八爪鱼企业版入门教程
八爪鱼系统操作文档

八爪鱼系统操作1 进入系统:开机后出现输入密码画面 输入正确的密码后点OK 开始密码为1 2 3 进入系统可以修改。
2 上分:在要上分的机号栏对应的上分数栏上点击 就可以增加要上分的分数。
每点一次增加一定的分数 增加的分数大小可点击左上角的+10 + 50 +100 +1000 +10000来改变。
当选择好上分数后点出本栏旁边的>>按纽既完成一次上分。
若选择的上分数有误 可点击 按纽清除上分数据。
3退分:在要退分的机号栏对应的退分数栏上点击 就可以增加要退分的分数。
第点一次增加一定的分数 增加的分数大小可点击左上角+10+50 +100 +1000 +10000来改变。
当选择好退分数后点出本栏旁边的>>按纽即完成一次退分。
若选择的退分数有错误 可点击X 按纽清除退分数据。
退分数不会超过该机台的总分。
4 退出:/当服务员要暂时离开时 点击该处即可锁机 输入开机密码后就可继续操作。
5 打印:输入密码进入打印 其中可进行以下操作。
1 清除帐目 重新游戏清除各分机的总上分、总退分、总押分、总赢分等帐目 轮数和局数从头开始。
2 查明细帐目查询和统计各分机的总上分、总退分、总押分、总赢分等帐目 并累加统计。
点击打印即可在打印机上打出帐目清单。
要在后台机器上查帐目3 上分界面设置显示机台总上分 选择上分机是否在上分画面显示机台总上分数。
显示总分 选择上机分是否在上分两面显示机台总分。
4 机台界面设置按横式显示牌路 选择是按横式还是按竖式显示牌路。
显示网上押分 选择显示网上实际押分还是虚拟押分。
押分后要按确认键 选择押分后是否要按确认键。
和中奖时退下闲庄押分 选择开出和中奖时下一局是否要自动退下闲庄的押分。
牌路从左到右 选择牌路的排列方向。
5 修改游戏参数修改游戏参数 方法是用鼠标点击要修改的参数项 然后输入新的值 参数如下 每局时间 每局倒计时用的时间押分键值 每按一次押分键所增加的押分数休息时间 每轮牌后的休息时间庄家抽水率 开出庄赢时奖分的抽水率 95——100 每天开牌轮数 每天开牌的轮数 5—12 押分的下限和上限值 每个门子押分的最低分和最高分 其中和的上限是指所有机台和押分的总数的上限。
八爪鱼验证码登陆-控件识别方法(7.0版本)
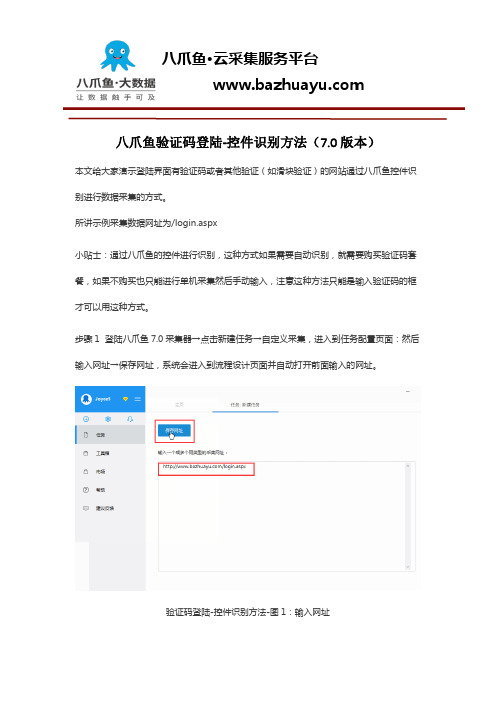
八爪鱼验证码登陆-控件识别方法(7.0版本)本文给大家演示登陆界面有验证码或者其他验证(如滑块验证)的网站通过八爪鱼控件识别进行数据采集的方式。
所讲示例采集数据网址为/login.aspx小贴士:通过八爪鱼的控件进行识别,这种方式如果需要自动识别,就需要购买验证码套餐,如果不购买也只能进行单机采集然后手动输入,注意这种方法只能是输入验证码的框才可以用这种方式。
步骤1 登陆八爪鱼7.0采集器→点击新建任务→自定义采集,进入到任务配置页面:然后输入网址→保存网址,系统会进入到流程设计页面并自动打开前面输入的网址。
验证码登陆-控件识别方法-图1:输入网址接下来步骤是输入用户名密码了,八爪鱼模拟的是人的操作行为,所以这一步过程也很简单步骤2 在浏览器中鼠标点击用户名输入框→在右边弹出的提示里面选择“输入文字”→输入自己的用户名→选择“确定”。
同样的方式输入密码,这样输入用户名密码的步骤就完成了。
验证码登陆-控件识别方法-图2:输入密码验证码登陆-控件识别方法-图3:输入密码这里八爪鱼采集器需要知道1.验证码图片在哪里2.输入框验证码的框在哪里步骤3 点击下方浏览器中验证码图片的位置→按照提示框中的提示选择浏览器中的验证码框→再按照提示框中的提示点击浏览器中的登陆按钮验证码登陆-控件识别方法-图4:点击验证码输入框验证码登陆-控件识别方法-图5:点击验证码图片位置、登录按钮接下来需要配置验证码输入失败和成功的两种场景步骤4 点击提示框中的确认按钮,系统会自动提交一个错误的验证码→然后点击浏览器中的“验证码不正确”提示→再点击提示框中的确认按钮→选择提示框中的“开始配置识别成功场景”→在提示框中输入显示出来的验证码→选择提示框中的“应用到网页并完成配置”选项 验证码登陆-控件识别方法-图6:点击确认按钮验证码登陆-控件识别方法-图7:配置验证码输入失败场景验证码登陆-控件识别方法-图8:配置验证码输入成功场景验证码登陆-控件识别方法-图9:配置验证码输入成功场景上述操作中验证码识别就完成了,接下来需要手动执行这个流程,任务会自动进去到登陆界面步骤5 点击“流程”按钮→进入到流程界面→手动点击流程步骤(可以看到浏览器中会按照会执行这些步骤)→点到识别验证码步骤时→在辅助模式选项中输入浏览器中当前显示的验证码→选择应用到网页并提交验证码登陆-控件识别方法-图10:辅助模式选项这样操作之后,可以看到任务就正常登陆进去了。
八爪鱼采集器使用进阶教程共24页文档

一起使用 •使用循环
与文本循环配合使用,达到循环输 入文本效果 •自定义
设置Xpath路径表达式,根据用户 需求自定义流程步骤位置
识别验证码
基本信息:
•识别验证码 流程步骤名称
高级选项:
•执行前等待 流程步骤执行前等待时间
•或者出现元素 填写Xpath路径,配合执行前等待
循环本身不产生任何操作,只负责建立循环,与
循环产生联动的是勾选了使用循环的流程步骤,来达到 循环的效果 循环/提取数据
与上述类似,循环本身不会产生任何操作,真正 与循环产生联动的是勾选了使用循环的提取数据
流程结束图标,此图片代表一个任务执行完成到 循环 结束
提取数据
运行逻辑
循环Ⅰ
循环Ⅰ第一项 循环Ⅰ第二项 循环Ⅰ第三项
。
。
。
循环Ⅰ第N项 。
。
。
循环Ⅰ结束
循环Ⅱ第一项 循环Ⅱ第二项
一起使用 •验证码图片Xpath
填写Xpath路径,告诉八爪鱼验证 码图片位置 •验证码输入框Xpath
输入框Xpath,用于配合验证码图 片Xpath,正确输入验证码 当前验证码
用于流程设计时调试规则用
判断条件
基本信息:
•判断条件 判断条件分为此次判断条件整体,
和各具体条件分支 条件分支
按不同分支条件执行不同流程步骤
•或者出现元素 填写Xpath路径,配合执行前等待一
起使用,在等待时间内元素出现则不再继 续等待 •使用当前循环
与循环配合使用 •添加其他特殊字段
网页标题、时间、当前时间、固定 字段等特殊字段
自定义数据字段(修改抓取方式, 定位方式即XPath,格式化数据 删除选中字段 将选中字段上移、下移
八爪鱼企业版入门教程

结语: 实践出真知,八爪鱼让数据触手可及
ቤተ መጻሕፍቲ ባይዱ
Ajax加载与新标签页
Ajax即通过在后台与服务器进行少量数据交换,意味着可以在 不重新加载整个网页的情况下,对网页的某部分进行更新。 最简单的方式是看在八爪鱼浏览器里点击的时候网页有没有改 变加载状态 这种表示网页正在加载 这种表示网页没有加载或者已加载完成 当网页状态有发生改变的时候就不需要设置ajax,因为八爪鱼会自动根 据网页的状态来判断是否可以进行下一步操作 而当网页状态没有发生改变的时候就需要设置ajax,因为八爪鱼没有可 判断的依据,运行本地采集时八爪鱼就会按照一个默认时长120秒后再 执行下一个操作,这时大部分新用户会发现八爪鱼不动了一直不提取数 据,所以这时需要设置ajax告诉八爪鱼,需要采集的网页内容已经出来 了,可以进行下一步操作了,这个ajax时间就是要观察从点击到需要采 集的数据出现需要多久,则设置多久即可。 如果不设置采集时出现的现象就会一直等待在这里不提取数据,感觉采 集速度会很慢,设置了之后会加快速度。 前面说了一般网页设置ajax的目的是局部刷新,后台与服务器 进行少量数据交换,而新标签打开的意思是重新打开加载整个网页,一 般来说设置了ajax是不需要再开新标签的,请在设置ajax的时候把勾选 的新标签取消掉。
进阶步骤,是指除基本步骤外,我们需要通过下列操作来辅助完成我们的数据采集,进 阶步骤如下: 1)输入文字 3)切换下拉选项 5)移动鼠标到元素上 7)结束流程 2)识别验证码 4)判断条件 6)结束循环
高级模式
一、打开网页:
打开网页,一般指我们所要采集数据的网站,正如平时我们浏 览该网站的数据信息时需要输入URL一样
高级模式
流程设计步骤:
在八爪鱼采集器中,一共有11个流程设计操作,其中分为常用步骤和进阶步骤,划分为
八爪鱼如何登录采集
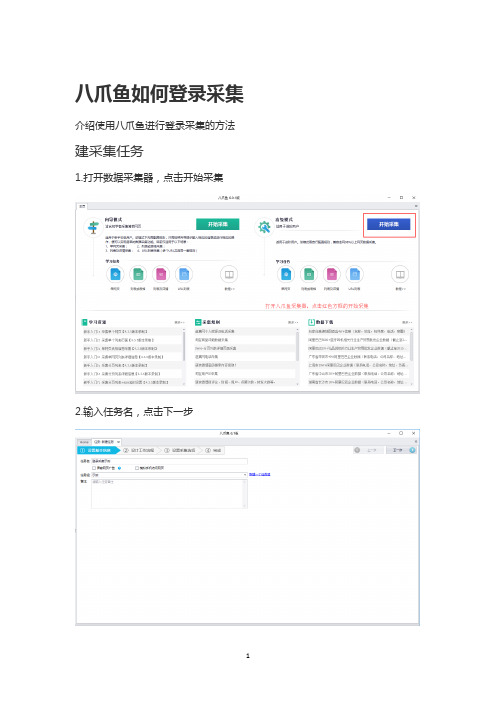
八爪鱼如何登录采集介绍使用八爪鱼进行登录采集的方法建采集任务
1.打开数据采集器,点击开始采集
2.输入任务名,点击下一步
编写采集规则
1.复制你要登录采集的网址
2.在流程设计器里选择打开网页,并拖动到设计器里,粘贴刚刚复制的网址,点击保存并打开网站
3.在下面打开的网址上找到账号输入框并点击右键,执行输入文本操作,如图所示
4.在红色方块指示区域输入登录账号,并点击保存
5.完成账号的保存好,继续右键点击密码输入框,执行输入文本操作,如图所示
6.在红色方框指示区域内输入登录密码,记得点击保存
7.最后一步,鼠标右键点击登录,再选择执行点击元素操作
8.成功登录采集页面,接下来就可以对需要采集的数据进行抓取了。
八爪鱼采集器流程步骤高级选项说明

八爪鱼采集器流程步骤高级选项说明1、打开网页该步骤根据设定的网址打开网页,一般为网页采集流程的第一个步骤,用来打开指定的网站或者网页。
如果有多个类似的网址需要分别打开执行同样的采集流程,则应该放置在循环的内部,并作为第一个子步骤1)页面URL页面URL,一般可以从网页浏览器地址栏中复制得到,如:/ 2)操作名自定义操作名3)超时在网页加载完成前等待的最大时间。
如果网页打开缓慢,或者长时间无法打开,则流程最多等待超时指定的时间,之后无论网页是否加载完成,都直接执行下一步骤。
应尽量避免设置过长的超时时间,因为这会影响采集速度4)阻止弹出用以屏蔽网页弹窗广告,如果打开的网页偶尔会变成另外一个广告页面,则可以使用本选项阻止广告页面弹出5)使用循环配合循环步骤来使用,用以重复打开多个类似的网页,然后执行同样的一套流程,循环打开网页时,应为作为循环步骤的第一个子步骤。
如果勾选此项,则无需手动设置网页地址,网页地址会自动显示循环设定的网址列表的当前循环项6)滚动页面个别网页在打开网页后并没有显示所有数据,需要滚动鼠标滚轮或者拖动页面滚动条到底部,才会加载没有显示的数据,使用此选项在页面加载完成后向下滚动,滚动方式有向下滚动一屏和直接滚动到底部两种7)清理缓存在八爪鱼中,如果需要切换账号,可使用清理浏览器缓存,重新设置其他账号8)自定义cookiecookie指某些网站为了辨别用户身份、进行session 跟踪而储存在用户本地终端上的数据(通常经过加密)。
在八爪鱼中,可以通过做一次预登录获取页面cookie,通过勾选打开网页时使用指定cookie获取登陆后的cookie,从而记住登录状态。
获取的当前页面cookie,可以通过点击查看cookie9)重试如果网页没有按照成功打开预期页面,例如显示服务器错误(500),访问频率太快等,或者跳转到其他正常执行不应该出现的页面,可以使用本选项进行重试,但必须配合以下几个重试参数执行,请注意以下几种判断的情况任意一种出现都会导致重试①当前网页的网址/文本/xpath,包含/不包含如果当前页面网址/文本/xpath总是出现/不出现某个特殊内容,则使用此选项可以判断有没有打开预期页面,需要重试②最大重试次数为了避免无限制重复尝试,请使用本选项限制最大重复尝试的次数,如果重试到达最大允许的次数,任然没有成功,则流程将停止重试,继续执行下一步骤③时间间隔在两次重试之间等待的时间,一般情况下,当打开网页出错时,立即重试很有可能是同样的错误,适当等待则可能成功打开预期网页,但应该尽量避免设置过长的等待时间,因为这会影响采集速度2、点击元素该步骤对网页上指定的元素执行鼠标左键单击动作,比如点击按钮,点击超链接等1)操作名自定义操作名2)执行前等待对此步骤设置执行前等待,即等待设置的时间后,再进行此步骤3)或者出现元素或者出现元素,配合执行前等待使用,在其中输入元素的xpath可以在出现该元素的时候结束执行前的等待。
八爪鱼验证码登陆-控件识别方法(7.0版本)
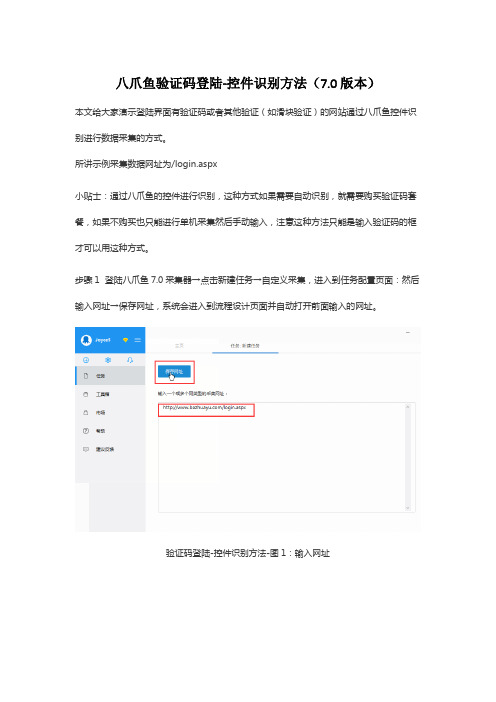
八爪鱼验证码登陆-控件识别方法(7.0版本)本文给大家演示登陆界面有验证码或者其他验证(如滑块验证)的网站通过八爪鱼控件识别进行数据采集的方式。
所讲示例采集数据网址为/login.aspx小贴士:通过八爪鱼的控件进行识别,这种方式如果需要自动识别,就需要购买验证码套餐,如果不购买也只能进行单机采集然后手动输入,注意这种方法只能是输入验证码的框才可以用这种方式。
步骤1 登陆八爪鱼7.0采集器→点击新建任务→自定义采集,进入到任务配置页面:然后输入网址→保存网址,系统会进入到流程设计页面并自动打开前面输入的网址。
验证码登陆-控件识别方法-图1:输入网址接下来步骤是输入用户名密码了,八爪鱼模拟的是人的操作行为,所以这一步过程也很简单步骤2 在浏览器中鼠标点击用户名输入框→在右边弹出的提示里面选择“输入文字”→输入自己的用户名→选择“确定”。
同样的方式输入密码,这样输入用户名密码的步骤就完成了。
验证码登陆-控件识别方法-图2:输入密码验证码登陆-控件识别方法-图3:输入密码这里八爪鱼采集器需要知道1.验证码图片在哪里2.输入框验证码的框在哪里步骤3 点击下方浏览器中验证码图片的位置→按照提示框中的提示选择浏览器中的验证码框→再按照提示框中的提示点击浏览器中的登陆按钮验证码登陆-控件识别方法-图4:点击验证码输入框验证码登陆-控件识别方法-图5:点击验证码图片位置、登录按钮接下来需要配置验证码输入失败和成功的两种场景步骤4 点击提示框中的确认按钮,系统会自动提交一个错误的验证码→然后点击浏览器中的“验证码不正确”提示→再点击提示框中的确认按钮→选择提示框中的“开始配置识别成功场景”→在提示框中输入显示出来的验证码→选择提示框中的“应用到网页并完成配置”选项验证码登陆-控件识别方法-图6:点击确认按钮验证码登陆-控件识别方法-图7:配置验证码输入失败场景验证码登陆-控件识别方法-图8:配置验证码输入成功场景验证码登陆-控件识别方法-图9:配置验证码输入成功场景上述操作中验证码识别就完成了,接下来需要手动执行这个流程,任务会自动进去到登陆界面步骤5 点击“流程”按钮→进入到流程界面→手动点击流程步骤(可以看到浏览器中会按照会执行这些步骤)→点到识别验证码步骤时→在辅助模式选项中输入浏览器中当前显示的验证码→选择应用到网页并提交验证码登陆-控件识别方法-图10:辅助模式选项这样操作之后,可以看到任务就正常登陆进去了。
八爪鱼的配置

连接八爪鱼到网络,遵循这些步骤:步骤一:确认路由器是关闭的。
步骤二:连接一端适当的串行电缆连接器卡上的面板上。
步骤三:连接另一端(RJ45)到适当设备的console上。
步骤四:配置连接八爪鱼的设备(一)首先确定是否重新配置八爪鱼,如果是原来的基础上配置,就要清理原来的数据:erase startup-configReload(二)接下完成基本配置:Hostname Rack_03_TserverEnable password cisco@kzy2012Line 0/3/0 0/3/15No execTransport input allExit(三)配置映射关系No ip domain lookupip host R1 2051 1.1.1.1ip host R2 2052 1.1.1.1ip host ASA 2053 1.1.1.1ip host SW5 2055 1.1.1.1ip host SW1 2056 1.1.1.1ip host SW2 2057 1.1.1.1ip host SW6 2058 1.1.1.1ip host SW3 2059 1.1.1.1ip host SW4 2060 1.1.1.1ip host R3 2062 1.1.1.1ip host R4 2063 1.1.1.1ip host R5 2064 1.1.1.1interface Loopback0ip address 1.1.1.1 255.255.255.0!interface FastEthernet0/0ip address 172.16.1.11 255.255.255.0配置默认路由Ip router 0.0.0.0 0.0.0.0 +ip 地址(四)配置line con 0 line vty 0 15Logging synchronousline vty 0 4password cisco@kzy2012logging synchronousno loginline vty 5 15password cisco@kzy2012logging synchronousno login配置banner motd 的设置banner motd ^CRack-012901 R1 cR1------------- clear line 51 2902 R2 cR2------------- clear line 52 ASA5510 ASA cASA------------ clear line 53 3560 SW5 cSW5------------ clear line 55 2960 SW1 cSW1------------ clear line 56 3560 SW2 cSW2------------ clear line 57 2960 SW6 cSW6------------ clear line 58 3560 Sw3 cSW3------------ clear line 59 2960 SW4 cSW4------------ clear line 602901 R3 cR3------------- clear line 62 2811 R4 cR4------------- ckear line 63 2811 R5 cR5------------- clear lien 64 ^Calias exec cR1 clear line 51alias exec cR2 clear line 52alias exec cASA clear line 53alias exec cSW5 clear line 55alias exec cSW1 clear line 56alias exec cSW2 clear line 57alias exec cSW6 clear line 58alias exec cSW3 clear line 59alias exec cSW4 clear line 60alias exec cR3 clear line 62alias exec cR4 clear line 63alias exec cR5 clear line 64privilege exec level 0 clear lineprivilege exec level 0 clear。
八爪鱼采集器新手入门必备的知识点(7.0版)18页PPT
八爪鱼采集器是一款模拟人的思维去访问网页
文档的互联网数据采集器。通过设计工作流程,可以 实现采集的程序自动化,以达到快速的对网页数据进 行收集整合,完成用户数据采集的目的。
深圳视界信息技术有限公司
界面简介
-八爪鱼界面功能介绍
深圳视界信息技术有限公司
界面简介
-智能模式介绍
深圳视界信息技术有限公司
界面简介
常用步骤:
常用步骤本身是应用较多的流程设计操作,通常来说,要实现一个网页的数据快速整理
与采集,这些步骤是必不可少的,基本步骤如下: 1)打开网页 2)点击元素 3)循环 4)提取数据
进阶步骤:
进阶步骤,是指除基本步骤外,我们需要通过下列操作来辅助完成我们的数据采集,进 阶步骤如下:
1)输入文字 3)切换下拉选项 5)移动鼠标到元素上
7)结束流程
2)识别验证码 4)判断条件 6)结束循环
深圳视界信息技术有限公司
实战演练
新浪财经 vip.stock.finance.sina/q/go.php/vIR_RatingNewest/index.phtml?p =1
58同城 bj.58/waiyu/30390652277055x.shtml?adtype=1&entinfo=303906 52277055_0&adact=3&psid=167579685196837197191772083&i uType=q_1&ClickID=2&PGTID=0d303871-0000-4c8d-427b904ef31bbe7d
结语: 实践出真知,八爪鱼让数据触手可及
深圳视界信息技术有限公司
实战演练
一、打开网页:
八爪鱼产品使用手册

八爪鱼产品使用手册目录1关于八爪鱼 (2)2Cookie (更多内容详见Cookie 视频) (2)2.1 Cookie诞生 (2)2.2 Cookie概述 (2)2.3 Cookie工作原理 (3)3Xpath、Html (3)3.1 Xpath、Html概念 (3)3.2 Html结构 (4)3.3 Html标签、元素、节点 (4)3.4 Html常见标签 (5)3.5 Html常见属性 (6)3.6 Xml、Xpath、Html关系和区别 (7)4常见问题 (7)5常见软件操作教程 (10)5.1 采集单个网页 (10)5.2 采集单个列表页面 (10)5.3 单网页表格信息采集 (10)5.4 采集单网页列表详细信息 (10)5.5 采集分页列表 (10)5.6 采集分页列表详细信息 (10)5.7 采集分页列表+ajax延时设置 (10)5.8 单个文本输入及各种登录方式采集 (11)5.9 Cookie登录 (11)5.10 文本循环输入 (11)5.11 循环切换下拉框 (11)5.12 xpath入门1 (11)5.13 xpath入门2 (11)5.14 一二页重复循环采集 (11)关于八爪鱼八爪鱼·大数据,通过自主创新研发,以分布式云平台架构为产品核心,帮助客户通过在极短的时间内,通过简单操作即可获取想要的数据,并以结构化数据展示,为企业数据挖掘与数据分析提供基础数据源。
于2015年1月,获得国家重点软件企业上市公司“拓尔思”投资。
Cookie (更多内容详见Cookie 视频)Cookie诞生当某个用户打开浏览器发出页面请求时,web服务器只是进行简单相应,然后就关闭与该用户的连接。
所以当用户每发起一个打开网页请求到web服务器的时候,无论是否是第一次打开同一个网页,web服务器都会把这个请求当作第一次来对待,那这样的缺陷可想而知,比如每次打开登录页面的时候都需要输入用户名、密码。
八爪鱼云爬虫如何使用

八爪鱼云爬虫如何使用目前,市面上的采集器五花八门,但云爬虫功能相对来说还是比较占优的,而云爬虫概念(云爬虫)是八爪鱼首创,无论国内还是国际。
旗舰版及以上用户在八爪鱼客户端将任务设置好后提交到云服务执行云爬虫,可以关闭软件和电脑,真正的实现无人值守。
除此之外,云爬虫通过云服务器集群的分布式部署方式,多节点同时进行作业,可以提高采集效率,并可高效的避开各种网站的IP封锁策略。
云爬虫的优势:可关机运行,也可设置定时云爬虫,采集加速,增量采集,自动入库等更多功能。
1、云爬虫设置示例网址:/cp01.05.00.00.00.00.html有三种方法可以启动云爬虫(立即启动,并且只运行一次)。
方法一:任务字段配置完毕后,点击“选中全部”,点击“采集以下数据”,选择“保存并开始采集”,进入到“运行任务”界面,选择“启动云爬虫”。
在任务列表内,会看到正在进行云爬虫的任务。
云爬虫使用方法(含定时云爬虫)-图1方法二:在任务列表页面,每个任务名称右方都有“启动云爬虫”选项,点击之后,任务就会立即启动一次云爬虫。
云爬虫使用方法(含定时云爬虫)-图2方法三:在任务列表页面,每个任务名称右方都有“更多操作”选项,点击之后,在下拉选项中选择云爬虫并启动,任务就会立即启动一次云爬虫。
云爬虫使用方法(含定时云爬虫)-图32、定时云爬虫设置定时云爬虫的设置有两种方法:方法一:任务字段配置完毕后,点击“选中全部”,“采集以下数据”,“保存并开始采集”,进入到“运行任务”界面,点击“设置定时云爬虫”,弹出“定时云爬虫”配置页面(图4)。
第一、如果需要保存定时设置,在“已保存的设置”输入框内输入名称,再保存配置,保存成功之后,下次如果其他任务需要同样的定时配置时可以选择这个配置(图5)。
第二、定时方式的设置有4种,可以根据自己的需求选择启动方式和启动时间(图5)。
所有设置完成之后,如果需要启动定时云爬虫选择下方“保存并启动”定时采集,然后点击确定即可; 如果不需要启动只需点击下方“保存”定时采集设置即可(图5)。
八爪鱼8月实战案例培训第四节课:京东网站

一:采集京东商品评价
打开网址: https:///5259286.html
采集商品评价(网页版、手机页版)
字段:标题 价格 评价数 商品参数 是否自营 商品 id 评价内容 评价者 评价时间 评价星级
注意: 1. 循环xpath定位修改:
中评:.//*[@id='comment-5']/div[@class="comment-item"] 差评:.//*[@id='comment-6']/div[@class="comment-item"]
提取店铺信息
字段:商品id 店铺名称 综合评分 服务态度 物流速度 商品质量满意 度 服务质量满意度 物流速度满意度 等
THANK YOU
9月份课程结束 拜拜
1.采集评价数大于1万条的商品列表页信息 2.采集详情页信息
字段:标题 价格 评价数 商品参数 是否自营 商品id 容 评价者 评价时间 评价星级 注意: 1.ajax加载设置
评价内
2. .//*[@id='detail']/div[2]/div[1]/div[1]/ul/li[contai ns(text(),"商品毛重")]
八爪鱼实战案例培训
八爪鱼官网:
第四课:京东网站
第一节课:亚马逊 9/18 周二晚8点
第二节课:新闻平台四晚八点开课
第四节课:京东 9/27 周四晚8点
一:采集京东商品数据
八爪鱼教程

八爪鱼教程我了解你想要的,所以下面是没有标题的八爪鱼教程:首先,让我们来介绍八爪鱼这个强大的工具。
八爪鱼是一个网络爬虫软件,它可以帮助我们自动化进行网页数据抓取和处理。
使用八爪鱼,我们可以快速获取大量的网页数据,并进行分析和应用。
接下来,我们将学习如何安装八爪鱼。
您可以在八爪鱼的官方网站上下载安装程序,并按照说明进行安装。
安装完成后,打开八爪鱼并注册一个账号。
登录后,我们将开始创建一个新的抓取项目。
点击“新建项目”,并填写项目名称和描述。
然后,选择需要抓取的网页,并根据需要进行配置。
您可以选择提取哪些数据字段,设置爬取频率,以及其他一些选项。
接下来,我们将配置八爪鱼以提取我们需要的数据。
在页面加载完成后,右键单击想要提取的数据,并选择“提取文本”或“提取链接”等相关选项。
根据网页的结构,八爪鱼将自动提取相应的数据。
提取和配置完成后,我们可以点击“运行”按钮来启动抓取任务。
八爪鱼会自动打开需要抓取的网页,并提取我们配置的数据。
您可以在任务列表中查看抓取进度和结果。
抓取完成后,我们可以对数据进行进一步的处理和分析。
八爪鱼提供了一些数据清洗和转换的功能,以及导出为Excel、CSV等格式的选项。
我们可以根据需求选择适合的处理方式。
最后,我们需要注意一些八爪鱼的使用注意事项。
首先,尊重网站的规则和政策,遵循爬虫行为的合法和道德准则。
其次,如果遇到网页结构变化或其他问题,及时更新和调整我们的抓取配置。
这就是关于八爪鱼的简单介绍和教程。
希望对您有所帮助!。
企业采集器使用方法

企业采集器使用方法对于有些销售朋友来说,企业信息的收集是非常重要的,如果一个个从网页上复制找相关企业信息,这样是非常浪费时间的,效率很低,另外网页也有一些企业数据包,但是应为时效性,可能已经不是最新的信息了,这样也不管用,那边其实可以用八爪鱼采集器,简单设置一下,就可以批量去采集最新的企业信息了。
下面以阿里巴巴企业名录举例,为大家详细介绍企业采集器的使用方法。
采集网站:https:///company/company_search.htm?keywords=%CE%E5 %BD%F0&button_click=top&earseDirect=false&n=y、使用功能点:●∙分页列表信息采集●∙Xpath●∙循环翻页设置步骤1:创建阿里巴巴企业名录采集任务1)进入八爪鱼采集器主界面,选择自定义模式阿里巴巴企业采集器使用步骤12)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”,就创建了一个阿里巴巴企业名录采集的任务。
阿里巴巴企业采集器使用步骤2步骤2:创建阿里巴巴企业名录翻页循环●找到翻页按钮,设置翻页循环●设置ajax翻页时间●设置滚动页面1)将页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,选择“循环点击下一页”这个选项。
阿里巴巴企业采集器使用步骤3步骤3:阿里巴巴企业名录信息采集用google或者火狐浏览器观察源代码,确定企业信息的xpath提取企业信息1)打开火狐或者google浏览器,我用的是google浏览器,鼠标移到企业信息这一栏,观察代码可以发现整个企业资料的xpath为//div[@class="wrap"],所以可以把整个企业资料作为一个循环,然后分别提取标题、主营产品,所在地,员工人数等等企业数据。
阿里巴巴企业采集器使用步骤42)观察公司标题的源代码可以发现,公司标题的xpath为//div[@class="list-item-title"]企业具体信息的xpath为阿里巴巴企业采集器使用步骤5-企业标题的xpath阿里巴巴企业采集器使用步骤6-企业具体信息的xpath 2)在流程图左侧可以推动一个循环以及提取数据进入流程图中。
八爪鱼的配置
连接八爪鱼到网络,遵循这些步骤:步骤一:确认路由器是关闭的。
步骤二:连接一端适当的串行电缆连接器卡上的面板上。
步骤三:连接另一端(RJ45)到适当设备的console上。
步骤四:配置连接八爪鱼的设备(一)首先确定是否重新配置八爪鱼,如果是原来的基础上配置,就要清理原来的数据:erase startup-configReload(二)接下完成基本配置:Hostname Rack_03_TserverEnable password cisco@kzy2012Line 0/3/0 0/3/15No execTransport input allExit(三)配置映射关系No ip domain lookupip host R1 2051 1.1.1.1ip host R2 2052 1.1.1.1ip host ASA 2053 1.1.1.1ip host SW5 2055 1.1.1.1ip host SW1 2056 1.1.1.1ip host SW2 2057 1.1.1.1ip host SW6 2058 1.1.1.1ip host SW3 2059 1.1.1.1ip host SW4 2060 1.1.1.1ip host R3 2062 1.1.1.1ip host R4 2063 1.1.1.1ip host R5 2064 1.1.1.1interface Loopback0ip address 1.1.1.1 255.255.255.0!interface FastEthernet0/0ip address 172.16.1.11 255.255.255.0配置默认路由Ip router 0.0.0.0 0.0.0.0 +ip 地址(四)配置line con 0 line vty 0 15Logging synchronousline vty 0 4password cisco@kzy2012logging synchronousno loginline vty 5 15password cisco@kzy2012logging synchronousno login配置banner motd 的设置banner motd ^CRack-012901 R1 cR1------------- clear line 51 2902 R2 cR2------------- clear line 52 ASA5510 ASA cASA------------ clear line 53 3560 SW5 cSW5------------ clear line 55 2960 SW1 cSW1------------ clear line 56 3560 SW2 cSW2------------ clear line 57 2960 SW6 cSW6------------ clear line 58 3560 Sw3 cSW3------------ clear line 59 2960 SW4 cSW4------------ clear line 602901 R3 cR3------------- clear line 62 2811 R4 cR4------------- ckear line 63 2811 R5 cR5------------- clear lien 64 ^Calias exec cR1 clear line 51alias exec cR2 clear line 52alias exec cASA clear line 53alias exec cSW5 clear line 55alias exec cSW1 clear line 56alias exec cSW2 clear line 57alias exec cSW6 clear line 58alias exec cSW3 clear line 59alias exec cSW4 clear line 60alias exec cR3 clear line 62alias exec cR4 clear line 63alias exec cR5 clear line 64privilege exec level 0 clear lineprivilege exec level 0 clear。
使用八爪鱼采集天猫店铺数据,以天猫男装为例

使用八爪鱼采集天猫店铺数据,以天猫男装为例本文介绍使用八爪鱼采集天猫店铺数据(采集天猫男装店铺)的方法采集网站:https:///search_product.htm?spm=a221t.1710963.8073444875.1.4b26aff6uvcb3b &q=%C7%EF&cat=53636001&active=1&style=g&from=sn_1_rightnav&acm=lb-zebra-7499-26241 9.1003.4.408088&sort=s&search_condition=23&scm=1003.4.lb-zebra-7499-262419.OTHER_1489 5286190510_408088使用功能点:分页列表信息采集/tutorial/fylb-70.aspx?t=1相关采集教程:淘宝评论采集天猫商品信息采集京东商品信息采集步骤1:创建采集任务1)进入主界面,选择“自定义模式”八爪鱼采集天猫店铺数据图12)将商品信息页的网址复制粘贴到网站输入框中,点击“保存网址”八爪鱼采集天猫店铺数据图2步骤2:创建列表循环并提取字段1)移动鼠标,在第一个宝贝中选择两个需要提取的字段,这样我们需要提取的字段都出来了,然后选择“选中全部”八爪鱼采集天猫店铺数据图32)然后选择“采集以下数据”八爪鱼采集天猫店铺数据图4 3)打开“流程图”,查看刚才提取的列表字段数据八爪鱼采集天猫店铺数据图54)将不相关的字段删除,修改相关字段标题。
八爪鱼采集天猫店铺数据图6步骤3:创建翻页循环1)将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”八爪鱼采集天猫店铺数据图7 2)然后选择“保存并启动”八爪鱼采集天猫店铺数据图8 3)选择“启动本地采集”八爪鱼采集天猫店铺数据图9步骤4:数据采集及导出1)采集完成后,会跳出提示,选择“导出数据”八爪鱼采集天猫店铺数据图102)选择“合适的导出方式”,将采集好的评论信息数据导出八爪鱼采集天猫店铺数据图113)这里我们选择excel作为导出为格式,数据导出后如下图八爪鱼采集天猫店铺数据图12以上为天猫店铺采集详细教程,按照步骤操作即可,其中部分操作顺序可以适当调整,最终也是可以正常采到数据的,灵活应用即可。
【八爪鱼v7采集教程】无下一页,数字翻页解决方法

【八爪鱼v7采集教程】无下一页,数字翻页解决方法我们可能遇到一些网页,页面上并没有翻页按钮,而是一排页码,我们需要直接点击页码进行翻页。
这种方式如何解决呢首先我们打开一个这样的网页,如:/news/打开之后翻页页面如下图显示无下一页、数字翻页-图1可以在火狐看下这个翻页的源码,如下图所示:当前页在第一页,源码是span标签开头的,其他页面是a标签开头的。
无下一页、数字翻页-图2我们再翻到其他页,看看是不是也是这个特点。
可以看到当前页在第7页,第7页的源码显示是span开头的,其他页码变为a标签开头的。
无下一页、数字翻页-图3我们可以根据这个特点相应的写xpath,然后手动创建翻页循环。
我们需要让八爪鱼选择的是当前页的下一页,也就是span元素的后面一个元素, 这时我们需要检验如何写Xpath才能准确定位到当前页。
借助于火狐浏览器,我们先定位span标签无下一页、数字翻页-图4看上图这个页面里面span标签有很多,我们再看一下原本需要的span标签,可以看到span 标签里面的class属性,根据这个属性定位。
无下一页、数字翻页-图5 如下图,//span[@class=’thisclass’]即能定位到我们需要的当前页无下一页、数字翻页-图6接下来我们打开八爪鱼中的Xpath工具,生成选择后面元素的Xpath无下一页、数字翻页-图8利用following-sibling定位当前页的下一页,后面元素是a,我们将a加在刚刚生成的Xpath 后//span[@class=’thisclass’]/following-sibling::a可以定位到当前span下面的所有兄弟元素,注意这个following-sibling后面的::是固定格式无下一页、数字翻页-图9由于我们只需要定位到当前页的下一页,所以只需要定位到第一个a标签,即给a一个标号//span[@class='thisclass']/following-sibling::a[1]无下一页、数字翻页-图10可以看到当前页为第7页,现在定位到了它的下一页即第8页。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
网页数据
八爪鱼采集器
数据库
EXCEL
API
其他
采集原理
高级模式
简单规则设置,灵活应对 各种复杂网页结构
强大的功能+简便的操作,我们提供两 种操作模式,满足不同用户的个性化应 用需求。
向导模式
内置向导流程,点击执行 轻松解决采集难题
原理: 模拟人进行网页访问,获取源码中数据
八爪鱼的规则配置流程模拟人的思维模式,可视化操作,贴合用户的操作习惯。网页上所有操作过程均记录在规则中, 规则时整个数据提取过程的逻辑体现。
二、循环翻页:
循环翻页,指一般我们需要快速收集整合时,是需要做到翻页 循环的,循环翻页的本质是一个单个元素的循环
三、提取数据:
正式的采集步骤
四、点击元素:
循环本身是不会有任何执行操作的,如果要实现循环翻页,则 需要一个点击元素来和循环产生联动
云采集原理
原理:
Ⅰ:自动拆分规则 Ⅱ:分布式数据采集 Ⅲ:自动将归类汇总 八爪鱼采集器云采集原理,是将定量或计算可定 量的任务自动拆分成多个子任务,分配至不同的云服 务器进行数据采集,自动将采集后的数据信息归类汇 总至客户端,以达到数据采集加速效果。
界面简介
-八爪鱼界面功能介绍
界面简介
-向导模式介绍
界面简介
-高级模式介绍
高级模式
一、设置基本信息: 此处用于填写规则名称与勾选网页展示选项 二、设计工作流程: 此处用于设计任务规则的自动化流程步骤,例如:你要让任 务规则打开哪一个网页,做哪些步骤等都在设计工作流程中完成,设计 工作流程是一个任务规则的核心步骤 三、设置执行计划: 此处你可以设置任务规则的相关选项,例如:禁止浏览器加 载图片、云采集不拆分任务、启动增量采集等 四、任务启动选择: 如果规则编写正确,此处你就可以启动一个任务规则进行单 机采集或云采集了,并且可以设置定时计划
结语: 实践出真知,八爪鱼让数据触手可及
Ajax加载与新标签页
Ajax即通过在后台与服务器进行少量数据交换,意味着可以在 不重新加载整个网页的情况下,对网页的某部分进行更新。 最简单的方式是看在八爪鱼浏览器里点击的时候网页有没有改 变加载状态 这种表示网页正在加载 这种表示网页没有加载或者已加载完成 当网页状态有发生改变的时候就不需要设置ajax,因为八爪鱼会自动根 据网页的状态来判断是否可以进行下一步操作 而当网页状态没有发生改变的时候就需要设置ajax,因为八爪鱼没有可 判断的依据,运行本地采集时八爪鱼就会按照一个默认时长120秒后再 执行下一个操作,这时大部分新用户会发现八爪鱼不动了一直不提取数 据,所以这时需要设置ajax告诉八爪鱼,需要采集的网页内容已经出来 了,可以进行下一步操作了,这个ajax时间就是要观察从点击到需要采 集的数据出现需要多久,则设置多久即可。 如果不设置采集时出现的现象就会一直等待在这里不提取数据,感觉采 集速度会很慢,设置了之后会加快速度。 前面说了一般网页设置ajax的目的是局部刷新,后台与服务器 进行少量数据交换,而新标签打开的意思是重新打开加载整个网页,一 般来说设置了ajax是不需要再开新标签的,请在设置ajax的时候把勾选 的新标签取消掉。
The End
谢谢大家
可拆分条件:循环方式为固定元素、URL列表、文本列表三 种之一
实战演练
新浪财经 /q/go.php/vIR_RatingNewest/i ndex.phtml?p=1
京东商城 https:///5001209.html#comment
高级模式
流程设计步骤:
在八爪鱼采集器中,一共有11个流程设计操作,其中分为常用步骤和进阶步骤,划分为
以下:
常用步骤:
常用步骤本身是应用较多的流程设计操作,通常来说,要实现一个网页的数据快速整理 与采集,这些步骤是必不可少的,基本步骤如下: 1)打开网页 2)点击元素 3)循环 4)提取数据
进阶步骤:
进阶步骤,是指除基本步骤外,我们需要通过下列操作来辅助完成我们的数据采集,进 阶步骤如下: 1)输入文字 3)切换下拉选项 5)移动鼠标到元素上 7)结束流程 2)识别验证码 4)判断条件 6)结束循环
高级模式
一、打开网页:
打开网页,一般指我们所要采集数据的网站,正如平我们浏 览该网站的数据信息时需要输入URL一样
八爪鱼 让数据触手可及
深圳视界信息技术有限公司 2017年11月
目录
1.产品介绍 2.八爪鱼采集原理 3.界面简介 4.云采集原理 5.实战演练 6.误区-AJAX与新标签
产品介绍
八爪鱼,深圳视界信息技术有限公司(国家高新企业)旗下产品,强大且易用的互联网数据采集平台。 八爪鱼可简单快速地将网页数据转化为结构化数据,存储于EXCEL或数据库等多种形式,并且提供基于云计算的大数据云采 集解决方案,实现精准、高效、大规模的数据采集。