Erdas非监督分类全过程
ERDAS操作技巧

ERDAS操作技巧加载波段成影像:interpreter---utilities---layer stackERDAS 操作⼩技巧:1、配准影像图:从Viewer 中打开两幅图(⼀幅参照,⼀幅配准)从菜单栏Raster 中选Geometric correction (⼏何校正)在Set Geometric Model 中选Polynomial ,后点击ok ,打开Polynomial Model Properties 对话框,在Parameters 中Polynomial Order (多项式次⽅)中选1或2[最少GCP 公式:2)2)(1++n n (],在Projection (投影参数)中Map Units 选Meters 点击Add/Change Projection 在Custom 中选择所需的Projection Type ,Spheroid Name ,Datum Name ,Scale factor at central meridian ,Longitude of central meridian (可以参考参照图中Imagine info 中的信息),Latitude of origin of projection ,False easting (⼀般选500000meters ),False northing (⼀般忽略为零),点击Ok Set Projection from GCP Tool 中选择Collect Reference Point From (选择视窗采点模式)中的 Existing Viewer 选项,Ok 。
RMS 误差(均⽅根)=22)()i r i r y y x x -+-(这⾥:x i 和y i 是输⼊的原坐标;x r 和y r 是逆变换后的坐标定义:RMS 误差是指GCP 的输⼊(原)位置和逆变换的位置之间的距离(或者说是在⽤转换矩阵对⼀个GCP 作转换时,所期望输出的坐标与实际输出的坐标之间的偏差)。
《Erdas遥感图像处理》实验指导书

《E r d a s遥感图像处理》实验指导书-CAL-FENGHAI.-(YICAI)-Company One1《遥感图像处理》实验指导书实验一、ERDAS视窗的基本操作实验目的:初步了解目前主流的遥感图象处理软件ERDAS的主要功能模块,在此基础上,掌握视窗操作模块的功能和操作技能,为遥感图像的几何校正等后续实习奠定基础。
实验内容:视窗功能介绍;文件菜单操作;实用菜单操作;显示菜单操作;矢量和删格菜单操作等。
视窗操作是ERDAS软件操作的基础, ERDAS所有模块都涉及到视窗操作。
本实验要求掌握视窗的基本功能,熟练掌握图像显示操作和矢量菜单操作,从而为深入理解和学习ERDAS软件打好基础。
1、视窗功能简介二维视窗(图1-1)是显示删格图像、矢量图形、注记文件、AOI等数据层的主要窗口。
通过实际操作,掌握视窗菜单的主要功能、视窗工具功能。
图1-1 二维视窗重点掌握ERDAS图表面板菜单条;ERDAS图表面板工具条;掌握视窗菜单功能和视窗工具功能等基本操作。
2、图像显示操作(Display an Image)第一步:启动程序(Start Program)视窗菜单条:File→open→ RasterLayer→Select Layer To Ad d对话框。
第二步:确定文件(Determine File)在Select Layer To Add对话框中有File和Raster Option两个选择项,其中File就是用于确定图像文件的,具体内容和操作实例如表。
参数项含义实例Look in确定文件目录examplesFile name确定文件名xs_truecolorFile of type确定文件类型IMAGINE Image(*.img)Recent选择近期操作过的文------件Go to改变文件路径-------图1-2 参数设置第四步:打开图像(Open Raster Layer)3、实用菜单操作了解光标查询功能;量测功能;数据叠加功能;文件信息操作;三维图像操作等。
Erdas非监督聚类教程

Erdas基础教程: 非监督分类1.图像分类简介(Introduction to classification)图像分类就是基于图像像元的数据文件值,将像元归并成有限几种类型、等级或数据集的过程。
常规图像分类主要有两种方法:非监督分类与监督分类,专家分类方法是近年来发展起来的新兴遥感图像分类方法,下面介绍这三种分类方法。
非监督分类运用1SODATA(Iterative Self-Organizing Data Analysis Technique )算法,完全按照像元的光谱特性进行统计分类,常常用于对分类区没有什么了解的情况。
使用该方法时。
原始图像的所有波段都参于分类运算,分类结果往往是各类像元数大体等比例。
由于人为干预较少,非监督分类过程的自动化程度较高。
非监督分类一般要经过以下几个步骤:初始分类、专题判别、分类合并、色彩确定、分类后处理、色彩重定义、栅格矢量转换、统计分析。
监督分类比非监督分类更多地要求用户来控制,常用于对研究区域比较了解的情况。
在监督分类过程中,首先选择可以识别或者借助其它信息可以断定其类型的像元建立模板,然后基于该模板使计算机系统自动识别具有相同特性的像元。
对分类结果进行评价后再对模板进行修改,多次反复后建立一个比较准确的模板,并在此基础上最终进行分类。
监督分类一般要经过以下几个步骤:建立模板(训练样本)、评价模板、确定初步分类图、检验分类结果、分类后处理、分类特征统计、栅格矢量转换。
专家分类首先需要建立知识库,根据分类目标提出假设,井依据所拥有的数据资料定义支持假设的规则、条件和变量,然后应用知识库自动进行分类,ERDAS IMAG1NE图像处理系统率先推出专家分类器模块,包括知识工程师和知识分类器两部分,分别应用于不同的情况。
由于基本的非监督分类属于IMAGINE Essentia1s级产品功能、但在1MAGINE Professional级产品中有一定的功能扩展,而监督分类和专家分类只属于IMAGINE ProfeSsiona1级产品,所以,非监督分类命令分别出现在Data Preparation菜单和classification菜单中,而监督分类和专家分类命令仅出现在Classification菜单中。
Erdas监督分类步骤

遥感图像分类的原理基本原理监督分类中常用的具体分类方法包括:最小距离分类法(minimum distance classifier):最小距离分类法是用特征空间中的距离作为像元分类依据的。
最小距离分类包括最小距离判别法和最近邻域分类法。
最小距离判别法要求对遥感图像中每一个类别选一个具有代表意义的统计特征量(均值),首先计算待分象元与已知类别之间的距离,然后将其归属于距离最小的一类。
最近邻域分类法是上述方法在多波段遥感图像分类的推广。
在多波段遥感图像分类中,每一类别具有多个统计特征量。
最近邻域分类法首先计算待分象元到每一类中每一个统计特征量间的距离,这样,该象元到每一类都有几个距离值,取其中最小的一个距离作为该象元到该类别的距离,最后比较该待分象元到所有类别间的距离,将其归属于距离最小的一类。
最小距离分类法原理简单,分类精度不高,但计算速度快,它可以在快速浏览分类概况中使用。
多级切割分类法(multi-level slice classifier):是根据设定在各轴上值域分割多维特征空间的分类方法。
通过分割得到的多维长方体对应各分类类别。
经过反复对定义的这些长方体的值域进行内外判断而完成各象元的分类。
这种方法要求通过选取训练区详细了解分类类别(总体)的特征,并以较高的精度设定每个分类类别的光谱特征上限值和下限值,以便构成特征子空间。
多级切割分类法要求训练区样本选择必须覆盖所有的类型,在分类过程中,需要利用待分类像元光谱特征值与各个类别特征子空间在每一维上的值域进行内外判断,检查其落入哪个类别特征子空间中,直到完成各像元的分类。
多级分割法分类便于直观理解如何分割特征空间,以及待分类像元如何与分类类别相对应。
由于分类中不需要复杂的计算,与其它监督分类方法比较,具有速度快的特点。
但多级分割法要求分割面总是与各特征轴正交,如果各类别在特征空间中呈现倾斜分布,就会产生分类误差。
因此运用多级分割法分类前,需要先进行主成分分析,或采用其它方法对各轴进行相互独立的正交变换,然后进行多级分割。
监督分类与专题制图(Erdas)

遥感实验报告实验目的:掌握遥感图像计算机分类的基本原理以及监督分类方法,掌握分类后处理方法、分类精度评价及专题地图制作。
实验内容:1、遥感图像计算机监督分类2、分类后处理3、分类精度评价4、专题图制作实验方法和步骤:实验方法:在监督分类的过程中,首先借助或者识别其他信息可以断定其类型的像元建立模板,然后基于该模板使计算机系统自动识别具有该特性的像元。
对分类结果进行评价后在对模板进行修改,多次反复后建立一个比较准确的模板,并在此基础上进行最终分类。
实验步骤:1.定义分类模板2.精度评价3.进行监督分类4.评价分类结果5.分类后处理6.专题制图实验的过程和结果:(一)监督分类1.定义分类模板第一步:打开分类的图像,南宁市1990年9月16日TM,目视判断该遥感图像中南宁市土地利用类型,确定土地利用分类体系为:耕地、灌草地、林地、水域、建设用地、裸地。
如图1-1:图1-1第二步:打开模板编辑器并调整显示字段点击主菜单上的classifier打开classification对话框,选择signature editor。
如图1-2:图1-2第三步:获取分类模板信息,点击AOI,利用AOI-tools中的多边形工具绘制某一地类的样区。
将画好的耕地AOI添加到模板。
signature editor-edit-add.如图1-3,1-4:图1-3图1-4重复步骤第三步,在图中采集多个耕地样本。
选择所有耕地样本模板,按merge 按纽合并这组分类模板。
合并后将模板取名为耕地。
利用同样的方法,依次做好其灌草地、林地、水域、建设用地、裸地土地覆盖类型模板。
如图1-5:图1-5第四步:保存分类模板。
2 .评价分类模板第一步:点signature editor-Evaluate-contingency,利用可能性矩阵方法评价分类模板精度。
达到90以上即为精度满足要求,否则重新选择训练样区,再次进行精度评价,直到精度满足。
Erdas监督分类步骤

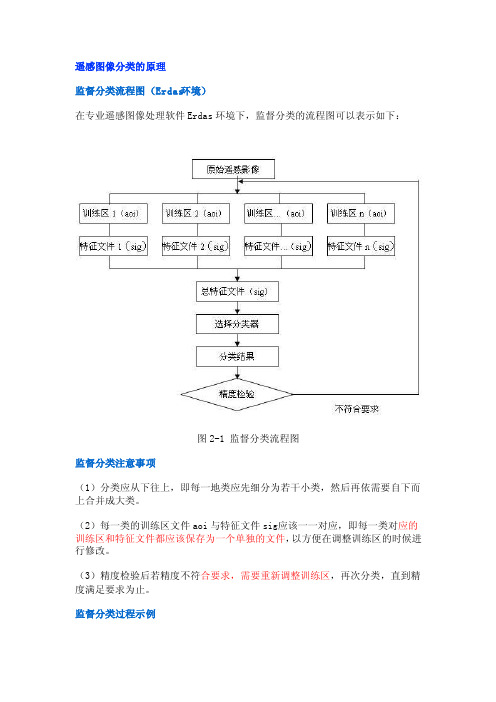
遥感图像分类的原理监督分类流程图(Erdas环境)在专业遥感图像处理软件Erdas环境下,监督分类的流程图可以表示如下:图2-1 监督分类流程图监督分类注意事项(1)分类应从下往上,即每一地类应先细分为若干小类,然后再依需要自下而上合并成大类。
(2)每一类的训练区文件aoi与特征文件sig应该一一对应,即每一类对应的训练区和特征文件都应该保存为一个单独的文件,以方便在调整训练区的时候进行修改。
(3)精度检验后若精度不符合要求,需要重新调整训练区,再次分类,直到精度满足要求为止。
监督分类过程示例1.图2-2为某地TM遥感影像,432波段假彩色合成。
图2-2TM影像(432波段合成)2.确定分类类别通过色调、纹理等图像特征,确定该区域分类类别为水体,植被和滩涂。
各类分类特征如表2-1所示。
表2-1 分类特征3.为每一类选择训练区及特征文件(1)AOI操作工具简介在Viewer窗口中选择“AOI”→“Tools…”,调出AOI(Area Of Interest,感兴趣区)浮动工具栏(如图2-3所示)。
图2-3AOI浮动工具栏其中较为常用的工具按钮为:(2)特征文件操作工具简介特征文件从AOI区域中获得。
使用“Erdas”→“Classifier”→“Signature Editor”,调出特征文件编辑器,如图2-4所示。
图2-4 特征文件编辑器其中较为常用的工具为:打开一个特征文件。
新建一个特征文件/打开新的特征文件编辑器。
添加选中的AOI 的特征到特征文件中。
使用选中的AOI特征替换当前特征。
合并选中的特征文件中的特征到一个特征。
一般建立特征文件的步骤是,在Viewer窗口中使用AOI工具勾画感兴趣区,使用把该AOI区域中的特征添加到特征文件中。
也可以选中多个AOI批量添加到特征文件图2-5中。
(2)为各类别建立训练区文件和特征文.件。
把遥感影像放大到像元级,选择矩形AOI选择工具,根据建立的判读标识,在遥感影像上选择AOI区域,然后使用依次图2-6 添加特征到特征文件中。
国外四大遥感软件影像分类过程及效果比较

4 PCI
PCI GEOMATICA 是 PCI 公司将其旗下的 4 个主要 产品系列。PCI GEOMATICA,该系列产品在每一级深 度层次上,尽可能多的满足该层次用户对遥感影像处 理、摄影测量、GIS 空间分析、专业制图功能的需要, 而且使用户可以方便地在同一界面下完成他们的工作。
PCI 的主要特点: 1)PCI 的几何处理能力比 ERDAS 强。PCI Geomatica Prime (PCI 地理咨讯专业版) PCI Geomatica Prime 包 含 PCI Geomatica Fundamentals 的所有功能。此外,增 加了 PCI Modeler、EASI、FLY、算法库等模块。Geomatica Prime 是强大的、低成本解决方案,提供的工具用于影 像几何校正、数据可视化以及专业标准地图生产。 2)PCI 对于雷达影像的处理效果很好。专业雷达 处理,雷达由于具有全天时、全天侯获取数据的能力, 加上在海洋、冰雪、植被、地质、军事很多应用领域 的独特优势,引起了各国的普遍重视。 PCI 公司紧紧 抓住了这一发展趋势,在雷达数据处理领域始终保持
1)强大的多光谱影像处理功能。ENVI 能够充分 提取图像信息,具备全套完整的遥感影像处理工具,能 够进行文件处理、图像增强、掩膜、预处理、图像计 算和统计,完整的分类及后处理工具,及图像变换和 滤波工具、图像镶嵌、融合等功能。ENVI 遥感影像处 理软件具有丰富完备的投影软件包,可支持各种投影 类型。同时,ENVI 还创造性地将一些高光谱数据处理 方法用于多光谱影像处理,可更有效地进行知识分类、 土地利用动态监测。
PCI--影像分类

PCI Focus影像分类实验内容:1非监督分类2分类后分析——非监督分类3监督分类前的准备工作4选择训练区5分析训练区6进行监督分类7分类后分析——监督分类一:非监督分类实验内容:·新建分类通道·非监督分类前的准备·进行分类和查看报告实验原理:非监督分类把影像信息分成离散的组,每个组中的像元波谱信息相似。
用Focus进行非监督分类,需要借助面板和对话框配置数据文件和选择计算机用来区分的类的数量。
当完成了配置信息,就可以进行分类了。
Focus自动地把影像数据中的波谱值分成不同的类,可以在Focus的视窗里查看分类结果并把它作为分类报告。
实验数据:stack_l7_b1-8_pansharp_erdas_correct.pix(福州地区2002年的landsat7数据)经erdas几何校正和pansharp融合。
具体步骤:1:新建工程并打开2:准备一个分类通道:1.在地图树上,右键点击stack_l7_b1-8_pansharp_erdas_correct.pix层;快捷菜单打开。
·2.在影像分类的子菜单上,点击Unsupervised(非监督分类);通道选择窗口打开。
3.点击New Session(新建通道);4.在描述框里,键入Unsupervised Session(非监督分类通道);5.选择RGB通道里面的相应波段;6.在输入通道一栏,选择1到8通道;图通道设置面板7.在输出通道一栏,选择一个空通道作为输出通道:8.点击面板左下方的Accept。
9:进行非监督分类:在分类面板上,选择K-Means算法;在K-Means的参数里,点击"Max Class"的输入框;输入16;在分类面板左下方,点击"Classify",Focus将用K-Means 算法进行分类。
一个进度条显示分类进度,分类结束后,进度条关闭,分类报告窗口打开,分类后的影像在Focus视窗区显示出来。
ERDAS二值化操作

1、图像导入在erdas的Import/Export模块中,分别导入TM图像的第1、2、3、4、5、7波段,具体操作步骤为①点击import模块,打开对话框②选择type类型为TIFF③media为file;④然后选择输入、输出文件名路径和文件名⑤分别对123457波段进行导入;⑥在此之前可以选择session->preference,选择输入、输出主目录。
2、图像波段合成在erdas的interpreter模块中将单波段影像进行合成,生成多波段文件,具体操作步骤为:interpreter->utilities->layer stack,①在出现的对话框中import框中依次选择需要合成的波段,每选择输入一个波段用Add添加一次;②output file选择导出文件路径及命名文件。
③Data type 设为Unsigned 8 bit;④Output option 设置为Union ,选中ignore zero stats;⑤进行操作。
3、用shape文件进行图像切割3.1 Shape文件制作AOI文件:①在ERDAS中点击Import图标,出现Import/Export对话框②选中Imput,Type栏选择Shapefile,Media栏选择File,在Input File(*.shp)中确定要转换的shape文件,在Output File(*.arcinfo)中确定输出路径及名称,单击OK按钮,出现Import Shapefile对话框,单击Import Shapefile Now。
③注意此步骤中输出路径及输出名称均为英文字母④建立拓扑多边形⑤在Arcgis中打开ArcToolbox,Data Management Tools—>Topology—>Build,双击Build,出现Build对话框,在Input 中填入*.arcinfo文件的路径,Feature选择Poly⑥单击OK按钮。
Erdas监督分类步骤
遥感图像分类的原理监督分类流程图(Erdas环境)在专业遥感图像处理软件Erdas环境下,监督分类的流程图可以表示如下:图2-1 监督分类流程图监督分类注意事项(1)分类应从下往上,即每一地类应先细分为若干小类,然后再依需要自下而上合并成大类。
(2)每一类的训练区文件ao i与特征文件sig应该一一对应,即每一类对应的训练区和特征文件都应该保存为一个单独的文件,以方便在调整训练区的时候进行修改。
(3)精度检验后若精度不符合要求,需要重新调整训练区,再次分类,直到精度满足要求为止。
监督分类过程示例1.图2-2为某地TM遥感影像,432波段假彩色合成。
图2-2 TM影像(432波段合成)2.确定分类类别通过色调、纹理等图像特征,确定该区域分类类别为水体,植被和滩涂。
各类分类特征如表2-1所示。
表2-1 分类特征3.为每一类选择训练区及特征文件(1)AOI操作工具简介在Viewe r窗口中选择“AOI”→“Tools…”,调出AOI(Area Of Intere st,感兴趣区)浮动工具栏(如图2-3所示)。
图2-3 AOI浮动工具栏其中较为常用的工具按钮为:(2)特征文件操作工具简介特征文件从A OI区域中获得。
使用“Erdas” →“Classi fier” →“Signat ure Editor”,调出特征文件编辑器,如图2-4所示。
图2-4 特征文件编辑器其中较为常用的工具为:打开一个特征文件。
新建一个特征文件/打开新的特征文件编辑器。
添加选中的A OI的特征到特征文件中。
使用选中的A OI特征替换当前特征。
合并选中的特征文件中的特征到一个特征。
一般建立特征文件的步骤是,在Viewe r 窗口中使用AOI工具勾画感兴趣区,使用把该AOI区域中的特征添加到特征文件中。
非监督分类(Erdas)

遥感实验报告图1-1第二步:进行非监督分类→确定初始分类数(Number of classes): 12分出12个类别实际工作中一般将分类数取为最终分类数的2倍以上。
.点击Initializing options按钮可以调出Fi1e Statistics Options对话框以设置ISODATA的一些统计参数,.点击Co1or Scheme Options按钮可以调出output color Scheme Options对话框以决定输出的分类图像是彩色的还是黑白的。
这两个设置项使用缺省值。
最大循环次数(Maximum Iterations)是指ISODATA重新聚类的最多次数,这是为了避免程序运行时间太长或由于没有达到聚类标准而导致的死循环。
一般在应用中将循环次数都取6次以上。
→设置循环收敛阈值(Convergence Threshold):0.95收敛阈值(Convergence Threshold)是指两次分类结果相比保持不变的像元所占最大百分之此值的设立可以避免ISODATA无限循环下去。
→点击OK按钮(关闭Unsupervised Classification对话框,执行非监督分类,获得一个初步的分类结果)生成如图1-2所示:图1-22 、分类评价( Evaluate Classification )第一步:显示原图像与分类图像在同一个窗口中,同时打开两个图像。
第二步:打开分类图像属性表并调整字段显示顺序→打开Raster工具面板→点击Raster工具面板的属性图标(Raster Attributes) →打开Raster Attribute Editor对话框(germtm_isodata的属性表),Rarster Attribute Editor对话框菜单条:Edit→Column Properties →Column Properties 对话框在Columns中选择要调整显示顺序的字段,通过UP、DOWN、TOP 、BOTTOM等几个按钮调整其合适的位置,通过选择DISPLAY WIDTH调整其显示宽度,通过Alignment 调整其对齐方式。
非监督分类
非监督分类非监督分类:也称为聚类分析或点群分类。
在多光谱图像中搜寻、定义其自然相似光谱集群的过程。
它不必对影像地物获取先验知识,仅依靠影像上不同类地物光谱(或纹理)信息进行特征提取,再统计特征的差别来达到分类的目的,最后对已分出的各个类别的实际属性进行确认。
目前比较常见也较为成熟的是ISODATA、K-Mean和链状方法等。
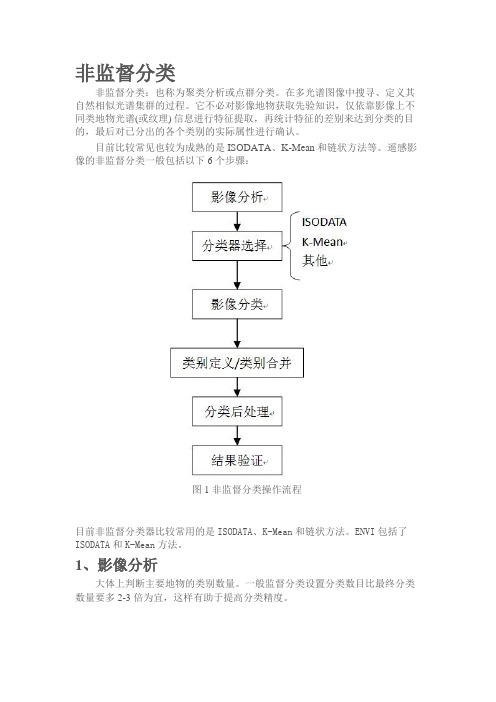
遥感影像的非监督分类一般包括以下6个步骤:图1非监督分类操作流程目前非监督分类器比较常用的是ISODATA、K-Mean和链状方法。
ENVI包括了ISODATA和K-Mean方法。
1、影像分析大体上判断主要地物的类别数量。
一般监督分类设置分类数目比最终分类数量要多2-3倍为宜,这样有助于提高分类精度。
本案例的数据源为ENVI自带的Landsat tm5数据Can_tmr.img,类别分为:林地、草地/灌木、耕地、裸地、沙地、其他六类。
确定在非监督分类中的类别数为15。
2、分类器选择ISODATA(Iterative Self-Orgnizing Data Analysize Technique)重复自组织数据分析技术,计算数据空间中均匀分布的类均值,然后用最小距离技术将剩余像元进行迭代聚合,每次迭代都重新计算均值,且根据所得的新均值,对像元进行再分类。
K-Means使用了聚类分析方法,随机地查找聚类簇的聚类相似度相近,即中心位置,是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的,然后迭代地重新配置他们,完成分类过程。
3、影像分类打开ENVI,选择主菜单->Classification->Unsupervised->IsoData或者K-Means。
这里选择IsoData,在选择文件时候,可以设置空间或者光谱裁剪区。
这里选择软件自带的Can_tmr.img,按默认设置,之后跳出参数设置,如图2。
这里主要设置类别数目(Number of Classes)为5-15、迭代次数(Maximum Iteration)为10。
《ERDAS IMAGE遥感图像处理方法》操作

《ERDAS IMAGE遥感图像处理方法》操作一空间增强(Spatial Enhancement)1卷积增强处理(Convolution)功能:用一个系数矩阵将整个图像按照象元分块进行平均处理,用于改变图像的空间频率特征。
to效果:地物的轮廓和线条勾勒变清晰了。
2非定向边缘增强(Non-directional Edge)功能:应用两个非常通用的滤波器(Sobel 滤波器和Prewitt 滤波器),首先通过两个正交卷积算子(Horizontal算子和Vertical算子)分别对遥感图像进行边缘检测,然后将两个正交结果进行平均化处理。
to效果:效果明显而且强烈分别出邻区不同的部分。
3.聚焦分析(Focal Analysis)功能:使用类似卷积滤波的方法,选择一定的窗口呼函数,对输入图像文件的数值进行多种变换,应用窗口范围内的象元数值计算窗口中心象元的值,达到图像增强的目的。
to效果:深色地方变模糊,浅色地物图象得到增强,但也变得不清晰。
4.纹理分析(Texture Analysis)功能:通过二次变异等分析使图象的纹理结构更加清晰。
to效果:纹理边缘部分十分清晰。
5.自适应滤波(Adaptive Filter)功能:应用自适应滤波器对图像的感兴趣区域进行对比度拉伸处理。
to效果:颜色变浅了。
6.分辨率融合(Resolution Merge)功能:对不同空间分辨率遥感图像的融合处理,使处理后的遥感图像即具有较好的空间分辨率,又具有多光谱特征,达到图象增强的目的。
+ =效果:处理后图象既有高分辨率又有多光谱特征(彩色)。
7.锐化增强处理(Crisp Enhancement)功能:对图像进行卷积滤波处理,使整景图像的亮度得到增强而不使其专题内容发生变化。
效果:区别不大,亮度得到些许增强。
二.辐射增强(Radiometric Enhancement)1.查找表拉伸(LUT Stretch)功能:通过修改图像查找表使输出图像值发生变化。
非监督分类的主要流程

非监督分类的主要流程
非监督分类的主要流程包括以下几个步骤:
1. 数据准备:收集待处理的数据集,并进行预处理,包括数据清洗、去噪、特征提取等。
2. 特征选择:针对数据集的特征进行筛选和选择,提取出最具代表性的特征进行后续处理。
3. 数据转换:对处理后的数据进行转换,使其适用于聚类算法的处理。
常见的数据转换方法包括特征缩放、数据平滑等。
4. 聚类算法选择:根据问题的特性和需求,选择适当的聚类算法进行分类。
常见的聚类算法有K-means、层次聚类、DBSCAN等。
5. 聚类处理:利用所选的聚类算法对数据进行处理,将数据集划分为若干个簇。
簇内的数据具有相似的特征,簇间的数据具有较大的差异。
6. 评估聚类结果:对聚类结果进行评估,包括内部评估和外部评估两种方式。
内部评估是通过比较簇内的相似性和簇间的差异来评估聚类结果的好坏;外部评估是通过将聚类结果与已知的类别进行比较来评估算法的准确性。
7. 结果分析和应用:根据聚类结果进行进一步的分析和应用,如可视化展示、数据挖掘等。
需要注意的是,非监督分类是在没有事先标记的情况下进行的分类,因此结果的准确性和可解释性可能会受到一定的影响。
对于非监督分类的结果,可能需要进一步进行验证和调整。
非监督分类的主要流程

非监督分类的主要流程1.数据预处理:数据预处理是非监督分类的第一步,其目的是将原始数据转换为适合进行非监督分类的形式。
数据预处理的过程中,可能需要对数据进行清洗、降维、归一化等操作。
清洗数据是指处理数据中存在的错误、缺失或异常值。
一般来说,可以通过检测和修补错误值、填补缺失值、剔除异常值等方法进行数据清洗。
归一化是指将数据的值映射到固定的区间内,使得不同特征之间的量纲一致。
归一化的方法包括线性缩放、标准化等。
2.特征提取:特征提取是非监督分类的第二步,其目的是从预处理后的数据中提取出能够描述数据特征的有意义的特征。
特征提取的方法包括特征选择和特征降维两种。
特征选择是指从原始数据中选择出最重要、最具有代表性的特征。
常用的特征选择方法包括信息增益、卡方检验、互信息等。
3.聚类:聚类是非监督分类的最后一步,其目的是将数据分成若干个不同的簇(Cluster),使得同一个簇内的数据之间的相似度高,而不同簇之间的相似度低。
聚类的方法可以分为层次聚类和划分聚类两种。
层次聚类是将数据点逐步合并形成聚类结构的过程。
常用的层次聚类算法有凝聚层次聚类(Agglomerative Hierarchical Clustering)和分裂层次聚类(Division Hierarchical Clustering)。
划分聚类是将数据划分成不同的簇的过程。
常用的划分聚类算法有K 均值聚类(K-means Clustering)和密度聚类(Density-based Clustering)。
在聚类过程中,还可以通过设置合适的聚类数量、选择合适的距离度量方法和聚类评价指标等手段对聚类结果进行优化和评估。
总结:非监督分类的主要流程包括数据预处理、特征提取和聚类三个步骤。
数据预处理的目的是将原始数据转换为适合进行非监督分类的形式;特征提取的目的是从预处理后的数据中提取出能够描述数据特征的有意义的特征;聚类的目的是将数据分成若干个不同的簇。
ERDAS监督分类(完美)

监督分类(Supervised Classification)监督分类比非监督分类更多地要用户来控制,常用于对研究区域比较了解的情况。
在监督分类过程中,首先选择可以识别或者借助于其他信息可以断定其类型的像元建立模板,然后基于该模板使计算机系统自动识别具有相同特性的像元。
对分类结果进行评价后再对模板进行修改,多次反复后建立一个比较准确的模板,并在此基础上最终进行分类。
监督分类一般要经过以下几个步骤:建立模板(训练样本)、评价模板、确定初步分类结果、检验分类结果、分类后处理、分类特征统计、栅格矢量转换。
1.建立模板(训练样本、定义分类模板Define Signatures)ERDAS IMAGINE 的监督分类是基于分类模板(Classification Signature)来进行的,而分类模板的生成、管理、评价和编辑等功能是由分类模板编辑器(SignatureEditor )来负责的。
在分类模板编辑器中生成分类模板的基础是原图像和(或)其特征空间图像。
第一步:显示需要分类的图像在视窗Viewer 中显示图像aaa.img第二步:打开分类模板编辑器(两种方式)①ERDAS 图标面板菜单条:Main Image Classification Classification 菜单Signature Editor 菜单项Signature Editor 对话框②ERDAS 图标面板工具条:点击Classifier 图标Classification 菜单Signature Editor 菜单项Signature Editor 对话框从上图中可以看到分类模板编辑器由菜单条、工具条和分类模板属性表(CellArray )三大部分组成。
第三步:调整分类属性字段Signature Editor 对话框中的分类属性表中有很多字段,分类名称(将带入分类图像)分类颜色(将带入分类图像)分类代码(只能用正整数)分类过程中的判断顺序分类样区中的像元个数分类可能性权重(用于分类判断)不同字段对于建立分类模板的作用或意义是不同的,为了突出作用比较大的字段,需要进行必要的调整。
非监督分类的主要流程

非监督分类的主要流程非监督学习是机器学习中的一种方法,它与监督学习不同,不需要预先标记的训练数据。
它的主要目标是通过对数据进行聚类、降维或异常检测等操作,自动发现数据中的模式和结构,从而实现对数据的分类。
非监督学习的主要流程可以分为以下几个步骤:1. 数据预处理:在进行非监督学习之前,通常需要对数据进行预处理。
这包括数据清洗、数据归一化、特征选择等操作,以确保数据的质量和一致性。
2. 特征提取:在非监督学习中,我们通常关注数据中的特征而不是标签。
特征提取是将原始数据转换为更具有代表性的特征表示的过程。
常用的特征提取方法有主成分分析(PCA)、独立成分分析(ICA)等。
3. 聚类:聚类是非监督学习的一项重要任务,其目标是将相似的数据样本分组到同一个簇中。
常用的聚类算法有K均值算法、层次聚类算法、DBSCAN算法等。
聚类可帮助我们发现数据中的内在结构和模式,并进行进一步的分析。
4. 降维:降维是将高维数据映射到低维空间的过程,旨在保留原始数据的重要信息。
常用的降维方法有主成分分析(PCA)、线性判别分析(LDA)等。
降维可以减少数据的维度,提高模型的效率和可解释性。
5. 异常检测:异常检测是非监督学习中的另一个重要任务,其目标是识别数据中的异常样本。
常用的异常检测方法有基于统计学的方法、基于聚类的方法、基于密度的方法等。
异常检测可以帮助我们发现数据中的异常情况,从而采取相应的措施。
6. 结果评估:在完成非监督学习任务后,需要对结果进行评估。
评估方法根据具体任务的不同而不同,可以使用聚类指标(如轮廓系数)、降维保留的信息比例、异常检测的精确度和召回率等进行评估。
非监督学习在实际应用中有着广泛的应用。
例如,在市场营销中,可以使用聚类分析来划分用户群体,从而制定针对性的营销策略。
在图像处理中,可以使用降维技术来提取图像的重要特征,从而实现图像的压缩和识别。
在金融领域,可以使用异常检测来识别异常交易行为,从而提高风险控制能力。
遥感图像处理的一般步骤

遥感图像处理的一般步骤针对TM影像的一般处理流程1、图像导入在ERDAS的Import/Export模块中,分别导入TM图像的第1、2、3、4、5、7波段,具体操作步骤为①点击import模块,打开对话框②选择type类型为TIFF③media为file;④然后选择输入、输出文件名路径和文件名⑤分别对123457波段进行导入;⑥在此之前可以选择session->preference,选择输入、输出主目录。
2、图像波段合成在erdas的interpreter模块中将单波段影像进行合成,生成多波段文件,具体操作步骤为:interpreter->utilities->layer stack,①在出现的对话框中import框中依次选择需要合成的波段,每选择输入一个波段用Add添加一次;②output file选择导出文件路径及命名文件。
③Data type 设为Unsigned 8 bit;④Output option 设置为Union ,选中ignore zero stats;⑤进行操作。
3、用shape文件进行图像切割3.1 Shape文件制作AOI文件:①在ERDAS中点击Import图标,出现Import/Export对话框②选中Imput,Type栏选择Shapefile,Media栏选择File,在Input File (*.shp)中确定要转换的shape文件,在Output File (*.arcinfo)中确定输出路径及名称,单击OK按钮,出现Import Shapefile对话框,单击Import Shapefile Now。
③注意此步骤中输出路径及输出名称均为英文字母④建立拓扑多边形⑤在Arcgis中打开ArcT oolbox,Data ManagementTools—>Topology—>Build,双击Build,出现Build对话框,在Input 中填入*.arcinfo文件的路径,Feature选择Poly⑥单击OK按钮。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Erdas基础教程: 非监督分类来源:师大学旅游与环境学院1.图像分类简介(Introduction to classification)图像分类就是基于图像像元的数据文件值,将像元归并成有限几种类型、等级或数据集的过程。
常规图像分类主要有两种方法:非监督分类与监督分类,专家分类方法是近年来发展起来的新兴遥感图像分类方法,下面介绍这三种分类方法。
非监督分类运用1SODATA(Iterative Self-Organizing Data Analysis Technique )算法,完全按照像元的光谱特性进行统计分类,常常用于对分类区没有什么了解的情况。
使用该方法时。
原始图像的所有波段都参于分类运算,分类结果往往是各类像元数大体等比例。
由于人为干预较少,非监督分类过程的自动化程度较高。
非监督分类一般要经过以下几个步骤:初始分类、专题判别、分类合并、色彩确定、分类后处理、色彩重定义、栅格矢量转换、统计分析。
监督分类比非监督分类更多地要求用户来控制,常用于对研究区域比较了解的情况。
在监督分类过程中,首先选择可以识别或者借助其它信息可以断定其类型的像元建立模板,然后基于该模板使计算机系统自动识别具有相同特性的像元。
对分类结果进行评价后再对模板进行修改,多次反复后建立一个比较准确的模板,并在此基础上最终进行分类。
监督分类一般要经过以下几个步骤:建立模板(训练样本)、评价模板、确定初步分类图、检验分类结果、分类后处理、分类特征统计、栅格矢量转换。
专家分类首先需要建立知识库,根据分类目标提出假设,井依据所拥有的数据资料定义支持假设的规则、条件和变量,然后应用知识库自动进行分类,ERDAS IMAG1NE图像处理系统率先推出专家分类器模块,包括知识工程师和知识分类器两部分,分别应用于不同的情况。
由于基本的非监督分类属于IMAGINE Essentia1s级产品功能、但在1MAGINE Professional级产品中有一定的功能扩展,而监督分类和专家分类只属于IMAGINE ProfeSsiona1级产品,所以,非监督分类命令分别出现在Data Preparation菜单和classification菜单中,而监督分类和专家分类命令仅出现在Classification菜单中。
2 非监督分类(Unsupervised Classification)ERDAS IMAGINE使用ISODATA算法(基于最小光谱距离公式)来进行非监督分类。
聚类过程始于任意聚类平均值或一个己有分类模板的平均值:聚类每重复一次,聚类的平均值就更新一次,新聚类的均值再用于下次聚类循环。
ISODATA实用程序不断重复,直到最大的循环次数已达到设定阈值或者两次聚类结果相比有达到要求百分比的像元类别已经不再发生变化。
2.1分类过程(classification ProcedUre )第一步:调出非监督分类对话框调出非监督分类对话框的方法有以下两种:方法一:在ERDAS图标面板工具条中,点击Dataprep图标→ Data Preparation →unsupervised Classification →Unsupervised Classification对话框如下:方法二:在ERDAS图标面板工具条中点击Classifier图标→C1assification →Unsupervised Classification---→unsupervised classification对话框如下:可以看到,两种方法调出的Unsupervised Classification对话框是有一些区别的。
第二步:进行非监督分类在Unsupervised classification对话框中:→确定输出文件(Input Raster File):lazhoucity.img(要被分类的图像)→确定输出文件(Output File):lz-isodat.img(即将产生的分类图像)→选择生成分类摸板文件: Output Signature Set(将产生一个模板文件)→确定分类摸板文件(Filename ): lz-isodat.sig→对Clustering options选择Initialize from Statistics单选框Initialize from Statistics指由图像文件整体(或其AOI区域)的统计值产主自由聚类,分出类别的多少由自己决定。
Use Signature Means是基于选定的模板文件进行非监督分类,类别的数目由模板文件决定。
→确定初始分类数(Number of classes): 18分出18个类别)实际工作中一般将分类数取为最终分类数的2倍以上。
.点击Initializing options按钮可以调出Fi1e Statistics Options对话框以设置ISODATA的一些统计参数,.点击Co1or Scheme Options按钮可以调出output color Scheme Options对话框以决定输出的分类图像是彩色的还是黑白的。
这两个设置项使用缺省值。
.定义最大循环次数(Maximum Iterations): 24最大循环次数(Maximum Iterations)是指ISODATA重新聚类的最多次数,这是为了避免程序运行时间太长或由于没有达到聚类标准而导致的死循环。
一般在应用中将循环次数都取6次以上。
→设置循环收敛阈值(Convergence Threshold):0.95收敛阈值(Convergence Threshold)是指两次分类结果相比保持不变的像元所占最大百分之此值的设立可以避免ISODATA无限循环下去。
→点击OK按钮(关闭Unsupervised Classification对话框,执行非监督分类,获得一个初步的分类结果)2.2 分类评价(Evaluate Classification )获得一个初步的分类结果以后,可以应用分类叠加(Classification over1ay)方法来评价检查分类精度。
其方法如下:第一步:显示原图像与分类图像在视窗中同时显示lanzhoucity.img和lz-isodat.img:两个图像的叠加顺序为lanzhoucity.img在下、lz-isodat.img在上,lanzhoucity显示方式用红(4)、绿(5)、蓝(3 )。
第二步:打开分类图像属性并调整字段显示顺序在视窗工具条中:点击图标(或者选择Raster菜单项—--选择Tools菜单)→打开Raster工具面板→点击RaSter工具面板的图标(或者在视窗菜单条:Rster---Attributes)→打开Raster Attribute Editor对话框(lz-isodat.img的属性表)属性表中的19个记录分别对应产生的18个类及Unclassified类,每个记录都有一系列的字段。
如果想看到所有字段,需要用鼠标拖动浏览条,为了方便看到关心的重要字段,需要调整字段显示顺序。
Raster Attribute Editor对话框菜单条:Edit→Column Properties →column properties对话框在Columns中选择要调整显示顺序的字段,通过Up、 Down、Top、Bottom等几个按钮调整其合适的位置,通过选择Display Width 调整其显示宽度,通过Alignment调整其对齐方式。
如果选择Editable复选框,则可以在Title中修改各个字段的名字及其它容。
→在Column Properties对话框中调整字段顺序,最后使Histogram、opacity、 color、 class_names四个手段的显示顺序依次排在前面。
→点击OK按钮(关闭Column properties对话框)→返回Raster Attribute Editor对话框(lz-isodat.img的属性表)第三步:给各个类别赋相应的颜色(如果在分类时选择了彩色,这一步就可以省去)Raster Attribute Editor对话框(lz-isodat.img的属性):→点击一个类别的Row字段从而选择该类别→右键点击该类别的Color字段(颜色显示区)→As Is菜单→选择一种颜色→重复以上步骤直到给所有类别赋予合适的颜色第四步:不透明度设置由于分类图像覆盖在原图像上面,为了对单个类别的判别精度进行分析,首先要把其它所有类别的不透明程度(Opacity)值设为0(即改为透明),而要分析的类别的透明度设为1(即不透明)。
Raster Attribute Editor 对话框(lz-isodat.img的属性表):→右键点击Opacity字段的名字→Column Options菜单→Formula菜单项→Formula对话框→在Formula对话框的Formula输入框中(用鼠标点击右上数字区)输入0→点击Apply按钮(应用设置)→返回Raster Attribute Editor 对话框(lz-isodat.img的属性表):→点击一个类别的ROW字段从而选择该类别→点击该类别的Opacity字段从而进入输入状态→在该类别的Opacity 字段中输入1,并按回车键此时,在视窗中只有要分析类别的颜色显示在原图像的上面,其它类别都是透明的。
第五步:确定类别专题意义及其准确程度视窗菜单条:Utility→flicker→viewer Flicker对话框→Auto Mode本小步是设置分类图像在原图像修背景上闪烁,观察它与背景图像之间的关系从而断定该类别的专题意义,并分析其分类准确与否。
第六步:标注类别的名称和相应颜色Raster Attribute Editor对话框(lz-isodat.img的属性表):→点击刚才分析类别的ROW字段从而选择该类别→点击该类别的class Names字段从而进入输入状态→在该类别的Class Names字段中输入其专题意义(如居民区),并按回车键→右键点击该类别的Color字段(颜色显示区)→As Is菜单→选择一种合适的颜色重复以上4、5、6三步直到对所有类别都进行了分析与处理。
注意,在进行分类叠加分析时,一次可以选择一个类别,也可以选择多个类别同时进行。
Erdas基础教程: 数据预处理来源:师大学旅游与环境学院在ERDAS中,数据预处理模块为Data preparation。
图标面板工具条中,点击图标——Data Preparation菜单1、图象几何校正第一步:显示图象文件在视窗中打开需要校正的Landsat TM图象:lanzhoucity.img.第二步:启动几何校正模块在Viewer#1的菜单条中,选择Raster|Geometric Correction.打开Set Geometric Model对话框.选择多项式几何校正模型 Polynomial——OK.程序自动打开Geo Correction Tools对话框和Polynomial Model Properties对话框.先选择Close关闭Polynomial Model Properties对话框.程序自动打开GCP Tool Reference Setup对话框.选择Keyboard Only.OK.程序自动打开 Reference Map Information提示框。