数据矩阵设论域U ={X i ,X 2,||l,X n }为被分类对象,每个对象又有m 个指标表示其性状,于是,得到原始数据矩阵为Xm 1X m2bI-Xnm」其中X nm 表示第n 个分类对象的第m 个指标的原始数据(2)数据标准化在实际问题中,不同的数据一般有不同的量纲,为了使不同的量纲也能进行 比较,通常需要对数据做适当的变换。
但是,即使这样,得到的数据也不一定在 区间[0,1]上。
因此,这里说的数据标准化,就是要根据模糊矩阵的要求,将数据 压缩到区间[0,1]上。
通常有以下几种变换: ① 平移•标准差变换X i = {x i1, X i2,川,X m }X i 1X2 1X n2 IHxik -(i 一 1,21 n, k_;HL 2mS k其中-1 n1 n_ 2xkxi , 2(xik~'兀)。
n i 4: n i 4经过变换后,每个变量的均值为 0,标准差为1,且消除了量纲的影响。
但是,再用得到的x k 还不一定在区间[0,1]上。
② 平移•极差变换显然有0乞x ik 乞1,而且也消除了量纲的影响 ③ 对数变换xk- lg x ik (i = 1,n , k; l [L 2 m取对数以缩小变量间的数量级。
2、第二步:标定(建立模糊相似矩阵)设论域U ={为公2,川,人} , X i ={为1必2,川,心},依照传统聚类方法确定相似 系数,建立模糊相似矩阵,x i 与X j 的相似程度用=R(X j ,X j )。
7-第七章-聚类分析

(xi , yi 0, xi yi 0)
该距离能克服量纲的影响,
但不能克服分量间的相关性。
9
第9页,共94页。
距离测度(差值测度) (6)马氏(Mahalanobis)距离
d 2 (xi , x j ) (xi x j )T V 1(xi x j )
其中
V
1 m 1
m i 1
( xi
( xi x j )T AT ( AT )1Vx1A1A( xi x j )
( xi x j )TVx1( xi x j )
d
2 x
(
xi
,
x
j
)
12
第12页,共94页。
马氏距离的一般定义
设 x、 y是从期望矢量为 、协方差矩阵为的母体G中抽
取的两个样本,则它们间的马氏距离定义为
d 2 (x, y) (x y)T 1(x y) 当 x和 y是分别来自两个数据集中的样本时,设C是它们
递推公式
Dkl max[Dkp , Dkq ] p
k q
23
第23页,共94页。
(三)中间距离
递推公式
D2 1 D2 1 D2 1 D2
2 2 4 kl
kp
kq
pq
l
p
p
Dpq
q
q
Dkl
Dkp
Dkq
k
k
24
第24页,共94页。
(四)重心距离
递推公式
D2 np D2 nq D2 npnq D2 kl np nq kp np nq kq (np nq )2 pq
7
第7页,共94页。
距离测度(差值测度)
设 x (x1, x2 , , xn )T ,y ( y1, y2, , yn )T ⑴ 欧氏(Euclidean)距离
第7章 聚类分析

多元统计分析及R语言建模
聚类分析的目的和意义
聚类分析中所使用的几种尺度的定义
主 要
初步掌握选用聚类方法与相应距离的原则
内
六种系统聚类方法的定义及其基本性质
容
R语言程序中有关聚类分析的算法基础
掌握R语言中kmeans聚类的方法和用法
7 聚类分析及R使用
基本概念
聚类分析法(Cluster Analysis)是研究“物以类聚”的
7 聚类分析及R使用
系统聚类分析的特点 综合性 形象性 客观性
关于kmeans算法 kmeans算法只有在类的均值被定义的情况下才能使用
对于“噪声”和孤立点是敏感的,这种数据对均值影响极大
7 聚类分析及R使用
关于变量变换
平移变换 极差变换 标准差变换 主成分变换 对数变换
7 聚类分析及R使用
k个类,使类内具有较高的相似度,类间的相
似度较低。
7 聚类分析及R使用
相似度计算是根据类中对象的均值mean来进行
概 念 和 原 理
7 聚类分析及R使用
【例7.3】kmeans算法的R语言实现及模拟分析:模拟正态随机变量
7 聚类分析及R使用
7 聚类分析及R使用
模拟10个变量2000个样品的正态随机矩阵
(4)绘制 系统聚类图
(3)合并距离 最近两类为新类
(4)计算新类与各 类距离,若类个数为 1,转到第5步,否则
回到第3步
例7-1数据的系统聚类 最短距离法(采用欧氏距离)
例7-1数据的系统聚类
最长距离法(采用欧氏距离)
例7-1数据的系统聚类
7 聚类分析及R使用
系 一、计算距离阵: dist 统 聚 二、进行系统聚类: hclust 类 R 三、绘制聚类图: plot 语 言 四、画分类框: rect.hclust 步 骤 五、确认续例3.1,研究全国31个省、市、自治区2007年城镇居民生活消费 的分布规律,根据调查资料做区域消费类型划分。
模糊数学2模糊聚类分析方法模糊综合评判方法

❖ (1)单层次模糊综合评判模型 设X={x1,x2…xn}是综合评判因素所组成集合,
Y={y1,y2…yn}是评语所组成的集合。
R:X→Y rij=µR(xi,yj) 元素rij表示xi符合yj标准的程度。
A=(a1,a2…an)是各评判因素的权重分配,
则评判结果 B=A◦R.
例
我们对于某学校的校园网络一期建设情况进行评判,设包括三个因 素,即硬件建设,软件建设、人员培训,用论域U表示为:
0.38 0.8 0.67
0.49 1375 931源自0.380.80.67
0.93
0.95 0.67 0.94
0.9
0.94 0.67 0.95
1
0.99
0.99 0.45 0.55
0.99
1
0.99 0.45 0.55
0.99
0.45 0.55
0.99
0.45 0.55
1
0.45 0.55
0.45 1
0.49137 5931
0.93
0.9
1 0.67 0.94 0.38
0.38
0.38 0.95 0.94
0.67 1 0.67
0.94 0.67 1
0.8 0.67
0.8 0.67
0.8 0.67
0.67 0.94 0.67 0.95
0.49137 5931
0.38 0.8 0.67
0.49137 5931
较好
40% 30% 10%
可以
10% 20% 30%
不好
0 10% 60%
0.2 R ~
0.7
0.1
0
上表就构成模糊矩阵 R= 0
0.4 0.5 0.1
模糊聚类分析的理论(17页)

模糊聚类分析的理论模糊聚类分析是一种基于模糊数学理论的聚类方法,它允许数据点属于多个类别,并且每个类别都有一个模糊度。
这种方法在处理现实世界中的问题时非常有效,因为现实世界中的数据往往不是完全确定的,而是具有模糊性的。
模糊聚类分析的基本思想是将数据点分为若干个类别,使得每个数据点属于各个类别的程度不同。
这种程度可以用一个介于0和1之间的数来表示,0表示不属于该类别,1表示完全属于该类别。
这种模糊性使得模糊聚类分析能够更好地处理现实世界中的不确定性。
模糊聚类分析的理论基础是模糊集合论。
模糊集合论是一种扩展了传统集合论的数学理论,它允许集合的元素具有模糊性。
在模糊集合论中,一个元素属于一个集合的程度可以用一个隶属度函数来表示。
隶属度函数是一个介于0和1之间的数,它表示元素属于集合的程度。
模糊聚类分析的理论方法有很多种,其中最著名的是模糊C均值(FCM)算法。
FCM算法是一种基于目标函数的迭代算法,它通过最小化目标函数来得到最优的聚类结果。
目标函数通常是一个关于隶属度函数和聚类中心之间的距离的函数。
模糊聚类分析的理论应用非常广泛,它可以在很多领域中使用,例如图像处理、模式识别、数据挖掘等。
在图像处理中,模糊聚类分析可以用于图像分割、图像压缩等任务;在模式识别中,模糊聚类分析可以用于特征提取、分类等任务;在数据挖掘中,模糊聚类分析可以用于发现数据中的隐含规律、预测未来趋势等任务。
模糊聚类分析的理论还有很多需要进一步研究和发展的地方。
例如,如何提高模糊聚类分析的效率和准确性,如何处理大规模数据集,如何将模糊聚类分析与其他方法相结合等。
这些问题都需要进一步的研究和探索。
模糊聚类分析的理论是一种强大的聚类方法,它能够处理现实世界中的不确定性,并且具有广泛的应用前景。
通过不断的研究和发展,模糊聚类分析的理论将会更加完善,并且将会在更多的领域中得到应用。
模糊聚类分析的理论模糊聚类分析是一种基于模糊数学理论的聚类方法,它允许数据点属于多个类别,并且每个类别都有一个模糊度。
模糊聚类分析

查德 1965 年给出的定义:
定义:从论域 U 到闭区间0, 1 的任意一个映射:A :U 0, 1 ,对 任意u U ,u A Au , Au 0, 1 ,那么A 叫做 U 的一个模糊
子集, Au 叫做 u 的隶属函数,也记做A u 。
简单地可表达为:
设U是论域,称映射 A(x):U→[0,1]
39 C 以上的一人,x1 ;
如 果 规 定 37.5 C 以 下 的 不 算 发 烧 , 问 有 多 少 发 烧 病 人 ? 医 生 就 可 以 回 答 :
x1, x3, x4 , x5 ,但所谓“发烧”实际上是一个模糊概念,它存在程度上的不同,也就是
说要用隶属函数来描述。如果根据医师的经验规定,对“发烧”来说:
(1) AB AB; (2) ≤ A A; (3) (A∪B)= A∪B,(A∩B)= A∩B.
4、隶属函数的确定
1. 模糊统计方法 与概率统计类似,但有区别:若把概率
统计比喻为“变动的点”是否落在“不动的 圈”内,则把模糊统计比喻为“变动的圈” 是否盖住“不动的点”.
2. 指派方法 一种主观方法,一般给出隶属函数的解
一、模糊集及模糊关系
1、模糊问题的提出
在自然科学或社会科学研究中,存在着许多定义 不很严格或者说具有模糊性的概念。这里所谓的模 糊性,主要是指客观事物的差异在中间过渡中的不 分明性,如某一生态条件对某种害虫、某种作物的 存活或适应性可以评价为“有利、比较有利、不那 么有利、不利”;灾害性霜冻气候对农业产量的影 响程度为“较重、严重、很严重”,等等。这些通 常是本来就属于模糊的概念,为处理分析这些“模 糊”概念的数据,便产生了模糊集合论。
体温39 C 以上的隶属函数 x 1 ; 体温38.5 C 以上不到39 C 的隶属函数 x 0.9 ; 体温38 C 以上不到38.5 C 的隶属函数 x 0.7 ; 体温37.5 C 以上不到38 C 的隶属函数 x 0.4 ; 体温37.5 C 以下的隶属函数 x 0 ;
模糊聚类分析

模糊聚类分析----96845308-7160-11ec-a68e-7cb59b590d7d聚类分析就是将一个没有类别标记的样本集按照某种准则划分成若干个子集(类),使相似的样本尽可能归为一类,而不相似的样本尽可能划分到不同的类中。
由于在对样本集进行聚类的过程中,没有任何关于类别的先验知识,所以聚类分析属于无监督分类的范畴。
传统的聚类分析是一种硬划分,它严格地将每个待识别对象划分为一个类。
阶级划分的界限是明确的,具有非此即彼的性质。
在现实世界中,无论是一组对象根据其亲和力和相似性形成一个组,还是一个对象是否属于一个类别,其边界往往是不明确的,并且具有“这个和那个”的性质。
对于这种具有不确定性的聚类问题,模糊聚类分析提供了一种强有力的分析工具。
模糊聚类分析能够建立样本对于类别的不确定性描述,表达样本类属的中介性,已经成为聚类分析研究的主流。
粗略来讲,模糊聚类分析方法可分为两类:基于模糊等价关系的聚类方法和基于目标函数的聚类方法。
有时,这两类方法也结合起来使用。
一、数据预处理在模糊聚类分析中,我们称待分类的对象为样本。
要对样本进行合理的分类,首先应考虑样本的各种特性指标(观测数据)。
设有n个被分类对象,即样本集为x={x1,x2,…,xn}每一个xi有m个特性指标,即xi可表示为特性指标向量xi={xi1,xi2,…,xim}其中xij表示第i个样本的第j个特性指标。
于是,n个样本的特性指标矩阵为⎜⎜x21⎜M⎜⎜十、⎜n1x12lx1m⎜x22lx2m⎜xn2lxnm⎜⎜通常,我们也将样本集记为特性指标矩阵的形式,即x=(xij)n×m。
如果M个特征指标的维度和数量级不同,在运行过程中可能会突出一些大数量级特征指标的作用,而一些小数量级特征指标的作用可能会减少甚至被排除,导致每个特征指标的分类缺乏统一的尺度。
因此,为了消除不同特征指标单位和数量级的影响,当特征指标的维度和数量级不同时,通常会提前对各种指标值进行数据标准化(归一化),使每个指标值统一在一个共同的数值特征范围内。
第七章聚类分析

第七章聚类分析第七章聚类分析§7.1聚类分析方法一、基本思想根据一批样品的多个观测指标,具体找出一些能够度量样品或指标间相似程度的统计量,以这些统计量为划分类型的依据,把一些相似程度较大的样品聚为一类。
关系密切的聚为一个小的分类单位,关系疏远的聚为一个大的分类单位,直到把所有样品或指标都聚类完毕,这样就可以形成一个由小到大的分类系统。
聚类分析分类:按聚类变量分为样品聚类(Q聚类)和指标聚类(R聚类);按聚类方法分为系统聚类和动态聚类二、相似性测度1、对样品进行聚类时,相似性一般用距离来衡量:(1)绝对值距离(2)欧氏距离(欧几里得距离)(3)平方欧氏距离(4)切比雪夫距离(5)闵可夫斯基距离2、对指标进行聚类时,相似性通常根据相关系数或某种关联性来决定(1)夹角余弦(2)皮尔逊相关系数(简单相关系数)§7.2系统聚类法一、基本思想系统聚类法分类:聚集法和分解法。
聚集法:首先将每个个体各自看成一群,将最相似的两个群合并,重新计算群间距离,再将最相似的两群合并,每步减少一群,直至所有个体聚为一群为止。
分解法:首先将所有个体看成一群,将最不相似的个体分成两群,每步增加一群,直至所有个体各自成为一群。
二、群间距离的定义1、最短距离法将两变量间的距离定义为一个群中所有个体与另一个群中的所有个体距离最小者。
设为群中的任一个体,为群中的任一个体,表示个体与间的距离,表示群与群间的距离,则最短距离法把两群间距离定义为:设类合并成一个新类记为,则任一类的距离为最短距离法进行聚类分析的步骤如下:(1)定义样品间距离,计算样品的两两距离,得一距离阵记为,开始每一个样品即为一类,显然这时(2)找出距离最小元素,设为,则将合并成一个新类,记为,即(3)按类间距离计算新类与其他类的距离(4)重复(2)(3)步,直到所有元素并成一类。
如果某一步距离最小的元素不止一个,则对应这些最小元素的类可以同时合并。
例7.1设有六个样品,每个只测量一个指标,分别是1, 2,5,7,9,10,试用最短距离法将它们分类。
计量地理学第七章

§1 地理系统的聚类分析 一、地理系统分类的意义和作用 地理系统是一种多要素、多类型、多种区域组合在一起的、具有特殊结构
与功能的综合体。因此对地理系统的研究很重要的一个问题就是要进行 地理分区与分类。 目前,地理学的分类已从传统的、主要依靠经验和定性的知识进行分类而 转向应用数学的方法和电子计算机进行定量分类。这种方法被称为“数 值分类法”、“数量分类法”或“聚类分析”。 聚类分析是根据地理变量(或样品)的属性或特征的相似性、亲疏程度, 用数学的方法把它们逐步地分型划类,最后得到一个能反映个体之间或 群体之间的亲疏关系的分类系统。
第七章 地理系统的聚类分析与判别分析
在进行聚类分析时,首先要根据一批地理数据或指标找出能度量这些数据 或指标相似程度的统计量;然后以统计量作为划分类型的依据,把一些 相似程度较大的样品首先聚合为一类,把另一些聚合为另一类。依次类 推,关系密切的样品便聚合到一小类,而关系疏远的站点则聚合到一大 类,直到把所有的点都聚合完毕,便可逐步画成一张完整的分类系统图, 又称谱系图。
中可知,新疆地区6个站点可分为两大类:一类为准噶尔盆地类,一类 为塔里木盆地类。在准噶尔盆地类中,又分为哈巴河-阿勒泰型和克拉 玛依型。在塔里木盆地中也分为巴楚-莎车型和于田型。这种聚类方式 符合该区实际情况。
第七章 地理系统的聚类分析与判别分析
新疆6个地点的系统聚类图
第八步,在D(3)表中,最小元素为D69=0.693,再将G6和G9合成一新类 G10,G10={G6,G9}={G6,G4,G5},然后再计算G10与其他类间的距离
G10,8=1.337。 第九步,作D(4)表7-9。作法同上。
第七章 地理系统的聚类分析与判别分析
7 第七章 聚类分析

l
p
p
D pq
q
q
Dkl
Dkp k Dkq
k
24
(四)重心距离 递推公式 np nq n p nq 2 2 2 2 Dkl Dkp Dkq D pq 2 np nq n p nq (n p nq )
2 xi 和 x j分别是i和j的重 式中 Dij ( xi x j )T ( xi x j ), 心, i, j=k, l, p, q 。
5
7.2 模式相似性测度
7.2.1 距 离 测 度
7.2.2 相 似 测 度 7.2.3 匹 配 测 度
6
7.2.1 距离测度(差值测度)
Distance (or Dissimilarity) Measure
设特征矢量 x 和 y 的距离为 d ( x , y ) 则 d ( x , y ) 一般应满足如下公理
15
7.2.3 匹 配 测 度
若特征只有两个状态: 0 => 有此特征;1 => 无此特征。称之为二值特征。 对于给定的二值特征矢量x和y中的某两个相对应的 分量xi与yj 若xi=1, yj=1 ,则称 xi与yj (1-1)匹配; 若xi=1, yj=0 ,则称 (1-0)匹配; 若xi=0, yj=1 ,则称 (0-1)匹配; 若xi=0, yj=0 ,则称 (0-0)匹配。 对于二值n维特征矢量可定义如下相似性测度:
其中 1 m T (协方差矩阵的无偏估计) V ( x x )( x x ) i i m 1 i 1
1 m x xi m i 1
(均值向量的估计)
性质:对一切非奇异线性变换都是不变的。 即,具有坐标系比例、旋转、平移不变性, 并且从统计意义上尽量去掉了分量间的相关性。
聚类分析ppt课件

第一节 引言 第二节 相似性的量度 第三节 系统聚类分析法 第四节 K均值聚类分析 第五节 两步聚类分析
1
第一节 引言
什么是聚类分析? ❖ 聚类分析是根据“物以类聚”的道理,对样本或指
标进行分类的一种多元统计分析方法,它们讨论的 对象是大量的样本,要求能合理地按各自的特性进 行合理的分类,没有任何模式可供参考或依循,即 在没有先验知识的情况下进行的。
1.明考夫斯基距离
p
dij (q) (
X ik X jk )q 1/ q
k 1
明考夫斯基距离简称明氏距离。
(7.1)
13
按q的取值不同又可分成下面的几个式子
(1)绝对距离( q 1)
p
dij (1) X ik X jk k 1
பைடு நூலகம்
(7.2)
(2)欧氏距离( q 2)
p
dij (2) (
X ik X jk )2 1/ 2
22
第三节 系统聚类分析法
一 系统聚类的基本思想 二 类间距离与系统聚类法
23
一、系统聚类的基本思想
❖ 系统聚类的基本思想是:距离相近的样品(或变量)先聚成 类,距离相远的后聚成类,过程一直进行下去,每个样品( 或变量)总能聚到合适的类中。系统聚类过程是:假设总共 有n个样品(或变量),第一步将每个样品(或变量)独自 聚成一类,共有n类;第二步根据所确定的样品(或变量) “距离”公式,把距离较近的两个样品(或变量)聚合为一 类,其它的样品(或变量)仍各自聚为一类,共聚成n 1类 ;第三步将“距离”最近的两个类进一步聚成一类,共聚成 n 2类;……,以上步骤一直进行下去,最后将所有的样品 (或变量)全聚成一类。为了直观地反映以上的系统聚类过 程,可以把整个分类系统画成一张谱系图。所以有时系统聚 类也称为谱系分析。除系统聚类法外,还有有序聚类法、动 态聚类法、图论聚类法、模糊聚类法等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
五、基于模糊划分的模糊聚类法
1. c-划分
(1) 普通 c-划分
如果划分把普通集合分成 c 类,则此划分就叫普通 c-划分,
即:若设 U u1, u2 , , un , u j 的特征可表为 u j ( x j1, x j 2 , , x jm ) , 那么U的普通c-划分是指U的c个子集 Ai i 1, 2, , c (2 c n) 满足: (1) Ai U ;
于是,称
ni || u i u ||2 (c 1) i 1 F c ni || u ij u i ||2
c
i 1 j 1
(n c)
为F-统计量,其中 || u i u || 为第i类中元素 uij 与中心 u i 的距离. 可见,F-统计量的分子表征类与类间的距离,分母表征类
如果分类矩阵为
1 0 0 0 0 1 1 0 0 0 0 1
则对应着 U 的分类为 {u1}, {u2,u3}, {u4}.
记 V 为 c×n 实矩阵的集合,且
c n M c A A (aij ) Vcn , aij 0,1 , aij 1, 0 aij n i 1 j 1
1 x ni
i k
x
j 1
ni
jk
(k 1, 2,
, m)
i ) 为第 i 类元素的第 k 个特征的平均值, 而称 u i ( x1i , x2i , , xm
为第 i 类的聚类中心向量; u ( x1 , x2 , , xm ) 为全体元素的中 心向量,而
1 n xk x jk (k 1, 2, n j 1 , m)
2 4
R R ,直至出现R R ,则t R R
2k 2k 1 2k 2k 1
2k
四、基于模糊相似关系的直接聚类法
聚类原则是:ui与uj在λ水平同类当且仅当在相似矩阵R
的图中,存在一条权重不低于λ的路联结ui与uj.
1.最大树法
(1)画出以被分类元素为结点,以相似矩阵R的元素 rij 为权 重的一颗最大树; (2)取定 0,1 ,砍断权重低于λ的枝,得到一个不连通图, 各连通分支变构成了在λ水平上的分类.
(x (x
k 1 k 1 m
m
ik
x jk ) . x jk )
ik
(5)算术平均最小法
rij 2 ( xik x jk )
m k 1 m
(x
k 1
.
ik
x jk )
(6)几何平均最小法
rij
(x
k 1 m
m
ik
x jk )
k 1
xik x jk
ui ( xi1, xi 2 , , xim ), u j ( x j1, x j 2 , , x jm ) , 以它们的贴近度 D(ui,uj)
为其相似程度.
i) 格贴近度
i j 1, rij D(ui , u j ), i j
m m ( xik x jk ) 1 ( xik x jk ) , 其中 D(ui , u j ) k 1 k 1
rij
m m
(x
k 1 k 1
ik
xi )( x jk x j )
2 ( x x ) jk j k 1 m
,
2 ( x x ) ik i
1 m 1 m 其中 xi xik , x j x jk . m k 1 m k 1
(4)最大最小法
rij
ii) 距离贴近度
rij 1 c d (ui , u j ) ,
其中 c,a 为适当选择参数值,d(ui,uj) 为模糊集各种距离.
iii) 算术平均最小贴近度
rij D(ui , u j ) 2 ( xik x jk )
m k 1 m
x x
k 1 ik k 1
力,有代表性,并确定描述特征的变量。
分类事物的特征指标选择的如何,对分
类结果有直接的影响。
2.数据标准化(正规化)
令
xi x xi (i 1, 2,
, n)
1 n 其中,xi 为原始数据;x xi 是原始数据的均值; n i 1
1 n 2 是原始数据的标准差; ( x x ) i n 1 i 1
(9)绝对值倒数法
1, M rij m x x ik jk k 1 i j, i j,
M 适当选取使 rij 在 [0,1] 中且分散开
(10)绝对值减数法
rij 1 c xik x jk
k 1 m
(11)非参数法 令
xik xik xi , x jk x jk x j ,
一、模糊聚类分析
聚类分析:按照一定要求和原则对事物进行分类。 聚类:普通分类——清晰事物 模糊分类——带有模糊性的事物
三种模糊聚类方法:
传递闭包法——基于模糊等价关系; 直接聚类法——基于模糊相似关系; 模糊聚类法——基于模糊划分.
二、模糊聚类分析的步骤
1.选取特征指标
特征要有明确的意义,要有较强的分辨
* * * x , ai2i j xk , 并设 k 在第 l 行,用 ai1i j xk
* , aik i j xk
分别代替 ai1l , ai2l ,
, aik l 及其对称矩阵,并把 all 圈起来
继续此过程,到 k = n-1,得到 t(A) .
还有逐步平方法:
计算R R R
( xik , x jk 0).
(7)绝对值指数法
m rij exp xik x jk k 1
(8)指数相似系数法
2 1 xik x jk rij exp m s k
其中 sk 适当选择.
j 1
i 1
n
(3)
反过来,任一满足条件(1)、(2)、(3)的矩阵对应着U的一个 分类.
例如,设 U={u1,u2,u3,u4}, 若分类结果为 {u1}, {u2,u3}, {u4}, 则对应的分类矩阵为
u1 u2 u3 un 1 2 3 1 0 0 0 0 1 1 0 0 0 0 1
m
.
jk
(13)主观评定法
请有实际经验者直接对 ui,uj 的相似程度评分,作为 rij 的值.
通过标定求出相似系数后,便可得到以 rij
为元素的模糊相似矩阵 R(rij) .
4.聚类
选择一种合适的聚类方法,便可得到分类结果.
三、传递闭包法
1. 传递闭包法
根据标定所得模糊矩阵R,求出其传递闭包 t ( R), R t ( R)
方法2 令
rij m (i j ) Mm
其中 m min rij , M max rij , 于是 rij 0,1. i j i j
(2)夹角余弦法
rij
m
x
k 1
m
ik
x jk
x
k 1
2
ik
x
k 1
m
,
2 jk
如果rij中出现负值,也可采用上面方法调整. (3)相关系数法
j
, x jm ,然后对于 ui与 uj ,用 rij 表示 ui 与 uj 的
的相似程度,要求 0 rij 1, rii 1
当rij=0时,表示ui与uj截然不同;
当rij=1时,表示ui与uj可以等同(不能说是完全相同); rij可根据具体问题来选取。方法有:
(1)数量积法
1, rij 1 M i j
其中
1, u j Ai (u j 属于第i类) aij 0, u j Ai (u j 不属于第i类)
c
(1)
且满足 (1) j, aij 1 (表示每个uj必属于且仅属于一类); (2) (2) i, 0 aij 1 (表示每类Ai至少有一个元素);
i 1 c
(2) Ai Aj (i j)
这样的分类结果可以用一个 c×n 矩阵(称为 c-划分)来表示.
u1 u2 A1 a11 a22 ac 2 un a1n 1 a2 n 2 acn c
显然,对于给定的 U 及分类数 c ,类的分法不是唯 一的. Mc 包含了 U 的所有可能 c 类划分的结果,Mc 称为 将 U 分成 c 类的分类空间. 这样的分类是通常的分类,
xi 是数据处理后的数据。
3.标定
就是根据实际情况,按一个准则或某一种方法,给论域 U中的元素两两之间都赋以区间[0,1]内的一个数,叫做相 似系数。它的大小表征两个元素彼此接近或相似的程度。 设 u1 , u2 , 数据, x j1 , x j2 ,
, un 为待分类的对象,u 有m个刻划其特征的
最后用圆圈将它们及 a pp 圈起来.
R2
(3) 假定 A 中有圈的 k 行 (k 1, 2,
, n 1) 是 i1 ( 1), i2 ,
, ik
* 行. 而 xk 1 所在的列是 ij 列,在这些行中剩下的元素中
找最大元
* xk max (aij ) i i1 ,i2 , ,ik j i1 ,i2 , ,ik
内元素间的距离. 因此,F 值越大,说明分类越合理,与此分
类相对应的 F-统计量最大的阈值λ为最佳值.
求传递闭包的简便方法
设 A (aij )nn 为模糊相似矩阵,求 t(A).
a1 j ,假定 a1m max a1 j , 把 A 中的 a1m,am1,a11,amm 用圆圈 (1) 求 max 2 j n 2 j n