第二章 线搜索技术
最优化方法第二章_线搜索算法_最速下降法
f x1 , x2 c, c>0,
2
改写为:
x12 2c 1
2 x2
2c 2
2
1
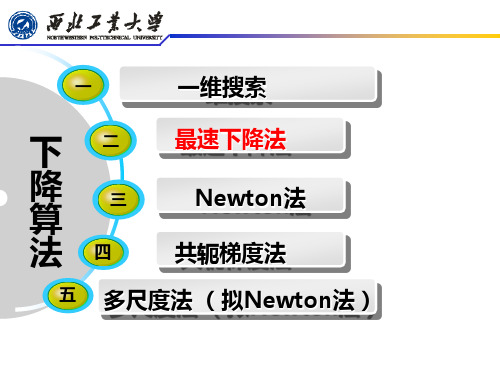
二、最速下降法
x2
这是以
2c
1
和
2c
2
为半轴的椭圆
2c
2c
2
2
从下面的分析可见 两个特征值的相对
x1
大小决定最速下降法的收敛性。
(1)当 1 2 时,等值线变为圆
2 2
4 f x , 2
2 x1 2 x2 4 f ( x) , 2 x1 +4x2
4 d = f x , 2
0 0
=40 2 20 3 令 0= ' ( ) 80 20, 得 0 =1/4,
一
一维搜索
二 三 四
下 降 算 法
五
最速下降法 Newton法 共轭梯度法
多尺度法 (拟Newton法)
二、最速下降法 假设 f 连续可微,取 线搜索方向
k
d f ( x )
k
步长k 由精确一维搜索得到。 从而得到第 k+1次迭代点,即
f ( x k k d k ) min f ( x k d k )
(推论)在收敛定理的假设下,若f (x)为凸函数,则最速下降 法或在有限迭代步后达到最小点;或得到点列 x k ,它的任 何聚点都是 f (x)的全局最小点。
二、最速下降法
最速下降法特征:相邻两次迭代的方向互相垂直。
令
( ) f ( x d ), 利用精确一维搜索,可得
非线性规划理论和算法

非线性最优化理论与算法第一章引论本章首先给出了一些常见的最优化问题和非线性最优化问题解的定义,并且根据不同的条件对其进行了划分。
接着给出了求解非线性优化问题的方法,如图解法等,同时又指出一个好的数值方法应对一些指标有好的特性,如收敛速度与二次终止性、稳定性等。
随后给出了在非线性最优化问题的理论分析中常用到的凸集和凸函数的定义和有关性质。
最后给出了无约束优化最优性条件。
第二章线搜索方法与信赖域方法无约束优化的算法有两类,分别是线搜索方法和信赖域方法。
本章首先给出了两种线搜索方法即精确线搜索方法和非精确线搜索方法。
线搜索方法最重要的两个要素是确定搜索方向和计算搜索步长,搜索步长可确保下降方法的收敛性,而搜索方向决定方法的收敛速度。
精确线搜索方法和非精确线搜索方法对于精确线搜索方法,步长ακ满足αk=arg minƒx k+αd kα≥0这一线搜索可以理解为αk是f(x k+αd k)在正整数局部极小点,则不论怎样理解精确线搜索,它都满足正交性条件:d k T∇ƒ(x k+αk d k)=0但是精确搜索方法一般需要花费很大的工作量,特别是当迭代点远离问题的解时,精确的求解问题通常不是有效的。
而且有些最优化方法,其收敛速度并不依赖于精确搜索过程。
对于非精确搜索方法,它总体希望收敛快,每一步不要求达到精确最小,速度快,虽然步数增加,则整个收敛达到快速。
书中给出了三种常用的非精确线搜索步长规则,分别是Armijo步长规则、Goldstein步长规则、Wolfe步长规则。
第一个步长规则的不等式要求目标函数有一个满意的下降量,第二个不等式控制步长不能太小,这一步长规则的第二式可能会将最优步长排除在步长的候选范围之外,也就是步长因子的极小值可能被排除在可接受域之外。
但Wolfe步长规则在可接受的步长范围内包含了最优步长。
在实际计算时,前两种步长规则可以用进退试探法求得,而最后一种步长规则需要借助多项式插值等方法求得。
线搜索方法

线搜索方法
最优化方法 6
解的二阶必要性条件
定 理 2 若f : ℜn → ℜ是 二次连续可微函数 , x∗ 是(1) 问 题 的 局 部 极 小值点, 则∇f (x∗ ) = 0,∇2 f (x∗ )是半正定的. 证 明:∇f (x∗ ) = 0由定理1可以得到, 我们用反证法 证明∇2 f (x∗ )是 半 正定 的. 假 设∇2 f (x∗ )的最小特征值λ∗ 是负的,d∗ 是 相 对 应 的 特 征 向 量, 即∇2 f (x∗ )d∗ = λ∗ d∗ . 由 中值定理可得到 1 2 ∗T 2 f (x + αd ) = f (x ) + α d ∇ f (x∗ )d∗ + o(α2 ), 2
为{xk }的根 收敛阶(也称 R-收敛阶).
线搜索方法
最优化方法 17
三 个Q-收 敛 阶
定 义 3 若0 < Q1 < 1,则称{xk }是Q-线性收敛到 x∗ 的; 若Q1 = 0, 则称{xk } 是Q-超线性收敛于x∗ 的; 如果rQ = 2,则称 {xk }是 Q-二 次收敛到x∗ 的. 序列{xk }线性收敛到x∗ 等价于存在Q1 ∈ (0, 1)满 足,对充分大的k ,有 ∥xk+1 − x∗ ∥ ≤ Q1 ∥xk − x∗ ∥.
α≥ 0
这 一 线 搜索 在ℜ+ := {t | t ≥ 0}上 求ϕ(t) := f (xk + tdk )的 全 局 极 小, 这 对于 复 杂的函数f 是 非常困难的,甚 至是不可能做到的,因 此 这 一 线 搜索 往 往理解为αk 是ϕ 在 ℜ+ 上的一局部极小 点,甚至αk 是ϕ在ℜ+ 上的一稳定点即可. 显 然,不 论怎样理解精确线搜索,下述性质都是 成立 的: ∇f (xk + αk dk )T dk = 0.
第二章 信息检索的基本知识

应用举例:
利用《中图法》在《全国报刊索引》中查找 有关“建筑抗震设计”方面的相关文献。 第一步:分析课题,按学科属性属于“T工业技术” 中的“TU建筑科学”大类。 第二步:查《中图法》确定分类号为:T工业技 术—TU建筑科学—TU3建筑结构—TU352.11抗震结 构。 第三步:根据《全国报刊索引》(科技版)的分 类目录给出的TU3建筑结构的页次,得到相关文献。 第四步:根据的出处索取原始文献。
第二章 信息检索的基本知识
主要内容
1.信息检索概述 2.信息检索原理及检索语言 3.信息检索系统与检索工具 4.信息检索的一般程序
2.1 信息检索概述
2.1.1信息检索的含义
信息检索(Information Retrieval)是指 将信息按一定的方式组织和存储起来,并根据用 户的需要找出有关信息的过程,又叫信息储存与 检索(Information storage and Retrieval), 这是广义的信息检索,如图2-1所示。狭义的信息 检索则是仅指该过程的后半部分,即从信息集合 中找出所需信息的过程。
内容特征 标题词 主题语言 关键词 叙词 描述文献外表特征的检索语言,例如篇名、著者姓名、文 献号等作为文献标识与检索依据直接明了,使用时较为简单。 而文献内容特征的语言,也就是分类语言和主题语言的原理和 使用方法是下面主要介绍的内容。
一条中文书目记录:
题名: 信息检索 作者: 徐天秀 出版项:北京:科学出版社,2006 页码: 320页 价格: CNY23.00 主题: 情报检索 索取号: G252.7/101 内容提要:本书是一本工具型书籍,提供的信息检索学科 范围广,内容尽量以最新版本为主,是一本适用性强的学 习信息检索方法和技巧的专著,尤其是本书配制的多媒体 光盘,为本课程的学习提供了便捷。 分类: G252.7
文献检索,信息检索(2)第二章 信息检索原理

缺点:常常落后于当前研究现状,分类表相对呆板的 学科关系,使得确定前沿概念、跨学科概念或非常具 体概念的分类,较困难。用户差异性。
分类语言
中国图书馆图书分类法 美国国会图书馆分类法 杜威十进位分类法 IPC国际专利分类法
基本部类 马列毛邓 哲学
(2)多概念课题
并列概念课题,如“新闻宣传研究”
“计算机在人文社会科学方面的应用” 上位类分类方法,如“灰色系统理论”
应用性课题,如“计算机在人口预测方面的应用”、
2.主题语言
是直接以代表信息内容特征和科学概念的概 念词作为检索标识,并按字顺组织的一种检索语 言。 是以表达文献主 是从文献的内容 是从文献的题目
一、检索算符 逻辑与
(一)布尔逻辑算符
布尔逻辑组配运算是采用布尔代数中的 逻辑“与”逻辑“或”、逻辑“非”等算符,
将检索提问式转换成逻辑表达式,限定检索
词在记录中必须存在的条件或不能出现的条 件。凡符合布尔逻辑所规定的条件的文献, 既为命中文献。
布尔逻辑运算符
————————————
1、逻辑“或” 2、逻辑“与” 3、逻辑“非”
2、逻辑“与”
————————————————
Chinese AND litera0,000 网络100,000,000) 用符号“and”或“*”表示,其逻辑表达式为: A * B 或 A and B 其意义为检索记录中必须同时含有检索词A和B 的文献,才算命中文献。
4、记录级
检索词在数据库的同一记录中。
(C)—citation
表示两侧的检索词(或检索项)必须出现在同一记录中,词
序不限,中间词数量不限,其作用与布尔逻辑算符AND相同。
复杂网络的路径搜索算法优化研究

复杂网络的路径搜索算法优化研究随着网络技术的发展和应用场景的不断拓展,人们对网络的需求也越来越高。
在各类网络中,路径搜索算法是一种非常重要的技术,用于计算网络中的两点之间的最短路径,从而方便信息的传输和流转。
但在实际应用中,复杂网络的建模和算法优化成为了亟待解决的问题。
复杂网络模型所谓复杂网络,就是具有复杂结构和动态性质的网络。
在研究路径搜索算法的时候,我们需要首先对网络进行建模。
目前比较常见的网络模型包括小世界网络、无标度网络和随机网络。
无标度网络具有高度集中性的特点,而随机网络则具有良好的均衡性。
小世界网络则同时兼具了这两种结构,既保持了高度集中性,又具有较好的均衡性。
在复杂网络的建模中,一个重要的问题是节点度分布的模拟。
度分布是指在一个网络中,节点的度数分别为多少的个数分布。
在实际应用中,节点度分布往往对计算节点路径的性质有着重要的影响,因此需要针对不同的网络模型进行不同的度分布模拟。
路径搜索算法路径搜索算法是指从图中的某个节点出发,找到到达目标节点的最短路径的算法。
常用的路径搜索算法包括最短路径算法、最小生成树算法和网络流算法等。
不同的算法依赖于不同的网络结构和节点度分布,因此需要针对不同的网络类型进行算法优化和改进。
最短路径算法是针对最短路径问题设计的算法,包括Dijkstra算法、Bellman-Ford算法和Floyd算法等。
Dijkstra算法通过计算从源节点到所有其他节点的最短路径,可以得到最短路长度和路径信息。
Bellman-Ford算法是一种基于动态规划的算法,可以处理负权边的情况。
Floyd算法是一种基于动态规划的算法,可以处理任意两个节点之间的最短路径。
最小生成树算法是指从有边权的无向连通图生成一个无向连通树,使得该树的所有边权之和最小的算法。
常用的最小生成树算法包括Prim算法和Kruskal算法。
Prim算法是一种贪心算法,每次将生成树扩展一个节点,并选择与该节点相连的边中权值最小的边。
计算机的信息检索技术有哪些详解信息检索的基本原理与方法

计算机的信息检索技术有哪些详解信息检索的基本原理与方法信息检索是指通过计算机技术,从大量数据中快速找到所需信息的过程。
随着互联网的普及和信息爆炸的时代,信息检索技术的重要性日益突出。
本文将详解信息检索的基本原理与方法,以及常见的信息检索技术。
一、信息检索的基本原理信息检索的基本原理是通过索引和检索两个步骤实现的。
首先,在建立索引的阶段,将待检索的数据进行预处理,提取出关键词和相关信息,并建立索引文件。
索引文件包含了每个文档中所有的关键词及其所在位置的信息。
其次,在检索的阶段,用户输入检索词,系统根据索引文件快速定位到相关文档,并将其返回给用户。
二、信息检索的方法1. 布尔检索法布尔检索法是最早的信息检索方法之一,它通过逻辑运算符(例如AND、OR、NOT)将用户检索词与索引文件中的关键词进行匹配,从而找到满足要求的文档。
这种方法简单直接,但需要用户具有一定的逻辑思维能力。
2. 向量空间模型向量空间模型将文档表示为向量,并利用向量之间的相似度进行检索。
在该模型中,每个文档可以看作是一个向量,而检索词也可以转换为向量。
通过计算文档向量与检索向量之间的相似度,可以确定与用户需求最匹配的文档。
3. 概率检索模型概率检索模型基于信息检索的概率理论,利用检索词在文档中出现的概率和文档的相关性进行检索。
常见的概率模型包括贝叶斯模型和语言模型。
这种方法能够更准确地计算文档与检索词的相关性,提高检索结果的质量。
4. 自然语言处理技术自然语言处理技术在信息检索中起着重要的作用。
通过对自然语言的分析和理解,能够更好地理解用户查询的意图,并将其转化为机器可理解的形式。
常见的自然语言处理技术包括词法分析、句法分析和语义分析。
三、常见的信息检索技术1. 网页搜索技术网页搜索技术是信息检索中最常见的应用之一。
通过搜索引擎,用户可以快速找到互联网上的相关信息。
网页搜索技术常用的算法包括页面排名算法(例如PageRank算法)和关键词匹配算法(例如倒排索引)。
第二章 信息检索基本方法与基本技术

2. 主题检索语言
• 标题词:经规范化处理的词或词组,先组式
语言
• 叙 词(单元词):经规范化处理的词或词
组,后组式语言,可自由灵活组配
• 关键词:未经规范化处理,直接从文献题名、
原文或文摘中选取的能反映原文主题内容的自 由词汇
二、检索工具
定义:检索工具是人们用来存储、报道和查找 文献的工具,它具有存储和检索的功能。
点击预约书刊可预约该书 预约图书:选定所需图书,输入证号、密码,执行预约 点击机读格式可查看该书的MARC信息
高级查询
• 在题名、著者、丛书名、主题词、出版社、 ISBN(书)、ISSN(刊)、索取号、起始年 代中填入自己确定的内容,其余的可以不填 写;选定语种(17种)和文献类型,然后进 行检索。 • 结果可检索到所需文献的题名、著者、出版 信息、索取号 • 查看选中图书的相关信息
图书馆信息查询系统
•书目查询 •读信者息 •新书通报:一个月内到馆的新书、馆藏 地,并可查看新书 •订购征询 •信息发布:预约到书列表、超期罚款、 超期催还、委托借阅到书列表
如何利用计算机进行检索
书刊查询
读者信息查询
图书馆主页的功能
信息发布功能:
图书馆最新服务动态、电子 资源试用等均及时在主页上发布。
一、信息检索原理
信息检索的原理(示意图)
存 储
特征化
表示
查 询
特征化
表示
信息 集合
选择与匹配
需求 集合
二、信息检索类型
手工检索 计算机检索 文献信息检索
• 信息检索(内容)
• 信息检索(工具手段)
数据信息检索
事实信息检索
第二节 信息检索语言与工具
一、信息检索语言
文献检索--第二讲(新)

英文:Yahoo、Alta Vista、Excite、Lycos 另有专门的搜索引擎。
常用的一些搜索引擎 (1)谷歌: 1997年,(简体中文)提供有类目检索和网站 检索两种方式。支持AND和“-”等条件查询。 以搜索精度高、速度快成为最受欢迎的搜索引索, 是目前搜索的领军人物。 • 检索方法与技巧:模块分类、关键词检索;支持布尔
(nW) 表示在此算符两侧的检索词必须按输入时 的前后顺序排列,不能颠倒。但允许在连接的两 个词之间最多插入n个单元词。 例: laser (1W) printer 结果中“ laser color printer”的文献为命中记录。 ii. (N)算符 N算符是Near的缩写,表示此算符两侧的检索词 必须紧密相连,所连接的词之间不允许插入任何 其他单词或字母。但词序可以颠倒。 例: intelligent (N) robot* ( Ei CPX Web) (nN)表示在两个检索词之间最多可插入n个单 词,且两词的词序任意。 例: intelligent (1N) robot
逻辑运算符有三种: 逻辑“与” :常用“*”或“AND”表示,检 索时,命中信息同时含有两个概念,专指性强。 可以缩小检索范围,提高查准率。
如:要检索“计算机网络”方面的有关信息 “computer AND network”
逻辑“或”:常用“+”、“OR” 表示,检索时,命
中信息包含所有关于逻辑A或逻辑B或同时有A和B的, 可以扩大检索范围,避免漏检,提高查全率。 用来检索同义词、近义词、俗称词、复合词等
如查找美国教育网上的宇宙大爆炸jpg图片 搜索:BIG BANG filetype:jpg site:edu • Site可将搜索定位于某一个域名上,有利于缩小搜索范围,提 高搜索效率 。 如 keywords site:,效果很好!可以方 便地搜索到各大学内有用的资源。 如:房屋建筑学 filetype:ppt site: (见网页) 土木工程 filetype:doc site:
Matlab学习手记——线搜索Wolfe准则

Matlab学习手记——线搜索Wolfe准则线是数值最优化算法中常用的一种方法,用于确定在给定方向上的最优步长。
Wolfe准则是一种经典的线准则,旨在保证策略能够在每一步都保持收敛性质,并且避免过大或过小的步长。
在Matlab中,我们可以利用内置函数和自定义函数来实现线Wolfe准则。
首先,我们需要定义一个目标函数和它的梯度函数。
例如,我们以Rosenbrock函数为例:```matlabfunction [value, gradient] = rosenbrock(x)value = 100*(x(2)-x(1)^2)^2 + (1-x(1))^2;if nargout > 1gradient = [-400*x(1)*(x(2)-x(1)^2)-2*(1-x(1)); 200*(x(2)-x(1)^2)];endend```其中,`x`是一个二维向量。
该函数计算了Rosenbrock函数的值和梯度。
接下来,我们可以定义一个函数来实现线Wolfe准则。
具体来说,我们需要实现Armijo准则和曲率条件。
以下是一个可能的实现:```matlabfunction [alpha, value] = line_search_wolfe(f, x, p, c1, c2, max_iter, alpha_max)alpha = alpha_max;[f0, gradient0] = f(x);value = f0;for iter = 1:max_iter[f_alpha, gradient_alpha] = f(x + alpha*p);if f_alpha > f0 + c1*alpha*gradient0'*p , (iter > 1 &&f_alpha >= f_alpha0)alpha = zoom(f, x, p, c1, c2, alpha0, alpha);return;endif abs(gradient_alpha'*p) <= -c2*gradient0'*preturn;endif gradient_alpha'*p >= 0alpha = zoom(f, x, p, c1, c2, alpha, alpha0);return;endalpha0 = alpha;f_alpha0 = f_alpha;alpha = min(2*alpha, alpha_max);endendfunction alpha = zoom(f, x, p, c1, c2, alpha_lo, alpha_hi) while truealpha = (alpha_lo + alpha_hi)/2;[f_alpha, gradient_alpha] = f(x + alpha*p);f_lo = f(x + alpha_lo*p);if f_alpha > f_lo + c1*alpha*(gradient_alpha'*p) ,f_alpha >= f_alpha_loalpha_hi = alpha;elseif abs(gradient_alpha'*p) <= -c2*(gradient_lo'*p)break;endif gradient_alpha'*p*(alpha_hi - alpha_lo) >= 0alpha_hi = alpha_lo;endalpha_lo = alpha;f_alpha_lo = f_alpha;endendend```该函数接受一个目标函数和它的参数 `x` 和方向 `p`。
李腾-线搜索-最速下降-最优化问题第一讲

3.无约束最优化问题——线搜索技术
在无约束优化问题迭代算法的一般框架中,其中有一个迭代步: 步3 通过某种搜索方式确定步长因子������������,使得������(������������+������������*������������) < ������(������������)。 令 ������(������) = ������(������������ + ������*������������),(2.2) 这样,搜索式(2.2) 等价于求步长������������ 使得������(������������) < ������(0)。
步2 计算左试探点. 若|������������ − ������������| ≤ ������, 停算, 输出������������. 否则, 令
������(������+1) := ������������, ������(������+1) := ������������, ������(������(������+1)) := ������(������������), ������(������+1) := ������������, ������(������+1) := ������(������+1) + 0.382(������(������+1) − ������(������+1)).
计算������(������(������+1)), ������ := ������ + 1, 转步1.
步3 计算右试探点. 若|������������ − ������������| ≤ ������, 停算, 输出������������. 否则, 令 ������(������+1) := ������������, ������(������+1) := ������������, ������(������(������+1)) := ������(������������), ������(������+1) := ������������, ������(������+1) := ������(������+1) + 0.618(������(������+1) − ������(������+1)). 计算������(������������+1), ������ := ������ + 1, 转步1.
1第二章信息检索的数学模型(7~8学时)

2.3.1 布尔检索模型 2.3.2 模糊集合模型 2.3.3 扩展布尔检索模型
2.3.1 布尔检索模型
布尔模型是一种简单的检索模型,它建立在经典集合论和 布尔代数的基础上。鉴于集合论中“集合”概念的直观性以及布 尔表达式所具有的准确语义,布尔模型非常容易被用户理解和 接受,在早期的大多数商业化书目检索系统中,布尔模型更是 得到了广泛关注和应用。
2.3.2.1 模糊集合论的基本知识
模糊集合论对经典集合论的推广,主要表现在它把元素属于集合 的概念模糊化,承认论域上存在既不完全属于某集合、又不完全不属 于某集合的元素,即变经典集合论“绝对的”属于概念为“相对的”属于 概念;同时,又进一步把属于概念数量化,承认论域上的不同元素对 于同一集合具有不同的隶属程度,引入了隶属度(membership)的概 念。 模糊集合的严格定义可以表述如下: 论域U到实区间[0,1]的任一映射 μA:U → [0,1] 对于任意x∈U,x →μA(x)都确定U上的一个模糊集合A,μA称做A 的隶属函数,μA(x)为元素x对A的隶属度。
1960年代末期,信息处理专家、美国著名学者萨尔顿(G. Salton) 基于“部分匹配”(partial matching)策略的信息检索思想,在其开发 的试验性检索系统SMART(System for Mechanical Analysis and Retrieval of Texts)中最早提出并采用线性代数的理论和方法构建出 一种新型的检索模型,这就是后来广为人知的向量空间模型(Vector Space Model,简称VSM)。
接上片
所谓“局部权值”是指第i个索引词在第j篇文档中的权值;而“全局权值” 则是指第i个索引词在整个系统文档集合中的权值。 现在,假设N为系统文档总数;ni为系统中含有索引词ki的文档数;freqij 为索引词ki在文档dj中的出现次数;idfi表示索引词ki的逆文档频率 (inverse document frequency,简称idf或IDF); maxtfj表示文档dj中所有 索引词出现次数的最大值。那么,对于文档dj中索引词ki的权值计算方法, 可以如下进行: fij = freqij / maxtfj idfi = log(N / ni) wij = fij * idfi
第三节课 第二章 文献检索原理与方法

思考题
1.《中国图书法》(简称《中图法》)将图书分为() A. 5大部类,22个大类 B. 5大部类,26个大类 C. 6大部类,22个大类 D. 6大部类,26个大类 2.《中国图书法》(简称《中图法》)是我国常用的分类法,要 检索农业方面的图书,需要在( )类目下查找。 A. S类目 B. Q类目 C. T类目 D. R类目
第一步,《全国新书目》的新书是安排在"新书视窗"专栏,在 2000年第3期《全国新书目》的目录中寻找到"新书视窗"专栏, 在第41~77页。 第二步,在第41~77页的"新书视窗"专栏里,我们可以看到, 该专栏是按照出版社的顺序排列的。高等教育出版社在第45页, 广东经济出版社第46页,教育科学出版社在第52页。 第三步,在第45、46、52页,你可以看到这几个出版社最 近所出版的新书目录。 如广东经济出版社的目录中有以下记载: 知识经济与改革创新 黄铁苗主编 2000 20cm 25.00元 本书围绕改革开放中的热点、难点问题进行探索,具体内容 包括:所有制问财政金融问题、农村经济问题、就业问题、地方 经济问题和其他问题。
2.检索工具-类型
目录 (bibliography,catalogue) 文摘(abstract) 索引(index)
2.1 目录
目录是一批相关文献信息的著录集合,是以报道文献 出版信息为主要功能的工具。 特点:以单位出版物为著录对象,反映馆藏情况,主 要揭示文献外部特征 目录的著录项目:出版名称、责任者、出版项和稽核 项 目录的类型:《全国总书目》《全国新书目》《全国 西文期刊联合目录》
主题词法与分类法的比较
主题词法 分类法
最优化第2章 精确线搜索

{
精确线性搜索
==>进退法、黄金分割法、二次插值逼近法
非精确线性搜索
==>Wolfe准则、Armijo准则
定义: 单峰函数
设 f ( x ) 是区间 [ a , b ] 上的一元函数,x 是 f ( x ) 在 [ a , b ] 上的极小点,且对任意的 x1 , x2 [ a , b ], x1 x2 , 有 (a)当 x 2 x 时, f ( x1 ) f ( x2 ); (b)当 x1 x 时,f ( x1 ) f ( x2 ) .
• 黄金分割点约等于0.618:1 是指分一线段为两部分,使得原来线段的长跟较长的那部分的比为黄 金分割的点。线段上有两个这样的点。 • 利用线段上的两黄金分割点,可作出正五角星,正五边形。
•
•
• •
黄金分割广泛用在建筑设计、美术、音乐、艺术等方面。
如在设计工艺品或日用品的宽和长时,常设计成宽与长的比近似为
0.618,这样易引起美感; 在拍照时,常把主要景物摄在接近于画面的黄金分割点处,会显得
更加协调、悦目;
舞台上报幕员报幕时总是站在近于舞台的黄金分割点处,这样音响 效果就比较好,而且显得自然大方;
•
• •
气温在人体正常体温的黄金分割点上23℃左右时,恰是人的身心最
适度的温度; 就连植物界也有采用黄金分割的地方,如果从一棵嫩枝的顶端向 下看,就会看到叶子是按照黄金分割的规律排列着的; 人体有许多黄金分割点
直到区间长度小到一定程度,此时区间上各点的函数
值均接近极小值。
[s,phis,k,ds,dphi,S]=qmin(inline('s^2-sin(s)'),0,1,1e-4,1e-6)
人工智能原理之搜索技术(PPT-77页)全

29
第2章 搜索技术
2.2.2 深度优先搜索和深度有限搜索
• 深度优先搜索过程:
• 总是扩展搜索树的当前扩展分支(边缘)中最 深的节点
• 搜索直接伸展到搜索树的最深层,直到那里 的节点没有后继节点
• 那些没有后继节点的节点扩展完毕就从边缘 中去掉
• 然后搜索算法回退下一个还有未扩展后继节 点的上层节点继续扩展
• 描述:设每个状态为(a1, a2, a3, …, an), ai=1, 2, 3—表示第i个盘子在第1/2/3根柱 子上
13
第2章 搜索技术
河内塔(2)
• 递归定义:{(a1, a2, a3, …, an)}为n阶河内 塔的状态集合,则{(a1, a2, a3, …, an, 1), (a1, a2, a3, …, an, 2), (a1, a2, a3, …, an, 3)} 是n+1阶河内塔的状态集合
• 约束规则:不使离开既定位置的数字数增加
10
第2章 搜索技术
八数码游戏的搜索树
既定位置=终态
Begin 1 5 2
4
3
678
152 43
678
*1
2
453
678
*1 5 2 43 678
152
473
6
8
*
12 453 678
12 453 678
*
15 432 678
152 438 67
*1 2 3 45 678
8
第2章 搜索技术
2.1.2 问题实例
• 玩具问题
• 八数码游戏(九宫图) • 河内塔 • 八皇后问题 • 真空吸尘器世界
• 现实问题
人工智能搜索技术

启发式搜索可以通过指导搜索向最有希望的方向前进,降低复杂性。通过删除某些状态及其延伸,启发 式搜索可以消除组合爆炸,并得到令人能接受的解(通常不一定是最佳解)。
4.4.2 估价函数
4.4.3 启发式搜索算法A
启发式搜索算法A,一般简称A算法,是一种典型的启发式搜索算法。其基本思想是:定义一个评价函 数,对当前的搜索状态进行评估,找出一个最有希望的节点来扩展。
4.3.1 宽度优先搜索
图4.5 搜索树(一)
人工智能导论
4.3.2 深度优先搜索
/// 12 ///
图4.6 搜索树(二)
人工智能导论
/// 13 ///
4.4 启发式搜索
启发式搜索(Heuristically Search)又称有信息搜索(Informed Search),利用问题拥有的启发信息 来引导搜索,达到缩小搜索范围、降低问题复杂度的目的。
4.5.3 α-β剪枝技术
首先分析极小极大分析法的效率:上述极小极大分析法,实际是先生成一棵博弈树,然后计算其倒推 值,致使极小极大分析法效率较低。于是在极小极大分析法的基础上提出了α-β剪枝技术。
人工智能导论
/// 17 ///
本章小结
搜索技术在人工智能中起着重要作用,人工智能的推理机制就是通过搜索实现的,很多问题也可 以转化为状况空间的搜索问题。深度优先搜索和宽度优先搜索是常用的盲目搜索方法,具有通用性好的 特点,但往往效率低下,不适合求解复杂问题。启发式搜索利用问题相关的启发信息,可以缩小搜索范 围,提高搜索效率。A*算法是一种典型的启发式搜索算法,可以通过定义启发函数提高搜索效率,并可 以在问题有解的情况下找到问题的最优解。计算机博弈(计算机下棋)也是典型的搜索问题,计算机通 过搜索寻找最好的下棋走法。像象棋、围棋这样的棋类游戏具有非常多的状态,不可能通过穷举的办法 达到战胜人类棋手的水平,算法在其中起着重要作用。
线搜索及牛顿算法

1
上一次讲课内容
z 必要性最优性条件(确认候选者)
幻灯片 1
x * 是局部最小点 ⇒ ∇f ( x*) = 0, ∇ 2 f ( x*) 半正定
z 最优型的充分条件
∇f(x*) = 0, ∇ 2 f(x) ' 半正定 ,x ∈ Bε (x*) ⇒ x* 局部极小点
z 凸性的特点
a.f 凸 ⇔ f(y) ≥ f(x) + ∇f(x) ' (y − x) ∀x,y b.f 凸 ⇔ ∇ 2 f(x)是 半正定的 ∀x
xk
0.01 0.0193 0.03599 0.062917 0.098124 0.128849782 0.141483700 0.142843938 0.142857142
xk
0.1 0.13 0.1417 0.14284777 0.142857142 0.142857143 0.142857143 0.142857143 0.142867143 幻灯片 22
k x2
x − x*
0.58925565 0.45083106 0.23848325 0.06306103 0.00874717 7.4133E-05 1.1953E-08 1.5701E-16
0.05 0.09659864 0.17647971 0.27324878 0.32623807 0.33325933 0.33333333 0.33333333
3 2
若牛顿算法的初始点接近 x * ,则迭代序列二次收敛到 x * 引理: 设 f ( x) ∈ C ,在 Rn 上,使 x 给定的
3
幻灯片 26
则 7.2
∀ε > 0, ∃β > 0 : x − y ≤ ε ⇒ ∇f ( x) − ∇f ( y ) − H ( y )( x − y ) ≤ β x − y
最优化 马昌凤 第二章作业

最优化方法及其Matlab程序设计习题作业暨实验报告学院:数学与信息科学学院班级:12级信计一班姓名:李明学号:1201214049第二章 线搜索技术一、上机问题与求解过程 1、用0.618法求解 .1)(min 2--=x x x f 初始区间]1,1[-,区间精度为50.=0δ. 解:当初始时不限制近似迭代函数值得大小,编写程序运行结果为:从结果可以看出迭代次数为9次,极小点为5016.0,极小点的函数值为2500.1-。
根据人工手算,极小值点应该为500.0,所以在设计程序的时候添加函数值误差范围,并取范围为10101-⨯。
编写的设计函数程序并调试改正如下:function [s,fs,k,G,FX,E]=gold(f,a,b,H,F) %输入:% f:目标函数,a :搜索区间左侧端点;b:搜索区间右侧端点; % H :搜索区间允许范围;F :搜索区间函数值允许范围; %输出:% s:近似极小值点:fa :近似极小点数值;k:迭代次数:% FX :近似迭代函数值;E=[h,fh],h 为近似区间误差,fh 为函数值误差 t=(sqrt(5)-1)/2;h=b-a; p=a+(1-t)*h;q=a+t*h;fa=feval(f,a);fb=feval(f,b); fp=feval(f,p);fq=feval(f,q); k=1;G(k,:)=[a,p,q,b];%初始时错误语句:G(1,:)=[a,p,q,b]; %初始调试的时候没有注意到后面需要开辟k 行空间 FX(k,:)=[fa,fp,fq,fb];while (abs(fa-fb)>F) ((b-a)>H) if (fp<fq)b=q;fb=fq;q=p;fq=fp;h=b-a;p=a+(1-t)*h;fp=feval(f,p); %初始时错误语句:b=q;fb=fq;h=b-a;q=a+t*h;fq=feval(f,q); %初始调试的时候对0.618方法没有充分理解所以出现错误 elsea=p;fa=fp;p=q;fp=fq;h=b-a;q=a+t*h;fq=feval(f,q);%初始时错误语句:a=p;fa=fp;h=b-a;p=a+(1-t)*h;fp=feval(f,p); %初始调试的时候对0.618方法没有充分理解所以出现错误 end极小点(s) 迭代次数搜索区间误差 函数值误差 0.501690.04260.0006k=k+1;G(k,:)=[a,p,q,b];%初始时错误语句:G(1,:)=[a,p,q,b]; %初始调试的时候没有注意到前面已经开辟k 行空间 FX(k,:)=[fa,fp,fq,fb]; end if (fp<fq) s=p;fs=fp; elses=q;fs=fq; endh=b-a;fh=abs(fb-fa);%选取试探点最小的数值为近似点,并且计算出以上为搜索区间的的最后误差以及函数值误差 E=[h,fh];在命令窗口内输入如下命令:[s,fs,k,G,FX,E]=gold(inline('s^2-s-1'),-1,1,0.05,1e-10) 回车之后得到如下数据结果:附:在窗口中输出的结果如下>> [s,fs,k,G,FX,E]=gold(inline('s^2-s-1'),-1,1,0.05,1e-10) s = 0.5000 fs = -1.2500 k = 24 G =-1.0000 -0.2361 0.2361 1.0000 -0.2361 0.2361 0.5279 1.0000 0.2361 0.5279 0.7082 1.0000极小点 极小点数值 迭代次数 搜索区间误差 函数值误差 0.500-1.250024410321.0-⨯0000.00.2361 0.4164 0.5279 0.70820.4164 0.5279 0.5967 0.70820.4164 0.4853 0.5279 0.59670.4164 0.4590 0.4853 0.52790.4590 0.4853 0.5016 0.52790.4853 0.5016 0.5116 0.52790.4853 0.4953 0.5016 0.51160.4953 0.5016 0.5054 0.51160.4953 0.4992 0.5016 0.50540.4953 0.4977 0.4992 0.50160.4977 0.4992 0.5001 0.50160.4992 0.5001 0.5006 0.50160.4992 0.4997 0.5001 0.50060.4997 0.5001 0.5003 0.50060.4997 0.5000 0.5001 0.50030.4997 0.4999 0.5000 0.50010.4999 0.5000 0.5000 0.50010.5000 0.5000 0.5000 0.50010.5000 0.5000 0.5000 0.50000.5000 0.5000 0.5000 0.50000.5000 0.5000 0.5000 0.5000 FX =1.0000 -0.7082 -1.1803 -1.0000 -0.7082 -1.1803 -1.2492 -1.0000 -1.1803 -1.2492 -1.2067 -1.0000 -1.1803 -1.2430 -1.2492 -1.2067 -1.2430 -1.2492 -1.2406 -1.2067 -1.2430 -1.2498 -1.2492 -1.2406 -1.2430 -1.2483 -1.2498 -1.2492 -1.2483 -1.2498 -1.2500 -1.2492 -1.2498 -1.2500 -1.2499 -1.2492 -1.2498 -1.2500 -1.2500 -1.2499 -1.2500 -1.2500 -1.2500 -1.2499 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.2500 -1.25001.0e-04*0.3121 0.00002、用0.618法求解.12)(min 3+-=x x x f的近似最优解,初始搜索区间为]3,0[,区间精度为50.=1δ. 解:当初始时不限制近似迭代函数值得大小,编写程序运行结果为:从结果可以看出迭代次数为8次,极小点为8115.0,极小点的函数值为0886.0-。
第二章--直线搜索

第二章 直线搜索直线搜索就是求一维函数的极值。
1.搜索区间定义1:设)(t ϕ是定义在1R 中区域L 上的实值函数,*t 是)(t ϕ在L 上的全局极小点。
如果对于L 上任取的两点1t ,2t 且21t t <,都有:当*2t t ≤时,)()(21t t ϕϕ>;当*1t t ≥时,)()(21t t ϕϕ< 那么称)(t ϕ是定义在区域L 上的单谷函数。
定义2: 设)(t ϕ是定义在1R 中区域L 上的实值函数,*t 是)(t ϕ在L 上的全局极小点,如果找到L t ∈1和L t ∈2,使得2*1t t t <<,那么此闭区间[]21,t t 称为)(t ϕ极小点的一个搜索区间,记为{}21,t t 。
性质:设{}b a ,是单谷函数)(t ϕ极小点的一个搜索区间。
在{}b a ,上任取两点1t 和2t 且21t t <。
若)()(21t t ϕϕ<,则{}2,t a 是)(t ϕ极小点的一个搜索区间。
若)()(21t t ϕϕ>,则{}b t ,1是)(t ϕ极小点的一个搜索区间。
2. 确定搜索区间的算法 已知: 目标函数)(t ϕ。
1)选定初始点0t 和步长h 。
2)计算并比较)(0t ϕ和)(0h t +ϕ ①)(0t ϕ<)(0h t +ϕ此时可断定h t +0位于极小点的右侧,故应朝自变量值减小的方向计算。
计算m k h t k ,...,2,1),)12((0=--ϕ,直到某一个m ,使得:))12(())12(())12((10010h t h t h t m m m --≤-->--+-ϕϕϕ因此搜索区间是[]h t h t m m )12(,)12(1010----+- ②)()(00h t t +≥ϕϕ此时可断定0t 位于极小点的左侧,计算h t -0已无意义,故应朝自变量值增大的方向计算。
计算m k h t k ,...,2,1),)12((0=-+ϕ,直到某一个m ,使得:))12(())12(())12((10010h t h t h t m m m -+<-+≥-++-ϕϕϕ因此搜索区间是[]h t h t m m )12(,)12(1010-+-++- 3.初始搜索步长的选定假定目标函数是)(t ϕ,初始点是0t 。
带线搜索的信赖域方法

带线搜索的信赖域方法什么是线搜素的信赖域方法?线搜索的信赖域(LRD)是一种算法,用于从带有阻力的现有连接中搜索解决方案的方法。
它的基本思想是从一系列系统或网络中搜索目标解决方案,考虑在每个阶段向先前信任域中添加一位新成员,直至找到目标解决方案。
按照这种方式,它通过网络分析系统检测阻塞障碍,并识别有前景的线索来提高搜索解决方案的效率。
LRD方法的优点1. 提高搜索效能:LRD方法通过分析网络结构和障碍力,有效地帮助搜索解决方案,以提高搜索效能。
2. 节省时间:LRD方法将目标解决方案的搜索时间缩短到最小,因此,它大大提高了搜索效率。
3. 增强网络安全:LRD方法有助于检测和屏蔽网络中的攻击,从而增强网络的安全性。
4. 信息完整性:LRD方法可以帮助确保网络中的信息完整性,从而防止网络中的恶意行为。
LRD方法的应用1. 网络安全:LRD方法用于安全检查,可以快速识别在网络中可能出现的恶意行为,以及有效地确定恶意行为的来源和目标。
2. 网络管理:LRD方法可以用于进行网络管理,即可以有效地进行路由规划、网络资源发现、服务授权、网络优化等。
3. 业务建模:LRD方法可以应用于业务建模和分析,即可以发现有用的关系和依赖,有助于管理者实施有效的解决方案。
4. 数据分析:LRD方法也可以应用于数据分析,以有效地从大量数据中提取有用的信息,以便实现良好的决策。
总结线搜索的信任域方法是一种有效的搜索解决方案的算法,用于从带有阻力的现有连接中搜索解决方案。
它的优点是可以提高搜索效能,节省时间,增强网络安全,保证信息完整性等。
LRD方法可以用于网络安全,网络管理,业务建模,数据分析等多种应用中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
f ( xk kdk ) f ( xk )
这样,搜索式(2.1)等价于求步长k使得
(k ) (0)
线搜索有精确线搜索和非精确线搜索之分, dk kk 所谓精确线搜索,是指求 使目标函数f (x)沿方向dk 达 到极小,即 0 f ( xk kdk ) min f ( xk dk ) 或
(k ) min ( )
) 若 f (x是连续可微的,那么由精确线搜索得到的步长因子 具有如下性质: T f ( xk akdk )T dk 0 亦即 g k 1dk 0 (2.3) 上述性质在后面的算法收敛分析中起着很重要的作用。
所谓非精确线搜索,是指选取 k 使目标函数f (x)得到 可接受的下降量,即 fk f ( xk ) f ( xk kdk ) 0 是可 接受的。 定义13 设 是定义在实数集上的一元函数, * [0,) 并且 ( *) min ( ) . 若存在区间[a,b] [0,)使 * (a, b) ,则称[a,b]是极小 化问题(2.4)的搜索区间。进一步,若 *使得 ( )在 [a, *] 上严格递减,在[ *, b上严格递增,则称[a,b]是 ( )的 ] 单峰区间,( )是[a,b]上的单峰函数。 下面介绍一种确定搜索区间并保证具有近似单峰 性质的数值算法—进退法 算法2(进退法)
计算 ( qi 1) ,i=i+1,转步1.
f (x) 程序1 (0.618 法程序) 用0.618 法求单变量函数������ 在单
• • • • • • • • • •
峰区间[a,b]上的近似极小点. function [s,phis,k,G,E]=golds(phi,a,b,delta,epsilon) %输入: phi是目标函数, a, b 是搜索区间的两个端点 % delta, epsilon分别是自变量和函数值的容许误差 %输出: s, phis分别是近似极小点和极小值, G是nx4矩阵, % 其第k行分别是a,p,q,b的第k次迭代值[ak,pk,qk,bk], % E=[ds,dphi], 分别是s和phis的误差限. t=(sqrt(5)-1)/2; h=b-a; phia=feval(phi,a); phib=feval(phi,b); p=a+(1-t)*h; q=a+t*h; phip=feval(phi,p); phiq=feval(phi,q);
步3 若 s1 s,则 s 2 s1, s1 s, 2 1, 1 转步1,否则, s 0 s1, s1 s, 0 1, 1 转步1. s 步4 若s1 s ,则s 2 s, 2 ,转步1,否则, 0 s, 0 ,转步1.
• • • • • • • • • • • •
k=1; G(k,:)=[a, p, q, b]; while(abs(phib-phia).epsilon)—(h.delta) if(phip.phiq) b=q; phib=phiq; q=p; phiq=phip; h=b-a; p=a+(1-t)*h; phip=feval(phi,p); else a=p; phia=phip; p=q; phip=phiq; h=b-a; q=a+t*h; phiq=feval(phi,q); end k=k+1; G(k,:)=[a, p, q, b]; end ds=abs(b-a); dphi=abs(phib-phia);
qi 1 pi, pi 1 ai 0.382(bi 1 ai 1)
计计算右试探点,若| bi pi | 停算,输出 qi 否 则,令
ai 1 pi, bi 1 bi, ( pi 1) (qi ) pi 1 qi, qi 1 ai 1 0.618(bi 1 ai 1)
• • • • • •
if(phip.=phiq) s=p; phis=phip; else s=q; phis=phiq; end E=[ds,dphi];
2.抛物线法
抛物线法也叫做二次插值法,其基本思想是:在搜索区 间中不断地使用二次多项式去近似目标函数,并逐步 用差值多项式的极小点去逼近先搜索问题s>0,
min ( s) f ( xk sdk )
的极小点. 算法4 (抛物线法) 步0 由算法2确定三点 s0 s1 s 2 对应的函数值分别 为 0, 1, 2 满足 1 0, 1 2 设定容许误差ε>0. s 步1 若 2 s0 ,停算,输出 s* s1 . (3 0 4 1 2)h s s0 s 0 h 计算 s 步2 计算插值点,根据 2( 0 2 1 2) 和, (s) 若 1 转步4,否则,转步3.
• while (k<maxk & err>epsilon &cond˜=5) • f1=(feval(phi,s0+ds)-feval(phi,s0-ds))/(2*ds); • if(f1>0), h=-abs(h); end • s1=s0+h; s2=s0+2*h; bars=s0; • phi0=feval(phi,s0); phi1=feval(phi,s1); • phi2=feval(phi,s2); barphi=phi0; cond=0; • j=0; %确定h使得phi1.phi0且phi1.phi2 • while(j.maxj&abs(h).delta&cond==0) • if (phi0=<phi1), • s2=s1; phi2=phi1; h=0.5*h; • s1=s0+h; phi1=feval(phi,s1); • else if (phi2<phi1), • s1=s2; phi1=phi2; h=2*h; • s2=s0+2*h; phi2=feval(phi,s2);
第二章 线搜索技术
• • • • 前章知识回顾与本章知识提要 2.1精确线搜索及其Matlab实现 2.2非精确线搜索及其Matlab实现 2.3线搜索法的收敛性
前章知识回顾
1.无约束优化问题: 对于函数hi(x), gj(x),若集合E={i: hi(x)=0}与 I={i: gj(x)≥0}构成的指标集E∪I为空集,则称之为 无约束优化问题。 2.凸函数: 设函数f:D包含于Rn→R,其中D为凸集。 称f是D上的凸函数,是指对任意的x,y∈D及任意的实 数λ ∈[0,1],都有 f(λ x+(1-λ )y)≤λ f(x)+(1-λ )f(y). 当等号不成立时f是严格的凸函数。
步1 选取 0 0, h0 0 计算 0 ( 0) 置k=0. 步2 令k 1 k hk 计算k 1 (k 1)若k 1 k 转 , 步3 否则转步4. 步3 加大步长,令
hk 1 2hk , k , k k 1, k k 1, k k 1
ai t (qi ai ) ai t 2 (ai bi )
若令 t 2 1 t ,t>0 (2.6) qi 1 ai (1 t )(bi ai ) pi 则 5 -1 解方程(2.6)得区间长度缩短率为t= ≈0.618
2
算法3 (0.618法) 步0 确定搜索区间[a 0, b0] 和容许误差ε>0,计算初始试探点
(2)若 ( pi ) (qi ) 则令qai 1 pi , bi 1 bi ② pi, i 我们要求两个试探点 满足下面两个条件: (a) [ai , qi ] 和 [ pi , bi ] 的长度相同,即 bi pi qi ai ③ (b)区间长度的缩短率相同,即 bi 1 ai 1 t (bi ai ) ④ 从而可得 pi ai (1 t )(bi ai ) qi ai t (bi ai ) (2.5) 先考虑情形(1),此时,新的搜索区间为[ai 1, bi 1] [ai, qi ] 为了进一步缩短搜索区间,需取新的试探点 pi 1, qi 1 由 qi 1 ai 1 t (bi 1 ai 1) (2.5)得
p0 a0 0.382(b0 a0) q0 a0 0.618(b0 a0)
及相应的函数值 ( p 0), (q 0) 置i=0. 步1 若 ( pi ) (qi ) 转步2,否则,转步3. 步2 计算左试探点,若| qi ai | 停算,输出 pi ,否则,令 ai 1 ai, bi 1 qi, (qi 1) ( pi )
转步2. 步4 反向搜索或输出,若k=0,令 h1 h0, 1, 1 0, 1 0 k=1,转步2,否则停止迭代,令
a min{ , k 1}, b max{ , k 1}
输出[a,b].
2.1精确线搜索及其Matlab实现
• 精确线搜索分为两类,一类是使用导数的搜索, 如插值法,牛顿法,及抛物线法等;另一类是不用导 数的搜索,如0.618法,分数法及成功-失败法等,这 里仅介绍0.618法和二次插值法。 1.黄金分割法 • 设 ( s) f ( xk sdk )其中 (s是搜索区间 [a 0, b0] 上 ) 的单峰函数,在第i次迭代时的搜索区间为 [ai , bi ] ,取两 个试探点 pi , qi [ai, bi ] 且pi qi,计算 ( pi ), ( qi ),根 据单峰函数的性质,可能会出现如下两种情形之一 (1)若 ( pi ) (qi ) 则令 ai 1 ai , bi 1 qi ① ( pi ) (qi )
(s ) [ a , s 0 ] [ s 0, b ]