Anne GG 10 Summary
微软消息分析器:一款高级网络包分析器说明书

Neil B MartinT est Manager WSSC-Interop and T oolsMicrosoft CorporationMicrosoft Message Analyzer Packet Analysis at a Higher LevelContent•Packet Analyzer -review •Abstracting views of protocols •Alternative data sources •ETW•Remote Capture•Bluetooth•USB•Evtx•Logs filesMessage Analyzer –What is it?• A packet analyzer is a computer program or a piece of computer hardware that can intercept and log traffic passing over all or part of a network•Packet analyzers capture network packets in real time and display them in human-readable format•WireShark, Microsoft NetMon3.4•These tools are dissectors•If they recognize a packet they dissect it and display the inner fields of the packet•The parsers are written based on the protocol specifications or in some cases through reverse engineering of the protocols whenno specification is available•Dissection and Abstraction•We want to allow a higher level of abstraction view of protcols•Pattern Matching•Match up request/response pairs where possible•Called an operation•Different Viewers and Charts•Addressing many of the challenges of diagnosing modern networks •Protocol Validation•Identify packets that do not match the specification•Data capture from multiple sources•NDIS, Bluetooth, USB, Windows Firewall Layer, Web Proxy•Header only network capture•Reduce data in volume scenarios•Correlation of data across multiple data sources and logs•Load and display multiple data source•Message Analyzer captures ETW •ETW -Event Trace for Windows •Message Capture from:•Traditional NDIS traffic from the Network Adapter •Windows Filtering Platform 9aka Firewall)•Web proxy•USB ports•Bluetooth•Windows SMB Client•Windows SMB Server ……•E vent T racing for W indows ETW•High-resolution (<<100µs)logging infrastructure allows any component to tell the outside world what it is currently doing by firing ETW events.• A powerful diagnostic tool to log every methods/lines inside the code with reasonable performance fordebugging/troubleshooting.•MSDN on ETW/en-us/library/bb968803(VS.85).aspxAll Windows ETW Sources are available to Message Analyzer•Capability to perform remote capture •Select machine and give credentials•Collect data via ETW from NIC on remote machine•Powerful, extensible viewing and analysis •Browse, Select, View•Browse for messages from various sources (live, or stored)•Select a set of messages from those sources by characteristic(s)•View messages in a provided viewer, configure or build your own • A new high-level grid view•High level “Operations” view with automatic re-assembly•“Bubbling up” of errors in the stack to the top level•Ability to drill down the stack to underlying messages and/or packets•On the fly grouping, filtering, finding, or sorting by any message property •Payload rendering•V alidation of message structures, behavior, and architecture•Does the protocol comply with the specifications?•Over 450 published specifications for Windows Protocols(as of Windows 8.1)(/en-us/library/gg685446.aspx)Available online and as PDFContinue to publish new documents with each release of Windows •Continue to develop tools and technology to aid with the development of protocol documents, parsers and test technologyHow to get MA: /en-us/download/details.aspx?id=40308 How to get help: Blog,Operating Guide, T echnet Forum for Message Analyzer •We invite you to Explore Message Analyzer•Connect Community•https:///site216/。
REPSOL_VETTING_PROCESS_AND_CRITERIA_2014_tcm11-689923

III. Effective Date
01 Aug 2014
Page 2 of 31
REPSOL VETTING PROCESS AND CRITERIA
IV. DEFINITIONS For the purpose of these procedures, the following definitions apply: Acceptable means the vessel can be used within the scope described above, and is the only rating that allows such use. This rating results from a favourable assessment based on information that we have deemed positive and sufficient. The rating of the vessel may be affected by relevant modifications concerning safety and operational systems, changes of name, technical operator, crew, flag, etc., as well as any incident, casualty or terminal negative feedback report, PSC detention or Memoranda or condition of Class. (See also “Vetting Assessment”.) Barge, for the purpose of these procedures, means a vessel carrying goods in rivers, inland navigation, lakes and ports, not sailing on open sea or bays and restricted by Flag Administration to inland water navigations. EBIS Barge: for the purpose of these procedures, means a vessel carrying goods in European rivers, not sailing on open sea or bay CAP (Condition Assessment Programme).- Independent and thorough scheme of inspections of the actual condition of a vessel. It is applicable as established in the present Vetting Process and Criteria and as defined in the Rules of the Classification Societies members of IACS. Cargo means any kind of material subject to a contract of transportation, mainly crude oil, oil products, chemical products, LPG, LNG, Lubricants, Liquid fertilizers and dry bulk cargoes. Charter Party means contract of affreightment signed between shipowner and charterer when hiring a vessel for the carriage of goods. Chief Officer and 2nd. Engineer terminology considered equivalent to 1st. Officer and 1st. Asst. Engineer for the purpose of these procedures. COA vessel means vessels included in a contract of affreightment to lift a fixed or determinable quantity of cargo of a specified type over a given period of time. EBIS the European Barge Inspection Scheme, is used to evaluate barges, tugs and dumb barges used to distribute oil and chemicals within Europe ESP (Enhanced Survey Programme).- It is applicable as established in SOLAS XI1/2 and as defined in Resolution A.744 (18). Heavy grade Oil: o o o crude oils, having a density at 15º C higher than 900 kg/m3; oils, other than crude oils, having either a density at 15º C higher than 900 kg/m3 or a kinematic viscosity at 50 º C higher than 180 mm2/s; or; bitumen, tar and their emulsions.
T.W. ANDERSON (1971). The Statistical Analysis of Time Series. Series in Probability and Ma

425 BibliographyH.A KAIKE(1974).Markovian representation of stochastic processes and its application to the analysis of autoregressive moving average processes.Annals Institute Statistical Mathematics,vol.26,pp.363-387. B.D.O.A NDERSON and J.B.M OORE(1979).Optimal rmation and System Sciences Series, Prentice Hall,Englewood Cliffs,NJ.T.W.A NDERSON(1971).The Statistical Analysis of Time Series.Series in Probability and Mathematical Statistics,Wiley,New York.R.A NDRE-O BRECHT(1988).A new statistical approach for the automatic segmentation of continuous speech signals.IEEE Trans.Acoustics,Speech,Signal Processing,vol.ASSP-36,no1,pp.29-40.R.A NDRE-O BRECHT(1990).Reconnaissance automatique de parole`a partir de segments acoustiques et de mod`e les de Markov cach´e s.Proc.Journ´e es Etude de la Parole,Montr´e al,May1990(in French).R.A NDRE-O BRECHT and H.Y.S U(1988).Three acoustic labellings for phoneme based continuous speech recognition.Proc.Speech’88,Edinburgh,UK,pp.943-950.U.A PPEL and A.VON B RANDT(1983).Adaptive sequential segmentation of piecewise stationary time rmation Sciences,vol.29,no1,pp.27-56.L.A.A ROIAN and H.L EVENE(1950).The effectiveness of quality control procedures.Jal American Statis-tical Association,vol.45,pp.520-529.K.J.A STR¨OM and B.W ITTENMARK(1984).Computer Controlled Systems:Theory and rma-tion and System Sciences Series,Prentice Hall,Englewood Cliffs,NJ.M.B AGSHAW and R.A.J OHNSON(1975a).The effect of serial correlation on the performance of CUSUM tests-Part II.Technometrics,vol.17,no1,pp.73-80.M.B AGSHAW and R.A.J OHNSON(1975b).The influence of reference values and estimated variance on the ARL of CUSUM tests.Jal Royal Statistical Society,vol.37(B),no3,pp.413-420.M.B AGSHAW and R.A.J OHNSON(1977).Sequential procedures for detecting parameter changes in a time-series model.Jal American Statistical Association,vol.72,no359,pp.593-597.R.K.B ANSAL and P.P APANTONI-K AZAKOS(1986).An algorithm for detecting a change in a stochastic process.IEEE rmation Theory,vol.IT-32,no2,pp.227-235.G.A.B ARNARD(1959).Control charts and stochastic processes.Jal Royal Statistical Society,vol.B.21, pp.239-271.A.E.B ASHARINOV andB.S.F LEISHMAN(1962).Methods of the statistical sequential analysis and their radiotechnical applications.Sovetskoe Radio,Moscow(in Russian).M.B ASSEVILLE(1978).D´e viations par rapport au maximum:formules d’arrˆe t et martingales associ´e es. Compte-rendus du S´e minaire de Probabilit´e s,Universit´e de Rennes I.M.B ASSEVILLE(1981).Edge detection using sequential methods for change in level-Part II:Sequential detection of change in mean.IEEE Trans.Acoustics,Speech,Signal Processing,vol.ASSP-29,no1,pp.32-50.426B IBLIOGRAPHY M.B ASSEVILLE(1982).A survey of statistical failure detection techniques.In Contribution`a la D´e tectionS´e quentielle de Ruptures de Mod`e les Statistiques,Th`e se d’Etat,Universit´e de Rennes I,France(in English). M.B ASSEVILLE(1986).The two-models approach for the on-line detection of changes in AR processes. In Detection of Abrupt Changes in Signals and Dynamical Systems(M.Basseville,A.Benveniste,eds.). Lecture Notes in Control and Information Sciences,LNCIS77,Springer,New York,pp.169-215.M.B ASSEVILLE(1988).Detecting changes in signals and systems-A survey.Automatica,vol.24,pp.309-326.M.B ASSEVILLE(1989).Distance measures for signal processing and pattern recognition.Signal Process-ing,vol.18,pp.349-369.M.B ASSEVILLE and A.B ENVENISTE(1983a).Design and comparative study of some sequential jump detection algorithms for digital signals.IEEE Trans.Acoustics,Speech,Signal Processing,vol.ASSP-31, no3,pp.521-535.M.B ASSEVILLE and A.B ENVENISTE(1983b).Sequential detection of abrupt changes in spectral charac-teristics of digital signals.IEEE rmation Theory,vol.IT-29,no5,pp.709-724.M.B ASSEVILLE and A.B ENVENISTE,eds.(1986).Detection of Abrupt Changes in Signals and Dynamical Systems.Lecture Notes in Control and Information Sciences,LNCIS77,Springer,New York.M.B ASSEVILLE and I.N IKIFOROV(1991).A unified framework for statistical change detection.Proc.30th IEEE Conference on Decision and Control,Brighton,UK.M.B ASSEVILLE,B.E SPIAU and J.G ASNIER(1981).Edge detection using sequential methods for change in level-Part I:A sequential edge detection algorithm.IEEE Trans.Acoustics,Speech,Signal Processing, vol.ASSP-29,no1,pp.24-31.M.B ASSEVILLE, A.B ENVENISTE and G.M OUSTAKIDES(1986).Detection and diagnosis of abrupt changes in modal characteristics of nonstationary digital signals.IEEE rmation Theory,vol.IT-32,no3,pp.412-417.M.B ASSEVILLE,A.B ENVENISTE,G.M OUSTAKIDES and A.R OUG´E E(1987a).Detection and diagnosis of changes in the eigenstructure of nonstationary multivariable systems.Automatica,vol.23,no3,pp.479-489. M.B ASSEVILLE,A.B ENVENISTE,G.M OUSTAKIDES and A.R OUG´E E(1987b).Optimal sensor location for detecting changes in dynamical behavior.IEEE Trans.Automatic Control,vol.AC-32,no12,pp.1067-1075.M.B ASSEVILLE,A.B ENVENISTE,B.G ACH-D EVAUCHELLE,M.G OURSAT,D.B ONNECASE,P.D OREY, M.P REVOSTO and M.O LAGNON(1993).Damage monitoring in vibration mechanics:issues in diagnos-tics and predictive maintenance.Mechanical Systems and Signal Processing,vol.7,no5,pp.401-423.R.V.B EARD(1971).Failure Accommodation in Linear Systems through Self-reorganization.Ph.D.Thesis, Dept.Aeronautics and Astronautics,MIT,Cambridge,MA.A.B ENVENISTE and J.J.F UCHS(1985).Single sample modal identification of a nonstationary stochastic process.IEEE Trans.Automatic Control,vol.AC-30,no1,pp.66-74.A.B ENVENISTE,M.B ASSEVILLE and G.M OUSTAKIDES(1987).The asymptotic local approach to change detection and model validation.IEEE Trans.Automatic Control,vol.AC-32,no7,pp.583-592.A.B ENVENISTE,M.M ETIVIER and P.P RIOURET(1990).Adaptive Algorithms and Stochastic Approxima-tions.Series on Applications of Mathematics,(A.V.Balakrishnan,I.Karatzas,M.Yor,eds.).Springer,New York.A.B ENVENISTE,M.B ASSEVILLE,L.E L G HAOUI,R.N IKOUKHAH and A.S.W ILLSKY(1992).An optimum robust approach to statistical failure detection and identification.IFAC World Conference,Sydney, July1993.B IBLIOGRAPHY427 R.H.B ERK(1973).Some asymptotic aspects of sequential analysis.Annals Statistics,vol.1,no6,pp.1126-1138.R.H.B ERK(1975).Locally most powerful sequential test.Annals Statistics,vol.3,no2,pp.373-381.P.B ILLINGSLEY(1968).Convergence of Probability Measures.Wiley,New York.A.F.B ISSELL(1969).Cusum techniques for quality control.Applied Statistics,vol.18,pp.1-30.M.E.B IVAIKOV(1991).Control of the sample size for recursive estimation of parameters subject to abrupt changes.Automation and Remote Control,no9,pp.96-103.R.E.B LAHUT(1987).Principles and Practice of Information Theory.Addison-Wesley,Reading,MA.I.F.B LAKE and W.C.L INDSEY(1973).Level-crossing problems for random processes.IEEE r-mation Theory,vol.IT-19,no3,pp.295-315.G.B ODENSTEIN and H.M.P RAETORIUS(1977).Feature extraction from the encephalogram by adaptive segmentation.Proc.IEEE,vol.65,pp.642-652.T.B OHLIN(1977).Analysis of EEG signals with changing spectra using a short word Kalman estimator. Mathematical Biosciences,vol.35,pp.221-259.W.B¨OHM and P.H ACKL(1990).Improved bounds for the average run length of control charts based on finite weighted sums.Annals Statistics,vol.18,no4,pp.1895-1899.T.B OJDECKI and J.H OSZA(1984).On a generalized disorder problem.Stochastic Processes and their Applications,vol.18,pp.349-359.L.I.B ORODKIN and V.V.M OTTL’(1976).Algorithm forfinding the jump times of random process equation parameters.Automation and Remote Control,vol.37,no6,Part1,pp.23-32.A.A.B OROVKOV(1984).Theory of Mathematical Statistics-Estimation and Hypotheses Testing,Naouka, Moscow(in Russian).Translated in French under the title Statistique Math´e matique-Estimation et Tests d’Hypoth`e ses,Mir,Paris,1987.G.E.P.B OX and G.M.J ENKINS(1970).Time Series Analysis,Forecasting and Control.Series in Time Series Analysis,Holden-Day,San Francisco.A.VON B RANDT(1983).Detecting and estimating parameters jumps using ladder algorithms and likelihood ratio test.Proc.ICASSP,Boston,MA,pp.1017-1020.A.VON B RANDT(1984).Modellierung von Signalen mit Sprunghaft Ver¨a nderlichem Leistungsspektrum durch Adaptive Segmentierung.Doctor-Engineer Dissertation,M¨u nchen,RFA(in German).S.B RAUN,ed.(1986).Mechanical Signature Analysis-Theory and Applications.Academic Press,London. L.B REIMAN(1968).Probability.Series in Statistics,Addison-Wesley,Reading,MA.G.S.B RITOV and L.A.M IRONOVSKI(1972).Diagnostics of linear systems of automatic regulation.Tekh. Kibernetics,vol.1,pp.76-83.B.E.B RODSKIY and B.S.D ARKHOVSKIY(1992).Nonparametric Methods in Change-point Problems. Kluwer Academic,Boston.L.D.B ROEMELING(1982).Jal Econometrics,vol.19,Special issue on structural change in Econometrics. L.D.B ROEMELING and H.T SURUMI(1987).Econometrics and Structural Change.Dekker,New York. D.B ROOK and D.A.E VANS(1972).An approach to the probability distribution of Cusum run length. Biometrika,vol.59,pp.539-550.J.B RUNET,D.J AUME,M.L ABARR`E RE,A.R AULT and M.V ERG´E(1990).D´e tection et Diagnostic de Pannes.Trait´e des Nouvelles Technologies,S´e rie Diagnostic et Maintenance,Herm`e s,Paris(in French).428B IBLIOGRAPHY S.P.B RUZZONE and M.K AVEH(1984).Information tradeoffs in using the sample autocorrelation function in ARMA parameter estimation.IEEE Trans.Acoustics,Speech,Signal Processing,vol.ASSP-32,no4, pp.701-715.A.K.C AGLAYAN(1980).Necessary and sufficient conditions for detectability of jumps in linear systems. IEEE Trans.Automatic Control,vol.AC-25,no4,pp.833-834.A.K.C AGLAYAN and R.E.L ANCRAFT(1983).Reinitialization issues in fault tolerant systems.Proc.Amer-ican Control Conf.,pp.952-955.A.K.C AGLAYAN,S.M.A LLEN and K.W EHMULLER(1988).Evaluation of a second generation reconfigu-ration strategy for aircraftflight control systems subjected to actuator failure/surface damage.Proc.National Aerospace and Electronic Conference,Dayton,OH.P.E.C AINES(1988).Linear Stochastic Systems.Series in Probability and Mathematical Statistics,Wiley, New York.M.J.C HEN and J.P.N ORTON(1987).Estimation techniques for tracking rapid parameter changes.Intern. Jal Control,vol.45,no4,pp.1387-1398.W.K.C HIU(1974).The economic design of cusum charts for controlling normal mean.Applied Statistics, vol.23,no3,pp.420-433.E.Y.C HOW(1980).A Failure Detection System Design Methodology.Ph.D.Thesis,M.I.T.,L.I.D.S.,Cam-bridge,MA.E.Y.C HOW and A.S.W ILLSKY(1984).Analytical redundancy and the design of robust failure detection systems.IEEE Trans.Automatic Control,vol.AC-29,no3,pp.689-691.Y.S.C HOW,H.R OBBINS and D.S IEGMUND(1971).Great Expectations:The Theory of Optimal Stop-ping.Houghton-Mifflin,Boston.R.N.C LARK,D.C.F OSTH and V.M.W ALTON(1975).Detection of instrument malfunctions in control systems.IEEE Trans.Aerospace Electronic Systems,vol.AES-11,pp.465-473.A.C OHEN(1987).Biomedical Signal Processing-vol.1:Time and Frequency Domain Analysis;vol.2: Compression and Automatic Recognition.CRC Press,Boca Raton,FL.J.C ORGE and F.P UECH(1986).Analyse du rythme cardiaque foetal par des m´e thodes de d´e tection de ruptures.Proc.7th INRIA Int.Conf.Analysis and optimization of Systems.Antibes,FR(in French).D.R.C OX and D.V.H INKLEY(1986).Theoretical Statistics.Chapman and Hall,New York.D.R.C OX and H.D.M ILLER(1965).The Theory of Stochastic Processes.Wiley,New York.S.V.C ROWDER(1987).A simple method for studying run-length distributions of exponentially weighted moving average charts.Technometrics,vol.29,no4,pp.401-407.H.C S¨ORG¨O and L.H ORV´ATH(1988).Nonparametric methods for change point problems.In Handbook of Statistics(P.R.Krishnaiah,C.R.Rao,eds.),vol.7,Elsevier,New York,pp.403-425.R.B.D AVIES(1973).Asymptotic inference in stationary gaussian time series.Advances Applied Probability, vol.5,no3,pp.469-497.J.C.D ECKERT,M.N.D ESAI,J.J.D EYST and A.S.W ILLSKY(1977).F-8DFBW sensor failure identification using analytical redundancy.IEEE Trans.Automatic Control,vol.AC-22,no5,pp.795-803.M.H.D E G ROOT(1970).Optimal Statistical Decisions.Series in Probability and Statistics,McGraw-Hill, New York.J.D ESHAYES and D.P ICARD(1979).Tests de ruptures dans un mod`e pte-Rendus de l’Acad´e mie des Sciences,vol.288,Ser.A,pp.563-566(in French).B IBLIOGRAPHY429 J.D ESHAYES and D.P ICARD(1983).Ruptures de Mod`e les en Statistique.Th`e ses d’Etat,Universit´e deParis-Sud,Orsay,France(in French).J.D ESHAYES and D.P ICARD(1986).Off-line statistical analysis of change-point models using non para-metric and likelihood methods.In Detection of Abrupt Changes in Signals and Dynamical Systems(M. Basseville,A.Benveniste,eds.).Lecture Notes in Control and Information Sciences,LNCIS77,Springer, New York,pp.103-168.B.D EVAUCHELLE-G ACH(1991).Diagnostic M´e canique des Fatigues sur les Structures Soumises`a des Vibrations en Ambiance de Travail.Th`e se de l’Universit´e Paris IX Dauphine(in French).B.D EVAUCHELLE-G ACH,M.B ASSEVILLE and A.B ENVENISTE(1991).Diagnosing mechanical changes in vibrating systems.Proc.SAFEPROCESS’91,Baden-Baden,FRG,pp.85-89.R.D I F RANCESCO(1990).Real-time speech segmentation using pitch and convexity jump models:applica-tion to variable rate speech coding.IEEE Trans.Acoustics,Speech,Signal Processing,vol.ASSP-38,no5, pp.741-748.X.D ING and P.M.F RANK(1990).Fault detection via factorization approach.Systems and Control Letters, vol.14,pp.431-436.J.L.D OOB(1953).Stochastic Processes.Wiley,New York.V.D RAGALIN(1988).Asymptotic solutions in detecting a change in distribution under an unknown param-eter.Statistical Problems of Control,Issue83,Vilnius,pp.45-52.B.D UBUISSON(1990).Diagnostic et Reconnaissance des Formes.Trait´e des Nouvelles Technologies,S´e rie Diagnostic et Maintenance,Herm`e s,Paris(in French).A.J.D UNCAN(1986).Quality Control and Industrial Statistics,5th edition.Richard D.Irwin,Inc.,Home-wood,IL.J.D URBIN(1971).Boundary-crossing probabilities for the Brownian motion and Poisson processes and techniques for computing the power of the Kolmogorov-Smirnov test.Jal Applied Probability,vol.8,pp.431-453.J.D URBIN(1985).Thefirst passage density of the crossing of a continuous Gaussian process to a general boundary.Jal Applied Probability,vol.22,no1,pp.99-122.A.E MAMI-N AEINI,M.M.A KHTER and S.M.R OCK(1988).Effect of model uncertainty on failure detec-tion:the threshold selector.IEEE Trans.Automatic Control,vol.AC-33,no12,pp.1106-1115.J.D.E SARY,F.P ROSCHAN and D.W.W ALKUP(1967).Association of random variables with applications. Annals Mathematical Statistics,vol.38,pp.1466-1474.W.D.E WAN and K.W.K EMP(1960).Sampling inspection of continuous processes with no autocorrelation between successive results.Biometrika,vol.47,pp.263-280.G.F AVIER and A.S MOLDERS(1984).Adaptive smoother-predictors for tracking maneuvering targets.Proc. 23rd Conf.Decision and Control,Las Vegas,NV,pp.831-836.W.F ELLER(1966).An Introduction to Probability Theory and Its Applications,vol.2.Series in Probability and Mathematical Statistics,Wiley,New York.R.A.F ISHER(1925).Theory of statistical estimation.Proc.Cambridge Philosophical Society,vol.22, pp.700-725.M.F ISHMAN(1988).Optimization of the algorithm for the detection of a disorder,based on the statistic of exponential smoothing.In Statistical Problems of Control,Issue83,Vilnius,pp.146-151.R.F LETCHER(1980).Practical Methods of Optimization,2volumes.Wiley,New York.P.M.F RANK(1990).Fault diagnosis in dynamic systems using analytical and knowledge based redundancy -A survey and new results.Automatica,vol.26,pp.459-474.430B IBLIOGRAPHY P.M.F RANK(1991).Enhancement of robustness in observer-based fault detection.Proc.SAFEPRO-CESS’91,Baden-Baden,FRG,pp.275-287.P.M.F RANK and J.W¨UNNENBERG(1989).Robust fault diagnosis using unknown input observer schemes. In Fault Diagnosis in Dynamic Systems-Theory and Application(R.Patton,P.Frank,R.Clark,eds.). International Series in Systems and Control Engineering,Prentice Hall International,London,UK,pp.47-98.K.F UKUNAGA(1990).Introduction to Statistical Pattern Recognition,2d ed.Academic Press,New York. S.I.G ASS(1958).Linear Programming:Methods and Applications.McGraw Hill,New York.W.G E and C.Z.F ANG(1989).Extended robust observation approach for failure isolation.Int.Jal Control, vol.49,no5,pp.1537-1553.W.G ERSCH(1986).Two applications of parametric time series modeling methods.In Mechanical Signature Analysis-Theory and Applications(S.Braun,ed.),chap.10.Academic Press,London.J.J.G ERTLER(1988).Survey of model-based failure detection and isolation in complex plants.IEEE Control Systems Magazine,vol.8,no6,pp.3-11.J.J.G ERTLER(1991).Analytical redundancy methods in fault detection and isolation.Proc.SAFEPRO-CESS’91,Baden-Baden,FRG,pp.9-22.B.K.G HOSH(1970).Sequential Tests of Statistical Hypotheses.Addison-Wesley,Cambridge,MA.I.N.G IBRA(1975).Recent developments in control charts techniques.Jal Quality Technology,vol.7, pp.183-192.J.P.G ILMORE and R.A.M C K ERN(1972).A redundant strapdown inertial reference unit(SIRU).Jal Space-craft,vol.9,pp.39-47.M.A.G IRSHICK and H.R UBIN(1952).A Bayes approach to a quality control model.Annals Mathematical Statistics,vol.23,pp.114-125.A.L.G OEL and S.M.W U(1971).Determination of the ARL and a contour nomogram for CUSUM charts to control normal mean.Technometrics,vol.13,no2,pp.221-230.P.L.G OLDSMITH and H.W HITFIELD(1961).Average run lengths in cumulative chart quality control schemes.Technometrics,vol.3,pp.11-20.G.C.G OODWIN and K.S.S IN(1984).Adaptive Filtering,Prediction and rmation and System Sciences Series,Prentice Hall,Englewood Cliffs,NJ.R.M.G RAY and L.D.D AVISSON(1986).Random Processes:a Mathematical Approach for Engineers. Information and System Sciences Series,Prentice Hall,Englewood Cliffs,NJ.C.G UEGUEN and L.L.S CHARF(1980).Exact maximum likelihood identification for ARMA models:a signal processing perspective.Proc.1st EUSIPCO,Lausanne.D.E.G USTAFSON, A.S.W ILLSKY,J.Y.W ANG,M.C.L ANCASTER and J.H.T RIEBWASSER(1978). ECG/VCG rhythm diagnosis using statistical signal analysis.Part I:Identification of persistent rhythms. Part II:Identification of transient rhythms.IEEE Trans.Biomedical Engineering,vol.BME-25,pp.344-353 and353-361.F.G USTAFSSON(1991).Optimal segmentation of linear regression parameters.Proc.IFAC/IFORS Symp. Identification and System Parameter Estimation,Budapest,pp.225-229.T.H¨AGGLUND(1983).New Estimation Techniques for Adaptive Control.Ph.D.Thesis,Lund Institute of Technology,Lund,Sweden.T.H¨AGGLUND(1984).Adaptive control of systems subject to large parameter changes.Proc.IFAC9th World Congress,Budapest.B IBLIOGRAPHY431 P.H ALL and C.C.H EYDE(1980).Martingale Limit Theory and its Application.Probability and Mathemat-ical Statistics,a Series of Monographs and Textbooks,Academic Press,New York.W.J.H ALL,R.A.W IJSMAN and J.K.G HOSH(1965).The relationship between sufficiency and invariance with applications in sequential analysis.Ann.Math.Statist.,vol.36,pp.576-614.E.J.H ANNAN and M.D EISTLER(1988).The Statistical Theory of Linear Systems.Series in Probability and Mathematical Statistics,Wiley,New York.J.D.H EALY(1987).A note on multivariate CuSum procedures.Technometrics,vol.29,pp.402-412.D.M.H IMMELBLAU(1970).Process Analysis by Statistical Methods.Wiley,New York.D.M.H IMMELBLAU(1978).Fault Detection and Diagnosis in Chemical and Petrochemical Processes. Chemical Engineering Monographs,vol.8,Elsevier,Amsterdam.W.G.S.H INES(1976a).A simple monitor of a system with sudden parameter changes.IEEE r-mation Theory,vol.IT-22,no2,pp.210-216.W.G.S.H INES(1976b).Improving a simple monitor of a system with sudden parameter changes.IEEE rmation Theory,vol.IT-22,no4,pp.496-499.D.V.H INKLEY(1969).Inference about the intersection in two-phase regression.Biometrika,vol.56,no3, pp.495-504.D.V.H INKLEY(1970).Inference about the change point in a sequence of random variables.Biometrika, vol.57,no1,pp.1-17.D.V.H INKLEY(1971).Inference about the change point from cumulative sum-tests.Biometrika,vol.58, no3,pp.509-523.D.V.H INKLEY(1971).Inference in two-phase regression.Jal American Statistical Association,vol.66, no336,pp.736-743.J.R.H UDDLE(1983).Inertial navigation system error-model considerations in Kalmanfiltering applica-tions.In Control and Dynamic Systems(C.T.Leondes,ed.),Academic Press,New York,pp.293-339.J.S.H UNTER(1986).The exponentially weighted moving average.Jal Quality Technology,vol.18,pp.203-210.I.A.I BRAGIMOV and R.Z.K HASMINSKII(1981).Statistical Estimation-Asymptotic Theory.Applications of Mathematics Series,vol.16.Springer,New York.R.I SERMANN(1984).Process fault detection based on modeling and estimation methods-A survey.Auto-matica,vol.20,pp.387-404.N.I SHII,A.I WATA and N.S UZUMURA(1979).Segmentation of nonstationary time series.Int.Jal Systems Sciences,vol.10,pp.883-894.J.E.J ACKSON and R.A.B RADLEY(1961).Sequential and tests.Annals Mathematical Statistics, vol.32,pp.1063-1077.B.J AMES,K.L.J AMES and D.S IEGMUND(1988).Conditional boundary crossing probabilities with appli-cations to change-point problems.Annals Probability,vol.16,pp.825-839.M.K.J EERAGE(1990).Reliability analysis of fault-tolerant IMU architectures with redundant inertial sen-sors.IEEE Trans.Aerospace and Electronic Systems,vol.AES-5,no.7,pp.23-27.N.L.J OHNSON(1961).A simple theoretical approach to cumulative sum control charts.Jal American Sta-tistical Association,vol.56,pp.835-840.N.L.J OHNSON and F.C.L EONE(1962).Cumulative sum control charts:mathematical principles applied to their construction and use.Parts I,II,III.Industrial Quality Control,vol.18,pp.15-21;vol.19,pp.29-36; vol.20,pp.22-28.432B IBLIOGRAPHY R.A.J OHNSON and M.B AGSHAW(1974).The effect of serial correlation on the performance of CUSUM tests-Part I.Technometrics,vol.16,no.1,pp.103-112.H.L.J ONES(1973).Failure Detection in Linear Systems.Ph.D.Thesis,Dept.Aeronautics and Astronautics, MIT,Cambridge,MA.R.H.J ONES,D.H.C ROWELL and L.E.K APUNIAI(1970).Change detection model for serially correlated multivariate data.Biometrics,vol.26,no2,pp.269-280.M.J URGUTIS(1984).Comparison of the statistical properties of the estimates of the change times in an autoregressive process.In Statistical Problems of Control,Issue65,Vilnius,pp.234-243(in Russian).T.K AILATH(1980).Linear rmation and System Sciences Series,Prentice Hall,Englewood Cliffs,NJ.L.V.K ANTOROVICH and V.I.K RILOV(1958).Approximate Methods of Higher Analysis.Interscience,New York.S.K ARLIN and H.M.T AYLOR(1975).A First Course in Stochastic Processes,2d ed.Academic Press,New York.S.K ARLIN and H.M.T AYLOR(1981).A Second Course in Stochastic Processes.Academic Press,New York.D.K AZAKOS and P.P APANTONI-K AZAKOS(1980).Spectral distance measures between gaussian pro-cesses.IEEE Trans.Automatic Control,vol.AC-25,no5,pp.950-959.K.W.K EMP(1958).Formula for calculating the operating characteristic and average sample number of some sequential tests.Jal Royal Statistical Society,vol.B-20,no2,pp.379-386.K.W.K EMP(1961).The average run length of the cumulative sum chart when a V-mask is used.Jal Royal Statistical Society,vol.B-23,pp.149-153.K.W.K EMP(1967a).Formal expressions which can be used for the determination of operating character-istics and average sample number of a simple sequential test.Jal Royal Statistical Society,vol.B-29,no2, pp.248-262.K.W.K EMP(1967b).A simple procedure for determining upper and lower limits for the average sample run length of a cumulative sum scheme.Jal Royal Statistical Society,vol.B-29,no2,pp.263-265.D.P.K ENNEDY(1976).Some martingales related to cumulative sum tests and single server queues.Stochas-tic Processes and Appl.,vol.4,pp.261-269.T.H.K ERR(1980).Statistical analysis of two-ellipsoid overlap test for real time failure detection.IEEE Trans.Automatic Control,vol.AC-25,no4,pp.762-772.T.H.K ERR(1982).False alarm and correct detection probabilities over a time interval for restricted classes of failure detection algorithms.IEEE rmation Theory,vol.IT-24,pp.619-631.T.H.K ERR(1987).Decentralizedfiltering and redundancy management for multisensor navigation.IEEE Trans.Aerospace and Electronic systems,vol.AES-23,pp.83-119.Minor corrections on p.412and p.599 (May and July issues,respectively).R.A.K HAN(1978).Wald’s approximations to the average run length in cusum procedures.Jal Statistical Planning and Inference,vol.2,no1,pp.63-77.R.A.K HAN(1979).Somefirst passage problems related to cusum procedures.Stochastic Processes and Applications,vol.9,no2,pp.207-215.R.A.K HAN(1981).A note on Page’s two-sided cumulative sum procedures.Biometrika,vol.68,no3, pp.717-719.B IBLIOGRAPHY433 V.K IREICHIKOV,V.M ANGUSHEV and I.N IKIFOROV(1990).Investigation and application of CUSUM algorithms to monitoring of sensors.In Statistical Problems of Control,Issue89,Vilnius,pp.124-130(in Russian).G.K ITAGAWA and W.G ERSCH(1985).A smoothness prior time-varying AR coefficient modeling of non-stationary covariance time series.IEEE Trans.Automatic Control,vol.AC-30,no1,pp.48-56.N.K LIGIENE(1980).Probabilities of deviations of the change point estimate in statistical models.In Sta-tistical Problems of Control,Issue83,Vilnius,pp.80-86(in Russian).N.K LIGIENE and L.T ELKSNYS(1983).Methods of detecting instants of change of random process prop-erties.Automation and Remote Control,vol.44,no10,Part II,pp.1241-1283.J.K ORN,S.W.G ULLY and A.S.W ILLSKY(1982).Application of the generalized likelihood ratio algorithm to maneuver detection and estimation.Proc.American Control Conf.,Arlington,V A,pp.792-798.P.R.K RISHNAIAH and B.Q.M IAO(1988).Review about estimation of change points.In Handbook of Statistics(P.R.Krishnaiah,C.R.Rao,eds.),vol.7,Elsevier,New York,pp.375-402.P.K UDVA,N.V ISWANADHAM and A.R AMAKRISHNAN(1980).Observers for linear systems with unknown inputs.IEEE Trans.Automatic Control,vol.AC-25,no1,pp.113-115.S.K ULLBACK(1959).Information Theory and Statistics.Wiley,New York(also Dover,New York,1968). K.K UMAMARU,S.S AGARA and T.S¨ODERSTR¨OM(1989).Some statistical methods for fault diagnosis for dynamical systems.In Fault Diagnosis in Dynamic Systems-Theory and Application(R.Patton,P.Frank,R. Clark,eds.).International Series in Systems and Control Engineering,Prentice Hall International,London, UK,pp.439-476.A.K USHNIR,I.N IKIFOROV and I.S AVIN(1983).Statistical adaptive algorithms for automatic detection of seismic signals-Part I:One-dimensional case.In Earthquake Prediction and the Study of the Earth Structure,Naouka,Moscow(Computational Seismology,vol.15),pp.154-159(in Russian).L.L ADELLI(1990).Diffusion approximation for a pseudo-likelihood test process with application to de-tection of change in stochastic system.Stochastics and Stochastics Reports,vol.32,pp.1-25.T.L.L A¨I(1974).Control charts based on weighted sums.Annals Statistics,vol.2,no1,pp.134-147.T.L.L A¨I(1981).Asymptotic optimality of invariant sequential probability ratio tests.Annals Statistics, vol.9,no2,pp.318-333.D.G.L AINIOTIS(1971).Joint detection,estimation,and system identifirmation and Control, vol.19,pp.75-92.M.R.L EADBETTER,G.L INDGREN and H.R OOTZEN(1983).Extremes and Related Properties of Random Sequences and Processes.Series in Statistics,Springer,New York.L.L E C AM(1960).Locally asymptotically normal families of distributions.Univ.California Publications in Statistics,vol.3,pp.37-98.L.L E C AM(1986).Asymptotic Methods in Statistical Decision Theory.Series in Statistics,Springer,New York.E.L.L EHMANN(1986).Testing Statistical Hypotheses,2d ed.Wiley,New York.J.P.L EHOCZKY(1977).Formulas for stopped diffusion processes with stopping times based on the maxi-mum.Annals Probability,vol.5,no4,pp.601-607.H.R.L ERCHE(1980).Boundary Crossing of Brownian Motion.Lecture Notes in Statistics,vol.40,Springer, New York.L.L JUNG(1987).System Identification-Theory for the rmation and System Sciences Series, Prentice Hall,Englewood Cliffs,NJ.。
R语言-summary()函数的用法解读

R语⾔-summary()函数的⽤法解读summary():获取描述性统计量,可以提供最⼩值、最⼤值、四分位数和数值型变量的均值,以及因⼦向量和逻辑型向量的频数统计等。
结果解读如下:1. 调⽤:Calllm(formula = DstValue ~ Month + RecentVal1 + RecentVal4 + RecentVal6 + RecentVal8 + RecentVal12, data = trainData)当创建模型时,以上代码表明lm是如何被调⽤的。
2. 残差统计量:ResidualsMin 1Q Median 3Q Max-4806.5 -1549.1 -171.8 1368.7 6763.3残差第⼀四分位数(1Q)和第三分位数(Q3)有⼤约相同的幅度,意味着有较对称的钟形分布。
3. 系数:CoefficientsEstimate Std. Error t value Pr(>|t|)(Intercept) 1.345e+06 5.659e+05 2.377 0.01879 *Month 8.941e+02 2.072e+02 4.316 3.00e-05 ***分别表⽰:估值标准误差 T值 P值Intercept:表⽰截距Month:影响因⼦/特征Estimate的列:包含由普通最⼩⼆乘法计算出来的估计回归系数。
Std. Error的列:估计的回归系数的标准误差。
P值估计系数不显著的可能性,有较⼤P值的变量是可以从模型中移除的候选变量。
t 统计量和P值:从理论上说,如果⼀个变量的系数是0,那么该变量是⽆意义的,它对模型毫⽆贡献。
然⽽,这⾥显⽰的系数只是估计,它们不会正好为0。
因此,我们不禁会问:从统计的⾓度⽽⾔,真正的系数为0的可能性有多⼤?这是t统计量和P值的⽬的,在汇总中被标记为t value和Pr(>|t|)。
其中,我们可以直接通过P值与我们预设的0.05进⾏⽐较,来判定对应的解释变量的显著性,我们检验的原假设是:该系数显著为0;若P<0.05,则拒绝原假设,即对应的变量显著不为0。
Summary

World Happiness Report 2015SummaryJohn Helliwell, Richard Layard, and Jeffrey SachsBackgroundThe world has come a long way since the first World Happiness Report launched in 2012. Increasingly happiness is considered a proper measure of social progress and goal of public policy. A rapidly increasing number of national and local governments are using happiness data and research in their search for policies that could enable people to live better lives. Governments are measuring subjective well-being, and using well-being research as a guide to the design of public spaces and the delivery of public services.Harnessing Happiness Data and Research to Improve Sustainable DevelopmentThe year 2015 is a watershed for humanity, with the pending adoption by UN member states of Sustainable Development Goals (SDGs) in September to help guide the world community towards a more inclusive and sustainable pattern of global development. The concepts of happiness and well-being are very likely to help guide progress towards sustainable development.Sustainable development is a normative concept, calling for all societies to balance economic, social, and environmental objectives. When countries pursue GDP in a lopsided manner, overriding social and environmental objectives, the results often negatively impact human well-being. The SDGs are designed to help countries to achieve economic, social, and environmental objectives in harmony, thereby leading to higher levels of well-being for the present and future generations.The SDGs will include goals, targets and quantitative indicators. The Sustainable Development Solutions Network, in its recommendations on the selection of SDG indicators, has strongly recommended the inclusion of indicators of Subjective Well-being and Positive Mood Affect to help guide and measure the progress towards the SDGs. We find considerable support of many governments and experts regarding the inclusion of such happiness indicators for the SDGs. The World Happiness Report 2015 once again underscores the fruitfulness of using happiness measurements for guiding policy making and for helping to assess the overall well-being in each society.Overview of the ChaptersThis report continues in the tradition of combining analysis of recent levels and trends of happiness data with chapters providing deeper analysis of specific issues.•Chapter 2, by John Helliwell, Haifang Huang, and Shun Wang, contains our primary rankings of and explanations for life evaluations.•Chapter 3, by Nicole Fortin, John Helliwell, and Shun Wang, presents a far broader range of happiness measures, and shows how they differ by gender, age and global region.•Chapter 4, by Richard Layard and Gus O’Donnell, advocates and explains the use of happiness as the measure of benefit in cost-benefit analysis.•Chapter 5, by Richard Davidson and Brianna Schuyler, surveys a range of important new results from the neuroscience of happiness.•Chapter 6, by Richard Layard and Ann Hagell, is aimed especially at the happiness of the young – the one-third of the world population that is under the age of 18 years.•Chapter 7, by Leonardo Becchetti, Luigino Bruni, and Stefano Zamagni, digs deeper into the ethical and community-level supports for happiness.•Chapter 8, by Jeffrey Sachs, discusses importance of social capital for well-being and describes ways that societies may invest in social capital in order to promote well-being.We now briefly describe the main findings of each chapter.Chapter 2: The Geography of HappinessAverage life evaluations, where 0 represents the worst possible life and 10 the best possible, range from an average above 7.5 at the top of the rankings to below 3 at the bottom. A difference of 4 points in average life evaluations separates the 10 happiest countries from the 10 least happy countries.Comparing the country rankings in World Happiness Report 2015 with those in World Happiness Report 2013, there is a combination of consistency and change. Nine of the top 10 countries in 2015 were also in the top 10 of 2013. But the ranking has changed, with Switzerland now at the top, followed closely by Iceland, Denmark and Norway. All four countries have average scores between 7.5 and 7.6, and the differences between them are not statistically significant. The rest of the top 10 (in order) are Canada, Finland, Netherlands, Sweden, New Zealand and Australia, all with average scores above 7.28. There is more turnover, almost half, among the bottom 10 countries, all with average ladder scores below 3.7. Most are in sub-Saharan Africa, with the addition of Afghanistan and a further drop for Syria.Three-quarters of the differences among countries, and also among regions, is accounted for by differences in six key variables: GDP per capita, healthy years of life expectancy, social support, trust, perceived freedom to make life decisions, and generosity. Differences in social support, incomes, and healthy life expectancy are the three most important factors.Analysis of changes in life evaluations from 2005-2007 to 2012-2014 shows big international differences in how the global recession affected national happiness. The top three gainers were Nicaragua, Zimbabwe and Ecuador, with increases ranging from 0.97 to 1.12. The biggest drop in average life evaluations was in Greece, which lost almost 1.5 points, followed by Egypt with -1.13 and Italy with -0.76 points. Of the 125 countries with data available for both 2005-2007 and 2012-2014, there were 53 countries with significant improvements, 41 with significant worsening, and 36 without significant change. These differing national experiences appear to be due some combination of differing exposure to the economic crisis and differences in the quality of governance, trust and social support. Countries with sufficiently high quality social capital appear to be able to sustain or even improve subjective well-being in the face of natural disasters or economic shocks, as the shocks provide them an opportunity to discover, use and build upon their communal links. In other cases, the economic crisis triggered drops in happiness greater than could be explained by falling incomes and higher unemployment.Chapter 3: How Does Subjective Well-being Vary around the World by Gender and Age?The analysis in this chapter extends beyond life evaluations to include a range of positive and negative experiences that show widely different patterns by gender, age and region. The positive experiences are happiness, smiling or laughter, enjoyment, feeling safe at night, feelingwell-rested, and feeling interested. The six negative experiences are anger, worry, sadness, depression, stress and pain. For life evaluations, differences by gender are very small relative to those across countries, or even across ages within a country. On a global average basis, women’s life evaluations are slightly higher than men’s, by about 0.09 on the 10-point scale, or about 2% as large as the 4-point difference between the 10 most happy and 10 least happy countries. The differences among age groups are much larger, and differ considerably by region. On a global basis, average life evaluations start high among the youngest respondents, fall by almost 0.6 points by middle age, and are fairly flat thereafter. This global picture masks big regional differences, with U-shapes in some countries and declines in others.For the six positive and six negative experiences, there are striking differences by gender, age and region, some revealing larger cross-cultural differences in experiences than had previously been studied.A parallel analysis of the six main variables used in Chapter 2 to explain international differences and changes in life evaluations also shows the value of considering age, gender and region at the same time to get a better understanding of the global trends and differences. The importance of the social context shows up strongly in the analysis by gender and age group. For example, the world regions where life evaluations are significantly higher in the older age groups are also those regions where perceived social support, freedom and generosity (but not household incomes) are higher in the older age groups. All three of those variables have quite different levels and age group dynamics in different regions.Chapter 4: Cost-benefit Analysis using Happiness as the Measure of BenefitIf the aim of policy is to increase happiness, policy makers will have to evaluate their options in a quite new way. This is the subject of Chapter 4. The benefits of a new policy should now be measured in terms of the impact of the change upon the happiness of the population. This can be achieved in a fully decentralized way by establishing a critical level of extra happiness which a project must yield per dollar of expenditure.This new form of cost-benefit analysis avoids many of the serious problems with existing methods, where money is the measure of benefit. It uses evidence to allow for the obvious fact that an extra dollar brings more happiness to the poor than to the rich. It also includes the effects of all the other factors beyond income, so it can be applied to a much wider range of policies.Chapter 5: The Neuroscience of HappinessChapter 5 highlights four supports for well-being and their underlying neural bases:1) sustained positive emotion; 2) recovery of negative emotion; 3) empathy, altruism and prosocial behavior; and 4) mind-wandering, mindfulness and “affective stickiness” or emotion-captured attention.There are two overall lessons that can be taken from the neuroscientific evidence. The first is the identification of the four highlighted elements, since they are not commonly emphasized in well-being research. The second is that the circuits we identify as underlying these four supports for well-being all exhibit plasticity, and therefore can be transformed through experience and training. There are now training programs being developed to cultivate mindfulness, kindness, and generosity. The chapter reviews evidence showing that some of these training regimes, even those as short as two weeks, can induce measurable brain changes. These findings highlight the view that happiness and well-being are best regarded as skills that can be enhanced through training.Chapter 6: Healthy Young Minds: Transforming the Mental Health ofChildrenChapter 6 turns the focus of attention to the world’s future, as embodied in the one-third of the current global population who are now under 18 years of age. It is vital to determine which aspects of child development are most important in determining whether a child becomes a happy, well-functioning adult. Studies that follow children from birth into adulthood show that of the three key features of child development (academic, behavioral, or emotional), emotional development is the best of the three predictors, and academic achievement the worst.This should not be surprising, since mental health is a key determinant of adult life satisfaction, and half of mentally ill adults already showed the symptoms by the age of 15. Altogether 200 million children worldwide are suffering from diagnosable mental health problems requiring treatment. Yet even in the richest countries only a quarter are in treatment. Giving more priority to the well-being of children is one of the most obvious and cost-effective ways to invest in future world happiness.Chapter 7: Human Values, Civil Economy and Subjective Well-BeingChapter 7 presents the history, evidence, and policy implications of the Italian Civil Economy paradigm. The approach attempts to keep alive the tradition of civil life based on friendship (Aristotle’s notion of philia), and a more socialized idea of person and community. It is contrasted with other economic approaches that give a less central role to reciprocity and benevolence.The empirical work in Chapter 7 echoes that presented in Chapters 2 and 8 in emphasizing the importance of positive social relations (as characterized by trust, benevolence and shared social identities) in motivating behavior, both contributing positively to economic outcomes as well as delivering happiness directly.The authors recommend changes to democratic mechanisms that incorporate these human capacities for pro-social actions.Chapter 8: Investing in Social CapitalWell-being depends heavily on the pro-social behavior of members of the society. Pro-sociality involves individuals making decisions for the common good that may conflict with short-run egoistic incentives. Economic and social life is rife with “social dilemmas,” in which the common good and individual incentives may conflict. In such cases, pro-social behavior – including honesty, benevolence, cooperation, and trustworthiness – is key to achieving the best outcome for society.Societies with a high level of social capital – meaning generalized trust, good governance, and mutual support by individuals within the society – are conducive to pro-social behavior. High social capital directly and indirectly raises well-being, by promoting social support systems, generosity and voluntarism, honesty in public administration, and by reducing the costs of doing business. The pressing policy question is therefore how societies with low social capital, riven by distrust and dishonesty, can invest in social capital. The chapter discusses various pathways to higher social capital, including education, moral instruction, professional codes of conduct, public opprobrium towards violators of the public trust, and public policies to narrow inequalities in the various supports for well-being, income, health and and social connections. This is important because social and economic equality is associated with higher levels of social capital and generalized trust.The Common Threads are SocialThere is a common social theme that emerges consistently from the World Happiness Report 2015. At both the individual and national levels, all measures of well-being, including emotions and life evaluations, are strongly influenced by the quality of the surrounding social norms and institutions. These include family and friendships at the individual level, the presence of trust and empathy at the neighborhood and community levels, and power and quality of the over-arching social norms that determine the quality of life within and among nations and generations. When these social factors are well-rooted and readily available, communities and nations are more resilient, and even natural disasters can add strength to the community as it comes together in response.The challenge is to ensure that policies are designed and delivered in ways that enrich the social fabric, and teach the pleasure and power of empathy to current and future generations. Under the pressures of putting right what is obviously wrong, there is often too little attention paid to building the vital social fabric. Paying greater attention to the levels and sources of subjective well-being has helped us to reach these conclusions, and to recommend making and keeping happiness as a central focus for research and practice.。
summary函数检验异常点和强影响点

summary函数检验异常点和强影响点在数据分析中,异常点和强影响点是两个重要的概念,它们可能会对数据分析结果产生较大的影响。
为了更准确地分析数据,我们需要对这些异常点和强影响点进行检验和处理。
异常点通常指的是在数据集中与其他数据点明显不同的数据点。
这些异常点可能是由于测量误差、数据录入错误或者真实的特殊情况造成的。
在数据分析中,如果不对异常点进行处理,可能会导致结果出现偏差,影响最终的结论。
因此,我们通常会使用summary函数来检验异常点。
summary函数可以帮助我们快速地了解数据的基本情况,比如最大值、最小值、平均值等。
通过查看summary函数的结果,我们可以发现是否存在异常点。
如果某个变量的最大值或最小值与其他数据点相差较大,那么很可能是存在异常点。
在实际分析中,我们可以将这些异常点剔除或者进行替换,以确保数据分析的准确性。
除了异常点,强影响点也是需要注意的。
强影响点通常指的是对数据分析结果具有较大影响的数据点。
这些数据点可能是由于特殊原因造成的,但是会对最终的分析结果产生较大的影响。
因此,我们也需要对强影响点进行检验和处理。
summary函数同样可以帮助我们检验强影响点。
通过查看summary 函数的结果,我们可以发现是否存在对数据分析结果产生较大影响的数据点。
如果某个变量的取值与其他数据点相差较大,那么很可能是存在强影响点。
在处理强影响点时,我们可以考虑将这些数据点剔除或者进行替换,以减小其对结果的影响。
总的来说,异常点和强影响点在数据分析中是需要重点关注的问题。
通过使用summary函数检验这些异常点和强影响点,并对其进行合理处理,可以提高数据分析的准确性和可靠性。
在实际应用中,我们应该充分理解summary函数的作用,及时发现并处理异常点和强影响点,以确保数据分析结果的准确性和可靠性。
A Hybrid Technique for Enhancing the Efficiency of Audio Steganography(IJIGSP-V8-N1-4)

A Hybrid Technique for Enhancing the Efficiency of Audio Steganography
37
man stego file. 5. Accurate extraction:
The secret message shouldn’t be out with any change when the receiver extracts it from stego file.
Fig.1. Comparison between Cryptography, Steganography and Watermarking
There are more types of steganography such as image steganography and audio steganography. In this paper, audio steganography is used where the secret message is hidden in digital audio file, [6]. The technique structure of audio steganography is clarified by using a general diagram in the following Fig .2. There are a lot of techniques that are used in audio steganography, such as, least Significant Bit (LSB), parity coding, echo coding and phase coding.
I.J. Image, Graphics and Signal Processing, 2016, 1, 36-42
Estimation-of-affine-term-structure-models-with-spanned-or-unspanned-stochastic-volatility

∗ We thank Yacine Ait-Sahalia, Boragan Aruoba, Michael Bauer, Alan Bester, John Cochrane, Frank Diebold, Rob Engle, Jim Hamilton, Chris Hansen, Guido Kuersteiner, Ken Singleton, two anonymous referees, and seminar and conference participants at Chicago Booth, NYU Stern, NBER Summer Institute, Maryland, Bank of Canada, Kansas, UMass, and Chicago Booth Junior Finance Symposium for helpful comments. Drew Creal thanks the William Ladany Faculty Scholar Fund at the University of Chicago Booth School of Business for financial support. Cynthia Wu also gratefully acknowledges financial support from the IBM Faculty Research Fund at the University of Chicago Booth School of Business. This paper was formerly titled “Estimation of non-Gaussian affine term structure models.” Correspondence: dcreal@; cynthia.wu@.
EN 55022-2010

EUROPEAN STANDARD EN 55022NORME EUROPÉENNEEUROPÄISCHE NORMDecember 2010CENELECEuropean Committee for Electrotechnical Standardization Comité Européen de Normalisation Electrotechnique Europäisches Komitee für Elektrotechnische NormungManagement Centre: Avenue Marnix 17, B - 1000 Brussels© 2010 CENELEC - All rights of exploitation in any form and by any means reserved worldwide for CENELEC members. Ref. No. EN 55022:2010 EICS 33.100.10 Supersedes EN 55022:2006 + A1:2007 + A2:2010English versionInformation technology equipment - Radio disturbance characteristics - Limits and methods of measurement(CISPR 22:2008, modified)Appareils de traitement de l'information - Caractéristiques des perturbations radioélectriques -Limites et méthodes de mesure (CISPR 22:2008, modifiée) Einrichtungen der Informationstechnik - Funkstöreigenschaften -Grenzwerte und Messverfahren (CISPR 22:2008, modifiziert)This European Standard was approved by CENELEC on 2010-12-01. CENELEC members are bound to comply with the CEN/CENELEC Internal Regulations which stipulate the conditions for giving this European Standard the status of a national standard without any alteration.Up-to-date lists and bibliographical references concerning such national standards may be obtained on application to the Central Secretariat or to any CENELEC member.This European Standard exists in three official versions (English, French, German). A version in any other language made by translation under the responsibility of a CENELEC member into its own language and notified to the Central Secretariat has the same status as the official versions.CENELEC members are the national electrotechnical committees of Austria, Belgium, Bulgaria, Croatia, Cyprus, the Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hungary, Iceland, Ireland, Italy, Latvia, Lithuania, Luxembourg, Malta, the Netherlands, Norway, Poland, Portugal, Romania, Slovakia, Slovenia, Spain, Sweden, Switzerland and the United Kingdom.--``,```,`,`,`,`,,````,,,,,```,,-`-`,,`,,`,`,,`---EN 55022:2010- 2 -ForewordThe text of the International Standard CISPR 22:2008, prepared by CISPR SC I, "Electromagnetic compatibility of information technology equipment, multimedia equipment and receivers", together with common modifications prepared by the Technical Committee CENELEC TC 210, "Electromagnetic compatibility (EMC)", was submitted to the Unique Acceptance Procedure and was approved by CENELEC as EN 55022 on 2010-12-01.Attention is drawn to the possibility that some of the elements of this document may be the subject of patent rights. CEN and CENELEC shall not be held responsible for identifying any or all such patent rights.This document supersedes EN 55022:2006 + A1:2007 + FprA2:2009. The following dates were fixed:– latest date by which the EN has to be implemented at national level by publication of an identical national standard or by endorsement(dop)2011-12-01 – latest date by which the national standards conflicting with the EN have to be withdrawn(dow)2013-12-01This European Standard has been prepared under a mandate given to CENELEC by the European Commission and the European Free Trade Association and covers essential requirements of EC Directives 2004/108/EC and 1999/5/EC. See Annex ZZ. Annexes ZA and ZZ have been added by CENELEC._________Endorsement noticeThe text of the International Standard CISPR 22:2008 was approved by CENELEC as a European Standard with agreed common modifications as given below.BS EN 55022:2010--``,```,`,`,`,`,,````,,,,,```,,-`-`,,`,,`,`,,`---- 3 - EN 55022:2010BS EN 55022:2010Annex ZAPublication Year Title EN/HD YearCISPR 16-1-1 A1 Specification for radio disturbance and immunitymeasuring apparatus and methods -Part 1-1: Radio disturbance and immunitymeasuring apparatus - Measuring apparatusEN 55016-1-1A120072007CISPR 16-1-4 Specification for radio disturbance and immunitymeasuring apparatus and methods -Part 1-4: Radio disturbance and immunitymeasuring apparatus - Ancillary equipment -Radiated disturbancesEN 55016-1-4 2007 Publication Year Title EN/HD YearCISPR 16-2-3 A1 20032005Specification for radio disturbance and immunitymeasuring apparatus and methods -Part 2-3: Methods of measurement ofdisturbances and immunity – Radiateddisturbance measurementsEN 55016-2-3A120042005(informative)--``,```,`,`,`,`,,````,,,,,```,,-`-`,,`,,`,`,,`---EN 55022:2010- 4 -BS EN 55022:2010Annex ZZ (informative)Coverage of Essential Requirements of EC DirectivesThis European Standard has been prepared under a mandate given to CENELEC by the European Commission and the European Free Trade Association and within its scope the standard covers essential requirements as given in Annex I Article 1(a) of the EC Directive 2004/108/EC, and essential requirements of Article 3.1(b) (emission only) of the EC Directive 1999/5/EC.Compliance with this standard provides one means of conformity with the specified essential requirements of the Directives concerned.WARNING: Other requirements and other EC Directives may be applicable to the products falling within the scope of this standard.______________--``,```,`,`,`,`,,````,,,,,```,,-`-`,,`,,`,`,,`-----``,```,`,`,`,`,,````,,,,,```,,-`-`,,`,,`,`,,`---This page deliberately set blankSC CIS/I/Publication CISPR 22 (2008), Sixth edition/I-SH 01INFORMATION TECHNOLOGY EQUIPMENT – RADIO DISTURBANCE CHARACTERISTICS – LIMITS AND METHODS OF MEASUREMENTINTERPRETATION SHEET 1This interpretation sheet has been prepared by CISPR subcommittee I: Electromagnetic compatibility of information technology equipment, multimedia equipment and receivers, of IEC technical committee CISPR: International special committee on radio interference. The text of this interpretation sheet is based on the following documents:ISHReport on votingCISPR/I/299/ISH CISPR/I/312/RVDFull information on the voting for the approval of this interpretation sheet can be found in the report on voting indicated in the above table.___________Introduction:At the CISPR SC I plenary, held on the 27thOctober 2007, a decision was taken to set the maintenance date for CISPR 22, Edition 6 to 2012. As a result the work identified within CISPR/I/279/MCR will not be started for the time being. At the subsequent meeting of CISPR SC I WG3 it was decided that certain items within the MCR would benefit now from further clarification and an interpretation sheet would be helpful to users of the standard, with the intent of including this information in a future amendment to the standard.This information does not change the standard; it serves only to clarify the points noted. CISPR SC I WG3 hopes that these clarifications will be of use to users and especially laboratories testing to CISPR 22, Edition 6.0. The document is based on the comments received on CISPR/I/290/DC. Interpretation:1. Selection of Average detectorCISPR 22 defines limits for radiated emissions at frequencies between 1 GHz and 6 GHz with respect to both average and peak detectors. CISPR 16-1-1 defines two types of Average detector for use above 1 GHz. For the limits given in CISPR 22 the appropriate average detector is the linear average detector defined in 6.4.1 of CISPR 16-1-1:2006 with its Amendments 1:2006 and 2:2007.BS EN 55022:2010--``,```,`,`,`,`,,````,,,,,```,,-`-`,,`,,`,`,,`---2. Measurement of conducted emissions on cabinets containing multiple items of equipmentWhere the EUT is a cabinet or rack that contains multiple items of equipment that are powered from an AC power distribution strip and where the AC power distribution strip is an integral part of the EUT as declared by the manufacturer, the AC power line conducted emissions should be measured on the input cable of power distribution strip that leaves the cabinet or rack, not the power cables from the individual items of equipment. This is consistent with the requirements in 9.5.1 paragraph 1 and sub paragraph c).___________BS EN 55022:2010--``,```,`,`,`,`,,````,,,,,```,,-`-`,,`,,`,`,,`---BS EN 55022:2010– 1 –SC CIS I/Publication CISPR 22:2008, Sixth edition/I-SH 02INFORMATION TECHNOLOGY EQUIPMENT –RADIO DISTURBANCE CHARACTERISTICS –LIMITS AND METHODS OF MEASUREMENTINTERPRETATION SHEET 2This interpretation sheet has been prepared by CISPR subcommittee I: Electromagnetic compatibility of information technology equipment, multimedia equipment and receivers, of IEC technical committee CISPR: International special committee on radio interference.The text of this interpretation sheet is based on the following documents:ISH Report on votingCISPR/I//323/ISH CISPR/I/326/RVDFull information on the voting for the approval of this interpretation sheet can be found in the report on voting indicated in the above table.___________IntroductionAt the CISPR SC I plenary, held on the 27th October 2007, a decision was taken to set the maintenance date for CISPR 22, Edition 6 to 2012. As a result the work identified within CISPR/I/279/MCR will not be started for the time being. At the subsequent meeting of CISPR SC I WG3 it was decided that 3 items within the MCR would benefit now from further clarification and an interpretation sheet would be helpful to users of the standard, with the intent of including this information in a future amendment to the standard.The first draft of an interpretation sheet CISPR/I/290/DC addressed the 3 items, however it was clear from the comments received (CISPR/I/293A/INF) that further work was required on the 3rd item related to ISN selection, and it was decided that this would be the subject of a separate document.This information does not change the standard; it serves only to clarify the points noted. CISPR SC I WG3 hopes that these clarifications will be of use to users and especially laboratories testing to CISPR 22:2008 (Edition 6.0).Selection of ISN for unscreened balanced multi-pair cablesSubclause 9.6.3.1 of CISPR 22 states that:“When disturbance voltage measurements are performed on a single unscreened balanced pair, an adequate ISN for two wires shall be used; when performed on unscreened cables containing two balanced pairs, an adequate ISN for four wires shall be used; when performed on unscreened cables containing four balanced pairs, an adequate ISN for eight wires shall be used (see Annex D)”Therefore the selection of ISN is based on the number of pairs physically in the cable, not the number of pairs actually used by the interface in question.--``,```,`,`,`,`,,````,,,,,```,,-`-`,,`,,`,`,,`---– 2 –However, selection of a suitable ISN design from the examples given in Annex D requires further consideration. The ISN designs given in Figures D.4 to D.7 are only appropriate for use where all of the balanced pairs in the cable are ‘active’ and hence their use requires a more detailed knowledge of the EUT port being tested. The ISN designs given in Figures D.1 to D.3 have no such limitation and are better suited to applications where the actual use of the pairs is unknown.The ISN designs given in Figures D.2 and D.3 are also suitable for measurements on unscreened cables containing fewer balanced pairs than the maximum number of pairs the ISN is designed for (see example 2).The following definitions have been developed to help in determining what should be considered an ‘active’ pair of conductors:An active pair is a pair of conductors that completes an active digital, analogue, or power circuit, or is terminated in a defined impedance, or is connected to earth or the equipment frame/chassis.NOTE These circuits include such applications as "Power over Ethernet".A circuit is an a ctive circuit when it is in a state that is performing its intended function, which may include communications, voltage/current sensing, impedance matching or power supply.NOTE A conductor with no intended function is not part of an active circuit.A measurement using an ISN described in Figures D.4 to D.7, when not all of the pairs are ‘active’, may result in a significant error in the measured emissions. It is therefore important that test laboratories determine on which of the designs given in the annexes their particular ISNs are based. From this they can then determine if they need to establish the number of ‘active’ pairs within the cable or not and then whether their ISNs are suitable for the port being measured or whether an alternative measurement technique needs to be used. This is applicable when measuring in accordance with 9.6.3.1 or 9.6.3.2. It is recommended that test reports should make reference to:• the ISN category used;• the Annex D figure corresponding to their particular ISN design;• the total number of pairs in the cable and number of these that where active. Example 1:The EUT has an Ethernet port to which either a CAT 5 or 6 cable is connected. Typically these cables have four pairs requiring use of a four pair ISN. Transmission using 1000Base-T Ethernet protocol uses all four pairs of a typical cable. Transmission using 10Base-T and 100 Base-T Ethernet protocol uses only two of the four pairs for communication. One of the following ISNs could therefore be used:1) ISN as shown in Figure D.3, or2) ISN as shown in Figures D.6 or D.7 if it is known that all the pairs within the cable are‘active’. This would be the case if a 1000BaseT Ethernet protocol were being used. These ISNs would also be suitable for 10BaseT or 100BaseT protocol if the unused pairs have controlled terminations in the EUT port by design, making all pairs ‘active’ from an EMC perspective. Should an EUT with an Ethernet port be provided with a cable that contains only 2 pairs within it, then any of the following types of ISN could be used: D2, D3, D4 or D5.BS EN 55022:2010--``,```,`,`,`,`,,````,,,,,```,,-`-`,,`,,`,`,,`---– 3 –Example 2:The EUT has a single ADSL port and is provided with a cable containing 2 pairs. ADSL is a single pair system so only 1 pair is active. The following ISNs could be used:1) ISN as shown in Figure D.2 or D.3.Cable length between ISN and EUT when measuring telecommunication portsSubclause 9.5.1 of CISPR 22 requires that the distance between the ISN and the EUT be nominally 0.8m and also clause 9.5.2 states that:“Signal cables shall be positioned for their entire lengths, as far as possible, at a nominal distance of 0,4 m from the ground reference plane (using a non-conductive fixture, if necessary).”No other requirement is given on the actual length of the cable to be used.Measurements have shown that non-inductive bundling of any excess cable can result in slightly higher emission levels measured at the ISN.It is therefore recommended that the cable between the telecommunication port and the ISN should be kept as short as possible, in order to avoid the need to bundle any excess, while maintaining the requirements given in 9.5.1 and 9.5.2.BS EN 55022:2010--``,```,`,`,`,`,,````,,,,,```,,-`-`,,`,,`,`,,`---CONTENTSINTRODUCTION (7)1Scope and object (8)2Normative references (8)3Definitions (9)4Classification of ITE (10)4.1Class B ITE (11)4.2Class A ITE (11)5Limits for conducted disturbance at mains terminals and telecommunication ports (11)5.1Limits of mains terminal disturbance voltage (11)5.2Limits of conducted common mode (asymmetric mode) disturbanceat telecommunication ports (12)6Limits for radiated disturbance (13)6.1Limits below 1 GHz (13)6.2Limits above 1 GHz (13)7Interpretation of CISPR radio disturbance limit (14)7.1Significance of a CISPR limit (14)7.2Application of limits in tests for conformity of equipment in series production (14)8General measurement conditions (15)8.1Ambient noise (15)8.2General arrangement (15)8.3EUT arrangement (18)8.4Operation of the EUT (20)9Method of measurement of conducted disturbance at mains terminals and telecommunication ports (21)9.1Measurement detectors (21)9.2Measuring receivers (21)9.3Artificial mains network (AMN) (21)9.4Ground reference plane (22)9.5EUT arrangement (22)9.6Measurement of disturbances at telecommunication ports (24)9.7Recording of measurements (28)10Method of measurement of radiated disturbance (28)10.1Measurement detectors (28)10.2Measuring receiver below 1 GHz (28)10.3Antenna below 1 GHz (28)10.4Measurement site below 1 GHz (29)10.5EUT arrangement below 1 GHz (30)10.6Radiated emission measurements above 1 GHz (30)10.7Recording of measurements (30)10.8Measurement in the presence of high ambient signals (31)10.9User installation testing (31)11Measurement uncertainty (31)Annex A (normative) Site attenuation measurements of alternative test sites (42)Annex B (normative) Decision tree for peak detector measurements.....................................48--` ` , ` ` ` , ` , ` , ` , ` , , ` ` ` ` , , , , , ` ` ` , , -` -` , , ` , , ` , ` , , ` ---Annex C (normative) Possible test set-ups for common mode measurements (49)Annex D (informative) Schematic diagrams of examples of impedance stabilizationnetworks (ISN) (56)Annex E (informative) Parameters of signals at telecommunication ports (65)Annex F (informative) Rationale for disturbance measurements and methods on telecommunications ports (68)Annex G (informative) Operational modes for some types of ITE (77)Bibliography (78)Figure 1 – Test site (32)Figure 2 – Minimum alternative measurement site (33)Figure 3 – Minimum size of metal ground plane (33)Figure 4 – Example test arrangement for tabletop equipment (conducted and radiated emissions) (plan view) (34)Figure 5 – Example test arrangement for tabletop equipment (conducted emission measurement - alternative 1a) (35)Figure 6 – Example test arrangement for tabletop equipment (conducted emission measurement – alternative 1b) (35)Figure 7 – Example test arrangement for tabletop equipment (conducted emission measurement – alternative 2) (36)Figure 8 – Example test arrangement for floor-standing equipment (conducted emission measurement) (37)Figure 9 – Example test arrangement for combinations of equipment (conductedemission measurement) (38)Figure 10 – Example test arrangement for tabletop equipment (radiated emission measurement) (38)Figure 11 – Example test arrangement for floor-standing equipment (radiated emission measurement) (39)Figure 12 – Example test arrangement for floor-standing equipment with vertical riser --``,```,`,`,`,`,,````,,,,,```,,-`-`,,`,,`,`,,`---and overhead cables (radiated and conducted emission measurement) (40)Figure 13 – Example test arrangement for combinations of equipment (radiatedemission measurement) (41)Figure A.1 – Typical antenna positions for alternate site NSA measurements (45)Figure A.2 – Antenna positions for alternate site measurements for minimumrecommended volume (46)Figure B.1 – Decision tree for peak detector measurements (48)Figure C.1 – Using CDNs described in IEC 61000-4-6 as CDN/ISNs (50)Figure C.2 – Using a 150 Ω load to the outside surface of the shield ("in situ CDN/ISN") (51)Figure C.3 – Using a combination of current probe and capacitive voltage probe with atable top EUT (52)Figure C.4 – Calibration fixture (54)Figure C.5 – Flowchart for selecting test method (55)Figure D.1 − ISN for use with unscreened single balanced pairs (56)Figure D.2 − ISN with high longitudinal conversion loss (LCL) for use with either one ortwo unscreened balanced pairs (57)Figure D.3 − ISN with high longitudinal conversion loss (LCL) for use with one, two,three, or four unscreened balanced pairs (58)Figure D.4 − ISN, including a 50 Ω source matching network at the voltage measuringport, for use with two unscreened balanced pairs (59)Figure D.5 − ISN for use with two unscreened balanced pairs (60)Figure D.6 − ISN, including a 50 Ω source matching network at the voltage measuringport, for use with four unscreened balanced pairs (61)Figure D.7 − ISN for use with four unscreened balanced pairs (62)Figure D.8 − ISN for use with coaxial cables, employing an internal common modechoke created by bifilar winding an insulated centre-conductor wire and an insulatedscreen-conductor wire on a common magnetic core (for example, a ferrite toroid) (62)Figure D.9 − ISN for use with coaxial cables, employing an internal common modechoke created by miniature coaxial cable (miniature semi-rigid solid copper screen or miniature double-braided screen coaxial cable) wound on ferrite toroids (63)Figure D.10 − ISN for use with multi-conductor screened cables, employing an internal common mode choke created by bifilar winding multiple insulated signal wires and an insulated screen-conductor wire on a common magnetic core (for example, a ferrite toroid) (63)Figure D.11 − ISN for use with multi-conductor screened cables, employing an internal common mode choke created by winding a multi-conductor screened cable on ferrite toroids (64)Figure F.1 – Basic circuit for considering the limits with defined TCM impedance of 150 Ω (71)Figure F.2 – Basic circuit for the measurement with unknown TCM impedance (71)Figure F.3 – Impedance layout of the components used in Figure C.2 (73)Figure F.4 – Basic test set-up to measure combined impedance of the 150 Ω and ferrites (74)Table 1 – Limits for conducted disturbance at the mains ports of class A ITE (11)Table 2 – Limits for conducted disturbance at the mains ports of class B ITE (12)Table 3 – Limits of conducted common mode (asymmetric mode) disturbanceat telecommunication ports in the frequency range 0,15 MHz to 30 MHz for class A equipment (12)Table 4 – Limits of conducted common mode (asymmetric mode) disturbance at telecommunication ports in the frequency range 0,15 MHz to 30 MHz for class B equipment (12)Table 5 – Limits for radiated disturbance of class A ITE at a measuring distance of 10 m (13)Table 6 – Limits for radiated disturbance of class B ITE at a measuring distance of 10 m (13)Table 7 – Limits for radiated disturbance of Class A ITE at a measurement distance of 3 m (13)Table 8 – Limits for radiated disturbance of Class B ITE at a measurement distance of 3 m (14)Table 9 – Acronyms used in figures (32)Table A.1 – Normalized site attenuation (A N (dB)) for recommended geometries with broadband antennas (44)Table F.1 – Summary of advantages and disadvantages of the methods described inAnnex C (69)INTRODUCTIONThe scope is extended to the whole radio-frequency range from 9 kHz to 400 GHz, but limits are formulated only in restricted frequency bands, which is considered sufficient to reach adequate emission levels to protect radio broadcast and telecommunication services, and to allow other apparatus to operate as intended at reasonable distance.--``,```,`,`,`,`,,````,,,,,```,,-`-`,,`,,`,`,,`---INFORMATION TECHNOLOGY EQUIPMENT –RADIO DISTURBANCE CHARACTERISTICS –LIMITS AND METHODS OF MEASUREMENT1 Scope and objectThis International Standard applies to ITE as defined in 3.1.Procedures are given for the measurement of the levels of spurious signals generated by the ITE and limits are specified for the frequency range 9 kHz to 400 GHz for both class A and class B equipment. No measurements need be performed at frequencies where no limits are specified.The intention of this publication is to establish uniform requirements for the radio disturbance level of the equipment contained in the scope, to fix limits of disturbance, to describe methods of measurement and to standardize operating conditions and interpretation of results.2 Normative referencesThe following referenced documents are indispensable for the application of this document. For dated references, only the edition cited applies. For undated references, the latest edition of the referenced document (including any amendments) applies.IEC 60083:2006, Plugs and socket-outlets for domestic and similar general use standardized in member countries of IECIEC 61000-4-6:2003, Electromagnetic compatibility (EMC) – Part 4-6: Testing and measurement techniques – Immunity to conducted disturbances, induced by radio-frequency fields1Amendment 1 (2004)Amendment 2 (2006)CISPR 11:2003, Industrial, scientific, and medical (ISM) radio-frequency equipment – Electro-magnetic disturbance characteristics – Limits and methods of measurement2Amendment 1 (2004)CISPR 13:2001, Sound and television broadcast receivers and associated equipment – Radio disturbance characteristics – Limits and methods of measurement3Amendment 1 (2003)Amendment 2 (2006)CISPR 16-1-1:2006, Specification for radio disturbance and immunity measuring apparatus and methods – Part 1-1: Radio disturbance and immunity measuring apparatus – Measuring apparatus4Amendment 1 (2006)Amendment 2 (2007)___________1There exists a consolidated edition 2.2 (2006) including edition 2.0, its Amendment 1 (2004) and its Amendment 2 (2006).2There exists a consolidated edition 4.1 (2004) including edition 4.0 and its Amendment 1 (2004).3There exists a consolidated edition 4.2 (2006) including edition 4.0, its Amendment 1 (2003) and its Amendment 2 (2006).4There exists a consolidated edition 2.2 (2007) including edition 2.0, its Amendment 1 (2006) and its Amendment 2 (2007). --` ` , ` ` ` , ` , ` , ` , ` , , ` ` ` ` , , , , , ` ` ` , , -` -` , , ` , , ` , ` , , ` ---CISPR 16-1-2:2003, Specification for radio disturbance and immunity measuring apparatus and methods – Part 1-2: Radio disturbance and immunity measuring apparatus – Ancillary equipment – Conducted disturbances 5Amendment 1 (2004)Amendment 2 (2006)CISPR 16-1-4:2007, Specification for radio disturbance and immunity measuring apparatus and methods – Part 1-4: Radio disturbance and immunity measuring apparatus – Ancillary equipment – Radiated disturbances6CISPR 16-2-3:2006, Specification for radio disturbance and immunity measuring apparatus and methods – Part 2-3: Methods of measurement of disturbances and immunity – Radiated disturbance measurementsCISPR 16-4-2:2003, Specification for radio disturbance and immunity measuring apparatus and methods – Part 4-2: Uncertainties, statistics and limit modelling – Uncertainty in EMC measurements3 DefinitionsFor the purposes of this document the following definitions apply:3.1information technology equipment (ITE)any equipment:a) which has a primary function of either (or a combination of) entry, storage, display,retrieval, transmission, processing, switching, or control, of data and of telecommunication messages and which may be equipped with one or more terminal ports typically operated for information transfer;b) with a rated supply voltage not exceeding 600 V.It includes, for example, data processing equipment, office machines, electronic business equipment and telecommunication equipment.Any equipment (or part of the ITE equipment) which has a primary function of radio trans-mission and/or reception according to the ITU Radio Regulations are excluded from the scope --``,```,`,`,`,`,,````,,,,,```,,-`-`,,`,,`,`,,`---of this publication.NOTE Any equipment which has a function of radio transmission and/or reception according to the definitions of the ITU Radio Regulations should fulfil the national radio regulations, whether or not this publication is also valid.Equipment, for which all disturbance requirements in the frequency range are explicitly formul-ated in other IEC or CISPR publications, are excluded from the scope of this publication.3.2equipment under test (EUT)representative ITE or functionally interactive group of ITE (system) which includes one or more host unit(s) and is used for evaluation purposes3.3host unitpart of an ITE system or unit that provides the mechanical housing for modules, which may contain radio-frequency sources, and may provide power distribution to other ITE. Power distribution may be a.c., d.c., or both between the host unit(s) and modules or other ITE___________5There exists a consolidated edition 1.2 (2006) including edition 1.0, its Amendment 1 (2004) and its Amendment 2 (2006).6There exists a consolidated edition 2.1 (2008) including edition 2.0 and its Amendment 1 (2007).。
手册:统计分析使用R - 第2版 - 布兰·S·埃维里特和托尔斯坦·豾伯恩说明书

A Handbook of Statistical Analyses Using R—2nd EditionBrian S.Everitt and Torsten HothornCHAPTER11Survival Analysis:Glioma Treatment andBreast Cancer Survival11.1Introduction11.2Survival Analysis11.3Analysis Using R11.3.1Glioma RadioimmunotherapyFigure11.1leads to the impression that patients treated with the novel radioimmunotherapy survive longer,regardless of the tumour type.In order to assess if this informalfinding is reliable,we may perform a log-rank test viaR>survdiff(Surv(time,event)~group,data=g3)Call:survdiff(formula=Surv(time,event)~group,data=g3)N Observed Expected(O-E)^2/E(O-E)^2/Vgroup=Control64 1.49 4.23 6.06group=RIT112 4.51 1.40 6.06Chisq= 6.1on1degrees of freedom,p=0.01which indicates that the survival times are indeed different in both groups. However,the number of patients is rather limited and so it might be danger-ous to rely on asymptotic tests.As shown in Chapter4,conditioning on the data and computing the distribution of the test statistics without additional assumptions are one alternative.The function surv_test from package coin (Hothorn et al.,2006,2008)can be used to compute an exact conditional test answering the question whether the survival times differ for grade III patients. For all possible permutations of the groups on the censored response variable, the test statistic is computed and the fraction of whose being greater than the observed statistic defines the exact p-value:R>library("coin")R>logrank_test(Surv(time,event)~group,data=g3,+distribution="exact")Exact Two-Sample Logrank Testdata:Surv(time,event)by group(Control,RIT)Z=-2,p-value=0.03alternative hypothesis:true theta is not equal to134SURVIVAL ANALYSIS R>data("glioma",package ="coin")R>library("survival")R>layout(matrix(1:2,ncol =2))R>g3<-subset(glioma,histology =="Grade3")R>plot(survfit(Surv(time,event)~group,data =g3),+main ="Grade III Glioma",lty =c(2,1),+ylab ="Probability",xlab ="Survival Time in Month",+legend.text =c("Control","Treated"),+legend.bty ="n")R>g4<-subset(glioma,histology =="GBM")R>plot(survfit(Surv(time,event)~group,data =g4),+main ="Grade IV Glioma",ylab ="Probability",+lty =c(2,1),xlab ="Survival Time in Month",+xlim =c(0,max(glioma$time)*1.05))02040600.00.20.40.60.81.0Grade III Glioma Survival Time in Month P r o b a b i l i ty 0204060..2.40.6.81.0Grade IV GliomaSurvival Time in MonthP ro bab i l i ty Figure 11.1Survival times comparing treated and control patients.which,in this case,confirms the above results.The same exercise can be performed for patients with grade IV gliomaR>logrank_test(Surv(time,event)~group,data =g4,+distribution ="exact")Exact Two-Sample Logrank Testdata:Surv(time,event)by group (Control,RIT)Z =-3,p-value =2e-04alternative hypothesis:true theta is not equal to 1which shows a difference as well.However,it might be more appropriate toANALYSIS USING R5 answer the question whether the novel therapy is superior for both groups of tumours simultaneously.This can be implemented by stratifying,or blocking,with respect to tumour grading:R>logrank_test(Surv(time,event)~group|histology,+data=glioma,distribution=approximate(B=10000)) Approximative Two-Sample Logrank Testdata:Surv(time,event)bygroup(Control,RIT)stratified by histologyZ=-4,p-value=1e-04alternative hypothesis:true theta is not equal to1Here,we need to approximate the exact conditional distribution since the exact distribution is hard to compute.The result supports the initial impression implied by Figure11.1.11.3.2Breast Cancer SurvivalBeforefitting a Cox model to the GBSG2data,we again derive a Kaplan-Meier estimate of the survival function of the data,here stratified with respect to whether a patient received a hormonal therapy or not(see Figure11.2).Fitting a Cox model follows roughly the same rules as shown for linear models in Chapter6with the exception that the response variable is again coded as a Surv object.For the GBSG2data,the model isfitted viaR>GBSG2_coxph<-coxph(Surv(time,cens)~.,data=GBSG2)and the results as given by the summary method are given in Figure11.3.Sincewe are especially interested in the relative risk for patients who underwent a hormonal therapy,we can compute an estimate of the relative risk and a corresponding confidence interval viaR>ci<-confint(GBSG2_coxph)R>exp(cbind(coef(GBSG2_coxph),ci))["horThyes",]2.5%97.5%0.7070.5490.911This result implies that patients treated with a hormonal therapy had a lowerrisk and thus survived longer compared to women who were not treated this way.Model checking and model selection for proportional hazards models are complicated by the fact that easy-to-use residuals,such as those discussed in Chapter6for linear regression models,are not available,but several possibil-ities do exist.A check of the proportional hazards assumption can be done by looking at the parameter estimatesβ1,...,βq over time.We can safely assume proportional hazards when the estimates don’t vary much over time.The null hypothesis of constant regression coefficients can be tested,both globally aswell as for each covariate,by using the cox.zph functionR>GBSG2_zph<-cox.zph(GBSG2_coxph)R>GBSG2_zph6SURVIVAL ANALYSIS R>data("GBSG2",package ="TH.data")R>plot(survfit(Surv(time,cens)~horTh,data =GBSG2),+lty =1:2,mark.time =FALSE,ylab ="Probability",+xlab ="Survival Time in Days")R>legend(250,0.2,legend =c("yes","no"),lty =c(2,1),+title ="Hormonal Therapy",bty ="n")050010001500200025000.00.2.4.6.81.Survival Time in DaysP r o babi l it y Hormonal TherapyyesnoFigure 11.2Kaplan-Meier estimates for breast cancer patients who either receiveda hormonal therapy or not.chisq df phorTh 0.23910.6253age 10.43810.0012menostat 5.40610.0201tsize 0.19110.6620tgrade 10.71220.0047pnodes 0.80810.3688progrec 4.38610.0362estrec 5.89310.0152GLOBAL 24.42190.0037There seems to be some evidence of time-varying effects,especially for age and tumour grading.A graphical representation of the estimated regression coeffi-ANALYSIS USING R7 R>summary(GBSG2_coxph)Call:coxph(formula=Surv(time,cens)~.,data=GBSG2)n=686,number of events=299coef exp(coef)se(coef)z Pr(>|z|)horThyes-0.3462780.7073160.129075-2.680.00730age-0.0094590.9905850.009301-1.020.30913menostatPost0.258445 1.2949150.183476 1.410.15895tsize0.007796 1.0078270.003939 1.980.04779tgrade.L0.551299 1.7355060.189844 2.900.00368tgrade.Q-0.2010910.8178380.121965-1.650.09920pnodes0.048789 1.0499980.007447 6.55 5.7e-11progrec-0.0022170.9977850.000574-3.870.00011estrec0.000197 1.0001970.0004500.440.66131exp(coef)exp(-coef)lower.95upper.95horThyes0.707 1.4140.5490.911age0.991 1.0100.973 1.009menostatPost 1.2950.7720.904 1.855tsize 1.0080.992 1.000 1.016tgrade.L 1.7360.576 1.196 2.518tgrade.Q0.818 1.2230.644 1.039pnodes 1.0500.952 1.035 1.065progrec0.998 1.0020.9970.999estrec 1.000 1.0000.999 1.001Concordance=0.692(se=0.015)Likelihood ratio test=105on9df,p=<2e-16Wald test=115on9df,p=<2e-16Score(logrank)test=121on9df,p=<2e-16Figure11.3R output of the summary method for GBSG2_coxph.cient over time is shown in Figure11.4.We refer to Therneau and Grambsch (2000)for a detailed theoretical description of these topics.The tree-structured regression models applied to continuous and binary responses in Chapter9are applicable to censored responses in survival analysis as well.Such a simple prognostic model with only a few terminal nodes might be helpful for relating the risk to certain subgroups of patients.Both rpart and the ctree function from package party can be applied to the GBSG2 data,where the conditional trees of the latter select cutpoints based on log-rank statisticsR>GBSG2_ctree<-ctree(Surv(time,cens)~.,data=GBSG2)and the plot method applied to this tree produces the graphical representation in Figure11.6.The number of positive lymph nodes(pnodes)is the most important variable in the tree,corresponding to the p-value associated with this variable in Cox’s regression;see Figure11.3.Women with not more than three positive lymph nodes who have undergone a hormonal therapy seem to have the best prognosis whereas a large number of positive lymph nodes and a small value of the progesterone receptor indicates a bad prognosis.8SURVIVAL ANALYSIS R>plot(GBSG2_zph,var ="age")−0.6−.4−0.20.00.2.4TimeBe ta(t)f o r age2704405607701100140018002300Figure 11.4Estimated regression coefficient for age depending on time for theGBSG2data.ANALYSIS USING R 9R>layout(matrix(1:3,ncol =3))R>res <-residuals(GBSG2_coxph)R>plot(res ~age,data =GBSG2,ylim =c(-2.5,1.5),+pch =".",ylab ="Martingale Residuals")R>abline(h =0,lty =3)R>plot(res ~pnodes,data =GBSG2,ylim =c(-2.5,1.5),+pch =".",ylab ="")R>abline(h =0,lty =3)R>plot(res ~log(progrec),data =GBSG2,ylim =c(-2.5,1.5),+pch =".",ylab ="")R>abline(h =0,lty =3)20406080−2−101age Ma r t i ngal eResi d uals010********−2−101pnodes 02468−2−11log(progrec)Figure 11.5Martingale residuals for the GBSG2data.10SURVIVAL ANALYSIS R>plot(GBSG2_ctree)050015002500050015002500050015002500050015002500Figure 11.6Conditional inference tree for the GBSG2data with the survival func-tion,estimated by Kaplan-Meier,shown for every subgroup of patientsidentified by the tree.BibliographyHothorn,T.,Hornik,K.,van de Wiel,M.,and Zeileis,A.(2008),coin: Conditional Inference Procedures in a Permutation Test Framework,URL /package=coin,R package version1.0-21. Hothorn,T.,Hornik,K.,van de Wiel,M.A.,and Zeileis,A.(2006),“A Lego system for conditional inference,”The American Statistician,60,257–263. Therneau,T.M.and Grambsch,P.M.(2000),Modeling Survival Data:Ex-tending the Cox Model,New York,USA:Springer-Verlag.。
EMMA2010 操作手册jensys

角的对位点后按面板上的 ENTER 键,再移动 B 针针尖对准 PCB 右上角的对位 点,按 ENTER(测首片的对位模式) 6. 将屏幕上显示的对位点与十字靶标对齐后按 ENTER(A,B,C,D 四个针, 每对准一个后按一次 ENTER,共四次) 7. 对位完成后开始测试 8. 测试完成结果 PASS 或 FAIL 9. FAIL 板需复测(RETEST)或检修 10. 换板后可将对位模式改为自动模式 11. 按 START 后 CCD 开始自动对位并测试
(2)菜单功能 ( I ) 打印设置
User Name:使用公司名称 Printer Type:印表机型号 While OK:测试 OK 打印 While NG:测试 NG 打印 While NO Test:没有测试完成打印 Stop Printing at temporary: 暂时停止打印 Skip panle information if the panel is OK: 跳过 OK 的 panle 不打印 Skip panle information if the panel is NG: 跳过 NG 的 panle 不打印 Serial Number:序列号 Start of Test:测试开始时间 Total Test Time:测试总时间 Number of Comp/Sold points:测试总点数 Number of Nets:测试网络数 Number of Adjacent Nets:短路测试网络数 Adjacency Distance:短路测试网络的范围(ADJ 值) Test Mode:测试模式
r语言十折交叉验证筛选诊断模型

《探索R语言中的十折交叉验证:筛选和优化诊断模型》一、引言在机器学习和数据分析领域,诊断模型的准确性和稳定性至关重要。
为了更好地评估和优化模型的表现,我们常常会使用十折交叉验证这样的技术来进行筛选。
本文将深入探讨R语言中的十折交叉验证,并探讨如何利用它来筛选和优化诊断模型。
二、十折交叉验证的概念和原理 1. 十折交叉验证的定义十折交叉验证是一种常用的评估和筛选模型的技术。
它将数据集划分为十个子集,一次性使用其中九个子集进行训练,而剩下的一个子集用于测试。
这个过程会循环进行十次,每次都选择不同的测试子集,最终将所有的测试结果进行平均,以得到模型的最终评估指标。
2.十折交叉验证的原理在进行十折交叉验证时,我们首先将数据集进行随机划分,确保每个子集包含尽可能均匀的样本。
我们将模型训练九次,每次都使用不同的训练集和相同的测试集。
我们将十次的测试结果进行平均,得到模型的最终评估结果。
三、十折交叉验证在诊断模型中的应用 1. 筛选模型通过十折交叉验证,我们可以对模型进行全面的评估,从而筛选出最优的模型。
在R语言中,我们可以使用函数train()来进行模型训练和交叉验证,得到模型的评估指标和性能表现。
通过比较不同模型的交叉验证结果,我们可以选择最适合我们数据的模型,并进行后续的优化和改进。
2.优化参数除了筛选模型外,十折交叉验证还可以帮助我们优化模型的参数。
在R语言中,我们可以使用函数tune()来进行参数调优,同时结合十折交叉验证的结果,找到最佳的参数组合。
这样可以提高模型的泛化能力,提升其在实际应用中的表现。
四、个人观点和总结通过本文的探讨,我们了解了R语言中的十折交叉验证在筛选和优化诊断模型中的重要性和应用。
在实际应用中,我们应该充分利用这一技术,选择合适的模型和优化参数,从而提高模型的稳定性和准确性。
我们也需要注意过拟合和欠拟合的问题,通过交叉验证来避免模型的过度训练或过度拟合。
结语通过本文的阐述,我们深入探讨了R语言中的十折交叉验证在筛选和优化诊断模型中的应用。
egen命令的用法

egen命令的用法egen命令是Stata数据管理中的一个常用命令,用于生成新的变量。
常用的用法如下:1. egen varname = function(varlist): 使用指定的函数对varlist中的变量进行计算,并将计算结果赋值给varname。
常用的函数有:- sum:求和- mean:求平均值- median:求中位数- min:求最小值- max:求最大值- count:计数例如,生成一个变量age_mean,表示age变量的平均值:```egen age_mean = mean(age)```2. egen varname = total(varlist): 对varlist中的变量进行求和,并将求和结果赋值给varname。
例如,生成一个变量income_total,表示income变量的总和:```egen income_total = total(income)```3. egen varname1 = varname2 if condition: 如果满足指定的条件,即condition为真,则将varname2的值赋给varname1。
例如,生成一个变量is_female,如果gender变量的值为"female",则is_female为1,否则为0:```egen is_female = gender=="female", label```4. egen varname1 = varname2, label: 将varname2的值赋给varname1,并附加标签。
例如,复制一个变量age到age_copy,并附加标签"Age(copy)":```egen age_copy = age, label("Age (copy)")```5. egen varname = group(varlist): 根据varlist中的变量对数据进行分组,并为每个组生成一个序号,赋值给varname。
booth算法超详细讲解精选全文

精选全文完整版(可编辑修改)Booth Recoding[Last modified 11:53:37 AM on Saturday, 8 May ]Booth multiplication is a technique that allows for smaller, faster multiplication circuits, by recoding the numbers that are multiplied. It is the standard technique used in chip design, and provides significant improvements over the "long multiplication" technique.Shift and AddA standard approach that might be taken by a novice to perform multiplication is to "shift andadd", or normal "long multiplication". That is, for each column in the multiplier, shift the multiplicand the appropriate number of columns and multiply it by the value of the digit in that column of the multiplier, to obtain a partial product. The partial products are then added to obtain the final result:.0 0 1 0 1 10 1 0 0 1 10 0 1 0 1 10 0 1 0 1 10 0 0 0 0 00 0 0 0 0 00 0 1 0 1 10 0 1 1 0 1 0 0 0 1W ith this system, the number of partial products is exactly the number of columns in the multiplier.Reducing the Number of Partial ProductsI t is possible to reduce the number of partial products by half, by using the technique of radix 4Booth recoding. The basic idea is that, instead of shifting and adding for every column of the multiplier term and multiplying by 1 or 0, we only take every second column, and multiply by ±1, ±2, or 0, to obtain the same results. So, to multiply by 7, we can multiply the partial product aligned against the least significant bit by -1, and multiply the partial product aligned with thethird column by 2:Partial Product 0 = Multiplicand * -1, shifted left 0 bits (x -1)Partial Product 1 = Multiplicand * 2, shifted left 2 bits (x 8)T his is the same result as the equivalent shift and add method:Partial Product 0 = Multiplicand * 1, shifted left 0 bits (x 1)Partial Product 1 = Multiplicand * 1, shifted left 1 bits (x 2)Partial Product 2 = Multiplicand * 1, shifted left 2 bits (x 4)Partial Product 3 = Multiplicand * 0, shifted left 3 bits (x 0)T he advantage of this method is the halving of the number of partial products. This is importantin circuit design as it relates to the propagation delay in the running of the circuit, and the complexity and power consumption of its implementation.I t is also important to note that there is comparatively little complexity penalty in multiplying by0, 1 or 2. All that is needed is a multiplexer or equivalent, which has a delay time that is independent of the size of the inputs. Negating 2's complement numbers has the added complication of needing to add a "1" to the LSB, but this can be overcome by adding a single correction term with the necessary "1"s in the correct positions.Radix-4 Booth RecodingT o Booth recode the multiplier term, we consider the bits in blocks of three, such that eachblock overlaps the previous block by one bit. Grouping starts from the LSB, and the first block only uses two bits of the multiplier (since there is no previous block to overlap):Figure 1 : Grouping of bits from the multiplier term, for use in Booth recoding. The least significant block uses only two bits of the multiplier, and assumes a zero for the third bit.T he overlap is necessary so that we know what happened in the last block, as the MSB of theTable 1 : Booth recoding strategy for each of the possible block values.S ince we use the LSB of each block to know what the sign bit was in the previous block, andthere are never any negative products before the least significant block, the LSB of the first block is always assumed to be 0. Hence, we would recode our example of 7 (binary 0111) as :0 1 1 1block 0 : 1 1 0 Encoding : * (-1)block 1 : 0 1 1 Encoding : * (2)I n the case where there are not enough bits to obtain a MSB of the last block, as below, we signextend the multiplier by one bit.0 0 1 1 1block 0 : 1 1 0 Encoding : * (-1)block 1 : 0 1 1 Encoding : * (2)block 2 : 0 0 0 Encoding : * (0)T he previous example can then be rewritten as:0 0 1 0 1 1 , multiplicand0 1 0 0 1 1 , multiplier1 1 -1 , booth encoding of multiplier1 1 1 1 1 1 0 1 0 0 , negative term sign extended0 0 1 0 1 10 0 1 0 1 10 0 0 0 1 , error correction for negation0 0 1 1 0 1 0 0 0 1 , discarding the carried high bitO ne possible implementation is in the form of a Booth recoder entity, such as the one in figure 2-16, with its outputs being used to form the partial product:Figure 2 : Booth Recoder and its associated inputs and outputs.I n figure 2,•The zero signal indicates whether the multiplicand is zeroed before being used as a partial product•The shift signal is used as the control to a 2:1 multiplexer, to select whether or not the partial product bits are shifted left one position.•Finally, the neg signal indicates whether or not to invert all of the bits to create a negative product (which must be corrected by adding "1" at some later stage)T he described operations for booth recoding and partial product generation can be expressed interms of logical operations if desired but, for synthesis, it was found to be better to implement the truth tables in terms of VHDL case and if/then/else statements.Sign Extension TricksOnce the Booth recoded partial products have been generated, they need to be shifted and added together in the following fashion:[Partial Product 1][Partial Product 2] 0 0[Partial Product 3] 0 0 0 0[Partial Product 4] 0 0 0 0 0 0The problem with implementing this in hardware is that the first partial product needs to be sign extended by 6 bits, the second by four bits, and so on. This is easily achievable in hardware, but requires additional logic gates than if those bits could be permanently kept constant.1 1 1 1 1 1 1 0 1 0 00 0 0 0 0 1 0 1 10 0 0 1 0 1 10 0 0 0 1 , error correction for negation0 0 1 1 0 1 0 0 0 1Fortunately, there is a technique that achieves this:•Invert the most significant bit (MSB) of each partial product•Add an additional '1' to the MSB of the first partial product•Add an additional '1' in front of each partial productThis technique allows any sign bits to be correctly propagated, without the need to sign extend all of the bits.0 1 0 1 0 1 1 (additional "1"s)0 0 1 0 01 1 0 1 11 1 0 1 10 0 0 0 1 , error correction for negation0 0 1 1 0 1 0 0 0 1References•Weste, Neil H.E. and Eshraghian, Kamran, Principles of CMOS VLSI Design: A systems perspective, Addison-Wesley Publishing Company, 2nd ed., 1993, pp547-555.在这一学年中,不仅在业务能力上,还是在教育教学上都有了一定的提高。
JMP中summary工具的应用详解
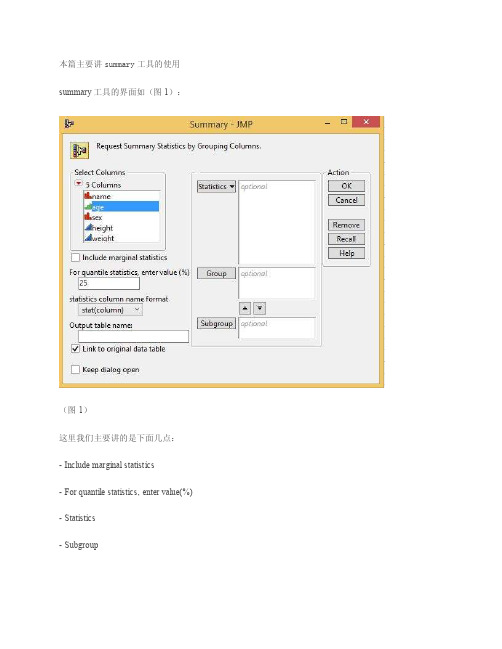
本篇主要讲summary工具的使用summary工具的界面如(图1):(图1)这里我们主要讲的是下面几点:- Include marginal statistics- For quantile statistics, enter value(%) - Statistics- Subgroup从简单的开始1. Include marginal statistics勾选这个选项后,JMP在给出group的结果的同时,多增加一行对各个group项的综合。
例如,18个女生的平均身高是60.9,22个男生的平均身高是63.9. 在给出男生/女生的平均身高后,第三行给出了所有人的总和:40,和平均身高:62.6相当于我们在使用excel的pivot table 功能里面的“Grand Total”2. For quantile statistics, enter value(%)这个比较直观,它有一个输入框(见图1),你想要哪个分位数的数据(0-100),就输入分位数,然后点statistics,选择quantiles。
结果如(图2)。
(图2)不过这里我主要想解释一下JMP中quantile的概念和算法,方便理解和编程。
首先,quantile的意思很明白,把所有的数按从小到大顺序排列,比如1~99的整数列:- quantile(50)的意思就是中位数,也叫median,在1~99的序列中刚好就是第50位数,即50。
- quantile(25)也叫1/4quartile,第25位数,在这里是25。
- quantile(75)也叫3/4quartile,第75位数,在这里是75。
quantile(x)的计算公式分两个部分:1. 首先计算第x分位数,它的公式是(x/100)*(n+1),其中n代表的是数列的个数。
在这个例子中n=99。
所以:- quantile(25) = (25/100)*(99+1)=25.00- quantile(50) = (50/100)*(99+1)=50.00- quantile(75) = (75/100)*(99+1)=75.002. q(x)=(1-f)*y(i)+f*y(i+1), f即步骤1计算得到的数字的小数部分,i是整数部分,y(i)指的是排序后的第i位数- quantile(25): f=0.00,i=25,y(i)= 25, y(i+1)= 26, q(x)= 25- quantile(50): f=0.00,i=50,y(i)= 50, y(i+1)= 51, q(x)= 50- quantile(75): f=0.00,i=75,y(i)= 75, y(i+1)= 76, q(x)= 75这个例子太特殊了,得出的都是整数分位数,换个例子:(1,2,3,4,5)数列,求quantile(25)。
summary 范文

Original:My neighbor's children love playing hide—and—seek as all children do, but no one imagine that a game they played last week would be reported in the local newspaper。
One afternoon, they were playing in the vacant lot down the corner. Young Paul,who is only five years old,found the perfect place to hide. His sister, Natalie,had shut her eyes and was counting to ten when Paul noticed the storage mail box at the corner and saw that the metal door was standing open。
The mailman had just taken out several sacks of mail and had carried them to his truck which was standing at the curb a few feet away. Paul climbed into the storage box and pulled the door closed so hard that it locked。
Soon realizing what he had done,he became frightened and started crying. Meanwhile,Natalie was looking for him everywhere but could not find him。
ggfittext 0.10.1 用户手册说明书

Package‘ggfittext’September5,2023Title Fit Text Inside a Box in'ggplot2'Version0.10.1Description A'ggplot2'extension tofit text into a box by growing,shrinking or wrapping the text. Depends R(>=3.6)License GPL-2LazyData trueImports grid(>=3.1),stringi(>=1.1.2),shades(>=1.3.1),gridtext(>=0.1.4),ggplot2(>=2.2.1)RoxygenNote7.2.3URL https:///ggfittext/BugReports https:///wilkox/ggfittext/issues/Suggests knitr,rmarkdown,testthat(>=3.0.0),vdiffr,spellingVignetteBuilder knitrEncoding UTF-8Language en-GBConfig/testthat/edition3NeedsCompilation noAuthor David Wilkins[aut,cre],Brady Johnston[ctb]Maintainer David Wilkins<****************>Repository CRANDate/Publication2023-09-0511:50:14UTCR topics documented:altitudes (2)animals (2)animals_rich (3)beverages (3)12animals beverages_rich (4)geom_bar_text (4)gold (7)Index9 altitudes Some craft and their altitudesDescriptionSome craft and their altitudesUsagealtitudesFormatA data frame with4rows and2variables:craft the name of the craftaltitude the craft’s normal cruising altitude in metresanimals Some animals and their attributesDescriptionSome animals and their attributesUsageanimalsFormatA data frame with6rows and4variables:animal the name of the animaltype the type of animalflies whether the animal canflymass the average mass of the animal in gramsanimals_rich3 animals_rich Some animals and their attributes,in rich textDescriptionSome animals and their attributes,in rich textUsageanimals_richFormatA data frame with6rows and4variables:animal the name of the animal,in rich texttype the type of animalflies whether the animal canflymass the average mass of the animal in gramsbeverages The compositions of some espresso-based beveragesDescriptionThe compositions of some espresso-based beveragesUsagebeveragesFormatA data frame with6rows and3variables:beverage the name of the beverageingredient the ingredientproportion the proportion of a cup tofill with the ingredientbeverages_rich The compositions of some espresso-based beverages,in rich textDescriptionThe compositions of some espresso-based beverages,in rich textUsagebeverages_richFormatA data frame with6rows and3variables:beverage the name of the beverageingredient the ingredient,in rich textproportion the proportion of a cup tofill with the ingredientgeom_bar_text A’ggplot2’geom tofit text inside a boxDescriptiongeom_fit_text()shrinks,grows and wraps text tofit inside a defined box.geom_bar_text()is a convenience wrapper around geom_fit_text()for labelling bar plots generated with geom_col() and geom_bar().Usagegeom_bar_text(mapping=NULL,data=NULL,stat="identity",position="identity",na.rm=FALSE,show.legend=NA,inherit.aes=TRUE,padding.x=grid::unit(1,"mm"),padding.y=grid::unit(1,"mm"),min.size=8,place=NULL,outside=NULL,grow=FALSE,reflow=FALSE,hjust=NULL,vjust=NULL,fullheight=NULL,width=NULL,height=NULL,formatter=NULL,contrast=NULL,rich=FALSE,...)geom_fit_text(mapping=NULL,data=NULL,stat="identity",position="identity",na.rm=FALSE,show.legend=NA,inherit.aes=TRUE,padding.x=grid::unit(1,"mm"),padding.y=grid::unit(1,"mm"),min.size=4,place="centre",outside=FALSE,grow=FALSE,reflow=FALSE,hjust=NULL,vjust=NULL,fullheight=NULL,width=NULL,height=NULL,formatter=NULL,contrast=FALSE,flip=FALSE,rich=FALSE,...)Argumentsmapping ggplot2::aes()object as standard in’ggplot2’.Note that aesthetics specifying the box must be provided.See Details.data,stat,position,na.rm,show.legend,inherit.aes,...Standard geom arguments as for ggplot2::geom_text().padding.x,padding.yHorizontal and vertical padding around the text,expressed in grid::unit()objects.Both default to1mm.min.size Minimum font size,in points.Text that would need to be shrunk below this sizetofit the box will be hidden.Defaults to4pt(8pt for geom_bar_text()) place Where inside the box to place the text.Default is’centre’;other options are’topleft’,’top’,’topright’,’right’,’bottomright’,’bottom’,’bottomleft’,’left’,and’center’/’middle’which are both synonyms for’centre’.For geom_bar_text(),will be set heuristically if not specified.outside If TRUE,text placed in one of’top’,’right’,’bottom’or’left’that would need tobe shrunk smaller than min.size tofit the box will be drawn outside the boxif possible.This is mostly useful for drawing text inside bar/column geoms.Defaults to TRUE for position="identity"when using geom_bar_text(),otherwise FALSE.grow If TRUE,text will be grown as well as shrunk tofill the box.Defaults to FALSE.reflow If TRUE,text will be reflowed(wrapped)to betterfit the box.Defaults to FALSE.hjust,vjust Horizontal and vertical justification of the text.By default,these are automati-cally set to appropriate values based on place.fullheight If TRUE,descenders will be counted when resizing and placing text;if FALSE,only the x-height and ascenders will be counted.The main use for this option isfor aligning text at the baseline(FALSE)or preventing descenders from spillingoutside the box(TRUE).By default this is set automatically depending on placeand grow.width,height When using x and/or y aesthetics,these set the width and/or height of the box.These should be either grid::unit()objects or numeric values on the x and yscales.formatter A function that will be applied to the text before it is drawn.This is usefulwhen using geom_fit_text()in context involving interpolated variables,suchas with the’gganimate’package.formatter will be applied serially to eachelement in the label column,so it does not need to be a vectorised function.contrast If TRUE and in combination with a fill aesthetic,the colour of the text will beinverted for better contrast against dark backgroundfills.FALSE by default forgeom_fit_text(),set heuristically for geom_bar_text().rich If TRUE,text will be formatted with markdown and HTML markup as imple-mented by gridtext::richtext_grob().FALSE by default.Rich text cannotbe drawn in polar coordinates.Please note that rich text support is experimentaland breaking changes are likelyflip If TRUE,when in polar coordinates’upside-down’text will beflipped the’rightway up’,to enhance readability.DetailsExcept where noted,geom_fit_text()behaves more or less like ggplot2::geom_text().There are three ways to define the box in which you want the text to be drawn.The extents of the box on the x and y axes are independent,so any combination of these methods can be used:1.If the x and/or y aesthetics are used to set the location of the box,the width or height will beset automatically based on the number of discrete values in x and/and y.gold72.Alternatively,if x and/or y aesthetics are used,the width and/or height of the box can beoverridden with a’width’and/or’height’argument.These should be grid::unit()objects;if not,they will be assumed to use the native axis scale.3.The boundaries of the box can be set using the aesthetics’xmin’and’xmax’,and/or’ymin’and’ymax’.If the text is too big for the box,it will be shrunk tofit the box.With grow=TRUE,the text will be made tofill the box completely whether that requires shrinking or growing.reflow=TRUE will cause the text to be reflowed(wrapped)to betterfit in the box.If the text cannot be made tofit by reflowing alone,it will be reflowed then shrunk tofit the box.Existing line breaks in the text will be respected when reflowing.geom_fit_text()includes experimental support for drawing text in polar coordinates(by adding coord_polar()to the plot),however not all features are available when doing so.Aesthetics•label(required)•(xmin AND xmax)OR x(required)•(ymin AND ymax)OR y(required)•alpha•angle•colour•family•fontface•lineheight•sizeExamplesggplot2::ggplot(ggplot2::presidential,ggplot2::aes(ymin=start,ymax=end, label=name,x=party))+geom_fit_text(grow=TRUE)gold Robert Frost’s poem Nothing Gold Can Stay(1923)DescriptionRobert Frost’s poem Nothing Gold Can Stay(1923)Usagegold8goldFormatA data frame with8rows and5variables:line a line from the poemxmin the xmin coordinate with which to draw the linexmax the xmax coordinate with which to draw the lineymin the ymin coordinate with which to draw the lineymax the ymax coordinate with which to draw the linelinenumber the line numberIndex∗datasetsaltitudes,2animals,2animals_rich,3beverages,3beverages_rich,4gold,7altitudes,2animals,2animals_rich,3beverages,3beverages_rich,4geom_bar_text,4geom_fit_text(geom_bar_text),4gold,79。
egen条件语句

egen条件语句egen条件语句是Stata中的一个命令,用于根据指定的条件生成新的变量。
它可以帮助我们对数据进行处理和分析。
下面将介绍egen 条件语句的一些常见用法。
1. egen语句的基本格式egen命令的基本格式为:egen 新变量名= 统计函数(被计算变量) if 条件2. egen命令的常见统计函数(1) count:计算满足条件的观测数量(2) sum:计算满足条件的观测值之和(3) mean:计算满足条件的观测值的平均值(4) min:计算满足条件的观测值的最小值(5) max:计算满足条件的观测值的最大值(6) sd:计算满足条件的观测值的标准差(7) median:计算满足条件的观测值的中位数3. 条件表达式的使用(1) 使用比较运算符,如>, <, >=, <=, !=等(2) 使用逻辑运算符,如&(与)、|(或)、~(非)(3) 使用in关键字,例如in 1/10表示在1到10之间4. egen命令的示例(1) 计算满足条件的观测数量egen num = count(var) if condition(2) 计算满足条件的观测值之和egen total = sum(var) if condition(3) 计算满足条件的观测值的平均值egen avg = mean(var) if condition(4) 计算满足条件的观测值的最小值egen min_val = min(var) if condition(5) 计算满足条件的观测值的最大值egen max_val = max(var) if condition(6) 计算满足条件的观测值的标准差egen std_dev = sd(var) if condition(7) 计算满足条件的观测值的中位数egen median_val = median(var) if condition5. egen命令的注意事项(1) egen命令只能用于数值型变量,不能用于字符串型变量(2) 条件表达式中的变量名需加上$符号,例如var$>10(3) egen命令可以与其他Stata命令结合使用,如egen命令生成新变量后,可以使用tab命令对新变量进行分组统计6. egen命令的优势(1) egen命令可以在一个命令中完成多个统计任务,提高了效率(2) egen命令可以根据不同的条件生成不同的新变量,灵活性较高(3) egen命令的结果可以直接用于后续的分析和绘图等操作,方便快捷7. egen命令的应用场景(1) 数据清洗:根据特定条件对数据进行筛选和整理(2) 数据分析:根据不同的条件对数据进行分组统计和比较(3) 数据展示:生成新的变量,用于后续的可视化展示8. egen命令的局限性(1) egen命令只能在Stata软件中使用,不适用于其他统计软件(2) egen命令对于大规模数据的处理速度较慢,可能需要较长的运行时间(3) egen命令在处理复杂的条件表达式时,可能需要一定的编程技巧和经验9. egen命令的进一步学习资源(1) Stata官方文档提供了关于egen命令的详细说明和示例(2) 在Stata的帮助文档中,可以通过help egen命令获取相关信息(3) 在Stata的官方网站和论坛上,可以找到其他用户分享的关于egen命令的经验和案例10. 小结egen条件语句是Stata中一个非常有用的命令,可以帮助我们灵活地处理和分析数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Summary—Chapter 10: Anne’s Apology
Anne remains in her room the entire next day, sulking and barely touching the food Marilla brings her. Matthew, concerned about Anne, waits for Marilla to leave the house and then creeps up to Anne’s room. He has not been upstairs for four years. He sneaks in and whispers to Anne that she should apologize to Mrs. Rachel, since Marilla is not likely to change her mind about the punishment. Anne admits that she is not as furious as she was, but says apologizing would be too humiliating. However, to oblige Matthew, she promises to go to Mrs. Rachel’s. Stunned by his success with Anne, Matthew hurries away so Marilla won’t find him interfering with Anne’s punishment.
Anne tells Marilla she is willing to apologize, and they walk to Mrs. Rachel’s house. During the first half of the walk, Anne’s gait and countenance suggest her shame, but midway through the walk, her step quickens and her eyes become dreamy. Upon arriving at Mrs. Rachel’s, A nne resumes slumping and throws herself on her knees before the older woman, clasping her hands and begging for forgiveness, saying,
I could never express all my sorrow, no, not if I used up a whole dictionary . . . I’m a dreadfully wicked and ungrateful girl, and I deserve to be punished and cast out by respectable people for ever.
Mrs. Rachel accepts the apology readily. In her way, Mrs. Rachel atones for her own thoughtlessness by telling Anne that her red hair might darken into auburn as she grows up. She tells Marilla that despite Anne’s odd ways, she likes her.
Marilla feels uneasy about Anne’s apology. She recognizes that Anne enjoyed her punishment, making her apology theatrical and flowery. Although Marilla feels the punishment has backfired, she would feel odd chastising Anne for apologizing too well. As they walk home, Anne slips her hand into Marilla’s, saying how happy she is to be going to a place that feels like home. At the touch of the little girl’s hand, Marilla feels a rush of motherly warmth that is both pleasurable and disarming. She tries to restore her usual emotional control and fends off this unfamiliar feeling of affection by moralizing to Anne about good behavior.
o How was Anne feeling when Marilla brought her food?
o What did Matthew do after Marilla left the house?
o What did Anne tell Marilla that she was going to do?
o When they arrived at Mrs. Rachel’s, how did Anne apologize?
o How did Mrs. Rachel react to Anne’s apology?
Find the meaning of the highlighted words in one of these dictionaries: Merriam Webster online,
If there are any words you don’t know in the last paragraph, highlight them and find the meaning. What highlighted words do you think the following pictures represent?
WORDFIND
D S B K H G N I K L U S Q Z T D
W S S O Z B I R K T C T J P Y T
P Q D E T B P U S P E E R C L S
C Y J N N A P N J L T J Y F R L
O V X C Q S J J B X W X S M E U
T I J Y J A S A P M M K A J H M
N H D B F K R E C T I X E C T P
I I E E N U Y T L L F G N Z O I
R L C A S D E I S T A A U C M N
S V I A T C L A T T H S L B X G
K O E R A R W G O X U G P A Q X
M L U B V S I N C Z A N U Z E M
P Q G W P X G C T W L T N O C Q
A C O U N T E N A N C E O E H K
R A U B U R N X L L P W L N D T
Z Z W M O R A L I Z I N G D E L
pleasurable atone
auburn slumping
clasp stunned
countenance sulking
creeps up theatrical
gait thoughtlessness
moralizing uneasy
motherly。