Python里面search()和match()的区别-
Python经典面试题

1:Python如何实现单例模式?Python有两种方式可以实现单例模式,下面两个例子使用了不同的方式实现单例模式:1.class Singleton(type):def __init__(cls, name, bases, dict):super(Singleton, cls).__init__(name, bases, dict)cls.instance = Nonedef __call__(cls, *args, **kw):if cls.instance is None:cls.instance = super(Singleton, cls).__call__(*args, **kw)return cls.instanceclass MyClass(object):__metaclass__ = Singletonprint MyClass()print MyClass()2. 使用decorator来实现单例模式def singleton(cls):instances = {}def getinstance():if cls not in instances:instances[cls] = cls()return instances[cls]return getinstance@singletonclass MyClass:…2:什么是lambda函数?Python允许你定义一种单行的小函数。
定义lambda函数的形式如下:labmda 参数:表达式lambda函数默认返回表达式的值。
你也可以将其赋值给一个变量。
lambda函数可以接受任意个参数,包括可选参数,但是表达式只有一个:>>> g = lambda x, y: x*y>>> g(3,4)12>>> g = lambda x, y=0, z=0: x+y+z>>> g(1)1>>> g(3, 4, 7)14也能够直接使用lambda函数,不把它赋值给变量:>>> (lambda x,y=0,z=0:x+y+z)(3,5,6)14如果你的函数非常简单,只有一个表达式,不包含命令,可以考虑lambda函数。
Python|文本处理:用正则表达式替换掉汉字(非英文)中间的空格
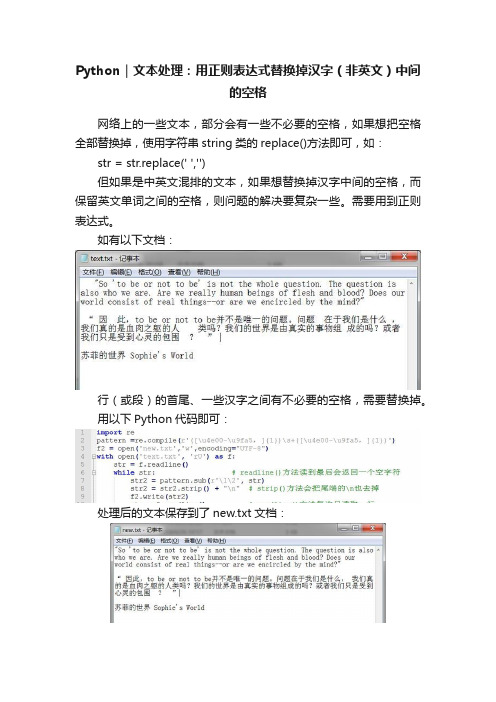
Python|文本处理:用正则表达式替换掉汉字(非英文)中间的空格网络上的一些文本,部分会有一些不必要的空格,如果想把空格全部替换掉,使用字符串string类的replace()方法即可,如:str = str.replace(' ','')但如果是中英文混排的文本,如果想替换掉汉字中间的空格,而保留英文单词之间的空格,则问题的解决要复杂一些。
需要用到正则表达式。
如有以下文档:行(或段)的首尾、一些汉字之间有不必要的空格,需要替换掉。
用以下Python代码即可:处理后的文本保存到了new.txt文档:当然,一些有规律的乱码也可以处理。
上面有提到全部是中文的简单处理方法,也可以用一个简单的正则表达式判断文档或字符串内容是否包含“英文+空格+英文”的形式,然后用一个条件判断分别处理:下面需要重点剖析一下上面关于正则表达式的概念及相关的一些内容:正则表达式是一种用来匹配字符串的强有力的武器。
它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。
1 compile()方法向pile()传入一个字符串值,表示编译一个正则表达式,它将返回一个Regex 模式对象(或者就简称为Regex 对象)。
我们在Python中使用正则表达式时,re模块内部会做两件事情:I 编译正则表达式,如果正则表达式的字符串本身不合法,会报错;II 用编译后的正则表达式去匹配字符串;如果一个正则表达式要重复使用多次或一些较复杂的正则表达式,出于效率的考虑,我们可以预编译该正则表达式,接下来重复使用时就不需要编译这个步骤了,直接匹配。
编译后生成Regular Expression对象。
可以向pile()传入re.IGNORECASE 或re.I,作为第二个参数,让正则表达式不区分大小写:>>> robocop = pile(r'robocop',re.I)>>> robocop.search('RoboCop is partman, part machine, all cop.').group()'RoboCop'2 r'……'的写法r'……'表示忽略……可中可能存在的转义字符,当做普通字符看待;3 中括号[]有时候你想匹配一组字符,但缩写的字符分类(\d、\w、\s 等)太宽泛。
python常用基础语法知识点大全

python常用基础语法知识点大全Python是一种高级编程语言,由于其简单易学和强大的功能,越来越受到开发者的欢迎。
在Python编程过程中,了解一些基础语法知识点是非常重要的。
在这篇文章中,我们将探讨Python常用的基础语法知识点。
1. 变量首先,我们需要了解Python中的变量。
变量是一个用于存储数据的名称,在Python中,可以使用任何字母、数字和下划线来定义变量名称。
例如:```x = 5y = "Hello, World!"```在这个例子中,变量 `x` 被赋值为 `5`,变量 `y` 被赋值为字符串 `"Hello, World!"`。
要输出变量的值,可以使用 `print()` 函数。
例如:```print(x)print(y)```这将打印 `5` 和 `Hello, World!`。
2. 数据类型Python支持许多不同的数据类型,每种数据类型都有不同的特点。
以下是一些常用的数据类型:- `int`:表示整数。
- `float`:表示浮点数,例如 `2.1` 或 `3.5`。
- `str`:表示字符串。
- `list`:表示一个有序的列表。
- `tuple`:表示一个不可变的有序元素列表。
- `dict`:表示一个键值对映射。
例如,以下是一些简单的Python代码片段,用于将不同类型的值分配给变量:```x = 5 # inty = 2.5 # floatz = "Hello, World!" # strmy_list = [1, 2, 3] # listmy_tuple = (1, 2, 3) # tuplemy_dict = {"name": "John", "age": 30} # dict```3. 运算符在Python中,有许多运算符可以用于操作不同类型的值。
match函数使用方法

match函数使用方法1. match函数的介绍在编程中,我们经常需要根据特定的模式来搜索、匹配和提取文本中的数据。
Python中的re模块提供了强大的正则表达式操作功能,其中的match函数就是用来匹配一个字符串的开头部分是否符合某个模式。
2. match函数的基本使用match函数的基本语法如下:re.match(pattern, string, flags=0)其中,pattern是要匹配的模式,string是要匹配的字符串,flags是匹配模式的标志位。
示例代码:import repattern = r'abc'string = 'abcd'result = re.match(pattern, string)print(result)运行结果:<re.Match object; span=(0, 3), match='abc'>从运行结果可以看出,当字符串的开头部分与模式匹配时,match函数返回一个类的实例,表示匹配成功;否则返回None。
需要注意的是,match函数只匹配字符串的开头部分。
如果要匹配整个字符串,可以使用search函数。
3. match函数的模式参数match函数的pattern参数可以是一个普通的字符串,也可以是一个正则表达式。
3.1 普通字符串模式当pattern是一个普通的字符串时,match函数会尝试从字符串的开头部分进行匹配。
示例代码:import repattern = '123'string = 'abc123def456'result = re.match(pattern, string)print(result)运行结果:None从运行结果可以看出,由于字符串的开头部分不是”123”,所以匹配失败,返回None。
3.2 正则表达式模式当pattern是一个正则表达式时,可以使用更为灵活的模式进行匹配。
利用Python语言爬取农产品网站的技术研究

利用Python语言爬取农产品网站的技术研究作者:徐东升张昊辰来源:《环球市场信息导报》2018年第09期一、前言我国政府非常重视农业的信息化建设,农业信息化已有30多年的历史,特别是近几年,基于物联网技术、传感器、移动通信、云计算等技术为基础的智慧农业的发展,农业的信息化建设已经融入到农业产业的各个领域。
随着农业信息量的加大,如何利用数据爬取的方法,帮助农业信息需求者从已存在的海量数据中快速定位自身需求的信息,从而使需求与信息匹配,最大程度的发挥农业信息对农业经济的支撑和引导作用是一个研究点。
二、技术研究从海量的数据中爬取需要的数据并入库是本研究的重点,以从农业信息网()获取“苹果”信息为例进行接下来的研究。
从农业信息需要者的视角登录并访问该网站,打开任意1条“苹果”的农业信息,需要从首页开始依次点击“水果”->“苹果”,并点击大图列表才能进入具体的页面。
这个过程是非常繁琐和低效的。
对有信息需求者而言,最关注的的就是三个信息,即联系人,联系方式和地址,可以看到对应网站上的条目分别是“联系人”、“手机号码”、“所在地区”。
加上要查找信息的条件,即“产品品种”,相当于对于任何来自于该网站的信息,最关键的只需要首先获取者以上4条信息即可。
接下来利用python编写一段程序,将该网站下的基于以上4个关键字段进行网页爬取。
部分代码如下:resp=requests.get(url,timeout=30)respencoding='utf-8'print(resp.status_code)products=refindall(r'pic_divxinxi_title.+?',resp.text,re.I)#print(products)for j in range(0,len(products)):producturl=re.findall(r'http:.+?\.aspx',products[j],re.I)purl=producturl[0]print(purl)resp2=requests.get(purl,timeout=301resp2.encoding='utf-8'print(resp2.status_code)#print(resp2.text)dw0=re.findall(r"联系人.+?",resp2.text,re.I)sj0=re.findall(r"手机号码.+?”,resp2.text,re.I)pz0=re.findall(r"产品品种+?”,resp2.text,re.I)dq0=refindall(r"所在地区。
python常用英文单词

python常用英文单词都在这以下是python代码编写和提示信息中的常用和常见的英文单词。
不需要背,看得多了用到的多了就熟悉了。
比如print,你不一定就需要背出来这个英文单词的意思是印刷打印,你只要知道在python中print能把你想要看的变量的值展现出来,起到一个输出的作用即可比如提示里出现syntax这个词,你不一定要知道这个单词怎么念,但是在报错信息中一旦出现这个,那就代表着你语法有问题,初学者经常会出现这类错误。
比如上图中这里函数定义后面少了一个冒号:error和invalid这些单词的出现,代表了你代码里哪里有错或者无效,这时候,如果是看我的python零基础教学视频的同学,就需要检查一下你的代码和我视频演示中的代码一致不一致,比如单词拼错了,或者是不是在中文输入法的情况下输的冒号,括号或者逗号,而正确的做法应该是先切换到英文输法。
又或者是缩进有问题,在python中特别注重缩进。
学习python对英文其实没有多大的要求,当然你如果英文好,一看到英文单词就知道是什么意思当然是有帮助的,在学习python 的过程中可以替你节省时间,减少代码编写中关键词拼错的概率,遇到问题能更快的从英文提示中知道问题出在哪,这是因为你在英文学习上花了大量的时间。
那如果以前没有花时间学习过英文,那必然也会在学习python 的起初比别人稍稍多花出一点时间,来完成这个不熟悉到熟悉的过程,所以英语不好的同学,不妨看看下面这些常见的python中的英文单词和意义:一、交互式环境与print输出1、print:打印/输出2、coding:编码3、syntax:语法4、error:错误5、invalid:无效6、identifier:名称/标识符7、character :字符二、字符串的操作1、user:用户2、name:姓名/名称3、attribute:字段/属性4、value:值5、key:键三、重复/转换/替换/原始字符串1、upper:上面2、lower:下面3、capitalize:用大写字母写或印刷4、title:标题5、replace:替换6、old:旧的7、new:新的8、count:计数9、swap:互换10、case:情形11、path:路径12、new:新的\新建13、project:项目14、test:测试15、file:文件16、data:数据四、去除/查询/计数1、strip:去除2、index:索引3、find:查找4、count:计数5、start:开始6、end:结束7、chars:字符8、sub:附属五、获取输入/格式化1、input:输入2、prompt:提示3、ID:身份证4、format:格式化5、args(argument):参数6、kwargs:关键字参数7、year:年8、month:月9、day:日六、元组1、tuple:元组2、max:最大3、min:最小4、iterable:可迭代5、key:关键字6、function:方法/函数7、stop:停止8、object:对象七、列表1、list:列表2、reverse:反向3、true:真4、false:假5、append:附加6、extend:扩展7、insert:插入8、pop:取出9、remove:移除10、del(delete):删除11、clear:清除12、sort:排序八、集合1、set:集合/设置2、add:添加3、update:更新4、discard:丢弃5、intersection:相交6、union:联合7、difference:差数8、symmetric:对称9、in:在…里面10、not:不/不是11、disjoint:不相交12、subset:子集13、superset:父集/超集14、copy:复制九、字典1、dict:字典2、key:键/关键字3、value:值4、item:项5、mapping:映射6、seq(sequence):序列7、from:从/来自8、get:获取9、default:默认10、none:没有11、arg:可变元素12、kwargs(keyword args):可变关键字元素十、循环1、for…in…循环的使用2、while…循环的使用3、range:范围4、sep(separate):分隔5、flush:冲刷6、step:步长7、continue:继续8、break:突破/跳出十一、条件/跳出与结束循环1、if:如果2、else:否则十二、运算符与随机数1、module:模块2、sys(system):系统3、path:路径4、import:导入5、from:从…十三、定义函数与设定参数1、birthday:出生日期2、year:年份3、month:月份4、day:日期5、type:类型6、error:错误7、missing:丢失8、required:必须9、positional:位置10、unsupported:不支持十四、设定收集参数1、create:创建2、info:信息3、age:年龄4、height:高度5、width:宽度6、weight:重量7、splicing:拼接8、params:参数9、volume:体积11、operand:操作数十五、嵌套函数/作用域/闭包1、inside:内部2、outside:外部3、radius:半径4、perimeter:周长5、case:情形6、synthesis:合成7、execute:执行十六、递归函数1、recursion:递归2、Infinite:无穷3、maximum:最大值4、depth:深度5、exceeded:超过6、factorial:阶乘7、search:查询8、power:幂9、lower:下方10、upper:上方11、middle:中间12、assert/assertion:异常十七、列表推导式/lambda表达式1、square:平方2、even:偶数3、comprehension:理解4、lambda:希腊字母λ的英文名称十八、列表推导式/lambda表达式1、regular:规则2、expression:表达式3、group:组4、match:匹配5、span:跨度6、ignore case:忽略大小写7、multi line:多行8、dot all:点全部9、unicode:万国码10、verbose:累赘11、pos/position:位置最后,虽然上面列举了一些python中常用的英文单词,但是每个人的情况还是有所不同,建议大家最好自己拿一个笔记本,每次遇到一个自己不认识的单词,查一下意思,然后记在本子上,当然主要是记单词在python的意义,而不是所有的英文解释都要记下来,刚开始可能会记得比较多,但是不需要多久,你就会发现本子上的单词就不再增加了,因为python常用词相比中高考英文单词,毕竟是数量有限的,而你所记的这些都是你经常会看到和用到的,是你最需要熟悉对你最有用的单词,看到了用多了之后就进入你的永久记忆了,到时候就不需要这本单词本了,成就感就是这么一点一点来的。
python 正则表达式 模糊匹配和精确匹配 -回复

python 正则表达式模糊匹配和精确匹配-回复Python正则表达式是一种强大的工具,用于文本匹配和处理。
在正则表达式中,我们常常需要进行模糊匹配和精确匹配。
本文将详细介绍这两种匹配方法,并给出一些具体的应用示例。
一、模糊匹配模糊匹配是指在匹配搜索时,允许一定程度的误差。
这在处理大量数据和不完整的数据时非常有用。
在正则表达式中,模糊匹配常常使用特殊字符来实现。
下面是几个常用的模糊匹配字符:1. ".":匹配任意字符,除了换行符。
例如,正则表达式"ca.e"可以匹配"case"、"cake"和"cave"等单词。
2. "*":匹配前一个字符的零个或多个实例。
例如,正则表达式"ca*t"可以匹配"ct"、"cat"、"caat"、"caaat"等单词。
3. "+":匹配前一个字符的一个或多个实例。
例如,正则表达式"ca+t"可以匹配"cat"、"caat"、"caaat"等单词,但不能匹配"ct"。
4. "?":匹配前一个字符的零个或一个实例。
例如,正则表达式"ca?t"可以匹配"ct"、"cat"等单词,但不能匹配"caat"。
5. "{m,n}":匹配前一个字符的m到n个实例。
例如,正则表达式"ca{1,3}t"可以匹配"cat"、"caat"、"caaat"等单词,但不能匹配"ct"和"caa"。
python re.search 正则用法 -回复

python re.search 正则用法-回复题目: Python re.search 正则用法导言:在Python编程中,正则表达式是一种强大且灵活的工具,它使我们能够通过模式匹配和搜索文本数据。
re模块是Python提供的正则表达式操作库,其中re.search()函数是在给定字符串中搜索模式的常用工具。
本文将一步一步回答关于Python re.search()函数的常见问题,并提供实例来帮助读者深入了解该函数的用法。
目录:1. re.search()函数概述2. 正则表达式基础3. re.search()函数的语法和参数4. re.search()函数的返回值5. 实例演示5.1 基本使用5.2 使用子组5.3 使用标志参数6. 结论1. re.search()函数概述:re.search()函数是re模块中最常用的函数之一,它用于查找给定的正则表达式模式是否存在于指定的字符串中。
re.search()函数返回匹配对象,其中包含有关匹配项的信息。
2. 正则表达式基础:在讨论re.search()函数之前,我们需要了解正则表达式的基础知识。
正则表达式是由特殊字符和普通字符组成的字符串,它可以用于表达文本模式。
一些基本的正则表达式元字符包括:- 字符:普通字符可以是字母、数字或其他字符,它们只匹配它们自己。
- 元字符:元字符具有特殊意义,例如. ^ * + ? { } [ ] \ ( ),需要进行转义才能匹配它们自身。
- 特殊序列:特殊序列是以反斜杠\开头的字符组合,用于匹配特殊模式。
- 字符类:字符类用于匹配特定字符范围中的任何一个字符,例如[a-z]匹配小写字母。
- 量词:量词用于指定匹配字符的数量,例如*匹配0个或多个重复字符。
3. re.search()函数的语法和参数:re.search()函数的语法如下:re.search(pattern, string, flags=0)- pattern:要搜索的正则表达式模式。
python re.match 匹配规则 -回复

python re.match 匹配规则-回复Python中的re.match函数是用于尝试从字符串的起始位置匹配一个模式。
它采用两个参数,一个是正则表达式模式,另一个是要匹配的字符串。
在本文中,我们将以中括号内的内容为主题,详细讨论re.match的匹配规则和用法。
一、re.match函数的基本用法re.match(pattern, string, flags=0)是re模块中的一个函数,用于在字符串的起始位置匹配一个模式。
它的参数说明如下:- pattern: 要匹配的正则表达式模式,可以是一个字符串或一个原始字符串。
- string: 要匹配的字符串。
- flags: 可选参数,用于控制匹配模式。
在使用re.match函数时,它会尝试从字符串的起始位置开始匹配模式。
如果匹配成功,则返回一个匹配对象;如果匹配失败,则返回None。
二、基本匹配规则1. 匹配普通字符在正则表达式中,使用普通字符(例如字母、数字和特殊字符)来进行匹配。
例如,表达式"abc"将匹配字符串中的"abc"这个子串。
2. 匹配特殊字符正则表达式中的一些字符具有特殊含义,比如"."、"^"、""等。
如果要匹配这些特殊字符本身,需要在其前面加上反斜线。
例如,表达式"\."将匹配字符串中的"."字符。
3. 匹配字符集合中括号[]用于定义一个字符集合,表示匹配其中的任意字符。
例子如下:- 表达式"[abc]"将匹配字符串中的"a"、"b"或"c"字符。
- 表达式"[0-9]"将匹配字符串中的任意数字。
- 表达式"[a-z]"将匹配字符串中的任意小写字母。
4. 排除字符集合中括号前面加上"^"符号,表示排除字符集合。
python中正则表达式 re.search 用法 -回复

python中正则表达式re.search 用法-回复题目:Python中正则表达式re.search用法详解引言:正则表达式(Regular Expression)是一种用于匹配字符串的强大工具,它可以通过定义一些规则来查找、匹配和替换文本中的特定模式。
在Python中,使用re模块可以轻松地实现对字符串的正则匹配。
re模块中的re.search函数是其中一个常用的函数,可以用于在文本中搜索指定的正则表达式,并返回第一个匹配到的结果。
本文将详细介绍re.search的用法,为读者提供使用正则表达式进行模式匹配的基础知识。
第一部分:re.search函数的基本介绍在Python的re模块中,re.search函数用于在指定的字符串中搜索指定的正则表达式。
它会从字符串的开头开始搜索,并在遇到匹配的部分时停止搜索,返回匹配到的结果。
re.search函数的语法如下:re.search(pattern, string, flags=0)其中,pattern为所要搜索的正则表达式,string为要搜索的字符串,flags 为正则表达式的标志位(可选)。
re.search函数的返回值是一个匹配对象(Match Object),通过该对象可以获取匹配到的结果。
第二部分:re.search函数的具体用法re.search函数的使用步骤如下:1. 导入re模块如下所示:pythonimport re2. 定义正则表达式首先,需要定义一个正则表达式,用于指定要搜索的模式。
正则表达式由一些特定的字符和符号组成,可以用于匹配不同的字符串模式。
例如,要匹配一个由3个小写字母组成的单词,可以使用正则表达式r'\b[a-z]{3}\b'。
3. 使用re.search进行匹配调用re.search函数,将定义好的正则表达式和要搜索的字符串作为参数传入。
如下所示:pythonresult = re.search(pattern, string, flags=0)这样,re.search函数会返回匹配到的结果,如果没有匹配到任何内容,则返回None。
python中match函数的用法

python中match函数的用法Python中的match函数是一个非常有用的函数,它可以用来匹配字符串中的模式。
在本文中,我们将深入探讨match函数的用法,包括如何使用它来匹配字符串中的模式,以及如何使用它来提取匹配的子字符串。
让我们来看一下match函数的基本用法。
match函数是re模块中的一个函数,它可以用来匹配一个字符串的开头部分。
下面是一个简单的例子:```import repattern = r"hello"string = "hello world"match = re.match(pattern, string)if match:print("Match found!")else:print("Match not found.")```在这个例子中,我们定义了一个模式,即字符串"hello",然后将其与字符串"hello world"进行匹配。
由于"hello"是字符串"hello world"的开头部分,因此匹配成功,程序将输出"Match found!"。
现在让我们来看一下match函数的一些高级用法。
首先,我们可以使用match函数来提取匹配的子字符串。
例如,假设我们有一个字符串,其中包含一个日期,我们想要提取这个日期。
我们可以使用match函数来实现这个目标,如下所示:```import repattern = r"(\d{4})-(\d{2})-(\d{2})"string = "Today is 2022-01-01."match = re.match(pattern, string)if match:year = match.group(1)month = match.group(2)day = match.group(3)print("Year: ", year)print("Month: ", month)print("Day: ", day)else:print("Match not found.")```在这个例子中,我们定义了一个模式,即一个日期,它由四位数字的年份、两位数字的月份和两位数字的日期组成,中间用"-"隔开。
re.search用法

re.search用法1.什么是r e.search?r e.s ea rc h是Py tho n中r e模块提供的一个函数,用于在字符串中搜索匹配某一模式的第一个位置,并返回一个包含匹配结果的m at ch对象。
re.s ea rc h会从字符串的开头开始匹配,一旦找到匹配的结果,就会停止搜索。
2. re.search的基本用法r e.s ea rc h的基本用法如下:r e.s ea rc h(pa tt ern,st ri ng,f la gs=0)*`pa tt er n`:匹配的模式字符串,可以是普通字符串,也可以是正则表达式。
*`st ri ng`:需要匹配的字符串。
*`fl ag s`:可选参数,用于指定匹配模式。
常用的fl ag s包括`r e.IG NO RE CA SE`(忽略大小写)、`r e.M UL TI LI NE`(多行匹配)等。
3.示例下面通过一些示例来演示re.s ea rc h的用法。
3.1匹配普通字符串i m po rt res t ri ng="He ll o,Wor l d!"p a tt er n="o"r e su lt=r e.se ar ch(p at te rn,s tr in g)p r in t(re su lt)输出结果为:<r e.Ma tc ho bj ec t;s p an=(4,5),m at ch='o'>3.2匹配正则表达式i m po rt res t ri ng="He ll o,Wor l d!"p a tt er n=r"w\w+d"r e su lt=r e.se ar ch(p at te rn,s tr in g)p r in t(re su lt)输出结果为:<r e.Ma tc ho bj ec t;s p an=(7,12),ma tch='W or ld'>3.3使用f l a g s参数i m po rt res t ri ng="He ll o,Wor l d!"p a tt er n="o"r e su lt=r e.se ar ch(p at te rn,s tr in g,f l ag s=re.I GN OR ECA S E)p r in t(re su lt)输出结果为:<r e.Ma tc ho bj ec t;s p an=(4,5),m at ch='o'>4.总结通过上述示例可以看出,re.s ea rc h是一个强大的字符串搜索函数,它不仅可以匹配普通字符串,还可以使用正则表达式进行更加灵活的匹配。
python正则根据开头和结尾字符串获取中间字符串的方法

python正则根据开头和结尾字符串获取中间字符串的方法Python正则表达式:根据开头和结尾字符串获取中间字符串的方法在Python中,正则表达式是处理文本操作非常关键的工具。
通过正则表达式,我们可以方便地匹配和提取字符串中的特定部分,从而实现数据处理的目的。
其中,要根据开头和结尾字符串获取中间的字符串,可以使用正则表达式中的“lookbehind”和“lookahead”语法。
以下是具体的实现方法:1. 根据开头和结尾字符串生成正则表达式模式我们可以使用正则表达式模式来匹配开头和结尾字符串,并同时保留中间的部分。
例如,在文本中查找以“Hello”为开头、以“World”为结尾的字符串,可以使用如下正则表达式模式:```pythonpattern = r'(?<=Hello).*?(?=World)'```这个正则表达式模式中,使用了“lookbehind”语法“(?<=Hello)”,表示匹配以“Hello”为开头的文本。
同时,也使用了“lookahead”语法“(?=World)”,表示匹配以“World”为结尾的文本。
最后,使用“.*?”匹配开头和结尾之间的任意文本,保留中间部分。
2. 使用正则表达式模式匹配字符串在生成正则表达式模式之后,我们可以使用Python中的re模块来进行字符串匹配操作。
例如,在文本“Hello, World!”中查找以“Hello”为开头、以“World”为结尾的字符串,代码如下:```pythonimport retext = 'Hello, World!'pattern = r'(?<=Hello).*?(?=World)'match = re.search(pattern, text)if match:result = match.group(0)print(result)```在以上代码中,使用了re模块中的search()函数进行正则表达式匹配。
python中模糊查询的用法

python中模糊查询的用法在Python中,我们经常需要对数据进行搜索或过滤操作。
有时候,我们需要进行模糊查询,也就是说不需要完全匹配,只需要匹配一部分即可。
这时候,就需要用到模糊查询。
常用的模糊查询方法有两种:通配符和正则表达式。
1. 通配符通配符是一种特殊的字符,可以代表任意一个或多个字符。
在Python中,通配符有两种,分别是“?”和“*”。
其中,“?”代表任意一个字符,而“*”代表零个或多个字符。
通配符可以用在字符串的任何位置,包括开头和结尾。
下面是一个例子,我们使用通配符来搜索文件中包含“python”的行。
代码如下:import rewith open('file.txt') as f:for line in f:if re.search('python.*', line):print(line)在这个例子中,我们使用了“*”通配符,表示匹配“python”后面的任意字符。
2. 正则表达式正则表达式是一种强大的工具,可以用于匹配任意字符串。
Python中的re模块提供了很多函数和方法,可以用于处理正则表达式。
下面是一个例子,我们使用正则表达式来搜索文件中包含“python”的行。
代码如下:import rewith open('file.txt') as f:for line in f:if re.search('python.*', line):print(line)在这个例子中,我们使用了re模块的search方法来搜索匹配正则表达式“python.*”的行。
这个正则表达式代表匹配“python”后面的任意字符。
总结模糊查询是Python中非常常用的操作之一,通配符和正则表达式是两种实现模糊查询的方法。
在开发过程中,我们可以根据具体需求选择合适的方法来实现模糊查询。
python正则表达式函数match()和search()的区别详解

python正则表达式函数match()和search()的区别详解match()和search()都是python中的正则匹配函数,那这两个函数有何区别呢?match()函数只检测RE是不是在string的开始位置匹配, search()会扫描整个string查找匹配, 也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none例如:1 2 3 4 5 6 7 8 9 10 11#! /usr/bin/env python# -*- coding=utf-8 -*-import retext ='pythontab'm =re.match(r"\w+", text) if m:print m.group(0) else:print'not match'结果是:pythontab ⽽:1 2 3 4 5 6 7 8 9 10 11 12#! /usr/bin/env python# -*- coding=utf-8 -*-#import retext ='@pythontab'm =re.match(r"\w+", text) if m:print m.group(0) else:print'not match'结果是:not matchsearch()会扫描整个字符串并返回第⼀个成功的匹配例如:1 2 3 4 5 6 7 8 9 10 11 12#! /usr/bin/env python# -*- coding=utf-8 -*-#import retext ='pythontab'm =re.search(r"\w+", text) if m:print m.group(0) else:print'not match'结果是:pythontab 那这样呢:1 2 3 4 5 6 7#! /usr/bin/env python# -*- coding=utf-8 -*-#import retext ='@pythontab'm =re.search(r"\w+", text)7 8 9 10 11 12m =re.search(r"\w+", text) if m:print m.group(0) else:print'not match'结果是:pythontab。
python正则表达式re使用模块(match()、search()和compile())

python正则表达式re使⽤模块(match()、search()和compile())摘录 python核⼼编程python的re模块允许多线程共享⼀个已编译的正则表达式对象,也⽀持命名⼦组。
下表是常见的正则表达式属性:函数/⽅法描述仅仅是re模块函数compile(pattern,flags=0)使⽤任何可选的标记来编译正则表达式的模式,然后返回⼀个正则表达式对象re模块函数和正则表达式对象的⽅法match(pattern,string,flags=0)尝试使⽤带有可选标记的正则表达式的模式来匹配字符串,成功则返回匹配的对象,失败则返回Nonesearch(pattern,string,flags=0)使⽤可选标记搜索字符串中第⼀次出现的正则表达式模式,成功则返回匹配对象,失败则返回Nonefindall(pattern,string[,flags])查找字符串中所有(⾮重复)出现的正则表达式模式,返回⼀个匹配列表finditer(pattern,string,[,flags])和findall()函数相同,但返回的是⼀个迭代器。
对于每次匹配,迭代器都返回⼀个匹配对象split(pattern,string,max=0)根据正则表达式的模式分隔符,split函数将字符串分割为列表,然后返回成功匹配的列表,分割最多操作max次(默认分割所有匹配成功的位置)re模块函数和正则表达式对象⽅法sub(pattern,repl,string,count=0)使⽤repl替换正则表达式模式在字符串中出现的位置,除⾮定义count,否则替换所有purge()清除隐式编译的正则表达式模式常⽤的匹配对象⽅法group(num=0)返回整个匹配对象,或者编号为num的特定⼦组groups(default=None)返回⼀个包含所有匹配⼦组的元组(如果没有,则返回⼀个空元组)groupdict(default=None)返回⼀个包含所有匹配的命名⼦组的字典,所有⼦组名称作为字典的键(如没有,则返回⼀个空字典)常⽤的模块属性re.I、re.IGNORECASE不区分⼤写的匹配re.L、re.LOCALE根据所使⽤的本地语⾔环通过\w\W\b\B\s\S实现匹配re.M、re.MULTILINE^和$分别匹配⽬标字符串中⾏的起始和结尾,⽽不是严格的匹配整个字符串本⾝的开始和结尾re.S、re.DOTALL点号.通常匹配除了换⾏符\n之外的所有单个字符,该标记表⽰点号能够匹配全部字符re.X、re.VERBOSE通过反斜线转义,否则所有空格加上#(以及在该⾏中所有后续问题)都被忽略,除⾮在⼀个字符类中或者允许注释并且提⾼可读性compile()编译正则表达式在模式匹配发⽣之前,正则表达式模式必须编译成正则表达式对象,⽽且正则表达式在执⾏的过程中可能进⾏多次的⽐较操作。
python笔记题带答案

1。
Python是如何进行内存管理的?答:从三个方面来说,一对象的引用计数机制,二垃圾回收机制,三内存池机制一、对象的引用计数机制Python内部使用引用计数,来保持追踪内存中的对象,所有对象都有引用计数。
引用计数增加的情况:1,一个对象分配一个新名称2,将其放入一个容器中(如列表、元组或字典)引用计数减少的情况:1,使用del语句对对象别名显示的销毁2,引用超出作用域或被重新赋值sys。
getrefcount()函数可以获得对象的当前引用计数多数情况下,引用计数比你猜测得要大得多。
对于不可变数据(如数字和字符串),解释器会在程序的不同部分共享内存,以便节约内存。
二、垃圾回收1,当一个对象的引用计数归零时,它将被垃圾收集机制处理掉。
2,当两个对象a和b相互引用时,del语句可以减少a和b的引用计数,并销毁用于引用底层对象的名称。
然而由于每个对象都包含一个对其他对象的应用,因此引用计数不会归零,对象也不会销毁。
(从而导致内存泄露)。
为解决这一问题,解释器会定期执行一个循环检测器,搜索不可访问对象的循环并删除它们.三、内存池机制Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
1,Pymalloc机制。
为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
2,Python中所有小于256个字节的对象都使用pymalloc实现的分配器,而大的对象则使用系统的malloc。
3,对于Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池.也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
2.什么是lambda函数?它有什么好处?答:lambda 表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数lambda函数:首要用途是指点短小的回调函数lambda [arguments]:expressiona=lambdax,y:x+ya(3,11)3.Python里面如何实现tuple和list的转换?答:直接使用tuple和list函数就行了,type()可以判断对象的类型4。
python笔记52-re正则匹配search(groupgroupsgroupdict)

python笔记52-re正则匹配search(groupgroupsgroupdict)前⾔re.search扫描整个字符串并返回第⼀个成功的匹配。
re.findall返回字符串中所有不重叠匹配项的列表,如果没有匹配到返回空list不会报错。
search匹配对象有3个⽅法:group() groups() groupdict() ,这3个⽅法使⽤上会有⼀些差异。
如果只需匹配⼀个,匹配到就结束就⽤search,匹配全部就⽤findallre.search 源码解读search扫描整个字符串并返回第⼀个成功的匹配,如果没匹配到返回None函数参数说明:pattern 匹配的正则表达式string 要匹配的字符串。
flags 标志位,⽤于控制正则表达式的匹配⽅式,如:是否区分⼤⼩写,多⾏匹配等等def search(pattern, string, flags=0):"""Scan through string looking for a match to the pattern, returninga match object, or None if no match was found."""return _compile(pattern, flags).search(string)跟前⾯findall⼀样有三种⽅式import rekk = pile(r'\d+') # 匹配数字res1 = kk.search('one1two2three3four4')print(res1)# <_sre.SRE_Match object; span=(3, 4), match='1'>kk = pile(r'\d+')res2 = re.search(kk,"one123two2")print(res2)# <_sre.SRE_Match object; span=(3, 6), match='123'># 也可以直接在search传2个参数res3 = re.search(r'\d+', "one123two2")print(res3)print(res3.group(0))# <_sre.SRE_Match object; span=(3, 6), match='123'># 123不同的是匹配成功re.search⽅法返回⼀个匹配的对象,否则返回None。
python正则表达式re模块详细介绍

python正则表达式re模块详细介绍本模块提供了和Perl⾥的正则表达式类似的功能,不关是正则表达式本⾝还是被搜索的字符串,都可以是Unicode字符,这点不⽤担⼼,python会处理地和Ascii字符⼀样漂亮。
正则表达式使⽤反斜杆(\)来转义特殊字符,使其可以匹配字符本⾝,⽽不是指定其他特殊的含义。
这可能会和python字⾯意义上的字符串转义相冲突,这也许有些令⼈费解。
⽐如,要匹配⼀个反斜杆本⾝,你也许要⽤'\\\\'来做为正则表达式的字符串,因为正则表达式要是\\,⽽字符串⾥,每个反斜杆都要写成\\。
你也可以在字符串前加上 r 这个前缀来避免部分疑惑,因为 r 开头的python字符串是 raw 字符串,所以⾥⾯的所有字符都不会被转义,⽐如r'\n'这个字符串就是⼀个反斜杆加上⼀字母n,⽽'\n'我们知道这是个换⾏符。
因此,上⾯的'\\\\'你也可以写成r'\\',这样,应该就好理解很多了。
可以看下⾯这段:复制代码代码如下:>>> import re>>> s = ' 5c' #0x5c就是反斜杆>>> print s\>>> re.match('\\\\', s) #这样可以匹配<_sre.SRE_Match object at 0xb6949e20>>>> re.match(r'\\', s) #这样也可以<_sre.SRE_Match object at 0x80ce2c0>>>> re.match('\\', s) #但是这样不⾏Traceback (most recent call last):File "<stdin>", line 1, in <module>File "/usr/lib/python2.6/re.py", line 137, in matchreturn _compile(pattern, flags).match(string)File "/usr/lib/python2.6/re.py", line 245, in _compileraise error, v # invalid expressionsre_constants.error: bogus escape (end of line)>>>另外值得⼀提的是,re模块的⽅法,⼤多也就是RegexObject对象的⽅法,两者的区别在于执⾏效率。
python列表查找函数

python列表查找函数Python列表是一种常用的数据结构,用于存储一系列的元素。
使用列表查找函数可以快速找到列表中的特定元素,提高程序的效率和可读性。
本文将介绍几个常用的列表查找函数,并分析其使用方法和注意事项。
一、index函数index函数用于查找列表中某个元素的索引位置。
它的基本语法如下:index(value, start, end)其中,value表示要查找的元素,start和end表示查找范围的起始位置和结束位置(可选参数)。
如果列表中存在多个相同的元素,index函数只返回第一个匹配的索引位置。
使用index函数时需要注意以下几点:1. 如果要查找的元素不存在于列表中,index函数会抛出ValueError 异常。
因此,在使用index函数之前,最好先使用in运算符判断元素是否存在于列表中。
2. 如果要查找的元素存在于列表中多次,可以通过循环和切片的方式来继续查找后面的匹配项。
二、count函数count函数用于统计列表中某个元素出现的次数。
它的基本语法如下:count(value)其中,value表示要统计的元素。
使用count函数时需要注意以下几点:1. 如果要统计的元素不存在于列表中,count函数会返回0。
2. count函数只能统计单个元素的出现次数,不能统计多个元素的组合。
三、sort函数sort函数用于对列表进行排序。
它的基本语法如下:sort(reverse=False)其中,reverse表示排序方式,如果设置为True,则按照降序排列;如果设置为False(默认值),则按照升序排列。
使用sort函数时需要注意以下几点:1. sort函数会改变原列表的顺序,如果不想改变原列表,可以使用sorted函数。
2. sort函数只能对相同类型的元素进行排序,不能对不同类型的元素进行排序。
四、reverse函数reverse函数用于将列表中的元素倒序排列。
它的基本语法如下:reverse()使用reverse函数时需要注意以下几点:1. reverse函数会改变原列表的顺序,如果不想改变原列表,可以使用切片的方式实现倒序排列。