内核协议栈数据包转发完全解析
内核协议栈收包流程

内核协议栈收包流程1.引言1.1 概述概述部分的内容可以包括对于内核协议栈收包流程的简要介绍和背景说明。
以下是一个示例:概述内核协议栈是计算机网络中的重要组成部分,负责管理和处理网络数据包的收发。
它是一种软件实现,通常作为操作系统的一部分运行,为网络通信提供必要的支持。
在现代计算机网络中,数据包在网络中的传输是一个复杂的过程,涉及到众多的协议和技术。
内核协议栈通过一系列的操作和算法来处理这些数据包,确保它们能够按照规定的协议和顺序进行传输。
本文将深入探讨内核协议栈的收包流程。
我们将从内核协议栈的基本概念和结构开始,然后逐步介绍收包流程的各个环节,包括数据包到达内核协议栈的过程、处理过程中的数据传递和处理逻辑,以及数据包的发送过程。
通过对这些环节的详细解析,我们可以更好地理解内核协议栈如何实现数据包的接收和处理,从而为我们理解计算机网络的工作原理提供一个全面的视角。
本文旨在帮助读者深入理解内核协议栈收包流程的工作机制和原理,并为读者提供从实践角度出发的技术参考。
通过学习内核协议栈收包流程的相关知识,读者将能够更好地应用和配置内核协议栈,提高网络的性能和安全性。
同时,本文还将对未来内核协议栈收包流程的发展进行展望,分析当前存在的挑战和可能采取的解决方案,以期对相关领域的研究和发展提供一些指导和启示。
下一篇文章我们将首先从内核协议栈的基本概念和结构入手,介绍其组成和工作原理。
通过对内核协议栈的概述,我们可以更好地理解收包流程的具体实现和过程。
敬请期待我们接下来的内容。
1.2文章结构文章结构指的是文章的组织和布局方式,用于引导读者理解和阅读文章的内容。
在本文中,我们将按照以下结构展开讨论:1. 引言1.1 概述:介绍内核协议栈收包流程的背景和重要性。
解释协议栈的概念及其在计算机网络中的作用。
1.2 文章结构:本节(1.2)将介绍整篇文章的章节划分和内容安排。
1.3 目的:说明本文的撰写目标和意义,明确阐述文章将涵盖的内容。
linux 内核协议栈丢包-解释说明

linux 内核协议栈丢包-概述说明以及解释1.引言1.1 概述Linux 内核协议栈作为网络通信的核心组成部分,在网络数据传输过程中扮演着至关重要的角色。
然而,随着网络流量的增加和网络环境的复杂化,出现丢包现象已经成为一种常见的问题,给网络通信质量以及数据传输的稳定性带来了不小的挑战。
本文将深入探讨Linux 内核协议栈丢包的问题,从丢包现象分析、常见原因及解决方法等方面展开探讨,希望通过对该问题的深入研究,能够为广大读者提供更加系统和全面的解决方案,以更好地应对日益复杂的网络环境与情况。
1.2 文章结构文章结构部分的内容应该涵盖本文的整体布局和组织架构,可以描述文章的章节设置和内容安排,让读者能够清晰地了解整篇文章的逻辑结构。
具体内容如下:文章结构部分将主要描述本文的整体架构和章节布局。
本文主要分为引言、正文和结论三个部分。
引言部分将概述本文的主题和目的,介绍Linux内核协议栈丢包问题的背景和重要性。
正文部分将详细介绍Linux 内核协议栈的简介,分析丢包现象的原因,以及常见的解决方法。
结论部分将对全文内容进行总结,并提出对策建议和展望未来的发展方向。
通过本文的结构安排,读者可以清晰地了解本文的逻辑脉络,帮助他们更好地理解和消化文章内容。
1.3 目的本文旨在探讨在使用Linux内核协议栈时可能出现的丢包现象及其原因,以及针对这些问题提出一些常见的解决方法。
通过对丢包现象进行分析和解决方案的讨论,旨在帮助读者更好地理解和解决在使用Linux系统中可能遇到的网络通信问题。
同时,也希望通过对这些问题的深入讨论,促进Linux内核协议栈的优化和改进,提升系统的稳定性和可靠性。
2.正文2.1 Linux 内核协议栈简介Linux内核协议栈是操作系统内核中的一个关键部分,负责网络数据包的接收、处理和发送。
它由多个层次构成,每个层次都有特定的功能,包括网络接口层、网络层、传输层和应用层。
在Linux系统中,协议栈的实现主要依赖于内核中的网络协议栈,其中包括传输层协议(如TCP和UDP)、网络层协议(如IP)和数据链路层协议(如Ethernet)。
计算机网络协议栈解析

计算机网络协议栈解析引言:计算机网络协议栈是指网络通信中的各种协议的集合,它对数据在网络中的传输进行了规范和控制。
本文将对计算机网络协议栈进行详细的解析,包括定义、发展和功能等方面。
一、定义和概念1. 计算机网络协议栈是指在计算机网络中用于数据传输和通信的一组协议的层次结构。
它由多个层次的协议组成,每个层次负责不同的功能。
2. 计算机网络协议栈的设计旨在实现网络中数据的高效传输和可靠通信。
二、发展历程1. ARPANET: ARPANET是美国国防部高级研究计划署(ARPA)于1969年建立的第一个分组交换网络,是计算机网络协议栈的雏形。
2. TCP/IP协议栈: TCP/IP协议栈是由互联网工程任务组(IETF)在20世纪70年代末和80年代初发展起来的一组协议,成为了当今计算机网络协议栈的主流。
三、协议栈的层次结构1. 应用层: 应用层是协议栈中的最高层,负责应用程序之间的通信。
常见的应用层协议有HTTP、FTP和SMTP等。
2. 传输层: 传输层为应用程序提供端对端的通信服务。
常见的传输层协议有TCP和UDP。
3. 网络层: 网络层负责通过互联网进行数据传输。
常见的网络层协议有IP。
4. 数据链路层: 数据链路层负责将数据帧从一个节点传输到相邻节点。
常见的数据链路层协议有以太网和WiFi等。
5. 物理层: 物理层负责将比特流转化为可以在物理介质上传输的信号。
它涉及到硬件,如网卡和光纤等。
四、协议栈的功能1. 分层管理: 协议栈的分层结构使得网络中的协议可以按照不同的功能划分到不同的层次中进行管理,提高了网络的可扩展性和可维护性。
2. 数据传输: 协议栈负责将上层的数据封装成数据包,并通过网络进行传输。
3. 错误检测和修复: 协议栈中的各个层次在数据传输过程中可以进行错误检测和修复,提高了数据的可靠性。
4. 网络地址分配: 协议栈中的网络层负责对数据包进行寻址和路由,确保数据能够准确地传输到目的地。
linux路由转发原理

linux路由转发原理
在Linux系统中,路由转发指的是将接收到的网络数据包从一
个网络接口转发到另一个网络接口的过程。
Linux系统通过以
下几个步骤实现路由转发:
1. 数据包接收:当一个网络接口接收到一个数据包时,操作系统会捕获数据包,并将其传递给网络协议栈进行处理。
2. 路由决策:在接收到数据包后,操作系统会根据其目的IP
地址进行路由决策,确定将数据包发送到哪个网络接口。
它会检查系统的路由表,找到与目的IP地址最匹配的路由项。
路
由表中的每个路由项包含目的网络地址、下一跳地址和出接口。
3. 数据包转发:根据路由决策,操作系统将数据包从接收网络接口转发到指定的出接口。
这个过程涉及到重新封装数据包,包括设置新的源和目的MAC地址。
通过重新封装,操作系统
可以将数据包发送到下一跳路由器或目的主机。
4. 数据包转发控制:操作系统还可以根据配置和策略控制路由转发过程。
例如,可以通过配置IP转发表来允许或拒绝特定
的数据包转发。
此外,还可以使用网络地址转换(NAT)来
修改数据包中的IP地址和端口。
总结起来,Linux系统的路由转发原理是根据目的IP地址查找路由表,然后将数据包从接收网络接口转发到指定的出接口,同时进行必要的数据包封装和重写。
内核协议栈数据包转发完全解析

内核协议栈数据包转发完全解析内核协议栈是计算机操作系统中负责网络通信的核心组件,它负责接收、处理和发送网络数据包。
数据包转发是内核协议栈的一项重要功能,它将接收到的数据包转发到目标主机或目标端口。
本文将对内核协议栈数据包转发的过程进行详细解析。
首先,内核协议栈接收数据包的过程如下:1.数据包到达网络接口:数据包通过网络接口(如网卡)到达操作系统。
2.数据包传递到网络协议栈:操作系统将数据包传递给网络协议栈,通常是通过中断请求完成。
3.数据包解析:网络协议栈对数据包进行解析,包括校验和验证、协议解封和头信息解析等。
4.路由决策:根据数据包的目标IP地址,网络协议栈进行路由决策,确定数据包的下一跳目标。
5.转发决策:根据路由决策结果,确定数据包的转发策略,包括直接转发、二层交换、ARP请求等。
6.调度到网络设备:如果数据包需要通过网络设备转发,网络协议栈将数据包调度到相应的网络设备队列等待发送。
接下来,内核协议栈进行数据包转发的过程如下:1.判断目标主机是否为本地主机:如果数据包的目标主机是本地主机,内核协议栈将数据包交给本地TCP/IP协议栈进行处理。
否则,继续下一步。
2.查找下一跳目标的MAC地址:内核协议栈通过ARP协议或缓存表查找下一跳目标的MAC地址,如果找不到则发送ARP请求。
3.生成数据包帧:内核协议栈根据下一跳目标的MAC地址,将数据包封装成网络帧。
4.发送数据包帧:内核协议栈将数据包帧发送到网络设备,通过物理介质转发到下一跳目标。
数据包转发过程中,还涉及到一些优化机制和特殊情况的处理:1.ARP缓存:内核协议栈会在本地维护一个ARP缓存表,用于存储IP 地址和对应的MAC地址。
当需要发送数据包时,首先检查ARP缓存表,如果有对应的MAC地址,则直接使用;否则,发送ARP请求获取MAC地址。
2.ARP请求:当内核协议栈需要发送ARP请求获取下一跳目标的MAC 地址时,它会封装一个ARP数据包,发送到网络上的广播地址。
数据包处理过程
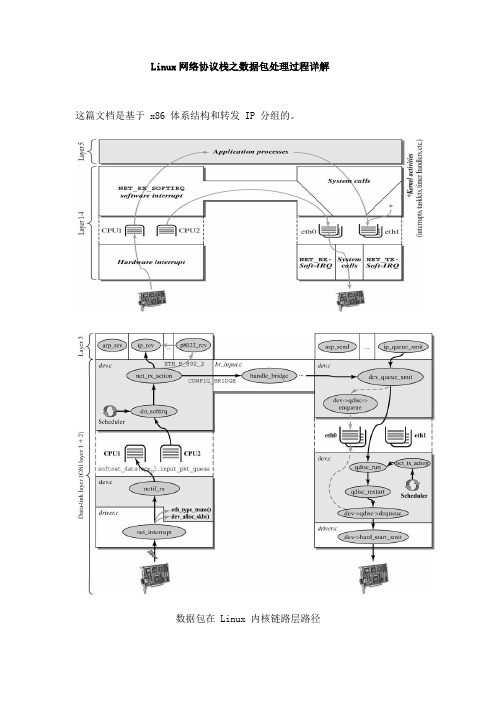
Linux网络协议栈之数据包处理过程详解这篇文档是基于 x86 体系结构和转发 IP 分组的。
数据包在 Linux 内核链路层路径图为NAPI 调用关系2 接收分组2.1 接收中断如果网卡收到一个和自己 MAC 地址匹配或链路层广播的以太网帧,它就会产生一个中断。
此网卡的驱动程序会处理此中断:从DMA/PIO 或其他得到分组数据,写到内存里去;接着,会分配一个新的套接字缓冲区skb ,并调用与协议无关的、网络设备均支持的通用网络接收处理函数netif_rx(skb) 。
netif_rx() 函数让内核准备进一步处理skb 。
然后,skb 会进入到达队列以便CPU 处理(对于多核CPU 而言,每个CPU 维护一个队列)。
如果FIFO 队列已满,就会丢弃此分组。
在skb 排队后,调用__cpu_raise_softirq() 标记NET_RX_SOFTIRQ 软中断,等待CPU 执行。
至此, netif_rx() 函数调用结束,返回调用者状况信息(成功还是失败等)。
此时,中断上下文进程完成任务,数据分组继续被上层协议栈处理。
以下是中断接收函数snull_regular_interrupt()的具体实现过程通常的中断过程能够告知新报文到达中断和发送完成通知的区别, 通过检查物理设备中的状态寄存器. snull 接口类似地工作, 但是它的状态字在软件中实现, 位于 dev->priv. 网络接口的中断处理看来如此:static void snull_regular_interrupt(int irq, void *dev_id, structpt_regs *regs){int statusword;struct snull_priv *priv;struct snull_packet *pkt = NULL;/*As usual, check the "device" pointer to be sure it isreally interrupting.Then assign "struct device *dev"*/struct net_device *dev = (struct net_device *)dev_id;/* ... and check with hw if it's really ours *//* paranoid */if (!dev)return;/* Lock the device */priv = netdev_priv(dev);spin_lock(&priv->lock);/* retrieve statusword: real netdevices use I/O instructions */ statusword = priv->status;priv->status = 0;if (statusword & SNULL_RX_INTR) {/* send it to snull_rx for handling */pkt = priv->rx_queue;if (pkt) {priv->rx_queue = pkt->next;snull_rx(dev, pkt);//见下文snull_rx()}}if (statusword & SNULL_TX_INTR) {/* a transmission is over: free the skb */priv->stats.tx_packets++;priv->stats.tx_bytes += priv->tx_packetlen;dev_kfree_skb(priv->skb);}/* Unlock the device and we are done */spin_unlock(&priv->lock);if (pkt) snull_release_buffer(pkt); /* Do this outside the lock! */ return;}中断处理的第一个任务是取一个指向正确 net_device 结构的指针. 这个指针通常来自作为参数收到的 dev_id 指针.以下是数据包接收函数snull_rx()具体实现过程snull_rx ()在硬件收到报文后从 snull 的"中断"处理中调用, 并且报文现在已经在计算机的内存中. snull_rx 收到一个数据指针和报文长度; 它唯一的责任是发走这个报文和运行附加信息给上层的网络代码. 这个代码独立于获得数据指针和长度的方式.void snull_rx(struct net_device *dev, struct snull_packet *pkt){struct sk_buff *skb;struct snull_priv *priv = netdev_priv(dev);/*The packet has been retrieved from the transmissionmedium. Build an skb around it, so upper layers can handle it*/skb = dev_alloc_skb(pkt->datalen + 2);if (!skb) {if (printk_ratelimit())printk(KERN_NOTICE "snull rx: low on mem - packetdropped\n");priv->stats.rx_dropped++; goto out;}memcpy(skb_put(skb, pkt->datalen), pkt->data, pkt->datalen);/* Write metadata, and then pass to the receive level */skb->dev = dev;skb->protocol = eth_type_trans(skb, dev);skb->ip_summed = CHECKSUM_UNNECESSARY; /* don't check it */priv->stats.rx_packets++;priv->stats.rx_bytes += pkt->datalen; netif_rx(skb);out:return;}这个函数足够普通以作为任何网络驱动的一个模板, 但是在你有信心重用这个代码段前需要一些解释.。
网络协议的基本原理

网络协议的基本原理网络协议是计算机网络中的重要组成部分,它定义了计算机和其他网络设备之间进行通信的规则和标准。
通过网络协议,不同的计算机和设备能够互相交流和传输数据。
本文将介绍网络协议的基本原理。
一、协议栈和层次结构网络协议通常采用协议栈的形式,由多个协议层次组成。
每个协议层次负责不同的功能,协议栈按照自下而上的方式工作。
1.物理层物理层是协议栈中最底层的层次,它负责传输比特流。
物理层主要涉及硬件设备,包括电缆、网卡、中继器等。
2.数据链路层数据链路层在物理层之上,负责将原始比特流转化为数据帧。
它还负责错误检测和纠正,以确保数据的可靠传输。
3.网络层网络层是协议栈的第三层,它负责数据的路由和转发。
网络层使用IP地址来标识不同的设备,并将数据包从源地址传输到目的地址。
4.传输层传输层为应用程序提供可靠的端到端通信。
它使用端口号标识不同的应用程序,并采用TCP或UDP协议来传输数据。
5.应用层应用层是协议栈中最高层的层次。
它负责处理特定的网络应用,如电子邮件、网页浏览等。
二、关键的网络协议在网络协议中,有一些关键的协议起到重要的作用,包括:1.互联网协议(IP)互联网协议是网络通信的核心协议,它定义了数据在网络中的传输方式和地址格式。
IP协议通过将数据分割成数据包,并根据目的地址将数据包传输到对应的目的地。
2.传输控制协议(TCP)TCP协议是一种可靠的传输协议,它负责将数据可靠地传输到目的地。
TCP协议通过序号和确认机制来确保数据的顺序和完整性。
3.用户数据报协议(UDP)UDP协议是一种不可靠的传输协议,它不保证数据的可靠性和顺序性。
UDP协议适用于延迟敏感的应用程序,如音频和视频流媒体。
4.超文本传输协议(HTTP)HTTP协议是用于在Web浏览器和服务器之间传输超文本的协议。
它通过请求和响应的方式进行通信,并使用URL来标识资源。
5.域名系统(DNS)DNS协议用于将域名转换为IP地址。
它通过将域名映射到对应的IP地址,使得用户可以通过易记的域名访问互联网资源。
内核协议栈数据包转发完全解析

内核协议栈数据包转发目录1 NAPI流程与非NAPI1.1NAPI驱动流程1.2非NAPI流程1.3NAPI和非NAPI的区别2内核接受数据2.1数据接收过程2.2 采取DMA技术实现3 e100采用NAPI接收数据过程3.1 e100_open 启动e100网卡3.2 e100_rx_alloc_list 建立环形缓冲区3.3 e100_rx_alloc_skb 分配skb缓存3.4 e100_poll 轮询函数3.5 e100_rx_clean 数据包的接收和传输3.6 e100_rx_indicate4 队列层4.1、软中断与下半部4.2、队列层5采用非NAPI接收数据过程5.1netif_rx5.2轮询与中断调用netif_rx_schedule不同点5.3 netif_rx_schedule5.4 net_rx_action5.5 process_backlog6数据包进入网络层6.1 netif_receive_skb():6.2 ip_rcv():6.3 ip_rcv_finish():6.4 dst_input():6.5本地流程ip_local_deliver:6.6转发流程ip_forward():1 NAPI流程与非NAPI1.1NAPI驱动流程:中断发生-->确定中断原因是数据接收完毕(中断原因也可能是发送完毕,DMA完毕,甚至是中断通道上的其他设备中断)-->通过netif_rx_schedule将驱动自己的napi结构加入softnet_data的poll_list 链表,禁用网卡中断,并发出软中断NET_RX_SOFTIRQ-->中断返回时触发软中断调用相应的函数net_rx_action,从softnet_data的poll_list上取下刚挂入的napi结构,并且调用其 poll函数,这个poll函数也是驱动自己提供的,比如e100网卡驱动中的e100_poll等。
计算机网络体系结构及协议栈详解

计算机网络体系结构及协议栈详解计算机网络是指互连的计算机,用于共享资源、通信和协作。
计算机网络可以分为多个层次,每个层次提供不同的功能,这些层次被称为计算机网络体系结构。
计算机网络体系结构通常由以下七层构成:1. 物理层物理层是计算机网络中最底层的层次,它负责处理诸如电气信号和光信号等基本网络物理参数。
因此,它的主要功能是将比特流转换为物理信号,并确保这些信号能够在各种介质上传输。
2. 链路层链路层是负责控制物理层互联设备之间的数据传输的层次。
它的任务是在透明而可信赖的传输介质上提供数据的可靠传输,并确保数据在不同物理设备之间传输的正确性。
3. 网络层网络层是计算机网络中实现逻辑互联的层次。
它的任务是通过路由选择在不同网络之间进行路由选择,并确保数据包及其关联的信息到达它的目的地。
4. 传输层传输层是控制在不同进程之间进行通信的层次。
它的任务是提供透明的、无差错的数据传输,并确保所传输的每个包到达目的地时的正确性和完整性。
5. 会话层会话层是与动态数据处理密切相关的层次。
它的任务是提供适当的会话控制和数据传输,以支持两个设备之间的互动。
6. 表示层表示层负责将计算机中的数据转换为网络上能够进行交流的格式,以便在不同计算机之间传输数据。
7. 应用层应用层是与最终用户密切相关的层次。
它负责在计算机网络中为各种应用提供支持,例如电子邮件、文件传输、Web浏览器等。
为了实现这些网络层次,需要使用一组协议栈。
协议栈是一组规定如何管理和分配网络通信的技术。
协议栈中的每一层都具有自己的协议,并且每个协议都应该遵循一系列标准,确保它可以与其他协议相互操作。
计算机网络的协议栈通常由以下四个层次组成:1. 应用层协议应用层协议是用于实现不同应用通信的协议,例如Web浏览器和邮件客户端使用HTTP和SMTP协议。
2. 传输层协议传输层协议是用于控制在网络中数据传输的协议。
例如TCP和UDP是两个常用的传输层协议,它们实现了可靠的数据传输。
内核协议栈 知识点

内核协议栈知识点
1. 什么是内核协议栈呀?就好比是网络世界的交通指挥官!比如你在网上看视频,内核协议栈就在背后默默指挥着数据怎么传输,让你能顺畅地看到画面。
2. 内核协议栈的分层结构可太重要啦!这就像盖房子,不同的层有不同的作用呀,相互配合才能盖出坚固的大楼。
你想想,要是没分好层,那不就乱套啦?
3. 数据在协议栈里的流动,那可真是神奇呢!就像水流在管道里有序地流淌一样。
你发送一个消息,它就在协议栈中按照既定路线前进呢。
4. 协议栈中的各种协议,那可是各显神通啊!就跟一个团队里的不同角色一样,TCP 啊、UDP 啊都有自己的本领。
你用手机上网的时候,它们都在努力工作哟。
5. 内核协议栈对网络性能的影响可大了去了!要是它出问题,那不就像高速路堵塞一样,让人着急上火。
你肯定也遇到过网络卡顿吧,说不定就和它有关系呢。
6. 对内核协议栈的优化可是门技术活!这就好比给赛车改装,得精心调试才能让它跑得更快更稳。
有技术人员在背后努力优化它呢,多棒呀。
7. 了解内核协议栈真的太有意义啦!就像知道了电脑的一个秘密武器。
以后你再遇到网络问题,也许就能明白是怎么回事啦。
我的观点结论:内核协议栈真的是网络世界中非常关键且神奇的存在,值得我们去深入了解和探索啊!。
LINUX内核网络协议栈

LINUX内核网络协议栈Linux内核网络协议栈是一个关键的软件组件,它实现了Linux操作系统的网络功能。
网络协议栈位于操作系统内核中,负责处理网络传输的各个层级。
Linux内核网络协议栈包括多个层级,从物理层到应用层。
每个层级都有特定的功能和协议。
下面是对每个层级的详细介绍:1.物理层:物理层是网络协议栈的最低层,负责传输数据的物理介质,如电缆、光纤等。
物理层由硬件设备支持,并通过设备驱动程序与内核进行通信。
2.数据链路层:数据链路层负责将数据转换为数据帧,并通过物理介质进行传输。
它包括两个子层:逻辑链路控制层和介质访问控制层。
逻辑链路控制层处理数据的流控制和错误检测,介质访问控制层则管理多个设备的访问冲突。
3.网络层:网络层处理数据包的路由和分组。
它使用IP协议进行路由和寻址,并通过路由表决定数据包的最佳路径。
网络层还可以处理一些附加功能,如分片和重新组装。
4.传输层:传输层负责在不同主机之间的进程之间提供可靠的数据传输。
它使用TCP协议和UDP协议来实现,TCP协议提供可靠的数据传输,而UDP协议提供不可靠但高效的传输。
5.会话层:会话层负责建立、管理和终止网络会话。
它处理会话标识符的生成和管理,并提供可靠的会话传输。
6.表示层:表示层负责数据的编码和解码,以确保数据在不同系统之间的互通。
它处理数据的格式、加密和压缩。
7.应用层:应用层是网络协议栈的最高层,提供用户与网络之间的接口。
它包括多个协议,如HTTP、FTP和SMTP,用于实现各种应用程序的网络功能。
Linux内核网络协议栈的功能包括数据传输、路由、安全、流量控制和错误检测。
内核通过各个层级的协议来实现这些功能。
内核还提供各种工具和接口,使用户可以配置网络设置、监控网络流量和诊断网络问题。
除了基本功能,Linux内核网络协议栈还支持各种高级功能,如多路复用、多队列和嵌入式系统。
它还可以通过加载额外的模块来支持特定的网络协议或功能。
旁路内核协议栈技术

旁路内核协议栈技术1. 概述旁路内核协议栈技术(Offload Kernel Protocol Stack Technology)是一种通过将网络协议栈的处理工作从主机CPU转移到专用硬件加速器上来提高网络性能和降低主机负载的技术。
它通过在网络接口控制器上实现一个独立的协议栈,使得数据包的处理可以在硬件层面完成,从而解放了主机CPU的计算资源。
2. 原理旁路内核协议栈技术利用计算机系统中的多个处理单元,将网络数据包的处理分流到专门设计的硬件加速器中。
这个硬件加速器通常被称为智能网卡或者网络接口控制器(NIC)。
该硬件加速器具备独立的处理能力,可以执行网络协议栈中的各种操作,如数据包解析、路由查找、安全检查等。
具体实现方式包括: - 利用网卡芯片中集成的专用处理引擎来执行部分或全部网络协议栈操作。
- 在网卡芯片中嵌入一个小型操作系统,该操作系统负责执行网络协议栈相关任务。
- 使用FPGA(可编程逻辑门阵列)或ASIC(专用集成电路)等硬件进行协议栈的加速处理。
3. 优势旁路内核协议栈技术具有以下优势: - 提高网络性能:通过将网络协议栈的处理工作从主机CPU转移到硬件加速器上,可以显著提高数据包的处理速度和吞吐量,降低网络延迟,提高网络性能。
- 减轻主机负载:将协议栈处理任务从主机CPU 中分离出来,可以减轻主机CPU的负载压力,释放计算资源供其他任务使用。
- 支持更多并发连接:由于硬件加速器具备独立的处理能力,可以同时处理更多的网络连接,提高系统的并发性能。
- 增强网络安全性:硬件加速器可以在数据包到达主机之前进行安全检查和过滤操作,有效防止恶意攻击和网络威胁。
4. 应用场景旁路内核协议栈技术在以下场景中得到广泛应用: - 数据中心:在大规模数据中心环境下,通过使用旁路内核协议栈技术可以加速虚拟化环境中的网络流量处理,提高服务器密度和整体性能。
- 云计算:在云计算环境中,旁路内核协议栈技术可以帮助提供更高的网络性能和更低的延迟,改善用户体验。
linux二层转发流程

linux二层转发流程Linux二层转发流程一、引言在计算机网络中,数据包的传输需要经过多个层次的处理与转发。
其中,二层转发是指在数据链路层进行的转发过程,主要涉及到以太网帧的封装、解封装、MAC地址的学习和转发决策等操作。
本文将详细介绍Linux系统中的二层转发流程。
二、Linux二层转发的基本原理Linux系统在进行二层转发时,主要依赖于内核中的网络协议栈和数据包处理模块。
其基本原理如下:1. 以太网帧的封装与解封装在进行二层转发时,Linux系统需要将上层协议的数据进行封装,生成以太网帧,以便在局域网中进行传输。
而在接收到以太网帧后,系统需要进行解封装,提取出上层协议的数据进行处理。
这一过程主要通过内核中的网络设备驱动程序来完成。
2. MAC地址的学习与转发决策在进行二层转发时,Linux系统需要学习各个网络设备的MAC地址,并建立转发表。
当接收到一个数据包时,系统会通过查找转发表来确定数据包的转发目的地。
如果目的MAC地址在转发表中存在对应的端口,则将数据包转发到相应的端口;如果不存在,则进行广播或丢弃处理。
三、Linux二层转发的详细流程在Linux系统中,二层转发的具体流程如下:1. 接收数据包当网络设备接收到一个数据包时,会触发中断通知内核,内核通过网络设备驱动程序将数据包从设备中读取到内存中。
2. 解封装数据包内核会对读取到的数据包进行解封装操作,提取出以太网帧中的数据和MAC地址等信息。
3. 查找转发表内核会根据目的MAC地址查找转发表,以确定数据包的转发目的地。
4. 转发数据包如果目的MAC地址在转发表中存在对应的端口,则将数据包转发到相应的端口。
否则,根据设置的转发策略进行广播或丢弃处理。
5. 更新转发表如果数据包的源MAC地址不在转发表中,则将该MAC地址与对应的端口进行学习,并更新转发表。
这样可以在下次转发时直接查找转发表,提高转发效率。
四、Linux二层转发的配置与管理在Linux系统中,可以通过配置和管理网络设备来实现二层转发的相关操作。
ip_forward转发原理

ip_forward转发原理IP转发是在网络中将IP数据包从源地址转发到目标地址的过程,其中涉及到的很多技术和原理需要熟练掌握,这里将具体介绍IP转发原理中的ip_forward转发。
ip_forward是Linux内核网络协议栈中的一个标志位,它表示系统是否开启IP路由功能,若该标志位置为1,表示系统开启了IP路由功能,可以将数据包在不同网络间转发。
ip_forward转发是Linux内核网络协议栈中非常重要的一环,它涉及到了Linux内核中多个协议层的相互协作,可以将近一步优化IP路由的效率和可靠性。
在Linux内核中,ip_forward转发是通过调用输入和输出协议栈中的相应函数实现的。
1.输入协议栈当系统收到一个IP数据包时,数据包首先会进入输入协议栈,进过IP层校验,获取接口地址和目标地址之后,内核将调用寻址函数,在路由表中搜索符合目标地址的路由条目,根据路由条目的下一跳地址和出网口确定发送时需要使用的接口。
数据包在经过ip_forward转发处理后,内核会将其重新打包,按指定的路径发送出去。
在Linux内核协议栈中,数据包在发送前会进过输出协议栈,经过协议栈中各层的处理后,最终发送到网卡驱动程序。
3.ARP查询在数据包发送前,还需要进行ARP查询以获得目标MAC地址,用于构建数据包的二层帧头,在ARP表中,数据包的目标地址和出接口可以找到对应的MAC地址,而路由器如果在自己的ARP表中找不到对应的MAC地址,就需要进行ARP查询,向同一网段中的其他设备广播ARP数据包,请求其他设备返回自己的MAC地址。
当收到其他设备的响应后,路由器会把获得的MAC地址存入其ARP表中,便于以后的数据包转发。
若路由器找不到目标设备的MAC地址并且其他设备也没有响应,就会丢弃该数据包,直到ARP响应返回为止。
总的来说,ip_forward是Linux内核网络协议栈中非常重要的一环,它可以将数据包在不同网络间转发,必要时进行ARP查询,提高数据传输的效率和可靠性。
linux libnetfilter_queue 数据转发的原理

linux libnetfilter_queue 数据转发的原理
libnetfilter_queue是Linux系统中一种使用用户空间处理网络
包的工具库。
它允许用户空间接收Linux内核中iptables规则
匹配到的网络数据包,并允许进行修改、丢弃或重新放行。
数据转发的原理如下:
1. 首先,用户程序使用libnetfilter_queue库创建一个netfilter
队列,并告诉Linux内核将匹配到的数据包发送到这个队列中。
2. 当有数据包匹配到iptables规则时,内核将数据包发送到创
建的netfilter队列中,由用户程序接收。
3. 用户程序收到数据包后,可以选择修改数据包的内容,如修改源IP地址、目标IP地址、端口等。
4. 用户程序可以根据自定义的逻辑进行判断,决定是否丢弃该数据包、修改后放行,或重新改写数据包后放行。
5. 最后,用户程序将修改后的数据包放行(通过)。
此时,内核将根据用户程序的操作决定是否将数据包继续传递给下一个规则进行匹配与处理。
值得注意的是,libnetfilter_queue只能在用户空间进行处理,
不能直接修改内核中的iptables规则。
因此,用户程序需要在iptables规则中将数据包发送到libnetfilter_queue中,然后在用
户程序中进行处理。
这样,用户程序可以根据自己的需求对数据包进行处理,而不受内核规则的限制。
dpdk三层转发详解

dpdk三层转发详解摘要:1.DPDK 简介2.三层转发的概念和原理3.DPDK 三层转发的实现4.DPDK 三层转发的性能优化5.总结正文:【DPDK 简介】DPDK(Data Plane Development Kit)是一个开源的软件开发工具包,主要用于加速数据平面的处理。
它提供了一组高效的库和驱动程序,以满足现代数据中心网络设备的需求。
DPDK 通过将数据平面与控制平面分离,使得开发者能够专注于优化数据包处理逻辑,从而提高网络设备的性能。
【三层转发的概念和原理】三层转发,也称为IP 层转发,是指在网络设备中处理IP 数据包的过程。
三层转发涉及将数据包从一个网络接口转发到另一个网络接口,通常包括以下步骤:接收数据包、解析数据包头部、根据目的IP 地址查找路由表、进行路由转发、发送数据包等。
【DPDK 三层转发的实现】DPDK 通过内核模块和用户空间库实现三层转发功能。
内核模块负责与硬件设备进行通信,并处理数据包的接收和发送。
用户空间库提供了一组API,用于配置网络设备、管理数据包缓冲区、处理数据包等。
具体实现过程如下:1.初始化DPDK 环境:配置内核模块和用户空间库,加载和初始化设备驱动程序。
2.配置网络设备:通过DPDK API 配置网络接口的参数,如速率、双工模式、MAC 地址等。
3.创建数据包缓冲区:分配内存空间,用于存储待处理的数据包。
4.处理接收到的数据包:通过DPDK API 解析数据包头部,根据目的IP 地址进行路由转发。
5.发送数据包:将处理好的数据包发送到目的网络接口。
【DPDK 三层转发的性能优化】为了提高DPDK 三层转发的性能,可以采取以下措施:1.使用多核处理器:多核处理器可以并行处理多个数据包,从而提高转发速度。
2.优化数据包缓冲区:合理分配数据包缓冲区的大小和数量,以减少内存访问延迟。
3.使用高速网络接口:高速网络接口可以提高数据包的接收和发送速度。
4.优化路由表:采用高效的路由算法,如RIP、OSPF 等,以减少路由查找时间。
内核协议栈数据包转发完全解析

内核协议栈数据包转发完全解析数据包转发涉及多个层次的处理,包括数据报文的解析、路由表的查询、路径选择和接口选择等。
下面我将详细解析内核协议栈数据包转发的过程。
首先,当一个网络数据包到达网卡时,网卡会将数据包传递给内核。
内核接收到数据包后,会将数据包传递给网络层进行处理。
在网络层,内核会对数据包进行解析,提取出目的IP地址和源IP地址。
然后,内核会检查目的IP地址是否为本机,如果是,则会将数据包传递给传输层的相应协议进行处理,如TCP或UDP。
如果目的IP地址不是本机,内核会查询路由表来确定数据包的下一跳。
路由表中存储了目的网络的信息,包括目的网络的网络地址和下一跳的地址。
内核会根据目的IP地址与路由表中的地址进行匹配,找到最匹配的路由。
匹配过程一般是根据最长前缀匹配算法进行的。
确定了下一跳后,内核会选择合适的接口将数据包发送出去。
接口选择是根据网络配置和路由表中的信息进行的。
内核可能会有多个网卡和接口可选择,需要根据一定的规则进行选择。
一旦确定了接口,内核就会将数据包封装到适当的链路层协议中,如以太网协议。
同时,内核会根据接口的MAC地址将数据包发送给网卡进行发送。
接收端的处理与发送端类似。
当数据包到达目的端的网卡时,网卡会将数据包传递给内核。
内核会进行相应的处理,解析数据包,将数据包传递给协议栈的上层,直到传输到应用层。
需要注意的是,上述描述是一个简化的数据包转发过程,实际情况可能更为复杂。
例如,内核可能会根据负载均衡策略选择多个路径进行转发,还可能会对数据包进行一些优化处理,如分片重组、IP地址转换等。
总结起来,内核协议栈数据包转发的过程包括数据包的解析、路由选择和接口选择等。
在转发过程中,内核会根据数据包的目的IP地址查询路由表,选择合适的下一跳和接口,并进行相应的封装和发送。
这个过程涉及多个层次的处理和多个协议的协同工作,是网络通信的基础。
计算机网络中的数据包处理与转发

计算机网络中的数据包处理与转发计算机网络是当今社会发展的重要基础设施,它负责将世界范围内的各个终端设备连接在一起,使得信息能够自由地传递和共享。
而在计算机网络中,数据包的处理与转发是其中的核心环节。
本文将探讨计算机网络中数据包的处理与转发的原理以及相关的技术。
一、数据包的处理数据包的处理是指计算机网络中对于传输的数据包进行接收、解析和处理的过程。
当一个数据包到达时,网络设备需要根据其中的信息来判断该数据包的最终目的地,并作出相应的处理。
这个过程需要经过多个步骤,其中包括数据包的解封装、目的地的确定以及出错处理等。
在数据包的处理过程中,首先需要进行数据包的解封装。
数据包在传输过程中往往会经过多个网络设备,每个设备都会为其添加一些额外的信息,比如源地址和目的地址等。
当数据包到达目的设备时,这些额外的信息就需要被去除,只留下数据部分。
这个过程叫做解封装,其目的是为了让数据包继续被后续的处理模块接收和处理。
接下来,数据包的目的地需要被确定。
网络设备会根据数据包中的目的地址来判断该数据包的最终目的地。
这个过程常常被称为路由选择,其中包括了路由表的查询以及路由算法的计算等。
路由表是一个网络设备保存的一个地址映射表,其中包含了每一个目的地址对应的下一跳地址。
路由算法则是根据网络的拓扑结构和其他的相关信息来计算出合适的下一跳地址。
最后,在数据包的处理过程中,还需要对错误进行处理。
在网络传输过程中,由于各种原因,数据包可能发生错误,比如丢包、损坏等。
网络设备会根据数据包中的错误检验码来判断数据包是否出错,并根据需要进行相应的纠正、丢弃或重传等操作。
二、数据包的转发数据包的转发是指计算机网络中将接收到的数据包发送到下一跳设备的过程。
在数据包的转发中,网络设备需要根据数据包中的目的地址来确定下一跳设备,并将数据包发送到该设备。
这个过程需要经过数据包的封装、寻址以及转发表的查询等步骤。
在数据包的转发过程中,首先需要进行数据包的封装。
dpdk三层转发详解

dpdk三层转发详解(原创版)目录1.DPDK 概述2.三层转发的原理3.DPDK 的三层转发实现4.DPDK 三层转发的优化正文【DPDK 概述】DPDK(Data Plane Development Kit)是一个开源的软件开发工具包,主要用于加速数据平面的处理。
它提供了一组丰富的库和驱动程序,以方便开发者快速实现高速网络接口卡(NIC)和虚拟交换机(vSwitch)等数据平面设备。
DPDK 广泛应用于云计算、虚拟化和软件定义网络(SDN)等领域。
【三层转发的原理】三层转发,也称为网络层转发,主要负责处理 IP 协议的数据包。
在网络通信中,数据包需要通过三层转发实现在不同网络之间的传输。
三层转发的原理主要包括以下几个步骤:1.接口接收数据包:网络接口卡(NIC)接收到来自物理层的数据包,并将其发送给 DPDK 内核。
2.数据包解析:DPDK 内核解析数据包的头部信息,提取目的 MAC 地址和目的 IP 地址。
3.路由查找:DPDK 内核根据目的 IP 地址进行路由查找,以确定数据包的下一跳(下一跳 IP 地址)。
4.数据包转发:DPDK 内核将数据包转发到下一跳,可以是同一网络接口卡,也可以是其他网络接口卡或远程网络设备。
【DPDK 的三层转发实现】DPDK 的三层转发实现主要依赖于其内部的数据结构和算法。
具体来说,DPDK 的三层转发实现包括以下几个方面:1.虚拟交换机:DPDK 提供了虚拟交换机(vSwitch)功能,可以实现多虚拟机之间的网络互通。
虚拟交换机内部使用虚拟端口(vPort)和虚拟链路(vLink)表示虚拟机之间的连接关系。
2.端口和链路:DPDK 将物理网卡抽象为逻辑端口(port),将物理链路抽象为逻辑链路(link)。
逻辑端口和逻辑链路可以方便地进行配置、绑定和解绑等操作。
3.报文处理:DPDK 提供了报文处理引擎(Packet Processing Engine, PPE),用于处理网络接口卡接收到的数据包。
内核协议栈原理

内核协议栈原理嘿,朋友们!今天咱来聊聊内核协议栈原理这个听起来有点高大上的玩意儿。
你看啊,这内核协议栈就像是一个超级复杂但又超级厉害的交通指挥中心。
网络里的数据就像是来来往往的车辆,它们都得听这个指挥中心的调度呢!比如说,当你在网上看视频的时候,那些视频数据就像是一辆辆急着要去你电脑这个“目的地”的车。
它们从遥远的服务器出发,一路上要经过好多关卡和道路。
这内核协议栈呢,就得把这些数据安排得妥妥当当,让它们能快速、准确地到达你的电脑,然后你才能愉快地看视频呀。
就好像你要去一个陌生的地方,没有好的导航可不行。
内核协议栈就是那个超厉害的导航,它知道怎么让数据走最快、最安全的路。
这里面有好多层呢,就像大楼有好多层一样。
每一层都有自己的职责和任务。
比如说,有的层负责把数据打包得整整齐齐,就像把行李打包好一样;有的层负责找路,确保数据能准确无误地到达目的地。
咱再打个比方,这内核协议栈就像是一个大管家,把网络里的各种事情都管理得井井有条。
它要操心数据怎么进来,怎么出去,怎么保证安全,怎么提高效率。
这可不是一般人能做到的呀!你想想,如果没有这个厉害的大管家,那网络不就乱套了嘛!数据可能会迷路,可能会被坏人偷走,那我们还怎么愉快地上网呀!而且啊,这个内核协议栈还得不断学习和进步呢。
就像我们人一样,要不断学习新的知识和技能,才能应对越来越复杂的情况。
它得适应新的网络技术,新的应用需求,这样才能一直保持厉害的状态。
你说,这内核协议栈是不是超级重要?它就像是网络世界的幕后英雄,默默地为我们服务,让我们能享受快速、便捷的网络生活。
所以啊,我们可得好好感谢这个默默付出的内核协议栈呀!下次当你顺畅地在网上冲浪的时候,别忘了在心里给它点个赞哦!这就是内核协议栈原理啦,虽然复杂,但真的很有意思呢!。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
内核协议栈数据包转发目录1 NAPI流程与非NAPI1.1NAPI驱动流程1.2非NAPI流程1.3NAPI和非NAPI的区别2内核接受数据2.1数据接收过程2.2 采取DMA技术实现3 e100采用NAPI接收数据过程3.1 e100_open 启动e100网卡3.2 e100_rx_alloc_list 建立环形缓冲区3.3 e100_rx_alloc_skb 分配skb缓存3.4 e100_poll 轮询函数3.5 e100_rx_clean 数据包的接收和传输3.6 e100_rx_indicate4 队列层4.1、软中断与下半部4.2、队列层5采用非NAPI接收数据过程5.1netif_rx5.2轮询与中断调用netif_rx_schedule不同点5.3 netif_rx_schedule5.4 net_rx_action5.5 process_backlog6数据包进入网络层6.1 netif_receive_skb():6.2 ip_rcv():6.3 ip_rcv_finish():6.4 dst_input():6.5本地流程ip_local_deliver:6.6转发流程ip_forward():1 NAPI流程与非NAPI1.1NAPI驱动流程:中断发生-->确定中断原因是数据接收完毕(中断原因也可能是发送完毕,DMA完毕,甚至是中断通道上的其他设备中断)-->通过netif_rx_schedule将驱动自己的napi结构加入softnet_data的poll_list 链表,禁用网卡中断,并发出软中断NET_RX_SOFTIRQ-->中断返回时触发软中断调用相应的函数net_rx_action,从softnet_data的poll_list上取下刚挂入的napi结构,并且调用其 poll函数,这个poll函数也是驱动自己提供的,比如e100网卡驱动中的e100_poll等。
-->在poll函数中进行轮询,直到接受完所有的数据或者预算(budget)耗尽。
每接收一个报文要分配skb,用eth_type_trans处理并交给netif_receive_skb。
-->如果数据全部接收完(预算没有用完),则重新使能中断并将napi从链表中取下。
如果数据没接收完,则什么也不作,等待下一次poll函数被调度。
1.2非NAPI流程:中断发生-->确定中断发生的原因是接收完毕。
分配skb,读入数据,用eth_type_trans处理并且将skb交给netif_rx-->在netif_rx中,将packet加入到softnet_data的input_pkt_queue末尾(NAPI 驱动不使用这个 input_pkt_queue),再通过napi_schedule将softnet_data中的backlog(这也是个napi结构)加入 softnet_data的poll_list,最后发出软中断 -->软中断net_rx_action从poll_list上取下softnet_data的backlog,调用其poll 函数,这个poll函数是内核提供的process_backlog-->函数process_backlog从softnet_data的input_pkt_queue末尾取下skb,并且直接交给netif_receive_skb处理。
-->如果input_pkt_queue中所有skb都处理完则将backlog从队列中除去(注意input_pkt_queue中可能有多个网卡加入的报文,因为它是每cpu公用的)并退出循环;如果预算用完后也跳出循环。
最后返回接受到的包数1.3 NAPI和非NAPI的区别NAPI和非NAPI的区别1.NAPI使用中断+轮询的方式,中断产生之后暂时关闭中断然后轮询接收完所有的数据包,接着再开中断。
而非NAPI采用纯粹中断的方式,一个中断接收一个数据包2.NAPI都有自己的struct napi结构,非NAPI没有3.NAPI有自己的poll函数,而且接收数据都是在软中断调用poll函数时做的,而非NAPI使用公共的process_backlog函数作为其poll函数,接收数据是在硬件中断中做的4.NAPI在poll函数中接收完数据之后直接把skb发给netif_receive_skb,而非NAPI 在硬件中断中接收了数据通过 netif_rx把skb挂到公共的input_pkt_queue上,最后由软中断调用的process_backlog函数来将其发送给 netif_receive_skb驱动以及软中断这块对skb仅仅做了以下简单处理:1.调用skb_reserve预留出2个字节的空间,这是为了让ip首部对齐,因为以太网首部是14字节2.调用skb_put将tail指向数据末尾3.调用eth_type_trans进行如下处理:(1)将skb->dev指向接收设备(2)将skb->mac_header指向data(此时data就是指向mac起始地址)(3)调用skb_pull(skb, ETH_HLEN)将skb->data后移14字节指向ip首部(4)通过比较目的mac地址判断包的类型,并将skb->pkt_type赋值PACKET_BROADCAST或PACKET_MULTICAST或者PACKET_OTHERHOST,因为PACKET_HOST为0,所以是默认值(5)最后判断协议类型,并返回(大部分情况下直接返回eth首部的protocol 字段的值),这个返回值被存在skb->protocol字段中总结,结束后,skb->data指向ip首部,skb->mac_header指向 mac首部,skb->protocol 储存L3的协议代码,skb->pkt_type已被设置,skb->len等于接收到的报文长度减去eth 首部长度,也就是整个ip报文的总长。
其余字段基本上还是默认值。
2 内核接受数据2.1数据接收过程内核从网卡接受数据,传统的经典过程:1、数据到达网卡;2、网卡产生一个中断给内核;3、内核使用I/O指令,从网卡I/O区域中去读取数据;就是大流量的数据来到,网卡会产生大量的中断,内核在中断上下文中,会浪费大量的资源来处理中断本身。
这就是no NAPI方式。
no NAPI:mac每收到一个以太网包,都会产生一个接收中断给cpu,即完全靠中断方式来收包,收包缺点是当网络流量很大时,cpu大部分时间都耗在了处理mac的中断。
NAPI:采用中断+ 轮询的方式:mac收到一个包来后会产生接收中断,但是马上关闭。
直到收够了netdev_max_backlog个包(默认300),或者收完mac上所有包后,才再打开接收中断。
通过sysctl来修改dev_max_backlog或者通过proc修改/proc/sys/net/core/netdev_max_backlog2.2 DMA技术实现从网卡的I/O区域,包括I/O寄存器或I/O内存中去读取数据,这都要CPU去读,也要占用CPU资源,“CPU从I/O区域读,然后把它放到内存(这个内存指的是系统本身的物理内存,跟外设的内存不相干,也叫主内存)中”。
Linux使用DMA技术——让网卡直接从主内存之间读写它们的I/O数据,就不关CPU的事。
1、首先,内核在主内存中为收发数据建立一个环形的缓冲队列(通常叫DMA环形缓冲区)。
2、内核将这个缓冲区通过DMA映射,把这个队列交给网卡;3、网卡收到数据,就直接放进这个环形缓冲区了——也就是直接放进主内存了;然后,向系统产生一个中断;4、内核收到这个中断,就取消DMA映射,这样,内核就直接从主内存中读取数据;这一个过程比传统的过程少了不少工作,因为设备直接把数据放进了主内存,不需要CPU的干预,效率提高了.对应以上4步,来看它的具体实现:1、分配环形DMA缓冲区Linux内核中,用skb来描述一个缓存,所谓分配,就是建立一定数量的skb,然后把它们组织成一个双向链表;2、建立DMA映射内核通过调用dma_map_single(struct device *dev,void *buffer,size_t size,enum dma_data_direction direction)建立映射关系。
struct device *dev,描述一个设备;buffer:把哪个地址映射给设备;也就是某一个skb——要映射全部,当然是做一个双向链表的循环即可;size:缓存大小;direction:映射方向——谁传给谁:一般来说,是“双向”映射,数据在设备和内存之间双向流动;对于PCI设备而言(网卡一般是PCI的),通过另一个包裹函数pci_map_single,这样,就把buffer交给设备了!设备可以直接从里边读/取数据。
3、这一步由硬件完成;4、取消映射dma_unmap_single,对PCI而言,大多调用它的包裹函数pci_unmap_single,不取消的话,缓存控制权还在设备手里,要调用它,把主动权掌握在CPU手里——因为我们已经接收到数据了,应该由CPU把数据交给上层网络栈;当然,不取消之前,通常要读一些状态位信息,诸如此类,一般是调用dma_sync_single_for_cpu()让CPU在取消映射前,就可以访问DMA缓冲区中的内容。
每个网卡(MAC)都有自己的专用DMA Engine,如上图的TSEC 和e1000 网卡intel82546。
上图中的红色线就是以太网数据流,DMA与DDR打交道需要其他模块的协助,如TSEC,PCI controller。
以太网数据在TSEC<-->DDR PCI_Controller<-->DDR 之间的流动,CPU的core是不需要介入的,只有在数据流动结束时(接收完、发送完),DMA Engine才会以外部中断的方式告诉CPU的core3 e100接收数据过程3.1 e100_open 启动e100网卡e100_open(struct net_device *dev),调用e100_up,就是环形缓冲区的建立,这一步,是通过e100_rx_alloc_list函数调用完成的。
3.2e100_rx_alloc_list 建立环形缓冲区static int e100_rx_alloc_list(struct nic *nic){struct rx *rx;unsigned int i, count = nic->params.rfds.count;nic->rx_to_use = nic->rx_to_clean = NULL;nic->ru_running = RU_UNINITIALIZED;/*结构struct rx用来描述一个缓冲区节点,这里分配了count个*/if(!(nic->rxs = kmalloc(sizeof(struct rx) * count, GFP_ATOMIC)))return -ENOMEM;memset(nic->rxs, 0, sizeof(struct rx) * count);/*虽然是连续分配的,不过还是遍历它,建立双向链表,然后为每一个rx的skb指针分员分配空间skb用来描述内核中的一个数据包,呵呵,说到重点了*/for(rx = nic->rxs, i = 0; i < count; rx++, i++) {rx->next = (i + 1 < count) ? rx + 1 : nic->rxs;rx->prev = (i == 0) ? nic->rxs + count - 1 : rx - 1;if(e100_rx_alloc_skb(nic, rx)) { /*分配缓存*/e100_rx_clean_list(nic);return -ENOMEM;}}nic->rx_to_use = nic->rx_to_clean = nic->rxs;nic->ru_running = RU_SUSPENDED;return 0;}3.3e100_rx_alloc_skb 分配skb缓存static inline int e100_rx_alloc_skb(struct nic *nic, struct rx *rx){/*skb缓存的分配,是通过调用系统函数dev_alloc_skb来完成的,它同内核栈中通常调用alloc_skb的区别在于,它是原子的,所以,通常在中断上下文中使用*/if(!(rx->skb = dev_alloc_skb(RFD_BUF_LEN + NET_IP_ALIGN)))return -ENOMEM;/*初始化必要的成员*/rx->skb->dev = nic->netdev;skb_reserve(rx->skb, NET_IP_ALIGN);/*这里在数据区之前,留了一块sizeof(struct rfd) 这么大的空间,该结构的一个重要作用,用来保存一些状态信息,比如,在接收数据之前,可以先通过它,来判断是否真有数据到达等,诸如此类*/memcpy(rx->skb->data, &nic->blank_rfd, sizeof(struct rfd));/*这是最关键的一步,建立DMA映射,把每一个缓冲区rx->skb->data都映射给了设备,缓存区节点rx利用dma_addr保存了每一次映射的地址,这个地址后面会被用到*/rx->dma_addr = pci_map_single(nic->pdev, rx->skb->data,RFD_BUF_LEN, PCI_DMA_BIDIRECTIONAL);if(pci_dma_mapping_error(rx->dma_addr)) {dev_kfree_skb_any(rx->skb);rx->skb = 0;rx->dma_addr = 0;return -ENOMEM;}/* Link the RFD to end of RFA by linking previous RFD to* this one, and clearing EL bit of previous. */if(rx->prev->skb) {struct rfd *prev_rfd = (struct rfd *)rx->prev->skb->data;/*put_unaligned(val,ptr);用到把var放到ptr指针的地方,它能处理处理内存对齐的问题prev_rfd是在缓冲区开始处保存的一点空间,它的link成员,也保存了映射后的地址*/ put_unaligned(cpu_to_le32(rx->dma_addr),(u32 *)&prev_rfd->link);wmb();prev_rfd->command &= ~cpu_to_le16(cb_el);pci_dma_sync_single_for_device(nic->pdev, rx->prev->dma_addr,sizeof(struct rfd), PCI_DMA_TODEVICE);}return 0;}e100_rx_alloc_list函数在一个循环中,建立了环形缓冲区,并调用e100_rx_alloc_skb为每个缓冲区分配了空间,并做了DMA映射。