Reiseregning_PDF
finite

On counting and generating curves over smallfinite fieldsQi Cheng a ,Ming-Deh Huang ba Schoolof Computer ScienceUniversity of Oklahoma,Norman,OK 73019,USAb Computer Science DepartmentUniversity of Southern CaliforniaLos Angeles,CA 90089,USA AbstractWe consider curves defined over small finite fields with points of large prime order over an extension field.Such curves are often referred to as Koblitz curves and are of considerable cryptographic interest.An interesting question is whether such curves are easy to construct as the target point order grows asymptotically.We show that under certain number theoretic conjecture,if q is a prime power,r is a prime and √q >(r log q )2+ ,then there are at least Ω(q r log 2q)non-isomorphic elliptic curves E/F q ,such that the quotient group E (F q r )/E (F q )has prime order.We also show that under the same conjecture,if q is a prime power and r is a prime satisfying q >(r log q )2+ and √q =o (q r 1+ log q ),then there are at least Ω(q r 1+ log q )curves H/F q of genus 2,such that the order of the quotient group Jac (H )(F q r )/Jac (H )(F q )is a prime.Based on these results we present simple and efficient algorithms for generating Ω(log 3n )non-isomorphic elliptic curves in Ω(log n )isogenous classes,each with a point of prime order Θ(n ).The average time to generate one curve is O (log 2n ).We also present an algorithm which generates Ω(log 3n )curves of genus two with Jacobians whose orders have a prime factor of order Θ(n ),in heuristic expected time O (log 4n )per curve.Keyword:Curve-based cryptography,Koblitz curve,Bateman-Horn conjecture.Email addresses:qcheng@ (Qi Cheng),huang@ (Ming-Deh Huang).Preprint submitted to Journal of Complexity 31July 20031IntroductionElliptic curve and other curve-based cryptosystems require the construction of curves over finite fields with points of large prime order on the Jacobians of the curves.This problem can be formulated as follows:Given a natural number n ,to construct a curve over some finite field and a point on the Jacobian of the curve whose order is prime and close to n .In the case of elliptic curves,the Jacobian of an elliptic curve is the curve itself.A random elliptic curve will have prime order with roughly the same probability as finding a prime in the range between p +1−2√p and p +1+2√p if the curve is defined over F p .Counting the order of the group of rational points on an elliptic curve has been made easier due to recent improvements on Schoof’s method [21,17].Hence a reasonable approach in the case of elliptic curves,is to find a prime p around n ,then randomly choose elliptic curves E over F p until #E (F p )is a prime,and find a nontrivial rational point on the curve.However,extending the approach to hyperelliptic curves is difficult since no practically efficient method is known for counting points on hyperelliptic curves and their Jacobians when p is large (say greater than 1025),despite some recent progress on the problem [9,8].An alternative approach which avoids point counting,is to apply the heuristic method of Atkin-Morain [3]and Elkies involving the CM theory of elliptic curves.Generalization of this method to hyperelliptic curves is possible but not practical [5,23].Dramatic progress has been made in point counting when the characteristic of the field is very small.Satoh first proposed a very efficient algorithm based on the canonical p -adic lift of the elliptic curve when the characteristic of the field,p ,is small but greater than5.His idea was extended to p =2,3subsequently [15].In [16],experimental results were reported.It was concluded in that paper that “it is no longer necessary to use precomputed curves in cryptography since one can easily compute new curves as desired.Finding a curve with a security level comparable with RSA-1024takes minutes or less.Curve generation for short-term security,with a level equivalent to DES,is feasible on a low-power chip.”Recently Kedlaya [10]gave a O (g 5r 3)counting algorithm for hyperelliptic curve over field F p r with genus g when p is fixed.The time complexity of all these algorithms depends polynomially on the characteristic of the field.The approach considered in this paper is to start with a relatively small finite field F q ,then look for curves defined over F q which,when considered as curves over an extension F q m ,has rational points of large prime order on their Jacobians.Such curves are sometimes called Koblitz curves [22,12,19].One simple and natural approach is to fix an elliptic curve over a small field F q and then consider it over F q r as r varies [11].This heuristic method seems to work well in the practical range of cryptographic interest.However it does not2work as r grows asymptotically,since the probability that#E (F q r )#E (F q )is prime when r varies is conjectured (in analogy to the the classical Mersenne primeproblem)to be about eγlog r r log q(where γis the Euler’s constant),which tends to 0as r increases and q is fixed.In this paper,we explore the possibility of determining a relatively small base field F q (say q =(log n )O (1))and some extension F q k (say k =O (log n/log log n )),so that curves with F q k -points of prime order Θ(n )can be constructed.The following theorems are proven based on a weak version of the Bateman-Horn conjecture concerning the density of primes when evaluating an integral polynomial.These theorems lead to methods which guarantee to generate curves of genus one and two with above-mentioned properties.Theorem 1Assume that the weak Bateman-Horn conjecture is true and a Siegel zero doesn’t exist.Let q be a prime power and r be a prime.If √q >(r log q )2+ ,there are at least Ω(q r log 2q )non-isomorphic elliptic curves E/F q in Ω(√q 1+ )F q r -isogenous classes,such that the order of the quotient group E (F q r )/E (F q )is prime.It is known that the Dirichlet L-function L (s,χ)of a Dirichlet character χmod q is zero free in σ>1−c/log(q (2+|t |)),where s =σ+it and c is an absolute constant,with at most one exception.If the exception exists,then χmust be real and the zero is also real.Such a zero is called a Siegel zero [6].Theorem 1will be proved in Section 3.It leads to an algorithm which on input n ,determines a suitable base field F q and extension degreer ,where r =Θ(log n (4+ )log log n)and q =Θ(log 4+ n );then generates Ω(log 3n )non-isomorphic elliptic curves in Ω(log n )isogenous classes,and a point on each curve with prime order greater than n and less than n (1+O (r +√q q ));in time O (log 5+ n ).The average time to generate one curve is O (log 2n ).Consequently this method is particularly efficient if we want to generate a large collection of good elliptic curves while minimizing the average construction time per curve.We note that,in contrast,it is hard to overcome log 4n per curve barrier if we first select a random curve,then do the point-counting and finally test the order for primality,since after all testing primality of a number around n takes O (log 3n )time,and such a number is a prime with probability only 1log n.Note that we use the fast arithmetic algorithm in primality testing,but the error probability needs to be kept below 1/n ,hence the time complexity per number is O (log 3n ).The advantage in looking for Koblitz curves defined over F q ,with q =O (log 4n ),is that there are Θ(√q )=Θ(log 2n )isogenous classes,hence Θ(log 2n )numbers to test for possible orders over the extension field F q r .Although O (log 3n )non-isomorphic Koblitz curves are generated,primality testing is3performed on only O (log 2n )numbers,and this is essentially why the average construction time per good curve can be as low as O (log 2n ).We refer to Section 4for more detailed analysis.We also prove a similar theorem for curves of genus two under the same conjecture.Theorem 2Assume that the weak Bateman-Horn conjecture is true,and a Siegel zero doesn’t exist.Let q be a prime power and r be a prime.If q >(2r log q )2+ and √q =o (q 1+ ),then there are at least Ω(q 1+ )curves H/F q of genus 2,such that the order of the quotient group Jac (H )(F q r )/Jac (H )(F q )is prime.We will prove this theorem in Section 5.It leads to an algorithm which generates Ω(log 3n )curves of genus two with Jacobians whose orders have a prime factor greater than n and less than n (1+O (r +√q )),in heuristic expected time O (log 4n )per curve.Setting q =103,r =19,as many as 400curves of genus 2were generated at the average rate of less than five minutes per curve,as we implement the algorithm on a PII 300Mhz computer using GP scripting.All of the group orders are about 240bits long.The method developed in this paper can be extended in a natural way to hyperelliptic curves of any fixed genus.However it seems to be difficult to have rigorous analysis of the method when the genus of interest is greater than two.2The weak Bateman-Horn conjectureGauss observed that the density of primes around x is 1log x .One might predict,as a more precise estimate,that the asymptotic formula isπ(x +y )−π(x )=(1+o (1))y log x ,(1)where π(x )is the number of primes less than x and y ≤x .The formula is proved for y >x α,αis any constant greater than 7/12and is disproved [14]if y is less than any fixed power of log x in the sense thatlim sup x →∞π(x +(log x )λ)−π(x )(log x )λ−1>1and lim inf x →∞π(x +(log x )λ)−π(x )(log x )λ−1<1.However,if the conjecture is modified to a weaker form which states that there exists anabsolute constant c such that π(x +y )−π(x )>c y for 10log 2x <y <x ,no counter 4example has been found.Moreover A.Selberg proved that under Riemann Hypothesis,(1) is true for almost all x if ylog2x→∞.More generally,it has been conjectured[4]that the number of prime values assumed by any irreducible polynomial F(X)is given by the formulaπF(x)=(C F+o(1))xlog|F(x)|,for x>log2+ |F(x)|.The constant C F is p prime(1−ωF(p))/(1−1)where w F(p)is num-ber of distinct roots F(x)=0in F p.We refer to this conjecture as the Bateman-Horn Conjecture.There are strong heuristic arguments[4]in support of the conjecture,at least in terms of the order of estimate implied in the conjecture.However the precise estimate predicted in the conjecture can be problematic in some cases.It was recently shown in[7]that for any given degree some polynomials can be constructed to take either significantly more or significantly less prime values than predicted by the conjecture.Such discrepancy seems to disappear if one does not insist on the precise estimate in the conjecture.If for example the conjecture is weakened to the followingπF(x)≥C F2xlog|F(x)|,for x>10log2max1≤y≤x|F(y)|and x>10deg F,then no counter example has been found. We refer to this conjecture as the weak Bateman-Horn Conjecture.Note that the constant C F depends on the polynomial F.Hence the probability that|F(x)|becomes a prime at a random integer x can be very different from the probability that a random integer of size around|F(x)|becomes a prime,unless that C F is very close to a constant.What we will need is a special case of this weaker statement where the polynomial F splits over a cyclotomicfield.In this case,C F will be shown to be bounded from below by a function on the degree of F.The function grows very slowly with the degree.Theorem3Let r be a prime.Letξbe r-th primitive root of unity.Let F be a monic irreducible polynomial with degree d=φ(r)=r−1(φis Euler function)and splittingfield Q(ξ).LetπF(x)be the number of integers n≤x for which|F(n)|is prime.Then under the weak Bateman-Horn Conjecture and the conjecture of non-existence of a Siegel zero,there is an absolute constant C such thatπF(x)>Cxlog|F(x)|e(log log r),whenever x>10log2max1≤y≤x|F(y)|and x>10d.5Proof:Denote Disc(F)/Disc(Q(ξ))byβ2.It is known[2]thatp≡i mod r,p≤x dp=log log x+A(r,i)+O(1log x)Now we evaluate the constant C F,C F= p1−ωF(p)p1−1.Observe thatωF(p)=d if p≡1mod r,p β,ωF(p)=1if p=r.AndωF(p)=0if p≡1mod r and p=r.HenceC F=(1−1) p≡1mod r,p β(1−d) p≡1mod r,p|β(1−ωF(p))p(1−1p)We havelog C F=−p≡1mod r,p βdp−p≡1mod r,p|βωF(p)p+ p1p+A,where|A|is bounded from above by an absolute constant.Hencelog C F=−p≡1mod r dp+p≡1mod r,p|βd−ωF(p)p+ p1p+A≥−p≡1mod r dp+ p1p+AWe also have−A(r,1)=−p≡1mod r dp+ p1p+D,where D is an absolute constant.Hence log C F≥−A(r,1)+A−D.Applying the method in[18],if a Siegel zero doesnot exist,one can have1(log log r)2≤A(r,1)≤(log log r)2.It implies that C F=Ω(1e(log log r)2).3Special bivariate polynomials associated with elliptic curvesLet E be an elliptic curve defined over F q,where q is prime power p d,with p=2,3.Then E has q+1−a points over F q where a is the trace of the Frobenius endomorphism of the6curve over F q ,and −2√q ≤a ≤2√q .Let αbe one root of x 2−ax +q =0.Let ¯αdenotethe complex conjugate of α.Then the order of abelian group E (F q r ),denoted by #E (F q r ),is (αr −1)(¯αr −1).Let Φn denote the n -th cyclotomic polynomial,the minimal polynomial of ξn =e 2πi n .Then x r −1= k>0,k |r Φk (x ).Therefore#E (F q r )=(αr −1)(¯αr −1)=k>0,k |r Φk (α)k>0,k |r Φ(¯α)= k>0,k |r Φk (α)Φk (¯α),and Φk (α)Φk (¯α)=gcd (i,k )=1,0<i ≤k (α−ξi k )(¯α−ξi k )= gcd (i,k )=1,0<i<k (q −aξi k +ξ2i k ).Denote gcd (i,k )=1,0<i<k (x −yξi k +ξ2i k )by Ψk (x,y ).The first three Ψk ’s are:Ψ1(p,a )=p +1−a ,Ψ2(p,a )=p +1+a ,and Ψ3(p,a )=p 2+(a −1)p +(a 2+a +1).From the above discussion we see that for an elliptic curve E defined over F q of trace a ,#E (F q r )= k>0,k |rΨk (q,a )(2)The polynomial Ψk (x,y )possesses several nice properties as shown in the following lemma.Lemma 1(1)Ψk (x,y )∈Z [x,y ].(2)If k >3is prime,then for any integer c ,F 1(x )=Ψk (c,x )and F 2(x )=Ψk (x,c )areirreducible polynomial over Q ,and has a cyclotomic field as its splitting field.(3)Ψk (x,y )is irreducible over Q .(4)If r is a prime,then for any −2√q ≤a ≤2√q ,q r −2q r/2+1≤(q +1−a )Ψr (q,a )≤q r +2q r/2+1.Proof:Part (1)follows directly from the definition.As for part (2),given any integer c ,F 1(x )=Ψk (c,x )is an irreducible polynomial if the only Galois element of Q (ξk )/Q thatfixes cξk −ξ2k is the identity.Similarly,F 2(x )=F 2(x,c )is irreducible if the only Galoiselement of Q (ξk )/Q that fixes cξ−1k +ξk is the identity.When k >3is a prime,the minimumpolynomial of ξk has degree k −1and has more than 5terms.For any Galois element σofQ (ξk )/Q ,σ(cξk −ξ2k )−(cξk −ξ2k )simplifies to a polynomial expression of ξk of degree less7than k with at most four terms.Hence if k >3,F 1(x )is irreducible and has cyclotomic fields as its splitting field.By a similar argument one can show that if k >3,F 2(y )is irreducible,Part (3)follows from Part (2).Part (4)follows from the equation 2.Proof of Theorem 1:The order of the quotient group E (F q r )/E (F q )is F 1(x )=Ψr (q,x ).The variable x will take value from −2√q to 2√q .From Lemma 1we see that as long as √q >(r log q )2+ ,we may apply Theorem 3to the polynomial F 1(x ),and it will evaluate to Ω(√q 1+ )number of primes.Hence there are Ω(√q 1+ )F q -isogenous classes,such that the order of the quotient group E (F q r )/E (F q )is prime.It is proved in [13,20]that there exist two constants c 1,c 2such that if A is a set of integers between q +1−√q and q +1+√q ,the number of non-isomorphic classes of elliptic curves defined over F q whose number of points over F q are in A isc 1√q (|A |−2)/log q ≤N ≤c 2√q |A |log q (log log p )2.Thus there are at least Ω(q 2)non-isomorphic elliptic curves over F q in these isogenous classes.4Algorithms for the case of elliptic curvesWe are ready to describe an algorithm for constructing an elliptic curve whose order has prime factor bigger than a given number n .Algorithm 1Input:n .Output:Two primes q,r >3,and a set of elliptic curves defined over F q .If E is any of the output curves,then the quotient group E (F q r )/E (F q )has a prime order larger than n ;(1)Let r be the largest prime less than log n ;(2)Let Q = n 1r −1 ;Make sure that Qr −2Q r/2+1Q +2√Q +1≥n .If not,increase Q to the least integer satisfying the inequality.(3)Search a prime q such that Q ≤q ≤Q +10log 2Q ;(4)Find a quadratic nonresidue c in F q ;(5)Compute polynomial f (x )=Ψr (q,x )= i>0,gcd (i,r )=1(q −xξi r +ξ2i r )∈Z [x ];(6)Search for numbers −2√q ≤a ≤2√q ,such that f (a )is prime;.(7)For all possible j -invariants j ∈F q of curves over F q ,compute the numberof points of its corresponding ly for j =1728,check all the curves y 2=x 3+αx ,α=0;for j =0,check all the curves y 2=x 3+β,8β=0;in all the remaining cases,letk =108jj −1728check the curves y 2=x 3−kx −4k and y 2=x 3−kc 2x −4kc 3.If any of the curves has q +1−a points over F q for any a chosen in the previous step,output the curve.Now we elaborate on the steps of the Algorithm 1.Step 1to 3in Algorithms 1determine a suitable base field F q and extension degree r .Theoutput curves will be defined over F q .Note that if r =log n (4+ )log log n,then Q =log 4+ n .In step 4,we search a quadratic residue in field F q .The naive search method is adequate as it takes time O (√q ),which is O (log 2+ n ).Step 5and 6search for traces of suitable elliptic curves.Note that if an elliptic curve E/F q has trace a ,then quotient group E (F q r )/E (F q )has order Ψr (q,a ),since r is a prime.Thus we look for those a where Ψr (q,a )is prime as a ranges from −2√q to 2√q .Theorem 1implies that in this range Ψr (q,a )will evaluate to Ω(√q 1+ )=Ω(log n )primes.We use Rabin-Miller’s primality testing algorithm to see whether Ψr (q,a )is prime.The pri-mality testing algorithm takes time O (log 3n )for each number.The total time complexity is O (log 5+ n )in these two steps.Notice that the maximum value for Ψr (q,a )will beq r +2q r/2q −2√q =q r −11+2/q r/21−2/√q =q r −1(1+O (1/√q ))=(Q +log 2Q )r −1(1+O (1/√q ))=Q r −1(1+log 2Q Q )r −1(1+O (1/√q ))=n (1+O (r +√q q))This illustrates a nice property of the algorithm:it will not find a curve with prime part of the order too far away from n .Step 7construct elliptic curve for all possible j -invariant values and output those whose traces a are good in the sense that f (a )is prime.The theory of elliptic curves assures that for every a in the search range,there is at least one elliptic curve over F q with trace a .We apply Shanks’s Baby-Step-Giant-Step (BSGS)strategy to count points over F q for each curve.This takes time O (q 1/4+ )=O (log 1+ n )for each curve.Hence the total complexity9for the last step is O(log5+ n).A variant of this algorithm is searching for a curve over F2a(or F q where q is small prime power).The Theorem3implies that by brute-force searching through elliptic curves over F2a of all possible j-invariants,we are guaranteed tofind a good curve very efficiently.Now suppose E is a curve generated by the algorithm,then group E(F q r)/E(F q)has prime order,hence is cyclic.Any point that has coordinates in F q r−F q must have order containing that big prime.It is easy to generate such a point.5The genus two curvesLet H be hyperelliptic curve with genus2over F q where q is a power of a prime p.If p>3, H may be given as y2=f(x),where f(x)∈F q[x]is a monic polynomial of degree5.LetP(X)=x4+a1x3+a2x2+qa1x+q2(3)be the characteristic polynomial of the Frobenius endomorphism on Jac(H).P(X)can be factored over C asP(X)=(x−α1)(x−¯α1)(x−α2)(x−¯α2),where¯αi is the conjugate ofαi.The order of Jacobian group over F q r is(1−αr1)(1−¯α1r)(1−αr2)(1−¯αr2)= k>0,k|rΦk(α1) k>0,k|rΦk(¯α1) k>0,k|rΦk(α2) k>0,k|rΦk(¯α2) = k>0,k|rΦk(α1)Φk(¯α1)Φk(α2)Φk(¯α2)We factorΦk over Q(ξk).Φk(α1)Φk(¯α1)Φk(α2)Φk(¯α2)=0<i<k,gcd(i,k)=1(ξik−α1)(ξi k−¯α1)(ξi k−α2)(ξi k−¯α2)=0<i<k,gcd(i,k)=1(ξ4ik+a1ξ3ik+a2ξ2ik+qa1ξik+q2)Definition1Define∆k(x,y,z)=i>0,gcd(i,k)=1(ξ4ik+yξ3ik+zξ2ik+xyξik+x2). 10Lemma 2(1)∆k (x,y,z )∈Z [x,y,z ].(2)If H is a curve defined over F q with genus 2and x 4+a 1x 3+a 2x 2+qa 1x +q 2is theminimal polynomial of its Frobenius endomorphism.Then the order of Jacobian of H over F q r is #Jac (H )(F q r )= k>0,k |r ∆k (q,a 1,a 2).(3)If r >8is prime,then for any integers c,d ,Z (z )=∆r (c,d,z )is an irreduciblepolynomial over Q ,and its splitting field is cyclotomic.(4)∆k (x,y,z )is irreducible over Q .Proof:Part (1)and (2)are directly from the definition of ∆k (x,y,z ).The proof of Part (3)is similar to that for Part (2)of Lemma 1,noting that for any integer c,d ,Z (z )=∆k (c,d,z )is irreducible polynomial if the only Galois action in Q (ξk )/Q that fixes ξ2k +dξk +cdξk −1k +c 2ξk −2k is the identity.Part (4)follows from part (3).Given a polynomial P ,one can ask whether P is the characteristic polynomial of the Frobenius endomorphism of a genus-2curve.This question is considerably harder than the similar question in the elliptic curve case.For simplicity we replace a 1,a 2by −a,b +2q respectively in (3)P (X )=(X 2+q )2−aX (X 2+q )+bX 2.In [1,page 54,59],a partial answer was obtained.Proposition 1If a pair of integers a,b satisfies following conditions:(1)0<b <a 2/4<q ,(2)b is not divisible by p ,and(3)neither of a 2−4b nor (b +4q )2−4qa 2is an integer square.Then there must exist a genus-2curve,whose Frobenius endomorphism has minimal poly-nomial (X 2+q )2−aX (X 2+q )+bX 2.It is easy to showLemma 3If q is a prime,a is the least prime less than 2√q .For all 0<b <a 24,there are only O (√q )number of b ’s such that one of a 2−4b and (b +4q )2−4qa 2is an integersquare.Proof of Theorem 2:If r is a prime,the order of Jac (H )(F q r )/Jac (H )(F q )is ∆r (q,−a,b +2q ).Fix a ,and let b vary from 0to a 2/4.From Lemma 2we see that if q >(2r log q )2+ then we can apply Theorem 3to the polynomial ∆r (q,−a,x +2q ),and there will beΩ(a 2/42(r −1)1+ log q )=Ω(q r 1+ log q)b ’s such that ∆r (q,−a,b +2q )is prime.Among them,there are only O (√q )number of b ’s such that one of a 2−4b and (b +4q )2−4qa 2is an integer square.Since √q =11o (q r 1+ log q ),there exist at least Ω(q r 1+ log q )curves H/F q of genus 2such that the order of Jac (H )(F q r )/Jac (H )(F q )is prime.If q =log 4+ n ,r =log n ,we will get at least Ω(log 3n )a 2’s,such that ∆r (q,−a,a 2)are primes,among them,at most O (√q )=O (log 2+ n )a 2’s make one of a 2−4b and(b +4q )2−4qa 2an integer square.This suggests the following strategy to set r and q .(1)Let r be the largest prime less thanlog n 8log log n ;(2)Let Q = n 12(r −1) ;Increase Q if necessary to satisfy (Q r/2−1)4(Q +1)≥n ;(3)Search for a prime between Q and Q +10log 2Q ,assign it to q ;Once q and r is fixed,the algorithm then randomly selects coefficients for a degree-5monic polynomial f (x ).It uses the BSGS method to count number of elements in H (F q )and H (F q 2),where H is the hyperelliptic curve defined by y 2=f (x ).Then we calculate Jac (H )(F q r )/Jac (H )(F q )and test for the primality.It is very hard to estimate the time complexity rigorously.Heuristically,we get a prime order with probability roughly equal to 1.The counting algorithm takes time O (q 3/4)=O (log 3n ).Hence the time complexity to generate one curve is O (log 4n ).Although our algorithms assume number theoretic conjectures,they work very well in practice.In fact,let n =2240,as many as 400curves of genus 2were generated at the average rate of less than five minutes per curve,as we ran a casual implementation of the algorithm on a PII 300Mhz computer.This algorithm is remarkably faster and generates much more curves than the other high genus curve generating algorithms.References[1]L.M.Adleman and M.A.Huang.Primality Testing and Abelian Varieties Over Finite Fields .Lecture Notes in Mathematics.Springer-Verlag,1992.[2]T.M.Apostol.Introduction to Analytic Number Theory .Springer-Verlag,1976.[3] A.O.L.Atkin and F.Morain.Elliptic curves and primality proving.Mathematics ofComputation ,61:29–67,1993.[4]P.T.Bateman and R.A.Horn.Primes represented by irreducible polynomials in one variable.In Proc.Symp.Pure Math ,pages 119–132,Providence,1965.AMS press.[5]Jinhui Chao,Kazuto Matsuo,Hiroto Kawashiro,and Shigeo Tsujii.Construction ofhyperelliptic curves with cm and its application to cryptosystems.In AsiaCrypto ,volume 1976of Lecture Notes in Computer Science .Springer-Verlag,2000.[6]H.Davenport.Multiplicative number theory .Springer-Verlag,2000.12[7]John Friedlander and Andrew Granville.Limitation to the equi-distribution of primes iv.Proc.Roy.Soc.London Ser.A,435(1893):197–204,1991.[8]P.Gaudry and R.Harley.Counting points on hyperelliptic curves overfinitefields.In ANTS,2000.[9]Ming-Deh Huang and D.Ierardi.Counting points on curves overfinitefields.J of Symboliccomputation,25:1–21,1998.[10]Kiran S.Kedlaya.Counting points on hyperelliptic curves using monsky-washnitzercohomology.J.Ramanujan Math.Soc.,16(4):323–338,2001.[11]N.Koblitz.Algebraic Aspects of Cryptography.Springer-Verlag,1998.[12]David R.Kohel.Rational groups of elliptic curves suitable for cryptography.Preprint,1999.[13]H.W.Lenstra.Factoring integers with elliptic curves.Annals of Mathematics,126:649–673,1987.[14]H.Maier.Primes in short intervals.Michigan Math.J.,32:221–225,1985.[15]M.Fouquet,P.Gaudry,and R.Harley.An extension of Satoh’s algorithm and itsimplementation.J.Ramanujan Math.Soc.,15:281—318,2000.[16]M.Fouquet,P.Gaudry,and R.Harley.Finding secure curves with the Satoh-FGH algorithmand an early-abort strategy.In Eurocrypt,2001.[17]N.D.Elkies.Elliptic and modular curves overfinitefields and related computational issues.In D.A.Buell and J.T.Teitelbaum,editors,Computational Perspectives on Number Theory: Proceedings of a Conference in Honor of A.O.L.Atkin,pages21–76.AMS/International Press, 1998.[18]Jan-Christoph Puchta.On the class number of p-th cyclotomicfield.Arch Math.,74:266–268,2000.[19]Y.Sakai and K.Sakurai.Design of hyperelliptic cryptosystems in small characteristic and asoftware implementation over f2n.In AsiaCrypt,volume1514of Lecture Notes in Computer Science,1998.[20]R.Schoof.Nonsingular plane cubic curves overfinitefibin.Theory Ser.A,46(2):183–211,1987.[21]R.Schoof.Counting points on elliptic curves overfinitefields.Journal of Theorie des Nombresde Bordeaux7,pages219–254,1995.[22]N.P.Smart.Elliptic curve cryptosystems over smallfields of odd characteristic.J.Cryptology,1999.[23]A.Weng.Constructing hyperelliptic curves of genus2suitable for cryptography.Preprint.13。
1997], Refinements for Restart Model Elimination
![1997], Refinements for Restart Model Elimination](https://img.taocdn.com/s3/m/4e82472c0066f5335a812158.png)
Peter Baumgartner Ulrich FurbachUniversit¨a t Koblenz Institut f¨u r InformatikRheinau1D–56075Koblenz GermanyE-mail:We present various refinements for the restart model elimination(RME)calculusand discuss their interrelationship.As a new variant of the calculus we introduceRME with early cancellation pruning and investigate its compatibility with the otherrefinements.Restart Model Elimination(RME)has been introduced as a variant of model elimination in[1] as a calculus which avoids contrapositives and which introduces case analysis.In[4]a variant for computing answers to disjunctive logic programs was introduced.RME is implemented as part of the PROTEIN system[2].One result of this paper is a table of completeness results with respect to the combination of the refinements head selection function,strictness,regularity,independance of the goal clause for RME(Figure1below).Another original result is completeness of“early cancellation pruning”1.In the following section we recall basic restart model elimination calculus,and in Section2.2 we introduce refinements.The main results of this paper are then presented in Section3.A pair of literals K L is a connection with MGUσiffσis a most general unifier for K and1Early cancellation pruning was introduced in[6]within the context of a nearHorn-Prolog variant,InH-Prolog.A tableaux is represented by a set of branches;branch sets are denoted by the letters P Q.We write P Q and mean P Q.Similarly,p Q means p Q.We write X p iff X occurs in p, where X is a node or a literal label.A substitutionσis applied to a branch set P,written as Pσ,by applyingσto all labels of all nodes in P.Branches may be labelled with a“”as closed;branches which are not closed are open.A tableaux is closed if each of its branches is closed,otherwise it is open.A computation rule is a total function c which maps a tableau to one of its open branches2.Let S be a clause set in Goal normal form.The inference rules of RME are defined as follows:p P A1A m B1B nExtensionStep:if L Leaf p is a connection with MGUσ,for some L p.p Pσp PRestartStep:2It is required that c is stable under lifting,which means that for any substitutionσ,whenever c Qσqσthenc Q q.A head selection function f is a function that maps a clause A 1A nB 1B m with n 1to an atom L A 1A n .L is called the selected literal of that clause by f 3.A RME derivation is called a derivation with selection functionf if in every extension step the extension literal A i is selected in A 1A nB 1B m by f .For example,to derive the RME tableaux in Section 2.1requires a head selection function which selects Q in Q P .The head selection function is a severe restriction of the calculus,but it can be applied and combined with some other refinements (but not all)to still yield a complete calculus.In RME there are two possibilities to further derive from an openbranch with positive leaf literal:either the branch can be closed by a reduction step or it can be extended in a restart step.In our sample refutation (Section 2.1)both possibilities are contained.In strict RME derivations we forbid reduction steps at positve leaf literals (i.e.in Definition 2.1,reduction step,Leaf p must be a negative literal).See [1]for further discussion.In order to arrive at a really goal -orientedcalculus,one wants to restrict the starting branch set to be derived from a negative clause (negative clause before the transformation to Goal normal form).Since we assume Goal normal form let uscall any clause Goal B 1B n S a goal clause .What we really want is to be independant of this goal clause:A (refinement of the)RME caculus is called independent of goal clause if everyderivationGoal P 0P 1where P 1is obtained by extension with a goal clause from a minimal unsatisfiable subset of the clause set S can be extended to a refutation,if a refutation exists.This is a well-know “loop-check”refinement:a branch is regular iffno literal occurs more than once on it;a tableaux is regular if each of its branches is regular.Reg-ularity is easy to implement 4and it is one of the most effective restrictions for model elimination procedures.Unfortunately,the regularity check is not compatible with RME.However,what can be achieved is blockwise reg-ularity :A branch p B 11B 1k 1A 1B 21B 2k 2A 2A n 1B n 1B n k n (where the A s and B s are atoms)is called blockwise regular iff1.A iA j for 1i j n 1,i j (Regularity wrt.positive literals),and 2.B l i B l j for 1l n ,1i j k l ,i j (Regularity inside blocks).A tableaux is called blockwise regular iff every branch in it is blockwise regular.For example,the RME tableaux in Section 2.1is blockwise regular.This refinement is essentially due to[6]and was called strong early cancellation pruning rule in Inh-Prolog.We allow to label positive nodes in RME tableaux by the symbol“r”(meaning:used for r eduction steps).If node L is labeled in this way we will write L r.The calculus RME with early cancellation pruning(RMEP)consists of the inference rule“extension step”of Def.2.1and the following inference rules:LabelingReductionStep:p L q Pp First p P if Leaf p is a positive literal,and the leafmost positive inner node of p,if it exists,is labeled with r.The notion of derivation is taken from Def.2.1.A RMEP refutation is a derivation of closed RME tableau where every inner positive node is labeled with r5.The idea of the early cancellation pruning is to achieve a relevance check:a new“case”by means of a restart step applied to L L may only be examined if the previous case L turned out to be“relevant”for the derivation of the new case L.Here,“relevant”means that L is the target for a reduction step before(hence“early”)the restart step at L is attempted.For example,in Figure2, restart at leaf D is not possible because ancestor B is not labelled with r.Most of our calculi variants allow for arbitrary computation rules.The notable exception are the variants which employ the early cancellation pruning.In these cases we have to restrict to the following class of computation rules which prefers negative leafs over positive ones:A negative preferrence compu-tation rule is a computation rule c such that whenever a positive inner node L is contained in an open branch p with positive leaf,and L is contained in an open branch p with negative leaf, then c does not select p.Calculus Selectionfunction RegularityIndep.ofgoal clauseComplete-ness5We emphasize that in order to make the labeling meaningfull,the r-label is to be attached to the node(but not to the label),such that it is shared with other branches.The negative results (the “no”entries in Figure 1)are shown by appropriate counterexamples to the assumption that the combination of the indicated features would yield a complete calculus.This ad-dresses line (3)in Figure 1.Consider the clause set M 1A A A C .There is no RMEP refutation of the Goal normal form of M 1with a head selec-tion function which selects in M 1the underlined atoms in the clause heads.Figure 2shows an exhaustive case analysis:either the derivation contains a negative leaf D and gets stuck because the sole clause containing D in the head is ABa)b)c)d)No extensionstep possible Not weaklyconnected ACCB GoalA AA B D Goal GoalFigure 2:“Selection Function”is incompatible to “Early Pruning”.Thisaddresses line (1)in Figure 1.Consider the clause set M 2P Q PA standard strategy for completeness proofs of related calculi is to prove completeness of the weakest variants only,i.e.the variants,the refutations of which can stepwisely be simulated by the other variants.For instance,strict RME is weaker than non-strict RME.For the case of restart model elimination there are the following two weakest variants:RME with“head selection function”,but without“independence of the goal clause.This addresses the“completeness”entry in line(1)in Figure1.See[4]for a proof.RME without“selection function”but with“independence of the goal clause”and with “early cancellation pruning”.This addresses the“completeness”entries in lines(2)and(4) in Figure1.Since this result is new we state it here explicitly;see the full version[3]for a proof.Let S be a minimal unsatisfiable ground clause set in Goal normal form,c be a negative preferrence com-putation rule.Then,for any clause G Goal B1B n S there is a strict,blockwise regular RMEP refutation via c with top clause Goal and goal clause G used in thefirst exten-sion step.We studied various refinements for the restart model elimination calculus.One of our main con-cerns was compatibility among them.Further,we developed a new variant,RME with early can-cellation pruning.1.Peter Baumgartner and Ulrich Furbach.Model Elimination without Contrapositives and its Applicationto PTTP.Journal of Automated Reasoning,13:339–359,1994.Short version in:Proceedings of CADE-12,Springer LNAI814,1994,pp87–101.2.Peter Baumgartner and Ulrich Furbach.PROTEIN:A PRO ver with a T heory E xtensionI nterface.In A.Bundy,editor,Automated Deduction–CADE-12,volume814of LectureNotes in Aritificial Intelligence,pages769–773.Springer,1994.Available in the WWW,URL:.3.Peter Baumgartner and Ulrich Furbach.Refinements for Restart Model Elimination.FachberichteInformatik24–96,Universit¨a t Koblenz-Landau,Institut f¨u r Informatik,Rheinau1,D-56075Koblenz, 1996.4.Peter Baumgartner,Ulrich Furbach,and Frieder puting Answers with Model Elimi-nation.Artificial Intelligence,90(1–2):135–176,1997.5. D.W.Loveland.Near-Horn Prolog.In ssez,editor,Proc.of the4th Int.Conf.on Logic Program-ming,pages456–469.The MIT Press,1987.6. D.W.Loveland and D.W.Reed.A near-Horn Prolog for Compilation.In Jean-Luis Lassez and GordonPlotkin,editors,Computational Logic—Essays in Honor of Alan Robinson,chapter III/16,pages542–564.MIT Press,1991.7. D.Plaisted.Non-Horn Clause Logic Programming Without Contrapositives.Journal of AutomatedReasoning,4:287–325,1988.。
REGIME SWITCHING GARCH MODELS

REGIME SWITCHING GARCH MODELS
Luc Bauwens1 , Arie Preminger,2 and Jeroen V.K. Rombouts3 June 2005, corrected July 17, 2006
ห้องสมุดไป่ตู้
1
Introduction
Over the past two decades there has been a large amount of theoretical and empirical research on modelling volatility in financial markets. Since volatility is commonly used as a measure of risk associated with financial returns, it is important to portfolio managers, option traders and market makers among others. Further, portfolio optimization, derivative pricing and risk management, such as Value-at-Risk (VaR), use volatility estimates as inputs. So far in the literature, the most widespread approach to modeling volatility consists of the GARCH model of Bollerslev (1986) and its numerous extensions that can account for the volatility clustering and excess kurtosis found in the data (see e.g. Bollerslev and Wooldridge (1992) for an overview of the GARCH literature). The accumulated evidence from empirical research suggests that the volatility of financial markets displays some type of persistence that cannot be appropriately captured by classical GARCH models. In particular, these models usually indicate high persistence in the conditional volatility. This persistence, as was noted by Hamilton and Susmel (1994), Gray (1996), and Klaassen (2002), is not compatible with the poor forecasting results of these models. Furthermore, Diebold (1986) and Lamoureux and Lastrapes (1990), among others, argue that the near integrated behavior of the conditional variance may originate from structural changes in the variance process, which are not accounted for by standard GARCH models. Mikosch and Starica (2004) show that estimating a GARCH(1,1) model on a sample displaying structural changes in the unconditional volatility does indeed create an integrated GARCH (IGARCH) effect. These findings clearly indicate a potential source of misspecification, to the extent that the structural form of the conditional mean and variance is relatively inflexible and held fixed throughout the entire sample period. For example, the existence of shifts in the variance process over time can induce volatility persistence (see Wong and Li (2001) and Lanne and Saikkonen (2003)). Hence the estimates of a GARCH model suffer from a substantial upward bias in the persistence parameter. Therefore, models in which the parameters are allowed to change over time may be more appropriate for modelling volatility. In this perspective, several models that are based on a mixture of distributions have been proposed. Schwert (1989) considers a model in which returns may have either a high or a low variance, and switches between these states are determined by a two-state Markov process. Hamilton and Susmel (1994) and Cai (1994) introduce an ARCH model with regime-switching 1
Polarimetric SAR Speckle Filtering

Polarimetric SAR Speckle Filtering and the Extended Sigma FilterJong-Sen Lee,Life Fellow,IEEE,Thomas L.Ainsworth,Fellow,IEEE,Yanting Wang,Member,IEEE,and Kun-Shan Chen,Fellow,IEEEAbstract—The advancement of synthetic aperture radar(SAR) technology with high-resolution and quad-polarization data de-mands better and efficient polarimetric SAR(PolSAR)speckle-filtering algorithms.Two requirements on PolSAR specklefiltering are proposed:1)specklefiltering should be applied to distributed media only,and strong hard targets should be kept unfiltered; and2)scattering mechanism preservation should be taken into consideration,in addition to speckle reduction.The purpose of this paper is twofold:1)to propose an effective algorithm that is an extension of the improved sigmafilter developed for single-polarization SAR;and2)to investigate speckle characteristics and the need for specklefiltering for very high resolution(decimeter) PolSAR data.The proposedfilter was specifically developed to ac-count for the aforementioned two requirements.Its effectiveness is demonstrated with Jet Propulsion Laboratory airborne synthetic aperture radar data,and comparisons are made with a boxcar filter,the refined Leefilter,and a Wishart-based nonlocalfilter. For very high resolution PolSAR systems,such as the German Aerospace Center F-SAR and Japanese Pi-SAR2,with decimeter spatial resolution,we found that the complex Wishart distribution is still valid to describe PolSAR speckle characteristics of dis-tributed media and that specklefiltering may be needed depending on the size of objects to be analyzed.F-SAR X-band data with 25-cm resolution is used for illustration.Index Terms—Polarimetric SAR(PolSAR),speckle reduction, very high resolution SAR.I.I NTRODUCTIONP OLARIMETRIC synthetic aperture radar(SAR)(Pol-SAR)backscattering returns can be characterized as the interaction of three correlated coherent interference processes: HH,VV,and HV polarizations.Due to the correlations be-tween polarizations,the speckle effect appears not only in the three intensities but also in the three complex correlation terms.For reliable interpretation and extraction of polarimetric information,the random aspect of polarimetric variables must be reduced by averaging the coherency or covariance matrices of neighboring pixels.This process forms data having theManuscript received December19,2013;revised April9,2014;accepted June19,2014.J.-S.Lee is with the Remote Sensing Division,Naval Research Labora-tory,Washington,DC20375USA,and also with Computation Physics Inc., Springfield,V A22151USA(e-mail:jong_sen_lee@).T.L.Ainsworth and Y.Wang are with the Remote Sensing Division,Naval Research Laboratory,Washington,DC20375USA.K.-S.Chen was with the National Central University,Zhongli32001, Taiwan.He is now with the Wave Scattering Research Center,University of Texas at Arlington,Arlington,TX32001USA.Color versions of one or more of thefigures in this paper are available online at .Digital Object Identifier10.1109/TGRS.2014.2335114characteristics of incoherent scattering[1].It is well known that incoherent averaging,which is also known as multilook pro-cessing,is an essential procedure before applying most PolSAR analysis techniques,such as the Cloude–Pottier eigenvalue and eigenvector decomposition[2],the Freeman–Durden model-based decomposition[3],etc.Without sufficient incoherent averaging,the derived parameters,such as entropy,alpha,and anisotropy,become biased and unusable.These bias effects have been analyzed in[4].The most commonly applied PolSAR specklefiltering is the boxcarfilter,which averages covariance or coherency matrices of neighboring pixels.The advantages of the boxcarfilter are in its simplicity,effectiveness in speckle reduction,and compu-tational efficiency.For applications such as forest biomass,sur-face roughness,and soil moisture extraction from homogeneous media,the boxcarfilter is frequently the preferred algorithm. The boxcarfilter is effective when the image does not contain distinctive features and when preservation of spatial resolution is not a concern.For general applications,however,speckle filtering using more sophisticated techniques is required to reduce speckle noise,to better retain spatial resolution and preserve scattering mechanisms.The objective of PolSAR specklefiltering is to reduce the speckle noise level while preserving1)spatial resolution,2)po-larimetric scattering property,and3)statistical characteristics, which is similar to multilook averaging of covariance matrices or coherency matrices[5].In this paper,we will discuss several important issues associated with PolSAR specklefiltering(see Section II)and propose a PolSARfiltering algorithm that is an extension of the improved sigmafilter developed forfil-tering single-channel SAR data.The proposed PolSARfilter possesses these desirable properties.Moreover,we will address the issue of speckle statistics and the requirement of speckle filtering for very high resolution(decimeter)PolSAR data. These results are illustrated with F-SAR X-band data of25-cm resolution.A.Multilook Covariance and Coherency Matrices Polarimetric radar measures the complex scattering matrix of a medium with quad polarizations[1].The scattering matrix in linear polarization base can be expressed asS=S hh S hvS vh S vv(1)where S hh is the scattering element of horizontal transmit-ting and horizontal receiving polarization,and the other three0196-2892©2014IEEE.Personal use is permitted,but republication/redistribution requires IEEE permission.See /publications_standards/publications/rights/index.html for more information.elements are similarly defined.For the reciprocal backscatter-ing case,S hv=S vh.The polarimetric scattering information can be represented by a complex vector in the linear basis or in the Pauli basis,as shown inΩ=[S hh √2S hv S vv]Tk=1√2[S hh+S vv S hh−S vv2S hv]T(2)where superscript“T”denotes matrix transpose.To obtain additional scattering information from incoherent scattering, we form N-look covariance matrix C or coherency matrix T shown inC=1NNi=1ΩiΩ∗T i T=1NNi=1k i k∗T i.(3)For speckle reduction,it is desirable to include a large number of pixels from homogeneous areas on the average.Frequently, PolSAR data were multilook processed in advance.For exam-ple,many Jet Propulsion Laboratory(JPL)/Airborne Synthetic Aperture Radar(AIRSAR)data sets are four-look processed. However,the quad-pol single-look complex(SLC)data are moreflexible and valuable for retaining spatial resolution,for better polarimetric calibration,and for polarimetric SAR inter-ferometry applications.RadarSAT-2and ALOS/PALSAR are important spaceborne systems producing SLC data.Currently, very high resolution(decimeter)airborne polarimetric SAR systems,such as F-SAR and Pi-SAR2,are taking SLC data. It should be noted that the direct averaging scattering matrices do not reduce speckle.B.Review of Existing PolSAR Speckle FiltersThe basic procedure in PolSAR specklefiltering is to locate pixels of similar scattering property and then perform statistical estimation techniques,such as simple average,minimum mean square estimation,etc.[5]–[12].The selection of homogeneous pixels of similar scattering property is the key to effective and robustfiltering.In the refined Lee PolSARfilter[5],eight edge-aligned windows are established,and the most homogeneous window is selected,and then,a minimum mean square estima-tor(MMSE)is applied.The algorithm has been generalized to apply to9×9,11×11,and larger windows from its original 7×7windows.Thisfilter is simple in concept and reason-ably effective in specklefiltering particularly when preserving edges.Vasile et al.[8]selected pixels by applying a region-growing technique.Most techniques in specklefiltering are based on statistical estimation,whereas a few specifically take polarimetric scattering properties into consideration.One ex-ample is that based on unsupervised classification results using scattering-model-based decomposition[6]and which selects pixels of the same scattering mechanisms(i.e.,surface,double bounce,and volume)to be included in thefiltering.This pro-cedure preserves the dominant scattering mechanisms of each pixel.Recently,the“nonlocal”PolSAR specklefilters[9],[10] have been developed,and successful results were claimed.The word“nonlocal”is a somewhat-misleading name.It could be easily misinterpreted that local pixels were not included in thefiltering and that all pixels of the image,as opposed to “local”pixels,were included in thefiltering of each pixel.As a matter of fact,it is a localfilter that uses a large window, typically15×15or larger.Thefilter selects pixels based on Conradsen’s hypothesis test[13]on the similarity between Wishart covariance matrices.A patch(i.e.,a group of connected pixels)associated with the pixel to befiltered is established, and all patches of similar statistics,within the large window, are selected and weighted in thefiltering.In practice,the patch is a smaller window that is typically3×3or5×5in size, and the center pixel is the one to befiltered.From the statistical test of Conradsen[13]on the similarity between two Wishart covariance matrices,the following test statistic(4)was derived for the similarity between two patches with covariance matrices C and D,respectively:ln H=N2qk ln2+J1(ln|C i|+ln|D i|−2ln|C i+D i|)(4) where J is the number of pixels in the patch,N is the number of looks of the data,and q=3denotes the dimension of the covariance matrix.The summation is over all the pixels in the patch.Tofilter the center pixel of patch C,the test statistics are computed for all patches in a very large window,and they are selected as similar if they fall within a preset threshold ln H t (refer to[9]).Then,the covariance matrices of all center pixels of the selected patches are weighted on the average,producing thefiltered result.For a SAR image containing similar repeated patterns,such as regularly gridded city blocks,the use of the structure similarity within a patch may have an advantage in filtering these areas with less blurring.However,a serious drawback of the nonlocalfilter is that it can only apply to multilook PolSAR data with the number of looks greater than2. This is because test statistics(4)contains ln|C|and ln|D|, which become undefined if the rank of C or D is less than3. Even the four-look AIRSAR data of San Francisco has about 5%of pixels with rank less than3.An improvised approach is to force the single-look matrices to be diagonal when computing (4),but to include the single-look covariance matrices in the weighted average.However,we found this procedure less than satisfactory,because the high speckle level makes patch match-ing inefficient.We will discuss the detail in Section V.The other drawbacks are that overfiltering is observed,which could eliminate minor features,and that the algorithm’s complexity and computational load could be prohibitive for large data sets from current spaceborne SAR systems.Illustrated examples will be presented later.C.Review of Improved Sigma Filter for Single-ChannelSAR DataThe sigmafilter for single-channel SAR data was introduced by Lee[14]in early1980as a way of selecting homogeneous areas.The Lee sigmafilter has been implemented in several GIS software because of its simplicity,its effectiveness in speckleTABLE IS IGMA R ANGE (I 1,I 2)FOR O NE -L OOK TO F OUR -L OOK I NTENSITY D ATA W AS C OMPUTED B ASED ON THE S PECKLE PDFS TO A VOID E STIMATIONB IAS .T HE R EVISED N OISE S TANDARD D EVIATION ηvI S FOR MMSE APPLICATIONreduction,and its computational efficiency.However,thefollowing deficiencies have been discovered:1)it fails to main-tain the mean value and produces biased results,particularly if the number of looks of the original SAR data is small (less than four looks);2)strong hard targets are blurred and their power is reduced;and 3)dark spotty pixels are not filtered.The improved sigma filter [15]developed in 2007was devised to overcome these deficiencies.Bias Compensation and Dark Pixel Removal:For single-look amplitude and intensity SAR data,the probability distribu-tion is far from symmetrical,because they follow the Rayleigh and the negative exponential distributions,respectively.This asymmetry produces biased estimates if the sigma ranges are not properly chosen.This is because the original sigma range was derived based on Gaussian distribution.Consequently,to remove the bias,the sigma ranges were recomputed based on the corresponding speckle distribution functions.The idea is to preserve the mean value.For the general case of the mean value of 1,the sigma range (I 1,I 2)of the intensity SAR data is computed for sigma values between 0.5and 0.95and for one-look to four-look,as shown in Table I.We note that,due to the asymmetric probability density functions (pdfs),the interval (1−I 1),between I 1and the mean value of 1,is always smallerthan the interval (I 2−1).The sigma range,for any a priori mean value x ,can be easily computed from these tables as (I 1 x,I 2 x ).The original sigma filter used the center pixel in a moving window as the a priori mean x ;this produced the isolated dark pixel problem,because the sigma range is close to zero for small x .To mitigate this problem,the 3×3average could be used as x ;however,it may introduce blurring albeit only slightly.The improved sigma filter applied the MMSE [5],[16]in the 3×3window to estimate the a priori mean x ,which effectively reduced the isolated dark pixels and improved the overall speckle filtering effect.The minimum mean square filter based on the multiplicative noise model has the formˆx =(1−b )¯z +bz(5)withb =Var(x )Var(z )(6)Var(x )=Var(z )−¯z 2η2v(1+ηv).(7)In (5)–(7),the local mean ¯z and the local variance Var(z )are computed using pixels in the 3×3window,and Var(x )is the variance of x ,which is computed by (7).The parameter ηv is the standard deviation of multiplicative noise v and is a function of number of looks.For example,for one-look intensity,ηv =1.For N -look SAR data,ηv is 1/√The a priori mean is obtained by (5),or x =ˆx .We should note that the MMSE will be applied again for final filtering using pixels within the sigma range.Final Filtering Using Pixels in the Sigma Range:In a mov-ing window of 7×7,9×9,11×11,or larger,pixels withinthe new sigma range,(I 1 x,I 2 x )are included in the filtering,where the sigma range I 1and I 2are mentioned in Table I.The MMSE filter of (5)–(7)is again applied here;however,the local mean and local variance are calculated using pixels selected in the sigma range.In addition,we found that the speckle noise standard deviation ηv in (7)has to be adjusted,because the valid range of the pdf is limited by the sigma range.The revised ηv ,which was listed in Table I,is used here.It has a value smaller than the original ηv .The data would be oversmoothed,if the original ηv were applied.Preservation of Point Targets:Preservation of signatures from strong point targets and man-made structures are desirable for image interpretation and other applications.These high-return pixels are generally produced by the double-bounce scattering mechanism or by direct specular reflection.Backscat-tering signatures of high power targets are significantly dif-ferent from those of distributed media.They are dominated by a small number of strong elementary scatterers,in contrast to the speckle characteristics of distributed media.In other words,they do not possess the typical speckle characteris-tics.Consequently,they have to be processed differently from backscattered signatures of distributed media.The algorithm is based on the detection of strong scatterers of several clustered pixels in size.The first step of this algorithm is to compute the 98th percentile of all pixels of the SAR data tobefiltered.We denote the98th percentile as Z98.If the power of the pixel to befiltered is greater than Z98,we count the number of such pixels in a3×3window,which are also greater than Z98.If the total number is greater than a threshold K,typically set between5and7,we consider all those pixels belong to the strong target,and they remain unfiltered.However,spikes that are sometimes seen in distributed media typically do not cluster together.Thus,using this procedure,isolated spikes in distributed media will befiltered.II.I SSUES A SSOCIATED W ITH P OL SARS PECKLE F ILTERING1)Point Targets Versus Distributed Targets:We have men-tioned that strong backscattering from point targets mainly comes from a few strong elementary scatterers within a res-olution cell.They do not possess the typical characteristics of speckle—not random in nature.Consequently,in principle, speckle-filtering actions should not be applied to strong targets but only to areas of distributed targets.Strong targets should not befiltered or should befiltered differently from distributed targets.Filtering strong targets may cause blurring due to aver-aging of neighboring pixels from distributed media.The impor-tant question is how to detect strong targets.A technique in the improved sigmafilter[15]has been implemented;however,it could be further improved by including scattering properties.2)Homogeneous Pixel Selection by Scattering Mechanisms: In principle,speckle reduction for distributed scatterers requires averaging pixels within a homogeneous area.For many algo-rithms,the criterion starts mainly from a statistical viewpoint based on the complex Wishart distribution.We do not consider this to be sufficient for homogeneous pixel selection.We con-sider that two pixels are similar in scattering property,if they are similar not only in statistical property but also in polarimetric scattering mechanism.3)Preservation of Underlying Reflectivity:Specklefiltering should preserve small variations that are not due to the speckle effect.Overfiltering can greatly reduce the speckle level at the cost of eliminating minor features and smoothing out the naturally occurring variations of underlying reflectivity.All credible PolSARfilters will blur minor features to some degree. The nonlocalfilter[9],[10]claims great speckle reduction results and rightly so,but we will show later that minor features and underlying reflectivity are compromised.This undesirable effect is to some degree equivalent to spatial resolution degrada-tion,although strong edges and large features were preserved.4)Filtering Each Element of Coherency Matrix Equally: Whenfiltering polarimetric SAR data,thefirst priority is to preserve the scattering property inherent in SAR data.If we filter each element of the coherency matrix separately,for ex-ample,the correlation between polarizations would be affected producing the adverse effect that the correlation coefficients are no longer preserved.During the last decade,most speckle-filtering algorithms[5]–[12]have followed the aforementioned principles.One exception is thefilter proposed by López-Martínez and Fabregas in[17]and López-Martínez in[22], in which the authors developed an additive and multiplicative noise model for the real and imaginary parts of the off-diagonal terms.The diagonal terms were similarlyfiltered as the refined Leefilter,but the off-diagonal terms werefiltered by wavelet transform based on his noise model.It is apparent that the diagonal terms and off-diagonal terms were separatelyfiltered. We believe that PolSAR specklefilters should aim to preserve scattering properties and not to enhance it.The principle of preserving the statistical characteristics was proposed Lee et al.[5]:1)The covariance or coherency matrix should befiltered ina manner similar to multilook processing by averaging matrices of neighboring pixels.That is,all terms of the matrix should be filtered identically.2)Moreover,to avoid introducing crosstalk between polarizations,each term should befiltered equally and statistically independent of other terms.5)Very High Resolution PolSAR Data:Recent advances in airborne PolSAR systems,such as the German Aerospace Center(DLR)F-SAR and Japanese Pi-SAR2,generate data with decimeter(0.25–0.65m)resolution.Future spaceborne PolSAR systems with decimeter resolution are expected.For these very high resolution data,the size of the resolution cell is close to the radar wavelength.Two important issues immedi-ately come to mind:1)the existence of speckle phenomenon; and2)the applicability of current specklefilters.One of the requirements of fully developed speckle is that the resolution cell is much larger than the radar wavelength.High-resolution data may violate this requirement,since the diameter of the resolution cell is only about six to ten times larger than radar wavelength.However,we notice from high-resolution SAR images the same kind speckle pattern as that shown in the lower resolution SAR images.We will show later that the amplitudes of pixels in homogeneous and nontextured regions are very much Rayleigh distributed for very high resolution X-band and S-band data.This is a strong indication that the assumption of Wishart distribution is still valid for distributed features. As far as the neediness of specklefiltering,it may not be needed,if the size of objects to be analyzed is much larger than the spatial resolution.However,for small object analysis and geophysical parameter estimation,the existing specklefilters can be effectively applied.These two issues will be addressed in more detail in Section V.6)Computational Efficiency and Algorithm Complexity: TerraSAR-X,Cosmo-Skymed,and other SAR systems image areas with large dimension and high-resolution data in single polarization,dual polarizations,and quad-polarizations.The dimension is on the order of10000×10000pixels.The large dimension of high-resolution SAR images demands a highly efficient algorithm,and the complexity of algorithms with many variable parameters and thresholds may considerably increase the computational load.The sigmafilter is known for its high efficiency,and it is extended to PolSAR specklefiltering while maintaining its efficiency.We will also discuss the extension of the proposed sigmafilter to cover dual-polarization data in Section VI.III.E XTENDED S IGMA F ILTER FOR P OL SAR F ILTERING Here,we extend the improved sigmafilter tofilter PolSAR images.To include the physical scattering process into consid-eration,we applyfiltering to the coherency matrix rather thancovariance matrix,because the coherency matrix is formulated closer to the physical scattering process than the covariance matrix.However,thefilter can be applied directly to covariance matrix data.A slightly modified procedure is given at the end of this section.It is well known that the diagonal terms of the coherency matrix,i.e.,T11,T22,and T33,are sensitive to surface (specular),double-bounce,and volume scattering,respectively. In thefirst step,strong targets were detected from each of the T11and T22intensity images,and all strong-target pixels are combined and kept unfiltered.In the next step,homogeneous pixels in distributed target regions were selected in a window (7×7,9×9,or larger)from pixels within the sigma range of each of these three images,and then,only pixels selected by all three images are included in thefiltering.By following this procedure,the selected pixels will have similar scattering mechanisms.Details are given in the following steps.1)Strong Target Detection:In PolSAR imagery,strong re-turns from hard targets are likely not induced by speckle phenomenon,because they are dominated by a few strong ele-mentary scatterers.They should be left unfiltered.The difficult task is to reliably separate them from distributed scatterers. An aforementioned procedure for single-channel SAR data was proposed in the improved sigmafilter[15].For PolSAR implementation,strong point targets are detected by|HH−VV|2(i.e.,T22)for double bounce and|HH+VV|2(i.e.,T11) for specular returns.The cross-pol term is not used for point target detection;most point targets have low returns in HV. However,it could be included,if the scene contains buildings or man-made structures not aligned in the azimuth dissection that induce higher cross-polarization power[21].A small3×3window is used for point target detection.The98th percentile and the threshold K=5are used for target detection from the T11image and the T22image separately.The98th percentile will include most strong targets,and the threshold on strong targets greater than5,in a3×3window,will weed out isolated spikes that could come from the speckle phenomenon.Since strong targets from double bounce generally have weak return in T11and strong specular returns have low returns in T22,the detected pixels are combined by the“logic-or”operation.These pixels will be left unfiltered( T=T).This initial approach is reasonably effective,but further improvement could be made by incorporating the procedure of region growing at the cost of increased complexity and computational load.2)Speckle Filtering for the Rest of the Pixels:For the rest of the pixels that include distributed media,homogeneous pixel selection is based on the sigma range for T11,T22,and T33. The sigma range is established using the a priori mean for each polarization.To preserve the scattering mechanism,only pixels selected by all three images are included in thefinalfiltering.a)Estimate the a priori mean:The a priori means,i.e., T11, T22,and T33,are estimated by the MMSEfilter in3×3windows with the regular standard deviation to mean ratio (for example,ηv=1for single-look intensity andηv=0.5for four-look).Then,the sigma ranges( T ii I1, T ii I2)are estab-lished for the selection of homogeneous pixels,where(I1,I2) are listed in Table I.b)Select pixels in the sigma range:Only pixels selected by all three polarizations are included in thefiltering.Other Fig.1.Flowchart of the extended sigma specklefilter for PolSAR data. pixels are considered as outliers and will be ignored.In otherwords,a pixel selected by one or two polarizations only willnot be included in thefiltering.This ensures that the selectedpixels have the same scattering mechanisms.The selection ofthe sigma value affects the degree of speckle reduction.Forfour-look PolSAR data,we use0.9,and for single-look data,we use0.6or0.7to avoid overfiltering,because the sigmarange(I2−I1)for single-look data is much larger than that of four-look data.It should be noted that,in rare cases(about one in400000pixels),no pixel is selected in the sigma range.The3×3average of coherency matrices will be applied tofilter the centerpixel.This happens more frequently when a small sigma valueis picked.3)Apply MMSE to the Coherency Matrices:After pixelsare selected,the span(s=T11+T22+T33)image is used toobtain the weight for thefinalfiltering of the coherency matrix.To apply MMSE,we substitute s for z in(5)–(7).Span valuesof selected pixels are included to evaluate the local mean z andthe local variance Var(z),and then,(6)and(7)are applied tocompute weight b using the reduced noise standard deviation ηv.Finally,all elements of the coherency matrix arefiltered equally and separately byˆT=(1−b)T+bT(8)where weight b is a scalar computed based on the span of the selected pixels using(6)and(7),T is the original coherency matrix,and T is the local mean value of T for the selected pixels.The revised ηv in Table I is applied here.For clarity, aflowchart is given in Fig.1.Implementation Remarks:a)When computing the sigma range,only the ranges for the data of integer number of looks (up to four-look)are listed in Table I.For PolSAR data with。
Using Introspective Reasoning to Re ne Indexing

A number of studies have examined the use of metareasoning to control the application of system domain knowledge and to guide acquisition of domain knowledge (e.g., Bradzil and Konolige, 1990 Davis, 1982]). A more recent use of introspective reasoning is to monitor a system's own reasoning processes in order to re ne those processes by failure-driven learning (e.g., Collins et al., 1993 Ram and Cox, 1994 Cox and Freed, 1995]). This paper presents an approach to introspective reasoning for re ning the case retrieval criteria of a case-based planning system. In the approach we are investigating, an introspective reasoning component monitors the processing of a case-based reasoning system and evaluates that processing in comparison to expectations for the ideal performance of the case-based reasoning process (for example, the expectation that the case retrieved will be the
Mastering Regular Expressions

Mastering Regular Expressions (mini version)Jeffrey E. F. Friedl1st Edition January 19971-56592-257-3, 366 pagesRegular expressions, a powerful tool for manipulating text and data, are found in scripting languages, editors, programming environments, and specialized tools. In this book, author Jeffrey Friedl leads you through the steps of crafting a regular expression that gets the job done. He examines a variety of tools and uses them in an extensive array of examples, with amajor focus on Perl.Release Team[oR] 2001Preface 1 Why I Wrote This BookAudienceIntended1 Introduction to regular expressions 21.1 What are regular expressions used for1.2 Solving real problems1.3 Regular expressions as a language1.4 The filename analogy1.5 The language analogy1.6 The regular expression from in mind1.7 Searching text files1.8 Grep, egrep, fgrep, perl, say what?2 Character classes 52.1 Matching list of characters2.2 Negated character classes2.3 Character class and special characters2.4 POSIX locales and character classes3 Regular expressions syntax 93.1 Marking start and end3.2 Matching any character3.3 Alternation and grouping3.4 Alternation and anchors3.5 Word boundaries3.6 Quantifiers (basic, greedy)3.7 Quantifiers (basic, additional)3.8 Quantifiers (extended, non-greedy)3.9 Ignoring case3.10 Parentheses and back references3.11 Problems with parentheses3.12 The escape character - backslash3.13 Backslash character notation in regular expressions3.14 Line endings \r \n and operating systems3.15 Perl shorthand regular expressions4 Perl zero width assertions 184.1 Beginning of line (^) and (\A)4.2 End of line ($) and (\Z) and (\z)4.3 Word (\b) and non-word (\B) boundaries4.4 Match continue from last position (\G)5 Perl Regular expression modifiers 205.1 Perl match operator5.2 Perl substitute command5.3 Modifiers in matches5.4 Do not reset position or continue (c)5.5 Global matching (g)5.6 Ignore case (i)5.7 Lock regular expression (o)5.8 Span multiple lines (m)5.9 Single line matches and dot (s)5.10 Extended writing mode (x)5.11 Evaluate perl code (e)6 Perl Extended regular expression patterns 256.1 Comment (?#text)6.2 Modifiers (?imsx-imsx)6.3 Non-capturing parenthesis (?:pattern)6.4 Zero-width positive lookahead (?=pattern)6.5 Zero-width negative lookahead (?!pattern)6.6 Zero-width positive lookbehind (?<=pattern)6.7 Zero-width negative lookbehind (?<!pattern)6.8 Zero-width Perl eval assertion (?{ code })6.9 Postponed expression (??{ code })subexpression (?>pattern)6.10Independent6.11 Conditional pattern (?(condition)yes-pattern|no-pattern)7 Regular expression discussion 287.1 Matching numeric ranges7.2 Pay attention to the use of .*7.3 Variable names7.4 A String within double quotes7.5 Dollar amount with optional cents7.6 Matching range of numbers7.7 Matching temperature values7.8 Matching whitespace7.9 Matching text between HTML tags7.10 Matching something inside parenthesis7.11 Reducing number of decimals to three (substituting)8 Different regular expression engines 338.1 Regexp engine types8.2 NFA engine relies on regexp (Perl, Emacs)8.3 DFA engine reads text8.4 Crafting regular expressionsin capabilitiesDifferences8.59 Appendix A - regular expressions 369.1 Perl regular expression syntax9.2 Regular expression engines9.3 Regular expression rules9.4 How to write good regular expressions9.5 Understanding negative lookahead10 Appendix B - Perl language 4010.1 Perl manual pages10.2 Useful Perl command line switches10.3 Perl environment variablesPrefaceThis book is about a powerful tool called "regular expressions."Here, you will learn how to use regular expressions to solve problems and get the most out of tools that provide them. Not only that, but much more: this book is about mastering regular expressions.If you use a computer, you can benefit from regular expressions all the time (even if you don't realize it). When accessing World Wide Web search engines, with your editor, word processor, configuration scripts, and system tools, regular expressions are often provided as "power user" options. Languages such as Awk, Elisp, Expect, Perl, Python, and Tcl have regular-expression support built in (regular expressions are the very heart of many programs written in these languages), and regular-expression libraries are available for most other languages. For example, quite soon after Java became available, a regular-expression library was built and made freely available on the Web. Regular expressions are found in editors and programming environments such as vi, Delphi, Emacs, Brief, Visual C++, Nisus Writer, and many, many more. Regular expressions are very popular. There's a good reason that regular expressions are found in so many diverse applications: they are extremely powerful. At a low level, a regular expression describes a chunk of text. You might use it to verify a user's input, or perhaps to sift through large amounts of data. On a higher level, regular expressions allow you to master your data. Control it. Put it to work for you. To master regular expressions is to master your data.Why I Wrote This BookYou might think that with their wide availability, general popularity, and unparalleled power, regular expressions would be employed to their fullest, wherever found. You might also think that they would be well documented, with introductory tutorials for the novice just starting out, and advanced manuals for the expert desiring that little extra edge.Sadly, that hasn't been the case. Regular-expression documentation is certainly plentiful, and has been available for a long time. (I read my first regular-expression-related manual back in 1981.) The problem, it seems, is that the documentation has traditionally centered on the "low-level view" that I mentioned a moment ago. You can talk all you want about how paints adhere to canvas, and the science of how colors blend, but this won't make you a great painter. With painting, as with any art, you must touch on the human aspect to really make a statement. Regular expressions, composed of a mixture of symbols and text, might seem to be a cold, scientific enterprise, but I firmly believe they are very much creatures of the right half of the brain. They can be an outlet for creativity, for cunningly brilliant programming, and for the elegant solution.I'm not talented at anything that most people would call art. I go to karaoke bars in Kyoto a lot, but I make up for the lack of talent simply by being loud. I do, however, feel very artistic when I can devise an elegant solution to a tough problem. In much of my work, regular expressions are often instrumental in developing those elegant solutions. Because it's one of the few outlets for the artist in me, I have developed somewhat of a passion for regular expressions. It is my goal in writing this book to share some of that passion.Intended AudienceThis book will interest anyone who has an opportunity to use regular expressions. In particular, if you don't yet understand the power that regular expressions can provide, you should benefit greatly as a whole new world is opened up to you. Many of the popular cross-platform utilities and languages that are featured in this book are freely available for MacOS, DOS/Windows, Unix, VMS, and more. Appendix A has some pointers on how to obtain many of them.Anyone who uses GNU Emacs or vi, or programs in Perl, Tcl, Python, or Awk, should find a gold mine of detail, hints, tips, and understanding that can be put to immediate use. The detail and thoroughness is simply not found anywhere else. Regular expressions are an idea—one that is implemented in various ways by various utilities (many, many more than are specifically presented in this book). If you master the general concept of regular expressions, it's a short step to mastering a particular implementation. This book concentrates on that idea, so most of the knowledge presented here transcend the utilities used in the examples.1.0 Introduction to regular expressions1.1 What are regular expressions used forHere comes the scenario: Your boss in the documentation department wants a tool to check double words e.g. "this this", a common problem with documents subject to heavy editing. Your job is to create a solution that will:•Accept any number of files to check, report each line of each file that has double words.•Work across lines, find word even in separate lines.•Find double words in spite of the capitalization differences "The", "the", as well as allowing whitespace in between the words.•Find doubled words that might even be separated by HTML tags. "it s very <I>very</I> important"That is not an easy task! If you use such a tool for existing documents, you may surprisingly find similar spelling mistakes in various sources. There are many programming languages one could use to solve the problem, but one with regular expression support can make the job substantially easier.Regular Expressions are the key to powerful, flexible, and efficient text processing. Regexps themselves, with a general pattern notation, almost like a mini programming language, allow you to describe and parse text. With additional support provided by the particular tool being used, regular expressions can add, remove, isolate, and generally fold, spindle all kinds of text and data. It might be as simple as text editor's search command or as powerful as a full text processing language. You have to start thinking in means of Regexps, and not the the way you have used to with your previous programming languages, because only then you are taking the full magnitude of their power.The host language (Perl, Python, Emacs Lisp) provides the peripheral processing support, but the real power comes from regular expressions. Using the Regexps right will make it possible to identify the text you want and bypass the portions that you are not interested in.1.2 Solving real problemsChecking text in filesAs a simple example, suppose you need to check slew of files (70-150) to confirm that each file contained SetSize exactly as often as contained ResetSize. To complicate matters, you should disregard the capitalization and accept SETSIZE. The total count of lines in those files could easily end up to 30000 or more and checking them by hand would give you a headache. Even using normal "find this word" with text processor would have been truly arduous, what with all the files and all the possible capitalizations. Regexps come to rescue. Typing just a single short command your make the work in seconds and confirm what you want to know.% perl -0ne "print qq($ARGV\n) if s/ResetSize//ig != s/setSize//ig" *Summary of Email mailboxIf you wanted to create a summary of the messages in your mailbox, it would be tedious to read all your 1000 mails and store the important lines to a separate lines by and (like From: and Subject:). What if you were behind dial-up? The on-line time spend in making such summary easily eats your pocket if you had to do it multiple times. In addition, you couldn't do that to some other person, because you would see the contents of his mailbox. Regexps come to rescue again. A very simple command could display summary of those two lines immediately.% perl -ne "print if /*(From|To):/" ~/Mail/*What if someone asked about that summary? It would be non-needed to send the 5000 line results, when you could send that little one-liner to the friend and ask him to run it for his mailbox.1.3 Regular expressions as a languageUnless you have had some experience with regular expressions, you wouldn't understand the above commands. There really is no special magic here, just set of rules that must be digested. once you learn how to hide a coin behind your hand, you know there is not much magic in it, just lot of practice and learning new skills. Like a foreign language, it will start stopping sound like "gibberish" after a while.1.4 The filename analogyIf you have only experience on the Win32/Windows environment, you have a grasp that following refers to multiple files:*.txtWith such filename patters like this (called file globs) there are few characters that have a special meaning.* => means: "MATCH ANYTHING"? => means: "MATCH ONE CHARACTER"The complete example above will be parsed as*.txt||||||||Match three characters in order "t" "x" "t"|Match a "dot"Match anything [A special character]And the whole patters is thus read as "Match files that start with anything and end with .txt"Most systems provide a few additional special characters, but in general these filename patterns are limited in expressive power. This is not much of a shortcoming because the scope of the problem (to provide convenient ways to specify group of files) is limited to filenames.On the other hand, dealing with general text is a much larger problem. Prose and poetry, program listings, reports, lyrics, HTML, articles, code tables, word lists ...you name it. over the years a generalized pattern language has developed which is powerful and expressive for wide variety of uses. Each program implements and uses them differently, but in general this powerful pattern language and the patterns themselves are called Regular Expressions.1.5 The language analogyFull regular expressions are composed of two types of characters. The special characters (like "*" in files) are called meta-characters, while everything else are called literal or normal text characters. What sets regular expressions apart from the filename patterns is the scope of power their meta-characters provide. Filename patterns provide limited patterns, but regular expression "Language" provides rich and expressive power to advanced users.1.6 The regular expression from in mindComplete regular expressions are built up from small building block units. Each building block is in itself quite simple, but since they can be combined in an infinite number of ways, knowing how to combine them to achieve a particular goal takes some experience. While some regular expressions may seem silly, they do really represent the kind of tasks that are done in real - you just might not realize it yet.Just as there are difference between playing musical piece well and making music, there is a difference between understanding regular expressions and really understanding them.1.7 Searching text filesFinding text is the simples uses of regular expressions - many text editors and word processors allow you to search a document using some kind of pattern matching. Let's return to the original example of finding some relevant lines from a mailbox, we study it in detail:Perl command part|| Regular expression part+------+ +-----------+% perl -ne "print if /*(From|To):/" file.txt| | | | || | | | Read from file| | | Start of the code Win32/Unix. Unix also accepts single(')| | || | Give some options| | -n Do not print unless requested| | -e Read expression or code immediately| || Call program "perl"|command shell's prompt. In Unix % or $ and in Win32 typically >Even more simple example would be searching every line containing word like "cat":% perl -ne "print if /cat/" Mail/*.*But things are not that simple, because how do you know which word is plain "cat", you must consider how "catalog", "caterpillar", "vacation" differs semantically from the animal "cat". The matched results do not show what was really matched and made the line selected, the lines are just printed. The key point is that regular expressions searching is not done a "word" basis, but in general only character basis without any knowledge about e.g. English language syntax.1.8 Grep, egrep, fgrep, perl, say what?There is a family of products that started the era of regular expressions in Unix tools know as grep(1),egrep(1), frep(1), sed(1) and awk(1). The first of all was grep, soon followed by extended grep egrep(1), which offered more patterns in regular expression syntax. The final evolution is perl(1) which enhanced the regular expressions way further that could be imaginable. Whenever you nowadays talk about regular expression, the foundation of new inventions lies in Perl language. The Unix man page about regular expression it in ´regexp(5)'.2.0 Character classesYou must THINK that the character class notation is something of its own regular expression sub language. It has its OWN rules that are not the same as outside of character classes.2.1 Matching list of charactersWhat if you want to search all colors of "grey" but also spelled like "gray" with a one character difference. You can define a list of characters to match, a character class. This regexp reads: "Find character g followed by e and try next character with e OR a and finally character y is required."./ge[ea]y/As another example, suppose you want to allow capitalization of word's first letter. Remember that this still matches lines that contain smith or Smith embedded in another word as blacksmith. This issue is usually the source of the problem among new users./[Ss]mith/You can list in the class as many characters as you like. Notice that you can list the items in any order:/[0123456]//[6543210]/Which might be a good set of choices to find HTML heading from the page with: <H1> <H2> .. <H6> (That is the maximum according to HTML 4.x specification. Refer to /)/<H[0123456]>/There are few rules concerning the character class: Not all characters inside it are pure literals, taken "as is". A dash(-) indicates a range of characters, and here is identical example:/<H[0-6]>/One thing to memorize is, that regular expressions are case sensitive. It is different to match "a" or "A", like if you would construct a set of alphabets for regular 7bit English text. (Different countries have different sets of characters, but that is a whole separate issue)/[a-z]/ Ehm.../[a-zA-Z]/ Maybe this is what you wanted?Remember that the dash(-) applies only to a character class, in here it is just a regular dash:/a-z/ Match character "a", character "-", character "z"Multiple dashes can be used inside a class in any order, but the dash-order must follow the ASCII-table sequence, and not run backwards:/[a-zA-Z0-9]/ ok/[A-Za-zA-Z0-9]/ Repetitive, but no problem/[0-9A-Za-z]/ ok/[9-0]/ Oops, you can't say it like "backwards"Exclamation and other special characters are just characters to match:/[!?:,.=]/Or pick your own personal set of characters. This does not match word "help":/[help]/2.2 Negated character classesIt is easy to write what charters you want to include, but what if you would like to match everything except few characters? It would be unpractical to list all the possible character and then leave out only some of them:/[ZXCVBNMASDFGHJKLQWERTYUIO ...]/A special character, inside character class tells "not to include". (this same character has different meaning outside of the class, where it means "beginning of line"):The NOT operator|/[^0-9]/ Match everything, but numbers.NOTE: The end-of-line marker is different is various OS platforms. The above regular expression will match a line containing only plain numbers, because there is embedded end-of-line marker at the end: In Unix "1234567\n", in win32 "1234567\r\n" and in Mac "1234567\r"Why would following regular expression list items below?% perl -ne "print if /q[^u\r\n]/" file.txtIraqiIraqianmiqraqasidaqintarqophzaqqumWhy didn't it list words likeQuantasIraq2.3 Character class and special charactersThe brackets ([])As we have learned earlier, some of the characters in character class are special, these include range(-) and negation(^), but you must remember that the characters continuing the class itself must also be special: ] and [. So, what happened if you really need to match any of these characters? Suppose you have text:See [ref] on page 55.And you need to find all texts that are surrounded within the brackets []. You must write like this, although it looks funny. It works, because an "empty set" is not a valid character class so in here there is not really two "empty character class sets":start of class| End of class| |/[][]/ => also /[]abcdef0-9]]/|||character "]"character "["Rule: ] can be anywhere in the class and [ must be at the beginning of classThe dash (-)If the dash operator is used to delimit a range in a character class we have problem what top do with it if we want to match person names like "Leary-Johnson". The solution can be found if we remember that dash need a FROM-TO, but if we omit either one, and write FROM- or -TO, then the special meaning is canceled./[-a-zA-Z]/ OR /[a-zA-Z-]/Rule: dash(-) character is taken literally, when it is put either to the beginning or to the end of character classThe caret (^)We still have one character that has a special meaning, the negation operator, that excludes characters from the set. We can solve the conflict, to take "^" literally, as plain character when we move it out from its special position: at the beginning of the class/[^abc]/ Means: all except "abc" characters/[abc^]/ Caret has no special meaning any more. Matchescharacters "a" "b" "c" and "^"/[a^bc] Works too. "^" is taken literally.Rule: caret(^) loses its special meaning, when it is not the first character in the class.How to put all togetherHuh, do we dare to combine all these exceptions in one regular expression that would say, "I want these character: ^, - , ] and [". It might be impossible or at least time consuming task if you didn't know the rules of these characters. With trial and error you could eventually come up with right solution, but you would never understand fully why it works. Here is the answer. Can you think of more possible choices?/[][^-]/And now the final master thesis question: how do you reverse the question, "I want to match everything, except characters ^, - , ] and [" ??2.4 POSIX locales and character classesPOSIX, short for Portable Operating System Interface, is a standard ensuring portability across operating systems. Within this ambitious standard are specifications for regular expressions and many of the traditional Unix tools use them.One feature of the POSIX standard is the notion of locale, setting which describe language and cultural conventions such as the display of dates, times and monetary values, the interpretation of characters in the active encoding, and so on. Locales aim at allowing programs to be internationalized. It is not regexp-specific concept, although it can affect regular expression use. For example when working with Latin-1 (ISO-8859-1) encoding, the character "a" has many different meanings in different languages (think adding ' at top of "a"). Perl defines \w to be word and as regexps [a-zA-Z0-9_], but this in not the whole story, since perl respects the use locale directive in programs and thus allows enlarging the A-Z character range.POSIX collating sequenceA locale can define collating sequences to describe how to treat certain characters or sets of characters, for sorting. For example Spanish ll as in *tortilla' traditionally sorts as if it were on logical character between l and m. These rules might be manifested in collating sequences named span-ll and eszet for German ss. As with span-ll, a collating sequence can define multi-character sequences that should be taken as single character. This means that the dot(.) in regular expression /torti.a/ matches "tortilla".POSIX character classA POSIX character class is one of several special meta sequences for use within a POSIX bracket expression. An example is [:lower:] which represents any lowercase letter within the current locale. For normal English that would be [a-z]. The exact list of POSIX character classes is locale independent, but the following are usually supported (appeared 2000-06 in perl 5.6). See more from the [perlre] manual page.[:class:] GENERIC POSIX SYNTAX, replace "class" with names below[:^class:] PERL EXTENSION, negated class[:alpha:] alphabetic characters[:alnum:] alphabetic characters and numeric characters[:ascii:][:cntrl:] control characters[:digit:] \d digits[:graph:] non-blank (no spaces or control characters)[:lower:] lowercase alphabetics[:print:] like "graph" but includes space[:punct:] punctuation characters[:space:] \s all whitespace characters[:upper:] uppercase alphabetics[:word:] \w[:xdigit:] any hexadecimal digit, [0-0a-fA-F]Here is an example how to use the basic regular expression syntax and the roughly equivalent POSIX syntax: They match a word that is started with uppercase letter./[A-Z][a-z]+//[[:upper:]][[:lower:]]+/POSIX character equivalentsSome locales define character equivalents to indicate that certain characters should be considered identical for sorting. The equivalent characters are lister with the [=...=] notation. For example to match Scandinavian "a" like characters, you could use [=a=]. Perl 5.6 2000-06 recognizes this syntax, but does not support it and according to [perlre] manual page: "The POSIX character classes [.cc.] and [=cc=] are recognized but not supported and trying to use them will cause an error: Character class syntax [= =] is reserved for future extensions"3.0 Regular expressions syntax3.1 Marking start and endA good start to regular expression is to discuss how regular expression define beginning-of-line (^) and end-of-line ($). Both have special meta-characters that mark the position correctly. As we have seen ´cat' will be batched everywhere in the line, but we may want to anchor the match to the start of the line. Get into habit interpreting the regular expressions in a rather literal way, don't loosen up your mind or you will read the regular expression wrongly. [IMPORTANT] The ^ and $ are particular in that they match a position. They do match any actual characters themselves./^cat/WRONG: matches line with "cat" at the beginning RIGHT: Matches at the beginning of line, FOLLOWED by character "c" and character "a" and character "t".How would you read following expressions:/^cat$//^$//$^//^//$////cat^//$cat/ # This is not "end-of-line" + "cat", but a variable3.2 Matching any characterThe meta-character dot(.) is shorthand for a pattern that matches an character, except newline. For example, if you want to search regular ISO 8601 YYYY-MM-DD dates like 2000-06-01, 2000/06/01 or 2000.06.01, you could construct the regular expression using the character classes or just allow any character in between:Note, the "/" must be escaped with \/ becauseit would otherwise terminate Perl Regexp / ..... /|/2000[.\/-]06[.\/-]/ This is more accurate/2000.06.01/ The "." accepts anything in placeNotice the different semantics again in the above regexps: The dot(.) is not a meta-character inside the character class, like in the first example. It only has the special meaning if it is used alone, outside of the class like in the second example. [IMPORTANT] Consider using dot(.) only if you know that the data is in consistent format, because it may cause trouble and match lines that you didn't want to, like lottery numbers. The first regexp is the most safest to use compared to second, which will match:Lottery this week: 12 2000106 01 20====.==.==3.3 Alternation and groupingWhen you are inclined to choose from several possibilities, you mean word OR. The regular expression atom for it is |, like in programming languages. When used in regexps, the parts of the regular expressions are called alternations.Try "Bob" first. If not found, then try "Joe" ...|/Bob|Joe|Mike|Helen/===This part is tried completely before moving to nextalternation after "|". The alternations are tried in orderfrom left to right (but refer to DFA and NFA engines)Looking back to color matching with gr[ea]y, it could have been written using the alternation/grey|gray/ Both of the regexps are effectively/gr[ea]y/ ..the same, but gr[ea]y is faster.。
sonarwiz seg-import and seisee tutorial说明书

SonarWiz SEG-import and SEISEE TutorialRevision 12.0, 1/22/2019Chesapeake Technology, Inc.eMail: **************************Main Web site: Support Web site: 1605 W. El Camino Real, Suite 100Mountain View, CA 94040Tel: 650-967-2045Fax: 650-450-9300Table of Contents1SEISEE Tutorial (2)1.1References (3)1.2SEISEE – Basic Usage Ideas (3)1.3SEISEE – Changing Trace Header Data (5)1.3.1CHANGE - Individual Field Changes (5)1.3.2CHANGE - Changing the Value for an Entire Column (6)1.3.3EXPORT-IMPORT - Changing Multiple Columns at a Time (9)1.4SEISEE – Changing EBCDIC Text Header Data (9)2SonarWiz SEG Import - using SEISEE for file review (12)2.1Required Trace Header Data for SEG File import (12)2.1.1Requirement 1: Valid Date/Time Data (12)2.1.2Requirement 2: Valid Navigation Data (14)2.1.3Requirement 3 – Enough Navigation Data (19)2.1.4Requirement 4: Project Loc = Coordinate System = Navigation Data (21)2.1.5Requirement 5: Sequential ping numbers (23)2.2Channels Count (#Data Traces Per Record) Requirement (25)3SonarWiz TRA File Import - using SEISEE for file review (27)4SonarWiz Sub-bottom 6.04 / 6.05 Special Import Techniques (30)5SEG ReTIME Tips for Exceptionally Slow Ping-Rate (32)1 SEISEE TutorialSEG is a common import format used for sub-bottom files, in SonarWiz post-processing. This document describes techniques for success in two areas:1) Viewing and repairing trace headers of SEG files with the SEISEE utility software,and2) Importing SEG files successfully into SonarWiz.We use the free utility SEISEE, for viewing and editing SEG-Y type files which may need analysis or repair, as a supplementary technique, in addition to the standard SonarWiz file-repair utility NavInjectorPro.The free SEISEE utility is available here:Web-site http://www.dmng.ru/seisview/ has a 4.8 MB self-extracting archive file at no cost. Current version was 2.1.5.4 (8/2010).1.1 ReferencesSEISEE displays and edits, and SonarWiz creates and imports, SEG files in accordance with this specification reference:Ref[1]: SEG_Y_FileFormatSpec2002_rev1.pdf, Release 1, May, 20021.2 SEISEE – Basic Usage IdeasSEISEE has an excellent HELP facility, so use that as your first recourse when trying to understand the program better.Primary viewing steps are to select File->Open and open your SEG file, then perhaps select SEISMIC and VIEW tabs, to see the data.A secondary look is TRACE HEADERS and VIEW tabs selected. In this view, you simply check what SEG file trace header fields to view.The main fields to look for in validating good data for import to SonarWiz or some other program are typically date, time, and navigation. Just look at those columns and see if any are all zeros … which would be a problem.1.3 SEISEE – Changing Trace Header DataYou can easily edit the SEG trace headers data by changing the values for an individual field, an entir e column, or multiple columns at a time. Here’s how to do it.1.3.1 CHANGE - Individual Field ChangesExport the data containing the columns where you want to make an edit, then use WORDPAD (recommended) to make changes to individual field values and re-import. Note that your SEG file cannot be READ-ONLY for this operation to work.1.3.2 CHANGE - Changing the Value for an Entire ColumnNote that your SEG file cannot be READ-ONLY for this operation to work.To change the value of SAMPLE INTERVAL, for example, for an entire column, first select CHANGE (1), then enter the column name = <new value> (2) then click the (3) Update iucon:In some versions of SEISEE this will appear as 4 steps instead of 3 steps:Select CHANGE and then check (enable) a single field, like bytes 117-118 Sample interval.Enter a new value (e.g. UNITS=75) to change every 25 to a 75 in all trace headersClick on the UPDATE iconClick on UPDATE to conclude it and make the change. Results:In the case of changing UNITs=1 to UNITS=2, the results look like this:1.3.3 EXPORT-IMPORT - Changing Multiple Columns at a TimeTo change one or more columns in an easy custom batch-change, useEXPORT/IMPORT technique, like this:Select some columns to VIEW, then use File->Export Trace Headers to export them and create a CSV file, then edit that in EXCEL or manually or via a script. The export CSV file will have a header line (keep that) and the trace header data itself in comma-separated-values format. Finally re-import the changed data file using File->Import Trace Headers.1.4 SEISEE – Changing EBCDIC Text Header DataYou can easily edit the SEG EBCDIC text headers data by changing the values for an individual line at a time. Here’s how to do it.1. Open your SEG file and in the summary area, select TEXT HEADER to see the existing text header:2. Type in a new line, for example this replacement of the line at C 4:2 SonarWiz SEG Import - using SEISEE for file reviewSEISEE can be used to supplement viewing of the SEG file internals, to help investigate situations where, for example, the SonarWiz error message says“No valid navigation data was extracted from: <file name>”.What’s up with that? Here’s how to find out.2.1 Required Trace Header Data for SEG File importGenerally speaking, you need valid data and time stamps, and navigation in the SEG file trace headers, and enough of it, to successfully import the SEG file into SonarWiz. These 3 requirements are explained in more detail below.2.1.1 Requirement 1: Valid Date/Time DataViewing the columns of SEISEE data, if you enable the date and time fields, look for a valid current date, and times with valid values and sequentially incrementing values, as pings (records) proceed into the file, rather than ZERO or NON-INCREMENTING or OUT-OF-SEQUENCE values.Good data might look like this, with valid values for year, day, hour, minute, and incrementing values for SCE (seconds) – in this case about 3 hz ping rate.If any of these columns is all zero, missing data, out of sequence … import may not work well.2.1.2 Requirement 2: Valid Navigation DataThere are 4 columns of navigation data, and at least 2 of these need to contain valid data for import to succeed:The SRCX/SRCY and GRPX/GRPY represent X/Y, or Easting/Northing. OrLat/Long,and may be coded in meters or arcseconds (you need a valid value, and a valid UNITS code), according to the SEG File Specification we use. In SonarWiz, these SEG trace header fields are interpreted like this:When you will be importing SEG files, in your CREATE PROJECT or CONFIGURE EXISTING PROJECT dialog you can select FISH (source) or SHIP (receiver) coordinates as the source of navigation data, or AUTO – to let SonarWiz decide which seems populated in the file (in case only one exists):You make this choice in the CREATE PROJECT or CONFIGURE EXISTING PROJECT dialog here:So you can see how this would mess up. If you did not specify AUTO, and instead specified FISH, and the only valid data in the SEG file was in the SCRX/SRCY columns, and GRPX/GRPY contained all-zero … it wo uld not import.Al so … e ven though you specify this at the project level, you might override it at the file import level by selecting in SEG File-Type-Specific-Options to read from Source (ship, aka Srcx/Srcy in the SEG trace header) or Receiver (Fish, aka Grpx/Grpy in the SEG tracer header) coordinates, so be sure to check this too:Again, it’s only really going to be a problem if 2 of the columns are all-zeros in your SEG file trace headers, and you selected those as the navigation source – in which case the file will not import well.Here is an example of a SEG file with ONLY SRCX/Y coordinates, so it would be best imported using SHIP or AUTO navigation source choice in the CREATE PROJECT dialog, and SOURCE COORDS for navigation source, in the SEG File-Type-Specific-Options dialog:2.1.3 Requirement 3 – Enough Navigation DataThe third requirement is that you have enough pings in the file to process. When you create a project, you may specify the minimum ping count and not realize it. Setting this value means you have to have at least that many pings in the file, or it will not import. The field which identifies this is called “Time Constant for Course Smoothing”, set in the CREATE or CONFIGURE EXISTING project dialogs:The valid values here range from 3 – 1200 with a default value of 300 pings. You can see that if you specify 300 pings for smoothing, and the file contains only 299 pings –well there you go – it will not import. It really helps smooth presentation of your file to smooth, but set a minimal value like 3 pings for a very small SEG file. 300 pings is a fine value for larger files. You can adjust this value at any time and then re-import your files. NOTES:(1) In 5.08.0002 and later releases, an enhancement is implemented which allows SonarWIz to temporarily relax the TC for Course Smoothing size down to the number of pings in your input file, just to import that (small) file successfully.(2) In current versions of SonarWiz, since July, 2016, the ability to relax Time Constant for Course Smoothing entirely and set TC=0 is available. This allows you to NOT SMOOTH the incoming navigation at all.2.1.4 Requirement 4: Project Loc = Coordinate System = Navigation DataThis section explains how a mismatch in any of 3 features if the import can cause an import failure.2.1.4.1 Setting project Location – Manually or via GET FROM FILEIn the CREATE PROJECT and CONFIGURE EXISTING PROJECT dialogs, a great way to validate navigation data in the file, and set project location (latitude, longitude) at the same time is use of the GET FROM FILE button:If we browse to the SampleRawSonarFile.SEG in this case and select it, the project location is set as 40 N latitude, 73 E longitude. Also, SonarWiz autiomatically selected the coordinate system to match this location (UTM84-43N).2.1.4.2 SEISEE View of Project Location (Navigation Data in Trace Headers)In the SEISEE view of the coordinates in the trace header, this project shows like this:The SAC column is a scalar and -100 means divide the coordinate units by 100.The coordinates are encoded in arcseconds (1 arcsecond = 1/3600 degree) as specified in the last co,umn, UNITS=2. The meaning of the data in each field can be seen in the SEGY File Specification (ref[1]).In this example 1, let’s convert the SRCX value 26,623,709 arcseconds to degrees by dividing by 3600 and then dividing by 100 = 73.95 deg E longitude. If it were W longitude, it would be a negative number (e.g. -26,623,709 = 73.95 deg W longitude).Likewise we can convert SRCY value 14,519,374 arcseconds / 360000 = 40.33 deg N latitude. If it were S latitude, it would be a negative number (e.g. -14,519374 = 40.33 deg S latitude)2.1.4.3 Import example1: Position Matches Lat/Long & Coordinate SystemIn this example, coordinate system UTM84-43N was used, and project location was set to latitude = 40.33 deg N, longitude =- 73.95 deg E, and the navigation data in the file matches these, so the import succeeded.2.1.4.4 Import example2: Position Does Not Match Lat/Long & Coordinate System In this example 2, we leave project location set to latitude = 40.33 deg N, longitude = 73.95 deg E, and the navigation data in the SEG file has not changed, but we set the coordinate system MANUALLY to UTM-84-18N (the western counterpart to zone 43N) . In this case, the import will fail and give these messages in the SYSTEM OUTPUT window:So the import will appear to fail, even though there is valid navigation data in the file, simply because all 3 need to match. A mismatch of any one of these 3 cal cause the import to fail:Navigation data in fileProject locationCoordinate systemTry this yourself with any valid file, and see how easy it is to set a coordinatesystem or project location wrong (e.g. specifying UTM84-43S with this data) and getting the import error.2.1.5 Requirement 5: Sequential ping numbersThe SEG file needs to have sequential ping numbers to import and display properly, and these are referred to as a "shot number" in the SEG "FileTypeSpecificOptions ..." settings.Often the TRACE NUMBER (SEQWL) is a sequential value, and this trace header position bytes 1-4 is used by default in SonarWiz 5:In the SEG File Type Specific Options settings, you see a reference to this here:If your file imports VERY slowly, and will not display properly in the DigitizerView, chances are you will need to re-select the ping number (shot number) from one of the other 2 choices available, like this:Here's an example file where we need to read ping number from the FFID field in byte positions 9-12, since SEQWL was used for channel number 0,1,2,0,1,2 instead:The 3-channel storage of the data is read properly by choosing the valid FFID, instead of SEQWL for the ping number, in this case:Check your trace header data with SEISEE yourself, if you are have an extremely slow or incorrect DigitizerView display of your SEG file.2.2 Channels Count (#Data Traces Per Record) RequirementFor 1-channel data, the channels count (# data traces per record) = 1 is necessary in binary header bytes 13-14. An invalid channels count like 60 will appear like this in a SEISEE view of the BINARY HEADER:A SonarWiz 7 error will occur if the channels count (# data traces per record) is invalid (very typically you expect 1 or 2-channel data, so the valid values are likely 1 or 2). With a value = 60 there, this is the error you get:Using SEISEE, just select the ability to EDIT the binary header and enter the correct channel count in the bytes 13-14 position like this:The file saves immediately with the change (in older versions of SEISEE, select UPDATE then OK, to save). Reopen the file to verify it is you want to confirm that the change was saved.3 SonarWiz TRA File Import - using SEISEE for file reviewTRA files are a special category of SEG file. They have the TRA extension, but are a form of SEG file.Some have poor formatting, such as missing navigation in early pings, missing year or day, things we normally expect in a SEG file, but even after simple repairs to a file, it can seem tricky to import. Here are some import tips that worked in the past.Main import dialog:(1) select NEGATIVE polarity, BIPOLAR type, Channel 1(2) File Type Specific OptionsSelect SHOT NUMBER from bytes 9-12Select SOURCE coordinatesWhen the file has imported, apply AGC and band-pass filtering as follows:The APPEARANCE settings to try:(1) NEGATIVE polarity(2) TOPO correction OFFGAIN SETTINGS to apply:(1) AGC ON - try resolution=30 Intensity = 25(2) BAND-PASS filtering - enable and tryLF = 300 hzHF = 2500 hzNum Taps = 50Type = BARTLETTApply gain starting at TIME ZERO.4 SonarWiz Sub-bottom 6.04 / 6.05 Special Import TechniquesWe have an entire PDF reference dedicated to explaining these new options, but we will summarize them here:(1) Since SonarWiz 6.04, the data polarity choice during sub-bottom import has become essential to set properly, in order to import your data and see it well. See the special PDF document referenced below, for advice about seeing which type of SEG file data you have - bipolar or unipolar.(2) Since SonarWiz 6.04.0014, the Color Windows technique for choosing your color palette, and setting the color-mapping by using the "SCALE TO DATA" button of the color window, has become essential. See the special PDF document referenced below, for advice about use of the color window.(3) Since SonarWiz 6.05.0002, the import data format of your sub-bottom files, inside SonarWiz, changed for the better. In 6.05.0001 and earlier, the CSF-file encoding of sub-bottom amplitudes were 8-bit bytes with a 0-255 scale, and your import techniques were used to map file data into this internal format. In 6.05.0002, the internal representation format of sub-bottom data because 16-bit floating-point database format. This means that it is not compatible with previous versions of SonarWiz, and when you open a project of say, imported SEG data, in 6.05.0002, if it had been imported using a previous version of SonarWiz, the CSF feil forma will "promote" to 6.05.0002 format.A second result is that some file import settings are not only unnecessary (e.g. gain x2, x4 etc), but they will have no effect, in 6.05.0002 and beyond, because they were only needed for encoding the SEG data into 8-bit bytes in the CSF file. The color-window and the histogram adjustment of the color window become essential to use for SEG file import in 6.05.002 and later versions.See the special PDF document referenced below, for advice about use of the color window and histogram.Special reference for 6.04 / 6.05 sub-bottom data import and display (already on your hard drive)Or find it in the SonarWiz downloads area of here: 6.04 / 6.05 sub-bottom import advice:/download/ctisupport/Sonarwiz_6/UserDocs/Sub-bottomImport_6.04_6.05_Advice.pdf5 SEG ReTIME Tips for Exceptionally Slow Ping-RateExceptionally slow ping-rate files can be a special case to manage inTOOLS -> SEG -> SEG-Y File Retime:If you do not have a "normal" ping-rate like 0.5 Hz - 5Hz but have a very slow file like 5-secs - 12 secs or more per ping, use a subtractive technique to create a 0.5 - 1.0 Hz ping-rate like this:(1) Compute the nominal inter-ping-time by multiplying sample interval x sample count - like in this example 4000 msec x 3000 sample = 12 seconds.(2) Then to create a 0.5 Hz ping rate (time changes 2 secs per ping), use -10000 as the inter-ping adjustment time like this:You are subtracting 10 secs per ping to create a nominally "normal" inter-ping time (2 secs) , to help avoid triggering inter-ping-time error thresholds during SonarWiz 7 import.。
ReVirt Enabling Intrusion Analysis through Virtual-Machine Logging and Replay

AbstractCurrent system loggers have two problems:they depend on the integrity of the operating system being logged,and they do not save sufficient information to replay and analyze attacks that include any non-deterministic events.ReVirt removes the dependency on the target operating system by moving it into a virtual machine and logging below the virtual machine.This allows ReVirt to replay the system’s execution before,during,and after an intruder compro-mises the system,even if the intruder replaces the target operating system.ReVirt logs enough information to replay a long-term execution of the virtual machine instruction-by-instruction.This enables it to provide arbitrarily detailed observations about what transpired on the system,even in the presence of non-deterministic attacks and executions. ReVirt adds reasonable time and space overhead.Overheads due to virtualization are imperceptible for interactive use and CPU-bound workloads,and13-58%for kernel-intensive workloads.Logging adds0-8%overhead,and logging traffic for our workloads can be stored on a single disk for several months.1. IntroductionImproving the security of today’s computer sys-tems is an urgent and difficult problem.The complexity and rapid rate of change in current software systems prevents developers from verifying or auditing their code thoroughly enough to eliminate vulnerabilities.As a result,even the most diligent system administrators have to cope routinely with computer break-ins.This situation is likely to continue for the foreseeable future—statistics from the CERT®Coordination Center show a steady increase over the past4years in the num-ber of incidents handled,the number of vulnerabilities reported, and the number of advisories posted [CER02].The infeasibility of preventing computer compro-mises makes it vital to analyze attacks after they occur. Post-attack analysis is used to understand an attack,fix the vulnerability that allowed the compromise,and repair any damage caused by the intruder.Most com-puter systems try to enable this type of analysis by log-ging various events[Anderson80].A typical Unix installation may record login attempts,mail processing events,TCP connection requests,file system mount requests,and commands issued by the superuser.Win-dows2000can record login/logoff events,file accesses, process start/exit events,security policy changes,and restart/shutdown events.Unfortunately,the audit logs provided by current systems fall short in two ways of what is needed: integrity and completeness.Current system loggers lack integrity because they assume the operating system kernel is trustworthy; hence they are ineffective against attackers who com-promise the operating system.One way current loggers trust the operating system is by keeping their logs on the localfile system;this allows attackers who compromise the kernel to hide their activities by deleting past log records[CER01a].Even if the existing logfiles are kept safely on another computer or on write-once media, attackers can forge misleading log records or prevent useful log records from being saved after they compro-mise the operating system.The absence of useful log records after the point of compromise makes it very dif-ficult to assess andfix the damage incurred in the attack. It is ironic that current loggers work best when the ker-nel is not compromised,since audit logs are intended to be used when the system has been compromised!Villains can attack kernels in many ways.The eas-iest way is to leverage the capabilities that the kernel provides to the superuser account.An attacker who has gained superuser privileges can change the kernel by writing to the physical memory through a special device (/dev/mem on Unix),by inserting a dynamically loaded kernel module,or by overwriting the boot sector or ker-nel image on disk.If an administrator has turned offReVirt: Enabling Intrusion Analysis throughVirtual-Machine Logging and ReplayGeorge W. Dunlap, Samuel T. King, Sukru Cinar, Murtaza A. Basrai, Peter M. Chen Department of Electrical Engineering and Computer ScienceUniversity of Michigancovirt@, /CoVirtProceedings of the 2002 Symposium on Operating Systems Design and Implementation (OSDI)these capabilities,an attacker can instead exploit a bug in the kernel itself.Kernels are large and complex and so tend to contain many bugs.In fact,a recent study used an automated tool tofind over100security vulnerabili-ties in Linux and OpenBSD [Ashcraft02].Current system loggers also lack completeness because they do not log sufficient information to recre-ate or understand all attacks.Typical loggers save only a few types of system events,and these events are ofteninsufficient to determine with certainty how the break-in occurred or what damage was inflicted after the break-in.Instead,the administrator is left to guess what might have happened,and this is a painful and uncertain task. The attack analysis published by the Honeynet project typifies this uncertainty by containing numerous phrases such as“may indicate the method”,“it seems reasonable to assume”,“appears to”,“likely edited”,“presumably to”, and “not clear what service was used” [Hon00].More secure installations may log all inputs into the system,such as network activity or keyboard input. However,even such extensive logging does not enable an administrator to re-create attacks that involve non-deterministic effects.Many attacks exploit the unin-tended consequences of non-determinism(e.g.time-of-check to time-of-use race conditions[Bishop96])—recent advisories have described non-deterministic exploits in the Linux kernel,Microsoft Java VM, FreeBSD,NetBSD,kerberos,ssh,Tripwire,KDE,and Windows Media Services.Furthermore,the effects of non-deterministic events tend to propagate,so it becomes impossible to re-create or analyze a large class of events without replaying all earlier events determinis-tically.Encryption is a good example of this:encryption algorithms use non-deterministic events to generate entropy when choosing cryptographic keys,and all future communication depends on the value of the these keys.Without logging non-deterministic events, encrypted communication can be decrypted only if the attacker forgets to delete the key.The goal of ReVirt is to solve the two problems with current audit logging.To improve the integrity of the logger,ReVirt encapsulates the target system(both operating system and applications)inside a virtual machine,then places the logging software beneath this virtual machine.Running the logger in a different domain than the target system protects the logger from a compromised application or operating system.ReVirt continues to log the actions of intruders even if they replace the target boot block or the target kernel.To improve the completeness of the logger,ReVirt adapts techniques used in fault-tolerance for primary-backup recovery[Elnozahy02],such as checkpointing, logging,and roll-forward recovery.ReVirt is able to replay the complete,instruction-by-instruction execu-tion of the virtual machine,even if that execution depends on non-deterministic events such as interrupts and user input.An administrator can use this type of replay to answer arbitrarily detailed questions about what transpired before, during, and after an attack.2. Virtual machinesA virtual-machine monitor(VMM)is a layer of software that emulates faithfully the hardware of a com-plete computer system(Figure1)[Goldberg74].The abstraction created by the virtual machine monitor is called a virtual machine.The hardware emulated by the VMM is very similar(often identical)to the hardware on which the VMM is running,so the same operating systems and applications that run on the physical machine can run on the virtual machine.The host plat-form that the VMM runs on can be another operating system(the host operating system)or the bare hardware. The operating system running in the virtual machine is called the guest operating system to distinguish it from the host operating system running on the bare hardware. The applications running on top of the guest operating system are called guest applications to distinguish them from applications running on the host operating system (of which the VMM is one).The VMM runs in a sepa-rate domain from the guest operating system and appli-cations;for example,the VMM may run in kernel mode and the guest software may run in user mode.Our research group(CoVirt)is interested in enhancing security by running the target operating sys-tem and all target services inside a virtual machine (making them guest operating system and applications), then adding security services in the VMM or host plat-form [Chen01].Of course,even the VMM may be subject to secu-rity breaches.Fortunately,the VMM makes a much bet-ter trusted computing base than the guest operating system,due to its narrow interface and small size.The Figure 1: Virtual-machine structure.host platformvirtual machine monitor (VMM)guest operating systemguestapplicationguestapplicationguestapplicationinterface provided by the VMM is identical or similar to the physical hardware(CPU,memory,disks,network card,monitor,keyboard,mouse),whereas the interface provided by a typical operating system is much richer (processes,virtual memory,files,sockets,GUIs).The narrow VMM interface restricts the actions of an attacker.In addition,the simpler abstractions provided by a VMM lead to a code size that is several orders of magnitude smaller than a typical operating system,and this smaller code size makes it easier to verify the VMM.As we will see,the narrow interface of the VMM also makes it easier to log and replay.Virtual machines can be classified by how similar they are to the host hardware.At one extreme,tradi-tional virtual machines such as IBM’s VM/370[Goldberg74]and VMware[Sugerman01]export an interface that is backward compatible with the host hardware(the interface is either identical or slightly extended).Operating systems and applications that were intended to run on the host platform can run on these VMMs without change.At the other extreme,language-level virtual machines like the Java VM export an inter-face that is completely different from the host hardware. These VMMs can run only operating systems and appli-cations written specifically for them.Other virtual machines such as the V AX VMM security kernel[Karger91]fall somewhere in the mid-dle—they export an interface that is similar but not iden-tical to the host hardware[Bellino73].These types of VMMs typically deviate from the host hardware inter-face when interacting with peripherals.Virtualizing the register interface to peripherals controllers is difficult and time consuming,so many virtual machines provide higher-level methods to invoke I/O.A guest operating system must be ported to run on these VMMs.Specifi-cally,the device drivers in the guest kernel must use the higher-level methods in the VMM;e.g.a disk device driver might use the host system calls read and write to access the virtual hard disk.The work required to port a guest operating system to these types of VMMs is sim-ilar to that done by device manufacturers who write drivers for their devices.3. UMLinuxReVirt uses a virtual machine called UMLinux [Buchacker01].1UMLinux falls in the last category of virtual machines;the VMM in UMLinux exports an interface that is similar but not identical to the host hard-ware.The version of UMLinux described and used in this paper is modified from code developed by research-ers at the University of Erlangen-Nürnberg.Our version of the UMLinux VMM uses custom optimizations in the underlying operating system to achieve an order of mag-nitude speedup over the original UMLinux [King02]. 3.1. UMLinux structure and operationThe virtual machine in UMLinux runs as a user process on the host.Both the guest operating system and all guest applications run inside this single host process (the virtual-machine process).The guest operating sys-tem in UMLinux runs on top of the host operating sys-tem and uses host services(e.g.system calls and signals)as the interface to peripheral devices(Figure2). We call this virtualization strategy OS-on-OS,and we call the normal structure where target applications run directly on the host operating system direct-on-host. The guest operating system used in this paper is Linux 2.4.18,and the host operating system is also Linux 2.4.18.2The VMM in our version of UMLinux is imple-mented as a loadable module in the host Linux kernel, plus some hooks in the kernel that invoke our VMM module.The VMM module is called before and after each signal and system call to/from the virtual-machine process.Most instructions executed within the virtual machine execute directly on the host CPU.Memory accesses are translated by the host’s MMU based on1.Note that UMLinux is different from the similarly-named User-Mode Linux [Dike00].2.The guest and host operating systems can also be different. We use the same operating system for guest and host to enable a more direct comparison between running applications on the UMLinux guest and running applications directly on the host. Figure2:UMLinux OS-on-OS structure.Our version of UMLinux is implemented as a loadable kernel module in the host operating system.The device and interrupt drivers in the guest operating system use host services such as system calls and signals.host operating systemVMM kernel moduleguest operating systemguestapplicationguestapplicationguestapplicationhost hardwaretranslations that are set up via the host operating sys-tem’s mmap ,munmap , and mprotect system calls.Figure 3shows the address space of the virtual-machine process.Host memory protections are used to prevent guest applications from accessing the guest ker-nel’s address space.UMLinux provides a software analog to each peripheral device in a normal computer system.Table 1shows the mapping from each host component or event to its software analog in the virtual machine.UMLinux uses a host file or raw device to emulate the hard disk,CD-ROM,and floppy.Our version of UMLinux uses the TUN/TAP virtual Ethernet device in Linux to emulate the network card.UMLinux uses a small X application on the host to display console output and read keyboard input;this application communicates with the guest ker-nel’s console driver via TCP.UMLinux uses no video card;instead it displays graphical output to a remote X server (which would typically be the host’s X server).UMLinux provides a software analog to the com-puter’s current privilege level.The VMM module main-tains a virtual privilege level,which is set to kernelwhen transferring control to the guest kernel,and is set to user when transferring control to a guest application.The VMM module uses the current virtual privilege level to distinguish between system calls issued by a guest application and system calls issued by the guest kernel.System calls issued by a guest application must be redirected to the guest kernel’s system-call trap handler.When a guest application executes a system-call instruc-tion (int 0x80),the host CPU traps to the host ker-nel’s system-call handler,which then transfers control to the VMM kernel module.If the current virtual privilege level is set to kernel ,then the VMM knows the guest kernel made the system call (typically to access a host device or change memory translations).In this case,the VMM checks that this system call is one that a UMLinux guest kernel is expected to make,then passes it through to the host kernel.If the virtual privilege level is set to user ,then the VMM knows a guest application made the system call.In this case,the VMM module notifies the guest kernel by sending it a signal (SIGUSR1).The VMM module passes the registers at the time of the trap to the guest kernel’s signal handler.The SIGUSR1signal handler in the guest kernel is theFigure 3:UMLinux address space.As with all Linux processes,the host kernel address space occupies [0xc0000000,0xffffffff],and the host user address space occupies [0x0,0xc0000000).The guest kernel occupies the upper portion of the host user space [0x70000000,0xc0000000),and the current guest application occupies the remainder of the host user space [0x0, 0x70000000).guest application0x00x6fffffff0x700000000xffffffffguest operatingsystemhost operating system0xbfffffff0xc0000000Table 1:Mapping between host components and UMLinux equivalents.equivalent of the system-call trap handler in a normal operating system.SIGALRM,SIGIO,and SIGSEGV signals are used to emulate the hardware timer,I/O device inter-rupts,and memory exceptions.As with SIGUSR1,the host kernel delivers these signals to the registered signal handler in the guest kernel.These signal handlers are the equivalent of the timer-interrupt,I/O-interrupt,and memory exception handlers in a normal operating sys-tem.UMLinux emulates the enabling and disabling of interrupts by masking signals(using the sigproc-mask system call).3.2. Trusted computing base for UMLinuxAll the virtualization strategies described in Sec-tion2depend on the trustworthiness of all layers below the guest operating system(the VMM and host platform in Figure1).For UMLinux,the trusted computing base (TCB)is comprised of the VMM kernel module and the host operating system.UMLinux’s TCB is larger than the TCB for virtual machines that run directly on the hardware,such as IBM’s VM/370or VMware’s ESX Server.UMLinux’s TCB is similar to other virtual machines that cooperate with a host operating system, such as VMware Workstation.A common question is whether a security service that is added to the host operating system in an OS-on-OS structure is more protected from attack than a secu-rity service that is added to the host operating system in a direct-on-host structure.For example,while the log-ging in an OS-on-OS structure does not depend on the integrity of the guest operating system,doesn’t it still depend on the integrity of the host operating system?We contend that the logging in an OS-on-OS struc-ture is much more difficult to attack than the logging in a direct-on-host structure,because the TCB for an OS-on-OS structure can be much smaller than the complete host operating system[Meushaw00].While both OS-on-OS and direct-on-host depend on the host operating system,the avenues a villain can use to attack the host differ greatly between the two structures.Assume for this comparison that the villain has gained control over all target applications and can send arbitrary network packets to the host.A villain can launch attacks against the host operating system from two directions.First,a villain can attack from above by causing application processes to invoke the host operat-ing system in dangerous ways.In a direct-on-host struc-ture,the attacker has complete freedom to invoke whatever functionality the host operating system makes available to user processes.The attacker can control multiple application processes,access multiplefiles,and issue arbitrary system calls.In an OS-on-OS structure, an attacker who has gained control of all application processes can use these same avenues to attack the guest operating system.However,even if the attacker gains control over the guest operating system,he/she is still severely restricted in the actions he/she can take against the host operating system.The guest kernel needs only a small subset of the functionality available to general-purpose host processes,and the VMM can easily disal-low functionality outside this subset[Goldberg96].For example,an attacker who has gained control over all tar-get applications and the guest operating system still con-trols only a single host process(the virtual-machine process),can access only a few hostfiles/devices(the virtual hard disk,the virtual CD-ROM,and the virtual floppy), and can make only a few system calls.Second,a villain can attack the low level of the network protocol stack by sending dangerous network packets to the host(e.g.ping-of-death).As with attacks from above,less of the host operating system is exposed to dangerous packets with an OS-on-OS structure than a direct-on-host structure.Without virtual machines, packets traverse through the entire network stack and are delivered to applications;villains can thus craft packets to attack any layer of the network stack.With virtual machines,packets need only traverse a small part of the network stack.The portion of the host operating system included in UMLinux’s TCB is the host OS code that the guest kernel or incoming packets can invoke(plus the VMM, which disallows invocations outside this portion).We have yet to measure the size of this code rigorously,but early indications suggest that this portion is significantly smaller than the entire host operating system.For exam-ple,our VMM restricts the guest kernel to use fewer than7%of the system calls available to general host processes,and network traffic to the virtual machine is processed mostly by the guest operating system’s TCP and UDP stacks(only a small IP-layer packetfilter is used in the host operating system).The TCB of our current UMLinux prototype, while smaller than the complete host operating system, is not yet as small as it could be.The host operating sys-tem in our prototype runs other processes which could be attacked(e.g.the X server),and network messages to these host processes traverse the entire host network stack.Our future work includes measuring and reducingthe size of the host operating system used to support UMLinux.For example,we could further restrict the system calls issued by the guest kernel to use only cer-tain parameter values,and we could move the X server into another virtual machine.4. Logging and replaying UMLinux4.1. OverviewLogging is used widely for recovering state.The basic concept is straightforward:start from a checkpoint of a prior state,then roll forward using the log to reach the desired state.The type of system being recovered determines the type of information that needs to be logged:database logs contain transaction records,file system logs containfile system data.Replaying a pro-cess requires logging the non-deterministic events that affect the process’s computation.These log records guide the process as it re-executes(rolls forward)from a checkpoint.Most events are deterministic(e.g.arith-metic,memory,branch instructions)and do not need to be logged;the process will re-execute these events in the same way during replay as it did during logging.Non-deterministic events fall into two categories: time and external input.Time refers to the exact point in the execution stream at which an event takes place.For example,to replay an interrupt,we must log the instruc-tion at which the interrupt occurred.External input refers to data received from a non-logged entity,such as a human user or another computer.External input enters the processor via a peripheral device,such as a key-board, mouse, or network card.Note that output to peripherals does not affect the replaying process and hence need not be saved(in fact, output to peripherals will be reconstructed during replay).Non-determinism in the micro-architectural state(e.g.cache misses,speculative execution)also need not be saved,unless it affects the architectural state.Replaying a shared-memory multiprocessor requires saving thefine-grained interleaving order of memory operations and is outside the scope of this paper [LeBlanc87].4.2. ReVirtThis section describes how we apply the general concepts of logging to enable replay of UMLinux run-ning on x86processors.ReVirt is implemented as a set of modifications to the host kernel.Before starting UMLinux,we checkpoint the state by making a copy of its virtual disk.We currently require replay to start from a powered-off virtual machine,so the virtual disk comprises all state in the virtual machine.We envision checkpointing being a rare event(once every few days),so copying speed is not critical.Log records are added and saved to disk in a man-ner similar to that used by the Linux syslogd daemon. The VMM kernel module and kernel hooks add log records to a circular buffer in host kernel memory,and a user-level daemon(rlogd)consumes the buffer and writes the data to a log file on the host.ReVirt must log all non-deterministic events that can affect the execution of the virtual-machine process. Note that many non-deterministic host events do not need to be logged,because they do not affect the execu-tion of the virtual machine.For example,host hardware interrupts do not affect the virtual-machine process unless they cause the host kernel to deliver a signal to the virtual-machine process.Likewise,the scheduling order of other host processes does not affect the virtual-machine process because there is no interprocess com-munication between the virtual-machine process and other host processes(no sharedfiles,memory,or mes-sages).ReVirt does have to log asynchronous virtual inter-rupts(synchronous exceptions like SIGSEGV are deter-ministic and do not need to be logged).Before delivering a SIGALRM or SIGIO host signal(represent-ing virtual timer and I/O interrupts)to the virtual-machine process,ReVirt logs sufficient information to re-deliver the signal at the same point during replay.To uniquely identify the interrupted instruction,ReVirt logs the program counter and the number of branches exe-cuted since the last interrupt[Bressoud96].Because the x86architecture allows a block memory instruction (repeat string)to be interrupted in the middle of its exe-cution,we also must log the register(ecx)that stores the number of iterations remaining at the time of the interrupt.x86processors provide a hardware performance counter that can be configured to compute the number of branches that have executed since the last interrupt [Int01].The branch_retired configuration of this performance counter on the AMD Athlon processor counts branches,hardware interrupts(e.g.timer and net-work interrupts),faults(e.g.page faults,memory protection faults,FPU faults),and traps(e.g.system calls).We use another hardware performance counter to count the number of hardware interrupts and subtract this from the branch_retired counter.Similarly, we instrument the host kernel to count the number of faults and traps and subtract this from thebranch_retired counter.We configure the branch_retired counter to count only user-level branches.This makes it easier to count the number of branches precisely,because it keeps the count indepen-dent of the code executed in the kernel interrupt han-dlers.In addition to logging asynchronous virtual inter-rupts,ReVirt must also log all input from external enti-ties.These include most virtual devices:keyboard, mouse,network interface card,real-time clock,CD-ROM,andfloppy.Note that input from the virtual hard disk is deterministic,because the data on the virtual hard disk will be reconstructed and re-read during replay. One can imagine requiring the user to re-insert the same floppy disk or CD-ROM during replay,in which case reads from the CD-ROM andfloppy would also be deterministic and would not need to be logged.How-ever,we do not expect data from these sources to be a significant portion of the log,because these data sources are limited in speed by the user’s ability to switch media.3The UMLinux guest kernel reads these types of input data by issuing host system calls recv,read, and gettimeofday.The VMM kernel module logs the input data by intercepting these system calls.In gen-eral,ReVirt must log any host system call that can yield non-deterministic results.The x86architecture includes a few instructions that can return non-deterministic results,but that do not normally trap when running in user mode.Specifically, the x86rdtsc(read timestamp counter)and rdpmc (read performance monitoring counter)instructions are difficult for us to log.To make the virtual-machine pro-cess completely deterministic during replay,we set the processor control register(CR4)to trap when these instructions are executed.We remove the guest kernel’s rdtsc instructions by replacing them with a gettim-eofday host system call(and scaling the result);it would also be possible to leave these calls in the guest kernel,then trap,emulate,and log the rdtsc instruc-tion.We disallow rdpmc in the guest kernel and guest applications.During replay,ReVirt prevents new asynchronous virtual interrupts from perturbing the replaying virtual-machine process.ReVirt plays back the original asyn-chronous virtual interrupts using the same combination of hardware counters and host kernel hooks that were used during logging.ReVirt goes through two phases to find the right instruction at which to deliver the original asynchronous virtual interrupt.In thefirst phase,ReVirt configures the branch_retired performance counter to generate an interrupt after most(all but128) of the branches in that scheduling interval.In the second phase,ReVirt uses breakpoints to stop each time it exe-cutes the target instruction.At each breakpoint,ReVirt compares the current number of branches with the desired amount.Thefirst phase executes at the same speed as the original run and is thus faster than the sec-ond phase,which triggers a breakpoint each time the tar-get instruction is executed.The second phase is needed to stop at exactly the right instruction,because the inter-rupt generated by the branch_retired counter does not stop execution instantaneously and may execute past the target number of branches.Replay can be conducted on any host with the same processor type as the original host.Replaying on a different host allows an administrator to minimize downtime for the original host.4.3. Cooperative loggingMost sources of non-determinism generate only a small amount of log data.Keyboard and mouse input is limited by the speed of human data entry.Interrupts are relatively frequent,but each interrupt generates only a few bytes of log data.Of all the sources of non-deter-minism,only received network messages have the potential to generate enormous quantities of log data.We can reduce the amount of logged network data with a simple observation:one computer’s received message is another computer’s sent message.If the sending computer is being logged via ReVirt,then the receiver need not log the message data because the sender can re-create the sent data via replay.This tech-nique is used commonly in message-logging recovery protocols[Elnozahy02]and can be viewed as expanding the domain of the replay system to include other com-puters.Thus the receiver need not log data sent from computers that can cooperate in the replay;the receiver need only log a unique identifier for the message(e.g. the identity of the sending computer and a sequence number).Cooperative logging can reduce the amount of logged network data dramatically in certain cases.For example,if all computers on a LAN participate,then only traffic from outside the LAN needs to be logged, thus reducing the maximum log growth rate from LAN bandwidths to WAN bandwidths.3.If the CD-ROM is switched by an automated jukebox,then the jukebox can participate in replay and CD-ROM reads can be considered deterministic.。
Finland

TMH-QPSR, KTH, Vol. 46, 2004Speech, Music and Hearing, KTH, Stockholm, Sweden TMH-QPSR, KTH, Vol. 46: 13-23, 200413Acoustic study of throaty voice qualityAnne-Maria Laukkanen1, Johan Sundberg2, Eva Björkner231 Department of Speech Communication and Voice Research, University of Tampere, Tampere, Finland;2Department of Speech Music Hearing, The Royal University of Technology, Stockholm, Sweden, 23 Laboratory of Acoustics and Audio Signal Processing, University of Technology, Helsinki, FinlandPaper presented at the Annual Symposium Care of the Professional Voice, Philadelphia, June 2003Abstract“Throaty” voice quality has been regarded by voice pedagogues as undesired andeven harmful. The present study attempts to identify acoustic and physiologicalcorrelates of this quality. One male and one female subject read a text habituallyand with a throaty voice quality. Oral pressure during p-occlusion was measuredas an estimate of subglottic pressure. Long-term-average spectrum (LTAS) analysiswas used to describe the average voice quality. Sixteen syllables, perceptuallyevaluated with regard to throaty quality by five experts, were selected for furtheranalyses. Formant frequencies and voice source characteristics were measured bymeans of inverse filtering, and the vocal tract shape of the male subject’s throatyand normal versions of the vowels [a,u,i,ae] was recorded by Magnetic Resonanceimaging. From this material area functions were derived and their resonancefrequencies were determined. To test the relevance of formant frequencies toperceived throaty quality, experts rated degree of throatiness in synthetic vowelsamples in which the subjects’ measured formant frequency values were used.The main acoustic correlates of throatiness seemed to be an increase of F1, adecrease of F4 and in front vowels also a decrease of F2, presumably resultingfrom a narrowing of the pharynx. In the male subject voice source parameterssuggested a more hyperfunctional voice in throaty samples.IntroductionVoice quality is determined by formantfrequencies and voice source characteristics.Voice qualities in general may be hard to define.The term “throaty voice” is an interestingexample. It is frequently used; the Internet returned more than 15000 quotes of “throatyvoice”. According to Titze (http://www.ncvs.-org/singers/longevi.pdf), throaty voice quality isassociated with high subglottal pressure andglottal hypertension resulting in e.g., irregularpops and transient sounds and producing a voicesounding strained, strangled, or otherwise hypertense. According to Reid (1983) it sounds “swallowed, dark, tight, covered, pinched”, and can be regarded as the opposite of forward placement, which is typically considered a desirable voice quality.Hammarberg (1986), considering phonatory rather than resonatory aspects of voice quality, included the quality throaty/guttural in her perceptual analysis of dysphonic voices and found it to be correlatedwith hyperfunctional phonation.The term even seems to have socialconnotations. According to Addington (1968),throatiness in male speakers is perceived as a sign of a realistic and mature personality, whilein a female speaker it gives an impression of aless intelligent, masculine, ugly and carelessperson.Many voice pedagogues and therapists con-sider throaty quality as undesirable or evenharmful to the voice. By contrast, it is often mentioned as a positive characteristic of singers’ voice quality in music reviews, apparently serving as a timbral ornament in some non-classical styles of singing.There are some reasons to assume thatresonatory characteristics are relevant to throatyvoice quality. Laver (1975; 1980) presented asystem for describing all possible variations ofLaukkanen AM et al.: Acoustic study of throaty voice quality14voice quality. He based his system on articulatory and glottal characteristics, referred to as supralaryngeal and laryngeal settings, and also documented the associated voice qualities in terms of audio recordings and some acoustic analyses. Nolan (1983) complemented his documentation by means of long-term-average spectra (LTAS) and spectrograms of speech produced with the various settings by Laver and by himself. Laver’s system includes some settings potentially related to throaty voice: uvularized, pharyngalized and laryngo-pharyngalized. The LTAS documentation did not suggest any striking resonatory deviations from a normal voice quality (neutral setting). Also, the audio examples did not sound clearly typical of a throaty quality according to the authors’ judgment. However, in the LTAS of uvularized, pharyngalized and laryngo-pharyngalized samples by Nolan there was a larger level difference between the regions of the fundamental (F0) and that of the peak near 0.6 kHz, the F0 region being weaker than in neutral voice. This could suggest a more hyperfunctional voice production (Laukkanen et al., 1981; Gauffin & Sundberg, 1978). Further-more, the spectrum slope was less steep around 1 kHz in pharyngalized voice and between approximately 0.5-1.2 kHz in laryngo-pharyngalized voice. This could reflect both a more hyperfunctional voice production (Gauffin & Sundberg, 1978; Hammarberg, 1986; Kitzing, 1986) and a downward shift of the frequency of the second formant (F2). In Laver's samples of laryngo-pharyngalized voice, the mean LTAS slope was less steep, especially between 0.5-1.5 kHz. The spectrograms taken from individual words uttered by Nolan revealed a tendency for F1 to be higher and F2 and F3 to be lower in pharyngalized voice compared to normal (neutral setting); in laryngo-pharyngalized voice F1 was higher and F2 lower (F3 could not be measured). In Laver's samples of pharyngalized voice, F2 and F3 were lower than in normal voice; F1 was lower in pharyngalized open vowels but higher in pharyngalized closed vowels as compared to the vowels in neutrally uttered words. Referring to Fant (1970) and to the phonetic classification system by Jacobson et al. (1952). Nolan interprets the results to reflect the so-called flatness, i.e. a decrease of the amplitudes or a lowering of the frequencies of the upper formants. Flatness has been regarded typical of lip-rounding, pharyngali-zation and retroflex articulation.The relation of the findings summarized above to the term “throaty voice” as used in vocal pedagogy is unclear. As a consequence, it is hardly possible to understand if/why the use of a throaty voice quality is harmful. The present investigation is an attempt to identify main acoustic characteristics of throaty voice quality and to elucidate their voice source, vocal tract, and formant frequency correlates.Material and MethodsRecordingsTwo subjects (male and female) with no known voice pathologies volunteered as subjects. They read a standard Swedish text (‘Ett svårt fall’) comprising 91 words, first with their habitual voice, and then with what they considered a throaty voice quality. The recordings were made twice. Second time the subjects held a plastic tube in the corner of the mouth so that the oral pressure could be recorded. In this case, the text was modified such that the first consonants of certain syllables were replaced by the consonant [p]. This resulted in nonsense words but allowed measurement of oral pressure for estimation of subglottic pressure (Löfqvist et al., 1982).The recordings were made in an ordinary room. Both the audio signal and the oral pressure signal were recorded on a multi -channel digital instrumentation recorder (TEAC RD-200T PCM). The audio signal was picked up by a microphone (TCM110, omni -directional, frequency response 50-18000 Hz, sensitivity –52 dB; length 11/16’’, diameter 5/16’’) attached to a headset providing a constant mouth-to-microphone distance of 15 cm. Oral pressure was picked up by a soft plastic tube of 16 cm length and 0.45 cm inner diameter attached to a pressure transducer (Glottal Enterprises MSIF-2). The audio signal was calibrated for sound pressure level (SPL) by recording two sounds, the SPL of w hich were measured by means of a sound level meter held next to the recording microphone. These SPL values were announced on the tape. Likewise, the pressure transducer was calibrated by recording a set of known pressures determined by means of a U -tube manometer. Also these pressure values were announced on the tape. On a later occasion, the male subject sustained the vowels [a:, i:, u:, ae:] in normal and throaty quality for about 15 seconds, while MR-images were shot of 14 sections,TMH-QPSR, KTH, Vol. 46, 2004Speech, Music and Hearing, KTH, Stockholm, Sweden TMH-QPSR, KTH, Vol. 46: 13-23, 200415tract length axis. The anterior-most sectiondepicted the tip of the nose. Each image in eachof the eight series (4 vowels x 2 qualities) wasanalyzed by means of the OSIRIS program(/www/UIN/html1/project s/osiris/osiris.html). A polygon was drawn alongthe vocal tract contours (Figure 1). The pixel co-ordinates of these polygons were then trans-formed into mm, using a custom made program(Papex, Roberto Bresin) which also calculatedthe co-ordinates of the cross-sectional area andits center of gravity in three dimensions.The position along the vocal tract length axis of each section was computed as the Pytha-gorean distance between the center of gravity co-ordinates of adjacent polygons. Figure 2 shows an example of the vocal tract length axis for the vowel [u]. In some vowels, the epiglottis divided the contour into two parts, each of which was traced by a separate polygon. The areas of these polygons were then added.The estimation of vocal tract length was nottrivial, since no information on larynx heightand lip conditions was available. Section 1,closest to the glottis, was located at an unknowndistance above the glottis level. When con-structing the area functions this distance was provisionally assumed to be 1 cm in all vowels. As the locations of the various sections weresection would have varied relative to the glottis, if the larynx position were changed. For example, a rise of the larynx would shorten the vocal tract, even though this wasLaukkanen AM et al.: Acoustic study of throaty voice quality16not evident from the MR images. Lip protrusion and spreading caused similar problems.The formant frequencies of the area functions obtained from the MR material were estimated using the custom-made Formflek program (Johan Liljencrants). This program accepts as input an area function and calculates the associated formant frequencies.AnalysesAnalyses were carried out using the various modules in the Soundswell Signal Workstation (Ternström, 1992) complemented by a custom made program for inverse filtering (DeCap, Svante Granqvist). The two subjects’ readings were digitized and stored as sound files. From these sound files, sixteen mono- or bisyllabic words or morphems (‘bond’, ‘bror’, ‘dag’, ‘den’, ‘din’, ‘där’, ‘från’, ‘först’, ‘i’, ‘sa’, ‘spade’, ‘står’, ‘sva’, ‘svar’, ‘till’, ‘ut’), uttered both habitually and in throaty voice, i.e., 64 words in total, were selected for further analysis. The selection was based on the authors’ impression of great difference in throatiness. Each of these samples was copied separately into a sound file. Five voice and speech specialists (2 females, 3 males) evaluated the files with respect to throatiness in a listening test run with the aid of the custom-made computer program (Judge, Svante Granqvist). This program presents the stimulus files in random order and allows each evaluator to listen to a given stimulus as many times as he/she wishes. The listeners give their ratings by adjusting the position of a slider controllable by the mouse. The ratings are automatically saved in files as numbers from 0 to 1000. The scale was labeled “Throatiness” and its extremes were marked “Nil” and “Extreme”. The stimuli were presented via headphones (Sennheiser HD 435 Manhattan). One evaluator l istened to all the samples twice on different days to estimate intrarater reliability. Average spectrum characteristics were analyzed in terms of LTAS of the whole reading samples using the spectrum analysis program of the Swell Workstation with 8 kHz frequency range, Hanning window and 150 Hz bandwidth; voiceless sounds were excluded from the analysis.Formant frequencies were measured in vowels carrying the main stress in the 16 words listed above. These measurements were made by means of the DeCap program which also provided the flow glottograms of the vowels. From these glottograms, the following para-meters were derived: period length, duration of the closed phase, closed quotient (Q closed , peak-to-peak amplitude, negative peak amplitude of the differentiated flow glottogram or maximum flow declination rate MFDR, normalized amplitude quotient NAQ defined as the peak-to-peak amplitude/MFDR x period duration (Alku et al., 2002), and level difference between the two lowest source spectrum harmonics H 1-H 2. Oral pressure during [p] was measured for an estimate of subglottic pressure (P sub ).A second listening test was carried out to test the relevance of formant frequencies to perception of throatiness. In this test, synthetic vowel stimuli were made using the KTH MUSSE synthesizer (Sundberg, 1989) with the formant frequencies measured in the vowels that had shown the greatest difference in perceived throatiness between the habitual and throaty versions in the first listening test. These vowels (20 in total) were [y:] and two different samples of [a:] from the female subject and [i:, i, e, æ:] and three samples of [a:] from the male. The following settings were used in the synthesis: F0 110 and 220 Hz for male and female voice synthesis examples, vibrato amplitude 6 cent, flutter amplitude 55 cent, flutter rate 6 Hz, flutter filter bandwidth 3 Hz. This provided reasonably natural sounding voice samples. The samples, which were of 2 second duration and had a smoothed onset and offset (linear amplitude change during 100 ms) were presented in Listening test 2 to seven voice and speech specialists (5 females, 2 males), who were asked to rate the degree of throatiness, following the same procedure as in Listening test 1. As the number of the stimuli was sufficiently small, each stimulus was included twice at random intervals in the set, thus allowing assessment of intra-rater reliability.ResultsListening test 1: Normal stimuliIntra- and inter-rater reliability were rather high (intrarater reliability: alpha = 0.99; inter-rater reliability: alpha = 0.77). The samples repre-senting throaty voice were perceived as signi-ficantly (p = 0.000) more throaty than the samples produced in the habitual way, although some habitual voice samples were evaluated somewhat throaty, too. The samples produced by the male subject in habitual voice were perceived to have a lower average degree ofTMH-QPSR, KTH, Vol. 46, 2004Speech, Music and Hearing, KTH, Stockholm, Sweden TMH-QPSR, KTH, Vol. 46: 13-23, 200417the male mean throatiness 20.1, SD 25.9; for thefemale M 149.3, SD 134.1). Likewise, thethroaty samples of the male were perceivedsomewhat throatier than those of the femalesubject (for the male M 765.6, SD 180.6; for thefemale M 612.4, SD 270). The highest meanthroatiness ratings, 866 and 893 out of a maximum of 1000, were obtained for the femalesubjects' words with [y, a]. For the male subject,the words with [a, i, e, æ] received the highestmean ratings, ranging between 875 and 976. LTASFigure 3 shows differences between habitual and throaty voice in text reading as reflected by LTAS. In the throaty samples, the level was higher between 1 and 3 kHz in the male and between 1 and 4 kHz in the female voice. The level in the region of F0 was lower in the throaty samples implying a relatively weaker funda-mental, while the level near 0.7 kHz was higher. In habitual but not in throaty voice, the male voice showed a sharp peak at 3.3 kHz, apparently an example of a “speaker’s formant” (Leino, 1994; Nawka et al., 1997; Bele, 2002).The level shown in LTAS curves is stronglyinfluenced by the overall vocal loudness.However, the two versions differed negligibly inthis respect, Leq being only 1 dB higher in the throaty version for both voices. Therefore, the LTAS differences illustrated in Figure 3 should reflect voice quality differences. The weak er fundamental and the higher LTAS level in the 1-3 kHz range could suggest a more hyper-functional voice production in throaty voice. Figure 4 shows the results of the formantfrequency measurements. In the graphs, onlythose samples have been included that differedby more than 600 in mean rating of throatiness.In both subjects’ throaty samples, F1 tended tobe higher than in habitual voice. For F2 and F3 differences were small, even though lowervalues were observed for F2 in front vowels. F4tended to be clearly lower in the throatyversions.Area functionsThe area functions for the male subject are shown in Figure 5. By and large, the area func-tions of the various vowels show expected characteristics. The [a] has a narrow pharynx and a wide mouth cavity, the [i] has a wide pharynx and a narrow mouth, the [u] shows a large mouth cavity and constrictions near the velum and at the lips. The habitual version of [ae] has a rather non-constricted vocal tract shape. In the throaty as compared to the normal versions, the lower part of the pharynx was consistently narrower for all vowels, particularly for [u] and [a]. Between 7 and 12 cm from the glottis the throaty versions showed a wider area. This may be a consequence of the fact that tongue volume is constant; a constriction at one point must be accompanied by an expansion elsewhere. This would suggest that the con-striction of the pharynx be caused, at least in part, by retraction of the tongue.The area measured in section 1, closest to theglottis, differs considerably between the twoversions for all vowels. This is an artifact causedLaukkanen AM et al.: Acoustic study of throaty voice quality18Figure 4. Scatterplots comparing formant frequencies in habitual and throaty voice. For each vowel, the values for habitual voice are plotted along the x-axis and those for throaty voice along the y-axis. Circles and triangles refer to the female and the male subject’s values, respectively. The graphs only include data for those samples that differed by more than 600 units (out of 1000) in mean rating of throatiness.by a higher laryngeal position in the throaty version (Reid, 1982). As the orientation of section 1 was fixed relative to the body, a raised larynx caused the glottis to approach this section. As can be observed in area function published by Engwall (2002), the area 2 cm above the glottis is considerably wider than that 1 cm above the glottis. Given the lack of detail regarding vocal tract length, only rough estimations of formant frequencies could be made. The black columns in the left and right panels in Figure 6 show the F1 and F2 ratios, respectively, between the subject’s throaty and the normal versions of the vowels. The white columns represent the results obtained for the area functions. There are considerable discrepancies. Part of these differences may be related to the difference in larynx height suggested by the vocal tract contour in section 1. An attempt to model this vocal tract length difference was made by adding 1 cm at the glottal end to the normalTMH-QPSR, KTH, Vol. 46, 2004Speech, Music and Hearing, KTH, Stockholm, Sweden TMH-QPSR, KTH, Vol. 46: 13-23, 200419in section 1. The formant frequency ratios between the throaty and normal versions obtained after this lengthening are represented by the gray columns in the same Figure 6. The added vocal tract length increased the similarity or decreased the dissimilarity with the subject’s data.Flow glottograms and subglottal pressuresFor the male subject, all parameters exceptTable 1). Thus, in throaty as compared with habitual voice, P sub was higher, pulse peak-to-peak amplitude was lower, Q closed was higher, NAQ was lower and H 1-H 2 was lower. These differences suggest a more hyperfunctional -/pressed type of phonation in the throaty samples. In the samples of the female subject, there was no significant difference in the flow glottogram parameters between the voice qualities studied.Laukkanen AM et al.: Acoustic study of throaty voice quality20Also, in the second listening test with synthesized stimuli, the intra- and inter-rater reliabilities were rather high (alpha 0.84 andstimuli synthesized with formants from throaty and normal vowels differed in the expected way in most cases (Figure 8). Even though [i:] andTMH-QPSR, KTH, Vol. 46, 2004Speech, Music and Hearing, KTH, Stockholm, Sweden TMH-QPSR, KTH, Vol. 46: 13-23, 200421[u:] di ffered negligibly in mean rating and the normal version of [i] was rated as more throaty than the throaty version, the results supported the assumption that formant frequencies are relevant to perceived throatiness. Thus, on average the stimuli synthesized with formant frequencies from throaty samples were per-ceived as significantly more throaty (p = 0.01) than the samples with the formant frequencies taken from habitual samples.The difference in mean rating between the throaty and habitual versions were substantially smaller for the synthesized than for the natural stimuli (Figure 8). For samples synthesized after habitually spoken vowels, the mean rated throatiness was 282 (SD 138) and for samples synthesized after throaty vowels the corre-sponding value was 421 (SD 175). This shows that the perception of throatiness was less clear for the synthetic than for the natural stimuli. Interestingly, some evaluators commented that some of the samples sounded more pressed but not necessarily throaty.DiscussionOur findings have shown that throaty voice quality was associated with a higher F1, a lower F2 in front vowels, and a lower F4 in all vowels. In the male voice, it was produced with a narrow pharynx. He used a more hyperfunctional/-pressed mode of phonation in throaty voice as shown by the higher P sub, the higher CQ closed, the lower pulse amplitude, the lower NAQ and the smaller H1-H2 difference. (Jacobson et al, 1952; Hammarberg, 1986; Verdolini et al, 1998).F1 is affected by jaw position, or, more specifically by the cross sectional area in the pharynx as compared to that in the mouth (Fant, 1970), a narrowing of the pharynx and a widening of the mouth raising F1. Hence the narrow pharynx found in the male subject’s MR images of throaty samples is in agreement with the higher F1 values observed. The lower F2 in front vowels may be caused by the narrowing of the pharynx observed in the MR material, even though a raised larynx would counteract this effect. Thus, many of the formant frequency shifts observed may be caused by the narrowing of the pharynx.An LTAS reflects both formant frequency and voice source characteristics and should hence agree with measurements of these para-meters. The LTAS of the throaty voice showed a lower spectrum level below 0.5 kHz, and higher levels in the range of 1-3 kHz, particularly in the male voice. When the frequency distance between two formants is decreased, spectrum level at and between these formants will rise (Fant, 1970). Therefore, an increase of F1 will raise the spectrum level above its frequency, other things being equal. At least part of the rise between 1 and 3 kHz may be caused by the higher F1. The lower LTAS level in the F0 range could be caused by the more hyper-functional type of phonation observed in the throaty samples of the male voice. Also, both subjects raised F0 when speaking with a throaty voice, and this may contribute to lowering the LTAS level in the low frequency range.The panel in both listening tests showed reasonably high intra- and inter-subject relia-bilities, suggesting that they had similar ideas of the term throaty. On the other hand, it is also possible that they simply rated the degree of voice abnormality. To test this, the term throaty should be included as one out of many perceptual parameters in a future test. On the other hand, there are reasons to assume that the term was familiar to the subjects and had a similar meaning. It may be relevant that arti-culation of throaty voice was actually throaty in the sense that the lower pharynx was moreLaukkanen AM et al.: Acoustic study of throaty voice quality22constricted in throaty than in habitual production of the vowels [u, i, a, ae].It is interesting that the term “throaty” is commonly used for this type of voice. Generally, our intuitive knowledge of articu-lation is quite limited and vague. Yet, the term throaty rightfully suggests that articulation is associated with a particular pharyngeal con-figuration. This reflects an intuitive realism, possibly based on proprioceptive feedback. Incidentally, such intuitive realism on articu-lation would constitute an essential part of voice teachers’ skills.The attempts to synthesize a throaty quality by formant frequency combination only were partly successful, and the perceptual voice quality difference between habitual and throaty was much smaller for the synthesized than for the natural stimuli. This indicates that the formant frequencies alone do not exhaustively define throaty quality. Also voice source characteristics seem relevant. Interestingly, the male subject’s examples, which differed also with respect to phonatory hyperfunction, were perceived as throatier than the female subject’s examples, which were produced with similar voice source properties in habitual and throaty voice. According to some listeners’ comments voice quality sounded more pressed in the male subject’s throaty samples.Our results support the assumption that throaty can be regarded as a setting in the sense of the term proposed by Laver (1980). It is then interesting to find out if this setting is identical with or similar to any setting described already by Laver (1980) or Nolan (1983). The LTAS differences we observed between normal and throaty samples resembled those obtained by Nolan (1983) between neutral and pharyngalized or laryngo-pharyngalized samples. In Nolan’s and Laver’s samples, F1 either rose (open vowels) or decreased (closed vowels) and F2 and F3 decreased. In the present study, F1 rose for the male both in front and back vowels and in open and closed vowels, F2 decreased in front vowels and F4 decreased i n all vowels. These findings suggest that apart from certain spectral similarities ‘throaty’ is not exactly the same as ‘pharyngalized’ or ‘laryngo-pharyngalized’. Our results strongly suggest that throaty voice quality is associated with a narrowing of the pharynx. It is tempting to speculate that this narrowing is caused by a contraction of the middle constrictor muscle, which also tends to raise the larynx. A raised larynx is oftenassociated with a more hyperfunctional type of phonation. Thus, a narrowing of the pharynx would easily (if not necessarily) lead to a firmer glottal adduction. This, in turn, may explain why throaty/guttural quality has been regarded even as harmful to voice. Hyperadduction increases collision force of the vocal folds during phonation (Jiang & Titze, 1994), which means higher mechanical loading on the vocal fold tissue and, hence, a higher risk for tissue damage.ConclusionsThroaty voice quality seems to result from a narrowing of the pharynx, probably combined with a somewhat hyperfunctional type of phonation. Acoustically the narrow pharynx appears to induce an increase of F1, a decrease of F2 in front vowels and a decrease of F4. The voice source characteristics lead to an attenu-ation of the fundamental and an increase of the spectrum level between 1 and 3 kHz. The formant characteristics and also hyperfunctional phonation seem perceptually important to throaty voice quality.AcknowledgementsThe kind cooperation of the subjects and the listeners is gratefully acknowledged. The MR recordings were made possible by Didier Demolin, Laboratoire de Phonologie Université Libre de Bruxelles and were made at the Hôpital Erasme, Brussels, in cooperation with radiologist Thierry Metens and phonetician Alain Soquet, Laboratoire de Phonologie Université Libre de Bruxelles . The investigation was presented at the Annual Symposium Care of the Professional Voice, Philadelphia, June 2003. Eva Björkner is financially supported by the European Community’s Human Potential Pro-gramme under contract HPRN-CT-2002-00276 (HOARSE-network).ReferencesAddington DW (1968). The relationship of selected vocal characteristics to personality perception. Speech Monographs : 35: 492-503.Alku P, Bäckström T & Vilkman E (2002). Normalized amplitude quotient for parametrization of the glottal flow. J Acoust Soc Am 112: 707-710. Bele I (2002). Professional Speaking Voice. A perceptual and acoustic study of actors’ and teachers’ voices, Doctoral thesis, Department of Special Needs Education, University of Oslo.。
EDGAR Filer Manual (Volume II).pdf_1697324140.8598

10.DETERMINING THE STATUS OF YOUR FILING10.1Filing Date of Electronically Transmitted SubmissionsIf you begin direct transmission of a live submission after 5:30 P.M. Eastern time and the submission is accepted, it will have a filing date as of 6:00 A.M. the next business day. If you start direct transmission at or before 5:30 P.M., it will receive that day's filing date if it is accepted. For special filing date processing of certain submission types, refer to Chapter 3, “Index To Forms.”Note: Remember that submission transmission does not begin until EDGAR receives the first byte of a transmission. When you make a time-sensitive submission, allow time for setup of your Internet, building and error checking the submission, and the start of thetransmission.10.2Receiving E-Mail Status of Filings from the SECYou can receive acceptance or suspense messages to an Internet electronic mail (e-mail) address; see Chapter 7, Section 7.3.5, “The EDGARLink Online Notification Information Page.”You cannot be sure EDGAR has accepted your submission unless you receive an acceptance message. You have not made an official filing unless your acceptance message includes a filing date. See APPENDIX A for more information.The EDGAR Filing Website provides a quick way to check the status of your submission. Log in to the website and query for information on your submission, see Section 10.5.1, “Retrieving Submission Notification.”How EDGAR Uses the Internet for E-MailIf you use the Notification page on your submission template to list additional e-mail addresses, EDGAR will forward acceptance and suspense messages to all specified e-mail addresses. As an EDGAR filer, you are entirely responsible for setting up a valid Internet address through an ISP. Internet access rates vary per ISP.Please note the following information about the EDGAR Internet services:∙With an Internet address, you can receive timely information regarding the acceptance or suspension of your filing∙You must use the Notification page for all filer-directed notifications for a specific filing∙The following information will not appear in Internet notifications for test or suspended live filings:o Subject-Company Nameo Subject-Company CIKo Form TypeNote: When you download your notifications from the EDGAR Filing Website, the Subject-Company Name, CIK, and Form Type appears in the body of the notice.EDGAR Filer Manual (Volume II) 10-2 December 2022 ∙ All Internet addresses have a maximum length of 80 characters. Only valid EDGARcharacters are accepted for Internet addresses. We also recommend that you do not use the double quote (") character in an Internet addressHow Mail Is Addressed to the Internet AddressEDGAR sends acceptance and suspense messages to a valid Internet e-mail address that you list in your Company Contact Information on the EDGAR Filing Website. When you use the Notification page, EDGAR will also send e-mail to additional Internet e-mail addresses on a filing-by-filing basis. In addition, your company contact Internet e-mail address, which may be updated on the EDGAR Filing Website, will always receive an acceptance/suspense message when you submit a filing, unless you activate the “Notify Via Filing Website” check box.On a per-filing basis, EDGAR sends submission notifications to any e-mail address listed either on the Company Contact Information form and the Notification Information page. TheNotification Information page adds supplementary addresses for receiving notifications. If you wish to permanently change the e-mail address, then edit the Company Contact Information form on the EDGAR Filing Website. When submitting filings after 5:30 P.M., Eastern time, we recommend that you retrieve submission information on the EDGAR Filing Website to inquire about your submission status.10.3 Accessing Submission InformationYou can access submission using the EDGAR Online Forms Website:1. Log in to the EDGAR Online Forms Website.2. Click the ‘Retrieve/Edit Data’ link.3. The Retrieve/Edit Data page appears and prompts you for your CIK and CCCinformation:▪ Enter your CIK in the CIK field and press [Tab].▪ Enter your CCC in the CCC field.▪Click the [Continue] button. This page verifies that you have access to retrieve or edit information on the EDGAR system.Figure 10-1: Retrieve/Edit Data PageThe next page is the Retrieve/Edit Company and Submission Data page, which is shown in Figure 10-2: Retrieve/Edit Company and Submission Data Page. You can access the following functions from this page:∙ Retrieve Submission Information∙Retrieve Company Information∙Request Asset-Backed Securities (ABS) Issuing Entities Creation∙Change Company Password or CCC∙Enter Another CIK/CCCFigure 10-2: Retrieve/Edit Company and Submission Data Page10.4Return Copy SupportSupport is no longer offered.10.5Submission InformationRetrieve Submission Information allows you to verify and retrieve information about any submission in EDGAR that is associated with that login CIK. Information will be returned only for submissions where the CIK (identified in the upper left corner of the Retrieve/Edit Company and Submission Data page) is either the Filer CIK or Login CIK of the related submission. Access to submission status information depends upon some time variables. In general, test filing information will only be available for two business days. Suspended filing information will be available for six business days. Accepted live filing information will be available for thirty business days.Retrieving Submission NotificationOnce you have logged into EDGAR and accessed the Submission Information Retrieval page, you can access submission notifications for your CIK:1.Click the ‘Retrieve Submission Information’ link. The Retrieve SubmissionInformation page appears.Figure 10-3: Retrieve Submission Information Page2.Enter query parameters for any or all of these three fields:▪Enter the accession number of the filing you are looking for in theAccession Number field. This query screen does not accept wild cardcharacters. To retrieve all submissions, leave the Accession Number fieldblank.▪Choose the type of submission you are looking for: Test, Live, or Bothfrom the Transmission Mode field.▪Choose the date range of when the submission was transmitted: Today,Within 5, 10, or 30 Days from the Receipt Date Range field.3.Click the [Get Information] button.EDGAR retrieves a list of submissions associated with your CIK using the criteria you entered above.Note: If the information you enter does not retrieve any submissions, you can click the [Back] button and enter different information.EDGAR Filer Manual (Volume II) 10-4 December 2022Figure 10-4: Submission Information PageWhen the Submission Information page appears, a list of filings displays. Click the accession number hyperlink to retrieve the Submission Notification page. This page displays the e-mail notification that the e-mail recipients received. You can print this page for future reference using your browser’s printing function.Figure 10-5: Submission Notification PageRetrieve Module/Segment InformationWhen you are creating a submission and want to include a reference to a module or segment, you can verify that it is residing on EDGAR by using the Retrieve Module and Segments page on the EDGAR Filing Website:1.Log in to EDGAR and access the Retrieve/Edit Company and Submission page.Refer to Volume I for details.2.Click the ‘Retrieve Module/Segment Information’ link.EDGAR Filer Manual (Volume II) 10-6 December 2022 3. The Module/Segment Information page appears. Click one of the two links to access the module or segment information page:▪Retrieve Module Information ▪Retrieve Segment InformationFigure 10-6: Module/Segment Information PageModule InformationWhen you access the Module Information page by clicking ‘Retrieve Module Information’, EDGAR displays a list of all the modules currently residing on EDGAR for your CIK. The list contains the names and dates the modules were posted.Figure 10-7: Module Information PageUse your browser’s print function to print this list for future reference in your submission documents, or reference in the Module/Segment page of EDGARLink Online.Note: You cannot view the contents of a module or segment from this page.10.5.3.1Deleting ModulesBecause modules are stored on EDGAR indefinitely, from time to time you may need to update modules on EDGAR. To replace a module, delete the existing module, and then transmit the new module with the same name.1.Log in to EDGAR and access the Module/Segment Information page.2.Click the ‘Retrieve Module Information’ link. The Module Information page appears.3.Click the [Yes] button at the bottom of this page to open the Delete Module page. On the Delete Module page, a list of your modules is displayed in the Select Module to Delete list.Figure 10-8: Delete Module Page4.Scroll down the list and select the module you want to delete by clicking it.5.Click the [Delete Module] button.The Module Delete Confirmation page appears listing the module name and confirming you want to delete the listed module from EDGAR.Figure 10-9: Module Delete Confirmation Page6.Click the [Confirm Module Deletion] button to delete the module.7.Click the [Cancel Changes] button to cancel the deletion, and return to the Companyand Submission Information Retrieval page.The Delete Module Results page appears confirming your module has been deleted. Return to the Delete Module page to remove any additional modules. Once your module has been deleted from EDGAR, you cannot restore it. You will have to prepare and resubmit the module using the Module/Segment template.Figure 10-10: Delete Module Results PageSegment InformationBecause segments are stored on EDGAR for only six (6) business days, you do not need to delete them. However, you can check to verify that a segment is still residing on EDGAR:1.Log in to EDGAR and access the Module/Segment Information Page,Figure 11-12: Module/Segment Information Page.2.Click the ‘Retrieve Segment Information’ link. The Segment Information pageappears with a list of all the segments related to your CIK.Figure 10-11: Segment Information PageEDGAR Filer Manual (Volume II) 10-8 December 2022You can print this page using your browser’s printing function for future reference.This page displays the Segment Name and the Receipt Date. Remember you have six business days from the time EDGAR receives your segment to reference it in your submission. If you do not use the segment within six business days, you will have to resubmit it.10.6Getting Help with the Content of Filings or Exemptions/AdjustmentsFor help regarding filing content or fees, see Section 2.3.5, “Getting Help with EDGAR.”。
RELIANCE_basepdf:reliance_basepdf
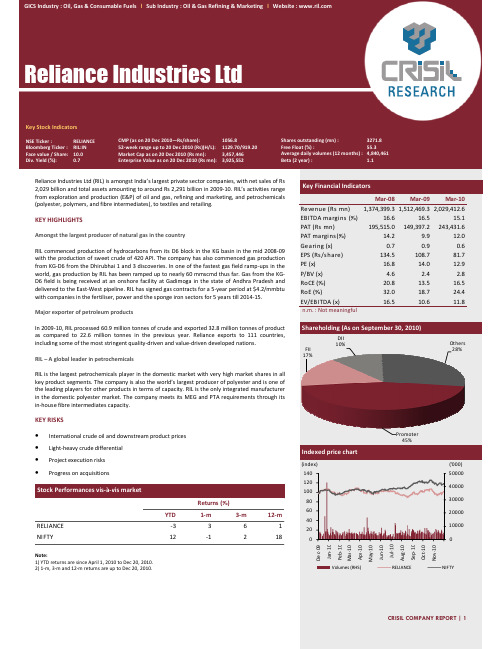
l l Beta (2 year) : 1.1 Key Stock Indicators Reliance Industries Ltd (RIL) is amongst India’s largest private sector companies, with net sales of Rs2,029 billion and total assets amounting to around Rs 2,291 billion in 2009-10. RIL’s activities rangefrom exploration and production (E&P) of oil and gas, refining and marketing, and petrochemicals (polyester, polymers, and fibre intermediates), to textiles and retailing.KEY HIGHLIGHTSAmongst the largest producer of natural gas in the countryRIL commenced production of hydrocarbons from its D6 block in the KG basin in the mid 2008-09 with the production of sweet crude of 420 API. The company has also commenced gas production from KG-D6 from the Dhirubhai 1 and 3 discoveries. In one of the fastest gas field ramp-ups in the world, gas production by RIL has been ramped up to nearly 60 mmscmd thus far. Gas from the KG-D6 field is being received at an onshore facility at Gadimoga in the state of Andhra Pradesh and delivered to the East-West pipeline. RIL has signed gas contracts for a 5-year period at $4.2/mmbtu with companies in the fertiliser, power and the sponge iron sectors for 5 years till 2014-15.Major exporter of petroleum productsIn 2009-10, RIL processed 60.9 million tonnes of crude and exported 32.8 million tonnes of product as compared to 22.6 million tonnes in the previous year. Reliance exports to 111 countries, including some of the most stringent quality-driven and value-driven developed nations.RIL – A global leader in petrochemicalsRIL is the largest petrochemicals player in the domestic market with very high market shares in all key product segments. The company is also the world’s largest producer of polyester and is one of the leading players for other products in terms of capacity. RIL is the only integrated manufacturer in the domestic polyester market. The company meets its MEG and PTA requirements through its in-house fibre intermediates capacity.KEY RISKS• International crude oil and downstream product prices • Light-heavy crude differential • Project execution risks •Progress on acquisitionsNote:1) YTD returns are since April 1, 2010 to Dec 20, 2010. 2) 1-m, 3-m and 12-m returns are up to Dec 20, 2010.BACKGROUNDRIL is India's largest private sector company. In 1975, the company expanded its presence into the textiles sector. Since its initial public offering in 1977, RIL has expanded rapidly and integrated backwards into other sectors, most notably petrochemicals production, crude oil refining and oil and gas E&P. Currently, the company’s operations range from the E&P of oil and gas, manufacturing of petroleum products, polyester products, polyester intermediates, plastics, polymer intermediates, chemicals and synthetic textiles and fabrics. Reliance enjoys a global leadership position in its businesses, and is the largest polyester yarn and fibre producer and one of the top ten producers of major petrochemical products in the world. It has the largest refining capacity at any single location. It has also ventured into organised retailing, telecom through broadband wireless access (BWA) and hotel businesses. The company’s international businesses include investment in GAPCO (GAPCO owns and operates large storage facilities and has a retail distribution network in East African countries) and upstream global oil and gas blocks, including investments in shale gas. COMPETITIVE POSITIONFINANCIAL PROFILELower GRMs reduce profitability despite rise in revenuesRIL’s revenues increased from Rs 1,512.5 billion in 2008-09 to Rs 2,029.4 billion in 2009-10 on the back of commencement of operations from its SEZ refinery at Jamnagar and production of gas from its KG-D6 block. However weak demand, significant global capacity additions, high level of inventories and rising crude oil prices weakened products cracks and refining margins across regions. This almost halved RIL’s GRM from $12.2 per bbl in 2009-10 to $6.6 per bbl in 2009-10. This decline lowered the company’s operating profitability from 16.5% in FY09 to 15.1% in FY10.Units Mar-08Mar-09Mar-10 Revenue Rs million1,374,399.31,512,469.32,029,412.6 EBITDA margins Per cent16.616.515.1 PAT Rs million195,515.0149,397.2243,431.6 PAT margins Per cent14.29.912.0 Revenue growth Per cent21.910.034.2 EBITDA growth Per cent10.09.323.2 PAT growth Per cent62.8-23.662.9 Gearing Times0.70.90.6 RoCE Per cent20.813.516.5 RoE Per cent32.018.724.4 Key Financial IndicatorsINDUSTRY PROFILERefining and marketingPetroleum product demand increased at a CAGR of 4.3 per cent from 111.6 million tonnes in 2004-05 to 138 million tonnes in 2009-10, whereas total domestic refinery capacity grew at a CAGR of 7.1 per cent to touch 170 mtpa in 2009-10. This increased capacity has led to increased exports of refined products. Global capacity utilisation rates of refineries have fallen from 88 per cent in 2005 to 83 per cent in 2009, thereby putting pressure on international product prices and hence capping GRMs. Indian GRMs were slightly better than the global GRMs due to strong demand and proportion of more complex refineries.Due to significant fall in crude oil prices in 2009-10, under-recoveries on cooking and auto fuels for PSU oil marketing companies (OMCs) also declined to 460 billion in 2009-10 from 1032 billion in 2008-09. In June 2010, the government deregulated petrol prices, while the domestic retail selling price of SKO, LPG, and HSD are still regulated. The OMCs dominate the retail marketing space and enjoy a near-monopoly status. As on September 2009, of the total 38,314 retail fuel outlets in India, IOC has 18278, BPCL has 8551 and HPCL has 8650, with private players like Reliance, Essar and Shell, making up the remainder.Oil and gas exploration:Domestic crude oil production rose from 6.8 MMT in 1970-71 to 33.0 million metric tonnes (MMT) in 1990-91. However, since 1987 no new oilfields (except for Cairn India’s Rajasthan fields) have been discovered, because of which, domestic production has stagnated at 31-34 MT till date.NELP was formulated in 1997-98 to encourage exploration activity and private sector participation in order to raise crude oil production in the country. The fiscal terms offered under the NELP rounds are attractive to augment investments - investors have been offered tax holiday for 7 years from the beginning of commercial production of crude oil. Subsequently, eight rounds under NELP have been conducted. A total of 126 discoveries have been made till date, of which 32 pertain to the pre-NELP period and 3 from the small and medium sized fields offered in 1992-93 and the remaining 70 pertain to the NELP blocks. The success of NELP is evident from the increase in the average accretion to in-place reserves, from 176.1 million metric tonnes (MMT) till 1999-2000 to 337.6 MMT till 2008-09. However, exploration stage is more risky as compared to production stage since there is high probability of misses and the gestation period is also very long.PetrochemicalsPetrochemicals can be categorised into two groups, namely basic petrochemicals and polymers. Basic petrochemicals like olefins (ethylene, propylene and butadiene) and aromatics (benzene and toluene) are obtained by cracking naphtha or natural gas. Ethylene is the main product and propylene and butadiene are by-products. They form the building blocks of a variety of products such as polymers, fibre intermediates and elastomers. Polymers, commonly referred to as plastics, are manufactured mainly from ethylene and propylene. They are used in packaging, automobiles, consumer durables, and furniture and household articles. Some of the most commonly used polymers include high-density polyethylene (hdPE), low-density polyethylene (ldPE), linear low-density polyethylene (lldPE), polypropylene (PP), poly vinyl chloride (PVC) and polystyrene (PS). The size of the petrochemicals market in India in 2009-10 was estimated at Rs 465 billion. During the year, the domestic consumption of polymers posted robust growth of 15 per cent due to healthy demand from end-user segments, whereas consumption of basic petrochemicals recorded a 10 per cent growth.ANNUAL RESULTSIncome Statement Balance sheetNet Sales1,369,900.61,511,008.02,028,043.5Equity share capital14,533.914,439.329,780.2 Operating Income1,374,399.31,512,469.32,029,412.6Reserves and surplus695,043.0871,414.71,083,469.2Tangible net worth709,576.9885,854.01,113,249.4 EBITDA227,834.4248,915.2306,608.1Deferred tax liablity:|asset|77,983.495,513.3106,775.7 EBITDA Margin16.616.515.1Long-term debt406,987.4671,633.9576,794.6Short-term-debt100,026.891,818.769,952.9 Depreciation50,042.056,509.8109,458.0Total debt507,014.2763,452.6646,747.5 Interest2,497.028,082.114,179.3Current liabilities234,121.8356,683.2388,213.4 Other Income54,850.217,670.219,980.9Total provisions33,765.730,524.036,235.2PBT230,470.9178,719.8286,126.5Gross block890,202.51,221,634.41,914,065.9 PAT195,515.0149,397.2243,431.6Net fixed assets953,070.91,480,837.31,469,756.9Investments118,482.364,355.4131,122.5 PAT Margin14.29.912.0Current assets490,908.8586,834.4690,341.8Receivables60,683.048,449.7100,829.2 No. of shares (Mn No.)1453.41374.72978.0Inventories191,261.4201,096.1343,933.2Cash44,741.6227,421.0138,908.3 Earnings per share (EPS)134.5108.781.7Cash flow RatioPre-tax profit230,145.6181,993.5202,951.7Revenue growth (%)21.910.034.2 Total tax paid-26,877.8-11,792.7-31,432.5EBITDA growth(%)10.09.323.2 Depreciation50,042.056,509.8109,458.0PAT growth(%)62.8-23.662.9 Change in working capital-68,893.3206,073.5-154,778.7EBITDA margins(%)16.616.515.1Tax rate (%)11.47.211.0 Capital Expenditure-265,838.5-616,392.5-100,852.3PAT margins (%)14.29.912.0 Investments and others-65,802.254,126.9-66,767.1Dividend payout (%)8.312.78.6Return on Equity (%)32.018.724.4 Equity raised/(repaid)420.0239,736.916,330.2Return on capital employed (%)20.813.516.5 Debt raised/(repaid)170,385.2256,438.4-116,705.1Dividend (incl. tax)-19,084.7-22,194.5-24,309.1Gearing (x)0.70.90.6 Others (incl extraordinaries)20,874.9-161,819.977,592.2Interest coverage (x)91.28.921.6Debt/EBITDA (x) 2.2 3.1 2.1Change in cash position25,371.2182,679.4-88,512.7Asset turnover (x) 1.6 1.4 1.3 Opening cash19,370.444,741.6227,421.0Current ratio (x) 1.3 1.2 1.4 Closing cash44,741.6227,421.0138,908.3Gross current assets (days)120134118 n.m : Not meaningful;QUARTERLY RESULTSProfit and loss accountNo of Months33366Revenue581,510.0100.0474,760.0100.0589,500.0100.01,171,010.0100.0793,720.0100.0 EBITDA100,680.017.378,450.016.5100,640.017.1201,320.017.2149,380.018.8 Interest5,420.00.94,620.0 1.05,410.00.910,830.00.99,220.0 1.2 Depreciation33,770.0 5.824,320.0 5.134,850.0 5.968,620.0 5.943,100.0 5.4 PBT61,490.010.649,510.010.460,380.010.2121,870.010.497,060.012.2 PAT49,230.08.538,520.08.148,510.08.297,740.08.375,180.09.5FOCUS CHARTS & TABLESDec 2009Mar 2010Jun 2010Sep 2010Promoter 46.644.844.844.7FII 16.817.617.216.8DII 9.810.710.710.3Others 26.827.027.328.2Shareholding Pattern (Per cent)Additional DisclosureThis report has been sponsored by NSE - Investor Protection Fund Trust (NSEIPFT).DisclaimerThis report is based on data publicly available or from sources considered reliable. CRISIL Ltd. (CRISIL) does not represent that it is accurate or complete and hence, it should not be relied upon as such. The data / report is subject to change without any prior notice. Opinions expressed herein are our current opinions as on the date of this report. Nothing in this report constitutes investment, legal, accounting or tax advice or any solicitation, whatsoever. The subscriber / user assume the entire risk of any use made of this data / report. CRISIL especially states that, it has no financial liability whatsoever, to the subscribers / users of this report. This report is for the personal information only of the authorised recipient in India only. This report should not be reproduced or redistributed or communicated directly or indirectly in any form to any other person – especially outside India or published or copied in whole or in part, for any purpose.CRISIL is not responsible for any errors and especially states that it has no financial liability whatsoever to the subscribers / users / transmitters / distributors of this report. For information please contact'ClientServicing'at+91-22-33423561,orviae-mail:**************************.。
421-06-7 reaxys_anonymous_20130816_010005_163[1]
![421-06-7 reaxys_anonymous_20130816_010005_163[1]](https://img.taocdn.com/s3/m/6108f62fccbff121dd3683bc.png)
Query1. QueryA solution of 3-PHENYLSULFONYL-8-PIPERAZIN-1-YL-QUINOLINE (D12) (200 mg, 0.55 MMOL) in dry THF (2 ML) was treated with sodium hydride (24mg, 0.6 mmol, 60percent oil dispersion), and 1-BROM-2, 2, 2-trifluoroethane (815 mg, 5 MMOL). The mixture was heated to 100 °C for 4 days then cooled, evaporated and the residue subjected to purification by flash chromatography on silica gel (eluting with dichloromethane-methanol-aq. NH3) to give the free base form of the title compound. This was treated with 1 M HCI in ether then crystallised from isopropanol to give the title compound (E8) as a yellow solid : Mass Spectrum: C21H20F3N302S requires 435; found 436 (MH+).With sodium hydride in tetrahydrofuran, Time= 96h, T= 100 °CPatent; GLAXO GROUP LIMITED; WO2005/26125; (2005); (A1) EnglishView in ReaxysAnilkumar, R.; Burton, Donald J.; Journal of Fluorine Chemistry; vol. 125; nb. 4; (2004); p. 561 - 566 View in ReaxysThe residue was absorbed on a silica gel column, eluted with chloroform to obtain 2.0 g of 1-(2,2,2-trifluoroethyl)-4-phenyl-6-methoxy-2(1H)-quinazolinone which was recrystallized from ethanolisopropyl ether to give yellow needles melting at 157.0°-158.0° C., and 1.44 g of 2-(2,2,2-trifluoroethoxy)-4-phenyl-6-methoxyquinazoline which was recrys-tallized from ethanol to give colorless fine crystals melting at 109.5°-110.5° C.With potassium iodide in N-methyl-acetamide, waterPatent; Sumitomo Chemical Company, Limited; US4202895; (1980); (A1) EnglishView in ReaxysExample Title EXAMPLE 1EXAMPLE 1This Example illustrates the preparation of bis-(2,2,2-trifluoromethyl) disulphide.A mixture of 2,2,2-trifluoroethyl bromide (9.8 g), sodium sulphide nonahydrate (14.4 g), sulphur (1.9 g), hexadecyl tributyl phosphonium bromide (1.0 g) and water (18.0 g) was charged to a Carius tube under a nitrogen atmosphere and the tube sealed.The tube was heated to 70° C. for 8 hours, cooled and the contents subjected to steam distillation to give bis-(2,2,2-trifluoroethyl) disulphide as an oil in a yield of 67° C.The product was identified by GC-mass spectroscopy.With hydrogen sulfide in waterPatent; Imperial Chemical Industries plc; US5258547; (1993); (A1) EnglishView in ReaxysIn the same manner as in Reference Example 5, 15.3 g of the above identified compound was prepared from 16.5 g of 4,5-dichloro-3(2H)pyridazinone, 17.9 g of 2,2,2-trifluoroethylbromide, 4.3 g of sodium hydride and 60 ml of dime-thylformamide.The melting point was 62° C. (as recrystallized from n-hexane).in N-methyl-acetamidePatent; Nissan Chemical Industries Ltd.; US4892947; (1990); (A1) EnglishView in ReaxysThe general procedure of Example 17 was repeated using 4'-bromo-4-(t-butyldimethylsiloxy)biphenyl, 4-n-propyl-4-phenyl-4-silacyclohexanone, and 1-bromo-2,2,2-trifluoroethane, thereby obtaining the intended compound.Patent; Shin-Etsu Chemical Co., Ltd.; US6004478; (1999); (A1) EnglishView in ReaxysView in Reaxys。
Redundant Picard–Fuchs system for Abelian integrals

The main result of this paper is an explicit derivation of the Picard{Fuchs system of linear ordinary di erential equations for integrals of polynomial 1-forms over level curves of a polynomial in two variables, regular at in nity. The explicit character of the construction makes it possible to derive upper bounds for the coe cients of this system. In turn, application of the bounded meandering principle 17, 15] to the system of di erential equations with bounded coe cients allows to produce upper bounds for the number of complex isolated zeros of these integrals on a positive distance from the rami cation locus. 1.1. Abelian integrals and tangential Hilbert 16th problem. If H (x; y) is a polynomial in two real variables, called the Hamiltonian, and ! = P (x; y) dx + Q(x; y) dy a real polynomial 1-form, then the problem on limit cycles appearing in the perturbation of the Hamiltonian equation,
Unit_4_PDF Slides 7ce (for printing)

Read sections 14.4 and 14.5 of your textof a bond, is the payment a holder will receive at the maturity ofthe bond. It almost always is $1,000 and it is also referred to as face value,the market interest rate (or “interest rate”) mix-up COUPON RATE and MARKET INTEREST RATEPV =You should get PV = $925.391000 [FV], [CMP] [PV]Note: Check your calculator manual or “google” it as different calculators have different keystrokes.That is, when market rates (‘r) increase , bond prices decrease and vice versa.+ PMT2+ PMT3+(1 + r)2 (1 + r)3must decrease1. If dealing with semi-annual coupon bond, convert all input variables tothe original maturity -> COMP PMTWhile current yield is easy tocalculate, it is not considered a veryuseful return, because to realize areturn on a bond, either the bondmust mature (so you need YTM), orinterest totaling $100 per year, that has six years until maturity andYou should also note that Since Market Price = Par Value,then the YTM must equal the Coupon Rate = 10%! B) Yield to maturityInstead we use an EAR formula (which incorporates compounding). For thisHere we are using the EAR formula towork backward from a multi-yearreturn, instead of using a period rateto find an annual return.Spread between AAA bonds and U.S. Govt bonds appx 200 basis points or 2% in March 2020interest rates increase to 12% one year later?A: Because the issuing corporation can replace bonds with cheaper, lower coupon paying bonds!rate of interest (i.e. lower coupons) -why?A: Because there is less risk that the company will have enough funds to pay the principal amount at maturity.Where does a “convertible bond” get its name?A) The option of converting into shares of common stock.The option of increasing its coupon payments when interestlower investment rating higher interest rate demanded by lower price for existing bonds!So the bondholders saw their investment drop in value and were。
Residual energy scans for monitoring wireless sensor networks

Residual Energy Scans for Monitoring Wireless Sensor NetworksYonggang“Jerry”Zhao,Ramesh GovindanComputer Science Department/ISIUniversity of Southern CaliforniaLos Angeles,CA90089{zhaoy,govindan}@Deborah EstrinComputer Science DepartmentUniversity of California,Los AngelesLos Angeles,CA90095estrin@AbstractIt is important to have continuously updated information about network resources and application activities after a wireless sensor network is deployed in unpredictable environment.Such information can help notify users of resourcedepletion or abnormal activities.However,the low user-to-node ratio and limited energy and bandwidth resources insensor networks make extracting states from each individual node infeasible.In this paper,we propose an approach toconstruct abstracted scans of sensor network health by applying in-network aggregation of network states.Specifically,we design a residual energy scan that approximately depicts the remaining energy distribution within a sensor network.Simulations show that our approach has good scalability and energy-efficiency characteristics,compared to continuouslyextracting the residual energy individually from each node.1IntroductionWireless sensor networks have been attracting increasing research interest given the recent advances in miniaturization and low-cost,low-power design.Unlike traditional computer networks such as the Internet,such a network will consist of a large collection of small wireless,low-power,unattended sensors and/or actuators[ADL98,EGHK99,KKP99,EGH00]. Sensor networks can enable“smart environments”which can monitor ambient conditions such as temperature,movement, sound,light,location and others.Wireless sensor network technology poses its unique design challenges.One important feature that distinguishes sensor networks from traditional distributed systems is their need for energy efficiency.Many nodes in the emerging sensor systems will be untethered,having onlyfinite energy reserves from a battery.The scale of a sensor net’s deployment will make recharging these energy reserves impossible.The requirement for energy-efficiency pervades all aspects of the system design[PK00].Another important feature that distinguishes wireless sensor networks from other distributed systems is their unattended nature.In these networks,nodes are not necessarily deployed in a regular way.Because of their compact form factor and their potential low cost,it might be possible for thousand of nodes to be autonomously deployed in an unplanned fashion.The working environment for those sensor nodes might be unpredictable and could affect the performance of the sensor network dramatically.The high node-to-human ratio also makes it infeasible to maintain individual node constantly.Given their unattended nature and their complexity,it is critical that the users be given continuously updated indications of the sensor network health,i.e.,explicit knowledge of the overall state of the sensor network after deployment.We call such indications of network health scans.Sensor network scans can provide early warning of system failure,aid in incremental deployment of sensors,or help test sensor collaboration algorithms.For example,knowing the remaining energy resource distribution within a sensor field,a user may be able to determine if any part of the network is about to suffer system failures in the near future,due to depleted energy.Similarly,given the practical difficulties in precisely planning sensorfield deployments,network scans can help guide incremental deployment of sensors by indicating energy-depleted regions of the sensorfield.By examining the distribution of node density,communication quality and other resources in the sensorfield,additional sensors can be placed selectively on those regions short of resources.Finally,a sensor scan can be designed to depict the overall response of the sensors to some known stimulus in a sensorfield.Such information is a valuable tool for validating expected functionality orfine-tuning detection algorithms.However,such continuous monitoring wireless sensor networks leads to different challenges compared to existing di-agnosis protocols for distributed systems[BH91,REG98,Bat95,TG98,BB99],or continuous monitoring in other domains such as telecommunication networks,or power generation systems[Boy93].The large number of sensor nodes in a sen-sorfield makes it infeasible,given energy and communication constraints,to collect detailed state information from each individual sensor node and then process centrally.In this paper,we propose an efficient monitoring infrastructure for sensor networks.Analogous to weather map or air traffic radar images,our sensor network scans describe the geographical distribution of network resources or activity of a sensorfield.We design and evaluate a mechanism for collecting a residual energy scan(eScan).Such a scan depicts an aggregated picture of the remaining energy levels for different regions in a sensorfield,and may look like Figure1. Instead of the detailed information of residual energy at individual sensors,this scan provides an abstracted view of energy resource distribution.Our proposed approach to construct an eScan applies localized algorithms in sensor networks for energy-efficient in-network aggregation of local representations of scans.Rather than collect all local scans centrally,this technique builds a composite scan by combining local scans piecewise.At each step of aggregation,these partial scans are auto-scaled by varying their resolutions.In this manner,the information content of the overall scan scales well with network size.We also propose to apply incremental updates to scans.When the state of a node changes,it should not need to re-send its entire scan.Rather,it should only need to send an update to a scan when its local state has changed dramatically.Furthermore,that update should only traverse up the aggregation hierarchy if it radically impacts some aspect of the overall representation. When local scans are aggregated,detailed information such as the residual energy at each individual node is lost.However, the compactness of such an abstracted representation can reduce the communication and processing cost significantly.As we show in this paper,the trade-off between reducedfidelity and increased lifetime is acceptable.To evaluate the performance of our design,we perform a simulation-based comparison to centralized collection of individual residual energy.We evaluate our design of residual energy scans by comparing the messaging costs of scan con-struction and the relative errors introduced by aggregation and incremental update.We show that eScanning can achieve significant saving on messaging cost over centralized collection,but only introduces acceptable and bounded error.Fur-thermore,the savings increases with network size.These two results show that sensor network scanning have better energy-efficiency and scalability characteristics than centralized collection of network state.To strengthen our result,all the experiments are repeated for three different energy dissipation models and varied parameters.The rest of the paper is organized as follows.In Section2,we give a summary of related work and why they are not applicable to sensor networks.Section3describes the design of residual energy scan collection.In Section4,our preliminary simulations results show that sensor network scanning is energy-efficient and scales well with network size, compared to collecting all residual energy information centrally.Section5concludes with some future work directions.2Related WorkTo our knowledge,there exists no ongoing or previous work that has attempted continuous monitoring of large-scale distributed sensor networks.In this section,we review peripherally related areas:wireless sensor networks in general, debugging and diagnosis protocols for parallel and distributed systems,monitoring other industrial systems and recent work on coverage problem in sensor networks.Wireless sensor networks can potentially support a variety of high profile applications[EGH00,Ten00].Researchers have been addressing various aspects of the design of sensor networks.For example,a design of wireless integrated network sensors is described in[ADL98].Reference[HKB99]proposes a family of adaptive protocols(SPIN)for information dissemination in energy-constrained wireless sensor networks.An energy-efficient paradigm(directed diffusion)for the design of protocols for sensor networks is proposed in[IGE00].Two important features of directed diffusion are data aggregation and localized bining data from several sensors,data aggregation can reduce data overlapping and produce more accurate data.The control decisions are made based solely on the interactions with neighbors or nodes with some vicinity.Localized interactions try to avoid the high cost to deliver data over long distance as much as possible but still be scalable,robust and energy-efficient.Inspired by directed diffusion,we also apply these two principles in our design of residual energy scan construction.Debugging distributed systems is related to continuously monitoring sensor networks.Distributed diagnosis protocols [HKR84,BH91,BB99]have been designed either for multiprocessor computers or for wired computer networks.Bates [Bat95]describes a high-level debugging approach for such systems by using events and behavior models.It provides a uniform view of heterogeneous systems and enables analysis to be performed in well-defined ways.Tarafdar and Garg [TG98]summarize distributed debugging as observation and control.They propose using Predicate Control as an active approach to debugging distributed systems,which involve a cycle of observation followed by controlled replaying of computations,based on observation.The Internet is growing every day but has been under-instrumented for a long time.Welles and Milliken[WM84] proposed Loader Debugger Protocol,which is an application layer protocol for loading,dumping and debugging target machines from hosts in a network environment.Written as early as in1984,it reveals some key requirements for remote debugging across computer networks.SNMP[CFSD96]is the de facto standard for inter-network management.Provid-ing interfaces to a virtual information database,SNMP allows users to query or set values of managed network objects. SCAN[REG98]provides a multicast-based continuous monitoring infrastructure with good scalability and robustness. This enables the system to be robust to different kinds of failure e.g.failed nodes or network partition.NIMI[MMP97] is a nation-wide infrastructure for detecting and debugging the performance problems within networks and their peers. It can detect both short-term and long-term performance degradation.MINC[CDHD99]utilized the method for deter-mining interior network performance from the edge measurement while sending multicast probes to measure end-to-end performance outwards.Industrial engineers have been designing monitoring mechanisms for power plants,gas companies,telephony systems and others.For example,SCADA(Supervisory Control and Data Acquisition)technology[Boy93]was introduced more than50years ago to enable a user to collect data and send commands to remote utilities in energy production,transport and distribution systems.In order to provide real-time alert of crucial events,those systems invest heavily on sophisticated and reliable devices for data acquisition and control.The deployment of those monitoring devices is also carefully engineered. Reliability is always thefirst concern in these critical systems.When instrumenting a sensor network,lots of ideas can be borrowed from those experiences.However,none of these techniques is directly applicable to continuously monitoring sensor networks.First,the sheer number of sensor nodes makes it infeasible,given energy and communication constraints in sensor networks,to centrally collect detailed state from individual sensor node and then display abstracted view of data.Second,collaborative interaction between individualnodes is,to some extent,inherent in wireless sensor network applications in order to achieve robustness and better accuracy. Knowledge of the overall state of nodes over a region is more helpful than knowledge of the state of individual nodes.Third, but most important,the monitoring activities within sensor network should be energy-efficient.Continuous monitoring itself is inherently energy consuming,and more specifically,considering the high cost of communication in wireless sensor networks,the messaging cost on monitoring data delivery should be carefully planned.Most relevant to our work is the coverage problem in wireless sensor networks studied in[MKPS01].Given the loca-tions of sensor nodes,these techniques detect maximal breach path(using V oronoi diagrams and Delaunay triangulations of the sensorfield)and maximal support path along which there is poorest and best coverage of sensors,respectively.These approaches and their distributed versions can detect one or more specific network vulnerabilities.Sensor network scanning is complementary in that it can provide the network provider an approximate indication of when to invoke these other tools.3Residual Energy ScanA residual energy scan(or eScan for short)depicts the remaining energy levels of sensor nodes.One possible representation of an eScan of a sensorfield is shown in Figure1.Different regions of the sensorfield are shaded differently,depending on the average residual energy resources of sensors within that region.An eScan can help users to decide where new sensor nodes need to be deployed to avoid energy depletion.It can also help verifying the behavior of energy-aware adaptive routing protocols[XHE00].An eScan is only one kind of sensor network scan.Not all scans are likely to be described in the same way.Where applicable in the rest of this section,we also discuss design choices for other scans.3.1System Model andWithout loss of generality,the wireless sensor network we intend to monitor consists N sensor nodes distributed on a 2-D planefield.Each node is immobile.Each node can communicate with other nodes within certain range.Each node knows its location on the plane.Obtaining reliable node location has been well studied in different contexts.In practice, geographical location can be determined by Global Positioning System(GPS)with fair accuracy[Kap96].Alternatively, when a GPS device is not available or applicable,other localization systems can be used.For example,a few of the sensor nodes called beacons know their coordinates in advance,either from GPS or predeployment.Relying on radio signal strength or acoustic measurement,other nodes can approximate distances to beacons and decide their locations by trilateration[BHE00,Gir00].Sensor nodes are powered by batteries with normalized capacity of100%.Each node can measure its local residual energy by interface similar to APM(Advanced Power Management)or ACPI(Advanced Configuration and Power Inter-faces).Each node executes one or more sensing tasks,which consumes energy during the whole lifetime of the sensor network.Energy consumption in this network is dominated by inter-node communication.We emphasize the high energy cost of communication compared to computation.For example,the energy consumed in transmitting a1kilobit packet 100m is approximately the same as performing3M instructions on prototype wireless sensor nodes[PK00].For this rea-son,sensor nodes will prefer to perform significant local collaborative processing of data,rather than transmit data over long distances.We also assume that there are one or more special nodes(user gateway s)at the network edge,from where human users will collect residual energy scans.We intend to design network communication and aggregation mechanisms for delivering energy scans to a user gateway with good scalability,robustness and energy efficiency characteristics.3.2Collecting Residual Energy ScansThe process of constructing a eScan of a sensorfield can be briefly described as follows(Figure2):1.Determining Local Residual Energy:At each node,the residual energy level is measured periodically.The localscan at a particular node comprises the node’s residual energy level and its location.A sensor node only need to report its local eScan when there is a significant energy level drop compared to the last time it reported its eScan.2.Disseminating eScans:Now that local eScans are available at each node,they must be disseminated across thenetwork to compute a composite eScan of the entire network.For this to happen,the user at the gateway expresses a special INTEREST message for a network-wide eScan.This INTEREST message propagates throughout the network byflooding.Upon receiving a INTEREST message,each node sets the sender as its parent node leading toward the user gateway.Thus an aggregation tree is constructed whose root is at the user gateway.Each node then sends the local eScans back towards the user.The aggregation tree is refreshed periodically to adapt network dynamics and failures.3.Aggregating eScans:Along the path to user gateway,nodes that receive two or more eScans may aggregate thoseeScans according to several rules.If the eScans are topologically adjacent and have the same or similar energy level,they can be aggregated into a tuple which contains a polygon that describes a collection of nodes,and the range of residual energy levels at those nodes.The goal of aggregation is to reduce the messaging cost on collecting eScans while losing little critical information content in the scans,and the detailed approach is discussed in the rest of section.There are several dimensions for us to explore in the design space,for example:What is the proper compact represen-tations for scans?How do we aggregate scans to reduce messaging cost?Are there other ways to organize the aggregation paths in terms of energy-efficiency and robustness?Which network characteristics are proper and which are not?All these questions are important and interesting,but in this paper,we will focus on designs of representation and aggregation schemes for eScans.3.3Abstracted RepresentationWireless sensor networks have limited energy resources,which makes centralized collection of individual node state infea-sible.We use sensor network scans to represented abstracted view of a particular network characteristics.More precisely, we can define a scan as a collection of(VALUE,COVERAGE)tuples.Figure2:Illustration of Residual Energy Scan CollectionVALUE is the quantitative representation of the network state that users are interested in.It may,in general,have a more complex form than a single scalar value.In eScan,we use VALUE=(min,max),where min,max are the minimum and maximal residual energy level of the nodes,respectively.For example in Figure3(a),the eScan VALUE is (35%,37%).COVERAGE denotes the region in the sensor network that VALUE describes.In eScan,we use a polygon to describe the COVERAGE of a scan.The nodes covered by this polygon share in common that their residual energy level falls in the range of VALUE.min and VALUE.max.The vertices of COVERAGE polygon are the locations of those boundary nodes.The polygon is not necessarily convex,but it is not self-overlapping(i.e.,none of the edges crosses another).In Figure3(a),the coverage polygon of the eScan is shown using a solid line.Our choice of representation scheme for eScan determines the energy savings on messaging cost.By combining locations of the nodes having similar energy level,the polygon representation is more compact.Intuitively,if all nodes within a square region have similar values,instead of a list of locations for each node,our scheme represents the region using information proportional toFigure3:Representation and Aggregation of eScansenergy sensor nodes when monitoring a network of sensors in a large number.The approximate values of residual energy are enough for the user to identify the near-depleted regions or discover energy consumption patterns.Another component of the price for aggregation is the cost for local CPU processing,but we assume that processing costs are much lower than delivering energy level data across the network.Our VALUE and COVERAGE representation is a reasonable choice for another reason.Over long time scales,the energy consumption pattern in a sensor network is expected to show spatial locality.We anticipate that all the nodes within a certain neighborhood detect,and participate in the processing of,similar events,thereby expending similar energy on the sensing task.If all nodes start out with comparable energy levels,spatial locality can results in good compressibility. Where these assumptions are broken,of course,scan collection performance may degrade.There exist alternative representation schemes for eScan and other scans.For example,VALUE in eScans can be in the form of(avg,wgt)instead,where avg is the averaged residual energy and wgt is the number of nodes.When aggregating multiple scans(Section3.4),the aggregated VALUE can be determined.For those scans also capturing spatial locality,for example,scans that show ambient sensing activities can be described in a manner similar to isothermal curves.3.4In-network Aggregation of eScansInitially,each node constructs its local scan using its residual energy level plus its location,and reports this scan to its parent node leading to the user gateway.Along the aggregation path,if a node receive two or more scans,it will try to aggregate those scans into a composite one.3.4.1Aggregation RulesOne of the most important characteristics of the scan is that they can be aggregated.i.e.two or more scans can be combined if their COVERAGES are adjacent and/or their VALUES are similar.For example,eScan A and eScan B can be aggregated if1.A.VALUE and B.VALUE are similar:.The aggregated VALUE will beIn order to support incremental update,each branch node in the distribution tree(Figure2)maintains afinite cache of eScans.Upon receiving one or more eScan updates,they arefirst compared with old eScans in cache.If an update is covered by an old eScan and their value are similar according to tolerance T,this update will be dropped because it does not change the scan significantly.If the update has a value that falls out of the value range of such old scan,the cached scan will be invalidated from cache by this recent update.The process of incremental update of eScans is described in Algorithm1in Appendix.3.5DiscussionIn Section3.3and3.4,we have described the core of residual energy scan construction:abstracted representation of resid-ual energy distribution and its corresponding aggregation operations.By applying in-network aggregation of abstracted residual energy distribution,we can achieve good scalability and energy-efficiency characteristics in eScan collection. There are some additional design issues that we are currently investigating.3.5.1Complementary ToolsAbstracted indications of network characteristics may fail to reveal interesting and useful information in some scenarios, compared to complete collection of node states.Some critical information may be lost because of abstraction.There exist solutions complementary to sensor network scans.As we state in Section2,centralized and distributed diagnosis protocols for sensor networks are complementary to sensor network scans.In some cases,sensor network scans can be used as input to those diagnosis protocols to identify particular network plementary to sensor network scans is drill down.When a human observer detects an anomaly in a scan,they may need to obtain detailed information from a specific region of sensorfield.The mechanisms for drill down are similar to those for query distribution and response aggregation described in[IGE00].3.5.2Aggregation Tolerance AdaptationWhen aggregating two or more scans,the value of aggregation tolerance decides the size and quality of resulted composite scan.When the user initiates the collection of residual energy scan,he/she can put the tolerance value to indicate how deeply each node should aggregate scans.However,to balance the savings in aggregation and the loss of accuracy in scans, each node should adaptively adjust its aggregation operation locally.For example,if a node keeps receiving a lot of scan updates,it can increase the aggregation tolerance value to reduce the size of resulted scan.If the node only receives a few escan updates or those updates are very similar to each other,it can reduce the the aggregation tolerance value to generate more detailed scans of residual energy.In general,given a resource budget that can be spent on scanning,the aggregation tolerance adaptation should provide residual energy scans as detailed as possible.We have not well studied designing adjustment policies and its impact on constructing eScans,but in principle aggregation tolerance adaptation is a important and necessary feature for monitoring a real wireless sensor networks.3.5.3Aggregation Path MaintenanceIn previous description of sensor network scans,we have not addressed the robustness issue in residual energy scans.For example,a node failure will partition the aggregation tree thus all the offspring nodes are not able to send eScan updates to the user.In Section3.2,we propose that the user periodically refresh INTEREST messages to adapt node failure and network dynamics.However,flooding over the whole network is cost and should only be issued with low frequency.Complementary to refreshment of aggregation paths,we are considering local recovery of aggregation tree.One possible simple scheme we are currently investigating is as follows.When a node N detects that its parent fails,it sends a special MARK message to all of its children and such MARK messages are further propagated to N’s k-th grandchildren in the sub tree using reliable communication primitives.Those offspring nodes will have temporary knowledge that N is their(grand)parent.Node N then broadcasts a REPAIR-REQUEST message to its neighbors and only those nodes that are not N’s offsprings will reply with a REPAIR-RELY message.N choose a non-offspring neighbor as its parent node.If there is no response,N will keep trying the repair process but for only for p times.Local recovery of the aggregation tree will be overridden upon reception of INTEREST messages.We have not well studied the performance of this protocol.Intuitively,it will avoid loops,and perform well in cases of sparse node failures.If there are massive failures in a small region,this protocol may take time to converge to the new aggregation path.However,the reconstruction of aggregation tree can compensate this drawback.4Experimental ResultsIn order to evaluate our design of residual energy scans,we compare its performance to centralized collection of individual residual energy information from each node.We use a stand-alone C++package to simulate the eScan construction process for large scale sensor networks.In this section,we present our results and discuss their implications and possible applications.4.1MetricsThe key performance criterion for residual energy scanning is the energy consumed in communicating the scans to the user node(Section3.1).We define the following metrics to evaluate the performance of residual energy scanning: Messaging Cost:Sensor network applications consume energy from time to time.After each sensing activity event,the energy dissipation may be significant enough to invoke an eScan update.We define the messaging cost for continuous monitoring as:a large indicates significant savings.Distortion:Aggregation with certain tolerance introduces error into eScans when compared with the actual node residual energy.We quantify the“fidelity”of an eScan snapshot by the root mean square error between perceived residual energy values in an eScan and the actual values:where is the estimated residual energy of node in the eScan and is the real value.is the size of the network. only reflects the absolute error due to aggregation and incremental update.We further define distortion as the fraction of the absolute error to average residual energy in the sensor network:。
NETGEAR RAEE 电子废弃物指引说明书

Guía de instalaciónEste símbolo se ha colocado conforme a la directiva 2002/96 de la UE sobre residuos de aparatos eléctricos y electrónicos (RAEE). Si se tuvieraque desechar este producto dentro de la Unión Europea, se tratará y se reciclará de conformidad con lo dispuesto en las leyes locales pertinentes, en aplicación de la directiva RAEE.NETGEAR, el logotipo de NETGEAR y Connect with Innovation son marcascomerciales o marcas comerciales registradas de NETGEAR, Inc. en Estados Unidos y en otros países. La información contenida en el documento puede sufrir modificaciones sin previo aviso. El resto de marcas y nombres de productos son marcas comerciales omarcas comerciales registradas por sus respectivos titulares. ©2011 NETGEAR, Inc. Todos los derechos reservados.Junio de 2011Descripciones de los botones y los indicadoresElementoDescripciónIndicador de alimentación•Verde fijo . El dispositivo recibe alimentación eléctrica.•Ámbar fijo. El adaptador está en modo de ahorro de energía.•Verde intermitente . El adaptador está configurando la seguridad.•Apagado . El dispositivo no recibe alimentación eléctrica.Indicador Powerline•Fijo . El adaptador está conectado a una red Powerline.•Apagado . El adaptador no ha detectado ningúndispositivo Powerline compatible que utilice la misma clave de cifrado.La función Pick A Plug (Selección de toma) permite elegir la toma de corriente con mayor intensidad, lo que se indica mediante el color del indicador.Verde : tasa de conexión > 80 Mbps (la mejor)Ámbar : tasa de conexión > 50 y <80 Mbps (muy buena)Rojo : tasa de conexión <50 Mbps (buena)Indicador Powerline Indicador de alimentaciónIndicador de Ethernet Restablecimiento deSeguridadla configuración de fábricaMiniadaptador Powerline AV 200 XAV1301Solución de problemasEl indicador de alimentación está apagado Asegúrese de que la toma eléctrica recibe corriente y compruebe que los dispositivos Powerline no estén conectados a ningún alargador, regleta o protector de sobretensión.El indicador de alimentación se ilumina en ámbarEl modo de ahorro de energía se activa cuando el indicador Ethernet está apagado. Esto puede producirse cuando:•El cable Ethernet está desenchufado.•El dispositivo conectado mediante el cable Ethernet está apagado.•El adaptador no realiza ninguna actividad durante 10 minutos. El dispositivo regresa al modo normal en menos de 2 segundos al activarse la conexión Ethernet.El indicador Powerline está apagado•Si ha configurado la seguridad de red, asegúrese de que todos los dispositivos Powerline utilizan la misma clave de cifrado. Puede obtener más información en el manual del usuario .•Pulse el botón de restablecimiento de la configuración de fábrica durante 1 segundo para restaurar los valores predeterminados del adaptador Powerline. El indicador Powerline seilumina en ámbar o en rojo Acerque el dispositivo Powerline.El indicador Ethernet estáapagado•Compruebe que los cables Ethernet funcionan y están conectados adecuadamente a los dispositivos.•Pulse el botón de restablecimiento de la configuración de fábrica durante 1 segundo para restaurar los valores predeterminados del adaptador Powerline.Contenido de la cajaAdvertencia: no pulse el botón de seguridad del adaptador Powerline hasta que haya finalizado la instalación y los adaptadores hayan establecidocomunicación (el indicador Powerline estará intermitente). De lo contrario, es posible que desactive temporalmente la comunicación de las unidades Powerline. Si esto sucede, utilice el botón de restablecimiento de laconfiguración de fábrica para restaurar los ajustes predeterminados del adaptador Powerline.Indicador de Ethernet•Fijo . El puerto Ethernet está conectado.•Apagado . No hay conexión Ethernet.Restableci-miento de la configura-ción de fábrica Pulse el botón de restablecimiento de laconfiguración de fábrica durante 1 segundo y, a continuación, suéltelo para restaurar los valores predeterminados del adaptador Powerline.Botón de seguridadTras enchufar su nuevo adaptador AV, pulse el botón de seguridad durante 2 segundos y, a continuación, pulse el botón de seguridad de uno de los otros adaptadores AV de la red durante otros 2 segundos. Se deben pulsar ambos botones en un tiempo máximo de 2 minutos. Nota : el botón de seguridad no funciona en el modo de ahorro de energía (consulte el apartado "El indicador de alimentación parpadea cada 3 segundos" de la tabla "Solución de problemas" que aparece a continuación).Elemento DescripciónMiniadaptador Powerline AV 200Cable EthernetEn algunos lugares, los dispositivos Powerline vendidos incluyen un CD de recursos.Habitación 1Habitación 2 Entre los dispositivos certificados Powerline y HomePlug AV compatibles se incluyen NETGEAR XAV101,XAV1004, XAV2001, XAV2501 y XAVN2001. Si desea obtener una lista completa de los dispositivos AV certificados,consulte /certified_rmación de seguridad •Entrada de CA: 100-240 V~, 60 mA (máx).•Temperatura de funcionamiento: de 0° a 35° C.•Asegúrese de que el enchufe o toma de corriente estén cerca del equipo y de que se pueda acceder a ellos con facilidad. Servicio técnicoGracias por elegir un producto NETGEAR.Una vez instalado el dispositivo, busque el número de serie en la etiqueta del producto y regístrelo en/register. De lo contrario, no podrá hacer uso de nuestro servicio telefónico de asistencia. Le recomendamos que se registre a través de nuestro sitio web. Para acceder a la utilidad XAV1301, consulte/app/answers/detail/a_id/17427. Podrá encontrar actualizaciones del producto y asistenciatécnica en la página /support.Si desea recibir información sobre la garantía y el servicio de atención al cliente, consulte el CD de recursos que se adjunta con el producto. Puede que este producto incluya una licencia GPL; visite ftp:///files/GPLnotice.pdf para consultar el acuerdo de licencia GPL.Para obtener la declaración de conformidad completa, visite el sitio web de declaraciones de conformidad de la UE de NETGEAR en/app/answers/detail/a_id/11621.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Beregning av kostgodtgjøring For kurs slutter reisen ved kursstart. Ny reise skal regnes fra kursslutt. Dersom regelen om 6 timer eller mer skal brukes ved utregning av kostgodtgjøringen, skal disse døgnene føres på forsiden under kostgodtgjøring ved overnatting - TT-kode 1086/1087/1052. Kost og overnatting etter regning På denne siden fører du kost og opphold som blir dekket etter regning. Hvis du i tillegg til dekning av utleggene får kursgodtgjøring, skriver du antall døgn under kode 1057 på forsiden. Samlet kursgodtgjøring skal stå i beløpsrubrikken.
Utlegg til hotell, mat o.l.
Dato Spesifikasjon Fremmed valuta Kode Beløp Kurs
Reiseutlegg - overføres til forsiden, TT-kode 1041
Overnatting
Navn og adresse på hotell pensjonat e.a. (ikke privat)
Merknader
Kommunenummer
Tj.stedsnummer Trekkprosent Dato Kl. Kl.
Utreise Retur
Dato
Regningen gjelder
Angi hva
Kurs
Tjenestereise
Reisested og -formål
Annet Reiseutlegg/ godtgjøringer
Etter fullmakt Parafering
Anvisning
Kvittering ved kontant betaling
Anvist dato
Mottatt beløp
Dato
Underskrift
Utbetalingsstedets merkn. ved utbetalingen
X-0095 B (Godkj. 03-2002) Elektronisk utgave
NETTOBELØP
Regningsutstederens underskrift
Skyldig
Dato
Jeg samtykker i at ev. skyldig beløp kan trekkes i lønn
Anvisende myndighet
Utbetales og posteres i samsvar med foranstående
614 1049 610 1050
1 1
(Spesifiser ev. på baksiden) Reise nr.
÷ ÷ ÷
Attestasjon fra overordnede
BRUTTO REISEREGNING
Reiseforskudd Utbetalingssted
Til gode
8020
Kryss av ved overføring av km
Sum
* For bruk av egen bil skal du ta med: reiseruten - kjørt distanse for hver tjenestereise, oppgitt etappevis og avlest på kilometertelleren årsak til omkjøringer - lokal kjøring på oppdragsstedet.
Regningen leveres senest 1 måned etter at reisen er avsluttet. Billettutlegg legitimeres etter reglene i reiseregulativet
Reiseregning
Fødselsnr. (11 siffer) Poststed
Reiseutlegg
Fremmed valuta Kode Beløp Kurs Beløp
Hjemmel for bruk av bil Gitt av
Dato
Sum km denne reisen, overføres eget skyssmiddel (bil) på forsiden + tidlig km i år
Overført fra baksiden
Admin. godtgj.
SDkode
TTkode
Sats M Antall kr øre kr
Beløp øre Kap., post, u.p., u.u.p.
Over- (Se baksiden) Pennatting sjonat Hotell Internregnskap Kode 2 Kode 3
Brukernummer R/N Vedleggsnr.
Etternavn og fornavn Privatadresse Stilling Etat/ institusjon Ansatt nr. (4 ev. 5 siffer) Postnr. Bankkto.
Avdeling/ tj.sted Skattekommune
Innland Innland overnatting hotell Utland Bil: 0-9000 km Bil: over 9000 km Hjem-arbeid (skattepliktig) Passasjertillegg Annet Kostgodtgjøring Nattillegg Annet
Utland Utland
1041 614 1083 614 1084 614 1085 614 1042 614 1042 610 1086 610 1087 610 1052 610 1052 610 1053 610 1078 610 1056
1) 2)
Natttillegg ulegitimert
Annet Kode 4
1041 619 1057
Kostgodtgjøring uten overnatting
Kostgodtgjøring ved overnatting
Under 5 timer 5-9 timer 9-12 timer Over 12 timer 6-12 timer Over 12 timer 8-12 timer Over 12 timer
Eget skyssmiddel. Spesifiser reisen på baksiden
111 1069 714 1045
Opphold utover 28 døgn Andre godtgj.
Til sammen
Frokost/ lunsj/middag Trekk Frokost/ lunsj/middag
For regnskapsføreren: 1) Kode SD 712/TT 1047 2) Kode SD 152/TT 1054
Navn
Fødselsnr.
Reisespesifikasjon
Dato FRA Kl. Sted Sted TIL Kl. Skyssmiddel *
Type km, eget