Spark Shuffle详解
sparkshuffle原理、shuffle操作问题解决和参数调优

Spark Shuffle原理、Shuffle操作问题解决和参数调优Spark Shuffle原理、Shuffle操作问题解决和参数调优摘要:1 shuffle原理1.1 mapreduce的shuffle原理1.1.1 map task端操作1.1.2 reduce task端操作1.2 spark现在的SortShuffleManager2 Shuffle操作问题解决2.1 数据倾斜原理2.2 数据倾斜问题发现与解决2.3 数据倾斜解决方案3 spark RDD中的shuffle算子3.1 去重3.2 聚合3.3 排序3.4 重分区3.5 集合操作和表操作4 spark shuffle参数调优内容:1 shuffle原理概述:Shuffle描述着数据从map task输出到reduce task输入的这段过程。
在分布式情况下,reducetask需要跨节点去拉取其它节点上的maptask结果。
这一过程将会产生网络资源消耗和内存,磁盘IO的消耗。
1.1 mapreduce的shuffle原理1.1.1 map task端操作每个,存储着map的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉数据。
Spill过程:这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写。
整个缓冲区有个溢写的比例spill.percent(默认是memory写,同时溢写线程锁定已用memory,先对key(序列化的字节)做排序,如果client程序设置了Combiner,那么在溢写的过程中就会进行局部聚合。
Merge过程:每次溢写都会生成一个临时文件,在maptask真正完成时会将这些文件归并成一个文件,这个过程叫做Merge。
1.1.2 reducetask端操作当某台TaskTracker上的所有map task执行完成,对应节点的reduce task开始启动,简单地说,此阶段就是不断地拉取(Fetcher)每个maptask所在节点的最终结果,然后不断地做merge形成reducetask的输入文件。
详谈Spark的shuffle过程

详谈Spark的shuffle过程shuffle操作,是在Spark操作中调用了一些特俗的算子才会触发的一种操作,因此会导致大量的数据在不同的节点之间传输,所以shuffle过程是spark中最复杂、最消耗性能的一种操作。
如reducerByKey算子会将上一个RDD中的每一个key对应的value都聚合成一个 value,然后生成一个新的RDD,新的RDD的元素类型就是<key,value>的格式,每个key 对应一个聚合起来的value。
这里会出现一个问题。
对于上一个RDD来说,不是一个key对应的所有value都在一个partition 中,也不是key的所有value都在一个节点上。
对于这种情况,就必须在集群中将各个节点上同一个 key 对应的value同一传输到一个节点上,这个过程会发生大量的网络IO。
Shuffle过程分为:shuffle write 和shuffle read 。
并且会在不同的stage中进行。
在进行一个key 对应的values的聚合时,首先,上一个stage的每个map task就必须保证将自己处理的当前分区中的数据相同的key写入一个分区文件中,可能会多个不同的分区文件。
接着下一个stage的reduce task就必须从上一个stage的所有task所在的节点上,从各个task写入的多个分区文件中找到属于自己的分区文件,然后将属于自己的分区数据拉取过来,这样就可以保证每个key对应的所有values都汇聚到一个节点上进行处理和聚合,这个过程就称为shuffle过程。
shuffle过程中的分区排序:默认情况下,shuffle操作是不会对每个分区中的数据进行排序的如果想排序,可以使用三种方法:1.使用mapPartitions算子。
2.使用repartitionAndSortWithinPartitions,该算子是对RDD进行重分区的算子,在重分区的过程中可以实现排序。
shuffle过程解析
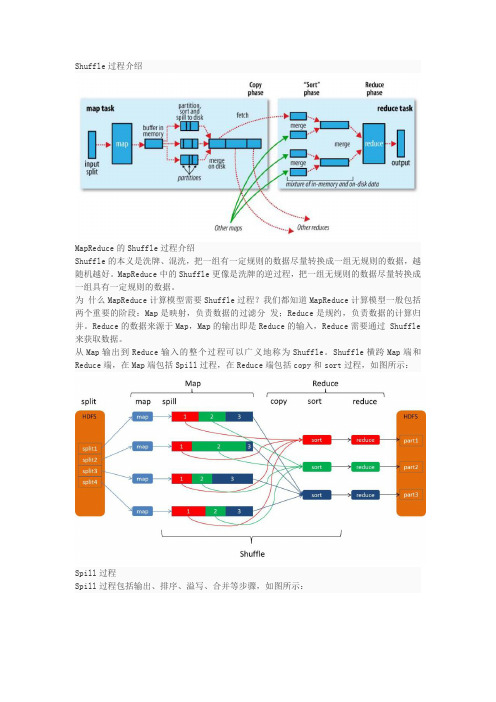
Shuffle过程介绍MapReduce的Shuffle过程介绍Shuffle的本义是洗牌、混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好。
MapReduce中的Shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数据。
为什么MapReduce计算模型需要Shuffle过程?我们都知道MapReduce计算模型一般包括两个重要的阶段:Map是映射,负责数据的过滤分发;Reduce是规约,负责数据的计算归并。
Reduce的数据来源于Map,Map的输出即是Reduce的输入,Reduce需要通过Shuffle 来获取数据。
从Map输出到Reduce输入的整个过程可以广义地称为Shuffle。
Shuffle横跨Map端和Reduce端,在Map端包括Spill过程,在Reduce端包括copy和sort过程,如图所示:Spill过程Spill过程包括输出、排序、溢写、合并等步骤,如图所示:Collect每个Map任务不断地以对的形式把数据输出到在内存中构造的一个环形数据结构中。
使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。
这个数据结构其实就是个字节数组,叫Kvbuffer,名如其义,但是这里面不光放置了数据,还放置了一些索引数据,给放置索引数据的区域起了一个Kvmeta的别名,在Kvbuffer的一块区域上穿了一个IntBuffer(字节序采用的是平台自身的字节序)的马甲。
数据区域和索引数据区域在Kvbuffer中是相邻不重叠的两个区域,用一个分界点来划分两者,分界点不是亘古不变的,而是每次Spill之后都会更新一次。
初始的分界点是0,数据的存储方向是向上增长,索引数据的存储方向是向下增长,如图所示:Kvbuffer的存放指针bufindex是一直闷着头地向上增长,比如bufindex初始值为0,一个Int型的key写完之后,bufindex增长为4,一个Int型的value写完之后,bufindex增长为8。
shuffle read blocked time

shuffle read blocked time
'Shufflereadblockedtime'(随机读取阻塞时间)是指在Spark 集群中,当执行shuffle操作时,由于数据分区数量和节点计算能力不匹配,导致某些节点需要等待其它节点的数据读取完成后才能开始计算,此时所耗费的时间即为shuffle read blocked time。
在处理大规模数据时,shuffle操作是非常常见的,因为它将数据分成不同的分区,并重新组合到不同的节点上进行计算。
但是,由于不同节点的计算能力不同,可能会导致某些节点需要等待其它节点的计算结果。
这种等待所耗费的时间,也就是shuffle read blocked time,会直接影响整个计算任务的执行效率。
为了缩短shuffle read blocked time,可以采取以下策略:
1. 增加节点的计算能力,以便更快地完成计算任务。
2. 调整数据分区的数量,使得数据能够更加均衡地分布在各个节点上。
3. 优化shuffle操作的算法,以减少数据的传输和等待时间。
总之,减少shuffle read blocked time对于提高Spark集群的计算能力和效率非常重要,需要认真考虑和实践。
- 1 -。
spark常见面试题

spark常见面试题Spark是一种快速、分布式计算引擎,被广泛应用于大数据处理和分析中。
在Spark的生态系统中,有许多常见的面试题目,用于评估候选人对Spark的理解和应用能力。
本文将介绍一些常见的Spark面试题,并提供相应的回答。
1. 什么是Spark?它与Hadoop有什么区别?Spark是一种快速、通用、分布式计算系统,可以处理大规模数据和执行复杂的数据处理任务。
与Hadoop相比,Spark的优势在于其内存计算模型,可大大提高计算速度。
此外,Spark提供了丰富的API,支持多种编程语言,并提供了图计算、流式处理和机器学习等扩展库。
2. Spark的核心组件是什么?Spark的核心组件包括Spark Core、Spark SQL、Spark Streaming、Spark MLlib和Spark GraphX。
Spark Core是Spark的基础,提供了任务调度、内存管理和存储系统等功能。
Spark SQL用于处理结构化数据,并提供了SQL查询的功能。
Spark Streaming支持实时数据处理。
Spark MLlib提供了机器学习算法的库。
Spark GraphX用于图计算任务。
3. 什么是RDD?如何创建一个RDD?RDD(弹性分布式数据集)是Spark中的基本数据抽象,是一个可并行操作的不可变分布式集合。
可以通过两种方式创建RDD:并行化已有集合(如列表或数组)或从外部存储系统(如HDFS、HBase)中读取数据。
4. RDD和DataFrame的区别是什么?RDD和DataFrame都是Spark中的数据抽象。
RDD是Spark最早引入的数据结构,它是一个不可变的分布式集合,需要手动指定数据的schema。
而DataFrame是结构化数据的概念,具有自动推断schema 的功能,并且可以基于SQL进行查询和操作。
5. Spark的作业调度器是什么?它的作用是什么?Spark的作业调度器是Spark Cluster Manager,其中包括Standalone、YARN和Mesos等。
MapReduce和spark的shuffle过程详解

MapReduce和spark的shuffle过程详解⾯试常见问题,必备答案。
mapReducehe和Spark之间的最⼤区别是前者较偏向于离线处理,⽽后者重视实效性,下⾯主要介绍mapReducehe和Spark两者的shuffle过程。
MapReduce的Shuffle过程MapReduce计算模型⼀般包括两个重要的阶段:Map是映射,负责数据的过滤分发;Reduce是规约,负责数据的计算归并。
Reduce的数据来源于Map,Map的输出即是Reduce的输⼊,Reduce需要通过 Shuffle来获取数据。
Spill过程Spill过程包括输出、排序、溢写、合并等步骤,如图所⽰:Collect(此过程较难理解,可简化说明)每个Map任务不断地以对的形式把数据输出到在内存中构造的⼀个环形数据结构中。
使⽤环形数据结构是为了更有效地使⽤内存空间,在内存中放置尽可能多的数据。
这个数据结构其实就是个字节数组,叫Kvbuffer,名如其义,但是这⾥⾯不光放置了数据,还放置了⼀些索引数据,给放置索引数据的区域起了⼀个Kvmeta的别名,在Kvbuffer的⼀块区域上穿了⼀个 IntBuffer(字节序采⽤的是平台⾃⾝的字节序)的马甲。
数据区域和索引数据区域在Kvbuffer中是相邻不重叠的两个区域,⽤⼀个分界点来划分两者,分界点不是亘古不变的,⽽是每次 Spill之后都会更新⼀次。
初始的分界点是0,数据的存储⽅向是向上增长,索引数据的存储⽅向是向下增长,如图所⽰:Kvbuffer的存放指针bufindex是⼀直闷着头地向上增长,⽐如bufindex初始值为0,⼀个Int型的key写完之后,bufindex增长为4,⼀个Int型的value写完之后,bufindex增长为8。
索引是对在kvbuffer中的索引,是个四元组,包括:value的起始位置、key的起始位置、partition值、value的长度,占⽤四个Int长度,Kvmeta的存放指针Kvindex每次都是向下跳四个“格⼦”,然后再向上⼀个格⼦⼀个格⼦地填充四元组的数据。
spark性能优化之shuffle优化

spark性能优化之shuffle优化1.Shuffle原理概述什么样的情况下,会发⽣shuffle?在spark中,主要是以下⼏个算⼦:groupByKey、reduceByKey、countByKey、join,等等。
什么是shuffle?groupByKey:要把分布在集群各个节点上的数据中的同⼀个key,对应的values,都给集中到⼀块⼉,集中到集群中同⼀个节点上,更严密⼀点说,就是集中到⼀个节点的⼀个executor的⼀个task中。
然后呢,集中⼀个key对应的values之后,才能交给我们来进⾏处理,<key, Iterable<value>>reduceByKey:算⼦函数去对values集合进⾏reduce操作,最后变成⼀个value;countByKey:需要在⼀个task中,获取到⼀个key对应的所有的value,然后进⾏计数,统计总共有多少个value;join,RDD<key, value>,RDD<key, value>,只要是两个RDD中,key相同对应的2个value,都能到⼀个节点的executor的task中,给我们进⾏处理。
shuffle,⼀定是分为两个stage来完成的。
因为这其实是个逆向的过程,不是stage决定shuffle,是shuffle决定stage。
reduceByKey(_+_),在某个action触发job的时候,DAGScheduler,会负责划分job为多个stage。
划分的依据,就是,如果发现有会触发shuffle操作的算⼦,⽐如reduceByKey,就将这个操作的前半部分,以及之前所有的RDD和transformation操作,划分为⼀个stage;shuffle 操作的后半部分,以及后⾯的,直到action为⽌的RDD和transformation操作,划分为另外⼀个stage。
spark知识点总结

spark知识点总结Spark是一种分布式计算引擎,可以在大规模数据上进行高效的数据处理。
它提供了丰富的API,可以支持各种类型的应用程序,包括批处理、交互式查询、流处理和机器学习。
Spark还提供了很多工具和库,可以简化大规模数据处理的工作,同时也提供了很多优化特性,可以确保性能和可靠性。
Spark的核心概念Spark的核心概念包括Resilient Distributed Datasets (RDD)、作业和任务、分区、转换和行动。
这些概念是理解Spark编程模型的关键。
1. Resilient Distributed Datasets (RDD)RDD是Spark的核心数据结构,它代表一个可以在集群上并行操作的数据集合。
RDD可以从外部数据源创建,也可以通过其他RDD进行转换得到。
RDD具有容错性,并且可以在节点之间进行数据分区和并行处理。
2. 作业和任务在Spark中,作业是指由一系列的任务组成的计算单元。
每个任务都是在一个数据分区上并行执行的。
Spark会根据数据依赖关系和调度策略来合并任务,并在集群上执行。
这样可以确保作业能够高效地执行,并且可以减少数据传输和计算开销。
3. 分区分区是指将数据集合分割成多个独立的部分,这样可以在集群上进行并行处理。
Spark提供了很多内置的分区方法,同时也支持自定义分区策略。
正确的分区策略可以提高计算效率,减少数据传输和数据倾斜。
4. 转换和行动在Spark中,转换是指对RDD进行操作来生成新的RDD,例如map、filter、flatMap等。
行动是指对RDD执行计算来获取结果,例如reduce、collect、count等。
转换和行动是Spark编程的核心操作,它们可以用来构建复杂的数据处理流程。
Spark的核心特性除了上述核心概念外,Spark还具有以下几个核心特性:1. 内存计算Spark将数据存储在内存中,可以在多次计算之间重用数据,从而避免了传统的磁盘读写开销。
spark源码解析--Shuffle输出追踪者--MapOutputTracker

spark源码解析--Shuffle输出追踪者--MapOutputTracker这个组件作为shuffle的一个辅助组件,在整个shuffle模块中具有很重要的作用。
我们在前面一系列的分析中,或多或少都会提到这个组件,比如在DAGScheduler提交一个stage时会将这个stage封装成一个任务集(TaskSet),但是可能有的分区已经计算过了,有了结果(stage由于失败可能会多次提交,其中有部分task可能已经计算完成),这些分区就不需要再次计算,而只需要计算那些失败的分区,那么很显然需要有一个组件来维护shuffle过程中的任务失败成功的状态,以及计算结果的位置信息。
此外,在shuffle读取阶段,我们知道一个reduce端的分区会依赖于多个map端的分区的输出数据,那么我们在读取一个reduce分区对应的数据时,就需要知道这个reduce分区依赖哪些map分区,每个block的物理位置是什么,blockId是什么,这个block中属于这个reduce分区的数据量大小是多少,这些信息的记录维护都是靠MapOutputTracker来实现的,所以我们现在知道MapOutputTracker的重要性了。
MapOutputTracker.scalaMapOutputTracker组件的主要功能类和辅助类全部在这个文件中,我先大概说一下各个类的主要作用,然后重点分析关键的类。
•ShuffleStatus,这个类是对一个stage的shuffle输出状态的封装,它内部的一个主要的成员mapStatuses是一个数组,这个数组的下标就是map的分区序号,存放了每个map分区的输出情况,关于MapStatus具体可以看MapStatus.scala,这里不打算展开。
•MapOutputTrackerMessage,用于rpc请求的消息类,有两个实现类:GetMapOutputStatuses用于获取某次shuffle的所有输出状态;StopMapOutputTracker用于向driver端的发送停止MapOutputTrackerMasterEndpoint端点的请求。
Spark(四)--Spark工作机制

Spark(四)--Spark⼯作机制⼀、应⽤执⾏机制⼀个应⽤的⽣命周期即,⽤户提交⾃定义的作业之后,Spark框架进⾏处理的⼀系列过程。
在这个过程中,不同的时间段⾥,应⽤会被拆分为不同的形态来执⾏。
1、应⽤执⾏过程中的基本组件和形态Driver:运⾏在客户端或者集群中,执⾏Application的main⽅法并创建SparkContext,调控整个应⽤的执⾏。
Application:⽤户⾃定义并提交的Spark程序。
Job:⼀个Application可以包含多个Job,每个Job由Action操作触发。
Stage:⽐Job更⼩的单位,⼀个Job会根据RDD之间的依赖关系被划分为多个Stage,每个Stage中只存有RDD之间的窄依赖,即Transformation算⼦。
TaskSet:每个Stage中包含的⼀组相同的Task。
Task:最后被分发到Executor中执⾏的具体任务,执⾏Stage中包含的算⼦。
明确了⼀个应⽤的⽣命周期中会有哪些组件参与之后,再来看看⽤户是怎么提交Spark程序的。
2、应⽤的两种提交⽅式Driver进程运⾏在客户端(Client模式):即⽤户在客户端直接运⾏程序。
程序的提交过程⼤致会经过以下阶段:1. ⽤户运⾏程序。
2. 启动Driver进⾏(包括DriverRunner和SchedulerBackend),并向集群的Master注册。
3. Driver在客户端初始化DAGScheduler等组件。
4. Woker节点向Master节点注册并启动Executor(包括ExecutorRunner和ExecutorBackend)。
5. ExecutorBackend启动后,向Driver内部的SchedulerBackend注册,使得Driver可以找到计算节点。
6. Driver中的DAGScheduler解析RDD⽣成Stage等操作。
7. Driver将Task分配到各个Executor中并⾏执⾏。
Spark性能优化

Spark性能优化本文章来自于阿里云云栖社区摘要: Spark的性能分析和调优很有意思,今天再写一篇。
主要话题是shuffle,当然也牵涉一些其他代码上的小把戏。
以前写过一篇文章,比较了几种不同场景的性能优化,包括portal的性能优化,web service的性能优化,还有Spark j ob的性能优化。
Spark的性能优化有一些特殊的地方,比如Spark的性能分析和调优很有意思,今天再写一篇。
主要话题是shuffle,当然也牵涉一些其他代码上的小把戏。
以前写过一篇文章,比较了几种不同场景的性能优化(原文链接:/3658?spm=5176.100239.blogcont53509.5.zDcg U3),包括portal的性能优化,web service的性能优化,还有Spark job的性能优化。
Spark的性能优化有一些特殊的地方,比如实时性一般不在考虑范围之内,通常我们用Spark来处理的数据,都是要求异步得到结果的数据;再比如数据量一般都很大,要不然也没有必要在集群上操纵这么一个大家伙,等等。
事实上,我们都知道没有银弹,但是每一种性能优化场景都有一些特定的“大boss”,通常抓住和解决大boss以后,能解决其中一大部分问题。
比如对于portal来说,是页面静态化,对于web service来说,是高并发(当然,这两种可以说并不确切,这只是针对我参与的项目总结的经验而已),而对于Spark来说,这个大boss就是shuffle。
首先要明确什么是shuffle。
Shuffle指的是从map阶段到reduce阶段转换的时候,即map的output向着reduce的input映射的时候,并非节点一一对应的,即干map 工作的slave A,它的输出可能要分散跑到reduce节点A、B、C、D …… X、Y、Z 去,就好像shuffle的字面意思“洗牌”一样,这些map的输出数据要打散然后根据新的路由算法(比如对key进行某种hash算法),发送到不同的reduce节点上去。
Spark内核源码解析十二:shuffle原理解析

Spark内核源码解析⼗⼆:shuffle原理解析第⼀个特点,在Spark早期版本中,那个bucket缓存是⾮常⾮常重要的,因为需要将⼀个ShuffleMapTask所有的数据都写⼊内存缓存之后,才会刷新到磁盘。
但是这就有⼀个问题,如果map side数据过多,那么很容易造成内存溢出。
所以spark在新版本中,优化了,默认那个内存缓存是100kb,然后呢,写⼊⼀点数据达到了刷新到磁盘的阈值之后,就会将数据⼀点⼀点地刷新到磁盘。
这种操作的优点,是不容易发⽣内存溢出。
缺点在于,如果内存缓存过⼩的话,那么可能发⽣过多的磁盘写io操作。
所以,这⾥的内存缓存⼤⼩,是可以根据实际的业务情况进⾏优化的。
第⼆个特点,与MapReduce完全不⼀样的是,MapReduce它必须将所有的数据都写⼊本地磁盘⽂件以后,才能启动reduce操作,来拉取数据。
为什么?因为mapreduce要实现默认的根据key的排序!所以要排序,肯定得写完所有数据,才能排序,然后reduce来拉取。
但是Spark不需要,spark默认情况下,是不会对数据进⾏排序的。
因此ShuffleMapTask每写⼊⼀点数据,ResultTask就可以拉取⼀点数据,然后在本地执⾏我们定义的聚合函数和算⼦,进⾏计算。
spark这种机制的好处在于,速度⽐mapreduce快多了。
但是也有⼀个问题,mapreduce提供的reduce,是可以处理每个key对应的value上的,很⽅便。
但是spark中,由于这种实时拉取的机制,因此提供不了,直接处理key对应的values的算⼦,只能通过groupByKey,先shuffle,有⼀个MapPartitionsRDD,然后⽤map算⼦,来处理每个key对应的values。
就没有mapreduce的计算模型那么⽅便。
shuffle原理图如下优化后也就是加⼊consolidation机制后的原理图如下,主要解决产⽣的⽂件太多在executor中执⾏任务时,主要是task的实现类来执⾏任务,其中shuffleMapTask,将针对rdd执⾏算⼦后的结果写⼊磁盘// 有mapstatus返回值,override def runTask(context: TaskContext): MapStatus = {// Deserialize the RDD using the broadcast variable.// 对要处理的rdd相关数据,做⼀些反序列化的,这个rdd是怎么拿到的,多个task运⾏在executor⾥⾯,并⾏运⾏或者并发运⾏// 可能不在⼀个地⽅,但是⼀个stage的task,要处理的rdd都是⼀样的,通过broadcast variable拿到val ser = SparkEnv.get.closureSerializer.newInstance()val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)metrics = Some(context.taskMetrics)var writer: ShuffleWriter[Any, Any] = nulltry {// 获取shuffleManagerval manager = SparkEnv.get.shuffleManagerwriter = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)// 调⽤rdd的iterator⽅法,并且传⼊当前task要处理哪个partition,核⼼逻辑就在rdd的iterator// ⽅法中在这⾥实现了针对某个partition执⾏算⼦和函数,针对rdd的partition进⾏处理,有返回数据通过shuffleWriter经过// HashPartition写⼊⾃⼰的分区,mapstatus封装了shufflemaptask计算后的数据,存储在那⾥,就是blockmanager信息// blockmanager就是spark底层内存、数据、磁盘管理组件writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])return writer.stop(success = true).get} catch {case e: Exception =>try {if (writer != null) {writer.stop(success = false)}} catch {case e: Exception =>log.debug("Could not stop writer", e)}throw e}}shuffle写的⼊⼝再HashShuffleWriter⾥⾯/** Write a bunch of records to this task's output* 将每个shuffleMapTask计算出来的新的RDD的partition数据,写⼊磁盘* */override def write(records: Iterator[_ <: Product2[K, V]]): Unit = {// ⾸先判断,是否需要在map端本地进⾏聚合,这⾥的话,如果是reduceBykey这种操作,它的dep.aggregator.isDefined就是true// 包括dep.mapSideCombine也是true// 那么就就进⾏map端的本地聚合val iter = if (dep.aggregator.isDefined) {if (dep.mapSideCombine) {// 执⾏本地聚合,如(hello,1)(hello,1)就成了(hello,2)bineValuesByKey(records, context)} else {records}//} else {require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")records}// 如果要本地聚合,那么先本地聚合,然后遍历数据,对每个数据掉⽤partitioner// ,默认是hashPartitioner,⽣成bucketId,也就是决定每⼀份数据要写⼊那个bucket。
大数据:Spark Shuffle(二)Executor、Driver之间Shuffle结果消息传递、追踪

大数据:Spark Shuffle(二)Executor、Driver之间Shuffle结果消息传递、追踪1. 前言输出Shuffle结果到Shuffle_shuffleId_mapId_0.data数据文件中,每个executor需要向Driver汇报当前节点的Shuffle结果状态,Driver保存结果信息进行下个Task的调度。
2. StatusUpdate消息当Executor运行完Task的时候需要向Driver汇报StatusUpdate的消息[plain] view plain copyoverride def statusUpdate(taskId: Long, state: TaskState, data: ByteBuffer) {val msg = StatusUpdate(executorId, taskId, state, data)driver match {case Some(driverRef) => driverRef.send(msg)case None => logWarning(s"Drop $msg because has not yet connected to driver")}}整个结构体中包含了ExecutorId: Executor自己的IDTaskId: task分配的IDState: Task的运行状态[plain] view plain copyLAUNCHING, RUNNING, FINISHED, FAILED, KILLED, LOSTData: 保存序列化的Result2.1 Executor端发送在Task运行后的结果,Executor会将结果首先序列化成ByteBuffer封装成DirectTaskResult,再次序列化DirectTaskResult成ByteBuffer,很显然序列化的结果的大小会决定不同的传递策略。
大数据:Spark Shuffle(三)Executor是如何fetch shuffle的数据文件

大数据:Spark Shuffle(三)Executor 是如何fetch shuffle的数据文件1. 前言Executor是如何获取到Shuffle的数据文件进行Action的算子的计算呢?在ResultTask中,Executor通过MapOutPutTracker向Driver获取了ShuffID的Shuffle数据块的结构,整理成以BlockManangerId为Key的结构,这样可以更容易区分究竟是本地的Shuffle还是远端executor的Shuffle2. Fetch数据在MapOutputTracker中获取到的BlockID的地址,是以BlockManagerId的seq数组[plain] view plain copySeq[(BlockManagerId, Seq[(BlockId, Long)])]BlockManagerId结构[plain] view plain copyclass BlockManagerId private (private var executorId_ : String,private var host_ : String,private var port_ : Int,private var topologyInfo_ : Option[String])extends Externalizable是以ExecutorId,Executor Host IP, Executor Port 标示从哪个Executor获取Shuffle的数据文件,通过Seq[BlockManagerId, Seq(BlockID,Long)]的结构,当前executor很容易区分究竟哪些是本地的数据文件,哪些是远端的数据,本地的数据可以直接本地读取,而需要不通过网络来获取。
2.1 读取本Executor文件如何认为是本地数据?Spark认为区分是通过相同的ExecutorId来区别的,如果ExecutorId和自己的ExecutorId相同,认为是本地Local,可以直接读取文件。
spark-宽依赖和窄依赖

杂的关系。那么,这种情况,就叫做两个RDD之间是宽依赖。同时,他们之间发生的,操作,是Shuffle,
网络错误421请刷新页面重试持续报错请尝试更换浏览器或网络环境
spark-宽依赖和窄依赖 一、窄依赖(Narrow Dependency,)
即一个RDD,对它的父RDD,只有简单的一对一的依赖关系。也就是说, RDD的每个partition ,仅仅依赖于父RDD中的一个partition,父 RDD和子RDD的partition之间的对应关系,是 一对一的!这种情况下,是简单的RDD之间的依赖关系,也被称之为窄依赖。
spark的四种模式,spark比MapReduce快的原因

spark的四种模式,spark比MapReduce快的原因2018年09月05日 20:09:05 wyqwilliamSpark 是美国加州大学伯克利分校的AMP 实验室(主要创始人lester 和 Matei)开发的通用的大数据处理框架。
λApache Spark™ is a fast and general engine for large-scale data processing.λ Apache Spark is an open source cluster computing system that aims to make data analyticsfast,both fast to run and fast to wrtieSpark 应用程序可以使用 R 语言、Java、Scala 和 Python 进行编写,极少使用 R 语言编写 Spark 程序,Java 和 Scala 语言编写的 Spark 程序的执行效率是相同的,但 Java 语言写的代码量多,Scala 简洁优雅,但可读性不如 Java,Python 语言编写的 Spark 程序的执行效率不如 Java 和 Scala。
Spark 有 4 中运行模式:1. local 模式,适用于测试2. standalone,并非是单节点,而是使用 spark 自带的资源调度框架3. yarn,最流行的方式,使用 yarn 集群调度资源4. mesos,国外使用的多Spark 比 MapReduce 快的原因1. Spark 基于内存迭代,而 MapReduce 基于磁盘迭代MapReduce 的设计:中间结果保存到文件,可以提高可靠性,减少内存占用,但是牺牲了性能。
Spark 的设计:数据在内存中进行交换,要快一些,但是内存这个东西,可靠性比不过MapReduce。
2. DAG 计算模型在迭代计算上还是比 MR 的更有效率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Spark Shuffle详解一:到底什么是Shuffle?Shuffle中文翻译为“洗牌”,需要Shuffle的关键性原因是某种具有共同特征的数据需要最终汇聚到一个计算节点上进行计算。
二:Shuffle可能面临的问题?运行Task的时候才会产生Shuffle(Shuffle已经融化在Spark的算子中了)。
1,数据量非常大,从其他各台机器收集数据占用大量网络。
2,数据如何分类,即如何Partition,Hash、Sort、钨丝计算;3,负载均衡(数据倾斜),因为采用不同的Shuffle方式对数据不同的分类,而分类之后又要跑到具体的节点上计算,如果不恰当的话,很容易产生数据倾斜;4,网络传输效率,需要在压缩和解压缩之间做出权衡,序列化和反序列也是要考虑的问题;说明:具体的Task进行计算的时候尽一切最大可能使得数据具备Process Locality的特性;退而求次是增加数据分片,减少每个Task处理的数据量。
注:除非你的计算特别复杂,否则的话,都要要求所有的数据在内存中,即是说任务很多需要排队,但是总体的运行速度更快,一般情况下,进行持久化是没有什么收益的,而读中间结果cache得到的价值,还不如出错的情况下重算一遍,除非计算链条特别长,计算特别的复杂。
Cache的风险:1. 有风险,例如,Memory溢出的风险,例如说被别人占用掉这个内存的风险。
2. 读磁盘是一个高风险的事,但是读内存就更安全,这是在一个Stage内提倡的。
但是Shuffle是需要网络通信,这个时候就需要持久化,因为所有的父Stage算完,才能进行下一个Stage的计算,所以没有持久化,下一个Stage出错的话就需要全部重计算,Shuffle默认持久化到磁盘里,也可以持久化到内存中,Tachyon,Locality System中。
Spark默认遇到Shuffle都会将结果进行持久化的。
二:Hash Shuffle1,要求key不能是Array;2,Hash Shuffle不需要排序,此时从理论上讲就节省了Hadoop MapReduce中进行Shuffle需要排序时候的时间浪费,因为实际生产环境有大量的不需要排序的Shuffle类型;思考:不需要排序的Hash Shuffle是否一定比需要排序的Sorted Shuffle速度更快?不一定!如果数据规模比较小的情形下,Hash Shuffle 会比Sorted Shuffle速度快(很多)!但是如果数据量大,此时Sorted Shuffle一般都会比Hash Shuffle快(很多),因为如果数据规模比较大,Hash Shuffle甚至无法处理,因为Hash Shuffle会产生很多的句柄,小文件,这时候磁盘和内存会变成瓶颈,而Sorted Shuffle就会极大的节省内存和磁盘的访问,所以更有利于更大规模的计算。
Hash Shuffle适合中小型规模的数据计算。
3,每个ShuffleMapTask会根据key的哈希值计算出当前的key需要写入的Partition,然后把决定后的结果写入单独的文件,此时会导致每个Task产生R(指下一个Stage的Task并行度)个文件,如果当前的Stage中有M个ShuffleMapTask,则会产生M*R个文件!!!此时数据已经分好类了,下一个Stage就会通过网络根据Driver端的注册信息,因为上一个Stage写过的内容会注册给Driver,然后向Driver 获取上一个Stage的输出位置,就会通过网络去读取数据,数据分成几种类型只跟下一个阶段分成多少个任务有关系,因为下一个阶段的任务数表示数据被分成多少类。
跟并行度没有关系,也就是说跟实际并行运行多少任务没有关系。
注意:Shuffle操作绝大多数情况下都要通过网络,如果Mapper和Reducer在同一台机器上,此时只需要读取本地磁盘即可。
Spark中的Executor是线程池中的线程复用的,这个线程有可能运行上一个Stage的Task,也有可能运行下一个Stage的Task。
Hash Shuffle Writer实现解析1,Shuffle Map Task计算是调用ShuffleMapTask.runTask执行的。
核心代码如下:1. 获得ShuffleManager为Hash Shuffle。
2. 获得Hash Shuffle的Writer方法:HashShuffleWriter.3. 调用HashShuffleWriter的write方法。
其中调用RDD的iterator方法计算,然后将结果传入给write。
val manager = SparkEnv.get.shuffleManager//获得ShuffleManager//获得Hash Shuffle的Writer方法writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)//调用HashShuffleWriter的write方法,writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])下面具体看write方法。
/** Write a bunch of records to this task's output */override def write(records: Iterator[Product2[K, V]]): Unit = {//判断aggregator是否被定义val iter = if (dep.aggregator.isDefined) {//判断数据是否需要聚合如果需要,聚合recordsif (dep.mapSideCombine) {bineValuesByKey(records, context)//中间代码省略//elem是(K,V)形式的,通过K计算出bucketIdfor (elem <- iter) {val bucketId = dep.partitioner.getPartition(elem._1)//然后再通过bucketId具体写入那个partition//此时Shuffle是FileShuffleBlockResolvershuffle.writers(bucketId).write(elem._1, elem._2)}2,具体看一下FileShuffleBlockResolver.writers:val writers: Array[DiskBlockObjectWriter] = {Array.tabulate[DiskBlockObjectWriter](numReducers) { bucketId =>val blockId = ShuffleBlockId(shuffleId, mapId, bucketId)val blockFile = blockManager.diskBlockManager.getFile(blockId)val tmp = With(blockFile)//tmp也就是blockFile如果已经存在则,在后面追加数据blockManager.getDiskWriter(blockId, tmp, serializerInstance, bufferSize, writeMetrics)}3,blockManager.getDiskWriter就会为每个文件创建一个DiskBlockObjectWriternew DiskBlockObjectWriter(file, serializerInstance, bufferSize, compressStream,syncWrites, writeMetrics, blockId)4,DiskBlockObjectWriter可以直接向一个在磁盘上的文件写数据,并且允许在后面追加数据* A class for writing JVM objects directly to a file on disk. This class allows data to be appended* to an existing block and can guarantee atomicity in the case of faults as it allows the caller to* revert partial writes.private[spark] class DiskBlockObjectWriter(Hash Shuffle的两大死穴:第一:Shuffle前会产生海量的小文件于磁盘之上,此时会产生大量耗时低效的IO操作;第二:内存不够用!!!由于内存中需要保存海量的文件操作句柄和临时缓存信息,如果数据处理规模比较庞大的话,内存不可承受,出现OOM 等问题!这里写图片描述从图上可以看到,进行HashShuffle的时候会根据后面的Task数,生成对应数量的小文件,而每个小文件也就是一种类型,在数据处理的时候,Task就从前面的小文件抓取需要的数据即可,它会导致同时打开过多的文件,这样就会占用过多的内存,写文件通过Write Handler默认是50KB。
三: Consalidate:为了改善上述的问题(同时打开过多文件导致Writer Handler内存使用过大以及产生过度文件导致大量的随机读写带来的效率极为低下的磁盘IO操作),Spark后来推出了Consalidate机制,来把小文件(指的是每个Map都要为所有的Reducer产生Reducer个数的小文件)合并,此时Shuffle时文件产生的数量为cores*R,对于ShuffleMapTask的数量明显多于同时可用的并行Cores的数量的情况下,Shuffle产生的文件会大幅度减少,会极大降低OOM的可能;如何将小文件进行合并?Consalidate机制:把同一个Task的输出变成一个文件进行合并,根据CPU的个数来决定具体产生多少文件,对于运行在同一个core的Shuffle Map Task,第一个Shuffle Map Task会创建一个,之后的就会将数据追加到这个文件上而不是新建一个文件。
但是在生成环境下,并行度特别大的话,还是会产生原来的问题。
为此Spark推出了Shuffle Pluggable开放框架,方便系统升级的时候定制Shuffle功能模块,也方便第三方系统改造人员根据实际的业务场景来开发具体最佳的Shuffle模块;核心接口ShuffleManager,具体默认实现有HashShuffleManager、SortShuffleManager等,Spark 1.6.0中具体的配置如下:默认情况下是Sort Shuffle。