计算机网络应用:Kettle例子
自己总结的Kettle使用方法和成果

KETTLE使用自己总结的Kettle使用方法和成果说明简介Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix 上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出.Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做.Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
Kettle可以在http://kettle。
pentaho。
org/网站下载到。
注:ETL,是英文Extract—Transform—Load 的缩写,用来描述将数据从来源端经过萃取(extract)、转置(transform)、加载(load)至目的端的过程.ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
下载和安装首先,需要下载开源免费的pdi-ce软件压缩包,当前最新版本为5.20。
0。
下载网址:/projects/pentaho/files/Data%20Integration/然后,解压下载的软件压缩包:pdi—ce—5。
2.0.0—209.zip,解压后会在当前目录下上传一个目录,名为data—integration。
由于Kettle是使用Java开发的,所以系统环境需要安装并且配置好JDK。
žKettle可以在http:///网站下载ž下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可。
运行Kettle进入到Kettle目录,如果Kettle部署在windows环境下,双击运行spoon.bat或Kettle.exe文件.Linux用户需要运行spoon。
sh文件,进入到Shell提示行窗口,进入到解压目录中执行下面的命令:# chmod +x spoon。
kettle 复杂转换示例

kettle 复杂转换示例"Kettle" 是一个开源的数据集成工具,也被称为 "Pentaho Data Integration" (PDI)。
它允许用户从多个源提取数据,进行转换和清洗,然后将数据加载到目标系统。
以下是一个简单的Kettle复杂转换示例,它涉及从一个CSV文件读取数据,进行一些转换,然后将结果写入另一个CSV文件。
1. 步骤1:从CSV文件读取数据假设我们有一个CSV文件,其内容如下:```pythonid,name,age1,John,252,Jane,303,Doe,40```首先,我们需要从CSV文件中读取数据。
为此,您需要创建一个“Table input”步骤,并指定CSV文件的路径。
2. 步骤2:转换数据接下来,我们可能希望添加一个新的列,该列是原始“age”列的两倍。
为此,您可以使用“Modified Java Script Value”步骤。
在脚本字段中,您可以编写以下代码:```javascriptvar age = age 2;```3. 步骤3:将数据写入CSV文件最后,我们将转换后的数据写入另一个CSV文件。
为此,您需要创建一个“Table output”步骤,并指定输出文件的路径。
确保在“Table output”步骤的配置中包含所有需要的列。
4. 连接步骤将“Table input”步骤连接到“Modified Java Script Value”步骤,然后将“Modified Java Script Value”步骤连接到“Table output”步骤。
这确保了数据从源传递到目标,同时经过所需的转换。
5. 运行作业完成所有步骤后,您可以在Kettle中运行作业以测试整个流程。
检查输出文件以确保数据已被正确读取、转换并写入。
请注意,这只是一个基本示例。
Kettle提供了许多其他功能和步骤,可以根据需要进行更复杂的转换和数据处理。
kettle制作实例以及查询效率分析

kettle制作实例以及查询效率分析今天一工作是利用kettle抽取数据形成新表输出至数据库,现有表1 ERR_CONT_INFO(销售合同基本信息),表内信息如下图所示:同时表2 ERP——CONT_PROD_D销售合同明细要求做一转换,根据指定的年月按年月抽取数据到目标表,目标表如下所示:CREATE TABLE ODS_SALESCONTAMT_D{STATMONTH VARCHAR(10) //月份统计SALESID VARCHAR(20) //销售员idCUSTID VARCHAR(10) //客户编号CONTCORP VARCHAR(20)CONTSOURCE INTERGERCONTTYPE INTERGERPRODID VARVHAR(10)ARCHIVENO VARVHAR(20) //合同号CONTDATE VARCHAR(20) //合同时间PRODAMT DECIMAL(14,2) //产品类别金额CONTAMT DECIMAL(14,2) //合同金额COUNT INTERGER //销售量}未经思考直接做的流程图是分析:可以看出第一次表输入需要读取一次所有值(很大的问题,若数据库1w 项记录,只有1k是有用的,如此读取数据造成9k无用的读入);通过判断年月后,需要再次对数据库进行查询,最终流程对数据库进行了2次读取,时间效率和利用值比较低。
改进:在数据库连接中,通过join查询将2张表一次性读取,减少对数据库的查询次数。
sql :select distinct a.amt,a.contid,a.salesid,a.contdate,a.custid,a.archiveno,a.contcor p,a.contsource,a.conttype,b.prodid ,b.saleprice,b.qty from ERP_CONT_INFO as a joinERP_CONT_PROD_D as b on a.contid=b.contid where a.contdate >=? and a.contdate < ? and b.saleprice is not NULL并且流程图也是更为简洁。
计算机网络Kettle命令行使用说明

保证原创精品已受版权保护Kettle命令行使用说明1.Kitchen——作业执行器是一个作业执行引擎,用来执行作业。
这是一个命令行执行工具,参数说明如下。
1)-rep:Repositoryname任务包所在存储名2)-user:Repositoryusername执行人3)-pass:Repositorypassword执行人密码4)-job:Thenameofthejobtolaunch任务包名称5)-dir:Thedirectory(don'tforgettheleading/or\)6)-file:Thefilename(JobXML)tolaunch7)-level:Thelogginglevel(Basic,Detailed,Debug,Rowlevel,Error,Nothing)指定日志级别8)-log:Theloggingfiletowriteto指定日志文件9)-listdir:Listthedirectoriesintherepository列出指定存储中的目录结构。
10)-listjobs:Listthejobsinthespecifieddirectory列出指定目录下的所有任务11)-listrep:Listthedefinedrepositories列出所有的存储12)-norep:Don'tlogintotherepository不写日志示例:1. Windows 中多个参数以/ 分隔,key 和value之间以:分隔✓作业存储在文件Kitchen.bat /level:Basic>D:\etl.log /file:F:\Kettledemo\email.kjb✓作业存储在数据库Kitchen.bat /rep kettle /user admin /pass admin /job F_DEP_COMP(Rep的值为数据库资源库ID)2.Linux 中参数以–分隔作业存储在文件kitchen.sh-file=/home/job/huimin.kjb >> /home/ log/kettle.log作业存储在数据库./kitchen.sh -rep=kettle1 -user=admin -pass=admin -level=Basic -job=job。
Kettle5.某使用步骤带案例解析详细版

Kettle5.某使用步骤带案例解析详细版Kettle使用方法介绍1、Kettle概念Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix 上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
2、下载和部署下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可3、Kettle环境配置1.安装JDK(略)2.测试JDK安装成功(略)3.运行KettleWindows下找到$KETTLE_HOME/spoon.dat,双击运行欢迎界面如下图所示:4、KETTLE组件介绍与使用4.1 Kettle使用Kettle提供了资源库的方式来整合所有的工作,;1)创建一个新的transformation,点击保存到本地路径,例如保存到D:/etltest下,保存文件名为Trans,kettle默认transformation文件保存后后缀名为ktr;2)创建一个新的job,点击保存到本地路径,例如保存到D:/etltest下,保存文件名为Job,kettle默认job文件保存后后缀名为kjb;4.2 组件树介绍4.2.1Transformation 的主对象树和核心对象分别如下图:Transformation中的节点介绍如下:Main Tree:菜单列出的是一个transformation中基本的属性,可以通过各个节点来查看。
DB连接:显示当前transformation中的数据库连接,每一个transformation的数据库连接都需要单独配置。
kettle系列教程二

kettle系列教程二1、H ello World 示例通过这个例子,介绍kettle的一些基础知识及应用:⏹使用Spoon工具⏹转换的创建⏹步骤及连线⏹预定义变量⏹在Spoon中预览和执行⏹使用pan工具在终端窗口执行转换概述我们要实现的目标是:通过一个包含人名称的CSV文件,创建一个XML文件,内容是针对每个人添加上问候。
如果csv文件内容如下:last_name, nameSuarez,MariaGuimaraes,JoaoRush,JenniferOrtiz,CamilaRodriguez,Carmenda Silva,Zoe则输出的XML文件内容如下:- <Rows>- <row><msg>Hello, Maria!</msg></row>- <row><msg>Hello, Joao!</msg></row>- <row><msg>Hello, Jennifer!</msg></row>- <row><msg>Hello, Camila!</msg></row>- <row><msg>Hello, Carmen!</msg></row>- <row><msg>Hello, Zoe!</msg></row></Rows>我们要设计的第一个转换就是创建由csv文件生成一个问候XML文件。
转换是由步骤和连接组成,这些步骤和连接构成数据流,因此转换是基于数据流的。
环境准备开始设计一个转换之前,我们先创建一个文件夹Tutorial,我们将保存所有的文件到该文件夹中,然后创建一个csv文件,内容就是前面人员信息,你可以复制到文本文件中,然后命名为list.csv。
Kettle使用手册及测试案例

一、【kettle】window安装与配置1、下载kettle包,并解压2、安装jdk,并配置java环境a).打开我的电脑--属性--高级--环境变量b).新建系统变量JA V A_HOME和CLASSPATH变量名:JA V A_HOME变量值:C:\Program Files\Java\jdk1.7.0[具体路径以自己本机安装目录为准]变量名:CLASSPATH变量值:.;%JA V A_HOME%\lib\dt.jar;%JA V A_HOME%\lib\tools.jar;c). 选择“系统变量”中变量名为“Path”的环境变量,双击该变量,把JDK安装路径中bin目录的绝对路径,添加到Path变量的值中,并使用半角的分号和已有的路径进行分隔。
变量名:Path变量值:%JA V A_HOME%\bin;%JA V A_HOME%\jre\bin;3、配置kettle环境在系统的环境变量中添加KETTLE_HOME变量,目录指向kettle的安装目录:D:\kettle\data-integration4、启动spoonWindows直接双击批处理文件Spoon.bat具体路径为:kettle\data-integration\Spoon.batLinux 则是执行spoon.sh,具体路径为:~/kettle/data-integration/spoon.sh二、使用Kettle同步数据同步数据常见的应用场景包括以下4个种类型:➢ 只增加、无更新、无删除➢ 只更新、无增加、无删除➢ 增加+更新、无删除➢ 增加+更新+删除只增加、无更新、无删除对于这种只增加数据的情况,可细分为以下2种类型:1) 基表存在更新字段。
通过获取目标表上最大的更新时间或最大ID,在“表输入”步骤中加入条件限制只读取新增的数据。
2) 基表不存在更新字段。
通过“插入/更新”步骤进行插入。
插入/更新步骤选项:只更新、无增加、无删除通过“更新”步骤进行更新。
kettle的案例

kettle的案例
1. 电热水壶
一个常见的kettle案例就是电热水壶。
这种kettle使用电力加热水,可以快速将水加热到沸腾的温度。
用户只需将水倒入水壶,按下开关,水壶就会开始加热。
一些电热水壶还配有温度控制器,用户可以选择不同的加热温度,以适应不同的饮品或烹饪需求。
这种kettle非常方便,适用于家庭、办公室和旅行等场合。
2. 燃气热水瓶
另一个kettle的案例是燃气热水瓶。
这种kettle使用燃气作为热源,通过热交换器将水加热。
用户只需打开燃气阀门,点燃火源,燃气热水瓶就会开始加热水。
一些燃气热水瓶还配有温度控制器和定时器,用户可以自定义加热温度和时间。
这种kettle适用于没有电力供应的地区或户外使用。
3. 电子壶
另一个kettle的案例是电子壶。
这种kettle主要用于煮茶或咖啡。
它通常具有预设的煮茶或咖啡程序,可以根据不同的茶叶或咖啡豆种类选择适当的温度和时间。
用户只需将水和茶叶或咖啡豆放入壶中,选择适当的程序,电子壶就会自动完成煮茶或咖啡的过程。
这种kettle非常方便,可以确保茶或咖啡的品质和口感。
总结:
kettle的案例包括电热水壶、燃气热水瓶和电子壶。
这些kettle都
具有加热水的功能,但使用不同的热源和加热方式。
它们在不同的场合和用途下都发挥着重要的作用,为用户提供了便利和舒适的热水体验。
kettle例子加文档

1.什么Kettle?Kettle是一个开源的ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程)项目,项目名很有意思,水壶。
按项目负责人Matt的说法:把各种数据放到一个壶里,然后呢,以一种你希望的格式流出。
Kettle包括三大块:Spoon——转换/工作(transform/job)设计工具(GUI方式)Kitchen——工作(job)执行器(命令行方式)Span——转换(trasform)执行器(命令行方式)Kettle是一款国外开源的etl工具,纯java编写,绿色无需安装,数据抽取高效稳定。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
2.Kettle简单例子2.1下载及安装Kettle下载地址:/projects/pentaho/files现在最新的版本是 3.6,为了统一版本,建议下载 3.2,即下载这个文件pdi-ce-3.2.0-stable.zip。
解压下载下来的文件,把它放在D:\下面。
在D:\data-integration文件夹里,我们就可以看到Kettle的启动文件Kettle.exe或Spoon.bat。
2.2 启动Kettle点击D:\data-integration\下面的Kettle.exe或Spoon.bat,过一会儿,就会出现Kettle的欢迎界面:稍等几秒,就会出现Kettle的主界面:2.3 创建transformation过程a.配置数据环境在做这个例子之前,我们需要先配置一下数据源,这个例子中,我们用到了三个数据库,分别是:Oracle、MySql、SQLServer,以及一个文本文件。
而且都放置在不同的主机上。
Oralce:ip地址为192.168.1.103,Oracle的实例名为scgtoa,创建语句为:create table userInfo(id int primary key,name varchar2(20) unique,age int not null,address varchar2(20));insert into userInfo values(1,'aaa',22,'成都市二环路');insert into userInfo values(2,'东方红',25,'中国北京');insert into userInfo values(3,'123',19,'广州白云区');MySql:ip地址为192.168.1.107,数据库名为test2,创建语句为:create database test2;use test2;create table login(id int primary key,realname varchar(20) unique,username varchar(20) unique,password varchar(20) not null,active int default 0);insert into login values(1,'aaa','admin','admin',0);insert into login values(2,'东方红','test','test',1);insert into login values(3,'123','xxx123','123456',1);SQLServer:本机,ip为192.168.1.115,创建语句为:create database test3;use test3;create table student(sid varchar(20) primary key,sname varchar(20) unique,teacher varchar(20) not null,);insert into student values('078','aaa','李老师');insert into student values('152','东方红','Mr Wu');insert into student values('034','123','徐老师');文本文件:名为dbtest.log,位于192.168.1.103\zhang\上,即跟Oracle同一个主机。
kettle 例子

kettle 例子Kettle(也称为Pentaho Data Integration)是一款开源的ETL (Extract, Transform, Load)工具,用于数据集成和数据转换。
它提供了一套直观且功能强大的图形化界面,使用户能够轻松地进行数据抽取、转换和加载操作。
下面是关于Kettle的十个例子,以展示其在数据集成和转换中的灵活应用。
1. 数据抽取:Kettle可以从各种不同的数据源中抽取数据,包括关系型数据库、文件(如CSV、Excel等)、Web服务和其他应用程序。
例如,可以使用Kettle从MySQL数据库中抽取销售数据。
2. 数据清洗:Kettle提供了丰富的数据清洗功能,可以处理数据中的重复值、缺失值、异常值等。
例如,可以使用Kettle清洗电子商务网站的用户数据,去除重复的用户记录并填补缺失的信息。
3. 数据转换:Kettle可以对抽取的数据进行各种转换操作,如数据格式转换、字段拆分合并、数据计算等。
例如,可以使用Kettle 将订单金额从美元转换为欧元,并计算订单总价。
4. 数据集成:Kettle可以将多个数据源的数据集成到一起,创建一个统一的数据视图。
例如,可以使用Kettle将来自不同地区的销售数据整合到一个数据仓库中,以便进行全局销售分析。
5. 数据加载:Kettle可以将转换后的数据加载到目标数据库或文件中。
例如,可以使用Kettle将清洗和转换后的数据加载到Oracle数据库中,以供进一步分析和报告。
6. 数据分析:Kettle可以与其他数据分析工具(如Pentaho BI)集成,实现更复杂的数据分析和报告功能。
例如,可以使用Kettle 将销售数据加载到Pentaho BI中,创建交互式的销售分析仪表板。
7. 定时任务:Kettle可以配置定时任务,自动执行数据集成和转换操作。
例如,可以使用Kettle每天凌晨自动抽取和清洗前一天的销售数据。
8. 并行处理:Kettle支持并行处理,可以同时处理多个数据源和转换操作,提高数据处理效率。
Kettle使用范例
Kettle使用范例1.错误处理在转换步骤的过程中,当某个步骤发生错误时可能要进行额外的步骤处理。
因此,在设置时就要求为步骤添加错误处理。
以下面的流程为例:该流程为将源表的数据同步到目标表中,在目标表中人为的设置某个字段的长度小于源表,让其能在处理过程中会报出异常。
为了可视化处理结果,将同步的结果输出到XML文件中。
选中“Target Table”步骤,点击鼠标右键,然后选择“Define error handling…”菜单项,将会弹出设置对话框。
在“Target step”中选择后续处理步骤即可。
在各个fieldname填上字段的名字,将会在结果集中多出相应的字段,以便后续步骤能读出相应的错误信息。
例如界面上的“ErrorDesc”字段,将用于保存错误信息。
以上的数据处理流程处理结束之后,“Success XML Output”步骤生成的XML文件内容为所有同步成功的数据;“Error XML Output”步骤生成的XML文件内容为所有同步错误的数据。
2.字典翻译2.1.单选字典翻译单选字典翻译要使用到“Stream lookup/流查询”步骤,分别要从业务表和字典表中抽取出数据。
“Query AJXX”步骤负责从业务表中抽取出数据。
“Query AJLX Dictionary”步骤负责从字典表中抽取出字典数据。
“Transform AJLX”步骤负责翻译“ajlx”字段的字典值。
由于使用这种方式翻译单选字段时,要多查询一个字典表,因此最好控制字典表的数据量,以免影响性能。
2.2.多选字典翻译由于“Stream lookup”只能实现单值的数据查询,无法实现像多选字典这类多值的数据查询,因此“Stream lookup”步骤无法实现多选字典字段的翻译。
多选字典的翻译,只能通过采用调用存储过程的方式实现,这就要使用到“Call DB Procedure”。
由于“Call DB Procedure”步骤在调用存储过程或是函数时,参数设置不能使用常量,只能调用数据流中的字段值。
kettle 典型案例

kettle 典型案例English Answer:## Kettle Use Cases.Apache Kettle, also known as Pentaho Data Integration, is a powerful ETL (Extract, Transform, Load) tool. It allows users to easily extract data from various sources, transform it, and load it into any destination of their choice. Kettle is widely used in various industries and domains for a wide range of use cases. Some of the most typical use cases of Kettle include:Data Integration: Kettle is extensively used for integrating data from different sources into a single unified data repository. It provides a wide range of connectors that allow seamless data extraction from various databases, files, and web services. The data integration capabilities of Kettle make it an ideal tool for creating data warehouses, data lakes, and other data repositories.Data Transformation: Kettle offers a comprehensive set of data transformation operators that allow users to perform a wide range of data manipulations. These include cleansing, filtering, sorting, aggregating, joining, splitting, and merging data. Kettle's data transformation capabilities make it a powerful tool for data preparation and data quality improvement.Data Loading: Kettle supports loading data into various target destinations, including databases, files, and cloud storage services. It provides a variety of output connectors that allow users to easily load data into the destination of their choice. The data loading capabilities of Kettle make it an ideal tool for populating data warehouses, data marts, and other data repositories.ETL Automation: Kettle allows users to automate ETL processes through its robust job scheduling and workflow management capabilities. Users can create complex workflows that involve multiple data extraction, transformation, and loading steps. Kettle's automation capabilities make it anideal tool for implementing data pipelines and ensuring the timely and reliable movement of data.Data Quality Management: Kettle provides a range ofdata quality management capabilities that allow users to ensure the quality of their data. These capabilitiesinclude data validation, data profiling, and data cleansing. Kettle's data quality management capabilities make it an ideal tool for improving the accuracy, completeness, and consistency of data.Data Governance: Kettle can be used to support data governance initiatives by providing a central platform for managing data assets and ensuring data compliance. Itallows users to track data lineage, enforce data access controls, and implement data security measures. Kettle's data governance capabilities make it an ideal tool for ensuring the responsible and ethical use of data.In addition to these typical use cases, Kettle is also widely used for a variety of other purposes, including:Data Migration.Data Warehousing.Business Intelligence.Data Analytics.Data Science.Kettle's versatility and extensibility make it a powerful tool that can be used to address a wide range of data integration, data transformation, and data management challenges.## Conclusion.Apache Kettle is a powerful and versatile ETL tool that offers a comprehensive set of features and capabilities. It is widely used in various industries and domains for a wide range of use cases, including data integration, data transformation, data loading, ETL automation, data qualitymanagement, and data governance. Kettle's ease of use, scalability, and extensibility make it an ideal tool for addressing a wide range of data integration and data management challenges.Chinese Answer:## Kettle 典型案例。
kettle 例子

kettle 例子
以下是一个使用Kettle进行数据同步的案例:
1. 配置表的设计:创建TM_ETL_TABLE表用于保存要增量同步的表的基本信息,包括表名、调度状态、表数据更新时间和记录更新时间。
2. 同步数据的流程开发:
2.1 更新元数据表的状态并获取表更新时间:将TM_ETL_TABLE表中的IS_RUN字段更新为0,表示开始同步数据,并将UPDATE_TIME字段初始化为'1970-01-01',表示要拉取所有的数据。
2.2 加载数据到中间表:使用表输入控件将数据插入到STAGING_TM_BOOK表中,并根据前面的更新时间变量获取增量数据,勾选上“替换SQL语句中的变量”。
2.3 加载数据到目标表:编写三段脚本,根据主键ID清空目标表数据,然后将数据插入到目标表,最后更新TM_ETL_TABLE表中的记录状态。
在实际应用中,你可以根据具体的业务需求和数据情况来调整和优化Kettle的使用方式。
如果你还有其他问题,请随时向我提问。
kettle字符类型

kettle字符类型摘要:1.Kettle 简介2.Kettle 字符类型分类3.Kettle 字符类型的使用示例4.Kettle 字符类型的优缺点5.Kettle 字符类型的发展前景正文:一、Kettle 简介Kettle 是一款开源的、基于Java 的ETL(Extract, Transform, Load)工具,用于数据集成和数据转换。
它提供了大量的数据源连接、数据转换和数据管理功能,使得数据工程师可以更高效地完成数据处理任务。
在Kettle 中,字符类型是一个非常重要的数据类型,用于表示文本信息。
二、Kettle 字符类型分类Kettle 中的字符类型主要分为以下几类:1.字符串(String):用于表示文本信息,可以包含字母、数字、汉字等字符。
2.固定字符串(Fixed String):用于表示固定长度的字符串,可以提高数据处理的性能。
3.日期时间(Date):用于表示日期和时间信息,可以精确到年、月、日、时、分、秒等。
4.日期(Date):用于表示日期信息,可以精确到年、月、日。
5.时间(Time):用于表示时间信息,可以精确到时、分、秒。
6.布尔值(Boolean):用于表示真或假,取值为true 或false。
7.整数(Integer):用于表示整数值,可以是正数、负数或零。
8.长整数(Long):用于表示大整数值,可以是正数、负数或零。
9.小数(Double):用于表示浮点数值,可以是正数、负数或零。
10.大小数(BigDecimal):用于表示精确的浮点数值,可以是正数、负数或零。
三、Kettle 字符类型的使用示例在Kettle 中,我们可以通过以下步骤使用字符类型:1.打开Kettle,选择“File”-> “New”-> “Transformation”。
2.在“Transformation”选项卡中,选择“Add”-> “Step”-> “Text File Input”。
kettle在数仓项目中的运用

kettle在数仓项目中的运用Kettle在数仓项目中的运用Kettle是一款开源的ETL工具,它可以帮助我们在数仓项目中进行数据的抽取、转换和加载。
在数仓项目中,数据的质量和准确性非常重要,而Kettle可以帮助我们实现数据的清洗、整合和转换,从而提高数据的质量和准确性。
在数仓项目中,Kettle可以用于以下几个方面:1. 数据抽取Kettle可以从各种数据源中抽取数据,包括关系型数据库、文件、Web服务等。
我们可以使用Kettle的抽取组件,如Table Input、CSV Input、XML Input等,来实现数据的抽取。
Kettle还支持增量抽取,可以根据时间戳或者增量字段来抽取数据,从而减少数据抽取的时间和成本。
2. 数据转换在数据抽取之后,我们需要对数据进行清洗、整合和转换,以满足数仓的需求。
Kettle提供了丰富的转换组件,如Filter Rows、Join Rows、Sort Rows等,可以帮助我们实现数据的清洗、整合和转换。
Kettle还支持自定义转换组件,可以根据项目需求来开发自己的转换组件。
3. 数据加载在数据转换之后,我们需要将数据加载到数仓中。
Kettle提供了多种数据加载组件,如Table Output、Dimension Lookup/Update、Fact Table Output等,可以帮助我们实现数据的加载。
Kettle还支持多种加载方式,如全量加载、增量加载、批量加载等,可以根据项目需求来选择合适的加载方式。
除了以上三个方面,Kettle还可以用于数据质量控制、数据集成、数据同步等方面。
Kettle提供了丰富的插件和扩展机制,可以满足不同项目的需求。
Kettle在数仓项目中的运用非常广泛,它可以帮助我们实现数据的抽取、转换和加载,提高数据的质量和准确性,从而为业务决策提供可靠的数据支持。
(完整版)kettle入门例子大全

Kettle 培训技术文档0507Etl 介绍ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于金融IT 来说,经常会遇到大数据量的处理,转换,迁移,所以了解并掌握一种etl工具的使用,必不可少。
Kettle是一款国外开源的etl工具,纯java编写,绿色无需安装,数据抽取高效稳定。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
kettle 部署运行将kettle2.5.1文件夹拷贝到本地路径,例如D 盘根目录。
双击运行kettle文件夹下的spoon.bat文件,出现kettle欢迎界面:稍等几秒选择没有资源库,打开kettle主界面创建transformation,job点击页面左上角的创建一个新的transformation,点击保存到本地路径,例如保存到D:/etltest下,保存文件名为EtltestTrans,kettle默认transformation 文件保存后后缀名为ktr点击页面左上角的创建一个新的job,点击保存到本地路径,例如保存到D:/etltest下,保存文件名为EtltestJob,kettle默认job文件保存后后缀名为kjb 创建数据库连接在transformation页面下,点击左边的【Main Tree】,双击【DB连接】,进行数据库连接配置。
connection name自命名连接名称Connection type选择需要连接的数据库Method of access选择连接类型Server host name写入数据库服务器的ip地址Database name写入数据库名Port number写入端口号Username写入用户名Password写入密码例如如下配置:点击【test】,如果出现如下提示则说明配置成功点击关闭,再点击确定保存数据库连接。
kettle案例实现
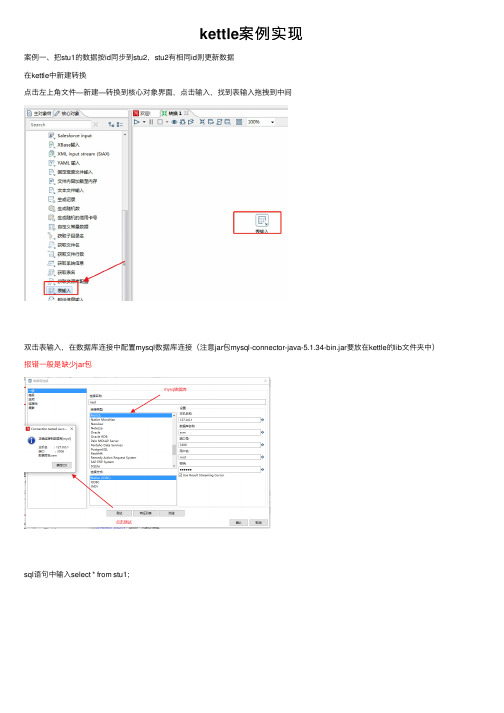
kettle案例实现
案例⼀、把stu1的数据按id同步到stu2,stu2有相同id则更新数据
在kettle中新建转换
点击左上⾓⽂件—新建—转换到核⼼对象界⾯,点击输⼊,找到表输⼊拖拽到中间
双击表输⼊,在数据库连接中配置mysql数据库连接(注意jar包mysql-connector-java-5.1.34-bin.jar要放在kettle的lib⽂件夹中)报错⼀般是缺少jar包
sql语句中输⼊select * from stu1;
点击预览可以看到数据
在输出中找到插⼊/更新组件拖拽到中间,点住表输⼊shift+⿏标左键连接到插⼊/更新组件上
双击插⼊/更新,点击⽬标表浏览,选择stu2
点击获取字段获取到3个字段
由于stu1与stu2通过id关联,故删除另2个字段,然后点击编辑映射,编辑2个表之间的映射
确定后如图
更新处,修改id的属性为n,确定
保存运⾏,到数据库中查看结果。
kettle集群实例

Kettle集群实例Kettle cluster example2011年9月27日高健唾沫星冲锋枪416922877技术群53272400 概述:本文的实例是我在实验以后编写的,有详细的步骤截图说明,适用于初用KETTLE做集群的朋友作为参考。
本文分两部分,先介绍实例操作后说原理。
Part A1.配置jetty容器配置文件在$kettlehome$ \data-integration\pwd下,没有的话手动建立一下, 需要修改的是三个xml文件内容,其中master为主服务的配置,另外两个为子服务。
Carte-config-master-8381.xmlCarte-config -8382.xmlCarte-config -8383.xml在kettle的路径下找到carte.bat,在控制台下启动,使用carte ip port命令。
三个容器启动成功。
3.配置集群子服务在spoon环境下配置子服务,其中Q1为主服务,要勾选上“是主服务器”,Q2和Q3为从服务器。
4.配置集群schemas5.制作转换转换制作完成后,在需要使用集群的步骤上选择集群即可。
如下图。
6.集群执行执行时选择集群执行。
如下图。
查看执行结果。
Part B集群允许转换以及转换中的步骤在多个服务器上并发执行。
在使用kettle集群时,首先需要定义的是Cluster schema。
所谓的Cluster schema就是一系列的子服务器的集合。
在一个集群中,它包含一个主服务器(Master)和多个从属服务器服务器(slave)。
如下图所示。
子服务器(Slave servers)允许你在远程服务器上执行转换。
建立一个子服务器需要你在远程服务器上建立一个叫做“Carte”的web 服务器,该服务器可以从Spoon(远程或者集群执行)或者转换任务中接受输入。
在以后的描述中,如果我们提到的是子服务器,则包括集群中的主服务器和从属服务器;否则我们会以主服务器和从属服务器来进行特别指定。
kettle字符类型

kettle字符类型摘要:1.Kettle 字符类型概述2.Kettle 字符类型的分类3.Kettle 字符类型的应用示例正文:一、Kettle 字符类型概述Kettle 字符类型是指在数据仓库和数据集成领域中,用于表示和存储字符数据的数据类型。
Kettle(开源数据集成工具)支持多种字符类型,以满足不同业务场景和数据需求。
Kettle 字符类型的使用有助于提高数据处理和集成的效率,同时也保证了数据的准确性和完整性。
二、Kettle 字符类型的分类在Kettle 中,字符类型可以分为以下几类:1.字符串类型(String):字符串类型用于表示文本数据,如姓名、地址等。
它可以存储任意长度的字符数据,并支持各种字符编码。
2.固定长度字符串类型(Fixed String):固定长度字符串类型用于表示长度固定的字符数据。
它可以有效地节省存储空间,并提高数据处理的性能。
3.变长字符串类型(Variable String):变长字符串类型用于表示长度可变的字符数据。
它支持动态扩展,以适应不同长度的字符数据。
4.日期类型(Date):日期类型用于表示日期数据,如出生日期、创建日期等。
它可以精确地存储日期信息,并支持各种日期格式。
5.时间类型(Time):时间类型用于表示时间数据,如开始时间、结束时间等。
它可以精确地存储时间信息,并支持各种时间格式。
6.日期时间类型(Date-Time):日期时间类型用于表示日期和时间数据,如创建时间、更新时间等。
它可以精确地存储日期和时间信息,并支持各种日期时间格式。
7.二进制数据类型(Binary):二进制数据类型用于表示二进制数据,如图片、音频、视频等。
它可以存储任意长度的二进制数据,并支持各种数据格式。
三、Kettle 字符类型的应用示例在实际业务场景中,Kettle 字符类型可以应用于各种数据处理和集成任务。
以下是一些典型的应用示例:1.在数据迁移任务中,使用字符串类型可以将源数据中的文本信息迁移到目标数据存储中。
kettle接口抽取同步应用实例

kettle应用实例Kettle是”Kettle E.T.T.L. Envirnonment”只取首字母的缩写,这意味着它被设计用来帮助你实现你的ETTL需要:抽取、转换、装入和加载数据。
软件版本:pdi-ce-4.1.0-stable,官方网址:/1.应用需求在SqlServer 数据库中有一些数据表,数据的增加和修改都有相应的时间字段来标示,要求定时提取增量数据,然后更新到Oracle 数据库的相应表中,以达到数据的同步。
2.设计思路我们将每个需要同步的数据表叫做一个数据接口,每个接口都给定一个接口编号,设计一个配置表来存放接口的相关信息。
每次运行时先根据接口编号从配置表中取出需要抽取数据的时间段。
按照特定时间段从源表提取增量数据,然后更新到目标数据库的相应表中。
3.实现步骤3.1.增加接口配置表表结构和数据实例如下,3.2.设计通用提取时间的Transformation先更改接口配置表的结束时间点到当前系统时间update etl_interface_config cset c.eic_end_time = casewhen c.eic_order_id = 1 then(sysdate - c.eic_delay_minute / 1440)else(select s.eic_end_timefrom etl_interface_config swhere c.eic_group_id = s.eic_group_idand s.eic_order_id = 1)endwhere c.eic_interface_code = '${InterfaceCode}'提取时间段select to_char(eic_begin_time,'yyyy-mm-dd hh24:mi:ss') as StartTime, to_char(eic_end_time,'yyyy-mm-dd hh24:mi:ss') as EndTimefrom etl_interface_configwhere eic_interface_code = '${InterfaceCode}'设置变量,供JOB使用3.3.设计抽取和装载的Transformation数据的提取,连接SqlServer,采用SQL语句,也是一个Table Input,重点看看时间的用法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
保证原创精品已受版权保护
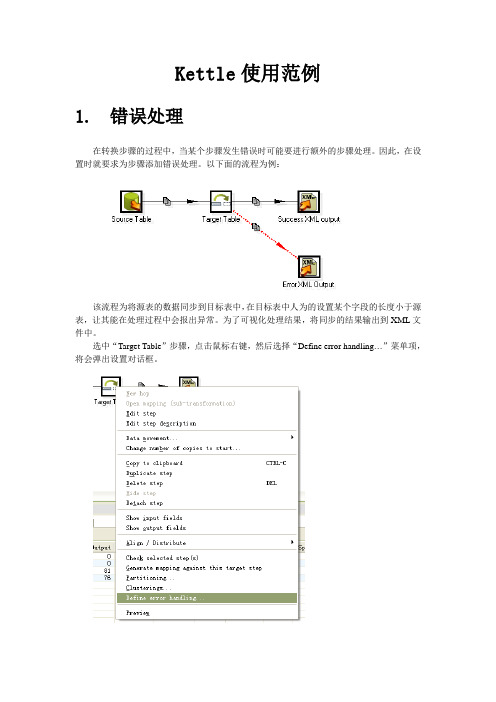
Kettle使用范例
1.错误处理
在转换步骤的过程中,当某个步骤发生错误时可能要进行额外的步骤处理。
因此,在设置时就要求为步骤添加错误处理。
以下面的流程为例:
该流程为将源表的数据同步到目标表中,在目标表中人为的设置某个字段的长度小于源表,让其能在处理过程中会报出异常。
为了可视化处理结果,将同步的结果输出到XML文件中。
选中“Target Table”步骤,点击鼠标右键,然后选择“Define error handling…”菜单项,将会弹出设置对话框。