图像相似度计算
origin曲线相似度

origin曲线相似度摘要:一、曲线相似度的概念与背景1.曲线相似度的起源2.曲线相似度在实际应用中的重要性二、曲线相似度的计算方法1.欧氏距离法2.曲率法3.特征点法4.基于遗传算法的曲线匹配方法三、曲线相似度计算方法的比较与分析1.各种方法的优缺点2.适用场景和局限性四、曲线相似度在实际应用领域的案例1.在计算机图形学中的应用2.在图像处理中的应用3.在数据挖掘中的应用正文:曲线相似度是一个在数学、计算机科学和工程领域中广泛使用的概念。
它的主要目的是衡量两个曲线之间的相似程度,从而在数据分析和处理中起到关键作用。
在计算曲线相似度时,有多种方法可供选择。
欧氏距离法是最常见的计算方法之一,它通过计算两个曲线之间的直线距离来衡量它们的相似度。
然而,对于复杂的曲线形状,欧氏距离法可能无法提供准确的相似度评估。
因此,曲率法和特征点法等其他方法也逐渐受到关注。
曲率法是通过计算曲线上某一点处的曲率来描述曲线形状的。
这种方法适用于评估具有相似曲率的曲线之间的相似度。
特征点法则是通过提取曲线的特征点(如拐点、尖点等)来计算相似度。
这种方法对于具有不同曲率的曲线具有较好的适用性。
此外,基于遗传算法的曲线匹配方法也是一种有效的计算曲线相似度的方法。
这种方法通过优化搜索策略,实现曲线之间的精确匹配,从而得到较高的相似度评估结果。
在实际应用中,不同的曲线相似度计算方法各有优缺点。
欧氏距离法简单易实现,但对于复杂曲线形状的匹配效果较差;曲率法和特征点法则能更好地适应不同曲线的特点,但计算复杂度较高。
因此,在实际应用中,需要根据具体需求和场景选择合适的曲线相似度计算方法。
曲线相似度在许多领域都有广泛应用。
例如,在计算机图形学中,曲线相似度可以用于评估图形模型之间的相似性,从而实现高效的模型检索和重用;在图像处理中,曲线相似度可以用于精确匹配图像中的形状,从而实现目标检测和识别;在数据挖掘中,曲线相似度可以用于评估时间序列数据之间的相关性,从而发现潜在的数据规律和关联。
人脸识别算法 欧氏距离 余弦相似度

人脸识别算法欧氏距离余弦相似度一、人脸识别算法的基本原理人脸识别算法是一种利用人脸特征信息进行身份识别的技术。
它主要通过采集图像或视频中的人脸信息,然后提取特征并对比库中已存在的人脸信息,最终确定身份的一种技术手段。
在人脸识别算法中,欧氏距离和余弦相似度是两种常用的相似度计算方法。
在我们深入讨论这两种方法之前,我们需要先了解一下它们的基本原理。
欧氏距离是一种用于度量向量之间的距离的方法,其计算公式为:d(x, y) = √((x1 - y1)² + (x2 - y2)² + ... + (xn - yn)²) 。
在人脸识别算法中,常用欧氏距离来度量两张人脸图像之间的相似度,即通过比较特征向量之间的欧氏距离来识别身份。
与欧氏距离相似,余弦相似度也是一种用于度量向量之间的相似度的方法,其计算公式为:sim(x, y) = (x·y) / (‖x‖·‖y‖),其中x和y分别为两个向量。
在人脸识别算法中,余弦相似度常用于比较两个特征向量之间的夹角,来度量它们之间的相似度。
二、人脸识别算法中的欧氏距离应用在人脸识别算法中,欧氏距离常被用于度量两张人脸图像之间的相似度。
通过将人脸图像转化为特征向量,并使用欧氏距离来比较这些向量之间的距离,来确定是否为同一人。
举例来说,当系统需要识别一个人脸时,它首先会将该人脸图像提取特征并转化为特征向量,然后与存储在数据库中的特征向量进行比较。
通过计算欧氏距离,系统可以得出两个特征向量之间的距离,从而确定该人脸是否为已知身份。
三、人脸识别算法中的余弦相似度应用除了欧氏距离外,余弦相似度在人脸识别算法中也有着广泛的应用。
与欧氏距离不同,余弦相似度更侧重于计算两个向量之间的夹角,而非距离。
在人脸识别算法中,余弦相似度被用来比较两个特征向量之间的夹角,通过夹角的大小来确定它们之间的相似度。
这种方法能够更好地捕捉到特征向量之间的方向性信息,从而提高识别的准确性。
Opencvpython图像处理-图像相似度计算
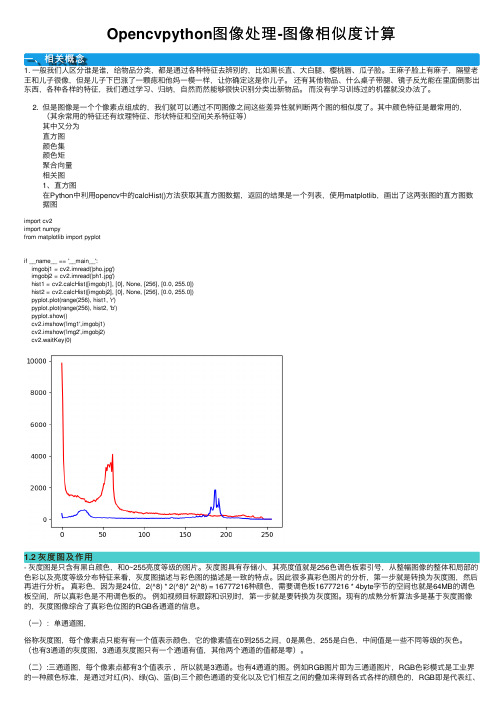
Opencvpython图像处理-图像相似度计算⼀、相关概念1. ⼀般我们⼈区分谁是谁,给物品分类,都是通过各种特征去辨别的,⽐如⿊长直、⼤⽩腿、樱桃唇、⽠⼦脸。
王⿇⼦脸上有⿇⼦,隔壁⽼王和⼉⼦很像,但是⼉⼦下巴涨了⼀颗痣和他妈⼀模⼀样,让你确定这是你⼉⼦。
还有其他物品、什么桌⼦带腿、镜⼦反光能在⾥⾯倒影出东西,各种各样的特征,我们通过学习、归纳,⾃然⽽然能够很快识别分类出新物品。
⽽没有学习训练过的机器就没办法了。
2. 但是图像是⼀个个像素点组成的,我们就可以通过不同图像之间这些差异性就判断两个图的相似度了。
其中颜⾊特征是最常⽤的,(其余常⽤的特征还有纹理特征、形状特征和空间关系特征等)其中⼜分为直⽅图颜⾊集颜⾊矩聚合向量相关图1、直⽅图在Python中利⽤opencv中的calcHist()⽅法获取其直⽅图数据,返回的结果是⼀个列表,使⽤matplotlib,画出了这两张图的直⽅图数据图import cv2import numpyfrom matplotlib import pyplotif __name__ == '__main__':imgobj1 = cv2.imread('pho.jpg')imgobj2 = cv2.imread('ph1.jpg')hist1 = cv2.calcHist([imgobj1], [0], None, [256], [0.0, 255.0])hist2 = cv2.calcHist([imgobj2], [0], None, [256], [0.0, 255.0])pyplot.plot(range(256), hist1, 'r')pyplot.plot(range(256), hist2, 'b')pyplot.show()cv2.imshow('img1',imgobj1)cv2.imshow('img2',imgobj2)cv2.waitKey(0)1.2 灰度图及作⽤- 灰度图是只含有⿊⽩颜⾊,和0~255亮度等级的图⽚。
相关相似度计算公式

相关相似度计算公式嘿,说起相关相似度计算公式,这可是个挺有意思的话题。
咱们先来说说啥是相关相似度。
简单来讲,它就是用来衡量两个东西或者两组数据在某些方面有多相似的一个工具。
就好比你有两个苹果,要看看它们长得有多像,颜色、大小、形状等等,这时候就需要一个办法来比较,相关相似度计算公式就派上用场啦。
比如说,在数学里,我们经常会遇到要比较两组数据的情况。
假设现在有两组学生的考试成绩,一组是甲班的,一组是乙班的。
那怎么知道这两个班的成绩相似程度呢?这就得靠相关相似度计算公式啦。
它的计算方法有好多呢,常见的像皮尔逊相关系数、余弦相似度等等。
咱先说说皮尔逊相关系数吧。
这玩意儿呢,会把两组数据的每个值都考虑进去,然后通过一系列复杂但有规律的运算,给你一个数值,这个数值就在 -1 到 1 之间。
如果接近 1,那就说明这两组数据相似度高,正相关;要是接近 -1 呢,就是负相关,相似度低;要是接近 0 ,那就是没啥明显的相关性。
我记得有一次,我在给学生们讲这个知识点的时候,有个特别调皮的小家伙举了个特别有趣的例子。
他说:“老师,这就像我和我同桌,有时候我们想法特别像,那就是正相关;有时候我俩老吵架,想法完全不一样,那就是负相关;要是有时候好有时候不好,那就是没啥相关。
”这一下子把全班同学都逗乐了,但是仔细一想,还真就是这么个理儿。
再来说说余弦相似度。
它呢,主要是看两个向量之间的夹角。
夹角越小,相似度就越高。
这就好比两个人走路的方向,如果方向差不多,那相似度就高;要是方向差得老远,那相似度就低。
在实际应用中,相关相似度计算公式用处可大了。
比如说在数据分析里,能帮我们找出潜在的规律和趋势;在图像识别中,可以判断两张图片是不是相似;在推荐系统里,能根据你的喜好给你推荐类似的东西。
就拿推荐系统来说吧,你在网上买东西或者看视频的时候,是不是经常会发现系统给你推荐的东西好像都是你喜欢的?这背后可就是相关相似度计算公式在起作用呢。
相似图片搜索原理

相似图片搜索原理
相似图片搜索是一种基于图像内容的检索技术,旨在根据输入的查询图像找到与其相似的其他图像。
其原理主要包括以下几个步骤:
1. 特征提取:通过计算图像的特征向量来描述其内容特征。
这些特征可以是局部的,如SIFT、SURF等,也可以是全局的,如颜色直方图、形状描述子等。
特征提取的目的是将图像从高维空间映射到低维向量空间,以便后续的相似度计算。
2. 相似度计算:通过比较查询图像的特征向量与数据库中其他图像的特征向量来计算它们之间的相似度。
常用的相似度度量方法包括欧氏距离、余弦相似度等。
相似度计算的目的是衡量两个图像之间在内容上的相似程度。
3. 数据库搜索:根据相似度计算的结果,将与查询图像最相似的图像从数据库中按照相似度排序进行检索。
对于大规模的数据库,可能会使用索引结构(如KD-Tree、局部敏感哈希等)
来加速搜索过程。
4. 结果展示:将检索得到的相似图像按照一定的规则展示给用户,通常会将这些图像以缩略图的形式呈现,并给出相似度的排名。
相似图片搜索的原理主要是通过提取图像的特征向量并比较相似度来实现的,并没有直接使用标题文字进行搜索。
相似图片
搜索可以在许多应用场景中发挥作用,如商品推荐、版权保护、图像鉴定等。
多维张量 计算相似度

多维张量计算相似度多维张量是一种高维度的数据结构,它在计算机科学和数据分析领域中具有广泛的应用。
通过计算多维张量之间的相似度,我们可以得到一些有关这些数据之间的关系的信息。
本文将介绍多维张量的概念和计算相似度的方法,并探讨其在实际应用中的一些应用案例。
让我们来了解一下多维张量的概念。
多维张量是一种扩展了矩阵的数据结构,可以表示多个维度的数据。
与矩阵不同的是,多维张量可以有任意数量的维度。
例如,一个二维的矩阵可以表示为一个2维张量,而一个三维的立方体可以表示为一个3维张量。
在实际应用中,多维张量可以用来表示图像、音频、文本等复杂的数据。
计算多维张量之间的相似度可以帮助我们理解它们之间的关系。
常用的相似度计算方法有欧氏距离、余弦相似度和相关系数等。
欧氏距离是最常见的相似度计算方法之一,它衡量了两个张量之间的距离。
余弦相似度则是衡量两个张量之间的夹角,它可以用来衡量它们之间的相似程度。
相关系数则可以用来衡量两个张量之间的线性相关性。
在实际应用中,多维张量的相似度计算可以应用于各种领域。
例如,在图像处理领域,可以使用多维张量的相似度计算方法来进行图像检索和图像分类。
通过计算不同图像之间的相似度,我们可以找到与给定图像最相似的其他图像。
这对于图像搜索引擎和图像识别系统来说非常有用。
另一个应用领域是自然语言处理。
在文本分析和情感分析中,可以使用多维张量的相似度计算方法来比较不同文本之间的相似度。
通过计算文本之间的相似度,我们可以找到与给定文本内容最相似的其他文本。
这对于信息推荐系统和舆情分析来说非常重要。
除了图像处理和自然语言处理,多维张量的相似度计算方法还可以应用于其他领域,如推荐系统、生物信息学和社交网络分析等。
通过计算多维张量之间的相似度,我们可以发现隐藏在数据背后的模式和规律,从而帮助我们做出更准确的决策和预测。
总结起来,多维张量的相似度计算是一种重要的数据分析方法,它可以帮助我们理解复杂数据之间的关系。
OpenCV实战(1)——图像相似度算法(比对像素方差,感知哈希算法,模板匹配(OCR数字。。。

OpenCV实战(1)——图像相似度算法(⽐对像素⽅差,感知哈希算法,模板匹配(OCR数字。
如果需要处理的原图及代码,请移步⼩编的GitHub地址 传送门: 如果点击有误:https:///LeBron-Jian/ComputerVisionPractice 最近⼀段时间学习并做的都是对图像进⾏处理,其实⾃⼰也是新⼿,各种尝试,所以我这个门外汉想总结⼀下⾃⼰学习的东西,图像处理的流程。
但是动起笔来想总结,⼀下却不知道⾃⼰要写什么,那就把⾃⼰做过的相似图⽚搜索的流程整理⼀下,想到什么说什么吧。
⼀:图⽚相似度算法(对像素求⽅差并⽐对)的学习1.1 算法逻辑1.1.1 缩放图⽚ 将需要处理的图⽚所放到指定尺⼨,缩放后图⽚⼤⼩由图⽚的信息量和复杂度决定。
譬如,⼀些简单的图标之类图像包含的信息量少,复杂度低,可以缩放⼩⼀点。
风景等复杂场景信息量⼤,复杂度⾼就不能缩放太⼩,容易丢失重要信息。
根据⾃⼰需求,弹性的缩放。
在效率和准确度之间维持平衡。
1.1.2 灰度处理 通常对⽐图像相似度和颜⾊关系不是很⼤,所以处理为灰度图,减少后期计算的复杂度。
如果有特殊需求则保留图像⾊彩。
1.1.3 计算平均值 此处开始,与传统的哈希算法不同:分别依次计算图像每⾏像素点的平均值,记录每⾏像素点的平均值。
每⼀个平均值对应着⼀⾏的特征。
1.1.4 计算⽅差 对得到的所有平均值进⾏计算⽅差,得到的⽅差就是图像的特征值。
⽅差可以很好的反应每⾏像素特征的波动,既记录了图⽚的主要信息。
1.1.5 ⽐较⽅差 经过上⾯的计算之后,每张图都会⽣成⼀个特征值(⽅差)。
到此,⽐较图像相似度就是⽐较图像⽣成⽅差的接近成程度。
⼀组数据⽅差的⼤⼩可以判断稳定性,多组数据⽅差的接近程度可以反应数据波动的接近程度。
我们不关注⽅差的⼤⼩,只关注两个⽅差的差值的⼤⼩。
⽅差差值越⼩图像越相似!1.2 代码:import cv2import matplotlib.pyplot as plt#计算⽅差def getss(list):#计算平均值avg=sum(list)/len(list)#定义⽅差变量ss,初值为0ss=0#计算⽅差for l in list:ss+=(l-avg)*(l-avg)/len(list)#返回⽅差return ss#获取每⾏像素平均值def getdiff(img):#定义边长Sidelength=30#缩放图像img=cv2.resize(img,(Sidelength,Sidelength),interpolation=cv2.INTER_CUBIC)#灰度处理gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#avglist列表保存每⾏像素平均值avglist=[]#计算每⾏均值,保存到avglist列表for i in range(Sidelength):avg=sum(gray[i])/len(gray[i])avglist.append(avg)#返回avglist平均值return avglist#读取测试图⽚img1=cv2.imread("james.jpg")diff1=getdiff(img1)print('img1:',getss(diff1))#读取测试图⽚img11=cv2.imread("durant.jpg")diff11=getdiff(img11)print('img11:',getss(diff11))ss1=getss(diff1)ss2=getss(diff11)print("两张照⽚的⽅差为:%s"%(abs(ss1-ss2))) x=range(30)plt.figure("avg")plt.plot(x,diff1,marker="*",label="$jiames$") plt.plot(x,diff11,marker="*",label="$durant$") plt.title("avg")plt.legend()plt.show()cv2.waitKey(0)cv2.destroyAllWindows() 两张原图: 图像结果如下:img1: 357.03162469135805img11: 202.56193703703704两张照⽚的⽅差为:154.469687654321 实验环境开始设置了图⽚像素值,⽽且进⾏灰度化处理,此⽅法⽐对图像相似对不同的图⽚⽅差很⼤,结果很明显,但是对⽐⽐较相似,特别相似的图⽚不适应。
两组数据相似度计算方法

两组数据相似度计算方法相似度计算是数据分析领域中一个重要的任务,它可以帮助我们了解不同数据集之间的相似程度或相关性。
在实际应用中,相似度计算可以用于推荐系统、搜索引擎、图像识别等领域。
本文将介绍两种常用的相似度计算方法——欧氏距离和余弦相似度,并分析它们的优缺点及适用场景。
一、欧氏距离(Euclidean Distance)欧氏距离是最常见的相似度计算方法之一,它计算的是两个数据点之间的直线距离。
假设有两个数据点A(x1, y1)和B(x2, y2),那么它们之间的欧氏距离可以用以下公式表示:欧氏距离= √((x2 - x1)² + (y2 - y1)²)欧氏距离越小,表示两个数据点越相似。
欧氏距离的优点是计算简单,直观易懂,而且可以适用于多维数据。
然而,欧氏距离对数据的尺度敏感,如果不同维度的数据尺度差异较大,会导致距离计算结果不准确。
二、余弦相似度(Cosine Similarity)余弦相似度是另一种常用的相似度计算方法,它计算的是两个向量之间的夹角余弦值。
假设有两个向量A(x1, y1)和B(x2, y2),那么它们之间的余弦相似度可以用以下公式表示:余弦相似度 = (x1 * x2 + y1 * y2) / (√(x1² + y1²) * √(x2² + y2²))余弦相似度的取值范围在[-1, 1]之间,值越接近1表示两个向量越相似。
余弦相似度的优点是不受数据尺度影响,适用于处理大规模数据。
然而,余弦相似度忽略了向量的绝对值,只关注它们的方向,可能导致计算结果不准确。
三、对比分析欧氏距离和余弦相似度是两种常用的相似度计算方法,它们分别适用于不同的场景。
欧氏距离适用于维度较小且尺度相似的数据,计算简单直观,但对数据尺度敏感;而余弦相似度适用于维度较大且尺度差异较大的数据,不受数据尺度影响,但忽略了向量的绝对值。
在实际应用中,我们需要根据具体情况选择合适的相似度计算方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
图像相似度计算
图像相似度计算主要用于对于两幅图像之间内容的相似程度进行打分,根据分数的高低来判断图像内容的相近程度。
可以用于计算机视觉中的检测跟踪中目标位置的获取,根据已有模板在图像中找到一个与之最接近的区域。
然后一直跟着。
已有的一些算法比如BlobTracking,Meanshift,Camshift,粒子滤波等等也都是需要这方面的理论去支撑。
还有一方面就是基于图像内容的图像检索,也就是通常说的以图检图。
比如给你某一个人在海量的图像数据库中罗列出与之最匹配的一些图像,当然这项技术可能也会这样做,将图像抽象为几个特征值,比如Trace变换,图像哈希或者Sift特征向量等等,来根据数据库中存得这些特征匹配再返回相应的图像来提高效率。
下面就一些自己看到过的算法进行一些算法原理和效果上的介绍。
(1)直方图匹配。
比如有图像A和图像B,分别计算两幅图像的直方图,HistA,HistB,然后计算两个直方图的归一化相关系数(巴氏距离,直方图相交距离)等等。
这种思想是基于简单的数学上的向量之间的差异来进行图像相似程度的度量,这种方法是目前用的比较多的一种方法,第一,直方图能够很好的归一化,比如通常的256个bin条的。
那么两幅分辨率不同的图像可以直接通过计算直方图来计算相似度很方便。
而且计算量比较小。
这种方法的缺点:
1、直方图反映的是图像像素灰度值的概率分布,比如灰度值为200的像素有多少个,但是对于这些像素原来的位置在直方图中并没有体现,所以图像的骨架,也就是图像内部到底存在什么样的物体,形状是什么,每一块的灰度分布式什么样的这些在直方图信息中是被省略掉得。
那么造成的一个问题就是,比如一个上黑下白的图像和上白下黑的图像其直方图分布是一模一样的,其相似度为100%。
2、两幅图像之间的距离度量,采用的是巴氏距离或者归一化相关系数,这种用分析数学向量的方法去分析图像本身就是一个很不好的办法。
3、就信息量的道理来说,采用一个数值来判断两幅图像的相似程度本身就是一个信息压缩的过程,那么两个256个元素的向量(假定直方图有256个bin条)的距离用一个数值表示那么肯定就会存在不准确性。
下面是一个基于直方图距离的图像相似度计算的Matlab Demo和实验结果.
%计算图像直方图距离
%巴氏系数计算法
M=imread('1.jpg');
N=imread('2.jpg');
I=rgb2gray(M);
J=rgb2gray(N);
[Count1,x]=imhist(I);
[Count2,x]=imhist(J);
Sum1=sum(Count1);Sum2=sum(Count2);
Sumup = sqrt(Count1.*Count2);
SumDown = sqrt(Sum1*Sum2);
Sumup = sum(Sumup);
figure(1);
subplot(2,2,1);imshow(I);
subplot(2,2,2);imshow(J);
subplot(2,2,3);imhist(I);
subplot(2,2,4);imhist(J);
HistDist=1-sqrt(1-Sumup/SumDown)
通过上图可以看到这种计算图像相似度的方法确实存在很大的弊端。
然而很多人也对于这种方法进行了修改,比如FragTrack算法,具体可以参见这篇论文《》。
其中对图像分成横纵的小块,然后对于每一个分块搜索与之最匹配的直方图。
来计算两幅图像的相似度,融
入了直方图对应位置的信息。
但是计算效率上很慢。
还有一种是计算一个图像外包多边形,一般得到跟踪图像的前景图后计算其外包多边形,根据外包多边形做Delauny三角形分解,然后计算每个三角形内部的直方图,对于这两个直方图组进行相似距离计算。
这样就融入了直方图的位置信息。
(2)数学上的矩阵分解
图像本身就是一个矩阵,可以依靠数学上矩阵分解的一些知识来获取矩阵中一些代表这个矩阵元素值和分布的一些鲁棒性特征来对图像的相似度进行计算。
最常用的一般是SVD分解和NMF分解。
下面简单介绍下SVD分解的一些性质,如果需要探究的更深入一点网上有一些相关文献,读者可以去探究的更清楚:
<1> 奇异值的稳定性
<2> 奇异值的比例不变性
<3> 奇异值的旋转不变性
<4> 奇异值的压缩性
综上所述,可以看出奇异值分解是基于整体的表示。
图像奇异值特征向量不但具有正交变换、旋转、位移、镜像映射等代数和几何上的不变性,而且具有良好的稳定性和抗噪性,广泛应用于模式识别与图像分析中。
对图像进行奇异值分解的目的是:得到唯一、稳定的特征描述;降低特征空间的维数;提高抵抗干扰和噪声的能力。
但是由于奇异值分解得到的奇异矢量中有负数存在所以不能很好的解释其物理意义。
非负矩阵分解(NMF):
NMF的主要思想是将非负矩阵分解为可以体现图像主要信息的基矩阵与系数矩阵,并且可以对基矩阵赋予很好的解释,比如对人脸的分割,得到的基向量正是人的“眼睛”,“鼻子”等主要概念特征,源图像表示为这些特征的加权组合。
所以NMF算法也在人脸识别等场合中发挥着巨大的作用。
下面一个实验说明了SVD+NMF数学上的这些分解在图像相似度判定方面的应用,这个跟我目前的课题有关细节方面就不再透露更多了。
当然基于数学上的矩阵特征值计算的还有很多方法比如Trace变换,不变矩计算等等,当然如果有需要这方面资料的同学可以找我,我可以进行相关的帮助。
(3)基于特征点的图像相似度计算
每一幅图像都有自己的特征点,这些特征点表征图像中比较重要的一些位置,比较类似函数的拐点那种,通常比较常用的有Harris角点和Sift特征点。
那么将得到的图像角点进行比较,如果相似的角点数目较多,那么可以认为这两幅图像的相似程度较高。
这里主要介绍基于Sift算子。
对于Sift的原理和代码可以参见David Lower的网站。
David G Lowe Sift网站
那么我们就可以通过找到匹配点的个数来判断两幅图像是否一致,这个算法的好处是对于一个物体,两个不同角度下得到的照片依然可以找到很多的匹配点,我也一直认为是一个综合来说结果相对较为准确的方法,但是由于每个特征点需要计算一个长度不小的特征值,也造成了该算法的时间消耗比较大。
所以不常用于实时的视频处理。
这个算法还有一个好处就是可以通过找到的匹配特征点进行图像校正。
关于使用Sift做图像校正请参见我的另外一篇博文。
我当时对于比如左边图像,找到50个特征点,如果其中有60%以上的与右边的匹配上了,认为两幅图像是相似图像。
上图使用Sift找到的匹配对应点,然后通过仿射变换的6维参数计算,然后逆变换得到校正后的图像,效果蛮不错的,可见Sift对于抗旋转和噪声的效果确实很好。
对于Sift也不能全部相信,一般使用RANSAC对于错误匹配点去除可以达到更好的效果,当然目前也有很多对SIFT进行改进的算法。
希望有这方面研究的可以多多交流。