分散加载
ARM中的RO、RW和ZI DATA说明

;
}
Prog2:
#include <stdio.h>
const char a = 5;
void main(void)
Prog3:
#include <stdio.h>
void main(void)
{
;
}
Prog4:
#include <stdio.h>
3; ZI
再看两个程序,他们之间的差别是一个未初始化的变量“a”,从之前的了解中,应该可以推测,这两个程序之间应该只有ZI大小有差别。
Prog3:
#include <stdio.h>
void main(void)
实际上,RO中的指令至少应该有这样的功能:
1. 将RW从ROM中搬到RAM中,因为RW是变量,变量不能存在ROM中。
2.
将ZI所在的RAM区域全部清零,因为ZI区域并不在Image中,所以需要程序根据编译器给出的ZI地址及大小来将相应得RAM区域清零。ZI中也是变量,同理:变量不能存在ROM中
Total RO Size(Code + RO Data) 1008 ( 0.98kB)
Total RW Size(RW Data + ZI Data) 97 ( 0.09kB)
Total ROM Size(Code + RO Data + RW Data) 1009 ( 0.99kB)
Code RO Data RW Data ZI Data Debug
948 60 1 96 0 Grand Totals
================================================================================
Keil分散文件加载

Keil分散文件加载分散加载能够将加载和运行时存储器中的代码和数据描述在被称为分散加载描述文件的一个文本描述文件中,以供连接时使用。
(1)分散加载区分散加载区域分为两类:? 加载区,包含应用程序复位和加载时的代码和数据。
? 执行区,包含应用程序执行时的代码和数据。
应用程序启动过程中,从每个加载区可创建一个或多个执行区。
映象中所有的代码和数据准确地分为一个加载区和一个执行区。
(2)分散加载文件示例ROM_LOAD 0x0000 0x4000{ROM_EXEC 0x0000 0x4000; Root region{* (+RO); All code and constant data}RAM 0x10000 0x8000{* (+RW, +ZI); All non-constant data}}(3)分散加载文件语法load_region_name start_address | "+"offset [attributes] [max_size]{execution_region_name start_address | "+"offset [attributes][max_size] {module_select_pattern ["("("+" input_section_attr | input_section_pattern)([","] "+" input_section_attr | "," input_section_pattern)) *")"]}}load_region:加载区,用来保存永久性数据(程序和只读变量)的区域;execution_region:执行区,程序执行时,从加载区域将数据复制到相应执行区后才能被正确执行;load_region_name:加载区域名,用于“Linker”区别不同的加载区域,最多31个字符;start_address:起始地址,指示区域的首地址;+offset:前一个加载区域尾地址+offset 做为当前的起始地址,且“offset”应为“0”或“4”的倍数;attributes:区域属性,可设置如下属性:PI 与地址无关方式存放;RELOC 重新部署,保留定位信息,以便重新定位该段到新的执行区;OVERLAY 覆盖,允许多个可执行区域在同一个地址,ADS不支持;ABSOLUTE 绝对地址(默认);max_size:该区域的大小;execution_region_name:执行区域名;start_address:该执行区的首地址,必须字对齐;+offset:同上;attributes:同上;PI 与地址无关,该区域的代码可任意移动后执行;OVERLAY 覆盖;ABSOLUTE 绝对地址(默认);FIXED 固定地址;UNINIT 不用初始化该区域的ZI段;module_select_pattern:目标文件滤波器,支持通配符“*”和“?”;*.o匹配所有目标,* (或“.ANY”)匹配所有目标文件和库。
scatter分析

;执行域包含1个或多个输入段
;输入段书写格式:包括模块描述和段描述
;
;模块描述:指定包含模块的文件(包括目标文件.o和库文件.LIB)搜索范围,可以使用通配符*和?
问题分析:
分散加载描述文件是一个文本文件,它向链接器描述目标系统的存储器映射。如果通过命令行使用链接器,则描述文件的扩展名并不重要。分散加载文件指定:
1)每个加载区的加载地址和最大尺寸;
2)每个加载区的属性;
3)从每个加载区派生的执行区;
4)每个执行区的执行地址和最大尺寸;
5)每个执行区的输入节。
{
*(+RW) ; RW被紧接着放置,不能移动
}
ER_ZI +0 ; ER_ZI执行域在ER_RW执行域后面
{
*(+ZI) ; 所有ZI段被连续放置
}
}
在上面的例程中, 代码从地址0x00000000处开始存放,并且将RESET程序段放在最开始处, 而可读写的数据从地址0x30000000处开始存放. 分散加载文件的段的名字(例如LR_ROM1, ER_ROM1等)可以是任意的名字。
ADS分散加载文件语法:
;如果片外RAM起始地址不为0x8000 0000,则需要修改mem_.scf文件
{
* (+RW,+ZI)
}
HEAP +0 UNINIT ;+0表示接着上一段,UNINIT 表示不初始化
; OVERLAY:覆盖,允许加载域互相重叠,可以在相同地址上建立多个执行域,ADS不支持本属性
STM32 分散加载文件

STM32 分散加载文件 IAP —MDK(2011-07-25 14:42:30); *************************************************************; *** Scatter-Loading Description File generated by uVision ***; *************************************************************LR_IROM1 0x08000000 0x00004000 ; load region size_region 第一个加载域,起始地址0x08000000,{ 大小0x00004000ER_IROM1 0x08000000 0x00004000 ; load address = execution address 第一个运行时域, { 起始0x08000000,大小0x00004000*.o (RESET, +First) IAP第一阶段还是在FLASH中运行*(InRoot$$Sections)startup_stm32f10x_md.o}ER_IROM2 0x20008000 0x00004000 ; load address = execution address第二个运行时域, { 起始0x20008000,大小0x00004000.ANY (+RO) IAP第二阶段加载到SDRAM中运行}RW_IRAM1 0x20000000 0x00008000 ; RW data 把可读写的数据和初始化为0的数据放在内存SDRAM的开头{.ANY (+RW +ZI)}}做个比喻:就像一列火车在起始地址0x08000000装上大小0x00004000的货物,然后把特定的货物送到指定的地方拿下来运行或者存放。
上面这辆火车就停了3个地方。
编译时出现一下警告:warning: L6314W: No section matches pattern address(RO).在Target中的Linker中有一栏Misc controls,键入--diag_suppress=L6314即可,如下--diag_suppress taglist禁用所有具有指定标签的诊断消息。
[M3_SN] ARM分散加载原理
![[M3_SN] ARM分散加载原理](https://img.taocdn.com/s3/m/775f334fe45c3b3567ec8b33.png)
ARM分散加载原理摘要从ARM ELF目标文件主要构成出发,详细介绍了分散加载的基本原理、分散加载文件的语法、分散加载时连接器生成的预定义符号及要重新实现的函数等;以定位目标外设和定义超大型结构体数组两项应用案例加以说明,并给出完整的工程实例和Bootloader代码。
这些都已经在实际工程中多次应用和验证,是笔者实际工程的萃取。
关键词分散加载嵌入式系统Scatter Loading Bootloader ARM ELF引言在当今的嵌入式系统设计中,ARM处理器以价格便宜、功耗低、集成度高、外设资源丰富和易于使用的特点而得到广泛的应用;在速度和性能方面已达到或超过了部分PC104嵌入式计算机的性能,而成本却比相应的PC104计算机低很多,广泛应用于手机、GPS接收机、地图导航、路由器、以太网交换机及其他民用和工业电子设备。
在一个采用ARM处理器的实时嵌入式系统中,目标硬件常常由Flash、SRAM、SDRAM 和NVRAM(非易失性RAM)等存储器组成,并定位于不同的物理地址范围,那么,怎样通过软件更好地访问和利用这些不同的存储器并让系统高效地运行?分散加载(Scatter loading)就提供了这样一种机制。
它可以将内存变量定位于不同的物理地址上的存储器或端口,通过访问内存变量即可达到访问外部存储器或外设的目的;同时通过分撒加载,让大多数程序代码在高速的内部RAM中运行,从而使得系统的实时性大大增强。
1.ARM ELF目标文件的主要构成ARM ELF(Executable and Linking Format)目标文件主要由.Text段、.Data段、.BSS段构成,其他段如.debug段、.comment段等与本文关系部大,不作介绍。
.Text 段由可执行代码组成,段类型为Code,属性为RO;.Data 段由已初始化数据组成,段类型为Data, 属性为RO;.BSS 段由未初始化数据组成,段类型为Zero, 属性为RW,在应用个程序启动时对该段的数据初始化为零。
基于分散加载的ARM软件加密方案设计

本 文 以 ARM Co r t e x—M3芯 片 为 例 , 设 计 并 实 现 了
引 言
ARM 芯 片作 为嵌 入 式 系 统 的 主 流 芯 片 , 已 经 广 泛 应 用 于手 机 、 路 由 器 及 其 他 工 业 和 民 用 电 子 设 备 】 。 在
ARM 处 理 器 得 到越 来 越 多 的 应 用 的 同 时 , 如 何 防 止 黑 客
臃
基 于 分 散 加 载 的 ARM 软 件 加 密 方 案 设 计
关峰 , 谢 晓 明
( 北 京 化 工 大 学 信 息 科学 与技 摘 要 :针 对 黑客 非 法 获取 ARM 芯 片 程 序 的 问题 , 提 出 了一 种 能 同 时 防 止 ARM 芯 片 程 序 被 非 法 复 制 及 源 码 窃 取 的 方
法 。该 方 法 以 分散 加 栽 方 式规 划存 储 器 , 以 ARM 芯 片 内全 球 唯 一 序 列 号 为 密钥 , 对 核 心 程 序 进 行 加 密 处 理 。在 程 序 运
行 时, 芯 片 内的唯 一序 列 号使 非 法拷 贝的 程 序在 同类 型 ARM 设 备 上 无 法运 行 ; 对核 心程序 进行加 密后存储 , 确 保 源 代
一
种 基 于 分 散 加 载 的 ARM 芯 片 加 密 方 案 , 此 方 案 将 经 过
加 密 的程 序 烧 写 到 存 储 器 上 , 从 而 完 全 打乱 程 序 在 存 储 器 上 的正 常 顺 序 , 使 其 反 汇 编 完 全 不 可 读 。以 A R M 芯片 内 全 球 唯 一 的序 列 号 为 密 钥 , 确 保 被 整 片 复制 的 程 序 无 法 正
Ab s t r ac t :A c c o r d i n g t O t he p r o bl e m t ha t h a c ke r s s t e a l A RM p r o gr a m c od e b y i l l e ga l me t ho ds ,a me t ho d t h a t c a n s i m ul t a ne o us l y pr e ve n t A RM pr o gr a m c o de be i ng i l l e ga l l y c op i e d a nd c r a c ke d i s pr op os e d. The me t ho d p l a n s me m or y uni t b a s e d o n s c a t t e r l o a di ng a n d e nc r yp t s
MTK Scatter文件学习

MTK Scatter文件学习概述:分散加载(scatter loading)是ARM 连接接器提供的一个机制,该机制可以把一个可执行映像文件(即Bin文件)分割放置到内存中不同的独立段。
映像(Image)文件有两个视图:加载视图(Load view) 和执行视图(execution view)。
在下载的时候Image regions被放置在memory map当中,而在执行Image前,或许你需要将一些regions放置在它们执行时的地址上,并建立起ZI regions。
例如,你初始化的RW数据需要从它在下载时的在ROM中的地址处移动到执行时RAM的地址处。
在scatter 文件中可以为每一个代码或数据段在装载和执行时指定不同的存储区域地址,Scatlertoading的存储区块可以分成二种类型:装载区:当系统启动或加载时应用程序的存放区。
执行区:系统启动后,应用程序进行执行和数据访问的存储器区域,系统在实时运行时可以有一个或多个执行区。
映像中所有的代码和数据都有一个装载地址和运行地址(二者可能相同也可能不同,视具体情况而定)。
在系统启动时,C函数库中的__main初始化代码会执行必要的复制及清零操作,使应用程序的相应代码和数据段从装载状态转入执行状态。
为什么需要Scatter文件:制定存储器映射(memory map)的方法基本上有二种,一是在link时使用命令行选项,并在程序执行前利用linker pre-define symbol使用汇编语言制定section的段初始化,二是使用scatter file,即采用“分散加载机制”。
以上二种方法依应用程序的复杂度而定,一针对简单的情况,二针对复杂的情况。
手机属于复杂的情况,必须使用scatter file。
Scatter文件语法:scatter文件是一个简单的文本文件,包含一些简单的语法(分号后面的内容是注释):My_Region 0x0000 0x1000 ;区域名称区起始地址区长度{the context of region ;区内容}每个区由一个头标题开始定义,头中至少包含区的名字和起始地址,另外还有最大长度和其他一些属性选项。
试图搞懂MDK程序下载到flash(二)--分散加载文件scatter

试图搞懂MDK程序下载到flash(二)--分散加载文件scatter分散加载文件概念对于分散加载文件的概念,在《ARM体系结构与编程》书第11章有明确介绍。
分散加载文件(即scatter file,后缀为 .scf)是一个文本文件,通过编写一个分散加载文件来指定ARM连接器在生成映像文件时如何分配RO、RW、ZI等数据的存放地址。
如果不用SCATTER文件指定,那么ARM连接器会按照默认的方式来生成映像文件,一般情况下我们是不需要使用分散加载文件的。
但在某些场合,我们希望把某些数据放在知道那个的地址处,那么这时候SCATTER文件就发挥了非常大的作用,而且SCATTER文件用起来非常简单好用。
我越看这个分散加载文件越感觉它的作用和uboot的连接脚本lds 一样。
分散加载文件的格式分散加载描述文件是一个文本文件,它向链接器描述目标系统的存储器映射。
如果通过命令行使用链接器,则描述文件的扩展名并不重要。
分散加载文件指定:①每个加载区的加载地址和最大尺寸;②每个加载区的属性;③从每个加载区派生的执行区;④每个执行区的执行地址和最大尺寸;⑤每个执行区的输入节。
从描述文件的格式就可以看出加载区、执行区和输入节的层次关系。
分散加载文件基本点①编译后输出的映像文件中各段是首尾相连的,中间没有空闲的区域,他们的先后关系是根据链接时参数的先后次序决定的armlinker -file1.o file2.o ...② scatter用于将编译后的映像文件中的特定段加载到多个分散的指定内存区域③有两类域(region):执行域(execution region,一般是ram区域)和加载域(load region,一般是rom区域)④加载域:就是编译之后得到的二进制文件烧写到rom中的这一段区域,所有的代码R0、预定义变量RW、堆栈之类和清不清空无关紧要的大片内存区域ZI,都包括在其中。
⑤执行域:就是把加载域进行“解压缩”后的样子。
嵌入式Linux名词解析

目录Shell (2)脚本Script (2)目标程序 (3)交叉编译 (5)进程线程和任务 (7)工具链 (7)文件系统 (8)什么是ioctl (8)根文件系统 (10)分散加载 (12)文件系统 (13)Busybox (13)驱动程序和内核的关系 (14)文件描述符 (14)struct file (17)struct inode (19)Shell文字操作系统与外部最主要的接口就叫做shell。
shell是操作系统最外面的一层。
shell管理你与操作系统之间的交互:等待你输入,向操作系统解释你的输入,并且处理各种各样的操作系统的输出结果。
GNU/Linux由于GNU/Linux这个词太长,下面如果没有特别指明,“Linux”就是指“GNU/Linux”。
BashBash(Bourne Again Shell)是目前大多数Linux(Red Hat,Slackware等)系统默认使用的Shell,它由Brian Fox和Chet Ramey共同完成,内部命令一共有40 个,它是Bourne Shell 的扩展,与Bourne Shell完全向后兼容,并且在Bourne Shell的基础上增加了很多特性。
Bash 是GNU计划的一部分,用来替代Bourne Shell。
Linux 下使用Shell 非常简单,打开终端就可以到Shell的提示符了,登录系统之后,系统将执行个称为Shell的程序,正是Shell进程提供了命令提示符。
作为Linux 默认的Bash,对于普通用户“$”作为Shell提示符,而对于根用户(root)用“#”作提示符。
如图3.2。
脚本Script动态程序一般有两种实现方式,一是二进制方式,一是脚本方式。
二进制方式是先将我们编写的程序进行编译,变成机器可识别的指令代码(如.exe文件),然后再执行。
这种编译好的程序我们只能执行、使用,却看不到他的程序内容。
脚本简单地说就是一条条的文字命令,这些文字命令是我们可以看到的(如可以用记事本打开查看、编辑),脚本程序在执行时,是由系统的一个解释器,将其一条条的翻译成机器可识别的指令,并按程序顺序执行。
Cortex-M3在MDK下汇编程序分散加载文件出错的解决方法

Cortex-M3在MDK下汇编程序分散加载文件出错的解决方法用LM3S系列的处理器在real view MDK下调试第一个汇编程序时出现了以下问题:Build target 'Target 1'assembling test.s...linking...test.sct(7): error: L6236E: No section matches selector - no section to be FIRST/LAST."test.axf" - 1 Error(s), 0 Warning(s).解决它可没有少费功夫。
找了很多资料才解决。
先总结如下,供初学者参考。
但还是有一点没有解决完善,望高手赐教:fengxu0217@。
1.对于汇编调试,不需要添加启动,仅设置堆栈即可2.默认分散加载文件如下(LM3S615,其实其他也差不多,都是自动生成):LR_IROM1 0x00000000 0x00008000 { ; load region size_regionER_IROM1 0x00000000 0x00008000 { ; load address = execution address*.o (RESET, +First)*(InRoot$$Sections).ANY (+RO)}RW_IRAM1 0x20000000 0x00002000 { ; RW data.ANY (+RW +ZI)}}需要注意的是,自己写的程序的入口必须是RESET,如下程序所示:STACK_TOP EQU 0x20002000AREA RESET,CODE,READWRITEDCD STACK_TOPDCD STARTENTRYSTARTMOV R0, #10MOV R1, #0loopADD R1, R0#1SUBS R0,BNE loopdeadloopB deadloopEND然后在编译的时候linker选项下如下图所示:编译之后输出结果如下所示:Build target 'Target 1'assembling test.s...linking...test.sct(8): warning: L6314W: No section matches pattern *(InRoot$$Sections).Program Size: Code=24 RO-data=0 RW-data=0 ZI-data=0"test.axf" - 0 Error(s), 1 Warning(s).此时,会出现这个警告。
周立功单片机:分散加载文件浅释

分散加载文件浅释ARM嵌入式开发广州周立功单片机科技有限公司目录1. 适用范围 (1)2. 基础知识 (2)2.1 基本概念 (2)3. 分散加载文件概述 (3)4. 分散加载文件语法 (4)4.14.24.35.15.25.35.45.55.6 加载时域的描述 (4)运行时域的描述 ....................................................................................................... 5 输入段描述 ............................................................................................................... 6 一个普通的分散加载配置 ....................................................................................... 8 多块RAM的分散加载文件配置 ............................................................................ 8 多块Flash的分散加载文件配置 .......................................................................... 10 Flash特殊要求应用 ............................................................................................... 13 段在分散加载文件中的应用 ................................................................................. 13 程序拷贝到RAM中执行应用 .............................................................................. 14 5. 分散加载应用实例 ................................................................................................... 8 工程技术笔记©2008 Guangzhou ZHIYUAN Electronics CO., LTD.11. 适用范围有时候用户希望将不同代码放在不同存储空间,也就是通过编译器生成的映像文件需要包含多个域,每个域在加载和运行时可以有不同的地址。
KEIL下分散加载文件的使用

KEIL下分散加载文件的使用在KEIL下进行分散加载文件的使用可以通过在工程设置中进行配置来实现。
KEIL是一种嵌入式开发工具,可用于开发各种微控制器架构的应用程序。
分散加载(Scatter Loading)是一种在嵌入式系统中进行内存映射的技术,它通过将不同的代码段和数据段分散加载到不同的物理地址上,实现有效的内存管理和资源分配。
要在KEIL下使用分散加载文件,可以按照以下步骤进行配置:1. 打开KEIL软件,选择要进行配置的项目工程,在菜单栏中选择Project -> Options for Target。
2. 在弹出的对话框中,选择"Output"选项卡,然后点击"Manage"按钮。
3. 在下方的列表中,点击"Add"按钮,然后选择要进行分散加载的文件。
4.在弹出的对话框中,选择要添加的文件,并设置加载地址和加载大小,然后点击"OK"。
5.重复步骤3和4,将所有要进行分散加载的文件都添加到列表中。
6.设置每个分散加载文件的加载地址和加载大小,以确保它们不会重叠或冲突。
7.在列表中选择每个分散加载文件,并使用上下箭头按钮来调整它们的加载顺序。
8.最后,点击"OK"保存配置信息。
通过上述步骤,我们可以实现对不同代码段和数据段的分散加载,从而实现对内存资源的有效管理和分配。
在KEIL中,配置完成后,编译和生成可执行文件时将按照配置的分散加载文件进行内存映射和分配。
使用分散加载文件可以帮助我们更好地管理内存资源,提高系统性能和效率。
需要注意的是,在进行分散加载文件配置时,需要确保分散加载文件之间不会出现重叠或冲突。
同时,还需要根据硬件平台和应用程序的需求,合理设定加载地址和加载大小。
KEIL作为一款功能强大的嵌入式开发工具,支持分散加载文件的配置,可以帮助开发人员更好地进行内存管理和资源分配,使嵌入式应用程序更加高效和可靠。
scf(分散加载描述文件)程序说明

LPC2294-.SCF文件[ 2007-4-14 3:33:00 | By: CANopen ]分散加载描述文件供ARM-ADS链接器使用,用来决定各个代码段和数据段的存储位置,下面为一个添加注释后的.scf文件例子:;YL-LPC2294片内FLASH分散加载文件;Internal Flash 256kBytes, Address range:0x00000000~0x0003ffff;Internal SRAM 16KBytes, Address range:0x40000000~0x40003fff;External Flash 2MBytes,SST39VF1601, Address range:0x80000000~0x401fffff;External SRAM 512KBytes,IS61LV25616,Address range:0x81000000~0x81080000ROM_LOAD 0x0 ;ROM_LOAD:Name of the load region.;0x0:Start address for ROM_LOAD region.{ROM_EXEC 0x00000000 ;ROM_EXEC:Name for the first execute region.;0x00000000:Start address for the execture region.{Startup.o (vectors, +First)* (+RO) ;Place all code and RO data into this exec region,;and make sure the "vectors" section from "Startup.o";be placed first.}IRAM 0x40000000 ;The second execute region;start address is 0x40000000. {Startup.o (+RW,+ZI) ;Place all RW and ZI data from Startup.o here.}ERAM 0x81068000 ;The third execute region;Start address:0x81068000.{* (+RW,+ZI) ;All reset RW/ZI data to be placed here.}HEAP +0 UNINIT ;The fourth execute region;Start address:Follow the;end of ERAM region.{heap.o (+ZI) ;All ZI data from heap.o to be placed here.}STACKS 0x40004000 UNINIT ;The fifth execute region.{stack.o (+ZI) ;All ZI data from stack.o to be placed here.}}一般一个简单的分散加载描述文件包含三部分:Loader region、Execute region、Input section。
Scatter文件编写

Scatter文件编写一个映像文件中可以包含多个域(region),在加载和运行映像文件时,每个域可以有不同的地址。
每个域可以包括多达3个输出段,每个输出段是由若干个具有相同属性的输入段组成。
这样在生成映像文件时,ARM链接器就需要知道下述两个信息。
•分组信息决定各域中的输出段是由哪些输入段组织而成;•定位信息决定各域在存储空间中的起始地址。
根据映像文件中地址映射的复杂程度,有两种方法来告诉ARM链接器这些相关的信息。
对于映像文件中地址映射关系比较简单的情况,可以使用命令行选项;对于映像文件中地址映射关系比较复杂的情况,可以使用一个scatter配置文件。
Scatter文件又称为分散加载文件,将重点讲解如何编写scatter文件。
1、Scatter文件结构Scatter文件是一个文本文件,使用BNF语法来描述ARM链接器生成映像文件时所需要的信息。
具体来说,在scatter文件中可以指定下列信息:•各个加载时域的加载时起始地址、最大尺寸和属性;•每个加载时域包含的输出段;•各个输出段的运行时起始地址、最大尺寸、存储访问特性和属性;•各个输出段中包含的输入段。
一个Scatter文件包含若干个加载域,一个加载域包含若干个输出段,一个输出段由若干个具有相同属性的输入段组成,其结构如图1所示。
图1 Scatter 文件结构示意图①加载时域的描述加载时域包括名称、起始地址、属性、最大尺寸和一个运行时域的列表。
使用BNF 语法描述,加载时域的格式如下所示:Load_name base_designator attribute max_size {……}•Load_name 运行时域名称,它除了唯一地标识一个运行时域外,还用来构成链接器生成的链接符号;•base_designator 用来表示本加载时域的起始地址,它可以有两种格式表示:起始地址或偏移量;•attribute 本加载时域的属性,其可能的取值为下面之一,默认的取值为ABSOLUTE:• PI 位置无关属性;• RELOC 重定位;• ABSOLUTE 绝对地址;按照例 scatter文件的描述,ARM链接器会生成相应的映像文件地址映射关系,如图2所示。
mdk 使用分散加载文件定位函数

在Keil MDK(Microcontroller Development Kit)中,分散加载文件(Scatter-Loading File)是一种用于配置和定位在嵌入式系统中加载到存储器的程序和数据的文件。
分散加载文件通常使用链接脚本(Linker Script)进行配置,以指定程序和数据在存储器中的位置。
您可以使用分散加载文件和链接脚本来定位函数、变量以及其他程序元素。
以下是在Keil MDK中使用分散加载文件和链接脚本来定位函数的一般步骤:1. **创建分散加载文件**:- 在Keil MDK中,您可以通过选择“Project” > “Options for Target” > “Linker”来配置链接器设置。
- 在链接器选项中,您可以指定分散加载文件的名称和路径。
2. **编辑链接脚本**:- 创建或编辑链接脚本,以便定义程序和数据的存储器布局。
- 在链接脚本中,您可以使用关键字(如`CODE`, `DATA`, `RODATA` 等)来指定不同类型的存储器区域,并在这些区域中定位函数和变量。
- 通过将函数所属的源文件分配给特定存储器区域,您可以将函数定位到相应的存储器位置。
3. **分配函数到存储器区域**:- 在链接脚本中,通过使用`__attribute__` 或`#pragma` 指令(具体语法取决于您的目标芯片和编译器),将函数分配到所需的存储器区域。
- 例如,您可以使用以下方式将函数`myFunction` 分配到FLASH 存储器区域:```cvoid myFunction(void) __attribute__((section(".text")));```或```c#pragma location=".text"void myFunction(void);```4. **编译和链接**:- 编译和链接您的项目,确保分散加载文件和链接脚本配置正确。
分散加载文件相关知识_摘录

分散加载⽂件相关知识_摘录⼀般⽽⾔,⼀个程序包括只读的代码段和可读写的数据段。
在ARM的集成开发环境中,只读的代码段和常量被称作RO段(ReadOnly);可读写的全局变量和静态变量被称作RW段(ReadWrite);RW段中要被初始化为零的变量被称为ZI段(ZeroInit)。
对于嵌⼊式系统⽽⾔,程序映象都是存储在Flash存储器等⼀些⾮易失性器件中的,⽽在运⾏时,程序中的RW段必须重新装载到可读写的RAM中,这就涉及到程序的加载域和运⾏域。
简单来说,程序的加载域就是指程序烧⼊Flash中所占空间,运⾏域是指程序执⾏时所占空间。
对于⽐较简单的情况,可以在ADS集成开发环境的ARM LINKER选项中指定RO BASE和RW BASE,告知连接器RO和RW的连接基地址。
对于复杂情况,如RO段被分成⼏部分并映射到存储空间的多个地⽅时,需要创建⼀个称为“分散加载⽂件”的⽂本⽂件,通知连接器把程序的某⼀部分连接在存储器的某个地址空间。
需要指出的是,分散加载⽂件中的定义要按照系统重定向后的存储器分布情况进⾏。
在引导程序完成初始化的任务后,应该把主程序转移到RAM中去运⾏,以加快系统的运⾏速度。
什么是arm的映像⽂件,arm映像⽂件其实就是可执⾏⽂件,包括bin或hex两种格式,可以直接烧到rom⾥执⾏。
在axd调试过程中,我们调试的是axf⽂件,其实这也是⼀种映像⽂件,它只是在bin⽂件中加了⼀个⽂件头和⼀些调试信息。
映像⽂件⼀般由域组成,域最多由三个输出段组成(RO,RW,ZI)组成,输出段⼜由输⼊段组成。
所谓域,指的就是整个bin映像⽂件所处在的区域,它⼜分为加载域和运⾏域。
加载域就是映像⽂件被静态存放的⼯作区域,⼀般来说flash⾥的整个bin⽂件所在的地址空间就是加载域,当然,程序⼀般都不会放在 flash⾥执⾏,⼀般都会搬到sdram⾥运⾏⼯作,它们在被搬到sdram⾥⼯作所处的地址空间就是运⾏域。
周立功单片机:分散加载文件浅释
分散加载文件浅释ARM嵌入式开发广州周立功单片机科技有限公司目录1. 适用范围 (1)2. 基础知识 (2)2.1 基本概念 (2)3. 分散加载文件概述 (3)4. 分散加载文件语法 (4)4.14.24.35.15.25.35.45.55.6 加载时域的描述 (4)运行时域的描述 ....................................................................................................... 5 输入段描述 ............................................................................................................... 6 一个普通的分散加载配置 ....................................................................................... 8 多块RAM的分散加载文件配置 ............................................................................ 8 多块Flash的分散加载文件配置 .......................................................................... 10 Flash特殊要求应用 ............................................................................................... 13 段在分散加载文件中的应用 ................................................................................. 13 程序拷贝到RAM中执行应用 .............................................................................. 14 5. 分散加载应用实例 ................................................................................................... 8 工程技术笔记©2008 Guangzhou ZHIYUAN Electronics CO., LTD.11. 适用范围有时候用户希望将不同代码放在不同存储空间,也就是通过编译器生成的映像文件需要包含多个域,每个域在加载和运行时可以有不同的地址。
分散加载文件的作用

分散加载文件的作用作用分散加载文件的作用前言在当今互联网时代,网络速度和用户体验成为了网站开发者和设计师们关注的焦点。
为了提升网站加载速度和用户体验,分散加载文件成为了一个常见的解决方案。
本文将探讨分散加载文件的作用及其在网站开发和设计中的应用。
一、定义分散加载文件是指将一个由多个组件构成的文件拆分为多个部分分别加载,达到优化网站性能和加快加载速度的目的。
该方法有效缩短了用户等待页面加载的时间,提供更好的用户体验。
二、作用1. 优化页面加载速度当一个网页文件过大时,浏览器需要较长时间来加载和渲染整个页面。
而将文件分散加载可以减小每个文件的体积,从而缩短了整个网页的加载时间。
这对于用户来说,能够更快地打开网页,减少等待时间,提高用户满意度和留存率。
2. 提高网站性能分散加载文件能够在一定程度上减轻服务器的负载压力。
由于文件被分开加载,服务器可以并行处理这些文件的请求,从而提高网站的整体性能和稳定性。
此外,更有效的利用了服务器的带宽,使网站对大量用户的访问依然能够保持较高的加载速度和稳定性。
3. 便于维护和更新当一个文件被拆分为多个部分时,每个部分可以独立进行维护和更新。
这为开发者和设计师们带来了便利。
比如,当需要更新一个网页的某个组件时,只需替换相应的部分文件,而无需重新加载整个文件。
这样不仅加快了更新速度,也减少了可能带来的错误和破坏性影响。
4. 提高网站的可扩展性采用分散加载文件的方法,在网站需要扩展时更为便捷。
开发人员可以只添加新的文件,而不需要对现有的文件进行修改。
这样可以将扩展过程与现有代码相互独立,减少了开发的风险和复杂度。
5. 优化搜索引擎排名网站加载速度是影响搜索引擎排名的重要因素之一。
通过采用分散加载文件的方法,网站可以提供更快的加载速度,从而提升在搜索引擎中的排名。
这对于网站的流量和曝光量都有积极的影响。
三、案例分析下面以一个常见的案例来说明分散加载文件的具体应用。
假设一个电子商务网站,该网站的主页由多个组件构成,包括导航栏、轮播图、商品列表等。
Cortex-M3在MDK下汇编程序分散加载文件出错的解决方法
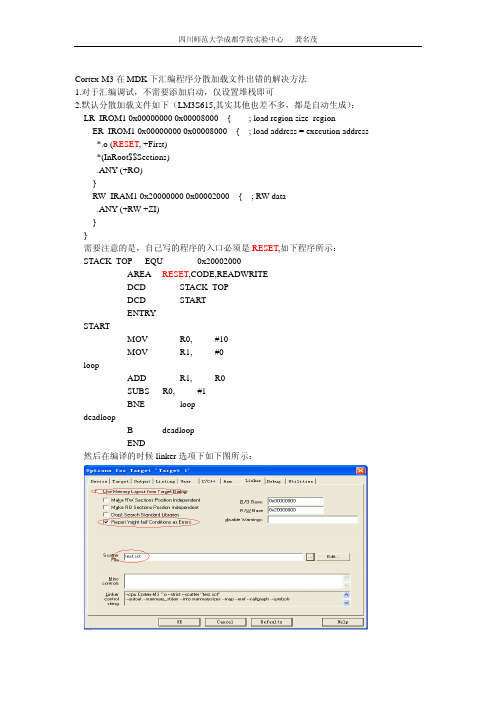
Cortex-M3在MDK下汇编程序分散加载文件出错的解决方法1.对于汇编调试,不需要添加启动,仅设置堆栈即可2.默认分散加载文件如下(LM3S615,其实其他也差不多,都是自动生成):LR_IROM1 0x00000000 0x00008000 { ; load region size_regionER_IROM1 0x00000000 0x00008000 { ; load address = execution address *.o (RESET, +First)*(InRoot$$Sections).ANY (+RO)}RW_IRAM1 0x20000000 0x00002000 { ; RW data.ANY (+RW +ZI)}}需要注意的是,自己写的程序的入口必须是RESET,如下程序所示:STACK_TOP EQU 0x20002000AREA RESET,CODE,READWRITEDCD STACK_TOPDCD STARTENTRYSTARTMOV R0, #10MOV R1, #0loopADD R1, R0SUBS R0,#1BNE loopdeadloopB deadloopEND然后在编译的时候linker选项下如下图所示:编译之后输出结果如下所示:Build target 'Target 1'assembling test.s...linking...test.sct(8): warning: L6314W: No section matches pattern *(InRoot$$Sections).Program Size: Code=24 RO-data=0 RW-data=0 ZI-data=0"test.axf" - 0 Error(s), 1 Warning(s).此时,会出现这个警告。
据网友们说是无关紧要的。
虽然如此,但是看着不爽。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ARM处理器的分散加载及特殊应用研究摘要从ARM ELF目标文件主要构成出发,详细介绍了分散加载的基本原理、分散加载文件的语法、分散加载时连接器生成的预定义符号及要重新实现的函数等;以定位目标外设和定义超大型结构体数组两项应用来加以说明,并给出完整的工程实例和Bootloader代码。
这些都已经在实际工程中多次应用和验证,是笔者实际工程项目的萃取。
关键词分散加载嵌入式系统 Scatter Loading Bootloader ARM ELF引言在当今的嵌入式系统设计中,ARM处理器以价格便宜、功耗低、集成度高、外设资源丰富和易于使用的特点而得到广泛的应用;在速度和性能方面已达到或超过部分PC104嵌入式计算机的性能,而成本却比相应的PC104计算机低很多,广泛应用于手机、GPS接收机、地图导航、路由器、以太网交换机及其他民用和工业电子设备。
在一个采用ARM处理器的实时嵌入式系统中,目标硬件常常由Flash、SRAM、SDRAM和NVRAM(非易失性RAM)等存储器组成,并定位于不同的物理地址范围,那么,怎样通过软件更好地访问和利用这些不同的存储器并让系统高效地运行?分散加载(scatter loading)就提供了这样一种机制。
它可以将内存变量定位于不同的物理地址上的存储器或端口,通过访问内存变量即可达到访问外部存储器或外设的目的;同时通过分散加载,让大多数程序代码在高速的内部RAM中运行,从而使得系统的实时性大大增强。
1 ARM ELF目标文件的主要构成ARM ELF(Executable and Linking Format)目标文件主要由.Text段、.Data 段、.BSS段构成,其他段如.debug段、.comment段等与本文关系不大,不作介绍。
.Text段由可执行代码组成,段类型为Code,属性为RO;.Data段由已初始化数据组成,段类型为Data,属性为RO;.BSS段由未初始化数据组成,段类型为Zero,属性为RW,在应用程序启动时对该段的数据初始化为零。
如果在分散加载文件中指定了UNINIT属性,则在应用程序启动时不初始化该段。
2 分散加载的基本原理假设一个采用ARM处理器的实时嵌入式系统目标硬件的存储器由ROM存储器和RAM存储器组成。
当一个嵌入式系统在仿真环境下调试完毕,需要脱机运行的时候,就需要将源程序编译连接成可执行目标代码并烧写到ROM存储器中。
由于ROM存储器存取数据的速率比RAM存储器慢,因此,让程序在ROM存储器中运行。
CPU每次取指令和取数据操作都要访问ROM存储器,这样需要在CPU的总线周期中插入等待周期,通过降低总线的速率来满足访问慢速的ROM存储器,这样势必会降低CPU的运行速率和效率,因此,分散加载就显得非常必要。
ARM的连接器提供了一种分散加载机制,在连接时可以根据分散加载文件(.scf文件)中指定的存储器分配方案,将可执行镜像文件分成指定的分区并定位于指定的存储器物理地址。
这样,当嵌入式系统在复位或重新上电时,在对CPU相应寄存器进行初始化后,首先执行ROM存储器的Bootloader(自举) 代码,根据连接时的存储器分配方案,将相应代码和数据由加载地址拷贝到运行地址,这样,定位在RAM存储器的代码和数据就在RAM存储器中运行,而不再从 ROM 存储器中取数据或取指令,从而大大提高了CPU的运行速率和效率。
分散加载的基本原理如图1所示。
3 分散加载文件语法在一个实时嵌入式系统中,分散加载文件是对目标硬件中的多个存储器块的分块描述,它直接对应目标硬件存储器的起始地址和范围。
同时,它在应用程序连接时用于告诉连接器用户程序代码和数据的加载地址和运行地址,在连接时由连接器产生相应的加载地址和运行地址符号,包括代码和数据的加载起始地址、运行地址和长度等。
这些符号用于上电后执行启动代码的数据拷贝工作,启动代码根据这些符号,将指定代码和数据由ROM中的加载地址拷贝到RAM中的运行地址中,从而实现代码在高速RAM存储器中的脱机运行。
其语法格式如下:注意:①每一个分散加载文件必须至少包含一个根区,每个根区的加载地址等于执行地址。
②每一个引导区必须至少包含一个执行区,每一个执行区必须至少包含一个代码段或数据段;一个引导区可以包含几个执行区,每一个执行区只能属于一个引导区。
4 分散加载时连接器生成的预定义符号在编译连接时如果指定了分散加载文件(.scf文件),在连接后会自动生成如下变量:5 重新实现_user_initial_stEickheap()函数分散加载机制提供了一种指定代码和静态数据布局的方法。
使用分散加载时,必须重新放置堆栈和堆。
应用程序的堆栈(stack)和堆(heap)是在C库函数初始化过程中建立起来的,在ADSl.2或更新版本中,在缺省状态下C库函数初始化代码会将连接器生成的符号Image$$ZI$$Limit地址作为堆的基地址。
在分散加载时,连接器会将用户的 __user_initidl_stackheap()函数代替C库函数默认的堆栈和堆初始化函数,并将其连接到用户的镜像文件中,用户可通过重新实现__user_initial_stackheap()函数来改变堆栈和堆的位置,从而适合自己的目标硬件。
__user_initial_stackheap()可以用C或汇编语言来实现。
它必须返回如下参数:r0—堆基地址;r1—堆栈基地址;r2—堆长度限制值(需要的话);r3—堆栈长度限制值(需要的话)。
当用户使用分散加载功能的时候,必须重新实现一user_initial_staacklaeap(),否则连接器会报错:Error:L6218E:Undefined symbol Imager$$ZI$$一Limit(referred from sys_stackheap.o)。
注:Image$$ZI$$Limit变量为零初始化段(ZI段)的末地址。
未使用分散加载时,堆默认就定位在ZI段的末地址,如图2所示。
__user_initial_stackheap()函数的实现有两种方法。
(1)共用一个存储区汇编语言如下:这种方式定义的堆栈和堆共用一个存储区,采用相向的增长方向,如图3所示。
(2)使用两个存储区汇编语言如下:这种方式定义的堆栈和堆分别采用两个不同存储区。
堆栈采用向下增长,从地址Ox40000到地址Ox20000;堆采用向上增长,从地址0x28000000到地址0x28080000,如图4所示。
6 特殊应用6. 1 定位目标外设使用分散加载,可以将用户定义的结构体或代码定位到指定物理地址上的外设,这种外设可以是定时器、实时时钟、静态SRAM或者是两个处理器间用于数据和指令通信的双端口存储器等。
在程序中不必直接访问相应外设,只需访问相应的内存变量即可实现对指定外设的操作,因为相应的内存变量定位在指定的外设上。
这样,对外设的访问看不到相应的指针操作,对结构体成员的访问即可实现对外设相应存储单元的访问,让程序员感觉到仿佛没有外设,只有内存。
例如,一个带有两个32位寄存器的定时器外设,在系统中的物理地址为Ox04000000,其C语言结构描述如下:要使用分散加载将上述结构体定位到Ox04000000的物理地址,可以将上述结构体放在一个文件名为timer_regs.c中,并在分散加载文件中指定即可,如下:属性UNINIT是避免在应用程序启动时对该执行段的ZI数据段初始化为零。
在程序连接后,通过Image map文件可查看该ZI数据段的存储器分配情况: Execution Region TIMER(Base:Ox04000000,Size:0x00000008,Max:0xffffffff,ABSOLUTE,UNINIT)Base Addr Size Type Attr Idx E Section Name 0bi ectOx04000000 0x00000008 Zero RW 32.bss tlmer_regs.o从Image map 文件可以看出,该TIMER执行区定位在物理地址0x04000000,即结构体timer_regs定位在Ox04000000,因此,在程序中对结构体的操作即是对定时器的操作。
6.2 定义超大型结构体数组分散加载机制在提供将指定代码和数据定位在指定物理地址的能力的同时,也提供了一种代码分割机制——可以将指定的零初始化段(ZI段)从可执行代码中分离出来。
这样最终生成的烧入ROM或Flash中的镜像文件就不包括那部分分割了的零初始化段,即使该零初始化段再大,也不影响最终生成的镜像文件的大小。
但不采用分散加载机制,零初始化段在编译连接后是直接生成到镜像文件中的。
它的大小直接影响最终要烧写的文件的大小,且零初始化段的大小还取决于内存的大小,它不能大到超过内存的大小;而采用分散加载机制,可以将某个零初始化段定位到非内存地址的一个存储器外设上,如NVRAM(非易失性随机存储器)。
笔者曾在一个实际工程中采用这种分散加载机制,将一个2MB的结构体数组定位到外部NVRAM中,用于记录设备在工作过程中采集到的数据;而在本系统中,ARM处理器的内存只有256 KB,Flash存储器也只有2 MB。
如果不采用分散加载,程序根本无法运行,也不能烧写到Flash中。
采用分散加载,把对复杂外设的访问变成对结构体数组的访问,使程序代码精简易懂。
对程序员来说,对结构体数组的操作还是和内存变量的操作一样的。
编者注:本文为期刊缩略版,全文见本刊网站www.mesnet.com.cn。
结语分散加载是嵌入式系统应用中不可或缺的一种加载方式,ARM、DSP、PowerPC 和MIPS等嵌入式处理器,都离不开分散加载。
这种分散加载的思想是通用的,只是不同处理器的实现方式不同。
本文详细阐述了基于ARM处理器的分散加载方法及其特殊应用,并以实际工程为例来说明怎样实现分散加载及使用分散加载的好处。
它是笔者在实际工程应用中的心得体会,同时也是笔者工作经验的总结,希望本文对从事嵌入式系统设计和应用的工程技术人员能有所帮助。