MySQL CLUSTER 集群方案
MySQL集群之五大常见的MySQL高可用方案(转)

MySQL集群之五⼤常见的MySQL⾼可⽤⽅案(转)1. 概述我们在考虑MySQL数据库的⾼可⽤的架构时,主要要考虑如下⼏⽅⾯:如果数据库发⽣了宕机或者意外中断等故障,能尽快恢复数据库的可⽤性,尽可能的减少停机时间,保证业务不会因为数据库的故障⽽中断。
⽤作备份、只读副本等功能的⾮主节点的数据应该和主节点的数据实时或者最终保持⼀致。
当业务发⽣数据库切换时,切换前后的数据库内容应当⼀致,不会因为数据缺失或者数据不⼀致⽽影响业务。
关于对⾼可⽤的分级在这⾥我们不做详细的讨论,这⾥只讨论常⽤⾼可⽤⽅案的优缺点以及⾼可⽤⽅案的选型。
2. ⾼可⽤⽅案2.1. 主从或主主半同步复制使⽤双节点数据库,搭建单向或者双向的半同步复制。
在5.7以后的版本中,由于lossless replication、logical多线程复制等⼀些列新特性的引⼊,使得MySQL原⽣半同步复制更加可靠。
常见架构如下:通常会和proxy、keepalived等第三⽅软件同时使⽤,即可以⽤来监控数据库的健康,⼜可以执⾏⼀系列管理命令。
如果主库发⽣故障,切换到备库后仍然可以继续使⽤数据库。
优点:1. 架构⽐较简单,使⽤原⽣半同步复制作为数据同步的依据;2. 双节点,没有主机宕机后的选主问题,直接切换即可;3. 双节点,需求资源少,部署简单;缺点:1. 完全依赖于半同步复制,如果半同步复制退化为异步复制,数据⼀致性⽆法得到保证;2. 需要额外考虑haproxy、keepalived的⾼可⽤机制。
2.2. 半同步复制优化半同步复制机制是可靠的。
如果半同步复制⼀直是⽣效的,那么便可以认为数据是⼀致的。
但是由于⽹络波动等⼀些客观原因,导致半同步复制发⽣超时⽽切换为异步复制,那么这时便不能保证数据的⼀致性。
所以尽可能的保证半同步复制,便可提⾼数据的⼀致性。
该⽅案同样使⽤双节点架构,但是在原有半同复制的基础上做了功能上的优化,使半同步复制的机制变得更加可靠。
MySQL中的高可用解决方案

MySQL中的高可用解决方案MySQL是一种常用的关系型数据库管理系统,被广泛用于各种应用场景。
对于很多企业和组织来说,保证MySQL数据库的可用性和可靠性是非常重要的,因为数据库宕机或者数据丢失可能会导致巨大的经济损失和业务中断。
因此,开发高可用解决方案成为MySQL数据库管理者们必须面对的挑战。
一、MySQL复制MySQL复制是MySQL中最常用的高可用解决方案之一。
通过使用MySQL的复制功能,可以将一个主数据库的数据实时复制到一个或多个备份数据库。
当主数据库出现故障时,备份数据库可以顶替其角色,从而实现无缝切换。
MySQL复制是基于日志的机制,主数据库将产生的数据更改事件写入二进制日志(Binary Log),备份数据库则通过读取主数据库的二进制日志来实时复制数据。
主数据库将所有更改记录下来,备份数据库则按照相同的顺序应用这些更改,从而实现数据的同步。
虽然MySQL复制是一种简单且有效的高可用解决方案,但它也存在一些局限性。
首先,MySQL复制是异步的,主数据库和备份数据库之间有一定的延迟,可能会导致数据的不一致。
其次,MySQL复制只能实现单主节点的高可用,即只有一个主数据库,其他都是备份数据库。
这对于一些高并发的应用来说,可能无法满足需求。
二、MySQL集群为了解决MySQL复制的限制,MySQL提供了集群(Cluster)解决方案。
MySQL集群是一种基于共享存储器(Shared Storage)的高可用解决方案。
在MySQL集群中,多个MySQL节点共享相同的数据存储,数据的一致性由底层共享存储器保证。
MySQL集群采用了多个MySQL节点协同工作的方式,每个节点都可以处理客户端请求。
当其中一个节点发生故障时,其他节点可以自动接管服务,保证了系统的连续性。
同时,MySQL集群也提供了负载均衡的功能,可以将请求分发到不同的节点上,从而提高了系统的性能。
然而,MySQL集群也有一些限制。
mysql cluster 原理

mysql cluster 原理小伙伴,今天咱们来唠唠MySQL Cluster这个超有趣的东西的原理呀。
MySQL Cluster呢,就像是一个超级团队,大家齐心协力来处理数据这个大任务。
它是一种分布式的数据库解决方案哦。
想象一下,你有好多好多的数据,就像有一堆宝贝要存放起来,要是都放在一个小盒子里,很容易就满了,而且万一这个小盒子出问题了,那宝贝可就危险啦。
MySQL Cluster就不一样啦,它把这些数据分散到好多地方去存放。
在MySQL Cluster里,有数据节点。
这些数据节点就像是一个个小仓库,每个小仓库都负责存放一部分数据。
它们可不会互相抢活儿干,而是各自安安静静地守着自己的那一份数据。
比如说,你有关于用户信息的数据,一部分可能就放在这个数据节点里,另一部分可能在另外一个数据节点里。
这样做的好处可多啦。
要是一个数据节点突然生病了,就像人会感冒一样,其他的数据节点还能正常工作呢,数据不会一下子就找不到了。
还有管理节点呀,这个管理节点就像是这个超级团队的大管家。
它知道每个数据节点都在干啥,数据都放在哪里。
它就负责指挥这些数据节点,让整个系统有条不紊地运行。
如果有新的数据要放进来,管理节点就会想办法找个合适的数据节点来接收这个新数据。
要是某个数据节点太满了,它也会安排一下,看看能不能把一些数据挪到其他不那么满的数据节点去。
这个管理节点可聪明啦,就像一个很有经验的老管家一样。
那客户端呢?客户端就像是来这个大仓库取东西或者放东西的客人。
当客户端想要找某个数据的时候,它就会跟管理节点说:“大管家,我要找这个数据呢。
”然后管理节点就会告诉客户端:“你去那个数据节点找吧。
”客户端就乖乖地跑到对应的数据节点去拿数据啦。
MySQL Cluster还有一个很厉害的地方就是它的冗余性。
啥叫冗余性呢?就是同样的数据,可能会在好几个地方都有备份。
这就像是你把重要的东西,不仅放在家里的柜子里,还在朋友家也放了一份一样。
mysql集群解决方案

mysql集群解决方案
《MySQL集群解决方案》
随着互联网应用的不断发展,数据库需求量也在不断增加。
为了提高数据库的性能和可用性,很多企业都开始使用数据库集群解决方案。
MySQL作为开源的关系型数据库管理系统,也
有着丰富的集群解决方案可供选择。
MySQL集群解决方案一般包括以下几种形式:主从复制、多
主复制、基于分布式文件系统的集群和基于分布式数据库的集群。
主从复制是最简单的MySQL集群解决方案,它通过在一个主
数据库上进行数据更新,然后将更新同步到多个从数据库上来实现负载均衡和故障转移。
多主复制则是在主从复制的基础上,实现了多个主数据库之间的双向同步,从而提高了数据库的可用性和性能。
基于分布式文件系统的集群是通过将数据库文件存储在一个共享的分布式文件系统中,从而实现了多个数据库实例之间的文件共享和数据同步。
而基于分布式数据库的集群则是通过将数据分片存储在不同的数据库实例上,每个实例只存储一部分数据,从而实现了数据库的分布式存储和查询加速。
在选择MySQL集群解决方案时,需要根据实际业务需求和性
能要求来进行选择。
同时,还需要考虑集群的部署和维护成本,以及数据一致性和故障恢复等方面的问题。
总的来说,MySQL集群解决方案可以帮助企业提高数据库的性能和可用性,从而满足不断增长的数据库需求。
通过选择适合自己业务需求的集群解决方案,并进行合理的部署和维护,可以有效地提升数据库的安全性和可靠性。
mysql 集群的方法

mysql 集群的方法MySQL 集群是为了提高数据库的可用性、性能和数据一致性而采用的一种技术。
以下是几种常见的 MySQL 集群方法:1.主从复制 (Master-Slave Replication):o一个主服务器(Master)负责写操作,并将数据变更复制到一个或多个从服务器(Slave)。
o从服务器处理读请求,确保数据保持同步。
o主要用途是读写分离、备份和故障恢复。
2.MySQL Group Replication:o这是 MySQL 5.7 之后引入的一个插件,允许 MySQL 实例形成一个互操作的组,并自动处理故障转移。
o它提供了数据冗余、自动故障转移和读写负载均衡。
3.MySQL Cluster:o基于 NDB(或 NDB Cluster)存储引擎,允许多个节点协同工作。
o提供高可用性、自动分片和并行处理。
o对于非常大的数据集和高并发的场景特别有用。
4.Galera Cluster for MySQL:o通过同步复制实现真正的多主复制。
o保证了数据一致性,提供了自动故障恢复和高可用性。
o Percona XtraDB Cluster 和 MariaDB Cluster 都使用了这种技术。
5.Proxy Solutions:o使用如 ProxySQL、HAProxy 或 MaxScale 等代理,可以基于路由规则将请求转发到不同的 MySQL 实例。
o可以实现负载均衡、读写分离、故障转移等功能。
6.分片 (Sharding):o将数据分布到多个数据库或服务器上,以实现水平扩展。
o使用如MySQL Sharding这样的中间件或工具,可以将请求路由到正确的分片。
7.使用云服务:o如 Amazon RDS 的 Multi-AZ (一个主数据库和一个或多个副数据库) 和 Read Replicas。
o这些解决方案通常提供了高可用性和自动故障转移。
8.其他第三方解决方案:如 Patroni、Codership、Vitess 等,都是为了解决特定问题的解决方案。
MySQLCluster方案概述
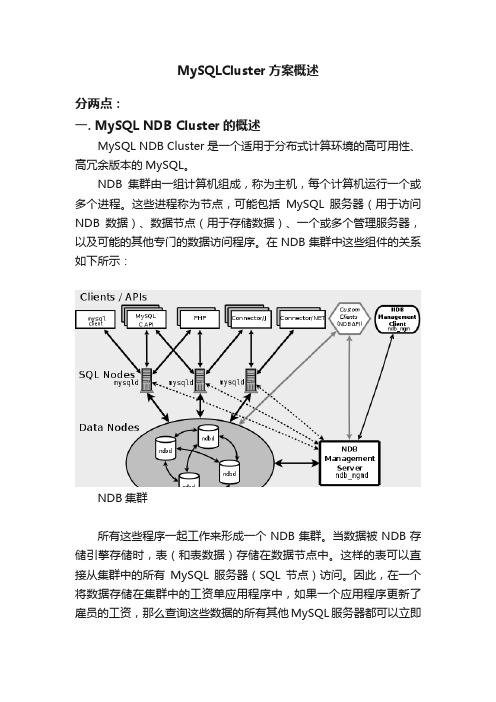
MySQLCluster方案概述分两点:一. MySQL NDB Cluster的概述MySQL NDB Cluster是一个适用于分布式计算环境的高可用性、高冗余版本的MySQL。
NDB集群由一组计算机组成,称为主机,每个计算机运行一个或多个进程。
这些进程称为节点,可能包括MySQL服务器(用于访问NDB数据)、数据节点(用于存储数据)、一个或多个管理服务器,以及可能的其他专门的数据访问程序。
在NDB集群中这些组件的关系如下所示:NDB集群所有这些程序一起工作来形成一个NDB集群。
当数据被NDB存储引擎存储时,表(和表数据)存储在数据节点中。
这样的表可以直接从集群中的所有MySQL服务器(SQL节点)访问。
因此,在一个将数据存储在集群中的工资单应用程序中,如果一个应用程序更新了雇员的工资,那么查询这些数据的所有其他MySQL服务器都可以立即看到这个变化。
NDB集群核心概念NDB CLUSTER(也称为NDB)是一个内存存储引擎,提供高可用的数据持久化功能。
NDB CLUSTER存储引擎可以配置一系列故障转移和负载平衡。
集群节点集群节点有三种类型,在最小的NDB集群配置中,至少会有三个节点。
1. Management node这种类型节点的作用是管理NDB集群中的其他节点,执行诸如提供配置数据、启动和停止节点以及运行备份等功能。
因为这个节点类型管理其他节点的配置,所以应该首先启动这种类型的节点,在任何其他节点之前。
执行ndb_mgmd命令启动该节点。
2. Data node这种类型节点的作用是存储集群数据。
一个副本足以用于数据存储,但不提供冗余;因此,建议使用2(或更多)副本来提供冗余,从而获得高可用性。
执行ndbd或ndbmtd(多线程)命令启动该节点。
NDB集群表通常存储在内存中,而不是在磁盘上(这就是为什么我们将NDB集群称为内存中的数据库)。
然而,一些NDB集群数据可以存储在磁盘上。
3. SQL node在NDB Cluster中SQL节点是一个使用NDBCLUSTER存储引擎的传统MySQL服务器。
mysql ndb cluster 架构原理

mysql ndb cluster 架构原理MySQL NDB Cluster是MySQL官方提供的,用于搭建高可用性、高并发性的分布式数据库平台。
NDB Cluster采用了数据分片、数据复制等策略,将数据存储在多个节点上,提高了数据访问的可用度和性能。
下面我们来看一下NDB Cluster的架构原理:1. 数据存储和访问模式NDB Cluster采用了两段式存储模式,即数据存储在内存中和磁盘上。
NDB存储引擎负责管理数据的传输和存储,具有高度的容错能力。
数据被划分成多个分区,每个分区存储在不同的节点上,节点之间互相备份和协作,实现数据分片和多点存储。
此外,NDB Cluster还具有分布式事务功能,支持跨节点的ACID事务。
2. 节点体系结构NDB Cluster每个节点都包含多个进程:Data Node、Management Node、SQL Node。
Data Node进程用于存储数据、备份数据,当某个Data Node崩溃时,其他节点可以顶替其工作。
Management Node进程管理整个NDB Cluster的运行状态和配置信息,如节点状态、分区分配等。
SQL Node进程负责处理SQL查询和数据操作请求。
3. 数据分片和复制策略NDB Cluster采用了水平分片,即将数据水平划分成多个分区,每个分区由不同的节点存储,从而实现负载均衡和数据并行处理。
同时,NDB Cluster还支持数据复制机制,即一个分区可以备份到多个节点。
每个节点存储数据的副本数量可以根据业务需求进行配置。
NDB Cluster还具有数据平衡功能,可以自动将数据均衡分配到空闲的节点上,从而优化资源利用率。
4. 高可用性和性能优化NDB Cluster具有高度可用性和性能优化策略。
NDB Cluster每个节点间建立多个通信链路,以达到负载均衡和故障转移的目的。
当某个节点失效时,整个分布式系统可以快速切换到另一个节点继续提供服务。
mysql 集群方案

MySQL集群方案介绍MySQL是一种常用的关系型数据库管理系统,被广泛应用于多种类型的软件开发和企业应用场景中。
随着数据量和访问量的增长,单一的MySQL实例可能无法满足业务需求,并面临诸如性能瓶颈、高可用性和容灾等问题。
为了解决这些问题,MySQL集群方案应运而生。
MySQL集群方案提供了高可用性、负载均衡和容灾备份等特性,使得数据库能够持续稳定地运行。
MySQL集群方案的架构MySQL集群方案一般由多个MySQL节点(MySQL instances)和相关组件组成。
以下是一个典型的MySQL集群方案架构:•负载均衡器(Load Balancer):负责分发来自客户端的请求到不同的MySQL节点,以实现负载均衡。
常用的负载均衡器有Nginx、HAProxy等。
•主节点(Master):主节点是MySQL集群中负责处理写操作(INSERT、UPDATE、DELETE)的节点。
主节点上的数据会同步到其他从节点。
•从节点(Slave):从节点是MySQL集群中负责处理读操作(SELECT)的节点。
从节点通过复制(Replication)机制从主节点同步数据。
从节点可以有多个。
•数据复制(Replication):通过数据复制机制,将主节点的数据同步到从节点。
一般情况下,主节点会将自己的二进制日志传输到从节点,从节点按照主节点的日志顺序进行重放,从而保证数据的一致性。
•数据同步监控(Monitoring):监控系统用于监控MySQL集群的状态和性能指标,以及及时发现问题和进行故障恢复。
•数据备份和恢复(Backup & Recovery):数据备份和恢复组件用于定期备份MySQL集群中的数据,并在需要时进行灾备恢复。
MySQL集群方案的实施步骤以下是MySQL集群方案的实施步骤:1.规划和设计:在实施MySQL集群之前,需进行规划和设计。
根据业务需求和系统要求,确定需要部署多少个MySQL节点、负载均衡器、监控系统和数据备份系统等组件。
MySQL集群部署与配置指南

MySQL集群部署与配置指南引言MySQL是一种开源的关系型数据库管理系统,被广泛应用于各种应用程序中。
在处理大规模数据和高并发访问时,单个MySQL服务器可能无法满足需求。
为了提高性能和可用性,使用MySQL集群来部署和配置数据库是一个不错的选择。
本文将详细介绍MySQL集群部署和配置的指南,帮助读者了解集群的概念,并提供一些实用的技巧。
1. 集群概述1.1 什么是MySQL集群MySQL集群是指由多个MySQL服务器组成的集合,通过共享数据和负载均衡来提供高性能和高可用性。
集群中的每个节点都存储相同的数据,并且可以处理来自客户端的查询请求。
如果其中一个节点发生故障,其他节点将继续提供服务,确保数据的有效性和可访问性。
1.2 集群的优势MySQL集群具有以下优势:- 高可用性:即使其中一个节点发生故障,其他节点也可以继续提供服务,避免了单点故障的风险。
- 负载均衡:通过将查询请求分发到不同的节点上,集群可以平衡负载,提高整个系统的性能。
- 扩展性:可以根据需求增加或减少集群节点,以应对不断增长的数据和用户访问量。
- 数据冗余:通过复制数据到多个节点,可以提供数据的冗余备份,避免数据丢失的风险。
2. 部署MySQL集群2.1 硬件要求部署MySQL集群需要考虑以下硬件要求:- 多台服务器:每个节点都需要一个独立的服务器来承载MySQL服务。
- 网络连接:节点之间需要可靠的网络连接,以便进行数据同步和通信。
2.2 软件要求部署MySQL集群还需要满足以下软件要求:- MySQL数据库:每个节点都需要安装并配置MySQL数据库。
- 集群管理软件:可以使用各种集群管理软件,如MySQL Cluster、Galera Cluster或Percona XtraDB Cluster等。
2.3 数据同步配置为了保持每个节点上的数据一致性,需要配置数据同步机制。
可以使用MySQL的复制功能来实现数据同步。
具体步骤如下:- 在一个节点上设置为主节点(master),并启用二进制日志功能。
Mysql_Cluster集群

安装版本:mysql cluster 7.2.6操作系统centos6.2 (X64)软件名称mysql-cluster-gpl-7.2.6-linux2.6-x86_64.tar.gz管理节点数据节点SQL节点在IP 10.8.10.38(master)数据节点SQL节点在IP 10.8.10.35首先,检查系统是否装载了mysql使用命令rpm -qa|grep -i mysql如果有显示全部卸载,如果没有说明没有安装mysqlrpm -e MySQL-python-1.2.3-0.3.c1.1.el6.x86_64rpm -e mysql-5.1.52-1.el6_0.1.x86_64rpm -e mysql-connector-odbc-5.1.5r1144-7.el6.x86_64rpm -e mysql-libs-5.1.52-1.el6_0.1.x86_64 –nodeps删除frm –fr /etc/ftar -zxvf mysql-cluster-gpl-7.2.6-linux2.6-x86_64.tar.gz解压完成后运行mv mysql-cluster-gpl-7.2.6-linux2.6-x86_64 /usr/local/mysql添加用户mysqluseradd mysqlchown -R mysql:mysql /usr/local/mysql/进入安装脚本路径cd /usr/local/mysql/scripts/带参数运行安装程序./mysql_install_db --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data &注意:&不带此符号,安装程序容易不进行安装,而且报错拷贝ndb_mgm ndb_mgmd 文件到/usr/local/bin/cp -fr /usr/local/mysql/bin/ndb_mgm* /usr/local/bin/创建mysql-cluster文件夹mkdir /var/lib/mysql-cluster创建config.ini文件vi /var/lib/mysql-cluster/config.ini文件内容[NDBD DEFAULT]NoOfReplicas: 1 #定义在Cluster环境中相同数据的份数最大为4# Data Memory, Index Memory, and String Memory #DataMemory: 500M #分配的数据内存大小IndexMemory: 250M #设定用于存放索引(非主键)数据的内存段大小#一个NDB节点能存放的数据量是会受到DataMemory和IndexMemory两个参数设置的约束,#两者任何一个达到限制数量后,都无法再增加能存储的数据量。
MySQL中的高可用集群方案实现

MySQL中的高可用集群方案实现MySQL 是一个开源的关系型数据库管理系统,被广泛应用于各种各样的业务场景。
在大规模应用和高并发的情况下,为了保证数据库服务的高可用性和数据的持久性,采用高可用集群方案是必不可少的。
本文将介绍一些常见的 MySQL 高可用集群方案,并深入探讨其实现原理和适用场景。
一、背景介绍1.1 MySQL 的高可用性问题在传统的单机 MySQL 架构中,当数据库服务器发生故障或者由于维护等原因需要停机时,会导致业务的中断和数据的丢失。
为了解决这个问题,需要引入高可用集群方案,以提供服务的持续性和数据的安全性。
1.2 高可用集群方案的作用高可用集群方案可以将多个数据库服务器组成一个集群,提供冗余和故障转移机制,当其中某一个节点出现故障时,其他节点会接管服务,保证数据库服务的不中断,并且数据不会丢失。
二、MySQL 高可用集群方案的实现原理2.1 主从复制主从复制是 MySQL 中最经典的高可用集群方案之一。
它的实现原理是将一个节点作为主节点,负责处理写操作,并将写操作的日志同步到其他节点作为从节点。
当主节点发生故障时,一个从节点会被选举为新的主节点,继续提供服务。
主从复制不仅可以提高可用性,还可以增加读取的吞吐量。
2.2 半同步复制半同步复制是在主从复制的基础上进行的改进,主要解决数据同步的延迟问题。
在传统的主从复制架构中,主节点将写操作的日志同步到从节点时,只需要将数据写入到主节点的本地磁盘即可返回成功,而不需要等待从节点的确认。
这种情况下,如果主节点发生故障,可能会导致部分数据的丢失。
半同步复制引入了一个等待从节点确认的机制,只有在从节点确认接收到数据后,主节点才会返回写操作的成功。
2.3 MHAMHA(Master High Availability)是一个针对 MySQL 的高可用性解决方案,它基于主从复制的架构,并通过自动监控和故障切换机制实现高可用性。
MHA 的工作原理是通过一个特殊的管理节点来监控主节点的状态,当主节点发生故障时,自动将一个从节点提升为新的主节点,并进行相应的配置更新和状态同步。
MySQL-Cluster集群+HA高可用+负载均衡安装部署操作轨迹

#ln -s /usr/local/lib/mysqlmanager /usr/bin ---这个在7.2.13版本上不需要
三、安装并配置节点
以下步骤需要在serverA和serverB上各做一源自 1.配置管理节点配置文件
# mkdir /var/lib/mysql-cluster
useradd -g mysql mysql
usermod -d /home/mysql mysql
3.将MySQL-Cluster上传到/home/mysql/目录下,开始安装MySQL-Cluster
[root@serverA sdd]# rpm -ivh MySQL-Cluster-server-gpl-7.2.14-1.rhel5.x86_64.rpm
/usr/bin/mysqladmin -u root -h serverA password 'new-password'
Alternatively you can run:
/usr/bin/mysql_secure_installation
which will also give you the option of removing the test
arbitrator with id 2 and db node with id 4 on same host 192.168.0.181
[root@serverA sbin]# ndb_mgmd --ndb_nodeid=1
MySQL Cluster Management Server mysql-5.5.31 ndb-7.2.13
mysql 集群解决方案

mysql 集群解决方案
《MySQL 集群解决方案》
随着数据量的不断增加和业务需求的复杂化,单节点的MySQL数据库已经无法满足企业的需求。
因此,企业开始转
向MySQL集群解决方案,以提高数据库的性能、可靠性和扩
展性。
MySQL集群解决方案是指将多个MySQL节点进行连接和协调,以实现高可用性和负载均衡。
这样一来,即使某个节点发生故障,集群仍然可以保持稳定运行,同时能够更好地分担业务流量,提高数据库的处理能力。
在MySQL集群解决方案中,常见的架构包括主从复制、主从
复制加读写分离、主主复制等。
通过这些架构,可以实现数据的备份和灾难恢复、负载均衡和高可用性等功能,从而更好地满足企业的需求。
除了架构方面,MySQL集群解决方案还涉及到集群管理工具、监控工具、自动故障转移和恢复机制等。
这些工具和机制可以帮助企业降低管理与运维成本,提高数据库的稳定性和性能。
总之,MySQL集群解决方案是目前企业数据库发展的一个必
然趋势,它能够帮助企业提高数据库的可用性、可靠性和性能,从而更好地支撑业务的发展。
希望企业可以充分认识到MySQL集群解决方案的重要性,积极采用这一解决方案,提
升数据库的管理水平和竞争力。
mysql的集群模式galera-cluster部署详解

mysql的集群模式galera-cluster部署详解⽬录⼀: galera-cluster 的介绍⼆: galera-cluster 的运⾏原理三: mariadb的galera-cluster 部署⼀: galera-cluster 的介绍官⽅给出的特性如下:真正的多主集群,Active-Active架构;同步复制,没有复制延迟;多线程复制;没有主从切换操作,⽆需使⽤虚IP;热备份,单个节点故障期间不会影响数据库业务;⽀持节点⾃动加⼊,⽆需⼿动拷贝数据;⽀持InnoDB存储引擎;对应⽤程序透明,原⽣MySQL接⼝;⽆需做读写分离;部署使⽤简单。
⼆: galera-cluster 的运⾏原理主要关注点是数据⼀致性。
事务既可以应⽤于每个节点,也可以不全部应⽤。
所以,只要它们配置正确,数据库保持同步。
Galera复制插件不同于传统的MySQL复制,可以解决多个问题,包括多主写⼊冲突,复制滞后和主从不同步。
三: mariadb的galera-cluster 部署3.1: 系统软件环境介绍系统: CentOS7.5x64192.168.20.33 192.168.20.34 192.168.20.35 软件: mariadb-galera-cluster.zip3.2: 配置时间同步服务器flyfish的主机已经配置好了chronyd 时间服务器时间服务器为: 192.168.20.3如果不会可以参考flyfish的其关于安装⼤数据集群CDH 的时间服务器的配置在此不再提供如何安装配置3.3 安装mariadb-galear-cluster所⽤集群节点都执⾏:yum remove -y mariadb-libsyum install -y unzip boost-devel lsof perl-DBI perl-Data-Dumperrpm -ivh rpm -ivh MariaDB-10.0.37-centos73-x86_64-*rpm -ivh MariaDB-Galera-10.0.37-centos73-x86_64-*3.4 节点配置⽂件节点⼀: cd /etc/f.dvim server.conf----[mysqld]## * Galera-related settings#[galera]# Mandatory settingswsrep_provider= /usr/lib64/galera/libgalera_smm.sowsrep_cluster_address="gcomm://192.168.20.33,192.168.20.34,192.168.20.35" wsrep_cluster_name = 'mycluster'wsrep_node_name = ''wsrep_node-address = '192.168.20.33'binlog_format=rowdefault_storage_engine=InnoDBinnodb_autoinc_lock_mode=2bind-address=0.0.0.0## Optional setting#wsrep_slave_threads=1----节点⼆:cd /etc/f.d/vim server.conf----[mysqld]## * Galera-related settings#[galera]# Mandatory settingswsrep_provider= /usr/lib64/galera/libgalera_smm.sowsrep_cluster_address="gcomm://192.168.20.33,192.168.20.34,192.168.20.35" wsrep_cluster_name = 'mycluster'wsrep_node_name = ''wsrep_node-address = '192.168.20.34'binlog_format=rowdefault_storage_engine=InnoDBinnodb_autoinc_lock_mode=2bind-address=0.0.0.0## Optional setting#wsrep_slave_threads=1#innodb_flush_log_at_trx_commit=0---节点三: cd /etc/f.d/vim server.conf----[mysqld]## * Galera-related settings#[galera]# Mandatory settingswsrep_provider= /usr/lib64/galera/libgalera_smm.sowsrep_cluster_address="gcomm://192.168.20.33,192.168.20.34,192.168.20.35" wsrep_cluster_name = 'mycluster'wsrep_node_name = ''wsrep_node-address = '192.168.20.35'binlog_format=rowdefault_storage_engine=InnoDBinnodb_autoinc_lock_mode=2bind-address=0.0.0.0## Optional setting#wsrep_slave_threads=1#innodb_flush_log_at_trx_commit=0----3.4 启动集群在集群的任意⼀个节点上执⾏service mysql start --wsrep-new-cluster此处以节点三为例:节点⼀和节点⼆执⾏:service mysql start3.5:创建数据库实例节点⼀:mysql -uroot create database nCalInfo在节点⼆,三上⾯查看mysql -uroot show databases以上就是本⽂的全部内容,希望对⼤家的学习有所帮助,也希望⼤家多多⽀持。
mysql数据库集群方案

mysql数据库集群方案随着互联网的快速发展,大型网站的访问量逐渐增加,单机mysql已经不能满足高并发、高可用、海量数据的需求。
因此,mysql数据库集群方案应运而生。
1.集群基础架构mysql集群是由多台服务器组成,它们协同工作以提供更高的可用性和可扩展性。
主要的组件包括管理节点、数据节点和客户端接口。
1.1 管理节点管理节点控制集群中的所有数据节点,并管理数据、用户和节点。
它还负责控制故障检测和修复。
管理节点可以被安装在物理服务器、虚拟机中或是云服务中。
1.2 数据节点数据节点是存储数据的主要组成部分,每个数据节点都包括一个mysql服务器实例和文件系统。
数据节点可以在物理服务器或虚拟机中安装。
每个数据节点都包含一部分数据,通过数据分片技术实现数据的分散存储。
1.3 客户端接口客户端接口是集群应用程序和集群之间的通信通道。
这个组件提供给应用程序公共命令和API,已实现对集群的管理和操作。
例如,可将在一个节点上执行的命令传递给整个集群中的所有节点。
2. 集群配置通常,在您配置mysql集群之前,需要考虑以下因素:2.1 负载均衡为了使集群运作良好,必须保持负载均衡。
通常,此功能通过VIP(虚拟IP)和透明路由器实现。
2.2 数据备份您可以使用MySQL自带的复制功能来备份数据。
另外,一些第三方备份和恢复方案也可用于mysql集群。
2.3 集群容错确保所有节点连通性通常需要在应用程序与查询期间检查节点。
在检测到故障时,故障的节点将自动从集群中删除,让其他节点继续提供服务。
2.4 系统监控系统监控是mysql集群的重要组成部分。
它可用于监控组件和节点的运行,以及故障检测和诊断。
3. mysql集群方案mysql有许多集群方案,其中最为常用的包括MySQL cluster、Galera cluster和Percona XtraDB Cluster。
3.1 MySQL ClusterMySQL Cluster是由MySQL AB开发的开源集群方案,可扩展性高、高可用性和很好的负载均衡。
MySQL Cluster配置参数详细介绍

c) 2代表本节点参与决策,但是优先权较1低,但是比0高
ArbitrationRank参数不仅仅管理节点有,MySQL节点也有。而且一般来说,所有的管理节点一般都应该设置成1,所有SQL节点都设置成2。
2) [NDB_MGMD]是每个管理节点配置一组,所需配置项如下(下面的参数只能设置在[NDB_MGMD]参数组中):
c) 还可以计入syslog里面如:LogDestination=SYSLOG:facility=syslog;
d) 甚至多种方式共存:LogDestination=CONSOLE;SYSLOG:facility=syslog;FILE:filename=/var/log/cluster-log
MaxNoOfLocalScans:和上面的这个参数相对应,只不过设置的是在本节点上面的并发table scan和range scan数量。如果在系统中有大量的并发而且一般都不使用并行的话,需要注意此参数的设置。默认为MaxNoOfConcurrentScans * node数目;
BatchSizePerLocalScan:该参用于计算在Localscan(并发)过程中被锁住的记录数,文档上说明默认为64;
DataDir:指定本地的pid文件,trace文件,日志文件以及错误日志子等存放的路径,无系统默认地址,所以必须设定;
DataMemory:设定用于存放数据和主键索引的内存段的大小。这个大小限制了能存放的数据的大小,因为ndb存储引擎需属于内存数据库引擎,需要将 所有的数据(包括索引)都load到内存中。这个参数并不是一定需要设定的,但是默认值非常小(80M),只也就是说如果使用默认值,将只能存放很小的数 据。参数设置需要带上单位,如512M,2G等。另外,DataMemory里面还会存放UNDO相关的信息,所以,事务的大小和事务并发量也决定了 DataMemory的使用量,建议尽量使用小事务;
mysql集群之MYSQLCLUSTER

mysql集群之MYSQLCLUSTER1. 参考⽂档2. 简介MySQL-Cluster是⼀种技术,该技术允许在⽆共享的系统中部署“内存中”数据库的簇。
通过⽆共享体系结构,系统能够使⽤廉价的硬件,⽽且对软硬件⽆特殊要求。
此外,由于每个组件都有⾃⼰的内存和磁盘,所以不存在单点故障。
MySQL簇将标准的MySQL服务器与名为NDB的“内存中”的簇式存储引擎集成了起来。
术语NDB指的是与存储引擎相关的设置部分,⽽术语“MySQL簇”指的是MySQL和NDB存储引擎的组合。
MySQL簇由⼀组计算机构成,每台计算机上均运⾏着多种进程,包括MySQL服务器,NDB簇的数据节点,管理服务器(MGM),以及(可能)专门的数据访问程序。
关于簇中组件的关系,如下图:所有这些程序⼀起构成了MySQL簇。
将数据保存到NBD簇引擎中时,表将保存在数据节点内。
能够从簇中所有其他MySQL服务器直接访问这些表。
因此,假如在将数据保存在簇内的⼯资应⽤程序中,如果某⼀应⽤程序更新了⼀位雇员的⼯资,所有查询该数据的其他MySQL 服务器能⽴刻发现这种变化。
对于MySQL簇,保存在数据节点的数据可被映射,簇能够处理单独数据节点的故障,除了少数事物将因事物状态丢失⽽被放弃外,不会产⽣其他影响。
由于事物性应⽤程序能够处理失败事宜,因⽽它不是问题源。
3. MySQL簇的基本概念NDB 是⼀种“内存中”存储引擎,它具有可⽤性⾼和数据⼀致性好的特点。
能够使⽤多种故障切换和负载平衡选项配置NDB 存储引擎,但以簇层⾯上的存储引擎开始最简单。
MySQL簇的NDB存储引擎包含完整的数据集,仅取决于簇本⾝内的其他数据。
下⾯名,我们将介绍设置由NDB存储引擎和⼀些MySQL服务器构成的MySQL簇的设置⽅法。
⽬前,MySQL簇的部分可以独⽴于MySQL服务器进⾏配置。
在MySQL簇中,簇的每个部分被视为⼀个节点。
注释:在很多情况下,术语“节点”⽤于指计算机,但在讨论MySQL簇时,它表⽰的是进程。
mysql 集群方案

MySQL 集群方案引言MySQL 是一种常用的关系型数据库管理系统,具有高性能、稳定性和可靠性。
然而,在高并发和大数据量的情况下,单机 MySQL 往往无法满足需求。
为了解决这一问题,可以采用集群方案来提高数据库的性能和可扩展性。
本文将介绍几种常见的 MySQL 集群方案,包括主从复制、主主复制和分片存储,并对它们的原理、优缺点进行分析。
此外,还将讨论如何选取最适合应用需求的 MySQL 集群方案。
1. 主从复制主从复制是最常见的 MySQL 集群方案之一。
它通过将一个 MySQL 服务器作为主节点,其他服务器作为从节点,实现数据的同步和复制。
主节点接收所有的写操作,并将写入的数据同步到从节点,从节点只负责读操作。
主从复制的原理是通过二进制日志将主节点的更新操作记录下来,然后从节点读取这些日志并执行相同的操作,以达到数据的同步和复制。
主从复制的优点是实现简单、易于管理和部署,同时可以提高读取数据的性能和提供高可用性。
然而,主从复制也存在一些缺点,如写操作集中在主节点、主节点故障需要手动切换等。
2. 主主复制主主复制是另一种常见的 MySQL 集群方案。
它和主从复制的区别是,主节点能够接收读写操作,从节点也可以接收读写操作。
这样可以实现负载均衡和高可用性。
主主复制的原理和主从复制类似,但需要对数据同步进行更复杂的处理。
通过在主节点之间进行双向同步,确保数据的一致性。
主主复制的优点是读写分散、高可用性和负载均衡。
然而,主主复制也存在一些问题,如数据冲突和同步延迟。
3. 分片存储当数据量非常大时,即使使用主从复制或主主复制也无法满足需求。
这时可以采用分片存储的方式来解决。
分片存储将数据按照一定的规则分散存储在不同的节点上,每个节点可以独立进行读写操作。
分片存储的原理是根据某一列或一组列的值进行分片,将相同值的数据存储在同一个节点上。
通过路由算法将查询请求发送到对应的节点上,以实现数据的分布式存储和查询。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
在任意一台机子上启动管理终端:
# ndb_mgm
键入show命令查看当前工作状态:(下面是一个状态输出示例)
– NDB Cluster — Management Client –
ndb_mgm> show
Connected to Management Server at: 192.168.1.111:1186
MySQL CLUSTER 集群方案
来源:网络
(1.双机实现高可用)
一、介绍
这篇文档旨在介绍如何安装配置基于2台服务器的MySQL集群。并且实现任意一台服务器出现问题或宕机时MySql集群依然能够继续运行。加下后续的(keepalived+lvs+mysql cluster文档),可以实现Mysql双机的高可用及负载均衡。
启动管理节点Server2为:
# ndb_mgmd –ndb_nodeid=2
注:在启动时有一个警告提示
Cluster configuration warning:
arbitrator with id 1 and db node with id 3 on same host 192.168.1.111
Id=1
HostName= 192.168.1.111
[ndb_mgmd]
Id=2
HostName= 192.168.1.110
[ndbd]
Id= 3
HostName= 192.168.1.111
[ndbd]
Id= 4
HostName= 192.168.1.110
[mysqld]
TimeBetweenWatchDogCheck= 30000
DataDir= /var/lib/mysql-cluster
MaxNoOfOrderedIndexes= 512
[ndb_mgmd default]
DataDir= /var/lib/mysql-cluster
[ndb_mgmd]
# cd /var/lib/mysql-cluster
# vi config.ini
在config.ini中添加如下内容:
[ndbd default]
NoOfReplicas= 2
MaxNoOfConcurrentOperations= 10000
DataMemory= 80M
IndexMemory= 24M
[ndb_mgmd(MGM)] 2 node(s)
id=1 @192.168.1.111 (Version: 5.2.3)
id=2 @192.168.1.110 (Version: 5.2.3)
[mysqld(API)] 4 node(s)
id=5 @192.168.1.111 (Version: 5.2.3)
[mysqld]
[tcp default]
PortNumber= 63132
2.配置通用f文件,mysqld及ndbd,ndb_mgmd均使用此文件.
# vi /etc/f
在f中添加如下内容:
[mysqld]
default-storage-engine=ndbcluster 避免在sql语句中还要加入ENGINE=NDBCLUSTER。
Cluster Configuration
———————
[ndbd(NDB)] 2 node(s)
id=3 @192.168.1.111 (Version: 5.2.3, Nodegroup: 0, Master)
id=4 @192.168.1.110 (Version: 5.2.3, Nodegroup: 0)
安装环境及软件包:
vmware workstation 5.5.3
mysql-5.2.3-falcon-alpha.tar.gz
gentoo 2006.1
Server1: 192.168.1.111
Server2: 192.168.1.110
二、在Server1和Server2上安装MySQL
说节点1和3,2和4的arbitrator一样,可能引起整个集群失败。(可以不用放在心上)
四、初始化集群
在Server1中
# ndbd –nodeid=3 –initial
在Server2中
# ndbd –nodeid=4 –iniitial
注:只有在第一次启动ndbd时或者对config.ini进行改动后才需要使用–initial参数!
以下步骤需要在Server1和Server2上各做一次
# mv mysql-5.2.3-falcon-alpha.tar.gz /tmp/package
# cd /tmp/package
# groupadd mysql
# useradd -g mysql mysql
# tar -zxvf mysql-5.2.3-falcon-alpha.tar.gz
测试完成后,只需要重新启动被破坏服务器的ndbd进程即可:
# ndbd –ndb_nodeid=此存储节点的Байду номын сангаасd
注意!前面说过了,此时是不用加–inital参数的!
至此,MySQL双机集群就配置完成了!
MySQL CLUSTER(集群)系列 (2.另类在线增加节点-online hotplugin)
> INSERT INTO ctest () VALUES (1);
> SELECT * FROM ctest;
应该可以看到1 row returned信息(返回数值1)。
如果上述正常,则换到Server2,观察效果。如果成功,则在Server2中执行INSERT再换回到Server1观察是否工作正常。
# rm -f mysql-5.2.3-falcon-alpha.tar.gz
# mv mysql-5.2.3-falcon-alpha mysql
# cd mysql
# ./configure –prefix=/usr –with-extra-charsets=complex –with-plugin-ndbcluster –with-plugin-partition –with-plugin-innobase
在Server1 中:
#mysqld_safe –ndb_nodeid=5 –user=mysql &
在Server2 中:
#mysqld_safe –ndb_nodeid=6 –user=mysql &
# ndb_mgm -e show
信息如下:
Connected to Management Server at: 192.168.1.111:1186
#ln -s /usr/libexec/mysqlmanager /usr/bin
#mysql_install_db –user=mysql
三、安装并配置节点
以下步骤需要在Server1和Server2上各做一次
1.配置管理节点配置文件:
# mkdir /var/lib/mysql-cluster
如果都没有问题,那么恭喜成功!
六、破坏性测试
将Server1或Server2的网线拔掉(即ifconfig eth0 down),观察另外一台集群服务器工作是否正常(可以使用SELECT查询测试)。测试完毕后,重新插入网线即可。
注意:在未对集群做任何读写操作前,此测试结果无效,因为,集群初始后只在/var/lib/mysql-cluster/下建了几个空目录,还没有正常协同工作,会出现整个所有存储(ndbd)节点关闭.
root 23532 0.0 0.1 3680 684 pts/1 S 07:59 0:00 grep ndbd
然后杀掉一个ndbd进程以达到破坏MySQL集群服务器的目的:
# kill -9 5578 5579
之后在另一台集群服务器上使用SELECT查询测试。并且在管理节点服务器的管理终端中执行show命令会看到被破坏的那台服务器的状态。
id=6 (not connected, accepting connect from any host)
ndb_mgm>
如果上面没有问题,现在开始加入mysqld(API):
注意,这篇文档对于MySQL并没有设置root密码,推荐你自己设置Server1和Server2的MySQL root密码。
[ndb_mgmd(MGM)] 2 node(s)
id=1 @192.168.1.111 (Version: 5.2.3)
id=2 @192.168.1.110 (Version: 5.2.3)
[mysqld(API)] 2 node(s)
id=5 (not connected, accepting connect from any host)
# make && make install
#ln -s /usr/libexec/ndbd /usr/bin
#ln -s /usr/libexec/ndb_mgmd /usr/bin
#ln -s /usr/libexec/ndb_cpcd /usr/bin
#ln -s /usr/libexec/mysqld /usr/bin
mysql-5.2.3-falcon-alpha.tar.gz
gentoo 2006.1
(每机单网卡多ip)
Server1: 192.168.1.111 (ndb_mgmd, id=1)