计算图像相似度——《Python也可以》之一
python实现查询重复图片功能

程序介绍通过比较大小是否相同,比较长和宽是否相同,比较每个像素是否相同进行图片的简单比较,把重复图片移动到新的文件夹中,实现图片去重功能程序源码import shutilimport numpy as npfrom PIL import Imageimport osimport timedef 比较图片大小(dir_image1, dir_image2):with open(dir_image1, "rb") as f1:size1 = len(f1.read())with open(dir_image2, "rb") as f2:size2 = len(f2.read())if(size1 == size2):result = "大小相同"else:result = "大小不同"return resultdef 比较图片尺寸(dir_image1, dir_image2):image1 = Image.open(dir_image1)image2 = Image.open(dir_image2)if(image1.size == image2.size):result = "尺寸相同"else:result = "尺寸不同"return resultdef 比较图片内容(dir_image1, dir_image2):image1 = np.array(Image.open(dir_image1))image2 = np.array(Image.open(dir_image2))if(np.array_equal(image1, image2)):result = "内容相同"else:result = "内容不同"return resultdef 比较两张图片是否相同(dir_image1, dir_image2):# 比较两张图片是否相同# 第一步:比较大小是否相同# 第二步:比较长和宽是否相同# 第三步:比较每个像素是否相同# 如果前一步不相同,则两张图片必不相同result = "两张图不同"大小= 比较图片大小(dir_image1, dir_image2)if(大小== "大小相同"):尺寸= 比较图片尺寸(dir_image1, dir_image2)if(尺寸== "尺寸相同"):内容= 比较图片内容(dir_image1, dir_image2)if(内容== "内容相同"):result = "两张图相同"return resultif __name__ == '__main__':time_start = time.time()load_path = os.getcwd()+"/data" # 要去重的文件夹save_path = os.getcwd()+"/err" # 空文件夹,用于存储检测到的重复的照片print(load_path+' '+save_path)# 获取图片列表file_map,字典{文件路径filename : 文件大小image_size} file_map = {}image_size = 0# 遍历filePath下的文件、文件夹(包括子目录)for parent, dirnames, filenames in os.walk(load_path):# for dirname in dirnames:# print('parent is %s, dirname is %s' % (parent, dirname))for filename in filenames:# print('parent is %s, filename is %s' % (parent, filename))#print('the full name of the file is %s' % os.path.join(parent, filename))image_size = os.path.getsize(os.path.join(parent, filename))file_map.setdefault(os.path.join(parent, filename), image_size)# 获取的图片列表按文件大小image_size 排序file_map = sorted(file_map.items(), key=lambda d: d[1], reverse=False)file_list = []for filename, image_size in file_map:if not filename.endswith('.db') and not filename.endswith('.lnk'):print(str(image_size)+' '+filename)file_list.append(filename)# 取出重复的图片file_repeat = []for currIndex, filename in enumerate(file_list):dir_image1 = file_list[currIndex]dir_image2 = file_list[currIndex + 1]result = 比较两张图片是否相同(dir_image1, dir_image2)if(result == "两张图相同"):file_repeat.append(file_list[currIndex + 1])currIndex += 1if currIndex >= len(file_list)-1:break# 将重复的图片移动到新的文件夹,实现对原文件夹降重for image in file_repeat:shutil.move(image, save_path)print("正在移除重复照片:", image)time_end = time.time()print("任务结束统计数量"+str(len(file_list)))print("任务结束用时(秒)"+str(time_end-time_start)) import shutilimport numpy as npfrom PIL import Imageimport osimport timedef 比较图片大小(dir_image1, dir_image2):with open(dir_image1, "rb") as f1:size1 = len(f1.read())with open(dir_image2, "rb") as f2:size2 = len(f2.read())if(size1 == size2):result = "大小相同"else:result = "大小不同"return resultdef 比较图片尺寸(dir_image1, dir_image2):image1 = Image.open(dir_image1)image2 = Image.open(dir_image2)if(image1.size == image2.size):result = "尺寸相同"else:result = "尺寸不同"return resultdef 比较图片内容(dir_image1, dir_image2):image1 = np.array(Image.open(dir_image1))image2 = np.array(Image.open(dir_image2))if(np.array_equal(image1, image2)):result = "内容相同"else:result = "内容不同"return resultdef 比较两张图片是否相同(dir_image1, dir_image2):# 比较两张图片是否相同# 第一步:比较大小是否相同# 第二步:比较长和宽是否相同# 第三步:比较每个像素是否相同# 如果前一步不相同,则两张图片必不相同result = "两张图不同"大小= 比较图片大小(dir_image1, dir_image2)if(大小== "大小相同"):尺寸= 比较图片尺寸(dir_image1, dir_image2)if(尺寸== "尺寸相同"):内容= 比较图片内容(dir_image1, dir_image2)if(内容== "内容相同"):result = "两张图相同"return resultif __name__ == '__main__':time_start = time.time()load_path = os.getcwd()+"/data" # 要去重的文件夹save_path = os.getcwd()+"/err" # 空文件夹,用于存储检测到的重复的照片print(load_path+' '+save_path)# 获取图片列表file_map,字典{文件路径filename : 文件大小image_size} file_map = {}image_size = 0# 遍历filePath下的文件、文件夹(包括子目录)for parent, dirnames, filenames in os.walk(load_path):# for dirname in dirnames:# print('parent is %s, dirname is %s' % (parent, dirname))for filename in filenames:# print('parent is %s, filename is %s' % (parent, filename))#print('the full name of the file is %s' % os.path.join(parent, filename))image_size = os.path.getsize(os.path.join(parent, filename))file_map.setdefault(os.path.join(parent, filename), image_size)# 获取的图片列表按文件大小image_size 排序file_map = sorted(file_map.items(), key=lambda d: d[1], reverse=False) file_list = []for filename, image_size in file_map:if not filename.endswith('.db') and not filename.endswith('.lnk'): print(str(image_size)+' '+filename)file_list.append(filename)# 取出重复的图片file_repeat = []for currIndex, filename in enumerate(file_list):dir_image1 = file_list[currIndex]dir_image2 = file_list[currIndex + 1]result = 比较两张图片是否相同(dir_image1, dir_image2)if(result == "两张图相同"):file_repeat.append(file_list[currIndex + 1])currIndex += 1if currIndex >= len(file_list)-1:break# 将重复的图片移动到新的文件夹,实现对原文件夹降重for image in file_repeat:shutil.move(image, save_path)print("正在移除重复照片:", image)time_end = time.time()print("任务结束统计数量"+str(len(file_list)))print("任务结束用时(秒)"+str(time_end-time_start))。
ssim指标 python

ssim指标 pythonSSIM(Structural Similarity Index)是一种衡量两幅图像相似度的指标,常用于评估图像处理算法的效果。
本文将介绍SSIM指标的原理和应用,并使用Python编程语言实现SSIM指标的计算。
一、SSIM指标简介SSIM指标是由Wang等人在2004年提出的,通过比较两幅图像的结构信息来评估它们的相似度。
与传统的PSNR(Peak Signal-to-Noise Ratio)指标相比,SSIM指标更能反映人眼对图像质量的感知。
SSIM指标综合考虑了亮度、对比度和结构三个方面的信息,通过计算亮度相似度、对比度相似度和结构相似度三个分量得到最终的相似度指标。
其中,亮度相似度衡量了两幅图像的平均亮度差异,对比度相似度衡量了两幅图像的对比度差异,结构相似度衡量了两幅图像结构的差异。
二、SSIM指标的计算公式SSIM指标的计算公式如下所示:SSIM(x, y) = (2μxμy + C1)(2σxy + C2) / (μx^2 + μy^2 + C1)(σx^2 + σy^2 + C2)其中,x和y分别表示两幅图像,μx和μy分别表示两幅图像的亮度均值,σx和σy分别表示两幅图像的亮度方差,σxy表示两幅图像的亮度协方差,C1和C2是常数,用于避免分母为零的情况。
三、Python实现SSIM指标的计算下面是使用Python编程语言实现SSIM指标的计算的示例代码:```pythonimport cv2def calculate_ssim(img1, img2):# 将图像转换为灰度图像gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)# 计算亮度均值、亮度方差和亮度协方差mean1, var1 = cv2.meanStdDev(gray1)mean2, var2 = cv2.meanStdDev(gray2)covar = cv2.mean(gray1 * gray2) - mean1 * mean2# 计算SSIM指标k1 = 0.01k2 = 0.03c1 = k1 ** 2c2 = k2 ** 2ssim = ((2 * mean1 * mean2 + c1) * (2 * covar + c2)) / ((mean1 ** 2 + mean2 ** 2 + c1) * (var1 ** 2 + var2 ** 2 +c2))return ssim[0][0]# 读取两幅图像img1 = cv2.imread('image1.jpg')img2 = cv2.imread('image2.jpg')# 计算SSIM指标ssim = calculate_ssim(img1, img2)print('SSIM:', ssim)```通过以上代码,可以计算得到两幅图像的SSIM指标。
Opencvpython图像处理-图像相似度计算
Opencvpython图像处理-图像相似度计算⼀、相关概念1. ⼀般我们⼈区分谁是谁,给物品分类,都是通过各种特征去辨别的,⽐如⿊长直、⼤⽩腿、樱桃唇、⽠⼦脸。
王⿇⼦脸上有⿇⼦,隔壁⽼王和⼉⼦很像,但是⼉⼦下巴涨了⼀颗痣和他妈⼀模⼀样,让你确定这是你⼉⼦。
还有其他物品、什么桌⼦带腿、镜⼦反光能在⾥⾯倒影出东西,各种各样的特征,我们通过学习、归纳,⾃然⽽然能够很快识别分类出新物品。
⽽没有学习训练过的机器就没办法了。
2. 但是图像是⼀个个像素点组成的,我们就可以通过不同图像之间这些差异性就判断两个图的相似度了。
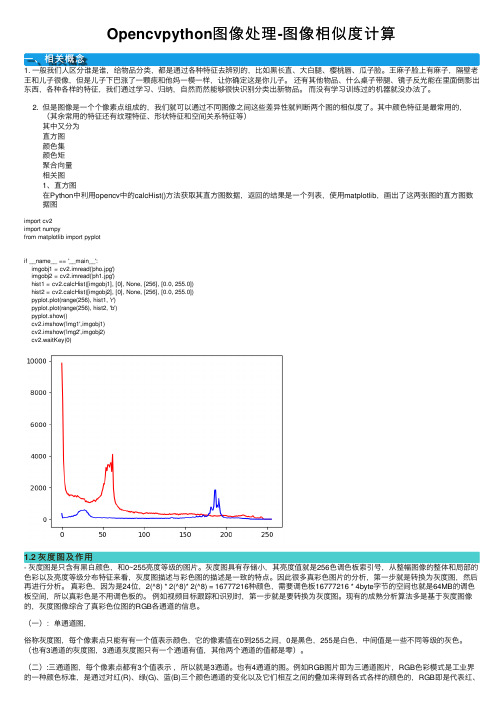
其中颜⾊特征是最常⽤的,(其余常⽤的特征还有纹理特征、形状特征和空间关系特征等)其中⼜分为直⽅图颜⾊集颜⾊矩聚合向量相关图1、直⽅图在Python中利⽤opencv中的calcHist()⽅法获取其直⽅图数据,返回的结果是⼀个列表,使⽤matplotlib,画出了这两张图的直⽅图数据图import cv2import numpyfrom matplotlib import pyplotif __name__ == '__main__':imgobj1 = cv2.imread('pho.jpg')imgobj2 = cv2.imread('ph1.jpg')hist1 = cv2.calcHist([imgobj1], [0], None, [256], [0.0, 255.0])hist2 = cv2.calcHist([imgobj2], [0], None, [256], [0.0, 255.0])pyplot.plot(range(256), hist1, 'r')pyplot.plot(range(256), hist2, 'b')pyplot.show()cv2.imshow('img1',imgobj1)cv2.imshow('img2',imgobj2)cv2.waitKey(0)1.2 灰度图及作⽤- 灰度图是只含有⿊⽩颜⾊,和0~255亮度等级的图⽚。
python 计算向量相似度的方法

python 计算向量相似度的方法【实用版3篇】《python 计算向量相似度的方法》篇1在Python 中,可以使用以下方法来计算向量相似度:1. 欧几里得距离(Euclidean Distance):使用欧几里得距离计算两个向量之间的相似度。
欧几里得距离是指两个点之间的直线距离。
在二维或三维空间中,可以使用勾股定理计算距离。
```pythonimport numpy as npdef euclidean_distance(vector1, vector2):return np.sqrt(np.sum((vector1 - vector2) ** 2))```2. 曼哈顿距离(Manhattan Distance):曼哈顿距离是指将一个向量映射到曼哈顿岛上,然后计算两个向量之间的最短路径。
```pythonimport numpy as npdef manhattan_distance(vector1, vector2):abs_diff = np.abs(vector1 - vector2)return np.sum(abs_diff)```3. 切比雪夫距离(Chebyshev Distance):切比雪夫距离是指在某些情况下,向量之间的欧几里得距离可能不是最短的。
切比雪夫距离是指在某些情况下,向量之间的最短距离。
```pythonimport numpy as npdef chebyshev_distance(vector1, vector2):# 计算两个向量的范数norm1 = np.linalg.norm(vector1)norm2 = np.linalg.norm(vector2)# 计算两个向量之间的夹角cos_theta = np.dot(vector1, vector2) / (norm1 * norm2)# 计算切比雪夫距离return norm1 * norm2 * (1 - cos_theta)```4. 哈达玛距离(Hamming Distance):哈达玛距离是指两个二进制向量之间的距离。
pytorch中六种常用的向量相似度评估方法

pytorch中六种常用的向量相似度评估方法在PyTorch中,计算向量之间的相似度有多种方法。
以下是六种常用的方法:1. 余弦相似度 (Cosine Similarity):这是通过计算两个向量的点积然后除以向量范数的乘积来计算的。
余弦相似度在0和1之间,其中0表示不相似,1表示完全相似。
```pythonimport torcha = ([1, 2, 3])b = ([4, 5, 6])cosine_similarity = (a b).sum() / ((a) (b))```2. 欧几里得距离 (Euclidean Distance):这是两点之间的直线距离。
距离为0表示两个向量完全相同,距离越大表示向量越不相似。
```pythoneuclidean_distance = (a - b)```3. 皮尔逊相关系数 (Pearson Correlation):这是衡量两个变量线性相关程度的指标,取值范围在-1到1之间。
接近1表示强正相关,接近-1表示强负相关,接近0表示无关。
```pythonpearson_correlation = _similarity(a, b)```4. 杰卡德相似系数 (Jaccard Similarity):用于比较两个集合的相似度。
它是交集大小除以并集大小。
取值范围在0和1之间,其中0表示不相似,1表示完全相似。
```pythonjaccard_similarity = ((a == b).type()) / float(())```5. 余弦距离 (Cosine Distance):它是余弦相似度的负值,所以距离为0表示完全相似,距离越大表示越不相似。
6. 汉明距离 (Hamming Distance):这是两个等长字符串(在这里可以看作是向量)之间不同位数的数量。
对于二进制向量,这可以很容易地计算出来。
```pythonhamming_distance = ((a != b).type()) / float(())```请注意,对于不同的数据和问题,可能需要选择不同的相似度度量方法。
python structural_similarity 参数

python structural_similarity 参数在Python中,`structural_similarity`函数是`skimage.metrics`模块中的一个函数,用于计算两个图像的结构相似度。
该函数接受三个参数:1. `img1`:第一个图像,可以是灰度图像或彩色图像。
2. `img2`:第二个图像,与`img1`具有相同的形状和类型。
3. `multichannel`:一个布尔值,指示是否将图像视为多通道(例如RGB)。
如果为True,则将计算多通道SSIM;如果为False,则将计算灰度SSIM。
函数返回两个图像的结构相似度分数,该分数介于-1和1之间。
值接近1表示两个图像非常相似,值接近-1表示两个图像非常不相似,值接近0表示两个图像之间的相似性中等。
下面是一个示例代码,演示如何使用`structural_similarity`函数:```pythonfrom skimage import io, metrics# 读取两个图像img1 = io.imread('image1.png')img2 = io.imread('image2.png')# 计算结构相似度分数ssim = metrics.structural_similarity(img1, img2, multichannel=True)# 输出结构相似度分数print('结构相似度分数:', ssim)```请注意,要使用`skimage.metrics`模块中的`structural_similarity`函数,您需要先安装`scikit-image`库。
您可以使用以下命令通过pip 安装它:```shellpip install scikit-image```。
python 曲线相似度计算

python 曲线相似度计算曲线相似度计算是衡量两个曲线或时间序列之间相似程度的一种方:1. 欧几里德距离(Euclidean Distance ):• 计算两个曲线上对应点之间的直线距离。
•公式:(,)D x y =2. 曼哈顿距离(Manhattan Distance ):• 计算两个曲线上对应点之间的城市街区距离(横纵坐标差的绝对值之和)。
• 公式:1(,)ni i i D x y x y ==−∑3. 动态时间规整(Dynamic Time Warping ,DTW ):• 考虑曲线上各点之间的时间延迟,寻找一种最优的对齐方式。
• DTW 考虑了曲线的局部结构,对于时间序列的相似性计算更具鲁棒性。
4. 余弦相似度(Cosine Similarity ):• 衡量两个曲线方向上的相似度,忽略其幅度。
•公式:(,)n i i x y Similarity x y ⋅=5. 皮尔逊相关系数(Pearson Correlation Coefficient ): • 衡量两个曲线之间的线性关系,范围在 -1 到 1 之间。
• 公式:cov(,)(,)x yx y x y ρσσ=⋅在 Python 中,你可以使用 NumPy 库来实现这些方法。
以下是一个简单的示例:import numpy as npfrom scipy.spatial.distance import euclideanfrom scipy.stats import pearsonr# 示例数据x = np.array([1, 2, 3, 4, 5])y = np.array([1, 2, 2, 4, 5])# 计算欧几里德距离euclidean_distance = euclidean(x, y)print("Euclidean Distance:", euclidean_distance)# 计算曼哈顿距离manhattan_distance = np.sum(np.abs(x - y))print("Manhattan Distance:", manhattan_distance)# 计算余弦相似度cosine_similarity = np.dot(x, y) / (np.sqrt(np.sum(x**2)) * np.sqrt(np.sum(y**2)))print("Cosine Similarity:", cosine_similarity)# 计算皮尔逊相关系数pearson_corr, _ = pearsonr(x, y)print("Pearson Correlation Coefficient:", pearson_corr) 对于DTW,你可能需要使用专门的库,如fastdtw 或dtw-python。
ssim指标 python

ssim指标 pythonSSIM(Structural Similarity Index)是一种用于测量两个图像之间结构相似性的指标,它在计算机视觉领域中被广泛应用。
本文将介绍SSIM指标的原理和应用,并提供使用Python计算SSIM的示例代码。
我们需要了解为什么需要衡量图像之间的结构相似性。
在许多图像处理任务中,比如图像压缩、图像质量评估和图像复原等,我们需要判断处理后的图像与原始图像之间的相似程度。
传统的图像相似度度量方法,如均方误差(MSE)和峰值信噪比(PSNR),只考虑了图像的亮度信息,而忽略了图像的结构信息。
而SSIM指标则综合考虑了亮度、对比度和结构三个方面的信息,因此更适合于评估图像的质量。
SSIM指标的计算方法比较复杂,涉及到图像的亮度、对比度和结构三个方面。
在这里,我们不会给出具体的计算公式,但可以简单介绍一下计算的步骤。
首先,计算图像的亮度、对比度和结构三个分量,然后对这三个分量计算加权平均值。
最后,将三个分量的加权平均值相乘,得到最终的SSIM值。
SSIM的取值范围为[-1,1],其中1表示两个图像完全相似,-1表示两个图像完全不相似。
在Python中,我们可以使用第三方库scikit-image来计算SSIM指标。
首先,我们需要安装scikit-image库,并导入相关的模块:```pythonpip install scikit-imagefrom skimage.measure import compare_ssimfrom skimage import io```接下来,我们可以加载两个图像,并使用compare_ssim函数计算它们之间的SSIM值:```pythonimage1 = io.imread('image1.jpg', as_gray=True)image2 = io.imread('image2.jpg', as_gray=True)ssim_value = compare_ssim(image1, image2)print("SSIM value:", ssim_value)```在上面的代码中,我们使用as_gray=True将彩色图像转换为灰度图像,因为SSIM指标只适用于灰度图像。
像素颜色相近计算 python

像素颜色相近计算 Python1. 背景介绍在图像处理和计算机视觉领域,像素颜色相近计算是一个非常重要的问题。
通过判断像素点之间的颜色相似度,我们可以实现图像的分割、目标检测、图像匹配等各种应用。
在本文中,我们将介绍使用Python编程语言来计算像素颜色相近度的方法和技巧。
2. 像素颜色的表示在计算机中,图像可以被表示为一个二维矩阵,每一个元素都是一个像素点。
每个像素点由红、绿、蓝三原色组成,通常用RGB值来表示,每个颜色通道的取值范围是0-255。
黑色可以表示为(0, 0, 0),白色可以表示为(255, 255, 255)。
对于彩色图像,每个像素点有三个通道的值,分别代表红、绿、蓝三种颜色。
3. 计算像素颜色相近度的方法为了判断两个像素点的颜色相近度,我们可以使用多种方法来计算它们之间的差异。
常用的方法包括欧几里得距离、曼哈顿距离、余弦相似度等。
这些方法可以简单粗暴地计算像素颜色之间的相似度,但在实际应用中,我们还需要考虑到人类视觉对颜色的敏感度,以及图像的特征和背景等因素。
4. Python中的像素颜色相近度计算在Python中,我们可以使用NumPy和OpenCV等库来进行像素颜色相近度的计算。
我们需要读取图像并将其转换为NumPy数组。
我们可以使用NumPy提供的函数来计算像素之间的差异,或者使用OpenCV提供的函数来计算像素之间的相似度。
另外,我们还可以使用Matplotlib等库来可视化像素颜色的相近度,以便更直观地理解图像的特征。
5. 实例演示下面,我们将演示一个简单的实例,来计算两个像素点之间的颜色相近度。
我们使用OpenCV库读取一张图像,并将其转换为NumPy 数组。
我们可以选择两个像素点,并使用欧几里得距离来计算它们之间的颜色相近度。
我们可以使用Matplotlib库来可视化这两个像素点的颜色,以及它们之间的相近度。
6. 总结本文介绍了使用Python来计算像素颜色相近度的方法和技巧。
python 向量相似度计算

python 向量相似度计算摘要:1.向量相似度计算概述2.Python中常用的向量相似度计算方法3.具体实现及示例正文:向量相似度计算是自然语言处理、推荐系统等领域中的重要技术。
它用于衡量两个向量之间的相似程度。
在Python中,有许多方法可以用于计算向量相似度。
本文将介绍几种常用的方法及其具体实现。
1.向量相似度计算概述向量相似度计算的目的在于找到两个向量之间的相似程度。
通常采用余弦相似度、欧氏距离、皮尔逊相关系数等指标进行衡量。
其中,余弦相似度计算公式如下:cos(θ) = (A · B) / (||A|| * ||B||)2.Python中常用的向量相似度计算方法(1)余弦相似度在Python中,可以使用sklearn库中的cosine_similarity函数计算余弦相似度。
示例代码如下:```pythonfrom sklearn.metrics.pairwise import cosine_similarity# 计算两个向量的余弦相似度vector2 = [...]similarity = cosine_similarity([vector1], [vector2])```(2)欧氏距离欧氏距离是最常见的距离度量方法。
在Python中,可以使用sklearn库中的euclidean函数计算欧氏距离。
示例代码如下:```pythonfrom sklearn.metrics.distance import euclidean# 计算两个向量的欧氏距离vector1 = [...]vector2 = [...]distance = euclidean(vector1, vector2)```(3)皮尔逊相关系数皮尔逊相关系数用于衡量两个向量之间的线性相关性。
在Python中,可以使用sklearn库中的pearson_correlation函数计算皮尔逊相关系数。
示例代码如下:```pythonfrom sklearn.metrics.pairwise import pearson_correlation# 计算两个向量的皮尔逊相关系数vector1 = [...]correlation = pearson_correlation([vector1], [vector2])```3.具体实现及示例以下为一个简单的示例,展示如何使用Python计算余弦相似度、欧氏距离和皮尔逊相关系数。
python实现连连看辅助(图像识别)

python实现连连看辅助(图像识别)个⼈兴趣,⽤python实现连连看的辅助程序,总结实现过程及知识点。
总体思路1、获取连连看程序的窗⼝并前置2、游戏界⾯截图,将每个⼀⼩图标切图,并形成由⼩图标组成的⼆维列表3、对图⽚的⼆维列表遍历,将⼆维列表转换成由数字组成的⼆维数组,图⽚相同的数值相同。
4、遍历⼆维数组,找到可消除的对象,实现算法:两个图标相邻。
(⼀条线连接)两个图标同⾏,同列,且中间的图标全部为空(数值为0)(⼀条线连接)两条线连接,转弯⼀次,路径上所有图标为空。
(⼆条线连接)三条线连接,转弯⼆次,路径上所有图标为空。
(三条线连接)分别点击两个图标,并将对应的⼆维数据值置为0实现过程中遇到的问题图⽚切割im = image.crop((left,top,right,bottom))//image.crop参数为⼀个列表或元组,顺序为(left,top,right,bottom)找到游戏运⾏窗⼝hdwd = win32gui.FindWindow(0,wdname)# 设置为最前显⽰win32gui.SetForegroundWindow(hdwd)窗⼝不要点击最⼩化,点击后⽆法弹出来。
图⽚缩放并转为灰度img1 = im1.resize((20, 20), Image.ANTIALIAS).convert('L')Image.ANTIALIAS 为抗锯齿的选项,图⽚⽆⽑边。
获取图⽚每个点的RGB值pi1 = list(img1.getdata())列表每个元素为⼀个三位数的值,分别代表该点的RGB值。
列表pi1共400个元素。
(因为图⽚为20*20)⿏标点击消除PyMouse.click()该⽅法默认双击,改为PyMouse.press() 或 PyMouse.release()判断图⽚相似汉明距离,平均哈希def compare_img(self,im1,im2):img1 = im1.resize((20, 20), Image.ANTIALIAS).convert('L')img2 = im2.resize((20, 20), Image.ANTIALIAS).convert('L')pi1 = list(img1.getdata())pi2 = list(img2.getdata())avg1 = sum(pi1) / len(pi1)avg2 = sum(pi2) / len(pi2)hash1 = "".join(map(lambda p: "1" if p > avg1 else "0", pi1))hash2 = "".join(map(lambda p: "1" if p > avg2 else "0", pi2))match = 0for i in range(len(hash1)):if hash1[i] != hash2[i]:match += 1# match = sum(map(operator.ne, hash1, hash2))# match 值越⼩,相似度越⾼return match计算直⽅图from PIL import Image# 将图⽚转化为RGBdef make_regalur_image(img, size=(8, 8)):gray_image = img.resize(size).convert('RGB')return gray_image# 计算直⽅图def hist_similar(lh, rh):assert len(lh) == len(rh)hist = sum(1 - (0 if l == r else float(abs(l - r)) / max(l, r)) for l, r in zip(lh, rh)) / len(lh)return hist# 计算相似度def calc_similar(li, ri):calc_sim = hist_similar(li.histogram(), ri.histogram())return calc_simif __name__ == '__main__':image1 = Image.open('1-10.jpg')image1 = make_regalur_image(image1)image2 = Image.open('2-11.jpg')image2 = make_regalur_image(image2)print("图⽚间的相似度为", calc_similar(image1, image2))# 值在[0,1]之间,数值越⼤,相似度越⾼图⽚余弦相似度from PIL import Imagefrom numpy import average, dot, linalg# 对图⽚进⾏统⼀化处理def get_thum(image, size=(64, 64), greyscale=False):# 利⽤image对图像⼤⼩重新设置, Image.ANTIALIAS为⾼质量的image = image.resize(size, Image.ANTIALIAS)if greyscale:# 将图⽚转换为L模式,其为灰度图,其每个像素⽤8个bit表⽰image = image.convert('L')return image# 计算图⽚的余弦距离def image_similarity_vectors_via_numpy(image1, image2):image1 = get_thum(image1)image2 = get_thum(image2)images = [image1, image2]vectors = []norms = []for image in images:vector = []for pixel_tuple in image.getdata():vector.append(average(pixel_tuple))vectors.append(vector)# linalg=linear(线性)+algebra(代数),norm则表⽰范数# 求图⽚的范数??norms.append(linalg.norm(vector, 2))a, b = vectorsa_norm, b_norm = norms# dot返回的是点积,对⼆维数组(矩阵)进⾏计算res = dot(a / a_norm, b / b_norm)return resif __name__ == '__main__':image1 = Image.open('1-9.jpg')image2 = Image.open('8-6.jpg')cosin = image_similarity_vectors_via_numpy(image1, image2)print('图⽚余弦相似度', cosin)# 值在[0,1]之间,数值越⼤,相似度越⾼,计算量较⼤,效率较低完整代码import win32guiimport timefrom PIL import ImageGrab , Imageimport numpy as npfrom pymouse import PyMouseclass GameAuxiliaries(object):def __init__(self):self.wdname = r'宠物连连看经典版2,宠物连连看经典版2⼩游戏,4399⼩游戏 - Google Chrome' # self.wdname = r'main.swf - PotPlayer'self.image_list = {}self.m = PyMouse()def find_game_wd(self,wdname):# 取得窗⼝句柄hdwd = win32gui.FindWindow(0,wdname)# 设置为最前显⽰win32gui.SetForegroundWindow(hdwd)time.sleep(1)def get_img(self):image = ImageGrab.grab((417, 289, 884, 600))# image = ImageGrab.grab((417, 257, 885, 569))image.save('1.jpg','JPEG')for x in range(1,9):self.image_list[x] = {}for y in range(1,13):top = (x - 1) * 38 + (x-2)left =(y - 1) * 38 +(y-2)right = y * 38 + (y-1)bottom = x * 38 +(x -1)if top < 0:top = 0if left < 0 :left = 0im_temp = image.crop((left,top,right,bottom))im = im_temp.crop((1,1,37,37))im.save('{}-{}.jpg'.format(x,y))self.image_list[x][y]=im# 判断两个图⽚是否相同。
python比较2张图片的相似度的方法示例

python⽐较2张图⽚的相似度的⽅法⽰例本⽂介绍了python ⽐较2张图⽚的相似度的⽅法⽰例,分享给⼤家,具体如下:#!/usr/bin/python# -*- coding: UTF-8 -*-import cv2import numpy as np#均值哈希算法def aHash(img):#缩放为8*8img=cv2.resize(img,(8,8),interpolation=cv2.INTER_CUBIC)#转换为灰度图gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#s为像素和初值为0,hash_str为hash值初值为''s=0hash_str=''#遍历累加求像素和for i in range(8):for j in range(8):s=s+gray[i,j]#求平均灰度avg=s/64#灰度⼤于平均值为1相反为0⽣成图⽚的hash值for i in range(8):for j in range(8):if gray[i,j]>avg:hash_str=hash_str+'1'else:hash_str=hash_str+'0'return hash_str#差值感知算法def dHash(img):#缩放8*8img=cv2.resize(img,(9,8),interpolation=cv2.INTER_CUBIC)#转换灰度图gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)hash_str=''#每⾏前⼀个像素⼤于后⼀个像素为1,相反为0,⽣成哈希for i in range(8):for j in range(8):if gray[i,j]>gray[i,j+1]:hash_str=hash_str+'1'else:hash_str=hash_str+'0'return hash_str#Hash值对⽐def cmpHash(hash1,hash2):n=0#hash长度不同则返回-1代表传参出错if len(hash1)!=len(hash2):return -1#遍历判断for i in range(len(hash1)):#不相等则n计数+1,n最终为相似度if hash1[i]!=hash2[i]:n=n+1return nimg1=cv2.imread('A.png')img2=cv2.imread('B.png')hash1= aHash(img1)hash2= aHash(img2)print(hash1)print(hash2)n=cmpHash(hash1,hash2)print '均值哈希算法相似度:'+ str(n)hash1= dHash(img1)hash2= dHash(img2)print(hash1)print(hash2)n=cmpHash(hash1,hash2)print '差值哈希算法相似度:'+ str(n)讲解相似图像搜索的哈希算法有三种:均值哈希算法差值哈希算法感知哈希算法均值哈希算法步骤缩放:图⽚缩放为8*8,保留结构,出去细节。
python 向量相似度计算

标题:Python中向量相似度计算方法及应用一、引言在数据分析和机器学习领域,向量相似度计算是一个非常重要的问题。
通过计算两个向量之间的相似度,我们可以衡量它们之间的关联程度,从而用于聚类分析、推荐系统等各种应用中。
Python作为一种功能强大且易于使用的编程语言,提供了丰富的库和工具,可以便捷地进行向量相似度计算。
本文将介绍Python中常用的向量相似度计算方法,并结合实际案例进行应用展示。
二、Python中常用的向量相似度计算方法1. 余弦相似度余弦相似度是一种常用的向量相似度计算方法,它通过计算两个向量的夹角余弦值来衡量它们之间的相似度。
在Python中,可以使用numpy库提供的函数来计算余弦相似度,例如:```pythonimport numpy as npdef cos_sim(a, b):dot_product = np.dot(a, b)norm_a = np.linalg.norm(a)norm_b = np.linalg.norm(b)return dot_product / (norm_a * norm_b)2. 欧氏距离欧氏距离是衡量两个向量之间距离的常用方法。
在Python中,可以使用scipy库提供的函数来计算欧氏距离,例如:```pythonfrom scipy.spatial import distancea = [1, 2, 3]b = [4, 5, 6]result = distance.euclidean(a, b)```3. 曼哈顿距离曼哈顿距离也是衡量两个向量之间距离的常用方法,它通过计算两个向量每个对应元素差的绝对值之和来求得。
在Python中,可以使用scipy库提供的函数来计算曼哈顿距离,例如:```pythonfrom scipy.spatial import distancea = [1, 2, 3]b = [4, 5, 6]result = distance.cityblock(a, b)4. 皮尔逊相关系数皮尔逊相关系数可以衡量两个向量之间的线性相关程度。
数据相似度指标 python

数据相似度指标 python数据相似度指标是衡量数据集合相似度的一种重要方式。
在数据分析和机器学习中,我们经常需要比较不同数据集之间的相似性,以便对它们进行分类、聚类或其他分析任务。
本文将介绍几个常用的数据相似度指标,以及如何在Python中使用它们。
1. 欧几里得距离欧几里得距离是最常用的相似度指标之一。
它基于数据点之间的距离计算相似度。
在二维空间中,欧几里得距离可以使用以下公式计算:d(x,y) = sqrt((x1-y1)^2 + (x2-y2)^2)在Python中,我们可以使用numpy库计算欧几里得距离:import numpy as npa = np.array([1,2,3])b = np.array([4,5,6])distance = np.sqrt(np.sum((a-b)**2))print(distance)输出:5.196152422712. 余弦相似度余弦相似度是一种基于向量夹角的相似度指标。
它计算两个向量之间的余弦值,越接近1表示两个向量越相似。
在Python中,我们可以使用scikit-learn库计算余弦相似度:from sklearn.metrics.pairwise import cosine_similaritya = np.array([1,2,3])b = np.array([4,5,6])similarity = cosine_similarity(a.reshape(1,-1),b.reshape(1,-1))print(similarity[0][0])输出:0.9746318461983. Jaccard相似度Jaccard相似度是一种用于比较集合相似度的指标。
它计算两个集合之间的交集与并集的比值,越接近1表示两个集合越相似。
在Python中,我们可以使用scipy库计算Jaccard相似度:from scipy.spatial.distance import jaccarda = np.array([1,2,3])b = np.array([2,3,4])similarity = 1 - jaccard(a,b)print(similarity)输出:0.5总结:本文介绍了三种常用的数据相似度指标:欧几里得距离、余弦相似度和Jaccard相似度。
ssim指标pytorch -回复

ssim指标pytorch -回复SSIM(结构相似性指标)是一种用于衡量图像质量的评估指标。
该指标通过比较原始图像与被评估图像之间的结构相似性,以及亮度和对比度的相似度,来评估图像质量的接近程度。
在本文中,我将一步一步地解释SSIM 指标的原理和应用,并介绍如何使用PyTorch来计算SSIM指标。
第一步:了解SSIM指标的原理SSIM指标是由Wang等人在2004年提出的。
该指标通过比较两幅图像的亮度、对比度和结构相似性来衡量它们之间的质量接近程度。
具体来说,SSIM指标通过以下三个方面来计算图像质量的相似度:1. 亮度相似度(Luminance similarity):亮度是指图像的明暗程度,亮度相似度衡量了两幅图像在亮度上的相似度。
2. 对比度相似度(Contrast similarity):对比度是指图像中不同区域之间亮度的差异程度,对比度相似度衡量了两幅图像在对比度上的相似度。
3. 结构相似度(Structure similarity):结构相似性衡量了两幅图像之间的结构变化程度,即图像中对象的位置和形状的相似度。
第二步:了解如何计算SSIM指标SSIM指标的计算可以通过以下步骤进行:1. 将原始图像和被评估图像分别转换为灰度图像。
这是因为SSIM指标主要关注图像的结构相似性,而不是颜色信息。
2. 将灰度图像分割为多个重叠的小块,称为块。
每个块的大小可以根据需要进行调整。
3. 对于每个块,计算亮度相似度、对比度相似度和结构相似度。
4. 对所有块的相似度进行平均。
5. 最终的SSIM指标是亮度相似度、对比度相似度和结构相似度的加权平均。
第三步:使用PyTorch计算SSIM指标使用PyTorch计算SSIM指标可以利用现有的计算图像相似度的函数。
首先,确保你已经安装了PyTorch库。
1. 导入必要的库:pythonimport torchimport torch.nn.functional as F2. 定义原始图像和被评估图像:pythonoriginal_image = torch.Tensor(...) # 原始图像evaluated_image = torch.Tensor(...) # 被评估图像3. 将图像转换为灰度图像:pythonoriginal_gray = original_image.mean(dim=0) # 将原始图像转换为灰度图像evaluated_gray = evaluated_image.mean(dim=0) # 将被评估图像转换为灰度图像4. 利用PyTorch的函数计算SSIM指标:pythonssim_value = F.mse_loss(original_gray, evaluated_gray).item() # 计算SSIM指标5. 打印结果:pythonprint("SSIM value:", ssim_value)通过上述步骤,我们可以使用PyTorch计算出两幅图像之间的SSIM指标。
Python计算相似度

博客园 用户登录 代码改变世界 密码登录 短信登录 忘记登录用户名 忘记密码 记住我 登录 第三方登录/注册 没有账户, 立即注册
Python计 算 相 似 度
1 #计算相似度 2 3 #欧式距离 4 # npve np.array(det_b) 5 # similirity=math.sqrt(((npvec1 - npvec2) ** 2).sum()) 6 # print('similirity:',similirity) 7 8 #余弦相似度 9 # def cos_sim(vector_a, vector_b): 10 # """ 11 # 计算两个向量之间的余弦相似度 12 # :param vector_a: 向量 a 13 # :param vector_b: 向量 b 14 # :return: sim 15 # """ 16 # vector_a = np.mat(vector_a) 17 # vector_b = np.mat(vector_b) 18 # num = float(vector_a * vector_b.T) 19 # denom = np.linalg.norm(vector_a) * np.linalg.norm(vector_b) 20 # cos = num / denom 21 # sim = 0.5 + 0.5 * cos 22 # return sim 23 24 #余弦值的范围在[-1,1]之间,值越趋近于1,代表两个向量的方向越接近; 25 ## 越趋近于-1,他们的方向越相反;接近于0,表示两个向量近乎于正交。 26 # vector_a, vector_b = np.array(det_a), np.array(det_b) 27 # similirity2=cos_sim(vector_a, vector_b) 28 # print('similirity2:',similirity2)
fsim python实现

fsim python实现在计算机图像处理中,图像的相似性度量是一个重要的问题。
其中,FSIM(Feature SIMilarity)是一种被广泛使用的图像相似性测量方法之一。
在本文中,我们将介绍FSIM在Python中的实现,并给出一些具体的代码示例。
1. 理解FSIM首先,让我们来了解一下FSIM的原理。
FSIM的主要思想是基于图像特征的多层次分析,通过对图像结构、亮度和颜色信息等的比较,计算图像之间的相似度。
在具体实现中,FSIM主要包含三个步骤:特征提取、特征加权和相似性度量。
在特征提取阶段,我们需要对图像进行高斯滤波,然后通过梯度算子提取图像的结构特征。
在特征加权和相似性度量阶段,我们需要根据图像的亮度和颜色信息进行加权,然后基于加权的特征向量计算欧式距离来度量图像之间的相似度。
2. 准备工作在实现FSIM之前,我们需要安装Python的一些图像处理库。
具体来说,我们需要安装numpy、cv2和scipy这三个包。
可以通过如下命令进行安装:```pip install numpypip install opencv-pythonpip install scipy```3. 实现FSIM接下来,我们将按照上述三个步骤,分别实现FSIM的特征提取、特征加权和相似性度量。
特征提取针对图像的特征提取,我们可以利用OpenCV的Sobel算子来计算图像的梯度。
具体来说,我们可以按照如下代码实现:```import cv2def grad_sobel(img):# 高斯滤波img = cv2.GaussianBlur(img, (5,5), 1.5)# Sobel算子grad_x = cv2.Sobel(img, cv2.CV_32F, 1, 0)grad_y = cv2.Sobel(img, cv2.CV_32F, 0, 1)# 计算梯度的幅值和方向grad_mag, grad_dir = cv2.cartToPolar(grad_x, grad_y)return grad_mag, grad_dir```特征加权针对特征加权,我们需要计算图像的亮度和颜色信息。
相似度计算python

相似度计算python相似度计算是指通过某种方法来衡量两个对象之间的相似程度。
在计算机领域中,相似度计算广泛应用于各种任务,比如文本相似度计算、图像相似度计算等。
本文将重点讨论在Python中进行相似度计算的方法和技巧。
一、文本相似度计算在自然语言处理领域,文本相似度计算是一个重要的任务。
常见的文本相似度计算方法包括余弦相似度、编辑距离、Jaccard相似系数等。
1. 余弦相似度余弦相似度是通过计算两个向量的夹角来衡量它们的相似度。
在Python中,可以使用scikit-learn库中的TfidfVectorizer类来计算文本的余弦相似度。
2. 编辑距离编辑距离是衡量两个字符串之间的相似度的一种方法。
在Python 中,可以使用NLTK库中的edit_distance函数来计算两个字符串的编辑距离。
3. Jaccard相似系数Jaccard相似系数是通过计算两个集合的交集与并集的比值来衡量它们的相似度。
在Python中,可以使用set类型来表示集合,并使用intersection和union方法来计算交集和并集。
二、图像相似度计算图像相似度计算是计算两个图像之间的相似程度的一种方法。
常见的图像相似度计算方法包括结构相似度指数(SSIM)、均方误差(MSE)等。
1. 结构相似度指数(SSIM)结构相似度指数是通过比较图像的亮度、对比度和结构来衡量它们的相似度。
在Python中,可以使用scikit-image库中的compare_ssim函数来计算图像的结构相似度指数。
2. 均方误差(MSE)均方误差是通过计算两个图像像素之间的差异来衡量它们的相似度。
在Python中,可以使用OpenCV库中的pareHist函数来计算图像的均方误差。
三、其他相似度计算方法除了文本和图像相似度计算外,还有其他领域的相似度计算方法。
比如,在推荐系统中,可以使用协同过滤算法来计算用户之间的相似度;在音频处理中,可以使用MFCC系数来计算音频之间的相似度。
ssim pytorch计算代码

ssim pytorch计算代码SSIM(pytorch)计算代码简介结构相似性(SSIM)是一种测量两幅图像的相似度的方法。
它在图像处理领域中广泛应用,特别是在图像压缩和图像过滤器等领域。
本文将介绍如何在PyTorch中使用SSIM来评估两幅图像的相似性。
SSIM的原理用图像I和J来代表两幅图片,计算结构相似性指数SSIM,可以使用以下公式:SSIM(I,J)= (2μIμJ + C1)(2 σIJ + C2) / (μI² + μJ² + C1)( σI² + σJ² + C2) 其中,μI、μJ分别是两幅图像的平均值;C1是常量,用来保证分母不为0;σI²、σJ²分别是两幅图像的方差,σIJ是I和J之间的协方差,C2也是常量,用来保证分母不为0。
代码实现首先,需要引入必要的库:import torch import torch.nn.functional as F接下来,我们定义一个函数来计算SSIM。
该函数需要输入两个张量,分别是I和J:def ssim(img1, img2, window_size=11,size_average=True): # 确定平均值和方差的公式window = create_window(window_size, img1.size(1)) mu1 = F.conv2d(img1, window,padding=window_size//2, groups=img1.size(1))mu2 = F.conv2d(img2, window,padding=window_size//2, groups=img1.size(1))mu1_sq = mu1.pow(2) mu2_sq = mu2.pow(2)mu1_mu2 = mu1 * mu2# 计算方差,协方差以及常量 sigma1_sq = F.conv2d(img1 * img1, window,padding=window_size//2, groups=img1.size(1)) -mu1_sq sigma2_sq = F.conv2d(img2 * img2, window, padding=window_size//2,groups=img1.size(1)) - mu2_sq sigma12 =F.conv2d(img1 * img2, window,padding=window_size//2, groups=img1.size(1)) -mu1_mu2# 计算结构相似性指数 C1 = 0.01 ** 2 C2 = 0.03 ** 2 ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / \ ((mu1_sq +mu2_sq + C1) * (sigma1_sq + sigma2_sq + C2)) if size_average: return ssim_map.mean()else: returnssim_map.mean(1).mean(1).mean(1)在上述代码中,我们使用了torch.nn.functional模块中的F.conv2d函数来卷积窗口,以计算平均值、方差以及协方差。
python 余弦相似度卷积

python 余弦相似度卷积
Python中,余弦相似度是一种常见的计算相似度的方法,而卷
积则是一种常见的信号处理方法。
在某些情况下,我们可能需要将这两种方法结合起来使用,以实现更复杂的功能。
例如,我们可以使用余弦相似度来计算两个文本段落之间的相似度,并使用卷积来处理文本段落中的语言模式。
具体而言,我们可以将文本段落表示为向量,并使用余弦相似度来计算它们之间的相似度。
然后,我们可以使用卷积来处理这些向量,以捕获它们之间的语言模式。
除了文本处理外,余弦相似度卷积也可以应用于图像处理、音频处理等领域。
在图像处理中,我们可以使用余弦相似度来计算两幅图像之间的相似度,并使用卷积来处理图像中的局部模式。
在音频处理中,我们可以使用余弦相似度来计算两段音频之间的相似度,并使用卷积来处理音频中的频率模式。
总之,余弦相似度卷积是一种功能强大的方法,可以用于处理各种类型的数据。
如果您对此感兴趣,建议您深入学习这些方法,并尝试将它们应用于您的项目中。
- 1 -。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
转化为规则图像之后,可以调用 img.histogram() 方法获得直方图数据,如上文两图的直方图如下:
得到规则图像之后,图像的相似度计算就转化为直方图的距离计算了,本文依照如下公式进行直方图相似度的定量度量:
29 li, ri = make_regalur_image(Image.open(lf)), make_regalur_image(Image.open(rf))
30 return calc_similar(li, ri)
31
32 if __name__ == '__main__':
33 path = r'test/TEST%d/%d.JPG'
16 for i in xrange(0, w, pw) /
17 for j in xrange(0, h, ph)]
相应地,把计算相似图的函数calc_similar()修改为:
23 def calc_similar(li, ri):
24 # return hist_similar(li.histogram(), ri.histogram())
找到一组很好的测试图片之后,我们需要再给 Python 环境安装一个图像库,我的选择是PIL(Python image library)。PIL 为 Python 提供了图像处理功能,并且支持数十种图像格式。(关于 PIL 的介绍,可以查看我之前的文章《用Python做图像处理》/lanphaday/archive/2007/10/28/1852726.aspx )
关于《Python也可以》系列:这是我打算把这几年里做的一些实验和代码写出来,涉及的面比较广,也比较杂,可能会有图像处理、检索等方面的内容,也会有中文分词、文本分类、拼音、纠错等内容。毫不掩饰地说:在博客发这系列文章的原因在于宣传 python ,所以这系列文章都会带有源码和相关的测试用例,这也是特色之一。但这系列文章都是“浅尝辄止”的,不会深入到专属领域,只是为了表明 python 功能很强大,不仅适合于web 或者 game 开发,也适合于科学研究。
22
23 def calc_similar(li, ri):
24 return hist_similar(li.histogram(), ri.histogram())
短短十行代码不到就完成了图片相似度的计算,再加上从硬盘读取图像的函数和测试代码,也不过二十行上下:
28 def calc_similar_by_path(lf, rf):
图像的相似度你要学习和研究更好的算法,也请记住 Python 也能帮助你哦~
本实验的所有代码和测试用例请猛击这里下载,再次感谢提供图片支持的西门同学。
有问题不明白?请教Google大神吧! 输入您的搜索字词 提交搜索表单 Web
25 return sum(hist_similar(l.histogram(), r.histogram()) for l, r in zip(split_image(li), split_image(ri))) / 16.0
进行这样的改进后,算法已经能够在一定的程序上反映色彩的局倍分布和颜色所处的位置,可以比较好的弥补全局直方图算法的不足。新的算法计算出来的结果如下:
虽然这两张图片大小都是一样的,但为了通用性,我们有必要把所有的图片都统一到特别的规格,在这里我选择是的256x256的分辨率。
因为 PIL 为 RGB 模式的图像计算的 histogram 样点数为 768,计算量并不算太大,所以本文就直接使用,没有再作降维处理了。
6 def make_regalur_image(img, size = (256, 256)):
要计算图像的相似度,肯定是要找出图像的特征。这样跟你描述一个人的面貌:国字脸,浓眉,双眼皮,直鼻梁,大而厚的嘴唇。Ok,这些特征决定了这个人跟你的同事、朋友、家人是不是有点像。图像也一样,要计算相似度,必须抽象出一些特征比如蓝天白云绿草。常用的图像特征有颜色特征、纹理特征、形状特征和空间关系特征等。颜色特征的算是最常用的,在其中又分为直方图、颜色集、颜色矩、聚合向量和相关图等。直方图能够描述一幅图像中颜色的全局分布,而且容易理解和实现,所以入门级的图像相似度计算都是使用它的;作为一篇示例性的“浅尝辄止”的文章,我们也不例外。
可以看到它们的色彩局部分布有相当大的不同,但事实上它们的全局直方图相当相似:
虽然从直方图来看两图是极其相似的,但上述算法计算出相似度为70.4%的结果肯定是不可接受的。那么,怎么样才能克服直方图的缺点呢?答案是把规则图像分块,再对相应的小块进行相似度计算,最后根据各小块的平均相似度来反映整个图片的相似度。在实验中,我们把规则图像分为 4x4 块,每块的分辨率为 64x64:
Sim(G,S)=,其中G,S为直方图,N 为颜色空间样点数
转换为相应的 Python 代码如下:
19 def hist_similar(lh, rh):
20 assert len(lh) == len(rh)
21 return sum(1 - (0 if l == r else float(abs(l - r))/max(l, r)) for l, r in zip(lh, rh))/len(lh)
test_case_1: 63.322%
test_case_2: 66.950%
test_case_3: 51.990%
test_case_4: 70.401%
test_case_5: 32.755%
test_case_6: 42.203%
结合我们肉眼对测试用例的观察,这个程序工作得还算可以。不过 test_case_4 就暴露了直方图的缺点:它只是图像中颜色的全局分布的描述,无法描述颜色的局部分布和色彩所处的位置。test_case_4 的规则图如下:
在进行我们试验之前,我们需要找到一批图片来作为测试用例。我上穷碧落下黄泉,最后终于在我的前同事西门的博客(/johnal1 )找到了一系列他在公司组织的年度旅游时去西藏林芝拍的一组风光图片(/johnal1/blog/static/9394912200812105654784 ),实在是难得之佳品,简直可以说得到了它们我们的实验已经完成了90%。哦耶!下面来看一下我们最重要的一组照片(两张):
test_case_1: 56.273%
test_case_2: 54.925%
test_case_3: 49.326%
test_case_4: 40.254%
test_case_5: 30.776%
test_case_6: 39.460%
可以看到,test_case_4的相似度由 70.4% 下降到 40.25%,基本上跟肉眼的判断是切合的;另外其它图像的相似度略有下降,这是因为加入了位置因子之的影响。从而可见基于分块的直方图相似算法是简单有效的。
分割图像的代码为:
9 def split_image(img, part_size = (64, 64)):
10 w, h = img.size
11 pw, ph = part_size
12
13 assert w % pw == h % ph == 0
14
15 return [img.crop((i, j, i+pw, j+ph)).copy() /
34 for i in xrange(1, 7):
35 print 'test_case_%d: %.3f%%'%(i, calc_similar_by_path('test/TEST%d/%d.JPG'%(i, 1), 'test/TEST%d/%d.JPG'%(i, 2))*100)
那么这样做的效果到底怎么样呢?且来看看测试结果(测试用例和代码请猛击这里下载):
计算图像相似度——《Python也可以》之一计算图像相似度——《Python也可以》之一
计算图像相似度——《Python也可以》之一
声明:本文最初发表于赖勇浩(恋花蝶)的博客/lanphaday,如蒙转载,敬请确保全文完整,未经同意,不得用于商业用途。