jieba分词原理
jieba模块的分词方法

jieba模块的分词方法【实用版3篇】目录(篇1)1.介绍 jieba 模块2.jieba 模块的分词方法概述3.jieba 模块的分词方法实现4.jieba 模块的分词方法应用实例5.总结正文(篇1)一、介绍 jieba 模块jieba 模块是一款中文分词工具,基于前缀词典实现高效的词图扫描,生成有向无环图(DAG),采用动态规划查找最大概率路径,实现分词。
该模块使用 Python 编写,支持 Python 2.7 及以上版本,具有较高的分词准确率和较快的分词速度。
二、jieba 模块的分词方法概述jieba 模块的分词方法采用了基于词典的分词策略,通过建立一个词典,将中文词汇按照一定的规则进行编码,然后根据这些编码进行分词。
在分词过程中,jieba 模块会根据词典中的词汇和句子的语义信息,选择最可能的分词结果。
三、jieba 模块的分词方法实现1.词典构建:jieba 模块首先需要构建一个词典,词典中包含了中文词汇的编码信息。
词典的构建方法有多种,如基于统计方法、基于规则方法等。
2.词图扫描:在分词过程中,jieba 模块会根据词典对句子进行词图扫描,生成有向无环图(DAG)。
词图是一个有向图,其中每个节点表示一个词汇,每条边表示一个词汇出现的概率。
3.最大概率路径查找:jieba 模块采用动态规划方法查找词图中的最大概率路径,从而确定分词结果。
动态规划是一种在数学、计算机科学和经济学领域中使用的,通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。
四、jieba 模块的分词方法应用实例以下是一个使用 jieba 模块进行分词的实例:```pythonimport jiebasentence = "我爱自然语言处理技术"seg_list = jieba.cut(sentence)print(seg_list)```运行上述代码,输出结果为:```["我", "爱", "自然语言", "处理", "技术"]```五、总结jieba 模块是一种高效的中文分词工具,采用基于词典的分词策略,具有较高的分词准确率和较快的分词速度。
jieba库的分词模式

jieba库的分词模式jieba库提供了三种不同的分词模式,分别是:1.精确模式(默认模式):在文本中找出所有可能成词的词语,对文本进行精准分词。
该模式适用于对文本内容要求高的场景。
2.全模式:将文本中所有可能成词的词语都提取出来,存在重叠的情况(如:“江南”和“南京”),适用于对文本要求不高的场景。
3.搜索引擎模式:在精确模式的基础上,对长词再次进行切分,可以适应搜索引擎对长词的需求,适用于对搜索引擎优化要求高的场景。
使用示例如下:```python。
import jieba。
text="今天天气真好,可以去公园放松一下。
"。
#精确模式。
seg_list = jieba.cut(text, cut_all=False)。
print("精确模式:", "/".join(seg_list))。
#全模式。
seg_list = jieba.cut(text, cut_all=True)。
print("全模式:", "/".join(seg_list))。
#搜索引擎模式。
seg_list = jieba.cut_for_search(text)。
print("搜索引擎模式:", "/".join(seg_list))。
```。
输出结果如下:```。
精确模式:今天天气/真好/,/可以/去/公园/放松/一下/。
全模式:今天/天气/真好/,/可以/去/公园/放松/松一/一下/。
搜索引擎模式:今天/天气/真好/,/可以/去/公园/放松/一下/松一/一下/。
jieba库的原理

jieba库的原理
jieba库是一款中文文本分词库,采用了基于前缀词典和动态规划算法的分词方法。
该库可用于中文文本的分词、关键词提取、词性标注等任务。
jieba库的原理主要有以下几个方面:
1. 前缀词典
jieba库采用了基于前缀词典的分词方法。
前缀词典是一个包含了所有中文单词的列表,每个单词都有一个或多个前缀。
例如,“中国”这个词的前缀可以是“中”、“中国”等。
在分词时,首先需要对中文文本进行分词,得到一个单词列表。
然后按照前缀词典中的单词顺序,从前往后匹配单词,直到找到匹配的单词为止。
如果找不到匹配的单词,则将当前单词与下一个单词合并,继续匹配,直到匹配成功或者无法匹配为止。
2. 动态规划算法
在基于前缀词典的分词方法中,如果匹配失败,则需要进行回溯。
jieba库采用了动态规划算法来避免回溯,提高分词速度。
动态规划算法是一种将问题分解成子问题并重复利用已经求解过的子问题结
果的算法。
在jieba库中,将文本划分成多个子问题,每个子问题的解决依赖于前面子问题的结果,并且已经求解过的子问题结果可以被重复利用。
3. HMM模型
jieba库还采用了隐马尔可夫模型(HMM)来进行词性标注。
HMM
模型是一种统计模型,可以根据给定的序列,推断出隐藏的状态序列。
在jieba库中,将文本划分成多个子问题,每个子问题都对应一个状态。
然后使用HMM模型来根据子问题的状态序列,对文本进行词性标注。
总之,jieba库的原理是将中文文本分解成多个子问题,使用前缀词典、动态规划算法和HMM模型来进行分词、关键词提取和词性标注等任务。
jieba的三种分词模式

jieba的三种分词模式
jieba是一个流行的中文分词工具,它提供了三种分词模式,
分别是精确模式、全模式和搜索引擎模式。
首先是精确模式,它试图将句子最精确地切开,适合文本分析。
在这种模式下,jieba会尽量将句子切分成最小的词语单元,从而
得到更准确的分词结果。
其次是全模式,它将句子中所有可能的词语都切分出来,适合
搜索引擎构建倒排索引或者实现高频词提取。
在这种模式下,jieba
会将句子中所有可能的词语都切分出来,包括一些停用词和无意义
的词语。
最后是搜索引擎模式,它在精确模式的基础上,对长词再次切分,适合搜索引擎构建倒排索引。
在这种模式下,jieba会对长词
再次进行切分,以便更好地匹配搜索引擎的检索需求。
这三种分词模式可以根据具体的应用场景和需求进行选择,以
达到最佳的分词效果。
精确模式适合对文本进行深入分析,全模式
适合构建倒排索引或者提取高频词,搜索引擎模式则适合搜索引擎
的检索需求。
通过合理选择分词模式,可以更好地满足不同场景下的分词需求。
jieba分词原理

jieba分词原理
jieba分词是一种基于统计和规则的中文分词工具。
它采用了基于前缀词典实现高效词图扫描的方法,同时利用了HMM模型进行未登录词识别,并通过了Viterbi算法实现中文分词。
jieba分词的算法步骤如下:
1. 构建前缀词典:jieba首先会生成一个前缀词典,将词库中的词按照字的前缀进行切分。
这可以大幅提高后续词图扫描的效率。
2. 生成词图:将待分词的文本转化为有向无环图(DAG),其中每个节点都代表了具体的片段。
这个图的目的是为了在后续步骤中进行词的组合。
3. 动态规划引擎:jieba使用了动态规划算法(Viterbi算法)来对词图进行路径搜索,找出最有可能的词组合。
这个算法同时也考虑了词的概率和语义等因素。
4. HMM模型:为了识别未登录词,jieba还采用了隐马尔可夫模型(HMM)进行标注。
它通过训练大量的中文语料库,学习词的出现概率和词性等信息,从而提高分词的准确性和鲁棒性。
5. 词性标注和歧义处理:jieba还可以对分词结果进行词性标注和歧义处理。
它可以根据具体需求,将分词结果进一步细分为名词、动词、形容词等不同的词性,并通过上下文信息来消
除歧义。
总的来说,jieba分词利用前缀词典、词图、动态规划引擎和HMM模型等技术手段,实现了高效、准确的中文分词。
它在许多中文文本处理任务中都被广泛应用,如信息检索、自然语言处理等。
jieba分词原理解析

jieba分词原理解析一、简介在自然语言处理(NL P)领域,中文分词是一个重要的基础任务。
分词就是将连续的汉字序列切分为独立的词语,是文本处理的第一步。
ji eb a 分词是一款基于P yth o n的中文分词工具,被广泛应用于文本挖掘、搜索引擎和机器学习等领域。
本文将详细解析j ie ba分词的原理和算法。
二、正向最大匹配算法j i eb a分词采用了一种正向最大匹配(M ax im um Fo rw ar dM a tc hi ng,M FM)的算法。
该算法从左到右扫描待分词语句,在词典中查找最长的词,然后将之作为一个词语输出。
例如,对于句子“结巴分词是一款很好用的中文分词工具”,算法将会将“结巴分词”、“是”、“一款”、“很好用”的词语分离出来。
三、逆向最大匹配算法除了正向最大匹配算法,ji eb a分词还使用了逆向最大匹配(M ax im um Ba ck wa rd M at ch in g,MB M)的算法。
逆向最大匹配算法与正向最大匹配算法类似,只是方向相反。
该算法从右到左扫描待分词语句,在词典中查找最长的词,然后将之作为一个词语输出。
对于同样的句子“结巴分词是一款很好用的中文分词工具”,逆向最大匹配算法将会将“分词工具”、“很好用的”、“是一款”的词语分离出来。
四、双向最大匹配算法除了正向最大匹配和逆向最大匹配算法,j i eb a分词还引入了双向最大匹配(Ma xi mu mB id i re ct io na lM at chi n g,BM M)算法,结合了两者的优点。
双向最大匹配算法先利用正向最大匹配算法进行分词,然后利用逆向最大匹配算法进行分词,最后根据词语切分结果的准确度来确定最终的分词结果。
双向最大匹配算法能够更准确地切分复杂的句子,提高了分词的准确率。
五、H M M模型j i eb a分词还引入了隐马尔可夫模型(Hi d de nM ar ko vM od el,H MM)来解决新词和歧义问题。
结巴分词原理

结巴分词原理
结巴分词是一种中文分词算法,采用基于词频和词汇概率的方法
对文本进行切割,将连续的中文字符序列切分成有意义的词语,“结”是“精准”的意思,“巴”是“速度”的意思,因此结巴分词也被称
为“高性能的中文分词工具”。
其原理是通过对中文文本进行扫描,利用前缀词典和后缀词典构
建起DAG(有向无环图)图,将词典中包含的所有可能的词语都列举出来,再通过最大匹配算法,找到其中最优的切分方案,从而实现对中
文文本的精准分词。
具体来说,结巴分词的前缀词典和后缀词典分别包含了一些常用
的前缀和后缀,例如“的”、“是”、“不”、“了”等等,这些前
缀和后缀可以用来构建DAG图中的节点,对于每个节点,它的出度连
接指向所有可能与该节点组合成词语的后缀节点,从而形成DAG图。
同时,结巴分词还采用了HMM(隐马尔可夫)模型,对分词结果进行统计和优化,从而提高了分词的准确率和速度。
总之,结巴分词算法采用了基于规则和统计的方法,通过前后缀
词典构建DAG图,并采用最大匹配算法和HMM模型优化,实现了对中
文文本的高性能分词。
jieba分词的几种分词模式

jieba分词的几种分词模式
jieba分词是一种常用的中文分词工具,它支持多种分词模式,包括精确模式、全模式、搜索引擎模式和自定义词典模式。
1. 精确模式,精确模式是指尽可能将句子中的词语精确地切分
出来,适合做文本分析和语义分析。
在精确模式下,jieba分词会
将句子中的词语按照最大概率切分出来,以保证分词结果的准确性。
2. 全模式,全模式是指将句子中所有可能的词语都切分出来,
适合用于搜索引擎构建倒排索引或者快速匹配。
在全模式下,jieba
分词会将句子中的所有可能词语都切分出来,以保证句子中的所有
词语都能被检索到。
3. 搜索引擎模式,搜索引擎模式是介于精确模式和全模式之间
的一种模式,它会对长词再次进行切分,适合用于搜索引擎的查询
分词。
在搜索引擎模式下,jieba分词会对长词进行再次切分,以
保证更多的词语能够被搜索到。
4. 自定义词典模式,自定义词典模式是指用户可以自行添加自
定义的词典,以保证特定领域的专有名词或者新词能够被正确切分。
在自定义词典模式下,jieba分词会优先使用用户自定义的词典进行分词,以保证分词结果的准确性和完整性。
这些分词模式能够满足不同场景下的分词需求,用户可以根据具体的应用场景选择合适的分词模式来进行文本分词处理。
jieba分词的公式

jieba分词的公式
jieba分词的公式主要包括基于词频统计的分词原则和关键词提取方法。
基于词频统计的分词原则是jieba分词的核心,它采用词频统计计算得分最高者,为最终分词结果。
具体计算公式如下:
输入文本:S,词典总词频:N(常量),单个词语的词频:P(A)
1)S = A+B+C+D 分词概率:p1= P(A)P(B)P(C)P(D)/NNNN 2)S = A +BC+D 分词概率:p2= P(A)P(BC)P(D)/NNN
字典新增词语时,词频设置基于此公式即可。
另外,jieba分词还提供了两种关键词提取方法,分别基于TF-IDF算法和TextRank算法。
基于TF-IDF算法的关键词提取是jieba分词中常用的方法之一,其计算公式为:TF-IDF = TF IDF。
其中,TF(term frequency,词频)表示某个给定的词语在该文件中出现的次数,IDF(inverse document frequency,逆
文件频率)表示如果包含词条的文件越少,则说明词条具有很好的类别区分能力。
以上是jieba分词的公式,仅供参考,如需获取更多信息,建议咨询专业的技术人员。
Pythonjieba结巴分词原理及用法解析

Pythonjieba结巴分词原理及⽤法解析1、简要说明结巴分词⽀持三种分词模式,⽀持繁体字,⽀持⾃定义词典2、三种分词模式全模式:把句⼦中所有的可以成词的词语都扫描出来, 速度⾮常快,但是不能解决歧义精简模式:把句⼦最精确的分开,不会添加多余单词,看起来就像是把句⼦分割⼀下搜索引擎模式:在精简模式下,对长词再度切分# -*- encoding=utf-8 -*-import jiebaif __name__ == '__main__':str1 = '我去北京天安门⼴场跳舞'a = jieba.lcut(str1, cut_all=True) # 全模式print('全模式:{}'.format(a))b = jieba.lcut(str1, cut_all=False) # 精简模式print('精简模式:{}'.format(b))c = jieba.lcut_for_search(str1) # 搜索引擎模式print('搜索引擎模式:{}'.format(c))运⾏3、某个词语不能被分开# -*- encoding=utf-8 -*-import jiebaif __name__ == '__main__':str1 = '桃花侠⼤战菊花怪'b = jieba.lcut(str1, cut_all=False) # 精简模式print('精简模式:{}'.format(b))# 如果不把桃花侠分开jieba.add_word('桃花侠')d = jieba.lcut(str1) # 默认是精简模式print(d)运⾏4、某个单词必须被分开# -*- encoding=utf-8 -*-import jiebaif __name__ == '__main__':# HMM参数,默认为True'''HMM 模型,即隐马尔可夫模型(Hidden Markov Model, HMM),是⼀种基于概率的统计分析模型,⽤来描述⼀个系统隐性状态的转移和隐性状态的表现概率。
如何运用jieba库分词
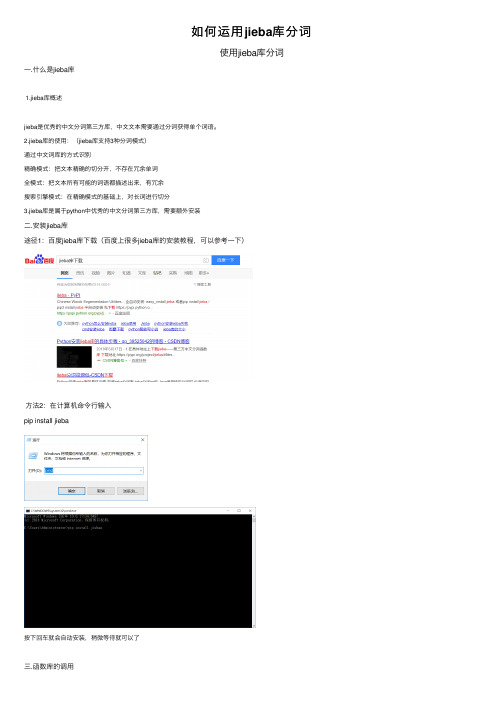
如何运⽤jieba库分词使⽤jieba库分词⼀.什么是jieba库1.jieba库概述jieba是优秀的中⽂分词第三⽅库,中⽂⽂本需要通过分词获得单个词语。
2.jieba库的使⽤:(jieba库⽀持3种分词模式)通过中⽂词库的⽅式识别精确模式:把⽂本精确的切分开,不存在冗余单词全模式:把⽂本所有可能的词语都描述出来,有冗余搜索引擎模式:在精确模式的基础上,对长词进⾏切分3.jieba库是属于python中优秀的中⽂分词第三⽅库,需要额外安装⼆.安装jieba库途径1:百度jieba库下载(百度上很多jieba库的安装教程,可以参考⼀下)⽅法2:在计算机命令⾏输⼊pip install jieba按下回车就会⾃动安装,稍微等待就可以了三.函数库的调⽤jieba库在python的 IDLE中运⾏时可以使⽤两种导⼊⽅式(1)导⼊库函数:import <库名>使⽤库中函数:<库名> . <函数名> (<函数参数>)例如:import jiebajieba.lcut()jieba.lcut(" ",cut_all=True)jieba.lcut_for_search()(2) 导⼊库函数:from <库名> import * ( *为通配符 )使⽤库中函数:<函数名> (<函数参数>)例如:from jieba import *lcut()lcut(" ",cut_all=True)lcut_for_search()四.jieba库的实际应⽤(对⽂本的词频统计)⽂本是⽔浒传,百度上下载的1from jieba import *2 excludes=lcut_for_search("头领两个⼀个武松如何只见说道军马众⼈那⾥")3 txt=open("⽔浒传.txt","r").read()4 words=lcut(txt)5 counts={}6for word in words:7if len(word)==1:8continue9elif word =="及时⾬"or word == "公明"or word =="哥哥"or word == "公明⽈": 10 rword ="宋江"11elif word =="⿊旋风"or word =="⿊⽜":12 rword ="李逵"13elif word =="豹⼦头"or word == "林教头":14 rword ="林冲"15elif word =="智多星"or word =="吴⽤⽈":16 rword ="吴⽤"17else:18 rword=word19 counts[word]=counts.get(word,0)+120for word in excludes:21del(counts[word])22 items=list(counts.items())23 items.sort(key=lambda x:x[1],reverse=True)24for i in range(10):25 word,count=items[i]26print("{0:<10}{1:>5}".format(word,count))运⾏结果:(有些多余的词语未做好排除,代码仍需要改进)五.词云图(jieba库与wordcloud库的结合应⽤)from wordcloud import WordCloudimport matplotlib.pyplot as pltfrom jieba import *# ⽣成词云def create_word_cloud(filename):text = open("{}.txt".format(filename)).read()font = 'C:\Windows\Fonts\simfang.ttf'wordlist = cut(text, cut_all=True) # 结巴分词wl = " ".join(wordlist)# 设置词云wc = WordCloud(# 设置背景颜⾊background_color="black",# 设置最⼤显⽰的词云数max_words=200,# 这种字体都在电脑字体中,⼀般路径font_path= font,height=1200,width=1600,# 设置字体最⼤值max_font_size=100,# 设置有多少种随机⽣成状态,即有多少种配⾊⽅案random_state=100,)myword = wc.generate(wl) # ⽣成词云# 展⽰词云图plt.imshow(myword)plt.axis("off")plt.show()wc.to_file('img_book.png') # 把词云保存下if __name__ == '__main__':create_word_cloud('⽔浒传') 运⾏结果 。
jieba分词归纳总结

jieba分词归纳总结
⼀、jieba介绍
jieba是NLP中常⽤的中⽂分词库
⼆、词库
1、默认词库
jieba 默认有349046个词,然后每⾏的含义是: 词词频词性
⾸先来看看jieba分词每次启动时,做了件什么事情,它做了2件事情:
1. 加载结巴⾃⾝的默认词库
2. 将默认词库模型加载到本机缓存,之后每次都从本地缓存中去加载默认词库缓存⽂件: jieba.cache
使⽤add_word(word, freq=None, tag=None)和del_word(word)可在程序中动态修改词典。
使⽤suggest_freq(segment, tune=True)可调节单个词语的词频,使其能(或不能)被分出来。
2、⾃定义词库
jieba.load_userdict(config.keywords_path)
三、词性标注
词性(词类)是词汇中剧本的语法属性,⽽词性标注是在给定句⼦中判定每个词的语法范畴,确定它的词性并加以标注的过程。
参考。
Python中文分词库——jieba

Python中⽂分词库——jieba(1).介绍 jieba是优秀的中⽂分词第三⽅库。
由于中⽂⽂本之间每个汉字都是连续书写的,我们需要通过特定的⼿段来获得其中的每个单词,这种⼿段就叫分词。
⽽jieba是Python计算⽣态中⾮常优秀的中⽂分词第三⽅库,需要通过安装来使⽤它。
jieba库提供了三种分词模式,但实际上要达到分词效果只要掌握⼀个函数就⾜够了,⾮常的简单有效。
安装第三⽅库需要使⽤pip⼯具,在命令⾏下运⾏安装命令(不是IDLE)。
注意:需要将Python⽬录和其⽬录下的Scripts⽬录加到环境变量中。
使⽤命令pip install jieba安装第三⽅库,安装之后会提⽰successfully installed,告知是否安装成功。
分词原理:简单来说,jieba库是通过中⽂词库的⽅式来识别分词的。
它⾸先利⽤⼀个中⽂词库,通过词库计算汉字之间构成词语的关联概率,所以通过计算汉字之间的概率,就可以形成分词的结果。
当然,除了jieba⾃带的中⽂词库,⽤户也可以向其中增加⾃定义的词组,从⽽使jieba的分词更接近某些具体领域的使⽤。
(2).使⽤说明 jieba分词有三种模式:精确模式、全模式和搜索引擎模式。
简单说,精确模式就是把⼀段⽂本精确的切分成若⼲个中⽂单词,若⼲个中⽂单词之间经过组合就精确的还原为之前的⽂本,其中不存在冗余单词。
精确模式是最常⽤的分词模式。
进⼀步jieba⼜提供了全模式,全模式是把⼀段中⽂⽂本中所有可能的词语都扫描出来,可能有⼀段⽂本它可以切分成不同的模式或者有不同的⾓度来切分变成不同的词语,那么jieba在全模式下把这样的不同的组合都挖掘出来,所以如果⽤全模式来进⾏分词,分词的信息组合起来并不是精确的原有⽂本,会有很多的冗余。
⽽搜索引擎模式更加智能,它是在精确模式的基础上对长词进⾏再次切分,将长的词语变成更短的词语,进⽽适合搜索引擎对短词语的索引和搜索,在⼀些特定场合⽤的⽐较多。
jieba库词频统计
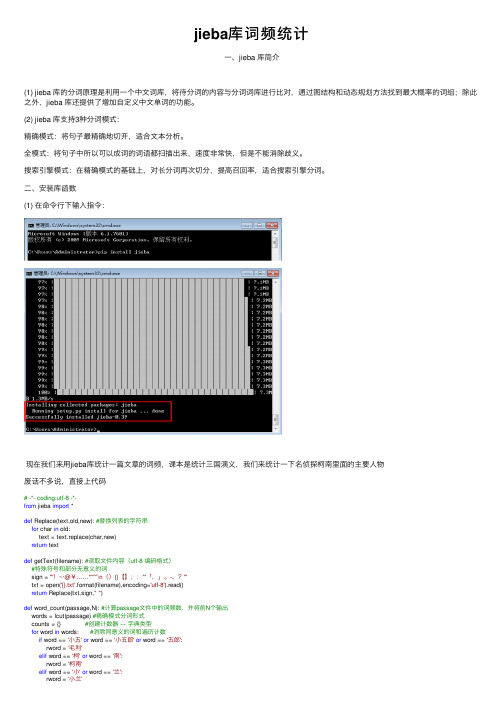
jieba库词频统计⼀、jieba 库简介(1) jieba 库的分词原理是利⽤⼀个中⽂词库,将待分词的内容与分词词库进⾏⽐对,通过图结构和动态规划⽅法找到最⼤概率的词组;除此之外,jieba 库还提供了增加⾃定义中⽂单词的功能。
(2) jieba 库⽀持3种分词模式:精确模式:将句⼦最精确地切开,适合⽂本分析。
全模式:将句⼦中所以可以成词的词语都扫描出来,速度⾮常快,但是不能消除歧义。
搜索引擎模式:在精确模式的基础上,对长分词再次切分,提⾼召回率,适合搜索引擎分词。
⼆、安装库函数(1) 在命令⾏下输⼊指令:现在我们来⽤jieba库统计⼀篇⽂章的词频,课本是统计三国演义,我们来统计⼀下名侦探柯南⾥⾯的主要⼈物废话不多说,直接上代码# -*- coding:utf-8 -*-from jieba import *def Replace(text,old,new): #替换列表的字符串for char in old:text = text.replace(char,new)return textdef getText(filename): #读取⽂件内容(utf-8 编码格式)#特殊符号和部分⽆意义的词sign = '''!~·@¥……*“”‘’\n(){}【】;:"'「,」。
-、?'''txt = open('{}.txt'.format(filename),encoding='utf-8').read()return Replace(txt,sign,"")def word_count(passage,N): #计算passage⽂件中的词频数,并将前N个输出words = lcut(passage) #精确模式分词形式counts = {} #创建计数器 --- 字典类型for word in words: #消除同意义的词和遍历计数if word == '⼩五'or word == '⼩五郎'or word == '五郎':rword = '⽑利'elif word == '柯'or word == '南':rword = '柯南'elif word == '⼩'or word == '兰':rword = '⼩兰'elif word == '⽬'or word == '暮'or word == '警官':rword = '暮⽬'else:rword = wordcounts[rword] = counts.get(rword,0) + 1excludes = lcut_for_search("你我事他和她在这也有什么的是就吧啊吗哦呢都了⼀个")for word in excludes: #除去意义不⼤的词语del(counts[word])items = list(counts.items()) #转换成列表形式items.sort(key = lambda x : x[1], reverse = True ) #按次数排序for i in range(N): #依次输出word,count = items[i]print("{:<7}{:>6}".format(word,count))if__name__ == '__main__':passage = getText('Detective_Novel') #输⼊⽂件名称读⼊⽂件内容word_count(passage,20) #调⽤函数得到词频数注:代码使⽤的⽂档 >>> [点击下载],也可⾃⾏找 utf-8 编码格式的txt⽂件。
jieba库的使用说明

jieba库的使⽤说明1、jieba库基本介绍(1)、jieba库概述1. jieba是优秀的中⽂分词第三⽅库2. -中⽂⽂本需要通过分词获得单个的词语3. - jieba是优秀的中⽂分词第三⽅库,需要额外安装4. - jieba库提供三种分词模式,最简单只需掌握⼀个函数(2)、jieba分词的原理1. Jieba分词依靠中⽂词库2. - 利⽤⼀个中⽂词库,确定汉字之间的关联概率3. - 汉字间概率⼤的组成词组,形成分词结果4. - 除了分词,⽤户还可以添加⾃定义的词组2、jieba库使⽤说明(1)、jieba分词的三种模式1. 精确模式、全模式、搜索引擎模式2. - 精确模式:把⽂本精确的切分开,不存在冗余单词3. - 全模式:把⽂本中所有可能的词语都扫描出来,有冗余4. - 搜索引擎模式:在精确模式基础上,对长词再次切分(2)、jieba库常⽤函数3.jieba应⽤实例4.利⽤jieba库统计三国演义中任务的出场次数import jiebatxt = open("D:\\三国演义.txt", "r", encoding='utf-8').read()words = jieba.lcut(txt) # 使⽤精确模式对⽂本进⾏分词counts = {} # 通过键值对的形式存储词语及其出现的次数for word in words:if len(word) == 1: # 单个词语不计算在内continueelse:counts[word] = counts.get(word, 0) + 1 # 遍历所有词语,每出现⼀次其对应的值加 1items = list(counts.items())#将键值对转换成列表items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进⾏从⼤到⼩排序for i in range(15):word, count = items[i]print("{0:<5}{1:>5}".format(word, count))统计了次数对多前⼗五个名词,曹操不愧是⼀代枭雄,第⼀名当之⽆愧,但是我们会发现得到的数据还是需要进⼀步处理,⽐如⼀些⽆⽤的词语,⼀些重复意思的词语。
自然语言处理之jieba分词

⾃然语⾔处理之jieba分词在所有⼈类语⾔中,⼀句话、⼀段⽂本、⼀篇⽂章都是有⼀个个的词组成的。
词是包含独⽴意义的最⼩⽂本单元,将长⽂本拆分成单个独⽴的词汇的过程叫做分词。
分词之后,⽂本原本的语义将被拆分到在更加精细化的各个独⽴词汇中,词汇的结构⽐长⽂本简单,对于计算机⽽⾔,更容易理解和分析,所以,分词往往是⾃然语⾔处理的第⼀步。
对于英⽂⽂本,句⼦中的词汇可以通过空格很容易得进⾏划分,但是在我们中⽂中则不然,没有明显的划分标志,所以需要通过专门的⽅法(算法)进⾏分词。
在Python中,有多种库实现了各种⽅法⽀持中⽂分词,例如:jieba、hanlp、pkuseg等。
在本篇中,先来说说jieba分词。
1 四种模式分词(1)精确模式:试图将句⼦最精确地切开,适合⽂本分析。
精确分词模式对应的⽅法是jieba.cut,该⽅法接受四个输⼊参数: 需要分词的字符串;cut_all 参数⽤来控制是否采⽤全模式,值为False时表⽰采⽤精确分词模式;HMM 参数⽤来控制是否使⽤ HMM 模型。
(2)全模式:把句⼦中所有的可以成词的词语都扫描出来,速度⾮常快,但是不能解决歧义。
全模式同样是调⽤jieba.cut⽅法实现,不过cut_all参数值设置为True。
(3)搜索引擎模式:在精确模式的基础上,对长词再词切分,提⾼召回率,适合⽤于搜索引擎分词。
搜索引擎模式对应的⽅法是jieba.cut_for_search。
该⽅法接受两个参数:需要分词的字符串;是否使⽤ HMM 模型。
该⽅法适合⽤于搜索引擎构建倒排索引的分词,粒度⽐较细。
注意,待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。
注意:不建议直接输⼊ GBK 字符串,可能⽆法预料地错误解码成 UTF-8。
另外,jieba.cut 以及 jieba.cut_for_search 返回的结构都是⼀个可迭代的generator,可以使⽤ for 循环来获得分词后得到的每⼀个词语(unicode),或者⽤jieba.lcut 以及 jieba.lcut_for_search 直接返回 list。
jieba:统计一篇文章中词语数

jieba:统计⼀篇⽂章中词语数1、jieba分词的四种模式精确模式、全模式、搜索引擎模式、paddle模式精确模式:把⽂本精确的切分开,不存在冗余单词,适合⽂本分析;全模式:把⽂本中所有可能的词语都扫描出来,不能解决歧义,有冗余搜索引擎模式:在精确模式的基础上,对长单词再次切分,提⾼召回率,适⽤于搜索引擎分词paddle模式:利⽤PaddlePaddle深度学习框架,训练序列标注(双向GRU)⽹络模型实现分词。
同时⽀持词性标注。
paddle模式需要安装paddlepaddle-tinypip install paddlepaddle-tiny==1.6.12、jieba库常⽤函数函数参数jieba.cut(s,cut_all=False,HMM=False,use_paddle=False)s:为需要分词的字符串cut_all:是否采⽤全模式(False情况下为精确模式)HMM:是否使⽤HMM模型use_paddle:是否使⽤paddle模式下的分词模式返回Generator类型jieba.cut_for_search(s,HMM=False)搜索引擎模式,参数含义同上,返回Generator类型jieba.lcut(s,cut_all=False,HMM=False,use_paddle=False)返回⼀个List类型jieba.lcut_for_search(s,HMM=False)搜索引擎模式,返回Listjieba.add_word(w)向分词词典中增加新词wjieba.Tokenizer(dictionary=DEFAULT_DICT)新建⾃定义分类器,可⽤于同时使⽤不同词典。
jieba.dt为默认分类器,所有全局分词相关函数都是该分类器的映射3、载⼊字典开发者可以指定⾃⼰⾃定义的词典,以便包含jieba词库没有的词。
虽然jieba有新词识别能⼒,但是⾃⾏添加新词可以保证更⾼的正确率。
结巴分词原理

结巴分词原理
结巴分词(jieba)是一款基于Python的中文分词工具,具有高效、准确、可定制化等特点,在自然语言处理领域中广泛应用。
那么,结巴分词的原理是什么呢?
首先,结巴分词采用了基于前缀词典实现的分词算法。
所谓前缀词典,就是将词语按照一定规则分成字的组合,然后根据这些组合建立一个前缀树(Trie树),每个节点代表一个词语的前缀。
当需要对一段文本进行分词时,结巴分词会遍历这个前缀树,将匹配到的词语作为分词结果输出。
其次,结巴分词还采用了基于隐马尔可夫模型(HMM)的分词算法。
隐马尔可夫模型是一种基于概率的统计模型,可以用于描述一个系统在一系列不可见的状态之间的转移,而这些状态会影响到可见的观测结果。
在结巴分词中,隐马尔可夫模型被用于统计每个词语在文本中出现的概率,从而提高分词的准确性。
最后,结巴分词还采用了基于最大匹配的分词算法。
最大匹配法是将文本按照一定的规则分成若干个候选词语,然后通过计算每个候选词语的评分来选择最合适的分词结果。
在结巴分词中,最大匹配法被用于对各个分词算法的结果进行评估和排序。
综上所述,结巴分词采用了前缀词典、隐马尔可夫模型和最大匹配法等多种分词算法,通过将它们有效的结合起来,使得结巴分词具有了高效、准确、可定制化等特点。
同时,结巴分词还可以通过添加自定义词典、调整分词算法参数等方式进行定制,以适应不同领域和
任务的需求。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
jieba分词原理
Jieba分词是一种中文分词工具,它基于字典匹配和规则匹配
的原理。
具体来说,它首先利用前缀词典和后缀词典对文本进行扫描,尝试匹配最长的词语;然后,对于未匹配到的词语,根据中文的特点,利用确定性有向无环图(DAG)进行再次扫描,通过动态规划算法计算得到最大概率路径,将文本进行分词。
在Jieba分词的过程中,采用了基于词频和互信息的词频统计
方法来构建字典。
对于未登录词(即字典中没有的词语),采用了基于HMM模型的隐马尔可夫分词方法对其进行切分。
除了基本的中文分词功能外,Jieba还提供了更细粒度的分词
功能,即将词语进行进一步细分,例如将"中国人"分为"中国"和"人"两个词语。
这一功能是通过采用了基于切分词典的前向
最大匹配算法实现的。
Jieba还提供了用户自定义词典的功能,用户可以根据自己的
需求增加、删除或修改词语,以达到更加准确的分词效果。
同时,Jieba对新词的识别也具有一定的能力,能够根据上下文
和词频进行分析,自动识别并合并新词到词典中。
总的来说,Jieba分词工具通过字典匹配和规则匹配的原理实
现了中文分词的功能,并提供了自定义词典和新词识别的功能,以适应不同的分词需求。