从问题域出发认识Hadoop生态系统
对hadoop的认识

Hadoop是一个分布式计算框架,由Apache软件基金会开发。
它允许在跨多个计算机集群上进行大规模数据处理和分析,是大数据处理领域的重要工具之一。
一、Hadoop的背景和意义随着互联网的快速发展,数据量呈指数级增长,传统的数据处理方式已经无法满足大规模数据处理的需求。
Hadoop的出现,为大数据处理提供了一种有效的解决方案。
Hadoop具有高可靠性、高扩展性、高效性和安全性等特点,能够处理海量数据,并且可以运行在廉价的硬件设备上。
二、Hadoop的核心组件HDFS(Hadoop Distributed File System):HDFS是Hadoop的核心组件之一,它是一个分布式文件系统,可以将数据存储在多个计算机节点上,并实现数据的高可靠性、高扩展性和高效性。
MapReduce:MapReduce是Hadoop的编程模型,它可以将大规模数据处理任务分解为多个小任务,并在多个计算机节点上并行执行,从而加速数据处理速度。
三、Hadoop的应用场景数据存储和处理:Hadoop可以用于存储和处理大规模数据,例如日志数据、社交媒体数据、电商数据等。
数据分析:Hadoop可以用于进行数据分析,例如数据挖掘、机器学习、数据可视化等。
数据备份和恢复:Hadoop可以用于数据备份和恢复,因为它具有高可靠性和高扩展性。
其他应用:除了上述应用场景外,Hadoop还可以用于搜索引擎、推荐系统、云计算等领域。
四、Hadoop的发展趋势生态系统的完善:随着Hadoop的不断发展,其生态系统也在不断完善。
越来越多的企业开始采用Hadoop技术,并且出现了许多与Hadoop相关的开源项目和商业产品。
性能的提升:随着硬件设备的不断升级和优化,Hadoop的性能也在不断提升。
未来,Hadoop将会更加高效、稳定和可靠。
云端化:随着云计算的不断发展,越来越多的企业开始将Hadoop部署在云端。
云端化可以提供更好的可扩展性、高可用性和安全性,并且可以更加方便地管理和维护Hadoop集群。
Hadoop 生态系统介绍

Hadoop 生态系统介绍Hadoop生态系统是一个开源的大数据处理平台,它由Apache基金会支持和维护,可以在大规模的数据集上实现分布式存储和处理。
Hadoop生态系统是由多个组件和工具构成的,包括Hadoop 核心,Hive、HBase、Pig、Spark等。
接下来,我们将对每个组件及其作用进行介绍。
一、Hadoop核心Hadoop核心是整个Hadoop生态系统的核心组件,它主要由两部分组成,一个是Hadoop分布式文件系统(HDFS),另一个是MapReduce编程模型。
HDFS是一个高可扩展性的分布式文件系统,可以将海量数据存储在数千台计算机上,实现数据的分散储存和高效访问。
MapReduce编程模型是基于Hadoop的针对大数据处理的一种模型,它能够对海量数据进行分布式处理,使大规模数据分析变得容易和快速。
二、HiveHive是一个开源的数据仓库系统,它使用Hadoop作为其计算和存储平台,提供了类似于SQL的查询语法,可以通过HiveQL 来查询和分析大规模的结构化数据。
Hive支持多种数据源,如文本、序列化文件等,同时也可以将结果导出到HDFS或本地文件系统。
三、HBaseHBase是一个开源的基于Hadoop的列式分布式数据库系统,它可以处理海量的非结构化数据,同时也具有高可用性和高性能的特性。
HBase的特点是可以支持快速的数据存储和检索,同时也支持分布式计算模型,提供了易于使用的API。
四、PigPig是一个基于Hadoop的大数据分析平台,提供了一种简单易用的数据分析语言(Pig Latin语言),通过Pig可以进行数据的清洗、管理和处理。
Pig将数据处理分为两个阶段:第一阶段使用Pig Latin语言将数据转换成中间数据,第二阶段使用集合行处理中间数据。
五、SparkSpark是一个快速、通用的大数据处理引擎,可以处理大规模的数据,支持SQL查询、流式数据处理、机器学习等多种数据处理方式。
hadoop的生态体系及各组件的用途

hadoop的生态体系及各组件的用途
Hadoop是一个生态体系,包括许多组件,以下是其核心组件和用途:
1. Hadoop Distributed File System (HDFS):这是Hadoop的分布式文件系统,用于存储大规模数据集。
它设计为高可靠性和高吞吐量,并能在低成本的通用硬件上运行。
通过流式数据访问,它提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
2. MapReduce:这是Hadoop的分布式计算框架,用于并行处理和分析大规模数据集。
MapReduce模型将数据处理任务分解为Map和Reduce两个阶段,从而在大量计算机组成的分布式并行环境中有效地处理数据。
3. YARN:这是Hadoop的资源管理和作业调度系统。
它负责管理集群资源、调度任务和监控应用程序。
4. Hive:这是一个基于Hadoop的数据仓库工具,提供SQL-like查询语言和数据仓库功能。
5. Kafka:这是一个高吞吐量的分布式消息队列系统,用于实时数据流的收集和传输。
6. Pig:这是一个用于大规模数据集的数据分析平台,提供类似SQL的查询语言和数据转换功能。
7. Ambari:这是一个Hadoop集群管理和监控工具,提供可视化界面和集群配置管理。
此外,HBase是一个分布式列存数据库,可以与Hadoop配合使用。
HBase 中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
《Hadoop生态系统全景介绍

《Hadoop生态系统全景介绍Hadoop是一个开源、分布式、高可扩展性的计算平台,用于存储和处理大数据。
并且它采用了MapReduce和HDFS技术来处理和存储大数据。
Hadoop 的开源社区成员和个人贡献者实现了Hadoop生态系统,它支撑了各种大数据处理任务。
在本文中,我们将讨论Hadoop生态系统中的各种组件和应用程序,以及这些组件和应用程序如何协同工作,以提高数据处理和存储的效率。
Hadoop生态系统的核心组件包括Hadoop Distributed File System (HDFS)和MapReduce。
HDFS是一个分布式文件系统,用于存储大型数据集。
它的目标是提供可靠的、高容错性的存储,并能在不同节点上快速访问文件。
MapReduce是一种编程模型,用于处理海量数据集,它可用于通过分布式计算生成大量数据。
Hadoop生态系统还有一些扩展组件,可以提供更广泛的实用和效益。
其中一些组件包括HBase、Hive、Pig、Spark、Mahout和Sqoop。
下面将对这些组件一一进行介绍。
HBase是一个基于Hadoop的分布式列式数据库,可实现随机实时读\/写访问大型数据集。
它可存储大量数据,并以列的形式在多台计算机上进行分布式计算。
HBase用于流行的电子商务网站,包括Facebook、Twitter和Yahoo等等,因其可扩展性和高吞吐量被广泛采用。
Hive是一个数据仓库,可用于将大型数据集存储在Hadoop集群中,并使用SQL语言进行查询。
它与HDFS紧密集成,可快速存储和检索数据。
它也是一个数据分析工具,它提供了一个称为HQL(Hive查询语言)的SQL 接口。
通过Hive,用户可以对存储在Hadoop集群中的数据进行透明查询。
Pig是一种基于Hadoop的处理语言,用于处理大规模的数据集。
它可以用于各种数据分析应用,包括ETL(抽取、转换、加载),实时数据流处理,以及复杂的数据流管道的构建。
hadoop生态系统及简介
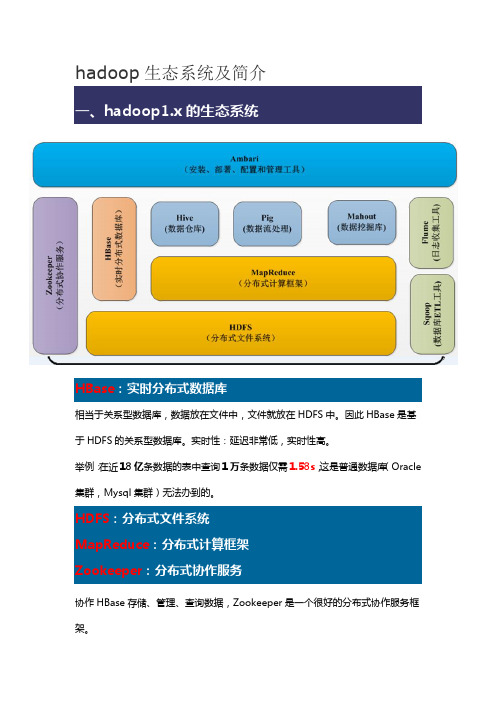
hadoop生态系统及简介HBase:实时分布式数据库相当于关系型数据库,数据放在文件中,文件就放在HDFS中。
因此HBase是基于HDFS的关系型数据库。
实时性:延迟非常低,实时性高。
举例:在近18亿条数据的表中查询1万条数据仅需1.58s,这是普通数据库(Oracle 集群,Mysql集群)无法办到的。
HDFS:分布式文件系统MapReduce:分布式计算框架Zookeeper:分布式协作服务协作HBase存储、管理、查询数据,Zookeeper是一个很好的分布式协作服务框架。
Hive数据仓库:比如给你一块1000平方米的仓库,让你放水果。
如果有春夏秋冬四季的水果,让你放在某一个分类中。
但是水果又要分为香蕉、苹果等等。
然后又要分为好的水果和坏的水果。
因此数据仓库的概念也是如此,他是一个大的仓库,然后里面有很多格局,每个格局里面又分小格局等等。
对于整个系统来说,比如文件系统。
文件如何去管理?Hive 就是来解决这个问题。
Hive:分类管理文件和数据,对这些数据可以通过很友好的接口,提供类似于SQL语言的HiveQL查询语言来帮助你进行分析。
其实Hive底层是转换成MapReduce的,写的HiveQL进行执行的时候,Hive提供一个引擎将其转换成MapReduce再去执行。
Hive设计目的:方便DBA很快地转到大数据的挖掘和分析中。
Pig基于MapReduce的,基于流处理的。
写了动态语言之后,也是转换成MapReduce 进行执行。
和Hive类似。
Mahout基于图形化的数据碗蕨。
SqoopELT:提取--> 转换--> 加载。
从数据库中获取数据,并进行一系列的数据清理和清洗筛选,将合格的数据转换成一定格式的数据进行存储,将格式化的数据存储到HDFS文件系统上,以供计算框架进行数据分析和挖掘。
格式化数据:TSV 格式:每行数据的每列之间以制表符(tab \t)进行分割CVS 格式:每行数据的每列之间以逗号进行分割Sqoop:将关系型数据库中的数据与HDFS(HDFS 文件,HBase中的表,Hive 中的表)上的数据进行相互导入导出。
Hadoop生态系统,hadoop介绍

Hadoop生态系统知识介绍首先我们先了解一下Hadoop的起源。
然后介绍一些关于Hadoop生态系统中的具体工具的使用方法。
如:HDFS、MapReduce、Yarn、Zookeeper、Hive、HBase、Oozie、Mahout、Pig、Flume、Sqoop。
Hadoop的起源Doug Cutting是Hadoop之父,起初他开创了一个开源软件Lucene(用Java语言编写,提供了全文检索引擎的架构,与Google类似),Lucene后来面临与Google同样的错误。
于是,Doug Cutting学习并模仿Google解决这些问题的办法,产生了一个Lucene的微缩版Nutch。
后来,Doug Cutting等人根据2003-2004年Google公开的部分GFS和Mapreduce 思想的细节,利用业余时间实现了GFS和Mapreduce的机制,从而提高了Nutch的性能。
由此Hadoop产生了。
Hadoop于2005年秋天作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
2006年3月份,Map-Reduce和Nutch Distributed File System(NDFS)分别被纳入Hadoop的项目中。
关于Hadoop名字的来源,是Doug Cutting儿子的玩具大象。
Hadoop是什么Hadoop是一个开源框架,可编写和运行分布式应用处理大规模数据。
Hadoop框架的核心是HDFS和MapReduce。
其中HDFS 是分布式文件系统,MapReduce 是分布式数据处理模型和执行环境。
在一个宽泛而不断变化的分布式计算领域,Hadoop凭借什么优势能脱颖而出呢?1. 运行方便:Hadoop是运行在由一般商用机器构成的大型集群上。
Hadoop在云计算服务层次中属于PaaS(Platform-as-a- Service):平台即服务。
2. 健壮性:Hadoop致力于在一般的商用硬件上运行,能够从容的处理类似硬件失效这类的故障。
hadoop生态系统

如今Apache Hadoop已成为大数据行业发展背后的驱动力。
Hive和Pig等技术也经常被提到,但是他们都有什么功能,为什么会需要奇怪的名字(如Oozie,ZooKeeper、Flume)。
Hadoop带来了廉价的处理大数据(大数据的数据容量通常是10-100GB或更多,同时数据种类多种多样,包括结构化、非结构化等)的能力。
但这与之前有什么不同?现今企业数据仓库和关系型数据库擅长处理结构化数据,并且可以存储大量的数据。
但成本上有些昂贵。
这种对数据的要求限制了可处理的数据种类,同时这种惯性所带的缺点还影响到数据仓库在面对海量异构数据时对于敏捷的探索。
这通常意味着有价值的数据源在组织内从未被挖掘。
这就是Hadoop与传统数据处理方式最大的不同。
本文就重点探讨了Hadoop系统的组成部分,并解释各个组成部分的功能。
MapReduce——Hadoop的核心Google的网络搜索引擎在得益于算法发挥作用的同时,MapReduce在后台发挥了极大的作用。
MapReduce框架成为当今大数据处理背后的最具影响力的“发动机”。
除了Hadoop,你还会在MapReduce上发现MPP(Sybase IQ推出了列示数据库)和NoSQL(如Vertica和MongoDB)。
MapReduce的重要创新是当处理一个大数据集查询时会将其任务分解并在运行的多个节点中处理。
当数据量很大时就无法在一台服务器上解决问题,此时分布式计算优势就体现出来。
将这种技术与Linux服务器结合可获得性价比极高的替代大规模计算阵列的方法。
Yahoo在2006年看到了Hadoop未来的潜力,并邀请Hadoop创始人Doug Cutting着手发展Hadoop技术,在2008年Hadoop已经形成一定的规模。
Hadoop项目再从初期发展的成熟的过程中同时吸纳了一些其他的组件,以便进一步提高自身的易用性和功能。
HDFS和MapReduce以上我们讨论了MapReduce将任务分发到多个服务器上处理大数据的能力。
揭秘Hadoop生态系统技术架构

揭秘Hadoop生态系统技术架构Hadoop是一个广泛应用于海量数据处理的开源平台。
其生态系统包含多个组件和技术,架构复杂,本文将从技术架构的角度解析Hadoop生态系统。
1. Hadoop技术架构概览Hadoop生态系统包含多个组件,其中最为重要的是Hadoop分布式文件系统(HDFS)和MapReduce。
HDFS是一种分布式文件系统,可在多个计算机之间共享文件,并提供数据存储和访问服务。
MapReduce则是一种分布式计算模型,用于将海量数据分成多个小块进行并行计算。
除了HDFS和MapReduce,Hadoop还包含多个组件,如HBase、ZooKeeper、Hive、Pig等。
这些组件共同构成了一个完整的Hadoop生态系统。
2. HDFS技术架构HDFS是Hadoop生态系统的核心部分之一,它提供了分布式文件存储和访问功能。
HDFS的技术架构包括以下三个部分:(1)NameNodeNameNode是HDFS的中央管理节点,它负责处理客户端请求和管理HDFS文件系统的元数据。
所有数据块的信息和位置信息都存储在NameNode中,因此,NameNode是HDFS中最重要的组件之一。
(2)DataNodeDataNode是存储实际数据块的节点。
当客户端上传数据时,DataNode将数据块存储到本地磁盘,并向NameNode注册该数据块的位置信息。
(3)Secondary NameNodeSecondary NameNode不是NameNode的备份节点,而是NameNode的辅助节点。
它可以定期备份NameNode的元数据,以便在NameNode的故障情况下恢复文件系统。
3. MapReduce技术架构MapReduce是Hadoop中用于分布式计算的核心组件,它的技术架构包括以下三个部分:(1)JobTrackerJobTracker是MapReduce计算集群的中央节点,它负责管理计算任务、调度Map和Reduce任务、监控任务执行状态等。
Hadoop生态系统基本介绍

基于QJM的HDFS HA架构概述
• 在HA模式的HDFS有如下的守护进程
a. Active NameNode(主) b. standby NameNode(主) c. DataNode(从) d. JournalNode(奇数个) e. ZKFC(主备)
写文件流程
HDFS client
1:create 3:write
• 2007年1月 研究集群增加到900个节点 • 2007年4月 研究集群增加到两个集群1000个节点 • 2008年4月 在900个节点上运行1TB的排序测试集仅需要209秒,成为全球最快 • 2008年10月 研究集群每天状态10TB的数据 • 2009年3月 17个集群共24000个节点 • 2009年4月 在每分钟排序中胜出,59秒内排序500GB(1400个节点上)和173分钟
Data store n
map
(Key 1, Values…)
Байду номын сангаас
(Key 2, Values…)
(Key 3, Values…)
==Barrier== : Aggregates intermediate values by output key
Key 1, Intermediate Values
Key 2, Intermediate Values
the aardvark sat on the sofa
• Intermediate data produced:
(the, 1), (cat, 1), (sat, 1), (on, 1), (the, 1) (mat, 1), (the, 1), (aardvark, 1), (sat, 1) (on, 1), (the, 1), (sofa, 1)
Hadoop生态系统的原理与应用场景

Hadoop生态系统的原理与应用场景一、Hadoop生态系统的概述Hadoop是一种开源的分布式计算框架,能够处理大规模的数据集。
它的核心由两部分组成:分布式文件系统Hadoop Distributed File System(HDFS)和用于大规模数据处理的MapReduce编程模型。
除此之外,Hadoop还由许多组件和工具组成,形成了一个完整的生态系统,包括Hive、Pig、HBase、Sqoop、Flume等。
二、Hadoop生态系统的原理1. HDFSHDFS是Hadoop的核心组件之一,它是一个分布式文件系统,适用于存储海量数据。
它采用主从架构,由一个NameNode和多个DataNode组成。
NameNode作为控制节点,维护了文件系统的目录树和每个文件的块信息。
DataNode则负责存储文件数据块。
HDFS的优点是高容错性和高可靠性,同时它还支持数据的随机读写和高并发处理。
2. MapReduceMapReduce是Hadoop的另一核心组件,是一种分布式计算编程模型。
它将大规模数据处理分解成两个步骤:Map和Reduce。
Map阶段先将数据切分为若干数据块,然后每个数据块由Map处理成一系列中间结果。
Reduce阶段将中间结果汇总起来,进行合并计算得到最终结果。
3. HiveHive是Hadoop生态系统中的一个关系型数据仓库管理工具,它能够将结构化数据转换为Hadoop上的MapReduce任务。
Hive提供了SQL语言的扩展,支持数据的查询、分区、连接等,同时它还支持自定义函数和UDF。
Hive将SQL转换成MapReduce任务的实现,大大提高了数据仓库的效率。
4. PigPig是Hadoop生态系统中的另一个大数据处理工具,它是一种高级脚本语言,支持数据的流式处理和查询。
Pig支持多种数据源,包括HDFS、HBase、Amazon S3等。
它可以将脚本转换成MapReduce任务,在Hadoop中执行各种数据处理操作。
大数据技术生态概述

– SVD – Stochastic SVD with PCA – PCA
– Collaboration Filtering using a parallel matrix factorization
– Slope One
– Independent Component Analysis
– Gaussian Discriminative Analysis
LDAΒιβλιοθήκη Spectral Clustering
谱聚类
Minhash Clustering
Top Down Clustering
26
自上而下聚类
Mahout中的其他算法
• Pattern Mining
– Parallel FP Growth
• Regression
– Locally Weighted Linear Regression
3
Spark分布式计算系统
4
总结
Hadoop生态系统
MapReduce
MapReduce使用方式 Hadoop提供了三种编程方式;
Java(最原始的方式) Hadoop Streaming(支持多语言) Hadoop Pipes(支持C/C++)
Java编程接口是所有编程方式的基础; 不同的编程接口只是暴露给用户的形式不同
Pig与Hive异同
相同点 运行在Hadoop之上 设计动机是为用户提供一种更简单的Hadoop上 数据分析方式
不同点 Hive要求待处理数据必须有Schema,而Pig则无 此要求; 编程语言不同,SQL与Pig Latin
SQL:得到什么样的结果,Pig Latin:如何处理数据 SQL:过程化语言,Pig Latin:数据流语言
Hadoop生态系统概述以及版本演化

Hadoop构成 YARN(资源管理系统)
Hadoop构成 YARN(资源管理系统)
Hadoop构成 MapReduce(分布式计算框架)
源自于Google的MapReduce论文
发表于2004年12月 Hadoop MapReduce是Google MapReduce克隆版
MapReduce特点
Spark …
(内存计算)
YARN
(分布式计算框架)
HDFS
(分布式存储系统)
Flume (日志收集 )
Hadoop构成 Hive(基于MR的数据仓库)
由facebook开源,最初用于解决海量结构化的日志数据统 计问题;
ETL(Extraction-Transformation-Loading)工具
Hadoop构成 YARN(资源管理系统)
YARN是什么
Hadoop 2.0新增系统 负责集群的资源管理和调度 使得多种计算框架可以运行在一个集群中
YARN的特点
良好的扩展性、高可用性 对多种类型的应用程序进行统一管理和调度 自带了多种多用户调度器,适合共享集群环境
Hadoop构成 YARN(资源管理系统)
Hadoop介绍 概述
分布式存储系统HDFS(Hadoop Distributed File System)
分布式存储系统 提供了高可靠性、高扩展性和高吞吐率的数据存储服务
资源管理系统YARN(Yet Another Resource Negotiator)
负责集群资源的统一管理和调度
分布式计算框架MapReduce
构建在Hadoop之上的数据仓库;
数据计算使用MR,数据存储使用HDFS
Hive 定义了一种类 SQL 查询语言——HQL;
搞懂Hadoop生态系统

01Hadoop概述Hadoop体系也是一个计算框架,在这个框架下,可以使用一种简单的编程模式,通过多台计算机构成的集群,分布式处理大数据集。
Hadoop是可扩展的,它可以方便地从单一服务器扩展到数千台服务器,每台服务器进行本地计算和存储。
除了依赖于硬件交付的高可用性,软件库本身也提供数据保护,并可以在应用层做失败处理,从而在计算机集群的顶层提供高可用服务。
Hadoop核心生态圈组件如图1所示。
图1Haddoop开源生态02Hadoop生态圈Hadoop包括以下4个基本模块。
1)Hadoop基础功能库:支持其他Hadoop模块的通用程序包。
2)HDFS:一个分布式文件系统,能够以高吞吐量访问应用中的数据。
3)YARN:一个作业调度和资源管理框架。
4)MapReduce:一个基于YARN的大数据并行处理程序。
除了基本模块,Hadoop还包括以下项目。
1)Ambari:基于Web,用于配置、管理和监控Hadoop集群。
支持HDFS、MapReduce、Hive、HCatalog、HBase、ZooKeeper、Oozie、Pig和Sqoop。
Ambari还提供显示集群健康状况的仪表盘,如热点图等。
Ambari以图形化的方式查看MapReduce、Pig和Hive应用程序的运行情况,因此可以通过对用户友好的方式诊断应用的性能问题。
2)Avro:数据序列化系统。
3)Cassandra:可扩展的、无单点故障的NoSQL多主数据库。
4)Chukwa:用于大型分布式系统的数据采集系统。
5)HBase:可扩展的分布式数据库,支持大表的结构化数据存储。
6)Hive:数据仓库基础架构,提供数据汇总和命令行即席查询功能。
7)Mahout:可扩展的机器学习和数据挖掘库。
8)Pig:用于并行计算的高级数据流语言和执行框架。
9)Spark:可高速处理Hadoop数据的通用计算引擎。
Spark提供了一种简单而富有表达能力的编程模式,支持ETL、机器学习、数据流处理、图像计算等多种应用。
把 Hadoop 生态的核心讲明白了!

Hadoop是一个由Apache基金会开发的分布式系统基础架构。
开发人员可以在不了解分布式底层细节的情况下开发分布式程序,充分利用集群的威力进行高速并行运算以及海量数据的分布式存储。
Hadoop大数据技术架构如图1所示。
图1Hadoop大数据技术架构然而,Hadoop不是一个孤立的技术,而是一套完整的生态圈,如图2所示。
在这个生态圈中,Hadoop最核心的组件就是分布式文件系统HDFS和分布式计算框架MapReduce。
HDFS为海量的数据提供了存储,是整个大数据平台的基础,而MapReduce则为海量的数据提供了计算能力。
在它们之上有各种大数据技术框架,包括数据仓库Hive、流式计算Storm、数据挖掘工具Mahout和分布式数据库HBase。
此外,ZooKeeper为Hadoop集群提供了高可靠运行的框架,保证Hadoop集群在部分节点宕机的情况下依然可靠运行。
Sqoop与Flume分别是结构化与非结构化数据采集工具,通过它们可以将海量数据抽取到Hadoop平台上,进行后续的大数据分析。
图2Hadoop大数据生态圈Cloudera与Hortonworks是大数据的集成工具,它们将大数据技术的各种组件集成在一起,简化安装、部署等工作,并提供统一的配置、管理、监控等功能。
Oozie是一个业务编排工具,我们将复杂的大数据处理过程解耦成一个个小脚本,然后用Oozie组织在一起进行业务编排,定期执行与调度。
01分布式文件系统过去,我们用诸如DOS、Windows、Linux、UNIX等许多系统来在计算机上存储并管理各种文件。
与它们不同的是,分布式文件系统是将文件散列地存储在多个服务器上,从而可以并行处理海量数据。
Hadoop的分布式文件系统HDFS如图3所示,它首先将服务器集群分为名称节点(NameNode)与数据节点(DataNode)。
名称节点是控制节点,当需要存储数据时,名称节点将很大的数据文件拆分成一个个大小为128MB的小文件,然后散列存储在其下的很多数据节点中。
Hadoop 生态系统浅析

Hadoop 生态系统浅析摘要:Apache Hadoop是一种著名的大数据技术。
通过在Hadoop社区添加模块,用户可以根据自己的目标和应用需求形成满足自己所需的个性化的Hadoop生态系统。
本文从数据存储、数据处理、数据查询、数据访问、数据分析等几个方面对Hadoop及其组件组成的生态系统进行了分析,为用户在进行大数据分析工具进行选择时提供帮助和支持。
关键词:Hadoop;生态系统;HDFS;HBase;1 Hadoop简介Apache Hadoop是一种著名的大数据技术,并行集群和分布式文件系统的架构使得它能够快速处理大型数据集。
Hadoop平台的强大功能基于两个主要的子组件:Hadoop分布式文件系统(HDFS)和MapReduce框架。
在Hadoop社区,用户可以根据自己的目标和应用需求,如容量、性能、可靠性、可扩展性、安全性等在Hadoop之上添加模块从而丰富其生态系统,而IT供应商也可以在Hadoop 分布中提供特殊的企业强化特性。
上述这些特色,使得Hadoop拥有强大的大数据处理能力,并且具有蓬勃的生命力。
下面我们将从数据存储、数据处理、数据查询、数据访问、数据分析等几个方面,对Hadoop生态系统进行介绍。
2数据存储层:HDFS和HBaseHadoop依赖于它的文件系统HDFS和一个名为Apache HBase的非关系数据库进行数据存储。
2.1 Hadoop分布式文件系统(HDFS)HDFS[1]是为高延迟操作批处理而设计的一种数据存储系统,支持一个集群中几百个节点的管理,可以处理结构化和非结构化数据,能保存大小大于1 TB的文件,支持跨异构硬件和软件平台的移植,通过将计算操作移到数据存储附近来减少网络拥塞和提高系统性能。
但HDFS不构成通用文件系统,也不提供文件中的快速记录查找。
HDFS基于主从架构,将大量数据分布在集群中,由一个唯一的主节点管理文件系统操作,许多的从节点来管理和协调单个计算代码上的数据存储。
Hadoop生态案例详解与项目实战 第一章 Hadoop介绍

大数据的概念
大数据特点
Volume(规模性):数据的价值和隐藏价值由数据的大小决定 Velocity(高速性):指获得数据的速度 Variety(多样性):数据的多样性 IDC认为大数据具有价值性(Value),大数据的价值往往呈现出稀疏性的特点,而 IBM则认为大数据必然具有真实性(Veracity)。
Hadoop生态体系
Hadoop项目及其介绍
Hadoop生态体系结构
Hadoop生态体系
Hadoop企业级应用
基于Hadoop的企业级应用
谢谢聆听
大数据的概念
大数据的产生
数据的产生方式经历了以下三个阶段: (1) 运营式系统阶段:数据库的出现大大降低了数据管理的复杂程度,实际中
数据库主要作为运营系统存储数据或作为运营系统的数据管理子系统。 (2) 用户原创内容阶段:由于互联网的诞生,人类社会数据存储量出现第二次
大的飞跃。 (3) 感知式系统阶段:感知式系统的广泛应用导致了数据技术
数据采集:使用数据采集工具将分布的、异构数据源中的数据如关系数据、平面数 据文件等抽取到临时中间层后进行清洗、转换、集成,而后加载到数据仓库或数据集 之中,成为联机分析处理、数据挖掘的基础。 数据存取:关系型数据库、非关系型数据库等。 存储架构:云存储、分布式文件系统(HDFS)等。 数据处理:把采集到的数据针对关键指标进行数据的处理和清洗等。 统计分析:方差分析、回归分析、简单回归分析技术等等。 数据挖掘:分类、估计、模型预测、结果呈现等方式。
Hadoop生态体系
Hadoop核心体系
HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。HDFS在集群上实现 了分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。HDFS在MapReduce 任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分 发、跟踪、执行等工作,收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
Hadoop生态系统概述以及版本演化
Linux Crontab 自己设计调度系统(淘宝等公司) 直接使用开源系统(Oozie)
Hadoop构成 认识Oozie
目录
1. Hadoop生态系统特点 2. Hadoop介绍 3. Hadoop生态系统 4. Hadoop版本衍化 5. 总结
49
Hadoop版本衍化 Apache Hadoop
Row Key: 行键 Table的主键 Table中的记录按照Row Key排序
Timestamp: 时间戳 每行数据均对应一个时间戳 版本号
Hadoop构成 HBase架构
Hadoop构成 Zookeeper(分布式协作服务)
源自Google的Chubby论文
发表于2006年11月 Zookeeper是Chubby克隆版纳
Hadoop构成 YARN(资源管理系统)
Hadoop构成 YARN(资源管理系统)
Hadoop构成 MapReduce(分布式计算框架)
源自于Google的MapReduce论文
发表于2004年12月 Hadoop MapReduce是Google MapReduce克隆版
MapReduce特点
自上而下聚类
Mahout介绍 分类算法
Logistic Regression
逻辑回归
Bayesian
贝叶斯分类算法
Support Vector Machines
支持向量机
Perceptron and Winnow
感知器算法
Neural Network
神经网络
Random Forests
构建在Hadoop之上的数据仓库 定义了一种数据流语言——Pig Latin 通常用于进行离线分析
(完整版)hadoop认识总结

一、对hadoop的基本认识Hadoop是一个分布式系统基础技术框架,由Apache基金会所开发。
利用hadoop,软件开发用户可以在不了解分布式底层细节的情况下,开发分布式程序,从而达到充分利用集群的威力高速运算和存储的目的。
Hadoop是根据google的三大论文作为基础而研发的,google的三大论文分别是:MapReduce、GFS和BigTable。
因此,hadoop也因此被称为是google技术的山寨版。
不过这种“山寨版”却成了当下大数据处理技术的国际标准(因为它是世界上唯一一个做得相对完善而又开源的框架)。
Hadoop框架中最核心的设计就是:MapReduce和HDFS。
MapReduce的思想是由Google的一篇论文所提及而被广为流传的,简单的一句话解释MapReduce就是“任务的分解与结果的汇总”。
HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写,为分布式计算存储提供了底层支持。
MapReduce从它名字上来看就大致可以看出个缘由,两个动词Map和Reduce,“Map(展开)”就是将一个任务分解成为多个任务,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。
这不是什么新思想,其实它的本质就是一种“分治法”的思想,把一个巨大的任务分割成许许多多的小任务单元,最后再将每个小任务单元的结果汇总,并求得最终结果。
在分布式系统中,机器集群就可以看作硬件资源池,将并行的任务拆分,然后交由每一个空闲机器资源去处理,能够极大地提高计算效率,同时这种资源无关性,对于计算集群的扩展无疑提供了最好的设计保证。
任务分解处理以后,那就需要将处理以后的结果再汇总起来,这就是Reduce要做的工作。
多任务、并行计算、云计算,这些词汇并不是新名词,在hadoop出现之前,甚至在google出现之前,就已经出现过分布式系统和分布式程序,hadoop 新就新在它解决了分布式系统复杂的底层细节,程序员可以在不了解底层分布式细节的情况下编写高效的分布式程序,hadoop服务会自动将任务分配给不同的计算机节点,由这些节点计算最后汇总并处理计算结果。
Hadoop生态体系简介

资源调度系统YARN
资源调度系统YARN
• Resource Manager (RM)负责管理集群的container分 配 • Node Manager管理每个节点上的资源和任务,主要有 两个作用,定期向RM汇报该节点的资源使用情况和各 个container的运行状态,接收并处理AM的任务启动、 停止等请求 • Application Master (AM),每个应用专属,负责该应用 下任务的调度和协调 • 每个container可看做是一个资源的封装实体,包括 CPU资源和内存资源
Hive优化技巧
原语句:SELECT COUNT( DISTINCT id ) FROM TABLE_NAME 由于语句没有group by,hive只在一个reduce处理数据 改写为:SELECT COUNT(*) FROM (SELECT DISTINCT id FROM TABLE_NAME) T
Hadoop发行版本
• • • • Cloudera Hadoop (CDH) Hortonworks Data Platform (HDP) MapR Intel
Hadoop生态体系结构
分布式文件系统HDFS
客户端读取HDFS中的数据
客户端将数据写入HDFS
HDFS复本如何存放
• 在运行客户端的节点上放第一个复本 • 第二个复本放在与第一个不同且随机另外选择 的机架中的节点上 • 第三个复本与第二个复本放在同一个机架上, 且随机选择另一个节点
Reduce阶段
• • • • Reduce通过http从NodeM输出到磁盘 最后把接收到的文件合并起来输入reduce 执行用户reducer方法,结果输出到hdfs
对Hadoop体系的一点认识

对Hadoop体系的⼀点认识前⾔:Hadoop体系核⼼⼤多源⾃Google的思想,⾥⾯的思想的确很精彩!⽐如分布式计算,云的思想等,⽐起其他简单技术,更使得我想写这⽂章,虽然这个东东在⼀般公司不可能⽤到!⾸先由于hadoop是分布计算、存储的东四,所有组件其实都是构建在Hadoop集群的基础之上,所有玩hadoop,⽐先说这个。
node&2nd namenode,类似master,但不是纯数据的,是个中央协调器的作⽤,可惜是单点的,不过有ZooKeeper----后⾯介绍下2.datanode,类似slave,存放数据的节点3.jobtracker,不管是java弄的还是其他脚本弄的东四,都⽤job表⽰,再转为MR运⾏的,⼀般跟在name上⾯4.tasktracker,就是对job的分解任务了,分布在每个数据节点上由于hadoop是建⽴在java体系的,所以有⼀堆配置的风格(或者说是Liunx风格)。
所以hadoop环境变量配置和core、hdfs、MR三个配置⽂件是要的,⽽在Linux下运⾏,其实主要也是⼀堆命令和配置了,还有ssh也是必备的等。
不过上⾯所有事情主要还是应该算DBA&运维的事。
还有个Hadoop⾥⾯提供他系统内部的类似Linux的命令给⽤户交互,当然Eclipse也有插件可以直接图形操作的,只是⼀般也没啥⽤。
好了,再说Hadoop的两⼤基础核⼼:HDFS&MR1.HDFS:这是分布式的⽂件系统,独⽴于附属系统(Linux等)的⼀个⽂件管理,有点像关系型数据库⽂件系统,但它能保存和管理任何⽂件,包括hbase的⽂件和其他任何类型⽂件。
⽽且是完全分布式的,也提供很好的可靠性机制,什么事务⽇志和镜像等概念,还有只写的,分⼩块存储(这个有点像mysql的分块思想)---可能因为这个才适合hbase的BigTable思想。
这⾥给个图---其实⾥⾯很多是旧思想hadoop可靠性机制⾥⾯还有提供java的API,以⽅便⼀些像直接可以⽤java操作⾥⾯⽂件。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
从问题域出发认识Hadoop生态系统
2013-05-27 10:01 Dong 董的博客字号:T| T
Hadoop作为一个生态系统,每个系统只解决某一个特定的问题域(甚至可能很窄),这也是Hadoop的魅力所在:不搞统一型的一个全能系统,而是小而精的多个小系统。
本文重点讨论分布式领域的几个系统问题域。
AD:51CTO网+ 首届中国APP创新评选大赛火热招募中……
近些年来Hadoop生态系统发展迅猛,它本身包含的软件越来越多,同时带动了周边系统的繁荣发展。
尤其是在分布式计算这一领域,系统繁多纷杂,时不时冒出一个系统,号称自己比MapReduce或者Hive高效几十倍,几百倍。
有一些无知的人,总是跟着瞎起哄,说Impala将取代Hive,Spark将取代HadoopMapReduce等。
本文则从问题域触发,解释说明Hadoop中每个系统独特的作用/魅力以及它们的不可替代性。
Hadoop作为一个生态系统,每个系统只解决某一个特定的问题域(甚至可能很窄),这也是Hadoop的魅力所在:不搞统一型的一个全能系统,而是小而精的多个小系统。
本文重点讨论分布式计算领域的几个开源系统可以解决的问题域。
(1)MapReduce:古老的分布式计算框架,它的特点是扩展性、容错性好,易于编程,适合离线数据处理,不擅长流式处理、内存计算、交互式计算等领域。
MapReduce网址是:/
(2)Hive:披着SQL外衣的MapReduce。
Hive是为方便用户使用MapReduce而在外面包了一层SQL,由于Hive采用了SQL,它的问题域比MapReduce更窄,因为很多问题,SQL 表达不出来,比如一些数据挖掘算法,推荐算法、图像识别算法等,这些仍只能通过编写MapReduce完成。
Hive网址是:/
(3)Pig:披着脚本语言外衣的MapReduce,为了突破Hive SQL表达能力的限制,采用了一种更具有表达能力的脚本语言PIG。
由于pig语言强大的表达能力,Twitter甚至基于Pig实现了一个大规模机器学习平台(参考Twitter在SIGMOD2012的文章“Large-Scale Machine Learning at Twitter”)。
Pig网址是:/(4)Stinger Initiative(Tez optimized Hive):Hortonworks开源了一个DAG计算框架Tez,该框架可以像MapReduce一样,可以用来设计DAG应用程序,但需要注意的是,Tez只能运行在YARN上。
Tez的一个重要应用是优化Hive和PIG这种典型的DAG应用场景,
它通过减少数据读写IO,优化DAG流程使得Hive速度提供了很多倍。
(Stinger正在开发中,Tez代码:https:///repos/asf/incubator/tez/branches/)(5)Spark:为了提高MapReduce的计算效率,伯克利开发了spark,spark可看做基于内存的MapReduce实现,此外,伯克利还在Spark基础上包了一层SQL,产生了一个新的类似Hive的系统Shark,但目前Spark和Shark尚属于实验室产品。
Spark网站是:
/
(6)Storm/S4:Hadoop在实时计算/流式计算领域(MapReduce假设输入数据是静态的,处理过程中不能被修改,而流式计算则假设数据源是流动的,数据会源源不断流入系统),一直比较落后,还好,Twitter开源的Storm和yahoo!开源的S4弥补了这一缺点,Storm 在淘宝,mediaV等公司得到广泛的应用。
Storm网址是:/,S4网址是:/s4/
(7)Cloudera Impala/Apache drill:Google Dremel的开源实现,也许是因为交互式计算需求太过强烈,发展迅猛,impala仅用了一年左右便推出1.0GA版本。
这种系统适用于交互式处理场景,最后产生的数据量一定要少。
Impala尽管发布了1.0版本,但在容错性、扩展性、支持自定义函数等方面,有很长的路要走。
Cloudera Impala网址是:https:///cloudera/impala,Apache drill网址是:
/drill/。
Hortonworks将应用需求进行了如下划分:
映射到上面几种系统,可知:
(1)实时应用场景(0~5s):Storm、S4、Cloudera Impala,Apache Drill等;
(2)交互式场景(5s~1m):这种场景通常能要求必须支持SQL,则可行系统有:Cloudera Impala、Apache Drill、Shark等;
(3)非交互式场景(1m~1h):通常运行时间较长,处理数据量较大,对容错性和扩展性要求较高,可行系统有:MapReduce、Hive、Pig、Stinger等;
(4)批处理场景(1h+):通常运行时间很长,处理数据量很大,对容错性和扩展性要求很高,可行系统有:MapReduce、Hive、Pig、Stinger等。
【作者信息】本文作者:Dong(董西成),专注于大规模数据处理相关技术,作者的Hadoop新书《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》已经开始在当当、京东、卓越等网站销售。
感兴趣的读者朋友们可以去看看。