编译原理 - 自下而上的语法分析
【编译原理】语法分析LL(1)分析法的FIRST和FOLLOW集

【编译原理】语法分析LL(1)分析法的FIRST和FOLLOW集 近来复习编译原理,语法分析中的⾃上⽽下LL(1)分析法,需要构造求出⼀个⽂法的FIRST和FOLLOW集,然后构造分析表,利⽤分析表+⼀个栈来做⾃上⽽下的语法分析(递归下降/预测分析),可是这个FIRST集合FOLLOW集看得我头⼤。
教课书上的规则如下,⽤我理解的语⾔描述的:任意符号α的FIRST集求法:1. α为终结符,则把它⾃⾝加⼊FIRSRT(α)2. α为⾮终结符,则:(1)若存在产⽣式α->a...,则把a加⼊FIRST(α),其中a可以为ε(2)若存在⼀串⾮终结符Y1,Y2, ..., Yk-1,且它们的FIRST集都含空串,且有产⽣式α->Y1Y2...Yk...,那么把FIRST(Yk)-{ε}加⼊FIRST(α)。
如果k-1抵达产⽣式末尾,那么把ε加⼊FIRST(α) 注意(2)要连续进⾏,通俗地描述就是:沿途的Yi都能推出空串,则把这⼀路遇到的Yi的FIRST集都加进来,直到遇到第⼀个不能推出空串的Yk为⽌。
重复1,2步骤直⾄每个FIRST集都不再增⼤为⽌。
任意⾮终结符A的FOLLOW集求法:1. A为开始符号,则把#加⼊FOLLOW(A)2. 对于产⽣式A-->αBβ: (1)把FIRST(β)-{ε}加到FOLLOW(B) (2)若β为ε或者ε属于FIRST(β),则把FOLLOW(A)加到FOLLOW(B)重复1,2步骤直⾄每个FOLLOW集都不再增⼤为⽌。
⽼师和同学能很敏锐地求出来,⽽我只能按照规则,像程序⼀样⼀条条执⾏。
于是我把这个过程写成了程序,如下:数据元素的定义:1const int MAX_N = 20;//产⽣式体的最⼤长度2const char nullStr = '$';//空串的字⾯值3 typedef int Type;//符号类型45const Type NON = -1;//⾮法类型6const Type T = 0;//终结符7const Type N = 1;//⾮终结符8const Type NUL = 2;//空串910struct Production//产⽣式11 {12char head;13char* body;14 Production(){}15 Production(char h, char b[]){16 head = h;17 body = (char*)malloc(strlen(b)*sizeof(char));18 strcpy(body, b);19 }20bool operator<(const Production& p)const{//内部const则外部也为const21if(head == p.head) return body[0] < p.body[0];//注意此处只适⽤于LL(1)⽂法,即同⼀VN各候选的⾸符不能有相同的,否则这⾥的⼩于符号还要向前多看⼏个字符,就不是LL(1)⽂法了22return head < p.head;23 }24void print() const{//要加const25 printf("%c -- > %s\n", head, body);26 }27 };2829//以下⼏个集合可以再封装为⼀个⼤结构体--⽂法30set<Production> P;//产⽣式集31set<char> VN, VT;//⾮终结符号集,终结符号集32char S;//开始符号33 map<char, set<char> > FIRST;//FIRST集34 map<char, set<char> > FOLLOW;//FOLLOW集3536set<char>::iterator first;//全局共享的迭代器,其实觉得应该⽤局部变量37set<char>::iterator follow;38set<char>::iterator vn;39set<char>::iterator vt;40set<Production>::iterator p;4142 Type get_type(char alpha){//判读符号类型43if(alpha == '$') return NUL;//空串44else if(VT.find(alpha) != VT.end()) return T;//终结符45else if(VN.find(alpha) != VN.end()) return N;//⾮终结符46else return NON;//⾮法字符47 }主函数的流程很简单,从⽂件读⼊指定格式的⽂法,然后依次求⽂法的FIRST集、FOLLOW集1int main()2 {3 FREAD("grammar2.txt");//从⽂件读取⽂法4int numN = 0;5int numT = 0;6char c = '';7 S = getchar();//开始符号8 printf("%c", S);9 VN.insert(S);10 numN++;11while((c=getchar()) != '\n'){//读⼊⾮终结符12 printf("%c", c);13 VN.insert(c);14 numN++;15 }16 pn();17while((c=getchar()) != '\n'){//读⼊终结符18 printf("%c", c);19 VT.insert(c);20 numT++;21 }22 pn();23 REP(numN){//读⼊产⽣式24 c = getchar();25int n; RINT(n);26while(n--){27char body[MAX_N];28 scanf("%s", body);29 printf("%c --> %s\n", c, body);30 P.insert(Production(c, body));31 }32 getchar();33 }3435 get_first();//⽣成FIRST集36for(vn = VN.begin(); vn != VN.end(); vn++){//打印⾮终结符的FIRST集37 printf("FIRST(%c) = { ", *vn);38for(first = FIRST[*vn].begin(); first != FIRST[*vn].end(); first++){39 printf("%c, ", *first);40 }41 printf("}\n");42 }4344 get_follow();//⽣成⾮终结符的FOLLOW集45for(vn = VN.begin(); vn != VN.end(); vn++){//打印⾮终结符的FOLLOW集46 printf("FOLLOW(%c) = { ", *vn);47for(follow = FOLLOW[*vn].begin(); follow != FOLLOW[*vn].end(); follow++){48 printf("%c, ", *follow);49 }50 printf("}\n");51 }52return0;53 }主函数其中⽂法⽂件的数据格式为(按照平时做题的输⼊格式设计的):第⼀⾏:所有⾮终结符,⽆空格,第⼀个为开始符号;第⼆⾏:所有终结符,⽆空格;剩余⾏:每⾏描述了⼀个⾮终结符的所有产⽣式,第⼀个字符为产⽣式头(⾮终结符),后跟⼀个整数位候选式的个数n,之后是n个以空格分隔的字符串为产⽣式体。
916073-编译原理原理与技术-第3章 语法分析
id
id
E E+E E E +E id E + E id id + E id id + id E
E +E
E
*
E id
id
id
3.2 语言和文法
• 文法的优点
–文法为语言给出了精确的、易于理解的语法规范 –自动产生高效的分析器 –可以给语言定义出层次结构 –以文法为基础的语言的实现便于语言的修改
FIRST(E) = FIRST(T) = FIRST(F) = { ( , id } FIRST(E ) = {+, } FRIST(T ) = {, } FOLLOW(E) = FOLLOW(E ) = { ), $} FOLLOW(T) = FOLLOW (T ) = {+, ), $} FOLLOW(F) = {+, , ), $}
id
+ term
term * factor
factor
id
id id + id id 分析树
3.2 语言和文法
3.2.5 消除二义性 stmt if expr then stmt
| if expr then stmt else stmt | other • 句型:if expr then if expr then stmt else stmt • 两个最左推导: stmt if expr then stmt if expr then if expr then stmt else stmt stmt if expr then stmt else stmt if expr then if expr then stmt else stmt
3.3 自上而下分析
编译原理课程设计之第三章上下文无关文法及分析

14
无关文法及分析
1. 上下文无关文法(即2型文法)的形式定义:
上下文无关文法是一个四元组(VT , VN , P , S):
① ②
终非结终符 结集 符合 集合VTVN(与VT产的不生左相式部交)
产生式 的右部
③ 产生式或文法规则A→α形成的集合P,
其中A∈VN,α∈(VT∪VN)* 4) 开始符号S,其中S∈VN
25
无关文法及分析
3.2 上下文无关文法的形式定义
1. 上下文无关文法(即2型文法)的形式定义 2. chomsky文法的分类 3. 推导和规约的定义 4. 句型和句子的定义 5. 最左和最右推导 6. 文法定义的语言 7. 递归产生式和递归文法 8. 文法和语言
mcy
编译原理课程设计之第三章上下文
mcy
编译原理课程设计之第三章上下文
1
无关文法及分析
第三章 上下文无关文法及分析
本章的目的是为语言的语法 描述寻求形式工具,要求该 工具对程序设计语言给出精 确无二义的语法描述。
mcy
编译原理课程设计之第三章上下文
2
无关文法及分析
第三章 上下文无关文法及分析
✓3.1 语法分析过程 ▪ 3.2 上下文无关文法的形式定义
下面的2型文法描述了包含加法、减法和乘法的简 单整型算术表达式的语法结构。
文法G[exp]:
exp → exp op exp exp →(exp) exp → number
34-3 是符合该 语法结构的简单 整型算术表达式 (句子)吗?
op → + | - | *
mcy
编译原理课程设计之第三章上下文
令G是一个如上所定义的文法,则G=(VT,VN,P,S)
编译原理_课件_第三章_语法分析1

3.2 推导和语法树
推导、规范推导 短语、句柄、素短语 语法树 文法的二义性
30
【例】设有文法G[N]: N →D|ND
D→0|1|2|3|4|5|6|7|8|9 则句子 12可由三种不同的推导序列推导出来:
(1) N ? ND ? N2 ? D2 ? 12 (2) N ? ND ? DD ? 1D ? 12 (3) N ? ND ? DD ? D2 ? 12
u∈V* ;且 V=VN∪VT。
U称为规则(产生式)左部 ,u称为规则(产生式) 右部。 ? 非终结符号 :需要进一步定义的符号,不会出现在 程序中。 ? 终结符号 :不需要再定义,会出现在程序中。
10
注意:
1、VN∩VT=? ,即文法中的任意一个符号要么是非 终结符,要么是终结符。
2、只用一个产生式并不足以定义一个语法范畴, 一般都需要几个产生式,特别是需要含有 递归的 产生式。
6
3.1.1 文法概述
引例1:
<句子>::=<主语><谓语><状语> <主语>::=<名词> <谓语>::=<动词> <状语>::=<介词><名词> <名词>::=Peter | Berry | river <动词>::=swims <介词>::=in 注:<句子>为要定义的目标,称为识别符号或开始符号。
? 形式语言,只是从语法上研究语言。它是抽象的数学系统, 用于模拟程序设计语言的语法,或者是并不很成功地模拟 自然语言如英语的语法。
? 形式语言理论是编译理论的重要基础,它主要研究组成符 号语言的符号串的集合及它们的表示法、结构与特性。
编译原理语法分析(1)

例如, 考虑句子 i+i*i 按文法G[E]的推导 最左推导: EE+Ei+Ei+E*E i+i*E i+i*i 最右推导: EE+EE+E*EE+E*i E+i*ii+i*i 注意: 推导过程不唯一, 通常只考虑最左 推导或最右推导。 最右推导又称为规范推导。 规范推导的逆过程称为规范归约。
+ 。 * 意味着或 = , 或 即1 n 1 n 1 n
例如,考虑算术表达式文法G[E]: E→E+E∣E*E∣(E)│i 非终结符E代表一类算术表达式, 从E出发可进行一系列推导, 表达式 i+i*i 的推导如下: E E+E E+E*E E+E*i E+i*i i+i*I 注意: 在每一步推 导中,只能对其中一个 非终结符用其对应的产生式右部的 一个候选式来替换。
文法可表示为 VN为非空非终结符集,且VT∩VN=Φ; (3) S为文法开始符, S∈VN; (4)ξ是产生式的非空有限集, 其中每个 产生式(规则)记作 → 或 ::= 左部∈(VT∪VN)+至少含一非终结符, 右部∈(VT∪VN)*。
B
3.1.3 正规式与上下文无关文法 1. 正规式到上下文无关文法的转换 由正规式构造CFG的一种方法: (1)构造正规式的NFA; (2)若0为初始状态, 则A0为开始符; (3)若存在映射关系f(i,a)=j, 则定义产生式Ai →aAj; (4)若存在映射关系f(i,ε)=j, 则定义产生式Ai →Aj; (5) 若i为终态, 则定义产生式Ai →ε。
产生式 (也称产生式规则或规则) 是 定义语法实体的一种书写规则。一个语 法实体的相关规则可能不止一个, 如: P→1, P→2 , P→n 相同左部的产生式可合并为一个: P→ 1| 2|„| n 其中, i(i=1,2,„,n)称为P的候选式。
编译原理实验三-自下而上语法分析及语义分析.docx

电力学院编译原理课程实验报告实验名称:实验三自下而上语法分析及语义分析院系:计算机科学与技术学院专业年级:学生:学号:指导老师:实验日期:实验三自上而下的语法分析一、实验目的:通过本实验掌握LR分析器的构造过程,并根据语法制导翻译,掌握属性文法的自下而上计算的过程。
二、实验学时:4学时。
三、实验容根据给出的简单表达式的语法构成规则(见五),编制LR分析程序,要求能对用给定的语法规则书写的源程序进行语法分析和语义分析。
对于正确的表达式,给出表达式的值。
对于错误的表达式,给出出错位置。
四、实验方法采用LR分析法。
首先给出S-属性文法的定义(为简便起见,每个文法符号只设置一个综合属性,即该文法符号所代表的表达式的值。
属性文法的定义可参照书137页表6.1),并将其改造成用LR分析实现时的语义分析动作(可参照书145页表6.5)。
接下来给出LR分析表。
然后程序的具体实现:● LR分析表可用二维数组(或其他)实现。
●添加一个val栈作为语义分析实现的工具。
编写总控程序,实现语法分析和语义分析的过程。
注:对于整数的识别可以借助实验1。
五、文法定义简单的表达式文法如下:(1)E->E+T(2)E->E-T(3)E->T(4)T->T*F(5)T->T/F(6)T->F(7)F->(E)(8)F->i五、处理程序例和处理结果例示例1:20133191*(20133191+3191)+ 3191#六、源代码【cifa.h】//cifa.h#include<string>using namespace std;//单词结构定义struct WordType{int code;string pro;};//函数声明WordType get_w();void getch();void getBC();bool isLetter();bool isDigit();void retract();int Reserve(string str);string concat(string str);【Table.action.h】//table_action.hclass Table_action{int row_num,line_num;int lineName[8];string tableData[16][8];public:Table_action(){row_num=16;line_num=8;lineName[0]=30;lineName[1]=7;lineName[2]=13;lineName[3]=8;lineName[4]=14;lineName[5]=1;lineName[6]=2;lineName[7]=15;lineName[8]=0;for(int m=0;m<row_num;m++)for(int n=0;n<line_num;n++)tableData[m][n]="";tableData[0][0]="S5";tableData[0][5]="S4";tableData[1][1]="S6";tableData[1][2]="S12";tableData[1][7]="acc";tableData[2][1]="R3";tableData[2][2]="R3";tableData[2][3]="S7";tableData[2][4]="S13";tableData[2][6]="R3";tableData[2][7]="R3";tableData[3][1]="R6";tableData[3][3]="R6"; tableData[3][4]="R6"; tableData[3][6]="R6"; tableData[3][7]="R6"; tableData[4][0]="S5"; tableData[4][5]="S4"; tableData[5][1]="R8"; tableData[5][2]="R8"; tableData[5][3]="R8"; tableData[5][4]="R8"; tableData[5][6]="R8"; tableData[5][7]="R8"; tableData[6][0]="S5"; tableData[6][5]="S4"; tableData[7][0]="S5"; tableData[7][5]="S4"; tableData[8][1]="S6"; tableData[8][2]="S12"; tableData[8][6]="S11"; tableData[9][1]="R1"; tableData[9][2]="R1"; tableData[9][3]="S7"; tableData[9][4]="S13"; tableData[9][6]="R1"; tableData[9][7]="R1"; tableData[10][1]="R4"; tableData[10][2]="R4"; tableData[10][3]="R4"; tableData[10][4]="R4"; tableData[10][6]="R4"; tableData[10][7]="R4"; tableData[11][1]="R7"; tableData[11][2]="R7"; tableData[11][3]="R7"; tableData[11][4]="R7"; tableData[11][6]="R7"; tableData[11][7]="R7"; tableData[12][0]="S5"; tableData[12][5]="S4"; tableData[13][0]="S5"; tableData[13][5]="S4"; tableData[14][1]="R2"; tableData[14][2]="R2";tableData[14][4]="S13";tableData[14][6]="R2";tableData[14][7]="R2";tableData[15][1]="R5";tableData[15][2]="R5";tableData[15][3]="R5";tableData[15][4]="R5";tableData[15][5]="R5";tableData[15][6]="R5";tableData[15][7]="R5";}string getCell(int rowN,int lineN){int row=rowN;int line=getLineNumber(lineN);if(row>=0&&row<row_num&&line>=0&&line<=line_num) return tableData[row][line];elsereturn"";}int getLineNumber(int lineN){for(int i=0;i<line_num;i++)if(lineName[i]==lineN)return i;return -1;}};【Table_go.h】//table_go.hclass Table_go{int row_num,line_num;//行数、列数string lineName[3];int tableData[16][3];public:Table_go(){row_num=16;line_num=3;lineName[0]="E";lineName[1]="T";lineName[2]="F";for(int m=0;m<row_num;m++)for(int n=0;n<line_num;n++)tableData[m][n]=0;tableData[0][0]=1;tableData[0][1]=2;tableData[0][2]=3;tableData[4][0]=8;tableData[4][1]=2;tableData[4][2]=3;tableData[6][1]=9;tableData[6][2]=3;tableData[7][2]=10;tableData[12][1]=14;tableData[12][2]=3;tableData[13][2]=15;}int getCell(int rowN,string lineNa){int row=rowN;int line=getLineNumber(lineNa);if(row>=0&&row<row_num&&line<=line_num) return tableData[row][line];elsereturn -1;}int getLineNumber(string lineNa){for(int i=0;i<line_num;i++)if(lineName[i]==lineNa)return i;return -1;}};【Stack_num.h】class Stack_num{int i; //栈顶标记int *data; //栈结构public:Stack_num() //构造函数{data=new int[100];i=-1;}int push(int m) //进栈操作{i++;data[i]=m;return i;}int pop() //出栈操作{i--;return data[i+1];}int getTop() //返回栈顶{return data[i];}~Stack_num() //析构函数{delete []data;}int topNumber(){return i;}void outStack(){for(int m=0;m<=i;m++)cout<<data[m];}};【Stack_str.h】class Stack_str{int i; //栈顶标记string *data; //栈结构public:Stack_str() //构造函数{data=new string[50];i=-1;}int push(string m) //进栈操作{i++;data[i]=m;return i;}int pop() //出栈操作{data[i]="";i--;return i;}string getTop() //返回栈顶{return data[i];}~Stack_str() //析构函数{delete []data;}int topNumber(){return i;}void outStack(){for(int m=0;m<=i;m++)cout<<data[m];}};【cifa.cpp】//cifa.cpp#include<iostream>#include<string>#include"cifa.h"using namespace std;//关键字表和对应的编码string codestring[10]={"main","int","if","then","else","return","void","cout","endl"}; int codebook[10]={26,21,22,23,24,25,27,28,29};//全局变量char ch;int flag=0;/*//主函数int main(){WordType word;cout<<"请输入源程序序列:";word=get_w();while(word.pro!="#")//#为自己设置的结束标志{cout<<"("<<word.code<<","<<"“"<<word.pro<<"”"<<")"<<endl;word=get_w();};return 0;}*/WordType get_w(){string str="";int code;WordType wordtmp;getch();//读一个字符getBC();//去掉空白符if(isLetter()){ //以字母开头while(isLetter()||isDigit()){str=concat(str);getch();}retract();code=Reserve(str);if(code==-1){wordtmp.code=0;wordtmp.pro=str;}//不是关键字else{wordtmp.code=code;wordtmp.pro=str;}//是关键字}else if(isDigit()){ //以数字开头while(isDigit()){str=concat(str);getch();}retract();wordtmp.code=30;wordtmp.pro=str;}else if(ch=='(') {wordtmp.code=1;wordtmp.pro="(";}else if(ch==')') {wordtmp.code=2;wordtmp.pro=")";}else if(ch=='{') {wordtmp.code=3;wordtmp.pro="{";}else if(ch=='}') {wordtmp.code=4;wordtmp.pro="}";}else if(ch==';') {wordtmp.code=5;wordtmp.pro=";";}else if(ch=='=') {wordtmp.code=6;wordtmp.pro="=";}else if(ch=='+') {wordtmp.code=7;wordtmp.pro="+";}else if(ch=='*') {wordtmp.code=8;wordtmp.pro="*";}else if(ch=='>') {wordtmp.code=9;wordtmp.pro=">";}else if(ch=='<') {wordtmp.code=10;wordtmp.pro="<";}else if(ch==',') {wordtmp.code=11;wordtmp.pro=",";}else if(ch=='\'') {wordtmp.code=12;wordtmp.pro="\'";}else if(ch=='-') {wordtmp.code=13;wordtmp.pro="-";}else if(ch=='/') {wordtmp.code=14;wordtmp.pro="/";}else if(ch=='#') {wordtmp.code=15;wordtmp.pro="#";}else if(ch=='|') {wordtmp.code=16;wordtmp.pro="|";}else {wordtmp.code=100;wordtmp.pro=ch;} return wordtmp;}void getch(){if(flag==0) //没有回退的字符ch=getchar();else //有回退字符,用回退字符,并设置标志flag=0;}void getBC(){while(ch==' '||ch=='\t'||ch=='\n')ch=getchar();}bool isLetter(){if(ch>='a'&&ch<='z'||ch>='A'&&ch<='Z')return true;elsereturn false;}bool isDigit(){if(ch>='0'&&ch<='9')return true;elsereturn false;}string concat(string str){return str+ch;}void retract(){flag=1;}int Reserve(string str){int i;for(i=0;i<=8;i++){if(codestring[i]==str) //是某个关键字,返回对应的编码return codebook[i];}if(i==9) //不是关键字return -1;}【LR.cpp】#include<iostream>#include<string>#include<cstdlib>#include"cifa.h"#include"stack_num.h"#include"stack_str.h"#include"table_action.h"#include"table_go.h"using namespace std;void process(){int stepNum=1;int topStat;Stack_num statusSTK; //状态栈Stack_str symbolSTK; //符号栈Stack_num valueSTK; //值栈WordType word;Table_action actionTAB; //行为表Table_go goTAB; //转向表cout<<"请输入源程序,以#结束:";word=get_w();//总控程序初始化操作symbolSTK.push("#");statusSTK.push(0);valueSTK.push(0);cout<<"步骤\t状态栈\t符号栈\t值栈\t当前词\t动作\t转向"<<endl;//分析while(1){topStat=statusSTK.getTop(); //当前状态栈顶string act=actionTAB.getCell(topStat,word.code);//根据状态栈顶和当前单词查到的动作//输出cout<<stepNum++<<"\t";statusSTK.outStack(); cout<<"\t";symbolSTK.outStack(); cout<<"\t";valueSTK.outStack(); cout<<"\t";cout<<word.pro<<"\t";//行为为“acc”,且当前处理的单词为#,且状态栈里就两个状态//说明正常分析结束if(act=="acc"&&word.pro=="#"&&statusSTK.topNumber()==1){cout<<act<<endl;cout<<"分析成功!"<<endl;cout<<"结果为:"<<valueSTK.getTop()<<endl;return;}//读到act表里标记为错误的单元格else if(act==""){cout<<endl<<"不是文法的句子!"<<endl;cout<<"错误的位置为单词"<<word.pro<<"附近。
编译原理第6章_1

STACK REMAINING INPUT
1
(int + int)#
2(
int + int)#
3 (int
+ int)#
4 (T
+ int)#
5 (E
+ int)#
6 (E +
int)#
7 (E + int
)#
8 (E + T
)#
9 (E
)#
10 (E)
#
11 T
#
12 E
#
13 S
#
PARSER ACTION Shift Shift Reduce: T –> int Reduce: E –> T Shift Shift Reduce: T –> int Reduce: E –> E + T Shift Reduce: T –> (E) Reduce: E –> T Reduce: S –> E
的左部而得到的
文法要求
shift-reduce or reduce-reduce 冲突(conflicts)
分析程序不能决定是shift 还是 reduce 或者分析程序归约时有多个产生式可选
例子 (dangling else) : S –> if E then S | if E then S else S
LR分析算法
then begin pop || 项 令当前栈顶状态为S’ push GOTO[S’, A]和A(进栈)
end else if ACTION[s,a]=acc
then return (成功) else error end
编译原理 第五章 语法分析-自下而上分析

5.2.2 算符优先分析算法
• 素短语:
–是一个短语,它至少含有一个终结符,并且,除 它自身之外不再含任何更小的素短语。
• 最左素短语:
–最左边的素短语是最左素短语。
• 例子:
– 对文法(5.3)p*p和i是句型p*p+i的素短语,而p*p+i 本身也是素短语。
பைடு நூலகம்
• 算符优先文法:
算符优先文法,我们把句型(括在两个#之间) 的一般形式写成: #N1a1N2a2…NnanNn+1# 其中,每个ai都是终结符,Ni是可有可无的非终结 符。 文法G的任何短语是满足如下条件的最左子串 Njaj…NiaiNi+1 aj-1⋖ aj aj ≖ aj+1 , …,aj-1 ≖ ai ai ⋗ ai+1
– 对于每个终结符a(包括#)令其对应两个符号fa 和ga ,画一张以fa 和ga 所有符号为结点的方向图, 如 果 a⋗≖b, 那 么 , 就 从 fa 画 一 箭 弧 至 gb ; 如 果 a ⋖≖b,就画一条从gb到fa的箭弧。 – 对每个结点都赋予一个数,此数等于从该结点能 到达结点(包括出发结点自身在内)的个数。赋 给fa的数作为f(a),赋给gb的数作为g(b)。 –检查所构造出来的函数f和g,看它们 同原来的关 系表是否有矛盾。如果没有矛盾,则f和g就是所 要的优先函数。如果有矛盾,那么,就不存在优 先函数。
• 例子:假定文法G
S→aAcBe A→b A→Ab B→d 输入串abbcde归约到S过程。
图5.1 规约中符号栈的变迁
步骤 动作
1 进 a
2 进 b
3 归 (2)
4 进 b
5 归 (3)
6 进 c
7 进 d d
编译原理LL(K)

S =>aAbc =>ababc 错误回退 ,再回退S 错误回退A,再回退
重复以上匹配过程,发现此时符号串abeB与abed 前3个符号均匹配,下面指针指向第四个符号d。 而符号串abeB 的第四个符号是B,若选择 B→ d 则得到下面语法树: S =>aB =>abeB =>abed
圆括号( ③ 圆括号( ) 利用圆括号可提出一个非终结符的多个产生式右部 的公共因子。例如, A→xy|xw|…|xz 可写成 A→x(y|w|…|z)
利用下面的两条规则,可把包含直接左递归 的产生式转换成用扩展BNF表示法表示的产生 式。
① 提公因子 每当一条产生式中有公因子可提的时候,就把它 提出来,若原产生式是 A→x|xy 则可写成 A→x(y|ε) A→x(y|ε),这里把ε当作最后一个 候选式。 这样,把本来具有相同开始符号的候选式 变成了开始符号不同的候选式,从而避免了实现 分析过程中的逐个试探,并且有助于消除文法的 直接左递归,同时也压缩了文法的长度。
end; 消除Ui Ui产生式中的直接左递归 消除Ui产生式中的直接左递归 end; 化简改写之后的文法,删除多余产生式。 ③ 化简改写之后的文法,删除多余产生式。
确定的自顶向下语法分析
4.4
LL(k)文法 LL(k)文法
LL(k)文法是上下文无关文法的一个真子集。同时, LL(k)文法也是允许采用确定的从左至右扫描(输入 串)和自上而下分析技术的最大一类文法。 LL系指:自左至右扫描(输入串),自上而下进行最 左推导。 分析过程中,如果每步仅利用当前的非终结符(事 实上已经位于栈顶)和至多向前查看k个输入符号 就能唯一确定采取什么动作 唯一确定采取什么动作,则这个文法称为LL(k) 唯一确定采取什么动作 文法。 下面主要讨论k=0,1时的情形。
编译原理-语法分析

自顶向下的语法分析方法简单直观,易于实现,但可能存在 左递归和回溯的问题。
自底向上的语法分析
01
自底向上的语法分析方法从源代码中的每个符号出发
,逐步归约到文法的起始符号。
02
该方法通常采用LR(0)、SLR(1)、LALR(1)等算法进行
实现。
03
自底向上的语法分析方法可以避免回溯问题,但需要
• 随着人工智能和机器学习技术的不断发展,可以利用这些技术来辅助语法分析 过程,提高语法分析的准确性和效率。例如,可以使用机器学习算法来自动识 别和处理语法规则和歧义问题。
• 另外,随着软件工程和代码质量的重视程度不断提高,对编译器和语法分析器 的要求也越来越高。未来的研究需要更加注重编译器和语法分析器的可维护性 和可扩展性,以满足不断变化的软件需求。
词法分析的算法
自底向上算法
自底向上算法是从源代码的左向右进行扫描,并从下到上构建语法结构。常见 的自底向上算法有预测分析法和移进-规约法。
自顶向下算法
自顶向下算法是从语法结构的顶层开始,向下进行推导,直到找到与源代码相 匹配的语法结构。常见的自顶向下算法有规范分析法和贪婪分析法。
语法分析概述
语法分析是编译过程的核心环节,其任务是将源代码分解成一系列的语法 结构,以便后续的语义分析和代码生成。
自底向上的算法,通过构建归 约表进行移进和规约操作。
LALR(1)算法
扩展的LR(0)算法,能够处理 更广泛的文法,生成更小的归 约表。
03
语义分析
语义分析概述
01
Байду номын сангаас02
03
语义分析是编译过程的 一个阶段,它是在语法
分析之后进行的。
语义分析的主要任务是 检查源代码的语义是否 正确,例如变量是否已 经声明,类型是否匹配
编译原理 第5章

例:有文法G(S):
S→bAb A→( B | a B→Aa ) 解:文法符号优先关系推导如下: (1) 求=· 关系: 由S→bAb , A→( B, B→Aa ) b =· A, A =· b, (=· B , A =· a, a =· )
自底向上的语法分析
• 核心问题
– 寻找可归约串。对“可归约串”概念的不同定义, 就形成了不同的自底向上的分析方法。在算符优 先分析法中我们用“最左素短语”来刻画“可归 约串”,在“规范归约”中,则用“句柄”来刻 画“可归约串”
分析方法
• 输入串:
abbcde
S → a A c B e A → A b|b B → d
S
b
>·
=· <·
>·
A
(
=·
<· <· =·
=·
<·
B
a
>·
>·
>·
>· =· =·
)
#
寻找句柄
>·
<· <·
>·
简单优先文法的定义: (1)在文法符号集中,任意两个符号之间最多只有 一种优先关系; (2)在文法中任意两个产生式没有相同的右部。
语法树结构如下:
S S S b S b
b
A b
B
b
U S0…Sj-1SjSj+1Sj+2… …Si-1SiSi+1…Sn
算符优先分析
• 我们要通过两个相邻符号SiSi+1之间的关系来找到句 柄: – SiSi+1在句柄内:必然有规则U …SiSi+1… – Si在句柄内部,但是Si+1在句柄之后:必然有规则 U …Si,且存在规范句型…USi+1…。 – 如果Si+1在句柄内,而Si在句柄外,那么必然存在 规范句型…SiU…,且U Si+1…。
编译原理第四章语法分析-自上而下分析

• 例 4.4
4.4 递归下降分析程序构造
• 递归下降分析器:
这个分析程序由一组递归过程组成的,每个过程对应 文法的一个非终结符。 E→TE’ E’→+TE’| T→FT’ T’→*FT’| F→(E)|i
PROCEDURE E BEGIN T ; E’ END PROCEDURE E’ IF SYM=‘+’THEN BEGIN ADVANCE ; T ; E’ END
4.2 自上而下分析面临的问题
• 例4.1 假定有文法
(1) SxAy (2)A**|*
对输入串x*y,构造语法树。 • 构造过程:
(1)把S作为根 (2)用S的产生式构造子树 (3)让输入串指示器IP指向输入串的第一个符号。
S x A y x
S
A y x
S
A y
*
*
*
(4)调整输入串指示器IP与叶结点进行匹配。 (5)如果为非终结符,用A的下一个产生式构建子树。 (6)如果匹配成功则结束;否则,回溯到步骤(4)。
• 一个反例:
– 文法:SQc|c;QRb|b;RSa|a虽然不是直接 左递归,但S、Q、R都是左递归。
• 消除左递归算法:
– 算法的思想是:
• • • • 首先构造直接左递归; 再利用一般转换规则,消除直接左递归 化简文法。 下面算法在不含PP,也不含在右部产生式时可以消除 左递归。
• 消除一个文法的左递归算法:
(1) 把文法 G 的所有非终结符按任一种顺利排列成 P1…Pn;按此顺序执行; (2) FOR i:=1 TO n DO
BEGIN FOR j:=1 TO i-1 DO 把形如Pj+1→Pj 的规则改写成 Pj+11|1|…k| 。其中 Pj1|1|…k 是关于 Pj 的 所有规则; 消除关于Pi规则的直接左递归性。 END 化简由(2)所得的文法。即去除那些从开始符号出发永 远无法到达的非终结符的产生规则。
编译原理语法分析—自上而下分析

对文法G的任何符号串=X1X2…Xn构造集 合FIRST()。
1. 置FIRST()=FIRST(X1)\{};
2. 若对任何1ji-1,FIRST(Xj), 则把FIRST(Xi)\{}加至FIRST()中; 特别是,若所有的FIRST(Xj)均含有, 1jn,则把也加至FIRST()中。显 然,若=则FIRST()={}。
T→T*F | F
F→(E) | i
经消去直接左递归后变成:
E→TE E→+TE | T→FT T→*FT | F→(E) | i
(4.2)
例如文法G(S): S→Qc|c Q→Rb|b R→Sa|a
虽没有直接左递归,但S、Q、R都是左递归的
SQcRbcSabc
(4.3)
一个文法消除左递归的条件: 不含以为右部的产生式 不含回路。
即A的任何两个不同候选 i和 j FIRST(i)∩FIRST( j)=
当要求A匹配输入串时,A就能根据它所面临的第
一个输入符号a,准确地指派某一个候选前去执
行任务。这个候选就是那个终结首符集含a的。
提取公共左因子:
假定关于A的规则是 A→ 1 | 2 | …| n | 1 | 2 | … | m (其中,每个 不以开头)
*
特别是,若S A ,则规定
#FOLLOW(A)
构造不带回溯的自上而下分析的文法条件
1. 文法不含左递归,
2. 对于文法中每一个非终结符A的各个产生式 的候选首符集两两不相交。即,若
A→ 1| 2|…| n 则 FIRST( i)∩FIRST( j)= (ij)
3. 对文法中的每个非终结符A,若它存在某个 候选首符集包含,则
1)算符优先分析法:按照算符的优先关系和结 合性质进行语法分析。适合分析表达式。
编译原理第三章语法分析

递归下降程序:
void F() { if(lookahead= =’i’) match(‘i’); else if(lookahead= =’(’) { match(‘(’); E(); if(lookahead= =’)’) match(‘)’); else error(); } else error(); }
输入串
id+id*id;# id+id*id;# id+id*id;# id+id*id;# id+id*id;# +id*id;# +id*id;#
动作
pop(L),push(E;L) pop(E),push(TE’) pop(T),push(FT’) pop(F),push(id) pop(id),next(ip) pop(T’)
形式语言分类
定义:若文法G=(N,T,P,S)的每个产生式α→β中,均有 α∈(N∪T)*N(N∪T)*,且至少含有一个非终结符, β∈(N∪T)*,则称G为0型文法(短语文法)。 ①1型文法(上下文有关文法):G的任何产生式α→β(S→ε 除外)均满足|α|≤| β| (|x|表示x中文法符号的个数); ②2型文法(上下文无关文法):G的任何产生式形如A→β, 其中A∈N,β∈(N∪T)*; ③3型文法(正规文法、线性文法):G的任何产生式形如A→a 或者A→aB(或者A→Ba),其中A,B∈N,a∈T*。
定义:将产生式A→γ的右部代替文法符号序列αAβ 中的A得到αγβ的过程,称为αAβ直接推导 出αγβ,记作:αAβαγβ。
编译原理笔记7 自上而下语法分析-下推自动机
1.引言
1)语法分析的地位:是编译程序的核心部分。
2)语法分析的任务:识别由词法分析得到的单词序列是否是给定文法的句子。
3)语法分析的理论基础:上下文无关文法和下推自动机。
4)语法分析的方式:(1)自上而下语法分析:反复使用不同产生式进行推导以谋求与输入符号串相匹配。
(2)自下而上语法分析:对输入符号串寻找不同产生式进行规约直到文法开始符号。
注:这里所说的输入符号指词法分析所识别的单词。
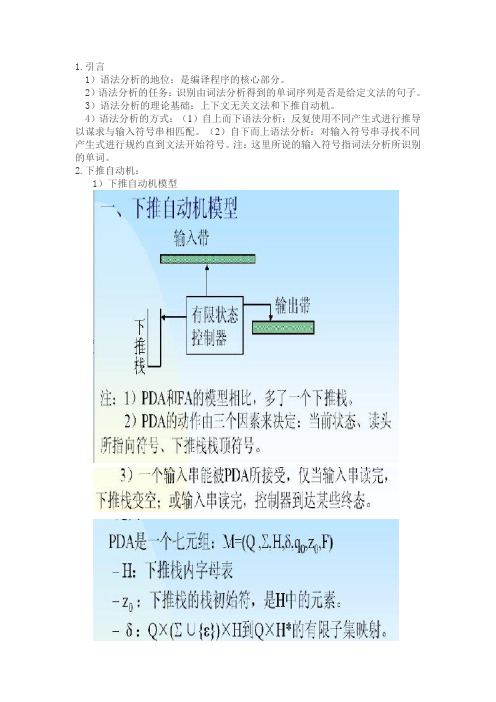
2.下推自动机:
1)下推自动机模型
2)下推自动机的形式定义:
注:a.由此定义的PDA肯定是不确定的PDA。
这给语法分析会带来不确定性。
我们在构造PDA M的算法的时候,要对PDA做一些限制。
b.PDA采用“|-”来表示PDA做了一步动作。
C.输入串能为PDA所接受,仅当输入串读完,下推栈为空;或者输入串读完,控制器到达某些终态。
D.有时,下推自动机还配置输出带,以记录推导或规约过程所有的产生式编号。
e.对于形如A->ω的产生式,有§(q,空串,A)=(q,ω),这称为推导。
编译原理 第05章_算符优先分析法

S)中不存在形如A…BC…的产生式,则称之为算符文
即:如果文法G中不存在具有相邻非终结符的产生式,
符文法,如果该文法中的任何终结符号对a,b之间,在三种
关系中最多只有一种成立,则称该文法为算符优先文法。
(1)求文法中每个非终结符P的首终结符集合FIRSTVT(P)
①定义:FIRSTVT(P)={a|P+a…或者P+Qa…,a ∈VT,P,Q
FOR
THEN
FIRSTVT(Xi+1)中的每个a DO THEN
置 Xi≮a;
IF Xi为非终结符而Xi+1为终结符
FOR
置 END;
LASTVT(Xi)中的每个a DO
a≯Xi+1;
4、直观算法优先算法:
(1)直观算符优先法的下推自动机:
两个工作栈:①算符栈OPTR:用于存放运算符
②算量栈OPND:用于存放运算量
E
E T F i + T T * F F i i
第5章 算符优先分析法
②算符优先分析法每一次归约时,可归约串中至少有一个终结符。
i+i*i# E+i*i# E+T*i# E+T*F# E+T# E#
E E i + T T * F i i
第5章 算符优先分析法
(3)最左素短语:
素短语是指至少含有一个终结符,并且除它自身 之外不再含有更小的素短语。 最左素短语指处于句型最左边的那个素短语。 最左素短语具备三个条件:
i+i-i*(i+i)
①矩阵元素M(a,b)表示a在前,b在后时,a与b之间的优先关系。
②矩阵元素M(a,b)的取值:≮,≯,≡ 。
编译原理第五章语法分析——自下而上分析

第五章语法分析——自下而上分析要紧内容:[1]自下而上分析的大体问题[2]算符优先分析法[3]算符优先分析表和优先函数的构造[4]LR分析器的大体原理大体要求:[1]明白得自下而上分析法的大体思想[2]明白得有关归约、短语、句柄、标准归约等概念[3]把握算符优先分析法[4]了解算符优先表和优先函数的构造技术[5]了解LR 分析器大体原理和工作方式教学要点:本章介绍自下而上语法分析方式。
所谓自下而上分析法确实是从输入串开始,慢慢进行“归约”,直至归约到文法的开始符号;或说,从语法树的结尾开始,步步向上“归约”,直到根结。
讲义摘要:5.1 自下而上分析大体问题自下而上分析法的大体思想:从输入串开始,慢慢进行“归约”,直到文法的开始符号。
即从树结尾开始,构造语法树。
所谓归约,是指依照文法的产生式规那么,把产生式的右部替换成左部符号。
自上而下分析的核心问题是:如何判定符号串的可归约性,和如何归约。
即,识别可归约串的问题。
归约自下而上分析法事实上确实是一种“移进-归约”法,即,采纳“移进-归约”思想进行。
实现思想是:对输入符号串自左向右进行扫描,并将输入符逐个移入一个后进先出栈中,边移入边分析,一旦栈顶符号串形成某个句型的句柄时,(该句型对应某产生式的右部,即栈顶生成了某产生式的右部的文法符号串),就将栈顶的这一部份替换成 (归约为) 该产生式的左部符号,这称为归约。
重复这一进程直到归约到栈中只剩文法的开始符号时那么为分析成功,也就确认输入串是文法的句子。
现举例说明。
例1:设文法G[S]为:(1) S→aAcBe(2) A→b(3) A→Ab(4) B→d试对abbcde进行“移进-归约”分析。
步骤: 1 2 3 4 5 6 7 8 9 10解:动作: 进a 进b 归(2) 进b 归(3) 进c 进d 归(4) 进e 归(1)表1符合栈的转变进程自下而上语法分析的进程也可看成自底向上构造语法树的进程,每步归约都是构造一棵子树,最后当输入串终止时恰好构造出整个语法树,如图1所示。
《编译原理》第6章 (1)

…a
a >b
24
由定义直接构造:
预备知识:
定义两个集合:
+ + FIRSTVT(B)={b|B b…或B Cb…},
+ + LASTVT(B)={b|B …b或B …bC}
即最后一个终结符 即第一个终结符
25
三种优先关系的计算为: a)≡关系 条件:A…ab... A…aBb… b) <关系 条件:A…aB… bFIRSTVT(B) 结论:a<b c) >关系 条件:A…Bb… aLASTVT(B) 结论:a>b
20
定义:设G是不含产生式的算符文法,若G中任何两个终 结符号之间至多有一种优先关系存在,则G是一个算符 优先文法OPG。 注:不允许有ab、 a≡b、 ab 中的两种同时存在 要完成运算符间优先级的比较,最简单的办法是先定义 各种可能相继出现的运算符的优先级,并将其表示成矩 阵形式,即得到一个算符优先关系表。在分析过程中通 过查询矩阵元素而获得算符间的优先关系。
了解算符优先分析法的优缺点和实际应用中的局限性
2
【学习指南】
算符优先分析法是自下而上语法分析的一种,它的算
法简单、直观、易于理解,故通常作为学习其它自下 而上语法分析的基础。在学习前,应复习有关语法分 析的知识,如:什么是语言、文法、句子、句型、短 语、简单短语、句柄、最右推导、规范归约基本概念
S
A
A→Ab
最右推导 句型
abbcde
句柄 归约用规则 b A→b
S→aAcBe
aAbcde
Ab
d
A→Ab
B→d
A
A→b
B
B→d
aAcde
编译原理-南京大学-自下而上语法分析共102页

36、如果我们国家的法律中只有某种 神灵, 而不是 殚精竭 虑将神 灵揉进 宪法, 总体上 来说, 法律就 会更好 。—— 马克·吐 温 37、纲纪废弃之日,便是暴政兴起之 时。— —威·皮 物特
38、若是没有公众舆论的支持,法律 是丝毫 没有力 量的。 ——菲 力普斯 39、一个判例造出另一个判例,它们 迅速累 聚,进 而变成 法律。 ——朱 尼厄斯
拉
60、生活的道路一旦选定,事物有规律,这是不 容忽视 的。— —爱献 生
56、书不仅是生活,而且是现在、过 去和未 来文化 生活的 源泉。 ——库 法耶夫 57、生命不可能有两次,但许多人连一 次也不 善于度 过。— —吕凯 特 58、问渠哪得清如许,为有源头活水来 。—— 朱熹 59、我的努力求学没有得到别的好处, 只不过 是愈来 愈发觉 自己的 无知。 ——笛 卡儿
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
5.1.3 先进后出栈
例:设文法G[S]: 设文法G (1) S → aAcBe (2) A → b (3) A → Ab (4) B → d 试对abbcde进行“移进-归约”分析。 abbcde进行 试对abbcde进行“移进-归约”分析。
e B d b c A b S a
abbcde bbcde bcde cde de e
5.1.7.2 短语
以非终结符为根的子树中所有从左到右排列的叶子 从文法开始符号经过0步推导得到 步推导得到E1, 从文法开始符号经过 步推导得到 ,从E1经过若干步推导得到 经过若干步推导得到 id1+id2*id3,所以 1+id2*id3是句型 1+id2*id3相对于 的短语 是句型id 相对于E1的短语 ,所以id id1+id2不是句型 1+id2*id3中相对于任何非终结符的短语,因为找 不是句型id 中相对于任何非终结符的短语, 不到任何一个非终结符,它的子树中的所有叶子构成id 不到任何一个非终结符,它的子树中的所有叶子构成 1+id2
是一种“移进 归约 归约” 是一种“移进-归约”法 基本思想
用一个寄存符号的先进后出栈 用一个寄存符号的先进后出栈 把输入符号一个一个地移进 移进到栈里 把输入符号一个一个地移进到栈里 栈顶形成某个产生式的候选式时 当栈顶形成某个产生式的候选式时,把栈顶的这一 部分替换成(归约为 该产生式的左部符号 部分替换成(归约为)该产生式的左部符号
具体实现采用移进 归约 移进—归约 移进 归约方法,用一个栈 栈 “记住”将要归约句柄的前缀,并用一个 分析表来确定何时栈顶已形成句柄,以及 分析表 形成句柄后选择哪个产生式进行归约。
5.1.3 符号栈的使用与语法树的表示
在移进 归约分析模式 移进—归约分析模式 移进 归约分析模式中,符号栈的使用 有以下四种操作形式。
B d
e
5.1.2 规范归约简述
定义:假定α是文法G的一个句子,我们称 序列 αn , αn - 1 , … , α0 是一个规范归约 规范归约,如果此序列满足: 规范归约
1 αn= α 2 α0为文法的开始符号,即α0=S α 3 对任何i,0 ≤ i ≤ n, αi-1是从αi经把 是从α 句柄替换成为相应产生式左部符号而得到的。 句柄替换成为相应产生式左部符号
5.1.7.3 直接短语与句柄
只有父子关系的树中所有从左到右排列的叶子 从考虑推导E1 ⇒ E2+id2*id3 ⇒ T2+id2*id3 ⇒ F1+id2*id3 从考虑推导 ⇒ id1+id2*id3 id1是相对于非终结符 、T2和F1的短语 是相对于非终结符E2、 和 的短语 特别地,相对于F1的直接短语 的直接短语, 特别地,相对于 的直接短语,也是句柄
E1 => => => => => => => => E2 + T1 E2 + T3 * F2 E2 + T3 * id3 E2 + F3 * id3 E2 + id2 * id3 T2 + id2 * id3 F1 + id2 * id3 id1 + id2 * id3 (a) (1) (2) (3) (4) (5) (6) (7) (8) (9) E1 E2 + T2 T3 F1 F3 id1 id2 (b) T1 * F2 id3 短语: id1+id2*id3(E1) id2*id3(T1) id1(E2, T2, F1) id2(T3, F3) id3(F2) 直接短语:id1(F1)、 id2(F3)、id3(F2) 句柄:id1(F1) (c)
图5.1 id1+id2*id3的最右推导、分析树与短语 (a) 最右推导;(b) 分析树;(c) 短语
5.1.7.1 归约的分析树
分析树的叶子与短语、 分析树的叶子与短语、直接短语和句柄有下述关系 短语 以非终结符为根的子树中所有从左到右排列的 叶子 直接短语 只有父子关系的树中所有从左到右排列的叶子 树高为2 树高为 句柄 最左边父子关系树中所有从左到右排列的叶子 句柄是唯一的
5.1.4 移进 归约分析 移进-归约分析
例:设文法G[S]: 设文法G (1) S → aAcBe (2) A → b (3) A → Ab (4) B → d 试对abbcde进行“移进-归约”分析。 试对abbcde进行“移进-归约”分析。 abbcde进行
骤 步 : 1 动 : 进 作 a 2 3 4 5 6 进 归 b (2) 进 归 b (3) 进 c 7 8 9 10 进 归 d (4) 进 归 e (1) e B c A a
5.1.2 规范归约简述
最右推导,推导的每一步结果都是一个右句 最右推导 型。该推导即分析树 “剪句柄 剪句柄”的全过程。 剪句柄
S a A B e a A S B e a A S B d e a A S B e S
A b c d b (a)
A b c d
(b)
(c)
(d)
(e)
图3.18 剪句柄的过程 (a) 句子;(b) 剪去b之后;(c) 剪去Abc之后;(d) 剪去d之后;(e) 开始符号
5.1.7 规范归约例一
例:文法G[E]: 文法 : E→E+T|T T→T*F|F F→(E)|–F|id 考虑文法G[E]上的句子 1+id2*id3 上的句子id 考虑文法 上的句子 最右推导和分析树如图 如图5.1(a)、(b)所示 其最右推导和分析树如图 、 所示
E1 => => => => => => => => E2 + T1 E2 + T3 * F2 E2 + T3 * id3 E2 + F3 * id3 E2 + id2 * id3 T2 + id2 * id3 F1 + id2 * id3 id1 + id2 * id3 (a) (1) (2) (3) (4) (5) (6) (7) (8) (9) E1 E2 + T2 T3 F1 F3 id1 id2 (b) T1 * F2 id3 短语: id1+id2*id3(E1) id2*id3(T1) id1(E2, T2, F1) id2(T3, F3) id3(F2) 直接短语:id1(F1)、 id2(F3)、id3(F2) 句柄:id1(F1) (c)
E E T * F i2 + T F i3
T F 1
短语: 短语: i1,i2,i3, i1*i2, i1*i2+i3 直接短语: 直接短语: i1,i2,i3 句柄: 句柄: i1
5.1.2 规范归约简述
可用句柄来对句子进行归约 用句柄来对句子进行归约 例:设文法G[S]: (1) S → aAcBe (2) A → b (3) A → Ab (4) B → d S 句型 归约规则 abbcde (2) A → b Abcde aAbcde (3) A → Ab a A c aAcd aAcde (4) B → d b A (1) S → aAcBe aAcBe S b
aAbcde (A → b) aAcde (A → Ab) aAcBe (B → d) S (S → aAcBe)
S A A b c b B d e
语法树的角度而言 从语法树的角度而言
从语法树的末端开始 步步向上“归约” 步步向上“归约” 直到根结
a
5.1.2 自下而上分析法的基本思想
自下而上分析法
5.1.8 规范归约例二
例:考虑文法G[E] 考虑文法G[E] E→T|E+T T→ T→F|T*F F→ F→(E)|I 和句型i 和句型i1*i2+i3 在一个句型对应的语法树中, 在一个句型对应的语法树中,以某非终结符为根的 两代以上的子树的所有末端结点从左到右排列就是 相对于该非终结符的一个短语 如果子树只有两代, 短语, 相对于该非终结符的一个短语,如果子树只有两代, 则该短语就是直接短语 直接短语。 则该短语就是直接短语。 E+i T+i E ⇒ E+T ⇒ E+F ⇒ E+i3 ⇒ T+i3 T*F+i T*i ⇒ T*F+i3 ⇒ T*i2+i3 ⇒ F*i2+i3 ⇒ i1*i2+i3
① 移进 移进(shift): 把当前输入中的下一个终结符 移进栈; ② 归约 归约(reduce): 句柄在栈顶已形成,用适当 产生式左部代替句柄; ③ 接受(accept): 宣告分析成功; 接受 ④ 报错 报错(error): 发现语法错误,调用错误恢复 例程。
考察文法G[S]: S→aABe A →b A→Abc B→d 的输入序列abbcde,移进—归约方法分析 的符号栈变化过程如下所示。
语法分析—自下而上分析 第五章 语法分析 自下而上分析
内容
自下而上分析基本问题 算符优先分析
5.1 自下而上分析基本问题
自下而上分析基本问题
归约 规范归约 符号栈的使用 语法树的表示
算符优先分析
5.1.1 自下而上分析
abbcde
自下而上分析
输入字符的角度而言 从输入字符的角度而言
从输入开始 逐步进行“归约” 逐步进行“归约” 直至归约到文法的开始符号
5.1.2 规范归约简述
把上例倒过来写,则得到: 把上例倒过来写,则得到:
S ⇒ aAcBe⇒ aAcde ⇒ aAbcde ⇒ abbcde ⇒
显然这是一个最右推导。 显然这是一个最右推导。 最右推导 规范归约是关于是一个最右推导的逆过程
最左归约 规范推导
由规范推导推出的句型称为规范句型。 由规范推导推出的句型称为规范句型。 规范句型 规范归约的中心问题:确定句型的句柄。 规范归约的中心问题:确定句型的句柄。