数据库系统概念习题课
数据库系统概念第六版课后习题部分答案2s

C H A P T E R2Introduction to the Relational ModelPractice Exercises2.1Consider the relational database of Figure??.What are the appropriateprimary keys?Answer:The answer is shown in Figure2.1,with primary keys under-lined.2.2Consider the foreign key constraint from the dept name attribute of in-structor to the department relation.Give examples of inserts and deletes tothese relations,which can cause a violation of the foreign key constraint.Answer:•Inserting a tuple:(10111,Ostrom,Economics,110,000)into the instructor table,where the department table does not have thedepartment Economics,would violate the foreign key constraint.•Deleting the tuple:(Biology,Watson,90000)from the department table,where at least one student or instructortuple has dept name as Biology,would violate the foreign key con-straint.employee(person name,street,city)works(person name company name,salary)company(company name,city)Figure2.1Relational database for Practice Exercise2.1.12Chapter2Introduction to the Relational Model2.3Consider the time slot relation.Given that a particular time slot can meetmore than once in a week,explain why day and start time are part of theprimary key of this relation,while end time is not.Answer:The attributes day and start time are part of the primary keysince a particular class will most likely meet on several different days,and may even meet more than once in a day.However,end time is notpart of the primary key since a particular class that starts at a particulartime on a particular day cannot end at more than one time.2.4In the instance of instructor shown in Figure??,no two instructors havethe same name.From this,can we conclude that name can be used as asuperkey(or primary key)of instructor?Answer:No.For this possible instance of the instructor table the namesare unique,but in general this may not be always the case(unless theuniversity has a rule that two instructors cannot have the same name,which is a rather unlikey scenario).2.5What is the result offirst performing the cross product of student andadvisor,and then performing a selection operation on the result with thepredicate s id=ID?(Using the symbolic notation of relational algebra,this query can be written ass id=I D(student×advisor).)Answer:The result attributes include all attribute values of studentfollowed by all attributes of advisor.The tuples in the result are asfollows.For each student who has an advisor,the result has a rowcontaining that students attributes,followed by an s id attribute identicalto the students ID attribute,followed by the i id attribute containing theID of the students advisor.Students who do not have an advisor will not appear in the result.Astudent who has more than one advisor will appear a correspondingnumber of times in the result.2.6Consider the following expressions,which use the result of a relationalalgebra operation as the input to another operation.For each expression,explain in words what the expression does.a.year≥2009(takes)1studentb.year≥2009(takes1student)c. ID,name,course id(student1takes)Answer:a.For each student who takes at least one course in2009,displaythe students information along with the information about whatcourses the student took.The attributes in the result are:ID,name,dept name,tot cred,course id,section id,semester,year,gradeb.Same as(a);selection can be done before the join operation.c.Provide a list of consisting ofExercises3ID,name,course idof all students who took any course in the university.2.7Consider the relational database of Figure??.Give an expression in therelational algebra to express each of the following queries:a.Find the names of all employees who live in city“Miami”.b.Find the names of all employees whose salary is greater than$100,000.c.Find the names of all employees who live in“Miami”and whosesalary is greater than$100,000.Answer:a. name(city=“Miami”(employee))b. name(salary>100000(employee))c. name(city=“Miami”∧salary>100000(employee))2.8Consider the bank database of Figure??.Give an expression in therelational algebra for each of the following queries.a.Find the names of all branches located in“Chicago”.b.Find the names of all borrowers who have a loan in branch“Down-town”.Answer:a. branch name(branch city=“Chicago”(branch))b. customer name(branch name=“Downtown”(borro w er1loan))。
数据库系统概论及习题及答案

数据库系统概论复习资料:第一章:一选择题:1.在数据管理技术的发展过程中,经历了人工管理阶段、文件系统阶段和数据库系统阶段。
在这几个阶段中,数据独立性最高的是阶段。
A.数据库系统 B.文件系统 C.人工管理 D.数据项管理答案:A2.数据库的概念模型独立于。
A.具体的机器和DBMS B.E-R图 C.信息世界 D.现实世界答案:A3.数据库的基本特点是。
A.(1)数据可以共享(或数据结构化) (2)数据独立性 (3)数据冗余大,易移植 (4)统一管理和控制B.(1)数据可以共享(或数据结构化) (2)数据独立性 (3)数据冗余小,易扩充 (4)统一管理和控制C.(1)数据可以共享(或数据结构化) (2)数据互换性 (3)数据冗余小,易扩充 (4)统一管理和控制D.(1)数据非结构化 (2)数据独立性 (3)数据冗余小,易扩充 (4)统一管理和控制答案:B4. 是存储在计算机内有结构的数据的集合。
A.数据库系统 B.数据库 C.数据库管理系统 D.数据结构答案:B5.数据库中存储的是。
A.数据 B.数据模型 C.数据以及数据之间的联系 D.信息答案:C6. 数据库中,数据的物理独立性是指。
A.数据库与数据库管理系统的相互独立 B.用户程序与DBMS的相互独立C.用户的应用程序与存储在磁盘上数据库中的数据是相互独立的 D.应用程序与数据库中数据的逻辑结构相互独立答案:C7. .数据库的特点之一是数据的共享,严格地讲,这里的数据共享是指。
A.同一个应用中的多个程序共享一个数据集合 B.多个用户、同一种语言共享数据C.多个用户共享一个数据文件D.多种应用、多种语言、多个用户相互覆盖地使用数据集合答案:D8.据库系统的核心是。
A.数据库B.数据库管理系统C.数据模型D.软件工具答案:B9. 下述关于数据库系统的正确叙述是。
A.数据库系统减少了数据冗余 B.数据库系统避免了一切冗余 C.数据库系统中数据的一致性是指数据类型一致D.数据库系统比文件系统能管理更多的数据答案:A10. 数将数据库的结构划分成多个层次,是为了提高数据库的①和②。
数据库系统原理第二章基本概念及课后习题有答案

数据库系统原理第二章基本概念及课后习题有答案一、数据库系统生存期1.数据库系统生存期:数据库应用系统从开始规划、设计、实现、维护到最后被新的系统取代而停止使用的整个期间。
2.数据库系统生存期分七个阶段:规划、需求分析、概念设计、逻辑设计、物理设计、实现、运行维护。
3.规划阶段三个步骤:系统调查、可行性分析、确定数据库系统总目标。
4.需求分析阶段:主要任务是系统分析员和用户双方共同收集数据库系统所需要的信息内容和用户对处理的需求,并以需求说明书的形式确定下来。
5.概念设计阶段:产生反映用户单位信息需求的概念模型。
与硬件和DBMS无关。
6.逻辑设计阶段:将概念模型转换成DBMS能处理的逻辑模型。
外模型也将在此阶段完成。
7.物理设计阶段:对于给定的基本数据模型选取一个最适合应用环境的物理结构的过程。
数据库的物理结构主要指数据库的存储记录格式、存储记录安排和存取方法。
8.数据库的实现:包括定义数据库结构、数据装载、编制与调试应用程序、数据库试运行。
二、ER模型的基本概念ER模型的基本元素是:实体、联系和属性。
2.实体:是一个数据对象,指应用中可以区别的客观存在的事物。
实体集:是指同一类实体构成的集合。
实体类型:是对实体集中实体的定义。
一般将实体、实体集、实体类型统称为实体。
3.联系:表示一个或多个实体之间的关联关系。
联系集:是指同一类联系构成的集合。
联系类型:是对联系集中联系的定义。
一般将联系、联系集、联系类型统称为联系。
4.同一个实体集内部实体之间的联系,称为一元联系;两个不同实体集实体之间的联系,称为二元联系,以此类推。
5.属性:实体的某一特性称为属性。
在一个实体中,能够惟一标识实体的属性或属性集称为实体标识符。
6. ER模型中,方框表示实体、菱形框表示联系、椭圆形框表示属性、实体与联系、实体与其属性、联系与其属性之间用直线连接。
实体标识符下画横线。
联系的类型要在直线上标注。
注意:联系也有可能存在属性,但联系本身没有标识符。
第1章数据库系统概论习题及解答

第 1 章数据库系统概论1.1复习纲要本章介绍的主要内容:·数据管理技术的发展·数据模型·数据库系统结构1.1.1 数据管理技术的发展从20世纪50年代中期开始,数据管理技术大致经历了三个发展阶段:人工管理阶段、文件系统管理阶段和数据库系统管理阶段。
1. 人工管理阶段20世纪50年代中期以前,计算机主要从事计算工作,计算机处理的数据由程序员考虑与安排。
这一阶段的主要特点是:数据不长期保存;数据与程序不具有独立性;系统中没有对数据进行管理的软件。
2. 文件系统管理阶段20世纪50年代后期到60年代中后期,计算机系统中由文件系统管理数据。
其主要特点:数据以文件的形式可长期存储在磁盘上,供相应的程序多次存取;数据文件可脱离程序而独立存在,使得数据与程序之间具有设备独立性。
如果数据文件结构发生变化时,则对应的操作程序必须修改。
即文件系统管理文件缺乏数据独立性,并且数据冗余度大。
数据之间联系弱,无法实施数据统一管理标准。
这些都是文件系统管理的主要缺陷。
3.数据库系统管理阶段70年代初开始,计算机采用数据库管理系统管理大量数据,使计算机广泛应用于数据处理。
数据库系统管理数据的主要特点:·采用数据模型组织和管理数据,不仅有效地描述了数据本身的特性,而且描述了之间的联系。
·具有较高的数据独立性。
即数据格式、大小等发生了改变,使得应用程序不受影响。
·数据共享程度更高,冗余度比较小。
·由DBMS软件提供了对数据统一控制功能,如安全性控制、完整性控制、并发控制和恢复功能。
·由DBMS软件提供了用户方便使用的接口。
数据库系统管理数据是目前计算机管理数据的高级阶段,数据库技术已成为计算机领域中最重要的技术之一。
1.1.2 数据模型数据模型是构建数据库结构的基础,在构建时要经历从概念模型设计到DB逻辑模型和物理模型转换过程。
因此,数据模型可分为两类共4种,两类为概念模型和结构模型,其中结构模型又分为外部模型、逻辑模型和内部模型三种。
数据库系统概论练习题库及参考答案

数据库系统概论练习题库及参考答案一、单选题(共80题,每题1分,共80分)1、下列不属于数据库系统特点的是( )A、数据独立性高B、数据冗余度高C、数据完整性D、数据共享正确答案:C2、把表和索引分开放在不同的磁盘上以提高性能是哪个阶段考虑的事项()A、需求分析B、数据库实施C、数据库物理设计D、数据库运行与维护正确答案:C3、下列关于数据模型中实体间联系的描述正确的是()。
A、单个实体不能构成E-R图B、仅在两个实体之间有联系C、实体间的联系不能有属性D、实体间可以存在多种联系正确答案:D4、同一个关系的任两个元组值( )。
A、其他三个答案均不正确B、必须完全相同C、不能完全相同D、可以完全相同正确答案:C5、下列模型中,广泛采用E-R模型设计方法的是()。
A、逻辑模型B、概念模型C、物理模型D、外模型正确答案:B6、在SQL的查询语句中,对应关系代数中“投影”运算的语句是()。
A、WHEREB、SELECTC、FROMD、SET正确答案:B7、下列关系代数操作中,哪些运算要求两个运算对象其属性结构完全相同()。
A、自然连接、除法B、并、交、差C、投影、选择D、笛卡尔积、连接正确答案:B8、设有三个域D1={A,B}、D2={C,D,E}、D3={F,G},则其笛卡尔积D1×D2×D3的基数为( )。
A、3B、7C、5D、12正确答案:D9、当前数据库应用系统的主流数据模型是()。
A、面向对象数据模型B、网状数据模型C、关系数据模型D、层次数据模型正确答案:C10、关于“死锁”,下列说法中正确的是()。
A、当两个用户竞争相同资源时不会发生死锁B、只有出现并发操作时,才有可能出现死锁C、在数据库操作中防止死锁的方法是禁止两个用户同时操作数据库D、死锁是操作系统中的问题,数据库操作中不存在正确答案:B11、在关系模式R中,函数依赖X→Y的语义是()。
A、在R的每一关系中,若两个元组的X值相等,则Y值也相等B、在R的某一关系中,Y值应与X值相等C、在R的某一关系中,若两个元组的X值相等,则Y值也相等D、在R的每一关系中,Y值应与X值相等正确答案:A12、从E-R图导出关系模式时,如果两实体间的联系是m:n;下列说法中正确的是()A、将n方码和联系的属性纳入m方的属性中B、增加一个关系表示联系,其中纳入m方和n方的码C、在m方属性和n方属性中均增加一个表示级别的属性D、将m方码和联系的属性纳入n方的属性中正确答案:B13、对于关系模式S-L(Sno,Sdept,Sloc),S-L中有下列函数依赖:Sno→Sdept,Sdept→Sloc ,SnoSloc,将S-L分解为下面三个关系模式:SN(Sno),SD(Sdept),SO(Sloc),这种分解是()。
数据库系统教程课后习题答案(部分)--何玉洁 李宝安

第一部分基础理论第1章数据库概述1.试说明数据、数据库、数据库管理系统和数据库系统的概念。
数据:描述事务的符号记录数据库:存储数据的仓库数据库管理系统:用于管理和维护数据的系统软件数据库系统:计算机中引入数据库后的系统,包括数据库,数据库管理系统,应用程序,数据库管理员2.数据管理技术的发展主要经历了哪几个阶段?两个阶段,文件管理和数据库管理9.数据独立性指的是什么?应用程序不因数据的物理表示方式和访问技术改变而改变,分为逻辑独立性和物理独立性。
物理独立性是指当数据的存储结构或存储位置发生变化时,不影响应用程序的特性;逻辑独立性是指当表达现实世界的信息内容发生变化时,不影响应用程序的特性。
10.数据库系统由哪几部分组成?由数据库、数据库管理系统、应用程序、数据库管理员组成。
第2章数据模型与数据库系统的结构4.说明实体一联系模型中的实体、属性和联系的概念。
实体是具有公共性质的并可相互区分的现实世界对象的集合。
属性是实体所具有的特征或性质。
联系是实体之间的关联关系。
6.数据库系统包含哪三级模式?试分别说明每一级模式的作用。
外模式、模式和内模式。
外模式:是对现实系统中用户感兴趣的整体数据结构的局部描述,用于满足不同用户对数据的需求,保证数据安全。
模式:是数据库中全体数据的逻辑结构和特征的描述,它满足所有用户对数据的需求。
内模式:是对整个数据库的底层表示,它描述了数据的存储结构。
7.数据库管理系统提供的两级映像的作用是什么?它带来了哪些功能?两级映像是外模式/模式映像和模式/内模式映像。
外模式/模式映像保证了当模式发生变化时可以保证外模式不变,从而使用户的应用程序不需要修改,保证了程序与数据的逻辑独立性。
模式/内模式映像保证了当内模式发生变化,比如存储位置或存储文件名改变,可以保持模式不变,保证了程序与数据的物理独立性。
两级印象保证了应用程序的稳定性。
第3章关系数据库1.试述关系模型的三个组成部分。
数据结构、关系操作集合、关系完整性约束2.解释下列术语的含义:(3)候选码当一个属性或属性集的值能够唯一标识一个关系的元组,而又不包含多余的元素,则称该属性或属性集为候选码。
《数据库系统概论》课后习题及参考答案

课后作业习题《数据库系统概论》课程部分习题及参考答案第一章绪论(教材41页)1.试述数据、数据库、数据库系统、数据库管理系统得概念。
数据:描述事物得符号记录称为数据。
数据得种类有文字、图形、图象、声音、正文等等。
数据与其语义就是不可分得。
数据库:数据库就是长期储存在计算机内、有组织得、可共享得数据集合。
数据库中得数据按一定得数据模型组织、描述与储存,具有较小得冗余度、较高得数据独立性与易扩展性,并可为各种用户共享。
数据库系统:数据库系统( DBS)就是指在计算机系统中引入数据库后得系统构成.数据库系统由数据库、数据库管理系统(及其开发工具)、应用系统、数据库管理员构成。
数据库管理系统:数据库管理系统 (DBMS)就是位于用户与操作系统之间得一层数据管理软件.用于科学地组织与存储数据、高效地获取与维护数据.DBMS主要功能包括数据定义功能、数据操纵功能、数据库得运行管理功能、数据库得建立与维护功能.2.使用数据库系统有什么好处?使用数据库系统得好处就是由数据库管理系统得特点或优点决定得.使用数据库系统得好处很多,例如可以大大提高应用开发得效率,方便用户得使用,减轻数据库系统管理人员维护得负担等。
为什么有这些好处,可以结合第 5题来回答。
使用数据库系统可以大大提高应用开发得效率。
因为在数据库系统中应用程序不必考虑数据得定义、存储与数据存取得具体路径,这些工作都由DBMS来完成。
此外,当应用逻辑改变,数据得逻辑结构需要改变时,由于数据库系统提供了数据与程序之间得独立性。
数据逻辑结构得改变就是DBA得责任,开发人员不必修改应用程序,或者只需要修改很少得应用程序。
从而既简化了应用程序得编制,又大大减少了应用程序得维护与修改。
使用数据库系统可以减轻数据库系统管理人员维护系统得负担.因为 DBMS在数据库建立、运用与维护时对数据库进行统一得管理与控制,包括数据得完整性、安全性,多用户并发控制,故障恢复等等都由DBMS执行。
数据库系统概念(database system concepts)英文第六版 课后练习题 答案 第25章

C H A P T E R25Advanced Data Types and New ApplicationsPractice Exercises25.1What are the two types of time,and how are they different?Why doesit make sense to have both types of time associated with a tuple?Answer:A temporal database models the changing states of someaspects of the real world.The time intervals related to the data storedin a temporal database may be of two types-valid time and transactiontime.The valid time for a fact is the set of intervals during which the factis true in the real world.The transaction time for a data object is the set oftime intervals during which this object is part of the physical database.Only the transaction time is system dependent and is generated by thedatabase system.Suppose we consider our sample bank database to be bitemporal.Only the concept of valid time allows the system to answer queries suchas-“What was Smith’s balance two days ago?”.On the other hand,queries such as-“What did we record as Smith’s balance two daysago?”can be answered based on the transaction time.The differencebetween the two times is important.For example,suppose,three daysago the teller made a mistake in entering Smith’s balance and correctedthe error only yesterday.This error means that there is a differencebetween the results of the two queries(if both of them are executedtoday).25.2Suppose you have a relation containing the x,y coordinates and namesof restaurants.Suppose also that the only queries that will be askedare of the following form:The query specifies a point,and asks if thereis a restaurant exactly at that point.Which type of index would bepreferable,R-tree or B-tree?Why?Answer:The given query is not a range query,since it requires onlysearching for a point.This query can be efficiently answered by a B-treeindex on the pair of attributes(x,y).12Chapter25Advanced Data Types and New Applications25.3Suppose you have a spatial database that supports region queries(withcircular regions)but not nearest-neighbor queries.Describe an algo-rithm tofind the nearest neighbor by making use of multiple regionqueries.Answer:Suppose that we want to search for the nearest neighbor of apoint P in a database of points in the plane.The idea is to issue multipleregion queries centered at P.Each region query covers a larger area ofpoints than the previous query.The procedure stops when the result ofa region query is non-empty.The distance from P to each point withinthis region is calculated and the set of points at the smallest distance isreported.25.4Suppose you want to store line segments in an R-tree.If a line segment isnot parallel to the axes,the bounding box for it can be large,containinga large empty area.•Describe the effect on performance of having large bounding boxes on queries that ask for line segments intersecting a given region.•Briefly describe a technique to improve performance for such queries and give an example of its benefit.Hint:You can divide segmentsinto smaller pieces.Answer:Large bounding boxes tend to overlap even where the regionof overlap does not contain any information.The followingfigure:Rshows a region R within which we have to locate a segment.Notethat even though none of the four segments lies in R,due to the largebounding boxes,we have to check each of the four bounding boxes toconfirm this.A significant improvement is observed in the follwoingfigure:Practice Exercises3Rwhere each segment is split into multiple pieces,each with its own bounding box.In the second case,the box R is not part of the boxes indexed by the R-tree.In general,dividing a segment into smaller pieces causes the bounding boxes to be smaller and less wasteful of area. 25.5Give a recursive procedure to efficiently compute the spatial join of tworelations with R-tree indices.(Hint:Use bounding boxes to check if leaf entries under a pair of internal nodes may intersect.)Answer:Following is a recursive procedure for computing spatial join of two R-trees.SpJoin(node n1,node n2)beginif(the bounding boxes of n1and n2do not intersect)return;if(both n1and n2are leaves)output all pairs of entries(e1,e2)such thate1∈n1and e2∈n2,and e1and e2overlap;if(n1is not a leaf)NS1=set of children of n1;elseNS1={n1};if(n1is not a leaf)NS1=set of children of n1;elseNS1={n1};for each ns1in NS1and ns2in NS2;SpJoin(ns1,ns2);end25.6Describe how the ideas behind the RAID organization(Section10.3)canbe used in a broadcast-data environment,where there may occasionally be noise that prevents reception of part of the data being transmitted.4Chapter25Advanced Data Types and New ApplicationsAnswer:The concepts of RAID can be used to improve reliability ofthe broadcast of data over wireless systems.Each block of data that isto be broadcast is split into units of equal size.A checksum value iscalculated for each unit and appended to the unit.Now,parity data forthese units is calculated.A checksum for the parity data is appendedto it to form a parity unit.Both the data units and the parity unit arethen broadcast one after the other as a single transmission.On reception of the broadcast,the receiver uses the checksums to verify whether each unit is received without error.If one unit is foundto be in error,it can be reconstructed from the other units.The size of a unit must be chosen carefully.Small units not only requiremore checksums to be computed,but the chance that a burst of noisecorrupts more than one unit is also higher.The problem with usinglarge units is that the probability of noise affecting a unit increases;thus there is a tradeoff to be made.25.7Define a model of repeatedly broadcast data in which the broadcastmedium is modeled as a virtual disk.Describe how access time anddata-transfer rate for this virtual disk differ from the correspondingvalues for a typical hard disk.Answer:We can distinguish two models of broadcast data.In the caseof a pure broadcast medium,where the receiver cannot communicatewith the broadcaster,the broadcaster transmits data with periodic cy-cles of retransmission of the entire data,so that new receivers can catchup with all the broadcast information.Thus,the data is broadcast in acontinuous cycle.This period of the cycle can be considered akin to theworst case rotational latency in a disk drive.There is no concept of seektime here.The value for the cycle latency depends on the application,but is likely to be at least of the order of seconds,which is much higherthan the latency in a disk drive.In an alternative model,the receiver can send requests back to the broadcaster.In this model,we can also add an equivalent of disk accesslatency,between the receiver sending a request,and the broadcasterreceiving the request and responding to it.The latency is a function ofthe volume of requests and the bandwidth of the broadcast medium.Further,queries may get satisfied without even sending a request,sincethe broadcaster happened to send the data either in a cycle or basedon some other receivers request.Regardless,latency is likely to be atleast of the order of seconds,again much higher than the correspondingvalues for a hard disk.A typical hard disk can transfer data at the rate of1to5megabytes persecond.In contrast,the bandwidth of a broadcast channel is typicallyonly a few kilobytes per second.Total latency is likely to be of the orderof seconds to hundreds or even thousands of seconds,compared to afew milliseconds for a hard disk.25.8Consider a database of documents in which all documents are keptin a central database.Copies of some documents are kept on mobilePractice Exercises5 computers.Suppose that mobile computer A updates a copy of docu-ment1while it is disconnected,and,at the same time,mobile computer B updates a copy of document2while it is disconnected.Show how the version-vector scheme can ensure proper updating of the central database and mobile computers when a mobile computer reconnects. Answer:Let C be the computer onto which the central database is loaded.Each mobile computer(host)i stores,with its copy of each document d,a version-vector–that is a set of version numbers V d,i,j, with one entry for each other host j that stores a copy of the document d,which it could possibly update.Host A updates document1while it is disconnected from C.Thus, according to the version vector scheme,the version number V1,A,A is incremented by one.Now,suppose host A re-connects to C.This pair exchanges version-vectors andfinds that the version number V1,A,A is greater than V1,C,A by1,(assuming that the copy of document1stored host A was updated most recently only by host A).Following the version-vector scheme, the version of document1at C is updated and the change is reflected by an increment in the version number V1,C,A.Note that these are the only changes made by either host.Similarly,when host B connects to host C,they exchange version-vectors,and host Bfinds that V1,B,A is one less than V1,C,A.Thus,the version number V1,B,A is incremented by one,and the copy of docu-ment1at host B is updated.Thus,we see that the version-vector scheme ensures proper updating of the central database for the case just considered.This argument can be very easily generalized for the case where multiple off-line updates are made to copies of document1at host A as well as host B and host C.The argument for off-line updates to document2is similar.。
数据库系统原理(2018年版)课后习题参考答案解析

第三代数据库系统必须保持或集成第二代数据库系统技术
第三代数据库系统必须对其他系统开放
2.描述数据仓库粒度的概念P182
粒度是指数据仓库数据单位中保存数据的细化或综合程度
3.描述数据挖掘技术的能P183
概念描述
关联分析
分类与预测
聚类
孤立点检测
趋势和演变分析
视图的内容是由存储在数据库中进行查询操作的SQL语句定义的,它的列数据与行数据均来自于定义视图的查询所引用的基本表。
视图不适宜数据集的形式存储在数据库中的,它所对应的数据实际上是存储在视图所引用的基本表中的。
视图是用来查看存储在别处的数据的一种虚拟表,本身不存储数据。
第五章 数据库编程
简答题
1.请简述存储过程的概念P125
答:参照完整性约束是指:若属性或属性组F是基本关系R的外码,与基本关系S的主码K相对应,则对于R中每个元组在F上的取值只允许有两种可能,要么是空值,要么与S中某个元组的主码值对应。
3.请简述关系规范化过程。
答:对于存在数据冗余、插入异常、删除异常问题的关系模式,应采取将一个关系模式分解为多个关系模式的方法进行处理。一个低一级范式的关系模式,通过模式分解可以转换为若干个高一级范式的关系模式,这就是所谓的规范化过程。
数据库系统是指在计算机中引入数据库技术之后的系统,包括数据库、数据库管理系统及相关实用工具、应用程序、数据库管理员和用户。
2.请简述早数据库管理技术中,与人工管理、文件系统相比,数据库系统的优点。
数据共享性高
数据冗余小
易于保证数据一致性
数据独立性高
可以实施统一管理与控制
减少了应用程序开发与维护的工作量
数据库系统概念(database system concepts)英文第六版 课后练习题 答案 第8章

C H A P T E R8Relational Database DesignExercises8.1Suppose that we decompose the schema R=(A,B,C,D,E)into(A,B,C)(A,D,E).Show that this decomposition is a lossless-join decomposition if thefollowing set F of functional dependencies holds:A→BCCD→EB→DE→AAnswer:A decomposition{R1,R2}is a lossless-join decomposition ifR1∩R2→R1or R1∩R2→R2.Let R1=(A,B,C),R2=(A,D,E),and R1∩R2=A.Since A is a candidate key(see PracticeExercise8.6),Therefore R1∩R2→R1.8.2List all functional dependencies satisfied by the relation of Figure8.17.Answer:The nontrivial functional dependencies are:A→B andC→B,and a dependency they logically imply:AC→B.There are19trivial functional dependencies of the form␣→,where⊆␣.Cdoes not functionally determine A because thefirst and third tuples havethe same C but different A values.The same tuples also show B does notfunctionally determine A.Likewise,A does not functionally determineC because thefirst two tuples have the same A value and different Cvalues.The same tuples also show B does not functionally determine C.8.3Explain how functional dependencies can be used to indicate the fol-lowing:910Chapter8Relational Database Design•A one-to-one relationship set exists between entity sets student andinstructor.•A many-to-one relationship set exists between entity sets studentand instructor.Answer:Let Pk(r)denote the primary key attribute of relation r.•The functional dependencies Pk(student)→Pk(instructor)andPk(instructor)→Pk(student)indicate a one-to-one relationshipbecause any two tuples with the same value for student must havethe same value for instructor,and any two tuples agreeing oninstructor must have the same value for student.•The functional dependency Pk(student)→Pk(instructor)indicates amany-to-one relationship since any student value which is repeatedwill have the same instructor value,but many student values mayhave the same instructor value.8.4Use Armstrong’s axioms to prove the soundness of the union rule.(Hint:Use the augmentation rule to show that,if␣→,then␣→␣.Apply theaugmentation rule again,using␣→␥,and then apply the transitivityrule.)Answer:To prove that:if␣→and␣→␥then␣→␥Following the hint,we derive:␣→given␣␣→␣augmentation rule␣→␣union of identical sets␣→␥given␣→␥augmentation rule␣→␥transitivity rule and set union commutativity8.5Use Armstrong’s axioms to prove the soundness of the pseudotransitiv-ity rule.Answer:Proof using Armstrong’s axioms of the Pseudotransitivity Rule:if␣→and␥→␦,then␣␥→␦.␣→given␣␥→␥augmentation rule and set union commutativity␥→␦given␣␥→␦transitivity rule8.6Compute the closure of the following set F of functional dependenciesfor relation schema R=(A,B,C,D,E).Exercises 11A →BCCD →EB →DE →AList the candidate keys for R .Answer:Note:It is not reasonable to expect students to enumerate all of F +.Some shorthand representation of the result should be acceptable as long as the nontrivial members of F +are found.Starting with A →BC ,we can conclude:A →B and A →C .Since A →B and B →D ,A →D (decomposition,transitive)Since A →C D and C D →E ,A →E (union,decom-position,transi-tive)Since A →A ,we have (reflexive)A →ABC DE from the above steps (union)Since E →A ,E →ABC DE (transitive)Since C D →E ,C D →ABC DE (transitive)Since B →D and BC →C D ,BC →ABC DE (augmentative,transitive)Also,C →C ,D →D ,B D →D ,etc.Therefore,any functional dependency with A ,E ,BC ,or C D on the left hand side of the arrow is in F +,no matter which other attributes appear in the FD.Allow *to represent any set of attributes in R ,then F +is B D →B ,B D →D ,C →C ,D →D ,B D →B D ,B →D ,B →B ,B →B D ,and all FDs of the form A ∗→␣,BC ∗→␣,C D ∗→␣,E ∗→␣where ␣is any subset of {A ,B ,C ,D ,E }.The candidate keys are A ,BC ,C D ,and E .8.7Using the functional dependencies of Practice Exercise 8.6,compute thecanonical cover F c .Answer:The given set of FDs F is:-A →BCCD →EB →DE →AThe left side of each FD in F is unique.Also none of the attributes in the left side or right side of any of the FDs is extraneous.Therefore the canonical cover F c is equal to F .12Chapter8Relational Database Design8.8Consider the algorithm in Figure8.18to compute␣+.Show that thisalgorithm is more efficient than the one presented in Figure8.8(Sec-tion8.4.2)and that it computes␣+correctly.Answer:The algorithm is correct because:•If A is added to result then there is a proof that␣→A.To see this,observe that␣→␣trivially so␣is correctly part of result.IfA∈␣is added to result there must be some FD→␥such thatA∈␥andis already a subset of result.(Otherwise f dcountwould be nonzero and the if condition would be false.)A full proofcan be given by induction on the depth of recursion for an executionof addin,but such a proof can be expected only from students witha good mathematical background.•If A∈␣+,then A is eventually added to result.We prove this byinduction on the length of the proof of␣→A using Armstrong’saxioms.First observe that if procedure addin is called with someargument,all the attributes inwill be added to result.Also if aparticular FD’s fdcount becomes0,all the attributes in its tail willdefinitely be added to result.The base case of the proof,A∈␣⇒A∈␣+,is obviously true because thefirst call to addinhas the argument␣.The inductive hypotheses is that if␣→A canbe proved in n steps or less then A∈result.If there is a proof inn+1steps that␣→A,then the last step was an application ofeither reflexivity,augmentation or transitivity on a fact␣→proved in n or fewer steps.If reflexivity or augmentation was usedin the(n+1)st step,A must have been in result by the end of the n thstep itself.Otherwise,by the inductive hypothesis⊆result.Therefore the dependency used in proving→␥,A∈␥willhave f dcount set to0by the end of the n th step.Hence A will beadded to result.To see that this algorithm is more efficient than the one presented inthe chapter note that we scan each FD once in the main program.Theresulting array a ppears has size proportional to the size of the givenFDs.The recursive calls to addin result in processing linear in the sizeof a ppears.Hence the algorithm has time complexity which is linear inthe size of the given FDs.On the other hand,the algorithm given in thetext has quadratic time complexity,as it may perform the loop as manytimes as the number of FDs,in each loop scanning all of them once.8.9Given the database schema R(a,b,c),and a relation r on the schema R,write an SQL query to test whether the functional dependency b→cholds on relation r.Also write an SQL assertion that enforces the func-tional dependency.Assume that no null values are present.(Althoughpart of the SQL standard,such assertions are not supported by anydatabase implementation currently.)Answer:Exercises13a.The query is given below.Its result is non-empty if and only ifb→c does not hold on r.select bfrom rgroup by bhaving count(distinct c)>1b.create assertion b to c check(not exists(select bfrom rgroup by bhaving count(distinct c)>1))8.10Our discussion of lossless-join decomposition implicitly assumed thatattributes on the left-hand side of a functional dependency cannot take on null values.What could go wrong on decomposition,if this property is violated?Answer:The natural join operator is defined in terms of the cartesian product and the selection operator.The selection operator,gives unknown for any query on a null value.Thus,the natural join excludes all tuples with null values on the common attributes from thefinal result.Thus, the decomposition would be lossy(in a manner different from the usual case of lossy decomposition),if null values occur in the left-hand side of the functional dependency used to decompose the relation.(Null values in attributes that occur only in the right-hand side of the functional dependency do not cause any problems.)8.11In the BCNF decomposition algorithm,suppose you use a functional de-pendency␣→to decompose a relation schema r(␣,,␥)into r1(␣,) and r2(␣,␥).a.What primary and foreign-key constraint do you expect to holdon the decomposed relations?b.Give an example of an inconsistency that can arise due to anerroneous update,if the foreign-key constraint were not enforcedon the decomposed relations above.c.When a relation is decomposed into3NF using the algorithm inSection8.5.2,what primary and foreign key dependencies wouldyou expect will hold on the decomposed schema?14Chapter8Relational Database DesignAnswer:a.␣should be a primary key for r1,and␣should be the foreign keyfrom r2,referencing r1.b.If the foreign key constraint is not enforced,then a deletion of atuple from r1would not have a corresponding deletion from thereferencing tuples in r2.Instead of deleting a tuple from r,thiswould amount to simply setting the value of␣to null in sometuples.c.For every schema r i(␣)added to the schema because of a rule␣→,␣should be made the primary key.Also,a candidate key␥for the original relation is located in some newly created relationr k,and is a primary key for that relation.Foreign key constraints are created as follows:for each relationr i created above,if the primary key attributes of r i also occur inany other relation r j,then a foreign key constraint is created fromthose attributes in r j,referencing(the primary key of)r i.8.12Let R1,R2,...,R n be a decomposition of schema U.Let u(U)be a rela-(u).Show thattion,and let r i= RIu⊆r11r21···1r nAnswer:Consider some tuple t in u.(u)implies that t[R i]∈r i,1≤i≤n.Thus,Note that r i= Rit[R1]1t[R2]1...1t[R n]∈r11r21...1r nBy the definition of natural join,t[R1]1t[R2]1...1t[R n]= ␣((t[R1]×t[R2]×...×t[R n]))where the conditionis satisfied if values of attributes with the samename in a tuple are equal and where␣=U.The cartesian productof single tuples generates one tuple.The selection process is satisfiedbecause all attributes with the same name must have the same valuesince they are projections from the same tuple.Finally,the projectionclause removes duplicate attribute names.By the definition of decomposition,U=R1∪R2∪...∪R n,which meansthat all attributes of t are in t[R1]1t[R2]1...1t[R n].That is,t is equalto the result of this join.Since t is any arbitrary tuple in u,u⊆r11r21...1r n8.13Show that the decomposition in Practice Exercise8.1is not a dependency-preserving decomposition.Answer:The dependency B→D is not preserved.F1,the restrictionof F to(A,B,C)is A→ABC,A→AB,A→AC,A→BC,Exercises 15A →B ,A →C ,A →A ,B →B ,C →C ,AB →AC ,AB →ABC ,AB →BC ,AB →AB ,AB →A ,AB →B ,AB →C ,AC (same as AB ),BC (same as AB ),ABC (same as AB ).F 2,the restriction of F to (C ,D ,E )is A →ADE ,A →AD ,A →AE ,A →DE ,A →A ,A →D ,A →E ,D →D ,E (same as A ),AD ,AE ,DE ,ADE (same as A ).(F 1∪F 2)+is easily seen not to contain B →D since the only FD in F 1∪F 2with B as the left side is B →B ,a trivial FD .We shall see in Practice Exercise 8.15that B →D is indeed in F +.Thus B →D is not preserved.Note that C D →ABC DE is also not preserved.A simpler argument is as follows:F 1contains no dependencies with D on the right side of the arrow.F 2contains no dependencies withB on the left side of the arrow.Therefore for B →D to be preserved theremustbe an FD B →␣in F +1and ␣→D in F +2(so B →D would follow by transitivity).Since the intersection of the two schemes is A ,␣=A .Observe that B →A is not in F +1since B +=B D .8.14Show that it is possible to ensure that a dependency-preserving decom-position into 3NF is a lossless-join decomposition by guaranteeing that at least one schema contains a candidate key for the schema being decom-posed.(Hint :Show that the join of all the projections onto the schemas of the decomposition cannot have more tuples than the original relation.)Answer:Let F be a set of functional dependencies that hold on a schema R .Let ={R 1,R 2,...,R n }be a dependency-preserving 3NF decompo-sition of R .Let X be a candidate key for R .Consider a legal instance r of R .Let j = X (r )1 R 1(r )1 R 2(r ) (1)R n (r ).We want to prove that r =j .We claim that if t 1and t 2are two tuples in j such that t 1[X ]=t2[X ],then t 1=t 2.To prove this claim,we use the following inductive argument –Let F ′=F 1∪F 2∪...∪F n ,where each F i is the restriction of F to the schema R i in .Consider the use of the algorithm given in Figure 8.8to compute the closure of X under F ′.We use induction on the number of times that the f or loop in this algorithm is executed.•Basis :In the first step of the algorithm,result is assigned to X ,and hence given that t 1[X ]=t 2[X ],we know that t 1[result ]=t 2[result ]is true.•Induction Step :Let t 1[result ]=t 2[result ]be true at the end of thek th execution of the f or loop.Suppose the functional dependency considered in the k +1th execution of the f or loop is →␥,and that ⊆result .⊆result implies that t 1[]=t 2[]is true.The facts that →␥holds for some attribute set Ri in ,and that t 1[R i ]and t 2[R i ]are inR i (r )imply that t 1[␥]=t 2[␥]is also true.Since ␥is now added to result by the algorithm,we know that t 1[result ]=t 2[result ]is true at theend of the k +1th execution of the f or loop.16Chapter8Relational Database DesignSinceis dependency-preserving and X is a key for R,all attributes in Rare in result when the algorithm terminates.Thus,t1[R]=t2[R]is true,that is,t1=t2–as claimed earlier.Our claim implies that the size of X(j)is equal to the size of j.Notealso that X(j)= X(r)=r(since X is a key for R).Thus we haveproved that the size of j equals that of ing the result of PracticeExercise8.12,we know that r⊆j.Hence we conclude that r=j.Note that since X is trivially in3NF,∪{X}is a dependency-preservinglossless-join decomposition into3NF.8.15Give an example of a relation schema R′and set F′of functional depen-dencies such that there are at least three distinct lossless-join decompo-sitions of R′into BCNF.Answer:Given the relation R′=(A,B,C,D)the set of functionaldependencies F′=A→B,C→D,B→C allows three distinctBCNF decompositions.R1={(A,B),(C,D),(B,C)}is in BCNF as isR2={(A,B),(C,D),(A,C)}R2={(A,B),(C,D),(A,C)}R3={(B,C),(A,D),(A,B)}8.16Let a prime attribute be one that appears in at least one candidate key.Let␣andbe sets of attributes such that␣→holds,but→␣does not hold.Let A be an attribute that is not in␣,is not in,and forwhich→A holds.We say that A is transitively dependent on␣.Wecan restate our definition of3NF as follows:A relation schema R is in3NF with respect to a set F of functional dependencies if there are nononprime attributes A in R for which A is transitively dependent on akey for R.Show that this new definition is equivalent to the original one.Answer:Suppose R is in3NF according to the textbook definition.Weshow that it is in3NF according to the definition in the exercise.Let A bea nonprime attribute in R that is transitively dependent on a key␣forR.Then there exists⊆R such that→A,␣→,A∈␣,A∈,and→␣does not hold.But then→A violates the textbookdefinition of3NF since•A∈implies→A is nontrivial•Since→␣does not hold,is not a superkey•A is not any candidate key,since A is nonprimeExercises17 Now we show that if R is in3NF according to the exercise definition,it is in3NF according to the textbook definition.Suppose R is not in3NF according the the textbook definition.Then there is an FD␣→that fails all three conditions.Thus•␣→is nontrivial.•␣is not a superkey for R.•Some A in−␣is not in any candidate key.This implies that A is nonprime and␣→A.Let␥be a candidate key for R.Then␥→␣,␣→␥does not hold(since␣is not a superkey), A∈␣,and A∈␥(since A is nonprime).Thus A is transitively dependent on␥,violating the exercise definition.8.17A functional dependency␣→is called a partial dependency if thereis a proper subset␥of␣such that␥→.We say thatis partially dependent on␣.A relation schema R is in second normal form(2NF)if each attribute A in R meets one of the following criteria:•It appears in a candidate key.•It is not partially dependent on a candidate key.Show that every3NF schema is in2NF.(Hint:Show that every partial dependency is a transitive dependency.)Answer:Referring to the definitions in Practice Exercise8.16,a relation schema R is said to be in3NF if there is no non-prime attribute A in R for which A is transitively dependent on a key for R.We can also rewrite the definition of2NF given here as:“A relation schema R is in2NF if no non-prime attribute A is partially dependent on any candidate key for R.”To prove that every3NF schema is in2NF,it suffices to show that if a non-prime attribute A is partially dependent on a candidate key␣,thenA is also transitively dependent on the key␣.Let A be a non-prime attribute in R.Let␣be a candidate key for R.Suppose A is partially dependent on␣.•From the definition of a partial dependency,we know that for someproper subsetof␣,→A.•Since⊂␣,␣→.Also,→␣does not hold,since␣is acandidate key.•Finally,since A is non-prime,it cannot be in eitheror␣.Thus we conclude that␣→A is a transitive dependency.Hence we have proved that every3NF schema is also in2NF.8.18Give an example of a relation schema R and a set of dependencies suchthat R is in BCNF but is not in4NF.18Chapter8Relational Database DesignAnswer:R(A,B,C)A→→BExercises19result:=∅;/*fdcount is an array whose i th element contains the number of attributes on the left side of the i th FD that arenot yet known to be in␣+*/for i:=1to|F|dobeginlet→␥denote the i th FD;fdcount[i]:=||;end/*appears is an array with one entry for each attribute.The entry for attribute A is a list of integers.Each integeri on the list indicates that A appears on the left sideof the i th FD*/for each attribute A dobeginappears[A]:=NI L;for i:=1to|F|dobeginlet→␥denote the i th FD;if A∈then add i to appears[A];endendaddin(␣);return(result);procedure addin(␣);for each attribute A in␣dobeginif A∈result thenbeginresult:=result∪{A};for each element i of appears[A]dobeginfdcount[i]:=fdcount[i]−1;if fdcount[i]:=0thenbeginlet→␥denote the i th FD;addin(␥);endendendendFigure8.18.An algorithm to compute␣+.。
数据库系统概述习题及答案

习题一第1章数据库系统概述一、填空题1. 在关系数据库中,一个元组对应表中。
解:一个记录(一行)2. 常用的数据模型有:、、和面向对象模型。
解:关系模型,层次模型,网状模型3. 用二维表来表示实体及实体之间联系的数据模型是。
解:关系模型4.关系模型数据库中最常用的三种关系运算是、、。
解:选择运算,投影运算,连接运算5. 在数据库系统中,数据的最小访问单位是。
解: 字段〔数据项〕对表进行水平方向的分割用的运算是。
解:选择运算7. 数据结构、和称为数据模型的三要素。
解:数据操作,数据约束条件8. 关系的完整性约束条件包括完整性、完整性和完整性三种。
解:用户定义,实体,参照二、单项选择题1. 对数据库进行规划、设计、协调、维护和管理的人员,通常被称为〔 D 〕。
A.工程师B. 用户C.程序员D. 数据库管理员2. 下面关于数据〔Data〕、数据库(DB)、数据库管理系统(DBMS)与数据库系统(DBS)之间关系的描述正确的选项是〔 B 〕。
A.DB包含DBMS和DBSB.DBMS包含DB和DBSC.DBS包含DB和DBMSD. 以上都不对3. 数据库系统的特点包括〔D 〕。
A.实现数据共享,减少数据冗余B. 具有较高的数据独立性、具有统一的数据控制功能C.采用特定的数据模型D. 以上特点都包括4. 以下各项中,对数据库特征的描述不准确的是〔 D 〕。
A.数据具有独立性B. 数据结构化C.数据集中控制D. 没有冗余5. 在数据的组织模型中,用树形结构来表示实体之间联系的模型称为( D )。
A.关系模型B. 层次模型C.网状模型D. 数据模型6. 在数据库中,数据模型描述的是( C ) 的集合。
A.文件B. 数据C.记录D. 记录及其联系7. 在关系数据库中,关系就是一个由行和列构成的二维表,其中行对应〔B 〕。
A. 属性B. 记录C.关系D. 主键8. 关系数据库管理系统所管理的关系是〔 C 〕。
A.一个二维表B. 一个数据库C.假设干个二维表D. 假设干个数据库文件9. 在同一所大学里,院系和教师的关系是〔 B 〕。
数据库课后习题参考答案与解析

第1章数据概述一.选择题1.下列关于数据库管理系统的说法,错误的是CA.数据库管理系统与操作系统有关,操作系统的类型决定了能够运行的数据库管理系统的类型B.数据库管理系统对数据库文件的访问必须经过操作系统实现才能实现C.数据库应用程序可以不经过数据库管理系统而直接读取数据库文件D.数据库管理系统对用户隐藏了数据库文件的存放位置和文件名2.下列关于用文件管理数据的说法,错误的是DA.用文件管理数据,难以提供应用程序对数据的独立性B.当存储数据的文件名发生变化时,必须修改访问数据文件的应用程序C.用文件存储数据的方式难以实现数据访问的安全控制D.将相关的数据存储在一个文件中,有利于用户对数据进行分类,因此也可以加快用户操作数据的效率3.下列说法中,不属于数据库管理系统特征的是CA.提供了应用程序和数据的独立性B.所有的数据作为一个整体考虑,因此是相互关联的数据的集合C.用户访问数据时,需要知道存储数据的文件的物理信息D.能够保证数据库数据的可靠性,即使在存储数据的硬盘出现故障时,也能防止数据丢失5.在数据库系统中,数据库管理系统和操作系统之间的关系是DA.相互调用B.数据库管理系统调用操作系统C.操作系统调用数据库管理系统D.并发运行6.数据库系统的物理独立性是指DA.不会因为数据的变化而影响应用程序B.不会因为数据存储结构的变化而影响应用程序C.不会因为数据存储策略的变化而影响数据的存储结构D.不会因为数据逻辑结构的变化而影响应用程序7.数据库管理系统是数据库系统的核心,它负责有效地组织、存储和管理数据,它位于用户和操作系统之间,属于AA.系统软件B.工具软件C.应用软件D.数据软件8.数据库系统是由若干部分组成的。
下列不属于数据库系统组成部分的是B A.数据库B.操作系统C.应用程序D.数据库管理系统9.下列关于客户/服务器结构和文件服务器结构的描述,错误的是DA.客户/服务器结构将数据库存储在服务器端,文件服务器结构将数据存储在客户端B.客户/服务器结构返回给客户端的是处理后的结果数据,文件服务器结构返回给客户端的是包含客户所需数据的文件C.客户/服务器结构比文件服务器结构的网络开销小D.客户/服务器结构可以提供数据共享功能,而用文件服务器结构存储的数据不能共享数据库是相互关联的数据的集合,它用综合的方法组织数据,具有较小的数据冗余,可供多个用户共享,具有较高的数据独立性,具有安全控制机制,能够保证数据的安全、可靠,允许并发地使用数据库,能有效、及时地处理数据,并能保证数据的一致性和完整性。
04735数据库系统原理(2018版)课后习题参考答案.pdf

2.请简述什么是参照完整性约束。 P55
答:参照完整性约束是指:若属性或属性组 F 是基本关系 R 的外码,与基本关系 S 的主码 K
相对应,则对于 R 中每个元组在 F 上的取值只允许有两种可能,要么是空值,要么与
S中
某个元组的主码值对应。
3.请简述关系规范化过程。
答:对于存在数据冗余、 插入异常、 删除异常问题的关系模式,应采取将一个关系模式分解
实体集 B 中的每个实体,实体集 A 中最多只有一个实体与之联系。举例:班级与班级成员,
每个班级对应多个班级成员,每个班级成员只对应一个班级。
多对多联系:对于实体集 A 中的每个实体,实体集 B 中有 N 个实体与之联系,反之,对于
实体集 B 中的每个实体,实体集 A 中有 M 个实体与之联系。举例:授课班级与任课教师,
3.请简述数据库系统的三级模式和两层映像的含义。
P31
答:
数据库的三级模式是指数据库系统是由模式、 外模式和内模式三级工程的, 对应了数据的三
级抽象。
两层映像是指三级模式之间的映像关系,即外模式
/ 模式映像和模式 / 内模式映像。
4.请简述关系模型与网状模型、层次模型的区别。
P35
使用二维表结构表示实体及实体间的联系
来自于定义视图的查询所引用的基本表。 视图不适宜数据集的形式存储在数据库中的,
它所对应的数据实际上是存储在视图所引用的
基本表中的。
视图是用来查看存储在别处的数据的一种虚拟表,本身不存储数据。
文档鉴赏
第五章 数据库编程
简答题
1. 请简述存储过程的概念 P125
存储过程是一组为了完成某项特定功能的
SQL 语句集,经过编译后存储在数据库中,可以
数据库系统概论习题及答案 其它题

数据库系统概论复习资料:第一章假设教学管理规定:①一个学生可选修多门课,一门课有若干学生选修;②一个教师可讲授多门课,一门课只有一个教师讲授;③一个学生选修一门课,仅有一个成绩。
学生的属性有学号、学生姓名;教师的属性有教师编号,教师姓名;课程的属性有课程号、课程名。
要求:根据上述语义画出ER图,要求在图中画出实体的属性并注明联系的类型;第2章关系数据库1、设有如下所示的关系S(S#,SNAME,AGE,SEX)、C(C#,CNAME,TEACHER)和SC(S#,C#,GRADE),试用关系代数表达式表示下列查询语句:(1)检索“程军”老师所授课程的课程号(C#)和课程名(CNAME)。
(2)检索年龄大于21的男学生学号(S#)和姓名(SNAME)。
(3)检索至少选修“程军”老师所授全部课程的学生姓名(SNAME)。
(4)检索”李强”同学不学课程的课程号(C#)。
(5)检索至少选修两门课程的学生学号(S#)。
(6)检索全部学生都选修的课程的课程号(C#)和课程名(CNAME)。
(7)检索选修课程包含“程军”老师所授课程之一的学生学号(S#)。
(8)检索选修课程号为k1和k5的学生学号(S#)。
(9)检索选修全部课程的学生姓名(SNAME)。
(10)检索选修课程包含学号为2的学生所修课程的学生学号(S#)。
(11)检索选修课程名为“C语言”的学生学号(S#)和姓名(SNAME)。
解:本题各个查询语句对应的关系代数表达式表示如下:(1). ∏C#,CNAME(σTEACHER=‘程军’(C))(2). ∏S#,SNAME(σAGE>21∧SEX=”男”(C))(3). ∏SNAME{s [∏S#,C#(sc )÷∏C#(σTEACHER=‘程军’(C))]}(4). ∏C#(C)- ∏C#(σSNAME=‘李强’(S) SC) (5). ∏S#(σ[1]=[4]∧[2]≠[5] (SC × SC))(6). ∏C#,CNAME(C (∏S#,C#(sc)÷∏S#(S)))(7). ∏S#(SC∏C#(σTEACHER=‘程军’(C)))(8). ∏S#,C#(sc )÷∏C#(σC#=’k1’∨ C#=’k5’(C)) (9). ∏SNAME{s[∏S#,C#(sc )÷∏C#(C)]}(10). ∏S#,C#(sc )÷∏C#(σS#=’2’(SC))(11). ∏S#,SNAME{s[∏S#(SCσCNAME=‘C 语言’(C))]}2、关系R 和S 如下图所示,试计算R ÷S 。
数据库系统原理版课后习题参考答案

答案仅供参考第一章数据库系统概述选择题B、B、A简答题1.请简述数据,数据库,数据库管理系统,数据库系统的概念。
P27数据是描述事物的记录符号,是指用物理符号记录下来的,可以鉴别的信息。
数据库即存储数据的仓库,严格意义上是指长期存储在计算机中的有组织的、可共享的数据集合。
数据库管理系统是专门用于建立和管理数据库的一套软件,介于应用程序和操作系统之间。
数据库系统是指在计算机中引入数据库技术之后的系统,包括数据库、数据库管理系统及相关实用工具、应用程序、数据库管理员和用户。
2.请简述早数据库管理技术中,与人工管理、文件系统相比,数据库系统的优点。
数据共享性高数据冗余小易于保证数据一致性数据独立性高可以实施统一管理与控制减少了应用程序开发与维护的工作量3.请简述数据库系统的三级模式和两层映像的含义。
P31答:数据库的三级模式是指数据库系统是由模式、外模式和内模式三级工程的,对应了数据的三级抽象。
两层映像是指三级模式之间的映像关系,即外模式/模式映像和模式/内模式映像。
4.请简述关系模型与网状模型、层次模型的区别。
P35使用二维表结构表示实体及实体间的联系建立在严格的数学概念的基础上概念单一,统一用关系表示实体和实体之间的联系,数据结构简单清晰,用户易懂易用存取路径对用户透明,具有更高的数据独立性、更好的安全保密性。
.第二章关系数据库选择题C、C、D简答题1.请简述关系数据库的基本特征。
P48答:关系数据库的基本特征是使用关系数据模型组织数据。
2.请简述什么是参照完整性约束。
P55答:参照完整性约束是指:若属性或属性组F是基本关系R的外码,与基本关系S的主码K相对应,则对于R中每个元组在F上的取值只允许有两种可能,要么是空值,要么与S中某个元组的主码值对应。
3.请简述关系规范化过程。
答:对于存在数据冗余、插入异常、删除异常问题的关系模式,应采取将一个关系模式分解为多个关系模式的方法进行处理。
一个低一级范式的关系模式,通过模式分解可以转换为若干个高一级范式的关系模式,这就是所谓的规范化过程。
数据库系统概论课后习题答案
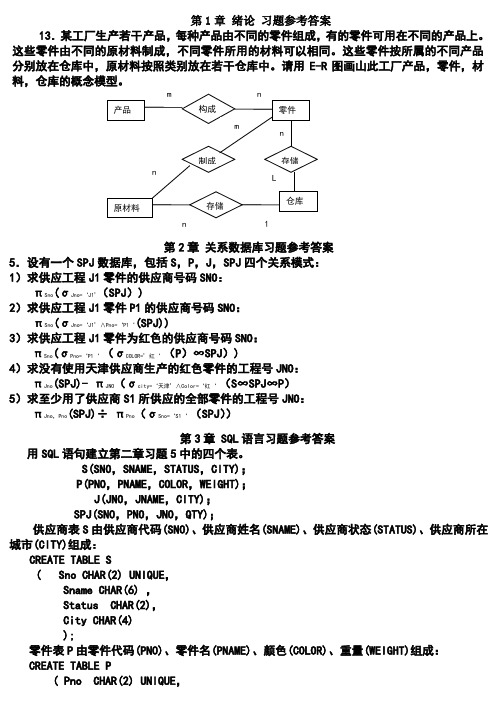
第1章绪论习题参考答案13.某工厂生产若干产品,每种产品由不同的零件组成,有的零件可用在不同的产品上。
这些零件由不同的原材料制成,不同零件所用的材料可以相同。
这些零件按所属的不同产品分别放在仓库中,原材料按照类别放在若干仓库中。
请用E-R图画山此工厂产品,零件,材第2章关系数据库习题参考答案5.设有一个SPJ数据库,包括S,P,J,SPJ四个关系模式:1)求供应工程J1零件的供应商号码SNO:πSno(σJno=‘J1’(SPJ))2)求供应工程J1零件P1的供应商号码SNO:πSno(σJno=‘J1’∧Pno=‘P1‘(SPJ))3)求供应工程J1零件为红色的供应商号码SNO:πSno(σPno=‘P1‘(σCOLOR=’红‘(P)∞SPJ))4)求没有使用天津供应商生产的红色零件的工程号JNO:πJno(SPJ)- πJNO(σcity=‘天津’∧Color=‘红‘(S∞SPJ∞P)5)求至少用了供应商S1所供应的全部零件的工程号JNO:πJno,Pno(SPJ)÷πPno(σSno=‘S1‘(SPJ))第3章 SQL语言习题参考答案用SQL语句建立第二章习题5中的四个表。
S(SNO,SNAME,STATUS,CITY);P(PNO,PNAME,COLOR,WEIGHT);J(JNO,JNAME,CITY);SPJ(SNO,PNO,JNO,QTY);供应商表S由供应商代码(SNO)、供应商姓名(SNAME)、供应商状态(STATUS)、供应商所在城市(CITY)组成:CREATE TABLE S( Sno CHAR(2) UNIQUE,Sname CHAR(6) ,Status CHAR(2),City CHAR(4));零件表P由零件代码(PNO)、零件名(PNAME)、颜色(COLOR)、重量(WEIGHT)组成:CREATE TABLE P( Pno CHAR(2) UNIQUE,Pname CHAR(6),COLOR CHAR(2),WEIGHT INT);工程项目表J由工程项目代码(JNO)、工程项目名(JNAME)、所在城市(CITY)组成:CREATE TABLE J( JNO CHAR(2) UNlQUE,JNAME CHAR(8),CITY CHAR(4));供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成:CREATE TABLE SPJ( SNO CHAR(2),PNO CHAR(2),JNO CHAR(2), QTY INT);4.针对上题中建立的四个表试用SQL语言完成第二章习题5中的查询:求供应工程J1零件的供应商号码SNO:SELECT SNO FROM SPJWHERE JNO=’J1’求供应工程J1零件P1的供应商号码SNO:SELECT SNO FROM SPJWHERE JNO='J1' AND PNO='P1'求供应工程J1零件为红色的供应商号码SNO:SELECT SNO FROM SPJ,PWHERE JNO='J1' AND = AND COLOR='红'求没有使用天津供应商生产的红色零件的工程号JNO:SELECT JNO FROM SPJWHERE JNO NOT IN (SELECT JNO FROM SPJ,P,SWHERE ='天津' AND COLOR='红' AND =AND =;或者:SELECT JNO FROM JWHERE NOT EXITS( SELECT * FROM SPJ,S,PWHERE = AND =;求至少用了供应商S1所供应的全部零件的工程号JNO。
数据库系统概念第七版课后习题答案

八、专业设计题(每题2分,共10分)1.设计一个简单的学生信息管理系统数据库,列出至少三个表的结构,包括字段名和数据类型。
2.假设有一个在线书店数据库,设计一个查询,显示所有库存少于10本的图书的详细信息。
3.设计一个数据库模式,用于存储一个医院的病人信息,包括医生和护士的信息。
4.为一个电子商务网站设计一个订单处理系统数据库,包括至少四个表和它们之间的关系。
5.设计一个数据库用于存储一个大学的课程信息,包括学生选课记录和成绩。
九、概念解释题(每题2分,共10分)1.解释关系型数据库中的“范式”概念,并简要说明第一范式和第三范式的区别。
2.简述SQL中“JOIN”操作的作用,并解释内连接和外连接的区别。
3.解释事务在数据库中的作用,以及ACID属性的重要性。
4.简述数据库中的索引是什么,以及它如何提高查询效率。
5.解释数据库中的“视图”是什么,以及它的主要用途。
十、附加题(每题2分,共10分)1.描述如何使用SQL语句在数据库中创建一个新的表。
2.解释数据库中的“触发器”是什么,并给出一个使用触发器的例子。
3.简述数据库备份的重要性,并说明两种常见的备份方法。
4.解释数据库中的“锁”是什么,以及它在并发控制中的作用。
5.描述如何使用SQL语句从一个表中删除重复的记录。
一、选择题答案1.C2.B3.A4.D5.A二、判断题答案1.错误2.正确3.错误4.正确5.错误三、填空题答案1.数据模型2.数据库管理系统3.SQL4.事务管理5.数据库设计四、简答题答案1.数据库管理系统是用于管理数据库的软件系统,它允许用户定义、创建、维护和控制访问数据库。
2.关系型数据库是基于关系模型的数据库,使用表格来表示数据,并通过SQL进行查询和管理。
3.数据库规范化是为了消除数据冗余和不一致性,提高数据效率和准确性。
4.数据库事务是一系列操作,它们要么全部执行,要么全部不执行,以确保数据库的一致性。
5.数据库安全包括访问控制、加密、审计和备份等措施,以保护数据不被未授权访问或破坏。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
18
Schema Normalization
Given is the following set of functional dependencies F for a relation schema R: R={A, B, C, D, E, G} F={ED, CB, CEG, BA} Attribute set (C, E) is the only candidate key of R. 1) Decide whether relation schema R is in BCNF. If it is not, describe why 2)Decompose relations R, if necessary, into a collection of relations that are in BCNF. Make sure to indicate which dependency you apply to each decomposition.
7
Compose SQL
1. Define the relation schema Operation in SQL (indicates Primary Key and Foreign Key) 2. List all patients diagnosed or operated by doctor “smith” 3. Find all doctors who have diagnosed all patients who‟s age are below 12.
5
Relational Algebra
A R4 = ΠA ( R ) — ( R ÷ S ) a3 a4
6
Compose SQL
• Consider the database of a clinic described below (the primary keys are underlined):
-Movies, with attributes movie_id, movie_name,
production_year, country. -Movie Theaters, with attributes theater_id, thearter_name, city. -Screen, with attributes screen_id, screen_name. It is a weak entity set, its identifying entity set is Movie Theaters, its discriminator is screen_id. (movie theater
16
movie_name
production_year country
movieen_name
Movie
Show
Date visitor_number
Screen
1.
In
city theater_id
Theater
theater_name
Chapter7 Relational Database Design
10
2. List all patients diagnosed or operated by
Using Subquery Select From Patient Where Exists( Select * From Doctor, Operation Where Doctor.DocCode=Operation.DocCode AND =‘Smith’ AND Operation.PatCode=Patient.PatCode) OR Exists( Select * From Doctor, Diagnosed_by Where Doctor.DocCode=Diagnosed_by.DocCode AND =‘Smith’ AND Diagnosed_by.PatCode=Patient.PatCode)
4
Answer The Following Questions
• Briefly describe the difference between database schema and database instance.
• Briefly describe the difference between tables and views.
– Patient (PatCode, Name, Age, Sex, Street, City, Occupation) – Operation (OperCode, PatCode, DoctCode, OperDate,OperTime, Detail) – Doctor (DoctCode, Name, Specialty, Age) – Diagnosed_By (PatCode, DoctCode, DiagDate, DiagTime, Prescription)
Detail VarChar(255), Primary Key(OperCode), Foreign Key(PatCode) References Patient, Foreign Key(DocCode) References Doctor)
9
doctor “smith” (Select
上次考试各题型所占分数:
习题
单选题:10分 填空题:10分
简答题:12分
关系代数运算:12分
SQL:30分
E-R图与转换:16分 模式分解:10分
Single Choice
• The database system provides an abstract view of the data, this is achieved through several level of abstraction, among these levels, the C (________) describes part of the logical structure of the database.
13
E-R Model
• The Chinese Film Institute collects statistics about movies and moviegoers in china. These statistics is stored in a database. • This database has the following entity sets
Union (Select From Doctor, Diagnosed_by, Patient Where Doctor.DocCode = Diagnosed_by.DocCode AND Diagnosed_by.PatCode=Patient.PatCode AND =„Smith‟)
A. In relational model, any legal relation schema must satisfies 1NF B. For any relation schema, there is always a lossless-join, dependency preserving decomposition into 3NFs C. Relations with only 3 attributes are automatically in BCNF D. If , then is a trivial functional dependency
17
2.
Movie(Movie_id, Movie_name, production_year,country)
Theater(theater_id, theater_name, city)
Screen(theater_id, screen_id, screen_name)
Show(movie_id, theater_id, screen_id, date, visitor_number)
2. List all patients diagnosed or operated by
Using Union
From Doctor, Operation, Patient
Where Doctor.DocCode = Operation.DocCode
AND Operation.PatCode=Patient.PatCode AND =„Smith‟)
11
doctor “smith”
3. Find all doctors who have diagnosed all
patients who‟s age are below 12. Select Using Subquery From Doctor D Where Not Exists( Select * From Patient P Where Age < 12 AND Not Exists( Select * From Diagnosed_by Where Diagnosed_by.DocCode=D.DocCode AND Diagnosed_by.PatCode=P.PatCode))
contains one or more screens, where the movies are shown.)
14
E-R Model
• In addition there are the following relationship sets:
-In, The identifying relationship set between Screen and Movie Theaters. -Shows, The movies are showed on different screens, and we need to store data about the movie shows that have occurred: which movie that was shown, on which screen, at what time, and how many visitors there were.