自然语言处理NPL 最大概率分词算法
常用nlp算法

常用nlp算法NLP(自然语言处理)是计算机科学和人工智能领域的一个重要分支,其主要目的是让计算机能够理解、分析和生成人类语言。
在NLP中,有许多常用的算法,本文将对其中一些进行详细介绍。
一、文本分类算法1. 朴素贝叶斯分类器朴素贝叶斯分类器是一种基于概率统计的分类算法,它假设所有特征都是相互独立的,并且每个特征对结果的影响是相同的。
在文本分类中,每个单词可以看作一个特征,而文本可以看作一个包含多个特征的向量。
朴素贝叶斯分类器通过计算每个类别下每个单词出现的概率来确定文本所属类别。
2. 支持向量机(SVM)SVM是一种常用的二分类算法,在文本分类中也有广泛应用。
它通过找到一个最优超平面来将不同类别的数据分开。
在文本分类中,可以将每个单词看作一个维度,并将所有文本表示为一个高维向量。
SVM通过最大化不同类别之间的间隔来确定最优超平面。
3. 决策树决策树是一种基于树形结构的分类算法,它通过对数据进行逐步划分来确定每个数据点所属的类别。
在文本分类中,可以将每个单词看作一个特征,并将所有文本表示为一个包含多个特征的向量。
决策树通过逐步划分特征来确定文本所属类别。
二、情感分析算法1. 情感词典情感词典是一种包含大量单词及其情感极性的词典,它可以用来对文本进行情感分析。
在情感词典中,每个单词都被标注为积极、消极或中性。
在进行情感分析时,可以统计文本中出现积极和消极单词的数量,并计算出总体情感倾向。
2. 深度学习模型深度学习模型是一种基于神经网络的模型,它可以自动从数据中学习特征并进行分类或回归。
在情感分析中,可以使用卷积神经网络(CNN)或长短期记忆网络(LSTM)等深度学习模型来对文本进行分类。
三、实体识别算法1. 基于规则的方法基于规则的方法是一种手工编写规则来进行实体识别的方法。
在这种方法中,可以通过正则表达式或其他模式匹配算法来识别特定类型的实体。
例如,在医疗领域中,可以通过匹配特定的病症名称或药品名称来识别实体。
最大概率分词算法

最大概率分词算法1.介绍分词是中文自然语言处理领域中非常重要的一项任务。
它是将一段连续的中文文本切割成有意义的词语序列。
在中文语言中,没有像英文单词之间有空格的间隔,因此中文分词技术可以将长串的文本切割成有意义的语调单元,是中文处理中的必要工作。
目前,中文的分词方法主要有基于词典的分词方法和基于统计学的分词方法。
基于词典的方法是指先将文本切成词,然后查找与语料中的词典匹配,来找到匹配的词语。
基于统计学的方法是指利用机器学习的算法来进行词语切割,例如最大熵词典、条件随机场等等。
本文将会介绍其中的一种经典的基于统计学的分词算法——最大概率分词算法。
2.最大概率分词算法原理最大概率分词算法是一个基于字符串概率模型的统计学分词算法,使用条件概率的方式确定文本中的最优切分点,最大化整个文本的概率值。
该算法的核心思想是在一个给定的文本中,找到一种词语分割的方式,使得分割出的词语结果正好等于所有信息单元的总集合,同时使得文本的分割概率最大。
首先,我们将文本分割成一个个的词语,假设有序的词语序列为$w_1,w_2,w_3....w_n$。
那么,我们的目标就是找到一个概率最大的序列$w_1,w_2,w_3....w_n$。
根据贝叶斯公式,可以将该问题转化为寻找概率最大的分割序列,即:$$P(w_1,w_2,w_3....w_n)=\maxP(w_1,w_2,w_3....w_k)P(w_{k+1},w_{k+2},w_{k+3}...w_n \midw_1,w_2,w_3....w_k)$$其中,$P(w_{k+1},w_{k+2},w_{k+3}...w_n \midw_1,w_2,w_3....w_k)$表示在知道$w_1,w_2,w_3....w_k$的情况下,$w_{k+1},w_{k+2},w_{k+3}...w_n$出现的条件概率值。
因为这是一个递归的问题,所以我们可以将该问题转换为子问题,即:$$P(w_1,w_2,w_3....w_n)=\max _{k=1}^nP(w_1,w_2,w_3....w_k)P(w_{k+1},w_{k+2},w_{k+3}...w_n \midw_1,w_2,w_3....w_k) $$当然,要计算最大概率,必须要考虑文本中各个词语的概率。
自然语言处理中的分词技术使用教程

自然语言处理中的分词技术使用教程自然语言处理(Natural Language Processing,NLP)是计算机科学与人工智能领域中一个重要的研究方向。
分词技术是NLP中的关键步骤之一,它能够将连续的自然语言文本分割成词汇序列,为后续的语言处理任务提供基础。
本教程将向您介绍自然语言处理中的分词技术和相关算法,重点解释常见的中文分词方法,并提供实际的示例和代码供您实践。
一、分词技术概述分词技术可以帮助我们解决自然语言文本的理解问题,使得计算机能够对文本进行更加深入的处理。
而中文分词则是NLP领域中一个具有挑战性的任务,因为中文没有像英文那样明确的词边界。
中文分词方法可以分为基于规则的方法和基于统计的方法两大类。
基于规则的方法通过事先定义规则和词典,使用正则表达式、有限状态机等技术进行分词。
基于统计的方法则通过分析大规模语料库中词汇的概率分布,利用统计模型对文本进行分词。
二、常见的中文分词算法1. 正向最大匹配法(Forward Maximum Match,FMM)正向最大匹配法是一种基于规则的分词算法。
它从文本的起始位置开始,找到满足词库中最长词的片段,并将其切分。
然后,从当前片段的末尾开始,重复这个过程,直到处理完整个文本。
2. 逆向最大匹配法(Backward Maximum Match,BMM)逆向最大匹配法是正向最大匹配法的变种,它从文本的末尾开始,逐渐向前匹配最长的词。
通过不断向前匹配,直至匹配完整个文本。
3. 双向最大匹配法(Bi-directional Maximum Match,BIMM)双向最大匹配法结合了正向和逆向最大匹配法的优点,它同时从文本的起始位置和末尾位置开始匹配最长的词。
然后,选择匹配词个数较少的结果作为最终的分词结果。
4. 隐马尔可夫模型(Hidden Markov Model,HMM)隐马尔可夫模型是一种统计模型,它可以对分词问题进行建模和求解。
通过训练大规模语料库,可以得到每个词在语料库中的概率分布。
自然语言处理中的文本分类算法介绍

自然语言处理中的文本分类算法介绍自然语言处理(Natural Language Processing,NLP)是人工智能领域中的一个重要分支,旨在使计算机能够理解和处理人类语言。
文本分类是NLP中的一个关键任务,它涉及将文本数据分为不同的类别或标签。
文本分类算法在各种应用中都得到了广泛的应用,如垃圾邮件过滤、情感分析、主题识别等。
文本分类算法的目标是根据文本的内容将其归类到特定的类别中。
以下是几种常见的文本分类算法:1. 朴素贝叶斯算法(Naive Bayes):朴素贝叶斯算法是一种基于贝叶斯定理的概率分类算法。
它假设特征之间相互独立,因此被称为“朴素”。
在文本分类中,朴素贝叶斯算法将文本表示为词袋模型,计算每个类别的概率,并选择具有最高概率的类别作为分类结果。
朴素贝叶斯算法简单高效,适用于大规模文本分类任务。
2. 支持向量机算法(Support Vector Machines,SVM):支持向量机算法是一种二分类算法,通过在特征空间中找到最优超平面来进行分类。
在文本分类中,特征通常是词语或短语,而超平面的目标是在不同类别的文本之间找到最大的间隔。
SVM算法在处理高维数据和非线性问题时表现出色,但对于大规模数据集可能存在计算复杂性。
3. 决策树算法(Decision Trees):决策树算法通过构建树状结构来进行分类。
每个节点代表一个特征,分支代表不同的取值,而叶节点代表最终的类别。
在文本分类中,决策树算法可以基于词语或短语的存在与否进行划分。
决策树算法易于理解和解释,但对于高维数据和过拟合问题可能存在挑战。
4. 随机森林算法(Random Forest):随机森林算法是一种集成学习方法,通过组合多个决策树来进行分类。
在文本分类中,随机森林算法可以通过对不同的特征子集和样本子集进行随机采样来构建多个决策树,并通过投票或平均预测结果来进行最终分类。
随机森林算法具有较好的泛化能力和抗过拟合能力。
5. 深度学习算法(Deep Learning):深度学习算法是一类基于神经网络的机器学习算法,通过多层神经网络来进行特征学习和分类。
npl自然语言处理常用算法模型

npl自然语言处理常用算法模型NPL自然语言处理常用算法模型自然语言处理(Natural Language Processing,NLP)是计算机科学与人工智能领域中的一个重要研究方向,旨在使计算机能够理解和处理人类的自然语言。
NLP常用算法模型是指在NLP领域中被广泛使用的一些算法模型,它们能够处理文本数据并从中提取有用的信息。
本文将介绍几个常用的NLP算法模型。
1. 词袋模型(Bag of Words)词袋模型是一种简单而常用的NLP算法模型,它将文本表示为一个词汇表,并统计每个词在文本中出现的频率。
词袋模型忽略了单词的顺序和上下文信息,只关注单词的频率。
通过词袋模型,我们可以将文本数据转化为数值型数据,以便于计算机处理。
2. TF-IDF模型TF-IDF(Term Frequency-Inverse Document Frequency)模型是一种用于评估一个词对于一个文档集或一个语料库中的一个特定文档的重要程度的统计方法。
TF-IDF模型综合考虑了一个词在文档中的频率(Term Frequency)和在整个语料库中的逆文档频率(Inverse Document Frequency),从而计算出一个词的权重。
TF-IDF模型常用于文本分类、信息检索和关键词提取等任务。
3. 词嵌入模型(Word Embedding)词嵌入模型是一种将词语映射到低维空间向量表示的方法。
它能够捕捉到词语之间的语义关系,使得相似含义的词在向量空间中更加接近。
Word2Vec和GloVe是两种常用的词嵌入模型。
词嵌入模型在NLP任务中广泛应用,如文本分类、命名实体识别和情感分析等。
4. 循环神经网络(Recurrent Neural Network,RNN)循环神经网络是一种具有记忆性的神经网络模型,可以处理序列数据,尤其适用于处理自然语言。
RNN通过引入循环结构,使得网络能够记住之前的信息,并在当前的输入上进行计算。
自然语言处理算法的预处理步骤详解

自然语言处理算法的预处理步骤详解自然语言处理(NLP)是人工智能领域的一个重要研究方向,致力于使计算机能够理解、处理和生成人类语言。
在实际应用中,NLP算法通常需要经过一系列的预处理步骤,以便更好地处理文本数据。
本文将详细介绍NLP算法的预处理步骤,包括文本清洗、分词、停用词去除、词干提取和词向量表示。
1. 文本清洗在NLP任务中,文本数据经常包含有噪声、特殊符号、HTML标签等杂质,这些杂质会对后续的处理步骤产生干扰,因此需要进行文本清洗。
文本清洗的步骤通常包括去除特殊字符、标点符号、数字、HTML标签和非字母字符等,同时将文本转换为小写形式,以便统一处理。
2. 分词分词是将连续的文本序列切分成离散的词汇单位的过程。
在英文中,直接以空格分割单词可能会导致错误的分割结果,因此通常采用更加复杂的分词算法,如基于规则的分词和基于概率的分词模型(如最大匹配法和隐马尔可夫模型),以提高分词的准确性。
3. 停用词去除停用词是指在文本中频繁出现但没有实际含义的词汇,例如英语中的“the”,“is”,“and”等。
这些词汇对于文本分析任务通常没有帮助,甚至可能干扰数据的分析结果,因此需要将这些停用词从文本中去除。
通常,可以通过预定义的停用词列表或基于词频统计的方法进行停用词去除。
4. 词干提取词干提取是将词汇的不同形态还原为其原本的词干形式的过程。
例如,将“running”和“runs”都还原为“run”。
词干提取可以减少数据维度并提高计算效率,同时还能更好地对同一词汇的不同形态进行统计和分析。
常用的词干提取算法有Porter算法和Snowball算法。
5. 词向量表示词向量是将词汇表示为实数向量的形式,用于表示词汇之间的语义相似性。
常见的词向量表示方法有独热编码、词袋模型和词嵌入模型等。
其中,词嵌入模型(如Word2Vec、GloVe和FastText)能够将语义相似的词汇映射到相似的向量空间,并且在许多NLP任务中取得了优秀的效果。
npl中英文分词方法

npl中英文分词方法English:There are various methods for segmenting Chinese and English text in Natural Language Processing (NLP). For English, the most common method is to simply split the text based on spaces or punctuation marks. More advanced techniques include using Part-of-Speech (POS) tagging to identify word boundaries and compound words. For Chinese, the most common method is to use word segmentation algorithms such as the Maximum Match method, which involves matching the longest possible word from a dictionary, or the Bi-LSTM-CRF model, which is a neural network model specifically designed for Chinese word segmentation. Additionally, character-based word segmentation methods can also be used for Chinese text, where words are segmented based on constituent characters and language-specific rules.中文翻译:在自然语言处理(NLP)中,有多种方法可以对中文和英文文本进行分词处理。
自然语言处理中的文本分类算法

自然语言处理中的文本分类算法自然语言处理(Natural Language Processing,NLP)是一种将人类语言模式转化为计算机可处理的形式,用机器学习、深度学习等技术让计算机能够理解、分析、生成人类语言的科学。
其中,文本分类是NLP中的一个重要应用方向,主要是将大量的文本数据分成不同的类别或者标签,方便进一步处理和分析,是很多场景下必不可少的一项技术。
在文本分类中,算法的选择和数据的处理起着至关重要的作用,下文将介绍常见的文本分类算法和一些经验性的处理技巧。
一、常用算法1. 朴素贝叶斯算法朴素贝叶斯(Naive Bayes)算法是一种基于概率论的分类方法,简单而高效。
该算法的主要思想是根据贝叶斯定理来计算文本在类别条件下的概率。
结合文本数据的特点,朴素贝叶斯算法假设所有特征之间相互独立,即“朴素”,因此该算法又称为朴素贝叶斯分类器。
2. 支持向量机算法支持向量机(Support Vector Machine,SVM)算法是一种基于统计学习的分类方法,其核心理念是通过构建一个具有最优划分面的超平面,将样本分为两类或多类。
在文本分类中,SVM算法将文本转化为向量表示,然后利用一些优化策略,选取最优超平面,从而实现文本分类。
3. 决策树算法决策树(Decision Tree)算法是一种基于树形结构的分类方法,将训练数据基于某些特征划分成不同的类别或标签。
对于文本分类而言,决策树算法可以根据文本中某些关键词、词性或语法规则等,来进行结构化的分类判断。
二、特征词汇的提取与选择在文本分类中,特征词汇的提取和选择是非常重要的,通常有以下几种方法。
1. 词频统计法:统计文本中每个单词出现的频率,将出现频率较高的单词作为特征词汇。
2. 信息增益法:通过计算特征词在训练集中对分类的贡献,筛选出信息增益较大的特征词作为分类依据。
3. 互信息法:通过计算特征词和类别标签之间的互信息,筛选出相关性较高的特征词。
最大概率分词算法

最大概率分词算法最大概率分词算法在自然语言处理领域是一种常用的分词方法。
它通过计算词语在语料库中出现的概率来确定最合理的分词结果。
本文将介绍最大概率分词算法的原理和应用,并探讨其优缺点。
一、最大概率分词算法的原理最大概率分词算法是基于马尔可夫模型的一种分词方法。
马尔可夫模型是一种统计模型,用于描述随机事件的状态转移过程。
在最大概率分词算法中,将分词问题转化为求解最大概率路径的问题,即给定一个句子,找到一个最有可能的分词方式。
最大概率分词算法的核心思想是利用已有的语料库来统计词语的出现频率,然后根据频率计算词语的概率。
在分词过程中,通过比较相邻词语的概率来确定最合理的切分位置。
具体来说,算法会计算每个位置是否是一个词语的起始位置,然后根据词语的概率来确定最优的切分结果。
最大概率分词算法在自然语言处理领域有着广泛的应用。
它可以用于搜索引擎的关键词提取、文本分类和信息检索等任务。
在搜索引擎中,最大概率分词算法可以根据用户输入的关键词来将查询语句切分为多个独立的词语,从而提高搜索结果的准确性和召回率。
在文本分类中,最大概率分词算法可以将文本切分为多个词语,并根据词语的频率来计算文本的特征向量,从而实现对文本的分类和识别。
在信息检索中,最大概率分词算法可以将查询语句切分为多个词语,并根据词语的概率来计算查询语句与文档的匹配程度,从而提高搜索结果的相关性。
三、最大概率分词算法的优缺点最大概率分词算法有着一些优点和缺点。
首先,最大概率分词算法具有较高的准确性和鲁棒性。
通过利用大规模的语料库来统计词语的概率,最大概率分词算法可以较准确地切分文本,避免出现歧义和错误的切分结果。
其次,最大概率分词算法具有较高的效率和可扩展性。
由于最大概率分词算法是基于马尔可夫模型的,它可以通过预先计算词语的概率来快速切分文本,适用于大规模的文本处理任务。
然而,最大概率分词算法也存在一些缺点。
首先,最大概率分词算法对于未登录词和歧义词的处理效果较差。
npl自然语言处理

npl自然语言处理自然语言处理(Natural Language Processing,NLP)是一种人工智能技术,能够处理和分析人类语言的形式和含义。
这种技术涉及文本、语音和图像等各种形式的语言数据,并且在当前各种应用场景中都起到了重要作用,如语音识别、机器翻译、信息提取等等。
在本文中,我们将就NLP的主要技术和应用进行探讨。
1. 分词分词是NLP中的一个重要步骤,它将长篇的文本分成多个词组。
例如中文中的“我爱北京天安门”,分词后就变成了“我爱北京天安门”。
分词是其他NLP技术的基础,例如语义分析、情感分析等等。
2. 语义分析语义分析是一种用于理解句子或文本的意义的方法。
通过该技术,计算机可以判断文本的含义以及上下文中单词和短语的含义。
例如,“我想看电影”和“我想买电影票”这两个句子经过语义分析后,计算机可以理解它们的含义。
3. 情感分析情感分析是一种通过识别文本中的情感或情绪的方法。
它也被称作意见挖掘或者评价挖掘。
通过情感分析,计算机可以自动识别文本中的情感,如积极、消极或中立。
这种技术可应用于各种应用程序,如评论分析、舆情监测等等。
4. 机器翻译机器翻译是一种将一种语言翻译成另一种语言的技术。
借助NLP技术,计算机能够识别原始文本的语义,并将其翻译成另一种语言。
虽然机器翻译已经相当成熟,但对于一些长句子或者文化差异较大的内容,翻译的准确性还难以保证。
5. 信息提取信息提取是一种从文本中提取出特定信息的技术。
例如,从新闻文章中识别出地点、人名和组织名称等信息。
当这些信息被整齐地提取出来,就形成了一个知识库,这种知识库可以用于各种智能应用程序。
总之,在NLP技术的支撑下,计算机可以像人类一样处理自然语言。
NLP已经在许多实际应用中得到了广泛应用,如语音助手、智能客服、智能写作等。
通过不断的技术发展和精进,NLP在未来肯定将会发挥更多的作用。
ngram计算句子概率python

N-gram是一种自然语言处理和文本挖掘中常见的方法,用于预测文本的后续词或计算文本的概率。
以下是一个Python代码示例,使用nltk库计算给定句子的n-gram概率:```pythonimport nltkfrom nltk.util import ngrams# 定义一个函数来计算n-gram概率def calculate_ngram_probability(sentence, n):# 分词words = nltk.word_tokenize(sentence)# 生成n-gramngrams_list = list(ngrams(words, n, pad_left=True, pad_right=True))# 计算n-gram概率ngram_prob = {f'{n}-gram': nltk.probability.FreqDist(ngrams_list).prob(ngram) for ngram, _ in ngrams_list}return ngram_prob# 测试句子sentence = "我来到北京清华大学"# 计算2-gram(二元)概率print(calculate_ngram_probability(sentence, 2))```这个代码首先将句子分词,然后生成n-gram。
接着,使用nltk 的`FreqDist`来计算n-gram的概率。
在这个例子中,我们计算了二元(bigram)的概率。
你可以改变`n`的值来计算其他n-gram的概率。
请注意,这个简单的模型没有考虑到更复杂的语言现象,比如上下文相关的概率(比如,“我”后面更可能跟着“来到”而不是“是”),也没有考虑更复杂的分词规则。
如果你需要处理更复杂的语言现象,可能需要使用更复杂的模型,比如nltk的`nltk.model`模块或者其他的自然语言处理库。
自然语言处理NPL最大概率分词算法

NLP基于最大概率的汉语切分Ytinrete要求:基于最大概率的汉语切分目标:采用最大概率法进行汉语切分。
其中:n-gram用bigram,平滑方法至少用Laplace平滑。
输入:接收一个文本,文本名称为:corpus_for_test.txt输出:切分结果文本,其中:切分表示:用一个字节的空格“”分隔,如:我们在学习。
每个标点符号都单算一个切分单元。
输出文件名为:学号.txtBigram参数训练语料:corpus_for_train.txt注:请严格按此格式输出,以便得到正确评测结果特别注意:代码雷同问题本次作业最后得分会综合考虑:切分性能、代码、文档等几个方面。
第三次作业上交的截止时间:2014 年1月7日24:001.关于最大概率分词基本思想是:一个待切分的汉字串可能包含多种分词结果,将其中概率最大的作为该字串的分词结果。
根据:由于语言的规律性,句子中前面出现的词对后面可能出现的词有很强的预示作用。
公式1:其中 w 表示词, s 表示待切分字符串。
公式2:例如:S :有意见分歧W1: 有/ 意见/ 分歧/W2: 有意/ 见/ 分歧/P(W1)=P(有)×P(意见)×P(分歧) =1.8*10-9P(W2)=P(有意)×P(见)×P(分歧) =1*10-11P(W1)> P(W2)所以选择 W1历史信息过长,计算存在困难p(wi|w1w2…wi-1)为了便于计算,通常考虑的历史不能太长,一般只考虑前面n-1个词构成的历史。
即: p(wi|wi-n+1…wi-1)1212(|)*()(|)()()()(,,...,)()*()*...*()i iP S W P W P W S P W P S P W P w w w P w P w P w =≈=≈n ()ii w P w =在语料库中的出现次数语料库中的总词数Nn-gramn 较大时:提供了更多的语境信息,语境更具区别性。
自然语言处理 常见算法

自然语言处理常见算法自然语言处理(Natural Language Processing,简称NLP)是计算机科学、人工智能、语言学等领域的交叉学科。
它主要研究基于计算机的自然语言处理,即使计算机能够与人在自然语言环境中进行有效的交流。
在研究NLP的过程中,需要利用一些常见的算法来实现自然语言处理的功能。
本文将介绍一些常用的自然语言处理算法。
1. 分词算法分词(Tokenization)是将一段自然语言文本按照定义好的规则进行分割,将其分割成一个个有意义的小段。
分词算法是NLP中最基础的算法之一,它将输入文本分割成一个个词语,即所谓的token。
常见的分词算法有:1.1 最大正向匹配算法最大正向匹配算法指从文本开始位置开始,尽量把长词语分出来,匹配成功后从该词语后开始新词的匹配,直到整个文本处理完成。
这个算法的缺点是它无法处理未登录词(即没有出现在词典里的词)。
最大逆向匹配算法与最大正向匹配算法类似,只不过是从文本末尾开始向前匹配。
最大双向匹配算法是将最大正向匹配算法和最大逆向匹配算法结合起来使用。
具体来说,它先使用最大正向匹配算法对文本进行分词,然后再使用最大逆向匹配算法,对切分后的结果进行确认和修正。
词性标注(Part-of-Speech Tagging,简称POS Tagging),也叫词类标注、词性标定,是标注文本中的每个词汇的词性的过程。
它是自然语言处理的一个重要步骤,它基于文本内容为每个单词推断词性,并建立词性标注体系。
常见的词性标注算法包括:2.1 隐马尔可夫模型(Hidden Markov Model,简称HMM)隐马尔可夫模型是以马尔可夫链为基础的统计模型,它通过词性转移概率和观测概率来对文本进行词性标注。
2.2 递归神经网络(Recurrent Neural Networks, 简称RNN)递归神经网络是一种可以自动处理序列数据的神经网络体系结构。
在NLP中,RNN被广泛用于自然语言处理任务中,如词性标注、命名实体识别和语言翻译。
python 最大匹配算法

python 最大匹配算法最大匹配算法是一种常用的中文分词算法,也被广泛应用于自然语言处理领域。
它的主要思想是从待分词的文本中寻找最长的词语,然后将其切分出来,再对剩余的文本进行同样的操作,直到所有的词语都被切分出来。
在中文分词中,最大匹配算法是一种基于词典的分词方法。
它通过比较待分词文本与词典中的词语,从而找到最长的匹配词语。
这种算法认为,较长的词语往往比较常见,因此能够提高分词的准确性。
最大匹配算法有两种常见的实现方式:正向最大匹配和逆向最大匹配。
正向最大匹配从待分词文本的左边开始,逐步向右匹配词语;逆向最大匹配则从待分词文本的右边开始,逐步向左匹配词语。
两种方式都会得到一个切分结果,我们可以根据一些标准进行评估和选择最佳的结果。
最大匹配算法的一个关键问题是词典的选择和构建。
一个好的词典应该覆盖尽可能多的常见词语,并且能够及时更新和维护。
常见的词典包括人工构建的词典、网络爬取的词典以及基于机器学习的词典等。
在实际应用中,最大匹配算法的性能和效果受到多种因素的影响。
首先,词典的质量和规模对算法的分词效果有很大影响。
其次,算法的匹配策略和优化方法也会对分词结果产生影响。
此外,一些特定的领域和文本类型可能需要针对性的优化和调整。
除了最大匹配算法,还有一些其他的中文分词算法,如正向最大匹配算法、逆向最大匹配算法、双向最大匹配算法、最短路径分词算法等。
每种算法都有其优缺点,适用于不同的场景和需求。
最大匹配算法作为一种简单而有效的中文分词方法,被广泛应用于各个领域的自然语言处理任务中,如机器翻译、信息检索、文本分类等。
它可以帮助我们更好地理解和处理中文文本,提高自然语言处理的效果和准确性。
最大匹配算法是一种常用的中文分词算法,通过寻找最长的匹配词语来实现分词。
它具有简单、高效的特点,并且在自然语言处理领域得到了广泛的应用。
通过合理选择词典和优化算法,我们可以获得更好的分词结果,提高文本处理的准确性和效果。
分词算法模型nlp

分词算法模型nlp
在自然语言处理(NLP)中,分词算法模型扮演着重要的角色。
以下是几种常见的分词算法模型:
1. 感知机模型:这是一种简单的二分类线性模型,通过构造超平面,将特征空间中的样本分为正负两类。
它也可以处理多分类问题。
2. CRF模型:这是目前最常用的分词、词性标注和实体识别算法之一,它对未登陆词有很好的识别能力,但开销较大。
3. 循环神经网络(RNN):在处理变长输入和序列输入问题中,RNN具有巨大的优势。
LSTM是RNN的一种变种,可以在一定程度上解决RNN在训练过程中梯度消失和梯度爆炸的问题。
4. 双向循环神经网络:这种网络分别从句子的开头和结尾开始对输入进行处理,将上下文信息进行编码,提升预测效果。
目前对于序列标注任务,公认效果最好的模型是BiLSTM+CRF。
5. 基于词表的分词算法:包括正向最大匹配法、逆向最大匹配法和双向最大匹配法等。
6. 基于统计模型的分词算法:包括基于N-gram语言模型的分词方法、基于HMM(隐马尔科夫模型)的分词和基于CRF(条件随机场)的分词方法等。
7. 基于深度学习的端到端的分词方法。
这些分词算法模型各有特点和优势,适用于不同的应用场景。
在选择合适的分词算法模型时,需要考虑具体的需求和数据特点。
《自然语言处理》教学上机实验报告
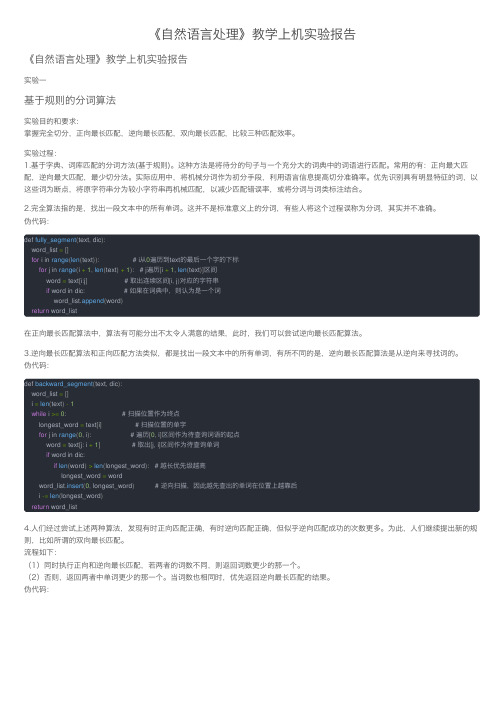
《⾃然语⾔处理》教学上机实验报告《⾃然语⾔处理》教学上机实验报告实验⼀基于规则的分词算法实验⽬的和要求:掌握完全切分,正向最长匹配,逆向最长匹配,双向最长匹配,⽐较三种匹配效率。
实验过程:1.基于字典、词库匹配的分词⽅法(基于规则)。
这种⽅法是将待分的句⼦与⼀个充分⼤的词典中的词语进⾏匹配。
常⽤的有:正向最⼤匹配,逆向最⼤匹配,最少切分法。
实际应⽤中,将机械分词作为初分⼿段,利⽤语⾔信息提⾼切分准确率。
优先识别具有明显特征的词,以这些词为断点,将原字符串分为较⼩字符串再机械匹配,以减少匹配错误率,或将分词与词类标注结合。
2.完全算法指的是,找出⼀段⽂本中的所有单词。
这并不是标准意义上的分词,有些⼈将这个过程误称为分词,其实并不准确。
伪代码:def fully_segment(text, dic):word_list =[]for i in range(len(text)): # i从0遍历到text的最后⼀个字的下标for j in range(i +1,len(text)+1): # j遍历[i +1,len(text)]区间word = text[i:j] # 取出连续区间[i, j)对应的字符串if word in dic: # 如果在词典中,则认为是⼀个词word_list.append(word)return word_list在正向最长匹配算法中,算法有可能分出不太令⼈满意的结果,此时,我们可以尝试逆向最长匹配算法。
3.逆向最长匹配算法和正向匹配⽅法类似,都是找出⼀段⽂本中的所有单词,有所不同的是,逆向最长匹配算法是从逆向来寻找词的。
伪代码:def backward_segment(text, dic):word_list =[]i =len(text)-1while i >=0: # 扫描位置作为终点longest_word = text[i] # 扫描位置的单字for j in range(0, i): # 遍历[0, i]区间作为待查询词语的起点word = text[j: i +1] # 取出[j, i]区间作为待查询单词if word in dic:if len(word)>len(longest_word): # 越长优先级越⾼longest_word = wordword_list.insert(0, longest_word) # 逆向扫描,因此越先查出的单词在位置上越靠后i -=len(longest_word)return word_list4.⼈们经过尝试上述两种算法,发现有时正向匹配正确,有时逆向匹配正确,但似乎逆向匹配成功的次数更多。
自然语言处理算法之词频统计

自然语言处理算法之词频统计自然语言处理(Natural Language Processing,NLP)是计算机科学与人工智能领域中的一个重要分支,旨在使计算机能够理解和处理人类语言。
在NLP中,词频统计是一种常见的算法,用于分析文本中的词汇使用情况。
本文将探讨词频统计算法的原理、应用以及可能的改进方法。
一、词频统计算法的原理词频统计算法的原理很简单:通过计算文本中每个词出现的频率,来衡量该词在文本中的重要性。
词频统计算法通常包括以下几个步骤:1. 分词:将文本划分为一个个单词或短语。
分词是NLP中的一个重要任务,可以使用各种方法,如基于规则的分词、统计分词和基于机器学习的分词等。
2. 统计词频:统计每个词在文本中出现的次数。
可以使用哈希表或字典等数据结构来存储词频信息。
3. 排序:按照词频从高到低对词进行排序。
排序可以使用快速排序、归并排序等常见的排序算法。
4. 输出结果:将排序后的词及其对应的词频输出。
可以选择输出前N个词,或者输出所有词。
二、词频统计算法的应用词频统计算法在文本挖掘、信息检索、自动摘要等领域有着广泛的应用。
以下是一些常见的应用场景:1. 关键词提取:通过词频统计,可以找出文本中出现频率最高的词,从而提取出文本的关键词。
关键词提取在搜索引擎、文本分类等任务中非常有用。
2. 文本摘要:通过词频统计,可以找出文本中出现频率较高的词,从而生成文本的摘要。
文本摘要在新闻报道、文献综述等场景中有着重要的应用价值。
3. 语言模型:通过词频统计,可以估计一个词在给定上下文中出现的概率,从而构建语言模型。
语言模型在机器翻译、语音识别等任务中起着关键作用。
三、词频统计算法的改进方法尽管词频统计算法简单易懂,但它也存在一些局限性。
例如,它无法处理词义消歧、停用词过滤和词序信息等问题。
为了改进词频统计算法,可以考虑以下几个方向:1. TF-IDF算法:TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本特征表示方法。
自然语言处理NPL最大概率分词算法

NLP基于最大概率的汉语切分Ytinrete要求:基于最大概率的汉语切分目标:采用最大概率法进行汉语切分。
其中:n-gram用b i gram,平滑方法至少用Lapl ace平滑。
输入:接收一个文本,文本名称为:corpus_for_test.txt输出:切分结果文本,其中:切分表示:用一个字节的空格“”分隔,如:我们在学习。
每个标点符号都单算一个切分单元。
输出文件名为:学号.txtBigram参数训练语料:corpus_for_train.txt注:请严格按此格式输出,以便得到正确评测结果切分性能评价:分切分结果评测F*100, F=2P*R/(P+R)特别注意:代码雷同问题本次作业最后得分会综合考虑:切分性能、代码、文档等几个方面。
第三次作业上交的截止时间:2014 年1月7日24:001.关于最大概率分词基本思想是:一个待切分的汉字串可能包含多种分词结果,将其中概率最大的作为该字串的分词结果。
根据:由于语言的规律性,句子中前面出现的词对后面可能出现的词有很强的预示作用。
公式1:其中 w 表示词, s 表示待切分字符串。
公式2:例如:S :有意见分歧W1: 有/ 意见/ 分歧/W2: 有意/ 见/ 分歧/P(W1)=P(有)×P(意见)×P(分歧) =1.8*10-9P(W2)=P(有意)×P(见)×P(分歧) =1*10-11P(W1)> P(W2)所以选择 W1历史信息过长,计算存在困难p(wi|w1w2…wi-1)为了便于计算,通常考虑的历史不能太长,一般只考虑前面n-1个词构成的历史。
即: p(wi|wi-n+1…wi-1)1212(|)*()(|)()()()(,,...,)()*()*...*()i i P S W P W P W S P W P S P W P w w w P w P w P w =≈=≈n ()i i w P w =在语料库中的出现次数语料库中的总词数Nn-gramn 较大时:提供了更多的语境信息,语境更具区别性。
自然语言处理NPL最大概率分词算法

NLP基于最大概率的汉语切分 Ytinrete要求:基于最大概率的汉语切分目标:采用最大概率法进行汉语切分。
其中:n-gram用bigram,平滑方法至少用Laplace平滑。
输入:接收一个文本,文本名称为:corpus_for_test.txt输出:切分结果文本,其中:切分表示:用一个字节的空格“ ”分隔,如:我们 在 学习 。
每个标点符号都单算一个切分单元。
输出文件名为:学号.txtBigram参数训练语料:corpus_for_train.txt注:请严格按此格式输出,以便得到正确评测结果切分性能评价:分切分结果评测 F*100, F=2P*R/(P+R)特别注意:代码雷同问题本次作业最后得分会综合考虑:切分性能、代码、文档等几个方面。
第三次作业上交的截止时间:2014 年1月7日24:001.关于最大概率分词基本思想是:一个待切分的汉字串可能包含多种分词结果,将其中概率最大的作为该字串的分词结果。
根据:由于语言的规律性,句子中前面出现的词对后面可能出现的词有很强的预示作用。
公式1:其中 w 表示词, s 表示待切分字符串。
公式2:例如:S:有意见分歧W1: 有/ 意见/ 分歧/W2: 有意/ 见/ 分歧/P(W1)=P(有)×P(意见)×P(分歧) =1.8*10-9P(W2)=P(有意)×P(见)×P(分歧) =1*10-11P(W1)> P(W2)所以选择 W1历史信息过长,计算存在困难p(wi|w1w2…wi-1)为了便于计算,通常考虑的历史不能太长,一般只考虑前面n-1个词构成的历史。
即: p(wi|wi-n+1…wi-1)1212(|)*()(|)()()()(,,...,)()*()*...*()i iP S W P W P W S P W P S P W P w w w P w P w P w n ()ii w P w 在语料库中的出现次数语料库中的总词数Nn-gramn 较大时:က 提供了更多的语境信息,语境更具区别性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
NLP基于最大概率的汉语切分Ytinrete要求:基于最大概率的汉语切分目标:采用最大概率法进行汉语切分。
其中:n-gram用bigram,平滑方法至少用Laplace平滑。
输入:接收一个文本,文本名称为:corpus_for_test.txt输出:切分结果文本,其中:切分表示:用一个字节的空格“”分隔,如:我们在学习。
每个标点符号都单算一个切分单元。
输出文件名为:学号.txtBigram参数训练语料:corpus_for_train.txt注:请严格按此格式输出,以便得到正确评测结果特别注意:代码雷同问题本次作业最后得分会综合考虑:切分性能、代码、文档等几个方面。
第三次作业上交的截止时间:2014 年1月7日24:001.关于最大概率分词基本思想是:一个待切分的汉字串可能包含多种分词结果,将其中概率最大的作为该字串的分词结果。
根据:由于语言的规律性,句子中前面出现的词对后面可能出现的词有很强的预示作用。
公式1:其中 w 表示词, s 表示待切分字符串。
公式2:例如:S :有意见分歧W1: 有/ 意见/ 分歧/W2: 有意/ 见/ 分歧/P(W1)=P(有)×P(意见)×P(分歧) =1.8*10-9P(W2)=P(有意)×P(见)×P(分歧) =1*10-11P(W1)> P(W2)所以选择 W1历史信息过长,计算存在困难p(wi|w1w2…wi-1)为了便于计算,通常考虑的历史不能太长,一般只考虑前面n-1个词构成的历史。
即: p(wi|wi-n+1…wi-1)1212(|)*()(|)()()()(,,...,)()*()*...*()i iP S W P W P W S P W P S P W P w w w P w P w P w =≈=≈n ()ii w P w =在语料库中的出现次数语料库中的总词数Nn-gramn 较大时:提供了更多的语境信息,语境更具区别性。
但是,参数个数多、计算代价大、训练语料需要多、参数估计不可靠。
n 较小时:语境信息少,不具区别性。
但是,参数个数少、计算代价小、训练语料,无需太多、参数估计可靠。
题目要求使用bigram,即考虑前一个词,即考虑左邻词。
左邻词假设对字串从左到右进行扫描,可以得到w1 ,w2 ,…,wi-1 wi,…等若干候选词,如果wi-1 的尾字跟wi 的首字邻接,就称wi-1 为wi 的左邻词。
比如上面例中,候选词“有”就是候选词“意见”的左邻词,“意见”和“见”都是“分歧”的左邻词。
字串最左边的词没有左邻词。
最佳左邻词如果某个候选词wi 有若干个左邻词wj ,wk ,…等等,其中累计概率最大的候选词称为wi 的最佳左邻词。
比如候选词“意见”只有一个左邻词“有”,因此,“有”同时也就是“意见”的最佳左邻词;候选词“分歧”有两个左邻词“意见”和“见”,其中“意见”的累计概率大于“见”累计概率,因此“意见”是“分歧”的最佳左邻词。
数据稀疏问若某n-gram在训练语料中没有出现,则该n-gram的概率必定是0。
解决的办法是扩大训练语料的规模。
但是无论怎样扩大训练语料,都不可能保证所有的词在训练语料中均出现。
由于训练样本不足而导致所估计的分布不可靠的问题,称为数据稀疏问题。
在NLP领域中,数据稀疏问题永远存在,不太可能有一个足够大的训练语料,因为语言中的大部分词都属于低频词。
解决办法: 平滑技术把在训练样本中出现过的事件的概率适当减小。
把减小得到的概率密度分配给训练语料中没有出现过的事件。
这个过程有时也称为discounting(减值)。
目前已经提出了很多数据平滑技术,如:Add-one 平滑Add-delta 平滑Witten-Bell平滑Good-Turing平滑Church-Gale平滑Jelinek-Mercer平滑Katz平滑这里我使用laplace平滑Add-one 平滑(Laplace’s law)规定任何一个n-gram在训练语料至少出现一次(即规定没有出现过的n-gram在训练语料中出现了一次)。
没有出现过的n-gram的概率不再是0。
2.算法描述1) 对一个待分词的字串S,按照从左到右的顺序取出全部候选词w1 ,w2 ,…,wi-1wi,…wn;2)到词典中查出每个候选词的概率值P(wi),当候选词没有出现时,由laplace平滑设其概率为1/(字典数+1),记录每个候选词的全部左邻词;3)按照公式1计算每个候选词的累计概率,同时比较得到每个候选词的最佳左邻词;4)如果当前wn是字串S的尾词,且累计概率P’(wn)最大,wn就是S的终点词。
5)从wn开始,按照从右到左的顺序,依次将每个词的最佳左邻词输出,即为S的分词结果。
3.程序设计整个程序我分为两个阶段,字典生成阶段和分词阶段。
(make_dic.cpp)字典生成:目标:输入为训练语料(corpus_for_train.txt),输出为字典(dic.txt),字典内容为单词和单词出现在字典中的频率,首行为词典总词数。
实现步骤:首先读入训练,通过空格和换行符作为判定,分出单个单词。
若单词没有在字典中出现,则将其加入字典,单词自身频数加一,单词总数加一;若单词在字典中出现,则单词自身频数加一。
将数据存入map中,然后再遍历map,创建一个输出流,输出为字典文件,数据为具体单词和他的出现概率(自身频数/单词总数)。
(zdgl_fenci.cpp)分词:目标:输入为字典和待切分语料(利用kill_space先将老师预先存好的待切分语料的空格和换行删去,成为为切分语料target.txt),输出为切分好的语料(2011211366.txt)。
实现步骤:首先在主函数中,循环取出待切分语料的每个句子,将句子传给分词子程序,分词子程序处理后返回分好的句子,将句子输出到文件,再取下一句,依次循环,直到处理完为止。
分词子程序,处理过程分为三步:1.将待切分的句子切成备选的切分词,并放在“单词池”中,切分标准参考一个假定的单词最大长度,程序里面我设置成20,也就是单词最长10个汉字(可以根据词典来决定),具体切分我考虑了两种,不同之处体现在对取到的单词(从一个汉字到10个汉字遍历地取),若不出现在词典中(出现在词典中的肯定会列入),第一种做法是只保留单个汉字形成的单词,另一种做法是保留全部的可能性。
若采取第一种则效率会有很大的提高,但理论上会降低准确性,第二种虽然能够考虑到所有的情况,但是数据往往是前一种的几十倍,而且对于句子中很多单词都有在词典时,分词结果几乎和前一种相同,如果句子中的所有词都能在词典中时,分词结果就一样了(laplace平滑使得未出现的概率是最低的,乘积也会最低,所以不会选择未出现的词),但会多出几十倍的运算。
两种的代码我都写出来了,考虑实际,我觉得第一种比较妥当,第二种我注释起来。
2.对“单词池”操作,通过循环的遍历,直到计算出所有的最佳左邻词。
3.在“单词池”中找出所有的句尾词,找到概率最大的,再通过左邻词,往回找,直到找到句头词,将这些词用空格分开,返回。
4.程序源码:1.kill_space.cpp将待切分文本corpus_for_test.txt变成不含空格和换行的待切分文本target.txt#include<iostream>#include<fstream>#include<map>#include<string>/*Name: 删除空格Description: 删除空格*/using namespace std;int main(){FILE *f_in, *f_out;//输入输出文件char ch;f_in=fopen("corpus_for_test.txt", "r");f_out=fopen("target.txt", "w");ch=getc(f_in);while(EOF!=ch){if(' '!=ch&&'\n'!=ch)putc(ch, f_out);ch=getc(f_in);}return 0;}2.make_dic.cpp读入训练预料corpus_for_train.txt输出词典文件dic.txt#include<iostream>#include<stdio.h>#include<fstream>#include<map>#include<string>using namespace std;const char *train_text = "corpus_for_train.txt";//训练文件const char *dic_text = "dic.txt";//输出词典文件map <string, int> dic;//词典表map <string, int>::iterator dic_it;//map<string, double> dic_in_text;//testint main(){FILE *f_in;f_in=fopen(train_text, "r");ofstream f_out(dic_text);double rate=0;int count=0;char ch;string word;ch=fgetc(f_in);while(EOF!=ch){if(' '!=ch&&'\n'!=ch)//词的一部分{word.append(1, ch);if("。
"==word)word.clear();}else//单词结束{if(" "==word||0==word.size()){word.clear();ch=fgetc(f_in);continue;}dic_it=dic.find(word);if(dic_it!=dic.end()){//找到dic_it->second=dic_it->second+1;word.clear();}else{//新单词count++;dic.insert(pair<string,int>(word,1));word.clear();}}ch=fgetc(f_in);// if('\n'==ch)//吸收换行// ch=fgetc(f_in);}f_out<<count<<endl;dic_it=dic.begin();while(dic_it!=dic.end()){f_out<<dic_it->first<<endl;rate=(double)(dic_it->second)/count;f_out<<rate<<endl;dic_it++;}f_out.close();fclose(f_in);/*测试用ifstream file(dic_text);int count_text;file>>count_text;string word_text;double rate_text;for(int i=0; i<count_text; i++){file>>word_text;file>>rate_text;dic_in_text.insert(pair<string,double>(word_text,rate_text));}file.close();*/return 0;}3.zdgl_fenci.cpp读入词典dic.txt和带切分文本target.txt输出分词结果2011211366.txt#include<iostream>#include<stdio.h>#include<fstream>#include<map>#include<string>#include<vector>#include<stack>using namespace std;const char *target = "target.txt";//输入文件const char *out_put= "2011211366.txt";//输出文件const char *dic_text = "dic.txt";//输入词典文件const int max_word=20;//假设一个词最长包括10个汉字double laplace ;//laplace平滑map<string, double> dic;//词典map <string, double>::iterator dic_it;typedef struct word_pre//单词池内元素{int num;//标记int p_begin;//起始位置int p_end;//结束位置double word_rate;//单词本身概率double plus_rate;//单词累进概率int best;//最佳左邻词string this_word;//词本身}word_pre;void dic_init_test(void)//测试用{int count_text=10000000;laplace = (double)1/(count_text+1);dic.insert(pair<string,double>("有",0.018));dic.insert(pair<string,double>("有意",0.0005));dic.insert(pair<string,double>("意见",0.001));dic.insert(pair<string,double>("见",0.0002));dic.insert(pair<string,double>("分歧",0.0001)); }void dic_init(void)//初始化词典{ifstream file(dic_text);int count_text;file>>count_text;laplace = (double)1/(count_text+1);string word_text;double rate_text;for(int i=0; i<count_text; i++){file>>word_text;file>>rate_text;dic.insert(pair<string,double>(word_text,rate_text));}file.close();}string zdgl_fenci(string sentance)//最大概率分词,输入为不带“。